The present section illustrates the results of two types of experiments intended to assess the performance of the neural controller produced using the evolutionary learning algorithm and to discuss the results of neural network topology selection in training effectiveness and control outcome.
The values of the parameters used in the following numerical simulations, which take constant values irrespective of the simulation at hand, are summarized as:
Each parameter value is expressed in International Systems units.
5.1. General Performance Assessment and Harshness Configuration Testing
The purpose of the tests presented in this section is to assess whether harsher training conditions yield more robust (less prone to crashing) and better-performing controllers for autonomous flight. In addition, the following tests demonstrate the performance of the controller in the task of following a trajectory, proving that—upon further refining—neural controllers are a viable alternative to other methods of control.
The harshness of the training is determined by the parameters
, where
x is a sub-vector of the state
, which substantially determine how far the initial state of a quadcopter lies from the desired state. Higher values in these parameters mean that the quadcopter will explore harder states to control, while evolution is supposed to favor individuals that can adapt to such situations. Every configuration refers to the same parameter values summarized at the beginning of the present section, while the starting-state parameters
are presented in
Table 1.
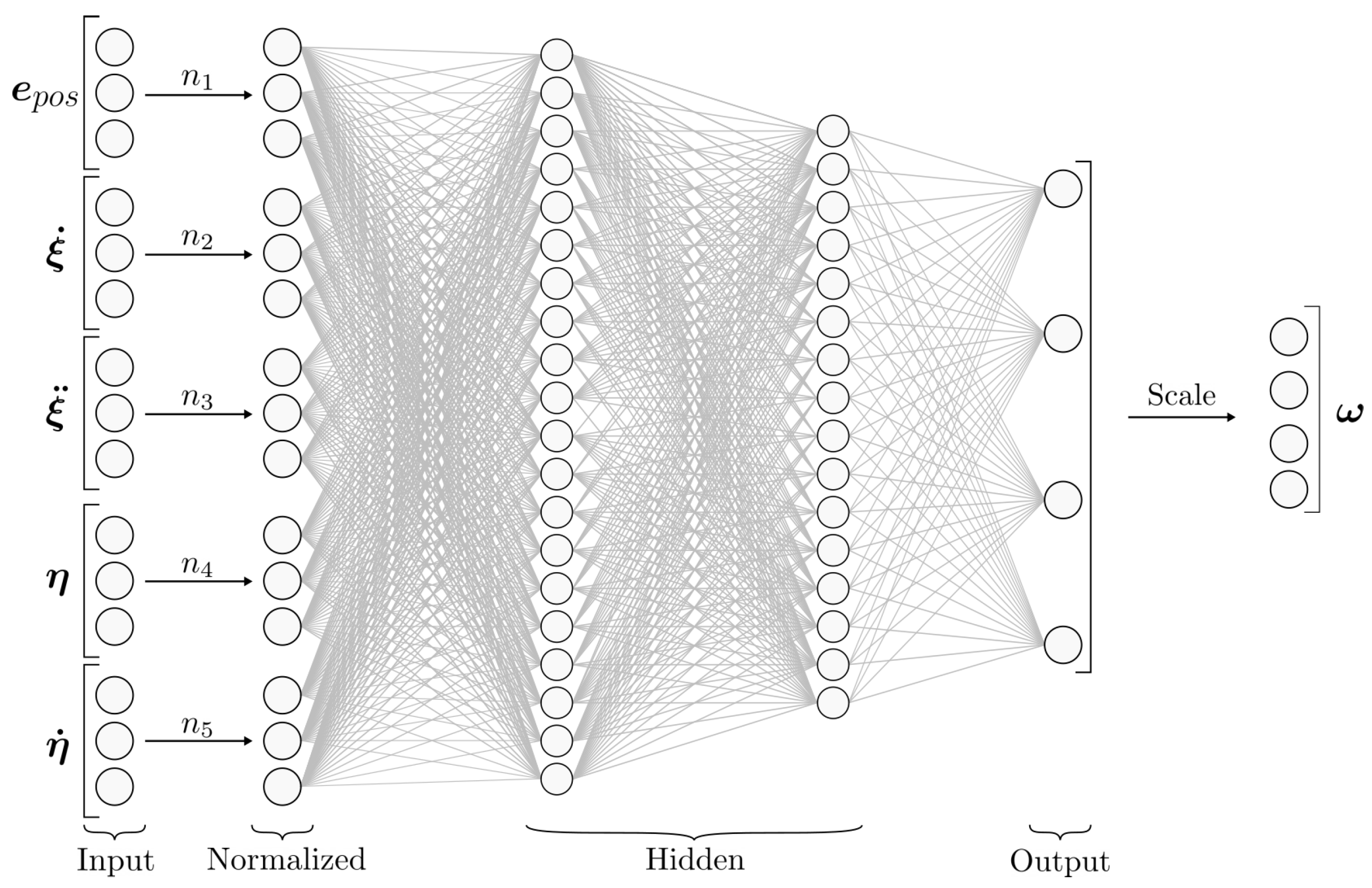
The topology of the neural network is the same for every configuration and was set to .
The test began by running the evolutionary algorithm for each configuration over G = 250,000 generations, yielding the trained population . As a benchmark for the algorithm performance, to run as many as 250,000 generations three times (one for each harshness configuration) takes 8 h on a dedicated server machine (2.30 GHz, 8 Intel® Nehalem class i7 cores, 16 GB RAM); hence, less than 3 h to complete training for a single configuration, on average.
