1. Introduction
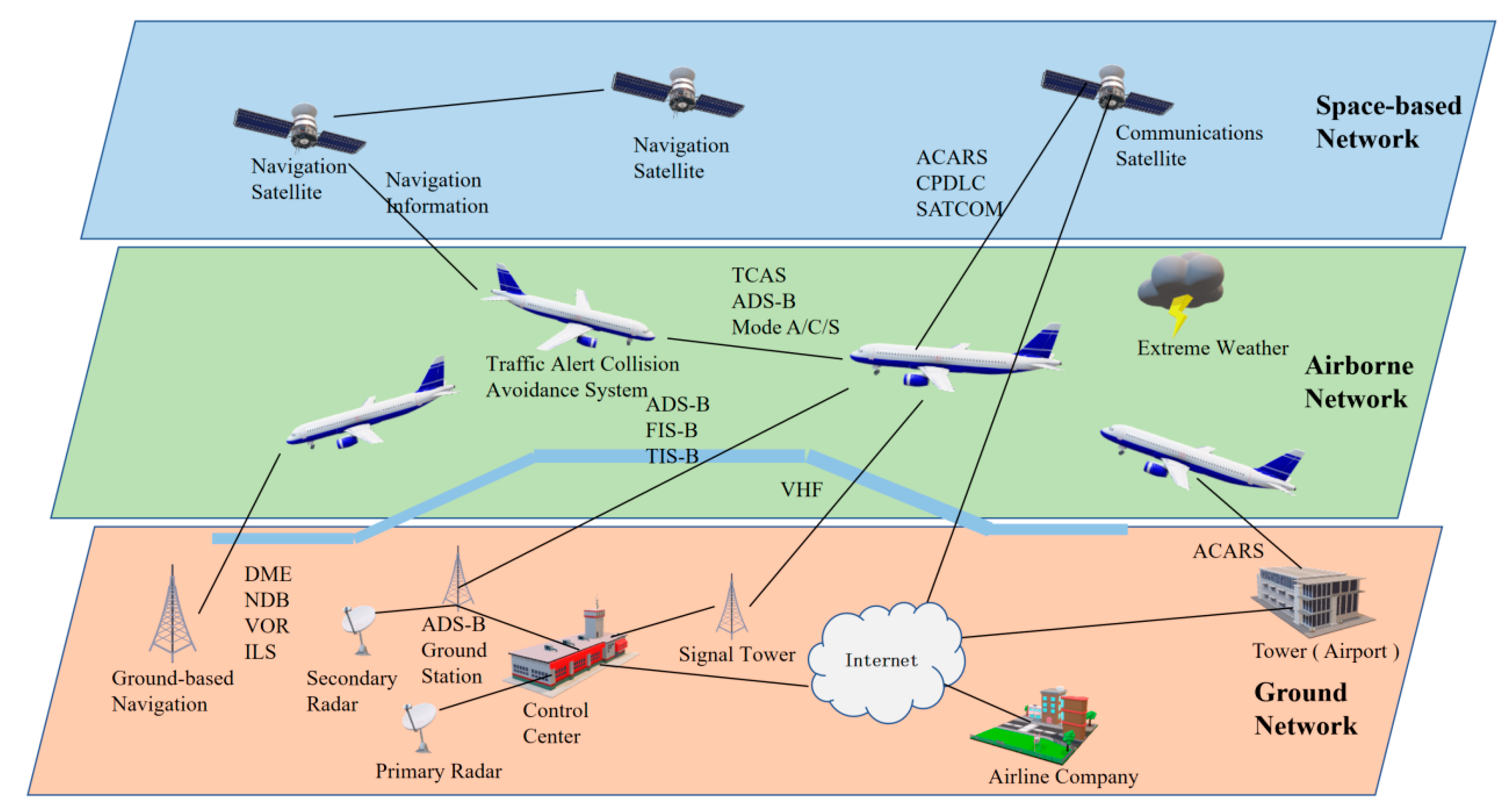
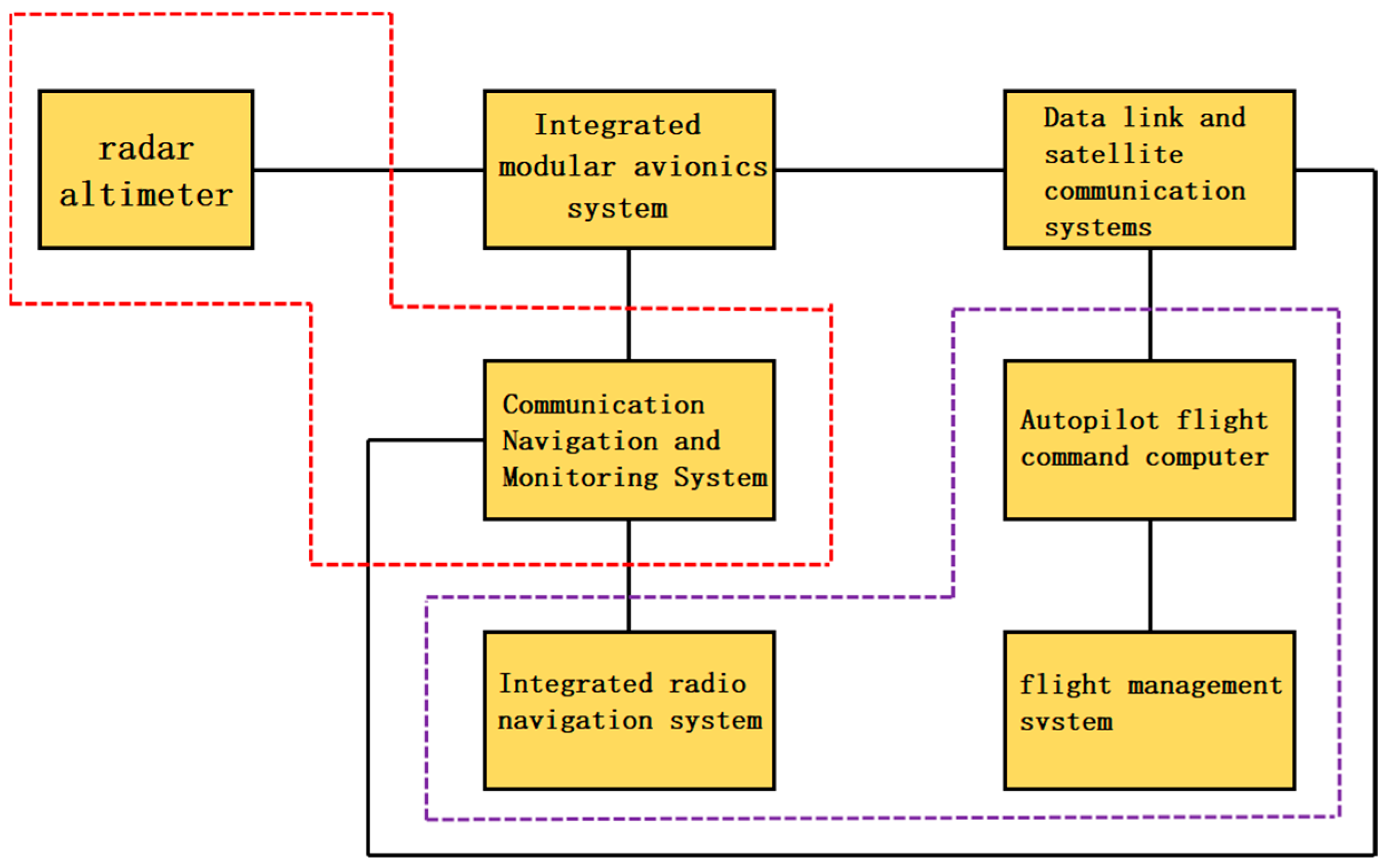
The air traffic management system (ATM) is a typical airspace integration network system [
1,
2,
3] (shown in
Figure 1), which plays a significant role in ensuring flight safety and enhancing flight efficiency by monitoring and controlling aircraft flight activities with communication, navigation technologies and monitoring systems. As more and more embedded devices and systems are digitized and connected to many wireless services and communications, attackers are exploiting security vulnerabilities to conduct virus ransom and cyberattacks, posing a serious threat to human travel safety. Meanwhile, air traffic management system cyberattacks are also developing towards a new trend. The degree of automation and attack correlation is constantly improving, and the attack actions are unpredictable. According to the International Threat Report Portugal Q1 2021 [
4], malware in the first quarter of 2021 increased by 24.2% compared to the same period last year. According to Check Point’s ransomware report [
5], the air transport industry experienced an 186% increase in weekly ransomware attacks between June 2020 and June 2021. A large amount of useful security information such as the international aviation security reports, cyber security vulnerability database, and threat database is seriously fragmented [
6], and these resources are not properly integrated and utilized. The current problem of ATM cyber security posture analysis is not the lack of available information, but how to fuse heterogeneous information from multiple sources to achieve ATM cyber security posture analysis and provide auxiliary decision support for penetration testing.
