
Detecting Pump-and-Dumps with Crypto-Assets: Dealing with Imbalanced Datasets and Insiders’ Anticipated Purchases



Abstract
:1. Introduction
2. Literature Review
2.1. Pump-and-Dumps
2.2. Cryptocurrency Pump-and-Dumps
2.3. The Class Imbalance Problem
3. Materials and Methods
3.1. Building Synthetic Balanced Datasets
3.2. Methods for Binary Classification: A (Brief) Review
4. Results
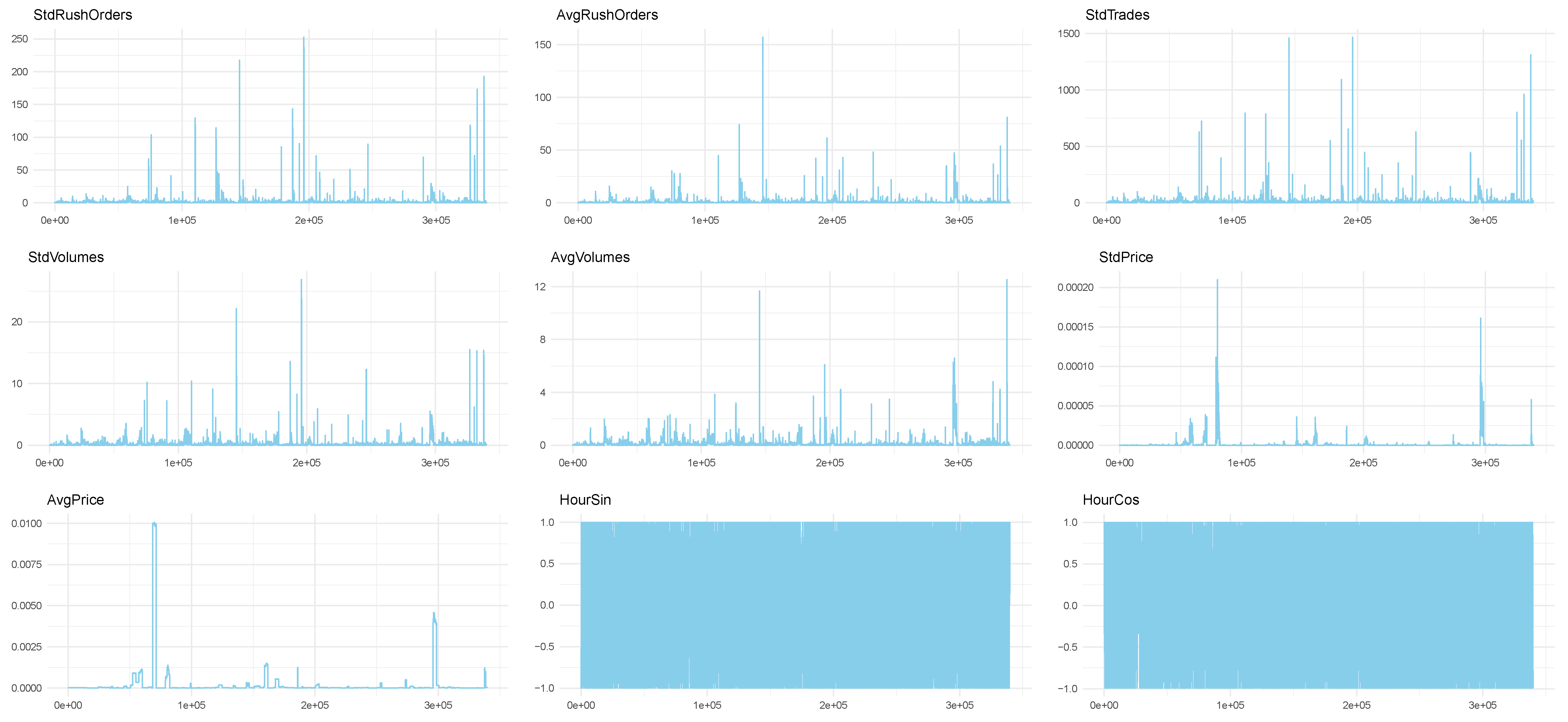
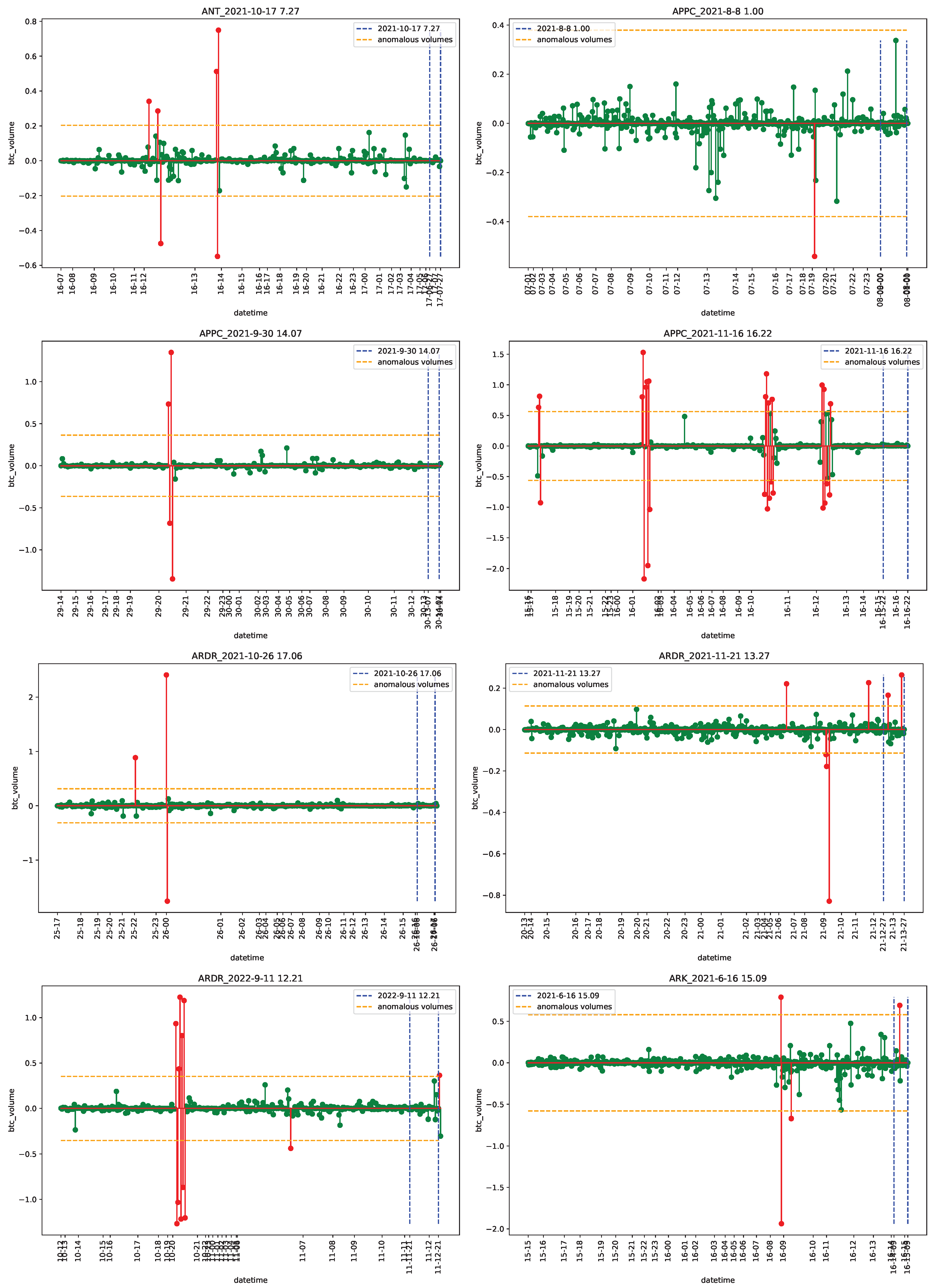
