



Service-Aware Hierarchical Fog–Cloud Resource Mappingfor e-Health with Enhanced-Kernel SVM





Abstract
:1. Introduction
- We propose a task classification algorithm, fusing features at the network level and service level for e-Health, which is efficient in achieving user-centric QoS maximization, with latency minimized for critical tasks. Support vector machine (SVM)-based task classification which is efficient in handling the defined latency-sensitive critical tasks is proposed. It is necessary to note that although deep learning algorithms increasingly gain markets, shallow machine learning (e.g., SVM) with low computational costs still presents strengths for latency-sensitive e-Health applications [5].
- A new kernel type is proposed for comprehensively classifying network-level and service-level features, fusing convolution, cross-correlation, and auto-correlation, which gains high overall classification accuracy for specificity and sensitivity enhancement.
- We propose a task priority assignment algorithm and a resource-mapping algorithm, which achieve sufficient overall latency for the defined critical tasks while improving the overall resource utilization efficiency.
2. Related Work

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | FN Capacity | Task Features | Task Priority | Latency | Execution Time | Network Modeling | Computation Modeling | Offloading to Cloud |
|---|---|---|---|---|---|---|---|---|
| [10] | ✘ | ✔ | ✔ | ✘ | ✔ | ✘ | ✘ | ✘ |