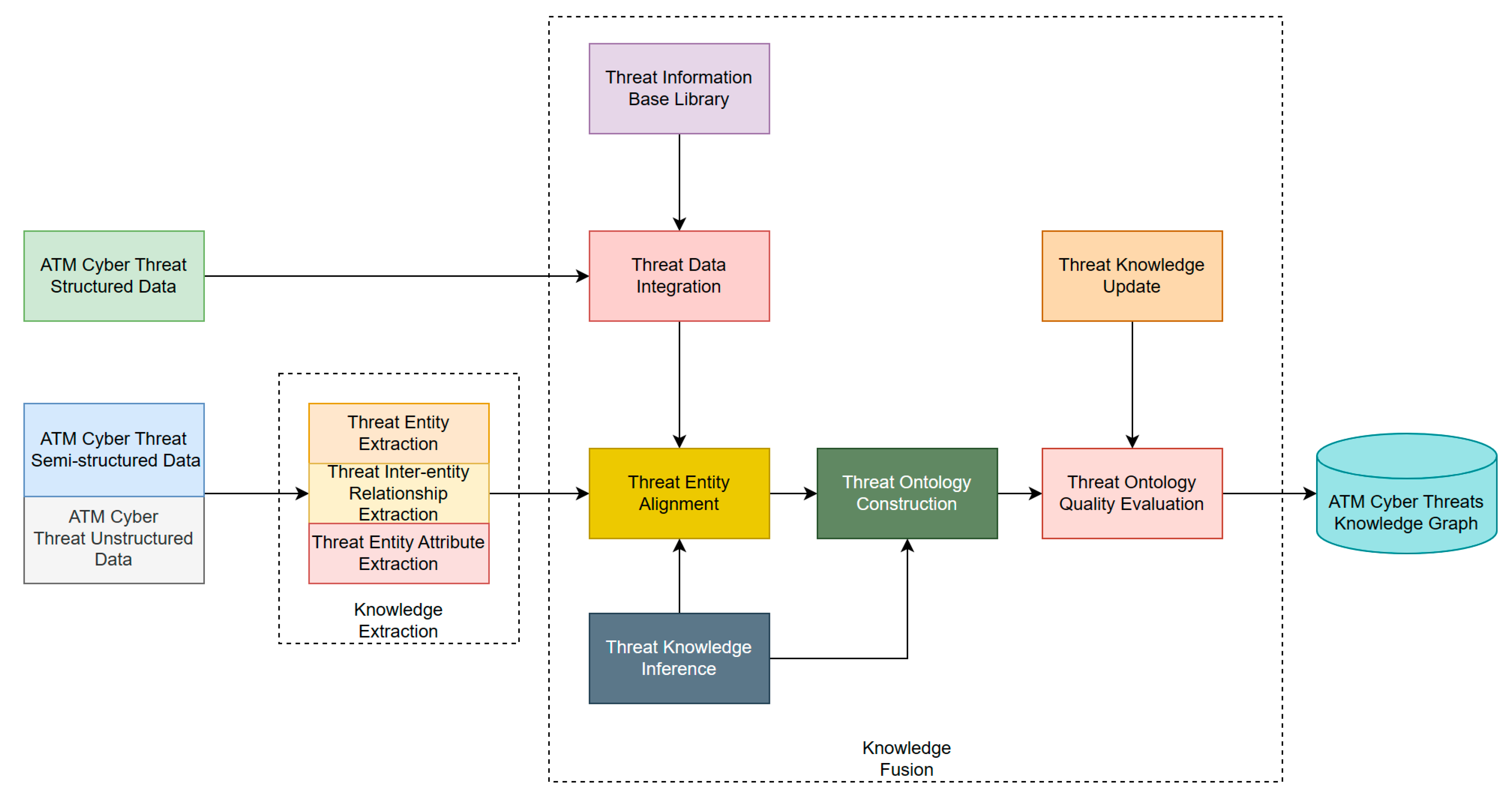
The ATM cyber threat knowledge graph construction includes the processes of knowledge extraction, knowledge fusion, quality assessment, and knowledge graph storage [
7] (as shown in
Figure 2). Knowledge extraction [
8] mainly includes entity recognition, relationship extraction, and attribute extraction. Knowledge fusion techniques include data integration, entity alignment, knowledge modeling, knowledge embedding [
9], etc. The construction process includes, firstly, preprocessing unstructured data and semistructured data, conducting knowledge extraction to obtain entities, interentity relationships, entity attributes, and performing integration of structured data with information databases and knowledge databases, and then entity alignment, disambiguation of knowledge, and finally ontology construction and knowledge modeling. Knowledge embedding can be used for entity alignment and ontology construction in the above process. Knowledge modeling is followed by quality assessment, continuously updating knowledge, and ultimately forming a knowledge graph. Through the analysis of the air traffic management system cyber threat knowledge graph, cyber security experts can more intuitively understand the threat intelligence and security posture and discover complex cyberattack patterns.
