Urban Crime Risk Prediction Using Point of Interest Data


Abstract
:1. Introduction
1.1. Contributions
- geographical aggregation: divide the urban area of interest into micro-areas and aggregate crime records and POI counts on the level of micro-areas,
- geographical attribute derivation: describe micro-areas by geographical attributes, derived from aggregated POI locations,
- hotspot identification: label micro-areas as high/low risk with respect to the number of aggregated historical crime events,
- hotspot modeling: create models for predicting high/low risk labels based on geographical attributes using classification algorithms,
- hotspot prediction: apply the created models to predict high/low-risk labels for particular micro-areas based on geographical attributes.
- predictive power evaluation: assess the quality of obtained crime predictions using the k-fold cross-validation procedure and the ROC analysis,
- attribute predictive utility evaluation: rank geographical attributes with respect to their utility for crime risk prediction using the random forest variable importance measure,
- dimensionality reduction: verify the possibility of reducing the data dimensionality without degrading model quality by attribute selection and principal component analysis,
- model transfer: verify the possibility of applying a model trained on data from one urban area for crime risk prediction in another urban area.
1.2. Related Work
- using data from four different urban areas, unaddressed by previous research, rather than a single city,
- risk prediction performed separately for several different crime types, with varying occurrence frequency,
- fine-grained -meter micro-areas used for geographical aggregation, hotspot labeling, and prediction, instead of much larger LSOA, community, or public statistics dissemination areas,
- a broad set of POI categories used to describe micro-areas,
- handling class imbalance by appropriate algorithm setup,
- systematic comparison of prediction quality using the ROC analysis,
- examining the effect of dimensionality reduction by attribute selection and principal component analysis,
- examining the possibility of transferring crime prediction models across different urban areas.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Work | Area | Data Sources | Aggregation Units | Hotspot Identification | Algorithms |
|---|---|---|---|---|---|
| traunmueller et al. [16] | London | cellular networks | grid cells a | none | correlation analysis |
| bogomolov et al. [18,19] | London | sociodemography, cellular networks | cellular network cells | comparison to median | random forest |