From the last generation of each configuration, the best individual (the one with the lowest value of cost function) is chosen to participate in the path-following tests. In these tests, the three individuals are given the same series of 1000 randomly determined paths. Each path is composed of ten random points in a sequence (in addition to the origin of the trajectory) and each point has a maximum distance of 10 m from the previous point, to form a random spatial path of at most 100 m in length.
Since the controllers are trained to drive a drone only from a starting point to a waypoint at a time, once the quadcopter enters a spherical neighborhood of the current target point of radius , it switches to the next point in the sequence, thus covering the whole path. As will be shown in the following, the choice of the radius significantly influences the performance in the three configurations and determines the precision of a quadcopter’s trajectory.
After the three best neurocontrollers were selected (one for each level of harshness, namely ‘harsh’, ‘medium’ and ‘soft’), a number of tests was conducted that aimed at evaluating their performance by challenging the controlled quadcopters to follow randomly-generated paths of different complexity and by requiring different levels of precision.
5.1.1. Loose Path-Following
In these tests, the radius was set to 1 m, namely, as soon as a quadcopter is closer than one meter to the current target, it will start to chase the next waypoint in the sequence. A radius of 1 m makes the actual trajectory quite loose with respect to the desired trajectory; therefore, the precision in reaching the targets will be less favored compared to the average flight speed.
Exemplary results pertaining to a single randomly generated trajectory are discussed in the following for illustrative purpose. In addition, cumulative results will be presented concerning a large set of path-following tasks that allows the extraction of some statistical information from the numerous single tests with reference, in particular, to the traveling time to complete a task.