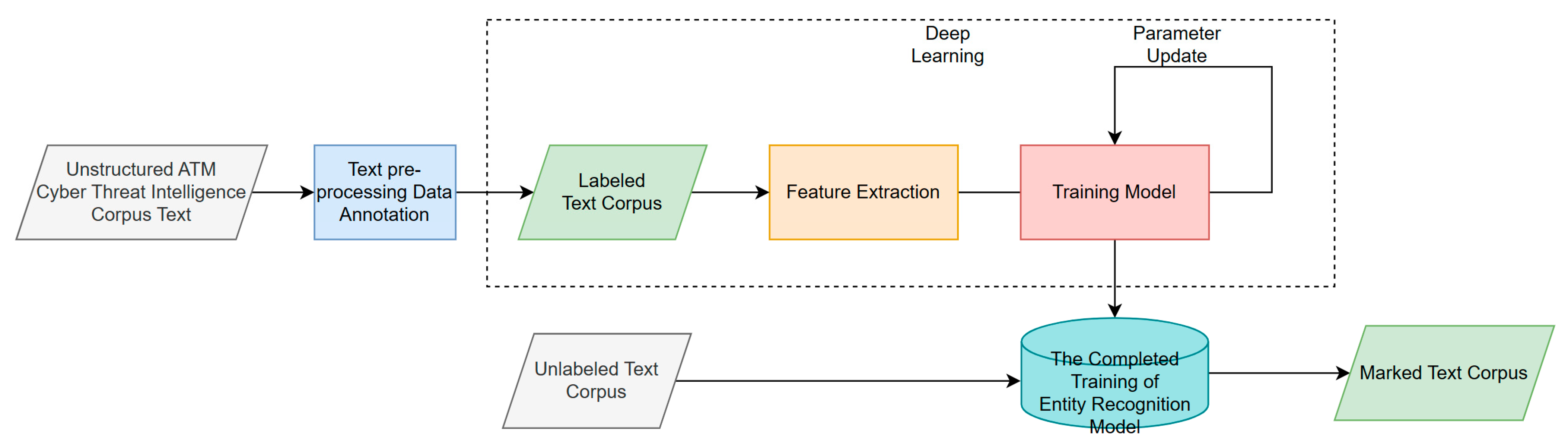
Entity recognition technology is the basis for the construction of the ATM cyber threat knowledge graph. To effectively build the ATM cyber threat knowledge graph, entities must be extracted from massive multisource intelligence data, especially from unstructured data. The principle of ATM cyber threat entity recognition [
10] (shown in
Figure 3) is as follows: first, preprocess the unstructured ATM cyber threat corpus text, and then, conduct data annotation and labeling. The labeled text corpus is then subjected to deep learning process, and the entity contextual features and entity internal features are extracted by the deep learning method, which is trained iteratively to finally obtain an entity recognition model. The unlabeled text corpus is automatically labeled by the completed training of the entity recognition model; as a result, the category of the entity can be obtained. The entity recognition method by deep learning can fully discover and utilize entity contextual features and entity internal features, and this method is more flexible with better robustness [
11]. ATM cyber threat entity recognition is a specific domain entity recognition in the field of named entity recognition. The main task is to recognize different types of threat entities such as malware, URL, IP address, and hash in text data. The purpose is to confirm and classify the professional vocabulary in the field of ATM cyber threats and provide data support for the later construction of knowledge graphs.
