Abstract
In this paper, we study forecasting problems of Bitcoin-realized volatility computed on data from the largest crypto exchange—Binance. Given the unique features of the crypto asset market, we find that conventional regression models exhibit strong model specification uncertainty. To circumvent this issue, we suggest using least squares model-averaging methods to model and forecast Bitcoin volatility. The empirical results demonstrate that least squares model-averaging methods in general outperform many other conventional regression models that ignore specification uncertainty.
JEL Classification:
C52; C53; G12; G17
1. Introduction
Bitcoin, the first and still one of the foremost applications of blockchain technology by far, was introduced early in 2008. Until the end of December 2018, the market capitalization of Bitcoin was roughly $65 billion with $3800 per token. As for the whole Bitcoin network, by the end of December 2018, there are more than 10,000 full nodes distributed across the world and roughly $2.5 billion of value transacted on the main network. With the growth of the Bitcoin market, many investors are starting to view it as an emerging new asset class. In September 2015, the Commodity Futures Trading Commission (CFTC) in the United States officially designated Bitcoin as a commodity. Improved measures of Bitcoin volatility enable us to better gauge the current level of volatility and to understand its dynamics. Most importantly, Bitcoin volatility is now directly tradable,1 which accredits the importance of Bitcoin volatility forecasting.
How to model and predict the volatility of financial assets is an interesting topic in risk management. Traditional approaches employ parametric models such as the generalized autoregressive conditional heteroskedasticity (GARCH) or stochastic volatility models. Recently a new approach to modeling volatility dynamics has relied on improved measures of ex post volatility composed from high-frequency intraday data. This new measure is called realized volatility (RV), which possesses a slowly decaying autocorrelation function, sometimes known as long-memory.2 Various models have been proposed to capture stylized facts of realized volatility series, such as the fractionally integrated autoregressive moving average (ARFIMA) models3 used in Andersen et al. (2001b) and the heterogeneous autoregressive (HAR) model proposed by Corsi (2009). Compared with the ARFIMA model, the HAR model soon gained popularity because of its computational simplicity (e.g., ordinary least squares) and excellent out-of-sample performance.4
The HAR model can provide an intuitive economic interpretation that agents with three frequencies of trading (daily, weekly, and monthly) perceive and respond to, which changes the corresponding components of volatility.5 Nevertheless, the suitability of such a specification is not subject to enough verification. Craioveanu and Hillebrand (2012) employed a parallel computing method to investigate all the possible combinations of lags in the additive model. Others tested the validity of the lag structure in the conventional HAR model from a model selection perspective; see, e.g., Audrino et al. (2015,2016); and Audrino et al. (2016), among others. While the lag terms in the HAR model survive the tests based on the least absolute shrinkage and selection operator (LASSO) and the adaptive LASSO (Audrino et al. 2015; Audrino and Knaus 2016) only in the case of simulated data by the HAR model, there is strong evidence in Audrino et al. (2016) that casts some doubts on the fixed choice of aggregation frequencies in the HAR model. In particular, Audrino et al. (2016) found that a conventional fixed lag structure was not statistically sustained by the group LASSO estimates for certain individual stocks in an unstable market environment such as the 2007–2009 crisis. They addressed the above issue with a proposed flexible HAR model, built dynamically from the group LASSO estimates.
The above conclusions may or may not hold in Bitcoin volatility forecasting considering the unique features of the crypto asset market. To tackle this question from a different angle, we consider the forecast implication of a flexible lag structure generated by the least squares model-averaging method. Unlike the model selection approach that picks only one winning model out of a pool of candidate models, model averaging calculates the weighted average of a group of candidate models. Barnard (1963) first discussed the concept of “model combination” in a paper studying airline passenger data. Buckland et al. (1997) suggested using the exponential Akaike information criterion (AIC) estimates as the model weights and proposed the model averaged AIC. There exists many other averaging-type approaches that provide a means to tackle model uncertainty, for instance, the Bayesian model-averaging method discussed in length in Hoeting et al. (1999), the weighted-average least squares method by Magnus et al. (2010), and the random forest method by Breiman (2001), among others.
