1. Introduction
The engine bleed air system is a vital component that provides air to various aircraft systems. It plays a crucial role in maintaining optimal cabin pressure and temperature during flight, ensuring the safety, comfort, and proper functioning of both passengers and crew members, as well as multiple onboard equipment. The functions of the engine bleed air system include: supplying compressed air, maintaining cabin pressure, controlling cabin temperature, providing environmental control. Aircraft manufacturers and airlines place significant importance on the design, maintenance, and monitoring of the engine bleed air system to ensure its stable and reliable performance [
1,
2].
The engine bleed air system has a high failure rate during actual aircraft operation, and troubleshooting by maintenance personnel often relies on manuals, resulting in high time costs and low efficiency. With the emergence of PHM (Prognostics and Health Management) technology, the maintenance approach has shifted from post-maintenance to condition-based maintenance, significantly reducing time and maintenance costs while improving maintenance efficiency [
3,
4]. Additionally, aircraft are equipped with data recorders, such as the commonly used QAR (Quick Access Recorder), making data-driven PHM techniques the mainstream approach. However, flight data presents challenges with its large volume and high dimensionality, making traditional data-driven fault diagnosis methods inadequate to meet the requirements [
5,
6].
For data-driven methods, data preprocessing and feature extraction have a significant impact on the effectiveness of deep learning in PHM applications. Actual QAR data presents challenges such as high dimensionality, inconsistent lengths, and lack of annotation, making it difficult to extract meaningful features. However, feature extraction is the first crucial step in building effective deep learning models [
7,
8]. Therefore, in the data processing and feature extraction stages, it is important to consider the characteristics of the system and the data itself and adopt targeted approaches to achieve effective state assessment [
9,
10].
In recent years, numerous studies have emerged that apply deep learning to aircraft health management. For instance, Reference [
11] proposed a novel one-dimensional multi-channel convolutional neural network (1DMCCNN) for diagnosing fault patterns. It extracts fault signals by constructing a landing gear hydraulic system using normal and fault models, and the inputs the extracted signals as multi-channel data into the convolutional neural network. The network used in the fault classification experiments achieves significantly higher accuracy compared to traditional machine learning algorithms. In Reference [
12], a particle swarm optimization hybrid fruit fly algorithm is employed to optimize the backpropagation neural network, effectively addressing the issues of weight and bias in the network. This optimization approach yields high performance in diagnosing faults in the rudder system. Reference [
