Prototyping a Social Media Flooding Photo Screening System Based on Deep Learning




Abstract
:1. Introduction
2. Related Work
2.1. Image Classification Based on Deep Learning
2.2. Flooding Photo Classification
3. Methodology
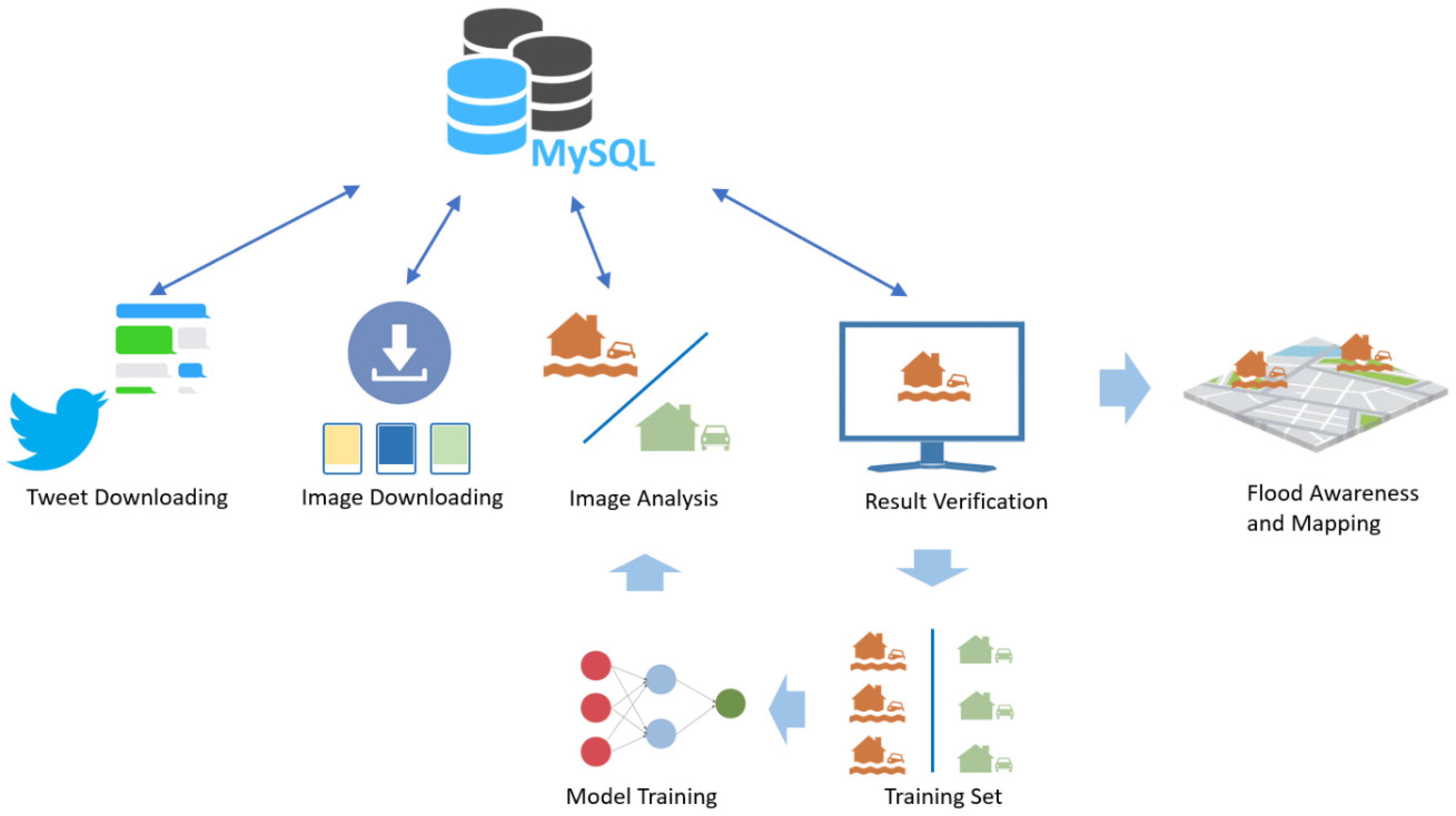
3.1. System Architecture
3.1.1. Tweet Downloading Module
3.1.2. Image Downloading Module
3.1.3. Image Analysis Module
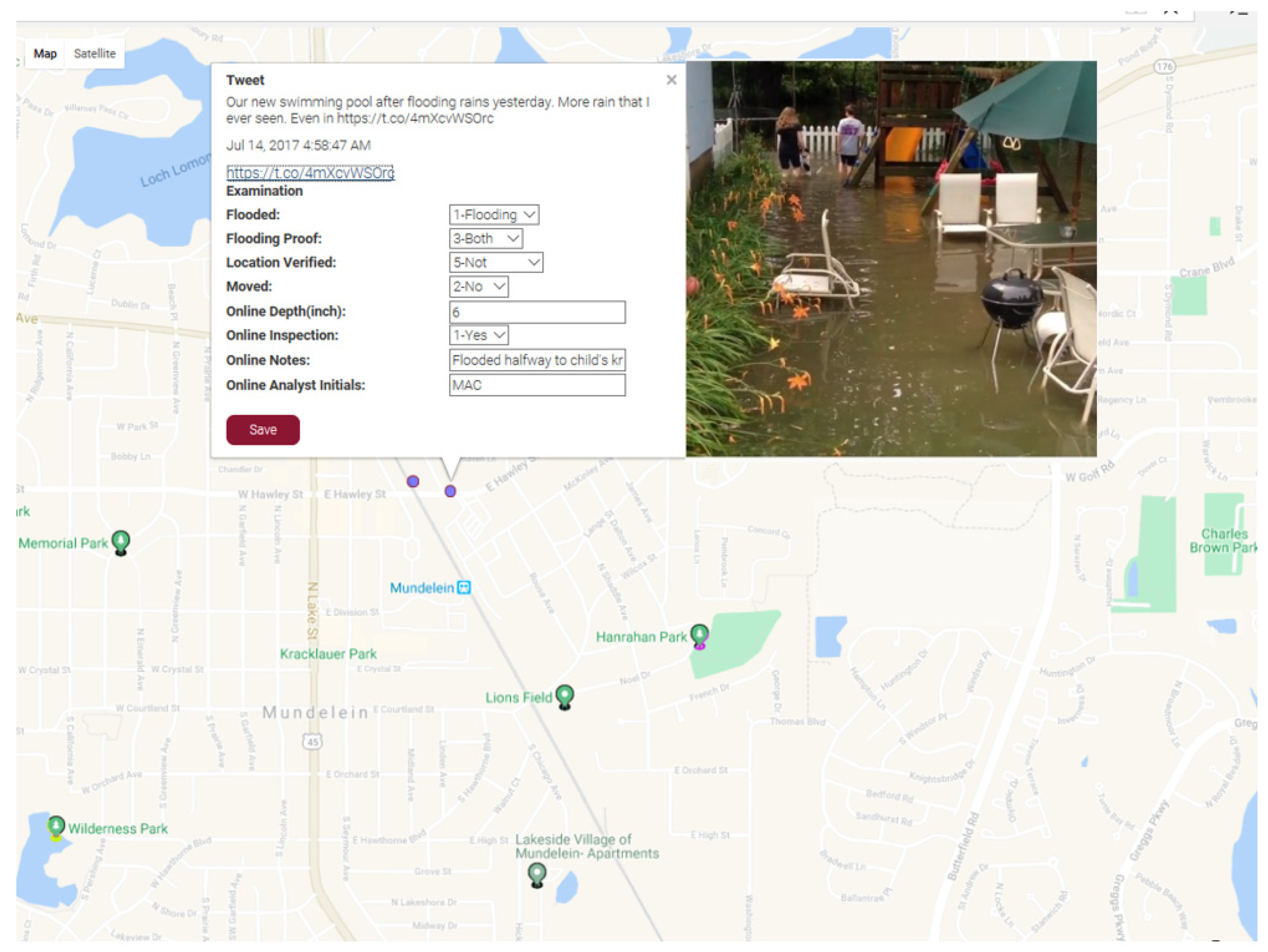
3.1.4. WebGIS-Based Result Verification Module
3.2. Dataset and Training
3.2.1. The Criteria for Identifying Flooding Photo
3.2.2. CNN Training and Selection
4. Case Studies of RIASM
4.1. Case 1: Houston Flood in 2017
4.2. Case 2: Hurricane Florence Flood in 2018
5. Discussions
6. Limitations and Future Research
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Union of Concerned Scientists Climate Change, Extreme Precipitation and Flooding: The Latest Science. 2018. Available online: https://www.ucsusa.org/global-warming/global-warming-impacts/floods (accessed on 22 March 2019).