| [11] | ✘ | ✘ | ✘ | ✔ | ✔ | ✘ | ✘ | ✘ |
| [12] | ✔ | ✔ | ✘ | ✔ | ✔ | ✘ | ✘ | ✘ |
| [16] | ✔ | ✘ | ✘ | ✔ | ✔ | ✔ | ✔ | ✘ |
| [18] | ✔ | ✔ | ✔ | ✘ | ✔ | ✘ | ✘ | ✔ |
| [19] | ✔ | ✘ | ✔ | ✘ | ✔ | ✔ | ✘ | ✔ |
| [20] | ✔ | ✘ | ✔ | ✔ | ✔ | ✔ | ✘ | ✔ |
| [21] | ✔ | ✘ | ✘ | ✔ | ✔ | ✔ | ✔ | ✘ |
| [23] | ✘ | ✔ | ✔ | ✔ | ✘ | ✘ | ✘ | ✘ |
| Proposed | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
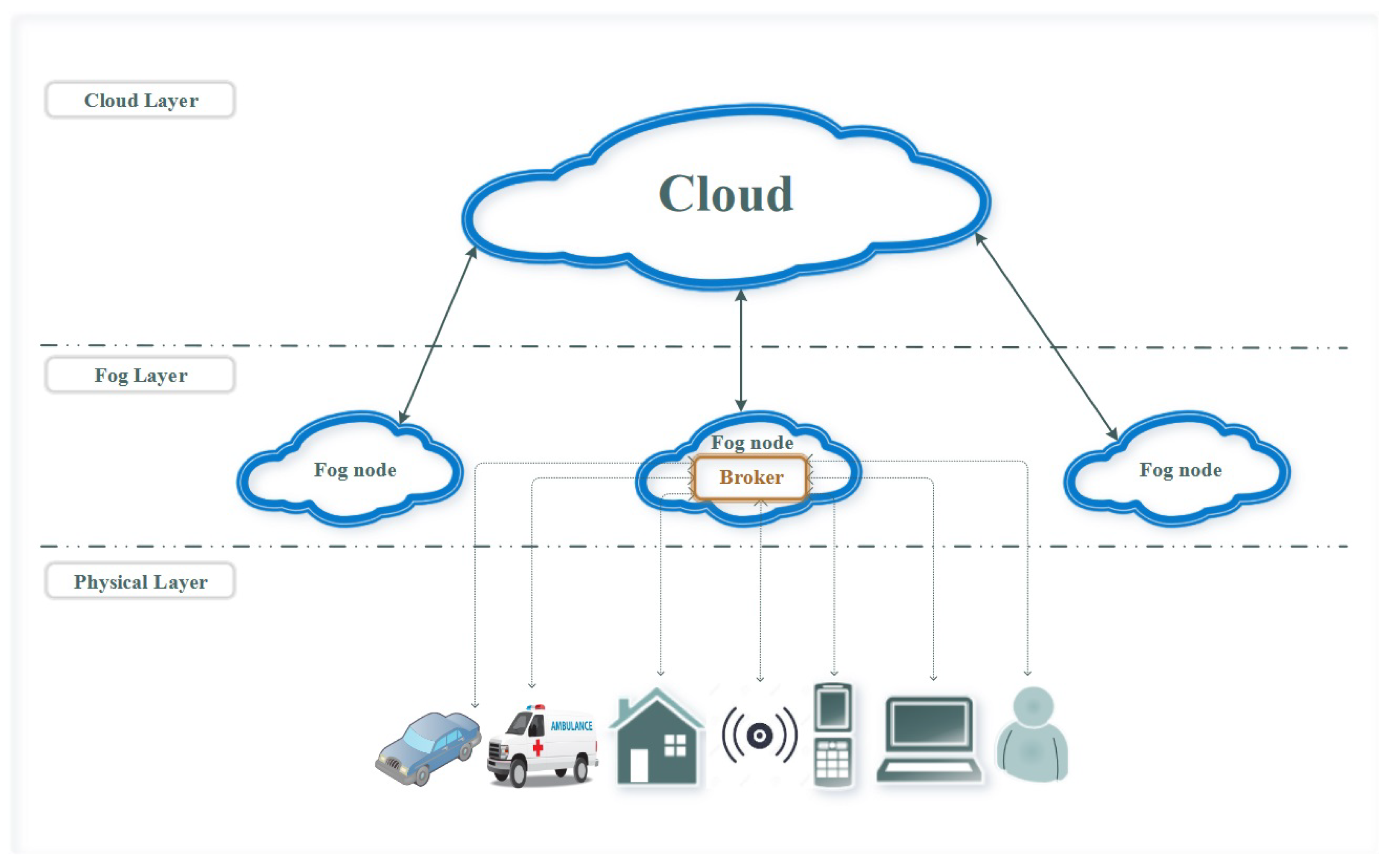
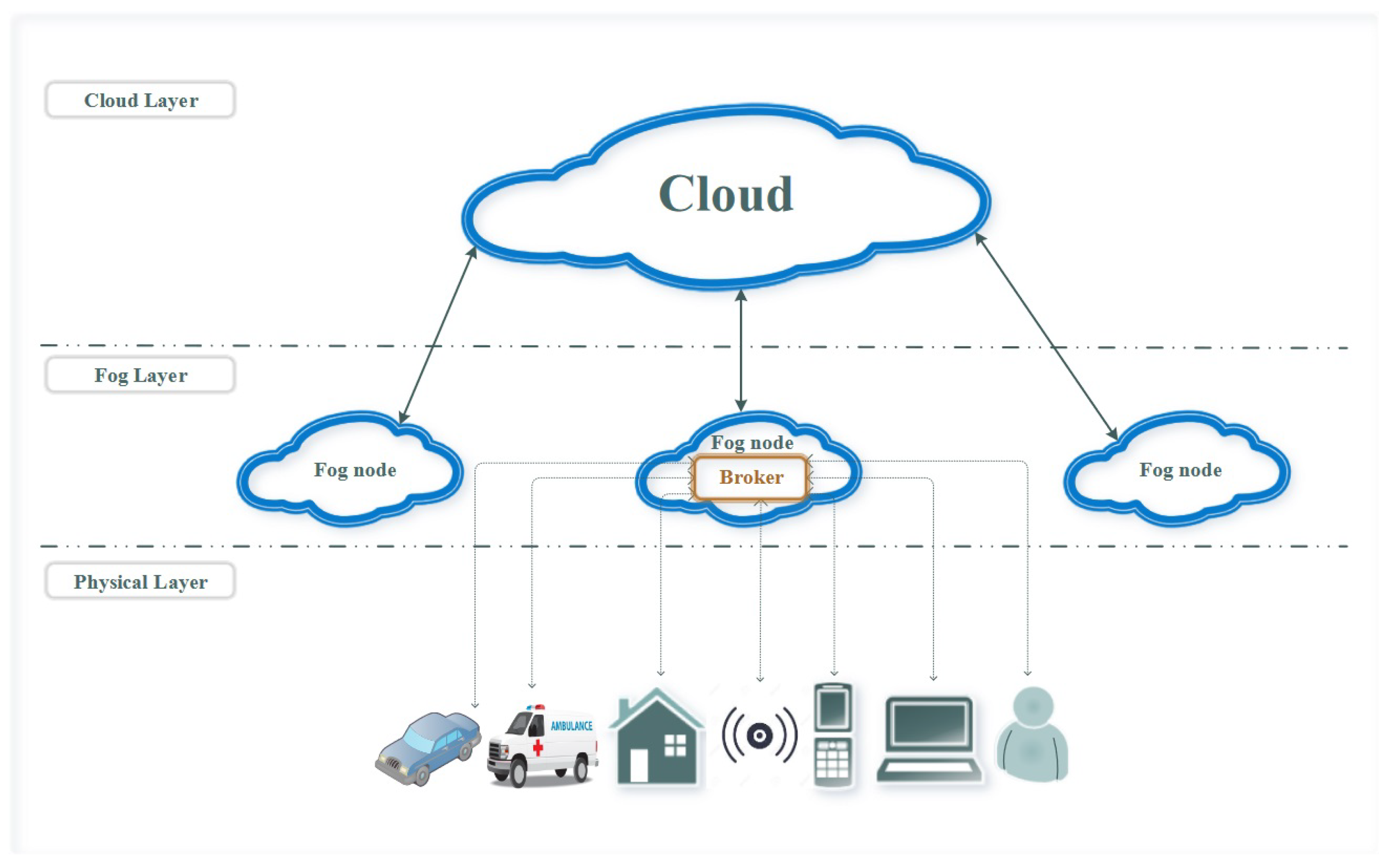
3. Fog–Cloud Hierarchical Infrastructure and Modeling for e-Health
3.1. Fog–Cloud Hierarchical Infrastructure for e-Health
- Inquiry: triggered for storing information in medical records;
- Backup: generated periodically to update medical records;
- Notification: set as reminders, e.g., pill time and therapy appointment for patients, medical status alert to medical workers, etc.;
- Alarm: generated based on the diagnosis results, which are also affected/referenced by the proposed orchestrator, regarding task classification.
| Algorithm 1 Task priority determination algorithm. |
|
3.2. Network Modeling
3.3. Computation Modeling
4. Support Vector Machine-Based Multi-Layer Task Classification
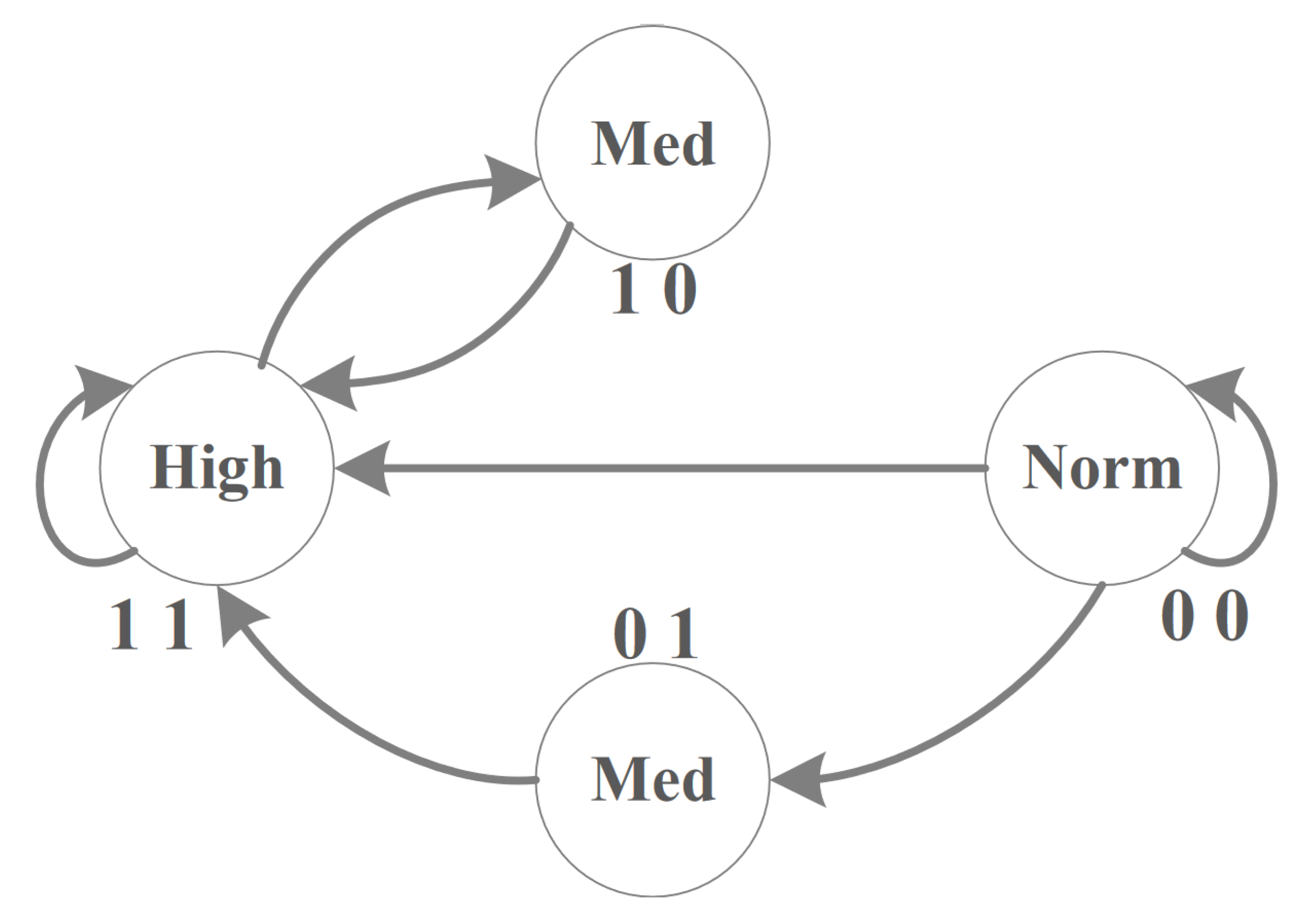
- High: This state indicates that the notification from one of the sensors has one of the symptoms labeled risky, in addition to the fact that the patient has an illness history within their profile; additionally, the received symptom is directly connected to the patient’s medical case.