The performance of the model-averaging method heavily relies on the weights chosen for the estimation process. In a pioneering study, Hansen (2007) proposed the Mallows model averaging (MMA) method that is asymptotically optimal in the sense of achieving the lowest possible mean squared errors. Wan et al. (2010) completed the theoretical foundation of the MMA. Extensions of the MMA that allow possible structural breaks, near unit root, and heteroskedasticity can be found in Hansen (2009,2010), and Hansen and Racine (2012), respectively. Xie (2015) proposed the prediction model averaging (PMA) method. Zhao et al. (2016) extended the PMA method to allow for heteroskedastic error terms (HPMA). Liu and Okui (2013) also proposed a heteroskedasticity-robust Mallows’ model-averaging method (HRCP).
There is a growing literature on solving the model uncertainty issue in volatility forecasting with least squares model averaging. Lehrer et al. (2018) proposed the model averaging HAR (MAHAR) method that optimally averages the forecasts of HAR models with different lag indexes. Qiu et al. (2019) showed that the above method can be extended to a more complicated HAR model with estimators of the variation of positive and negative returns (semi-variance components). Besides the above methods, we consider the approach designed by Qiu and Xie (2018), who proposed the heteroskedasticity-robust model averaging HAR method (H-MAHAR) that mainly applies the HPMA as the core model averaging estimator to exchange rate volatility. As a complement to the HPMA, we also include the jackknife model averaging (JMA) and the heteroskedasticity robust (HRCP) model averaging estimators as companion methods in this paper.
In the empirical exercise, we consider a series of estimators including 9 conventional regression methods, 1 LASSO method, and 4 model-averaging methods to model and forecast the realized variance of Bitcoin prices. We show that the model-averaging methods that account for model uncertainty generally outperform the conventional regressions and the model-selection-based LASSO method. Moreover, the heteroskedasticity-robust methods tend to perform relatively better. Compared with non-model-averaging methods, the H-MAHAR method yields the highest forecasting accuracy in most of the exercises. The improvement that H-MAHAR provides is statistically significant at the 5% level, as confirmed by the Giacomini–White test (Giacomini and White 2006).
The reminder of the paper is arranged as follows. Section 2 provides a more detailed overview of existing HAR strategies. Section 3 discusses the way to model uncertainty under heteroskedasticity using least squares model averaging. Section 4 describes the data. Section 5 presents the empirical results, where we compared 14 methods in rolling window exercises. In all cases, model-averaging methods tended to have the dominating performance. To examine the robustness of the results, we tried different experimental settings in Section 6. Section 7 concludes this paper.
2. Prior HAR-Type Strategies to Forecast Volatility
Following Andersen and Bollerslev (1998), we estimate daily RV at day t () by summing the corresponding M equally spaced intra-daily squared returns . Here, the subscript t indexes day t and j indicates the time within day t,
where , , and define continuously compounded high-frequency returns by differing log-prices ().
Among the RV models, the HAR model proposed by Corsi (2009) is quite prevalent. Not only is this because the HAR model accurately approximates the long-memory and multiscaling properties of RV but also this is very easy to implement in practice. The standard HAR model in Corsi (2009) postulates that the h-step-ahead daily can be described by
where the explanatory variables can take the general form of . is defined by
where l is the period averages of daily RV, is the coefficients, and is a zero mean innovation process. The standard HAR model in Equation (2) is pinned down by some vector of lag index .
Andersen et al. (2007) extended the standard HAR model two ways. First, they added the daily jump component to Equation (2) to explicitly capture its impacts. The extended model is denoted the HAR-J model:
where the empirical measurement of the squared jumps is and the standardized realized bipower variation (BPV) is defined as
Second, through a decomposition of RV into the continuous sample path and the jump component based on the statistic, Andersen et al. (2007) reconstructed the HAR-J model by explicitly incorporating the two types of volatility components mentioned above. The statistic identifies the “significant” jumps and the continuous sample path components respectively as
where is the ratio statistic in Huang and Tauchen (2005)6 and is the cumulative distribution function (CDF) of a standard Gaussian distribution with an level of significance. The daily, weekly, and monthly average components of CSP and CJ are then constructed in the same manner as in Equation (3). The model specification for the continuous HAR-J, in other words, the HAR-CJ, is given by
Note the HAR-CJ model explicitly controls for the weekly and monthly effects of continuous jumps through the CJ, CJ, and CJ terms, whereas the HAR-J model consists of only one aggregate jump term J. Thus, the HAR-J model can be regarded as a special and restrictive case of the HAR-CJ model for , , , and .
