1. Introduction
The digital elevation model (DEM) has wide applications and significant value in surveying and mapping [
1], hydrology [
2] and earth science [
3]. As of now, the common way to obtain DEM data is by low-altitude photogrammetry, in which the point cloud data is obtained by dense matching. By covering a large scope of areas, this method can provide image texture information so as to basically meet the requirement of DEM construction [
4]. However, due to a series of reasons, such as the dead angle of aerial photography, matching deviation and insufficient point position, the DEM constructed in most circumstances has holes of different sizes and shapes. The DEM data with holes hinders the acquisition of various terrain and geomorphic structure information, which would further make it difficult to provide and couple geospatial information well. For example, in the process of actual production, if the constructed high spatial resolution DEM has voids, it will produce an incomplete expression of the morphological characteristics of erosion trenches [
5], while the missing data would also easily cause erroneous estimation of the material balance accuracy of mountain glaciers [
6] and difficulties in eliminating topographic cracks [
7].
For those reasons, a large number of related studies have been carried out by scholars, both at home and abroad. The literature [
8] uses the inverse distance weight method (IDW), local polynomial interpolation method (LPI), spline with tension method (ST) and other algorithms to interpolate the elevation sampling points, construct the DEM and obtain both the advantages and disadvantages of the above methods through comparative analyses. The extraction and interpolation functions of fractal simulation parameters were improved in [
9], but despite that, the method would nonetheless have great limitations in correcting DEM errors caused by two-phase unwrapping. The literature [
10] realized triangle network reconstruction without prior knowledge by calculating the Delaunay neighborhood projection of each data neighborhood point on the tangent plane of the point. However, the results of the above two methods depend on the sparsity and uniformity of the sampling points, while the algorithm is highly disturbed by known data. A radial basis function was originally used to interpolate scattered data [
11]. The function and its improved form [
12,
13,
14,
15] were proposed, which had higher degrees of precision than interpolation fitting. Due to the fact that the radial basis function has a dense and tedious solution matrix, algorithm implementation is more complicated [
16].
In recent years, compared with the traditional image inpainting methods, the algorithm of the deep generation model based on machine learning has shown excellent performances in its related fields [
17,
18,
19,
20]. Depending on the developments of such models, different solutions have been proposed for filling the DEM void. The appearance of the generative adversarial network (GAN) provides another way of thinking for spatial interpolation, in spite of some remaining problems, such as unstable training, easy disappearance of the gradient and mode collapse, which may cast about certain influence to the training of the model. Conditional GAN (CGAN) refers to a GAN with conditional constraints, which is used to guide network training given the corresponding label. The literature [
21,
22] used CGAN and the improved CGAN model to analyze the structural expression of spatial interpolation. However, CGAN still has the same defects as GAN, such as the disappearance of gradients. The literature [
23] considered a generation model based on Wasserstein GAN (WGAN) for DEM void filling, but the use of local feature extraction in the network cannot guarantee that the model recovers the overall DEM semantic information. Despite that, there are various open sources and crowd sources of DEM datasets sufficient to support deep trainings (such as the Advanced Spaceborne Thermal Emission and Reflection Radiometer Global Digital Elevation Model (ASTER GDEM) series, Shuttle Radar Topography Mission (SRTM) terrain data, the Global Land Surveys (GLS products and Norwegian Bureau of Surveying and Mapping (
http://www.hoydedata.no/) publicly provided data), though research on applying generative models to the field of digital elevation models is still rarely involved and effective as of now.
Hence, with regard to the existing traditional methods and problems in DEM void filling, this paper constructs a model suitable for filling the DEM void in different terrains (gentle and complex terrains) based on the algorithm of deep learning so as to recover the general features of overall DEM semantics. The advantages of this method for filling accuracy are proven, and comparisons with many other existing methods are made.