- Medium: This state includes two cases: The first one implies that the notification has one of the risky symptoms but the patient’s medical profile is marked as healthy and has no illness history; this case is represented by (01). The second case is when the patient is labeled as having one of the chronic diseases which requires constant surveillance and the patient has no symptoms at the moment; this case is represented by (10).
- Normal: This state refers to the situation where all incoming notifications are within safe limits, such as periodic readings, with a clear illness history for the patient.
| Algorithm 2 Resource classification algorithm. |
|
| Algorithm 3 Resource-mapping algorithm. |
|
4.1. Feature and Database Determination
4.2. New Kernel Design and Margin Maximization
5. Task Scheduling Based on Resource Mapping
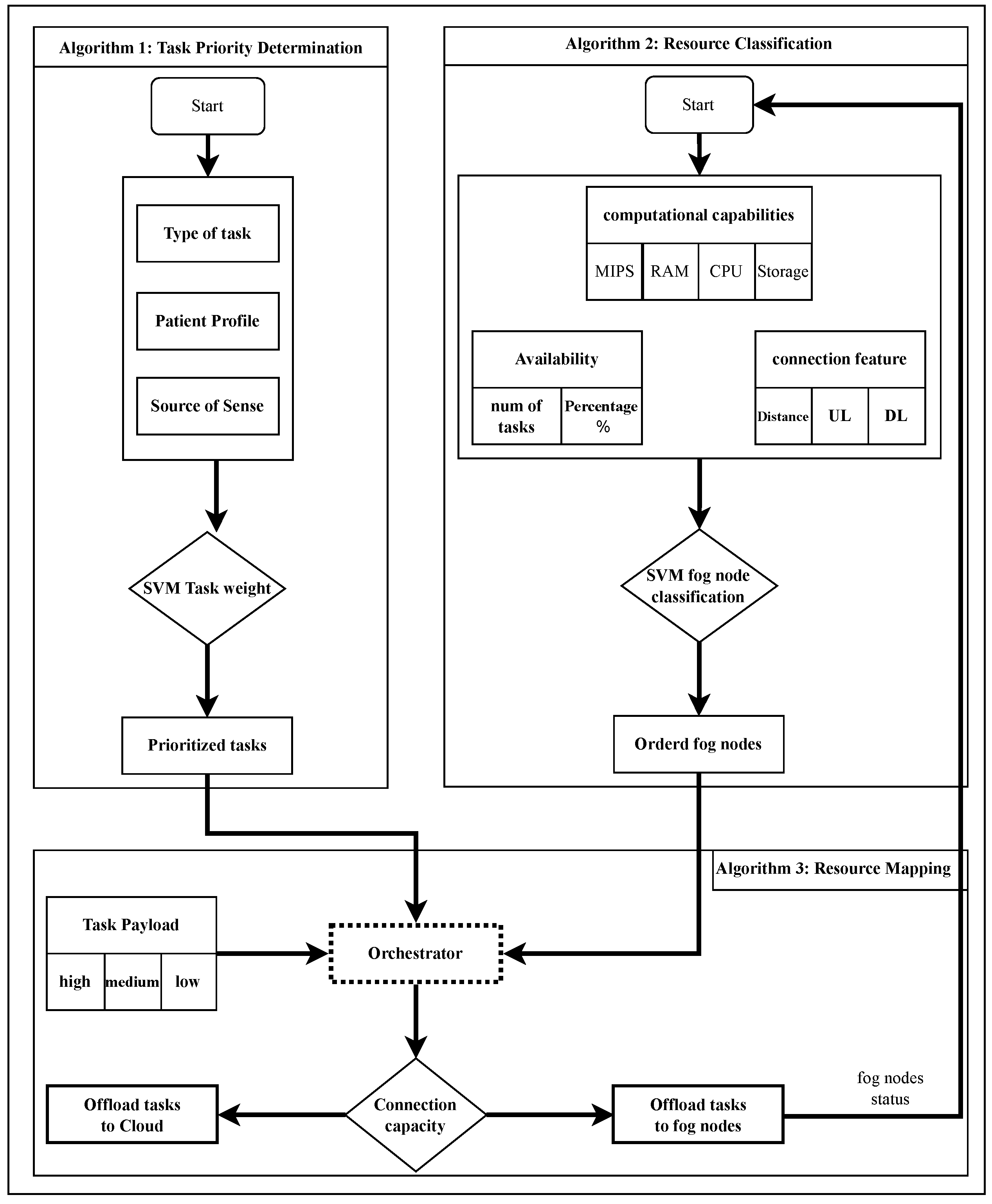
5.1. Task Priority Determination Algorithm
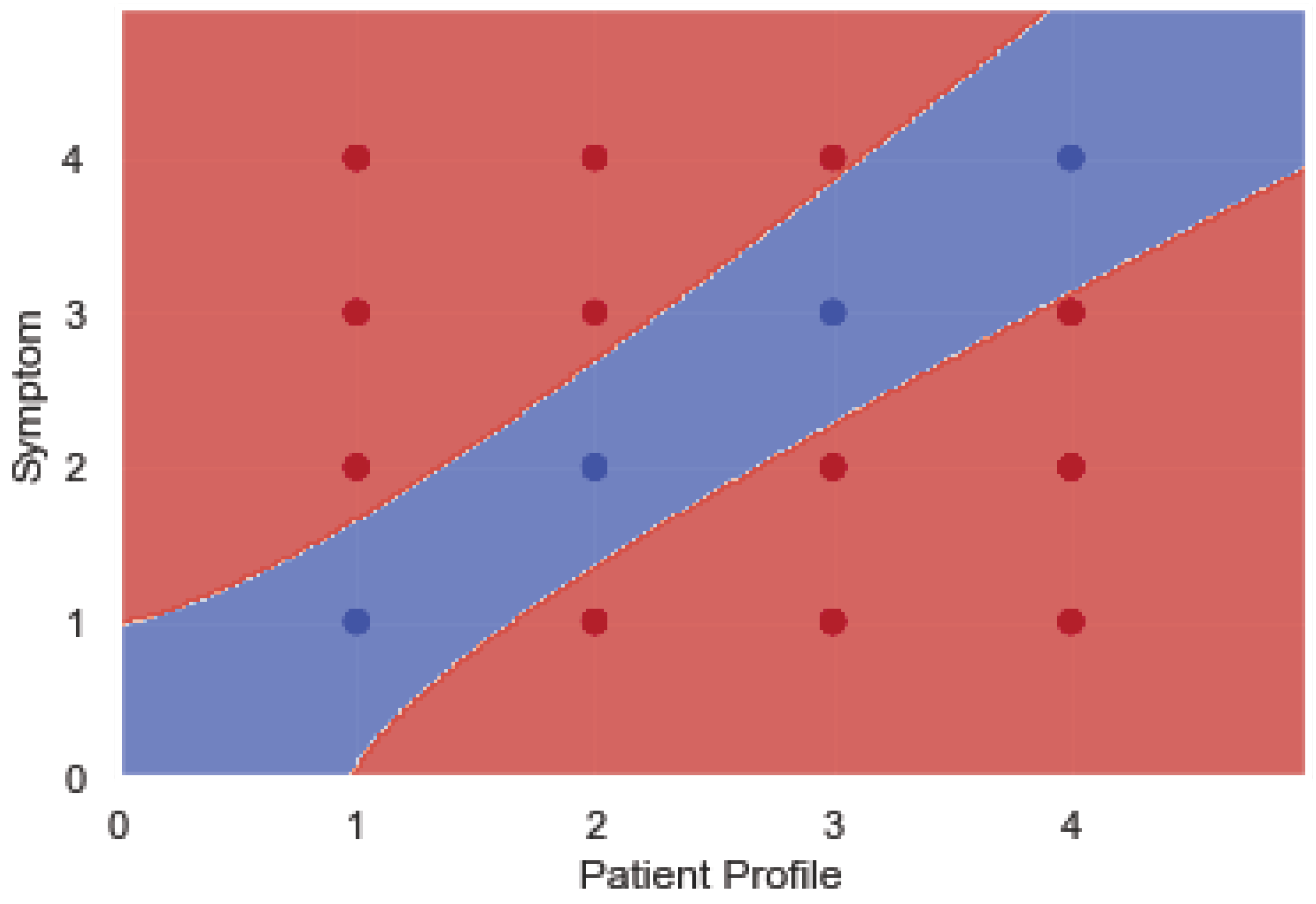
- Algorithm 1 checks the values of two fields (patient profile and symptom) in addition to other parameters, such as the payload of the task. If the two values of patient profile and symptom are equal, the SVM_weight of the task is high. On the contrary, if the values of patient profile and symptom are not equal, the SVM_weight of the task is medium. The case of SVM_weight equal to low is when the patient’s health record is labeled healthy and the symptom field contains vital indicators in the normal limits.