To capture the role of the “leverage effect” in predicting volatility dynamics, Patton and Sheppard (2015) developed a group of models using signed realized measures. The first model, denoted as HAR-RS-I, decomposes the daily RV in the standard HAR model (Equation (2)) into two asymmetric semi-variances: and .
where and . To verify whether the realized semi-variances add something beyond the classical leverage effect, Patton and Sheppard (2015) augmented the HAR-RS-I model with a term interacting the lagged RV with an indicator for negative lagged daily returns . The second model in Equation (7) is named HAR-RS-II.
where is designed to capture the effect of negative daily returns. As in the HAR-CJ model, the third and fourth models in Patton and Sheppard (2015), denoted as HAR-SJ-I and HAR-SJ-II respectively, disentangle the signed jump variations and the BPV from the volatility process.
where , , and . The HAR-SJ-II model extends the HAR-SJ-I model by distinguishing the effect of a positive jump variation from that of a negative jump variation.
3. Model Uncertainty
It has been a tradition for the past literature to assume the lag structure of the HAR model to be , which mimics the daily, weekly, and monthly traders in traditional financial markets that only open on workdays. On the other hand, given the 24/7 nonstop nature of bitcoin trading, it may not be appropriate to set the lag index at . An initial guess for the lag index would be that represents the tradition of daily, weekly, and monthly averages. However, the suitability of such a specification is subject to a statistical investigation, which is likely to cause evident model uncertainty.
Suppose the dependent variable is and the explanatory variable is ,7 where the specification of takes the general form of the HAR model
Here, we do not restrict the lag index to be . Instead, we acknowledge the specification uncertainty in and consider a group of M candidate models to approximate the true data generating process. Following an usual approach in the model averaging literature, the set of M candidate models is constructed by taking a full permutation of all the lags from to ( and ). The maximum lag order is chosen as 30. In this way, there are distinct model weights assigned to each HAR-type model with different lag combinations. Moreover, as the underlying data sets vary, this will alter the relevant model weights, which effectively makes the method dynamic and data-driven.
Note that the model averaging estimator with pre-screened candidate models is implemented in this paper, since keeping the total number of candidate models manageable or slowing its convergence to infinity is a necessary condition to maintain the asymptotic optimality of least square model averaging estimators. However, in the context of the HAR model with a maximum lag order of , we could end up with candidate models and the number of potential models grows exponentially with . To solve this issue, we first apply the model screening method, for example, the adaptive regression by mixing with the model selection (ARMS) approach by Yuan and Yang (2005) or the hetero-robust model screening (HRMS) approach by Xie (2017). Both methods shrink the number of potential models by specifying model selection criteria before model averaging to an appropriate degree.
The true model is presumed to be
where , , and . can be considered the conditional mean in the period t, , and the error term has the zero conditional mean . Note that the error term is assumed to be heteroskedastic such that , which reflects a more realistic characterization of the realized volatility for a wide class of financial assets. In addition, we also hypothesize that is not serially correlated and .8 Let the mth candidate model be
where are subsets of columns of . With at hand, can be estimated by , and thus, is estimated by
where is a projection matrix for the model m. Extending from Hansen (2008), the optimal mean-square h-period ahead forecast is the conditional mean . Therefore, the least-squares forecast of from the mth approximation model is then . Note that by the definition of Equation (10), is observable in period t.
We obtain the forecasts of from all approximation models and define the vector of forecasts
The model averaging forecast is simply the weighted average of such that
where is a weight vector in the unit simplex in
The performance of model averaging forecast crucially depends on the weight vector . The model averaging estimator of the conditional mean is then given by
where is the averaged projection matrix. The H-MAHAR method is the heteroskedasticity-robust version of the model averaging HAR (MAHAR) method proposed by Lehrer et al. (2018). The MAHAR criterion function is defined as follows:
where is the effective number of parameters and is the number of regressors in the model m. We estimate the MAHAR weight estimator by minimizing the MAHAR criterion function under the restriction of .
Like most model selection and model averaging criteria, the H-MAHAR criterion balances between the fit and the complexity of a model:
where is the averaged estimate of the matrix using model averaging residuals .
The criterion in Equation (15) can be implemented to compute the empirical weight vector through
Therefore, we obtain the model averaging forecast of following . Note that the H-MAHAR estimator can be considered an extension to the model averaging with averaging covariance matrix (MAACM) estimator of Zhao et al. (2016) under the HAR framework, whereas the original MAACM estimator assumes no dynamic model structures.
