1. Introduction
Population growth has placed certain pressures on society, resources, and the ecological environment, and even affected ecosystem functions [
1,
2]. The critical role of population data in the study of social economy, resource utilization, and ecosystem change has been widely recognized [
3]. In particular, population density data can be broadly applied in quantifying the intensity of human activities, depicting the spatial patterns of eco-environmental quality, simulating the spatial distribution of pollutant emissions, and evaluating ecological problems brought about by urbanization [
4,
5,
6,
7], as well as in other ecological research. With the development of remote sensing technology, population data based on administrative units has become a bottleneck restricting the integrated analysis of social and natural systems [
8,
9]. The spatialization of population data is based on distribution rules redistributing the data from the administrative unit scale to a specified grid size, in order to estimate and simulate real population spatial distribution. The establishment of such distribution rules often takes demographic data as input, and social and economic data, administrative divisions, transportation, terrain and other elements as references [
10].
At present, spatial population datasets shared at the global and regional scales include Gridded Population of the World (GPW) [
11], Global Human Settlement Layer (GHSL) [
12], History Database of the Global Environment (HYDE) [
13,
14,
15], WorldPop [
16,
17], Global Urban Footprint (GUF), High-Resolution Settlement Layer (HRSL), and so on. These data have been widely used in disaster assessment and risk management [
18,
19,
20,
21,
22], land use change modeling [
23,
24,
25,
26], public health services [
27,
28,
29], and ecological environment change [
30,
31,
32,
33,
34] and socioeconomic analysis [
35] as important references for developing new population spatial datasets [
36,
37,
38]. Goldewijk et al. used HYDE [
13] to estimate land use change in historical periods. Gleeson et al. used GPWv3 data from 2000 [
22] to study the sustainability of groundwater, finding that about 1.7 billion people lived in areas affected by groundwater pressure, and more than half of the affected population lived in China and India. Based on the malaria stability index and WorldPop data [
19], Kibret et al. measured the infection rate of
Plasmodium falciparum in areas of relevant reservoirs and found that 723 of 1268 dams were located in diseased areas (about 15 million people). Melchiorri et al. used GHSL [
24] to study the evolution of global urbanization from 1990 to 2015 and the current situation, and clarified the key role of urban areas in the development and mode of global urban development.
The datasets construct spatial population data by various methods, which naturally leads to different results in the same research with other datasets. For example, when estimating how much of the population suffers from flood risk in Mexico, Haiti, and 18 other countries, the estimations using WorldPop and LandScan were 20.79% and 32.67%, respectively, higher than that obtained by HRSL [
17]. In order to select the appropriate data, research about the accuracy of comparisons or validations of datasets is gradually carried out in various case areas. The research results of Bai [
39] in China showed that WorldPop had the highest and GPW the lowest estimation accuracy, but the estimation accuracy of GPW in plain and basin areas was slightly higher than in other regions. The results of a validation study [
40] on the GHSL datasets in urban and rural areas of the United States showed that the data were very accurate in areas with a high development level, while in rural areas, the accuracy may be low due to sparse built-up areas and a lack of reference data. Ye [
37], Yang [
41] and Sliuzas [
42] reached different conclusions on the accuracy of datasets—Ye thought that the WorldPop dataset permitted low estimation of urban populations and high estimation of rural populations, and Yang found that there were more errors in the WorldPop data in areas with high or very low population density. The research results of Sliuzas showed that GHSL could only describe the main forms of cities, but there were quite a lot of misclassifications at the pixel level, so the accuracy was not high.
