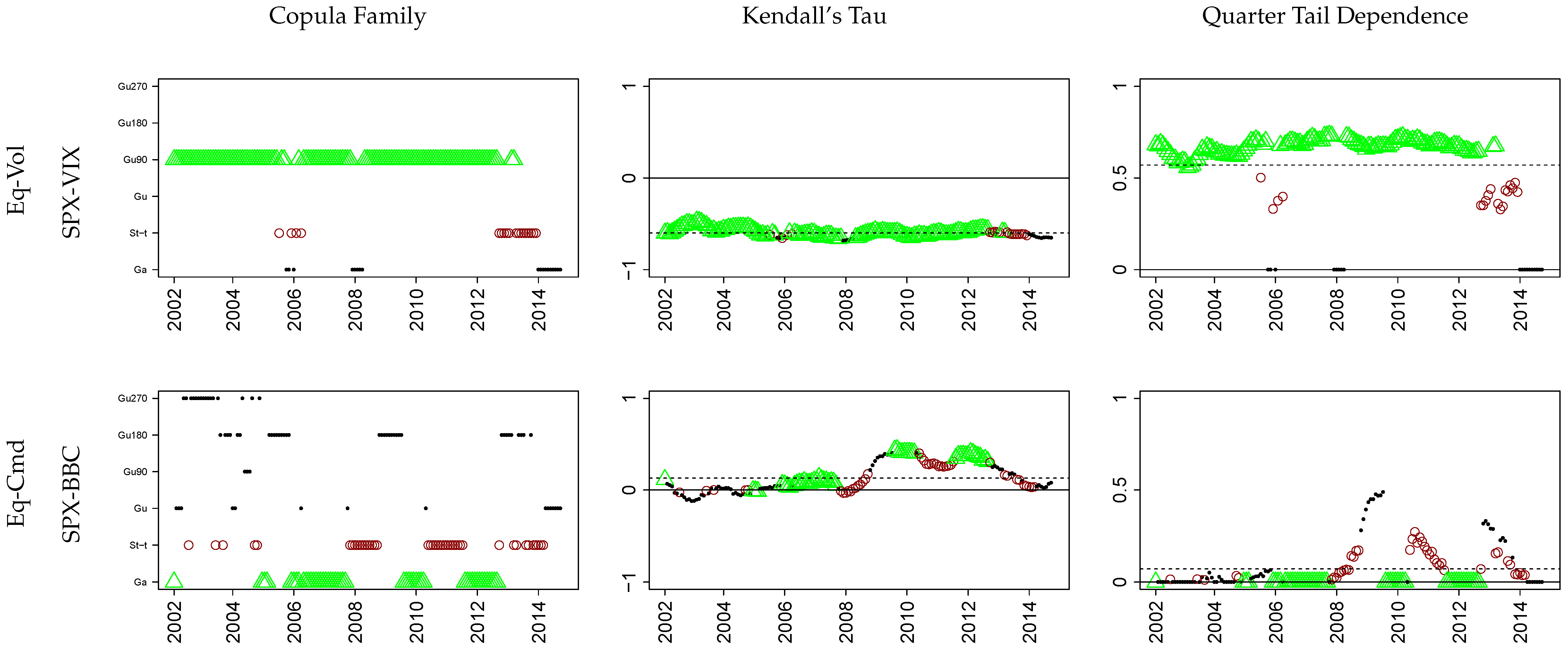
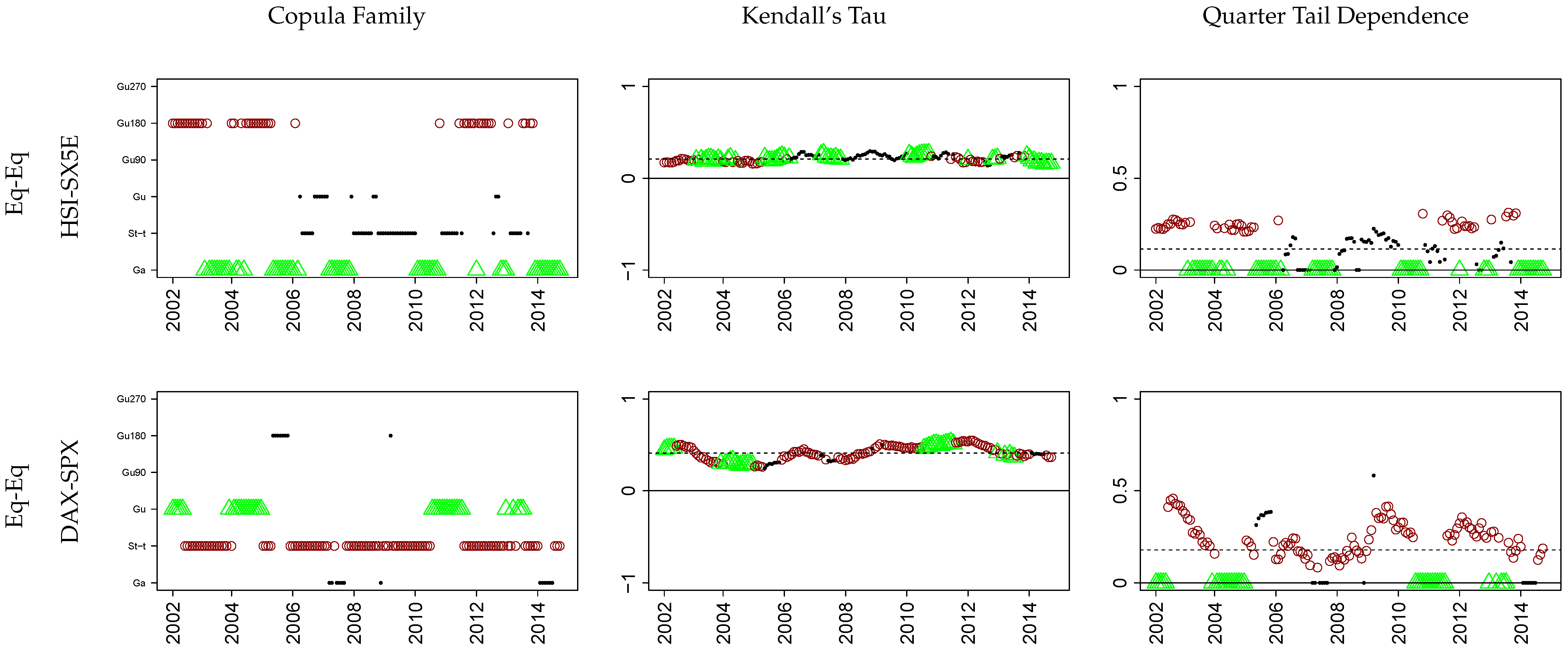
Appendix A. Model Summaries
The following section contains all estimated model specifications. To compactly summarize each setup, we follow the
R-vine notation of [
68]: The
R-vine-matrix
stores the specific nodes and edges for each tree (cf. Equation (
4) and Figure 2 of [
68]) while the copula-family-matrix
contains the respective bivariate copula types using the abbreviations of [
40] (i.e., ‘1 = Ga’, ‘2 = St-
t’, ‘4=Gu’, ‘14 = Gu180’, ‘24 = Gu90’ and ‘34 = Gu270’). Finally, the copula parameters are presented via
(and additionally
for the degrees of freedom in the Student-
t case) while the switching probabilities are denoted by
P.