- Wuebbles, D.J.; Fahey, D.W.; Hibbard, K.A. Climate Science Special Report: Fourth National Climate Assessment; U.S. Global Change Research Program: Washington, DC, USA, 2017; Volume I. [Google Scholar]
- National Weather Service. Summary of Natural Hazard Statistics for 2017 in the United States; National Weather Service: Silver Spring, MD, USA, 2017.
- U.S. Department of the Interior; U.S. Geological Survey (USGS). Flood Event Viewer. Available online: https://water.usgs.gov/floods/FEV/ (accessed on 22 March 2019).
- Koenig, T.A.; Bruce, J.L.; O’Connor, J.; McGee, B.D.; Holmes, R.R., Jr.; Hollins, R.; Forbes, B.T.; Kohn, M.S.; Schellekens, M.; Martin, Z.W.; et al. Identifying and Preserving High-Water Mark Data; Techniques and Methods; U.S. Geological Survey: Reston, VA, USA, 2016; p. 60.
- Li, Z.; Wang, C.; Emrich, C.T.; Guo, D. A novel approach to leveraging social media for rapid flood mapping: A case study of the 2015 South Carolina floods. Cartogr. Geogr. Inf. Sci. 2018, 45, 97–110. [Google Scholar] [CrossRef]
- Goodchild, M.F.; Glennon, J.A. Crowdsourcing geographic information for disaster response: A research frontier. Int. J. Digit. Earth 2010, 3, 231–241. [Google Scholar] [CrossRef]
- Sheth, A. Citizen Sensing, Social Signals, and Enriching Human Experience. IEEE Internet Comput. 2009, 13, 87–92. [Google Scholar] [CrossRef] [Green Version]
- Nagarajan, M.; Sheth, A.; Velmurugan, S. Citizen Sensor Data Mining, Social Media Analytics and Development Centric Web Applications. In Proceedings of the 20th International Conference Companion on World Wide Web, Hyderabad, India, 28 March–1 April 2011; ACM: New York, NY, USA, 2011; pp. 289–290. [Google Scholar]
- Adam, N.R.; Shafiq, B.; Staffin, R. Spatial Computing and Social Media in the Context of Disaster Management. IEEE Intell. Syst. 2012, 27, 90–96. [Google Scholar] [CrossRef]
- Fohringer, J.; Dransch, D.; Kreibich, H.; Schröter, K. Social media as an information source for rapid flood inundation mapping. Nat. Hazards Earth Syst. Sci. 2015, 15, 2725–2738. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.; Li, Z.; Huang, X. Geospatial assessment of flooding dynamics and risks of the October’15 South Carolina Flood. Southeast. Geogr. 2018, 58, 164–180. [Google Scholar] [CrossRef]
- Huang, X.; Wang, C.; Li, Z. Reconstructing Flood Inundation Probability by Enhancing Near Real-Time Imagery With Real-Time Gauges and Tweets. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4691–4701. [Google Scholar] [CrossRef]
- Huang, X.; Wang, C.; Li, Z. A near real-time flood-mapping approach by integrating social media and post-event satellite imagery. Ann. GIS 2018, 24, 113–123. [Google Scholar] [CrossRef]
- Sayce, D. Number of Tweets per Day? Available online: https://www.dsayce.com/social-media/tweets-day/ (accessed on 23 March 2019).