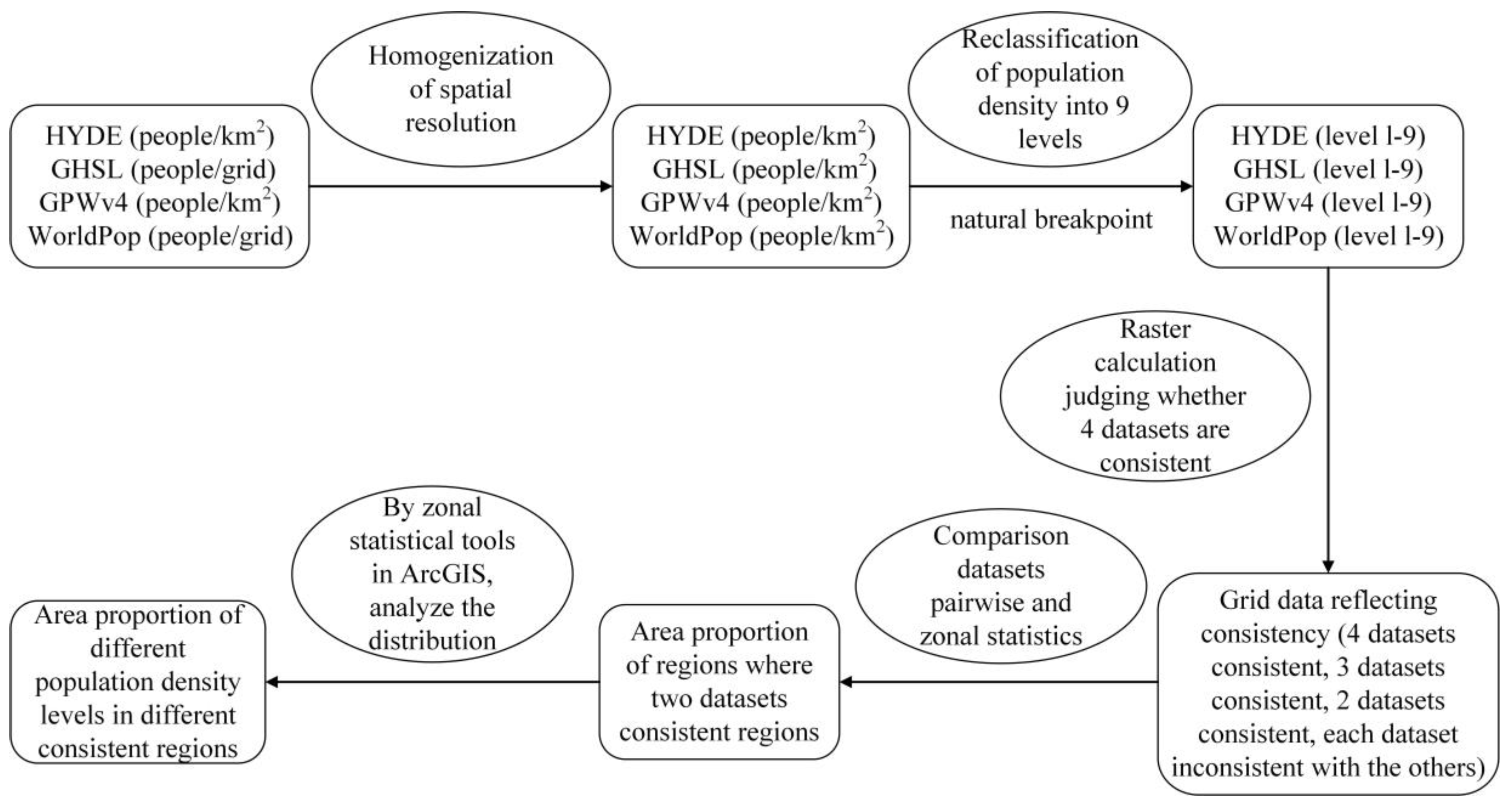
The selection and application of global datasets is a difficult for all kinds of data, and the reliability requires sufficient verification. However, validating spatial population data is far more difficult than validating a global land cover dataset, which can be verified by high-resolution remote sensing data, and a global ecosystem productivity dataset, which can be verified by long-term data collected from located observations. Therefore, mastering the characteristics of spatial and temporal layout, and the advantages of each set of data to select that is appropriate to the use of data in the research process, will better reduce the uncertainty of research. Therefore, we chose four datasets, HYDE, GPWv4, GHSL and WorldPop, which are widely used and have different spatiotemporal resolution, to conduct a comparative study in terms of the reliability of the population and the difference of spatial distribution. In order to reflect the difficulty of collecting demographic data and the influence of population density distribution on spatial data, we selected the United Kingdom, Argentina, Sri Lanka and Tibet Autonomous Region of China as the case areas. We analyzed the differences between the four datasets and the reasons for these differences from the aspects of the data production process, estimation deviation [
43], consistency of spatial population distribution [
44], and population density level distribution at the administrative unit and pixel scale, so as to provide a reference for the selection of population datasets in socioeconomic or ecological environment research [
41,
45].