2. Materials and Methods
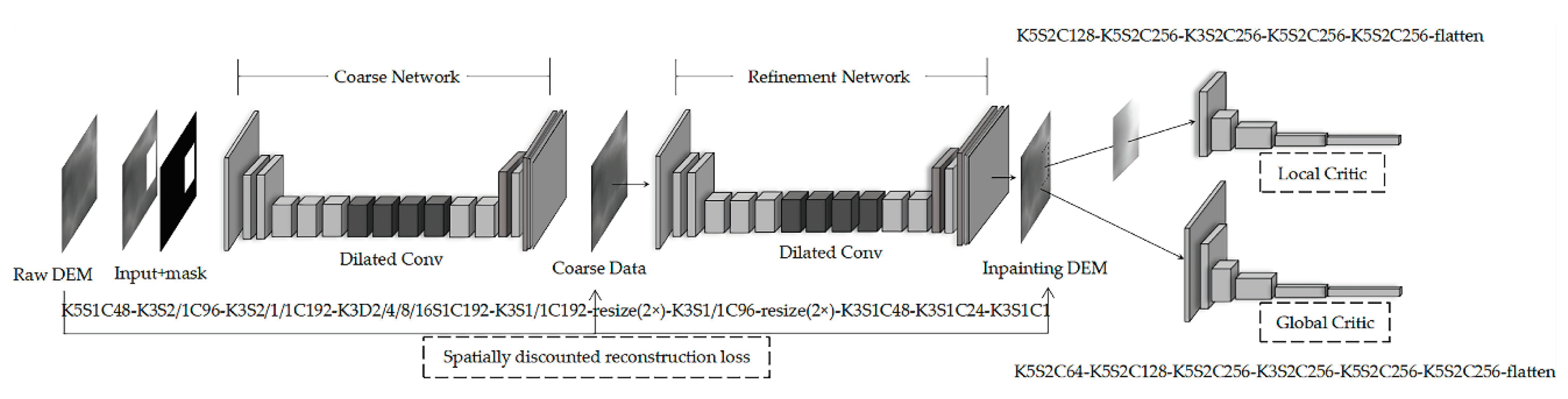
Through the adaptive modification of a feedforward generation network with the context concern layer [
19], the pixel value of the image’s missing part was transformed into the missing elevation data of the DEM prediction. The network structure was composed of two parts: the first part generated the model through deep training to obtain the filling result, while the model architecture was designed as a network form from coarse to refined; the second part combined the context concern layer to assist and optimize the training process.
2.1. Deep Generation Model
2.1.1. Deep Generation Model Network Structure
The network structure of the first part is shown in
Figure 1, where K represents the kernel size, D represents the dilation, S represents the stride size, and C represents the channel number.
A DEM of the same size was adopted as the input of the network, while a missing area was randomly sampled at the front end of its training to ensure that the model post-training had the perceptual ability to complete void filling tasks with different numbers, sizes and areas.
DEM void filling based on the generated model has a network structure system of two stages. In the previous stage, the coarse network used reconstruction loss to assist the training and generate the approximate elevation value of the missing part. In the second stage, the detailed filling results are generated through the auxiliary continuous training of reconstruction loss and two GAN losses. The core significance of refinement network lies in the re-prediction of rough generated values so it has the ability to see a more complete field of vision than the missing area while having better feature representation than the coarse network.
2.1.2. Deep Generation Model Discriminant Loss
A WGAN uses earth mover’s (EM) distance to replace the Kullback–Leibler (KL) divergence in the GAN. The literature [
24] described the WGAN as in Equation (1):
where all functions
that satisfy the 1-Lioschitzlimit are represented by a neural network with a parameter
and obtain the upper bound of
. The reverse of this can be used to construct the discriminant loss function in Equation (2):
where
in the formula.
The literature [
20] proposed an improved version of the WGAN with a gradient penalty (WGAN-GP) term to eliminate the effect of gradient instability. A penalty term
(
= 1) was added on the basis of the above loss. Finally, a new discriminant loss function can be obtained to form Equation (3):
For the purpose of this study, the gradient penalty term is only used inside the hole, and the mask
placed in Equation (4) is as follows:
The filling network that relied on global and local GAN losses for adversarial supervision training allowed for the learning of image features through inlining. Therefore, the network used the discriminant loss based on WGAN-GP to attach the output of the refinement network.
2.1.3. Spatially Discounted Reconstruction Loss
DEM void repair involves the prediction of different elevation values. For any given context information, there are different and semantic filling methods. A feasible repair result may be quite different from the original DEM. Under this condition, if the original data is used as the reference standard for calculating the reconstruction loss, it will cause a deviation in the model training process. The proposal of spatial attenuation reconstruction loss was reasonably applied to solve such problems. Since the semantic information of the hole boundary is far more than the information in the middle of the hole, if the mask with weight is used, the weight of each point to be inserted in the mask is , where is the distance from the point to be interpolated to the known sampling point. If the value of is set to less than 1, then as the point to be interpolated is closer to the center of the hole, the weight will decrease as the distance increases. The smaller center weight reduces the error effect that may be caused by the gap between the repair result and the original image.