13] utilizes an improved extreme learning machine to establish a novel fault diagnosis model for a commercial aircraft’s elevator system. Additionally, Kernel Principal Component Analysis (KPCA) is employed to reduce the dimensionality of the aircraft fault data, thereby enhancing the diagnostic accuracy of the model. These studies demonstrate that applying deep learning techniques to aircraft health management can yield promising results.
Furthermore, in the context of the engine bleed air system, there are also several notable research works. For instance, Reference [
14] focuses on the fault detection of commercial aircraft bleed air systems and proposes a fault detection method using a multi-cycle data feature multiple linear regression model. Reference [
15] presents a multivariate state estimation technique based on a dynamic process memory matrix to provide early warning for fault risks in the bleed air system. Reference [
16] models multiple components of the engine bleed air system and predicts the failure rates of these components using neural networks. The study verifies that neural networks exhibit superior predictive performance compared to Weibull models.
However, most of these studies rely on simulated data to conduct their research due to the challenges associated with real aircraft operational data. These challenges include a scarcity of fault data relative to normal data and a lack of annotations, which make it difficult to establish effective deep learning algorithm models. In the context of the bleed air system, models mentioned above exhibit weaker learning capabilities in handling complex data features. There is relatively limited research available on the application of deep learning techniques to health management. Furthermore, the utilization of unsupervised learning to address the issue of data lacking annotations in real-world scenarios has been relatively limited in previous studies. Unsupervised learning offers several advantages in handling unannotated data without the need for manual labeling, which significantly reduces time costs [
17]. This aligns well with the characteristic of flight data lacking annotations. Additionally, unsupervised learning can automatically extract features and uncover underlying patterns within the data [
18], facilitating the exploration of latent patterns and hidden information within flight data.
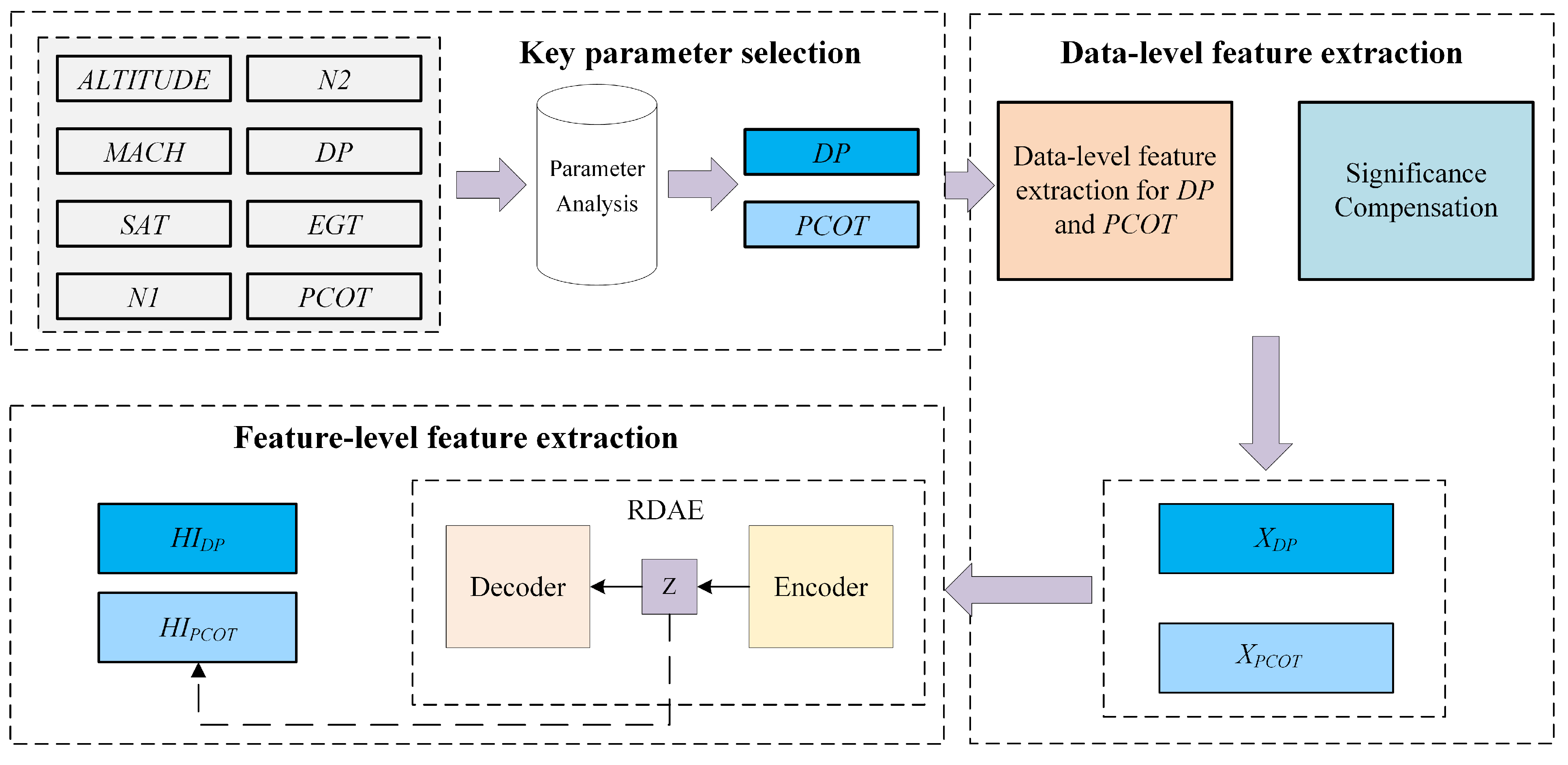
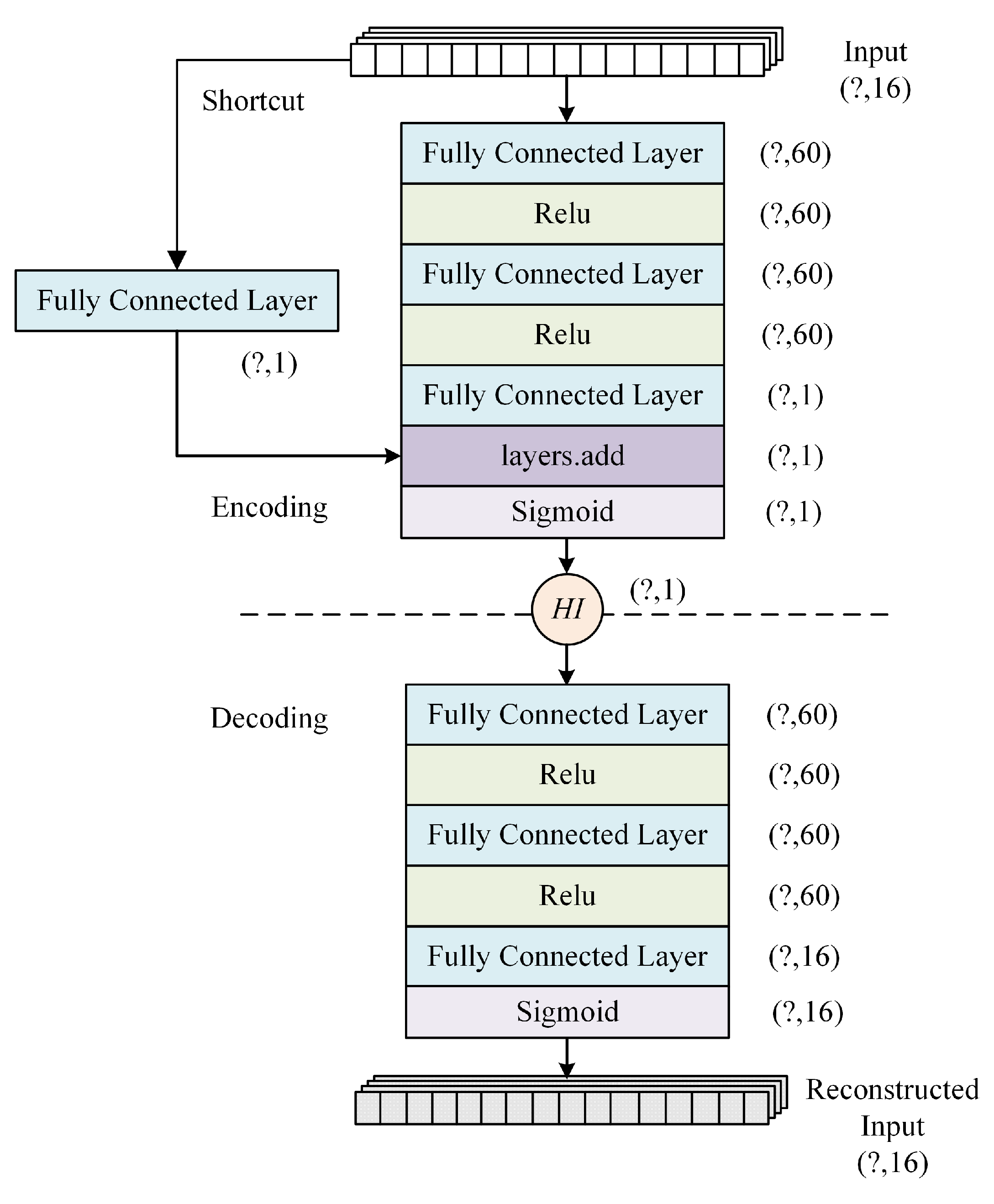
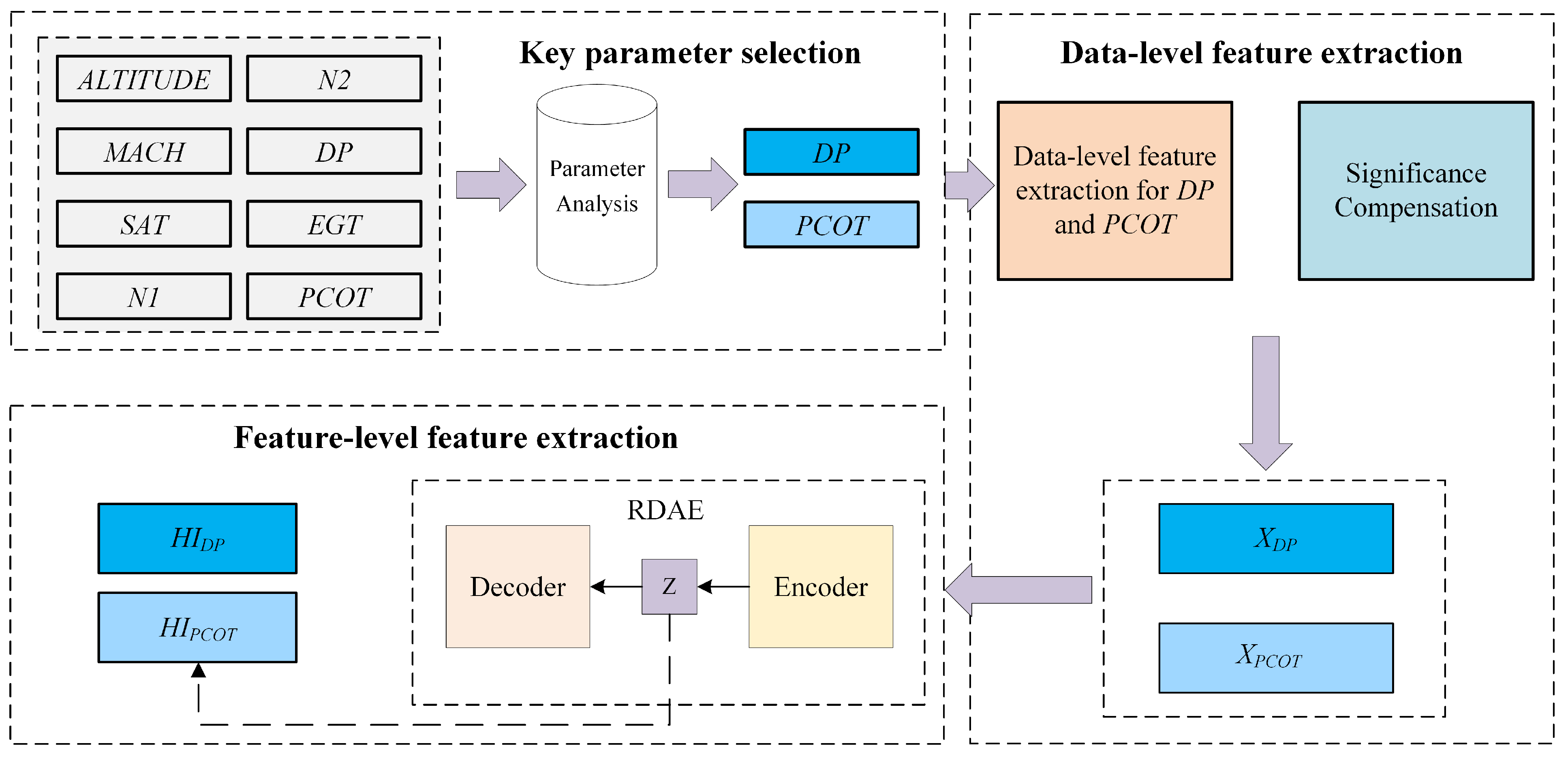
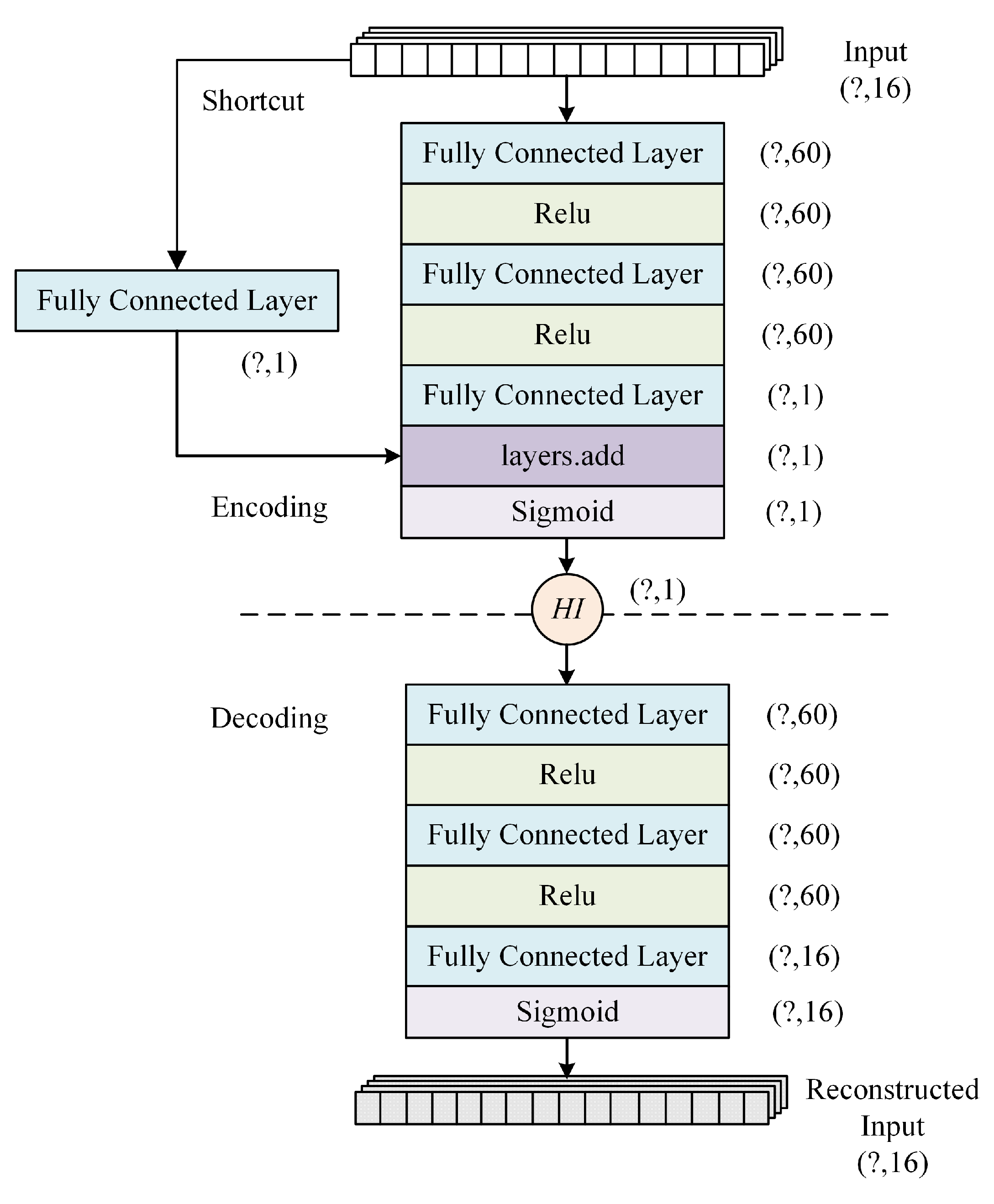
Therefore, to address the aforementioned issues present in actual flight data, we propose a method for constructing health indicator of the engine bleed system based on multi-level feature extraction. The study utilizes Quick Access Recorder (QAR) data as the basis for experimental research. The proposed method does not require annotated data. Instead, it involves data-level feature extraction by extracting statistical features of the duct pressure of 5th stage bleed and the bleed air temperature from the QAR data. Second, it involves feature-level feature extraction where unsupervised learning is employed using RDAE to map the data-level features. The method enables effective evaluation of the health status of the engine bleed air system.