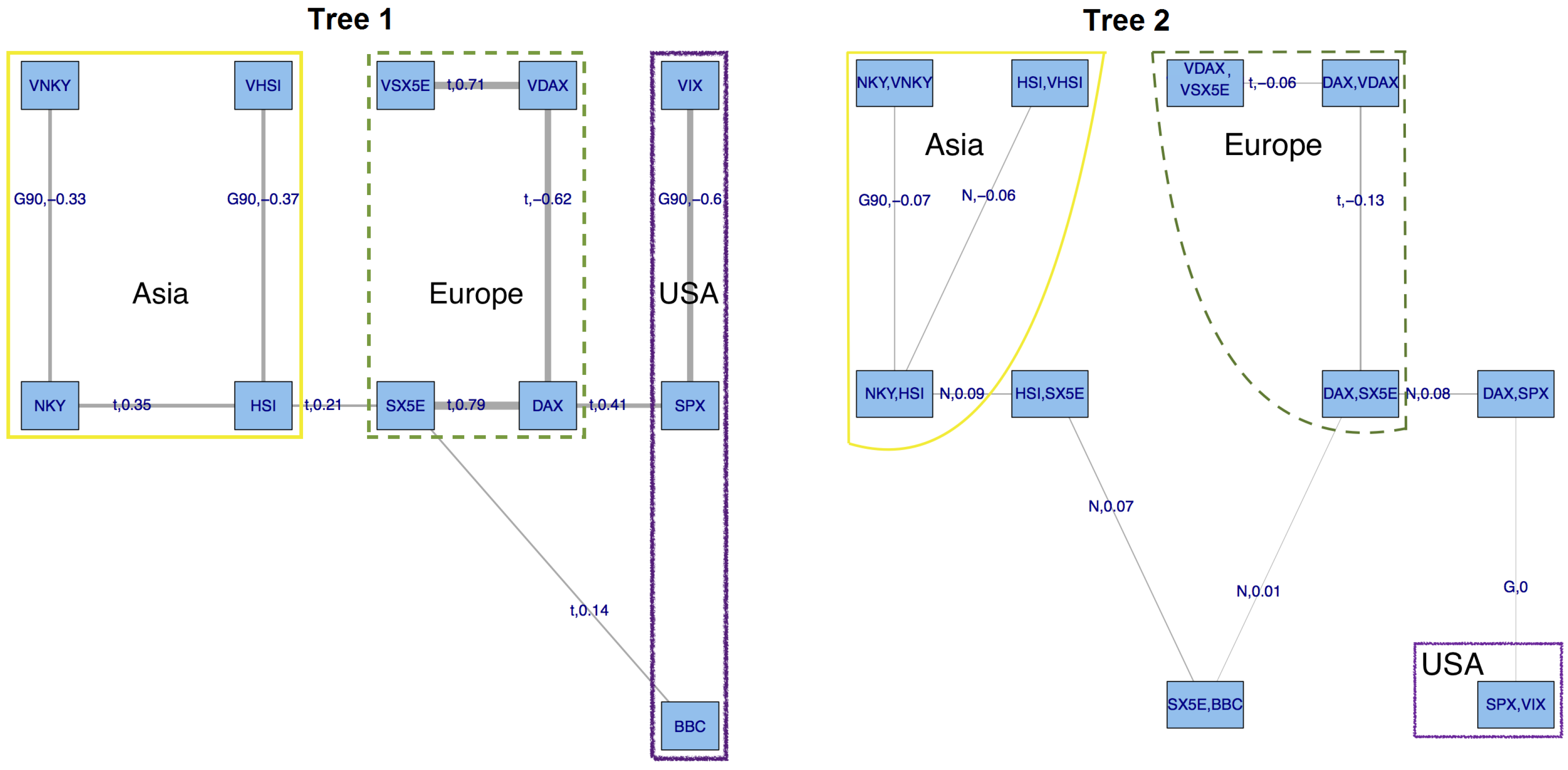
We want to stress that (1-dependent) is the only setup where a selection algorithm determined the
R-Vine structure
and the bivariate copula families
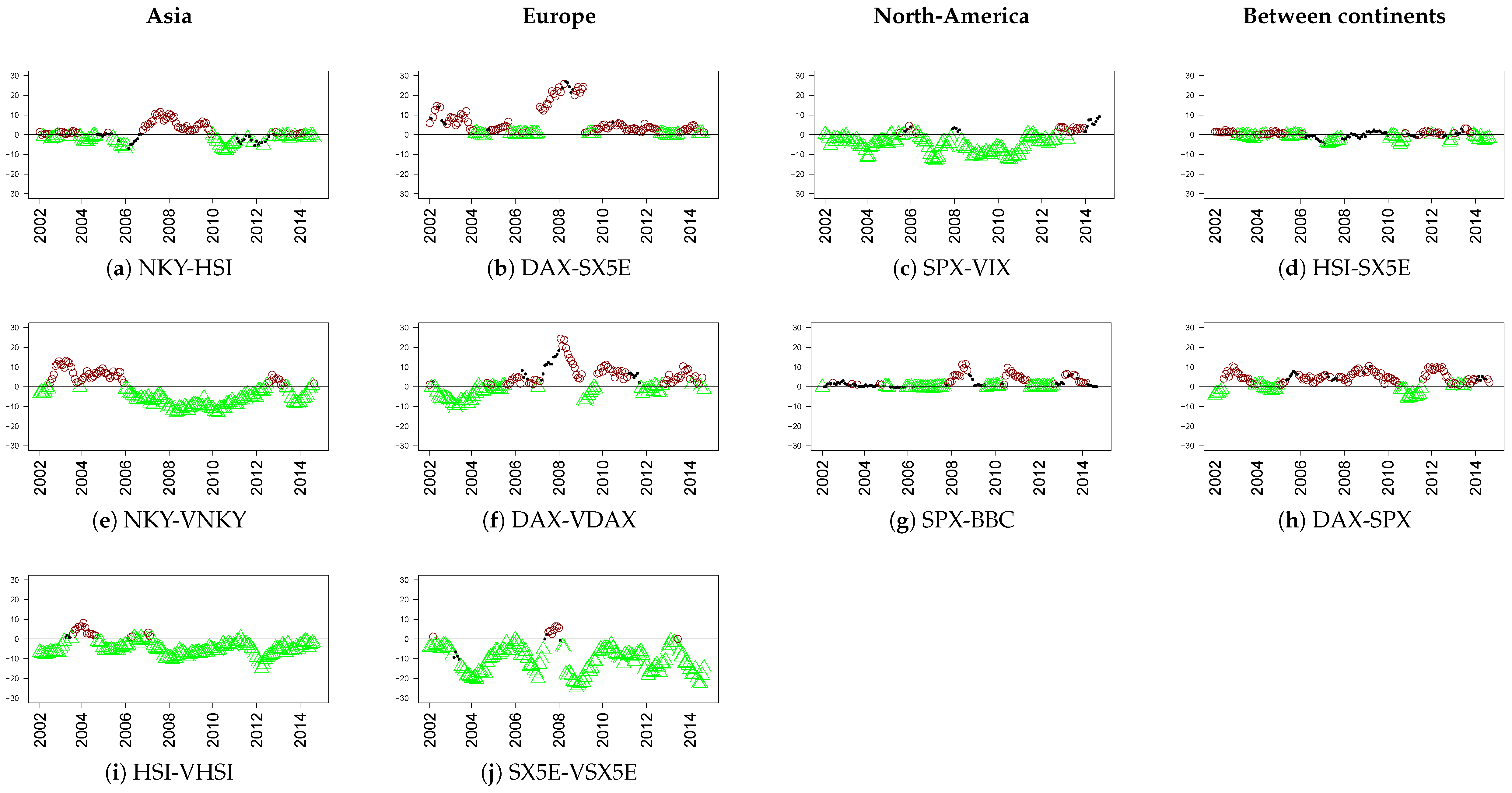
. For the non-switching regional models (Asia
–Asia
