
A Virtual Simulation-Pilot Agent for Training of Air Traffic Controllers

 , , and
, , and
Abstract
1. Introduction
- Could human simulation pilots be replaced (or aided) by an autonomous AI-based system? This paper presents an end-to-end pipeline that utilizes a virtual simulation-pilot capable of replacing human simulation-pilots. Implementing this pipeline can speed up the training process of ATCos while decreasing the overall training costs.
- Is the proposed virtual simulation-pilot engine flexible enough to handle multiple ATC scenarios? The virtual simulation-pilot system is modular, allowing for a wide range of domain-specific contextual data to be incorporated, such as real-time air surveillance data, runway numbers, or sectors from the given training exercise. This flexibility boosts the system performance, while making its adaptation easier to various simulation scenarios, including different airports.
- Are open-source AI-based tools enough to develop a virtual simulation-pilot system? Our pipeline is built entirely on open-source and state-of-the-art pre-trained AI models that have been fine-tuned on the ATC domain. The Wav2Vec 2.0 and XLSR [26,27] models are used for ASR, BERT [28] is employed for natural language understanding (NLU), and FastSpeech2 [29] is used for the text-to-speech (TTS) module. To the best of our knowledge, this is the first study that utilizes open-source ATC resources exclusively [11,30,31,32].
- Which scenarios can a virtual simulation-pilot handle? The virtual simulation-pilot engine is highly versatile and can be customized to suit any potential use case. For example, the system can employ either a male or a female voice or simulate very high-frequency noise to mimic real-life ATCo–pilot dialogues. Additionally, new rules for NLP and ATC understanding can be integrated based on the target application, such as approach or tower control.
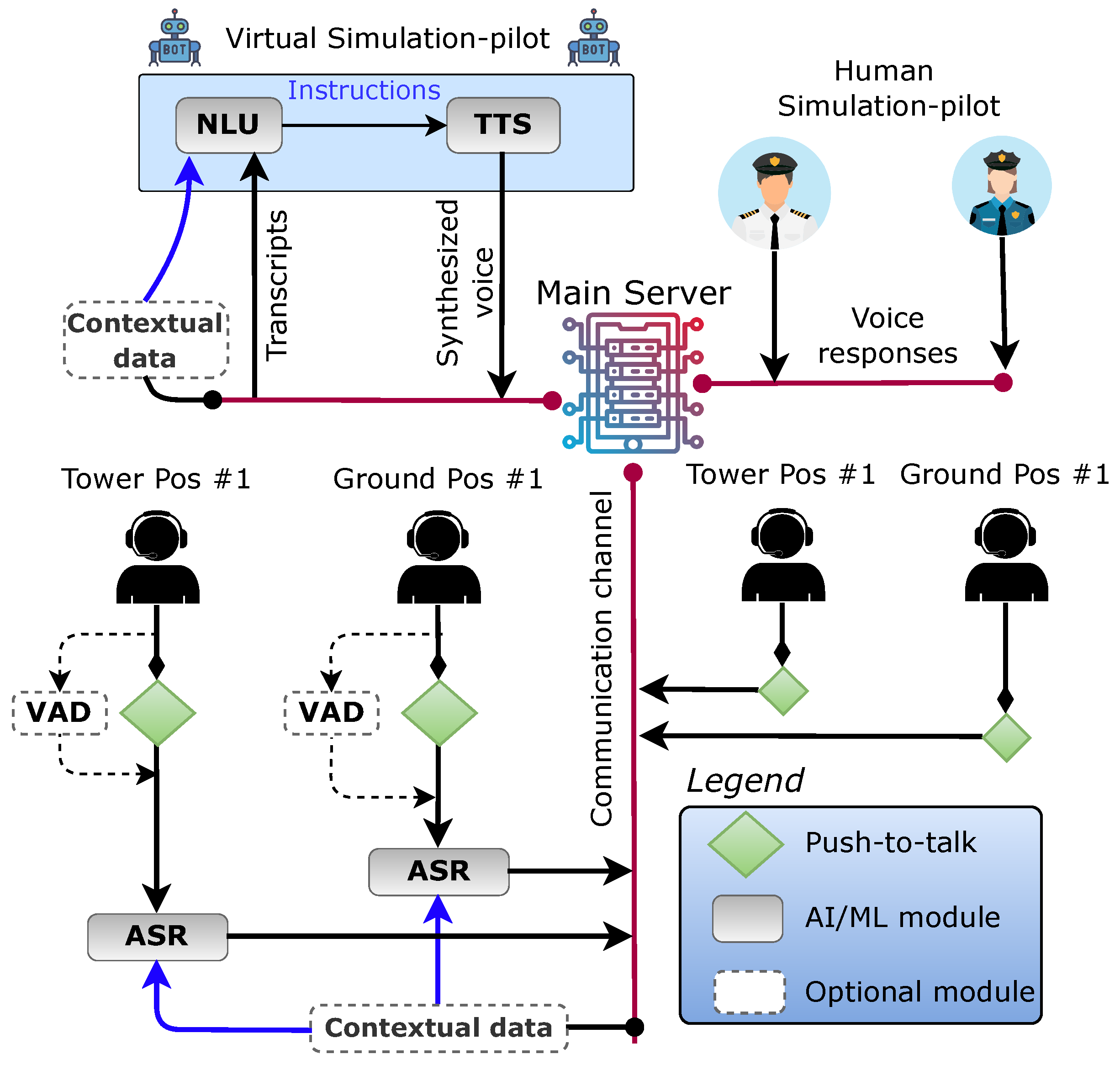
2. Virtual Simulation-Pilot System
2.1. Base Modules
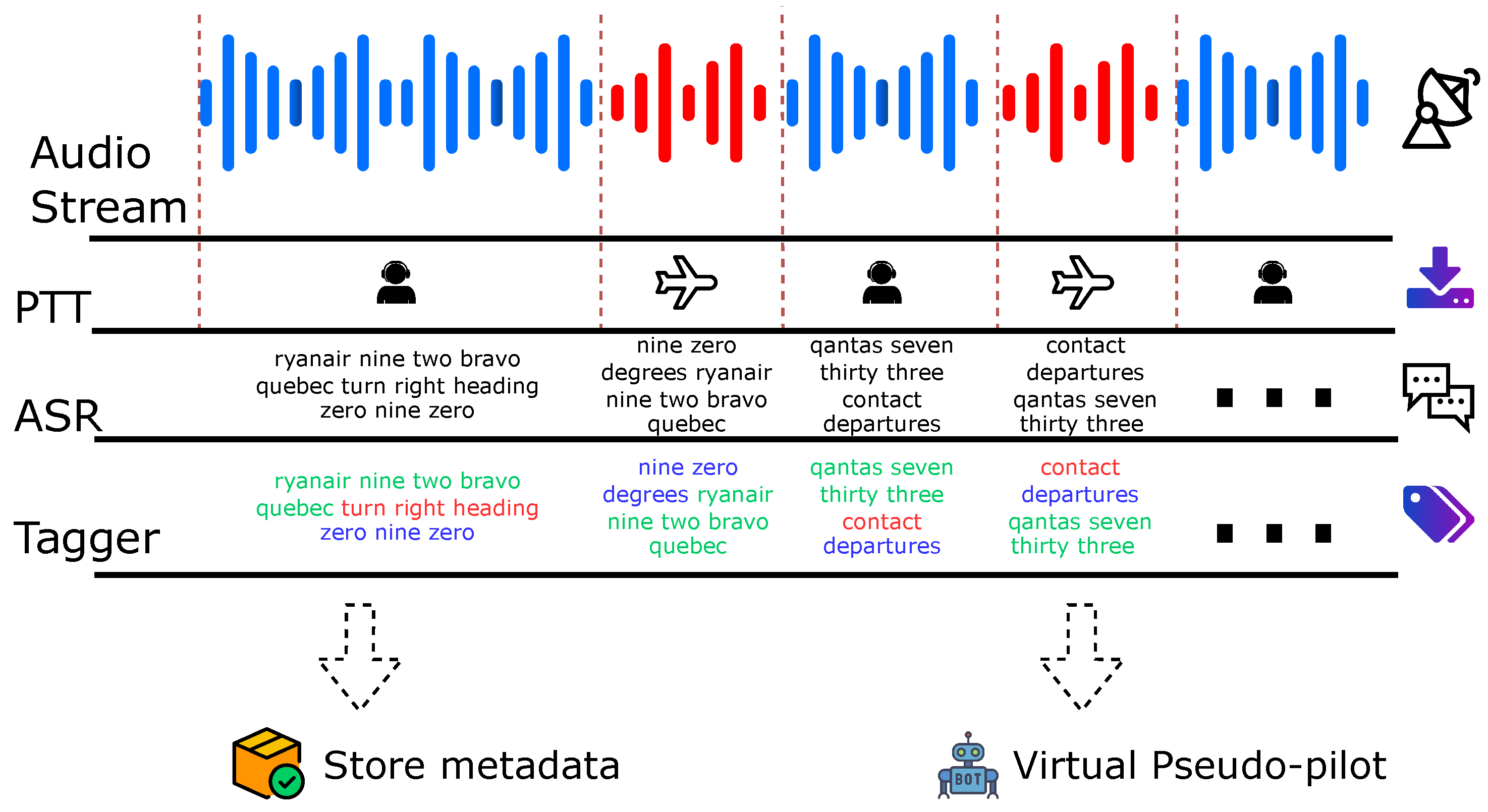
2.1.1. Automatic Speech Recognition
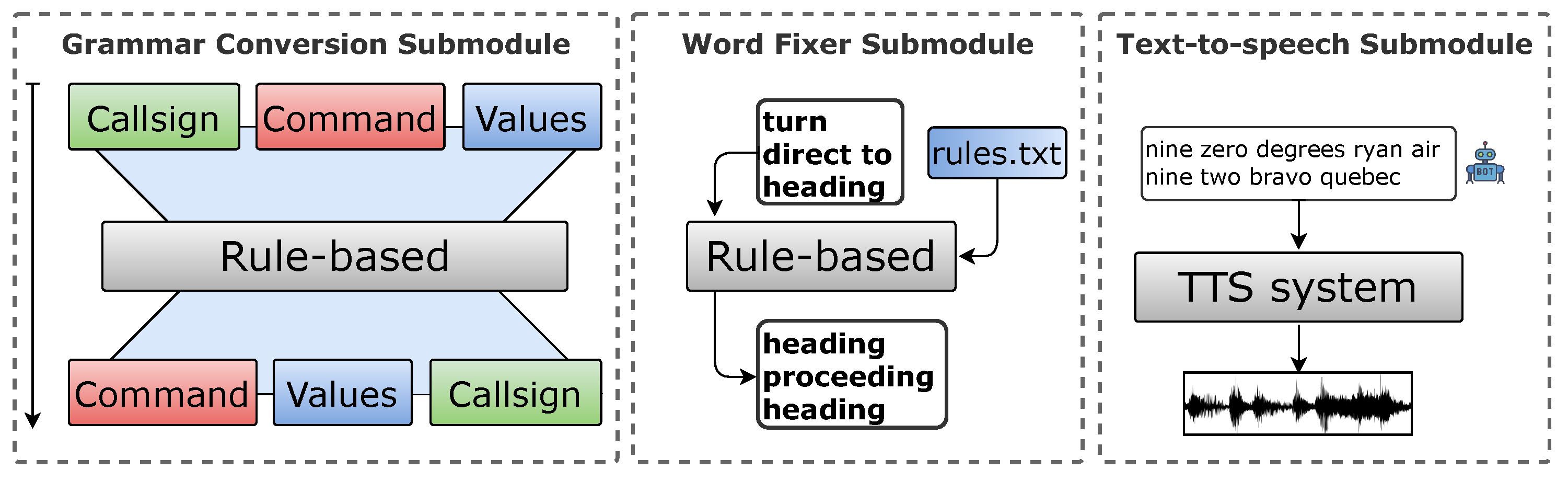
2.1.2. Natural Language Understanding
- ASR transcript: ryanair nine two bravo quebec turn right heading zero nine zero,
- would be parsed to high-level ATC entity format:
- Output: <callsign> ryanair nine two bravo quebec </callsign> <command> turn right heading </command> <value> zero nine zero </value>.