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Tkachenko, N.; Zubiaga, A.; Procter, R. WISC at MediaEval 2017: Multimedia Satellite Task. In Proceedings of the MediaEval 2017: Multimedia Benchmark Workshop, Dublin, Ireland, 13–15 September 2017; p. 4. [Google Scholar]
- Feng, Y.; Sester, M. Extraction of Pluvial Flood Relevant Volunteered Geographic Information (VGI) by Deep Learning from User Generated Texts and Photos. ISPRS Int. J. Geo-Inf. 2018, 7, 39. [Google Scholar] [CrossRef] [Green Version]
- Huang, X.; Li, Z.; Wang, C.; Ning, H. Identifying disaster related social media for rapid response: A visual-textual fused CNN architecture. Int. J. Digit. Earth 2019, 1–23. [Google Scholar] [CrossRef]
- Huang, X.; Wang, C.; Li, Z.; Ning, H. A visual–textual fused approach to automated tagging of flood-related tweets during a flood event. Int. J. Digit. Earth 2018, 1–17. [Google Scholar] [CrossRef]
- Druzhkov, P.N.; Kustikova, V.D. A survey of deep learning methods and software tools for image classification and object detection. Pattern Recognit. Image Anal. 2016, 26, 9–15. [Google Scholar] [CrossRef]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; Volume 2, pp. 1150–1157. [Google Scholar]
- Bay, H.; Tuytelaars, T.; Van Gool, L. Surf: Speeded Up Robust Features. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 404–417. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Gebru, T.; Krause, J.; Wang, Y.; Chen, D.; Deng, J.; Fei-Fei, L. Fine-Grained Car Detection for Visual Census Estimation. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–10 February 2017; Volume 2, p. 6. [Google Scholar]
- Sladojevic, S.; Arsenovic, M.; Anderla, A.; Culibrk, D.; Stefanovic, D. Deep Neural Networks Based Recognition of Plant Diseases by Leaf Image Classification. Available online: https://www.hindawi.com/journals/cin/2016/3289801/ (accessed on 11 November 2018).
- Tajbakhsh, N.; Shin, J.Y.; Gurudu, S.R.; Hurst, R.T.; Kendall, C.B.; Gotway, M.B.; Liang, J. Convolutional Neural Networks for Medical Image Analysis: Full Training or Fine Tuning? IEEE Trans. Med. Imaging 2016, 35, 1299–1312. [Google Scholar] [CrossRef] [Green Version]
- Wang, D.; Khosla, A.; Gargeya, R.; Irshad, H.; Beck, A.H. Deep Learning for Identifying Metastatic Breast Cancer. arXiv 2016, arXiv:1606.05718. [Google Scholar]
- Bar, Y.; Diamant, I.; Wolf, L.; Greenspan, H. Deep learning with non-medical training used for chest pathology identification. In Proceedings of the Medical Imaging 2015: Computer-Aided Diagnosis; International Society for Optics and Photonics, Orlando, FL, USA, 21–26 February 2015; Volume 9414, p. 94140V. [Google Scholar]
- Yoon, Y.-C.; Yoon, K.-J. Animal Detection in Huge Air-view Images using CNN-based Sliding Window. In Proceedings of the International Workshop on Frontiers of Computer Vision (IWFCV), International Workshop on Frontiers of Computer Vision (IWFCV), Hakodate, Japan, 21–23 February 2018. [Google Scholar]
- Bischke, B.; Helber, P.; Schulze, C.; Srinivasan, V.; Dengel, A.; Borth, D. The Multimedia Satellite Task at MediaEval 2017. In Proceedings of the MediaEval 2017: MediaEval Benchmark Workshop, Dublin, Ireland, 13–15 September 2017. [Google Scholar]
- Bischke, B.; Bhardwaj, P.; Gautam, A.; Helber, P.; Borth, D.; Dengel, A. Detection of Flooding Events in Social Multimedia and Satellite Imagery using Deep Neural Networks. In Proceedings of the MediaEval 2017: MediaEval Benchmark Workshop, Dublin, Ireland, 13–15 September 2017. [Google Scholar]
- Thomee, B.; Shamma, D.A.; Friedland, G.; Elizalde, B.; Ni, K.; Poland, D.; Borth, D.; Li, L.-J. YFCC100M: The New Data in Multimedia Research. Commun ACM 2016, 59, 64–73. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2818–2826. [Google Scholar]
- Kim, Y. Convolutional neural networks for sentence classification. arXiv 2014, arXiv:14085882. [Google Scholar]
- Goutte, C.; Gaussier, E. A probabilistic interpretation of precision, recall and F-score, with implication for evaluation. In Proceedings of the European Conference on Information Retrieval, Santiago de Compostela, Spain, 21–23 March 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 345–359. [Google Scholar]
- Alam, F.; Imran, M.; Ofli, F. Image4Act: Online Social Media Image Processing for Disaster Response. In Proceedings of the 2017 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Sydney, Australia, 31 July–3 August 2017; pp. 601–604. [Google Scholar]
- Levandoski, J.J.; Larson, P.; Stoica, R. Identifying hot and cold data in main-memory databases. In Proceedings of the 2013 IEEE 29th International Conference on Data Engineering (ICDE), Brisbane, QLD, Australia, 8–12 April 2013; pp. 26–37. [Google Scholar]
- Kornacker, M.; Behm, A.; Bittorf, V.; Bobrovytsky, T.; Ching, C.; Choi, A.; Erickson, J.; Grund, M.; Hecht, D.; Jacobs, M. Impala: A Modern, Open-Source SQL Engine for Hadoop. In Proceedings of the CIDR, Asilomar, CA, USA, 4–7 January 2015; Volume 1, p. 9. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems 25; Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q., Eds.; Curran Associates, Inc.: New York, NY, USA, 2012; pp. 1097–1105. [Google Scholar]
- Ng, A. Machine Learning Yearning. Available online: https://www.deeplearning.ai/machine-learning-yearning/ (accessed on 3 February 2020).
