1. Introduction
To meet the increasing requirements of the new generation aircraft, the aero-engine is developed to have more control variables, more complex structures, and more changeable flight environments. The design of controllers remains one of the major challenges in the field of the aero-engine. Facing such multivariable and strongly nonlinear plants, it is difficult for traditional control methods to fully exploit the aero-engine performance [
1].
Reinforcement learning (RL), as a typical branch of machine learning, is concerned with the agent’s behavior in an environment so as to maximize some notion of cumulative rewards. It is regarded as the key to the possible realization of general artificial intelligence [
2,
3]. RL is developed from cybernetics and is suitable for solving nonlinear control problems. When applying deep neural networks to reinforcement learning, Ref. [
3] solved the encountered problems and greatly improved the overall performance, opening the era of deep reinforcement learning (DRL). During the past few years, a variety of excellent RL algorithms have been proposed [
4,
5,
6,
7,
8]. As the baseline algorithm of OpenAI, an artificial intelligence research company whose core purpose is “to realize safe general artificial intelligence”, the proximal policy optimization algorithm (PPO) is one of the most advanced and practical algorithms in recent years [
9]. Nowadays, DRL has been widely developed in intelligent robots, automatic driving, intelligent transportation systems, game competition, and other fields [
10,
11,
12,
13,
14,
15,
16]. Due to its powerful representation ability, deep reinforcement learning is suitable for dealing with the multivariable and strongly nonlinear controlled plants, just like today’s aero-engines. This is the motivation for our research on aero-engine control based on deep reinforcement learning.
Another research focus in the field of aero-engine control is the establishment of a digital model. A control system needs to be verified by a digital simulation model before it is put into use. Additionally, the airborne adaptive model can provide more useful information for the control system, including analytical redundancy for sensor diagnosis. Machine learning methods, such as nonlinear support vector machine (NSVM), extreme gradient boosting decision tree (XGBoost), and deep neural network (DNN), are suitable for the strong nonlinear plants [
17,
18,
19]. The deep neural network is suitable for characterizing the strongly nonlinear dynamic transfer characteristics of aero-engines. More importantly, we found that the samples in the replay buffer of deep reinforcement learning contain the dynamic transfer characteristics of aero-engine, which can be directly used for the training of the aero-engine digital model. In view of this, this paper establishes the dynamic prediction model of an aero-engine based on a deep neural network and supported by the replay buffer of deep reinforcement. Compared with the widely used component-level model based on rotor dynamics, this neural network model has the advantage of avoiding time-consuming iterative calculation and manual parameter adjustment.
One of the disadvantages of reinforcement learning is its low learning efficiency. The essence of RL is to learn by trial and error, so effective information needs to be extracted from a large number of training samples. With the support of the dynamic prediction model, the model-based reinforcement learning method can be developed. The dynamic prediction model above can improve the accuracy of value function approximation in the process of deep reinforcement learning and finally improve the learning efficiency [
20,
21,
22]. Meanwhile, with more information about the environment, the risk of exploration behavior can be reduced in the learning process.
This paper trains the deep reinforcement learning controller and the deep network dynamic prediction model at the same time and obtains twice the result with half the effort. The proximal policy optimization algorithm is selected to train the controller, and the recurrent neural network is selected as the structure of the dynamic prediction model of the aero-engine. The replay buffer of deep reinforcement learning provides the training samples for the dynamic prediction model. In turn, the dynamic prediction model is used to improve the learning efficiency of deep reinforcement learning.
This paper proceeds as follows. In
Section 2, the related work is discussed. In
Section 3, the aero-engine control system is designed based on deep reinforcement learning.
Section 4 devotes to the algorithm of deep reinforcement learning.
Section 5 establishes the dynamic prediction model of the aero-engine, which is used to improve the learning efficiency of deep reinforcement learning with the model-based method. To demonstrate the effectiveness and superiority of our methods, simulation experiments are conducted in
Section 6. Finally,
Section 7 concludes the paper.
2. Related Work
In this section, the related work that aims to study aero-engine control based on deep reinforcement learning is discussed.