2.1.3. Response Generator
2.2. Optional Modules
2.2.1. Voice Activity Detection
2.2.2. Contextual Biasing with Surveillance Data
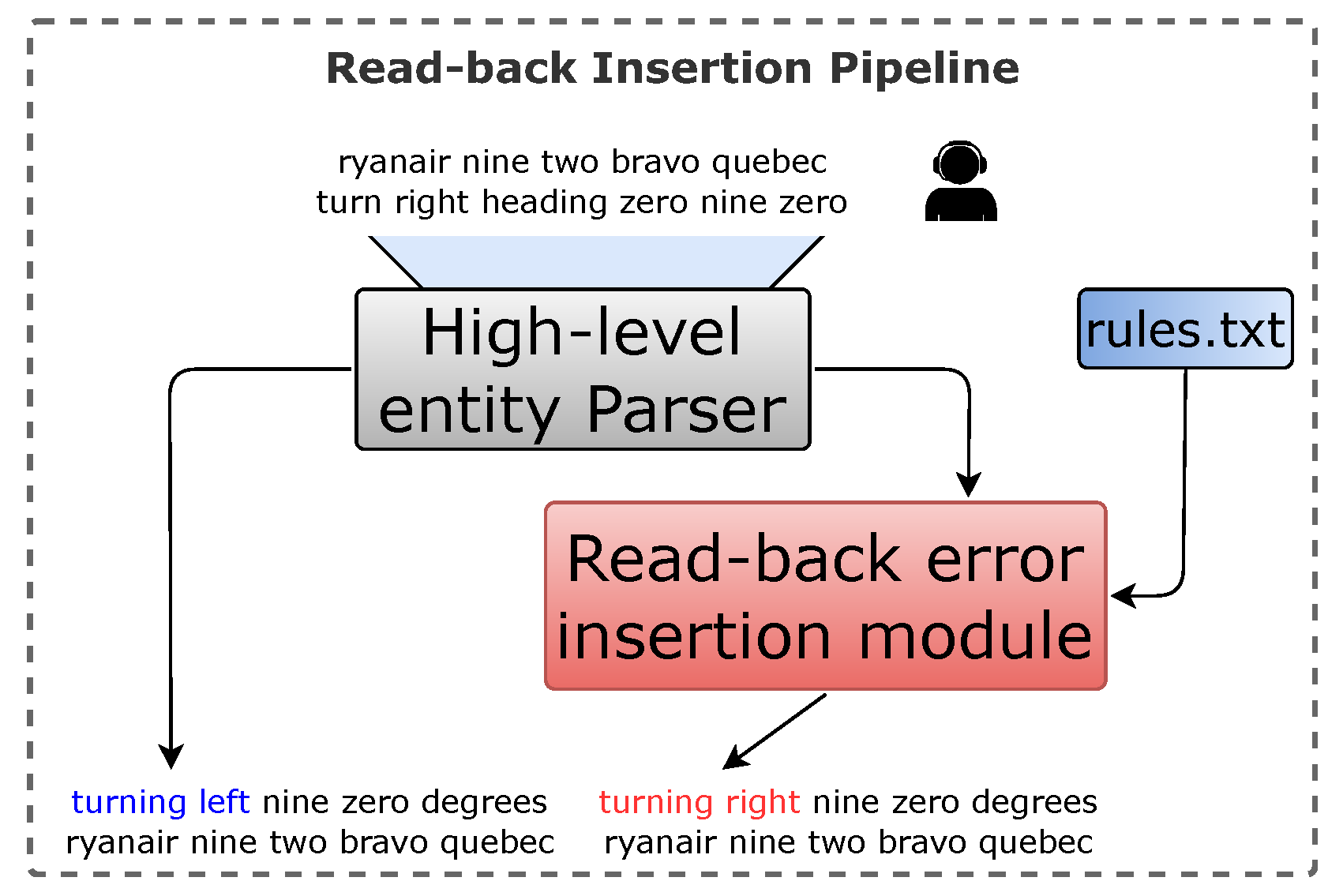
2.2.3. Read-Back Error-Insertion Module
3. Datasets
3.1. Public Databases
3.2. Private Databases
4. Experimental Setup and Results
4.1. Automatic Speech Recognition
4.1.1. Architectures
4.1.2. Training and Test Data
4.1.3. Evaluation Metric
4.1.4. Speech Recognition Results
4.2. High-Level Entity Parser
4.3. Response Generator
4.4. Text to Speech
5. Limitations and Future Work
6. How to Develop Your Own Virtual Simulation-Pilot
- Start by defining the set of rules and grammar to use for the annotation protocol. You can follow the cheat-sheet from the ATCO2 project [11]. See https://www.spokendata.com/atc and https://www.atco2.org/, accessed on 12 May 2023. In addition, one can use previous ontologies developed for ATC [17].
- For training or adapting the virtual simulation-pilot engine, you need three sets of annotations: (i) gold annotations of the ATCo–pilot communications for ASR adaptation; (ii) high-level entity annotations (callsign, command and values) to perform NLU for ATC; and (iii) a set of rules to convert ATCo commands into pilots read-backs, e.g., “descend to” → “descending to”.
- Fine-tune a strong pre-trained ASR model, e.g., Wav2Vec 2.0 or XLSR [26,27] with the ATC audio recordings. For instance, if the performance is not sufficient, you can use open-source corpora (see Table 2) to increase the amount of annotated samples (see [11,30,31,32]). We recommend acquiring the ATCO2-PL dataset [11], which has proven to be a good starting point when no in-domain data are available. This is related to ASR and NLU for ATC.
- Fine-tune a strong pre-trained NLP model, e.g., BERT [28] or RoBERTa [67], with the NLP tags. If the performance is not sufficient, one can follow several text-based data-augmentation techniques. For example, it is possible to replace the callsign in one training sample with different ones from a predefined callsign list. In that way, one can generate many more valuable training samples. It is also possible to use more annotations during fine-tuning, e.g., see the ATCO2-4h corpus [11].
- Lastly, in case you need to adapt the TTS module to pilot speech, you could adapt the FastSpeech2 [29] system. Then, you need to invert the annotations used for ASR, i.e., using the transcripts as input and the ATCo or pilot recordings as targets. This step is not strictly necessary, as already-available pre-trained modules possess a good quality.