Another heteroskedasticity-robust model-averaging method is the JMA estimator by Hansen and Racine (2012). The original JMA deals with cross-sectional data. Zhang et al. (2013) proved the asymptotic optimality of the JMA estimator under a dependent time-series. The JMA estimator is also known as leave-one-out cross-validation model averaging. As its name indicates, the JMA requires the use of jackknife residuals for the average estimator. The jackknife residual vector for model m can be conveniently expressed as , where is the least squares residual vector and is the diagonal matrix with the ith diagonal element equal to . The term is the ith diagonal element of the projection matrix . Define an matrix with all the jackknife residuals, in which The least squares cross-validation criterion for the JMA is simply
with model weights estimated through .
Liu and Okui (2013) adopted the same model setup to propose the HRCP model averaging estimator for linear regression models with heteroskedastic errors. They demonstrated the asymptotic optimality of the HRCP estimator when the error term exhibits heteroskedasticity. They proposed estimating the model weights by the following feasible HRCP criterion:
with . Obtaining by minimizing Equation (16) under the condition is a quadratic optimization process.
Equation (16) includes a preliminary estimate that must be obtained prior to estimation. Liu and Okui (2013) discussed several ways to obtain in practice. When the models are nested, Liu and Okui (2013) suggested using the residuals from the largest model. When the models are non-nested, they recommended building a model that contains all the regressors in the potential models and taking the corresponding predicted residuals. In addition, a degree-of-freedom correction on is reccomended to improve finite-sample properties. For example, when the mth model is chosen to obtain , we may use
instead of to generate the preliminary estimate .
4. Data Description
Binance was founded in September 2017 and is now the largest crypto exchange around the world. Since the Bitcoin to U.S. dollar (BTC/USD) price data on Binance has only recently become available, we use the data from 1 January 2018 to 20 December 2018 for this exercise. The total number of daily observations is 352. We estimate the daily RV using Equation (1) at the 5-min interval.
The evolution of the RV data over this period is plotted by the solid line in the upper panel of Figure 1, whereas the horizontal axis represents the date and the vertical axis on the left-hand side stands for RV. Besides RV, the price of BTC/USD is also depicted by the dashed line with the vertical axis on the right-hand- ide representing the price. We also list the corresponding daily trading volume in the lower panel of Figure 1. As seen in Figure 1, the dynamics of the RV follow the movements of price and volume: the RV increases as the price changes dramatically, which is usually accompanied by a noticeable peak in the trading volume.
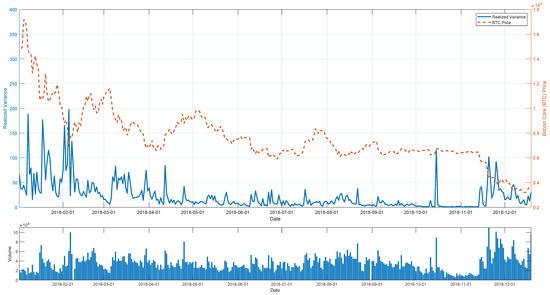
Figure 1.
BTC/USD price, realized variance, and volume on Binance.
Table 1 presents summary statistics for the data and p-values of both the Jarque–Bera (JB) test for normality and of the Augmented Dickey–Fuller (ADF) tests for unit root. Note that, for the JB and ADF test statistics that are outside tabulated critical values, we report the maximum (0.999) or minimum (0.001) p-values. In Table 1, we consider the first half, the second half, and full samples in columns 2–4, respectively. Each of the series exhibits tremendous variability and a large range across the respective sample period. Furthermore, none of the series are normally distributed or nonstationary at the 5% level.

Table 1.
Descriptive statistics of the BTC/USD RV.
5. The Empirical Exercise
To investigate the relative prediction efficiency of the H-MAHAR estimator and its comparison methods, we conduct an h-step-ahead rolling window exercise of forecasting the BTC/USD RV for various forecasting horizons.9 Table 2 lists each estimator considered in the exercise. For all the HAR-type estimators in Panel A, except the HAR-Full model with all the lagged covariates from 1 to 30, we set . For the model-averaging methods in Panel B, our general unrestricted model that includes all covariates is the HAR-Full model which only replaces RV10 with the semi-variance components from the HAR-RS-I. The candidate model set is first pre-screened by the ARMS method of Yuan and Yang (2005), and we only pick the top 10 models. The tuning parameter in LASSO is estimated through a 5-fold cross-validation.11 Throughout the experiment, the window length is fixed at 100 observations. We also tried other window lengths and reached similar conclusions. See Section 6.2 for additional details.