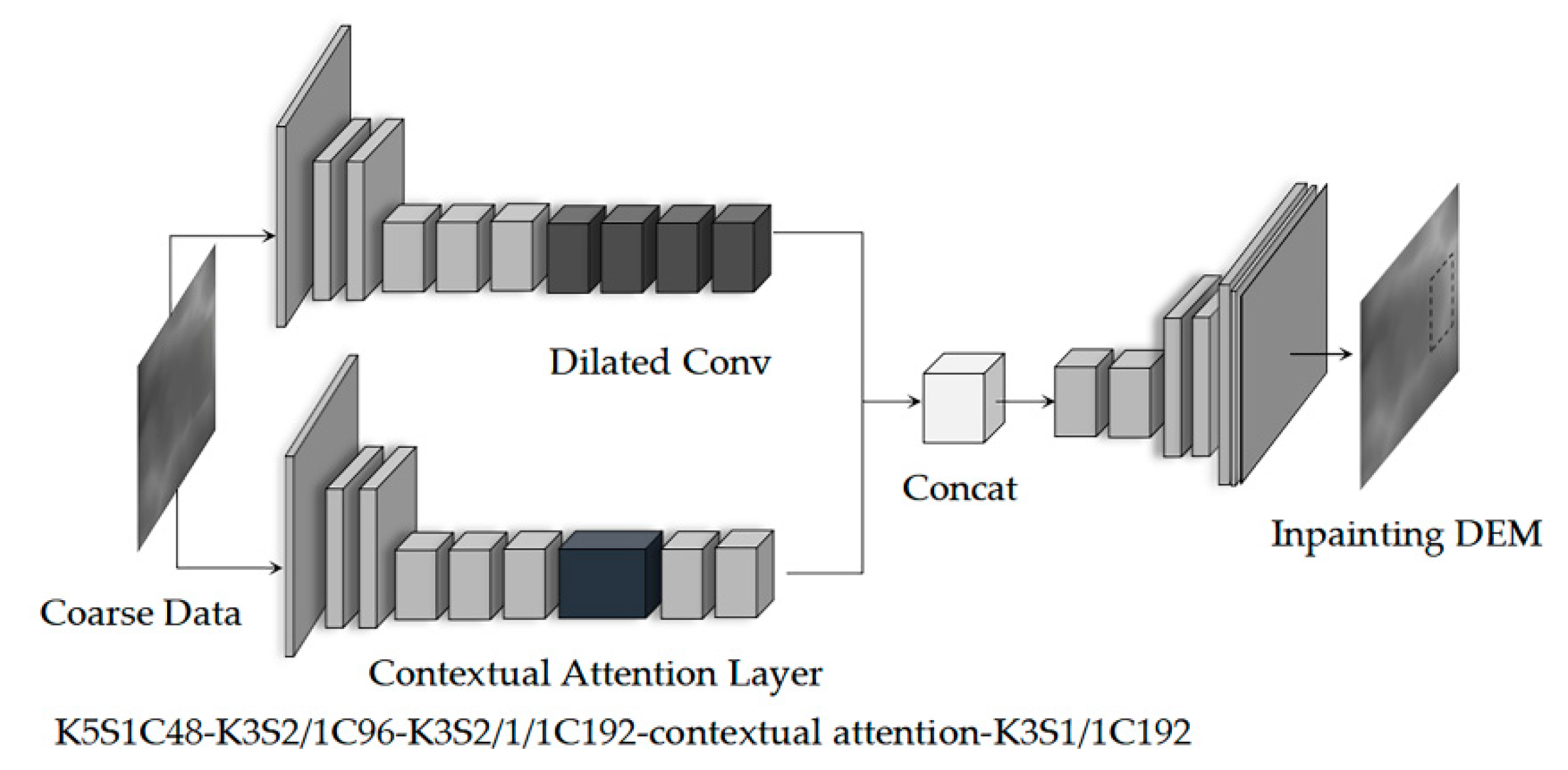
2.2. Contextual Attention Layer
The contextual attention layer borrows (or copies) feature information from a known background to fill the relevant properties of the void area. In the network training process, the context focuses on the model matching the missing value (foreground) and the surrounding environment (background) features, using the normalized inner product to measure the matching between the foreground block
and the background block
as in Equation (5):
where
represents the similarity of feature matching between the foreground
and the background
. One can calculate the weight (
) of each background block, select the optimal block
and deconvolute it to get the foreground region.
Attention was paid to the existence of propagation to maintain the overall consistency of the image. The idea was based on the foreground block corresponding to the background block, and they may change together, such as in the similarity between the point to be interpolated and the value of the surrounding point. Taking left–right propagation as an example, a similarity degree similar to Equation (6) can be obtained:
where
is the kernel size.
2.3. Unified Inpainting Network
The network combined the context attention layer into the fine network and formed a parallel encoder, as shown in the second part of
Figure 2.