- The task’s priority value is assigned based on the previously mentioned values.
- The value of the field type of task is assigned based on the task’s priority value.
- The tasks are ordered in descending order based on their priority.
- The prioritized-labeled tasks are sent to the orchestrator to be distributed to the proper FNs.
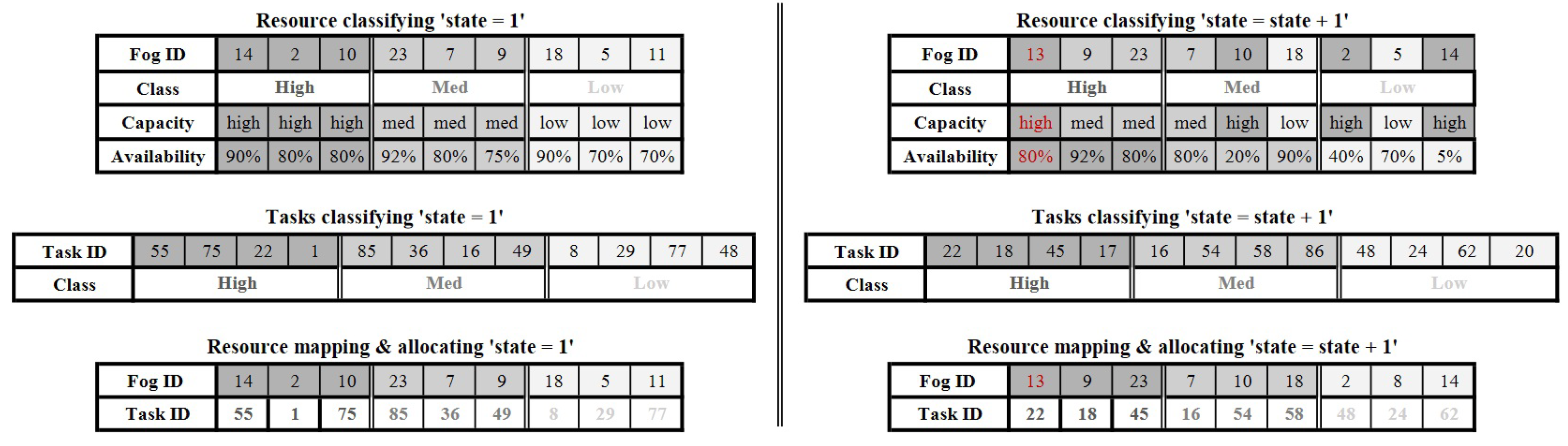
5.2. Resource Classification Algorithm
- The FN computational capacity, which includes MIPS, RAM, storage, and the number of CPUs and their capacity, is extracted.
- The topology of the service area is scanned to determine the characteristics of the connection, including the uplink/downlink bandwidth and the distance between the FNs and the devices that should connect to them; this distance is divided into three levels (near, medium, and far) based on the area where the device is located.
- The FN sends the processing occupancy percentage, i.e., the volume of resources occupied in favor of processing tasks and the percentage of resources available to process new tasks.
- According to the previous parameters, using the SVM algorithm, the FNs are classified and ordered in descending order into three levels: high, medium, and low.
- The order of the classified FNs is sent to the orchestrator.
5.3. Resource-Mapping Algorithm
- The orchestrator receives the classified fog nodes from Algorithm 2.
- The orchestrator receives the prioritized tasks from Algorithm 1.
- It checks the value of the payload field and assigns it the label high or medium based on the SVM threshold.
- The orchestrator maps and offloads tasks to the FNs or CNs based on priority and classification.
- The orchestrator checks if the network connection capacity is sufficient to serve the incoming requests to meet the latency requirement. If not, the type of task field is labeled with an alarm and forwarded to the cloud node.
5.4. Complexity Analysis
- Algorithm 1 task priority determination algorithm: The complexity of this algorithm is primarily dependent on the number of tasks. If N represents the total number of tasks, then the complexity is , as each task requires a constant amount of time for processing.
- Algorithm 2 resource classification algorithm: The complexity is influenced by the number of fog nodes, denoted by M. Since each node is classified independently, the algorithm exhibits linear complexity, .
- Algorithm 3 resource-mapping algorithm: This algorithm combines aspects of both task prioritization and resource classification. With N tasks and M fog nodes, the worst-case complexity could be , particularly in scenarios where each task must be considered for every node.