The main contributions of this paper are summarized as follows:
- 1.
To address the challenge of assessing the operational status of engine bleed air systems, we propose a multi-level feature extraction approach for constructing HIs (Health Indicators) that quantify the health status of the engine bleed air system based on data collected from each flight cycle.
- 2.
In the process of constructing health indicators for the engine bleed air system, we solve the issue of varying cycle lengths in the flight data. We introduce a data-level feature extraction method that transforms the original QAR data, which has unequal cycle lengths, into samples of equal length with consistent feature spaces. Additionally, we apply significant compensation to certain elements within the samples to highlight their numerical features.
- 3.
Considering the unannotated nature of actual flight data, we propose an enhanced approach named RDAE (ResNet Deep Autoencoder). RDAE is based on the autoencoder algorithm and aims to extract features from preprocessed data using unsupervised learning. The effectiveness of the proposed methods was validated through experiments conducted on one year of QAR data from a specific airline company.
The remainder of this paper is organized as follows.
Section 2 presents the methodology part of the proposed framework, including key parameter selection, data-level features extraction and feature-level feature extraction.
Section 3 describes our experimental results and analysis, as well as the comparison results with other methods.
Section 4 offers our conclusion.
3. Results and Discussion
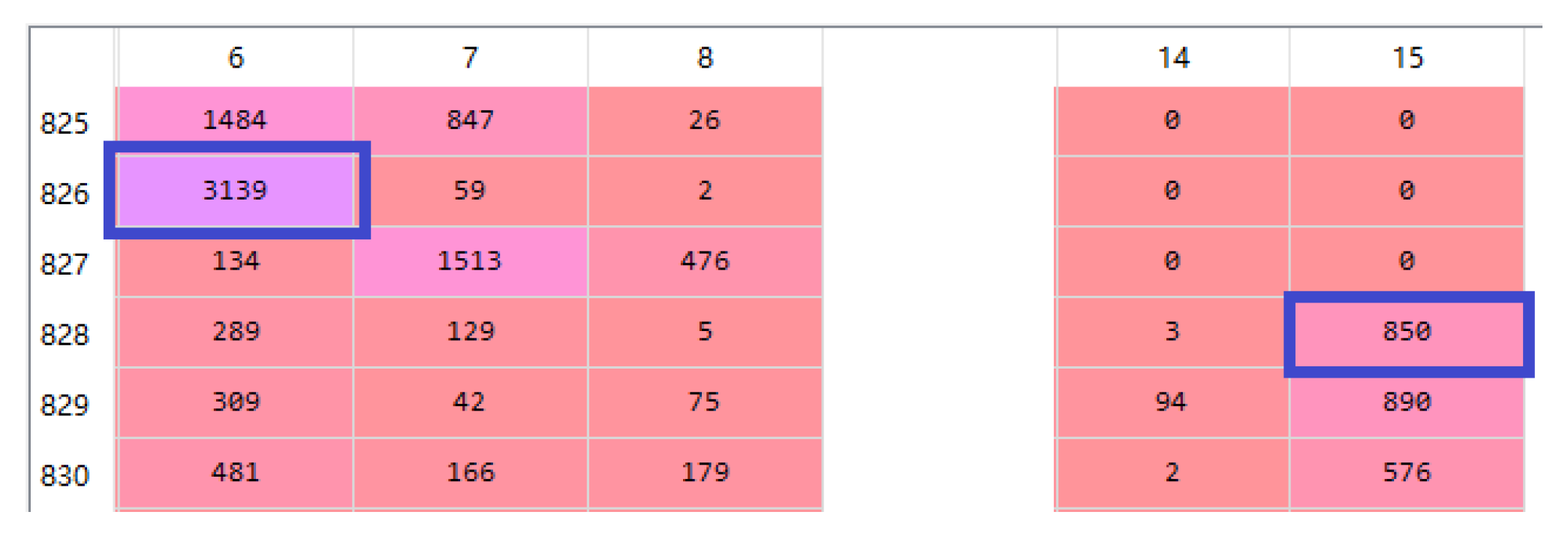
In this study, the QAR data from a Boeing 737 fleet of an airline company for one year was used as the experimental dataset. Each aircraft in the dataset recorded fault data from the engine bleed air system, providing maintenance segments as well as several preceding normal flight segments. Additionally, considering that the dual-engine bleed air systems operate independently, the dataset was divided based on the left and right engine data to allow the model to learn the distinctive features of system degradation. Each sample in the dataset corresponds to the data from a single engine’s flight cycle. After data preprocessing, the experimental dataset consists of 2474 samples.
Following the experimental method described in