Deep Q-learning (DQN) is the first deep reinforcement learning algorithm used in aero-engine control [
23,
24]. However, DQN takes the value function as the output and indirectly takes it as the basis of action selection. It is difficult to deal with the control problem of continuous action space and needs the assistance of a nonlinear optimization algorithm. While the actor-critic framework combines the advantages of the value function method and the gradient method, in which the actor directly takes the action as its output, thus a series of algorithms based on it, such as the deep deterministic policy gradient algorithm (DDPG) and the advantage actor-critic algorithm (A2C) are more suitable for continuous action space problems such as the aero-engine control [
25,
26,
27]. In order to alleviate the oscillation caused by the sudden change of control variables, the phase-based reward function is proposed [
24]. In Ref. [
25], the momentum term is introduced to suppress this oscillation problem, and the error integral term is introduced to improve the steady-state performance of the reinforcement learning controller. In Ref. [
26], deep reinforcement learning is applied to the optimization control problem of minimum fuel consumption performance of variable cycle engines. Ref. [
27] applies the long-short-term memory recurrent neural network to design the thrust estimator and the proximal policy optimization algorithm (PPO) to realize the direct thrust control of the aero-engine.
The main contributions of this paper are as follows: (1) a novel application of deep reinforcement learning (DRL) is presented for aero-engine control. (2) In order to fully tap the potential of deep reinforcement learning, an aero-engine dynamic prediction model with excellent performance is trained by using the samples in the replay buffer of deep reinforcement learning. (3) Based on the above dynamic prediction model, the learning efficiency of deep reinforcement learning is improved by adopting the model-based method.
3. DRL Control System for Aero-Engine
The cross-sectional schematic diagram of a turbofan engine (the controlled plant in this paper) is shown in
Figure 1. The number and name of each section of the aero-engine are given in the figure. The control task of this paper is to make the corrected compressor rotor speed
and the engine pressure ratio
track the reference control instruction while ensuring the safety of the engine by adjusting the corrected main fuel flow
and the throat cross-sectional area
. The above variables are expressed as follows:
where
is the physical compressor rotor speed,
the total temperature of the engine
Section 1,
the pressure of the engine
Section 5,
the pressure of the engine
Section 2,
the main fuel flow,
the total pressure of the engine
Section 1.
3.1. The Structure of Aero-Engine Control System
The standard reinforcement learning setting is an infinite-horizon discounted Markov decision process (MDP), defined by a tuple , where is the set of states, the set of actions, the transition dynamic probability distribution, the reward function, the probability distribution of the initial state , and the discounted factor determining the priority of short-term rewards. In reinforcement learning, an agent interacts with the environment and learns the reward-maximizing behavior, which is denoted as . The policy maps the states to a probability distribution over the actions, i.e., .
The process of the agent learning in the interaction with the environment is shown in
Figure 2. After the agent performs a certain action
, the environment will switch to a new state
, and the environment will generate a reward signal
according to the new state. Subsequently, the agent executes a new action
according to a certain policy
and environmental feedback
. In this paper, the agent is the aero-engine controller, and the environment is the aero-engine that performs the acceleration process. Every time the controller interacts with the aero-engine, a tuple
is generated and stored in the replay buffer, which will provide training sample support to optimize the policy
.
