
Prediction of Temperature Distribution on an Aircraft Hot-Air Anti-Icing Surface by ROM and Neural Networks


Abstract
:1. Introduction
2. Sample Data Acquisition and Processing
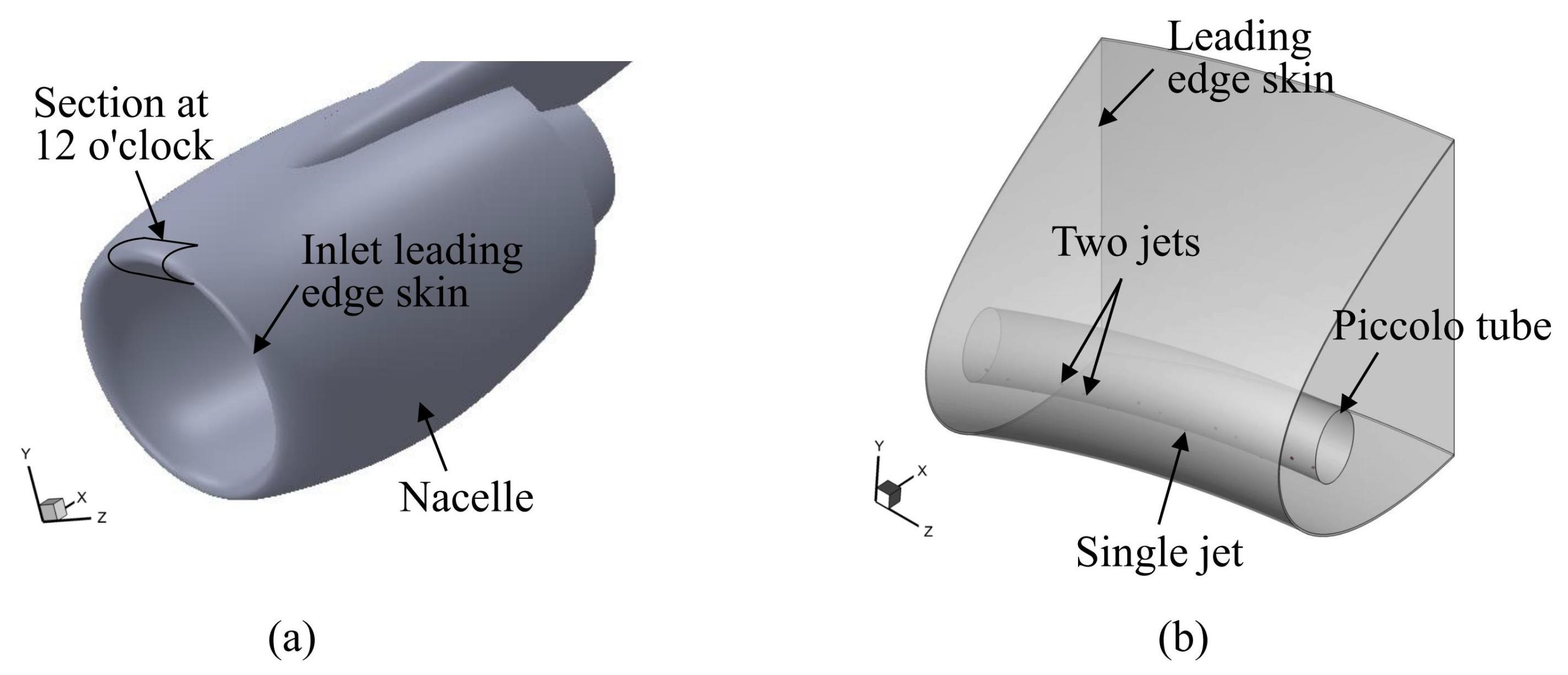
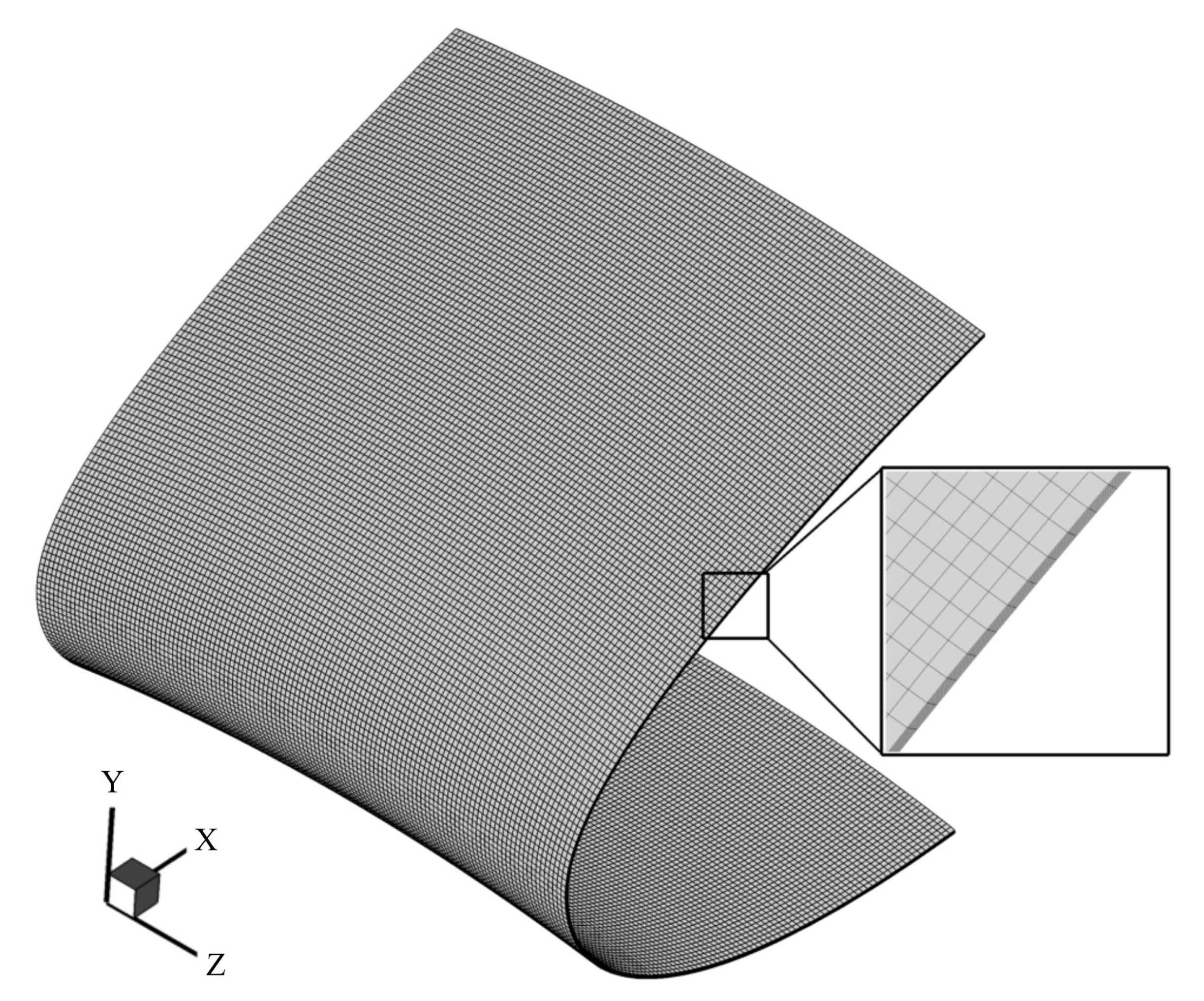
2.1. Data Collection
2.2. Training Data Processing
3. Rapid Prediction Method of Temperature Distribution
3.1. Basic Principles
3.1.1. Proper Orthogonal Decomposition
- Data collection: Organize the temperature distribution matrix X so that each column represents a temperature distribution sample and each row corresponds to a grid point.
- Calculate the covariance matrix: The covariance matrix C of the matrix X can be expressed using the following equation:Here, X is an matrix, where n represents the number of temperature points on the surface and m represents the number of samples; denotes the transpose of matrix X, resulting in the covariance matrix C being of dimension .
- Eigenvalue decomposition: The eigenvalue decomposition of the covariance matrix C yields the eigenvalues and the corresponding eigenvectors :
- Select main eigenvalues and eigenvectors: The top k eigenvalues and their corresponding eigenvectors are selected based on the magnitude of the eigenvalues. These eigenvectors will serve as POD basis functions.