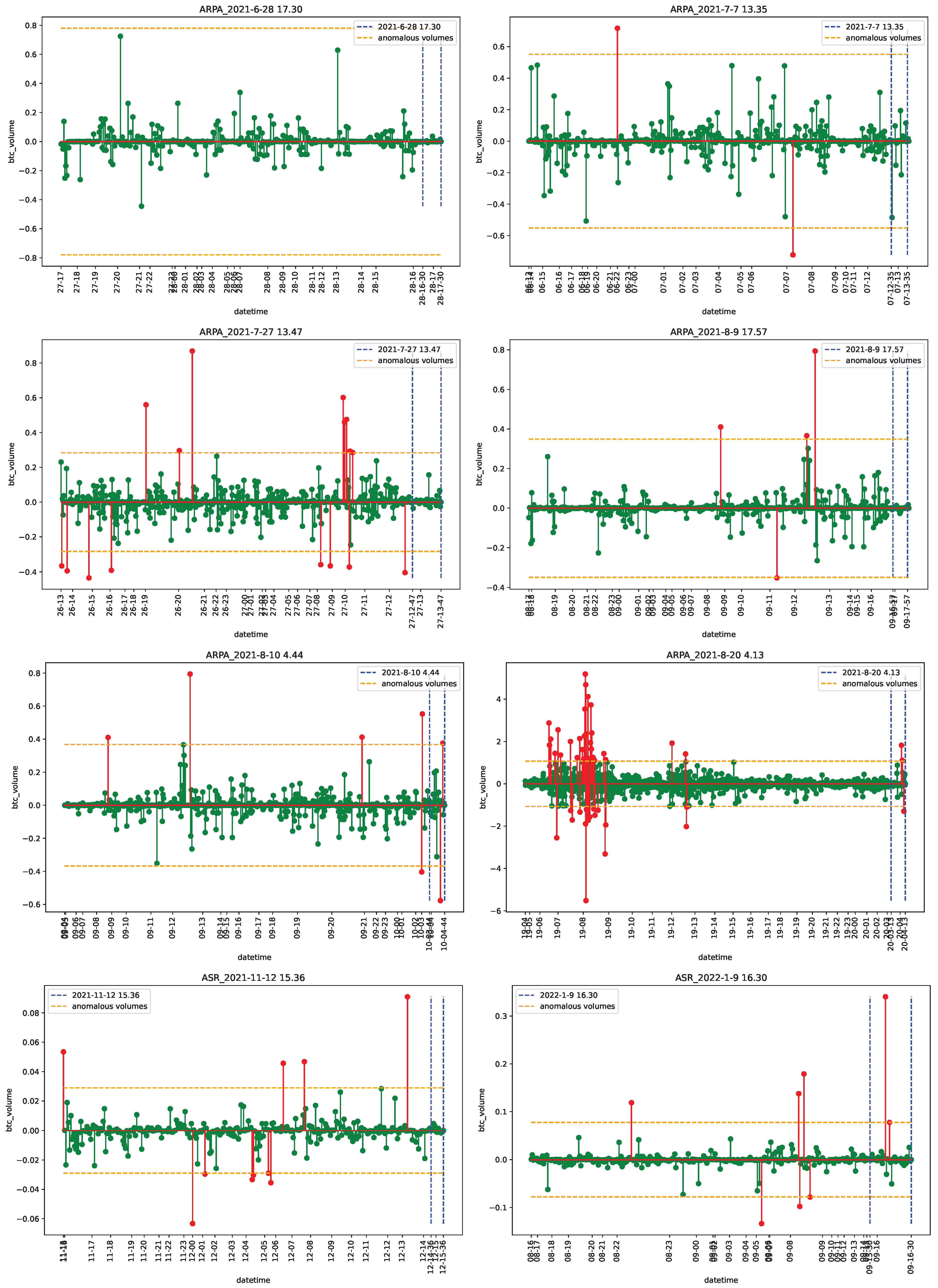
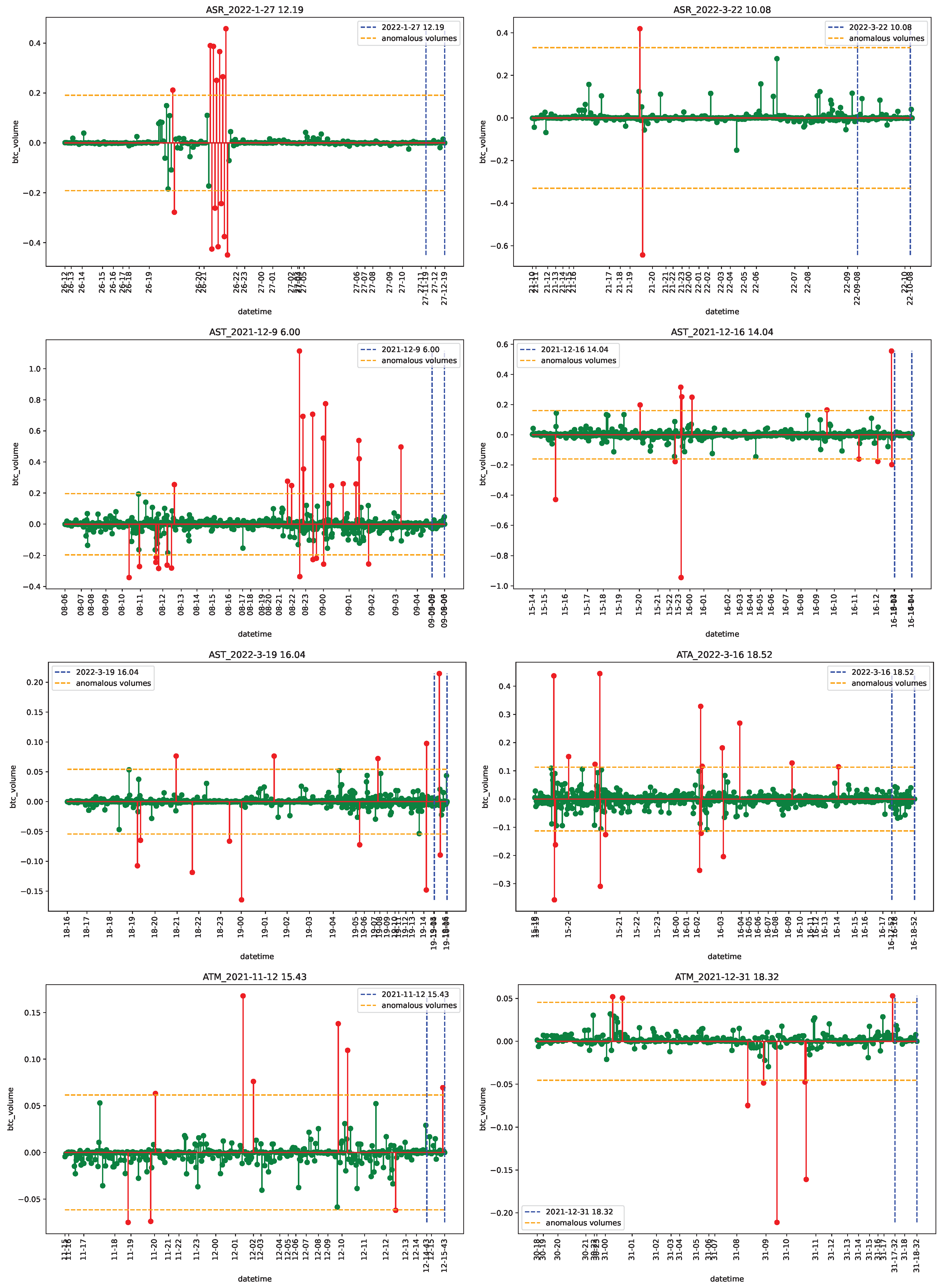
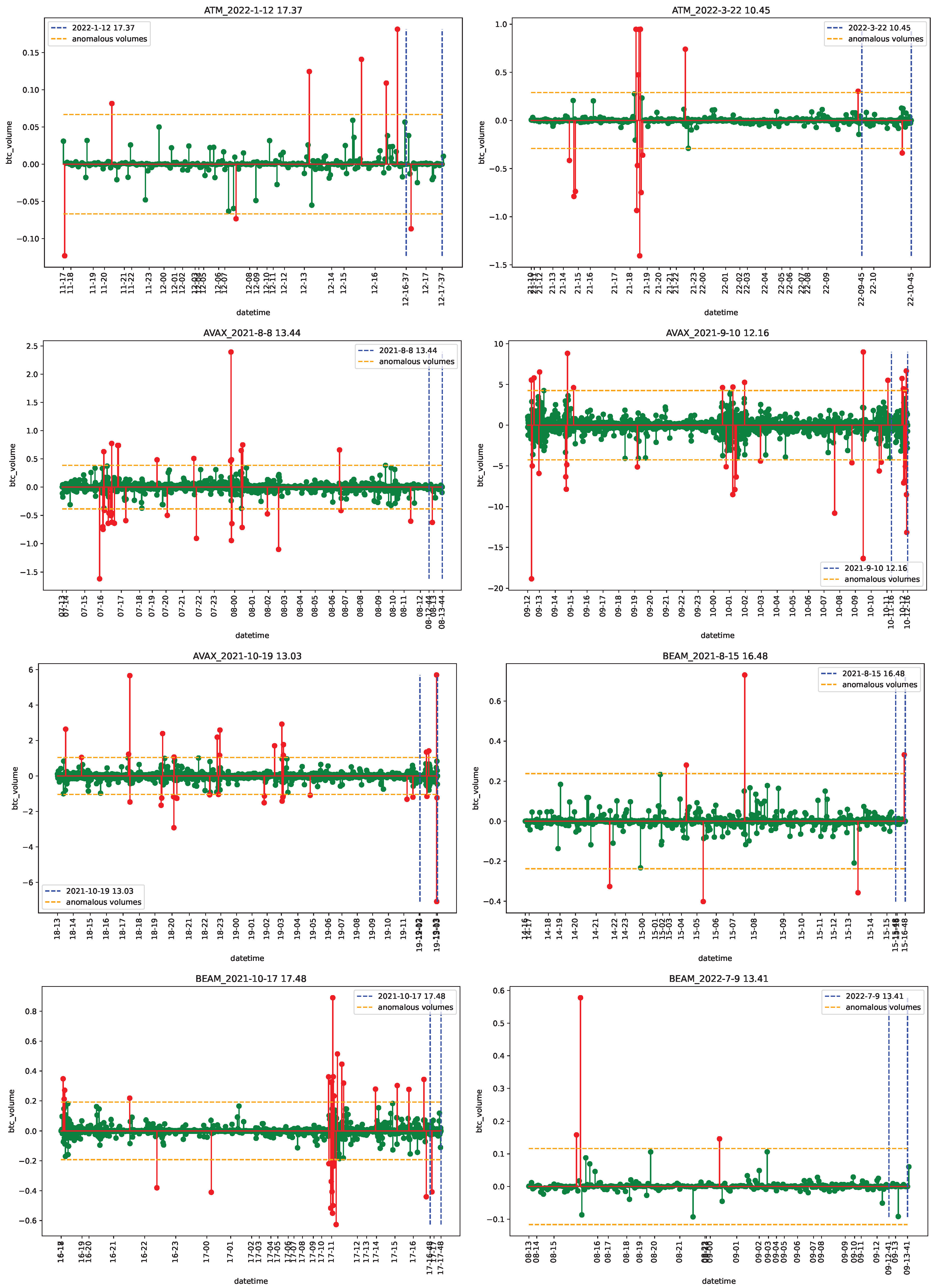
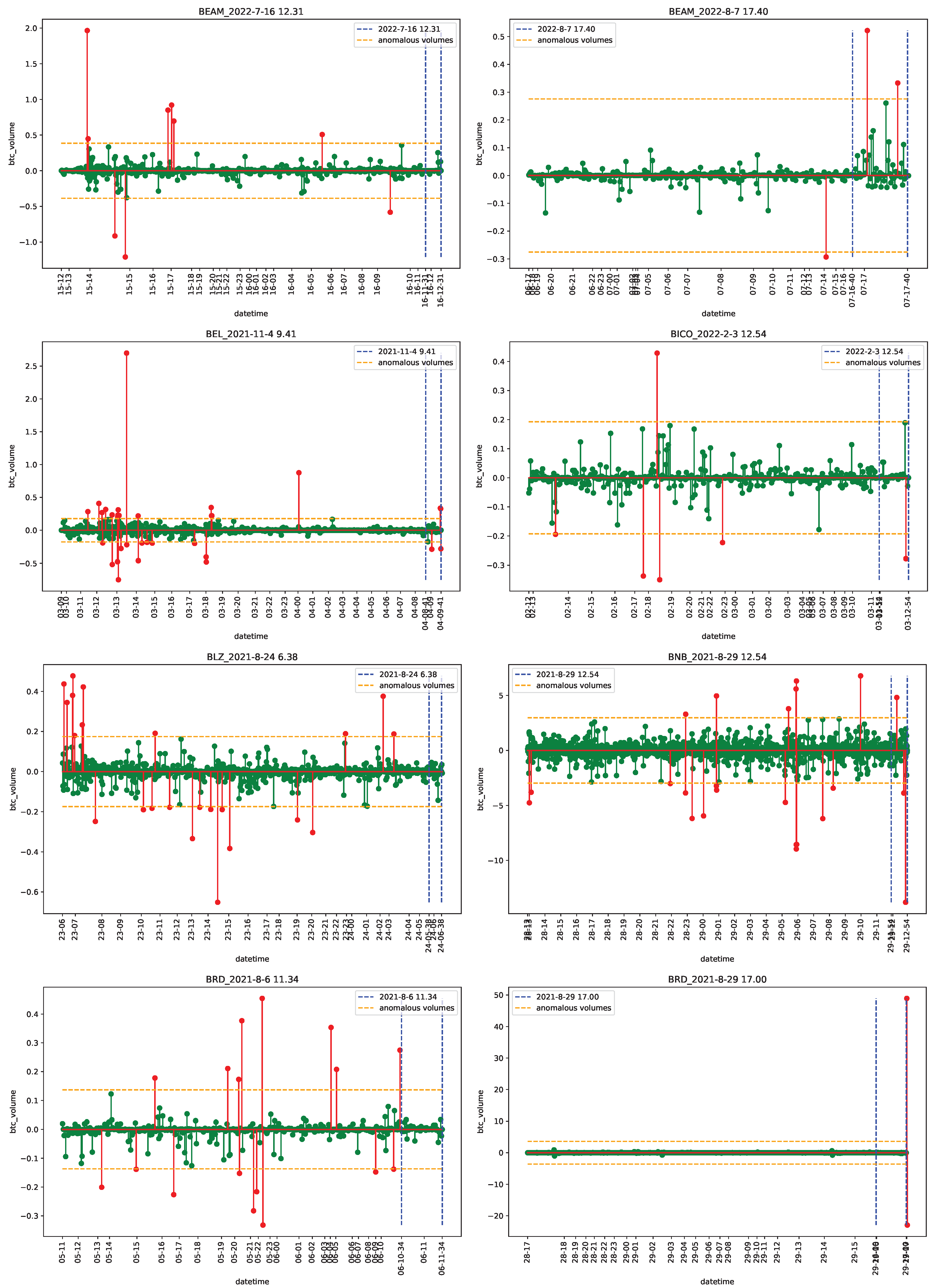
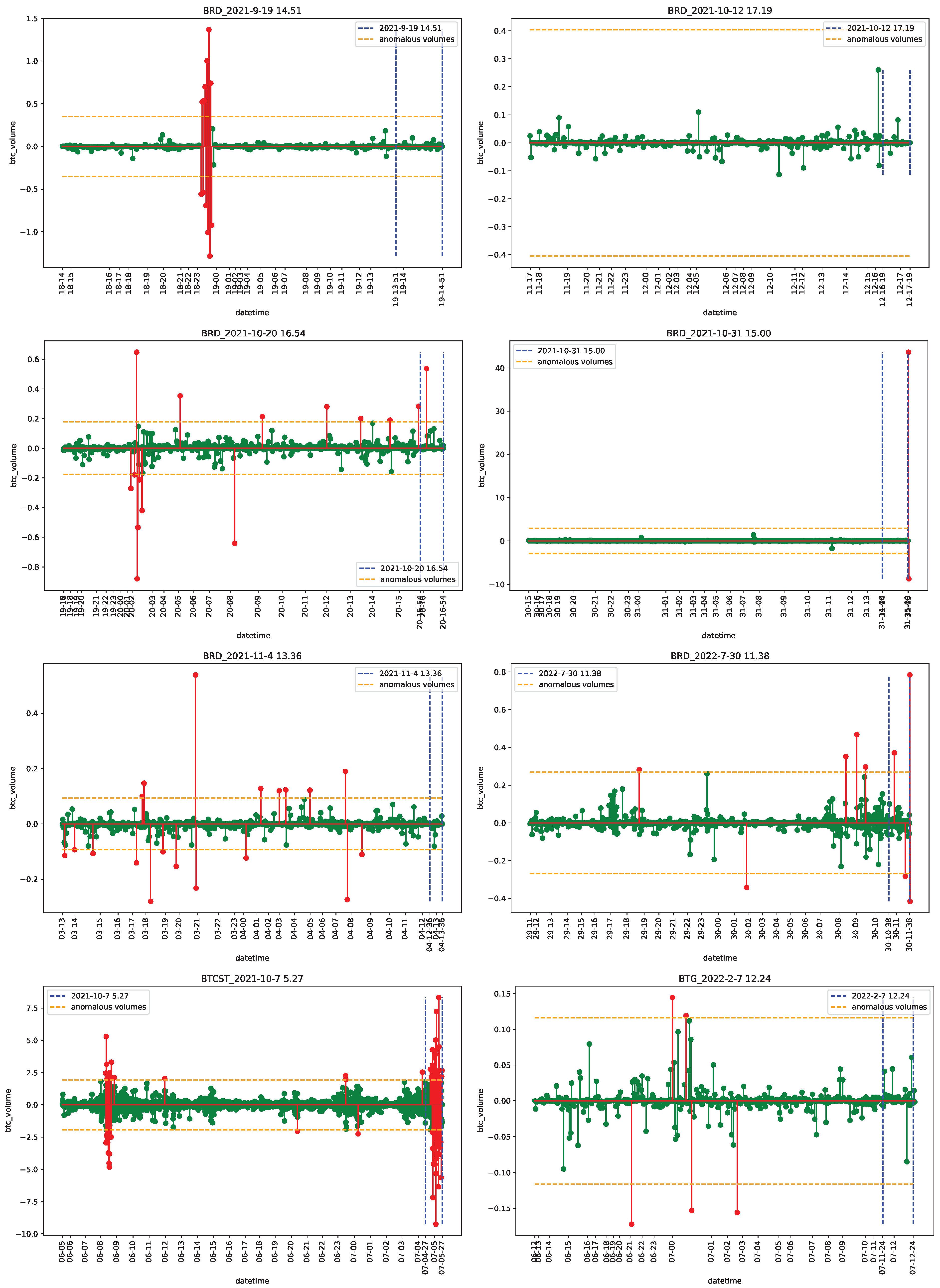
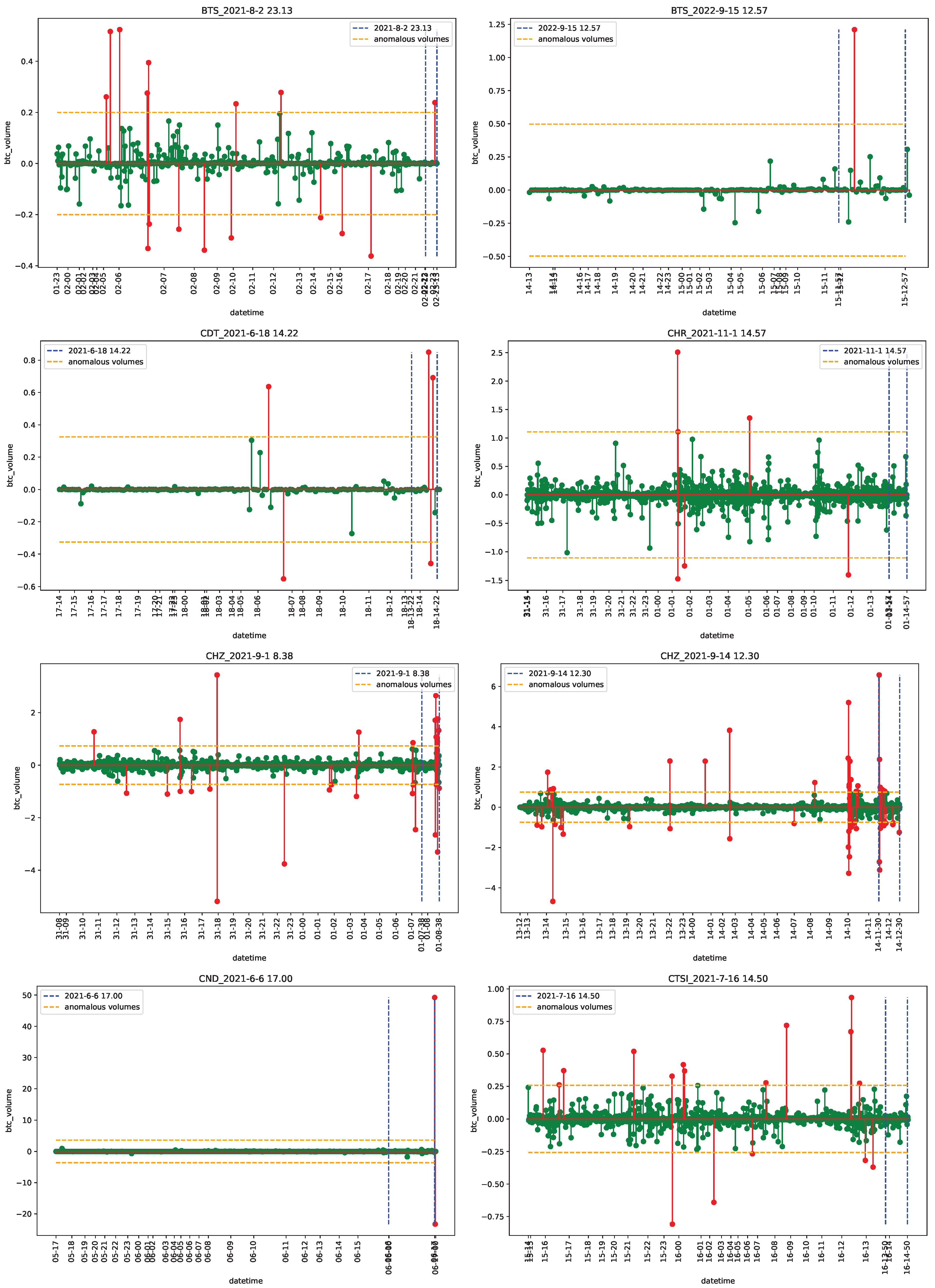
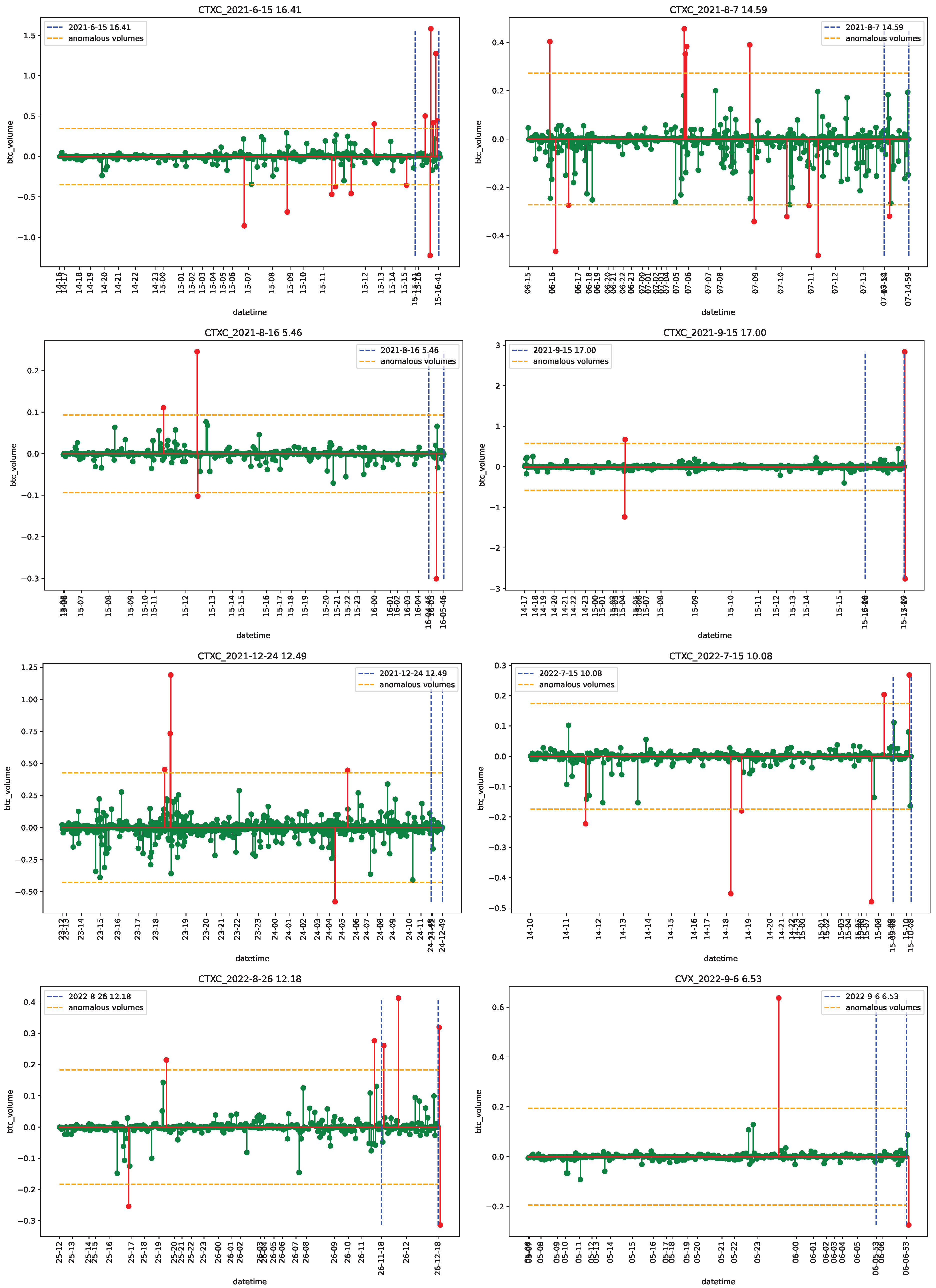
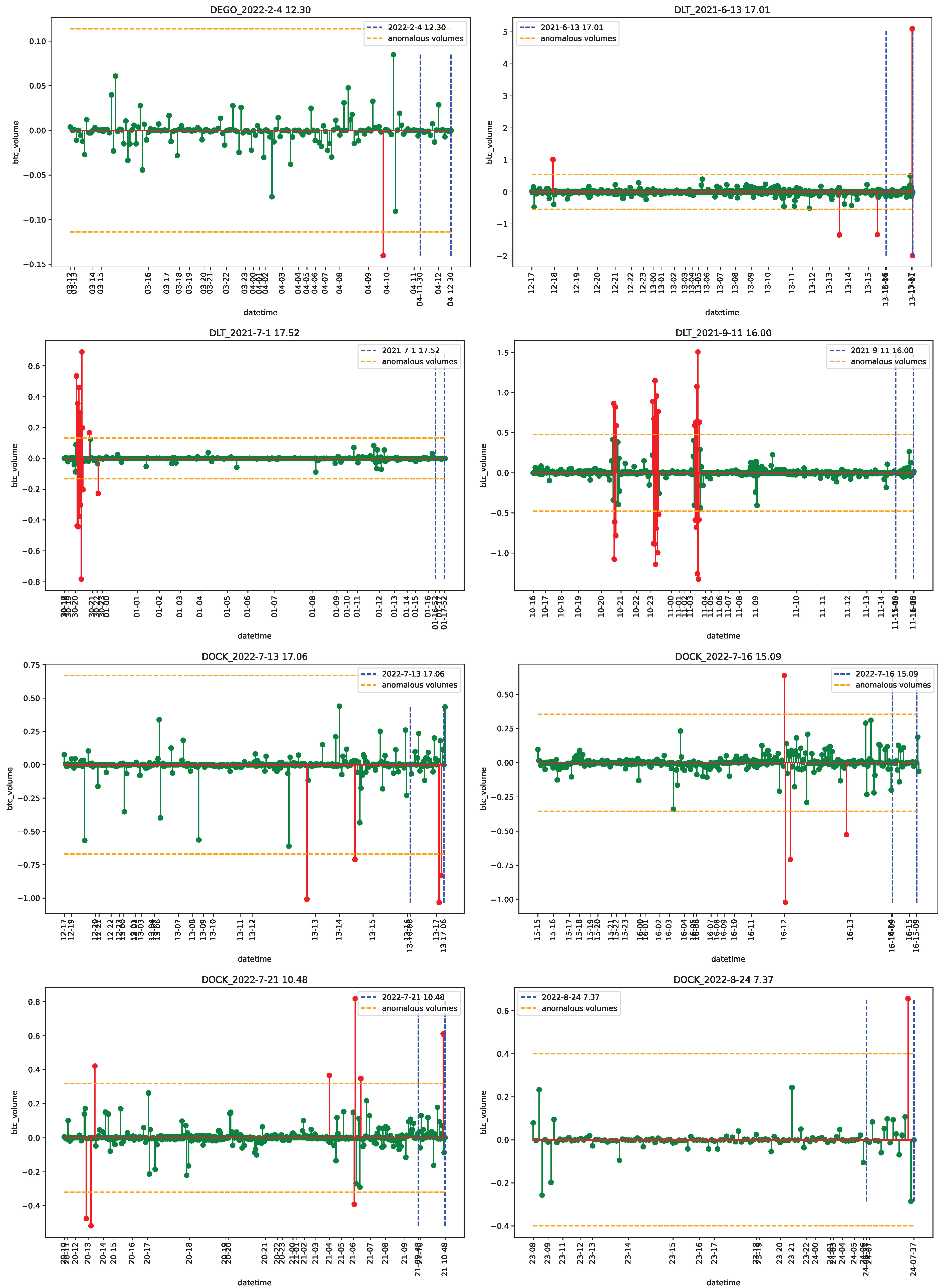
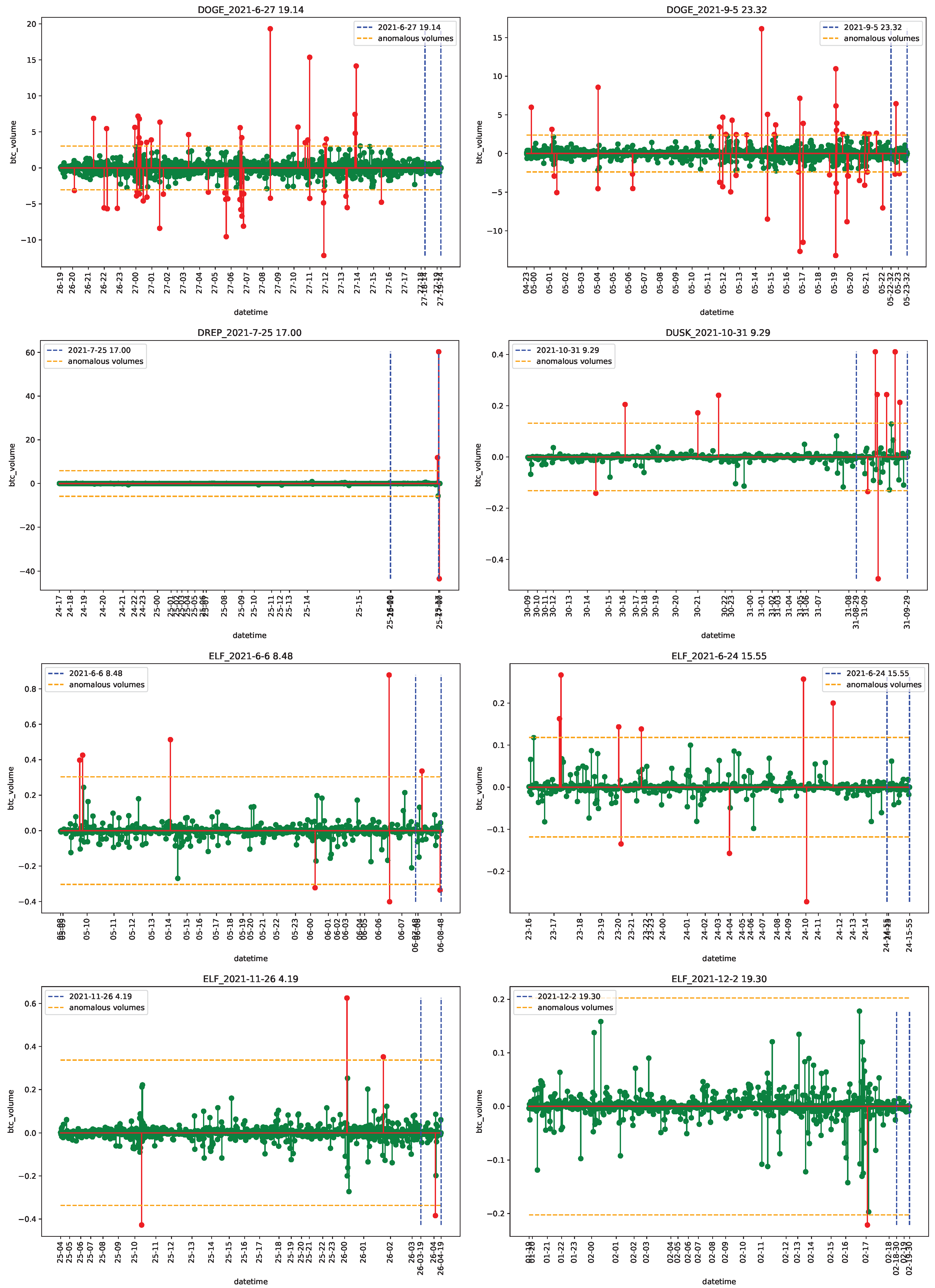
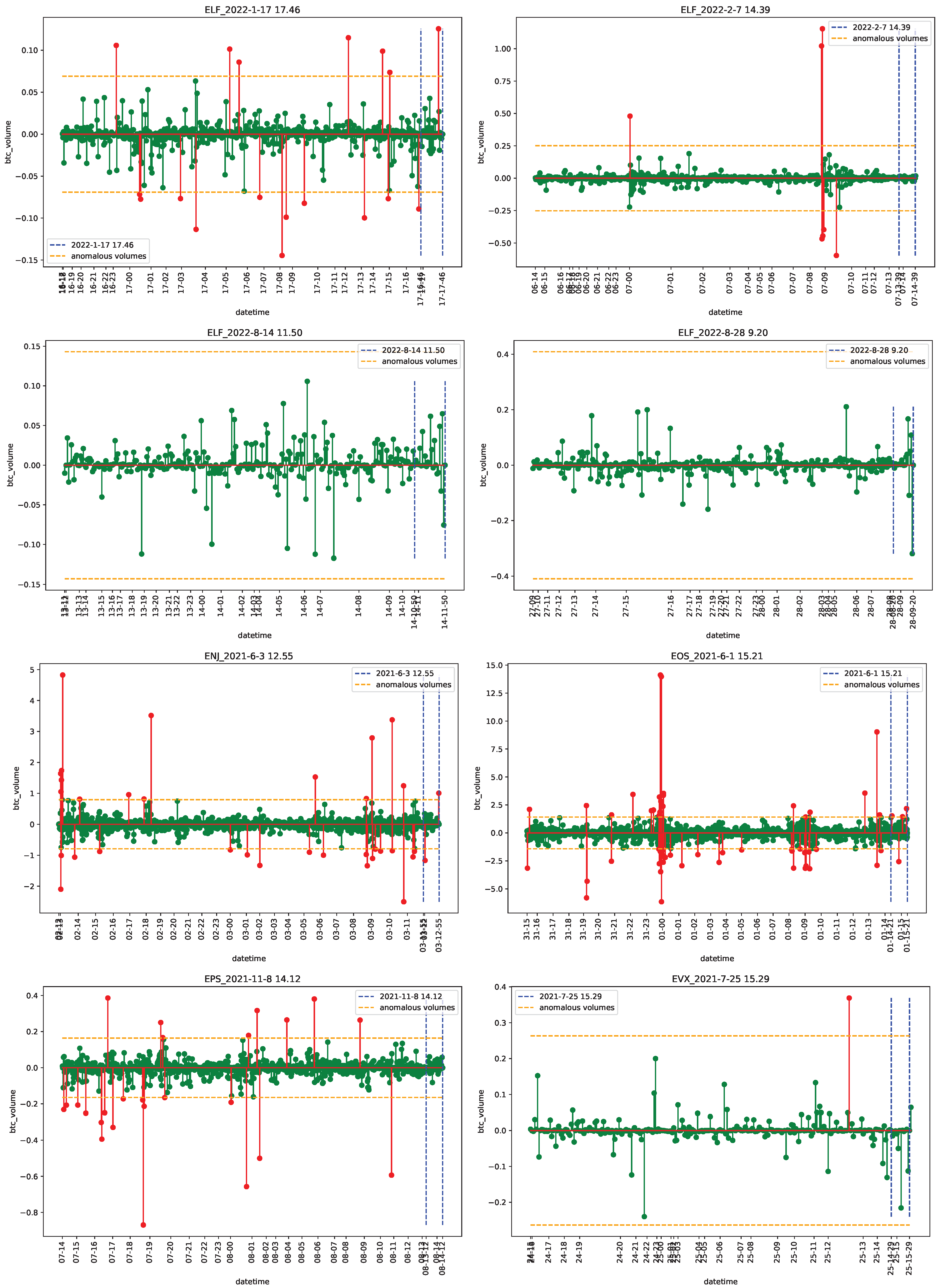
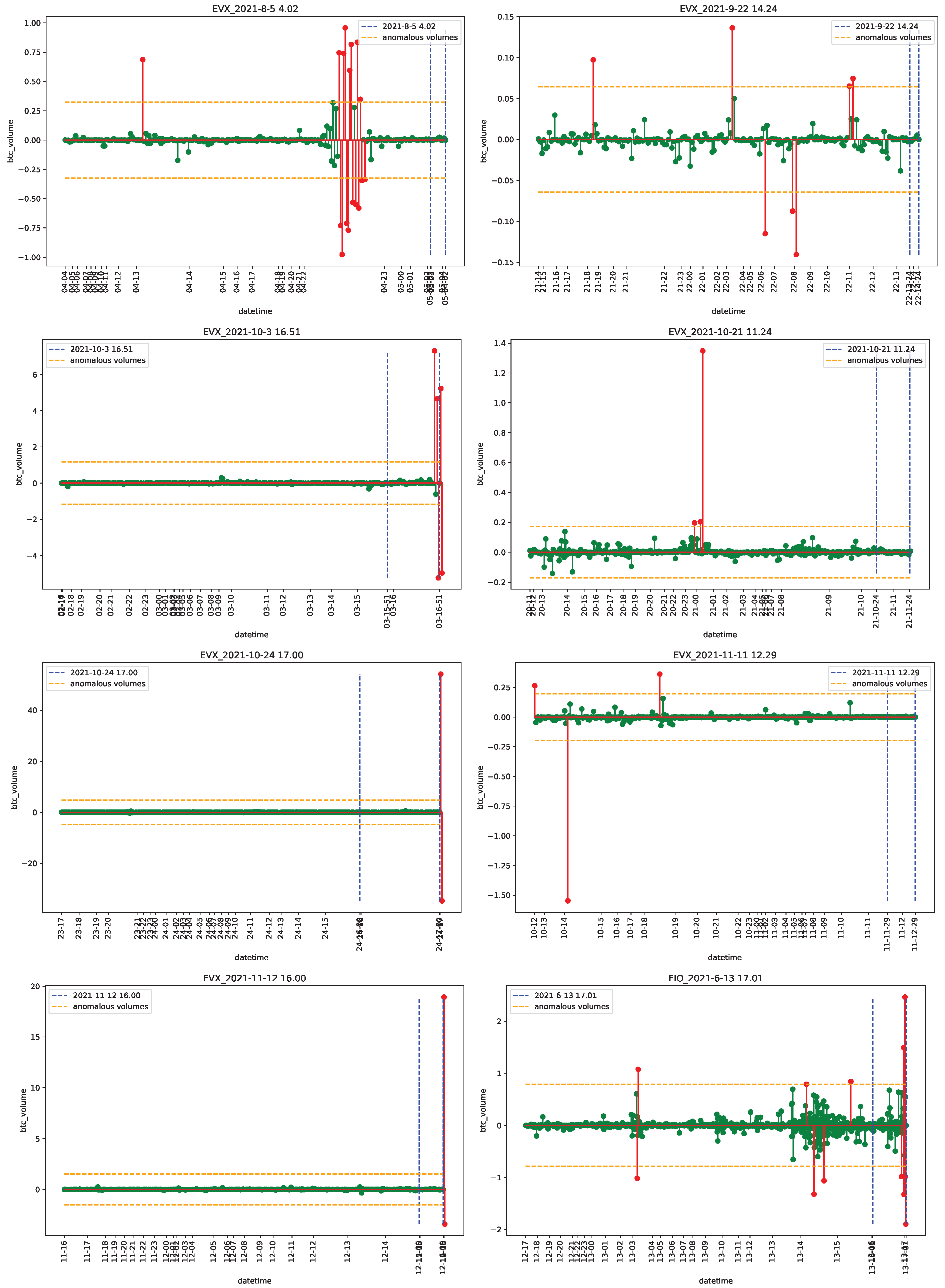
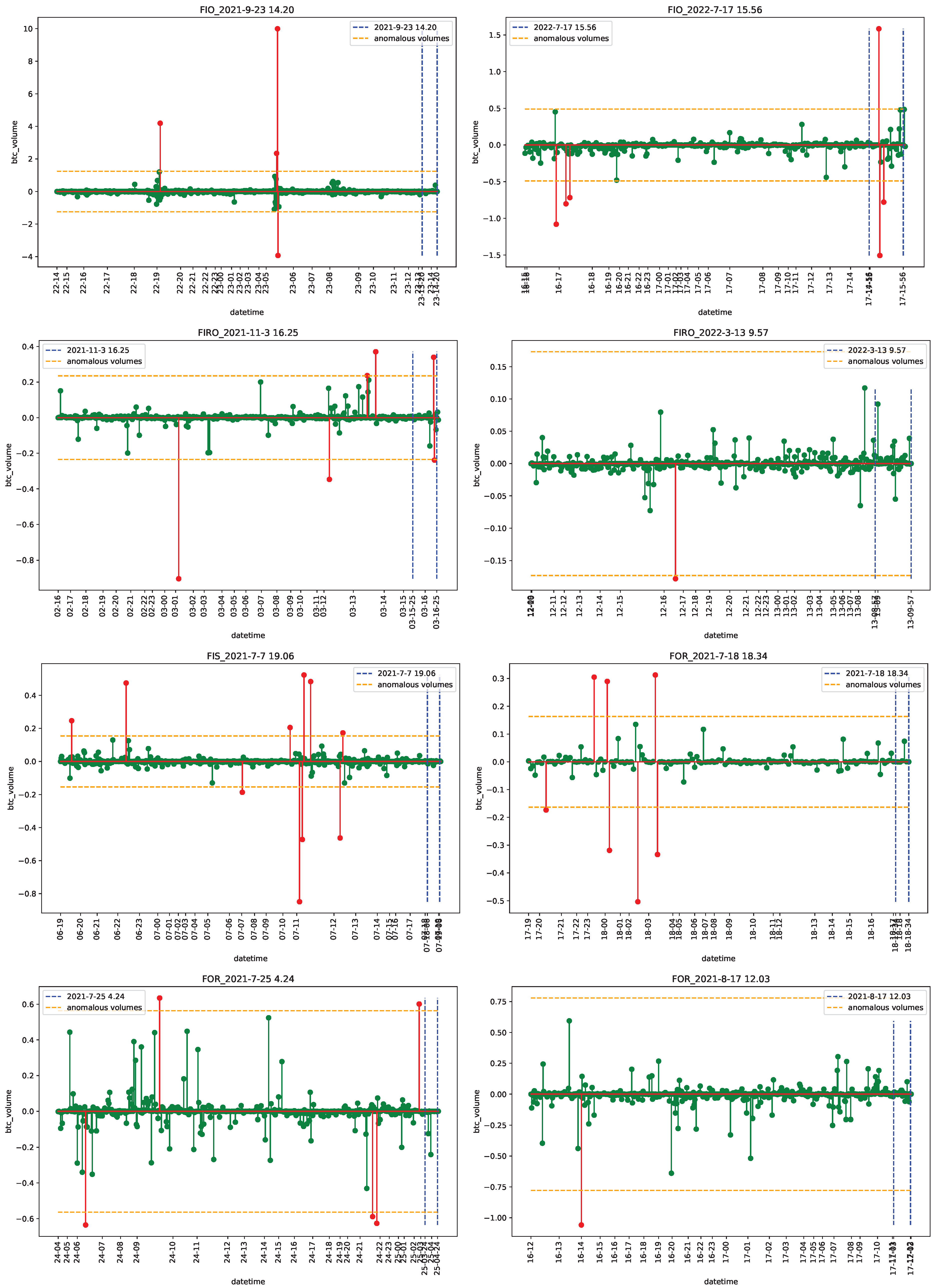