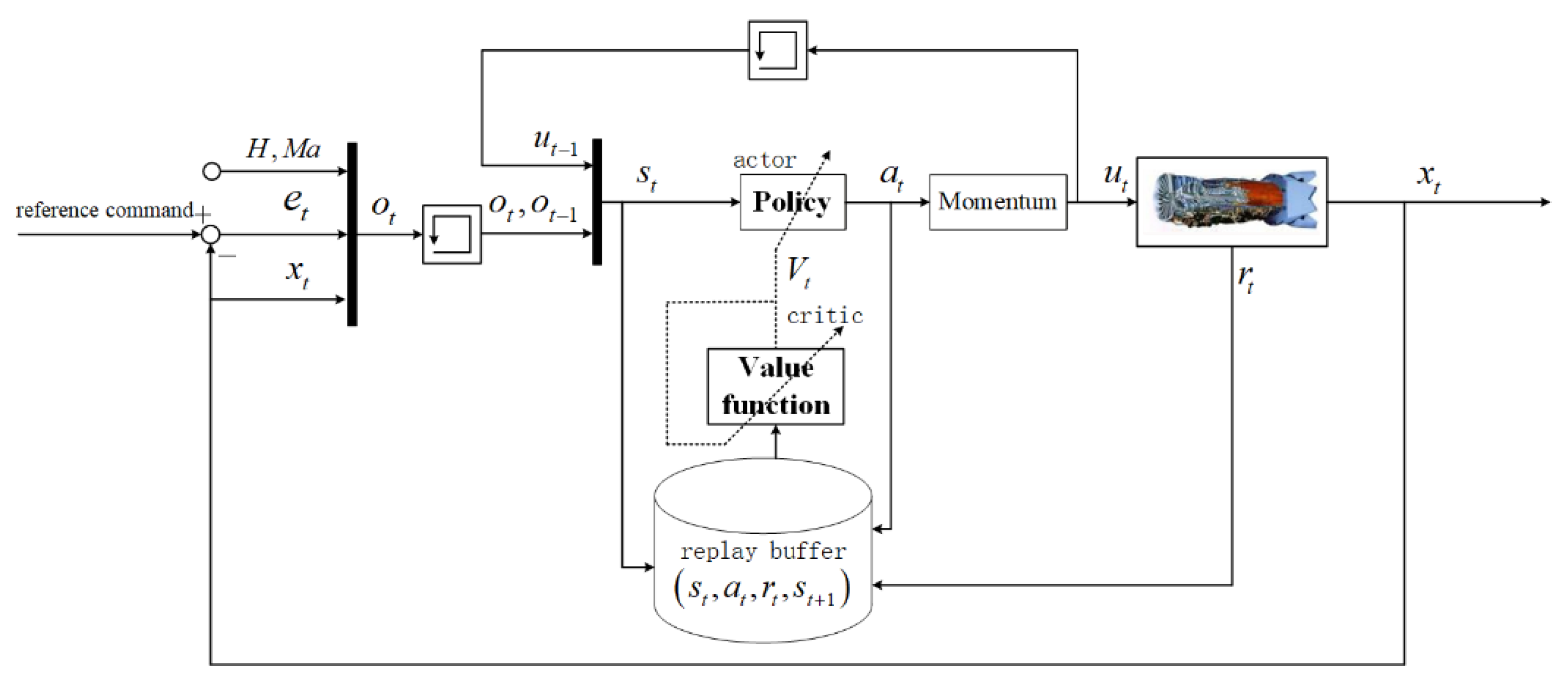
Figure 3 shows the structure of the aero-engine control system. The agent adopts the actor-critic framework, in which the actor is responsible for performing the action according to a certain policy while the critic is responsible for evaluating the quality of the action by outputting the advantage function. This process will be explained in detail in
Section 4. The input of the actor is the state
, where
is the depth of the trajectory and
the observation of the environment at time
. If
takes a larger value, which means that the current trajectory will have a longer influence of on the future. In the following simulation, the trajectory depth is selected as
m = 2. The observation
includes the states of the aero-engine
, the control error
, and the flight conditions
:
The state of the aero-engine is selected as , where is the corrected compressor rotor speed, is the engine pressure ratio, is the physical fan rotor speed, is the physical compressor rotor speed, is the compressor surge margin, is the fan surge margin, and is the high-pressure turbine outlet temperature. After the aero-engine executes the control variable vector , the aero-engine state will shift from to , and the aero-engine will output a reward signal . The tuple constitutes a training sample, stored in the replay buffer.
3.2. Formulation of the Reward Signal
The reward is a very crucial signal, which is fed back to the critic from the aero-engine and contains information about the task goal. The process of formulating the reward is equivalent to the process of formulating learning goals for the agent.
The control objective is to minimize the error between the controlled variables and the reference instructions by adjusting the input of the aero-engine under different flight conditions. Due to the extreme operating environment of the aero-engines, it is necessary to ensure that the key performance parameters do not exceed the limit, including , , , , and .
