
Pair-Copula Constructions for Financial Applications: A Review

{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
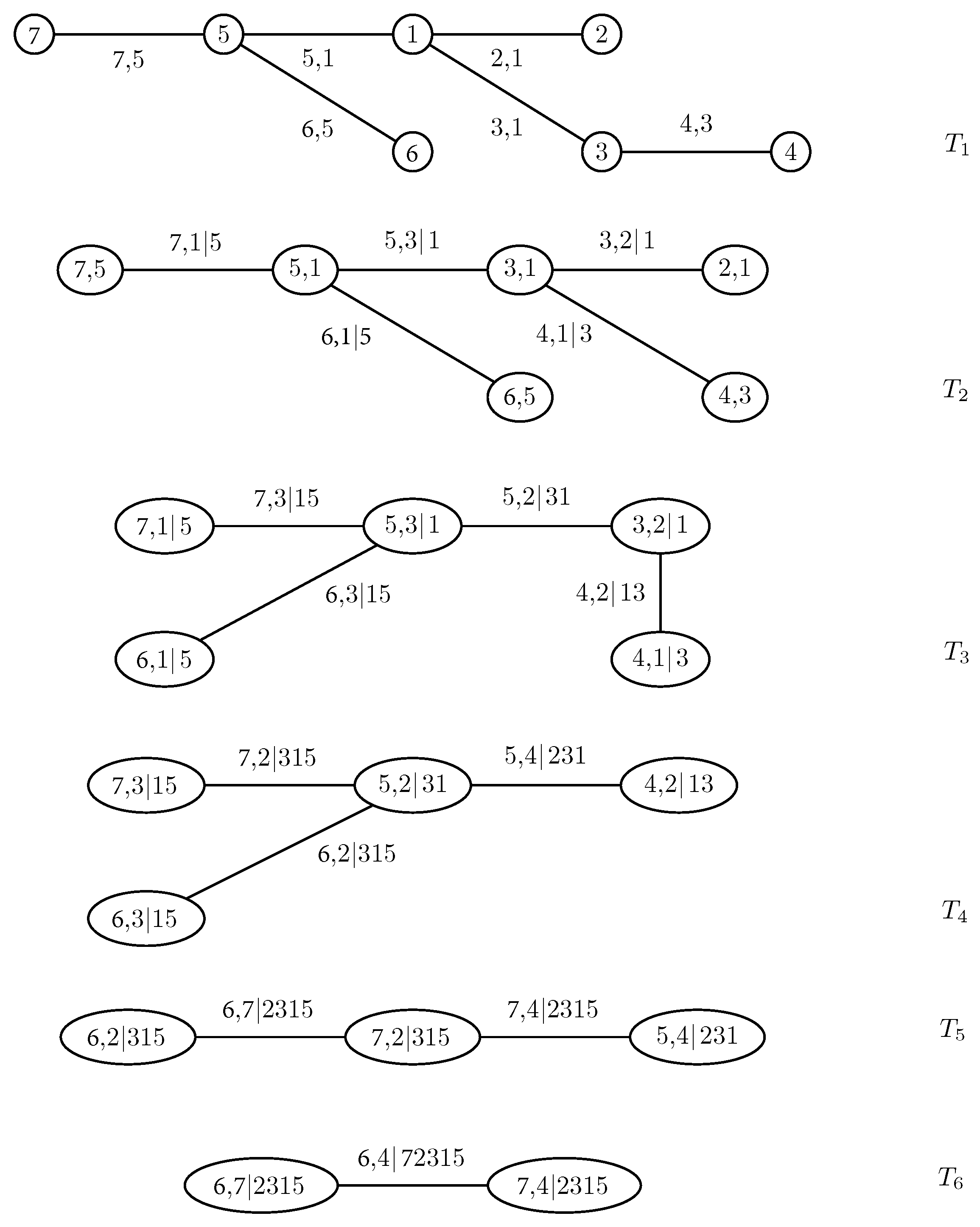
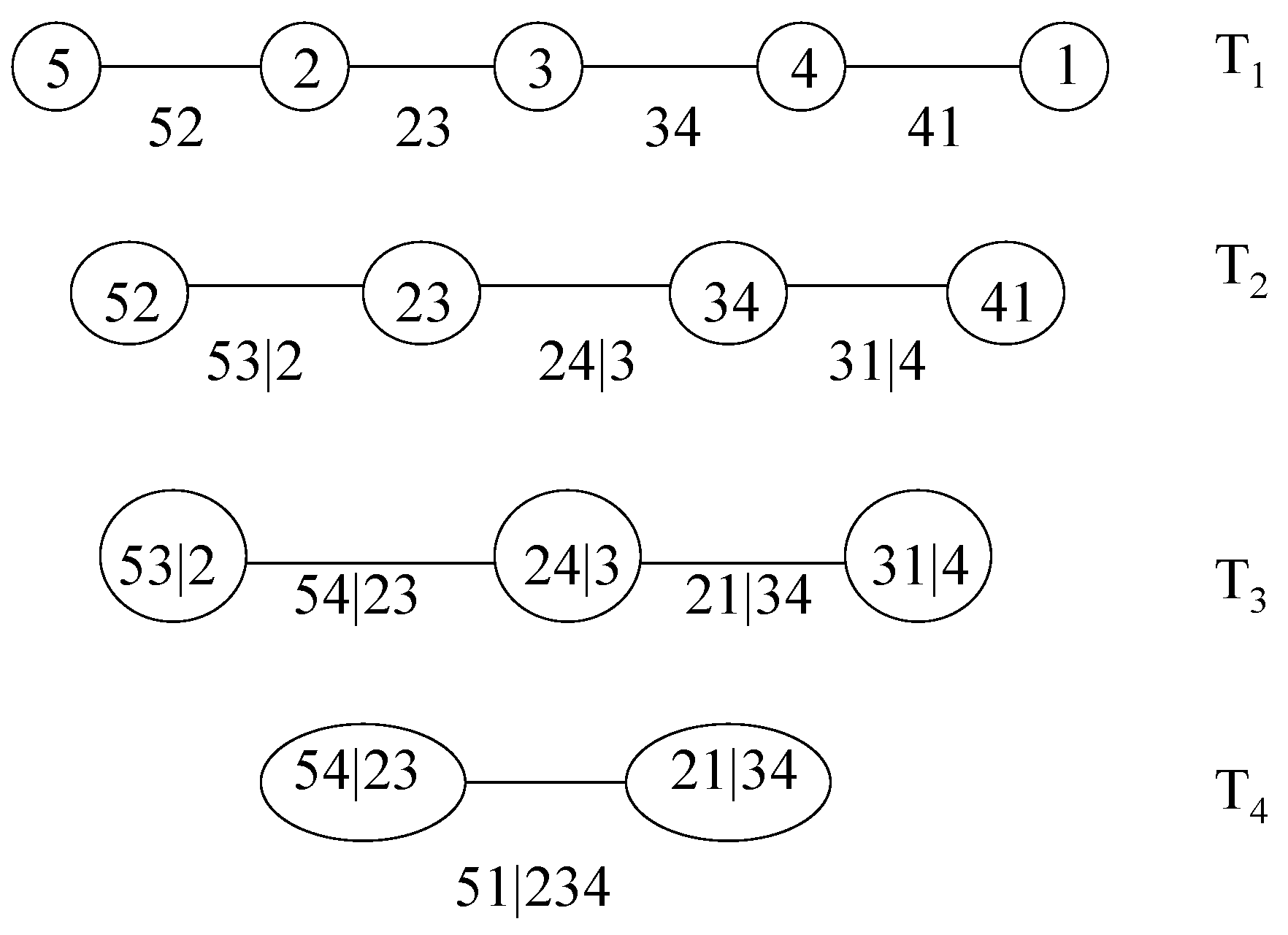
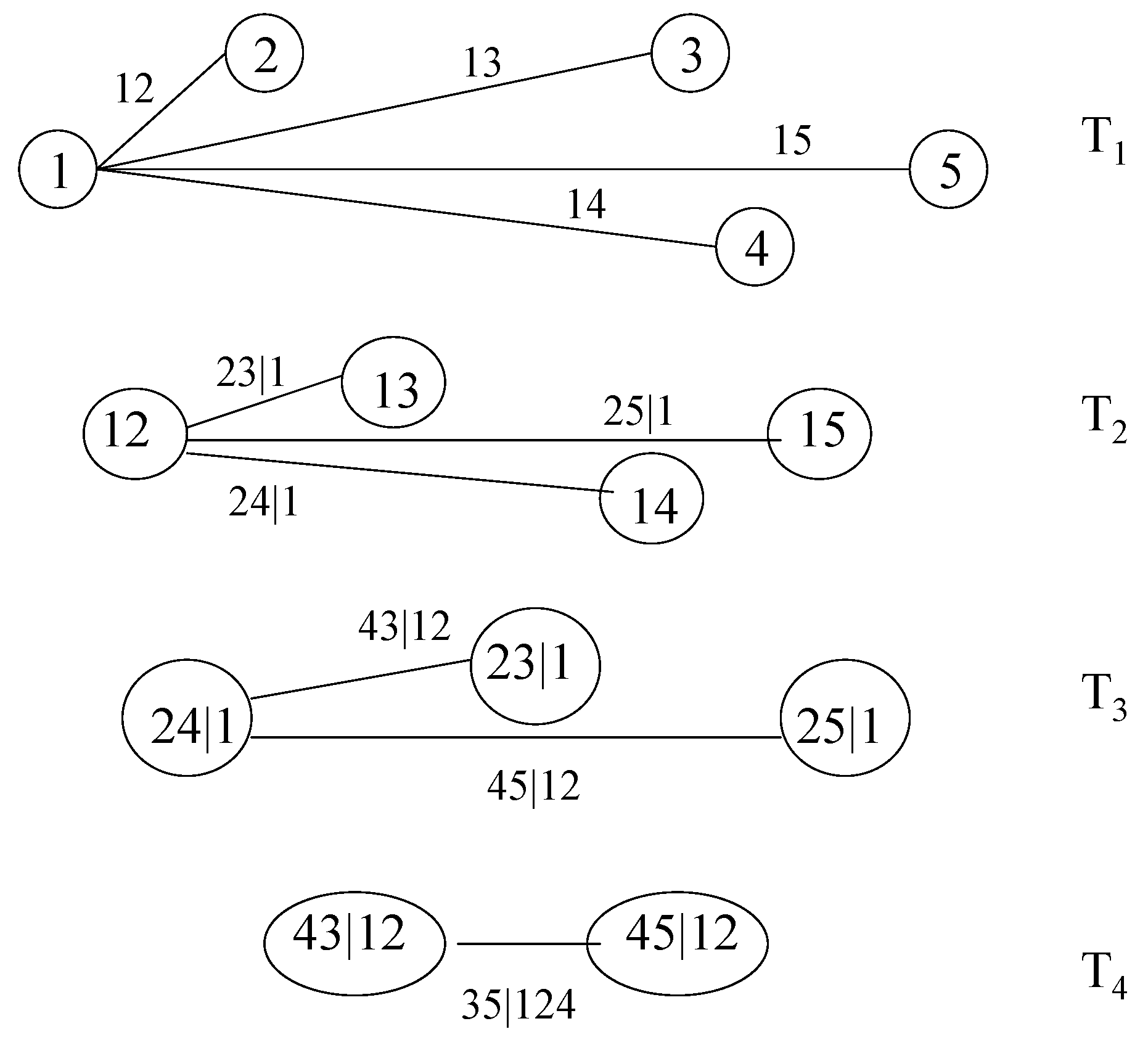
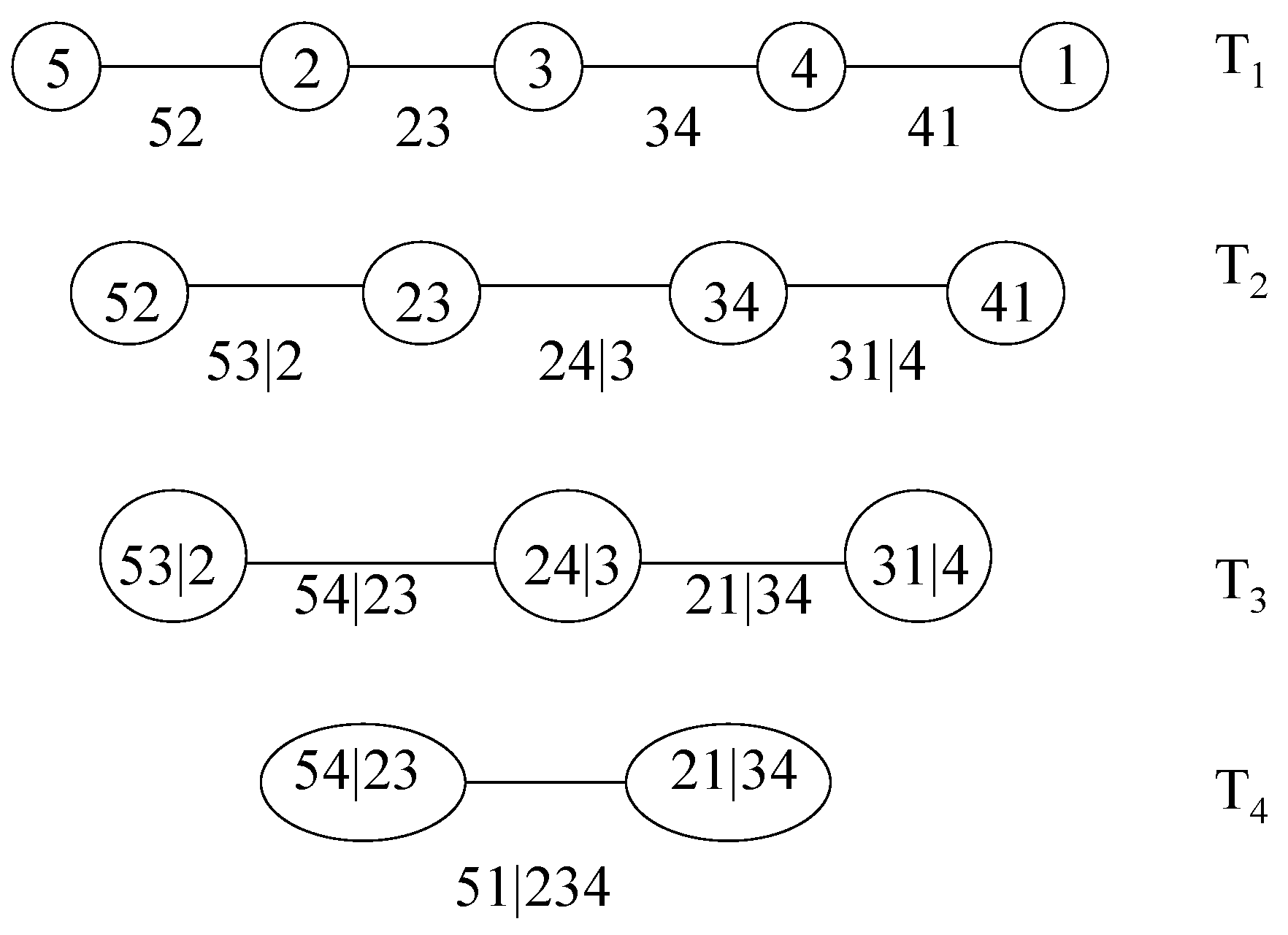
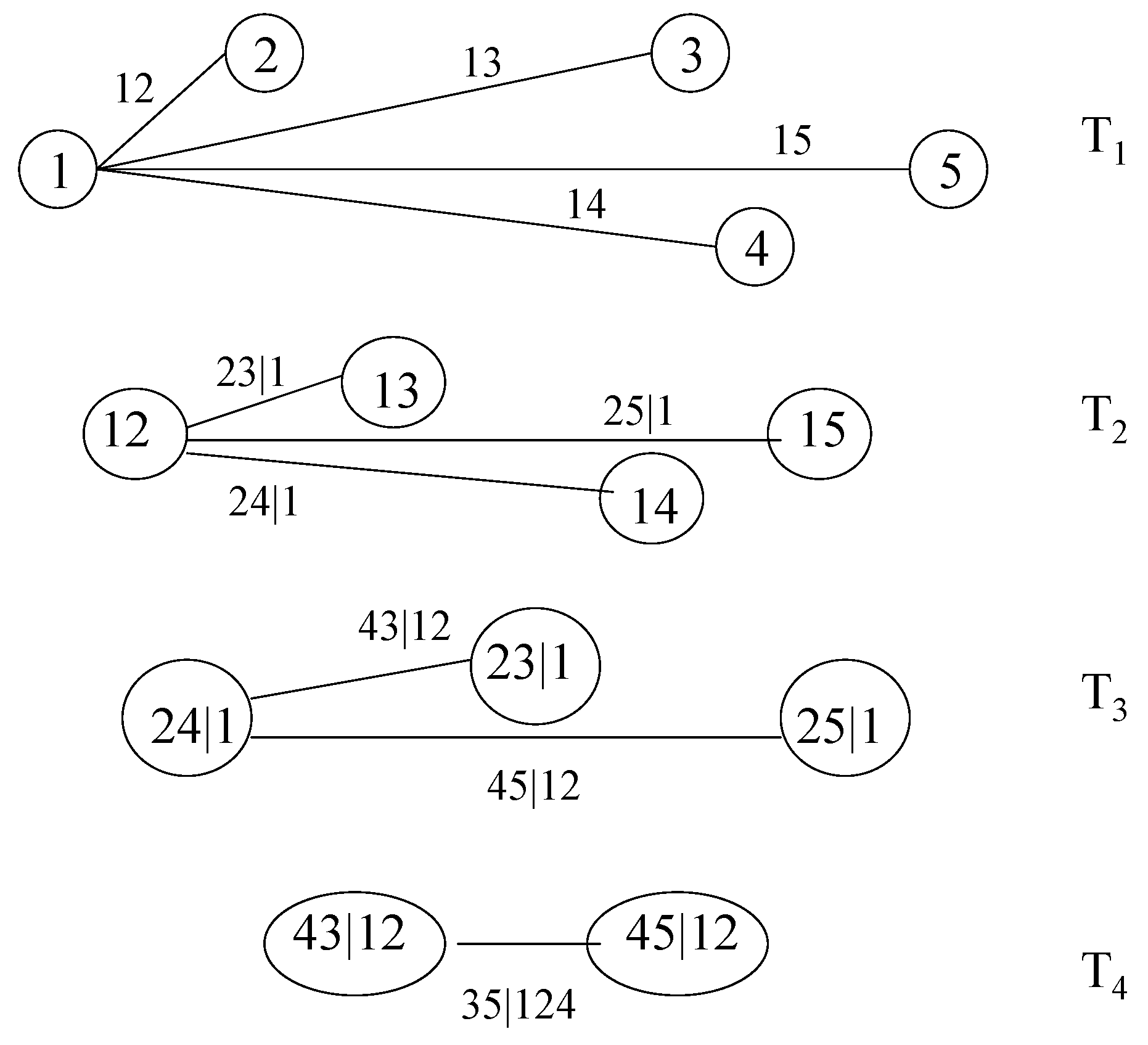
2. The Pair-Copula Construction and the Regular Vine
- Tree has nodes and edges .
- For , the nodes in tree are the edges in tree , i.e., .
- Proximity condition: if two edges in tree are to be joined as nodes in tree by an edge, they must share a common node in .
2.1. Simplifying Assumption
2.2. Canonical Vines and D-Vines
2.3. Serial Dependence
3. Inference
3.1. Structure Selection
3.2. Choosing Copula Families
3.3. Parameter Estimation for a Given Structure and Copula Families
Time-Varying Models
3.4. Pruning and Truncation
3.4.1. Pruning
3.4.2. Truncation
4. Model Validation
5. Financial Applications
5.1. Market Risk
5.2. Capital Asset Pricing
5.3. Credit Risk
5.4. Operational Risk
5.5. Liquidity Risk
5.6. Systemic Risk
5.7. Portfolio Optimization
5.8. Option Pricing
6. Conclusions
Conflicts of Interest
References
- H. Joe. Multivariate Models and Dependence Concepts. London, UK: Chapman & Hall, 1997. [Google Scholar]
- R. Nelsen. An Introduction to Copulas. New York, NY, USA: Springer, 1999. [Google Scholar]