The downlink encoder was trained to predict the output missing graph block, and the uplink encoder convolved out the foreground area. The output features of the two encoders were aggregated into a decoder, and the final deconvolution results were obtained.
In the filling task,
is defined as the original DEM data. By randomly generating a mask
, the input DEM is
. The filling network
takes
and
as inputs, and the DEM based on this output is
. Then, one can find the filling result in the same position as the mask area in
, map it to
and get the final repaired DEM
. The training process is as follows:
| Algorithm: DEM Null Filling |
| Input: with holes, mask . |
| Output: Final prediction . |
| 1: while has not reached convergence do |
| 2: Sample batch DEMs from training data. |
| 3: Generate masks with random holes for each . |
| 4: Create input data . |
| 5: The network allows and to be entered together. |
| 6: Get predicted DEMs data . |
| 7: Match the repaired area in to . |
| 8: Get the final forecast DEMs . |
| 9: Update the completion network with spatial discounted reconstruction loss and two WGAN-GP losses. |
| 10: end while |
2.4. Boundary Reprocessing
Bilateral filtering was selected in this paper to alias the DEM results, as the mapping behavior after filling brought certain boundary effects. The basic idea underlying bilateral filtering is to do it in the range of an image that traditional filters do in its domain. Two pixels can be close to one another—that is, occupy nearby spatial location—or they can be similar to one another; that is, they can have nearby values, possibly in a perceptually meaningful fashion [
25]. The formula is defined as follows:
The above formula represents the product of the weight, calculated by the spatial proximity between each point and its central point , within a certain range of and the weight calculated by pixel value similarity. Through the convolution calculation, the DEM data were output. Finally, the obtained data were mapped to the repaired DEM data to eliminate the boundary effect.
4. Discussion
We mainly put forward the application of this kind of model in surveying and mapping science and technology in order to discuss the popularization and application of a generating model in surveying and mapping. In the theory of probability and statistics, the generation model refers to the model which can generate the observation data randomly under the conditions of some implicit parameters. It assigns a joint probability distribution to the observation value and the labeled data sequence. In machine learning, a generative model can be used to model data directly or to establish conditional probability distribution among variables.
The introduction of a discriminate model leads to the emergence of a game type training process. The use of this kind of neural network as the model type is called a generative confrontation network (GAN). A GAN and its improvement [
24,
29,
30,
31,
32] make generative models become a hot research direction of artificial intelligence technology. At present, it has been applied in Natural Language Processing (NLP), image generation, super-resolution, image restoration and other fields.
Extended to the current research of surveying and mapping disciplines, we have always believed that such models can be better applied in the following aspects:
In the construction and repair of 3D models, the data collected by 3D sensors are often affected by occlusion, sensor noise and light, resulting in the incompleteness of 3D models and the generation of noise. However, one can understand and describe the geometry of the entire building based on a damaged 3D model. The method described in [
33] attempted to imitate this ability and reconstruct a complete three-dimensional model from incomplete data.
Cloud removal. Satellite images are increasingly used in a variety of applications, including monitoring the environment, mapping economic development, crop type classification, land cover and measuring the leaf index. However, satellite images are often obscured by clouds, which cover about two-thirds of the world. Thick clouds hide the content of the image, and even thin, translucent clouds can greatly affect the effectiveness of satellite images by distorting the ground below. Therefore, it is the first important step in most satellite image analysis to remove cloud cover and generate cloud free images [
34].
Target identification. In recent years, deep learning has achieved great success in the field of image object recognition. Its advantage is that it can use a large amount of data to train the network, learn the characteristics of the goal, avoid complex preprocessing and achieve better results. Presented in [
35] was a semi-supervised learning method based on standard deep convolution generative adversarial networks (DCGAN) for the target recognition of synthetic aperture radar images.
