1. Introduction
Many eyewitness records, travel notes, and historical documents contain descriptions of the spatial location of objects that no longer exist, for example, the area of vanished historical sites, a possible crime location, and the location of special natural phenomena. In these descriptions, location and spatial relations are often the key evidence to the relevant content or event. Furthermore, the spatial objects are not isolated. Their location and spatial interactions are important to help to understand their value and function [
1,
2]. Therefore, it is necessary to extract the spatial location and regional information from the object’s vague location description from the observer’s perspective and express it in the geographic information system (GIS).
The crisp directions, coordinates, and areas can be expressed directly in the GIS using objects such as points, lines, and polygons [
3]. However, in the real world, vagueness characters pervasively exist in the objects, especially at the boundary of the objects [
4,
5]. In addition to surveying and mapping data, different degrees of vagueness existing in describing the geographical location and spatial relations needs to be processed in the GIS [
6,
7,
8].
In the field of mapping and ground object modeling, there is a vagueness and trade-off relationship between strict classification results and geographical representation of geographical regions. Therefore, it is necessary to introduce an analytical method to describe this characteristic of vagueness [
9]. The main methods of dealing with the vagueness of ground objects include fuzzy sets, rough sets, similarity relation, statistical procedures, and prototype-based approaches [
10,
11,
12,
13,
14]. By using fuzzy sets to process the boundary of forest mapping, Brown [
15] transformed the expressions from the point of individual tree to a polygon of the types of trees. The ground object’s data may have double vagueness, the co-existence of dimension and spatial vagueness; this problem can be solved by fuzzy memberships at each scale and combined process [
16]. Through statistical quantification of uncertainty, Rocchini [
17] conducted the continuous deriving ecosystem-related mapping. Gorini [
18] carried out DEM morphometric analysis through the fuzzification of morphometric classification rules. Based on the fuzzy set theory, coastal risks can be represented through ill-defined risk zone boundaries and the inherent uncertainty issues [
19]. Guilbert [
20] proposed a prototypical and object-oriented based approach to the identification of landforms with qualitative and inherent vagueness. Liu [
21] proposed a categorization system to obtain appropriate fuzzy representation based on the analysis of the various vagueness characters of geographic objects.
In the field of natural language understanding and cognitive region and place, spatial localization information also exists widely in text messages and web documents. The collection of this massive spatial location information can facilitate the construction of the geographical analysis service [
22,
23]. Spatial location semantics in texts can be extracted through natural language processor and artificial intelligence (AI) methods [
24,
25]. The semantic location content of spatial objects can be extracted by measuring distance, direction, and topology similarity [
26,
27]. It also can be assessed between scenes or relations to other objects [
28,
29]. In natural language, the name of the places can be ambiguous or synonymous. Spatial information extracted from place descriptions can be achieved by the graph matching process [
30]. The comprehension of the semantics of location, a multidisciplinary and multiparadigmatic field, depends on the social attributes of a person rather than the crisp geographic coordinates and boundaries [
31,
32]. Massive user-generated data from social networks can be used as a key data source to explore the relationship between people and places [
33]. Vague name of the places can be better handled by using knowledge from the Web. The web-harvesting and crowd-sourcing can help to achieve the goal of unambiguous recognition and sufficient performance of spatial reasoning with the name of the places [
34]. Based on web big-data, Gao [
35] proposed a method realizing the direct correspondence between location semantics and regions to present vague cognitive regions of Northern California and Southern California. Wu [
36] used fuzzy formal concept analysis to uncover the spatial hierarchies among vague places. Furthermore, text and images contained in Tweets can be applied to extract useful information about flood events [
37]. In addition, human cognition of the relationship between spatial objects also contains uncertainty characteristics. This uncertainty can be defined through fuzzy topological representation methods [
38]. Topological relations between regions can be used to handle vagueness in image interpreting, uncertainties of natural phenomena and uncertainty knowledge [
39,
40,
41]. Liu [
42] induced the fuzzy topology method to qualitative measure boundary between spatial objects. Zhang [
43] proposed a spatial fuzzy influence diagram to support the decision-making process of tree-related electric outages. Dilo [
44] defined vague objects representation and corresponding fuzzy operators to deal with the relationship between objects without crisp boundaries. Majic [
45] defined fuzzy topological operations on all types of 2D spatial objects.
Although achievements have been made in the studies on the vagueness of boundary, region, location and the name of the places, they are still inadequate to deal with the spatial location extraction from the eyewitness records, travel notes, and historical documents. The spatial location extraction process has the following application value:
It helps to locate disappeared historical objects. For example, it can obtain the location of ancient boundary monuments between the two countries. In particular, those vanished or may have been deliberately damaged or maliciously removed in history. When the physical monument is vanished, with the proposed model, the existing historical documents can help to locate the most possible location of these boundary monuments even though the descriptions do not contain mapping coordinate information. This derivation of location information is of importance in the determination of the boundary monuments. The extracted location can be used as the data basis for historical research, border policymaking, and state relations handling.
It can be used to analyze the spatial information on the basis of the witness report. Based on the provided descriptions, we can extract the corresponding spatial locations and ranges of the objects under observation that are currently physically unavailable. Further, this spatial information helps to detect the authenticity of descriptions. For example, it can identify conflict descriptions of spatial information, a false report, or recorded observation from currently inaccessible locations. This application of the proposed model can assist investigations such as restore history/natural scenes and landscapes and the scene of a crime. The extracted spatial information of witnesses can provide supporting materials for the studies or practices mentioned above.
These texts are observer-centered descriptions with vague location expressions. They have the following characteristics:
The observer’s perception of spatial relations and properties is subjective. It reflects the understanding and experience of space of specific groups. Therefore, the existing methods cannot directly transform the subjective spatial knowledge into the object expressions in a GIS.
Object’s vague location expression does not contain clear coordinate information. Instead, it is observed. Its location needs to be determined by taking the observer as the referent.