Based on the control objective, the reward signal can be defined as follows:
where
and
are the positive gain coefficients,
is a key performance parameter, and
is the limit of the corresponding key performance parameter. The first error term
on the right side of Equation (3) can ensure the tracking performance of the controller. The role of the second term on the right side of Equation (3) is to achieve restrictive protection. When the key performance parameters do not exceed the limit margin
, this term is equal to zero, so the control policy will not be affected when the key performance parameters do not exceed the limit. However, when the key performance parameters exceed the limit, the second term will give the agent a large negative benefit, which will drive the agent to avoid making a decision that will cause the over-limit problem.
3.3. The Structure of the Agent
As mentioned in
Section 3.1, the agent is composed of the actor and the critic. The actor is a deep neural network to approximate the policy
, as shown in
Figure 4. In the learning process, the agent needs to explore all the schemes in the feasible region to find the optimal policy without falling into the local optimum. Therefore, the policy learned by the actor would have some randomness. In
Figure 4, the actor does not directly output the action
, but outputs the relevant parameters of the probability distribution of the action value. The normal distribution is adopted in this paper to approximate the probability distribution of the action, that is, the actor outputs the mean
and variance
of the normal distribution
.
To prevent serious accidents such as surges and stalls caused by the randomness of the actions, a momentum term is introduced to suppress abrupt changes in the engine input, as shown in
Figure 3 as follows:
where
is the momentum factor and
the input of the aero-engine. In this way, even if
changes abruptly, the input
can remain stable when
is much less than 1.
Similar to the actor, the critic is also a deep neural network the difference is that its output is the approximate state value function
, where
is the parameter vector of the critic network. The definition and use of
will be explained in
Section 4.
4. Parameters Update of Actor-Critic Based on Deep Reinforcement Learning
Let
denote the expected discounted cumulative reward of the policy
:
where
,
,
.
The aim of the agent is to learn the optimal policy
to maximize the expected discounted cumulative rewards
. The state value function
and the action value function
are defined as follows:
where
and
.
It can be inferred from the Equation (6) that the state value function is the expectation of the action value function:
. The advantage function is defined as follows:
which indicates the advantage of the action
under the state
. Ref. [
21] has proved that the gap between the two expected discounted cumulative rewards
and
can be represented by the advantage function as follows:
where
,
,
.
The second term on the right side of the Equation (8) can be expanded to the following:
where
means the probability the state is
at time
when the actions are chosen according to policy
.
Define
. Equation (9) can be simplified to the following:
Equation (9) implies a policy optimization method by maximizing the second term
. If the policy parameterized, i.e.,
is a differentiable function of the parameter vector
, the parameter update law can be constructed as follows:
where
is the update step size.
However, due to the complex dependency of
on
, it is impractical to optimize the policy with Equation (11) directly. A simple way to avoid this problem is to introduce a local approximation is as follows:
where
is replaced by
.
matches
to first order. It means that for any
, there is the following:
Equation (13) implies that a sufficiently small step that updates the policy and increases will also lead to an increase in . However, there is no guidance on how small the step size is to meet the requirements.
Ref. [
22] has proved the following:
where
,
, and
is the Kullback-Leibler Divergence.
According to Equations (14) and (15), can be maximized by maximizing , thus improving the policy.
The objective function needs to be transformed into an expectation representation so that it can be approximated using sampling-based methods, such as Monte Carlo simulation. Replace the sum over the actions with an importance sampling estimator the contribution of a single state
to the objective function can be expressed as follows:
where
denotes the sampling distribution. In this paper, the training data are sampled according to the old policy
, so that
. Further replace
with the expectation
, the second term on the right side of Equation (12) is exactly equivalent to Equation (16), written in terms of expectations as follows:
The second term on the right side of Equation (15)
is difficult to calculate. Actually, it can be regarded as a penalty item to reduce the update step size of the policy. In PPO, the objective is simplified to a form that is easier to implement the following:
where
is an adaptive penalty coefficient, which will change with the average KL divergence
:
where
is a coefficient set heuristically, and
the target value of the KL divergence. When
takes a small value, the adaptive coefficient
will reduce the impact of the penalty term. Vice versa.