| Malleson and Andresen [17] | London | sociodemography, cellular networks, social media, POI | LSOA units b | comparison to neighborhood | correlation analysis, descriptive statistics |
| Wang et al. [24] | Chicago | POI, taxi traffic | community areas c | none | linear regression, negative binomial regression |
| Yang et al. [25] | New York | POI, social media | grid cells d | kernel density estimation | logistic regression, naive Bayes classifier, SVM, neural network, decision trees, random forest |
| Lin et al. [20] | Taoyuan | POI | grid cells e | comparison to a threshold | neural networks, kNN, SVM, random forest |
| Dash et al. [21] | Chicago | school, library, and police station locations, library visits, emergency number calls | community areas c | none | polynomial regression, SVM, autoregression |
| Yi et al. [22] | Chicago | sociodemography, POI, taxi trajectories, city hotline requests | community areas c | none | correlation analysis, clustered continuous conditional random field |
| Bappee et al. [23] | Halifax | POI, streetlight infrastructure, social media | dissemination areas f | comparison to a threshold | random forest, gradient boosting |
1.3. Paper Overview
2. Materials and Methods
2.1. Data
2.1.1. Crime Data
- Greater Manchester Police,
- Merseyside Police,
- Dorset Police,
- West Yorkshire Police,
- Manchester District (referred to as Manchester thereafter),
- Liverpool District (referred to as Liverpool thereafter),
- Bournemouth, Christchurch and Poole District (referred to as Bournemouth thereafter),
- Wakefield District (referred to as Wakefield thereafter).
- Anti-social behaviour (referred to as ANTISOCIAL thereafter),
- Violence and sexual offences (referred to as VIOLENCE thereafter),
- Burglary (referred to as BURGLARY thereafter),
- Shoplifting (referred to as SHOPLIFTING thereafter),
- Other theft (referred to as THEFT thereafter),
- Robbery (referred to as ROBBERY thereafter).
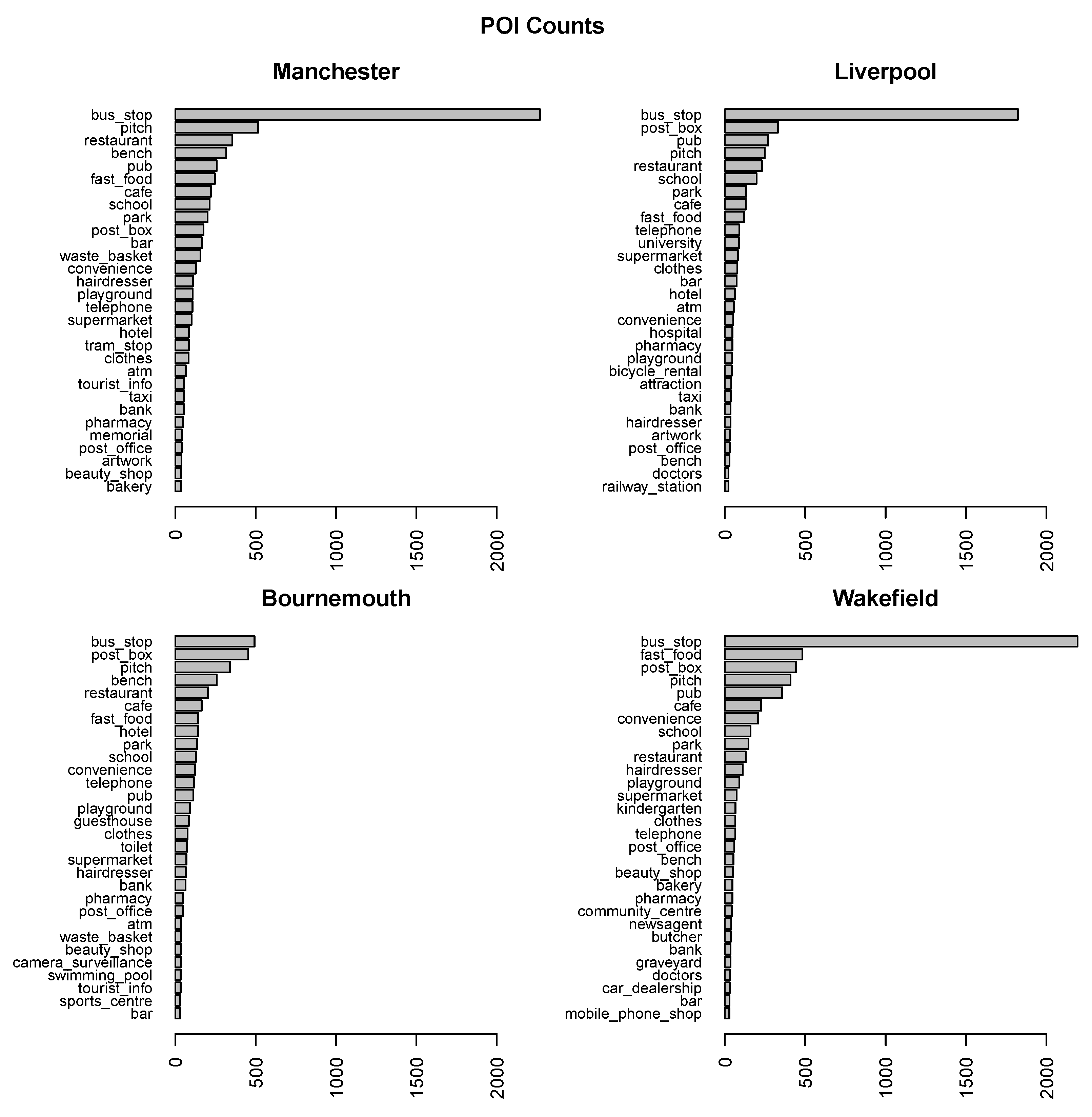
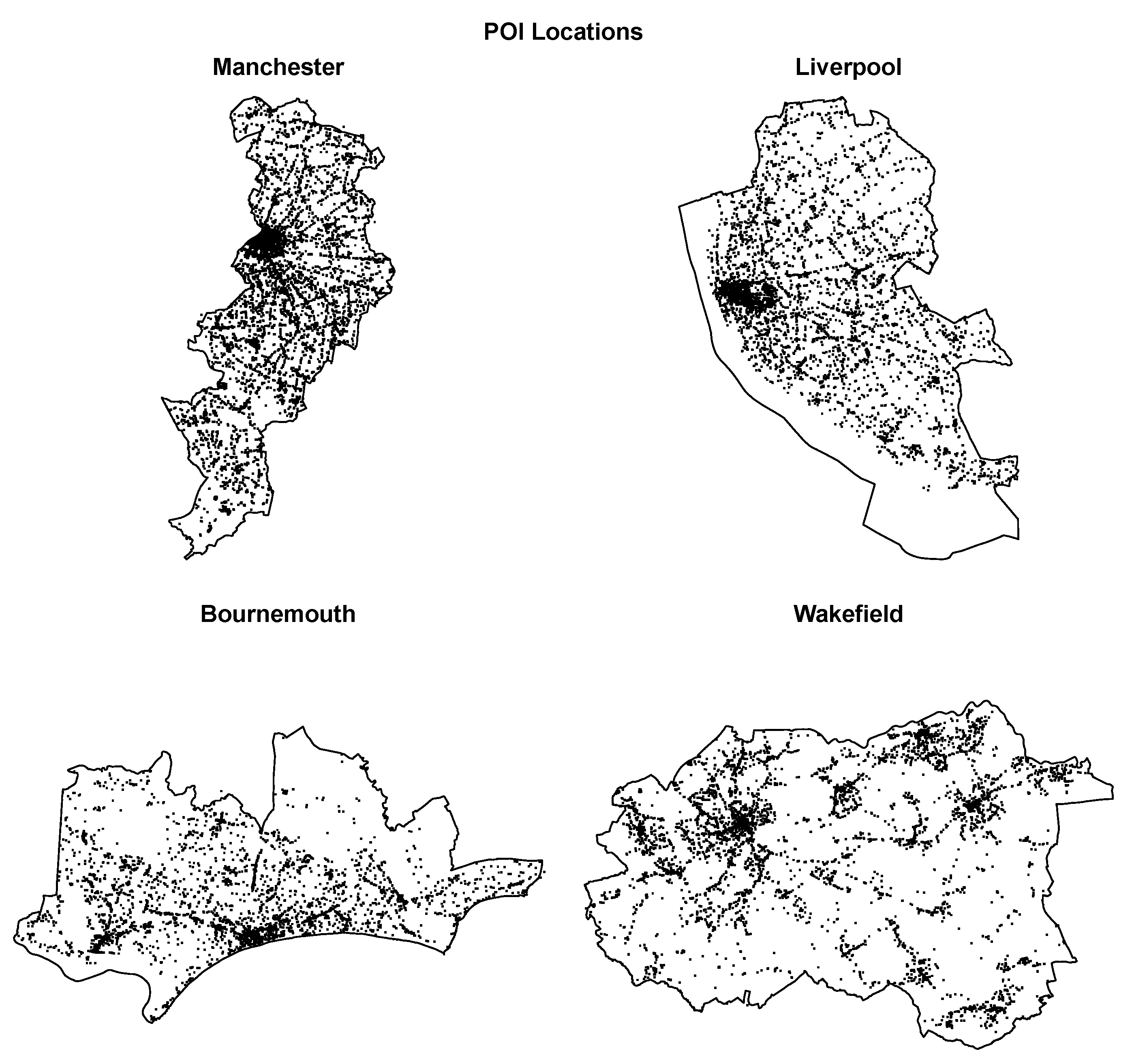
2.1.2. POI Data
- pois:
- POI objects represented as points,
- pois_a:
- POI objects represented as polygons,
- transport:
- transport objects represented as points,
- transport_a:
- transport objects represented as polygons.
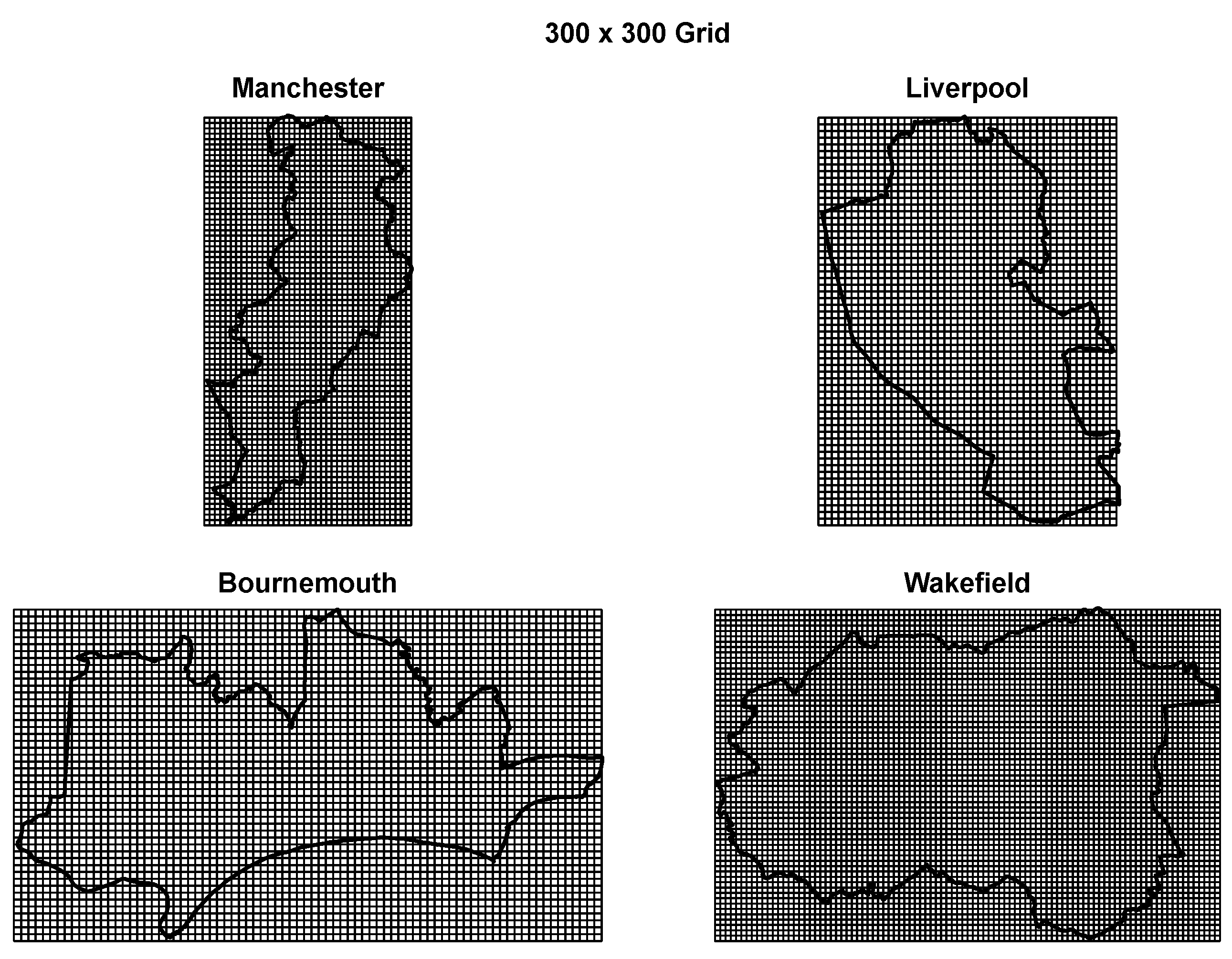
2.1.3. Geographical Aggregation
2.1.4. Hotspot Identification
2.1.5. Combined Data
2.2. Algorithms
2.2.1. Logistic Regression
2.2.2. Support Vector Machines
- margin maximization: the location of the decision boundary (separating hyperplane) is optimized with respect to the classification margin,
- soft margin: incorrectly separated instances are permitted,
- kernel trick: complex nonlinear relationships can be represented by representation transformation using kernel functions.