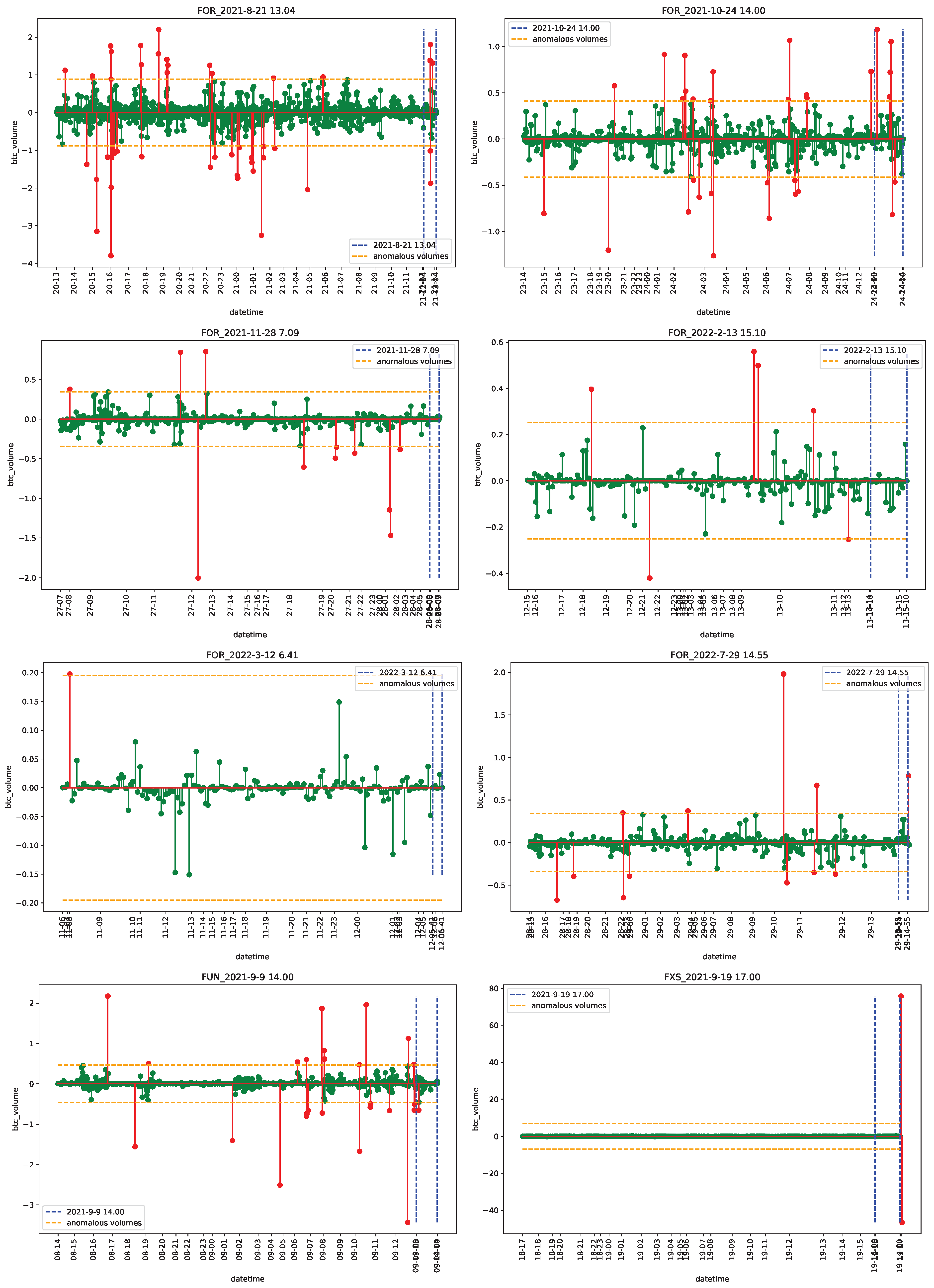
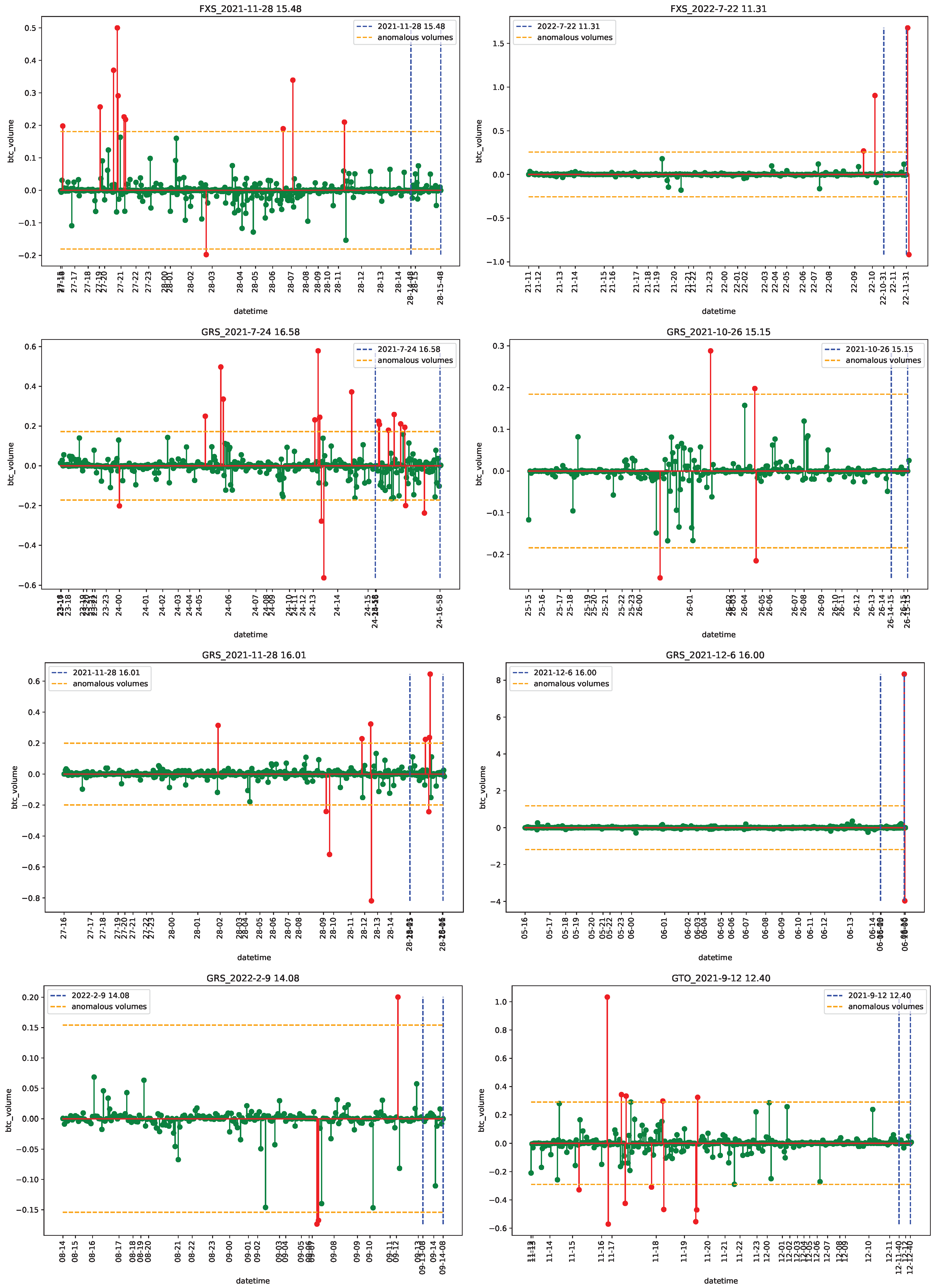
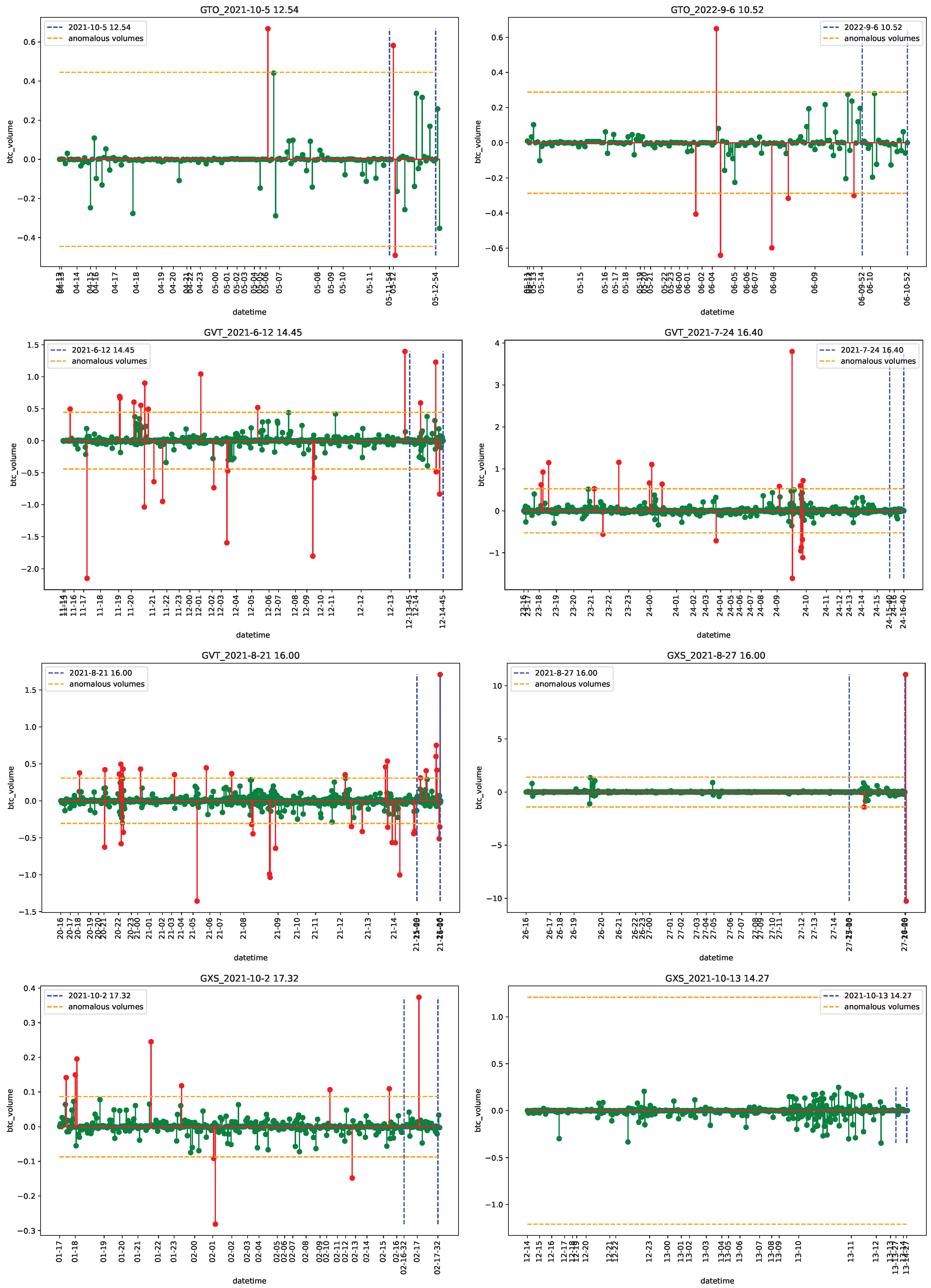
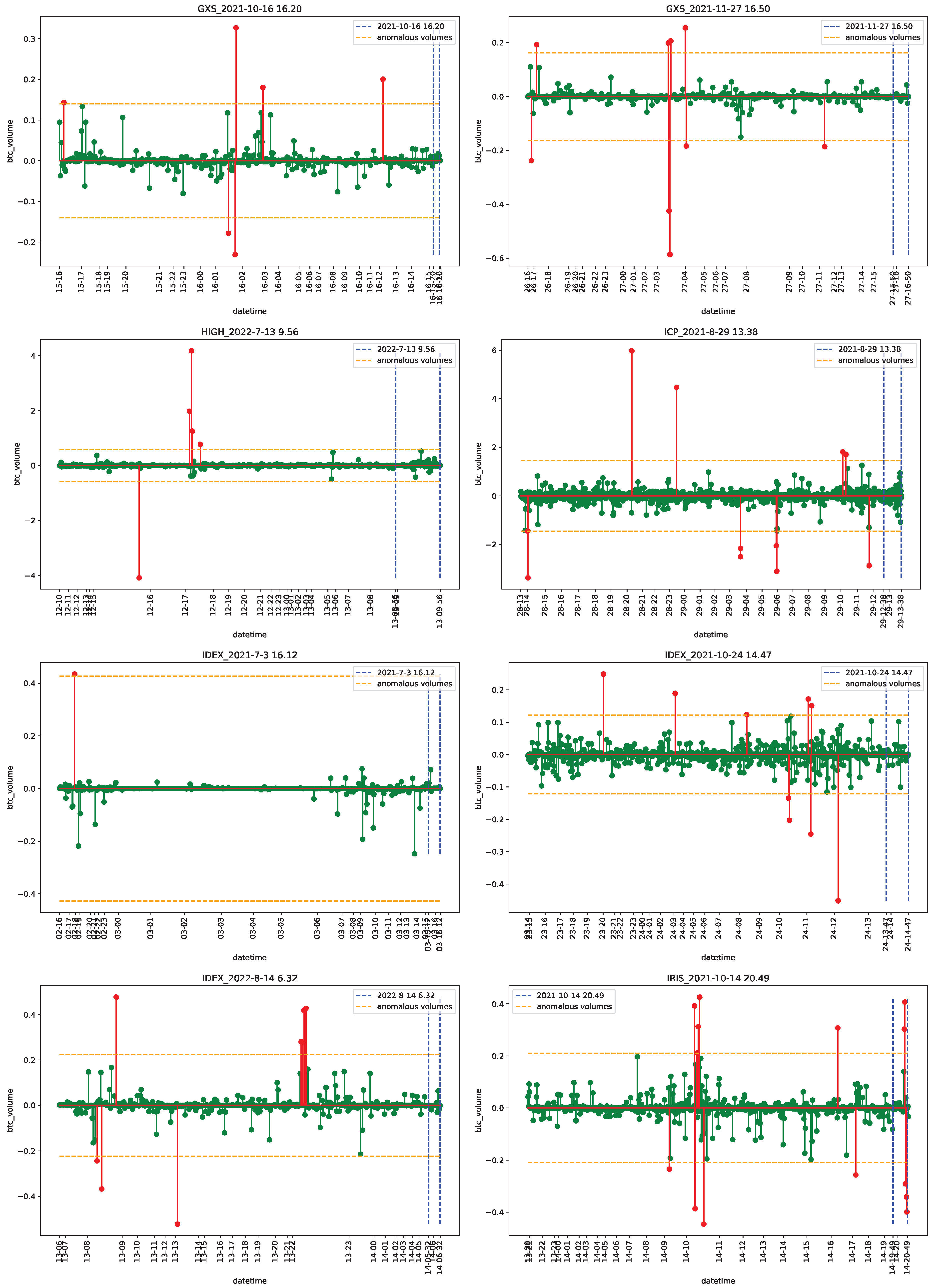
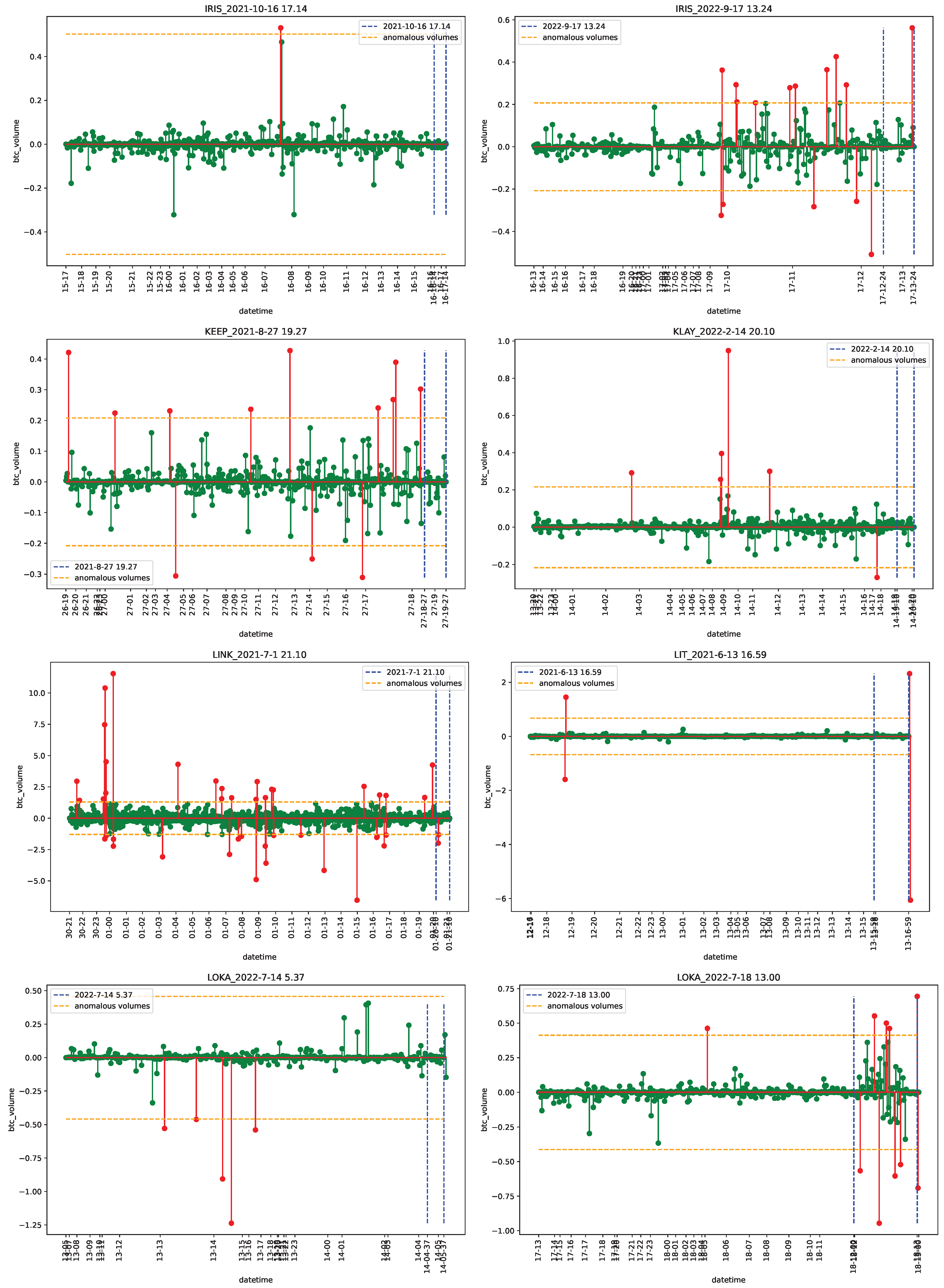
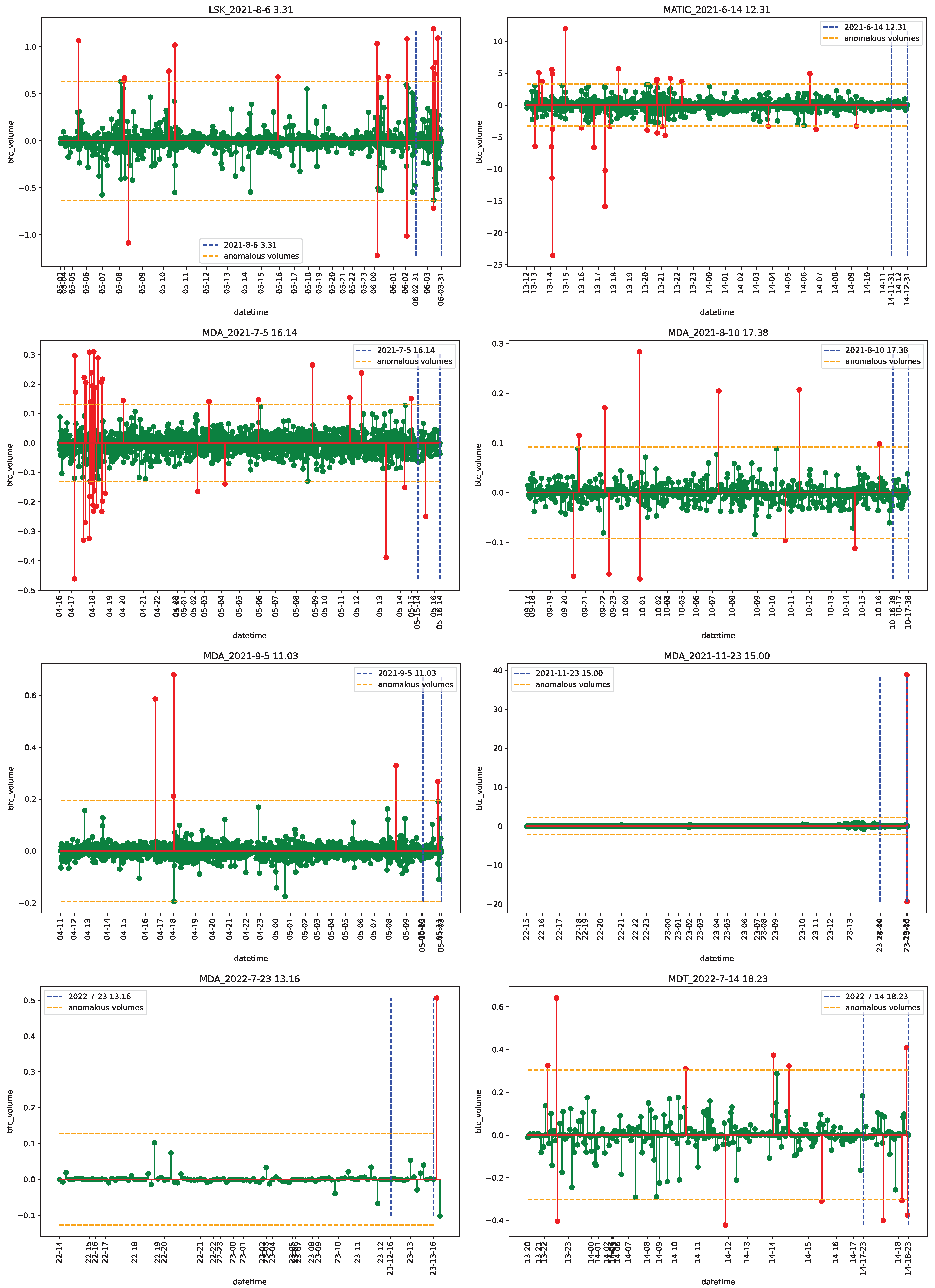
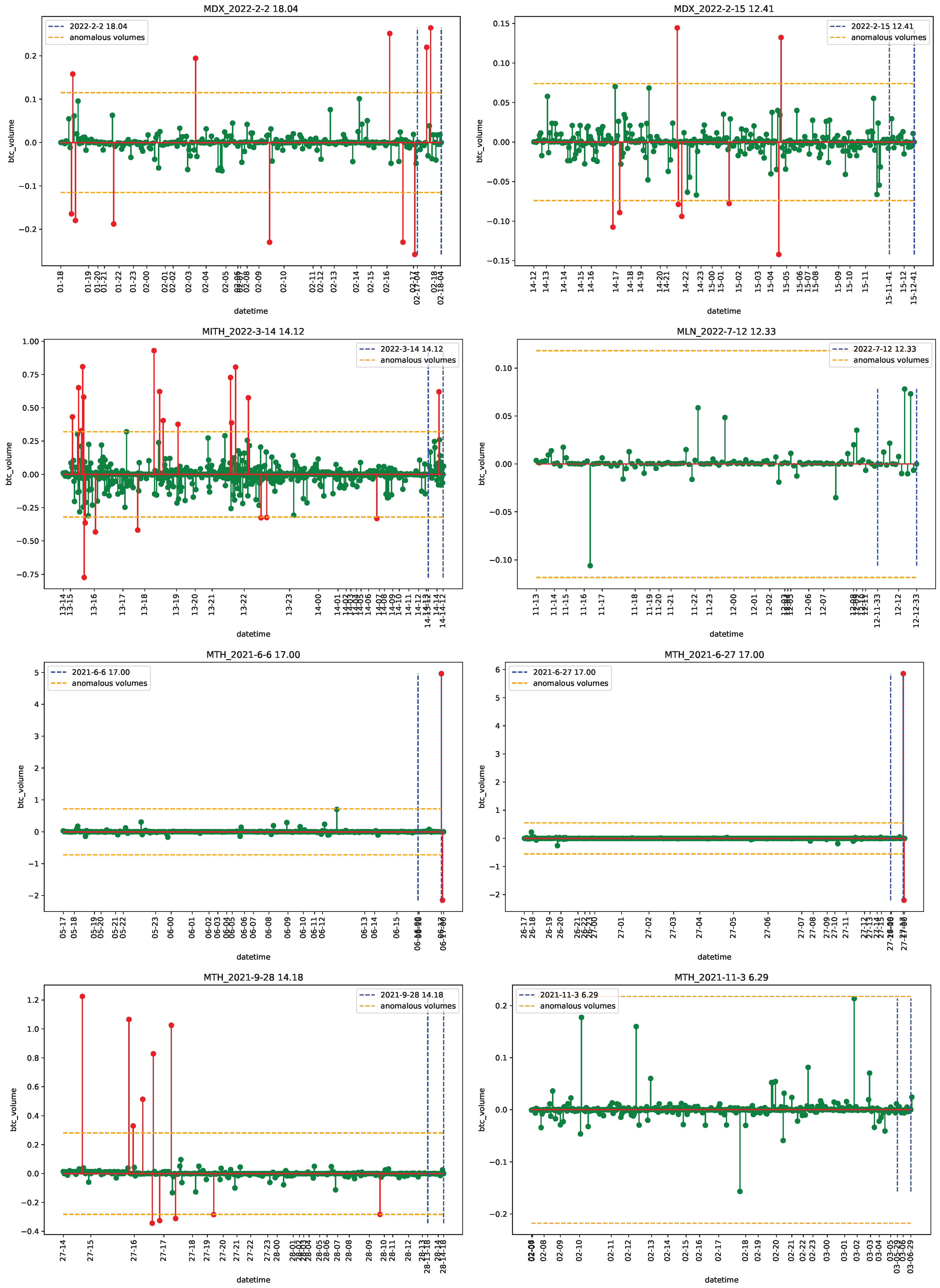
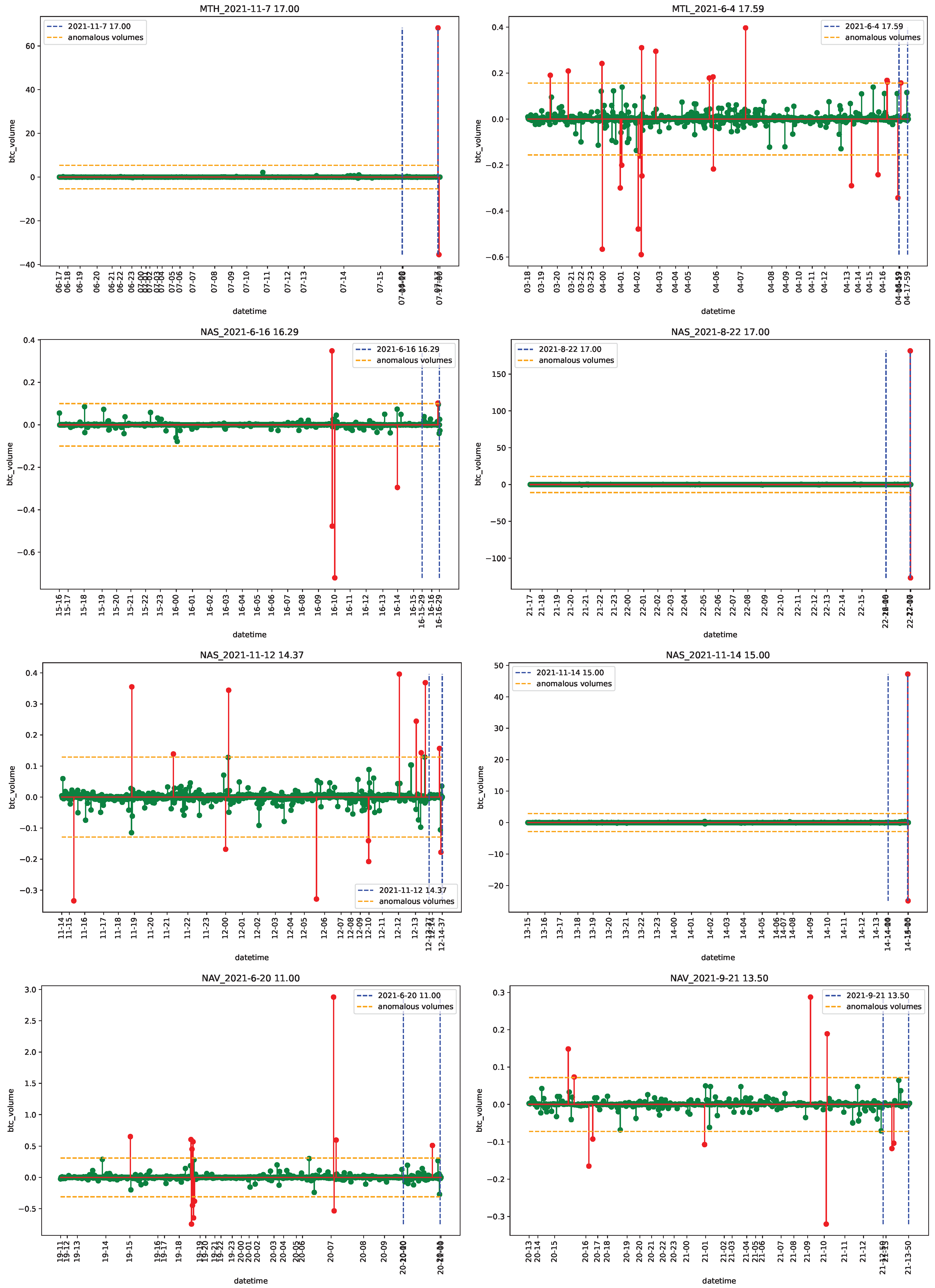
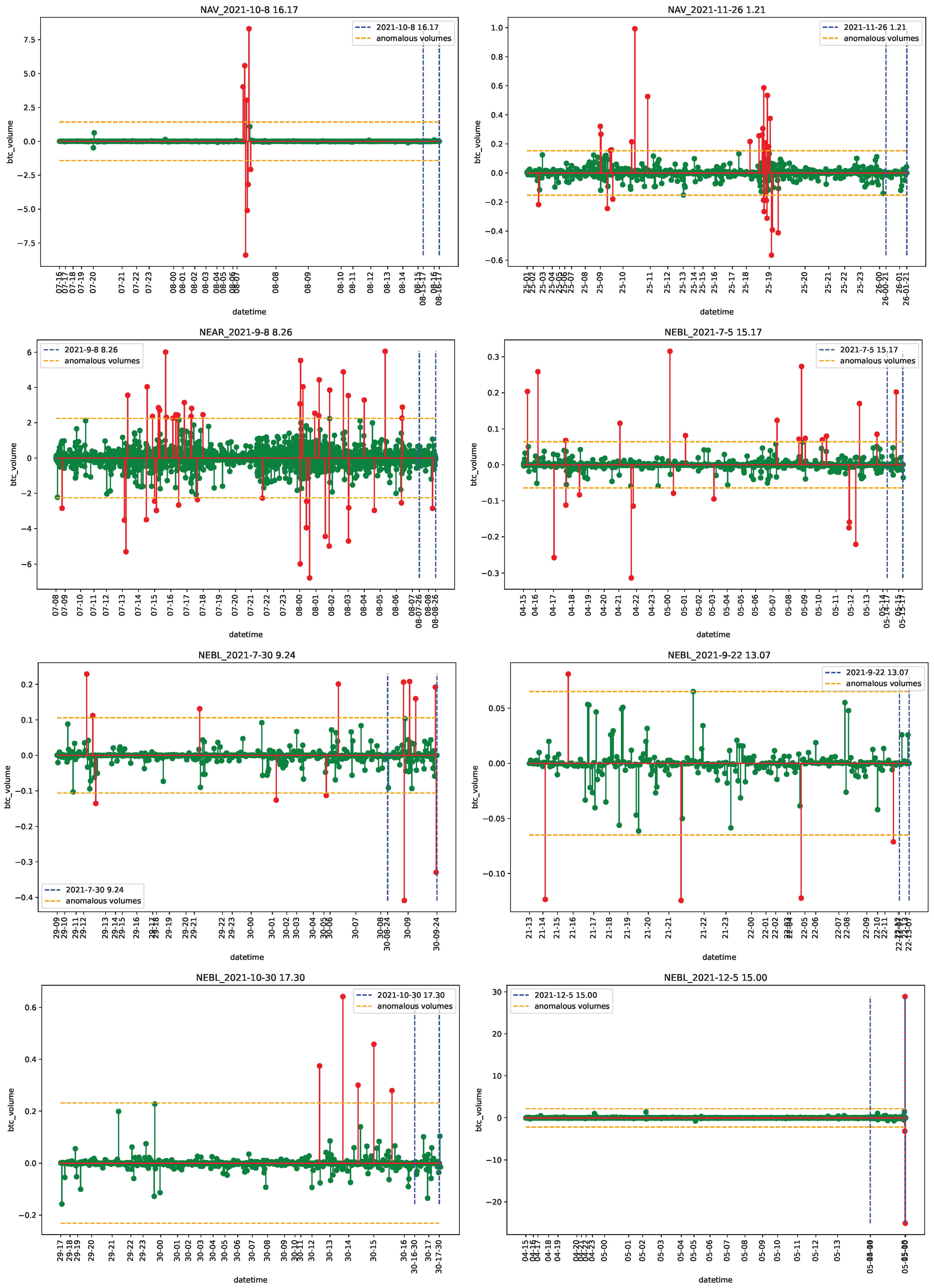
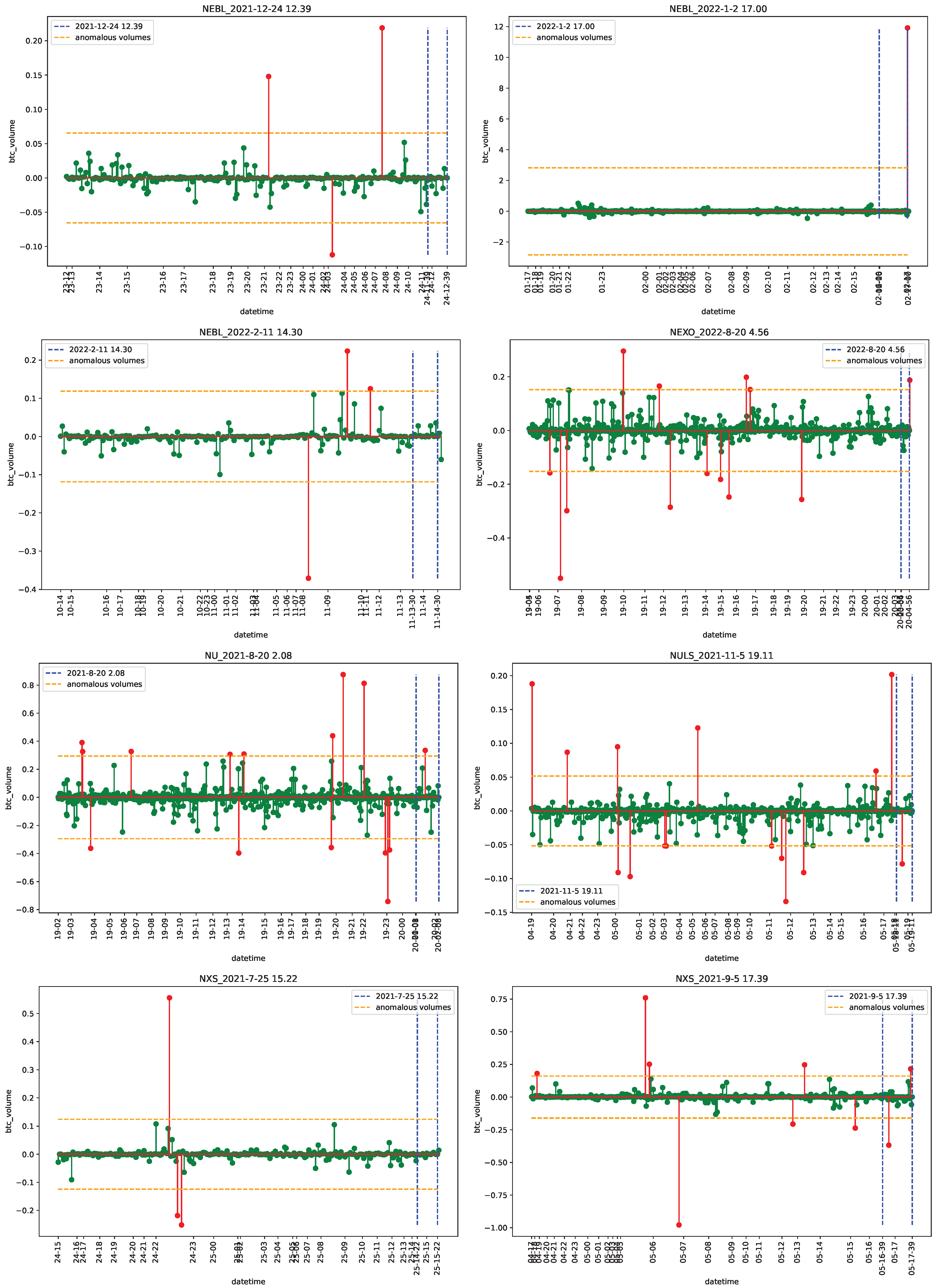
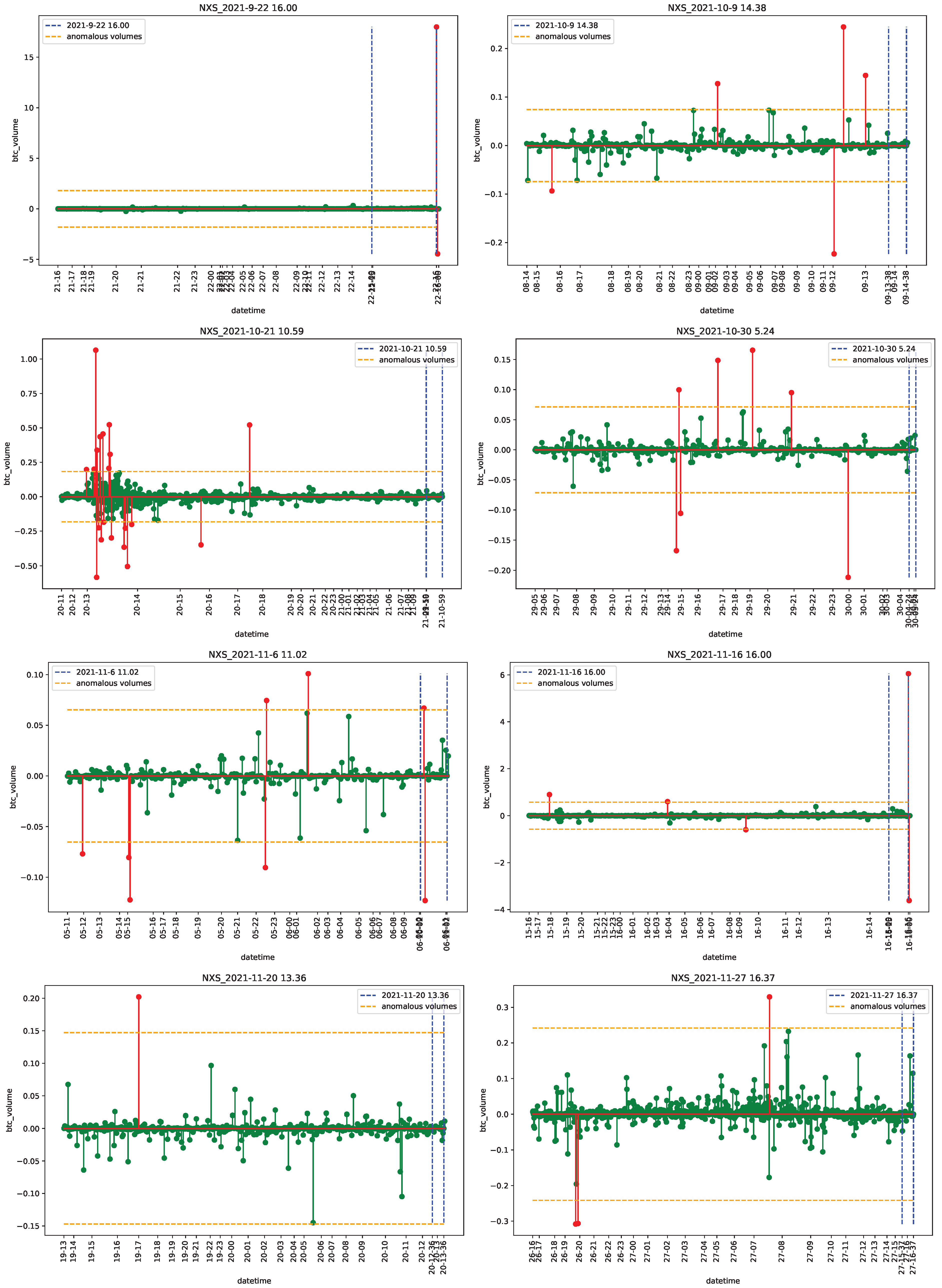