5. Conclusions
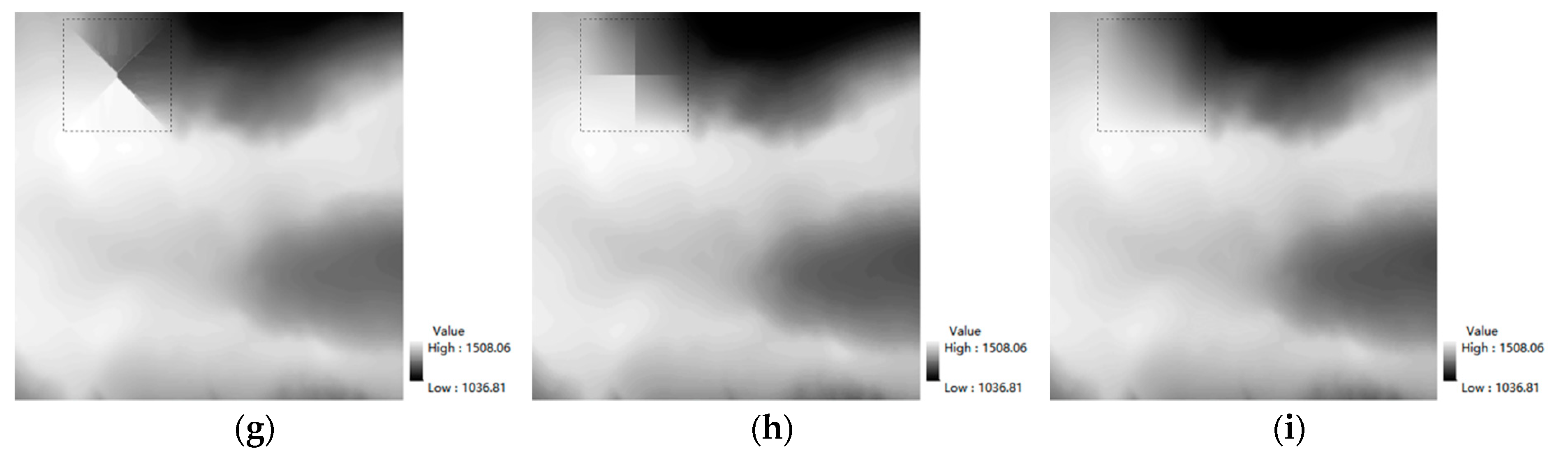
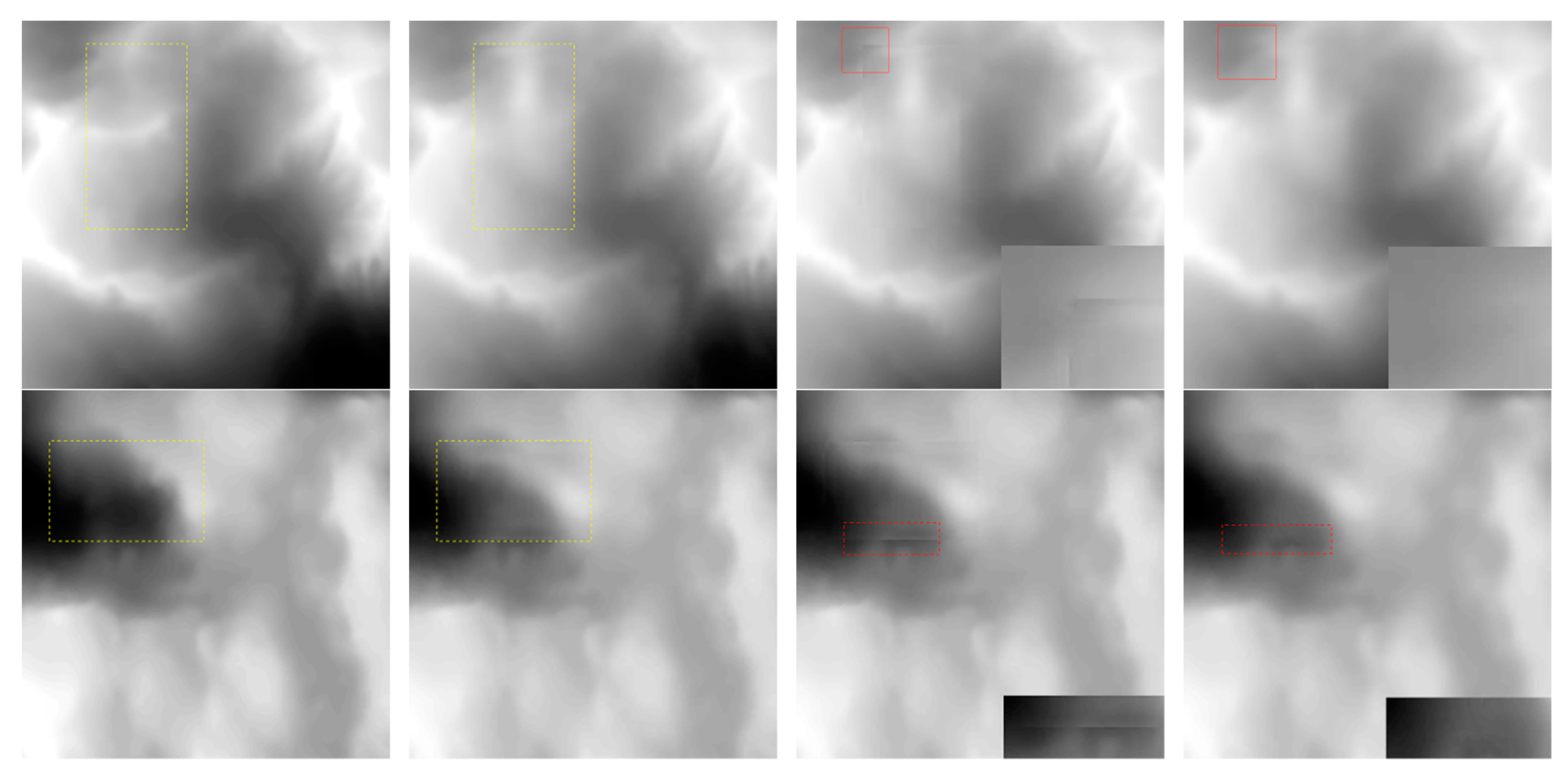
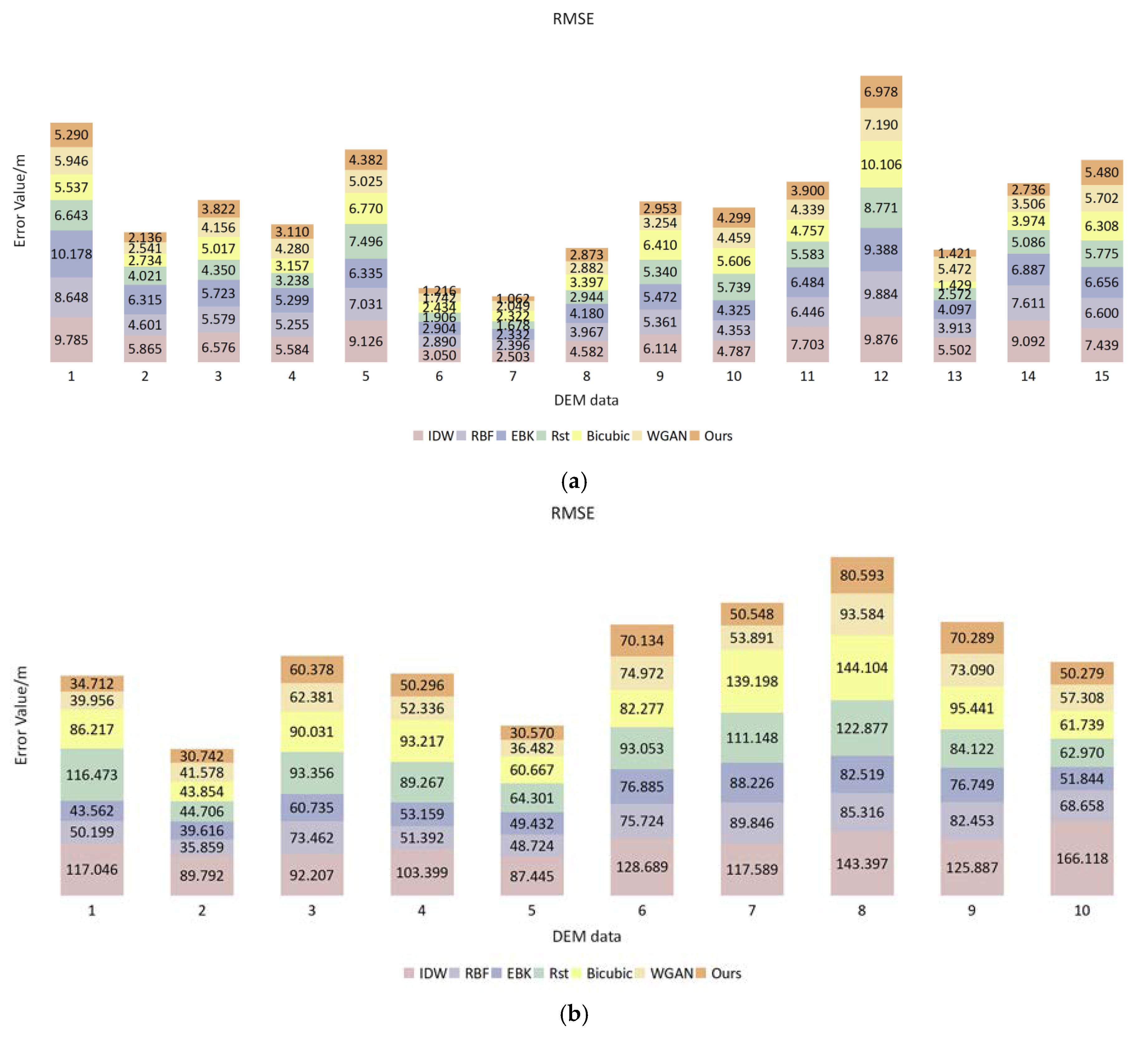
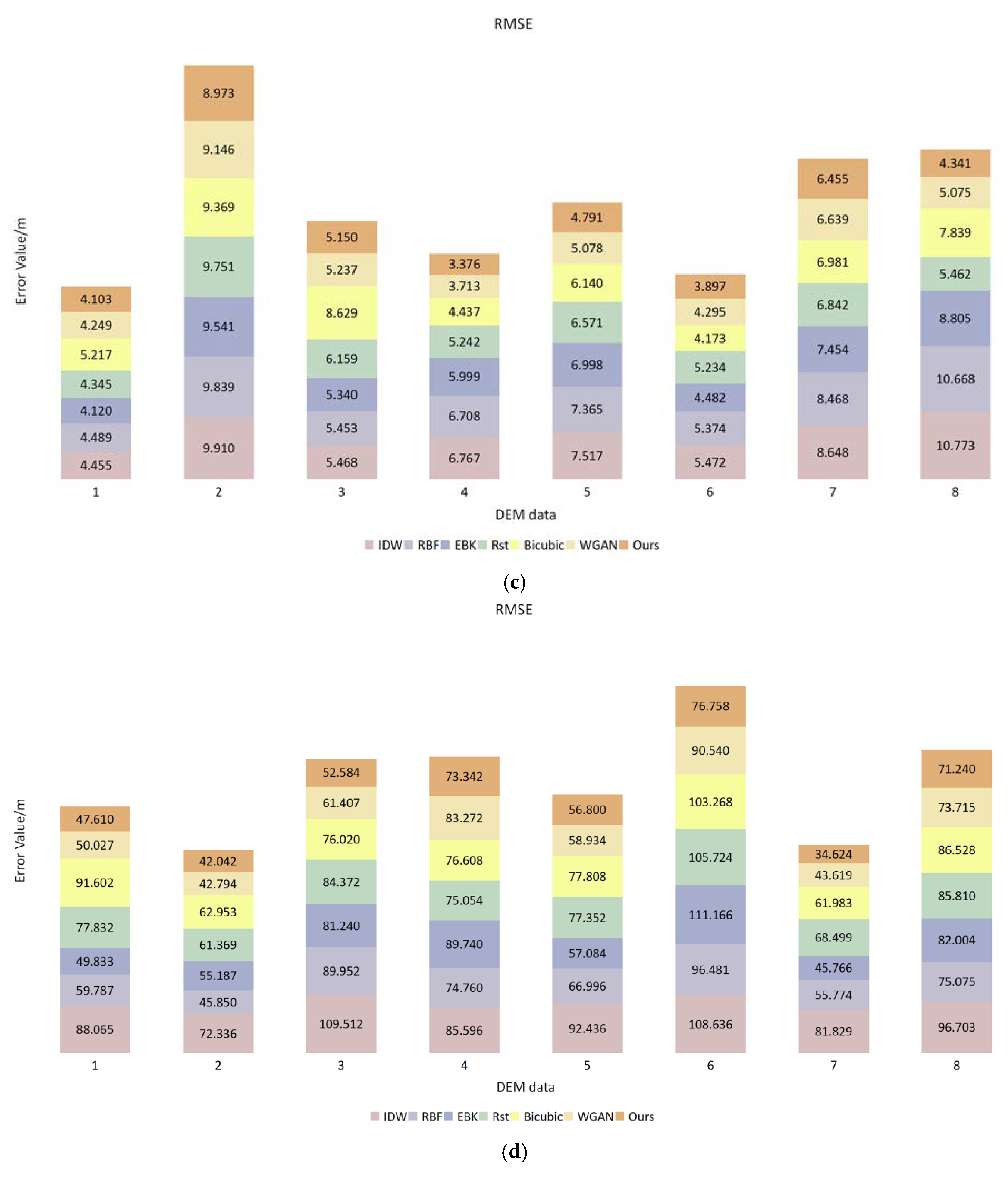
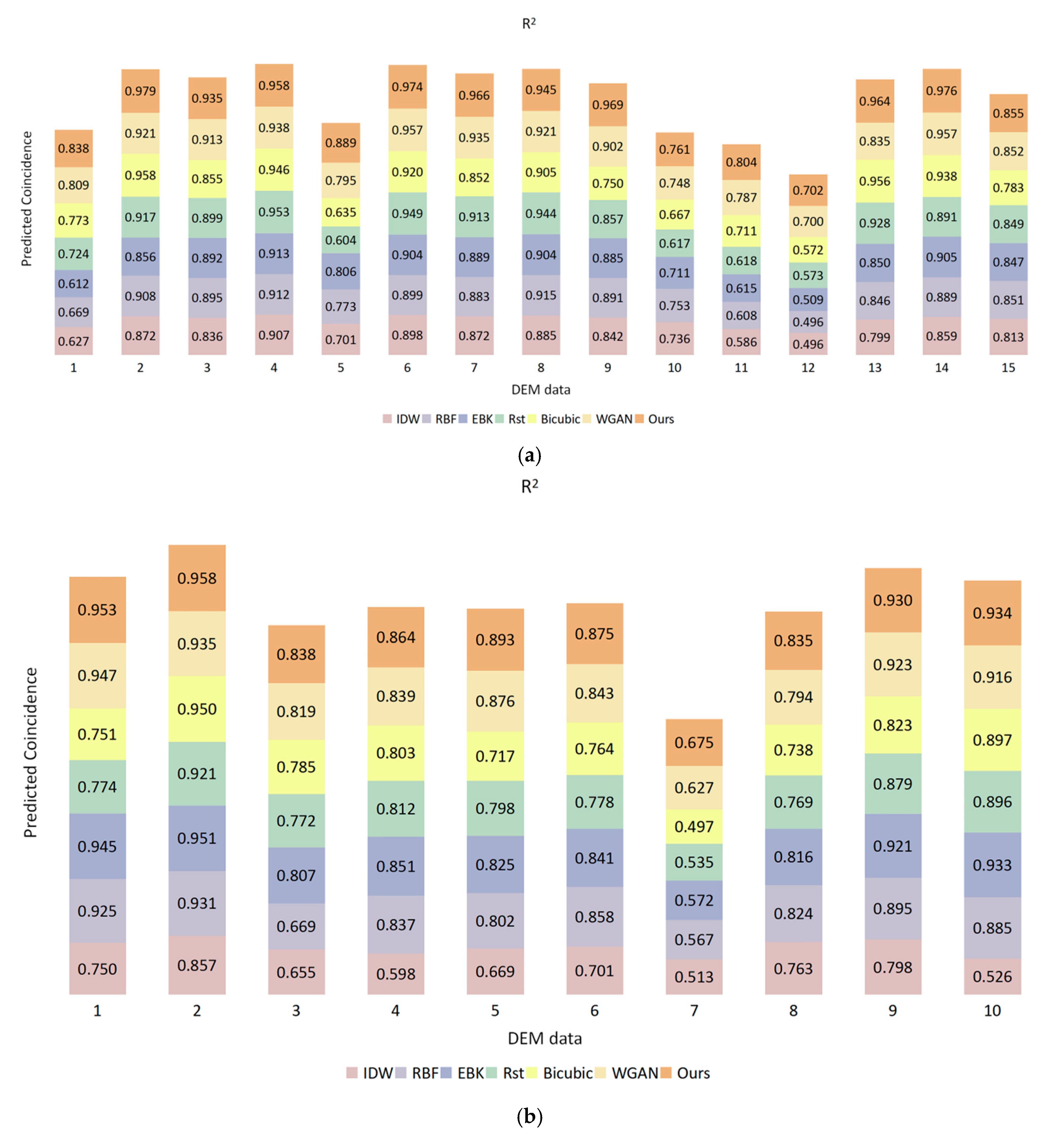
With regard to the remaining problems in the traditional method of DEM void filling, this paper introduced a method based on the algorithm of deep learning, aiming to repair the DEM. At the first stage of the network, the global and local countermeasures were used to ensure the consistency of the predicted data. At its second stage, the contextual attention layer was combined to perceive global information and enhance the representational ability of the data texture structure. In order to verify the effectiveness and universality of this proposed method, three kinds of data were compared with different repair methods. As indicated by the results, the traditional method focused more on the image’s gray value and could not interpolate the missing data of elevation well, leading to the obtained DEM being broken and discontinuous. Meanwhile, the repairing results obtained by the WGAN manifested weakness in its characteristic expressiveness, which may have failed in soundly obtaining the prediction results. By the method of DEM void filling, as illustrated in this paper, it is easier to grasp the elevation information and its related characteristics so that the post-repair data would possess a certain degree of space continuity and heterogeneity. In this way, the post-repair data would possess higher alignment with the original DEM data and manifest excellence in the forecast for filling from different data sources, so as to be a kind of filling method with high reliability and strong adaptability.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}