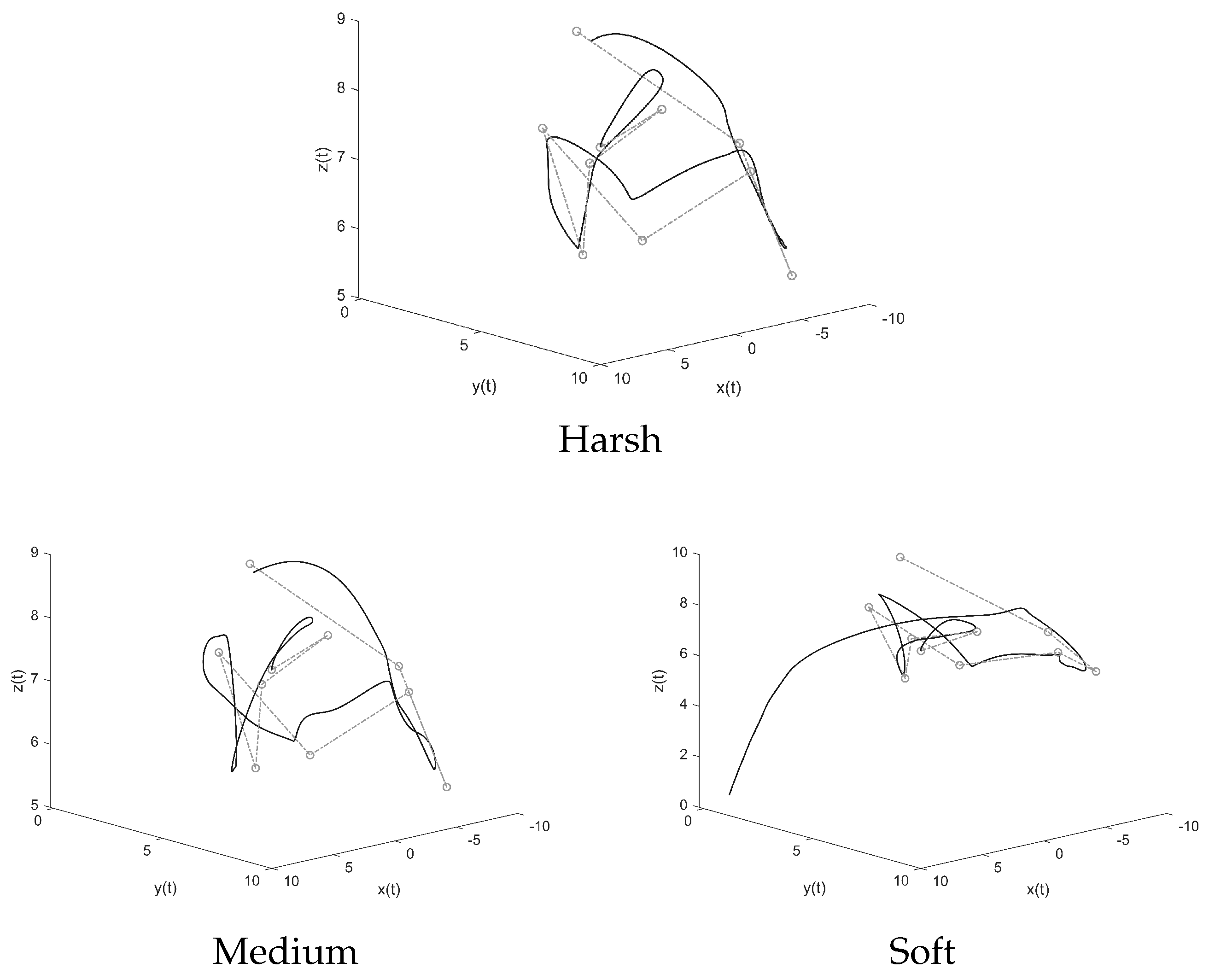
Figure 6 shows the trajectory of three quadcopters over one of the randomly generated paths.
A first qualitative analysis can be carried out. The configuration learned from harsh conditions shows no problem in following the path and the resulting trajectory appears more steady than the others. The configuration trained from medium-harshness training conditions also completes the path, even though more jerky movements can be observed. The configuration trained on low-harshness conditions initially starts following the path but eventually crashes to the ground.
The trajectories followed by three quadcopters (each driven by one of the three selected controllers) can be observed with more detail in
Figure 7, where the 3D path is projected along the three planes orthogonal to the coordinate axes.