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| ASR | Automatic Speech Recognition |
| NLP | Natural Language Processing |
| ATCo | Air Traffic Controller |
| ATC | Air Traffic Control |
| CPDLC | Controller-Pilot Data Link Communications |
| AI | Artificial Inteligencce |
| WER | Word Error Rate |
| ML | Machine Learning |
| VAD | Voice Activity Detection |
| ATM | Air Traffic Management |
| TTS | Text-To-Speech |
| NLU | Natural Language Understanding |
| PTT | Push-To-Talk |
| LM | Language Model |
| AM | Acoustic Model |
| WFST | Weighted Finite State Transducer |
| FST | Finite State Transducer |
| HMM | Hidden Markov Models |
| DNN | Deep Neural Networks |
| MFCCs | Mel-frequency Cepstral Coefficients |
| LF-MMI | Lattice-Free Maximum Mutual Information |
| VHF | Very-High Frequency |
| E2E | End-To-End |
| CTC | Connectionist Temporal Classification |
| NER | Named Entity Recognition |
| RG | Response Generator |
| ICAO | International Civil Aviation Organization |
| SNR | Signal-To-Noise |
| dB | Decibel |
| RBE | Read-back Error |
| ATCC | Air Traffic Control Corpus |
| ELDA | European Language Resources Association |
| ANSPs | Air Navigation Service Providers |
| CNN | Convolutional Neural Network |
| GELU | Gaussian Error Linear Units |
| Conformer | Convolution-augmented Transformer |
References
- Nassif, A.B.; Shahin, I.; Attili, I.; Azzeh, M.; Shaalan, K. Speech recognition using deep neural networks: A systematic review. IEEE Access 2019, 7, 19143–19165. [Google Scholar] [CrossRef]
- Otter, D.W.; Medina, J.R.; Kalita, J.K. A survey of the usages of deep learning for natural language processing. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 604–624. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Wang, S.; Liu, B. Deep learning for sentiment analysis: A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1253. [Google Scholar] [CrossRef]
- Lugosch, L.; Ravanelli, M.; Ignoto, P.; Tomar, V.S.; Bengio, Y. Speech Model Pre-Training for End-to-End Spoken Language Understanding. In Proceedings of the Interspeech 2019, 20th Annual Conference of the International Speech Communication Association, Graz, Austria, 15–19 September 2019; pp. 814–818. [Google Scholar] [CrossRef]
- Beek, B.; Neuberg, E.; Hodge, D. An assessment of the technology of automatic speech recognition for military applications. IEEE Trans. Acoust. Speech Signal Process. 1977, 25, 310–322. [Google Scholar] [CrossRef]
- Hamel, C.J.; Kotick, D.; Layton, M. Microcomputer System Integration for Air Control Training; Technical Report; Naval Training Systems Center: Orlando, FL, USA, 1989. [Google Scholar]
- Matrouf, K.; Gauvain, J.; Neel, F.; Mariani, J. Adapting probability-transitions in DP matching processing for an oral task-oriented dialogue. In Proceedings of the International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Albuquerque, NM, USA, 3–6 April 1990; pp. 569–572. [Google Scholar]
- Helmke, H.; Ohneiser, O.; Mühlhausen, T.; Wies, M. Reducing controller workload with automatic speech recognition. In Proceedings of the 2016 IEEE/AIAA 35th Digital Avionics Systems Conference (DASC), Sacramento, CA, USA, 25–29 September 2016; pp. 1–10. [Google Scholar]
- Helmke, H.; Ohneiser, O.; Buxbaum, J.; Kern, C. Increasing ATM efficiency with assistant based speech recognition. In Proceedings of the 13th USA/Europe Air Traffic Management Research and Development Seminar, Seattle, WA, USA, 27–30 June 2017. [Google Scholar]
- Nigmatulina, I.; Zuluaga-Gomez, J.; Prasad, A.; Sarfjoo, S.S.; Motlicek, P. A two-step approach to leverage contextual data: Speech recognition in air-traffic communications. In Proceedings of the ICASSP, Singapore, 23–27 May 2022. [Google Scholar]
- Zuluaga-Gomez, J.; Veselỳ, K.; Szöke, I.; Motlicek, P.; Kocour, M.; Rigault, M.; Choukri, K.; Prasad, A.; Sarfjoo, S.S.; Nigmatulina, I.; et al. ATCO2 corpus: A Large-Scale Dataset for Research on Automatic Speech Recognition and Natural Language Understanding of Air Traffic Control Communications. arXiv 2022, arXiv:2211.04054. [Google Scholar]
- Kocour, M.; Veselý, K.; Blatt, A.; Zuluaga-Gomez, J.; Szöke, I.; Cernocký, J.; Klakow, D.; Motlícek, P. Boosting of Contextual Information in ASR for Air-Traffic Call-Sign Recognition. In Proceedings of the Interspeech 2021, 22nd Annual Conference of the International Speech Communication Association, Brno, Czechia, 30 August–3 September 2021; pp. 3301–3305. [Google Scholar] [CrossRef]
- Zuluaga-Gomez, J.; Sarfjoo, S.S.; Prasad, A.; Nigmatulina, I.; Motlicek, P.; Ondre, K.; Ohneiser, O.; Helmke, H. BERTraffic: BERT-based Joint Speaker Role and Speaker Change Detection for Air Traffic Control Communications. In Proceedings of the 2022 IEEE Spoken Language Technology Workshop (SLT), Doha, Qatar, 9–12 January 2023. [Google Scholar]
- Lin, Y.; Li, Q.; Yang, B.; Yan, Z.; Tan, H.; Chen, Z. Improving speech recognition models with small samples for air traffic control systems. Neurocomputing 2021, 445, 287–297. [Google Scholar] [CrossRef]
- Zuluaga-Gomez, J.; Veselỳ, K.; Blatt, A.; Motlicek, P.; Klakow, D.; Tart, A.; Szöke, I.; Prasad, A.; Sarfjoo, S.; Kolčárek, P.; et al. Automatic call sign detection: Matching air surveillance data with air traffic spoken communications. Proceedings 2020, 59, 14. [Google Scholar]
- Fan, P.; Guo, D.; Lin, Y.; Yang, B.; Zhang, J. Speech recognition for air traffic control via feature learning and end-to-end training. arXiv 2021, arXiv:2111.02654. [Google Scholar] [CrossRef]