Table 2.
List of heterogeneous autoregressive (HAR)-type estimators.
We first consider the case of one-day-ahead forecast (). The results of the prediction experiment are reported in Table 3. The estimation strategies are listed in the first column, and the remaining columns present alternative criteria to evaluate the forecast performance. The criteria include (i) the mean squared forecast error (MSFE), (ii) the mean absolute forecast error (MAFE), (iii) the standard deviation of the forecast error (SDFE), and (iv) the Mincer–Zarnowitz pseudo .
Table 3.
Out-of-sample forecast comparison for the BTC/USD RV.
To ease interpretation, the results that identify the estimator with the best performance in each column of Table 3 is marked in bold. The performance of autoregressive models, represented by the AR(1) and HAR-Full models, is weak. For each panel, the HAR-type methods demonstrate noticeably improved performances relative to the autoregressive models. In the case of Bitcoin volatility, there is not much gain from including the jump and/or semi-variance components in the standard HAR model. The above set of results suggests that the heterogeneity in modeling Bitcoin volatility cannot be fully accommodated by simply adding extra covariates to the linear model. The least squares model-averaging methods that acknowledge model uncertainty show superior forecasting accuracy under all the evaluation criteria. Among the averaging methods, H-MAHAR displays the best performance. On the other hand, the model-selection-based LASSO method has the worst performance in this situation.
To examine if the improvement from the least squares model-averaging methods is statistically significant, we perform the modified Giacomini–White (GW) test (Giacomini and White 2006)12 of the null hypothesis that the column method performs equally as well as the row method in terms of MAFE. The corresponding p-values are presented in Table 4 for . We see that the gains in forecast accuracy from the model-averaging methods relative to other strategies are statistically significant at the 5% level.
Table 4.
Results of the Giacomini–White test for .
By exploring weight estimates of the H-MAHAR estimator on the full dataset, we can shed light on both the relative importance of the candidate models and the inclusion of various HAR-type lagged components. The models that are assigned the five highest weights by the H-MAHAR estimator are described in Table 5 (presented in the 2nd row of Table 5 in a descending fashion). The “x” sign indicates that the corresponding covariate (listed in the first column) is contained in the model. Certain variables, like RV and RV, are included in every model, but variables like RV or RV are excluded from each of the top five dominant models.
Table 5.
Top 5 models from the heteroskedasticity-robust model averaging HAR (H-MAHAR) estimator.
Throughout our analysis, we find that the incorporation of negative semi-variances improves the prediction accuracy and explains a large fraction of the variation in RV, which is consistent with the finding of the literature (Patton and Sheppard 2015). The H-MAHAR method places large weights on models with HAR components of lag indices greater than 15, which may be in part due to the strong short-term performance of the RV variable. We also observe that HAR components with high lag indices (for example, RV and RV) mimicking the long-term dynamics of RV are intensively picked by the model averaging process. Most importantly, none of the top 5 models has the conventional lag index specification of . The above exercise uncovers the sheer existence of model uncertainty for Bitcoin volatility and accredits the use of model-averaging methods.
6. Robustness Check
In this section, we perform three robustness checks on our results in Section 5. We first extend the exercises to relatively longer forecast horizons. Specifically, we consider and 4. In the second robustness check, we consider alternative window lengths. In the last robustness check, the H-MAHAR method is compared with Model 1 from Table 5, the one with the highest model weight among all candidate models.
6.1. Various Forecast Horizons
Table 6 represents the forecast performance of the considered estimators for , 3, and 4 periods ahead.13 Table 7 examines the statistical significance of the forecasting accuracy improvement. For all h periods, the forecasts by least squares model averaging estimators dominate those by other methods in general. Among all the model averaging estimators, the HRCP method is seen to perform the best in most times according to the criteria we used, although such improvement is not statistically significant according to the results in Table 7.
Table 6.
Forecast performance comparison for various horizons.
Table 7.
Results of the Giacomini–White test for various forecast horizons.
6.2. Alternative Window Lengths
In the main exercises, we set the window length at . In this section, we also tried other window lengths such as and 200. We present the estimation results for . Although not reported here, we also tried other forecast horizons and the robustness remains intact.