Section 2, multi-level feature extraction was performed on the data to construct health indicators for each flight cycle. Additionally, to obtain better HI values corresponding to a good health status, performance baselines are set in the region of HI. This allowed for the separation of normal and abnormal samples. According to the discussion in
Section 2 regarding
Table 1 and
Table 2, the performance baselines were determined based on Boeing’s service bulletins and considering the cost requirements of the airlines. For
, the normal range is 34–50 psi. Taking into consideration that the engine thrust during takeoff phase can cause a slight deviation, it is possible for the pressure to slightly exceed the specified range. Therefore, the range is set at 34–53 psi. The baseline is determined by the maximum and minimum values of all the samples within this range. Similarly, for
, the maximum temperature is set at 455 °F. The lower bound of the baseline is determined by all the samples with temperatures that have not exceeded this range. If the calculated HI falls below this baseline, it indicates that the temperature has exceeded 455 °F. The HI curves with baseline annotations are shown in
Figure 4 and
Figure 5.
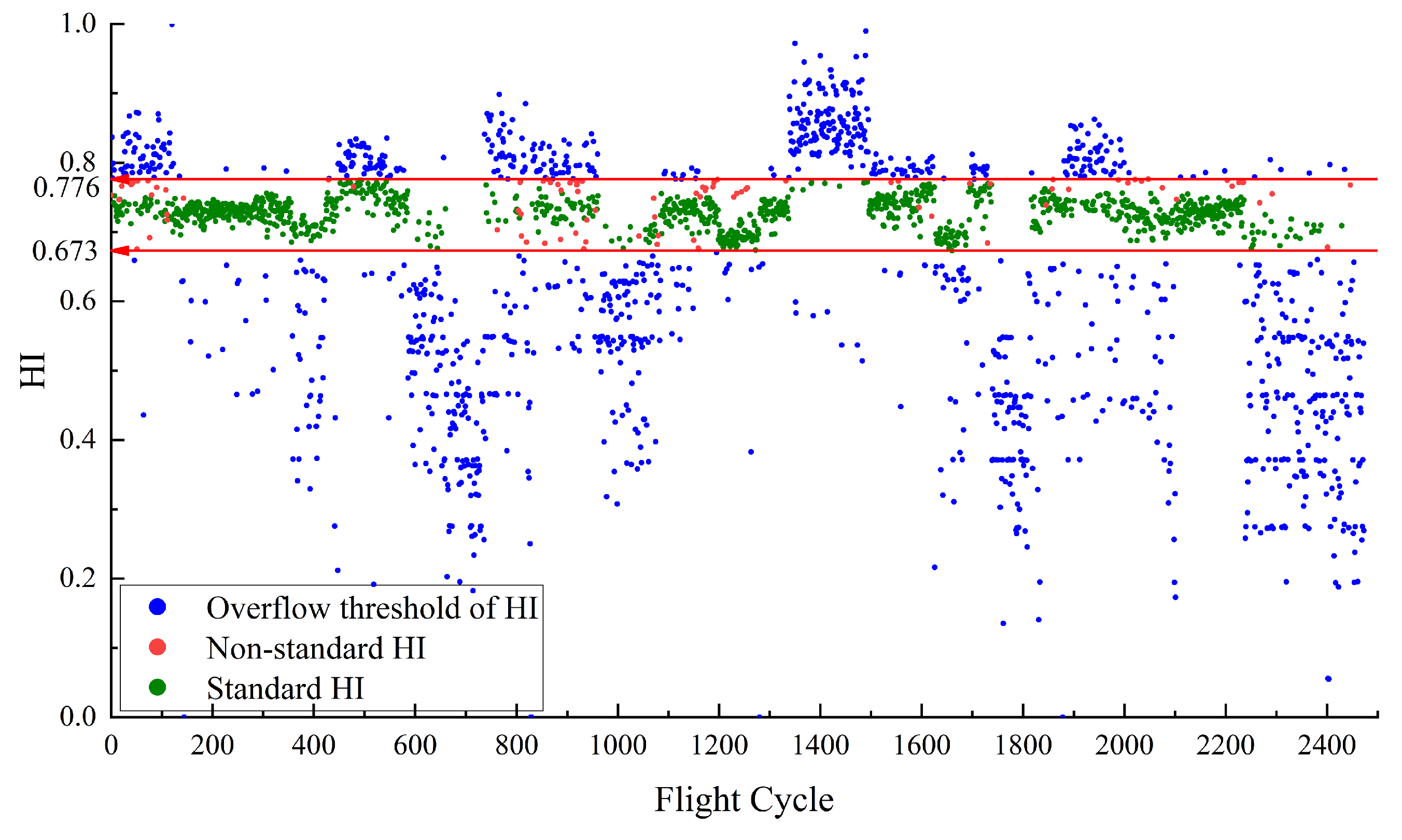
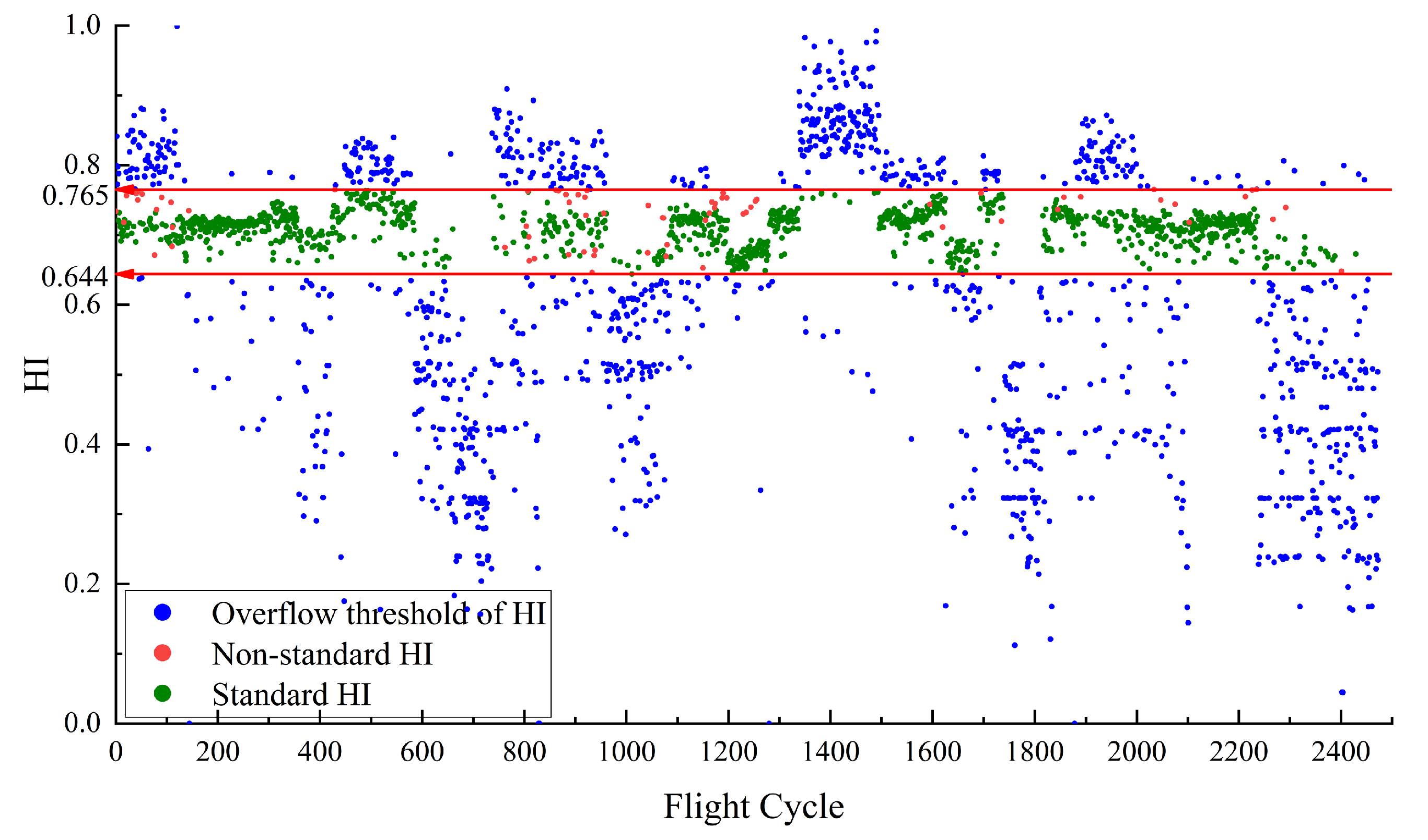
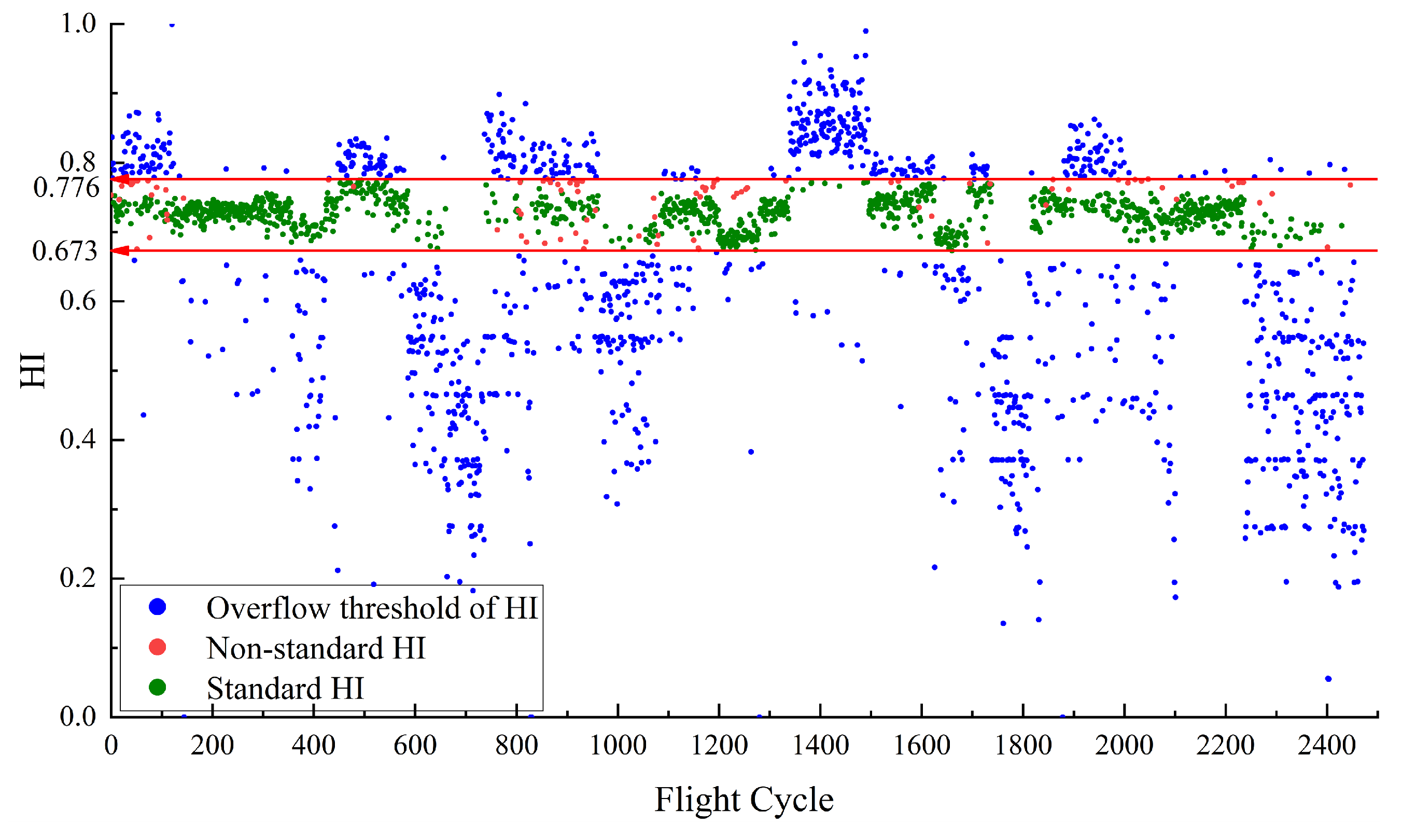
Figure 4 illustrates the HI for
constructed using RDAE. The red line in
Figure 4 represents the performance baseline, with a HI threshold range of [0.644, 0.765]. The green points indicate the normal samples that satisfy the maximum and minimum values of
. sample points that satisfy
are considered as normal sample points. Their corresponding HI values are defined as the standard HI, which are in HI range of [0.644, 0.765].
Figure 4 illustrates that due to the baseline [0.644, 0.765], the green points and blue points are effectively separated. However, there are some red points within the baseline. The red points are defined as non-standard HI, indicating samples that do not meet the normal feature conditions but fall within the baseline boundary. There are no red points which means all abnormal points are separated.
The presence of some red points within the baseline range in
Figure 4 can be attributed to the different mechanism for mapping data features and setting threshold values. The red points correspond to
that exceed the experimentally set threshold values. However, the extracted data features by the model are complex and do not solely represent the magnitude of
. As a result, these samples are mistakenly mapped within the baseline range.