- Helmke, H.; Slotty, M.; Poiger, M.; Herrer, D.F.; Ohneiser, O.; Vink, N.; Cerna, A.; Hartikainen, P.; Josefsson, B.; Langr, D.; et al. Ontology for transcription of ATC speech commands of SESAR 2020 solution PJ. 16-04. In Proceedings of the IEEE/AIAA 37th Digital Avionics Systems Conference (DASC), London, UK, 23–27 September 2018; pp. 1–10. [Google Scholar]
- Guo, D.; Zhang, Z.; Yang, B.; Zhang, J.; Lin, Y. Boosting Low-Resource Speech Recognition in Air Traffic Communication via Pretrained Feature Aggregation and Multi-Task Learning. In IEEE Transactions on Circuits and Systems II: Express Briefs; IEEE: Piscataway, NJ, USA, 2023. [Google Scholar]
- Fan, P.; Guo, D.; Zhang, J.; Yang, B.; Lin, Y. Enhancing multilingual speech recognition in air traffic control by sentence-level language identification. arXiv 2023, arXiv:2305.00170. [Google Scholar]
- Guo, D.; Zhang, Z.; Fan, P.; Zhang, J.; Yang, B. A context-aware language model to improve the speech recognition in air traffic control. Aerospace 2021, 8, 348. [Google Scholar] [CrossRef]
- International Civil Aviation Organization. ICAO Phraseology Reference Guide; ICAO: Montreal, QC, Canada, 2020. [Google Scholar]
- Bouchal, A.; Had, P.; Bouchaudon, P. The Design and Implementation of Upgraded ESCAPE Light ATC Simulator Platform at the CTU in Prague. In Proceedings of the 2022 New Trends in Civil Aviation (NTCA), Prague, Czech Republic, 26–27 October 2022; pp. 103–108. [Google Scholar]
- Lin, Y. Spoken instruction understanding in air traffic control: Challenge, technique, and application. Aerospace 2021, 8, 65. [Google Scholar] [CrossRef]
- Lin, Y.; Wu, Y.; Guo, D.; Zhang, P.; Yin, C.; Yang, B.; Zhang, J. A deep learning framework of autonomous pilot agent for air traffic controller training. IEEE Trans. Hum.-Mach. Syst. 2021, 51, 442–450. [Google Scholar] [CrossRef]
- Prasad, A.; Zuluaga-Gomez, J.; Motlicek, P.; Sarfjoo, S.; Nigmatulina, I.; Vesely, K. Speech and Natural Language Processing Technologies for Pseudo-Pilot Simulator. In Proceedings of the 12th SESAR Innovation Days, Budapest, Hungary, 5–8 December 2022. [Google Scholar]
- Baevski, A.; Zhou, Y.; Mohamed, A.; Auli, M. wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations. In Proceedings of the Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, Virtual, 6–12 December 2020. [Google Scholar]
- Conneau, A.; Baevski, A.; Collobert, R.; Mohamed, A.; Auli, M. Unsupervised cross-lingual representation learning for speech recognition. arXiv 2021, arXiv:2006.13979. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers); Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Ren, Y.; Hu, C.; Tan, X.; Qin, T.; Zhao, S.; Zhao, Z.; Liu, T. FastSpeech 2: Fast and High-Quality End-to-End Text to Speech. In Proceedings of the 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Godfrey, J. The Air Traffic Control Corpus (ATC0)—LDC94S14A; Linguistic Data Consortium: Philadelphia, PA, USA, 1994. [Google Scholar]
- Šmídl, L.; Švec, J.; Tihelka, D.; Matoušek, J.; Romportl, J.; Ircing, P. Air traffic control communication (ATCC) speech corpora and their use for ASR and TTS development. Lang. Resour. Eval. 2019, 53, 449–464. [Google Scholar] [CrossRef]
- Hofbauer, K.; Petrik, S.; Hering, H. The ATCOSIM Corpus of Non-Prompted Clean Air Traffic Control Speech. In Proceedings of the Sixth International Conference on Language Resources and Evaluation (LREC’08); European Language Resources Association (ELRA): Marrakech, Morocco, 2008. [Google Scholar]
- Pavlinović, M.; Juričić, B.; Antulov-Fantulin, B. Air traffic controllers’ practical part of basic training on computer based simulation device. In Proceedings of the International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 22–26 May 2017; pp. 920–925. [Google Scholar]
- Juričić, B.; Varešak, I.; Božić, D. The role of the simulation devices in air traffic controller training. In Proceedings of the International Symposium on Electronics in Traffic, ISEP 2011 Proceedings, Berlin, Germany, 26–28 September 2011. [Google Scholar]
- Chhaya, B.; Jafer, S.; Coyne, W.B.; Thigpen, N.C.; Durak, U. Enhancing scenario-centric air traffic control training. In Proceedings of the 2018 AIAA modeling and Simulation Technologies Conference, Kissimmee, FL, USA, 8–12 January 2018; p. 1399. [Google Scholar]
- Updegrove, J.A.; Jafer, S. Optimization of air traffic control training at the Federal Aviation Administration Academy. Aerospace 2017, 4, 50. [Google Scholar] [CrossRef]
- Eide, A.W.; Ødegård, S.S.; Karahasanović, A. A post-simulation assessment tool for training of air traffic controllers. In Human Interface and the Management of Information. Information and Knowledge Design and Evaluation; Springer: Cham, Switzerland, 2014; pp. 34–43. [Google Scholar]
- Némethová, H.; Bálint, J.; Vagner, J. The education and training methodology of the air traffic controllers in training. In Proceedings of the International Conference on Emerging eLearning Technologies and Applications (ICETA), Starý Smokovec, Slovakia, 21–22 November 2019; pp. 556–563. [Google Scholar]
- Zhang, J.; Zhang, P.; Guo, D.; Zhou, Y.; Wu, Y.; Yang, B.; Lin, Y. Automatic repetition instruction generation for air traffic control training using multi-task learning with an improved copy network. Knowl.-Based Syst. 2022, 241, 108232. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Mohri, M.; Pereira, F.; Riley, M. Weighted finite-state transducers in speech recognition. Comput. Speech Lang. 2002, 16, 69–88. [Google Scholar] [CrossRef]