From these graphs it can be observed that the quadcopters never quite reach the trajectory’s waypoints, because the value of the radius was set to a relatively large value. In addition, especially in the x–y plane (third row of graphs in the figure), the difference in the three trajectories is more marked.
As a safety note to correctly interpret the graphical results, let us recall that in
Figure 6 and
Figure 7 the dashed trajectories are just the connection between successive target points and do not constitute a reference input for the quadcopter. Moreover, the dashed trajectory is not always guaranteed to be the optimal trajectory for a quadcopter to follow.
The harsh training configuration drives the quadcopter through smooth movements with less pronounced bumps, and its trajectory follows more closely the straight path between the points. The medium training configuration yields a more erratic trajectory compared to the harsh configuration, but nevertheless completes the path-following task.
The soft training configuration initially closely follows the path. A noteworthy outcome is that, on the x–y plane, the soft training configuration even follows the path better than the harsh training configuration, which was expected to perform better than the other two configurations. Then, once it reaches a condition that it has not evolved to endure, the quadcopter crashes into the ground.
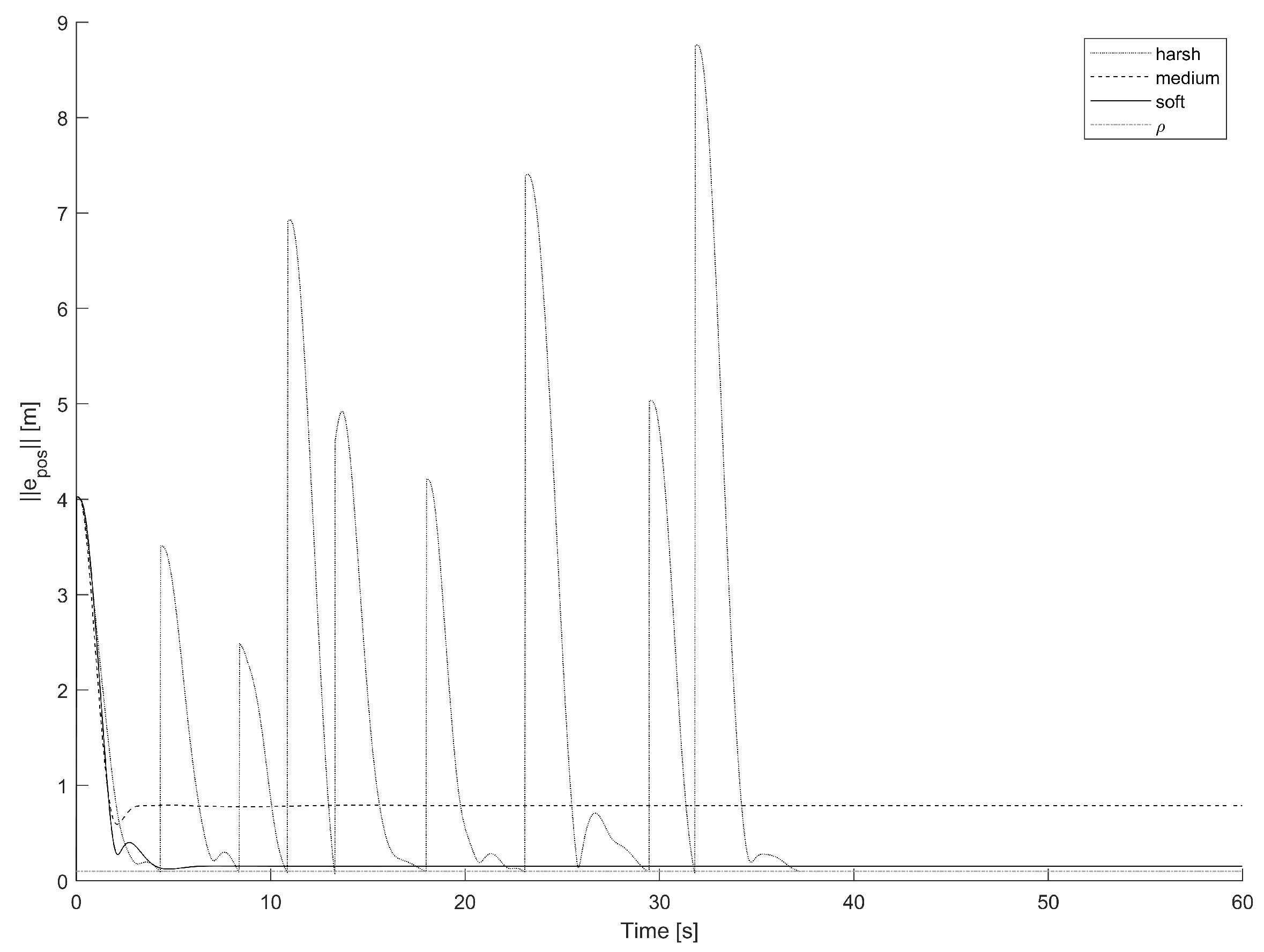
Again with reference to the single path-following test discussed via the
Figure 6 and
Figure 7, it is instructive to check the course of the norm of the positional error
over time, as illustrated in
Figure 8.
From this figure it is immediate to see how the positional error is lower-bounded by the safety radius
. Moreover, in this specific test, the positional error keeps bound along the whole trajectory in the harsh and the medium configuration, while it diverges for the soft controller. Such behavior reflects the results shown, e.g., in
Figure 6, where it can be clearly witnessed as eventually the controlled quadcopter crashes to the ground.
Since every controller of each configuration has to traverse the same 1000 paths, the time each quadcopter takes to traverse a path can be used as a reference for its performance. The average travel time was determined by averaging these 1000 travel intervals. In addition, the minimum and maximum travel times were recorded.