4. Discussion
It can be seen that the spatial patterns of the spatial population datasets produced by different methods and data sources are very similar in Tibet, where data are scarce and the population is sparse. In the data selection of such regions, the accuracy of population estimation and the time scale needed for research are the main considerations. For regions with high levels of urbanization, we should not only consider spatiotemporal resolution and accurate quantity, but also pay more attention to the uncertainty of data in areas with medium population density. Based on the results, a table is summarized to show the applicability of datasets in different population density areas (
Table 8.). This study serves as a basis for not only the selection of population data, but also the future development of population spatialization. In areas where data are lacking, improving the accuracy of spatial population datasets depends more on continuously refining demographic data [
52,
53,
54,
55,
56] and abundant data sources [
57]. The difficulty in obtaining data in areas at high altitude and with poor data quality may be the reason for the large relative error in the Tibet Autonomous Region of China [
58]. Remote sensing, mobile communication, and other big data will play important roles in improving the accuracy of spatial population data in areas with deficient data. For areas with medium population density, with the development of spatialization methods, from simple interpolation to machine algorithms based on intelligent models such as neural networks, decision trees, genetic algorithms and random forest [
9,
48,
59,
60], strengthening the experimental research and verifying such areas will improve the reliability and consistency between datasets. Verifying the accuracy of spatial population datasets is a massive problem in the research. According to the comparison between the population of spatial datasets and census data in this study, not only are there differences in spatial layout, but there is also about 20% deviation in the population. Therefore, in areas with different geographical characteristics and with more detailed statistical units, even at grid scale, it is also a necessary development direction of population spatialization to develop standard experimental areas, and to provide verification data for the accurate quantity and spatiotemporal layout of spatial data designed by various applications. Besides, urban/rural populations are two concepts of population geography corresponding to urban and rural areas. When it comes to urban population in most countries, the population of small cities generally is included, while in China, it usually refers to the population of towns [