To solve this problem, this paper proposes a Fuzzy Spatial Region Extraction Model for Object’s Vague Location Description from Observer Perspective (FSREM-OP). In this model, the spatial relationship between the observer and the object are represented as spatial knowledge that composed of “phrase” and “region”; based on the spatial knowledge, three components of spatial inference is constructed: Spatial Entities (SEs), Fuzzy Spatial Regions (FSRs), and Spatial Actions (SAs). Through knowledge and components of FSREM-OP, we can infer an object’s location from an observer’s describing text, and transform vagueness and subjectivity location description into fuzzy spatial regions, and these regions can be presented in the GIS directly. In the experiments, the FSREM-OP was tested by constructing a group of observers, object position relationships and vague descriptions. The results show that FSREM-OP has good spatial information extraction capability, and can represent descriptions in the GIS despite their contents have vagueness and subjective spatial relation expressions.
2. Methodology
2.1. Research Object and the Construction of Spatial Knowledge
The research objective of this research is: There is a description c that contains the spatial information/relation of observer p and object x; in c, the x’s location is not given directly but it is observed by p; we need to extract the possible location/region of the object x and represent it in GIS. A typical example of c is as follows:
“After walking forward for two minutes from position l, p sees the target object x not far to the front-left.”
In this description c, the observer is p whose initial position is the known coordinate l; the target object is x, whose position is not exactly described in c; however, the spatial relationship from the perspective of p implies its possible position of x. To obtain the possible area occupied by x, the following issues need to be considered:
Relative position based on virtual perspective: there is no x position data in c, and x is “seen” in the virtual perspective by using p as the reference. The spatial position of x can be indirectly determined by the reference p.
Character of vagueness: In c, although the spatial attributes such as forward, front-left, and not too far have spatial information, they cannot be represented by crisp direction and quantity variables. Therefore, relatively vague areas and ranges need to be used.
Individual differences lead to differences in spatial features variation. In other words, the difference in physical status results in the variation of the different spatial features. Taking “walking forward for two minutes” as an example, of the same two minutes walking, the distance of two-meter tall basketball players will be greatly different from that of elderly people with poor physical fitness. Therefore, it is necessary to introduce individual characteristics when extracting the spatial position of x.
Subjective properties: Some descriptions, such as “right side,” can be viewed by a “robot” as the result of clockwise π/2 rotation directly in front; but for “human” either the neck rotation π/2 or the measurement of an angle equal to π/2 is difficult. These directions and positions can be broadened to a range that is often determined by subjective opinion, experience, or feeling rather than by mathematical function; so we also need a method to embody this subjective knowledge to the spatial range.
To cope with the problems above, this paper proposes a Fuzzy Spatial Region Extraction Model for Object’s Vague Location Description from Observer Perspective (FSREM-OP). One key function of FSREM-OP is to transform the description of vagueness and subjectivity of spatial relationships into qualitative or quantitative objects (such as polygon or raster) that can be expressed within GIS.
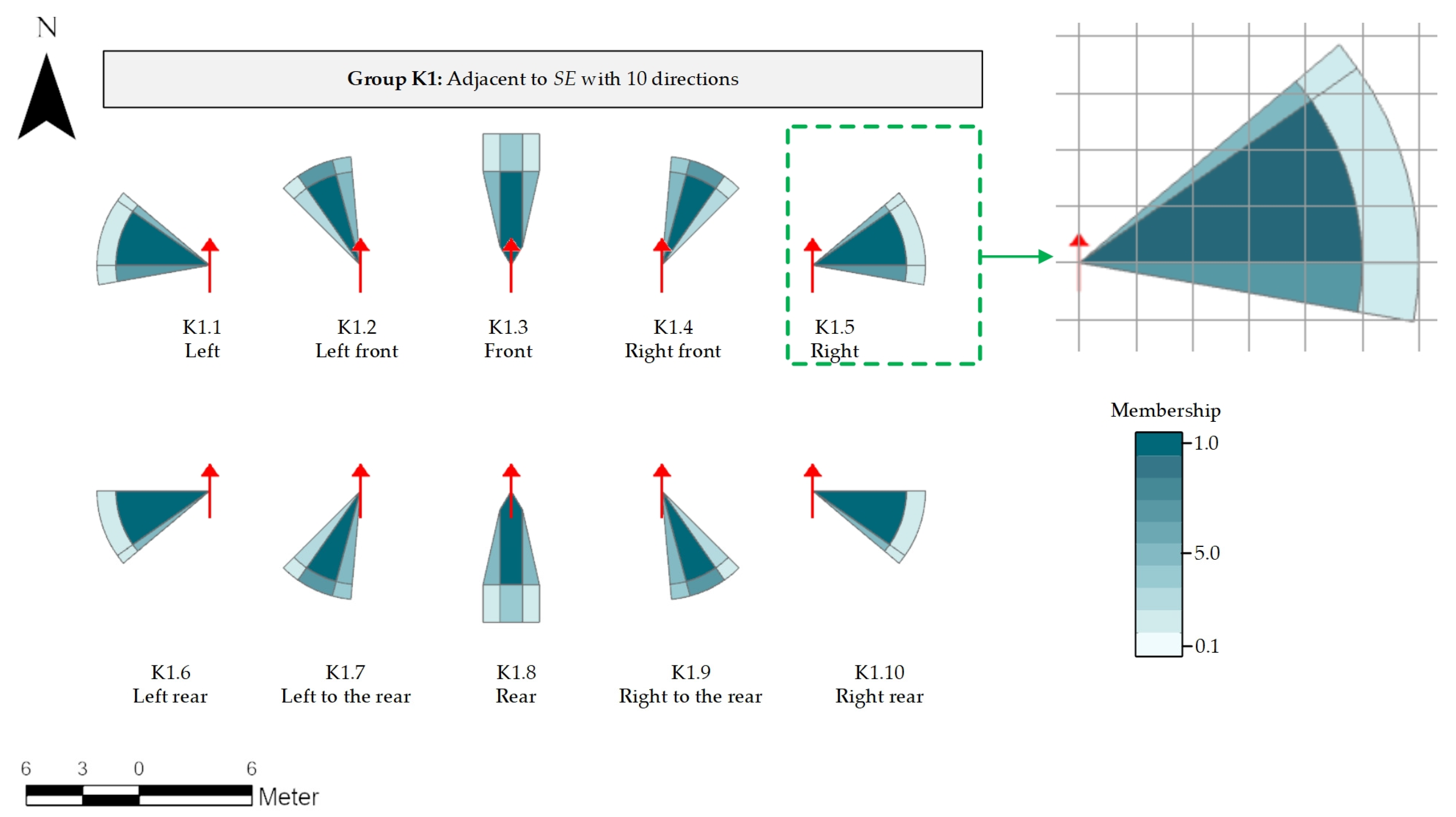
To realize the quantitative or qualitative expression of vague and subjective content required by FSREM-OP, this paper constructed the knowledge set of spatial relations K = {k1, k2, …, kn}; Each ki in the K is corresponding to the rule of spatial relationships or features’ variation. The construction of K requires the introduction of context content or expert experience related to c. The expression of these experiences in this method is ki = {Phrases, Regions}. Phrases are the language description of a spatial relationship or attribute, such as “turn to the front-left” and “walking ahead for two minutes”. Regions are groups of spatial areas that Phrases correspond; the difference of this knowledge expression method to traditional Fuzzy methods in that:
Greater description granularity: For the description corresponding to the knowledge, we used a larger granularity of phrases instead of keywords. For example, we used “near the front-left” as a single knowledge description, instead of trying to combine the three keywords of “near” + “left” + “front”. The significance of adopting this strategy lies in that this granularity can prevent the overlap of an overly broad area caused by combining too many fuzzy spatial words at one time. Moreover, the greater granular the easier to match meaning in c and facilitate to obtain the corresponding regions.