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. arXiv 2016, arXiv:160806993. [Google Scholar]
- US Department of Commerce. Historical Hurricane Florence. 12–15 September 2018. Available online: https://www.weather.gov/mhx/Florence2018 (accessed on 26 December 2019).
- Irfan, U. Hurricane Florence’s “1000-year” Rainfall, Explained. Available online: https://www.vox.com/2018/9/20/17883492/hurricane-florence-rain-1000-year (accessed on 25 March 2019).
- Langone, A.; Martinez, G.; Quackenbush, C.; De La Garza, A. Hurricane Florence Makes Landfall and Looks to Stick Around. Available online: https://time.com/5391394/hurricane-florence-track-path/ (accessed on 26 December 2019).
- Feng, Q.; Liu, J.; Gong, J. Urban flood mapping based on unmanned aerial vehicle remote sensing and random forest classifier—A case of Yuyao, China. Water 2015, 7, 1437–1455. [Google Scholar] [CrossRef]
- Tralli, D.M.; Blom, R.G.; Zlotnicki, V.; Donnellan, A.; Evans, D.L. Satellite remote sensing of earthquake, volcano, flood, landslide and coastal inundation hazards. ISPRS J. Photogramm. Remote Sens. 2005, 59, 185–198. [Google Scholar] [CrossRef]
- Won, D.; Steinert-Threlkeld, Z.C.; Joo, J. Protest Activity Detection and Perceived Violence Estimation from Social Media Images. In Proceedings of the 25th ACM International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 786–794. [Google Scholar]
- Kalliatakis, G.; Ehsan, S.; Fasli, M.; Leonardis, A.; Gall, J.; McDonald-Maier, K. Detection of Human Rights Violations in Images: Detection of Human Rights Violations in Images: Can Convolutional Neural Networks help? arXiv 2017, arXiv:1703.04103. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A Unified Embedding for Face Recognition and Clustering. In Proceedings of the CVPR, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Jia, S.; Lansdall-Welfare, T.; Cristianini, N. Gender Classification by Deep Learning on Millions of Weakly Labelled Images. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining Workshops (ICDMW), Barcelona, Spain, 12–15 December 2016; pp. 462–467. [Google Scholar]
- Ryu, H.J.; Adam, H.; Mitchell, M. InclusiveFaceNet: Improving Face Attribute Detection with Race and Gender Diversity. arXiv 2017, arXiv:171200193. [Google Scholar]
- Buda, M.; Maki, A.; Mazurowski, M.A. A systematic study of the class imbalance problem in convolutional neural networks. Neural Netw. 2018, 106, 249–259. [Google Scholar] [CrossRef] [Green Version]
- Jiang, Y.; Li, Z.; Ye, X. Understanding demographic and socioeconomic biases of geotagged Twitter users at the county level. Cartogr. Geogr. Inf. Sci. 2019, 46, 228–242. [Google Scholar] [CrossRef]
- Martín, Y.; Li, Z.; Cutter, S.L. Leveraging Twitter to gauge evacuation compliance: Spatiotemporal analysis of Hurricane Matthew. PLoS ONE 2017, 12, e0181701. [Google Scholar] [CrossRef] [Green Version]
- Jiang, Y.; Li, Z.; Cutter, S.L. Social network, activity space, sentiment and evacuation: What can social media tell us? Ann. Am. Assoc. Geogr. 2019. [Google Scholar] [CrossRef]
- Klein, G.; Kim, Y.; Deng, Y.; Senellart, J.; Rush, A.M. OpenNMT: Open-Source Toolkit for Neural Machine Translation. arXiv 2017, arXiv:170102810. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time | Text | URLs |
|---|---|---|
| 2015/10/2 17:11 | If you didn’t know, but I are under a flash flood warning??AND today was??????? | https://t.co/Qi8Xs5jopp |
| 2015/10/2 17:15 | You could not ask for a better cuddle buddy... @ The Gentry??????? | https://t.co/QBT04Dlk6p |