5.5. Offloading Scheme
6. Performance Analysis
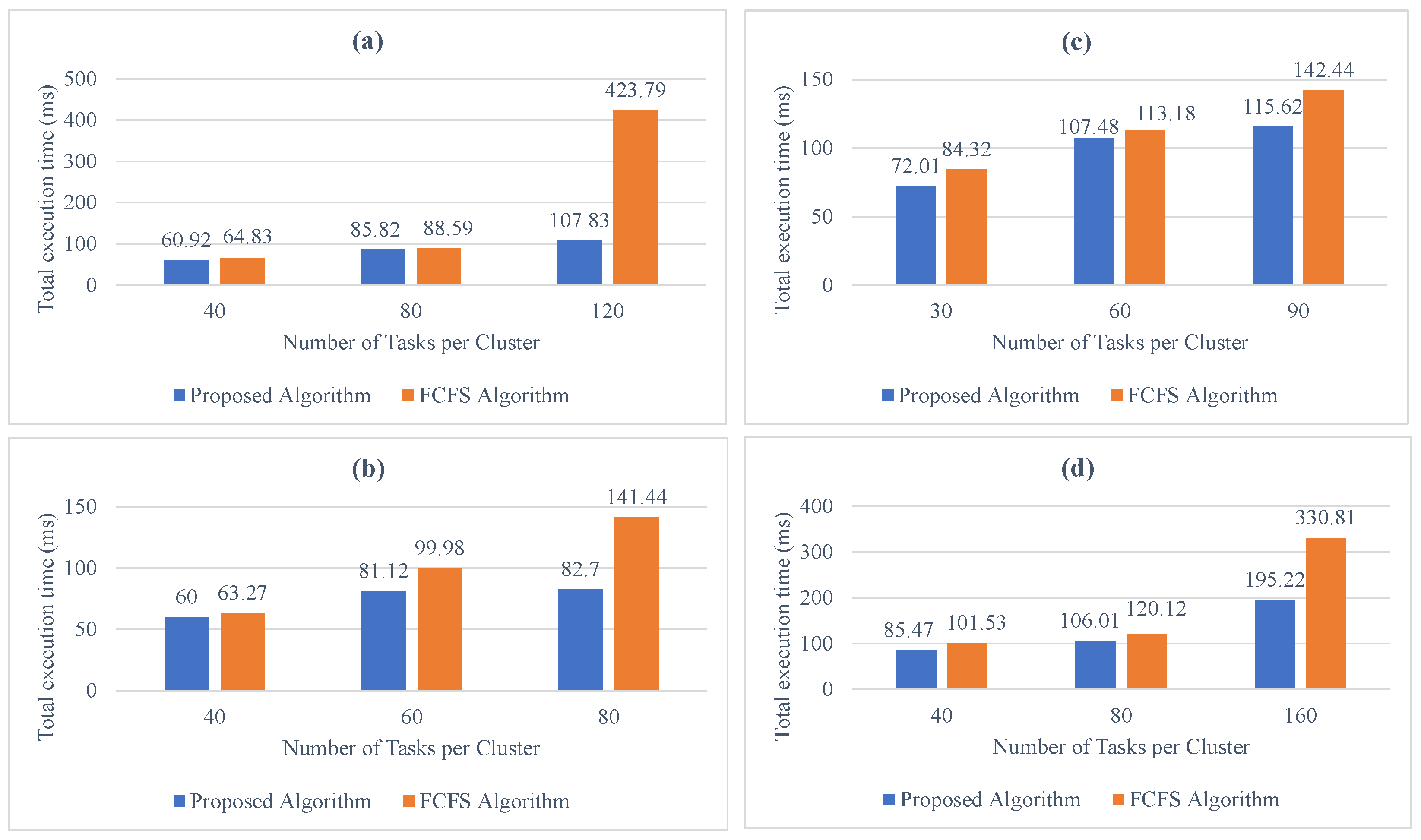
6.1. Execution Time
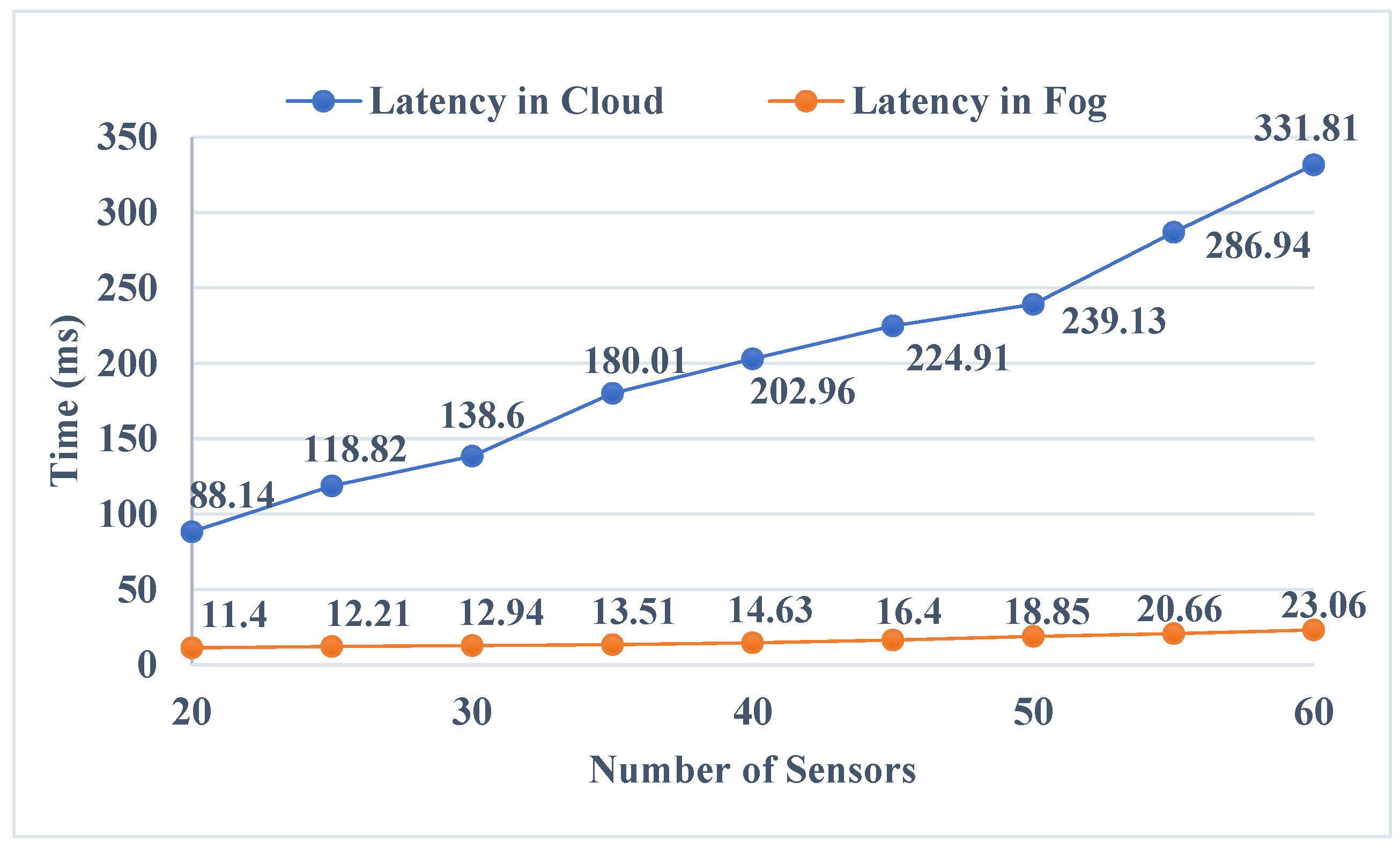
6.2. Latency
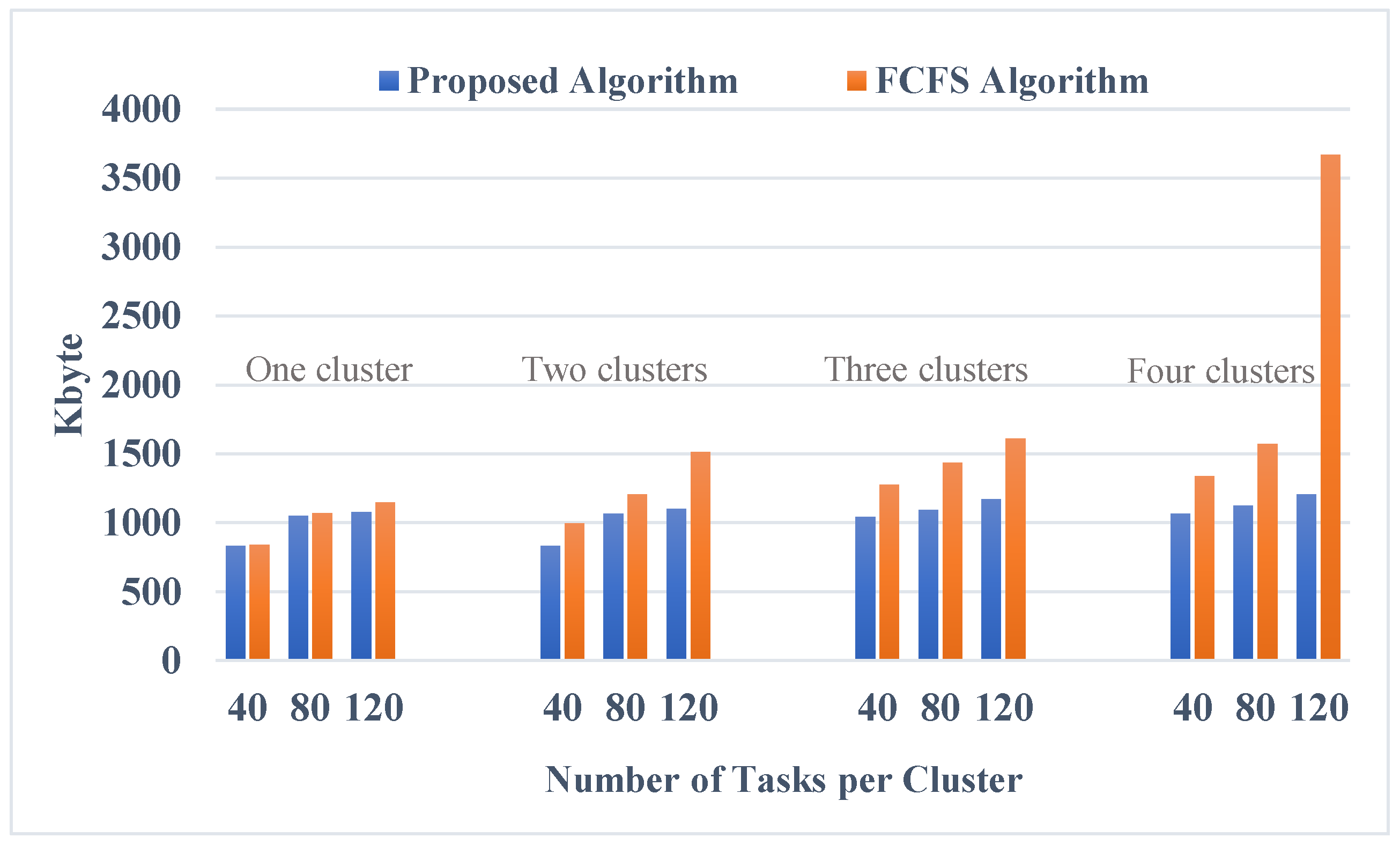
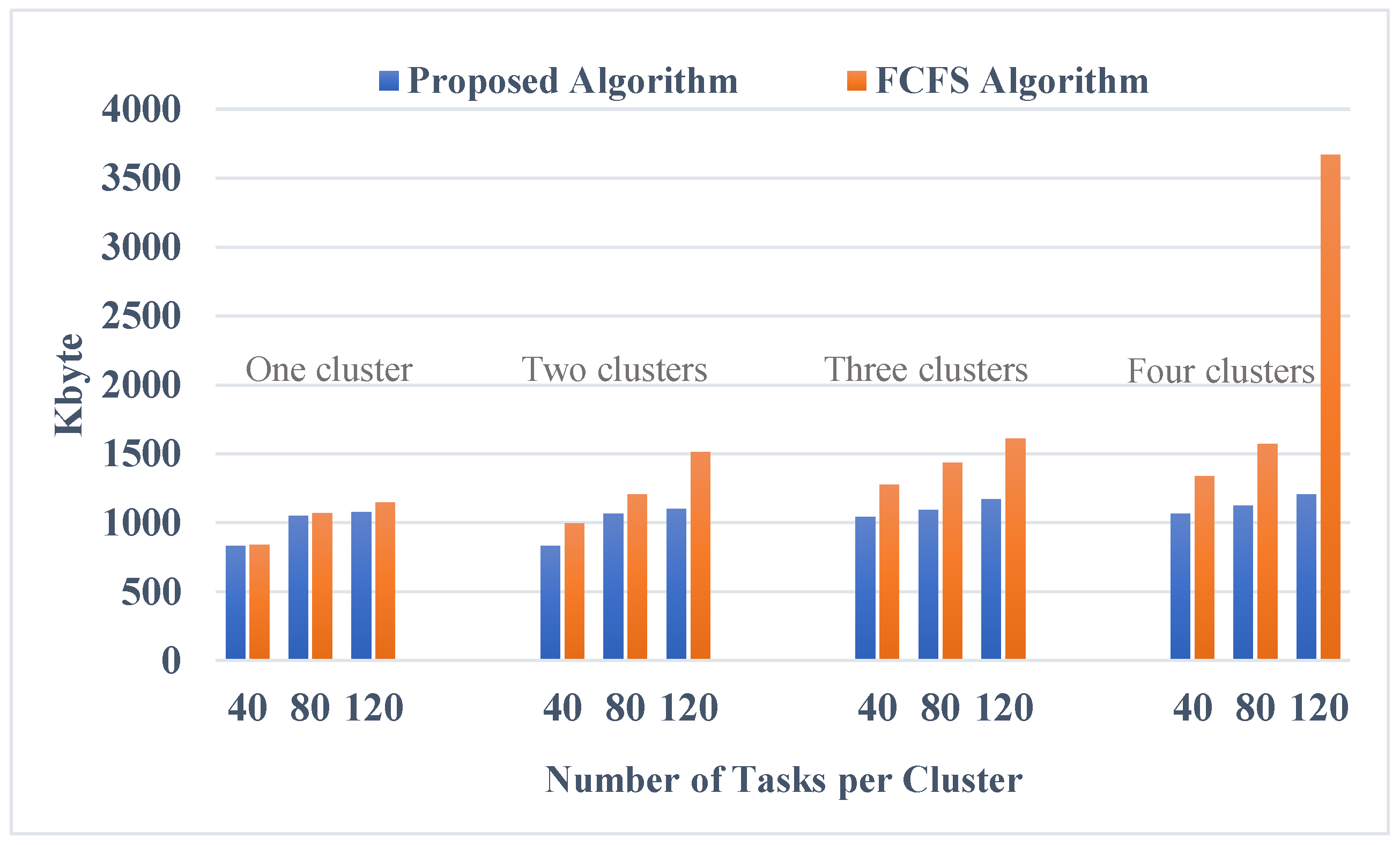
6.3. Network Utilization
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| Cloud node | |
| Fog node | |
| IoT device | |
| Task | |
| Cost | |
| Priority of a task | |
| Latency of a task | |
| Payload of a task | |
| Type of task | |
| Patient profile | |
| Patient preliminary symptoms | |
| Distance between an IoT device and a fog node | |
| Distance from a fog node to the cloud | |
| Communication time of a task | |
| Waiting time of a task | |
| Processing time of a task | |
| Transmission delay | |
| Data rate of a fog node and that of a cloud node | |
| Link bandwidth of a fog node and that of a cloud node | |
| Signal-to-interference-plus-noise ratio | |
| Uplink transmitting rate | |
| Processing time of a task | |
| Computing capacity of a fog node and that of a cloud node | |
| Total number of time slots in a processing node | |
| Required resources for a task in a given slot time |
References
- Liu, J.; Ahmed, M.; Mirza, M.A.; Khan, W.U.; Xu, D.; Li, J.; Aziz, A.; Han, Z. RL/DRL Meets Vehicular Task Offloading Using Edge and Vehicular Cloudlet: A Survey. IEEE Internet Things J. 2022, 9, 8315–8338. [Google Scholar] [CrossRef]
- Chi, H.R.; Domingues, M.F.; Radwan, A. QoS-aware Small-Cell-Overlaid Heterogeneous Sensor Network Deployment for eHealth. In Proceedings of the 2020 IEEE SENSORS, Rotterdam, The Netherlands, 25–28 October 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Chi, H.R. Editorial: Edge Computing for the Internet of Things. J. Sens. Actuator Netw. 2023, 12, 17. [Google Scholar] [CrossRef]
- Kashani, M.H.; Mahdipour, E. Load Balancing Algorithms in Fog Computing. IEEE Trans. Serv. Comput. 2023, 16, 1505–1521. [Google Scholar] [CrossRef]
- Chi, H.R.; Domingues, M.d.F.; Zhu, H.; Li, C.; Kojima, K.; Radwan, A. Healthcare 5.0: In the Perspective of Consumer Internet-of-Things-Based Fog/Cloud Computing. IEEE Trans. Consum. Electron. 2023, 1. [Google Scholar] [CrossRef]
- Radwan, A.; Chi, H.R. Towards Cell-Free Networking: Analytical Study of Ultra-Dense On-Demand Small Cell Deployment for Internet of Things. In Proceedings of the 2023 International Wireless Communications and Mobile Computing (IWCMC), Marrakesh, Morocco, 19–23 June 2023; pp. 1202–1207. [Google Scholar] [CrossRef]
- Strumberger, I.; Tuba, M.; Bacanin, N.; Tuba, E. Cloudlet Scheduling by Hybridized Monarch Butterfly Optimization Algorithm. J. Sens. Actuator Netw. 2019, 8, 44. [Google Scholar] [CrossRef]