More subjective spatial expression: In knowledge
ki,
Regions = {
r1,
r2, …,
rn}, each
ri corresponds to a polygon that can be expressed in the geographic information system. We choose polygon as the basic unit of expression because polygon corresponds to a region in GIS, which is easier to express the characteristics of vagueness than points and lines. Each polygon has a corresponding fuzzy membership
t ∈ (0,1], 0 means no membership,1 means the full membership. Polygons represent the spatial knowledge of the corresponding phrases. The shape and size of the polygons in
Figure 1 is different in the subsequent section of the article, but there is no conflict between them. Different phrases, group and cognitions will lead to different subjective cognitive results; this character just reflects the subjective viewpoints representation ability of our method. In
Regions, neither strict membership function nor the requirement of all Regions’ integral to be 1 is needed in
t. The only requirement is to subjectively and artificially specify the membership
t of each
ri.
The
Region of
ti is an area relative to Spatial Entities (SEs), it can be further divided into two types
Regions ∈ (
Rlocal ∨
Rglobal).
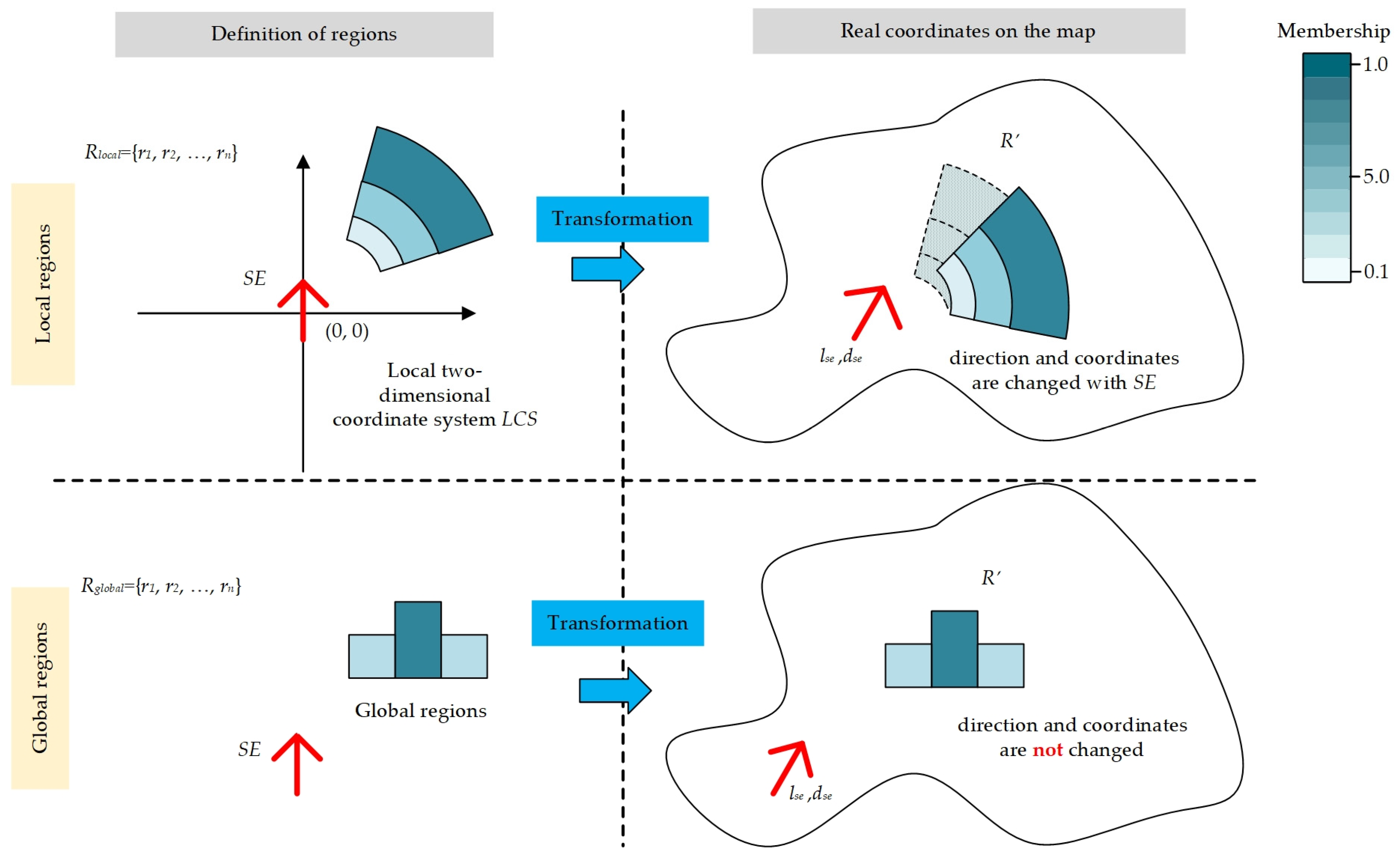
Rlocal refers to local Regions and
Rglobal refers to global Regions. The structure and coordinate transformation methods of the two kinds of Regions are shown in
Figure 1:
Local regions: In
Figure 1, local regions are a set of regions that the shape and membership depend on the location and direction of the
SE.