- Mohri, M.; Pereira, F.; Riley, M. Speech recognition with weighted finite-state transducers. In Springer Handbook of Speech Processing; Springer: Berlin/Heidelberg, Germany, 2008; pp. 559–584. [Google Scholar]
- Riley, M.; Allauzen, C.; Jansche, M. OpenFst: An Open-Source, Weighted Finite-State Transducer Library and its Applications to Speech and Language. In Proceedings of Human Language Technologies: The 2009 Annual Conference of the North American Chapter of the Association for Computational Linguistics, Companion Volume: Tutorial Abstracts; Association for Computational Linguistics: Boulder, CO, USA, 2009; pp. 9–10. [Google Scholar]
- Veselý, K.; Ghoshal, A.; Burget, L.; Povey, D. Sequence-discriminative training of deep neural networks. Interspeech 2013, 2013, 2345–2349. [Google Scholar]
- Bourlard, H.A.; Morgan, N. Connectionist Speech Recognition: A Hybrid Approach; Springer Science & Business Media: Berlin/Heidelberg, Germany, 1993; Volume 247. [Google Scholar]
- Povey, D.; Cheng, G.; Wang, Y.; Li, K.; Xu, H.; Yarmohammadi, M.; Khudanpur, S. Semi-Orthogonal Low-Rank Matrix Factorization for Deep Neural Networks. In Proceedings of the Interspeech 2018, 19th Annual Conference of the International Speech Communication Association, Hyderabad, India, 2–6 September 2018; pp. 3743–3747. [Google Scholar] [CrossRef]
- Zuluaga-Gomez, J.; Motlicek, P.; Zhan, Q.; Veselỳ, K.; Braun, R. Automatic Speech Recognition Benchmark for Air-Traffic Communications. Proc. Interspeech 2020, 2297–2301. [Google Scholar] [CrossRef]
- Srinivasamurthy, A.; Motlícek, P.; Himawan, I.; Szaszák, G.; Oualil, Y.; Helmke, H. Semi-Supervised Learning with Semantic Knowledge Extraction for Improved Speech Recognition in Air Traffic Control. In Proceedings of the Interspeech 2017, 18th Annual Conference of the International Speech Communication Association, Stockholm, Sweden, 20–24 August 2017; pp. 2406–2410. [Google Scholar]
- Zuluaga-Gomez, J.; Nigmatulina, I.; Prasad, A.; Motlicek, P.; Veselỳ, K.; Kocour, M.; Szöke, I. Contextual Semi-Supervised Learning: An Approach to Leverage Air-Surveillance and Untranscribed ATC Data in ASR Systems. Proc. Interspeech 2021, 3296–3300. [Google Scholar] [CrossRef]
- Kocour, M.; Veselý, K.; Szöke, I.; Kesiraju, S.; Zuluaga-Gomez, J.; Blatt, A.; Prasad, A.; Nigmatulina, I.; Motlíček, P.; Klakow, D.; et al. Automatic processing pipeline for collecting and annotating air-traffic voice communication data. Eng. Proc. 2021, 13, 8. [Google Scholar]
- Chen, S.; Kopald, H.; Avjian, B.; Fronzak, M. Automatic Pilot Report Extraction from Radio Communications. In Proceedings of the 2022 IEEE/AIAA 41st Digital Avionics Systems Conference (DASC), Portsmouth, VA, USA, 18–22 September 2022; pp. 1–8. [Google Scholar]
- Povey, D.; Ghoshal, A.; Boulianne, G.; Burget, L.; Glembek, O.; Goel, N.; Hannemann, M.; Motlicek, P.; Qian, Y.; Schwarz, P.; et al. The Kaldi speech recognition toolkit. In Proceedings of the IEEE Workshop on Automatic Speech Recognition and Understanding, Waikoloa, HI, USA, 11–15 December 2011. [Google Scholar]
- Madikeri, S.; Tong, S.; Zuluaga-Gomez, J.; Vyas, A.; Motlicek, P.; Bourlard, H. Pkwrap: A pytorch package for lf-mmi training of acoustic models. arXiv 2020, arXiv:2010.03466. [Google Scholar]
- Graves, A.; Jaitly, N. Towards End-To-End Speech Recognition with Recurrent Neural Networks. In Proceedings of the 31th International Conference on Machine Learning, ICML 2014, Beijing, China, 21–26 June 2014; Volume 32, pp. 1764–1772. [Google Scholar]
- Chorowski, J.; Bahdanau, D.; Serdyuk, D.; Cho, K.; Bengio, Y. Attention-Based Models for Speech Recognition. In Proceedings of the Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015; pp. 577–585. [Google Scholar]
- Schneider, S.; Baevski, A.; Collobert, R.; Auli, M. wav2vec: Unsupervised Pre-Training for Speech Recognition. In Proceedings of the Interspeech 2019, 20th Annual Conference of the International Speech Communication Association, Graz, Austria, 15–19 September 2019; pp. 3465–3469. [Google Scholar] [CrossRef]
- Baevski, A.; Mohamed, A. Effectiveness of Self-Supervised Pre-Training for ASR. In Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2020, Barcelona, Spain, 4–8 May 2020; pp. 7694–7698. [Google Scholar] [CrossRef]
- Zhang, Z.Q.; Song, Y.; Wu, M.H.; Fang, X.; Dai, L.R. Xlst: Cross-lingual self-training to learn multilingual representation for low resource speech recognition. arXiv 2021, arXiv:2103.08207. [Google Scholar]
- Chen, S.; Wang, C.; Chen, Z.; Wu, Y.; Liu, S.; Chen, Z.; Li, J.; Kanda, N.; Yoshioka, T.; Xiao, X.; et al. Wavlm: Large-scale self-supervised pre-training for full stack speech processing. arXiv 2021, arXiv:2110.13900. [Google Scholar] [CrossRef]
- Oord, A.v.d.; Li, Y.; Vinyals, O. Representation learning with contrastive predictive coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- Baevski, A.; Schneider, S.; Auli, M. vq-wav2vec: Self-Supervised Learning of Discrete Speech Representations. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Zuluaga-Gomez, J.; Prasad, A.; Nigmatulina, I.; Sarfjoo, S.; Motlicek, P.; Kleinert, M.; Helmke, H.; Ohneiser, O.; Zhan, Q. How Does Pre-trained Wav2Vec2.0 Perform on Domain Shifted ASR? An Extensive Benchmark on Air Traffic Control Communications. In Proceedings of the IEEE Spoken Language Technology Workshop (SLT), Doha, Qatar, 9–12 January 2023. [Google Scholar]
- Yadav, V.; Bethard, S. A Survey on Recent Advances in Named Entity Recognition from Deep Learning models. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; Association for Computational Linguistics: Santa Fe, NM, USA, 2018; pp. 2145–2158. [Google Scholar]