The contributions of this paper are summarized into three points:
Firstly, a TextCNN-Flat-Lattice Transformer (TCFLTformer) with CNN-transformer hybrid architecture is proposed for ATM cyber threat recognition entities, in which a relative positional embedding (RPE) is designed to encode position text content information, and a multibranch prediction head (MBPH) is utilized to improve deep feature learning.
Secondly, ATM cyber threat entity recognition datasets (ATMCTERD) are provided for our research needed, which contain 13,570 sentences, 497,970 words, and 15,720 token entities. We collect data from multiple sources, which are mainly from international aviation authorities and cyber security companies, We manually annotate the datasets with BIO annotation rules, and the annotation entity types are malware, URL, IP address, and hash.
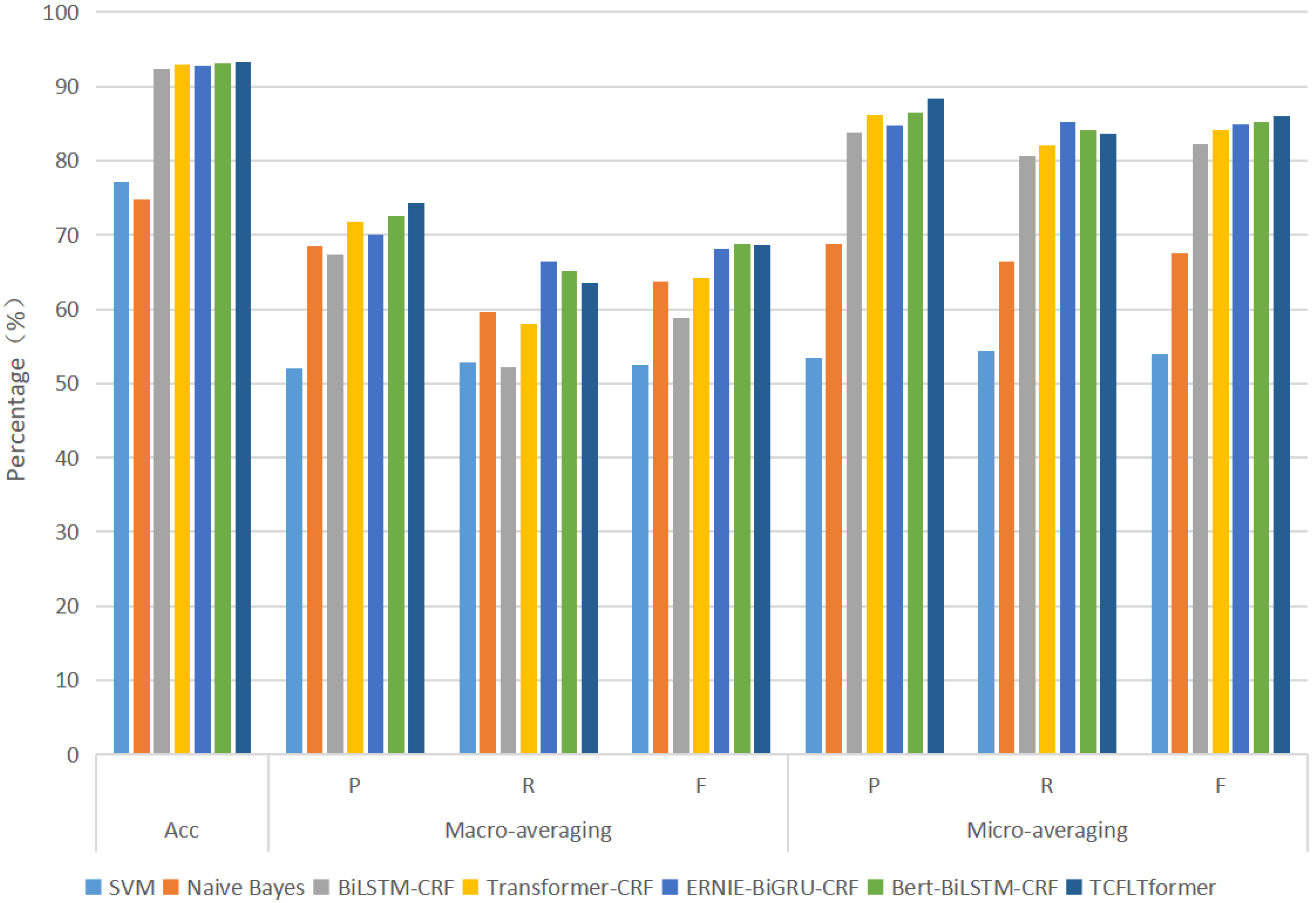
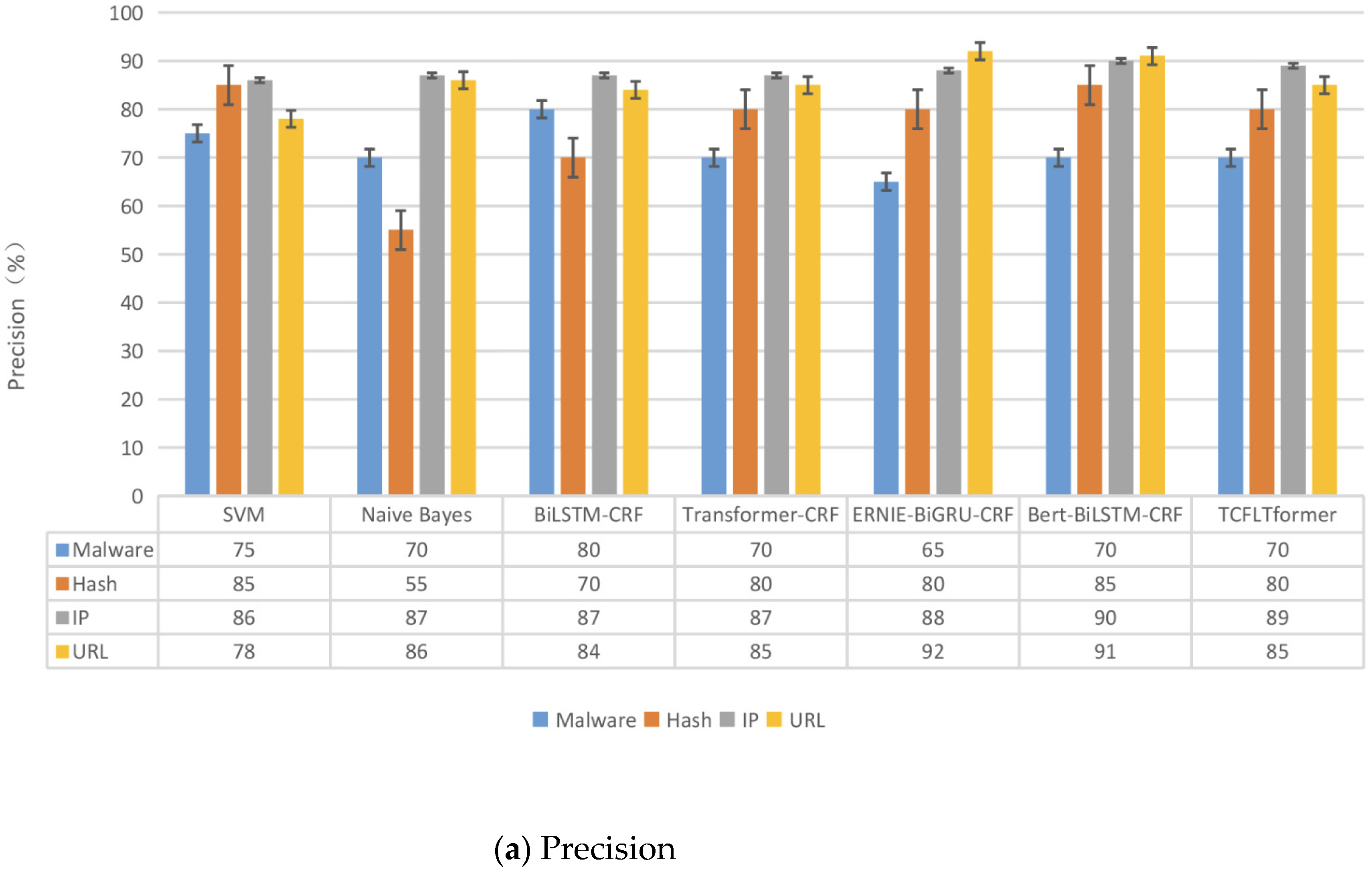
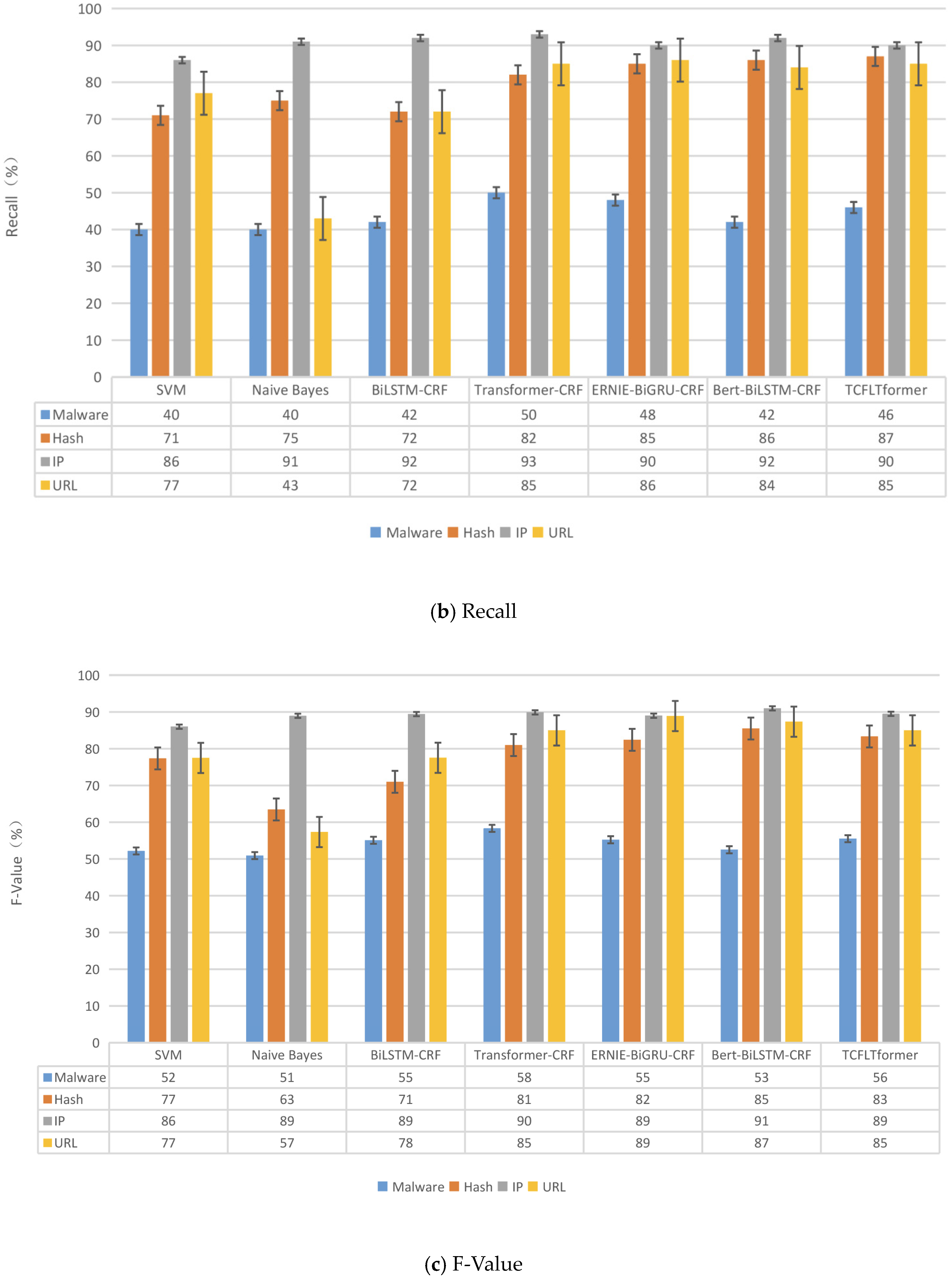
Finally, in comparative experiments with six NER models on our datasets that we proposed, TCFLTformer can obtain the highest accuracy scores of 93.31% and the highest precision scores of 74.29%, while the highest accuracy rate and precision rate of other methods are 93.10% and 72.61%, respectively, which is an improvement of 0.21% in accuracy rate and 1.68% in precision rate. Then, we carry out the additional experiments on MSRA