61]. Although the population scale for towns in China is equivalent to that for small cities of other countries, the difference in definition for urban/rural population may have a slight effect.
5. Conclusions
In order to understand differences in the number and spatial distribution of the main spatial population datasets in the world, four datasets with different spatiotemporal resolutions (HYDE, GPWv4, GHSL and WorldPop), developed based on multiple data sources and spatialization methods, were selected, and Sri Lanka, the UK, Argentina and the Tibet Autonomous Region of China were taken as the case areas. This paper conducted research from the aspects of relative error of population, consistency of population spatial distribution, and the characteristics of population density distribution within consistent and inconsistent regions. Furthermore, this paper analyzed the causes of the differences by combining the data production process and the difficulty of data acquisition, urbanization level and the characteristics of population distribution for the case areas. The results show the following:
(1) The differences in source data and spatialization methods between datasets affect their accuracy. The development of remote sensing and deep learning technology promotes the progress of data collection and spatialization methods. Therefore, the accuracy of each dataset in the study is very different. Because GPWv4 is based on 2010 census data for allocation according to the principle that the population in each administrative unit is unchanged, and GHSL is based on GPWv4 for secondary spatialization, their absolute value for the relative error of total population is the smallest, both of which being within 3%. Although WorldPop uses the same data source as GPWv4, the relative error of the former is as high as 20% in Argentina, Sri Lanka and the Tibet Autonomous Region of China, due to different spatialization methods. HYDE, for the purpose of producing long time series historical data, has medium accuracy for estimating the population of the UK, Argentina and Sri Lanka;