Notice that, in general, not every quadcopter reaches the end of each path, since either a quadcopter crashes into the ground or it eventually keeps hovering mid-way without ever entering the safety bubble around a target that will trigger the next target (such a disruptive event is referred to as a stall).
In the loose path-following tests, incomplete trajectories only resulted from crashing (none from stalling), since the spherical neighborhood was chosen to be relatively wide. (The steady-state positional error should have been larger than 1 m if a quadcopter was to reach a stall situation, which turned out not to be the case with the chosen target-switch threshold ).
The numerical results for the traveling times are reported in
Table 2.
The harshly-trained quadcopter controller appears to be the most attitude-limitation-compliantof the three: over 1000 paths traversed, it never caused crashes or stalls once. However, as a counterpoint to the attitude-limitation compliance, the controlled quadcopter flight appears to be slower than the quadcopter evolved with softer starting states. The softly-trained configuration performs the fastest, with an average time of 17.59 s to run across 100 m, which corresponds to an average speed of 20.47 km per hour. The medium training configuration figures do not stand in between the harshly-trained and the softly-trained, exhibiting much more crashes and slower flight compared to the other configurations.
On the basis of the above results, we concluded that:
The harsh training produces more stable and more ‘careful’ controllers that are not prone to make a quadcopter crash, at the cost of some slowdown along the trajectory.
The soft training yields faster and more ‘reckless’ individuals, at the cost of occasional crashes where the quadcopter visits a state that it was not evolved to cope with.
The medium-harshness training causes deplorable effects compared to the harsh and the soft training in terms of speed and reliability. Such a result is due to the fact that the training conditions are not harsh enough to produce reliable individuals, yet they are harsh enough to hinder the training process in evolving fast individuals.
The gathered numerical-experimental data show that with harsh training conditions, the evolutionary algorithm produces neural controllers that are both reliable and well-performing in the task of loose path-following autonomous flight.