and Boson datasets to fully and comprehensively evaluate the effectiveness of our model. This indicates that the method proposed in this paper can recognize cyber threat entities in the ATM more accurately and better perform.
The rest of the manuscript is organized as follows.
Section 2 reveals related work,
Section 3 reveals detailed structures of the methodology, while
Section 4 gives model training and optimization. The experimental settings and the experimental results are demonstrated and analyzed in
Section 5. The discussion part is in
Section 6. Finally, we make the conclusions and outlook in
Section 7.
3. Methodology
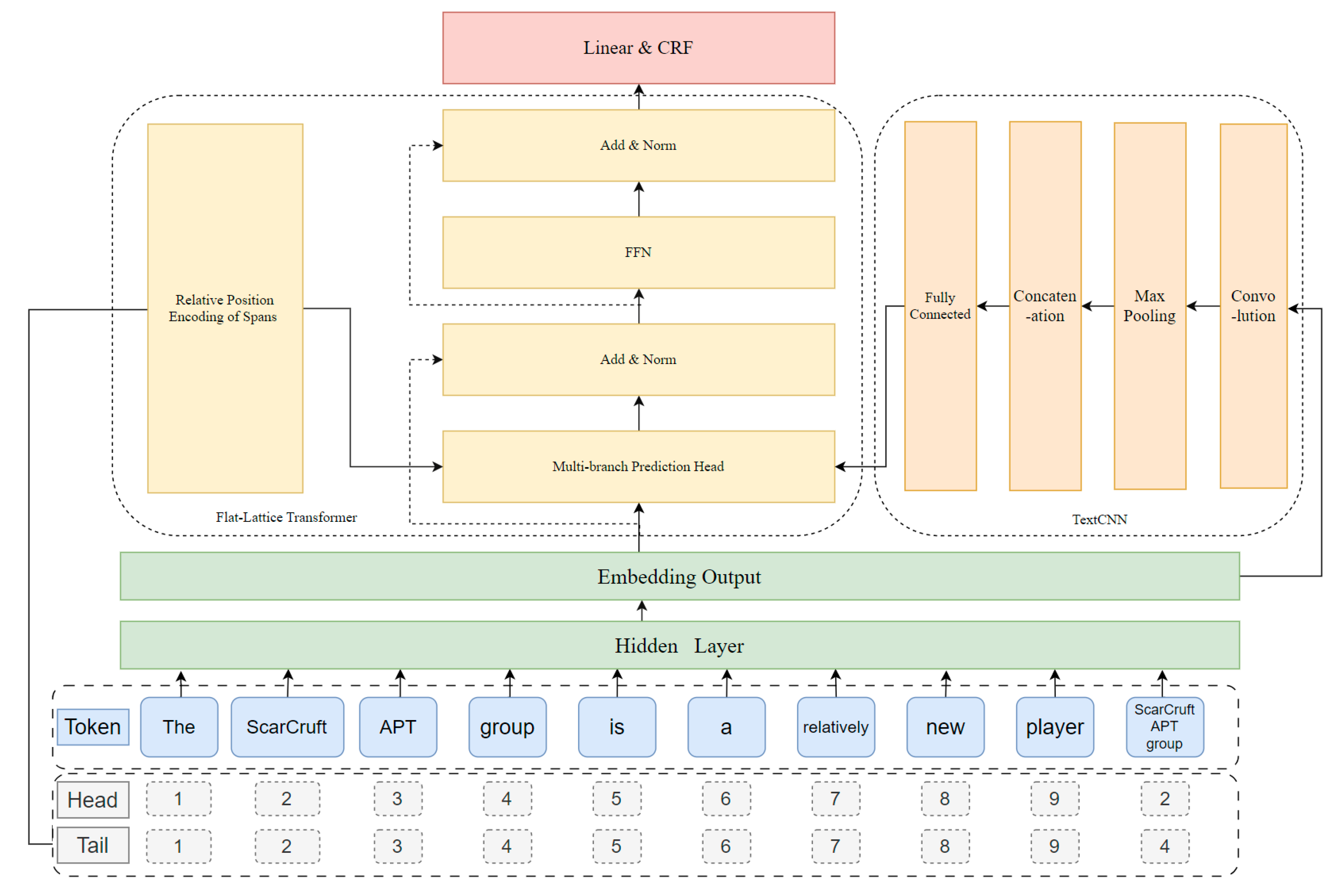
In this paper, we propose a TCFLTformer model for the recognition of ATM cyber threat entities, which can be divided into two parts, the TextCNN module and the Flat-Lattice Transformer module (as shown in
Figure 4). Among them, TextCNN [
28] is a text model based on a convolutional neural network, which mainly extracts local features from text and enhances the ability of the model to learn to acquire local features. Flat-Lattice Transformer [
29] is a flat graph structure model based on Transformer [
30], which can process long hierarchical text data. It mainly learns the temporal and relative positional characteristics from the text data. This method combines the advantages of TextCNN and Flat-Lattice Transformer, which can improve the accuracy of recognition cyber threat entities in ATM.