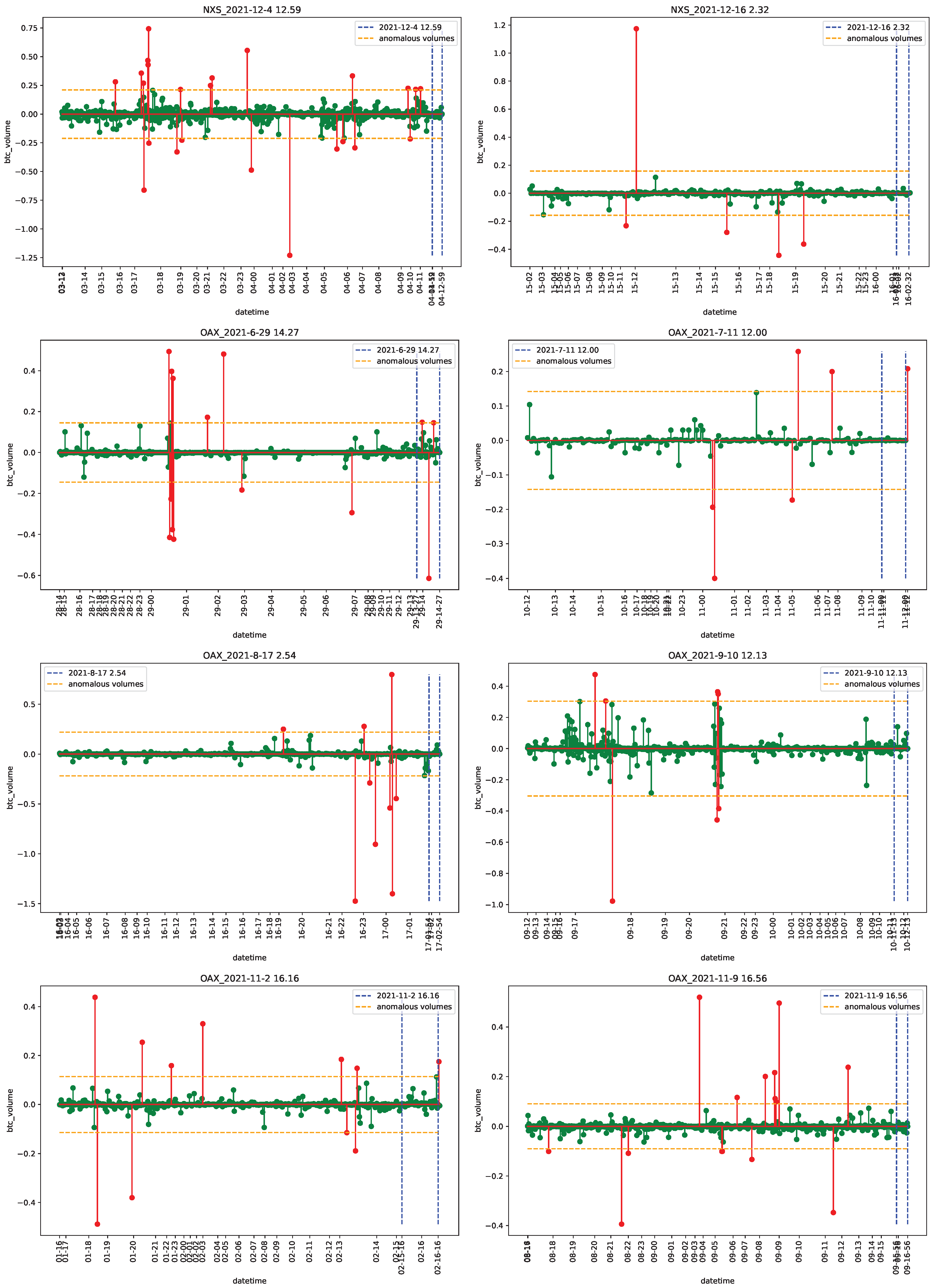
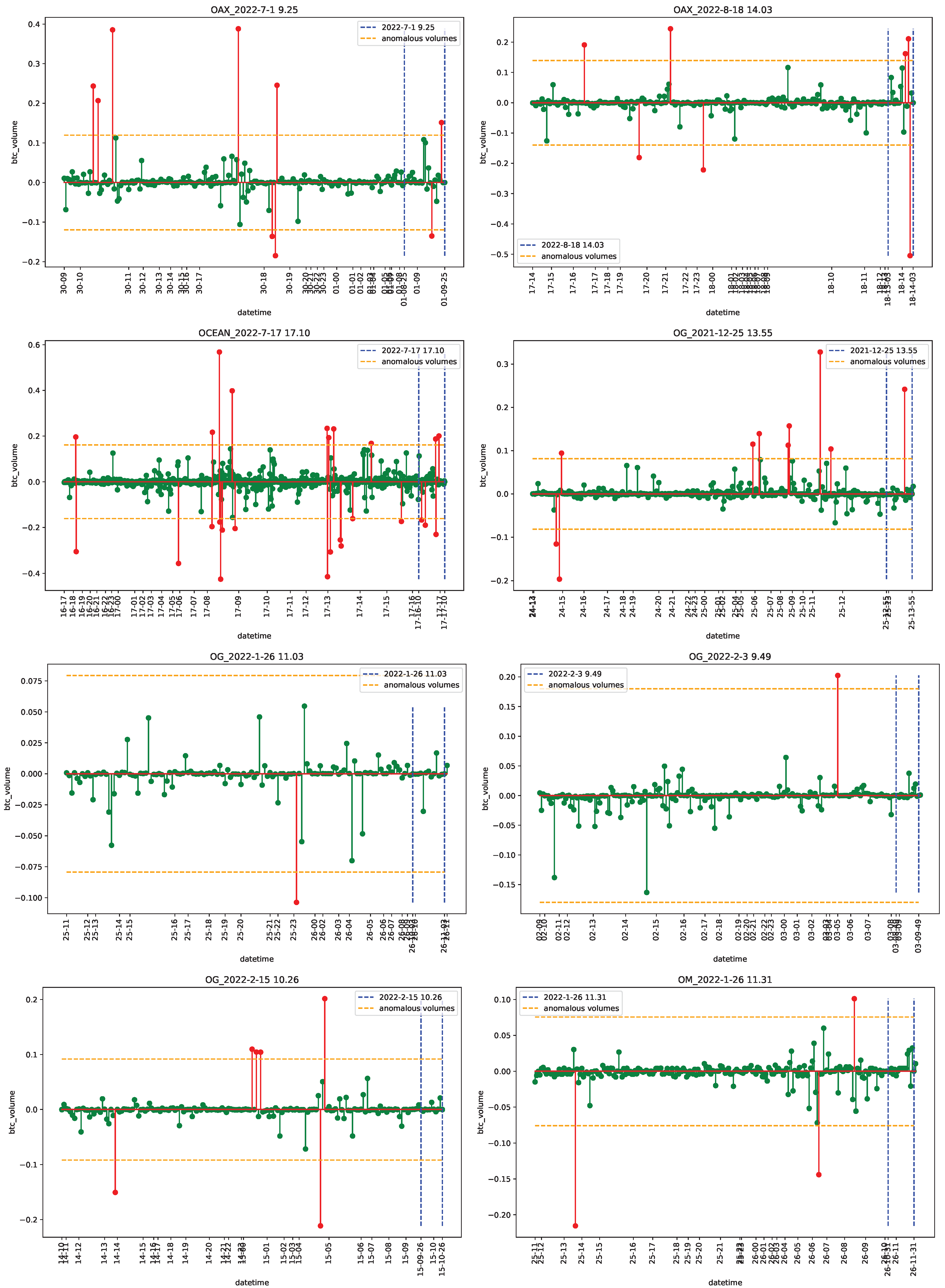
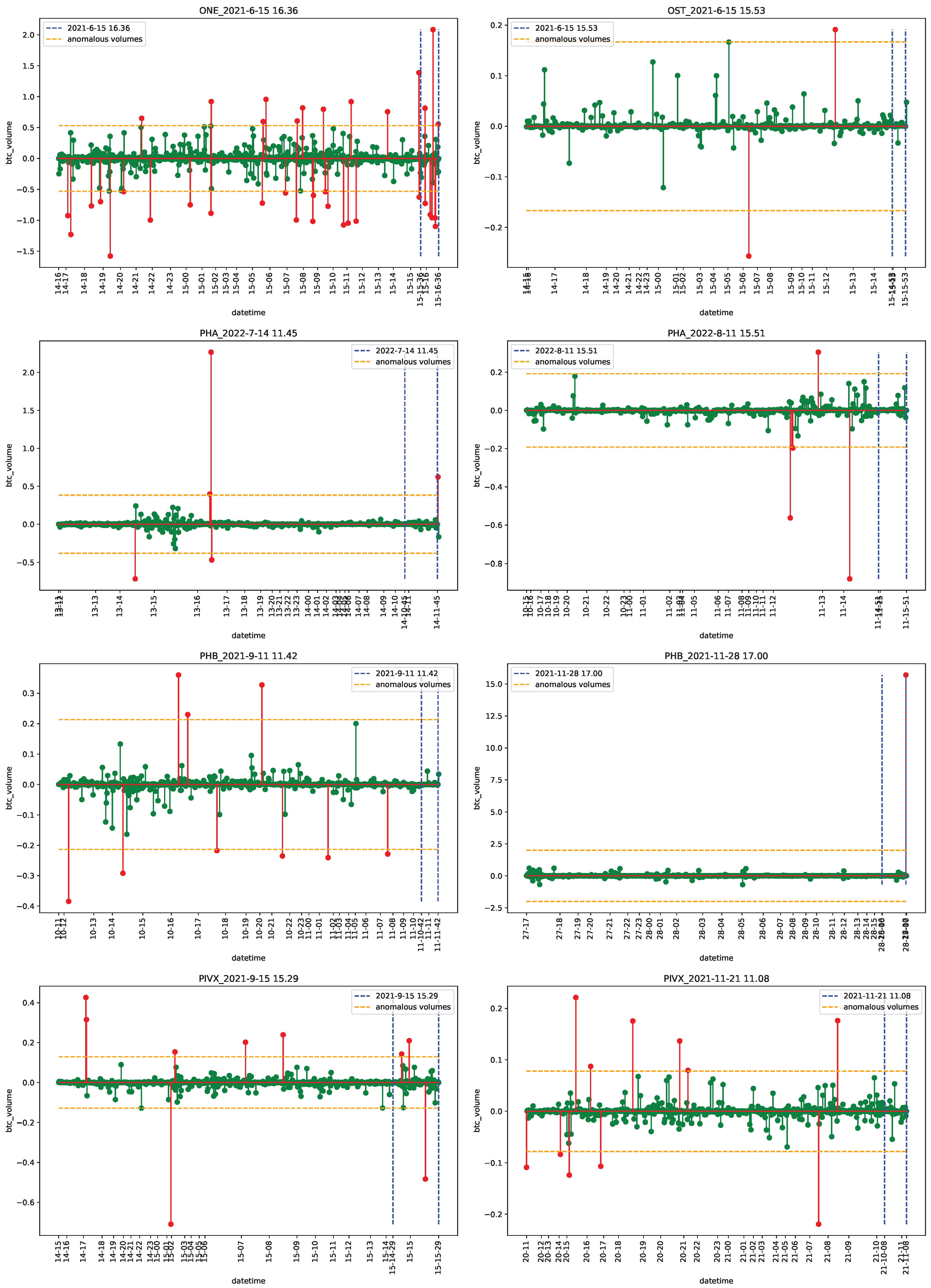
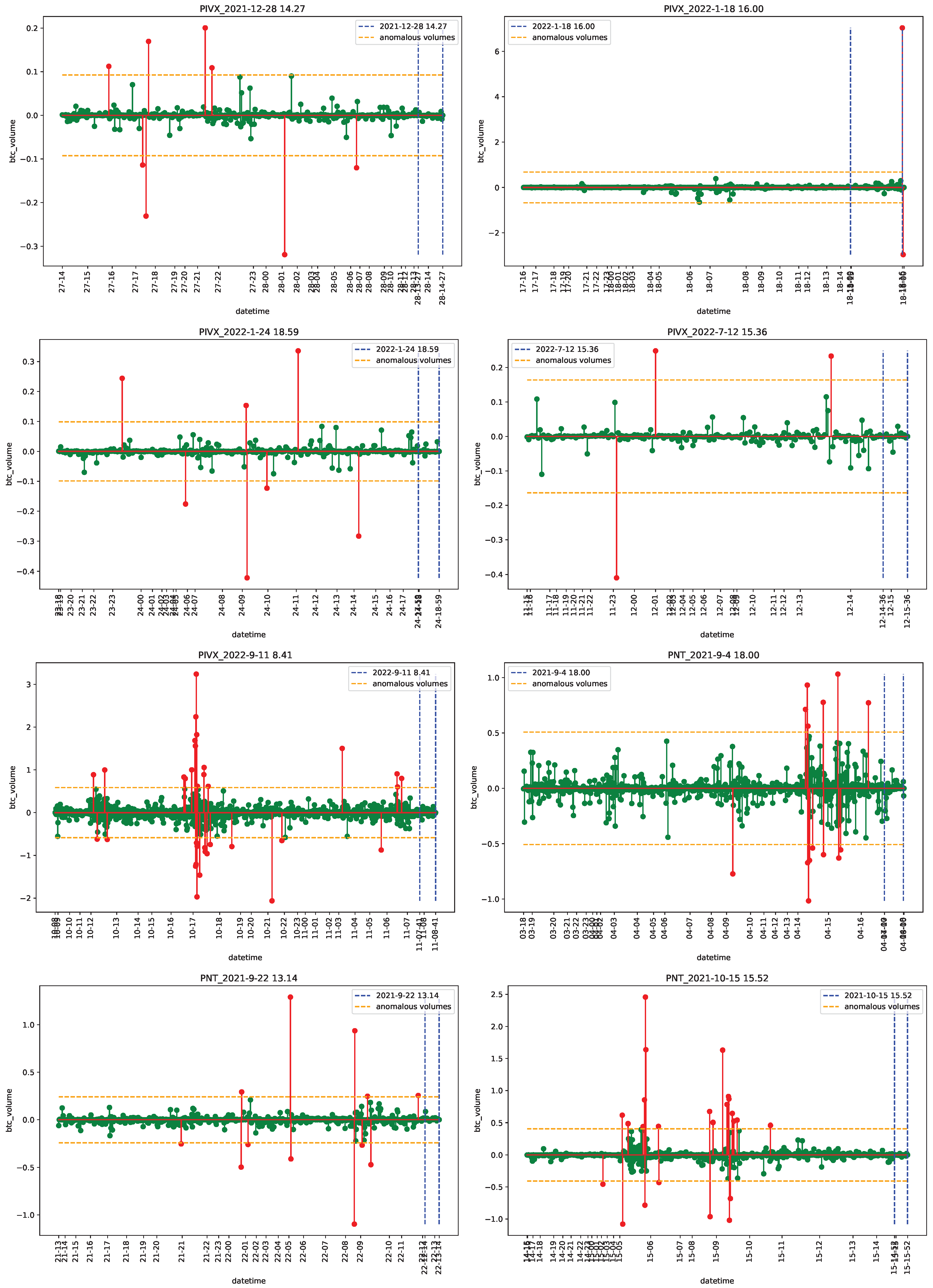
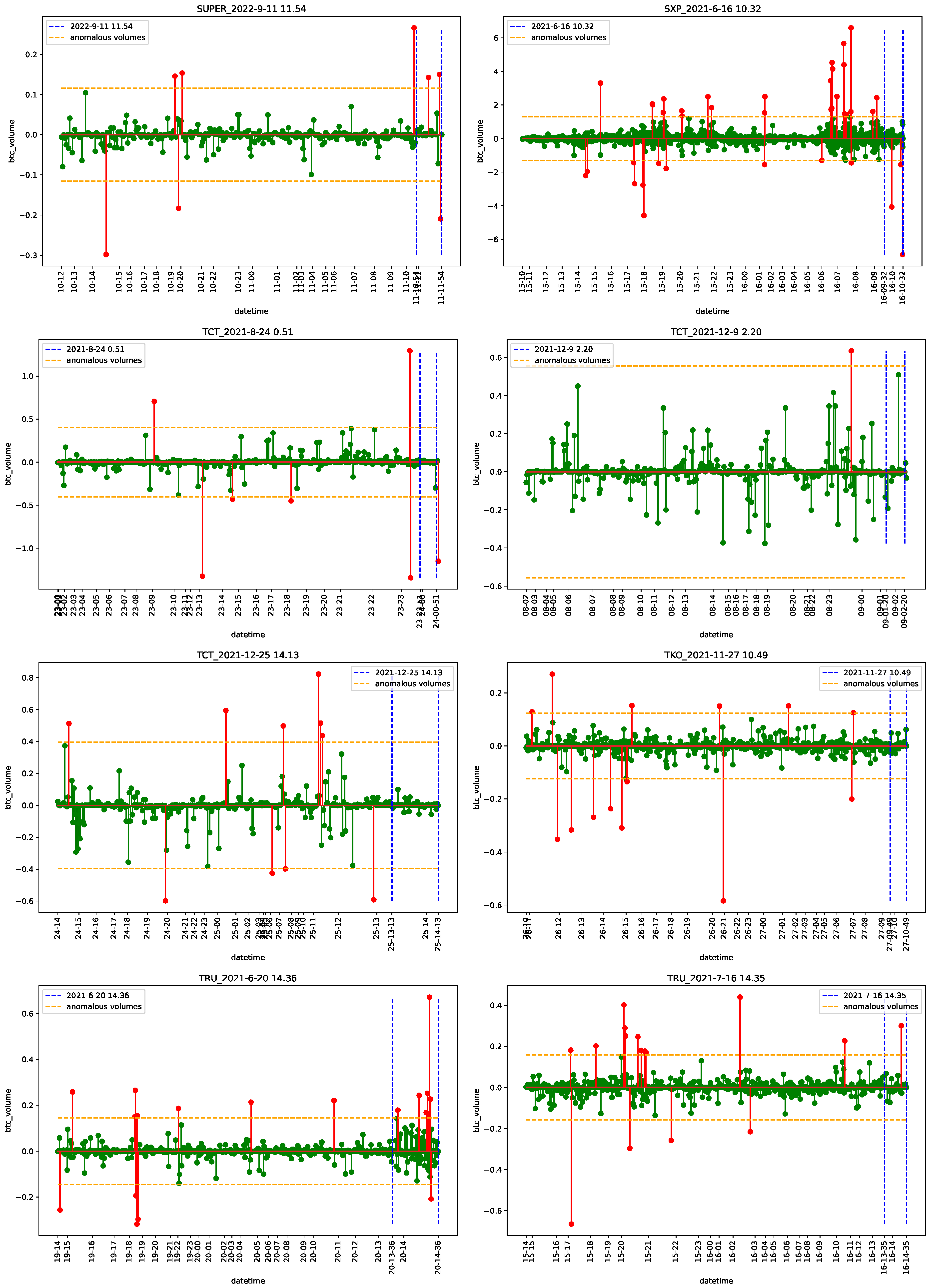
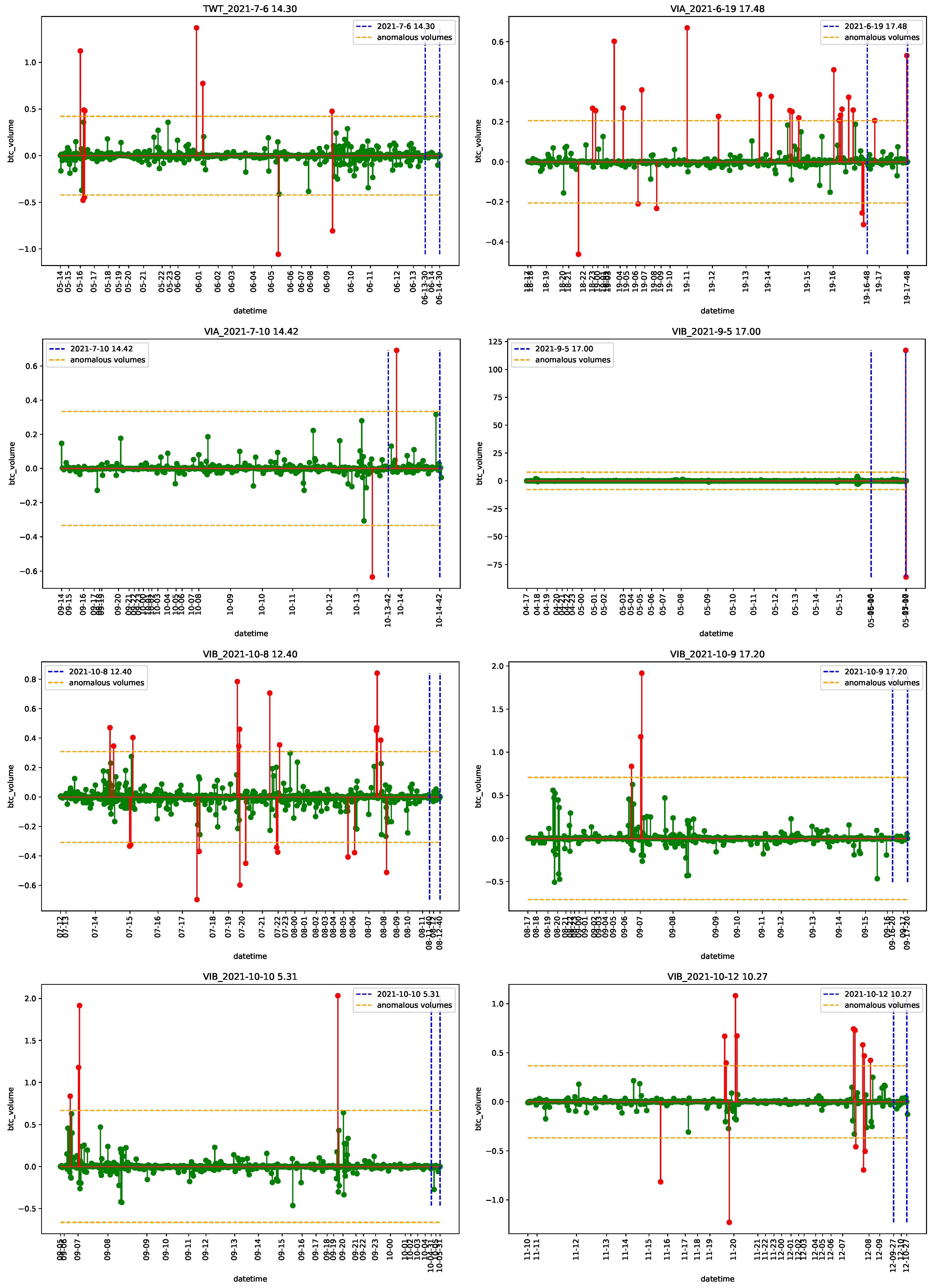
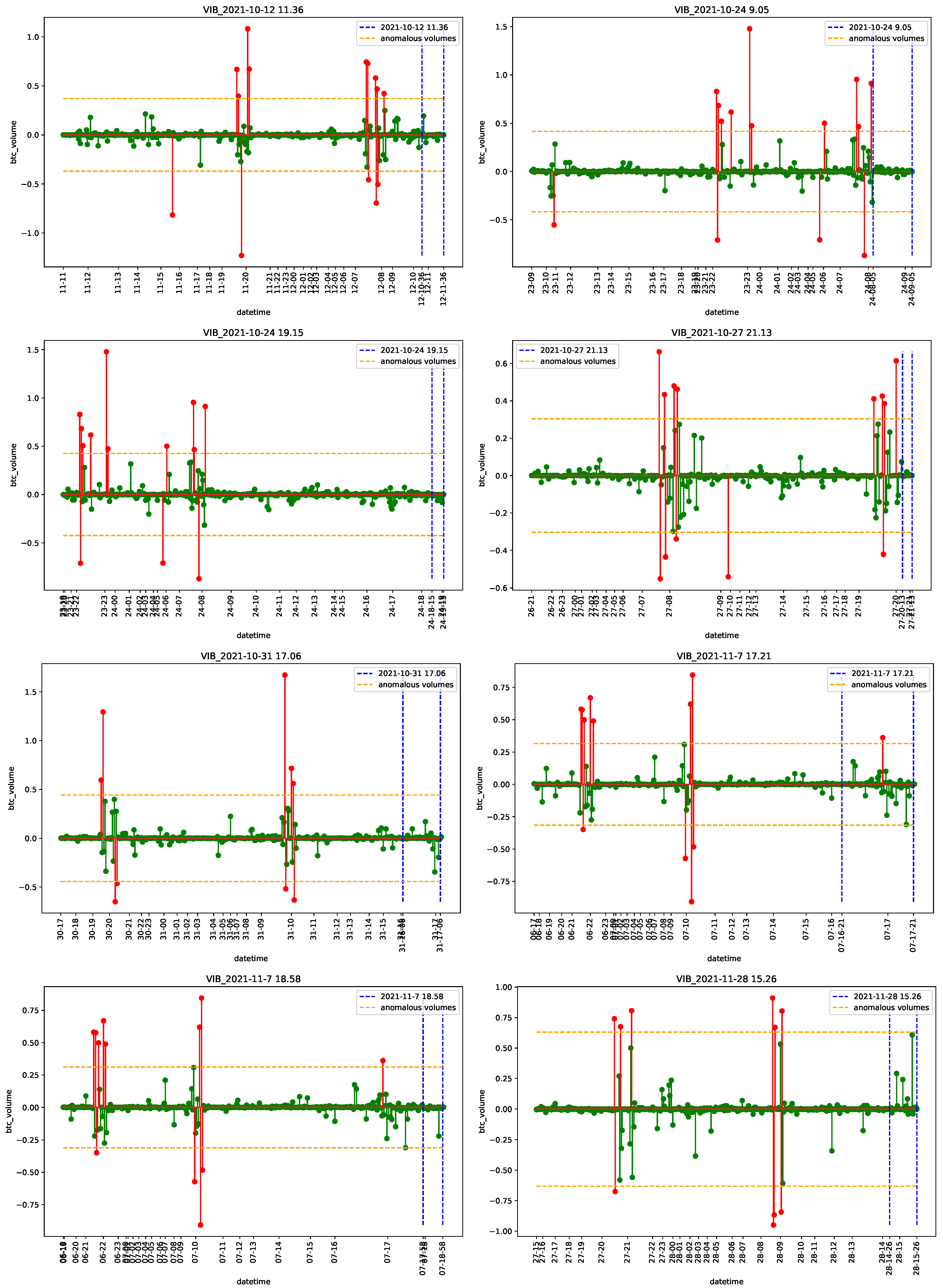
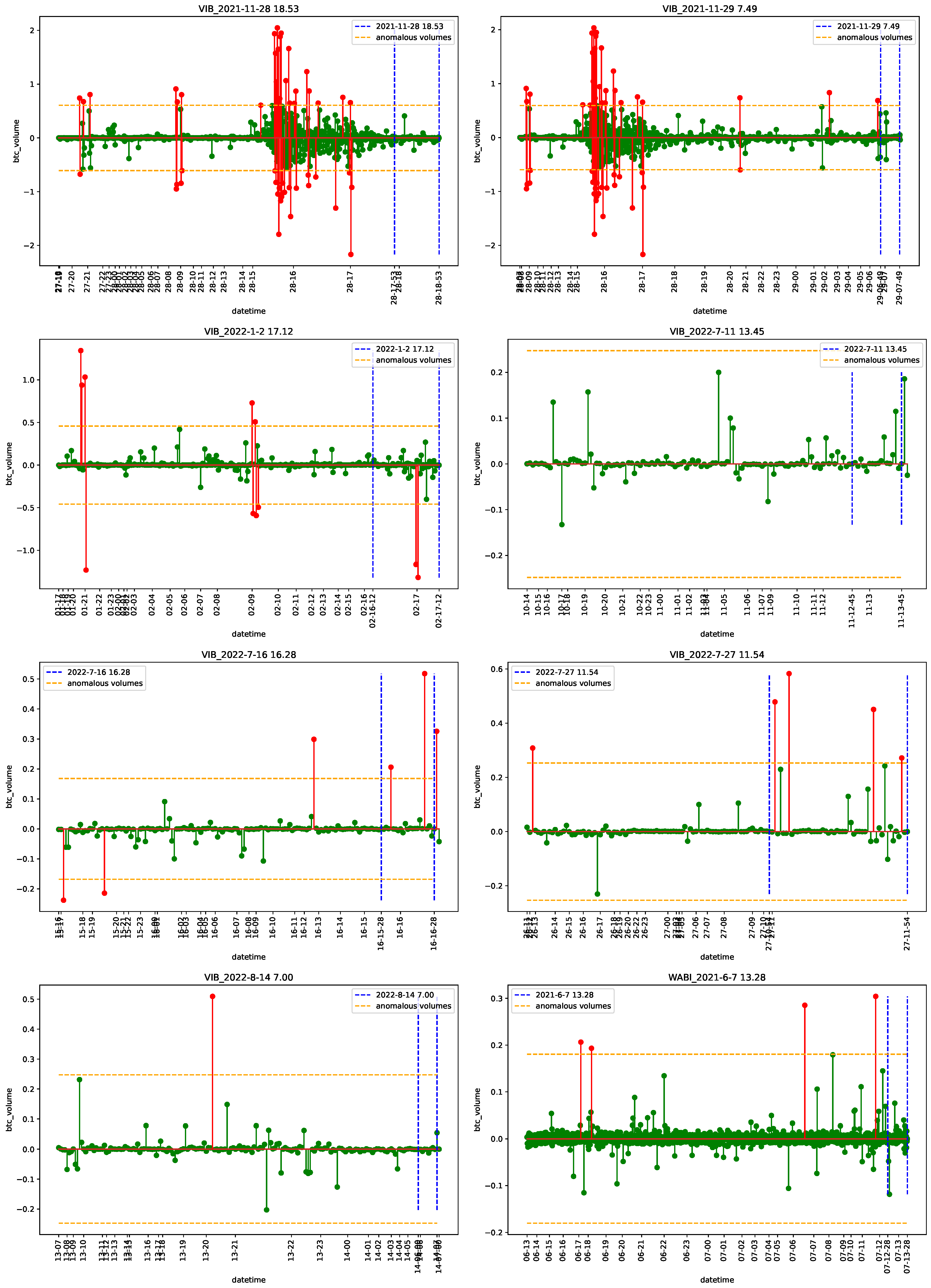
4.1. Data
- StdRushOrders and AvgRushOrders: the moving standard deviation and the average of the volume of rush orders in each chunk of the moving window.