(2) The application of geospatial data makes the datasets more accurate in the UK with abundant information, where the absolute value of the relative error of the four datasets is less than 4%. In other case areas, the absolute value of the relative error of GPWv4 and GHSL is less than 3%, and that of HYDE and WorldPop is between 5% and 25%. Affected by the imprecision of statistical data and the difficulty in obtaining new auxiliary data, the relative error of datasets in the Tibet Autonomous Region of China is relatively large, especially with HYDE using historical literature data and WorldPop using multi-source geographic information data. With regard to the ability to describe spatial distribution, the pairwise consistency between WorldPop and the other three datasets is the highest due to the fusion of multiple data sources, and GHSL, which mixes built-up area distribution information extracted from remote sensing, has more advantages in terms of spatial consistency in areas with a high urbanization level. It is difficult to spatialize population distribution in areas with complex variation, characterized by reduced consistency in spatial distribution. The consistency of population spatial distribution for the four datasets is the highest in the Tibet Autonomous Region of China, where the total proportion of four and three datasets being consistent is as high as 97.01%. On the other hand, in the UK, where the population spatial distribution is complex, only 66.75% of the regions are completely or highly consistent;
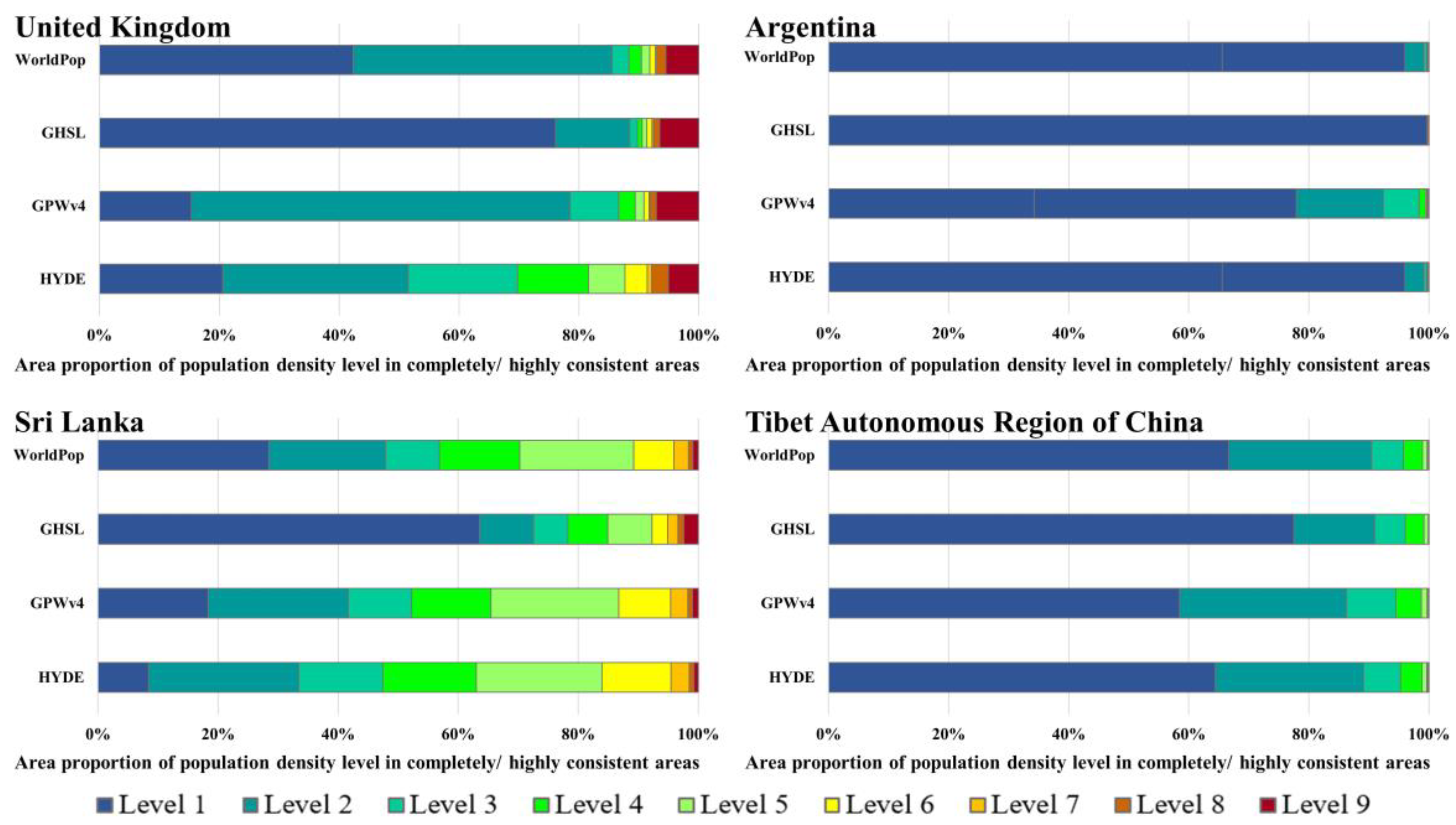
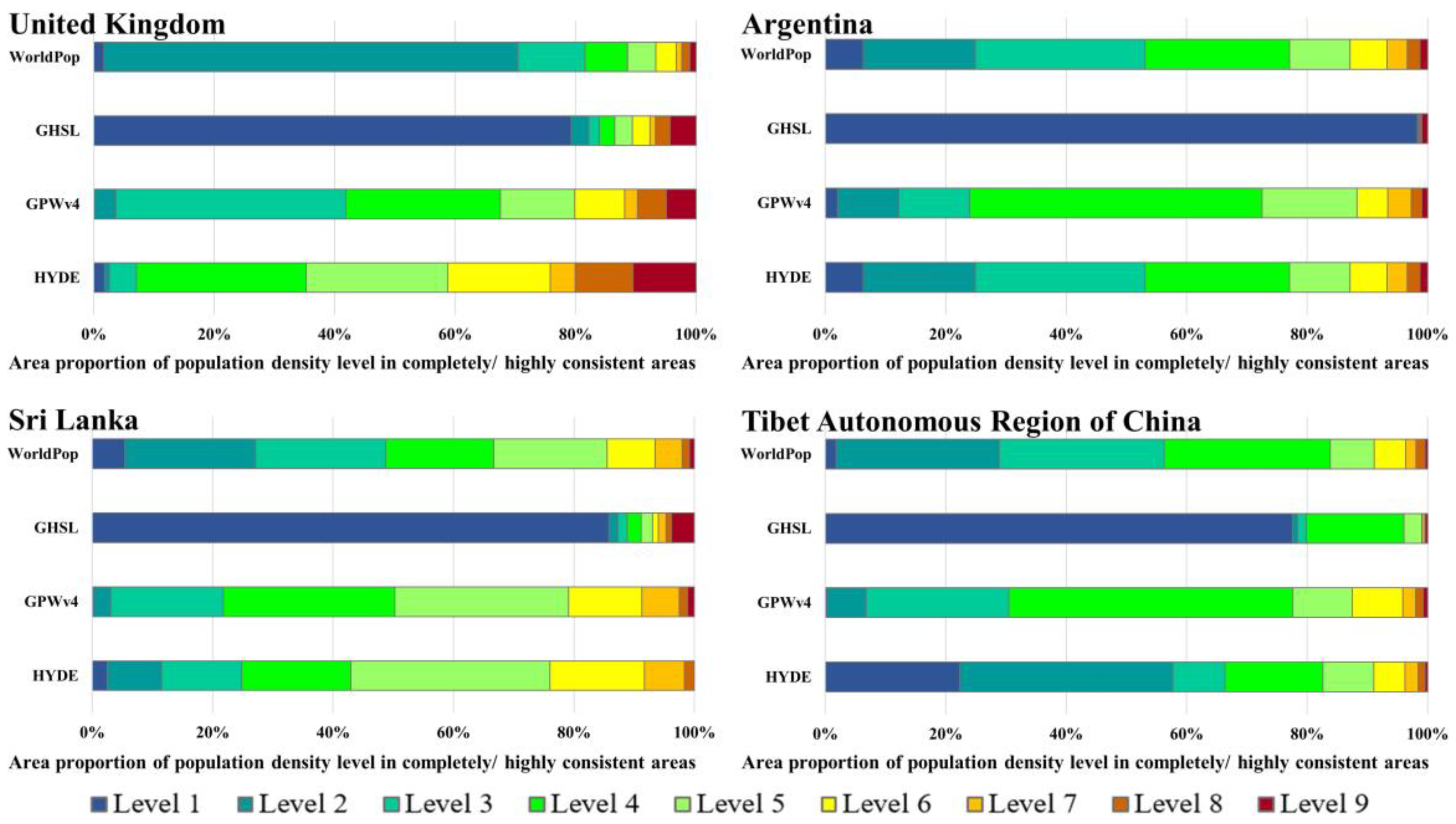
(3) Areas where the four datasets are completely/highly consistent are mainly distributed in low population density areas. In Tibet, Argentina and the UK, the proportions of level 1 and 2 in completely/highly consistent areas are as high as 89%, 76% and 92,% respectively, indicating that data consistency is great in low-density areas. In addition, in highly urbanized and densely populated areas, the spatial distribution of each dataset is also highly consistent, and 62% of high-density population areas in the UK are completely/highly consistent areas. The lowly consistent/completely inconsistent regions are mainly distributed in the middle density areas with a high urbanization rate, and 62–93% of middle density population areas in the UK and Argentina are lowly consistent/completely inconsistent regions.






{kind=link}
{kind=link}
{kind=link}
{kind=link}