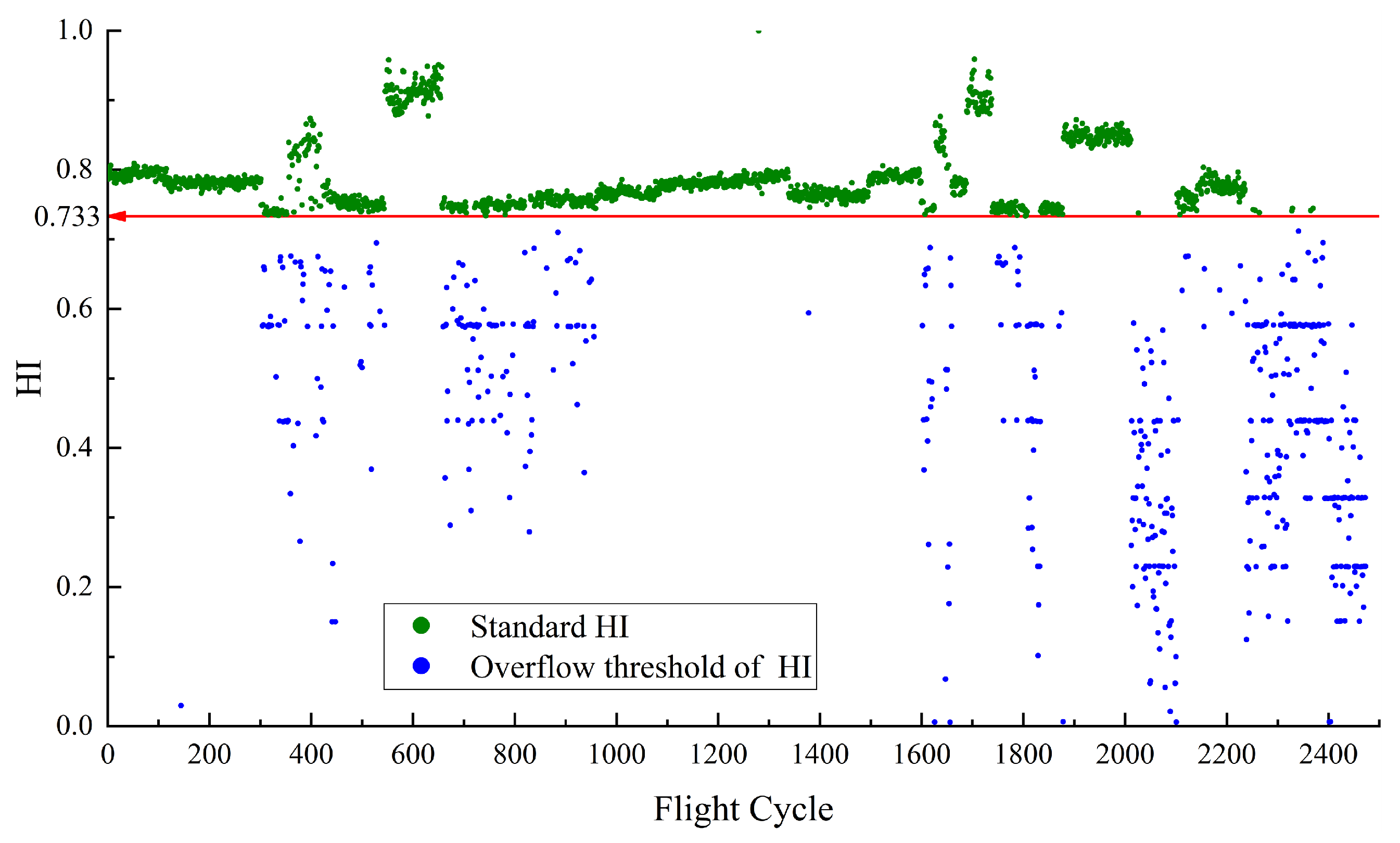
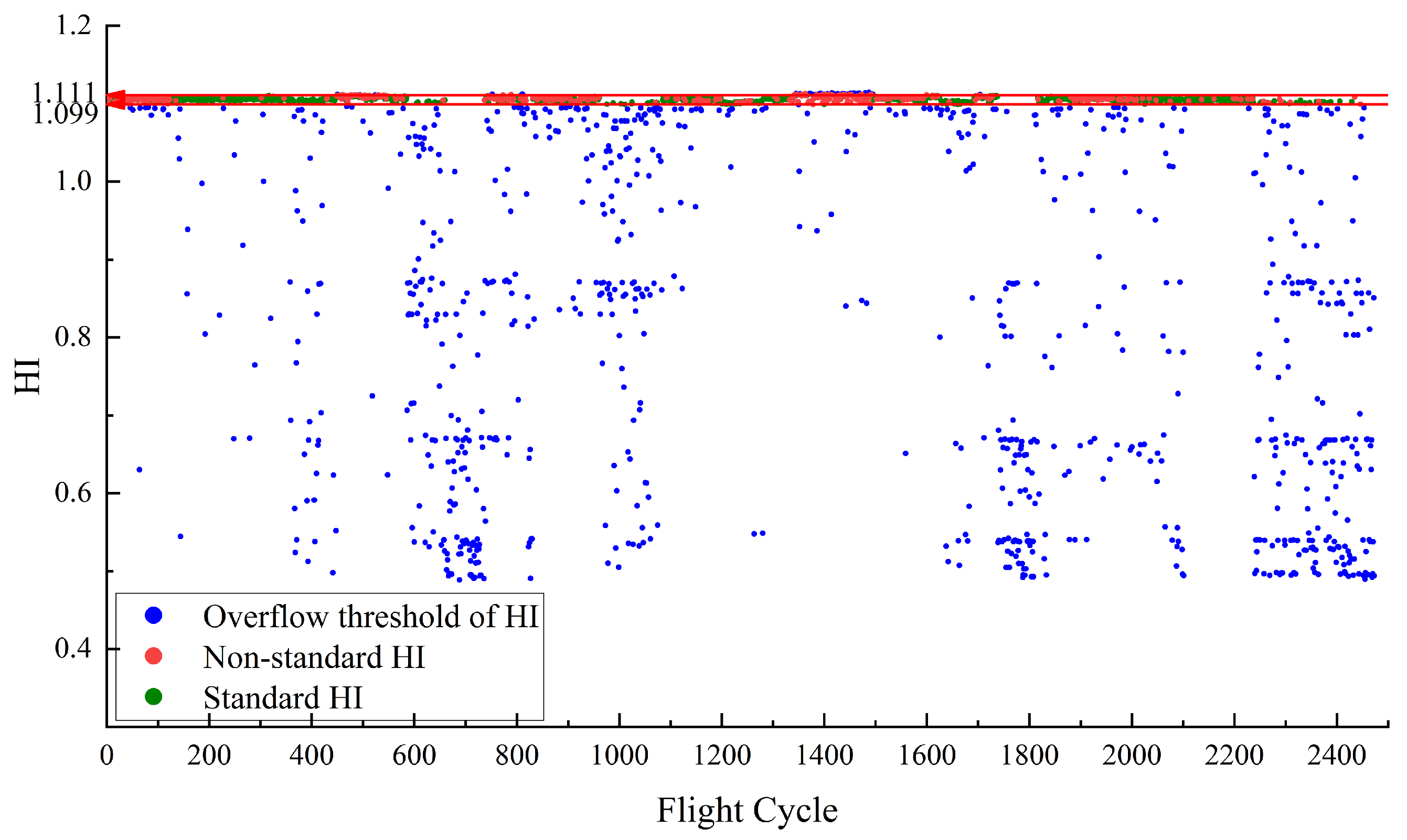
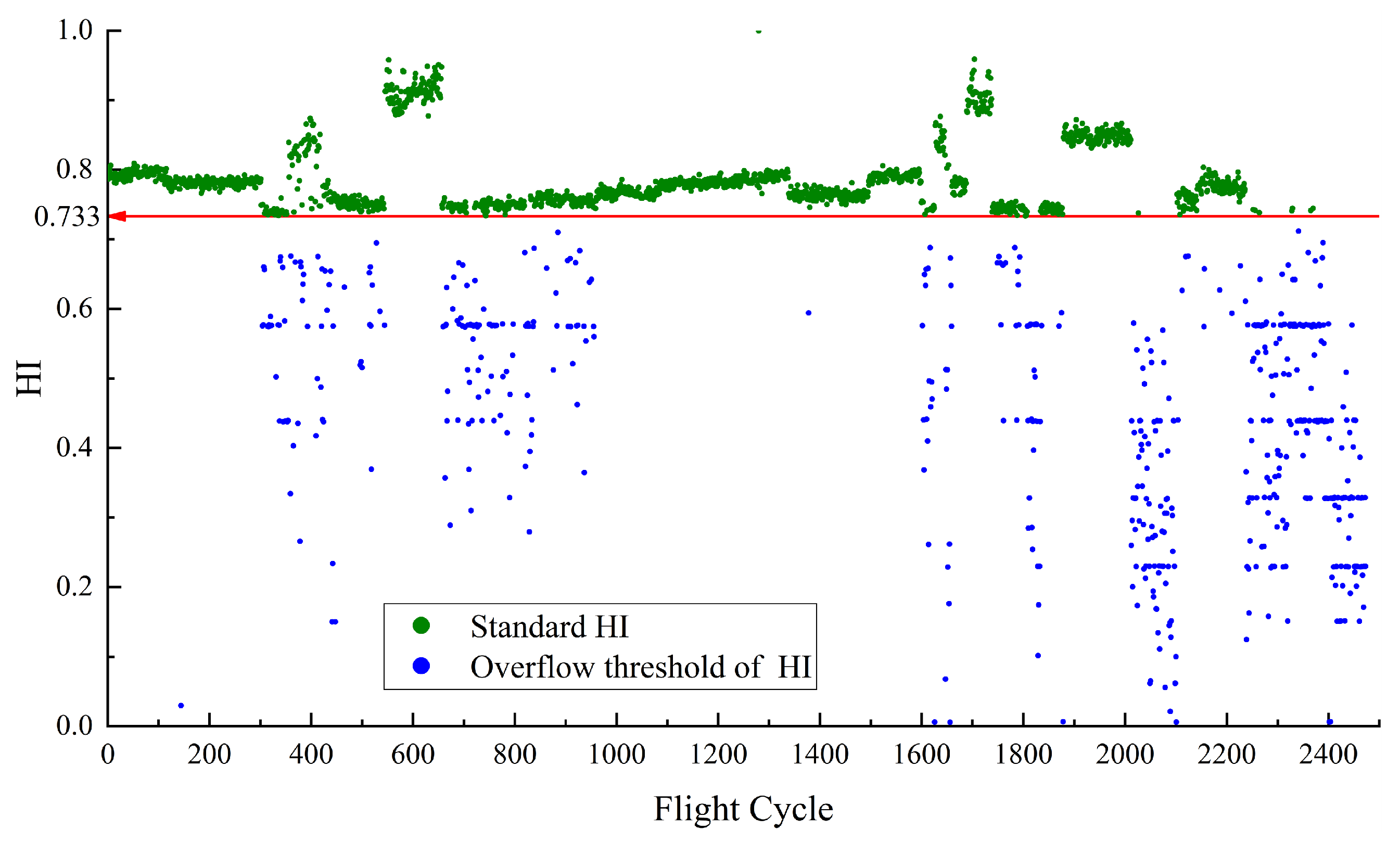
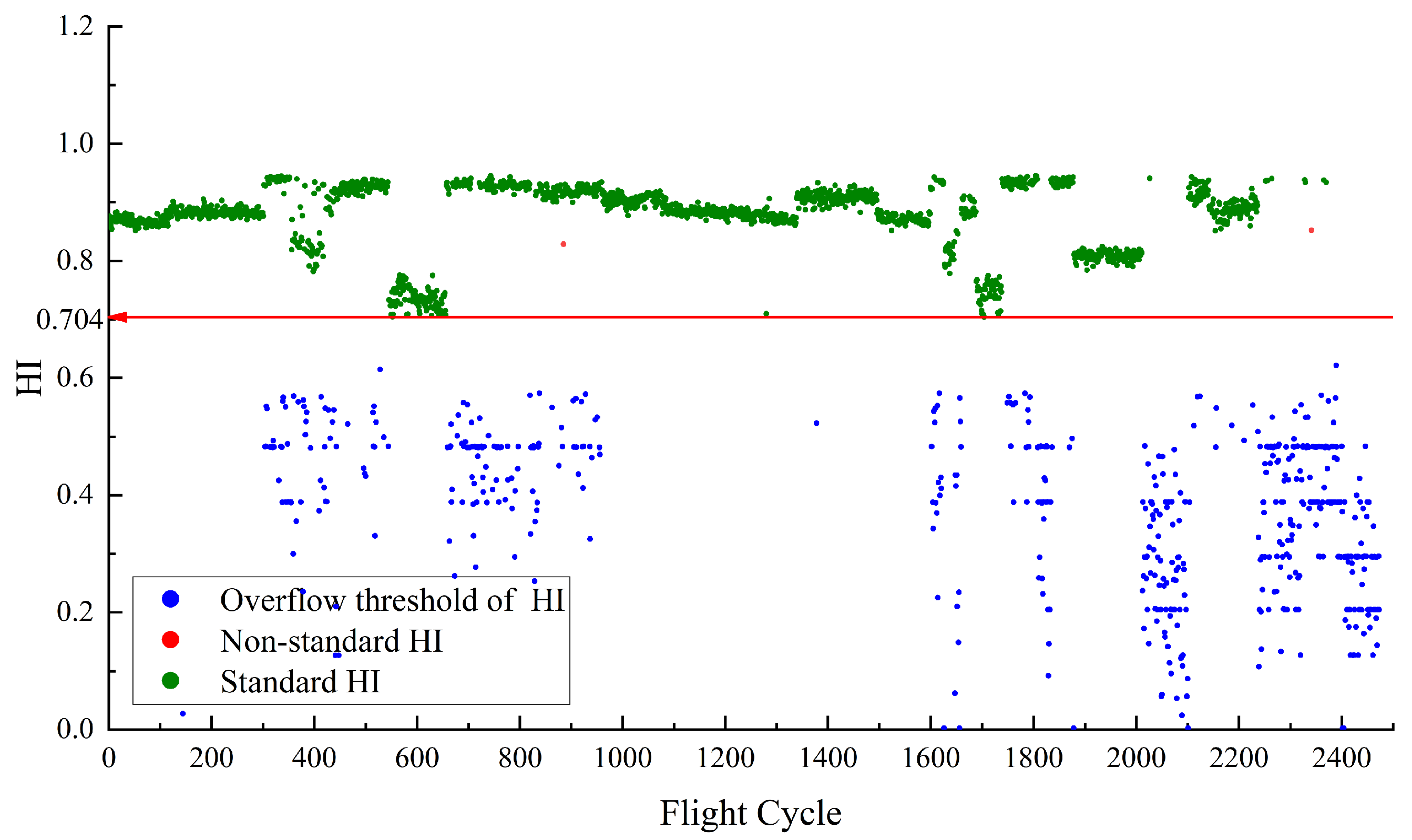
Figure 5 depicts the HI for
constructed using RDAE. In the calculation of HI, if the
temperature is higher, the resulting HI value is smaller. Therefore, the upper limit value of temperature corresponds to the lower limit value of HI. The red line in the
Figure 5 represents the performance baseline, with a HI lower limit of 0.733. The normal sample points for this case are determined by selecting the samples that satisfy
. Their corresponding HI values are defined as the standard HI, which are the points above the baseline 0.733. As the performance anomaly detection is focused on high temperatures, no upper limit is specified for the HI of
. The red points represent non-standard HI samples that do not meet the normal feature conditions but fall within the baseline threshold. There are no red points which means all abnormal points are separated.
Once the health indicators are constructed, it becomes easy to distinguish between normal and abnormal values for and . For , the baseline is defined as a range. When the calculated HI based on falls within this range, it can be considered as normal. For , the baseline is a lower limit. When the calculated HI based on is above this value, it can be considered as normal. This provides a relatively intuitive evaluation indicator, HI, which is concise and effective. The graph also shows some points