A critic neural network is built to estimate the state-value function
, where
is the parameter vector.
can be calculated through Equation (7), where
can be approximated by
,
. Thus, Equation (18) can be updated to the following:
where
.
The aim of the critic neural network is to estimate the action-value function
accurately. With the insight of the Bellman function, its loss function can be designed as follows:
The expectation in Equations (19) and (20), and , can be approximated by sampling from the replay buffer , where represents the replay buffer. According to , the parameter vector of the actor can be updated with the following gradient ascending method: , while the parameter vector can be updated with the gradient descent method according to : , where is the learning rate.
5. Deep Neural Network Dynamic Prediction Model and Model-Based Reinforcement Learning
5.1. Deep Neural Network Dynamic Prediction Model
The tuple in the replay buffer contains the state transition information of the aero-engine, which can be used to train and identify the dynamic characteristics of the aero-engine. Therefore, a dynamic prediction model of the aero-engine based on a deep neural network is established in this section.
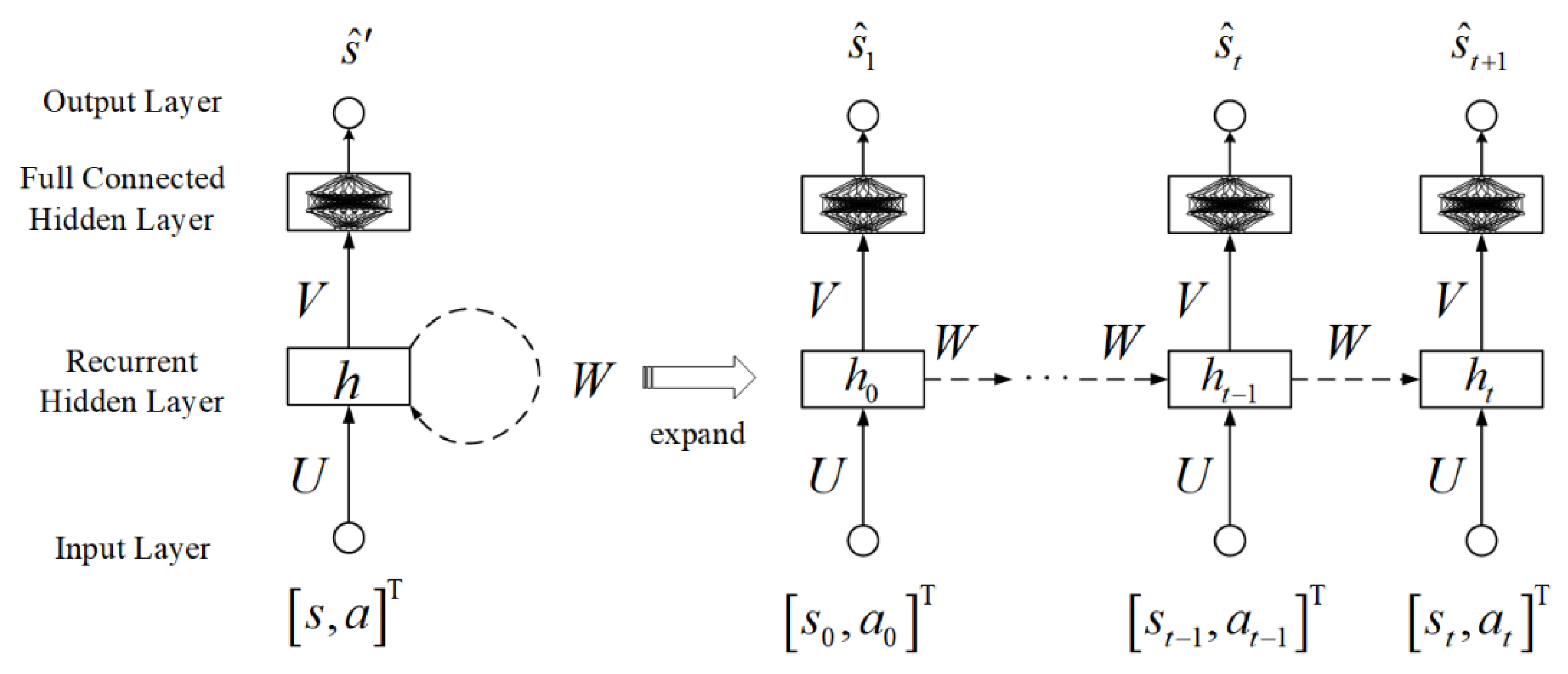
As shown in
Figure 5, the recurrent neural network is selected as the network structure of the dynamic prediction model. The characteristic of the recurrent neural network is that the intermediate vector obtained by the operation of neurons at the last time can continue to be used as the input of neurons at the next time, which makes the relationship of input data in the time dimension reflect. The recurrent neural network can better mine a large amount of context information between training data and analyze the complex correlation between data in the time dimension. Moreover, the mechanism of recurrent neural network sharing parameter vectors for each time data can reduce the complexity of the model and the difficulty of training. As shown in
Figure 5, the input layer transfers the network input, the state, and action vector pairs
, to the recurrent hidden layer. Through the loop connection on the recurrent hidden layer, the influence of times series samples in the future is retained, and the recurrent hidden layer vector
is generated. Finally, the nonlinear ability is improved by the fully connected hidden layer, and the state prediction in the future
is realized by the output layer. The forward propagation equation can be expressed as follows:
where
is the weight matrix from the input layer to the recurrent hidden layer,
is the weight matrix of the recurrent hidden layer connected in time dimension,
is the weight matrix of the recurrent hidden layer to the fully connected hidden layer, while
and
are offset vectors,
is the activation function of the recurrent hidden layer,
is simplified to represent the whole fully connected hidden layer.
predicted at time
can be used as the network input at time
. According to the policy
,
can be continuously predicted, and multi-step prediction can be realized by this cycle.