- A. Sklar. “Fonctions de répartition à n dimensions et leurs marges.” Publ. Inst. Stat. Univ. Paris 8 (1959): 229–231. [Google Scholar]
- P. Embrechts, A.J. McNeil, and D. Straumann. “Correlation: Pitfalls and alternatives.” Risk 12 (1999): 69–71. [Google Scholar]
- C. Genest, H.U. Gerber, M.J. Goovaerts, and R.J. Laeven. “Editorial to the special issue on modeling and measurement of multivariate risk in insurance and finance.” Insur. Math. Econ. 44 (2009): 143–145. [Google Scholar] [CrossRef]
- H. Joe. “Families of m-variate distributions with given margins and m(m–1)/2 bivariate dependence parameters.” In Distributions with Fixed Marginals and Related Topics. Edited by L. Rüschendorf, B. Schweizer and M.D. Taylor. Hayward, CA, USA: Institute of Mathematical Statistics, 1996, Volume 28, pp. 120–141. [Google Scholar]
- T. Bedford, and R.M. Cooke. “Probability density decomposition for conditionally dependent random variables modeled by vines.” Ann. Math. Artif. Intell. 32 (2001): 245–268. [Google Scholar] [CrossRef]
- T. Bedford, and R.M. Cooke. “Vines—A new graphical model for dependent random variables.” Ann. Stat. 30 (2002): 1031–1068. [Google Scholar] [CrossRef]
- D. Kurowicka, and R. Cooke. Uncertainty Analysis with High Dimensional Dependence Modeling. Chichester, UK: Wiley, 2006. [Google Scholar]