- StdTrades: the moving standard deviation of the number of trades.
- StdVolumes and AvgVolumes: the moving standard deviation and the average of the volume of trades in each chunk of the moving window.
- StdPrice and AvgPrice: the moving standard deviation and average of the closing price.
- HourSin, HourCos, MinuteCos, MinuteSin: the hour and minute of the first transaction in each chunk. We used the sine and cosine functions to express their cyclical nature3.
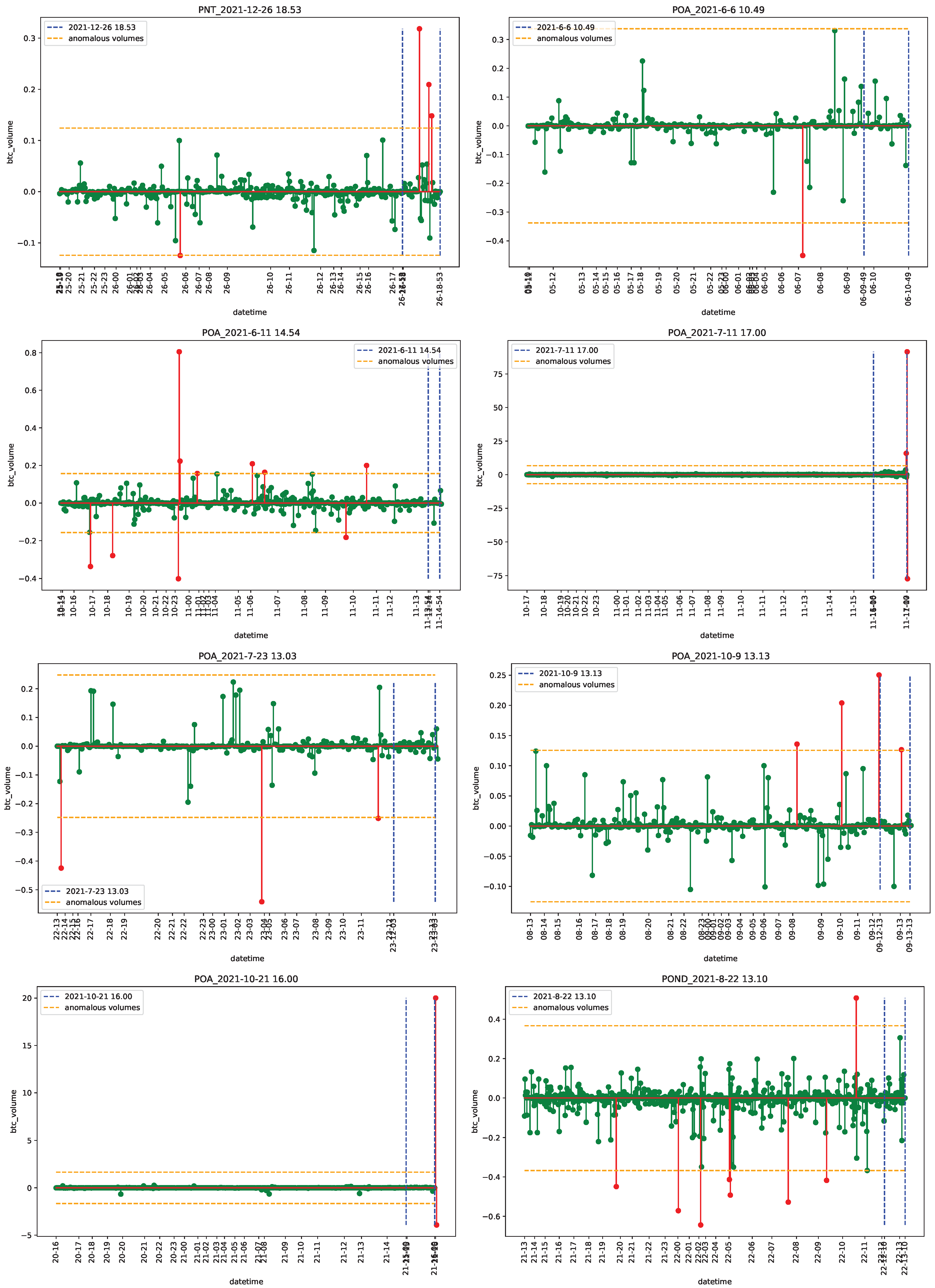
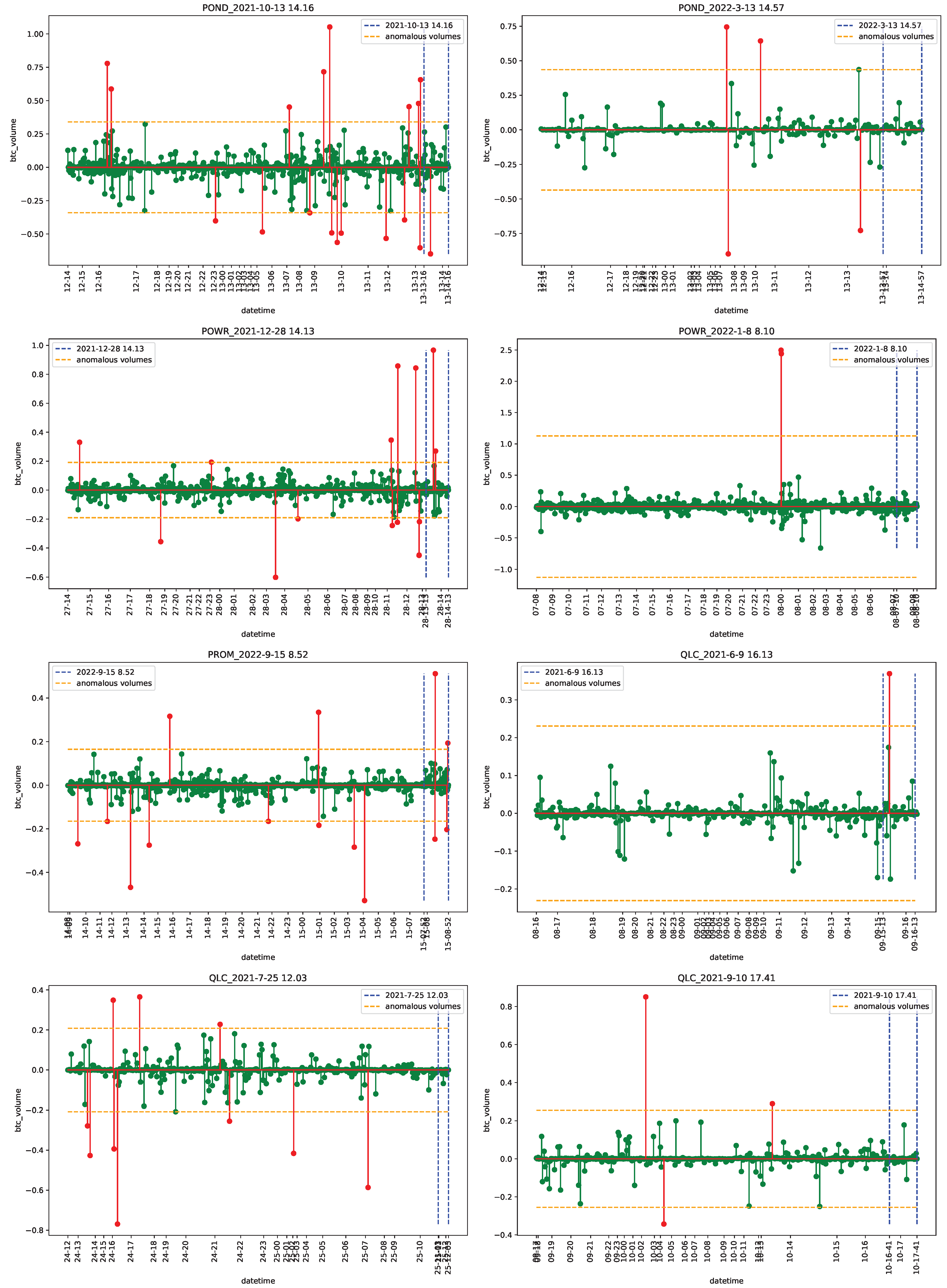
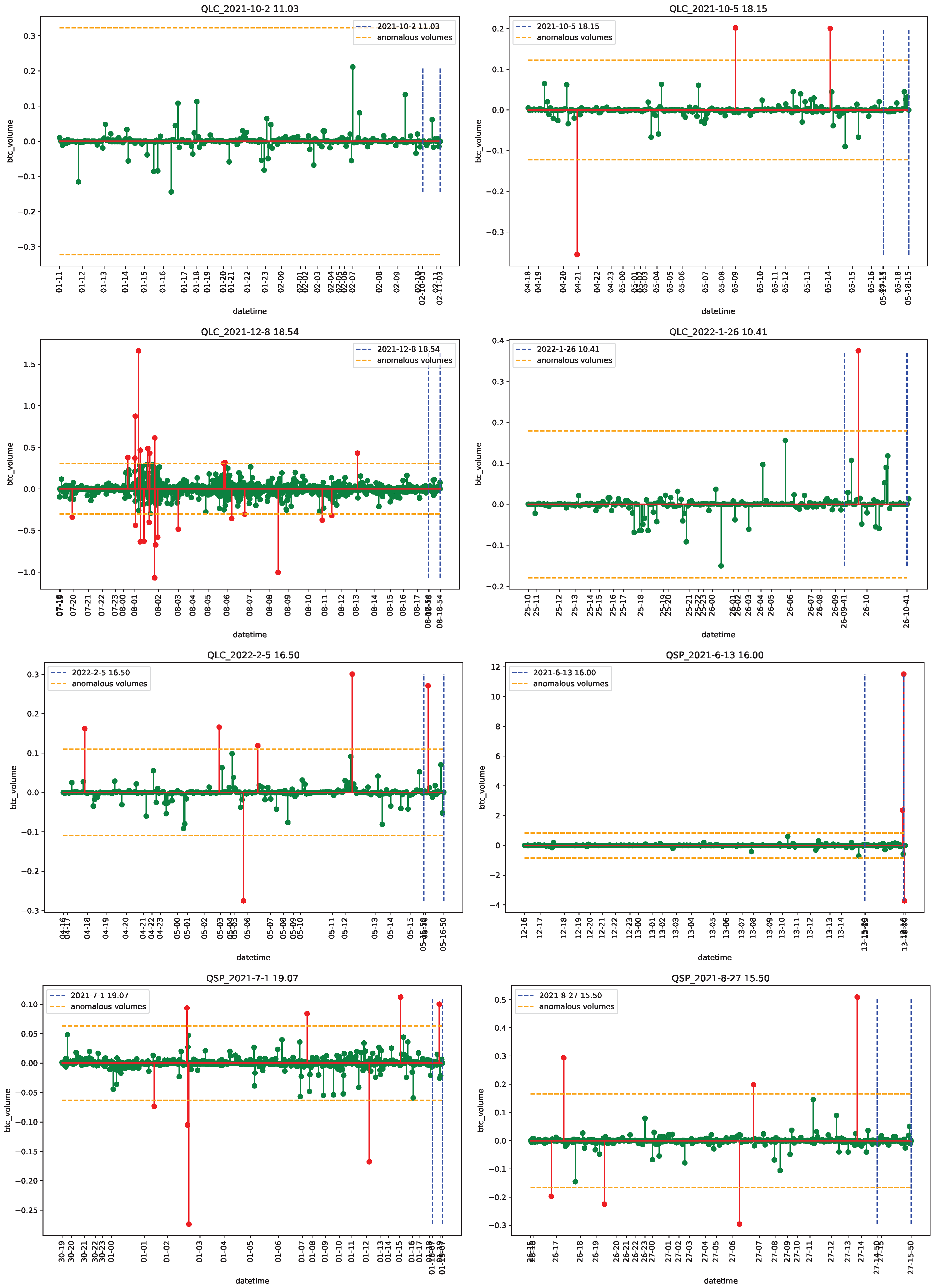
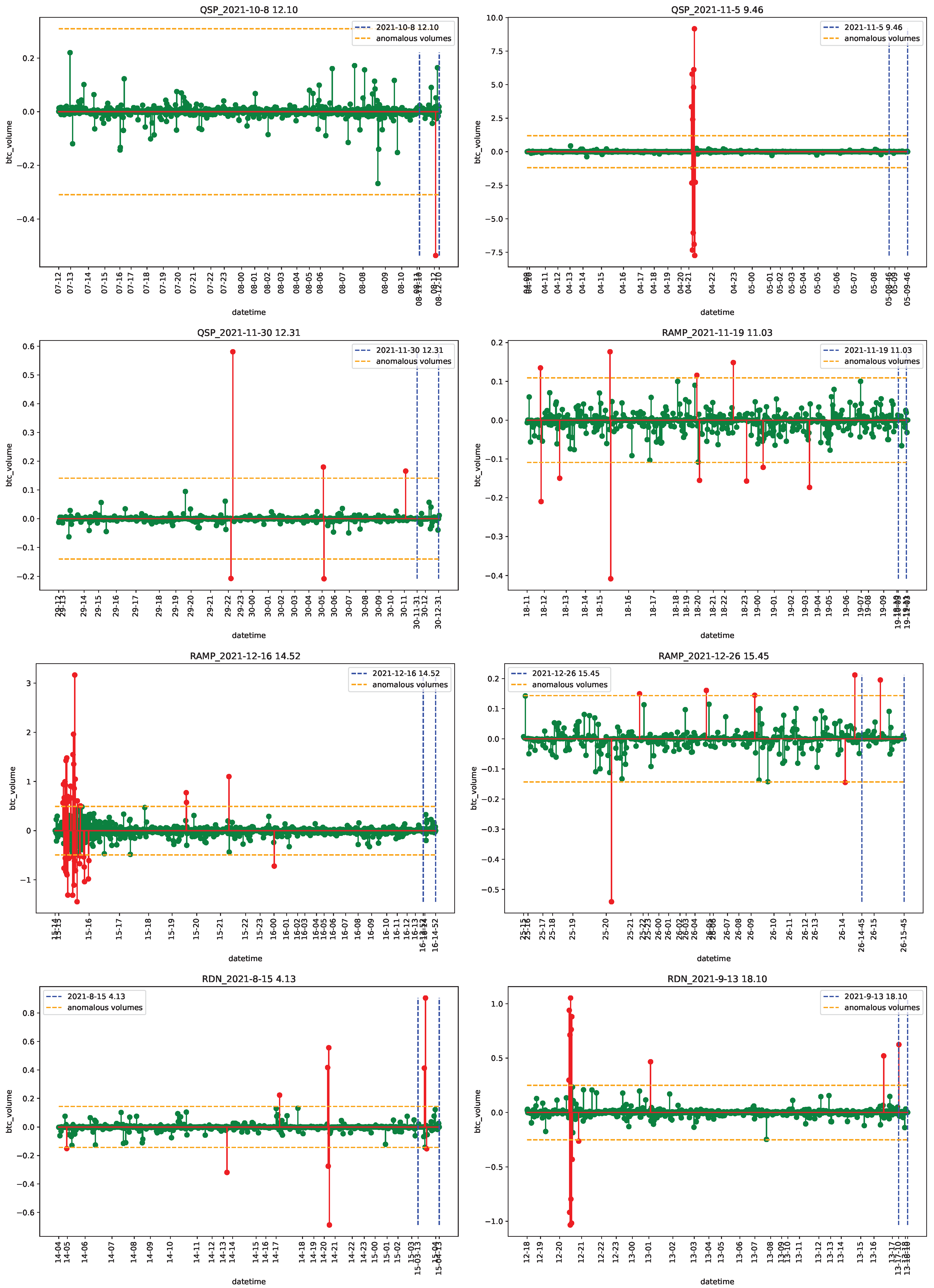
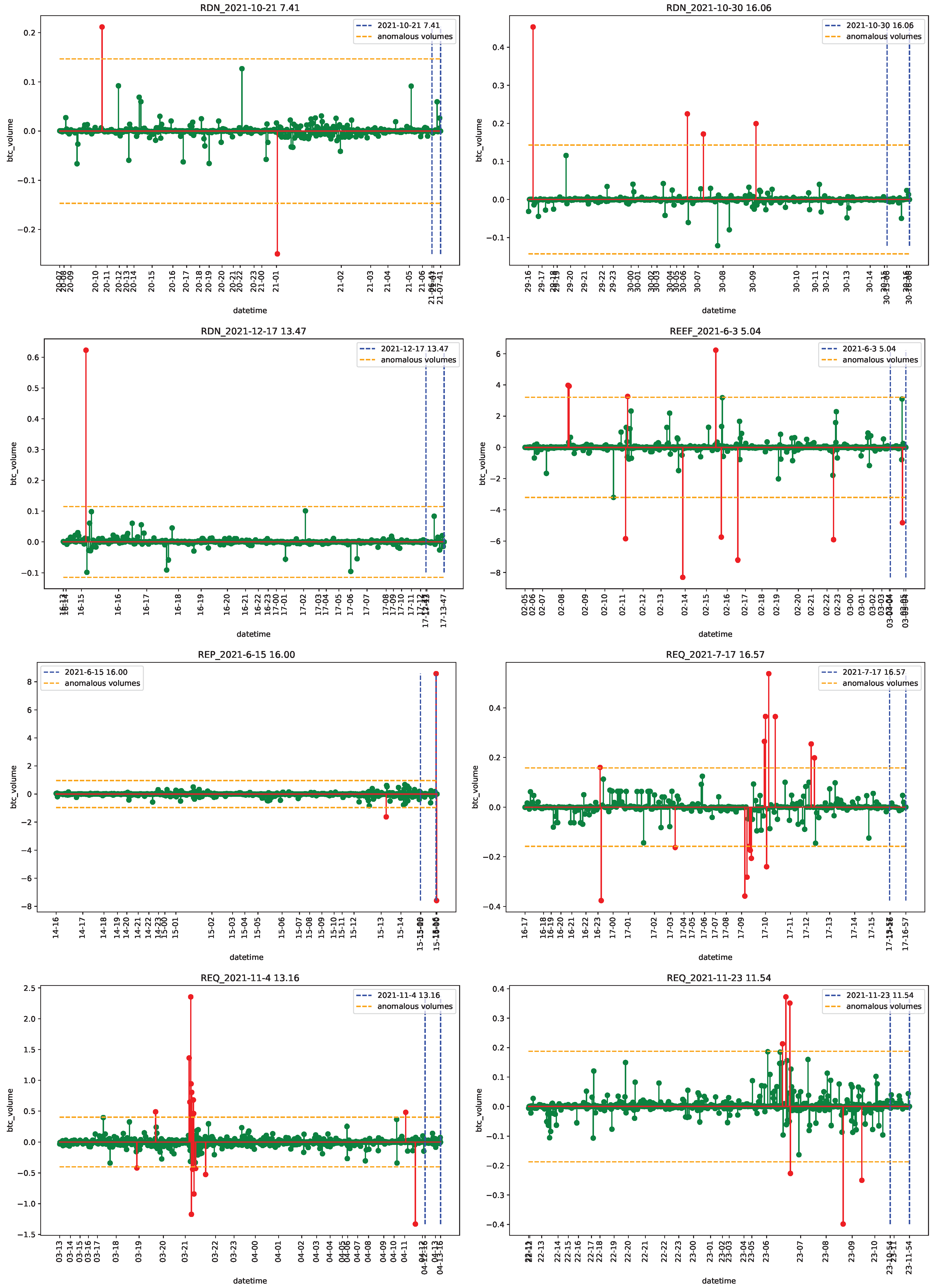
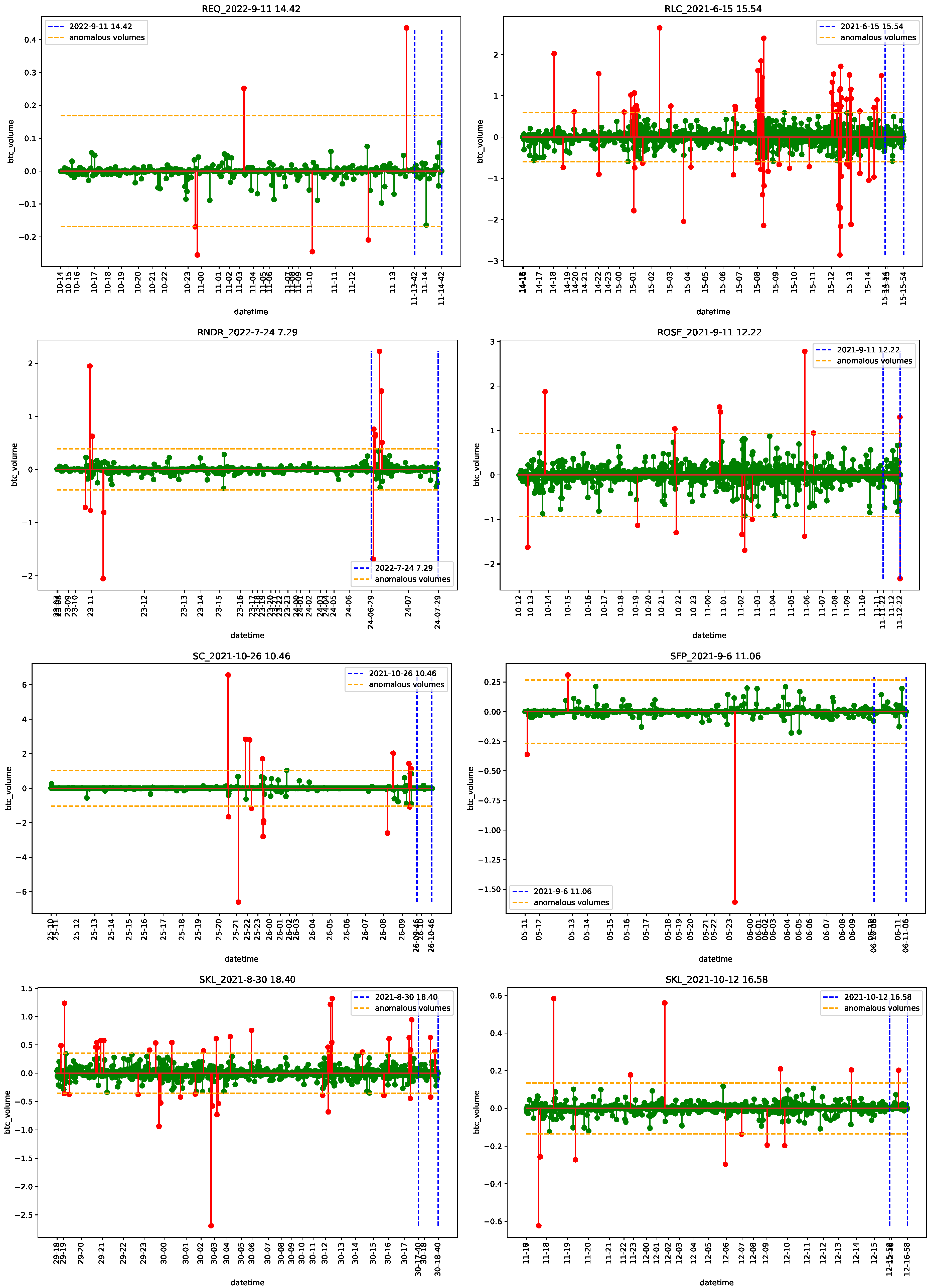
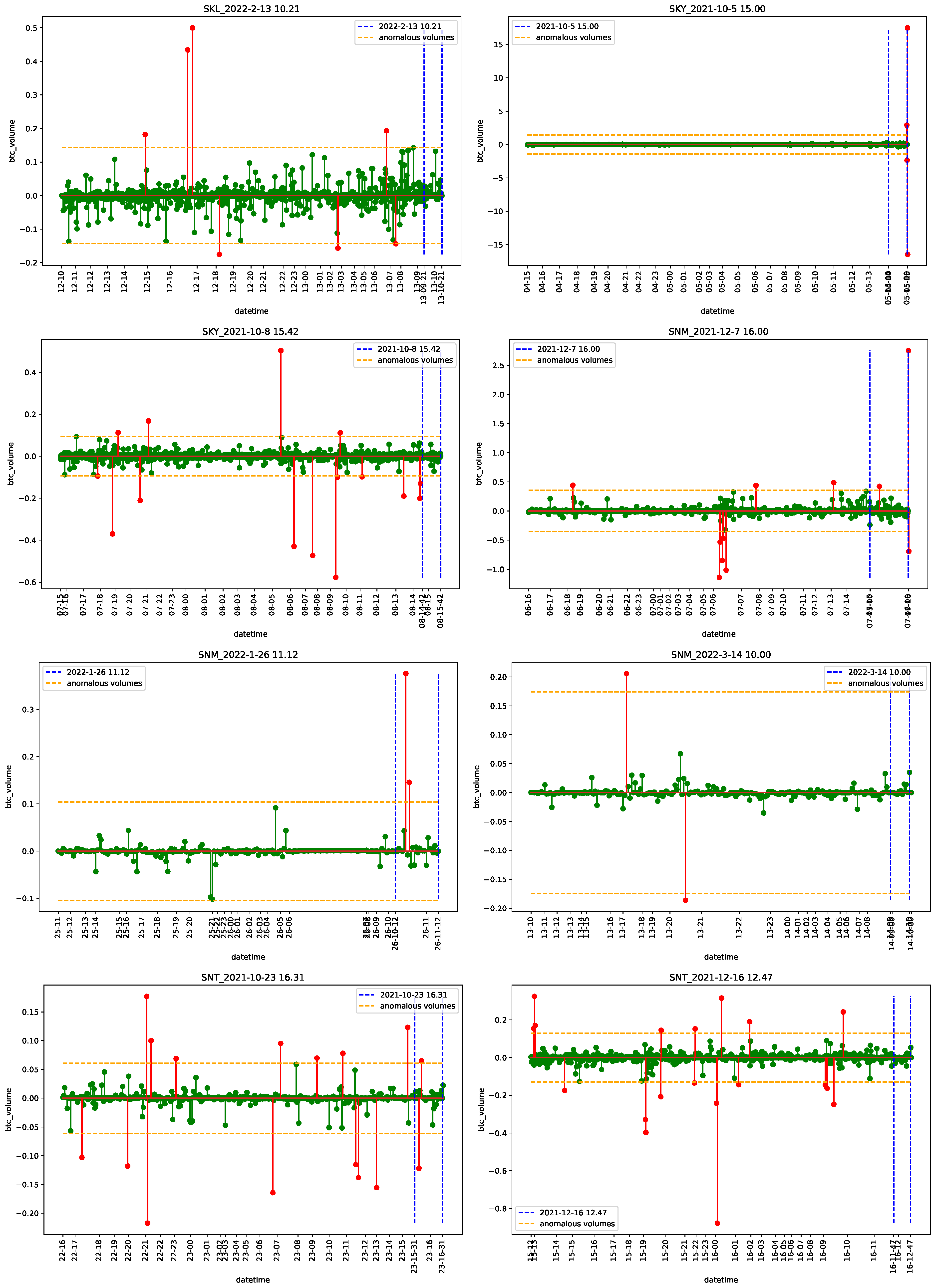
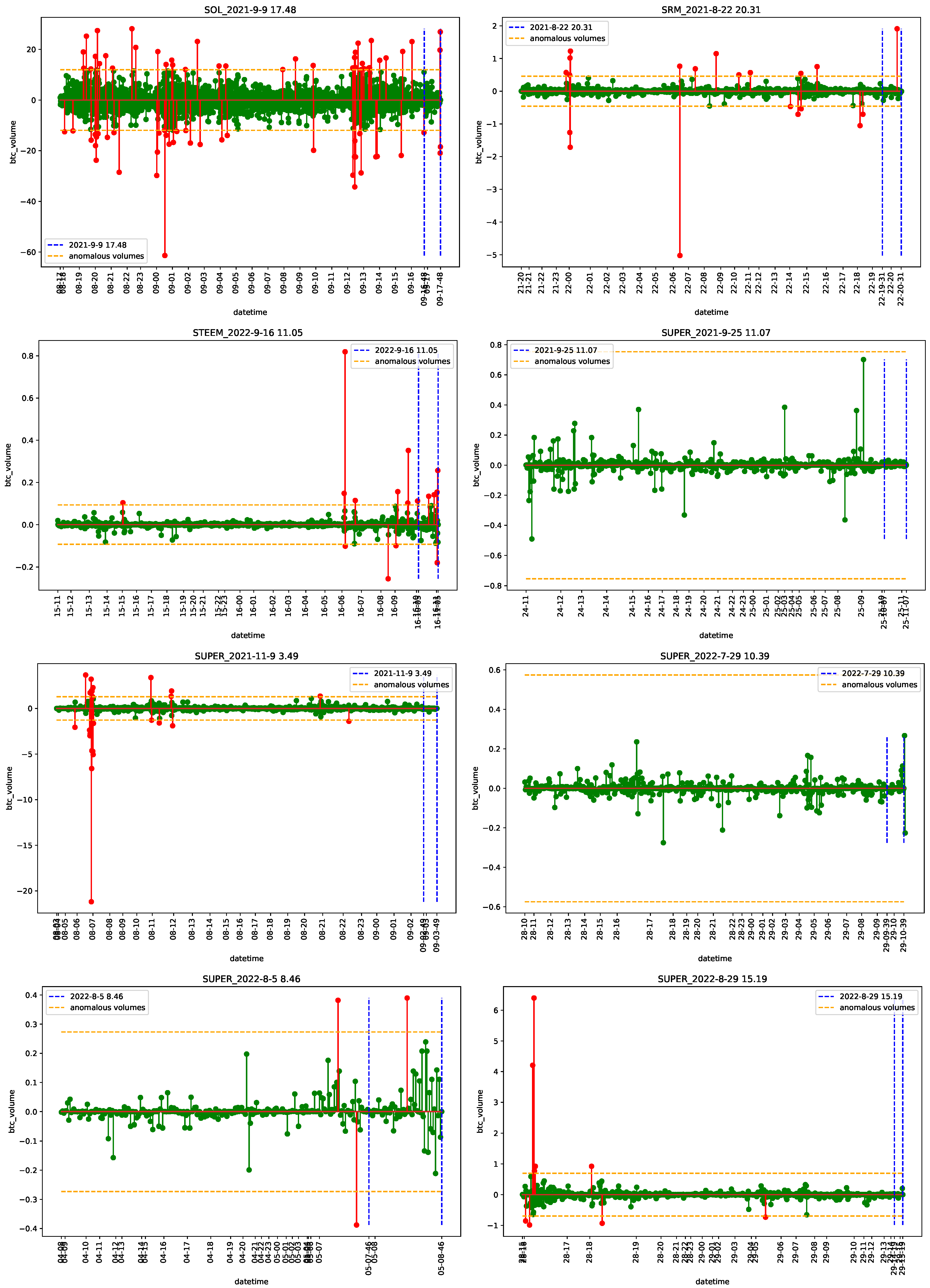
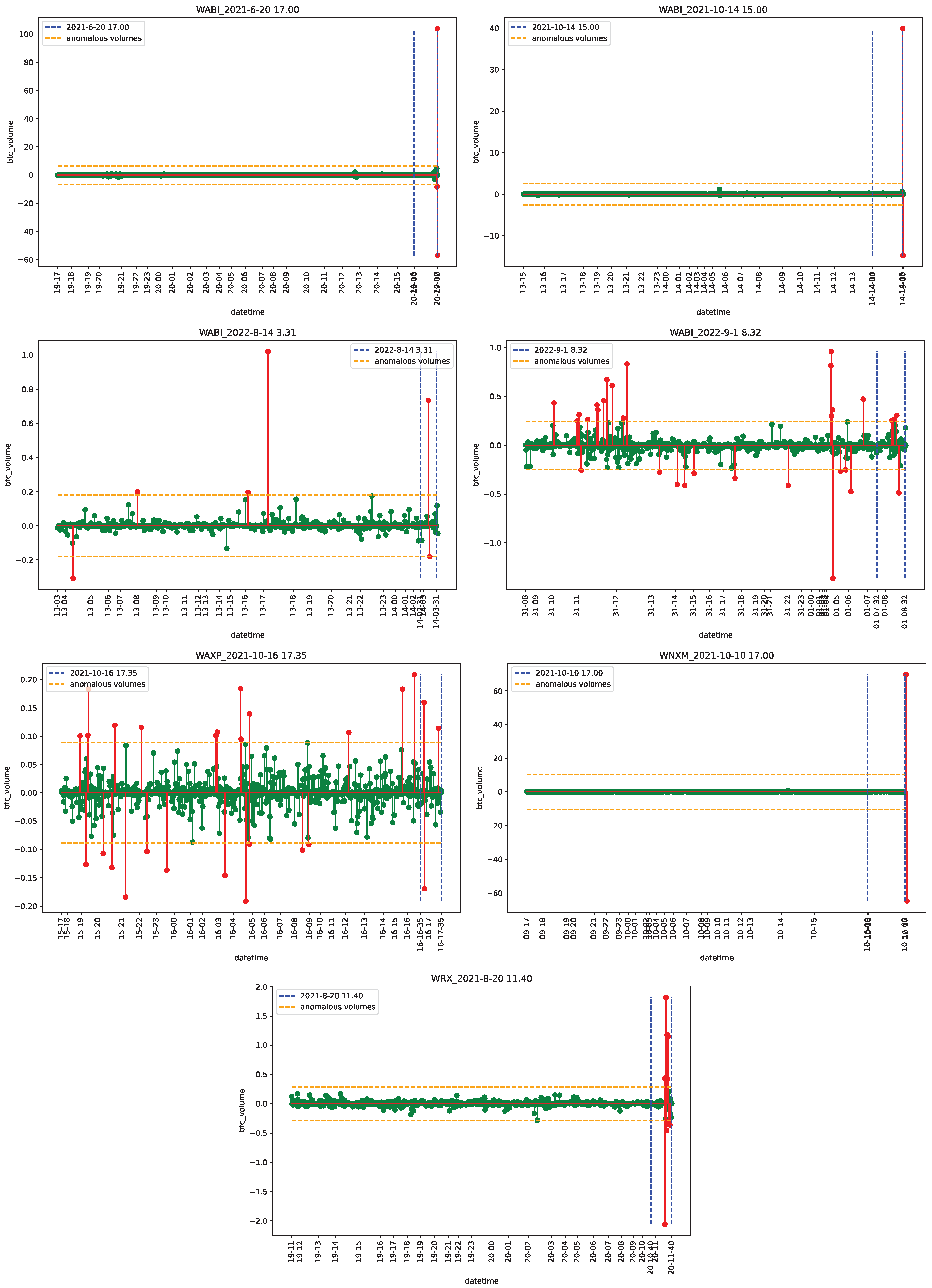
4.2. Empirical Analysis
- 1
- Model training using the original dataset with pump-and-dumps flagged 1 or 2 min before the public announcement;
- 2–5
- Model training using synthetic balanced data created with Random Under-Sampling (RUS), Random Over-Sampling (ROS), Synthetic Minority Over-sampling Technique (SMOTE), and the Random Over-Sampling Examples (ROSE) method, respectively, with pump-and-dumps flagged 1 or 2 min before the public announcement.