Rlocal = {
r1,
r2, …,
rn} contains multiple polygon
ri. All
ri are defined in a local two-dimensional coordinate system. In this coordinate system,
SE is at the coordinate position (0, 0), and the direction points to the north direction (
Y-axis direction). When
SE is put on the real map, each
ri is adjusted and converted to the coordinates on the real map according to the actual coordinates of
SE. The role of
Rlocal is to describe the position and region that are relative to
SE, such as the left side, front side, rear side, etc.
Global Regions: In
Figure 1, global regions are ground objects with different parts, and the shape and membership are determined by their own spatial features. For
Rglobal = {
r1,
r2, …,
rn}, where each
ri is the object on the real map, and their content remains unchanged. The role of
Rglobal is to describe the objects that
p interacts in a real geographical environment. For example, the roads or buildings that
p wants to reach. These objects have a certain influence on the spatial features of
p.
The transformation algorithm for the spatial coordinates of
Regions is represented in Algorithm 1:
| Algorithm 1: The CoordinateTransform algorithm |
| Input:Regions, SE |
| Ouput: Transformed regions R’ |
| Begin |
| if Regions is global regions |
| R’ = R; |
| return R’; |
| R’ = ø; |
| foreach ri in Regions |
| ri’ = Rotate ri in SE’s direction and move according to SE’s location; |
| R’←ri’; |
| return R’; |
| End |
By CoordinateTransform algorithm, the coordinates of Regions on the real map can be obtained by referring to the spatial position and direction of SE.
The definition of K will be easily facilitated based on the regions. For each spatial knowledge, such as “a person’s front-left”, the knowledge creator can construct a Phrase, then manually draw Regions within local SE coordinates, and assign weights to each polygons based on a subjective point of view or experience. This knowledge can be converted into regions according to the spatial attributes of SE in the actual map. In this way, the vague and subjective description of spatial relation is transformed into qualitative or quantitative polygons that can be expressed in the GIS.
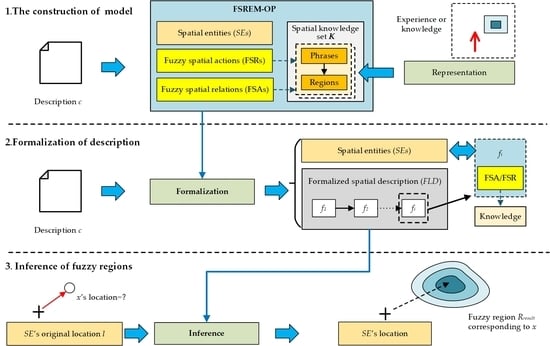
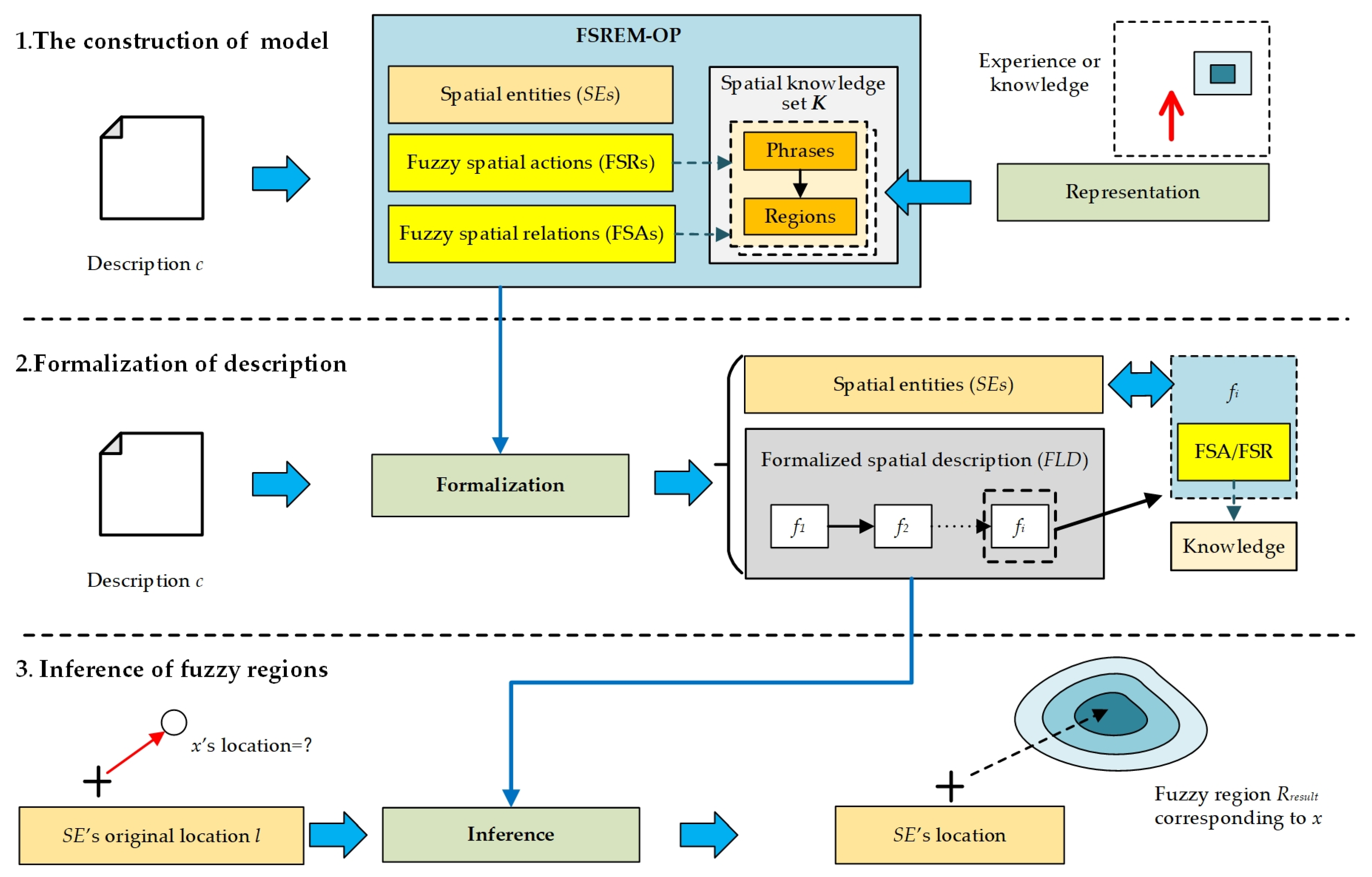
2.2. The Overall Process of Obtaining Inference Results
The overall process of FSREM-OP is shown in
Figure 2:
Figure 2 shows that the context, experience, and knowledge related to
c should be first introduced. This subjective knowledge is transformed into spatial knowledge set
K.