- K. Aas, C. Czado, A. Frigessi, and H. Bakken. “Pair-copula constructions of multiple dependence.” Insur. Math. Econ. 44 (2009): 182–198. [Google Scholar] [CrossRef] [Green Version]
- O. Morales-Napoles. “Counting vines.” In Dependence Modeling: Vine Copula Handbook. Edited by D. Kurowicka and H. Joe. Hackensack, NJ, USA: London, UK: Singapore: Beijing, China: Shanghai, China: Hong Kong: Taipei, Taiwan: Chennai, India: World Scientific Publishing Co., 2011, pp. 189–218. [Google Scholar]
- J. Dißmann, E.C. Brechmann, C. Czado, and D. Kurowicka. “Selecting and estimating regular vine copulae and application to financial returns.” Comput. Stat. Data Anal. 59 (2013): 52–69. [Google Scholar] [CrossRef]
- I. Hobæk Haff, K. Aas, and A. Frigessi. “On the simplified pair-copula construction—Simply useful or too simplistic? ” J. Multivar. Anal. 101 (2010): 1296–1310. [Google Scholar] [CrossRef]
- J. Stöber, H. Joe, and C. Czado. “Simplified pair copula constructions—Limitations and extensions.” J. Multivar. Anal. 119 (2013): 101–118. [Google Scholar] [CrossRef]
- M. Killiches, D. Kraus, and C. Czado. “Examination and visualization of the simplifying assumption for vine copulas in three dimension.” arXiv, 2016. [Google Scholar]
- F. Spanhel, and M.S. Kurz. “Simplified vine copula models: Approximations based on the simplifying assumption.” arXiv, 2015. [Google Scholar]
- E.F. Acar, C. Genest, and J. Neslehova. “Beyond simplified pair-copula constructions.” J. Multivar. Anal. 110 (2012): 74–90. [Google Scholar] [CrossRef]