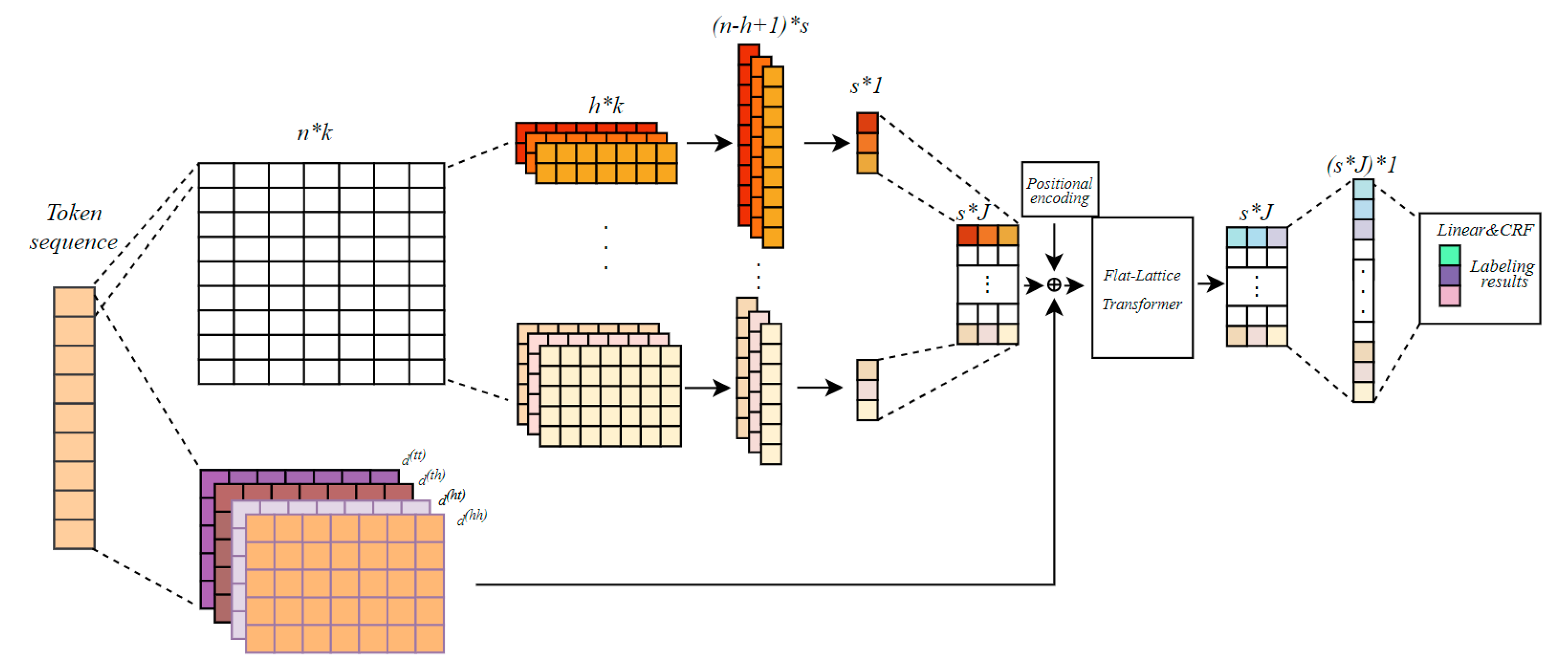
The TCFLTformer model is a deep learning-based entity recognition model, and the principle of this model is shown in
Figure 5. Firstly, the text is word-vectorized
n ×
k, and then the TextCNN model is used to extract the cyber threat entity features in the ATM. In the process of feature extraction, we use multiple convolution kernels of different sizes
h ×
k for convolution operation to capture the text features of different lengths (
n −
h + 1) ×
s of text features, and the features
s × 1 obtained from the convolution operation are pooled, the convolution operation can extract local features, and the pooling operation can downscale the features to reduce the number of parameters of the model. Then, the feature vectors are input into the fully connected layer to obtain fixed-length feature vectors
s ×
J, then they are input into the multibranch prediction head, then they are processed by the Flat-Lattice Transformer model processing, and finally, the labeling results of the input entities are obtained after probabilistic judgment of the linear CRF layer.
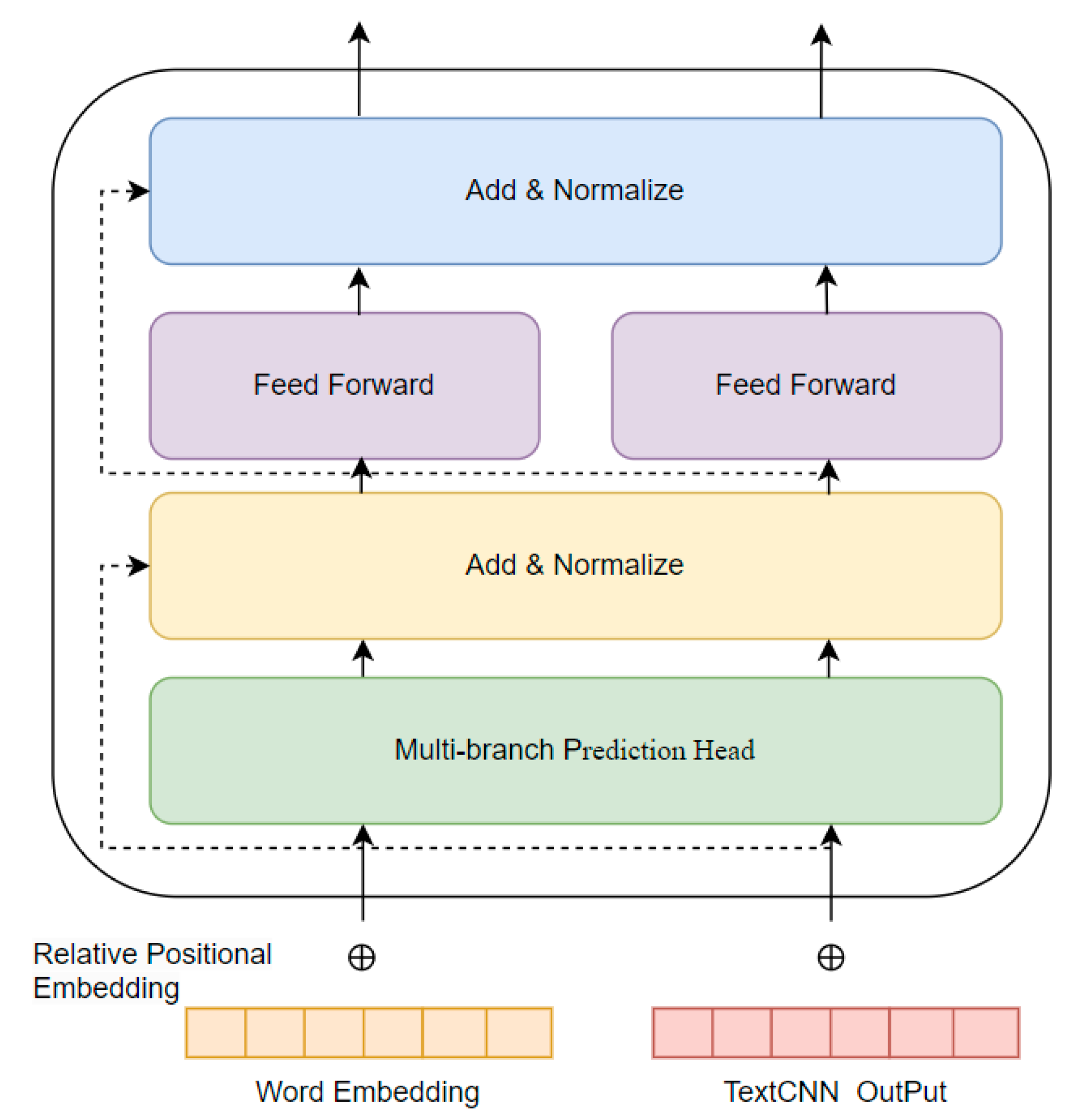
It is noteworthy that the input of the multibranch prediction head (MBPH) of the TCFLTformer module has two parts, as shown in
Figure 6: one is the word vector matrix and the relative position encoding matrix composed of the ATM cyber threat entities, the other is the output matrix of the fully connected TextCNN module, which fully learns the entity features through the two parts of matrix data to obtain a richer feature representation and enhance the model. The details of each network layer of the model are as follows:
① Token Embedding
We use character-level
N-gram [
31] to represent a word. For example, the word “scarcruft”, assuming the value of n is 3, has the trigram “<sc”, “sca”, “car”, “arc”, “rcr”, “cru”, “ruf”, “uft”, and “ft>”, where “<” is the prefix and “>” is the suffix. Thus, we use these trigrams to represent the word “scarcruft”, and here the vector of 9 trigrams can be superimposed to represent the word vector of “scarcruft”. The word vectorization hierarchy is the same as the CBOW [
32] structure and consists of three layers: an input layer, an implicit layer, and an output layer, where the input layer is multiple words represented by vectors and their
N-gram features and location features, the implicit layer has only one layer (shown in
Figure 4), which is a superimposed average of multiple word vectors, and the output layer is the word vector corresponding to the completion of processing.
The is the k-dimensional word vector corresponding to the i-th word in a sentence. A sequence of length n can be expressed as a matrix . Then, the matrix is taken as the input into the convolution layer.
② TextCNN
In the convolution layer,
J filters of different sizes are convolved
to extract local features. The width of each filter window is the same
, only the height is different. In this way, different filters can obtain relationships for different ranges of words. Each filter has
, a convolution kernel. Convolutional neural networks learn parameters in a convolutional kernel, with each filter having its focus, allowing multiple filters to learn multiple different pieces of information. We designed multiple convolutional kernels of the same size to learn features complementary to each other from the same window. The specific formula is as follows:
where
denotes the weight of the
j-th (
) filter of the convolution operation,
is the new feature resulting from the convolution operation,
is a bias, and
f is a nonlinear function. Many filters with varying window sizes slide over the full rows
, generating a feature map
. The most important feature
was obtained by one-max pooling for one scalar and mathematically written as:
S convolution kernels are computed to obtain
S feature values, which are concatenated to obtain a feature vector
Pj:
Finally, the feature vector of all filters is stacked into a complete feature mapping matrix
:
③ multibranch prediction Head (MBPH)
For ease of exposition, according to
Figure 6, the input consists of a word vector matrix referred to as
, the TextCNN layer output feature mapping matrix referred to as
. Then, both
F and
F′ will be reshaped, referred to as