K expresses the spatial relations corresponding to
c. It can be reused and support all the inference work under the same background as
c (e.g., the expression of spatial relations of the same group of people). Based on the
K, the whole process is divided into the following three steps:
Model Construction: Set FSREM-OP = {SE, FSRs, FSAs} includes Spatial Entity (SE), its corresponding Fuzzy Spatial relations (FSRs) and Fuzzy Spatial actions (FSAs). In FSRs and FSAs, the process of spatial relationships is based on the content in K.
Formalization of description: As to the description c: its content is analyzed to obtain the observer p; the instance corresponding spatial entity (SE) is built based on p, and form the formalized spatial description (FLD). FLD is a sequential structure {f1, f2, …, fn}, in which fi is an FSR or FSA. Each fi will exert an influence on the spatial position and direction of SE or output of certain spatial regions.
Inference of fuzzy regions: Each fi in the FLD is successively executed to extract the fuzzy regions Rresult = {r1, r2, …, rn} where x is located; ri is polygon in Rresult that expresses the probability that x is in a particular area.
Through the above three steps, the spatial content of c can be extracted, and the possible regions of object x can be expressed as a set of polygon on the map to achieve fuzzy spatial region extraction.
2.3. Composition of FSREM-OP and Formalization of Description
The FSREM-OP model consists of the following three parts:
Spatial entity (SE): SE indicates the position and direction of p on the real map, which can be expressed as SE = {lse, dse}, where lse is the spatial coordinate of p on the map. dse is the direction of p, and this direction is a clockwise angle with due north direction as angle 0.
Fuzzy spatial relations (FSRs): FSREM-OP contains multiple spatial relations FSRs = {fsr1, fsr2, …, fsrn}, where each fsri corresponds to the knowledge in K. The function of the FSRs is to directly output a set of spatial regions according to the spatial description Phrase.
Fuzzy spatial actions (FSAs): FSAs = {fsa1, fsa2, …, fsan}, where fsai also corresponds to the knowledge in K. Different from FSRs, the function of FSAs is to change the position and direction of SE.
With the support of the FSREM-OP model, a description
c can be transformed and expressed as formalized spatial description (
FLD) by sequential analysis using
FSRs and
FSAs. Its corresponding algorithm is represented in Algorithm 2:
| Algorithm 2: The FLDConstruction algorithm |
| Input: description c, FSREM-OP |
| Output: formalized spatial description FLD |
| Begin |
| klist = Filter and separate c into blocks according to all the phrases in K |
| FLD = ø; |
| foreach phrase in klist |
| if phrarse a description of the location |
| FLD←corresponding fsr; |
| else if phrase a description of the action |
| FLD←corresponding fsa; |
| return FLD; |
| End |
The FLD can be built by FLDConstruction algorithm. The internal FLD is composed of FSRs or FSAs. The position of x can be inferred by the sequential parsing of the FLD.
2.4. Inference of Fuzzy Regions
The inference of FLD is the process of successively analyzing each fi within the FLD to adjust the position and direction of SE or outputting regions. As for FSRs process, since FSRs represent spatial relations, a FSR only needs to output the regions in the corresponding knowledge.