- C. Schellhase, and F. Spanhel. “Estimating non-simplified vine copulas using penalized splines.” arXiv, 2016. [Google Scholar]
- D. Kurowicka, and R.M. Cooke. “Distribution—Free Continuous Bayesian Belief Nets.” In Proceedings of the Fourth International Conference on Mathematical Methods in Reliability Methodology and Practice, Santa Fe, NM, USA, 21–25 June 2004.
- M. Smith, A. Min, C. Czado, and C. Almeida. “Modeling longitudinal data using a pair-copula decomposition of serial dependence.” J. Am. Stat. Assoc. 105 (2010): 1467–1479. [Google Scholar] [CrossRef]
- B. Vaz de Melo Mendes, and V.B. Accioly. “Robust pair-copula based forecasts of realized volatility.” Appl. Stoch. Models Bus. Ind. 30 (2014): 183–199. [Google Scholar] [CrossRef]
- M.B. Righi, and P.S. Ceretta. “Forecasting Value at Risk and Expected Shortfall based on serial pair-copula constructions.” Expert Syst. Appl. 42 (2015): 6380–6390. [Google Scholar] [CrossRef]
- E.C. Brechmann, and C. Czado. “COPAR—Multivariate time series modeling using the copula autoregressive model.” Appl. Stoch. Models Bus. Ind. 31 (2015): 495–514. [Google Scholar] [CrossRef]
- C. Czado, E.C. Brechmann, and L. Gruber. “Selection of vine copulas.” In Copulae in Mathematical and Quantitative Finance, Proceedings of the Workshop Held in Cracow, Cracow, Poland, 10–11 July 2012. Edited by P. Jaworski, F. Durante and K.W. Härdle. Berlin/Heidelberg, Germany: Springer, 2013, pp. 17–37. [Google Scholar]