The tuples in the replay buffer are stored according to time to form a state-decision series chain
, which is used as the training sample. The loss function related to the samples at time
is the two norms of error vector between the real state
and the predicted state
at time
:
While the overall loss function can be expressed as follows:
where
is defined as the prediction lag degree.
Finally, the gradient descent method is applied to train the network parameter vector according to the following overall loss function:
For convenience, all the trainable parameters of the recurrent neural network are represented by parameter vector , including , , , and the trainable parameters in .
5.2. Model-Based Method for Improving Training Efficiency
The algorithm mentioned in
Section 4 is model-free, in which the transition dynamic probability distribution
is unnecessary. In
Section 4, it is mentioned that the advantage function is calculated by the following:
where the action-value function
is estimated by the following:
The first term is the real value, while the second term itself is an estimate, which will aggravate the estimation error of . However, with the dynamic prediction model, the influence of on the estimation error of can be weakened. Under the current state and action , the prediction state-action pairs, , can be obtained by multi-step prediction using the dynamic prediction model and policy, where is the prediction depth. According to the prediction state, the prediction reward function can be calculated: .
The Equation (25) can thereby be replaced by the following:
Because the discount factor , becomes the key to reducing the influence of . Although the prediction error in steps is introduced in, it also provides more information. From the empirical point of view, the convergence rate of the supervised learning of the dynamic prediction model is much faster than that of the reinforcement learning. Hence at the initial stage of the learning process, the addition of a dynamic prediction model can provide a more accurate estimation of the action value function , thus improving training efficiency of reinforcement learning.
Both Equations (19) and (20) can be improved to (27) and (28) with
:
This model-based reinforcement learning is summarized in Algorithm 1.
| Algorithm 1 |
| Initialize critic with , actor with , model network with , and replay buffer . |
| for do |
| Receive initial observation state |
| for do |
|
|
|
|
| Execute and observe reward , and new states . |
| Store transition in replay buffer |
| end for |
| Update by minimizing the loss function with epochs |
| Update by minimizing the loss function with epochs |
| Update by maximizing the objective function with epochs |
| Initialize replay buffer |
|
|
| end for |
6. Simulations and Analyses
In this paper, the digital simulation experiments are carried out based on the aero-engine component-level model. The control performance is verified by the acceleration task from the idle state to the intermediate state.