where the actual values exceed the limits but the calculated HI still falls within the baseline range. The proportion of these points is known as the miss rate, which is an important metric for evaluating HI construction algorithms.
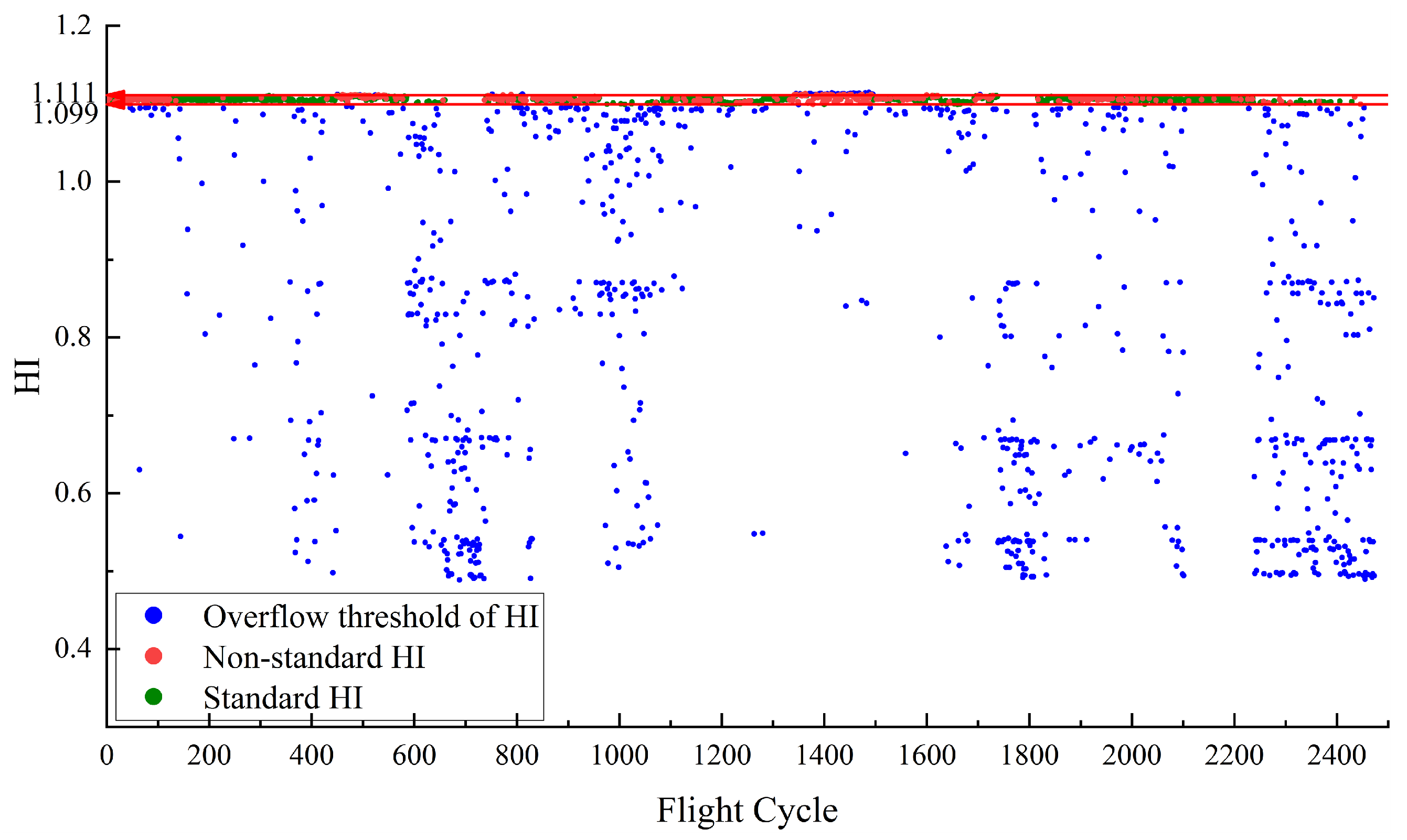
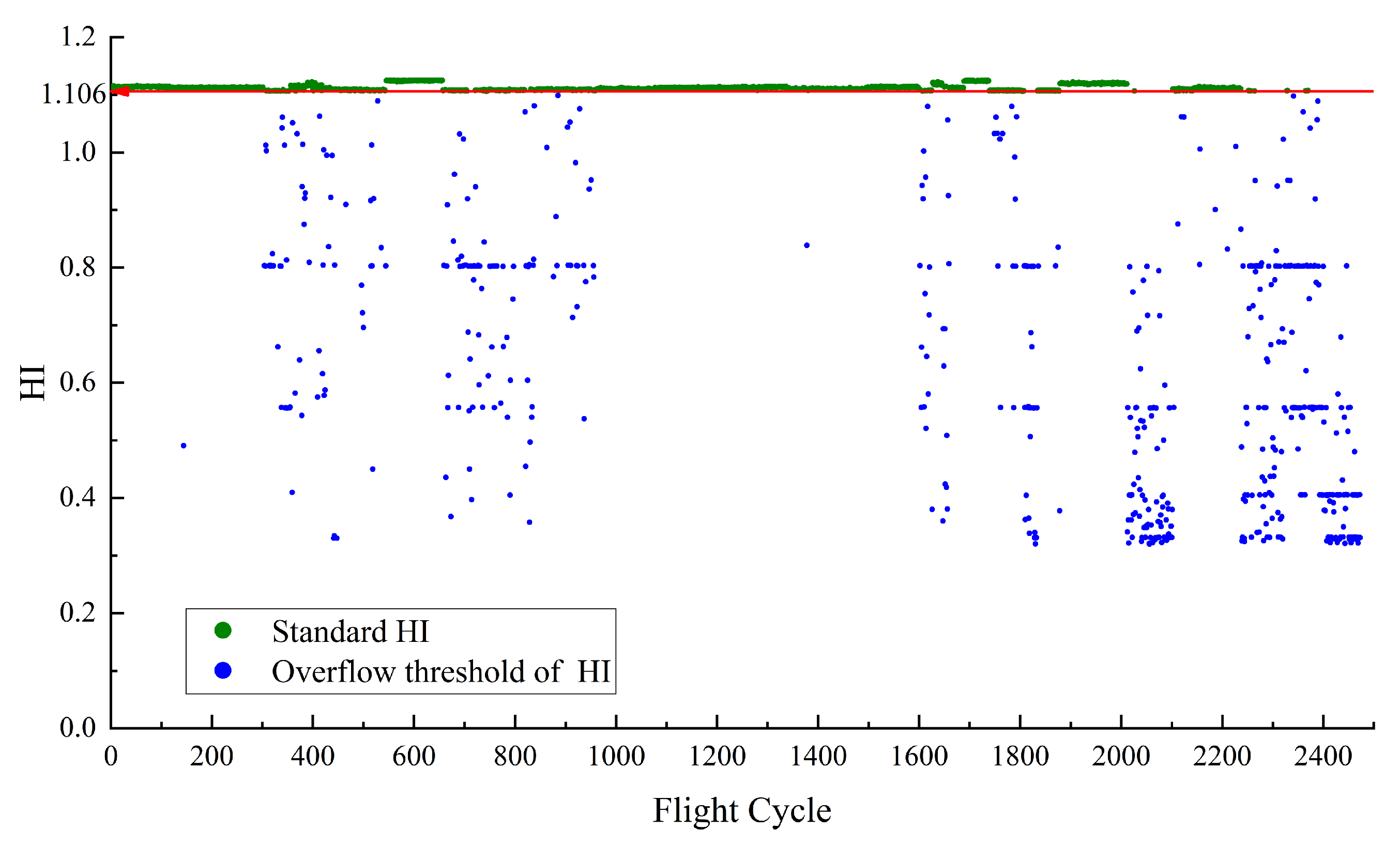
In addition, we also used the classical Deep Autoencoder (DAE) and Kernel Principal Component Analysis (KPCA) as comparative models to validate the performance of the health indicator construction in this paper. The HIs constructed by DAE are shown in
Figure 6 and
Figure 7, respectively. The HIs constructed by KPCA are shown in
Figure 8 and
Figure 9, respectively.
By comparing
Figure 4,
Figure 6 and
Figure 8, RDAE has learned the distribution of data-level features more effectively than KPCA. Through RDAE feature mapping, the health status of the system for each flight cycle can be quantitatively evaluated.
Figure 6 shows The
HI constructed by DAE has a higher number of non-standard HIs compared to RDAE, indicating slightly weaker separation performance between normal and abnormal samples. However,
Figure 8 shows that there is a significant number of non-standard HIs within the baseline constructed by KPCA. This can introduce interference in the analysis of system performance in practical engineering.
Figure 5,
Figure 7 and
Figure 9 reveal the performance differences among the three models in constructing the HI for
. It is important to note that in