- C. Czado, S. Jeske, and M. Hofmann. “Selection strategies for regular vine copulae.” J. Soc. Franç. Stat. 154 (2013): 174–191. [Google Scholar]
- R.C. Prim. “Shortest connection networks and some generalizations.” Bell Syst. Tech. J. 36 (1957): 1389–1401. [Google Scholar] [CrossRef]
- D. Kurowicka. “Optimal truncation of vines.” In Dependence Modeling: Vine Copula Handbook. Edited by D. Kurowicka and H. Joe. Hackensack, NJ, USA: London, UK: Singapore: Beijing, China: Shanghai, China: Hong Kong: Taipei, Taiwan: Chennai, India: World Scientific Publishing Co., 2011. [Google Scholar]
- L. Gruber, and C. Czado. “Sequential Bayesian model selection of regular vine copulas.” Bayesian Anal. 10 (2015): 937–963. [Google Scholar] [CrossRef]
- S. Grønneberg, and N.L. Hjort. “The copula information criteria.” Scand. J. Stat. 41 (2014): 436–459. [Google Scholar] [CrossRef] [Green Version]
- H. Manner. “Estimation and Model Selection of Copulas with an Application to Exchange Rates.” METEOR, research memorandum 07/056. Maastricht University. Available online: http://digitalarchive.maastrichtuniversity.nl/fedora/objects/guid:2a9aead2-9b11-48c3-a2fa-4ef9eb39e167/datastreams/ASSET1/content (accessed on 10 August 2016).