| 2015/10/2 17:16 | Drinking in the rain. (@ Pearlz Oyster Bar in Columbia; SC) | https://t.co/ZqNykREp30 |
| 2015/10/2 17:23 | This is what a rainy afterschool Friday afternoon looks like around here. Ahhhh....??????? | https://t.co/G9nGFGeJb7 |
| 2015/10/2 17:33 | At 4:30 PM; Myrtle Beach [Horry Co; SC] DEPT OF HIGHWAYS reports FLOOD | http://t.co/Sr8UHDxWnf |
| No.1 | Description | Photos with clear features inundated by water outdoors. |
| Reason | Inundated features, which are normally not in the water, such as houses, cars, and trees, are critical to characterizing a flooding photo. | |
| No.2 | Description | Indoors photos with clear features inundated by water. |
| Reason | Indoor flooding photos also reflect the on-site formation of ongoing floods | |
| No.3 | Description | A mosaic image contains ongoing flooding photos. |
| Reason | Mosaic images formed by flooding photos satisfy No.1 and No.2 contain the same information of their sub-photos. | |
| No.4 | Description | The photo satisfies No.1 – No. 3 and with text from the uploader. |
| Reason | The flooding photo with text (usually a description or the date for photos) reflect the on-site formation of ongoing floods. |
| No.1 | Description | Screenshots from mass media or social network users. |
| Reason | Cannot be considered as firsthand information. | |
| No.2 | Description | Thin water in urban areas. |
| Reason | The situation is still under control, not a flood. | |
| No.3 | Description | Water bodies with high water levels but inundate nothing. |
| Reason | The situation is still under control, not a flood. | |
| No.4 | Description | Advertisements or posters with flooding backgrounds. |
| Reason | Cannot indicate an ongoing flood. | |
| No.5 | Description | No water in the photo. |
| Reason | Cannot indicate an ongoing flood. | |
| No.6 | Description | Water bodies without referencing objects. |
| Reason | Cannot tell whether there is a flood. | |
| No.7 | Description | Modified flooding photos. |
| Reason | Cannot provide reliable information about the ongoing flood. | |
| No.8 | Description | Historical flooding photos. |
| Reason | Cannot provide reliable information about the ongoing flood. | |
| No.9 | Description | Fake flooding photos. |
| Reason | Cannot indicate an ongoing flood. |
| Network | Method | Total Accuracy |
|---|---|---|
| VGG16 | Trained from scratch | 93% |
| VGG16 | Transfer learning | 91% |
| Inception V3 | Transfer learning | 91% |
| ResNet 152 | Transfer learning | 91% |
| DenseNet201 | Trained from scratch | 91% |
| DenseNet201 | Transfer learning | 91% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ning, H.; Li, Z.; Hodgson, M.E.; Wang, C. Prototyping a Social Media Flooding Photo Screening System Based on Deep Learning. ISPRS Int. J. Geo-Inf. 2020, 9, 104. https://doi.org/10.3390/ijgi9020104
Ning H, Li Z, Hodgson ME, Wang C. Prototyping a Social Media Flooding Photo Screening System Based on Deep Learning. ISPRS International Journal of Geo-Information. 2020; 9(2):104. https://doi.org/10.3390/ijgi9020104
Chicago/Turabian StyleNing, Huan, Zhenlong Li, Michael E. Hodgson, and Cuizhen (Susan) Wang. 2020. "Prototyping a Social Media Flooding Photo Screening System Based on Deep Learning" ISPRS International Journal of Geo-Information 9, no. 2: 104. https://doi.org/10.3390/ijgi9020104
APA StyleNing, H., Li, Z., Hodgson, M. E., & Wang, C. (2020). Prototyping a Social Media Flooding Photo Screening System Based on Deep Learning. ISPRS International Journal of Geo-Information, 9(2), 104. https://doi.org/10.3390/ijgi9020104