Figure 7, there are non-standard HIs present in the points constructed by DAE, indicating its relatively inferior performance in separating normal and abnormal samples compared to RDAE and KPCA. Although KPCA has constructed an HI curve with almost no non-standard HIs within the baseline, the distribution is not sufficiently uniform. The overall curve in the early stage of performance degradation is too flat, which hinders the prediction model from fully learning the characteristics of HI variations.
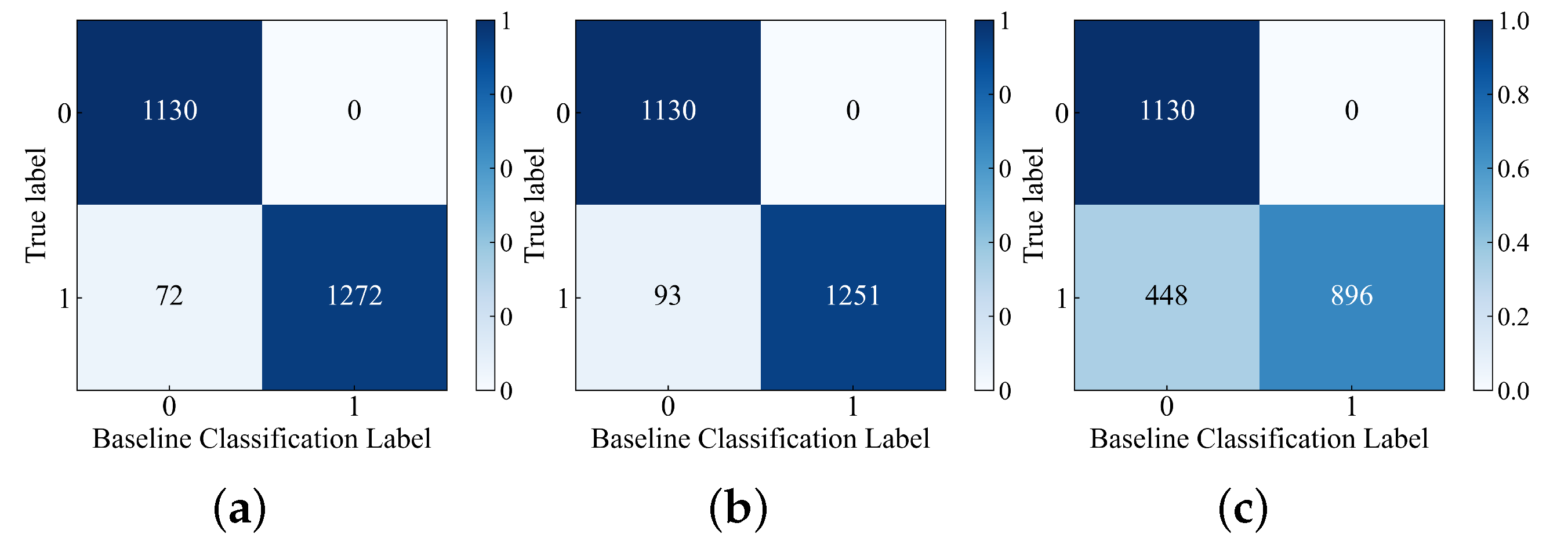
To visually assess the performance of the HI construction models in separating normal and abnormal samples, the results obtained from
Figure 4,
Figure 5,
Figure 6,
Figure 7,
Figure 8 and
Figure 9 were visualized using confusion matrix plots, as shown in
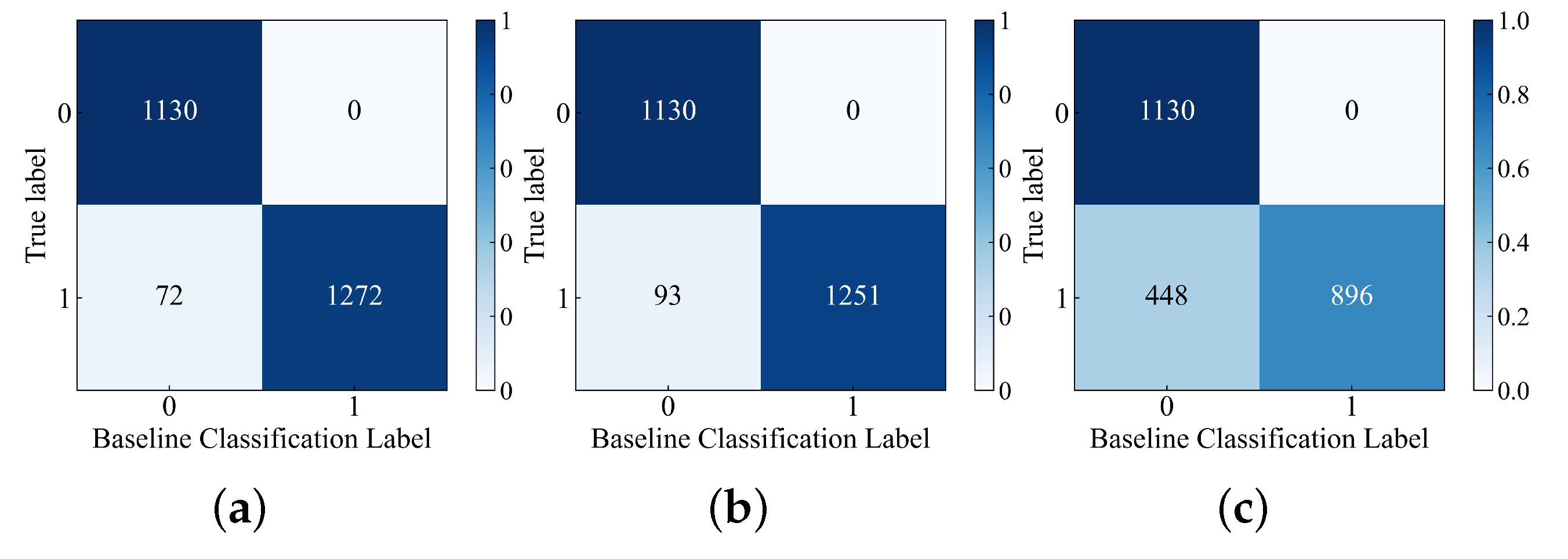
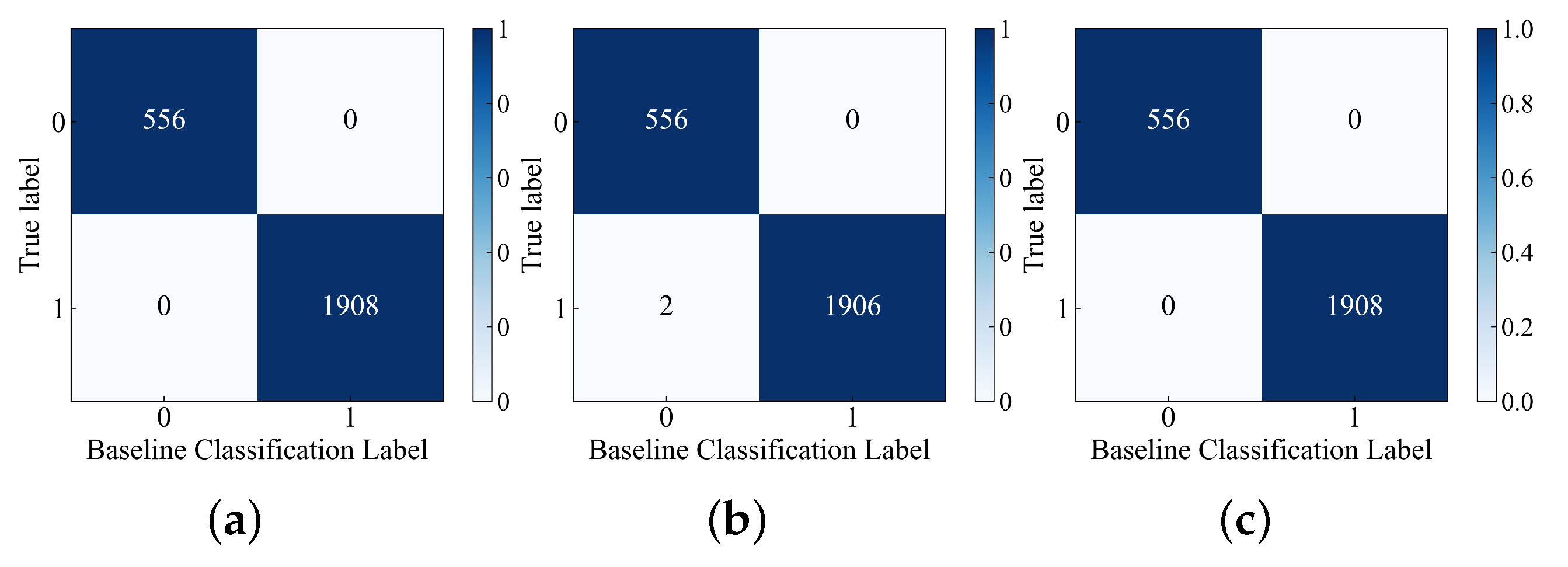
Figure 10 and
Figure 11. In
Figure 10 and
Figure 11, the label “0” represents normal samples, and the label “1” represents abnormal samples. The confusion matrix represents the cases of classification errors. For example, in
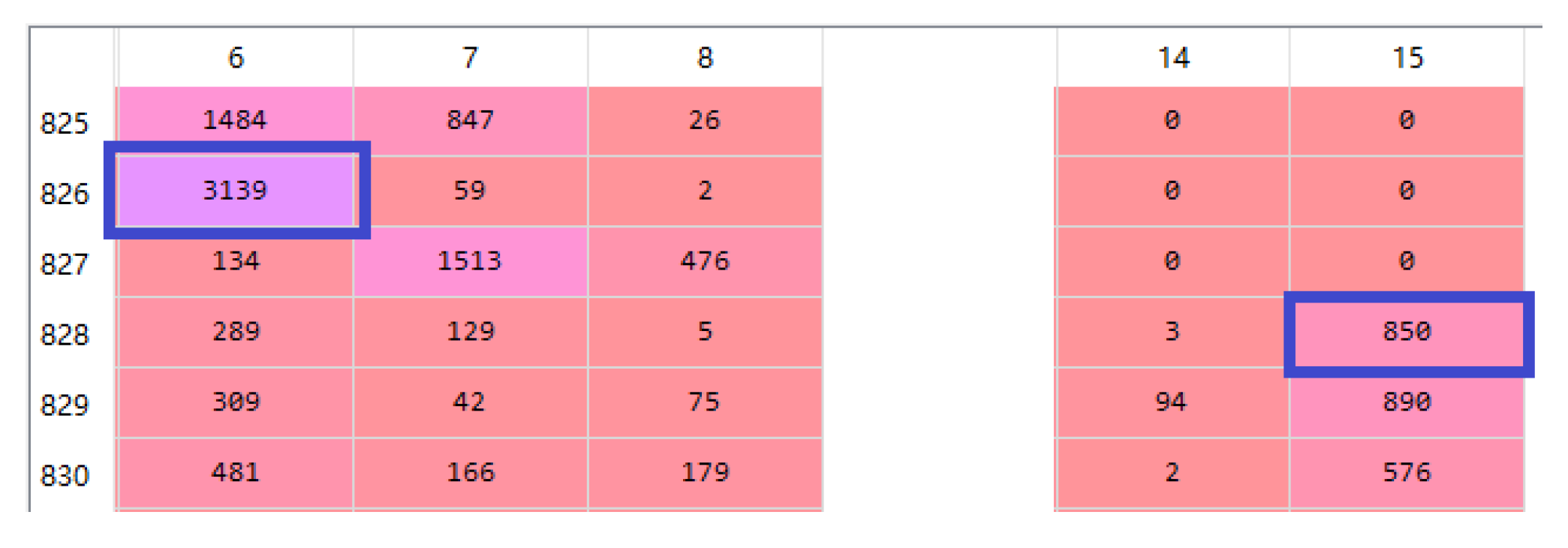
Figure 10a, the true label “0” is classified into baseline classification label “0” and “1” with counts of 1130 and 0 respectively. Similarly, the true label “1” is classified into baseline classification label “0” and “1” with counts of 72 and 1272 respectively. The meanings of the remaining figures are also similar.
Since the baselines in
Figure 4,
Figure 5,
Figure 6,
Figure 7,
Figure 8 and