- I. Hobæk Haff. “Estimating the parameters of a pair-copula construction.” Bernoulli 19 (2013): 462–491. [Google Scholar] [CrossRef]
- H. Joe. “Asymptotic effiency of the two stage estimation method for copula-based models.” J. Multivar. Anal. 94 (2005): 401–419. [Google Scholar] [CrossRef]
- C. Genest, K. Ghoudi, and L.P. Rivest. “A semi-parametric estimation procedure of dependence parameters in multivariate families of distributions.” Biometrika 82 (1995): 543–552. [Google Scholar] [CrossRef]
- J. Shih, and T. Louis. “Inferences on the association parameter in copula models for survival data.” Biometrics 51 (1995): 1384–1399. [Google Scholar] [CrossRef] [PubMed]
- I. Hobæk Haff. “Comparison of estimators for pair-copula constructions.” J. Multivar. Anal. 110 (2012): 91–105. [Google Scholar] [CrossRef]
- A. Min, and C. Czado. “Bayesian inference for multivariate copulas using pair-copula constructions.” J. Financial Econom. 8 (2010): 511–546. [Google Scholar] [CrossRef]
- A. Min, and C. Czado. “Bayesian model selection for D-vine pair-copula constructions.” Can. J. Stat. 39 (2011): 239–258. [Google Scholar] [CrossRef]
- I. Hobæk Haff, and J. Segers. “Nonparametric estimation of pair-copula constructions with the empirical pair-copula.” Comput. Stat. Data Anal. 84 (2015): 1–13. [Google Scholar] [CrossRef]
- M. Scheffer, and G. Weiß. “Smooth nonparametric Bernstein vine copulas.” Quant. Finance, 2016. accepted. [Google Scholar] [CrossRef]
- T. Nagler, and C. Czado. “Evading the curse of dimensionality in nonparametric density estimation with simplified vine copulas.” arXiv, 2016. [Google Scholar]
- C. Almeida, C. Czado, and H. Manner. “Modeling high-dimensional time-varying dependence using dynamic D-vine models.” Appl. Stoch. Models Bus. Ind., 2016. [Google Scholar] [CrossRef]
- A. Vesper. “A time dynamic pair copula construction: With financial applications.” Appl. Financial Econ. 22 (2012): 1697–1711. [Google Scholar] [CrossRef]
- M.K. So, and C.Y. Yeung. “Vine-copula GARCH model with dynamic conditional dependence.” Comput. Stat. Data Anal. 76 (2014): 655–671. [Google Scholar] [CrossRef]
- R.F. Engle. “Dynamic conditional correlation: A simple class of multivariate generalized autoregressive conditional heteroskedasticity models.” J. Bus. Econ. Stat. 17 (2002): 339–350. [Google Scholar] [CrossRef]
- L. Chollete, A. Heinen, and A. Valdesogo. “Modeling international financial returns with a multivariate regime switching copula.” J. Financial Econom. 7 (2009): 437–480. [Google Scholar] [CrossRef]
- J. Stöber, and C. Czado. “Regime switches in the dependence structure of multidimensional financial data.” Comput. Stat. Data Anal. 76 (2014): 672–686. [Google Scholar] [CrossRef]
- C. Genest, and A.C. Favre. “Everything you always wanted to know about copula modeling but were afraid to ask.” J. Hydrol. Eng. 12 (2007): 347–368. [Google Scholar] [CrossRef]
- E. Brechmann, C. Czado, and K. Aas. “Truncated regular vines in high dimensions with application to financial data.” Can. J. Stat. 40 (2012): 68–85. [Google Scholar] [CrossRef]
- E.C. Brechmann, and H. Joe. “Truncation of vine copulas using fit indices.” J. Multivar. Anal. 138 (2015): 19–33. [Google Scholar] [CrossRef]
- Q.H. Vuong. “Likelihood ratio tests for model selection and non-nested hypotheses.” Econometrica 57 (1989): 307–333. [Google Scholar] [CrossRef]
- M. Rosenblatt. “Remarks on a multivariate transformation.” Ann. Math. Stat. 23 (1952): 470–472. [Google Scholar] [CrossRef]
- W. Breymann, A. Dias, and P. Embrechts. “Dependence structures for multivariate high-frequency data in finance.” Quant. Finance 1 (2003): 1–14. [Google Scholar] [CrossRef]
- D. Berg, and K. Aas. “Models for construction of multivariate dependence.” Eur. J. Finance 15 (2009): 639–659. [Google Scholar]
- J.D. Fermanian. “Goodness-of-fit tests for copulas.” J. Multivar. Anal. 95 (2005): 119–152. [Google Scholar] [CrossRef]
- C. Genest, J.F. Quessy, and B. Rémillard. “Goodness-of-fit procedures for copula models based on the probability integral transform.” Scand. J. Stat. 33 (2006): 337–366. [Google Scholar] [CrossRef]
- H. White. “Maximum likelihood estimation of misspecified models.” Econometrica 50 (1982): 1–26. [Google Scholar] [CrossRef]
- U. Schepsmeier. “Efficient information based goodness-of-fit tests for vine copula models with fixed margins: A comprehensive review.” J. Multivar. Anal. 138 (2015): 34–52. [Google Scholar] [CrossRef]