- Grishman, R.; Sundheim, B. Message Understanding Conference- 6: A Brief History. In Proceedings of the COLING 1996 Volume 1: The 16th International Conference on Computational Linguistics, Copenhagen, Denmark, 5–9 August 1996. [Google Scholar]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural language processing (almost) from scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Piskorski, J.; Pivovarova, L.; Šnajder, J.; Steinberger, J.; Yangarber, R. The First Cross-Lingual Challenge on Recognition, Normalization, and Matching of Named Entities in Slavic Languages. In Proceedings of the 6th Workshop on Balto-Slavic Natural Language Processing; Association for Computational Linguistics: Valencia, Spain, 2017; pp. 76–85. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- He, P.; Liu, X.; Gao, J.; Chen, W. Deberta: Decoding-Enhanced Bert with Disentangled Attention. In Proceedings of the 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, 3–7 May 2021. [Google Scholar]
- Klatt, D.H. Review of text-to-speech conversion for English. J. Acoust. Soc. Am. 1987, 82, 737–793. [Google Scholar] [CrossRef]
- Murray, I.R.; Arnott, J.L.; Rohwer, E.A. Emotional stress in synthetic speech: Progress and future directions. Speech Commun. 1996, 20, 85–91. [Google Scholar] [CrossRef]
- Tokuda, K.; Nankaku, Y.; Toda, T.; Zen, H.; Yamagishi, J.; Oura, K. Speech synthesis based on hidden Markov models. Proc. IEEE 2013, 101, 1234–1252. [Google Scholar] [CrossRef]
- Wang, Y.; Skerry-Ryan, R.J.; Stanton, D.; Wu, Y.; Weiss, R.J.; Jaitly, N.; Yang, Z.; Xiao, Y.; Chen, Z.; Bengio, S.; et al. Tacotron: Towards End-to-End Speech Synthesis. In Proceedings of the Interspeech 2017, 18th Annual Conference of the International Speech Communication Association, Stockholm, Sweden, 20–24 August 2017; pp. 4006–4010. [Google Scholar]
- Shen, J.; Pang, R.; Weiss, R.J.; Schuster, M.; Jaitly, N.; Yang, Z.; Chen, Z.; Zhang, Y.; Wang, Y.; Ryan, R.; et al. Natural TTS Synthesis by Conditioning Wavenet on MEL Spectrogram Predictions. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2018, Calgary, AB, Canada, 15–20 April 2018; pp. 4779–4783. [Google Scholar] [CrossRef]
- Kaur, N.; Singh, P. Conventional and contemporary approaches used in text to speech synthesis: A review. Artif. Intell. Rev. 2022, 1–44. [Google Scholar] [CrossRef]
- Jeong, M.; Kim, H.; Cheon, S.J.; Choi, B.J.; Kim, N.S. Diff-TTS: A Denoising Diffusion Model for Text-to-Speech. In Proceedings of the Interspeech 2021, 22nd Annual Conference of the International Speech Communication Association, Brno, Czechia, 30 August–3 September 2021; pp. 3605–3609. [Google Scholar] [CrossRef]
- Sarfjoo, S.S.; Madikeri, S.R.; Motlícek, P. Speech Activity Detection Based on Multilingual Speech Recognition System. In Proceedings of the Interspeech 2021, 22nd Annual Conference of the International Speech Communication Association, Brno, Czechia, 30 August–3 September 2021; pp. 4369–4373. [Google Scholar] [CrossRef]
- Ariav, I.; Cohen, I. An end-to-end multimodal voice activity detection using wavenet encoder and residual networks. IEEE J. Sel. Top. Signal Process. 2019, 13, 265–274. [Google Scholar] [CrossRef]
- Ding, S.; Wang, Q.; Chang, S.y.; Wan, L.; Moreno, I.L. Personal VAD: Speaker-conditioned voice activity detection. arXiv 2019, arXiv:1908.04284. [Google Scholar]
- Medennikov, I.; Korenevsky, M.; Prisyach, T.; Khokhlov, Y.Y.; Korenevskaya, M.; Sorokin, I.; Timofeeva, T.; Mitrofanov, A.; Andrusenko, A.; Podluzhny, I.; et al. Target-Speaker Voice Activity Detection: A Novel Approach for Multi-Speaker Diarization in a Dinner Party Scenario. In Proceedings of the Interspeech 2020, 21st Annual Conference of the International Speech Communication Association, Virtual Event, Shanghai, China, 25–29 October 2020; pp. 274–278. [Google Scholar] [CrossRef]
- Ng, T.; Zhang, B.; Nguyen, L.; Matsoukas, S.; Zhou, X.; Mesgarani, N.; Veselỳ, K.; Matějka, P. Developing a speech activity detection system for the DARPA RATS program. In Proceedings of the Thirteenth Annual Conference of the International Speech Communication Association, Portland, OR, USA, 9–13 September 2012. [Google Scholar]
- Helmke, H.; Ondřej, K.; Shetty, S.; Arilíusson, H.; Simiganoschi, T.; Kleinert, M.; Ohneiser, O.; Ehr, H.; Zuluaga-Gomez, J.; Smrz, P. Readback Error Detection by Automatic Speech Recognition and Understanding—Results of HAAWAII Project for Isavia’s Enroute Airspace. In Proceedings of the 12th SESAR Innovation Days, Budapest, Hungary, 5–8 December 2022. [Google Scholar]
- Cordero, J.M.; Dorado, M.; de Pablo, J.M. Automated speech recognition in ATC environment. In Proceedings of the 2nd International Conference on Application and Theory of Automation in Command and Control Systems, London, UK, 29–31 May 2012; pp. 46–53. [Google Scholar]
- Delpech, E.; Laignelet, M.; Pimm, C.; Raynal, C.; Trzos, M.; Arnold, A.; Pronto, D. A Real-life, French-accented Corpus of Air Traffic Control Communications. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018); European Language Resources Association (ELRA): Miyazaki, Japan, 2018. [Google Scholar]
- Segura, J.; Ehrette, T.; Potamianos, A.; Fohr, D.; Illina, I.; Breton, P.; Clot, V.; Gemello, R.; Matassoni, M.; Maragos, P. The HIWIRE Database, a Noisy and Non-Native English Speech Corpus for Cockpit Communication. 2007. Available online: http://www.hiwire.org (accessed on 12 May 2023).