2.2.3. Decision Trees
2.2.4. Random Forest
- large maximally fitted trees are grown (with splitting continued until reaching a uniform class, exhausting the set of instances, or exhausting the set of possible splits),
- whenever a split has to be selected for a tree node, a small subset of available attributes is selected randomly and only those attributes are considered for candidate splits.
2.3. Dimensionality Reduction
- attribute selection, which retains a small subset of the set of original attributes,
- representation transformation, which replaces the original attributes with a small subset of new attributes.
2.3.1. Attribute Selection
2.3.2. PCA Transformation
2.4. Predictive Performance Evaluation
2.5. Algorithm Implementations and Setup
- the cost of constraint violation (cost): 1,
- the kernel type (kernel):radial,
- the kernel parameter (gamma): the inverse of the number of attributes (input dimensionality),
- class weights in constraint violation penalty (class.weights): 3 for the high risk class, 1 for the low risk class.
- the number of trees (ntree): 500,
- the number of attributes for split selection at each node (mtry): the square root of the total number of available attributes,
- the stratified bootstrap sample size (sampsize): the number of instances of the high risk class (the minority class).
3. Results
- prediction quality: evaluating the level of crime risk prediction quality achieved by particular algorithms using all POI attributes,
- attribute predictive utility: assessing the predictive utility of particular POI attributes,
- dimensionality reduction: examining the effects of dimensionality reduction by attribute selection and principal component analysis,
- model transfer: verifying the possibility of applying a model trained on data from one urban area to predict crime risk in another urban area.
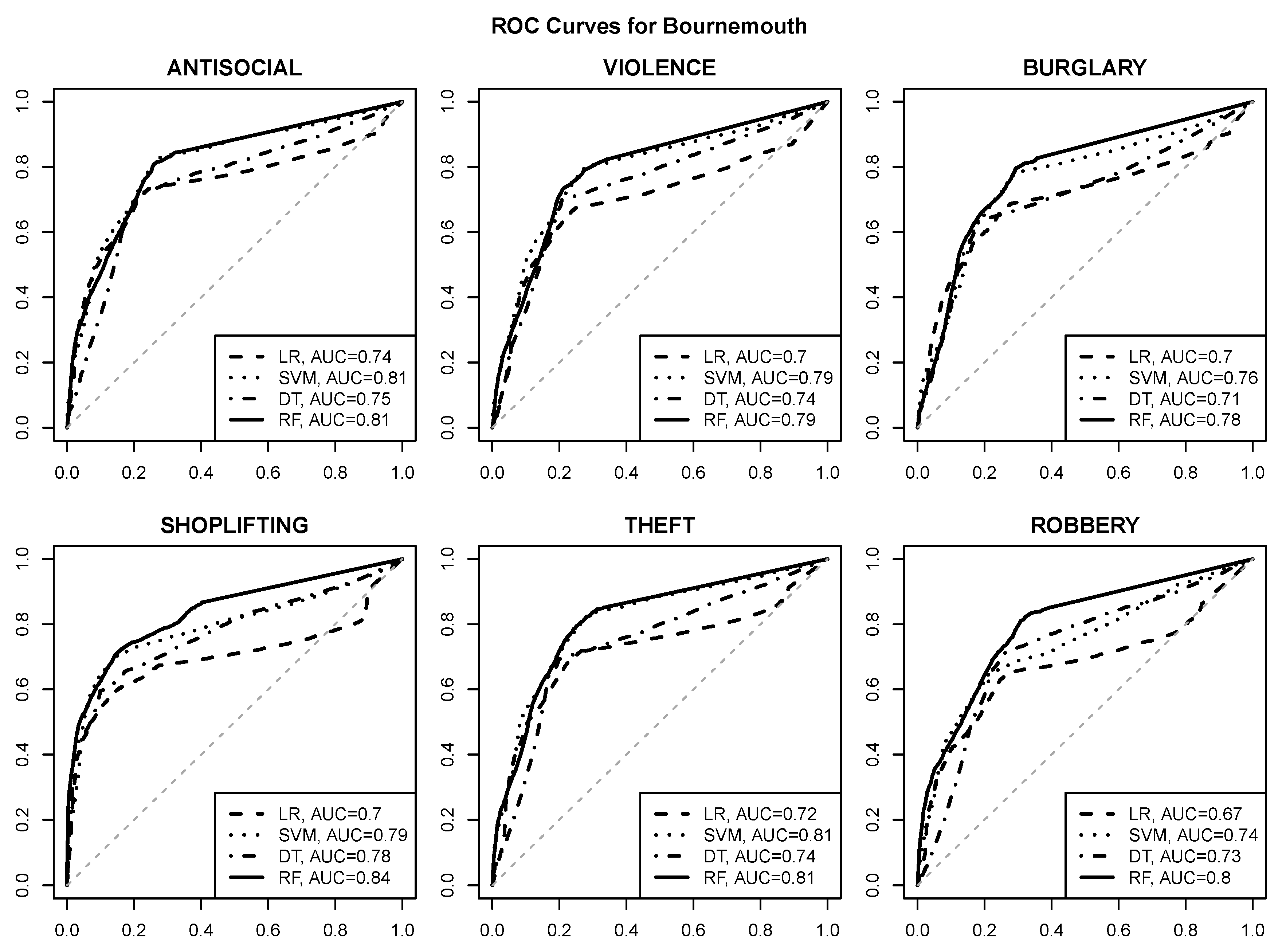
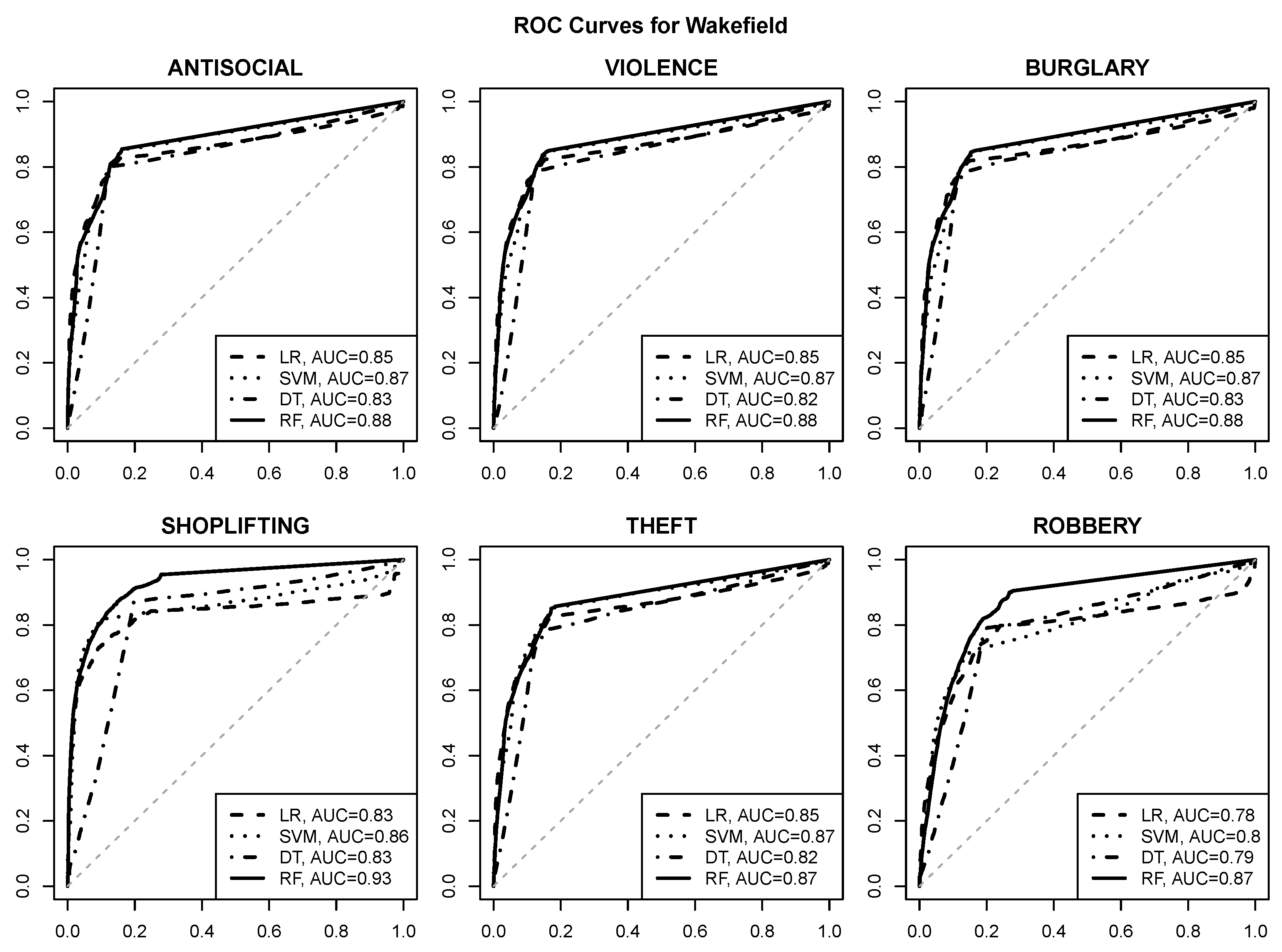
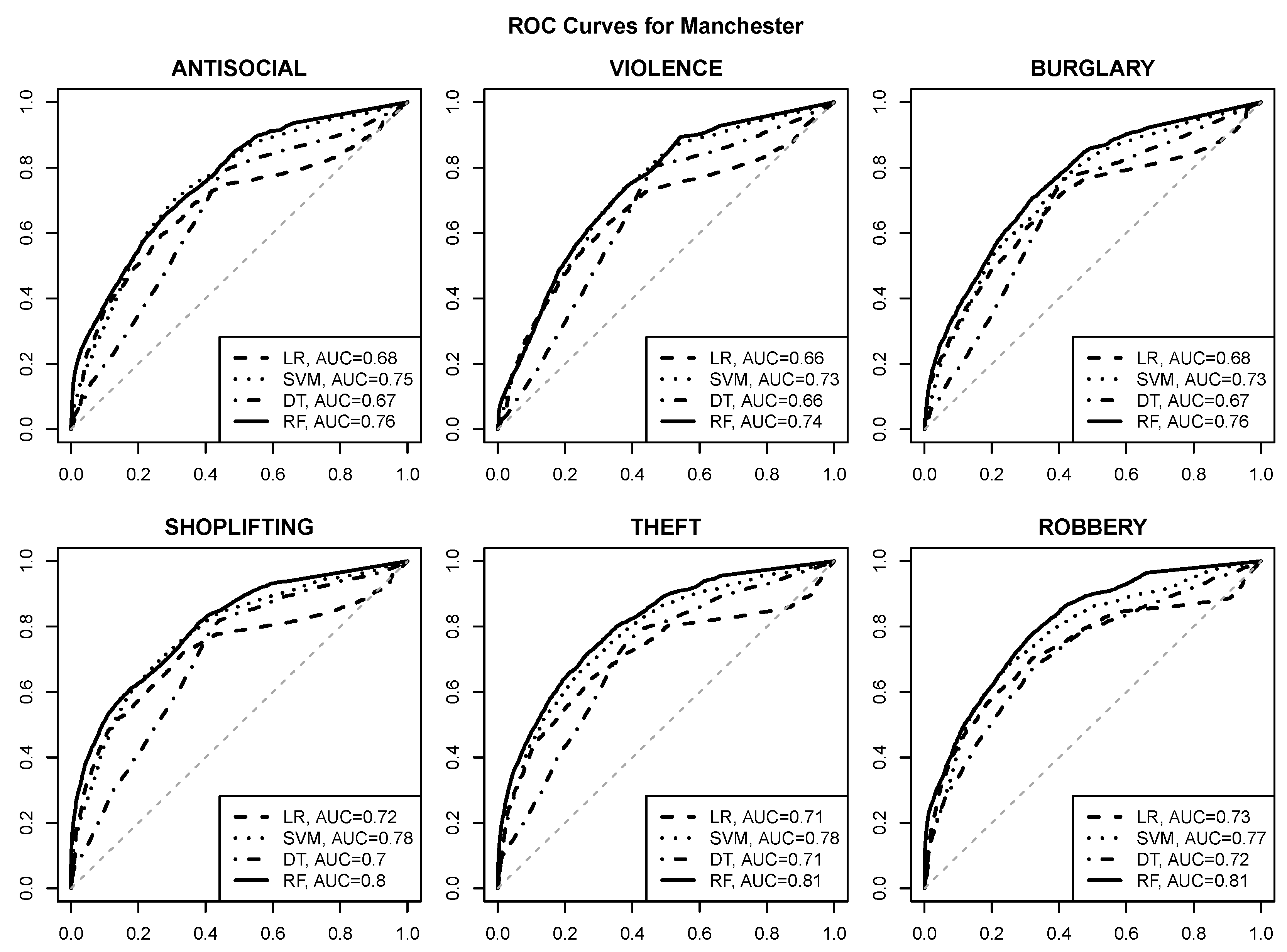
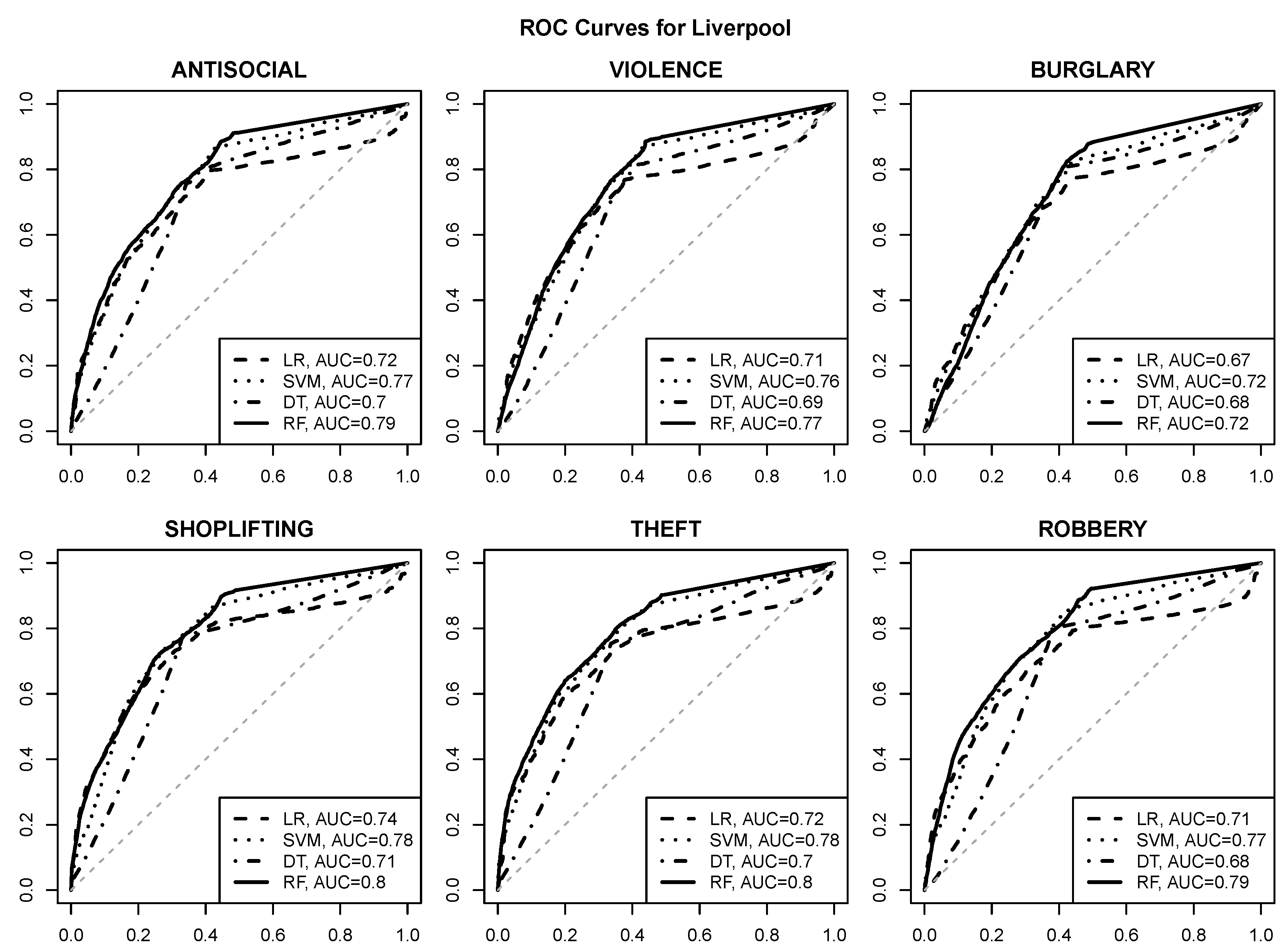
3.1. Prediction Quality
- good quality risk prediction for each of the six selected crime types is possible using POI attributes, with AUC values approaching or exceeding for most urban areas and crime types,