- 6
- Model training using the original dataset with pump-and-dumps flagged 60 min before the public announcement;
- 7–10
- Model training using synthetic balanced data created with Random Under-Sampling (RUS), Random Over-Sampling (ROS), Synthetic Minority Over-sampling Technique (SMOTE), and the Random Over-Sampling Examples (ROSE) method, respectively, with pump-and-dumps flagged 60 min before the public announcement.
- Area under the Receiver Operating Characteristic (ROC) curve (AUC): it is a metric that measures the ability of a binary classification model to distinguish between positive and negative classes. It is calculated as the area under the receiver operating characteristic (ROC) curve, which plots the true positive rate against the false positive rate at various classification thresholds. AUC is commonly used to evaluate the overall performance of a classification model, and it ranges from 0 to 1, with a higher score indicating better performance; see Sammut and Webb (2011), pp. 869–75, and references therein for more details.
- H-measure: the AUC has some well-known drawbacks, such as potentially providing misleading results when ROC curves cross. However, a more serious deficiency of the AUC (recognized only recently by Hand (2009) is that it is fundamentally incoherent in terms of misclassification costs, as it employs different misclassification cost distributions for different classifiers. This is problematic because the severity of misclassification for different points is a property of the problem rather than the classifiers that have been selected. The H-measure, proposed by Hand (2009) and Hand and Anagnostopoulos (2022), is a measure of classification performance that addresses the incoherence of AUC by introducing costs for different types of misclassification. However, it is common for the precise values of costs to be unknown at the time of classifier evaluation. To address this, they proposed taking the expectation over a distribution of likely cost values. While researchers should choose this distribution based on their knowledge of the problem, Hand (2009) and Hand and Anagnostopoulos (2022) also recommended a standard default distribution, such as beta distribution, for conventional measures, and they also generalized this approach to cover cases when class sizes are unknown. Moreover, in many problems, class sizes are extremely unbalanced (as in our case with pump-and-dumps), and it is rare to want to treat the two classes symmetrically. To address this issue, the H-measure requires a Severity Ratio (SR) that represents how much more severe misclassifying a class 0 instance is than misclassifying a class 1 instance. The severity ratio is formally defined as , where is the cost of misclassifying a class 0 datapoint as class 1. It is sometimes more convenient to consider the normalized cost , so that , where c is in the range [0,1]. By default, the severity ratio is set to the reciprocal of the relative class frequency, i.e., , so that misclassifying the rare class is considered a graver mistake. For more detailed motivation of this default value, see Hand and Anagnostopoulos (2014).
- Accuracy: it is a measure of the correct classification rate, which is the ratio of the number of correct predictions to the total number of predictions made. It is a widely used performance metric for binary classification, but it can be misleading in cases of imbalanced datasets.
- Sensitivity: it measures the proportion of true positive predictions out of all the actual positive cases in the dataset. In other words, it measures how well the model identifies the positive cases correctly (in our case, the number of pump-and-dumps).
- Specificity: it measures the proportion of true negative predictions out of all the actual negative cases in the dataset. In other words, it measures how well the model identifies the negative cases correctly.
- : this is the classical level used in many applications in various fields;
- : this level is close to the empirical frequency of pump-and-dumps in the dataset where they are flagged 1 or 2 min before the public announcement (that is, close to the so-called observed prevalence5, );
- : this level is close to the empirical frequency of pump-and-dumps in the dataset where they are flagged 60 min before the public announcement ().
5. A Robustness Check: Transforming the Data Using a Generalized Box–Cox Tranformation
6. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
- Identify the minority class observations with .
- Randomly select a minority class observation from the dataset.
- Find the k nearest minority class neighbors of in the feature space, where k is a user-defined parameter.
- Create synthetic observations: for each nearest neighbor , generate a synthetic observation by randomly interpolating between and in the feature space:where is a random number between 0 and 1.
- Repeat steps 2–4 until the desired number of synthetic observations have been generated.
- Resample the majority class data using a bootstrap resampling technique to reduce the number of majority class samples to a ratio of 50% via under-sampling.
- Resample the minority class data using a bootstrap resampling technique to increase the number of minority class samples to a ratio of 50% via over-sampling.
- Combined the data from steps 1 and 2 to create a new training sample.
- Generate new synthetic data for both the majority and minority classes in their respective neighborhoods. The neighborhood shape is defined by the kernel density function with a Gaussian kernel and a smoothing matrix , , with a d dimension (where d is the number of independent variables), where and is defined as follows:Here, is the standard deviation of the q-th dimension of the observations belonging to a given class.
Appendix B

Appendix C

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Estimate | Std. Error | z Value | Pr (>|z|) | |
|---|---|---|---|---|
| (Intercept) | −4.0103 | 0.0162 | −247.02 | 0.0000 |
| std_order | 0.1446 | 0.0154 | 9.36 | 0.0000 |
| avg_order | −0.2473 | 0.0248 | −9.97 | 0.0000 |
| std_trades | −0.0144 | 0.0023 | −6.31 | 0.0000 |
| std_volume | −0.1615 | 0.0849 | −1.90 | 0.0572 |
| avg_volume | 0.6975 | 0.1505 | 4.63 | 0.0000 |
| std_price | 40,943.0551 | 2073.1201 | 19.75 | 0.0000 |
| avg_price | −66.3994 | 14.6226 | −4.54 | 0.0000 |
| hour_sin | −0.6654 | 0.0181 | −36.84 | 0.0000 |
| hour_cos | −1.1178 | 0.0196 | −56.96 | 0.0000 |
| minute_sin | −0.0380 | 0.0156 | −2.43 | 0.0150 |
| minute_cos | 0.0332 | 0.0152 | 2.18 | 0.0291 |

Appendix D












































| 1 | https://pumpolymp.com (accessed on 1 December 2022). |
| 2 | https://github.com/ccxt/ccxt (accessed on 1 December 2022). |
| 3 | The original Python code used by La Morgia et al. (2020, 2023) to compute these regressors can be found at https://github.com/SystemsLab-Sapienza/pump-and-dump-dataset/blob/master/features.py (accessed on 1 December 2022). |
| 4 | For a couple of combinations of chunk sizes and window sizes, both ADF and KPSS tests rejected their null hypotheses. We remark that a lack a unit root does not immediately imply (strict) stationarity. Moreover, strong heteroskedasticity, nonlinear time trends, or other reasons can make a time series non stationary. Furthermore, there is simulation evidence showing that the ADF test should be preferred in the case of a large time sample; see Arltová and Fedorová (2016) and references therein. It is for all these reasons that we will also use a generalized Box–Cox transformation to evaluate the robustness of our analysis. |
| 5 | The observed prevalence is the proportion of positive cases in the actual dataset, which is calculated as the number of positive cases divided by the total number of cases in the dataset. |
| 6 | This generalization of the Box–Cox transformation is implemented in the R package car. |
| 7 | The authors want to thank an anonymous referee for bringing this issue to our attention. |
References
- Akbani, Rehan, Stephen Kwek, and Nathalie Japkowicz. 2004. Applying support vector machines to imbalanced datasets. In Machine Learning: ECML 2004: 15th European Conference on Machine Learning, Pisa, Italy, September 20–24. 2004. Proceedings 15. Berlin: Springer, pp. 39–50. [Google Scholar]
- Antonopoulos, Andreas. 2014. Mastering Bitcoin: Unlocking Digital Cryptocurrencies. Sonoma County: O’Reilly Media, Inc. [Google Scholar]
- Arltová, Markéta, and Darina Fedorová. 2016. Selection of Unit Root Test on the Basis of Length of the Time Series and Value of AR(1) Parameter. Statistika: Statistics & Economy Journal 96: 47–64. [Google Scholar]
- Barua, Sukarna, Md Monirul Islam, Xin Yao, and Kazuyuki Murase. 2012. MWMOTE–majority weighted minority oversampling technique for imbalanced data set learning. IEEE Transactions on Knowledge and Data Engineering 26: 405–25. [Google Scholar] [CrossRef]
- Bouraoui, Taoufik. 2015. Does’ pump and dump’affect stock markets? International Journal of Trade, Economics and Finance 6: 45. [Google Scholar] [CrossRef]
- Breiman, Leo. 2001. Random forests. Machine Learning 45: 5–32. [Google Scholar] [CrossRef]
- Breiman, Leo, Jerome Friedman, Richard Olshen, and Charles Stone. 1984. Classification and Regression Trees. Monterey: Wadsworth & Brooks. [Google Scholar]
- Bunkhumpornpat, Chumphol, Krung Sinapiromsaran, and Chidchanok Lursinsap. 2009. Safe-level-smote: Safe-level-synthetic minority over-sampling technique for handling the class imbalanced problem. In Advances in Knowledge Discovery and Data Mining: 13th Pacific-Asia Conference, PAKDD 2009 Bangkok, Thailand, April 27–30. Proceedings 13. Berlin: Springer, pp. 475–82. [Google Scholar]
- Charu, C. Aggarwal. 2019. Outlier Analysis. Berlin: Springer. [Google Scholar]
- Chawla, Nitesh V. 2003. C4. 5 and imbalanced data sets: Investigating the effect of sampling method, probabilistic estimate, and decision tree structure. In Proceedings of the ICML. Toronto: CIBC, vol. 3, p. 66. [Google Scholar]
- Chawla, Nitesh V., Kevin W. Bowyer, Lawrence O. Hall, and W. Philip Kegelmeyer. 2002. Smote: Synthetic minority over-sampling technique. Journal of Artificial Intelligence Research 16: 321–57. [Google Scholar] [CrossRef]
- Cieslak, David A., and Nitesh V. Chawla. 2008. Learning decision trees for unbalanced data. In Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2008, Antwerp, Belgium, September 15–19. Proceedings, Part I 19. Berlin: Springer, pp. 241–56. [Google Scholar]
- Dhawan, Anirudh, and Tālis Putniņš. 2023. A new wolf in town? pump-and-dump manipulation in cryptocurrency markets. Review of Finance 27: 935–75. [Google Scholar] [CrossRef]
- Feder, Amir, Neil Gandal, J. T. Hamrick, Tyler Moore, Arghya Mukherjee, Farhang Rouhi, and Marie Vasek. 2018. The Economics of Cryptocurrency Pump and Dump Schemes. Technical Report, CEPR Discussion Papers, No. 13404. London: Centre for Economic Policy Research. [Google Scholar]
- Freeman, Elizabeth A., and Gretchen G. Moisen. 2008. A comparison of the performance of threshold criteria for binary classification in terms of predicted prevalence and kappa. Ecological Modelling 217: 48–58. [Google Scholar] [CrossRef]
- Frieder, Laura, and Jonathan Zittrain. 2008. Spam works: Evidence from stock touts and corresponding market activity. Hastings Communications and Entertainment Law Journal 30: 479–520. [Google Scholar] [CrossRef]
- Guo, Hongyu, and Herna L. Viktor. 2004. Boosting with data generation: Improving the classification of hard to learn examples. In Innovations in Applied Artificial Intelligence: 17th International Conference on Industrial and Engineering Applications of Artificial Intelligence and Expert Systems, IEA/AIE 2004, Ottawa, Canada, May 17–20. Proceedings 17. Berlin: Springer, pp. 1082–91. [Google Scholar]
- Hamrick, J. T., Farhang Rouhi, Arghya Mukherjee, Amir Feder, Neil Gandal, Tyler Moore, and Marie Vasek. 2021. An examination of the cryptocurrency pump-and-dump ecosystem. Information Processing & Management 58: 102506. [Google Scholar]
- Hand, David J. 2009. Measuring classifier performance: A coherent alternative to the area under the roc curve. Machine Learning 77: 103–23. [Google Scholar] [CrossRef]
- Hand, David J., and Christoforos Anagnostopoulos. 2014. A better beta for the h measure of classification performance. Pattern Recognition Letters 40: 41–46. [Google Scholar] [CrossRef]
- Hand, David J., and Christoforos Anagnostopoulos. 2022. Notes on the h-measure of classifier performance. Advances in Data Analysis and Classification 17: 109–24. [Google Scholar] [CrossRef]
- Hand, David J., and Veronica Vinciotti. 2003. Choosing k for two-class nearest neighbour classifiers with unbalanced classes. Pattern Recognition Letters 24: 1555–62. [Google Scholar] [CrossRef]
- Hastie, Trevor, Robert Tibshirani, and Jerome Friedman. 2017. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed. 12th Printing. Berlin: Springer. [Google Scholar]
- Hawkins, D. M., and S. Weisberg. 2017. Combining the box-cox power and generalised log transformations to accommodate nonpositive responses in linear and mixed-effects linear models. South African Statistical Journal 51: 317–28. [Google Scholar] [CrossRef]
- He, Haibo, and Edwardo A. Garcia. 2009. Learning from imbalanced data. IEEE Transactions on Knowledge and Data Engineering 21: 1263–84. [Google Scholar]
- Janitza, Silke, Carolin Strobl, and Anne-Laure Boulesteix. 2013. An auc-based permutation variable importance measure for random forests. BMC Bioinformatics 14: 119. [Google Scholar] [CrossRef]
- Kamps, Josh, and Bennett Kleinberg. 2018. To the moon: Defining and detecting cryptocurrency pump-and-dumps. Crime Science 7: 18. [Google Scholar] [CrossRef]
- King, Gary, and Langche Zeng. 2001. Logistic regression in rare events data. Political Analysis 9: 137–63. [Google Scholar] [CrossRef]
- Kotsiantis, Sotiris, Dimitris Kanellopoulos, and Panayiotis Pintelas. 2006. Handling imbalanced datasets: A review. GESTS International Transactions on Computer Science and Engineering 30: 25–36. [Google Scholar]
- Krinklebine, Karlos. 2010. Hacking Wall Street: Attacks And Countermeasures. Chicago: Independently Published. [Google Scholar]
- Kukar, Matjaz, and Igor Kononenko. 1998. Cost sensitive learning with neural networks. In ECAI 98: 13th European Conference on Artificial Intelligence. Hoboken: John Wiley & Sons, Ltd., vol. 15, pp. 88–94. [Google Scholar]
- La Morgia, Massimo, Alessandro Mei, Francesco Sassi, and Julinda Stefa. 2020. Pump and dumps in the bitcoin era: Real time detection of cryptocurrency market manipulations. Paper presented at 2020 29th International Conference on Computer Communications and Networks (ICCCN), Honolulu, HI, USA, August 3–6; pp. 1–9. [Google Scholar]
- La Morgia, Massimo, Alessandro Mei, Francesco Sassi, and Julinda Stefa. 2023. The doge of wall street: Analysis and detection of pump and dump cryptocurrency manipulations. ACM Transactions on Internet Technology 23: 1–28. [Google Scholar] [CrossRef]
- Lee, Sauchi Stephen. 1999. Regularization in skewed binary classification. Computational Statistics 14: 277–92. [Google Scholar] [CrossRef]
- Lin, Yi, Yoonkyung Lee, and Grace Wahba. 2002. Support vector machines for classification in nonstandard situations. Machine Learning 46: 191–202. [Google Scholar] [CrossRef]
- López-Ratón, Mónica, María Xosé Rodríguez-Álvarez, Carmen Cadarso-Suárez, and Francisco Gude-Sampedro. 2014. OptimalCutpoints: An R package for selecting optimal cutpoints in diagnostic tests. Journal of Statistical Software 61: 1–36. [Google Scholar] [CrossRef]
- Lunardon, Nicola, Giovanna Menardi, and Nicola Torelli. 2014. Rose: A package for binary imbalanced learning. R Journal 6: 79–89. [Google Scholar] [CrossRef]
- McCarthy, Kate, Bibi Zabar, and Gary Weiss. 2005. Does cost-sensitive learning beat sampling for classifying rare classes? In Proceedings of the 1st International Workshop on Utility-Based Data Mining. New York: Gary Weiss, pp. 69–77. [Google Scholar]
- Mease, David, Abraham J. Wyner, and Andreas Buja. 2007. Boosted classification trees and class probability/quantile estimation. Journal of Machine Learning Research 8: 409–39. [Google Scholar]
- Menardi, Giovanna, and Nicola Torelli. 2014. Training and assessing classification rules with imbalanced data. Data Mining and Knowledge Discovery 28: 92–122. [Google Scholar] [CrossRef]
- Narayanan, Arvind, Joseph Bonneau, Edward Felten, Andrew Miller, and Steven Goldfeder. 2016. Bitcoin and Cryptocurrency Technologies: A Comprehensive Introduction. Princeton: Princeton University Press. [Google Scholar]
- Nghiem, Huy, Goran Muric, Fred Morstatter, and Emilio Ferrara. 2021. Detecting cryptocurrency pump-and-dump frauds using market and social signals. Expert Systems with Applications 182: 115284. [Google Scholar] [CrossRef]
- Ouyang, Liangyi, and Bolong Cao. 2020. Selective pump-and-dump: The manipulation of their top holdings by chinese mutual funds around quarter-ends. Emerging Markets Review 44: 100697. [Google Scholar] [CrossRef]
- Pukelsheim, Friedrich. 1994. The three sigma rule. The American Statistician 48: 88–91. [Google Scholar]
- Riddle, Patricia, Richard Segal, and Oren Etzioni. 1994. Representation design and brute-force induction in a boeing manufacturing domain. Applied Artificial Intelligence an International Journal 8: 125–47. [Google Scholar] [CrossRef]
- Rousseeuw, Peter J., and Annick M. Leroy. 2005. Robust Regression and Outlier Detection. Hoboken: John Wiley & Sons. [Google Scholar]
- Sammut, Claude, and Geoffrey Webb. 2011. Encyclopedia of Machine Learning. Berlin: Springer. [Google Scholar]
- Schiavo, Rosa A., and David J. Hand. 2000. Ten more years of error rate research. International Statistical Review 68: 295–310. [Google Scholar] [CrossRef]
- Shao, Sisi. 2021. The effectiveness of supervised learning models in detection of pump and dump activity in dogecoin. In Second IYSF Academic Symposium on Artificial Intelligence and Computer Engineering. Bellingham: SPIE, Volume 12079, pp. 356–63. [Google Scholar]
- Siering, Michael. 2019. The economics of stock touting during internet-based pump and dump campaigns. Information Systems Journal 29: 456–83. [Google Scholar] [CrossRef]
- Siris, Vasilios A., and Fotini Papagalou. 2004. Application of anomaly detection algorithms for detecting syn flooding attacks. Paper presented at IEEE Global Telecommunications Conference, GLOBECOM’04, Dallas, TX, USA, November 29–December 3; Volume 4, pp. 2050–54. [Google Scholar]
- Strobl, Carolin, Anne-Laure Boulesteix, Achim Zeileis, and Torsten Hothorn. 2007. Bias in random forest variable importance measures: Illustrations, sources and a solution. BMC Bioinformatics 8: 25. [Google Scholar] [CrossRef] [PubMed]
- Sun, Yanmin, Andrew K. C. Wong, and Mohamed S. Kamel. 2009. Classification of imbalanced data: A review. International Journal of Pattern Recognition and Artificial Intelligence 23: 687–719. [Google Scholar] [CrossRef]
- Tantithamthavorn, Chakkrit, Ahmed E. Hassan, and Kenichi Matsumoto. 2018. The impact of class rebalancing techniques on the performance and interpretation of defect prediction models. IEEE Transactions on Software Engineering 46: 1200–19. [Google Scholar] [CrossRef]
- Thiele, Christian, and Gerrit Hirschfeld. 2021. Cutpointr: Improved Estimation and Validation of Optimal Cutpoints in R. Journal of Statistical Software 98: 1–27. [Google Scholar] [CrossRef]
- Ting, Kai Ming. 2002. An instance-weighting method to induce cost-sensitive trees. IEEE Transactions on Knowledge and Data Engineering 14: 659–65. [Google Scholar] [CrossRef]
- US Security and Exchange Commission. 2005. Pump&Dump.con: Tips for Avoiding Stock Scams on the Internet; Technical Report. Washington, DC: US Security and Exchange Commission.