6.1. Hyperparameter Setting
There are some hyperparameters that need to be selected as follows to complete the simulation. The simulation step size is 0.02 s. The definitions and the values of some partial hyperparameters are listed in
Table 1. The hyperparameters
,
,
are selected according to Ref. [
22]. The momentum factor
is introduced to prevent major accidents and model collapse in simulation, but too large a momentum factor will lead to too conservative a control algorithm. In the experiment, it is concluded that when
is around 0.015, the model can run stably, and the influence on the control performance can be minimized. The key to the selection of hyperparameters
and
is that
is much larger than
to ensure the effect of limiting protection. In the experiment, the control policy of agent learning basically converges to the optimal policy within 2000 episodes, while the key parameters of the engine can be stable within 500 steps.
The actor network has 3 fully connected hidden layers with 256, 256, and 256 units, respectively, while the critic network has 2 fully connected hidden layers with 256 and 256 units, respectively. The dynamic prediction model has a recurrent hidden layer and 2 fully connected hidden layers with 128 and 128 units, respectively. These three neural networks both use the rectified linear unit (ReLU) as the activation function for hidden layers, except that the output layer of the mean of the actor network is a tanh layer, the output layer of the variance of the actor network is a sigmoid layer, and the recurrent layer of the dynamic prediction model is a tanh layer.
6.2. Performance of the DRL Controller
Since the essence of the DRL controller is a deep neural network estimator, estimation errors are inevitable. Such estimation errors have a great impact on the asymptotic performance of acceleration control. The steady-state error cannot be guaranteed to be zero, but it can be reduced to an acceptable range. The impact of the flight conditions on aero-engine performance is also a problem. The optimal policy learned by the agent should ensure satisfactory asymptotic performance under various flight conditions in the whole experimental flight envelope. Thousands of accelerated experiments are conducted, and training samples are collected to ensure that the trained agent learns the average optimal policy within the experimental flight envelope. Considering that the aero-engine acceleration process usually occurs at low altitudes and low Mach number, the flight conditions are set as , . The asymptotic performance in this paper is reflected by the steady-state error .
The steady-state errors in the flight envelope are shown in
Figure 6. As can be seen from the results, the maximum steady-state error is 0.003542, and the average steady-state error is 0.001144, which is small enough to be negligible and will not affect aero-engine performance in practical applications.
This paper shows our controller’s dynamic performance of the complete acceleration task compared with the traditional PID controller with the min-max limit protection. The simulation results are shown in
Figure 7, where the red solid lines represent the control curve of the DRL controller, the black solid lines represent the control curve of the traditional PID controller, the brown dot lines indicate the control reference instructions, and the yellow dash-dot lines indicate the limit boundary of key performance parameters. All variables in the Figure are normalized according to the design point parameters, so they are dimensionless.
As shown in
Figure 7, the adjustment times of
in the DRL controller and the PID controller are 3.62 s and 4.98 s, respectively, and the adjustment times of
are 3.75 s and 4.98 s, respectively. The overshoots of
and
of the DRL controllers are 0.48% and 0.33%, respectively, while the overshoots of the PID controller are 0.5% and 0.5%, respectively. It can be seen from the figure that the acceleration process is mainly restricted by the surge margin of the compressor
. The
of the DRL controller reaches the limit boundary at the first time and keeps close to it. Therefore, the dynamic process of the DRL controller’s acceleration task has reached the optimal performance under the condition of meeting the limit requirements, while the traditional PID controller is more conservative.
6.3. Performance of the Deep Neural Network Dynamic Prediction Model
This subsection will show the prediction accuracy of the dynamic prediction model from various aspects.