, Europe
–Europe
and USA
–USA
) as well as (2-dependent) the structure was manually chosen and only the copulas
were algorithmically selected based on maximum likelihood and AIC (cf.
RVineCopSelect out of the
VineCopula package by [
40]). For the Markov-switching setups (Asia
, Europa
, USA
and (3-dependent-MS))
and
for both regimes were manually determined. Parameters were always estimated and never fixed.
All “independence” model log-likelihoods were obtained via the sum of the regional setups.
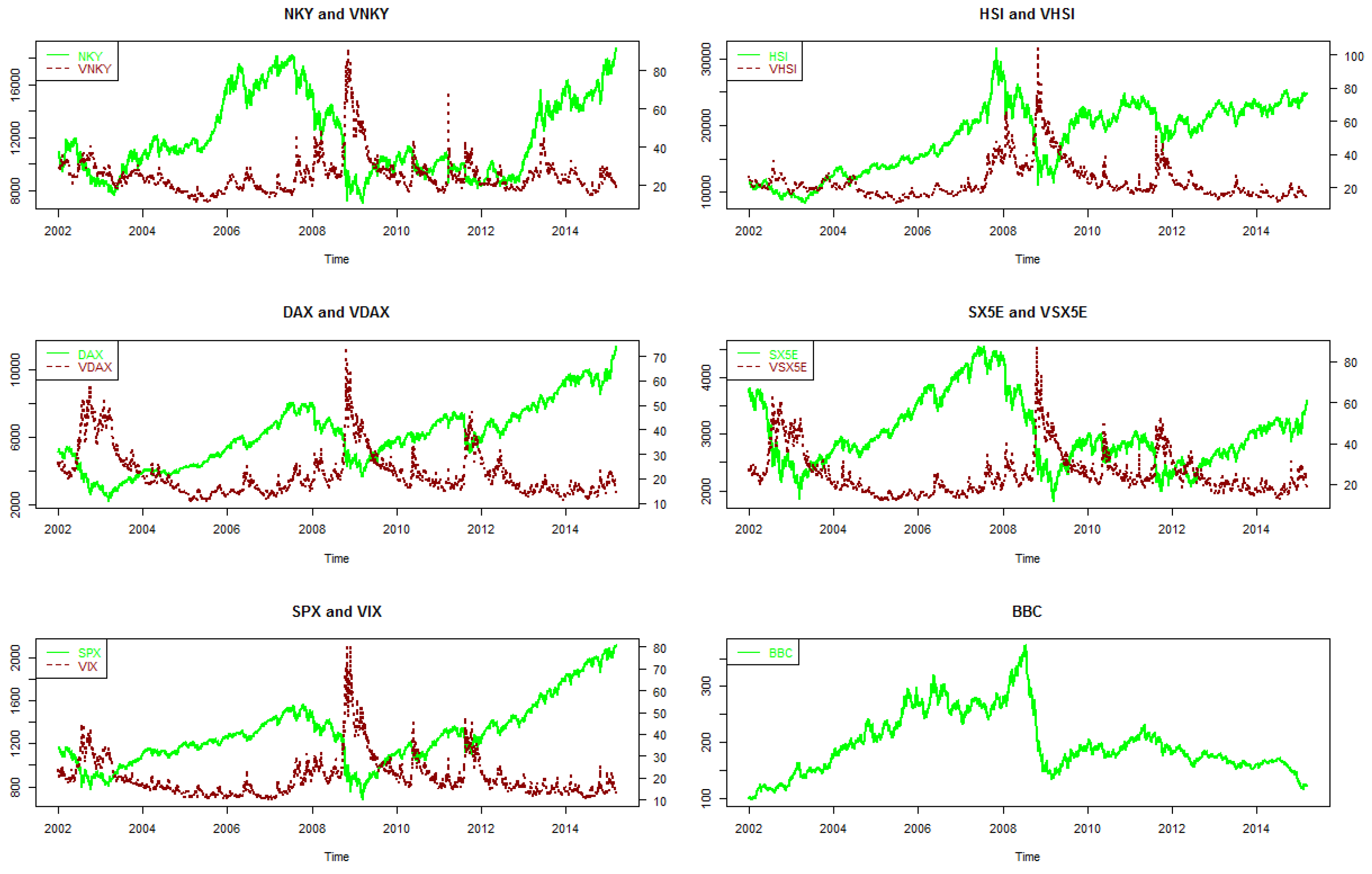
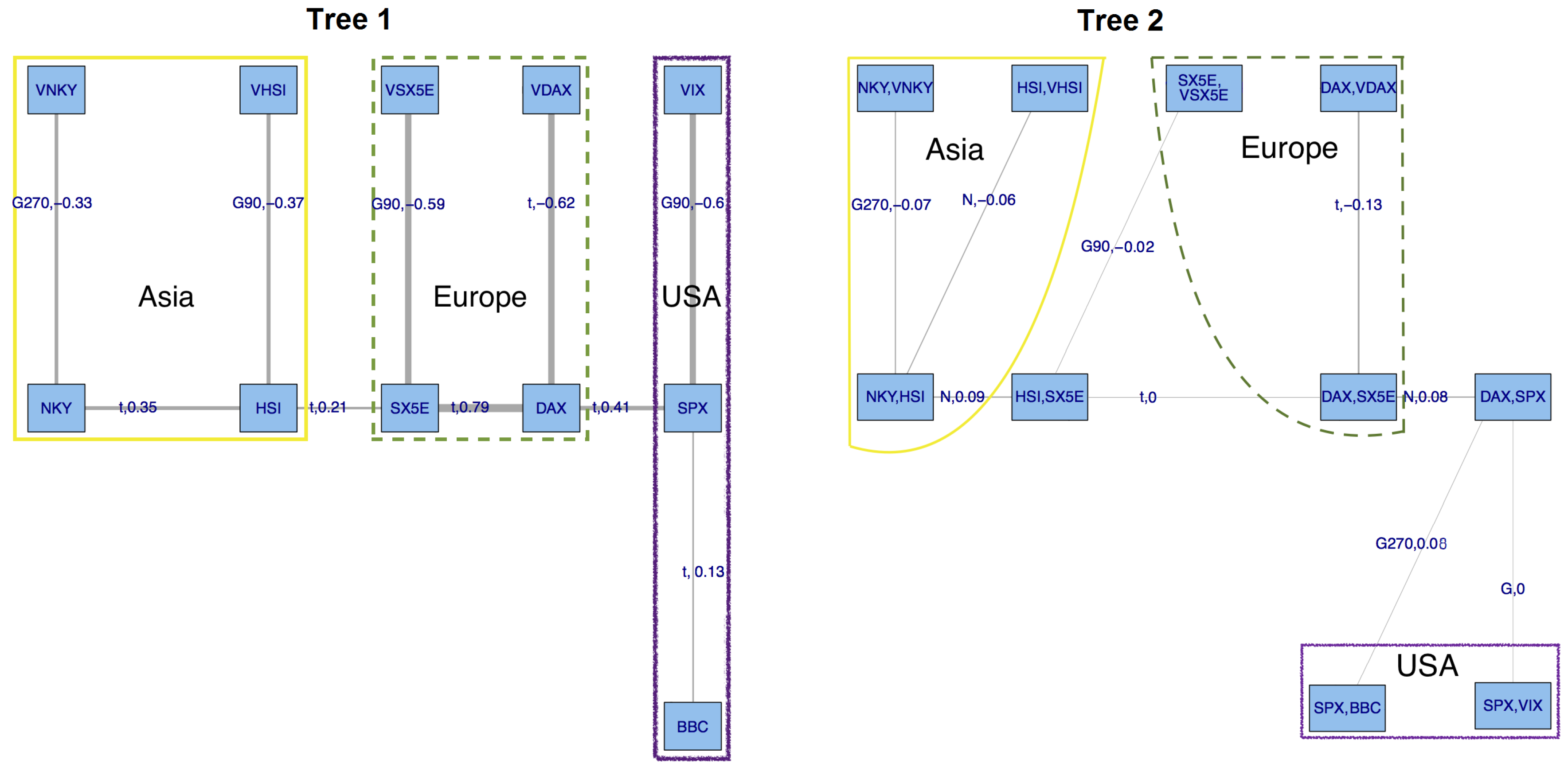