- reasonable operating points with a true positive rate of about and a false positive rate of at most are usually achievable (and can be identified, e.g., by selecting class probability cutoff values yielding the maximum true positive rate with the false positive rate not exceeding ),
- the random forest algorithm achieves the best predictive performance regardless of the urban area and the crime type,
- the SVM algorithm is similarly successful in most cases,
- logistic regression and decision tree models give clearly inferior prediction quality, which suggests that the relationship between crime risk and POI attributes may not be simple enough to be adequately represented by a linear function or a small tree,
- crime predictability for Wakefield appears to be better than for the other urban areas, with AUC values approaching or exceeding ,
- SHOPLIFTING appears to be the best predictable crime type based on POI attributes, which is not surprising given its obvious relationship to store locations.
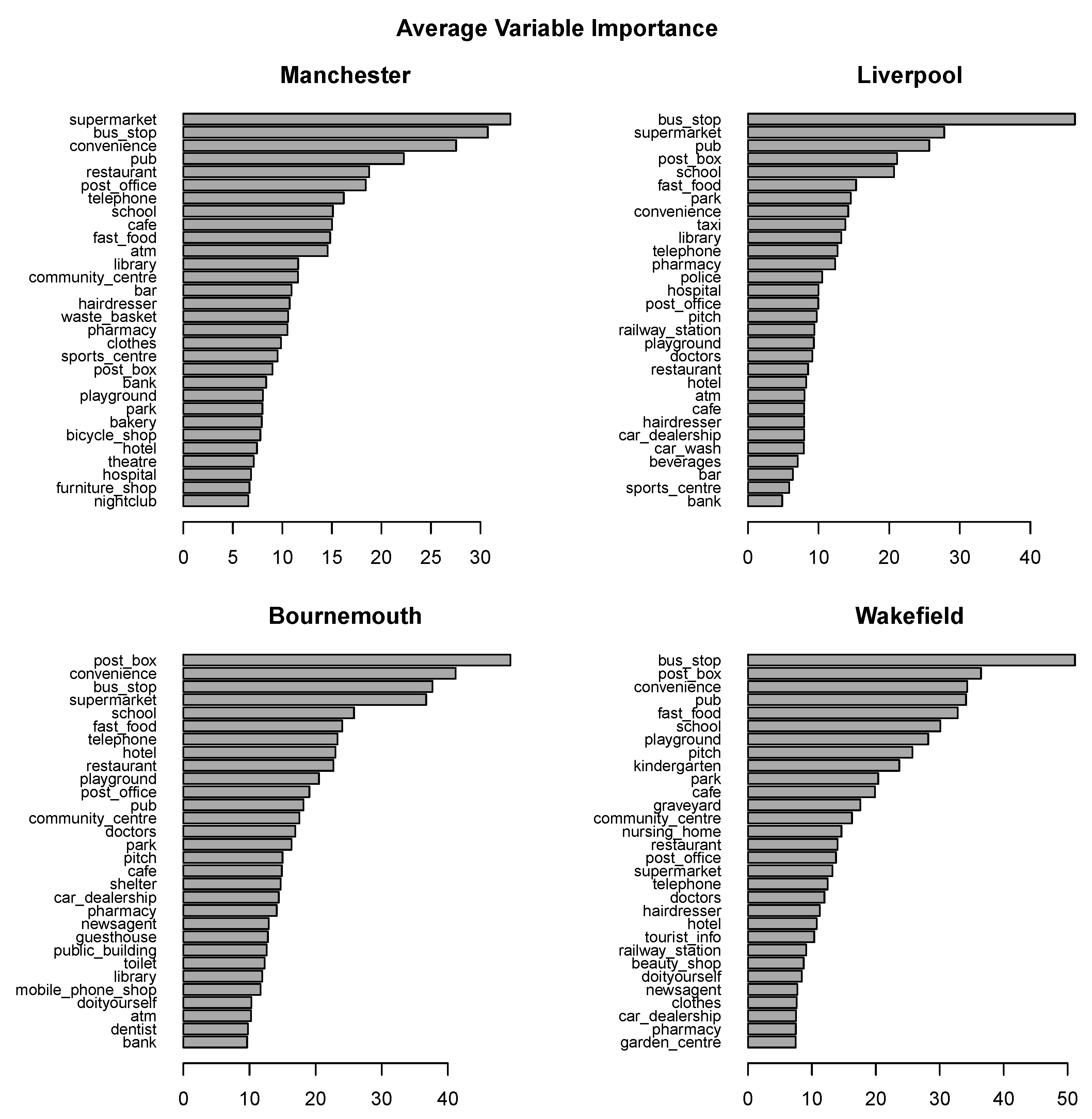
3.2. Attribute Predictive Utility
3.3. Dimensionality Reduction
- with attribute selection: using 5, 10, and 25 top attributes according to the random forest variable importance ranking,
- with PCA: using 5, 10, and 25 first principal components.