- U. Schepsmeier. “A goodness-of-fit test for regular vine copula models.” Econom. Rev., 2016. accepted. [Google Scholar] [CrossRef]
- W. Huang, and A. Prokhorov. “A goodness-of-fit test for copulas.” Econom. Rev. 33 (2014): 751–771. [Google Scholar] [CrossRef] [Green Version]
- Q.M. Zhou, P.X.K. Song, and M.E. Thompson. “Information ratio test for model misspecification in quasi-likelihood inference.” J. Am. Stat. Assoc. 107 (2012): 205–213. [Google Scholar] [CrossRef]
- M. Fischer, C. Köck, S. Schlüter, and F. Weigert. “An empirical analysis of multivariate copula models.” Quant. Finance 9 (2009): 839–854. [Google Scholar] [CrossRef]
- G.N.F. Weiß, and H. Supper. “Forecasting liquidity-adjusted intraday Value-at-Risk with vine copulas.” J. Bank. Finance 37 (2013): 3334–3350. [Google Scholar] [CrossRef]
- B. Zhang, Y. Wei, J. Yu, X. Lai, and Z. Peng. “Forecasting VaR and ES of stock index portfolio: A Vine copula method.” Phys. A 416 (2014): 112–124. [Google Scholar] [CrossRef]
- A. Min, and C. Czado. “Bayesian model selection for multivariate copulas using pair-copula constructions.” Can. J. Stat. 39 (2011): 239–258. [Google Scholar] [CrossRef]
- M.B. Righi, S.G. Schlender, and P.S. Ceretta. “Pair copula constructions to determine the dependence structure of Treasury bond yields.” IIMB Manag. Rev. 27 (2015): 216–227. [Google Scholar] [CrossRef]
- C. Czado, U. Schepsmeier, and A. Min. “Maximum likelihood estimation of mixed C-vines with application to exchange rates.” Stat. Model. 12 (2012): 229–255. [Google Scholar] [CrossRef]
- A. Min, and C. Czado. “SCOMDY models based on pair-copula constructions with application to exchange rates.” Comput. Stat. Data Anal. 76 (2014): 523–535. [Google Scholar] [CrossRef]
- R.A. Loaiza Maya, J.E. Gomez-Gonzalez, and L.F. Melo Velandia. “Latin American exchange rate dependencies: A regular vine copula approach.” Contemp. Econ. Policy 33 (2015): 535–549. [Google Scholar] [CrossRef]
- Z. Zhang, L. Ding, F. Zhang, and Z. Zhang. “Optimal currency composition for China’s foreign reserves: A copula approach.” World Econ. 38 (2015): 1947–1965. [Google Scholar] [CrossRef] [Green Version]
- B. Goodwin, and A. Hungerford. “Copula based models of systemic risk in U.S. agriculture: Implications for crop insurance and reinsurance contracts.” Am. J. Agric. Econ. 97 (2014): 879–896. [Google Scholar] [CrossRef]
- Z. Shen, M. Odening, and O. Okhrin. “Can expert knowledge compensate for data scarcity in crop insurance pricing? ” Eur. Rev. Agric. Econ., 2015. [Google Scholar] [CrossRef]
- J.C. Reboredo, and A. Ugolini. “Downside/upside price spillovers between precious metals: A vine copula approach.” N. Am. J. Econ. Finance 34 (2015): 84–102. [Google Scholar] [CrossRef]
- W. Mensi, S. Hammoudeh, J.C. Reboredo, and D.K. Nguyen. “Are Sharia stocks, gold and U.S. Treasury hedges and/or safe havens for the oil-based GCC markets? ” Emerg. Mark. Rev. 24 (2015): 101–121. [Google Scholar] [CrossRef]
- M.S. Smith. “Copula modeling of dependence in multivariate time series.” Int. J. Forecast. 31 (2015): 815–833. [Google Scholar] [CrossRef]
- D.M. Zimmer. “Analyzing comovements in housing prices using vine copulas.” Econ. Inq. 53 (2015): 1156–1169. [Google Scholar] [CrossRef]
- W. Sharpe. “Capital asset prices: A theory of market equilibrium under conditions of risk.” J. Finance 19 (1964): 425–442. [Google Scholar] [CrossRef]
- J. Lintner. “The valuation of risk assets and the selection of risky investments in stock portfolios and capital budgets.” Rev. Econ. Stat. 47 (1965): 13–37. [Google Scholar] [CrossRef]
- A. Heinen, and A. Valdesogo. “Asymmetric CAPM Dependence for Large Dimensions: The Canonical Vine Autoregressive Model.” CORE discussion papers 2009069. Université catholique de Louvain, Center for Operations Research and Econometrics (CORE), 2009. Available online: http://www.uclouvain.be/cps/ucl/doc/core/documents/coredp2009_69web.pdf (accessed on 18 August 2016).
- E.C. Brechmann. “Risk management with high-dimensional vine copulas: An analysis of the Euro Stoxx 50.” Stat. Risk Model. 30 (2013): 307–342. [Google Scholar] [CrossRef]
- M. Crouhy, R.A. Jarrow, and S.M. Turnbull. “The subprime Credit Crisis of 07.” J. Deriv. 16 (2008). [Google Scholar] [CrossRef]
- F. Salmon. “Receipe for Disaster: The formula that killed Wall Street.” Wired Magazine. 2009. Available online: https://www.wired.com/2009/02/wp-quant/ (accessed on 10 August 2016).