(1-dependent): 1-NKY 2-VNKY 3-HSI 4-VHSI 5-DAX 6-VDAX 7-SX5E 8-VSX5E 9-SPX 10-VIX 11-BBC
(2-dependent): 1-NKY 2-VNKY 3-HSI 4-VHSI 5-DAX 6-VDAX 7-SX5E 8-VSX5E 9-SPX 10-VIX 11-BBC
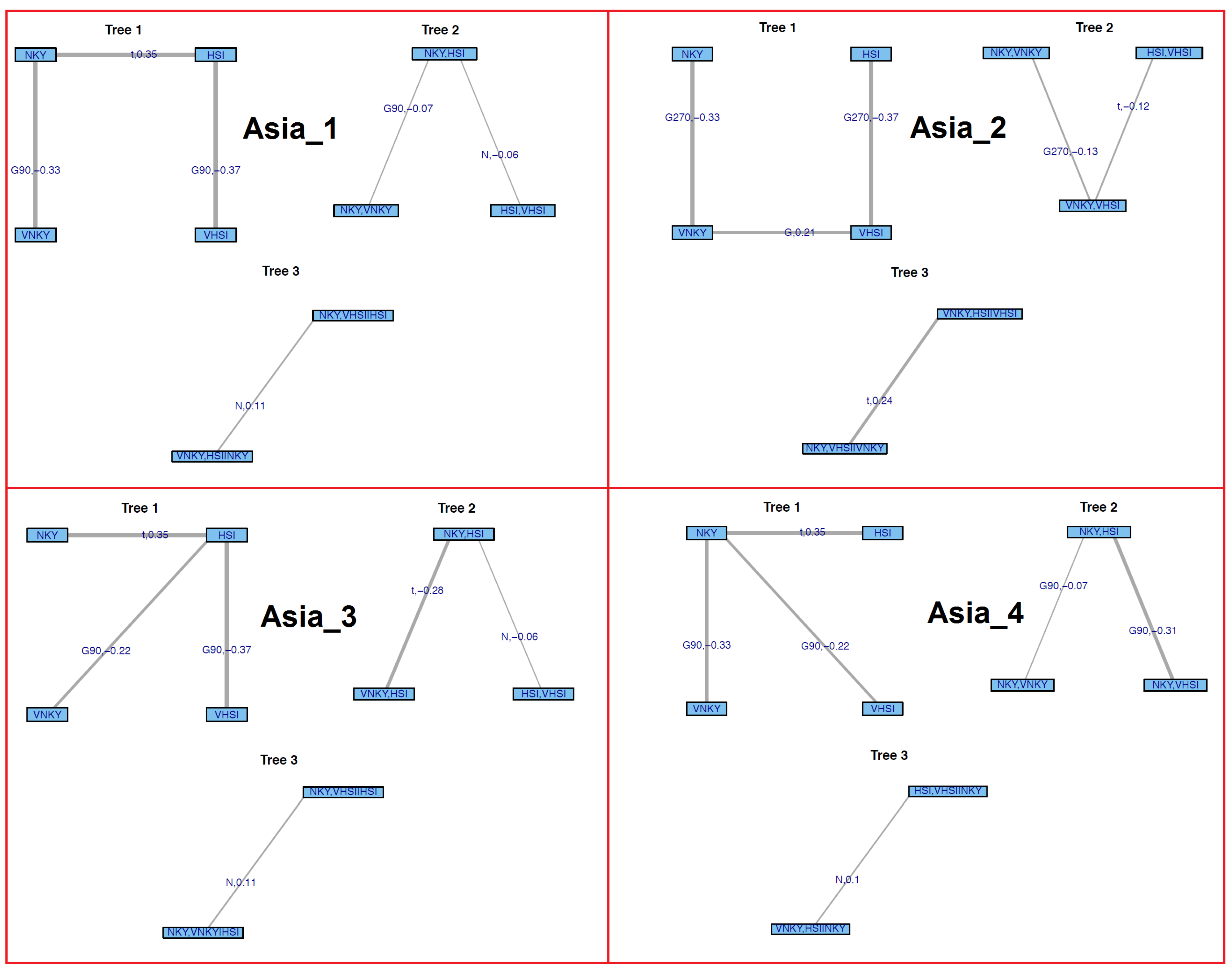
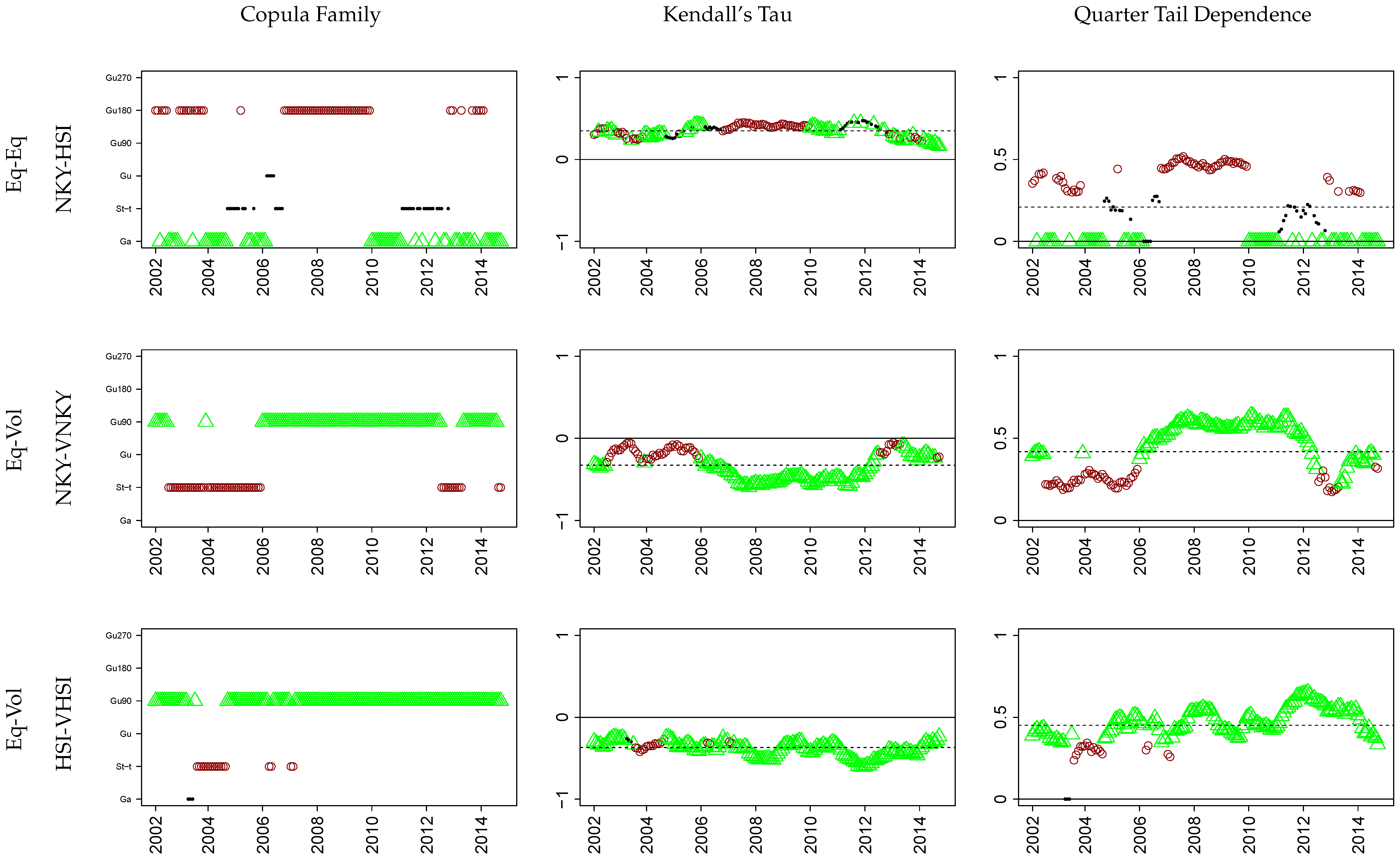