For FSAs, the
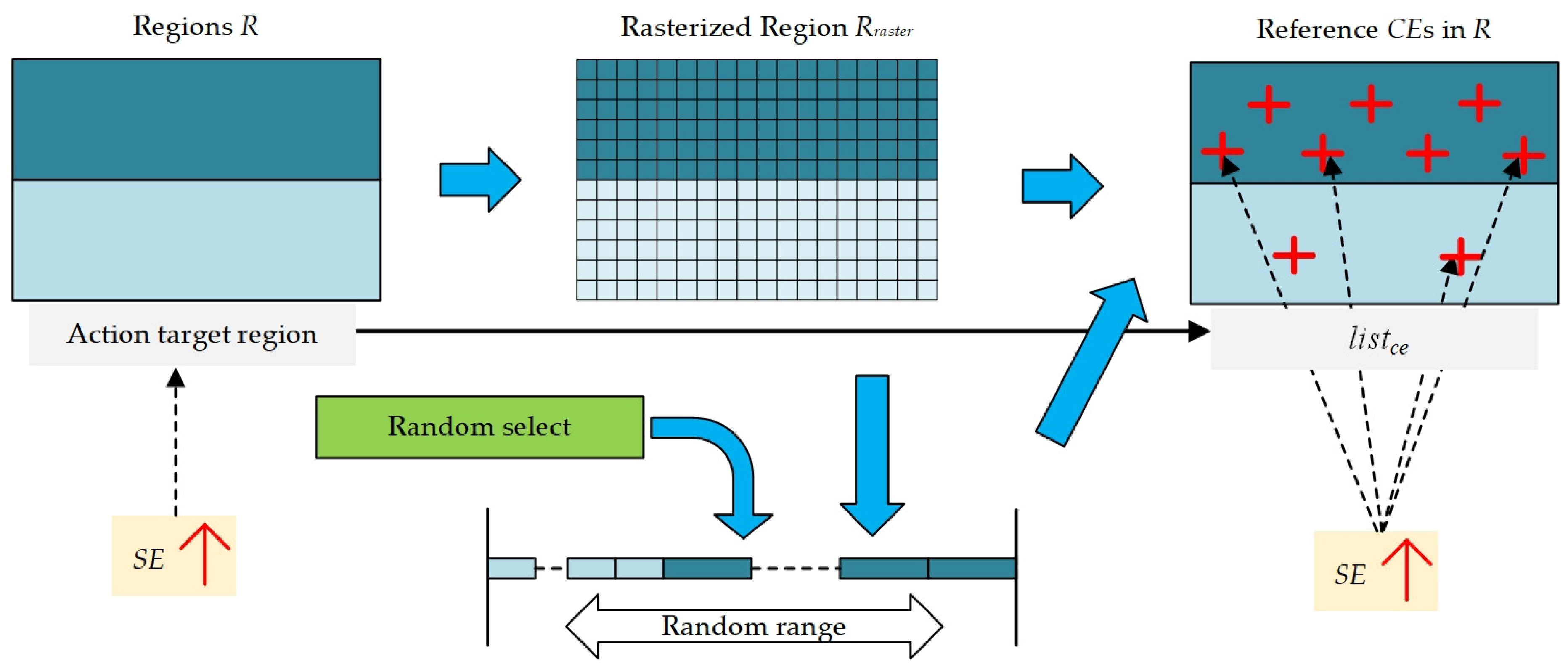
Regions in corresponding knowledge can bring certain fuzziness. For example, even if the same person walks for one minute, the distance traveled each time can be different. A single
SE cannot express this fuzziness (one cannot be in two places at the same time), so this paper introduces the Reference
CE List (
listce) to express the fuzziness of different regions through the location and density of multiple
CE. The specific pattern is shown in
Figure 3:
In
Figure 3, it is assumed that
Regions is converted into the raster data of
Rraster, each raster has a fuzzy membership degree; when performs random selection, the raster with a higher membership degree is more likely to be selected, whereas the opposite is less likely. In this paper, an algorithm is proposed to convert this selection idea into the selection of distances within a certain range. The corresponding algorithm is represented in Algorithm 3:
| Algorithm 3: The RandomSelect algorithm |
| Input:Rraster |
| Output: Selected raster rselected |
| Begin |
| length = 0; intervallist = ø; |
| foreach r in Rraster |
| intervallist←[length, length+r.t); |
| length = length+ r.t; |
| rand = gets a random number of [0,length); |
| postion = Find an interval that contain rand in intervallist, and obtain this inverval’s position in intervallist; |
| rselected = Rraster[postion]; |
| End |
RandomSelect algorithm is taken as the basis of the random selection mechanism. As shown in
Figure 3, the
FSAs inference is a process where a
SE is transformed into a group of
SE after the transformation of direction and position. Its corresponding algorithm is represented in Algorithm 4:
| Algorithm 4: The FSAInference algorithm |
| Input: Spatial entity SE, Region R, Number of reference CEs Nce |
| Output: list of CE listce |
| Begin |
| Rraster = transform R in to raster format; |
| listce = ø; |
| for i in 1: Nce |
| rselected = RandomSelect (Rraster); |
| SEcopy = clone a SE; |
| Adjusts the position and direction of SEcopy based on the rselected position |
| listce←SEcopy |
| return listce; |
| End |
Based on
FSAInference algorithm,
SE and
R can be converted into a group of SE
listce. In polygons of
Regions, the
CE density with a high membership will be higher, and vice versa. Based on this model, the expression of the fuzzy region of location and direction can be realized, and then the fuzziness of behavior can be quantified in the result. Based on the all above algorithms, the entire
FLD inference process is represented in Algorithm 5:
| Algorithm 5: The FLDInference algorithm |
| Input: formalized spatial description FLD, Description c |
| Output: Result regions Rresult |
| Begin |
| SE = build initial direction and coordinates of SE based on c; |
| listce = ø; Rresult = ø; |
| listce←SE; |
| for fi in FLD |
| listtemp = ø; |
| foreach eCE in listce |
| R = CoordinateTransform(R of fi, eCE); |
| if fi is a FSR then |
| Rresult←R; listtemp←eCE; |
| else |
| listtemp←FSAInference(eCE, R, Nce); |
| listce = listtemp; |
| return Rresult; |
| End |
Since FSR and FSA are employed throughout the whole derivation of FLD inference, the CE is constantly created to describe the fuzzy action characteristics of p during the execution, and the final result is the Rresult outputted by FLD Inference.