Table 8 shows the forecast performance of all the methods for various window lengths. In all the cases, the H-MAHAR estimator yields the smallest MSFE, MAFE, and SDFE and the largest Pseudo . We examine the statistical significance of the forecast accuracy improvement in Table 9. The small p-values on the H-MAHAR method against other methods, especially that with no model averaging estimators, indicate that the improvement is significant at the 5% level in most cases.
Table 8.
Forecast performance comparison under different window lengths.
Table 9.
Results of the Giacomini–White test for different window lengths.
7. Conclusions
In this paper, we study the forecast performance of least squares model-averaging methods when predicting Bitcoin volatility. Our method allows for a more general lag structure under the HAR framework, instead of restricting it to daily, weekly, and monthly frequencies. Specially, we estimate the semi-variance HAR models in Patton and Sheppard (2015) with the least squares model-averaging method and consider constructing the potential model set with a full permutation of all of the possible lags and the maximum lag order of 30. The H-MAHAR-embedded model is data-driven, as the empirical weights on potential models with different lag combinations vary with underlying volatility series and forecast horizons.
In the out-of-sample application to high-frequency data of the realized variance of BTD/USD, we provide suggestive evidence that there exists excessive model uncertainty when modeling the Bitcoin volatility by conventional regression methods. We further demonstrate that the model-averaging methods can generally outperform conventional regression methods under various forecast criteria as well as across all forecast horizons . Specifically, we apply the GW test to examine the statistical significance of the improvement made by the model-averaging method. We reveal that the model-averaging method, especially the one robust to heterskedasicity (the H-MAHAR), performs significantly better than conventional regressions at a 5% confidence level. Therefore, the least squares model-averaging methods adapt themselves remarkably well to a relatively short sample with evident model uncertainty.
This research also shed some light on future works related to the emerging asset class such as the cryptocurrency. When a new asset class is introduced, proper asset valuation theory is always invented with lags and institutional investors will hesitate to enter the market for risk control purposes. Regulations and technology developments are also likely to keep the market structure susceptible to shocks and to cause great price variations. Moreover, the lack of trading data of long durations is particularly a concern compared with other well-established asset classes. In this situation, model averaging contributes to alleviating model specification uncertainty and even to controlling for heteroskedasticity. There are still some interesting questions left to further research, for instance, the deep relationship between the crypto trading environment (i.e., the impact of sentiment ) and volatility data structure.
Funding
This research was funded by the National Natural Science Foundation of China grant number 71701175 and the Humanities and Social Science Fund of Ministry of Education of China grant number 17YJC790174.
Acknowledgments
I wish to thank Yue Qiu, Guanxi Yi, and Jun Yu, seminar participants at the SoFiE 2019 Conference in Shanghai from Xiamen University, Shanghai University of Finance and Economics, and Singapore Management University, respectively, for their helpful comments and suggestions. The usual caveat applies.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Andersen, Torben G., and Tim Bollerslev. 1998. Answering the Skeptics: Yes, Standard Volatility Models Do Provide Accurate Forecasts. International Economic Review 39: 885–905. [Google Scholar] [CrossRef]
- Andersen, Torben G., Tim Bollerslev, and Francis X. Diebold. 2007. Roughing It Up: Including Jump Components in the Measurement, Modeling, and Forecasting of Return Volatility. The Review of Economics and Statistics 89: 701–20. [Google Scholar] [CrossRef]
- Andersen, Torben G., Tim Bollerslev, Francis X. Diebold, and Heiko Ebens. 2001a. The distribution of realized stock return volatility. Journal of Financial Economics 61: 43–76. [Google Scholar] [CrossRef]