- M. Fischer, and K. Jakob. “Copula-Specific Credit Portfolio Modeling. How the Sector Copula Affects the Tail of the Portfolio Loss Distribution.” In Innovations in Quantitative Risk Management: TU München, September 2013. Edited by K. Glau, M. Scherer and R. Zagst. Volume 99 of the series Springer Proceedings in Mathematics and Statistics; Cham, Switzerland: Springer International Publishing, 2015, pp. 129–145. [Google Scholar]
- M. Geidosch, and M. Fischer. “Application of vine copulas to credit portfolio risk modeling.” J. Risk Financial Manag. 9 (2016): 4. [Google Scholar] [CrossRef]
- L. Changqing, L. Yanlin, and L. Mengzhen. “Credit portfolio risk evaluation based on the pair copula VaR models.” J. Finance Econ. 3 (2015): 15–39. [Google Scholar]
- L. Dalla Valle, M.E. De Giuli, C. Tarantola, and C. Manelli. “Default probability estimation via pair copula constructions.” Eur. J. Oper. Res. 249 (2016): 298–311. [Google Scholar] [CrossRef]
- E. Brechmann, C. Czado, and S. Paterlini. “Modeling dependence of operational loss frequencies.” J. Oper. Risk 8 (2013): 105–126. [Google Scholar] [CrossRef]
- E. Brechmann, C. Czado, and S. Paterlini. “Flexible dependence modeling of operational risk losses and its impact on total capital requirements.” J. Bank. Finance 40 (2014): 271–285. [Google Scholar] [CrossRef]
- G.A. Karolyi, K.H. Lee, and M.A. van Dijk. “Understanding commonality in liquidity around the world.” J. Financial Econ. 105 (2012): 82–112. [Google Scholar] [CrossRef]
- International Monetary Fund, the Bank for International Settlements and the Financial Stability Board. “Report to the G-20 Finance Ministers and Central Bank Govenors: Guidance to Assess the Systemic Importance of Financial Institutions, Markets and Instruments: Initial Considerations.” 2009, p. 2. Available online: https://www.imf.org/external/np/g20/pdf/100109.pdf (accessed on 10 August 2016).
- E.C. Brechmann, K. Hendrich, and C. Czado. “Conditional copula simulation for systemic risk stress testing.” Insur. Math. Econ. 53 (2013): 722–732. [Google Scholar] [CrossRef]
- A. Pourkhanali, J. Kim, L. Tafakori, and F.A. Fard. “Measuring systemic risk using vine-copula.” Econ. Model. 53 (2016): 63–74. [Google Scholar] [CrossRef]
- M.B. Righi, and P.S. Ceretta. “Risk prediction management and weak form market efficiency in Eurozone financial crisis.” Int. Rev. Financial Anal. 30 (2013): 384–393. [Google Scholar] [CrossRef]
- O. Abbara, and M. Zevallos. “Assessing stock market dependence and contagion.” Quant. Finance 14 (2014): 1627–1641. [Google Scholar] [CrossRef]
- T. Markwat. “The rise of global stock market crash probabilities.” Quant. Finance 14 (2014): 557–571. [Google Scholar] [CrossRef]
- J.C. Reboredo, and A. Ugolini. “A vine-copula conditional value-at-risk approach to systemic sovereign debt risk for the financial sector.” N. Am. J. Econ. Finance 32 (2015): 98–123. [Google Scholar] [CrossRef]
- D. Zhang. “Vine copulas and applications to the European Union sovereign debt analysis.” Int. Rev. Financial Anal. 36 (2014): 46–56. [Google Scholar] [CrossRef]
- H. Markowitz. “Portfolio selection.” J. Finance 7 (1952): 77–91. [Google Scholar] [CrossRef]
- R.T. Rockafellar, and S. Uryasev. “Optimization of conditional value-at-risk.” J. Risk 2 (2000): 21–41. [Google Scholar] [CrossRef]
- R.K.Y. Low, J. Alcock, R. Faff, and T. Brailsford. “Canonical vine copulas in the context of modern portfolio management: Are they worth it? ” J. Bank. Finance 37 (2013): 3085–3099. [Google Scholar] [CrossRef]
- B. Hansen. “Autoregressive conditional density estimation.” Int. Econ. Rev. 35 (1994): 705–730. [Google Scholar] [CrossRef]
- B.V.M. Mendes, and D.S. Marques. “Choosing an optimal investment strategy: The role of robust pair-copulas based portfolios.” Emerg. Mark. Rev. 13 (2012): 449–464. [Google Scholar] [CrossRef]
- J.A. Hernandez. “Are oil and gas stocks from the Australian market riskier than coal and uranium stocks? Dependence risk analysis and portfolio optimization.” Energy Econ. 45 (2014): 528–536. [Google Scholar] [CrossRef]
- S. Bekiros, J.A. Hernandez, S. Hammoudeh, and D.K. Nguyen. “Multivariate dependence risk and portfolio optimization: An application to mining stock portfolios.” Resour. Policy 46 (2015): 1–11. [Google Scholar] [CrossRef]
- C. Bernard, and C. Czado. “Multivariate option pricing using copulae.” Appl. Stoch. Models Bus. Ind. 29 (2013): 509–526. [Google Scholar] [CrossRef]
© 2016 by the author; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aas, K. Pair-Copula Constructions for Financial Applications: A Review. Econometrics 2016, 4, 43. https://doi.org/10.3390/econometrics4040043
Aas K. Pair-Copula Constructions for Financial Applications: A Review. Econometrics. 2016; 4(4):43. https://doi.org/10.3390/econometrics4040043
Chicago/Turabian StyleAas, Kjersti. 2016. "Pair-Copula Constructions for Financial Applications: A Review" Econometrics 4, no. 4: 43. https://doi.org/10.3390/econometrics4040043
APA StyleAas, K. (2016). Pair-Copula Constructions for Financial Applications: A Review. Econometrics, 4(4), 43. https://doi.org/10.3390/econometrics4040043