- Mattia, G.P.; Beraldi, R. On real-time scheduling in Fog computing: A Reinforcement Learning algorithm with application to smart cities. In Proceedings of the 2022 IEEE International Conference on Pervasive Computing and Communications Workshops and other Affiliated Events (PerCom Workshops), Pisa, Italy, 21–25 March 2022; pp. 187–193. [Google Scholar] [CrossRef]
- AlZailaa, A.; Chi, H.R.; Radwan, A.; Aguiar, R. Low-Latency Task Classification and Scheduling in Fog/Cloud based Critical e-Health Applications. In Proceedings of the ICC 2021-IEEE International Conference on Communications, Montreal, QC, Canada, 14–23 June 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Semmoud, A.; Hakem, M.; Benmammar, B.; Charr, J.C. Load balancing in cloud computing environments based on adaptive starvation threshold. Concurr. Comput. Pract. Exp. 2020, 32, e5652. [Google Scholar] [CrossRef]
- Benblidia, M.A.; Brik, B.; Merghem-Boulahia, L.; Esseghir, M. Ranking Fog nodes for Tasks Scheduling in Fog-Cloud Environments: A Fuzzy Logic Approach. In Proceedings of the 2019 15th International Wireless Communications & Mobile Computing Conference (IWCMC), Tangier, Morocco, 24–28 June 2019; pp. 1451–1457. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; El-Shahat, D.; Elhoseny, M.; Song, H. Energy-Aware Metaheuristic Algorithm for Industrial-Internet-of-Things Task Scheduling Problems in Fog Computing Applications. IEEE Internet Things J. 2021, 8, 12638–12649. [Google Scholar] [CrossRef]
- Hosseini, E.; Nickray, M.; Ghanbari, S. Optimized task scheduling for cost-latency trade-off in mobile fog computing using fuzzy analytical hierarchy process. Comput. Netw. 2022, 206, 108752. [Google Scholar] [CrossRef]
- Tuli, S.; Basumatary, N.; Gill, S.S.; Kahani, M.; Arya, R.C.; Wander, G.S.; Buyya, R. HealthFog: An ensemble deep learning based Smart Healthcare System for Automatic Diagnosis of Heart Diseases in integrated IoT and fog computing environments. Future Gener. Comput. Syst. 2020, 104, 187–200. [Google Scholar] [CrossRef]
- Azizi, S.; Shojafar, M.; Abawajy, J.; Buyya, R. Deadline-aware and energy-efficient IoT task scheduling in fog computing systems: A semi-greedy approach. J. Netw. Comput. Appl. 2022, 201, 103333. [Google Scholar] [CrossRef]
- Kanbar, A.B.; Faraj, K. Region aware dynamic task scheduling and resource virtualization for load balancing in IoT–Fog multi-cloud environment. Future Gener. Comput. Syst. 2022, 137, 70–86. [Google Scholar] [CrossRef]
- Okegbile, S.D.; Maharaj, B.T.; Alfa, A.S. A Multi-User Tasks Offloading Scheme for Integrated Edge-Fog-Cloud Computing Environments. IEEE Trans. Veh. Technol. 2022, 71, 7487–7502. [Google Scholar] [CrossRef]
- Mutlag, A.A.; Khanapi Abd Ghani, M.; Mohammed, M.A.; Maashi, M.S.; Mohd, O.; Mostafa, S.A.; Abdulkareem, K.H.; Marques, G.; de la Torre Díez, I. MAFC: Multi-Agent Fog Computing Model for Healthcare Critical Tasks Management. Sensors 2020, 20, 1853. [Google Scholar] [CrossRef] [PubMed]