- dimensionality reduction helps the logistic regression and decision tree algorithms achieve better prediction quality (only PCA gives an improvement for the latter),
- the quality of SVM and random forest predictions does not improve due to dimensionality reduction,
- dimensionality reduction by PCA is more effective than by attribute selection (the latter gives a smaller improvement for logistic regression and no improvement for decision trees),
- the top 25 attributes are usually sufficient to achieve the best possible level of prediction quality,
- the first five principal components are usually sufficient to achieve the best possible level of prediction quality.
3.4. Model Transfer
- model transfer can be generally considered successful, with the difference of AUC values between “foreign” and “native” models not exceeding – in most cases,
- the models trained on the Manchester and Liverpool data have better transfer performance than those trained on the Bournemouth and Wakefield data,
- when applied for prediction in Bournemouth and Wakefield, “foreign” models are as good as the “native” ones.
4. Discussion
Data and Code Availability
Funding
Conflicts of Interest
References
- Goodchild, M.F. Geographic Information Systems and Science: Today and Tomorrow. Ann. GIS 2009, 15, 3–9. [Google Scholar] [CrossRef] [Green Version]
- Longley, P.A.; Goodchild, M.F.; Maguire, D.J.; Rhind, D.W. Geographic Information Systems and Science, 4th ed.; Wiley: New York, NY, USA, 2015. [Google Scholar]
- Faiz, S.; Mahmoudi, K. (Eds.) Handbook of Research on Geographic Information Systems Applications and Advancements; IGI Global: Hershey, PA, USA, 2017. [Google Scholar]
- Smith, T.R. Artificial Intelligence and Its Applicability to Geographical Problem Solving. Prof. Geogr. 1984, 36, 147–158. [Google Scholar] [CrossRef]
- Leung, Y.; Leung, K.S. An Intelligent Expert System Shell for Knowledge-Based Geographical Information Systems: 1. The Tools. Int. J. Geogr. Inf. Syst. 1993, 7, 189–199. [Google Scholar] [CrossRef]
- Leung, Y.; Leung, K.S. An Intelligent Expert System Shell for Knowledge-Based Geographical Information Systems: 2. Some Applications. Int. J. Geogr. Inf. Syst. 1993, 7, 201–213. [Google Scholar] [CrossRef]
- Hagenauer, J.; Helbich, M. Mining Urban Land-Use Patterns from Volunteered Geographic Information by Means of Genetic Algorithms and Artificial Neural Networks. Int. J. Geogr. Inf. Sci. 2012, 26, 963–982. [Google Scholar] [CrossRef]
- Janowicz, K.; Gao, S.; McKenzie, G.; Hu, Y.; Bhaduri, B. GeoAI: Spatially Explicit Artificial Intelligence Techniques for Geographic Knowledge Discovery and Beyond. Int. J. Geogr. Inf. Sci. 2019. [Google Scholar] [CrossRef]
- Perry, W.L.; McInnis, B.; Price, C.C.; Smith, S.; Hollywood, J.S. The Role of Crime Forecasting in Law Enforcement Operations; Technical Report RR-233-NJ; RAND Corporation: Santa Monica, CA, USA, 2013. [Google Scholar]
- Chen, H.; Chung, W.; Xu, J.J.; Wang, G.; Qin, Y.; Chau, M. Crime Data Mining: A General Framework and Some Examples. Computer 2004, 37, 50–56. [Google Scholar] [CrossRef] [Green Version]
- Bernasco, W.; Nieuwbeerta, P. How Do Residential Burglars Select Target Areas? A New Approach to the Analysis of Criminal Location Choice. Br. J. Criminol. 2005, 45, 296–315. [Google Scholar] [CrossRef] [Green Version]
- Bowers, K.J.; Johnson, S.D.; Pease, K. Prospective Hot-Spotting: The Future of Crime Mapping? Br. J. Criminol. 2004, 44, 641–658. [Google Scholar] [CrossRef]
- Short, M.B.; D’Orsogna, M.R.; Brantingham, P.J.; Tita, G.E. Measuring and Modeling Repeat and Near-Repeat Burglary Effects. J. Quant. Criminol. 2009, 25, 325–339. [Google Scholar] [CrossRef] [Green Version]
- Mohler, G.O.; Short, M.B.; Brantingham, P.J.; Schoenberg, F.P.; Tita, G.E. Self-Exciting Point Process Modeling of Crime. J. Am. Stat. Assoc. 2011, 106, 100–108. [Google Scholar] [CrossRef]
- Malleson, N.; Heppenstall, A.; See, L.; Evans, A. Using an Agent-Based Crime Simulation to Predict the Effects of Urban Regeneration on Individual Household Burglary Risk. Environ. Plan. Plan. Des. 2013, 40, 405–426. [Google Scholar] [CrossRef] [Green Version]
- Traunmueller, M.; Quattrone, G.; Capra, L. Mining Mobile Phone Data to Investigate Urban Crime Theories at Scale. In Proceedings of the Sixth International Conference on Social Informatics, Barcelona, Spain, 10–13 November 2014. [Google Scholar]
- Malleson, N.; Andresen, M.A. Exploring the Impact of Ambient Population Measures on London Crime Hotspots. J. Crim. Justice 2016, 46, 52–63. [Google Scholar] [CrossRef] [Green Version]
- Bogomolov, A.; Lepri, B.; Staiano, J.; Oliver, N.; Pianesi, F.; Pentland, A. Once Upon a Crime: Towards Crime Prediction from Demographics and Mobile Data. In Proceedings of the Sixteenth International Conference on Multimodal Interaction, Istanbul, Turkey, 12–16 November 2014. [Google Scholar]
- Bogomolov, A.; Lepri, B.; Staiano, J.; Letouzé, E.; Oliver, N.; Pianesi, F.; Pentland, A. Moves on the Street: Classifying Crime Hotspots Using Aggregated Anonymized Data on People Dynamics. Big Data 2015, 3, 148–158. [Google Scholar] [CrossRef] [PubMed]
- Lin, Y.L.; Yen, M.F.; Yu, L.C. Grid-Based Crime Prediction Using Geographical Features. ISPRS Int. J. Geo Inf. 2018, 7, 298. [Google Scholar] [CrossRef] [Green Version]
- Dash, S.K.; Safro, I.; Srinivasamurthy, R.S. Spatio-Temporal Prediction of Crimes Using Network Analytic Approach. arXiv 2018, arXiv:1808.06241. [Google Scholar]
- Yi, F.; Yu, Z.; Zhuang, F.; Zhang, X.; Xiong, H. An Integrated Model for Crime Prediction Using Temporal and Spatial Factors. In Proceedings of the Eighteenth IEEE International Conference on Data Mining, Singapore, 17–20 November 2018. [Google Scholar]
- Bappee, F.K.; Petry, L.M.; Soares, A.; Matwin, S. Analyzing the Impact of Foursquare and Streetlight Data with Human Demographics on Future Crime Prediction. arXiv 2020, arXiv:2006.07516. [Google Scholar]
- Wang, H.; Kifer, D.; Graif, C.; Li, Z. Crime Rate Inference with Big Data. In Proceedings of the Twenty-Second ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Yang, D.; Heaney, T.; Tonon, A.; Wang, L.; Cudré-Mauroux, P. CrimeTelescope: Crime Hotspot Prediction Based on Urban and Social Media Data Fusion. World Wide Web 2017, 21, 1323–1347. [Google Scholar] [CrossRef] [Green Version]
- Ramm, F. OpenStreetMap Data in Layered GIS Format. Available online: https://www.geofabrik.de/data/geofabrik-osm-gis-standard-0.6.pdf (accessed on 22 May 2018).