- Construct the basis mode matrix: Construct the POD basis mode matrix using the selected k eigenvectors :
- Data dimensionality reduction: Project the original data X onto the POD basis mode matrix to obtain a low-dimensional representation Y:Here, Y is referred to as the matrix of fitting coefficients.
3.1.2. Convolutional Neural Networks
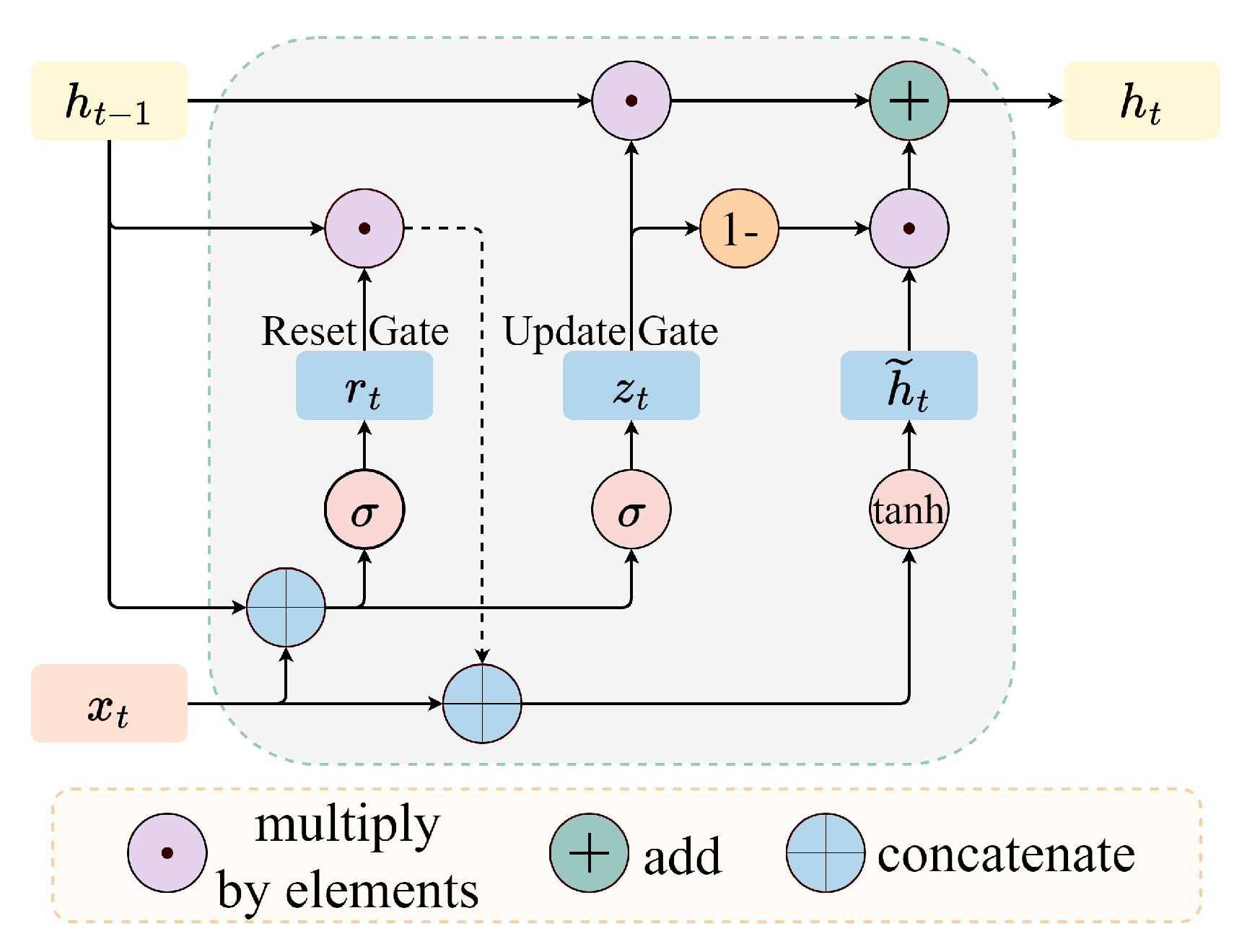
3.1.3. Recurrent Neural Networks
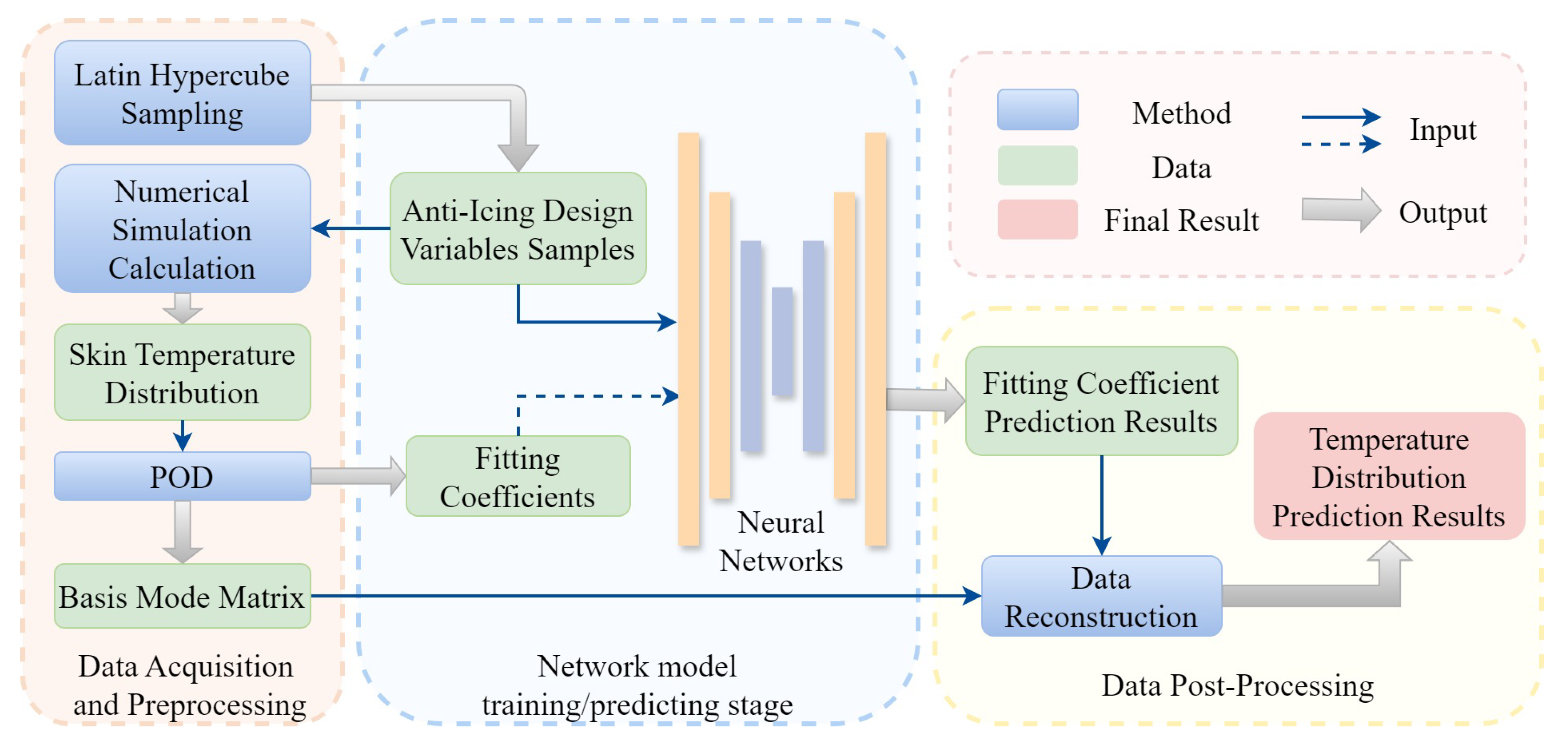
3.2. Temperature Distribution Prediction Method Based on ROM
- Data acquisition and preprocessing stage: First, the LHS method is used to sample, generating 5000 design variable samples of the piccolo tube. Then, the three-dimensional anti-icing numerical simulation method calculates the surface temperature of the hot-air anti-icing cavity in the turbofan engine inlet, resulting in the formation of the temperature distribution matrix. Subsequently, the POD method, described in Section 3.1.1, reduces data dimensionality on the temperature distribution matrix, obtaining the basis mode matrix and the matrix of fitting coefficients. During this process, the top 128 eigenvectors, chosen based on the magnitude of their eigenvalues, are compiled into the basis mode matrix. The truncated number, 128, is determined based on the cumulative energy ratio of the modes, as shown in Figure 7.