5.1.2. Tight Path-Following
In order to gain a deeper insight about the features of the devised neurocontroller training method, further tests were run by setting the target-switch threshold to be equal to 0.1 m. Such a choice implies that the evolutionary neurocontrollers will have to steer a quadcopter to ensure it reaches the current target more tightly to trigger the next waypoint.
To this aim, and to make sure a quadcopter is effectively able to seamlessly reach the end of each path, attitude-limitation compliance in control is a tight requirement to avoid crashing into the ground, and a low steady-state error
is also compulsory to avoid stalling in midair. In contrast to the tests described in
Section 5.1.1, precision in reaching the target points is to be favored over travel speed; hence, longer travel times were expected.
As can be seen in
Figure 9, the quadcopter’s controller trained under harsh training conditions is more than capable of following the prescribed trajectory with enough precision (relative to the target points), while the quadcopters’ controllers trained under medium and soft training configurations fail to reach the end of the path because they stall, hovering around one point, without reaching a distance less than
to the current target and, hence, never advancing towards the end of the sequence.
For the sake of better clarity, in this tight path-following test, the actual trajectories followed by three quadcopters whose neurocontrollers were each trained under harsh, medium and soft conditions were represented through projections on the planes perpendicular to the three axes, as shown in
Figure 10.
It is immediate to recognize that, in this particular path taken as an example, the controller is not always able to drive a quadcopter along a whole trajectory. In fact, both controllers trained under medium and a soft training conditions fail to properly direct the quadcopter.
The above result confirms that the softness of the training conditions is a primary cause of a lack of ability of a neurocontroller: the harder the conditions of training, the better the resulting control performances. In contrast, soft training conditions make a neurocontrolled quadcopter more prone to crashing into the ground and to stalling in mid-air. It is certainly beneficial to investigate the causes of such disruptive events more closely.
By observing
Figure 11, the phenomenon of stalling, in particular, can be inspected more closely. Let us recall that a steady decrease in the positional error
indicates that a controlled quadcopter is becoming closer and closer to the current target waypoint. In addition, a spike in the error curve means that the individual reached the spherical neighborhood of radius
m and was henceforth triggered to started chasing the next waypoint in the sequence.
The error curve corresponding to the harsh configuration exhibits a sequence of nine spikes, which indicate that all of the ten waypoints in the path have been visited. The medium-trained and soft-trained individuals start chasing the first target point, but never reach an error less than ; thus, these neurocontrolled quadcopters keep hovering around the first waypoint without visiting any further locations in the path sequence. As a matter of fact, the medium-trained neurocontrolled quadcopter exhibits a steady-state error of about 0.8 m, while the soft-trained quadcopter shows a steady-state error of about 0.12 m, while the threshold that triggers the next waypoint was fixed to 0.1 m.
The travel times and number of incomplete paths (due to disruptive events recognized as stalls and crashes) are presented in
Table 3.
By comparing these results with those in
Table 2, the difference in the three configurations appears more evident. The quadcopters controllers trained through a harsh configuration showed no issues in completing both the loose path-following task (with
m) and the tight path-following task (with
= 0.1 m), albeit showing an increase in travel times to complete the tight path-following task. In contrast, the neural controllers yielded by the medium and soft training configurations did not achieve a sufficiently low steady-state error to even complete one path out of one thousand.
The results of this test clearly show that harsh training conditions are required to train neuro-evolutionary controllers that are stable enough to avoid crashing, even at high speeds (shown in
Table 2) and with steady-state errors low enough to follow paths more tightly (as shown in
Table 3).
5.1.3. Additional Precision Tests
Since the medium and soft training configurations have been proven inadequate, to further test the precision of the neural controller learned by the harsh training configuration, a number of additional tests was conducted. To evaluate the performance of the harsh training configuration, a series of trials, each conducted over a set of 10,000 randomly generated paths corresponding to different settings, was realized. The aim of these tests was to define the boundary of the test conditions within which the harsh training may still yield a successful controller.
The obtained results are summarized in
Table 4.