Figure 9 are set based on the HI values of normal samples, there are no cases in
Figure 10 and
Figure 11 where label “0” is misclassified as label “1”. In
Figure 10a, the number of cases where label “1” is misclassified as label “0” is the lowest compared to
Figure 10b,c, indicating that the RDAE model has the strongest performance in separating normal and abnormal samples. In
Figure 11, both
Figure 11a,c plots have no misclassifications. Therefore, it can be concluded that the RDAE model has the best performance.
Additionally, this study compares the miss rate (Equation (
3)) [
21] as an evaluation metric to quantify the performance of the HI construction models in separating normal and abnormal samples. The results are shown in
Table 2.
In Equation (
3),
M is the miss rate.
represents the number of abnormal samples that fall within the baseline threshold.
represents the total number of abnormal samples. According to
Table 3, the miss rate of RDAE for
is 0.0523, indicating that it can correctly identify 94.77% of abnormal HI in the batch of flight cycles. The RDAE model achieves a miss rate of 0.00% for
, meaning it can identify all abnormal samples in the batch. DAE exhibits weaker performance in separating normal and abnormal samples, while KPCA has a high miss rate of 33.33% for
. It is evident that RDAE outperforms the other two models in terms of the miss rate, demonstrating superior performance in separating normal and abnormal samples for both
and
.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}