- Network model training and predicting stage: As illustrated in Figure 8, during the training of the neural network model, the design variables serve as inputs, while the decomposed fitting coefficients are the target values. For predictions, the trained neural network uses the provided design variables to predict the fitting coefficients.
- Data post-processing stage: The predicted fitting coefficients from the neural network, combined with the basis mode matrix obtained from the POD decomposition, are used for data reconstruction, resulting in the final predicted temperature distribution.
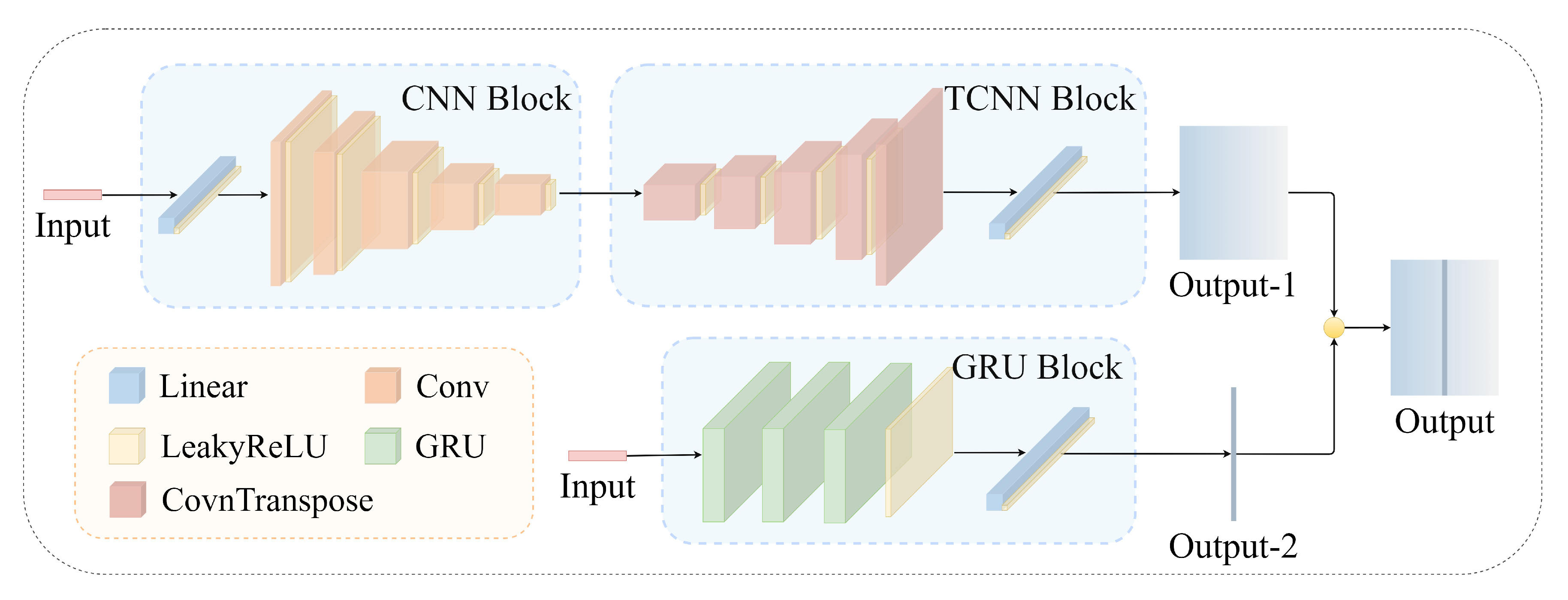
3.3. Temperature Distribution Prediction Method Based on High-Dimensional Data
- Path 1: The initial part of this path expands a 1 × 6 input vector into a 32 × 32 matrix through a fully connected layer and a reshaping operation, facilitating subsequent processing. Subsequently, a CNN block composed of multiple convolution layers is applied to capture features and patterns in the expanded vector. Following the CNN block, a TCNN block, made up of several transposed convolution layers, aims to enlarge the dimensions of the feature map while retaining feature correlations. Finally, a fully connected layer processes the output to promote high-level abstraction and feature aggregation.
- Path 2: This path employs three layers of GRU to extract relevant features from the input sequence, effectively capturing patterns and correlations within it. It learns the mapping relationship between the anti-icing design variables and the temperature distribution at the z = 0 m position.