- Andersen, Torben G., Tim Bollerslev, Francis X. Diebold, and Paul Labys. 2001b. The Distribution of Realized Exchange Rate Volatility. Journal of the American Statistical Association 96: 42–55. [Google Scholar] [CrossRef]
- Audrino, Francesco, and Simon D. Knaus. 2016. Lassoing the HAR Model: A Model Selection Perspective on Realized Volatility Dynamics. Econometric Reviews 35: 1485–521. [Google Scholar] [CrossRef]
- Audrino, Francesco, Huang Chen, and Okhrin Ostap. 2019. Flexible HAR Model for Realized Volatility. Studies in Nonlinear Dynamics & Econometrics 23: 1–22. [Google Scholar]
- Audrino, Francesco, Lorenzo Camponovo, and Constantin Roth. 2015. Testing the lag Structure of Assets’ Realized Volatility Dynamics. Economics Working Paper Series 1501; St. Gallen: University of St. Gallen, School of Economics and Political Science. [Google Scholar]
- Barnard, George A. 1963. New Methods of Quality Control. Journal of the Royal Statistical Society. Series A (General) 126: 255–58. [Google Scholar] [CrossRef]
- Breiman, Leo. 2001. Random Forests. Machine Learning 45: 5–32. [Google Scholar] [CrossRef]
- Buckland, Steven T., Kenneth P. Burnham, and Nicole H. Augustin. 1997. Model Selection: An Integral Part of Inference. Biometrics 53: 603–18. [Google Scholar] [CrossRef]
- Corsi, Fulvio, Francesco Audrino, and Roberto Renò. 2012. HAR Modeling for Realized Volatility Forecasting. In Handbook of Volatility Models and Their Applications. Hoboken: John Wiley & Sons, Inc., pp. 363–82. [Google Scholar]
- Corsi, Fulvio, Stefan Mittnik, Christian Pigorsch, and Uta Pigorsch. 2008. The Volatility of Realized Volatility. Econometric Reviews 27: 46–78. [Google Scholar] [CrossRef]
- Corsi, Fulvio. 2009. A Simple Approximate Long-Memory Model of Realized Volatility. Journal of Financial Econometrics 7: 174–96. [Google Scholar] [CrossRef]
- Craioveanu, Mihaela, and Eric Hillebrand. 2012. Why It Is OK to Use the HAR-RV (1, 5, 21) Model. Technical Report. Missouri: University of Central Missouri. [Google Scholar]
- Dacorogna, Michael M., Ulrich A. Müller, Robert J. Nagler, Richard B. Olsen, and Olivier V. Pictet. 1993. A geographical model for the daily and weekly seasonal volatility in the foreign exchange market. Journal of International Money and Finance 12: 413–38. [Google Scholar] [CrossRef]
- Giacomini, Raffaella, and Halbert White. 2006. Tests of Conditional Predictive Ability. Econometrica 74: 1545–78. [Google Scholar] [CrossRef]
- Hansen, Bruce E. 2007. Least Squares Model Averaging. Econometrica 75: 1175–89. [Google Scholar] [CrossRef]
- Hansen, Bruce E. 2008. Least-squares forecast averaging. Journal of Econometrics 146: 342–50. [Google Scholar] [CrossRef]
- Hansen, Bruce E. 2009. Averaging Estimators for Regressions with A Possible Structural Break. Econometric Theory 25: 1498–514. [Google Scholar] [CrossRef]
- Hansen, Bruce E. 2010. Averaging Estimators for Autoregressions with A Near Unit Root. Journal of Econometrics 158: 142–55. [Google Scholar] [CrossRef]
- Hansen, Bruce E., and Jeffrey S. Racine. 2012. Jackknife model averaging. Journal of Econometrics 167: 38–46. [Google Scholar] [CrossRef]
- Hoeting, Jennifer A., David Madigan, Adrian E. Raftery, and Chris T. Volinsky. 1999. Bayesian Model Averaging: A Tutorial. Statistical Science 14: 382–401. [Google Scholar]
- Huang, Xin, and George Tauchen. 2005. The Relative Contribution of Jumps to Total Price Variance. Journal of Financial Econometrics 3: 456–99. [Google Scholar] [CrossRef]
- Lehrer, Steven F., Tian Xie, and Xinyu Zhang. 2018. Wits versus Tweets: Does Adding Social Media Wisdom Trump Admitting Ignorance when Forecasting the CBOE VIX? Working Paper A0167. Hong Kong, China: The City University of Hong Kong. [Google Scholar]
- Liu, Qingfeng, and Ryo Okui. 2013. Heteroskedasticity-robust Cp Model Averaging. The Econometrics Journal 16: 463–72. [Google Scholar] [CrossRef]
- Magnus, Jan R., Owen Powell, and Patricia Prüfer. 2010. A comparison of two model averaging techniques with an application to growth empirics. Journal of Econometrics 154: 139–53. [Google Scholar] [CrossRef]
- Müller, Ulrich A., Michel M. Dacorogna, Rakhal D. Davé, Olivier V. Pictet, Richard B. Olsen, and J. Robert Ward. 1993. Fractals and Intrinsic Time—A Challenge to Econometricians. Technical Report. Zürich: Olsen & Associates. [Google Scholar]
- Patton, Andrew J., and Kevin Sheppard. 2015. Good Volatility, Bad Volatility: Signed Jumps and The Persistence of Volatility. The Review of Economics and Statistics 97: 683–97. [Google Scholar] [CrossRef]