- van den Goorbergh, Ruben, Maarten van Smeden, Dirk Timmerman, and Ben Van Calster. 2022. The harm of class imbalance corrections for risk prediction models: Illustration and simulation using logistic regression. Journal of the American Medical Informatics Association 29: 1525–34. [Google Scholar] [CrossRef]
- Victor, Friedhelm, and Tanja Hagemann. 2019. Cryptocurrency pump and dump schemes: Quantification and detection. Paper presented at 2019 International Conference on Data Mining Workshops (ICDMW), Beijing, China, November 8–11; pp. 244–51. [Google Scholar]
- Weiss, Gary M. 2004. Mining with rarity: A unifying framework. ACM Sigkdd Explorations Newsletter 6: 7–19. [Google Scholar] [CrossRef]
- Weiss, Gary M., and Foster Provost. 2001. The Effect of Class Distribution on Classifier Learning: An Empirical Study. Technical Report. Piscataway: Rutgers University. [Google Scholar]
- Withanawasam, Rasika, Peter Whigham, and Timothy Crack. 2013. Characterising trader manipulation in a limit-order driven market. Mathematics and Computers in Simulation 93: 43–52. [Google Scholar] [CrossRef]
- Wongvorachan, Tarid, Surina He, and Okan Bulut. 2023. A comparison of undersampling, oversampling, and smote methods for dealing with imbalanced classification in educational data mining. Information 14: 54. [Google Scholar] [CrossRef]
- Xu, Jiahua, and Benjamin Livshits. 2019. The anatomy of a cryptocurrency pump-and-dump scheme. In USENIX Security Symposium. Santa Clara: USENIX Association, pp. 1609–25. [Google Scholar]
- Zaki, Mohamed, David Diaz, and Babis Theodoulidis. 2012. Financial market service architectures: A “pump and dump” case study. Paper presented at 2012 Annual SRII Global Conference, San Jose, CA, USA, July 24–27; pp. 554–63. [Google Scholar]
| Coin Symbol | Exchange | Buy Range | Target 1 | Target 2 | Target 3 | Stop Loss |
|---|---|---|---|---|---|---|
| ADX | Binance | 800–830 | 900 | 1100 | 1200 | 750 |
| AGIX | Binance | 280–290 | 320 | 350 | 380 | 250 |
| POLY | Binance | 1020–1050 | 1150 | 1200 | 1300 | 900 |
| CTSI | Binance | 720–740 | 800 | 900 | 1100 | 650 |
| FOR | Binance | 93–98 | 110 | 115 | 125 | 90 |
| Names | Dates and Time | Names | Dates and Time | Names | Dates and Time | Names | Dates and Time |
|---|---|---|---|---|---|---|---|
| ADX | 2022-09-20 15:56:00 | ATM | 2022-01-12 17:37:00 | SNT | 2021-10-23 16:31:00 | NAS | 2021-08-22 17:00:00 |
| IRIS | 2022-09-17 13:24:00 | ASR | 2022-01-09 16:30:00 | ADX | 2021-10-23 16:15:00 | POND | 2021-08-22 13:10:00 |
| STEEM | 2022-09-16 11:05:00 | POWR | 2022-01-08 08:10:00 | AGIX | 2021-10-22 13:28:00 | GVT | 2021-08-21 16:00:00 |
| BTS | 2022-09-15 12:57:00 | VIB | 2022-01-02 17:12:00 | POA | 2021-10-21 16:00:00 | FOR | 2021-08-21 13:04:00 |
| PROM | 2022-09-15 08:52:00 | NEBL | 2022-01-02 17:00:00 | EVX | 2021-10-21 11:24:00 | AION | 2021-08-20 13:41:00 |
| REQ | 2022-09-11 14:42:00 | ATM | 2021-12-31 18:32:00 | NXS | 2021-10-21 10:59:00 | WRX | 2021-08-20 11:40:00 |
| ARDR | 2022-09-11 12:21:00 | PIVX | 2021-12-28 14:27:00 | RDN | 2021-10-21 07:41:00 | ARPA | 2021-08-20 04:13:00 |
| SUPER | 2022-09-11 11:54:00 | POWR | 2021-12-28 14:13:00 | BRD | 2021-10-20 16:54:00 | NU | 2021-08-20 02:08:00 |
| AGIX | 2022-09-11 09:19:00 | PNT | 2021-12-26 18:53:00 | AVAX | 2021-10-19 13:03:00 | FOR | 2021-08-17 12:03:00 |
| PIVX | 2022-09-11 08:41:00 | RAMP | 2021-12-26 15:45:00 | BEAM | 2021-10-17 17:48:00 | OAX | 2021-08-17 02:54:00 |
| GTO | 2022-09-06 10:52:00 | TCT | 2021-12-25 14:13:00 | ANT | 2021-10-17 07:27:00 | CTXC | 2021-08-16 05:46:00 |
| CVX | 2022-09-06 06:53:00 | OG | 2021-12-25 13:55:00 | WAXP | 2021-10-16 17:35:00 | ADX | 2021-08-15 17:31:00 |
| WABI | 2022-09-01 08:32:00 | AGIX | 2021-12-24 17:21:00 | IRIS | 2021-10-16 17:14:00 | BEAM | 2021-08-15 16:48:00 |
| SUPER | 2022-08-29 15:19:00 | CTXC | 2021-12-24 12:49:00 | GXS | 2021-10-16 16:20:00 | RDN | 2021-08-15 04:13:00 |
| AION | 2022-08-29 10:29:00 | NEBL | 2021-12-24 12:39:00 | PNT | 2021-10-15 15:52:00 | MDA | 2021-08-10 17:38:00 |
| ELF | 2022-08-28 09:20:00 | RDN | 2021-12-17 13:47:00 | IRIS | 2021-10-14 20:49:00 | ARPA | 2021-08-10 04:44:00 |
| ADX | 2022-08-26 14:08:00 | RAMP | 2021-12-16 14:52:00 | WABI | 2021-10-14 15:00:00 | ARPA | 2021-08-09 17:57:00 |
| CTXC | 2022-08-26 12:18:00 | AST | 2021-12-16 14:04:00 | GXS | 2021-10-13 14:27:00 | AVAX | 2021-08-08 13:44:00 |
| DOCK | 2022-08-24 07:37:00 | SNT | 2021-12-16 12:47:00 | POND | 2021-10-13 14:16:00 | APPC | 2021-08-08 01:00:00 |
| AION | 2022-08-23 10:43:00 | NXS | 2021-12-16 02:32:00 | BRD | 2021-10-12 17:19:00 | ANKR | 2021-08-07 15:16:00 |
| NEXO | 2022-08-20 04:56:00 | AST | 2021-12-09 06:00:00 | SKL | 2021-10-12 16:58:00 | CTXC | 2021-08-07 14:59:00 |
| OAX | 2022-08-18 14:03:00 | TCT | 2021-12-09 02:20:00 | VIB | 2021-10-12 11:36:00 | BRD | 2021-08-06 11:34:00 |
| ELF | 2022-08-14 11:50:00 | QLC | 2021-12-08 18:54:00 | VIB | 2021-10-12 10:27:00 | LSK | 2021-08-06 03:31:00 |
| VIB | 2022-08-14 07:00:00 | SNM | 2021-12-07 16:00:00 | WNXM | 2021-10-10 17:00:00 | EVX | 2021-08-05 04:02:00 |
| IDEX | 2022-08-14 06:32:00 | GRS | 2021-12-06 16:00:00 | VIB | 2021-10-10 05:31:00 | BTS | 2021-08-02 23:13:00 |
| WABI | 2022-08-14 03:31:00 | ADX | 2021-12-06 06:45:00 | VIB | 2021-10-09 17:20:00 | NEBL | 2021-07-30 09:24:00 |
| PHA | 2022-08-11 15:51:00 | NEBL | 2021-12-05 15:00:00 | NXS | 2021-10-09 14:38:00 | ARPA | 2021-07-27 13:47:00 |
| BEAM | 2022-08-07 17:40:00 | NXS | 2021-12-04 12:59:00 | POA | 2021-10-09 13:13:00 | DREP | 2021-07-25 17:00:00 |
| SUPER | 2022-08-05 08:46:00 | ELF | 2021-12-02 19:30:00 | ADX | 2021-10-09 06:27:00 | EVX | 2021-07-25 15:29:00 |
| BRD | 2022-07-30 11:38:00 | QSP | 2021-11-30 12:31:00 | NAV | 2021-10-08 16:17:00 | NXS | 2021-07-25 15:22:00 |
| FOR | 2022-07-29 14:55:00 | VIB | 2021-11-29 07:49:00 | SKY | 2021-10-08 15:42:00 | QLC | 2021-07-25 12:03:00 |
| SUPER | 2022-07-29 10:39:00 | ALPHA | 2021-11-29 05:21:00 | VIB | 2021-10-08 12:40:00 | FOR | 2021-07-25 04:24:00 |
| AGIX | 2022-07-29 08:32:00 | VIB | 2021-11-28 18:53:00 | QSP | 2021-10-08 12:10:00 | GRS | 2021-07-24 16:58:00 |
| VIB | 2022-07-27 11:54:00 | PHB | 2021-11-28 17:00:00 | ANT | 2021-10-07 05:39:00 | GVT | 2021-07-24 16:40:00 |
| RNDR | 2022-07-24 07:29:00 | GRS | 2021-11-28 16:01:00 | BTCST | 2021-10-07 05:27:00 | POA | 2021-07-23 13:03:00 |
| MDA | 2022-07-23 13:16:00 | FXS | 2021-11-28 15:48:00 | QLC | 2021-10-05 18:15:00 | FOR | 2021-07-18 18:34:00 |
| FXS | 2022-07-22 11:31:00 | VIB | 2021-11-28 15:26:00 | SKY | 2021-10-05 15:00:00 | REQ | 2021-07-17 16:57:00 |
| DOCK | 2022-07-21 10:48:00 | FOR | 2021-11-28 07:09:00 | GTO | 2021-10-05 12:54:00 | CTSI | 2021-07-16 14:50:00 |
| LOKA | 2022-07-18 13:00:00 | GXS | 2021-11-27 16:50:00 | EVX | 2021-10-03 16:51:00 | TRU | 2021-07-16 14:35:00 |
| OCEAN | 2022-07-17 17:10:00 | NXS | 2021-11-27 16:37:00 | GXS | 2021-10-02 17:32:00 | POA | 2021-07-11 17:00:00 |
| FIO | 2022-07-17 15:56:00 | TKO | 2021-11-27 10:49:00 | QLC | 2021-10-02 11:03:00 | OAX | 2021-07-11 12:00:00 |
| VIB | 2022-07-16 16:28:00 | ELF | 2021-11-26 04:19:00 | APPC | 2021-09-30 14:07:00 | VIA | 2021-07-10 14:42:00 |
| DOCK | 2022-07-16 15:09:00 | NAV | 2021-11-26 01:21:00 | MTH | 2021-09-28 14:18:00 | FIS | 2021-07-07 19:06:00 |
| BEAM | 2022-07-16 12:31:00 | MDA | 2021-11-23 15:00:00 | SUPER | 2021-09-25 11:07:00 | ARPA | 2021-07-07 13:35:00 |
| CTXC | 2022-07-15 10:08:00 | REQ | 2021-11-23 11:54:00 | FIO | 2021-09-23 14:20:00 | TWT | 2021-07-06 14:30:00 |
| MDT | 2022-07-14 18:23:00 | ARDR | 2021-11-21 13:27:00 | NXS | 2021-09-22 16:00:00 | MDA | 2021-07-05 16:14:00 |
| PHA | 2022-07-14 11:45:00 | PIVX | 2021-11-21 11:08:00 | EVX | 2021-09-22 14:24:00 | NEBL | 2021-07-05 15:17:00 |
| LOKA | 2022-07-14 05:37:00 | NXS | 2021-11-20 13:36:00 | PNT | 2021-09-22 13:14:00 | IDEX | 2021-07-03 16:12:00 |
| DOCK | 2022-07-13 17:06:00 | RAMP | 2021-11-19 11:03:00 | NEBL | 2021-09-22 13:07:00 | LINK | 2021-07-01 21:10:00 |
| HIGH | 2022-07-13 09:56:00 | APPC | 2021-11-16 16:22:00 | NAV | 2021-09-21 13:50:00 | QSP | 2021-07-01 19:07:00 |
| PIVX | 2022-07-12 15:36:00 | NXS | 2021-11-16 16:00:00 | FXS | 2021-09-19 17:00:00 | DLT | 2021-07-01 17:52:00 |
| MLN | 2022-07-12 12:33:00 | NAS | 2021-11-14 15:00:00 | BRD | 2021-09-19 14:51:00 | OAX | 2021-06-29 14:27:00 |
| ADX | 2022-07-11 14:09:00 | EVX | 2021-11-12 16:00:00 | AION | 2021-09-18 12:47:00 | ARPA | 2021-06-28 17:30:00 |
| VIB | 2022-07-11 13:45:00 | ATM | 2021-11-12 15:43:00 | CTXC | 2021-09-15 17:00:00 | DOGE | 2021-06-27 19:14:00 |
| BEAM | 2022-07-09 13:41:00 | ASR | 2021-11-12 15:36:00 | PIVX | 2021-09-15 15:29:00 | MTH | 2021-06-27 17:00:00 |
| OAX | 2022-07-01 09:25:00 | NAS | 2021-11-12 14:37:00 | CHZ | 2021-09-14 12:30:00 | ADX | 2021-06-26 16:08:00 |
| ATM | 2022-03-22 10:45:00 | EVX | 2021-11-11 12:29:00 | RDN | 2021-09-13 18:10:00 | ELF | 2021-06-24 15:55:00 |
| ASR | 2022-03-22 10:08:00 | OAX | 2021-11-09 16:56:00 | GTO | 2021-09-12 12:40:00 | WABI | 2021-06-20 17:00:00 |
| AST | 2022-03-19 16:04:00 | SUPER | 2021-11-09 03:49:00 | DLT | 2021-09-11 16:00:00 | TRU | 2021-06-20 14:36:00 |
| ATA | 2022-03-16 18:52:00 | EPS | 2021-11-08 14:12:00 | ROSE | 2021-09-11 12:22:00 | NAV | 2021-06-20 11:00:00 |
| MITH | 2022-03-14 14:12:00 | VIB | 2021-11-07 18:58:00 | PHB | 2021-09-11 11:42:00 | VIA | 2021-06-19 17:48:00 |
| SNM | 2022-03-14 10:00:00 | VIB | 2021-11-07 17:21:00 | ALGO | 2021-09-11 07:24:00 | CDT | 2021-06-18 14:22:00 |
| POND | 2022-03-13 14:57:00 | MTH | 2021-11-07 17:00:00 | QLC | 2021-09-10 17:41:00 | NAS | 2021-06-16 16:29:00 |
| FIRO | 2022-03-13 09:57:00 | NXS | 2021-11-06 11:02:00 | AVAX | 2021-09-10 12:16:00 | ARK | 2021-06-16 15:09:00 |
| FOR | 2022-03-12 06:41:00 | NULS | 2021-11-05 19:11:00 | OAX | 2021-09-10 12:13:00 | SXP | 2021-06-16 10:32:00 |
| MDX | 2022-02-15 12:41:00 | QSP | 2021-11-05 09:46:00 | SOL | 2021-09-09 17:48:00 | CTXC | 2021-06-15 16:41:00 |
| OG | 2022-02-15 10:26:00 | BRD | 2021-11-04 13:36:00 | FUN | 2021-09-09 14:00:00 | ONE | 2021-06-15 16:36:00 |
| KLAY | 2022-02-14 20:10:00 | REQ | 2021-11-04 13:16:00 | NEAR | 2021-09-08 08:26:00 | REP | 2021-06-15 16:00:00 |
| FOR | 2022-02-13 15:10:00 | BEL | 2021-11-04 09:41:00 | ADX | 2021-09-07 14:28:00 | RLC | 2021-06-15 15:54:00 |
| SKL | 2022-02-13 10:21:00 | FIRO | 2021-11-03 16:25:00 | ALGO | 2021-09-06 16:53:00 | OST | 2021-06-15 15:53:00 |
| NEBL | 2022-02-11 14:30:00 | MTH | 2021-11-03 06:29:00 | SFP | 2021-09-06 11:06:00 | MATIC | 2021-06-14 12:31:00 |
| GRS | 2022-02-09 14:08:00 | OAX | 2021-11-02 16:16:00 | DOGE | 2021-09-05 23:32:00 | DLT | 2021-06-13 17:01:00 |
| ELF | 2022-02-07 14:39:00 | CHR | 2021-11-01 14:57:00 | NXS | 2021-09-05 17:39:00 | FIO | 2021-06-13 17:01:00 |
| BTG | 2022-02-07 12:24:00 | VIB | 2021-10-31 17:06:00 | VIB | 2021-09-05 17:00:00 | LIT | 2021-06-13 16:59:00 |
| QLC | 2022-02-05 16:50:00 | BRD | 2021-10-31 15:00:00 | MDA | 2021-09-05 11:03:00 | QSP | 2021-06-13 16:00:00 |
| DEGO | 2022-02-04 12:30:00 | DUSK | 2021-10-31 09:29:00 | PNT | 2021-09-04 18:00:00 | GVT | 2021-06-12 14:45:00 |
| AGIX | 2022-02-03 14:40:00 | NEBL | 2021-10-30 17:30:00 | ALPHA | 2021-09-02 17:03:00 | POA | 2021-06-11 14:54:00 |
| BICO | 2022-02-03 12:54:00 | RDN | 2021-10-30 16:06:00 | CHZ | 2021-09-01 08:38:00 | QLC | 2021-06-09 16:13:00 |
| OG | 2022-02-03 09:49:00 | NXS | 2021-10-30 05:24:00 | SKL | 2021-08-30 18:40:00 | WABI | 2021-06-07 13:28:00 |
| MDX | 2022-02-02 18:04:00 | VIB | 2021-10-27 21:13:00 | BRD | 2021-08-29 17:00:00 | CND | 2021-06-06 17:00:00 |
| ASR | 2022-01-27 12:19:00 | ARDR | 2021-10-26 17:06:00 | ICP | 2021-08-29 13:38:00 | MTH | 2021-06-06 17:00:00 |
| OM | 2022-01-26 11:31:00 | GRS | 2021-10-26 15:15:00 | BNB | 2021-08-29 12:54:00 | POA | 2021-06-06 10:49:00 |
| SNM | 2022-01-26 11:12:00 | SC | 2021-10-26 10:46:00 | KEEP | 2021-08-27 19:27:00 | ELF | 2021-06-06 08:48:00 |
| OG | 2022-01-26 11:03:00 | VIB | 2021-10-24 19:15:00 | GXS | 2021-08-27 16:00:00 | MTL | 2021-06-04 17:59:00 |
| QLC | 2022-01-26 10:41:00 | EVX | 2021-10-24 17:00:00 | QSP | 2021-08-27 15:50:00 | ENJ | 2021-06-03 12:55:00 |
| PIVX | 2022-01-24 18:59:00 | IDEX | 2021-10-24 14:47:00 | BLZ | 2021-08-24 06:38:00 | REEF | 2021-06-03 05:04:00 |
| PIVX | 2022-01-18 16:00:00 | FOR | 2021-10-24 14:00:00 | TCT | 2021-08-24 00:51:00 | EOS | 2021-06-01 15:21:00 |
| ELF | 2022-01-17 17:46:00 | VIB | 2021-10-24 09:05:00 | SRM | 2021-08-22 20:31:00 |
| Symbol | Timestamp | Datetime | Side | Price | Amount | btc_VOLUME |
|---|---|---|---|---|---|---|
| ADX/BTC | 1663602963725 | 2022-09-19T15:56:03.725Z | sell | 8.23 × 10 | 694 | 0.00571162 |
| ADX/BTC | 1663602965541 | 2022-09-19T15:56:05.541Z | sell | 8.23 × 10 | 192 | 0.00158016 |
| ADX/BTC | 1663602970102 | 2022-09-19T15:56:10.102Z | sell | 8.23 × 10 | 705 | 0.00580215 |
| ADX/BTC | 1663602978208 | 2022-09-19T15:56:18.208Z | buy | 8.24 × 10 | 415 | 0.0034196 |
| ADX/BTC | 1663603016649 | 2022-09-19T15:56:56.649Z | buy | 8.25 × 10 | 2910 | 0.0240075 |
| ADX/BTC | 1663603028493 | 2022-09-19T15:57:08.493Z | buy | 8.26 × 10 | 2928 | 0.02418528 |
| ADX/BTC | 1663603029672 | 2022-09-19T15:57:09.672Z | sell | 8.26 × 10 | 457 | 0.00377482 |
| ADX/BTC | 1663603037503 | 2022-09-19T15:57:17.503Z | buy | 8.27 × 10 | 1276 | 0.01055252 |
| … | … | … | … | … | … | … |
| Chunk Size/… …/Window Size | N. of Data | N. of Times (%) P&D Flagged 1 or 2 min before Announcement | N. of Times (%) P&D Flagged 60 min before Announcement |
|---|---|---|---|
| 30 s./10 m. | 441,130 | 518 (0.12%) | 11,534 (2.61%) |
| 30 s./30 m. | 457,804 | 535 (0.12%) | 11,900 (2.60%) |
| 30 s./60 m. | 460,033 | 537 (0.12%) | 11,938 (2.60%) |
| 60 s./10 m. | 320,178 | 503 (0.15%) | 8378 (2.62%) |
| 60 s./30 m. | 337,519 | 532 (0.16%) | 8777 (2.60%) |
| 60 s./60 m. | 339,782 | 537 (0.16%) | 8818 (2.60%) |
| 90 s./10 m. | 258,095 | 455 (0.18%) | 6659 (2.58%) |
| 90 s./30 m. | 274,723 | 484 (0.18%) | 7035 (2.56%) |
| 90 s./60 m. | 277,034 | 488 (0.18%) | 7076 (2.55%) |
| Chunk Size/… …/Window Size | AvgRushOrders ADF/KPSS | AvgPrice ADF/KPSS | AvgVolumes ADF/KPSS | AvgRushOrders JB (p-Value) | AvgPrice JB (p-Value) | AvgVolumes JB (p-Value) |
|---|---|---|---|---|---|---|
| 30 s./10 m. | −60.28 **/0.66 * | −6.27 **/1.40 ** | −40.28 **/0.76 ** | 0.00 | 0.00 | 0.00 |
| 30 s./30 m. | −45.86 **/0.57 * | −6.38 **/1.37 ** | −36.87 **/0.69 ** | 0.00 | 0.00 | 0.00 |
| 30 s./60 m. | −40.25 **/0.51 * | −6.40 **/1.37 ** | −32.49 **/0.68 ** | 0.00 | 0.00 | 0.00 |
| 60 s./10 m. | −56.26 **/0.41 | −7.48 **/0.88 ** | −35.60 **/0.45 | 0.00 | 0.00 | 0.00 |
| 60 s./30 m. | −39.42 **/0.35 | −7.67 **/0.88 ** | −30.69 **/0.42 | 0.00 | 0.00 | 0.00 |
| 60 s./60 m. | −36.91 **/0.32 | −7.70 **/0.88 ** | −29.58 **/0.41 | 0.00 | 0.00 | 0.00 |
| 90 s./10 m. | −51.46 **/0.31 | −8.21 **/0.70 * | −33.82 **/0.35 | 0.00 | 0.00 | 0.00 |
| 90 s./30 m. | −37.26 **/0.27 | −8.45 **/0.65 * | −28.71 **/0.32 | 0.00 | 0.00 | 0.00 |
| 90 s./60 m. | −32.93 **/0.24 | −8.49 **/0.68 * | −25.69 **/0.31 | 0.00 | 0.00 | 0.00 |
| (1) ORIGINAL DATA (P&Ds Flagged 1 or 2 min before Announcement) | ||||||||
|---|---|---|---|---|---|---|---|---|
| Chunk/Window | Threshold Independent | Threshold Dependent (p = 50%) | Threshold Dependent (p = 0.18%) | |||||
| …/Model | AUC | H-Measure | Accuracy | Sensitivity | Specificity | Accuracy | Sensitivity | Specificity |
| 30 s./10 m. Ada. | 0.52 | 0.04 | 1.00 | 0.01 | 1.00 | 1.00 | 0.05 | 1.00 |
| Logit | 0.73 | 0.16 | 1.00 | 0.01 | 1.00 | 0.76 | 0.53 | 0.76 |
| Random Forest | 0.82 | 0.55 | 1.00 | 0.07 | 1.00 | 0.97 | 0.65 | 0.97 |
| 30 s./30 m. Ada. | 0.52 | 0.03 | 1.00 | 0.01 | 1.00 | 1.00 | 0.04 | 1.00 |
| Logit | 0.73 | 0.16 | 1.00 | 0.00 | 1.00 | 0.75 | 0.53 | 0.75 |
| Random Forest | 0.81 | 0.53 | 1.00 | 0.08 | 1.00 | 0.97 | 0.63 | 0.97 |
| 30 s./60 m. Ada. | 0.51 | 0.02 | 1.00 | 0.00 | 1.00 | 1.00 | 0.03 | 1.00 |
| Logit | 0.73 | 0.16 | 1.00 | 0.00 | 1.00 | 0.75 | 0.54 | 0.75 |
| Random Forest | 0.84 | 0.60 | 1.00 | 0.07 | 1.00 | 0.97 | 0.69 | 0.97 |
| 60 s./10 m. Ada. | 0.53 | 0.05 | 1.00 | 0.04 | 1.00 | 1.00 | 0.06 | 1.00 |
| Logit | 0.72 | 0.16 | 1.00 | 0.02 | 1.00 | 0.64 | 0.72 | 0.64 |
| Random Forest | 0.75 | 0.39 | 1.00 | 0.09 | 1.00 | 0.95 | 0.53 | 0.95 |
| 60 s./30 m. Ada. | 0.53 | 0.04 | 1.00 | 0.03 | 1.00 | 1.00 | 0.05 | 1.00 |
| Logit | 0.72 | 0.16 | 1.00 | 0.01 | 1.00 | 0.64 | 0.73 | 0.64 |
| Random Forest | 0.74 | 0.38 | 1.00 | 0.11 | 1.00 | 0.95 | 0.51 | 0.95 |
| 60 s./60 m. Ada. | 0.51 | 0.02 | 1.00 | 0.00 | 1.00 | 1.00 | 0.02 | 1.00 |
| Logit | 0.72 | 0.15 | 1.00 | 0.01 | 1.00 | 0.64 | 0.73 | 0.64 |
| Random Forest | 0.77 | 0.43 | 1.00 | 0.07 | 1.00 | 0.95 | 0.57 | 0.95 |
| 90 s./10 m. Ada. | 0.53 | 0.05 | 1.00 | 0.05 | 1.00 | 1.00 | 0.06 | 1.00 |
| Logit | 0.73 | 0.18 | 1.00 | 0.03 | 1.00 | 0.61 | 0.77 | 0.61 |
| Random Forest | 0.71 | 0.30 | 1.00 | 0.10 | 1.00 | 0.94 | 0.46 | 0.94 |
| 90 s./30 m. Ada. | 0.53 | 0.05 | 1.00 | 0.04 | 1.00 | 1.00 | 0.06 | 1.00 |
| Logit | 0.73 | 0.17 | 1.00 | 0.01 | 1.00 | 0.61 | 0.77 | 0.61 |
| Random Forest | 0.72 | 0.34 | 1.00 | 0.09 | 1.00 | 0.94 | 0.49 | 0.94 |
| 90 s./60 m. Ada. | 0.52 | 0.04 | 1.00 | 0.02 | 1.00 | 1.00 | 0.05 | 1.00 |
| Logit | 0.73 | 0.17 | 1.00 | 0.01 | 1.00 | 0.62 | 0.77 | 0.62 |
| Random Forest | 0.75 | 0.39 | 1.00 | 0.07 | 1.00 | 0.95 | 0.53 | 0.95 |
| RANDOM UNDER-SAMPLING (P&Ds Flagged 1 or 2 min before Announcement) | ||||||||
| Chunk/Window | Threshold Independent | Threshold Dependent (p = 50%) | Threshold Dependent (p = 0.18%) | |||||
| …/Model | AUC | H-Measure | Accuracy | Sensitivity | Specificity | Accuracy | Sensitivity | Specificity |
| 30 s./10 m. Ada. | 0.74 | 0.16 | 0.61 | 0.75 | 0.61 | 0.31 | 0.94 | 0.31 |
| Logit | 0.74 | 0.17 | 0.60 | 0.76 | 0.60 | 0.00 | 1.00 | 0.00 |
| Random Forest | 0.87 | 0.45 | 0.76 | 0.80 | 0.76 | 0.00 | 1.00 | 0.00 |
| 30 s./30 m. Ada. | 0.74 | 0.15 | 0.56 | 0.81 | 0.56 | 0.29 | 0.95 | 0.29 |
| Logit | 0.72 | 0.15 | 0.60 | 0.77 | 0.60 | 0.00 | 1.00 | 0.00 |
| Random Forest | 0.87 | 0.45 | 0.75 | 0.81 | 0.75 | 0.00 | 1.00 | 0.00 |
| 30 s./60 m. Ada. | 0.74 | 0.15 | 0.54 | 0.84 | 0.54 | 0.26 | 0.96 | 0.26 |
| Logit | 0.73 | 0.15 | 0.60 | 0.78 | 0.60 | 0.00 | 1.00 | 0.00 |
| Random Forest | 0.89 | 0.52 | 0.74 | 0.85 | 0.74 | 0.00 | 1.00 | 0.00 |
| 60 s./10 m. Ada. | 0.76 | 0.18 | 0.65 | 0.75 | 0.65 | 0.28 | 0.96 | 0.28 |
| Logit | 0.73 | 0.17 | 0.60 | 0.76 | 0.60 | 0.00 | 1.00 | 0.00 |
| Random Forest | 0.84 | 0.36 | 0.73 | 0.77 | 0.73 | 0.00 | 1.00 | 0.00 |
| 60 s./30 m. Ada. | 0.73 | 0.14 | 0.59 | 0.77 | 0.59 | 0.27 | 0.95 | 0.26 |
| Logit | 0.73 | 0.15 | 0.59 | 0.77 | 0.59 | 0.00 | 1.00 | 0.00 |
| Random Forest | 0.82 | 0.33 | 0.71 | 0.78 | 0.71 | 0.00 | 1.00 | 0.00 |
| 60 s./60 m. Ada. | 0.73 | 0.14 | 0.54 | 0.82 | 0.54 | 0.25 | 0.95 | 0.25 |
| Logit | 0.72 | 0.14 | 0.60 | 0.76 | 0.60 | 0.00 | 1.00 | 0.00 |
| Random Forest | 0.83 | 0.33 | 0.71 | 0.77 | 0.71 | 0.00 | 1.00 | 0.00 |
| 90 s./10 m. Ada. | 0.77 | 0.21 | 0.70 | 0.69 | 0.70 | 0.25 | 0.97 | 0.25 |
| Logit | 0.74 | 0.18 | 0.62 | 0.75 | 0.62 | 0.00 | 1.00 | 0.00 |
| Random Forest | 0.82 | 0.34 | 0.73 | 0.76 | 0.73 | 0.00 | 1.00 | 0.00 |
| 90 s./30 m. Ada. | 0.75 | 0.17 | 0.63 | 0.76 | 0.63 | 0.30 | 0.95 | 0.30 |
| Logit | 0.73 | 0.16 | 0.60 | 0.76 | 0.60 | 0.00 | 1.00 | 0.00 |
| Random Forest | 0.81 | 0.31 | 0.72 | 0.74 | 0.72 | 0.00 | 1.00 | 0.00 |
| 90 s./60 m. Ada. | 0.74 | 0.16 | 0.61 | 0.76 | 0.61 | 0.24 | 0.97 | 0.24 |
| Logit | 0.73 | 0.16 | 0.61 | 0.77 | 0.61 | 0.00 | 1.00 | 0.00 |
| Random Forest | 0.81 | 0.31 | 0.71 | 0.73 | 0.71 | 0.00 | 1.00 | 0.00 |
| RANDOM OVER-SAMPLING (P&Ds Flagged 1 or 2 min before Announcement) | ||||||||
| Chunk/Window | Threshold Independent | Threshold Dependent (p = 50%) | Threshold Dependent (p = 0.18%) | |||||
| …/Model | AUC | H-Measure | Accuracy | Sensitivity | Specificity | Accuracy | Sensitivity | Specificity |
| 30 s./10 m. Ada. | 0.68 | 0.10 | 0.56 | 0.77 | 0.56 | 0.53 | 0.80 | 0.53 |
| Logit | 0.74 | 0.17 | 0.60 | 0.76 | 0.60 | 0.00 | 1.00 | 0.00 |
| Random Forest | 0.83 | 0.52 | 1.00 | 0.18 | 1.00 | 0.92 | 0.69 | 0.92 |
| 30 s./30 m. Ada. | 0.65 | 0.07 | 0.63 | 0.66 | 0.63 | 0.60 | 0.70 | 0.60 |
| Logit | 0.73 | 0.15 | 0.60 | 0.78 | 0.60 | 0.00 | 1.00 | 0.00 |
| Random Forest | 0.82 | 0.53 | 1.00 | 0.19 | 1.00 | 0.93 | 0.68 | 0.93 |
| 30 s./60 m. Ada. | 0.67 | 0.09 | 0.53 | 0.80 | 0.53 | 0.52 | 0.80 | 0.52 |
| Logit | 0.73 | 0.15 | 0.60 | 0.78 | 0.60 | 0.00 | 1.00 | 0.00 |