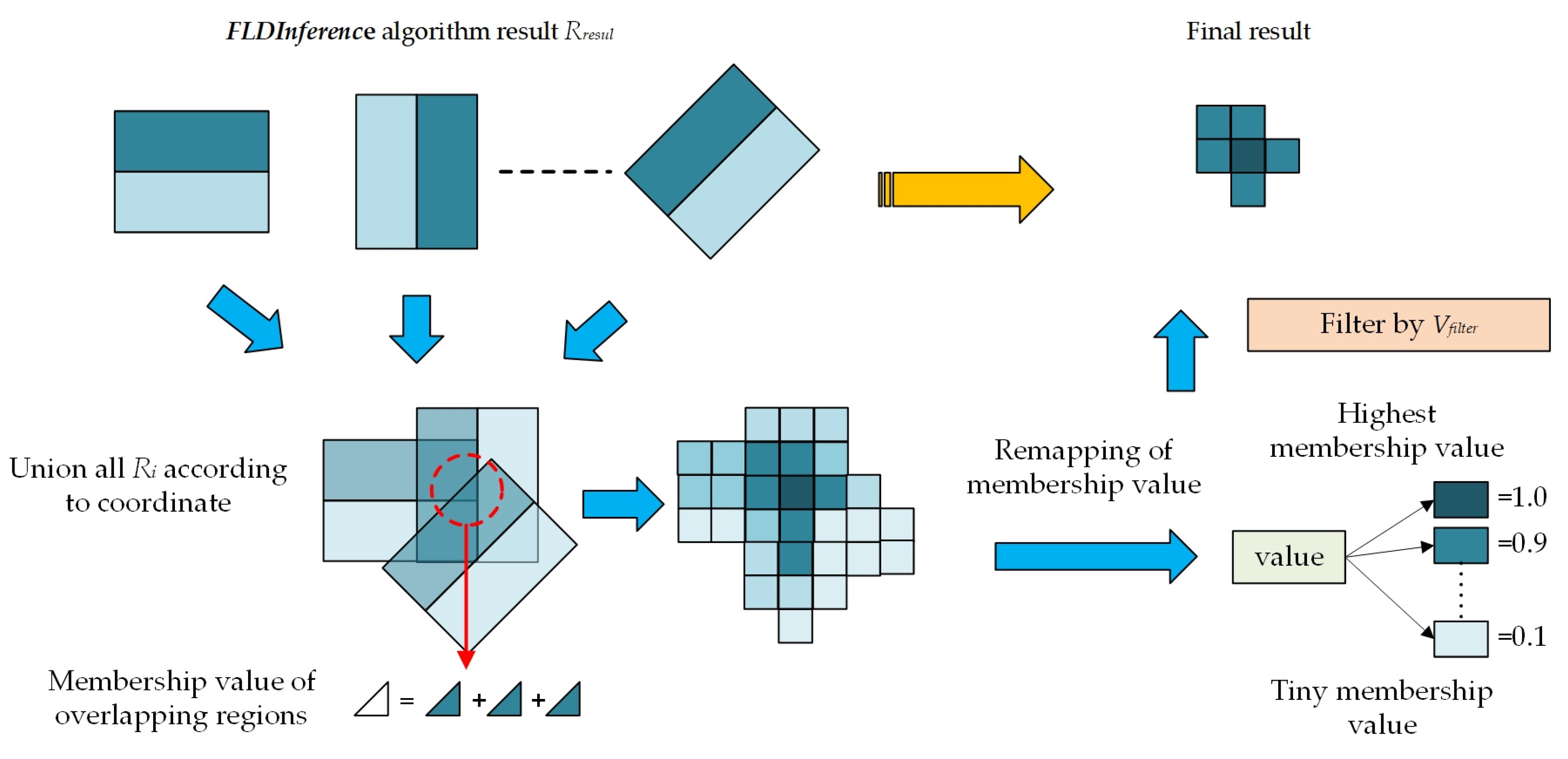
2.5. Merger of Results
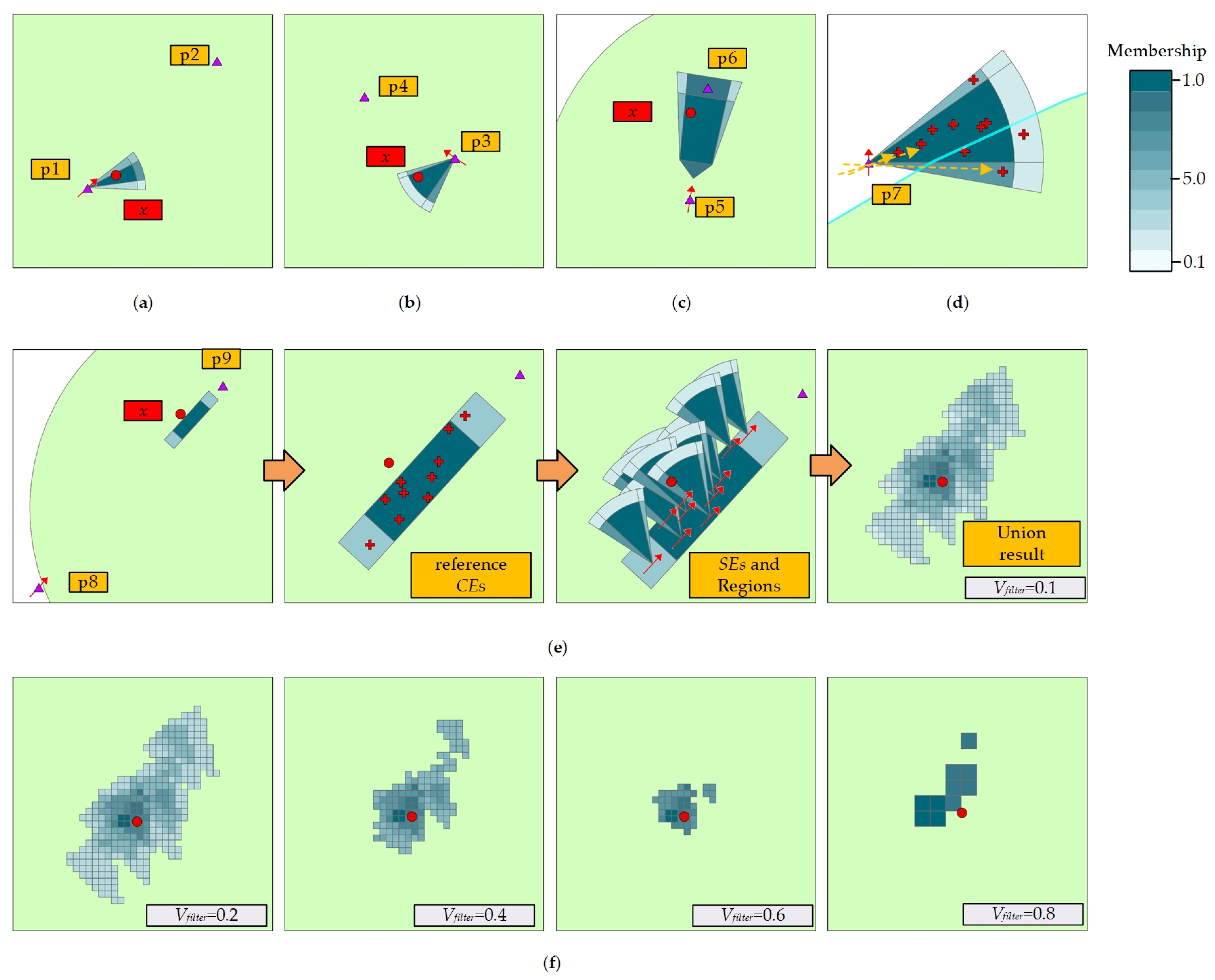
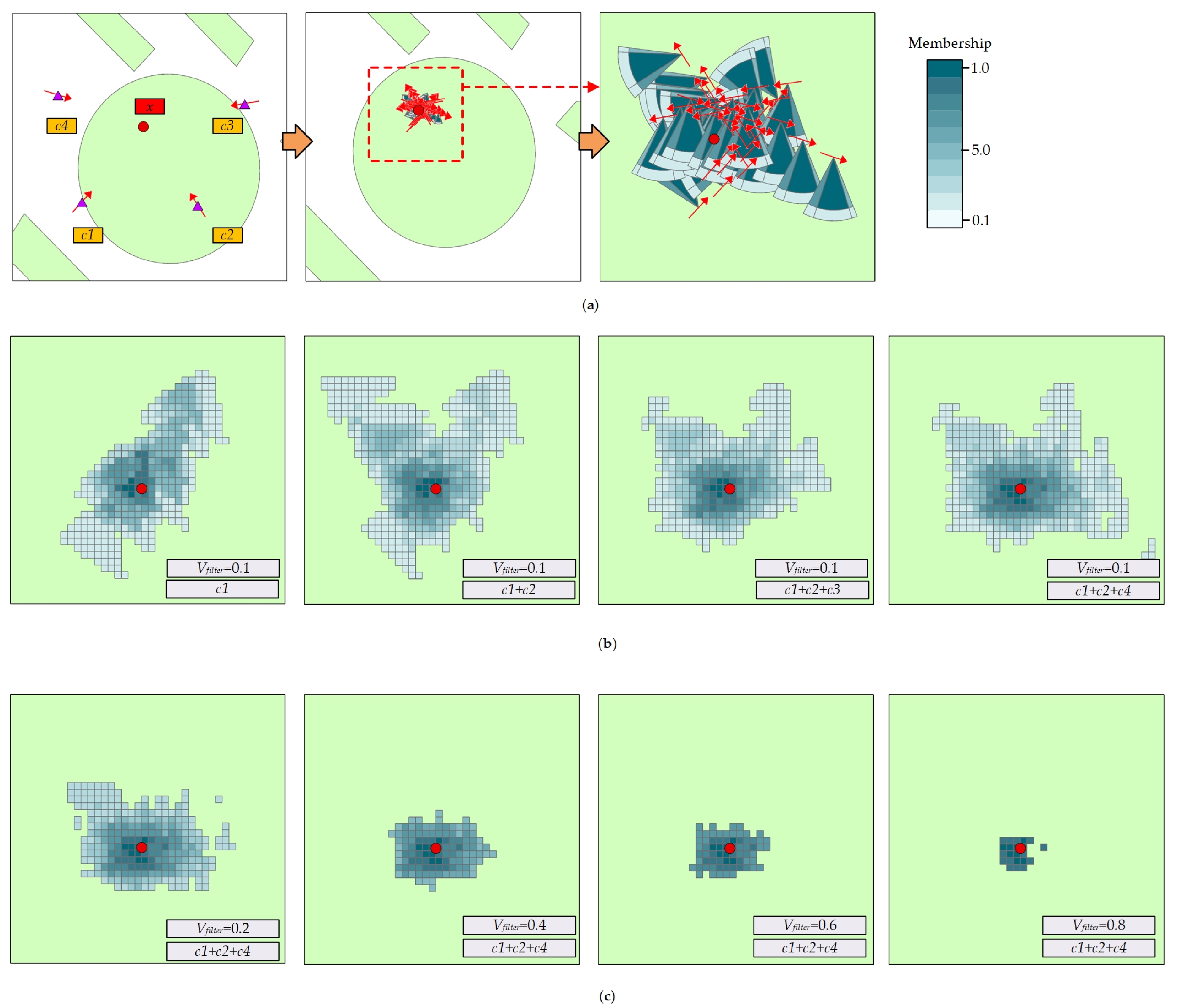
Because the result produced by FLD Inference is the list of regions, Rresult = {R1, R2, …, Rn}, where each Ri = {r1, r2, …, rn}. If the Rresult contains only one R, it means the final result of FLD Inference comes from the content of a single spatial knowledge, which can be outputted directly to the map as a result.
If the
Rresult contains multiple regions, an overlapping of these regions will occur. The final processed output is illustrated in
Figure 4:
The steps to combine the contents of Rresult into the final output are:
Firstly, all Ri in Rresult are combined based on coordinate positions. As shown from the result of the combination, each overlapping polygon is separately represented to form Runion = {r1, r2, …, rn} according to the different overlapping. For ri, its membership value is equal to the sum of the membership of all regions forming this region. At this point, if the number of polygons is too large, there will be too many fragmented polygons in Runion, to be conducive to people’s understanding of the final output result. Therefore, we need to perform transformation. Based on the Runion corresponding area we create Mcell = {r1,r2, …, rn}. In the area corresponding to Mcell, the whole area is divided into polygons ri which a width×width sized square; the membership value of ri equals to the highest membership value of polygons in Runion that intersects with it.
In the
Runion, too many overlapped regions will lead to
ri’s membership value higher than 1, which is not conducive to truly showing and comparing the membership of different regions. Therefore, this method also remaps the weights in
ri.
The membership values are remapped from 0.1 to 1.0. After that, a filter parameter, Vfilter, is specified to filter out all the cells that are smaller than the parameter to get the final merging result.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}