- Qiu, Yue, and Tian Xie. 2018. Forecasting Foreign Exchange Realized Volatility: A Least Squares Model Averaging Approach. Journal of Systems Science and Mathematical Sciences 38: 725–44. [Google Scholar]
- Qiu, Yue, Xinyu Zhang, Tian Xie, and Shangwei Zhao. 2019. Versatile HAR model for realized volatility: A least square model averaging perspective. Journal of Management Science and Engineering 4: 55–73. [Google Scholar] [CrossRef]
- Wan, Alan TK, Xinyu Zhang, and Guohua Zou. 2010. Least Squares Model Averaging by Mallows Criterion. Journal of Econometrics 156: 277–83. [Google Scholar] [CrossRef]
- Xie, Tian. 2015. Prediction Model Averaging Estimator. Economics Letters 131: 5–8. [Google Scholar] [CrossRef]
- Xie, Tian. 2017. Heteroscedasticity-robust Model Screening: A Useful Toolkit for Model Averaging in Big Data Analytics. Economics Letters 151: 119–22. [Google Scholar] [CrossRef]
- Yuan, Zheng, and Yuhong Yang. 2005. Combining Linear Regression Models: When and How? Journal of the American Statistical Association 100: 1202–14. [Google Scholar] [CrossRef]
- Zhang, Xinyu, Alan TK Wan, and Guohua Zou. 2013. Model averaging by jackknife criterion in models with dependent data. Journal of Econometrics 174: 82–94. [Google Scholar] [CrossRef]
- Zhao, Shangwei, Xinyu Zhang, and Yichen Gao. 2016. Model Averaging with Averaging Covariance Matrix. Economics Letters 145: 214–17. [Google Scholar] [CrossRef]
| 1. | The CME Group Inc. (Chicago Mercantile Exchange & Chicago Board of Trade) in December 2017 launched Bitcoin future (XBT), with Bitcoin as the underlying asset. |
| 2. | This phenomenon has been documented by Dacorogna et al. (1993) and Andersen et al. (2001b) for the foreign exchange market and by Andersen et al. (2001a) for stock market returns. |
| 3. | ARFIMA is designed to model time series with long memory at the beginning. It is now a popular tool for modeling volatility, since volatility exhibits long memory. |
| 4. | Corsi et al. (2012) provided a comprehensive review of the development of HAR-type models and their various extensions. |
| 5. | Müller et al. (1993) referred to this interpretation as the Heterogeneous Market Hypothesis. |
| 6. | The ratio statistic is defined as
|
| 7. | Although all the elements in are h-period lags from the period t, we follow the conventional notation in time series and denote as the explanatory variable corresponding to the period t dependent variable. |
| 8. | Corsi et al. (2008) also demonstrated that the residuals of commonly used realized volatility models for the S&P 500 index exhibit non-Gaussianity and volatility clustering. They assessed its relevance for modeling and forecasting volatility in the proposed HAR-GARCH model. |
| 9. | Additional results using both the GARCH and the ARFIMA models are available upon request. These estimators performed poorly relative to the HAR model and thus are not included for space limitation. |
| 10. | The reason we have to exclude RV is because the summation of semi-variance terms equals RV. |
| 11. | We also tried the 10-fold cross-validation and fixed tuning parameter . The results remain qualitatively intact. |
| 12. | Giacomini and White (2006) proposed a framework for out-of-sample predictive ability testing and forecast selection designed for use in the realistic situation in which the forecasting model is possibly misspecified due to unmodeled dynamics, unmodeled heterogeneity, incorrect functional form, or any combination of these. The null hypothesis of the GW test is that the two models we want to compare are equally accurate on average based on certain criterion. |
| 13. | Note that the forecasting horizons we considered in this paper are all short. The HAR-type models which our model-averaging methods build upon do not perform well in the long forecasting horizons. One possible explanation is that the Bitcoin market is relatively small compared to conventional stock markets; therefore, it is more sensitive to various policy shocks, information impact, and even social media sentiment changes. Most of these shocks are short-lived, and it seems that the momentum effect does not last long in Bitcoin realized volatility. How to model Bitcoin volatility in a long forecasting horizon is beyond the scope of this paper and guarantees future research. |

© 2019 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).