| Random Forest | 0.83 | 0.56 | 1.00 | 0.18 | 1.00 | 0.92 | 0.69 | 0.92 |
| 60 s./10 m. Ada. | 0.71 | 0.15 | 0.62 | 0.80 | 0.62 | 0.62 | 0.81 | 0.62 |
| Logit | 0.73 | 0.17 | 0.60 | 0.75 | 0.60 | 0.00 | 1.00 | 0.00 |
| Random Forest | 0.76 | 0.37 | 1.00 | 0.13 | 1.00 | 0.89 | 0.59 | 0.89 |
| 60 s./30 m. Ada. | 0.67 | 0.09 | 0.58 | 0.75 | 0.58 | 0.57 | 0.77 | 0.57 |
| Logit | 0.72 | 0.15 | 0.60 | 0.76 | 0.60 | 0.00 | 1.00 | 0.00 |
| Random Forest | 0.75 | 0.38 | 1.00 | 0.11 | 1.00 | 0.91 | 0.56 | 0.91 |
| 60 s./60 m. Ada. | 0.66 | 0.08 | 0.57 | 0.74 | 0.57 | 0.54 | 0.77 | 0.54 |
| Logit | 0.72 | 0.15 | 0.60 | 0.77 | 0.60 | 0.00 | 1.00 | 0.00 |
| Random Forest | 0.77 | 0.43 | 1.00 | 0.09 | 1.00 | 0.93 | 0.58 | 0.93 |
| 90 s./10 m. Ada. | 0.71 | 0.14 | 0.67 | 0.71 | 0.67 | 0.59 | 0.80 | 0.59 |
| Logit | 0.74 | 0.19 | 0.61 | 0.77 | 0.61 | 0.00 | 1.00 | 0.00 |
| Random Forest | 0.72 | 0.29 | 1.00 | 0.13 | 1.00 | 0.88 | 0.52 | 0.88 |
| 90 s./30 m. Ada. | 0.70 | 0.13 | 0.66 | 0.71 | 0.66 | 0.64 | 0.74 | 0.64 |
| Logit | 0.74 | 0.17 | 0.60 | 0.79 | 0.60 | 0.00 | 1.00 | 0.00 |
| Random Forest | 0.72 | 0.33 | 1.00 | 0.11 | 1.00 | 0.92 | 0.50 | 0.92 |
| 90 s./60 m. Ada. | 0.69 | 0.11 | 0.59 | 0.77 | 0.59 | 0.57 | 0.78 | 0.57 |
| Logit | 0.73 | 0.16 | 0.60 | 0.79 | 0.60 | 0.00 | 1.00 | 0.00 |
| Random Forest | 0.74 | 0.37 | 1.00 | 0.10 | 1.00 | 0.92 | 0.54 | 0.93 |
| Synthetic Minority Over-Sampling Technique (SMOTE)-(P&Ds Flagged 1 or 2 min before Announcement) | ||||||||
| Chunk/Window | Threshold Independent | Threshold Dependent (p = 50%) | Threshold Dependent (p = 0.18%) | |||||
| …/Model | AUC | H-Measure | Accuracy | Sensitivity | Specificity | Accuracy | Sensitivity | Specificity |
| 30 s./10 m. Ada. | 0.69 | 0.12 | 0.60 | 0.78 | 0.60 | 0.60 | 0.78 | 0.60 |
| Logit | 0.74 | 0.17 | 0.61 | 0.75 | 0.61 | 0.00 | 1.00 | 0.00 |
| Random Forest | 0.83 | 0.50 | 1.00 | 0.24 | 1.00 | 0.83 | 0.74 | 0.83 |
| 30 s./30 m. Ada. | 0.67 | 0.09 | 0.61 | 0.73 | 0.60 | 0.60 | 0.73 | 0.60 |
| Logit | 0.73 | 0.15 | 0.61 | 0.77 | 0.61 | 0.00 | 1.00 | 0.00 |
| Random Forest | 0.83 | 0.54 | 1.00 | 0.27 | 1.00 | 0.87 | 0.72 | 0.87 |
| 30 s./60 m. Ada. | 0.68 | 0.11 | 0.61 | 0.75 | 0.61 | 0.56 | 0.78 | 0.55 |
| Logit | 0.73 | 0.15 | 0.61 | 0.77 | 0.61 | 0.00 | 1.00 | 0.00 |
| Random Forest | 0.85 | 0.58 | 1.00 | 0.24 | 1.00 | 0.89 | 0.75 | 0.89 |
| 60 s./10 m. Ada. | 0.67 | 0.11 | 0.74 | 0.57 | 0.74 | 0.72 | 0.61 | 0.72 |
| Logit | 0.73 | 0.17 | 0.61 | 0.75 | 0.61 | 0.00 | 1.00 | 0.00 |
| Random Forest | 0.78 | 0.36 | 1.00 | 0.14 | 1.00 | 0.78 | 0.68 | 0.78 |
| 60 s./30 m. Ada. | 0.66 | 0.10 | 0.76 | 0.56 | 0.76 | 0.76 | 0.56 | 0.76 |
| Logit | 0.72 | 0.15 | 0.61 | 0.76 | 0.61 | 0.00 | 1.00 | 0.00 |
| Random Forest | 0.79 | 0.40 | 1.00 | 0.14 | 1.00 | 0.82 | 0.69 | 0.82 |
| 60 s./60 m. Ada. | 0.66 | 0.09 | 0.66 | 0.65 | 0.66 | 0.66 | 0.65 | 0.66 |
| Logit | 0.72 | 0.15 | 0.60 | 0.77 | 0.60 | 0.00 | 1.00 | 0.00 |
| Random Forest | 0.79 | 0.42 | 1.00 | 0.12 | 1.00 | 0.85 | 0.67 | 0.85 |
| 90 s./10 m. Ada. | 0.69 | 0.13 | 0.71 | 0.64 | 0.71 | 0.69 | 0.67 | 0.69 |
| Logit | 0.74 | 0.18 | 0.62 | 0.76 | 0.62 | 0.00 | 1.00 | 0.00 |
| Random Forest | 0.74 | 0.30 | 1.00 | 0.13 | 1.00 | 0.79 | 0.62 | 0.79 |
| 90 s./30 m. Ada. | 0.67 | 0.12 | 0.74 | 0.59 | 0.74 | 0.72 | 0.62 | 0.72 |
| Logit | 0.74 | 0.17 | 0.61 | 0.79 | 0.61 | 0.00 | 1.00 | 0.00 |
| Random Forest | 0.76 | 0.34 | 1.00 | 0.14 | 1.00 | 0.82 | 0.63 | 0.82 |
| 90 s./60 m. Ada. | 0.67 | 0.11 | 0.71 | 0.62 | 0.71 | 0.71 | 0.62 | 0.71 |
| Logit | 0.74 | 0.17 | 0.61 | 0.79 | 0.61 | 0.00 | 1.00 | 0.00 |
| Random Forest | 0.76 | 0.37 | 1.00 | 0.11 | 1.00 | 0.86 | 0.60 | 0.86 |
| Random Over-Sampling Examples (ROSE)-(P&Ds Flagged 1 or 2 min before Announcement) | ||||||||
| Chunk/Window | Threshold Independent | Threshold Dependent (p = 50%) | Threshold Dependent (p = 0.18%) | |||||
| …/Model | AUC | H-Measure | Accuracy | Sensitivity | Specificity | Accuracy | Sensitivity | Specificity |
| 30 s./10 m. Ada. | 0.54 | 0.06 | 0.98 | 0.10 | 0.99 | 0.98 | 0.10 | 0.98 |
| Logit | 0.74 | 0.17 | 0.60 | 0.77 | 0.59 | 0.00 | 1.00 | 0.00 |
| Random Forest | 0.55 | 0.07 | 1.00 | 0.08 | 1.00 | 0.96 | 0.14 | 0.96 |
| 30 s./30 m. Ada. | 0.53 | 0.04 | 0.98 | 0.08 | 0.98 | 0.98 | 0.09 | 0.98 |
| Logit | 0.73 | 0.15 | 0.59 | 0.78 | 0.59 | 0.00 | 1.00 | 0.00 |
| Random Forest | 0.55 | 0.06 | 1.00 | 0.07 | 1.00 | 0.92 | 0.17 | 0.92 |
| 30 s./60 m. Ada. | 0.53 | 0.02 | 0.97 | 0.08 | 0.97 | 0.97 | 0.08 | 0.97 |
| Logit | 0.73 | 0.15 | 0.59 | 0.78 | 0.59 | 0.00 | 1.00 | 0.00 |
| Random Forest | 0.57 | 0.06 | 1.00 | 0.07 | 1.00 | 0.83 | 0.30 | 0.83 |
| 60 s./10 m. Ada. | 0.54 | 0.06 | 0.99 | 0.09 | 0.99 | 0.99 | 0.10 | 0.99 |
| Logit | 0.73 | 0.16 | 0.59 | 0.77 | 0.59 | 0.00 | 1.00 | 0.00 |
| Random Forest | 0.55 | 0.07 | 1.00 | 0.08 | 1.00 | 0.97 | 0.12 | 0.97 |
| 60 s./30 m. Ada. | 0.54 | 0.05 | 0.99 | 0.09 | 0.99 | 0.98 | 0.09 | 0.99 |
| Logit | 0.72 | 0.14 | 0.59 | 0.77 | 0.59 | 0.00 | 1.00 | 0.00 |
| Random Forest | 0.54 | 0.06 | 1.00 | 0.07 | 1.00 | 0.95 | 0.12 | 0.95 |
| 60 s./60 m. Ada. | 0.53 | 0.03 | 0.98 | 0.07 | 0.98 | 0.98 | 0.07 | 0.98 |
| Logit | 0.72 | 0.14 | 0.59 | 0.78 | 0.59 | 0.00 | 1.00 | 0.00 |
| Random Forest | 0.52 | 0.05 | 1.00 | 0.07 | 1.00 | 0.92 | 0.12 | 0.92 |
| 90 s./10 m. Ada. | 0.55 | 0.07 | 0.99 | 0.10 | 0.99 | 0.99 | 0.11 | 0.99 |
| Logit | 0.74 | 0.18 | 0.59 | 0.80 | 0.59 | 0.00 | 1.00 | 0.00 |
| Random Forest | 0.55 | 0.08 | 1.00 | 0.09 | 1.00 | 0.97 | 0.12 | 0.98 |
| 90 s./30 m. Ada. | 0.54 | 0.05 | 0.99 | 0.08 | 0.99 | 0.98 | 0.09 | 0.99 |
| Logit | 0.73 | 0.16 | 0.59 | 0.79 | 0.59 | 0.00 | 1.00 | 0.00 |
| Random Forest | 0.54 | 0.06 | 1.00 | 0.07 | 1.00 | 0.96 | 0.11 | 0.96 |
| 90 s./60 m. Ada. | 0.53 | 0.04 | 0.98 | 0.08 | 0.99 | 0.98 | 0.08 | 0.98 |
| Logit | 0.73 | 0.16 | 0.59 | 0.80 | 0.59 | 0.00 | 1.00 | 0.00 |
| Random Forest | 0.53 | 0.05 | 1.00 | 0.07 | 1.00 | 0.94 | 0.12 | 0.94 |
| (6) ORIGINAL DATA (P&Ds Flagged 60 min before Announcement) | ||||||||
|---|---|---|---|---|---|---|---|---|
| Chunk/Window | Threshold Independent | Threshold Dependent (p = 50%) | Threshold Dependent (p = 2.6%) | |||||
| …/Model | AUC | H-Measure | Accuracy | Sensitivity | Specificity | Accuracy | Sensitivity | Specificity |
| 30 s./10 m. Ada. | 0.51 | 0.01 | 0.97 | 0.01 | 1.00 | 0.97 | 0.01 | 1.00 |
| Logit | 0.71 | 0.13 | 0.97 | 0.00 | 1.00 | 0.58 | 0.77 | 0.57 |
| Random Forest | 0.98 | 0.83 | 0.99 | 0.44 | 1.00 | 0.87 | 0.96 | 0.87 |
| 30 s./30 m. Ada. | 0.51 | 0.01 | 0.97 | 0.00 | 1.00 | 0.97 | 0.01 | 1.00 |
| Logit | 0.71 | 0.14 | 0.97 | 0.00 | 1.00 | 0.58 | 0.78 | 0.58 |
| Random Forest | 0.99 | 0.91 | 0.99 | 0.63 | 1.00 | 0.91 | 0.98 | 0.91 |
| 30 s./60 m. Ada. | 0.50 | 0.01 | 0.97 | 0.00 | 1.00 | 0.97 | 0.01 | 1.00 |
| Logit | 0.72 | 0.14 | 0.97 | 0.00 | 1.00 | 0.59 | 0.79 | 0.58 |
| Random Forest | 0.99 | 0.94 | 0.99 | 0.73 | 1.00 | 0.93 | 0.99 | 0.93 |
| 60 s./10 m. Ada. | 0.50 | 0.01 | 0.97 | 0.00 | 1.00 | 0.97 | 0.01 | 1.00 |
| Logit | 0.71 | 0.13 | 0.97 | 0.00 | 1.00 | 0.58 | 0.78 | 0.58 |
| Random Forest | 0.96 | 0.75 | 0.98 | 0.27 | 1.00 | 0.83 | 0.94 | 0.83 |
| 60 s./30 m. Ada. | 0.50 | 0.01 | 0.97 | 0.01 | 1.00 | 0.97 | 0.01 | 1.00 |
| Logit | 0.72 | 0.14 | 0.97 | 0.00 | 1.00 | 0.58 | 0.78 | 0.58 |
| Random Forest | 0.99 | 0.87 | 0.99 | 0.52 | 1.00 | 0.88 | 0.97 | 0.88 |
| 60 s./60 m. Ada. | 0.50 | 0.01 | 0.97 | 0.00 | 1.00 | 0.97 | 0.01 | 1.00 |
| Logit | 0.72 | 0.14 | 0.97 | 0.00 | 1.00 | 0.59 | 0.80 | 0.58 |
| Random Forest | 0.99 | 0.91 | 0.99 | 0.62 | 1.00 | 0.90 | 0.98 | 0.90 |
| 90 s./10 m. Ada. | 0.50 | 0.01 | 0.97 | 0.00 | 1.00 | 0.97 | 0.01 | 1.00 |
| Logit | 0.71 | 0.14 | 0.97 | 0.00 | 1.00 | 0.59 | 0.77 | 0.59 |
| Random Forest | 0.94 | 0.70 | 0.98 | 0.20 | 1.00 | 0.81 | 0.92 | 0.81 |
| 90 s./30 m. Ada. | 0.50 | 0.01 | 0.97 | 0.00 | 1.00 | 0.97 | 0.01 | 1.00 |
| Logit | 0.72 | 0.14 | 0.97 | 0.00 | 1.00 | 0.60 | 0.78 | 0.59 |
| Random Forest | 0.97 | 0.82 | 0.98 | 0.39 | 1.00 | 0.86 | 0.95 | 0.85 |
| 90 s./60 m. Ada. | 0.50 | 0.01 | 0.97 | 0.00 | 1.00 | 0.97 | 0.01 | 1.00 |
| Logit | 0.72 | 0.15 | 0.97 | 0.00 | 1.00 | 0.60 | 0.79 | 0.59 |
| Random Forest | 0.99 | 0.89 | 0.99 | 0.54 | 1.00 | 0.89 | 0.98 | 0.89 |
| RANDOM UNDER-SAMPLING (P&Ds Flagged 60 min before Announcement) | ||||||||
| Chunk/Window | Threshold Independent | Threshold Dependent (p = 50%) | Threshold Dependent (p = 2.6%) | |||||
| …/Model | AUC | H-Measure | Accuracy | Sensitivity | Specificity | Accuracy | Sensitivity | Specificity |
| 30 s./10 m. Ada. | 0.70 | 0.13 | 0.73 | 0.61 | 0.73 | 0.57 | 0.78 | 0.56 |
| Logit | 0.70 | 0.13 | 0.58 | 0.77 | 0.58 | 0.03 | 1.00 | 0.00 |
| Random Forest | 0.96 | 0.70 | 0.85 | 0.92 | 0.85 | 0.11 | 1.00 | 0.09 |
| 30 s./30 m. Ada. | 0.72 | 0.14 | 0.70 | 0.64 | 0.70 | 0.53 | 0.82 | 0.52 |
| Logit | 0.71 | 0.13 | 0.59 | 0.77 | 0.59 | 0.03 | 1.00 | 0.00 |
| Random Forest | 0.98 | 0.81 | 0.90 | 0.95 | 0.90 | 0.16 | 1.00 | 0.14 |
| 30 s./60 m. Ada. | 0.72 | 0.15 | 0.70 | 0.65 | 0.70 | 0.54 | 0.83 | 0.54 |
| Logit | 0.71 | 0.14 | 0.60 | 0.77 | 0.60 | 0.03 | 1.00 | 0.00 |
| Random Forest | 0.99 | 0.86 | 0.93 | 0.96 | 0.93 | 0.21 | 1.00 | 0.19 |
| 60 s./10 m. Ada. | 0.71 | 0.14 | 0.68 | 0.67 | 0.68 | 0.55 | 0.82 | 0.54 |
| Logit | 0.71 | 0.13 | 0.58 | 0.77 | 0.58 | 0.03 | 1.00 | 0.00 |
| Random Forest | 0.93 | 0.60 | 0.80 | 0.90 | 0.80 | 0.08 | 1.00 | 0.06 |
| 60 s./30 m. Ada. | 0.73 | 0.15 | 0.59 | 0.79 | 0.58 | 0.46 | 0.89 | 0.45 |
| Logit | 0.71 | 0.14 | 0.59 | 0.77 | 0.59 | 0.03 | 1.00 | 0.00 |
| Random Forest | 0.97 | 0.75 | 0.87 | 0.94 | 0.87 | 0.11 | 1.00 | 0.08 |
| 60 s./60 m. Ada. | 0.73 | 0.15 | 0.65 | 0.71 | 0.65 | 0.47 | 0.89 | 0.46 |
| Logit | 0.72 | 0.14 | 0.60 | 0.77 | 0.60 | 0.03 | 1.00 | 0.00 |
| Random Forest | 0.98 | 0.81 | 0.90 | 0.95 | 0.90 | 0.14 | 1.00 | 0.11 |
| 90 s./10 m. Ada. | 0.73 | 0.15 | 0.58 | 0.79 | 0.57 | 0.49 | 0.88 | 0.48 |
| Logit | 0.71 | 0.13 | 0.59 | 0.78 | 0.58 | 0.03 | 1.00 | 0.00 |
| Random Forest | 0.91 | 0.53 | 0.77 | 0.88 | 0.77 | 0.07 | 1.00 | 0.05 |
| 90 s./30 m. Ada. | 0.72 | 0.14 | 0.61 | 0.76 | 0.61 | 0.46 | 0.90 | 0.45 |
| Logit | 0.72 | 0.14 | 0.59 | 0.78 | 0.59 | 0.03 | 1.00 | 0.00 |
| Random Forest | 0.95 | 0.67 | 0.83 | 0.92 | 0.83 | 0.09 | 1.00 | 0.06 |
| 90 s./60 m. Ada. | 0.72 | 0.14 | 0.61 | 0.76 | 0.61 | 0.50 | 0.88 | 0.49 |
| Logit | 0.72 | 0.14 | 0.61 | 0.78 | 0.60 | 0.03 | 1.00 | 0.00 |
| Random Forest | 0.97 | 0.76 | 0.87 | 0.94 | 0.87 | 0.11 | 1.00 | 0.09 |
| RANDOM OVER-SAMPLING (P&Ds Flagged 60 min before Announcement) | ||||||||
| Chunk/Window | Threshold Independent | Threshold Dependent (p = 50%) | Threshold Dependent (p = 2.6%) | |||||
| …/Model | AUC | H-Measure | Accuracy | Sensitivity | Specificity | Accuracy | Sensitivity | Specificity |
| 30 s./10 m. Ada. | 0.67 | 0.12 | 0.75 | 0.58 | 0.75 | 0.75 | 0.59 | 0.75 |
| Logit | 0.71 | 0.13 | 0.58 | 0.77 | 0.58 | 0.03 | 1.00 | 0.00 |
| Random Forest | 0.98 | 0.79 | 0.99 | 0.65 | 1.00 | 0.61 | 0.99 | 0.60 |
| 30 s./30 m. Ada. | 0.67 | 0.12 | 0.75 | 0.58 | 0.76 | 0.74 | 0.60 | 0.74 |
| Logit | 0.71 | 0.13 | 0.59 | 0.77 | 0.59 | 0.03 | 1.00 | 0.00 |
| Random Forest | 0.99 | 0.89 | 0.99 | 0.77 | 1.00 | 0.70 | 0.99 | 0.70 |
| 30 s./60 m. Ada. | 0.69 | 0.14 | 0.74 | 0.60 | 0.74 | 0.70 | 0.64 | 0.70 |
| Logit | 0.72 | 0.14 | 0.60 | 0.77 | 0.60 | 0.03 | 1.00 | 0.00 |
| Random Forest | 0.99 | 0.93 | 1.00 | 0.83 | 1.00 | 0.78 | 1.00 | 0.78 |
| 60 s./10 m. Ada. | 0.70 | 0.12 | 0.64 | 0.71 | 0.64 | 0.61 | 0.75 | 0.61 |
| Logit | 0.71 | 0.13 | 0.58 | 0.77 | 0.58 | 0.03 | 1.00 | 0.00 |
| Random Forest | 0.96 | 0.73 | 0.99 | 0.50 | 1.00 | 0.58 | 0.98 | 0.57 |
| 60 s./30 m. Ada. | 0.70 | 0.12 | 0.54 | 0.84 | 0.53 | 0.52 | 0.85 | 0.51 |
| Logit | 0.71 | 0.14 | 0.59 | 0.77 | 0.59 | 0.03 | 1.00 | 0.00 |
| Random Forest | 0.98 | 0.87 | 0.99 | 0.69 | 1.00 | 0.72 | 0.99 | 0.72 |
| 60 s./60 m. Ada. | 0.69 | 0.12 | 0.58 | 0.78 | 0.58 | 0.58 | 0.79 | 0.57 |
| Logit | 0.72 | 0.14 | 0.60 | 0.78 | 0.60 | 0.03 | 1.00 | 0.00 |
| Random Forest | 0.99 | 0.90 | 0.99 | 0.76 | 1.00 | 0.74 | 0.99 | 0.73 |
| 90 s./10 m. Ada. | 0.69 | 0.11 | 0.58 | 0.79 | 0.57 | 0.57 | 0.80 | 0.56 |
| Logit | 0.71 | 0.13 | 0.59 | 0.78 | 0.58 | 0.03 | 1.00 | 0.00 |
| Random Forest | 0.95 | 0.67 | 0.98 | 0.39 | 1.00 | 0.56 | 0.98 | 0.55 |
| 90 s./30 m. Ada. | 0.69 | 0.11 | 0.60 | 0.76 | 0.60 | 0.58 | 0.80 | 0.57 |
| Logit | 0.72 | 0.14 | 0.60 | 0.77 | 0.59 | 0.03 | 1.00 | 0.00 |
| Random Forest | 0.97 | 0.81 | 0.99 | 0.59 | 1.00 | 0.65 | 0.98 | 0.64 |
| 90 s./60 m. Ada. | 0.70 | 0.12 | 0.56 | 0.82 | 0.56 | 0.55 | 0.84 | 0.54 |
| Logit | 0.72 | 0.14 | 0.61 | 0.78 | 0.60 | 0.03 | 1.00 | 0.00 |
| Random Forest | 0.98 | 0.88 | 0.99 | 0.71 | 1.00 | 0.73 | 0.99 | 0.72 |
| Synthetic Minority Over-Sampling Technique (SMOTE) (P&Ds Flagged 60 min before Announcement) | ||||||||
| Chunk/Window | Threshold Independent | Threshold Dependent (p = 50%) | Threshold Dependent (p = 2.6%) | |||||
| …/Model | AUC | H-Measure | Accuracy | Sensitivity | Specificity | Accuracy | Sensitivity | Specificity |
| 30 s./10 m. Ada. | 0.70 | 0.12 | 0.63 | 0.70 | 0.63 | 0.55 | 0.79 | 0.54 |
| Logit | 0.71 | 0.13 | 0.58 | 0.77 | 0.58 | 0.03 | 1.00 | 0.00 |
| Random Forest | 0.97 | 0.75 | 0.98 | 0.72 | 0.99 | 0.53 | 0.99 | 0.52 |
| 30 s./30 m. Ada. | 0.68 | 0.12 | 0.75 | 0.58 | 0.76 | 0.71 | 0.62 | 0.71 |
| Logit | 0.71 | 0.13 | 0.59 | 0.77 | 0.59 | 0.03 | 1.00 | 0.00 |
| Random Forest | 0.99 | 0.86 | 0.99 | 0.82 | 1.00 | 0.62 | 0.99 | 0.61 |
| 30 s./60 m. Ada. | 0.68 | 0.12 | 0.74 | 0.60 | 0.74 | 0.70 | 0.64 | 0.70 |
| Logit | 0.71 | 0.14 | 0.61 | 0.78 | 0.60 | 0.03 | 1.00 | 0.00 |
| Random Forest | 0.99 | 0.91 | 0.99 | 0.88 | 1.00 | 0.68 | 1.00 | 0.67 |
| 60 s./10 m. Ada. | 0.67 | 0.12 | 0.76 | 0.57 | 0.76 | 0.76 | 0.57 | 0.76 |
| Logit | 0.71 | 0.13 | 0.58 | 0.77 | 0.58 | 0.03 | 1.00 | 0.00 |
| Random Forest | 0.94 | 0.64 | 0.97 | 0.58 | 0.98 | 0.47 | 0.98 | 0.46 |
| 60 s./30 m. Ada. | 0.69 | 0.11 | 0.58 | 0.79 | 0.57 | 0.57 | 0.80 | 0.57 |
| Logit | 0.71 | 0.14 | 0.59 | 0.77 | 0.59 | 0.03 | 1.00 | 0.00 |
| Random Forest | 0.98 | 0.81 | 0.99 | 0.73 | 1.00 | 0.58 | 0.99 | 0.56 |
| 60 s./60 m. Ada. | 0.69 | 0.13 | 0.68 | 0.68 | 0.68 | 0.62 | 0.73 | 0.62 |
| Logit | 0.72 | 0.14 | 0.61 | 0.78 | 0.60 | 0.03 | 1.00 | 0.00 |
| Random Forest | 0.99 | 0.86 | 0.99 | 0.81 | 1.00 | 0.61 | 1.00 | 0.60 |
| 90 s./10 m. Ada. | 0.67 | 0.12 | 0.76 | 0.57 | 0.76 | 0.74 | 0.59 | 0.74 |
| Logit | 0.71 | 0.13 | 0.59 | 0.77 | 0.58 | 0.03 | 1.00 | 0.00 |
| Random Forest | 0.92 | 0.58 | 0.97 | 0.48 | 0.98 | 0.45 | 0.98 | 0.43 |
| 90 s./30 m. Ada. | 0.68 | 0.12 | 0.66 | 0.68 | 0.66 | 0.63 | 0.72 | 0.63 |
| Logit | 0.72 | 0.14 | 0.60 | 0.77 | 0.59 | 0.03 | 1.00 | 0.00 |
| Random Forest | 0.96 | 0.74 | 0.98 | 0.65 | 0.99 | 0.51 | 0.99 | 0.50 |
| 90 s./60 m. Ada. | 0.70 | 0.12 | 0.64 | 0.71 | 0.64 | 0.59 | 0.77 | 0.59 |
| Logit | 0.72 | 0.14 | 0.61 | 0.78 | 0.60 | 0.03 | 1.00 | 0.00 |
| Random Forest | 0.98 | 0.81 | 0.99 | 0.75 | 0.99 | 0.57 | 0.99 | 0.56 |
| Random Over-Sampling Examples (ROSE) (P&Ds Flagged 60 min before Announcement) | ||||||||
| Chunk/Window | Threshold Independent | Threshold Dependent (p = 50%) | Threshold Dependent (p = 2.6%) | |||||
| …/Model | AUC | H-Measure | Accuracy | Sensitivity | Specificity | Accuracy | Sensitivity | Specificity |
| 30 s./10 m. Ada. | 0.50 | 0.00 | 0.92 | 0.05 | 0.94 | 0.91 | 0.06 | 0.94 |
| Logit | 0.70 | 0.12 | 0.58 | 0.77 | 0.57 | 0.03 | 1.00 | 0.00 |
| Random Forest | 0.66 | 0.08 | 0.96 | 0.06 | 0.98 | 0.34 | 0.87 | 0.33 |
| 30 s./30 m. Ada. | 0.50 | 0.00 | 0.94 | 0.05 | 0.96 | 0.93 | 0.05 | 0.96 |
| Logit | 0.71 | 0.13 | 0.59 | 0.77 | 0.58 | 0.03 | 1.00 | 0.00 |
| Random Forest | 0.73 | 0.14 | 0.86 | 0.30 | 0.88 | 0.13 | 0.99 | 0.10 |
| 30 s./60 m. Ada. | 0.50 | 0.00 | 0.93 | 0.05 | 0.95 | 0.92 | 0.05 | 0.94 |
| Logit | 0.71 | 0.13 | 0.59 | 0.76 | 0.59 | 0.03 | 1.00 | 0.00 |
| Random Forest | 0.76 | 0.17 | 0.61 | 0.80 | 0.61 | 0.06 | 1.00 | 0.04 |
| 60 s./10 m. Ada. | 0.50 | 0.00 | 0.94 | 0.04 | 0.97 | 0.93 | 0.04 | 0.95 |
| Logit | 0.71 | 0.13 | 0.58 | 0.78 | 0.58 | 0.03 | 1.00 | 0.00 |
| Random Forest | 0.55 | 0.02 | 0.97 | 0.03 | 0.99 | 0.76 | 0.33 | 0.77 |
| 60 s./30 m. Ada. | 0.50 | 0.00 | 0.94 | 0.04 | 0.97 | 0.93 | 0.04 | 0.95 |
| Logit | 0.71 | 0.13 | 0.59 | 0.77 | 0.58 | 0.03 | 1.00 | 0.00 |
| Random Forest | 0.66 | 0.08 | 0.96 | 0.05 | 0.99 | 0.37 | 0.87 | 0.36 |
| 60 s./60 m. Ada. | 0.50 | 0.00 | 0.93 | 0.04 | 0.95 | 0.93 | 0.04 | 0.95 |
| Logit | 0.71 | 0.14 | 0.59 | 0.77 | 0.59 | 0.03 | 1.00 | 0.00 |
| Random Forest | 0.73 | 0.14 | 0.91 | 0.19 | 0.93 | 0.16 | 0.98 | 0.13 |
| 90 s./10 m. Ada. | 0.50 | 0.00 | 0.95 | 0.02 | 0.98 | 0.94 | 0.03 | 0.97 |
| Logit | 0.71 | 0.13 | 0.58 | 0.78 | 0.58 | 0.03 | 1.00 | 0.00 |
| Random Forest | 0.52 | 0.01 | 0.97 | 0.02 | 0.99 | 0.83 | 0.19 | 0.85 |
| 90 s./30 m. Ada. | 0.50 | 0.00 | 0.94 | 0.04 | 0.96 | 0.93 | 0.04 | 0.96 |
| Logit | 0.71 | 0.14 | 0.59 | 0.78 | 0.59 | 0.03 | 1.00 | 0.00 |
| Random Forest | 0.62 | 0.05 | 0.97 | 0.03 | 0.99 | 0.54 | 0.68 | 0.54 |
| 90 s./60 m. Ada. | 0.50 | 0.00 | 0.93 | 0.04 | 0.96 | 0.93 | 0.04 | 0.96 |
| Logit | 0.72 | 0.14 | 0.59 | 0.77 | 0.59 | 0.03 | 1.00 | 0.00 |
| Random Forest | 0.70 | 0.10 | 0.95 | 0.08 | 0.98 | 0.25 | 0.95 | 0.23 |
| (1) ORIGINAL DATA (P&Ds Flagged 1 or 2 min before Announcement) | ||||||||
|---|---|---|---|---|---|---|---|---|
| Chunk/Window | Threshold Independent | Threshold Dependent (p = 50%) | Threshold Dependent (p = 0.18%) | |||||
| …/Model | AUC | H-Measure | Accuracy | Sensitivity | Specificity | Accuracy | Sensitivity | Specificity |
| 30 s./10 m. Ada. | 0.00 | 0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 0.01 | 0.00 |
| Logit | −0.02 | −0.03 | 0.00 | 0.01 | 0.00 | −0.03 | −0.02 | −0.03 |
| Random Forest | 0.01 | 0.02 | 0.00 | 0.01 | 0.00 | 0.00 | 0.03 | 0.00 |
| 30 s./30 m. Ada. | −0.01 | −0.01 | 0.00 | 0.00 | 0.00 | 0.00 | −0.01 | 0.00 |
| Logit | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | −0.02 | −0.03 | −0.02 |
| Random Forest | 0.00 | −0.01 | 0.00 | 0.00 | 0.00 | 0.00 | −0.01 | 0.00 |
| 30 s./60 m. Ada. | −0.01 | −0.01 | 0.00 | 0.00 | 0.00 | 0.00 | −0.01 | 0.00 |
| Logit | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | −0.02 | 0.00 |
| Random Forest | 0.01 | 0.02 | 0.00 | 0.01 | 0.00 | 0.00 | 0.02 | 0.00 |
| 60 s./10 m. Ada. | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Logit | −0.03 | −0.04 | 0.00 | 0.02 | 0.00 | −0.07 | 0.06 | −0.07 |
| Random Forest | 0.01 | 0.02 | 0.00 | 0.00 | 0.00 | 0.00 | 0.02 | 0.00 |
| 60 s./30 m. Ada. | 0.00 | 0.00 | 0.00 | −0.02 | 0.00 | 0.00 | 0.00 | 0.00 |
| Logit | −0.01 | −0.01 | 0.00 | 0.01 | 0.00 | −0.03 | 0.05 | −0.03 |
| Random Forest | −0.01 | −0.02 | 0.00 | 0.01 | 0.00 | 0.00 | −0.01 | 0.00 |
| 60 s./60 m. Ada. | 0.00 | 0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 0.01 | 0.00 |
| Logit | 0.00 | 0.00 | 0.00 | 0.01 | 0.00 | −0.01 | 0.03 | −0.01 |
| Random Forest | 0.00 | 0.00 | 0.00 | 0.01 | 0.00 | 0.00 | 0.01 | 0.00 |
| 90 s./10 m. Ada. | 0.00 | −0.01 | 0.00 | 0.00 | 0.00 | 0.00 | −0.01 | 0.00 |
| Logit | −0.03 | −0.05 | 0.00 | 0.03 | 0.00 | −0.07 | 0.06 | −0.07 |
| Random Forest | 0.00 | −0.01 | 0.00 | 0.01 | 0.00 | 0.00 | −0.01 | 0.00 |
| 90 s./30 m. Ada. | 0.00 | 0.00 | 0.00 | 0.01 | 0.00 | 0.00 | 0.00 | 0.00 |
| Logit | −0.02 | −0.02 | 0.00 | 0.01 | 0.00 | −0.05 | 0.04 | −0.05 |
| Random Forest | 0.02 | 0.03 | 0.00 | 0.00 | 0.00 | 0.00 | 0.04 | 0.00 |
| 90 s./60 m. Ada. | 0.00 | 0.00 | 0.00 | 0.01 | 0.00 | 0.00 | 0.00 | 0.00 |
| Logit | −0.01 | −0.01 | 0.00 | 0.01 | 0.00 | −0.02 | 0.03 | −0.02 |
| Random Forest | 0.03 | 0.04 | 0.00 | 0.00 | 0.00 | 0.00 | 0.05 | 0.00 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fantazzini, D.; Xiao, Y. Detecting Pump-and-Dumps with Crypto-Assets: Dealing with Imbalanced Datasets and Insiders’ Anticipated Purchases. Econometrics 2023, 11, 22. https://doi.org/10.3390/econometrics11030022
Fantazzini D, Xiao Y. Detecting Pump-and-Dumps with Crypto-Assets: Dealing with Imbalanced Datasets and Insiders’ Anticipated Purchases. Econometrics. 2023; 11(3):22. https://doi.org/10.3390/econometrics11030022
Chicago/Turabian StyleFantazzini, Dean, and Yufeng Xiao. 2023. "Detecting Pump-and-Dumps with Crypto-Assets: Dealing with Imbalanced Datasets and Insiders’ Anticipated Purchases" Econometrics 11, no. 3: 22. https://doi.org/10.3390/econometrics11030022