and
. Finally,
and
will be turned into a token embedding through einsum operation, which can be denoted as:
where
l is the token length, and
b,
c,
h, and
w denote the batch size, number of channels, height, and width of the input feature
F.
The MBPH first expands
t into a new embedding
t′ by a linear layer, which can be denoted as:
where
is the weight of the linear layer,
n is the head number of MBPH, and
d is the dimension for subsequent tensors.
Then, the embedding t′ will be forwarded to different heads. Parameters are not shared among heads. Each head contains two steps: linear transformation and scale dot-product attention (SDPA).
The linear layers are applied to map
t′ into a query (
), key (
), and value (
), which can be denoted as:
where
denotes the weights of the linear layers to map
Q, K, and
V, respectively.
Thereafter, the correlation between them is calculated through dot-product operation and softmax activation to generate an attention map, which will be used as the weight
V. The process can be expressed as:
The output of each head will be concatenated together before a linear layer is applied, then we will obtain the final output of the MBPH, which can be expressed by the following formula:
where
denotes the weights of the linear layers of the
m-th head to map
Q, K, and
V, respectively.
is the weight of the last linear layer in MBPH.
④ Relative Position Embedding
While the original Transformer captures sequence information by absolute position encoding, we use Lattice’s relative position for encoding [
33]. The flat-lattice structure consists of spans of different lengths. To encode the interactions between spans, the relative position of the spans is encoded. For two spans
xi and
xj in the lattice, there are three relationships between them—intersection, inclusion, and separation—and dense vectors are used to model the relationship between them. For example, head[
i] and tail[
i] denote the head and tail positions of span
xi, and then the relationship between the two spans
xi and
xj is expressed in terms of four relative distances, which are calculated as:
denotes the distance between the head of
xi and the head of
xj,
denotes the distance between the head of
xi and the tail of
xj, and the same for others. The final relative position encoding is a simple nonlinear transformation of the four distances, which are calculated as:
where
is the learnable parameter, ⊕ is the connection operator,
Pd is computed by referring to [
30], and then the positions of the words composing the sequence are encoded to obtain the corresponding positional embedding [
29], which is computed as the following equation:
where
pos denotes the sequential position of the word, and
i is the dimensional index of the positional encoding, denoting the
i-th dimension of the word vector,
i ∈ [0,
−1], where the dimension of the positional embedding coincides with the dimension of the word vector. It is then summed with the word vector of the corresponding input so that the distance between words can be characterized for the model to learn to understand the order of information between the input words.
where
,
,
is the learnable parameter, and then
A is replaced by
A*.
⑤ Residual Connection
A residual connection has also been added to the model, as shown in
Figure 6, for the add operation. Suppose the output of a layer in the encoder is
f(x) for a nonlinear variation of the input
x. Then, after adding the residual connection, the output becomes
f(x) + x. The
+x operation is equivalent to a shortcut. The purpose of adding the residual structure is mainly to avoid the gradient vanishing problem when updating the model parameters during backpropagation: thanks to the residual connection, an additional term
x is added to the output, then the layer network can generate a constant term when biasing the input, and thus will not cause gradient vanishing when applying the chain rule during backpropagation.
⑥ Layer Normalization
In deep learning, there are various ways to handle data normalization, but they all have a common purpose: they want the input data to fall in the nonsaturated region of the nonlinear activation function, and therefore transform it into data that obey a distribution with a mean of 0 and a variance of 1.