- Chakraborty, C.; Mishra, K.; Majhi, S.K.; Bhuyan, H.K. Intelligent Latency-Aware Tasks Prioritization and Offloading Strategy in Distributed Fog-Cloud of Things. IEEE Trans. Ind. Inform. 2023, 19, 2099–2106. [Google Scholar] [CrossRef]
- Gupta, S.; Iyer, S.; Agarwal, G.; Manoharan, P.; Algarni, A.D.; Aldehim, G.; Raahemifar, K. Efficient Prioritization and Processor Selection Schemes for HEFT Algorithm: A Makespan Optimizer for Task Scheduling in Cloud Environment. Electronics 2022, 11, 2557. [Google Scholar] [CrossRef]
- Alatoun, K.; Matrouk, K.; Mohammed, M.A.; Nedoma, J.; Martinek, R.; Zmij, P. A Novel Low-Latency and Energy-Efficient Task Scheduling Framework for Internet of Medical Things in an Edge Fog Cloud System. Sensors 2022, 22, 5327. [Google Scholar] [CrossRef]
- Khosroabadi, F.; Fotouhi-Ghazvini, F.; Fotouhi, H. SCATTER: Service Placement in Real-Time Fog-Assisted IoT Networks. J. Sens. Actuator Netw. 2021, 10, 26. [Google Scholar] [CrossRef]
- Nagarajan, S.M.; Devarajan, G.G.; Mohammed, A.S.; Ramana, T.V.; Ghosh, U. Intelligent Task Scheduling Approach for IoT Integrated Healthcare Cyber Physical Systems. IEEE Trans. Netw. Sci. Eng. 2022, 10, 2429–2438. [Google Scholar] [CrossRef]
- Chen, J.; He, Y.; Zhang, Y.; Han, P.; Du, C. Energy-aware scheduling for dependent tasks in heterogeneous multiprocessor systems. J. Syst. Archit. 2022, 129, 102598. [Google Scholar] [CrossRef]
- Abdelmoneem, R.M.; Benslimane, A.; Shaaban, E. Mobility-aware task scheduling in cloud-Fog IoT-based healthcare architectures. Comput. Netw. 2020, 179, 107348. [Google Scholar] [CrossRef]
- Ali, I.M.; Sallam, K.M.; Moustafa, N.; Chakraborty, R.; Ryan, M.; Choo, K.K.R. An Automated Task Scheduling Model Using Non-Dominated Sorting Genetic Algorithm II for Fog-Cloud Systems. IEEE Trans. Cloud Comput. 2022, 10, 2294–2308. [Google Scholar] [CrossRef]
- Cheikhrouhou, O.; Mershad, K.; Jamil, F.; Mahmud, R.; Koubaa, A.; Moosavi, S.R. A lightweight blockchain and fog-enabled secure remote patient monitoring system. Internet Things 2023, 22, 100691. [Google Scholar] [CrossRef]
- Tong, Z.; Deng, X.; Ye, F.; Basodi, S.; Xiao, X.; Pan, Y. Adaptive computation offloading and resource allocation strategy in a mobile edge computing environment. Inf. Sci. 2020, 537, 116–131. [Google Scholar] [CrossRef]
- Balevi, E.; Gitlin, R.D. Optimizing the number of fog nodes for cloud-fog-thing networks. IEEE Access 2018, 6, 11173–11183. [Google Scholar] [CrossRef]
- Chui, K.T.; Tsang, K.F.; Chi, H.R.; Ling, B.W.K.; Wu, C.K. An Accurate ECG-Based Transportation Safety Drowsiness Detection Scheme. IEEE Trans. Ind. Inform. 2016, 12, 1438–1452. [Google Scholar] [CrossRef]