- Gulati, A.; Qin, J.; Chiu, C.; Parmar, N.; Zhang, Y.; Yu, J.; Han, W.; Wang, S.; Zhang, Z.; Wu, Y.; et al. Conformer: Convolution-augmented Transformer for Speech Recognition. In Proceedings of the Interspeech 2020, 21st Annual Conference of the International Speech Communication Association, Virtual Event, Shanghai, China, 25–29 October 2020; pp. 5036–5040. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y. Convolutional networks for images, speech, and time series. Handb. Brain Theory Neural Netw. 1995, 3361, 1995. [Google Scholar]
- Vyas, A.; Madikeri, S.; Bourlard, H. Lattice-Free Mmi Adaptation of Self-Supervised Pretrained Acoustic Models. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 6219–6223. [Google Scholar] [CrossRef]
- Ravanelli, M.; Parcollet, T.; Plantinga, P.; Rouhe, A.; Cornell, S.; Lugosch, L.; Subakan, C.; Dawalatabad, N.; Heba, A.; Zhong, J.; et al. SpeechBrain: A general-purpose speech toolkit. arXiv 2021, arXiv:2106.04624. [Google Scholar]
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An ASR corpus based on public domain audio books. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2015, South Brisbane, Australia, 19–24 April 2015; pp. 5206–5210. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Gaussian error linear units (gelus). arXiv 2016, arXiv:1606.08415. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Karita, S.; Chen, N.; Hayashi, T.; Hori, T.; Inaguma, H.; Jiang, Z.; Someki, M.; Soplin, N.E.Y.; Yamamoto, R.; Wang, X.; et al. A comparative study on transformer vs rnn in speech applications. In Proceedings of the 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Singapore, 14–18 December 2019; pp. 449–456. [Google Scholar]
- Graves, A.; Graves, A. Connectionist temporal classification. In Supervised Sequence Labelling with Recurrent Neural Networks; Springer: Berlin/Heidelberg, Switzerland, 2012; pp. 61–93. [Google Scholar]
- Chen, Z.; Jain, M.; Wang, Y.; Seltzer, M.L.; Fuegen, C. End-to-end Contextual Speech Recognition Using Class Language Models and a Token Passing Decoder. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2019, Brighton, UK, 12–17 May; pp. 6186–6190. [CrossRef]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-Art Natural Language Processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16–20 November 2020; pp. 38–45. [Google Scholar] [CrossRef]
- Lhoest, Q.; Villanova del Moral, A.; Jernite, Y.; Thakur, A.; von Platen, P.; Patil, S.; Chaumond, J.; Drame, M.; Plu, J.; Tunstall, L.; et al. Datasets: A Community Library for Natural Language Processing. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 7–11 November 2021; pp. 175–184. [Google Scholar] [CrossRef]
- Pascanu, R.; Mikolov, T.; Bengio, Y. On the difficulty of training recurrent neural networks. In Proceedings of the 30th International Conference on Machine Learning, ICML 2013, Atlanta, GA, USA, 16–21 June 2013; Volume 28, pp. 1310–1318. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Word Fixer Submodule—Rules.txt | |
|---|---|
| Horizontal commands | Handover commands |
| continue heading → continuing altitude | contact tower → contact tower |
| heading → heading | station radar → station radar |
| turn → heading | squawk → squawk |
| turn by → heading | squawking → squawk |
| direct to → proceeding direct | contact frequency → NONE |
| Level commands | Speed commands |
| maintain altitude → maintaining altitude | reduce → reducing |
| maintain altitude → maintain | maintain speed → maintaining |
| descend → descending | reduce speed → reduce speed |
| climb → climbing | speed → NONE |
| Characteristics | Research Topics | Other | |||||
|---|---|---|---|---|---|---|---|
| Database | Accents | Hrs | ASR/TTS | SpkID | NLU | License | Ref. |
| Private databases | |||||||
| MALORCA | cs, de | 14 | ✓ | ✓ | ✓ | ✗ | [48] |
| AIRBUS | fr | 100 | ✓ | - | ✓ | ✗ | [83] |
| HAAWAII | is, en-GB | 47 | ✓ | ✓ | ✓ | ✗ | [62] |
| Internal | several | 44 | ✓ | ✗ | ✗ | ✗ | - |
| Public databases | |||||||
| ATCOSIM | de, fr, de-CH | 10.7 | ✓ | ✗ | ✗ | ✓ | [32] |
| UWB-ATCC | cs | 13.2 | ✓ | ✓ | ✗ | ✓ | [31] |
| LDC-ATCC | en-US | 26.2 | ✓ | ✓ | ✓ | ✓ | [30] |
| HIWIRE | fr, it, es, el | 28.7 | ✓ | ✗ | ✗ | ✓ | [84] |
| ATCO2 | several | 5285 | ✓ | ✓ | ✓ | ✓ | [11] |
| Model | Test Sets | |||||
|---|---|---|---|---|---|---|
| NATS | ISAVIA | Prague | Vienna | ATCO2-1h | ATCO2-4h | |
| scenario (a)—only supervised data | ||||||
| CNN-TDNNF | 7.5 | 12.4 | 6.6 | 6.3 | 27.4 | 36.6 |
| XLSR-KALDI | 7.1 | 12.0 | 6.7 | 5.5 | 18.0 | 25.7 |
| CONFORMER | 9.5 | 13.7 | 5.7 | 7.0 | 41.8 | 46.2 |
| scenario (b)—only ATCO2-PL 500 h data | ||||||
| CNN-TDNNF | 26.7 | 34.1 | 11.7 | 11.8 | 19.1 | 25.1 |
| CONFORMER | 21.6 | 32.5 | 7.6 | 12.5 | 15.9 | 24.0 |
| General ATC Model | ATCO2 Model-500h | |||||
|---|---|---|---|---|---|---|
| Boosting | WER | EntWER | ACC | WER | EntWER | ACC |
| scenario (a)—only supervised data | scenario (b)—only ATCO2-PL 500 h data | |||||
| Baseline | 7.4 | 4.1 | 86.7 | 26.7 | 30.0 | 39.9 |
| Unigrams | 7.4 | 3.6 | 88.0 | 25.6 | 24.1 | 46.2 |
| N-grams | 6.7 | 2.0 | 93.3 | 23.4 | 19.8 | 61.3 |
| GT boosted | 6.4 | 1.3 | 96.1 | 22.0 | 16.2 | 70.0 |
| Model | Callsign | Command | Values | ||||||
|---|---|---|---|---|---|---|---|---|---|
| @P | @R | @F1 | @P | @R | @F1 | @P | @R | @F1 | |
| bert-base-uncased | 97.1 | 97.8 | 97.5 | 80.4 | 83.6 | 82.0 | 86.3 | 88.1 | 87.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zuluaga-Gomez, J.; Prasad, A.; Nigmatulina, I.; Motlicek, P.; Kleinert, M. A Virtual Simulation-Pilot Agent for Training of Air Traffic Controllers. Aerospace 2023, 10, 490. https://doi.org/10.3390/aerospace10050490
Zuluaga-Gomez J, Prasad A, Nigmatulina I, Motlicek P, Kleinert M. A Virtual Simulation-Pilot Agent for Training of Air Traffic Controllers. Aerospace. 2023; 10(5):490. https://doi.org/10.3390/aerospace10050490
Chicago/Turabian StyleZuluaga-Gomez, Juan, Amrutha Prasad, Iuliia Nigmatulina, Petr Motlicek, and Matthias Kleinert. 2023. "A Virtual Simulation-Pilot Agent for Training of Air Traffic Controllers" Aerospace 10, no. 5: 490. https://doi.org/10.3390/aerospace10050490
APA StyleZuluaga-Gomez, J., Prasad, A., Nigmatulina, I., Motlicek, P., & Kleinert, M. (2023). A Virtual Simulation-Pilot Agent for Training of Air Traffic Controllers. Aerospace, 10(5), 490. https://doi.org/10.3390/aerospace10050490