Layer normalization is processed for a single sample, and the number of hidden layer nodes in a layer is denoted by
H.
ai denotes the output of the
i-th hidden layer node, and the statistics in layer normalization can be calculated using the following formula:
Using Equation (21) to calculate the layer-normalized values through
μ and
σ:
where
ε is a very small number to avoid the denominator being 0. It is worth pointing out that the calculation of layer normalization is not related to the number of samples, it only depends on the number of hidden layer nodes, so as long as the number of hidden layer nodes is guaranteed to be sufficient, the statistics of layer normalization can be guaranteed to be representative enough.
⑦ Feed-Forward Neural Network Module
This paper refers to the design of the Transformer encoder. It implements the feed-forward neural network (FFN) submodule of the inattention encoder, using two fully connected layers. The first layer uses
ReLU as the activation function, and the second layer uses a linear activation function. If the input of the feed-forward neural network is denoted by
Z, the output of the feed-forward neural network can be expressed as follows:
where
W1 and
W2 are the weight matrices of each layer, and b
1 and b
2 are their corresponding biases.
In addition, we also use residual connection and layer normalization in the above two submodules to speed up the convergence of network training and prevent the gradient vanishing problem:
where
X are the outputs of the above two submodules.
⑧ Linear CRF
The basic form of the linear chain conditional random field model parameters
is defined as follows:
where
denotes the transfer feature function defined on the edge, which is related to the current position and the previous position
− 1. The state feature function defined on the node represented by
is only relevant to the current position
. In general, the characteristic function takes the value of 1 when the corresponding conditions are met, otherwise, it is 0.
and
are the feature functions and the corresponding weights, respectively, whose values are updated during the training process [
34]. Equation (26) is the normalized factor term whose value corresponds to the summation of scores using the characteristic function for all possible candidate state sequences.
For the sequence annotation task, given a linear chain of conditional random fields
, an input text sequence
x, and a set
y of all possible candidate annotation results, the desired optimal annotation result
, as in Equation (28), can be computed quickly and efficiently using the Viterbi algorithm.
6. Discussion
In this part, we will discuss two widely concerned issues around the safety of air traffic management system (ATM).
Military interventions may occur in any State at any time and pose risks to civil aviation. For example, downing Ukrainian Flight 752 took place in Iranian airspace on 8 January 2020; moreover, downing Malaysia Airlines Flight 17 (MH-17) happened in Ukraine, on 17 July 2014. We briefly discuss the impact of military intervention in conflict zones relating to aviation safety.
1.1 The risk of surface-to-air missiles
The principal weapons of concern for these purposes are those surface-to-air missiles (SAMs) with the capability of reaching aircraft at cruising altitudes (which for these purposes are taken to be altitudes in excess of 25,000 ft (7600 m) above ground level). These are large, expensive, and complex pieces of military equipment which are designed to be operated by trained personnel. In this context, civil aircraft represent a relatively easy and highly vulnerable target, due to their size and predictable flight paths.
1.2 The risk of intentional attack
Some terrorist groups are known to have a continuing and active interest in attacking civil aviation. Such terrorist groups tend to conflict where there is a breakdown of State control. Should they at some point succeed along with the capability to operate them, the vulnerability of aircraft using airspace over those areas to identify and target specific aircraft or aircraft would be high operators with some reliability and would be relatively straightforward. The risk to civil aircraft in those circumstances could immediately become high.
1.3 The risk of unintentional attack
Past incidents, although rare, have proved that there is a great risk to civil aviation as an unintended target when flying over or near conflict zones, in particular, the deliberate firing of a missile whose target is perceived to be a military aircraft, which either misses its intended target or makes the misidentification on a civil aircraft. Moreover, higher levels of risk are particularly associated with overflying areas of armed conflict.
1.4 The risk of air-to-air attacks
The risk factors associated with an unintentional attack using air-to-air missiles launched by a military aircraft are due to misidentification of civilian aircraft flying in combat zones or zones of high tension/sensitivity. Such air-to-air attacks deliberately act where a civilian aircraft is perceived by State authorities as a potential means of terrorist attack, usually because it has reported an unlawful interference incident on board (e.g., breach of the cockpit or hijack) or is exhibiting suspicious behavior (e.g., not communicating with Air Traffic Control or deviating from its air traffic control clearance).
- 2.
Analysis about the impact of cyberattacks on ATM
The ATM consists of different subsystems, such as the flight management system, communication, navigation and surveillance system, in-flight entertainment system, etc., and there may exist certain dependency relationships between the subsystems, i.e., the failure of a subsystem by an attack may lead to the damage of other subsystems with which it has a dependency relationship, e.g., the failure of Mode S transponders by an attack may lead to damage of the TCAS and the communication, navigation and surveillance system, which may lead to the damage of the flight management system. For example, the failure of Mode S transponders will lead to the damage of the TCAS, communication, navigation and monitoring system, and then lead to the damage of the flight management system, which will eventually lead to the damage of the autopilot flight command computer and the damage of the autopilot function of the airplane. Therefore, a network cascade failure model based on dynamic dependency groups is proposed to be used to analyze the process of impact propagation after a cyberattack.
The analysis model is described as follows. As shown in
Figure 10, it is proposed to consider a network composed of certain subsystems in an ATM system as nodes and connectivity relationships as edges, with the nodes in the dashed box forming a dependency group, and the nodes in the group depending on each other. When a node in the dependency group fails, the remaining nodes are impacted to a certain extent, and the intensity of the impact is controlled by the decoupling coefficient α, i.e., each edge of each of the remaining nodes is retained with a probability of α, and deleted with a probability of 1-α. When α → 1, the coupling strength of the nodes in the dependency group is the weakest, and the failure of one node cannot cause any impact on the rest of the nodes in the group; whereas when α → 0, the coupling strength of the nodes in the dependency group is the strongest, and the failure of a single node can cause all the nodes in the group to be damaged. By adjusting the parameter α, the dependency strength of different subsystems in the avionics network can be described.
Network cascade failure is triggered by attacking certain nodes in the ATM system; the attacked nodes and their connections will be removed from the network altogether, which, in turn, leads to fragmentation of the network. In the network, the nodes that can connect to the giant branch are considered functional nodes, and the rest of the nodes are considered failed nodes. Due to a certain degree of dependency between nodes within the dynamic dependency group, the failure of a node in the network causes two kinds of impacts:
- (1)
Out-of-group impact, the failure of a node causes network fragmentation, which, in turn, leads to the failure of some nodes outside the group that cannot connect to the network mega branch through that node;
- (2)
In-group impact: the rest of the nodes in the dependency group in which the failed node is located are damaged and each of its connected edges is deleted with probability 1 − α, i.e., it is retained with probability α.
When a node fails, the out-group influence causes the failure to be able to propagate across the dependency group, thus extending the failure to a wider range, while the in-group influence causes the remaining nodes within the group to have their edges damaged, thus causing more nodes within the group to be damaged. Under the alternating effects of these two influences, cascading failures occur on the network.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}