- Bivand, R.; Keitt, T.; Rowlingson, B. rgdal: Bindings for the ’Geospatial’ Data Abstraction Library. R Package Version 1.3-4. 2018. Available online: https://cran.r-project.org/web/packages/rgdal/index.html (accessed on 26 June 2020).
- Pebesma, E.J.; Bivand, R.S. Classes and Methods for Spatial Data in R: The sp Package. R News 2005, 5, 9–13. [Google Scholar]
- Eck, J.E.; Chainey, S.; Cameron, J.G.; Leitner Wilson, R.E. Mapping Crime: Understanding Hot Spots; National Institute of Justice Special Report; National Institute of Justice Special: Rockville, MD, USA, 2005.
- Rosser, T.; Bowers, K.J.; Johnson, S.D.; Cheng, T. Predictive Crime Mapping: Arbitrary Grids or Street Networks? J. Quant. Criminol. 2017, 33, 569–594. [Google Scholar] [CrossRef] [Green Version]
- Wand, M.P.; Jones, M.C. Kernel Smoothing; Chapman and Hall: London, UK, 1995. [Google Scholar]
- Hirschfield, A.; Bowers, K. (Eds.) Mapping and Analysing Crime Data: Lessons from Research and Practice; CRC Press: London, UK, 2001. [Google Scholar]
- Chainey, S.P.; Ratcliffe, J.H. GIS and Crime Mapping; John Wiley & Sons: Chichester, UK, 2005. [Google Scholar]
- Chainey, S.; Tompson, L.; Uhlig, S. The Utility of Hotspot Mapping for Predicting Spatial Patterns of Crime. Secur. J. 2008, 21, 4–28. [Google Scholar] [CrossRef]
- Gerber, M.S. Predicting Crime Using Twitter and Kernel Density Estimation. Decis. Support Syst. 2014, 61, 115–125. [Google Scholar] [CrossRef]
- Shiode, S.; Shiode, N. Network-Based Space-Time Search-Window Technique for Hotspot Detection of Street-Level Crime Incidents. Int. J. Geogr. Inf. Sci. 2013, 27, 866–882. [Google Scholar] [CrossRef]
- Cichosz, P. Data Mining Algorithms: Explained Using R; Wiley: Chichester, UK, 2015. [Google Scholar]
- Hilbe, J.M. Logistic Regression Models; Chapman and Hall: London, UK, 2009. [Google Scholar]
- Cortes, C.; Vapnik, V.N. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Platt, J.C. Fast Training of Support Vector Machines using Sequential Minimal Optimization. In Advances in Kernel Methods: Support Vector Learning; Schölkopf, B., Burges, C.J.C., Smola, A.J., Eds.; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Hamel, L.H. Knowledge Discovery with Support Vector Machines; Wiley: New York, NY, USA, 2009. [Google Scholar]
- Cristianini, N.; Shawe-Taylor, J. An Introduction to Support Vector Machines and Other Kernel-Based Learning Methods; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Schölkopf, B.; Smola, A.J. Learning with Kernels; MIT Press: Cambridge, MA, USA, 2001. [Google Scholar]
- Platt, J.C. Probabilistic Outputs for Support Vector Machines and Comparison to Regularized Likelihood Methods. In Advances in Large Margin Classifiers; Smola, A.J., Barlett, P., Schölkopf, B., Schuurmans, D., Eds.; MIT Press: Cambridge, MA, USA, 2000. [Google Scholar]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Chapman and Hall: London, UK, 1984. [Google Scholar]
- Quinlan, J.R. Induction of Decision Trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef] [Green Version]
- Dietterich, T.G. Ensemble Methods in Machine Learning. In Proceedings of the First International Workshop on Multiple Classifier Systems, Cagliari, Italy, 21–23 June 2000. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Bagging Predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Mitchell, T. Machine Learning; McGraw-Hill: New York, NY, USA, 1997. [Google Scholar]
- Liu, H.; Motoda, H. Feature Selection for Knowledge Discovery and Data Mining; Springer: New York, NY, USA, 1998. [Google Scholar]
- Kohavi, R.; John, G.H. Wrappers for Feature Subset Selection. Artif. Intell. 1997, 97, 273–324. [Google Scholar] [CrossRef] [Green Version]
- Strobl, C.; Boulesteix, A.L.; Zeileis, A.; Hothorn, T. Bias in Random Forest Variable Importance Measures: Illustrations, Sources and a Solution. BMC Bioinform. 2007, 8, 25. [Google Scholar] [CrossRef] [Green Version]
- Kursa, M.B. Feature Selection with the Boruta Package. J. Stat. Softw. 2010, 36, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Jolliffe, I.T. Pricipal Component Analysis; Springer: New York, NY, USA, 2002. [Google Scholar]
- Abdi, H.; Williams, L.J. Principal Component Analysis. WIREs Comput. Stat. 2010, 2, 433–459. [Google Scholar] [CrossRef]
- Trefethen, L.N.; Bau, D., III. Numerical Linear Algebra; SIAM: Philadelphia, PA, USA, 1997. [Google Scholar]
- Egan, J.P. Signal Detection Theory and ROC Analysis; Academic Press: New York, NY, USA, 1975. [Google Scholar]
- Fawcett, T. An Introduction to ROC Analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Arlot, S.; Celisse, A. A Survey of Cross-Validation Procedures for Model Selection. Stat. Surv. 2010, 4, 40–79. [Google Scholar] [CrossRef]
- R Development Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2018. [Google Scholar]
- Meyer, D.; Dimitriadou, E.; Hornik, K.; Weingessel, A.; Leisch, F. e1071: Misc Functions of the Department of Statistics; R Package Version 1.7-0; Probability Theory Group (Formerly: E1071), TU Wien: Vienna, Austria, 2018. [Google Scholar]
- Therneau, T.; Atkinson, B.; Ripley, B. rpart: Recursive Partitioning and Regression Trees. R Package Version 2017, 4, 1–9. [Google Scholar]