- Ramani, P.; Pradhan, N.; Sharma, A.K. Classification Algorithms to Predict Heart Diseases—A Survey. In Proceedings of the Computer Vision and Machine Intelligence in Medical Image Analysis, Accra, Ghana, 29–31 May 2019; Gupta, M., Konar, D., Bhattacharyya, S., Biswas, S., Eds.; WikiCFP: Singapore, 2020; pp. 65–71. [Google Scholar]
- Kumar, P.; Chauhan, R.; Stephan, T.; Shankar, A.; Thakur, S. A Machine Learning Implementation for Mental Health Care. Application: Smart Watch for Depression Detection. In Proceedings of the 2021 11th International Conference on Cloud Computing, Data Science and Engineering (Confluence), Noida, India, 28–29 January 2021; pp. 568–574. [Google Scholar] [CrossRef]
- Mahmud, R.; Pallewatta, S.; Goudarzi, M.; Buyya, R. iFogSim2: An extended iFogSim simulator for mobility, clustering, and microservice management in edge and fog computing environments. J. Syst. Softw. 2022, 190, 111351. [Google Scholar] [CrossRef]
- Sing, R.; Bhoi, S.K.; Panigrahi, N.; Sahoo, K.S.; Bilal, M.; Shah, S.C. EMCS: An Energy-Efficient Makespan Cost-Aware Scheduling Algorithm Using Evolutionary Learning Approach for Cloud-Fog-Based IoT Applications. Sustainability 2022, 14, 15096. [Google Scholar] [CrossRef]
- Hassan, S.R.; Ahmad, I.; Ahmad, S.; Alfaify, A.; Shafiq, M. Remote Pain Monitoring Using Fog Computing for e-Healthcare: An Efficient Architecture. Sensors 2020, 20, 6574. [Google Scholar] [CrossRef]






| Element | Parameter | Units | Value |
|---|---|---|---|
| Cloud | CPU | MIPS | 44,800 |
| RAM | MB | 40,000 | |
| Uplink | bytes/ms | 20,000 | |
| Downlink | bytes/ms | 20,000 | |
| Fog device | CPU | MIPS | {2048, 1024, 768, 512, 256} |
| RAM | MB | {2048, 1024, 768, 512, 256} | |
| Uplink | bytes/ms | {8000, 4000, 2000} | |
| Downlink | bytes/ms | {8000, 4000, 2000} | |
| Task | CPU length | MIPS | {2000, 1000, 700, 500, 200} |
| Network length | bytes | {4000, 2000, 1000} |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
AlZailaa, A.; Chi, H.R.; Radwan, A.; Aguiar, R.L. Service-Aware Hierarchical Fog–Cloud Resource Mappingfor e-Health with Enhanced-Kernel SVM. J. Sens. Actuator Netw. 2024, 13, 10. https://doi.org/10.3390/jsan13010010
AlZailaa A, Chi HR, Radwan A, Aguiar RL. Service-Aware Hierarchical Fog–Cloud Resource Mappingfor e-Health with Enhanced-Kernel SVM. Journal of Sensor and Actuator Networks. 2024; 13(1):10. https://doi.org/10.3390/jsan13010010
Chicago/Turabian StyleAlZailaa, Alaa, Hao Ran Chi, Ayman Radwan, and Rui L. Aguiar. 2024. "Service-Aware Hierarchical Fog–Cloud Resource Mappingfor e-Health with Enhanced-Kernel SVM" Journal of Sensor and Actuator Networks 13, no. 1: 10. https://doi.org/10.3390/jsan13010010
APA StyleAlZailaa, A., Chi, H. R., Radwan, A., & Aguiar, R. L. (2024). Service-Aware Hierarchical Fog–Cloud Resource Mappingfor e-Health with Enhanced-Kernel SVM. Journal of Sensor and Actuator Networks, 13(1), 10. https://doi.org/10.3390/jsan13010010