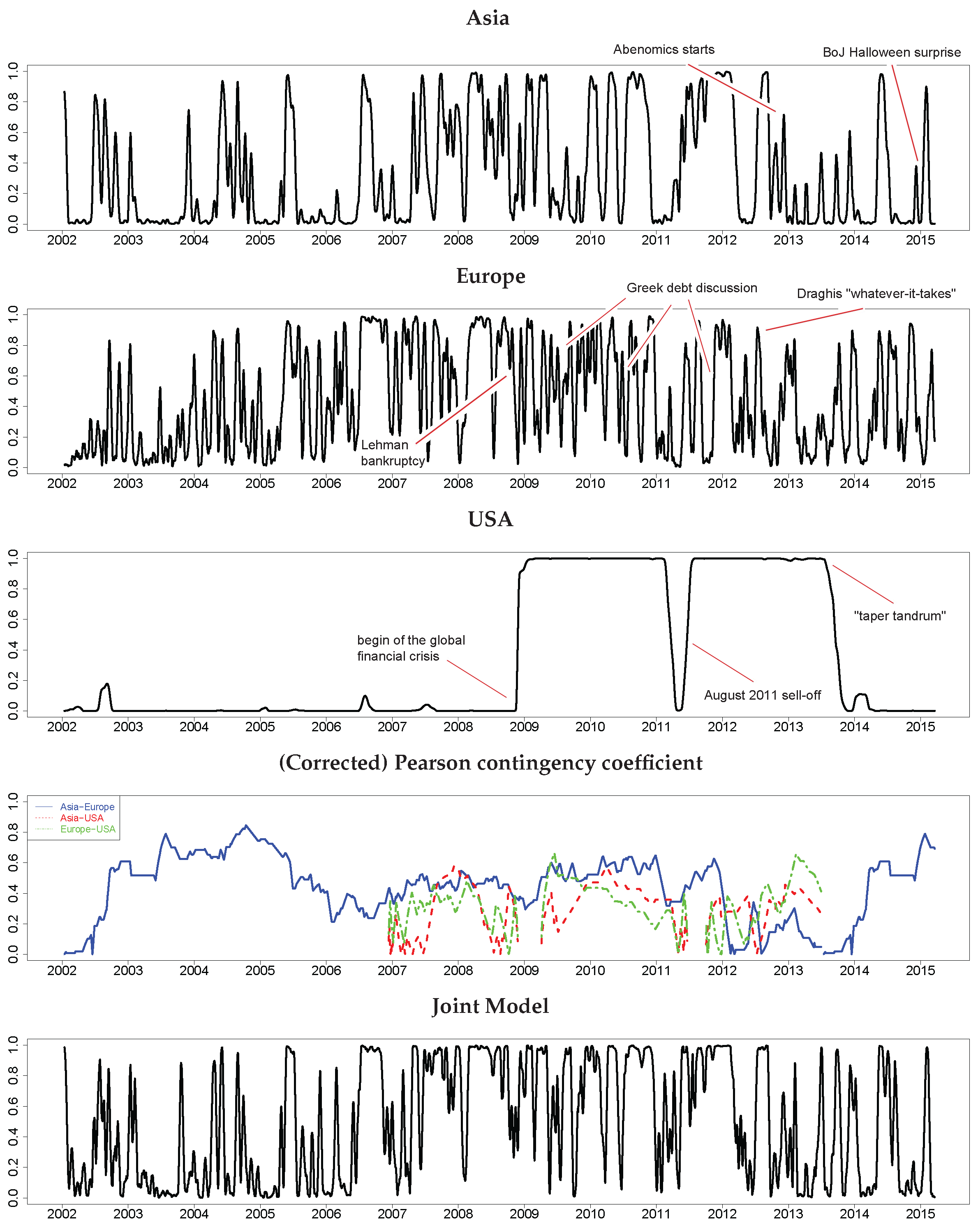
Asia: 1-NKY 2-VNKY 3-HSI 4-VHSI
Asia: 1-NKY 2-VNKY 3-HSI 4-VHSI
Asia: 1-NKY 2-VNKY 3-HSI 4-VHSI
Asia: 1-NKY 2-VNKY 3-HSI 4-VHSI
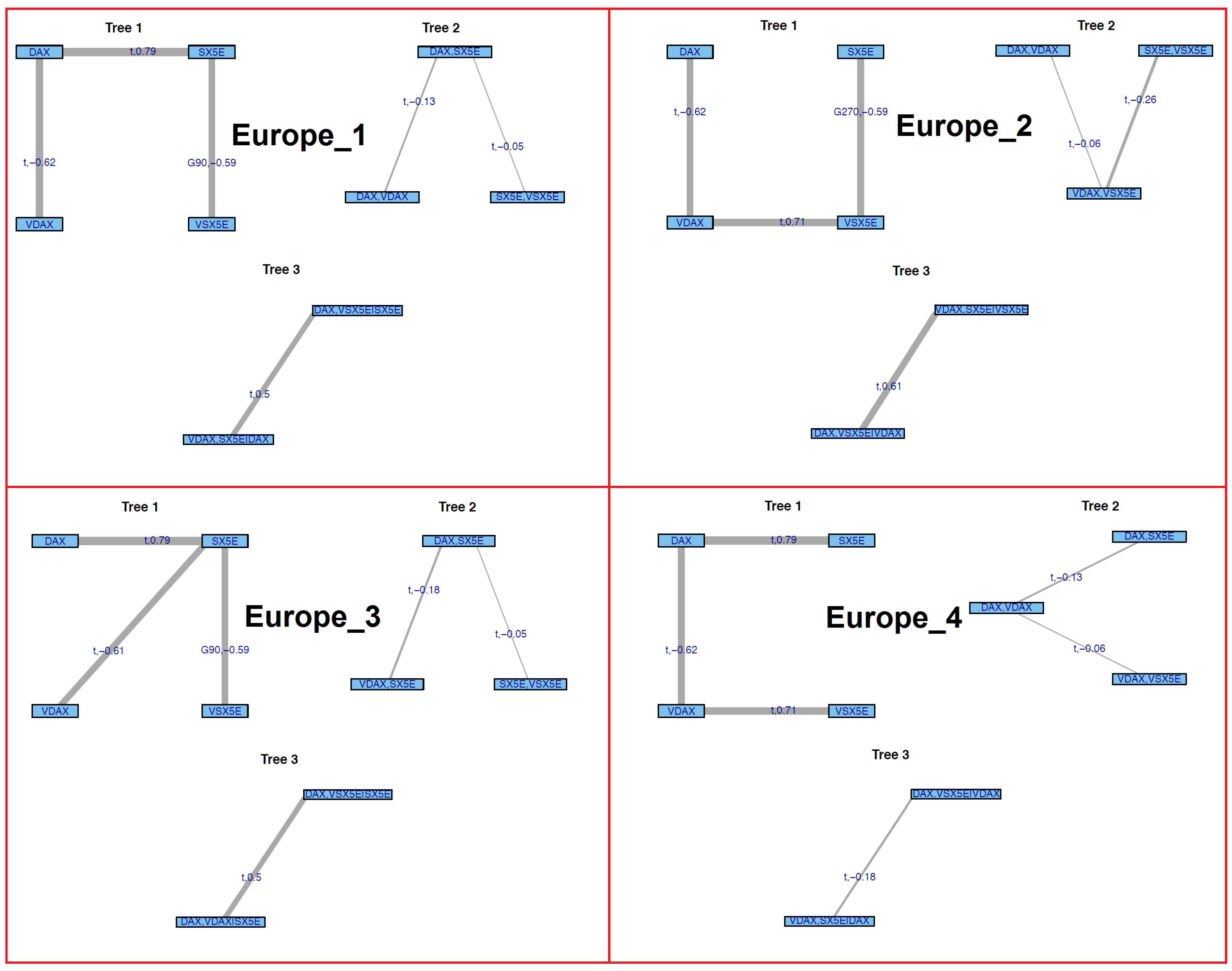
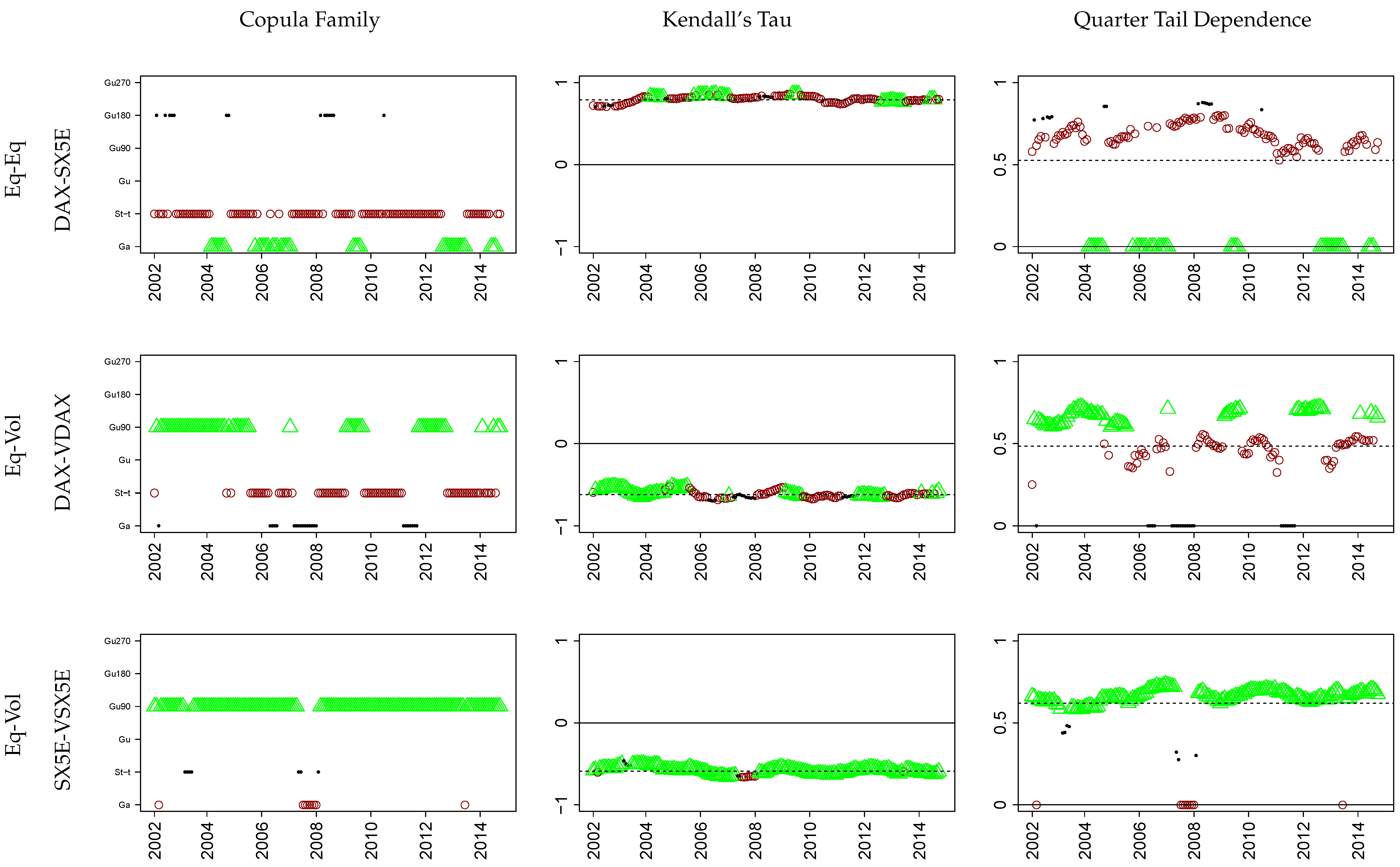
Europe: 1-DAX 2-VDAX 3-SX5E 4-VSX5E