Each row of the table pertains to the results of 10,000 randomly generated paths corresponding to specific values of two parameters:
ℓ represents the number of points in a path and
denotes the maximum distance between consecutive points of the paths (in meters). The parameter
denotes the safety radius that triggers the next chased target in a path sequence. The results summarized in
Table 4 indicate that for values of
less than
m the controller’s steady-state positional error is larger than the required threshold
to advance the sequence of points in the path. This observation gives an approximate indication that the steady-state error
is not larger than 0.085 m.
The neural controller trained and selected through the evolutionary algorithm with the harsh training configuration reached adequate levels of precision, with an average steady-state error of about 8 cm. It also ensures adherence to attitude-limitation constraints, with no crashes over the course of all tests.
5.2. Experiments on Different Network Topologies
The purpose of the following tests is to evaluate the effect that a network’s topology has on the performance of a neurocontroller in terms of learning ability. Three configurations of a neurocontroller were chosen that differ from one another only in the number of layers and number of neurons per layer. These topologies were selected to be:
Complex topology: (which will be referred to as ‘complex’),
Medium-size topology: (which will be referred to as ‘medium’),
Simple topology: (which will be referred to as ‘simple’).
In order to train each neural network with the evolutionary learning algorithm, as many as G = 200,000 generations with as many as p = 100 individuals each were used.
On the basis of these parameters values, the evolutionary-type learning algorithm insists on less-trained individuals than the parameters chosen in the tests discussed in
Section 5.1 (namely, 50,000 generations and 50 individuals less than the previous harshness tests). Such a pair
was in fact chosen so as to highlight the effects of neural network topology on training times, disregarding the goal of producing fully trained individuals. Moreover, the primary objective of these tests was to qualitatively evaluate the effect that topology has on the training algorithm, although some path-following tests were also performed to obtain an approximate evaluation of the performance of the evolved individuals, albeit not fully trained.
To gather information on the training process, in each configuration’s generation the minimum cost of the entire population was recorded. Since the starting state resets every generations, the costs exhibit large fluctuations. Notice that the starting states are randomly determined, and the starting states that each configuration’s training session endures are independent of the starting states of the other two configurations.
Therefore, in order to increase the readability and interpretability of the results illustrated in
Figure 12, the values to report in the plots were chosen to be the moving average (MA) of each generation’s minimum costs, calculated within a window of 2000 generations.
The curves in this figure show that initially the simple topology learns the quickest (lowest decreasing cost over each generation), the complex learns the slowest and the medium-topology training performance stands in between. After the initial learning phase, the simple topology exhibits, on average, the highest costs, while the medium and complex configurations exhibit lower costs. It is hard to determine the best topology between the medium and complex ones.
In order to assess the performance of the trained controllers, each controller was evaluated on a series of path-following tests, each totaling 500 paths with different numbers of waypoints and different maximal distances between two consecutive waypoints. This comparison was conducted in terms of the minimal, maximal and average traveling times for each category of paths. The obtained results are shown in
Table 5.
The obtained results show that in loose path-following ( = 1 m) the neural network with the medium-complexity topology performs better, in terms of both travel time and attitude-limitation compliance, than the two competing instances of topology. The neural network with the simplest topology cannot complete a single test without crashing or stalling. The most complex topology in the loose path-following test performs adequately, but in the tests where the quadcopter must get closer to the path’s target waypoints ( = 0.5 m and = 0.1 m), the controller did not perform well enough to complete the paths reliably.
Such observations suggest that the topology of a neural controller must be chosen carefully. A complex topology (in both depth and width) requires more training time and does not necessarily entail an optimal performance. In contrast, a simpler topology requires less training time but does not possess enough capabilities for learning more complex tasks nor for learning the correct behavior corresponding to the states visited during training. Therefore, a good balance between the training speed and learning potential must be established by specifying a correct neural network topology.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}