- Liaw, A.; Wiener, M. Classification and Regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- DeLong, E.R.; DeLong, D.M.; Clarke-Pearson, D.L. Comparing the Areas under Two or More Correlated Receiver Operating Characteristic Curves: A Nonparametric Approach. Biometrics 1988, 44, 837–845. [Google Scholar] [CrossRef]
- Adepeju, M.; Rosser, G.; Cheng, T. Novel Evaluation Metrics for Sparse Spatio-Temporal Point Process Hotspot Predictions—A Crime Case Study. Int. J. Geogr. Inf. Sci. 2016, 30, 2133–2154. [Google Scholar] [CrossRef]








| Manchester | Liverpool | Bournemouth | Wakefield | |
|---|---|---|---|---|
| Number of Rows | 1460 | 1626 | 2006 | 4035 |
| Hotspot percentage | ||||
| ANTISOCIAL | 25% | 24% | 25% | 24% |
| VIOLENCE | 25% | 25% | 25% | 24% |
| BURGLARY | 24% | 25% | 23% | 25% |
| SHOPLIFTING | 22% | 24% | 13% | 7% |
| THEFT | 23% | 25% | 24% | 22% |
| ROBBERY | 22% | 22% | 13% | 9% |
| #(↓ better than →) | Logistic Regression | Support Vector Machines | Decision Trees | Random Forest |
|---|---|---|---|---|
| Logistic Regression | 0 | 10 | 0 | |
| Support Vector Machines | 24 | 22 | 0 | |
| Decision Trees | 4 | 0 | 0 | |
| Random Forest | 24 | 14 | 24 |
| Logistic Regression | ||||
| Subset size | Manchester | Liverpool | Bournemouth | Wakefield |
| 5 | 0.75 | 0.77 | 0.75 | 0.85 |
| 10 | 0.76 | 0.78 | 0.78 | 0.87 |
| 25 | 0.76 | 0.77 | 0.79 | 0.88 |
| 97 | 0.70 | 0.71 | 0.71 | 0.84 |
| Support Vector Machines | ||||
| Subset size | Manchester | Liverpool | Bournemouth | Wakefield |
| 5 | 0.72 | 0.72 | 0.71 | 0.79 |
| 10 | 0.73 | 0.74 | 0.73 | 0.83 |
| 25 | 0.75 | 0.75 | 0.76 | 0.83 |
| 97 | 0.76 | 0.76 | 0.78 | 0.86 |
| Decision Trees | ||||
| Subset size | Manchester | Liverpool | Bournemouth | Wakefield |
| 5 | 0.68 | 0.70 | 0.73 | 0.81 |
| 10 | 0.68 | 0.70 | 0.74 | 0.82 |
| 25 | 0.68 | 0.70 | 0.74 | 0.82 |
| 97 | 0.69 | 0.69 | 0.74 | 0.82 |
| Random Forest | ||||
| Subset size | Manchester | Liverpool | Bournemouth | Wakefield |
| 5 | 0.73 | 0.75 | 0.76 | 0.85 |
| 10 | 0.75 | 0.76 | 0.78 | 0.87 |
| 25 | 0.77 | 0.77 | 0.79 | 0.87 |
| 97 | 0.78 | 0.78 | 0.81 | 0.88 |
| Logistic Regression | ||||
| Subset size | Manchester | Liverpool | Bournemouth | Wakefield |
| 5 | 0.77 | 0.77 | 0.80 | 0.85 |
| 10 | 0.77 | 0.76 | 0.80 | 0.87 |
| 25 | 0.76 | 0.76 | 0.80 | 0.85 |
| 97 | 0.70 | 0.71 | 0.71 | 0.84 |
| Support Vector Machines | ||||
| Subset size | Manchester | Liverpool | Bournemouth | Wakefield |
| 5 | 0.76 | 0.77 | 0.78 | 0.86 |
| 10 | 0.77 | 0.77 | 0.79 | 0.86 |
| 25 | 0.76 | 0.75 | 0.78 | 0.85 |
| 97 | 0.76 | 0.76 | 0.78 | 0.86 |
| Decision Trees | ||||
| Subset size | Manchester | Liverpool | Bournemouth | Wakefield |
| 5 | 0.73 | 0.71 | 0.77 | 0.84 |
| 10 | 0.73 | 0.72 | 0.78 | 0.84 |
| 25 | 0.73 | 0.72 | 0.78 | 0.84 |
| 97 | 0.69 | 0.69 | 0.74 | 0.82 |
| Random Forest | ||||
| Subset size | Manchester | Liverpool | Bournemouth | Wakefield |
| 5 | 0.76 | 0.76 | 0.79 | 0.87 |
| 10 | 0.76 | 0.76 | 0.79 | 0.87 |
| 25 | 0.75 | 0.76 | 0.79 | 0.86 |
| 97 | 0.78 | 0.78 | 0.81 | 0.88 |
| ANTISOCIAL | ||||
| training↓/prediction→ | Manchester | Liverpool | Bournemouth | Wakefield |
| Manchester | 0.84 | 0.80 | 0.82 | 0.88 |
| Liverpool | 0.75 | 0.84 | 0.82 | 0.88 |
| Bournemouth | 0.76 | 0.76 | 0.85 | 0.88 |
| Wakefield | 0.73 | 0.76 | 0.82 | 0.89 |
| VIOLENCE | ||||
| training↓/prediction→ | Manchester | Liverpool | Bournemouth | Wakefield |
| Manchester | 0.84 | 0.78 | 0.81 | 0.87 |
| Liverpool | 0.73 | 0.83 | 0.80 | 0.86 |
| Bournemouth | 0.73 | 0.74 | 0.84 | 0.87 |
| Wakefield | 0.70 | 0.74 | 0.80 | 0.89 |
| BURGLARY | ||||
| training↓/prediction→ | Manchester | Liverpool | Bournemouth | Wakefield |
| Manchester | 0.84 | 0.76 | 0.79 | 0.87 |
| Liverpool | 0.71 | 0.80 | 0.78 | 0.86 |
| Bournemouth | 0.75 | 0.74 | 0.83 | 0.88 |
| Wakefield | 0.70 | 0.73 | 0.78 | 0.89 |
| SHOPLIFTING | ||||
| training↓/prediction→ | Manchester | Liverpool | Bournemouth | Wakefield |
| Manchester | 0.87 | 0.81 | 0.84 | 0.93 |
| Liverpool | 0.78 | 0.85 | 0.84 | 0.91 |
| Bournemouth | 0.80 | 0.81 | 0.87 | 0.93 |
| Wakefield | 0.80 | 0.81 | 0.84 | 0.94 |
| THEFT | ||||
| training↓/prediction→ | Manchester | Liverpool | Bournemouth | Wakefield |
| Manchester | 0.87 | 0.81 | 0.83 | 0.88 |
| Liverpool | 0.80 | 0.84 | 0.83 | 0.87 |
| Bournemouth | 0.79 | 0.77 | 0.85 | 0.87 |
| Wakefield | 0.74 | 0.76 | 0.82 | 0.88 |
| ROBBERY | ||||
| training↓/prediction→ | Manchester | Liverpool | Bournemouth | Wakefield |
| Manchester | 0.88 | 0.80 | 0.80 | 0.88 |
| Liverpool | 0.79 | 0.85 | 0.80 | 0.87 |
| Bournemouth | 0.77 | 0.76 | 0.85 | 0.87 |
| Wakefield | 0.78 | 0.77 | 0.80 | 0.89 |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cichosz, P. Urban Crime Risk Prediction Using Point of Interest Data. ISPRS Int. J. Geo-Inf. 2020, 9, 459. https://doi.org/10.3390/ijgi9070459
Cichosz P. Urban Crime Risk Prediction Using Point of Interest Data. ISPRS International Journal of Geo-Information. 2020; 9(7):459. https://doi.org/10.3390/ijgi9070459
Chicago/Turabian StyleCichosz, Paweł. 2020. "Urban Crime Risk Prediction Using Point of Interest Data" ISPRS International Journal of Geo-Information 9, no. 7: 459. https://doi.org/10.3390/ijgi9070459
APA StyleCichosz, P. (2020). Urban Crime Risk Prediction Using Point of Interest Data. ISPRS International Journal of Geo-Information, 9(7), 459. https://doi.org/10.3390/ijgi9070459