Europe: 1-DAX 2-VDAX 3-SX5E 4-VSX5E
Europe: 1-DAX 2-VDAX 3-SX5E 4-VSX5E
Europe: 1-DAX 2-VDAX 3-SX5E 4-VSX5E
USA: 1-SPX 2-VIX 3-BBC
USA: 1-SPX 2-VIX 3-BBC
Asia: 1-NKY 2-VNKY 3-HSI 4-VHSI
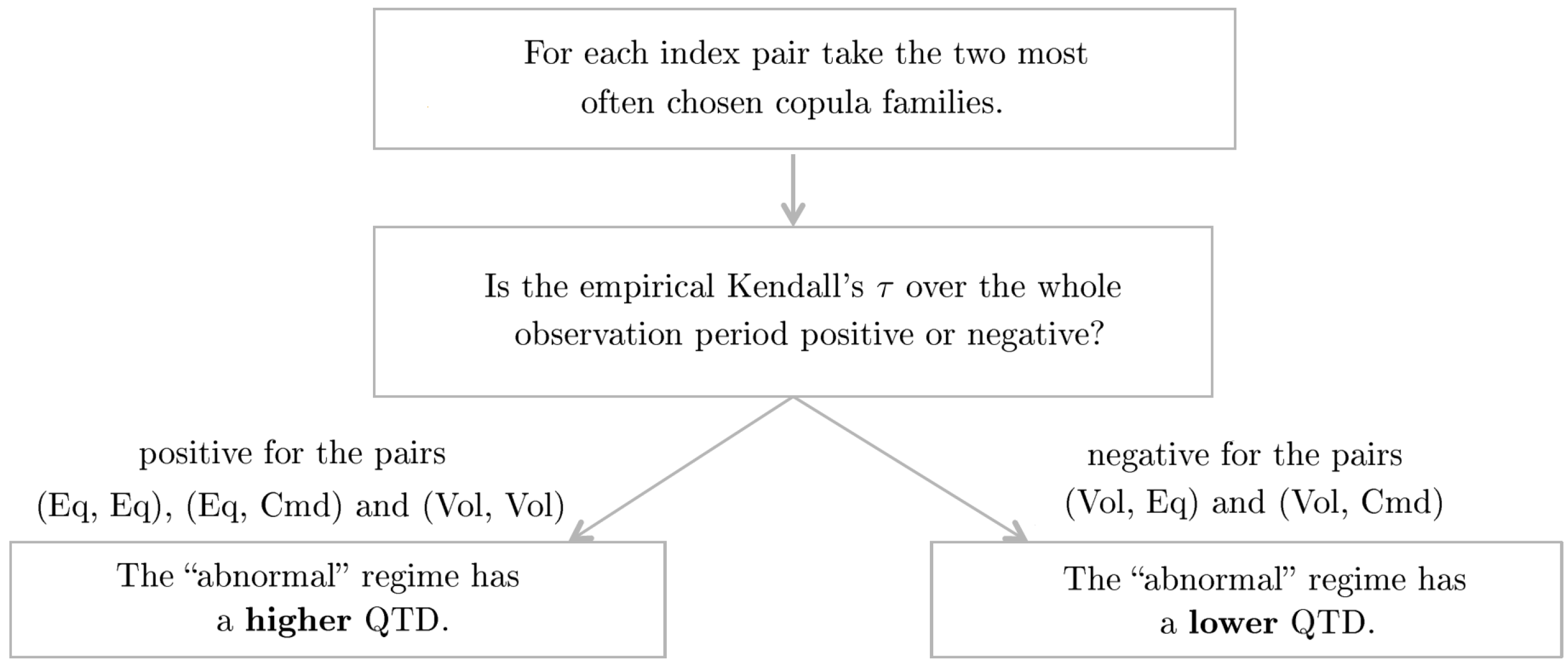
“normal” regime
“abnormal” regime
Europe: 1-DAX 2-VDAX 3-SX5E 4-VSX5E
“normal” regime
“abnormal” regime
USA: 1-SPX 2-VIX 3-BBC
“normal” regime
“abnormal” regime
(3-dependent-MS): 1-NKY 2-VNKY 3-HSI 4-VHSI 5-DAX 6-VDAX 7-SX5E 8-VSX5E 9-SPX 10-VIX 11-BBC
“normal” regime
“abnormal” regime

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