This subsection first focuses on the influence of the prediction lag degree on the prediction accuracy. As mentioned in
Section 5.1, the training samples are multiple state-decision series chains
from time
to
. The prediction starting time of the model is time
. Therefore, taking time
as the prediction start time to predict
, at least
is needed. The relationship between the model prediction accuracy and the prediction lag degree is shown in
Figure 8. The average value of the norm 1 of the state prediction error is applied to measure the model prediction accuracy as follows:
, where
is the number of samples and
the dimension of the state
. When the prediction lag degree
,
is the highest, while when
,
is the lowest. The figure shows that
decreases roughly with the increase in the prediction lag degree
. However, in the case of a high prediction degree, the increase in
has less and less influence on the model prediction accuracy. Because of the randomness, there may even be cases where the prediction lag is increased, but the prediction accuracy is reduced. In addition, the higher prediction lag degree means more computation in practical application. Therefore, it is necessary to make a balanced choice between the accuracy and the cost of computation. When the prediction lag degree is 4 or 5, the satisfactory prediction accuracy can be guaranteed with a low amount of computation.
The precondition of Equation (26) is to use the model to predict the future
-step state. Therefore, it is necessary to consider the error accumulation of multi-step rolling prediction.
Figure 9 shows the relationship between the model prediction accuracy
and the prediction depth
. When the prediction depth
,
is the lowest. With the increase in
, the prediction errors accumulated, but they all remained in the same order of magnitude, and all of them do not exceed 0.005. Therefore, the error accumulation of multi-step rolling prediction has negligible influence on the prediction accuracy.
Figure 10 compares the dynamic process simulation curves of the component-level model and the trained dynamic prediction model performing the same control task under the same control policy. Except for the same initial state, there is no data and information transmission between the component-level model, and the dynamic prediction model in the subsequent process. With the 2500 simulation steps, the prediction accuracy of the dynamic prediction model is not affected by error accumulation, and the whole simulation process has high prediction accuracy. Compared with the steady state process, the prediction accuracy of the transition state process is higher. The reason, we guess, is that the samples in the replay buffer are mostly transitional process data, which leads to more adequate training in fitting the transitional process. In
Figure 10, the simulation curves of
,
,
are partially enlarged. It can be clearly seen that the dynamic prediction model has a strong dynamic fitting ability, and even the slight vibration of the component-level model can be well reflected.
6.4. Simulation Analysis of Model-Based Reinforcement Learning Method
The cumulative rewards of each episode in the learning process of the model-free and model-based methods are shown in
Figure 11. The higher the reward, the better the control performance of the policy. Several simulation experiments are carried out to eliminate the influence of the randomness of the RL learning process. In
Figure 11, the solid lines represent the average cumulative rewards in multiple experiments. The borders of the shadow region represent the maximum and minimum cumulative rewards in multiple experiments respectively. The blue part and the orange part represent the simulation results obtained from the model-based method and the model-free method, respectively. In the simulation episodes, the cumulative rewards of the two methods have an upward trend as a whole, which means that both methods can realize the optimization of the policy. The cumulative rewards of the model-free method and the model-based methods exceed −200 for the first time in the 250th episode and the 135th episode, respectively. At the beginning of the training process, the cumulative rewards have a downward trend, which is because the estimation of the value function is inaccurate, and the agent explores cluelessly. The agent in this period may output some dangerous actions. The model-based method can reduce the downward trend of the cumulative rewards in the early learning process. Consequently, compared with the model-free method, the model-based reinforcement learning method improved by using the dynamic prediction model can improve the learning efficiency, reduce the instability in the initial stage of learning, and realize the equivalent optimal policy faster.
7. Conclusions
This paper trains both the reinforcement learning controller and dynamic prediction model for the aero-engine. The proximal policy optimization algorithm is applied to train the controller, and the recurrent neural network is used as the structure of the dynamic prediction model.
The samples in the replay buffer of the reinforcement learning are used to train the dynamic prediction model, which in turn is used to improve the learning efficiency of reinforcement learning. Therefore, the combination of the two can obtain twice the result with half the effort.
The simulation results show that the deep reinforcement learning controller in this paper has satisfactory steady-state performance, and has a faster response speed than the traditional controller in the acceleration task from the idle state to the intermediate state. The dynamic prediction model itself has high prediction accuracy, and it can obviously improve the learning efficiency of reinforcement learning.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}