- Integration and output: The output of Path 1 is reshaped into a 198 × 121 format. Then, the central column is replaced with the output of Path 2 to obtain the final result.
4. Experiments and Results Analysis
4.1. Loss Function
4.2. Performance Metrics
4.3. Temperature Distribution Prediction Based on ROM
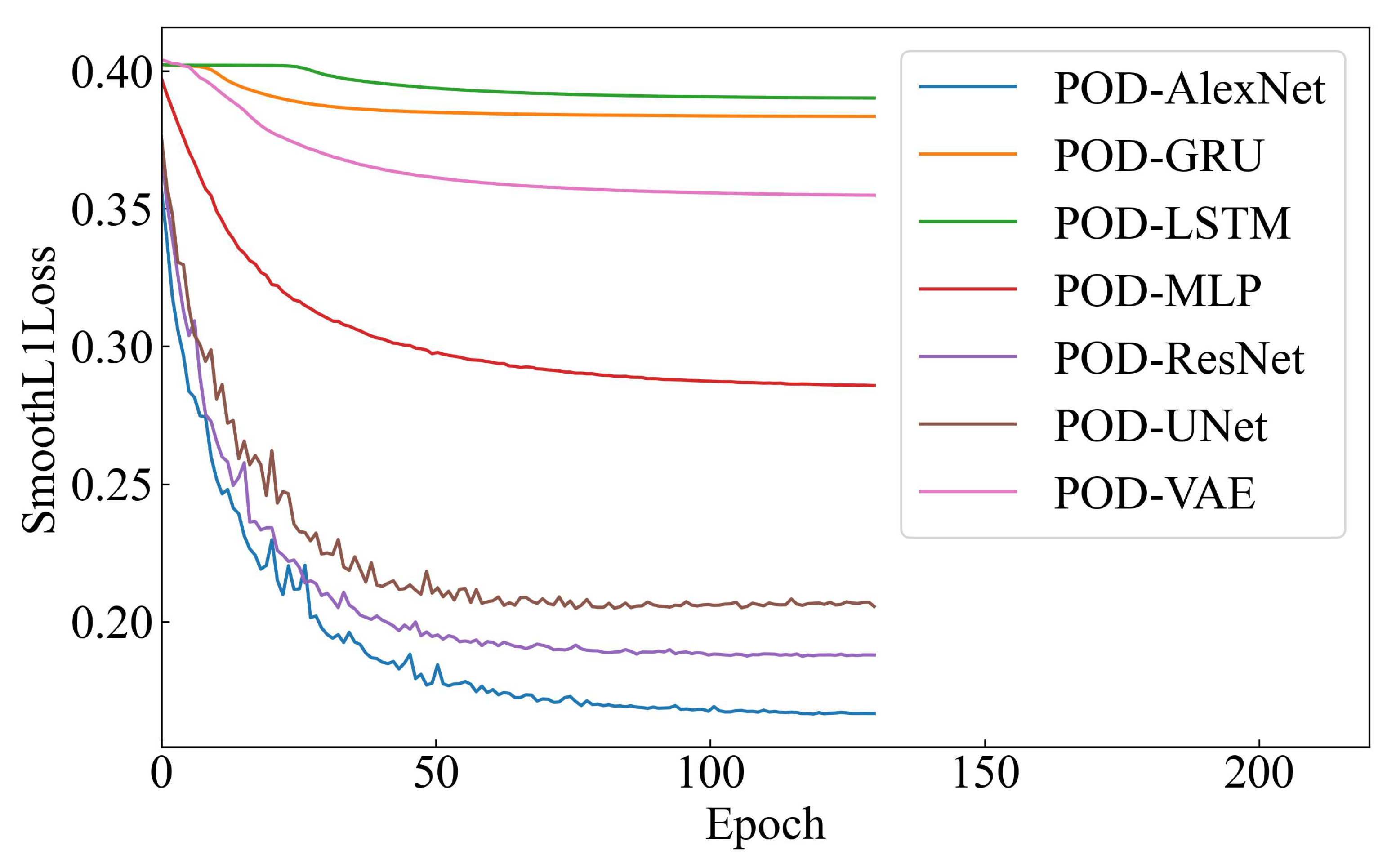
4.3.1. Comparative Test Results Analysis of ROMs
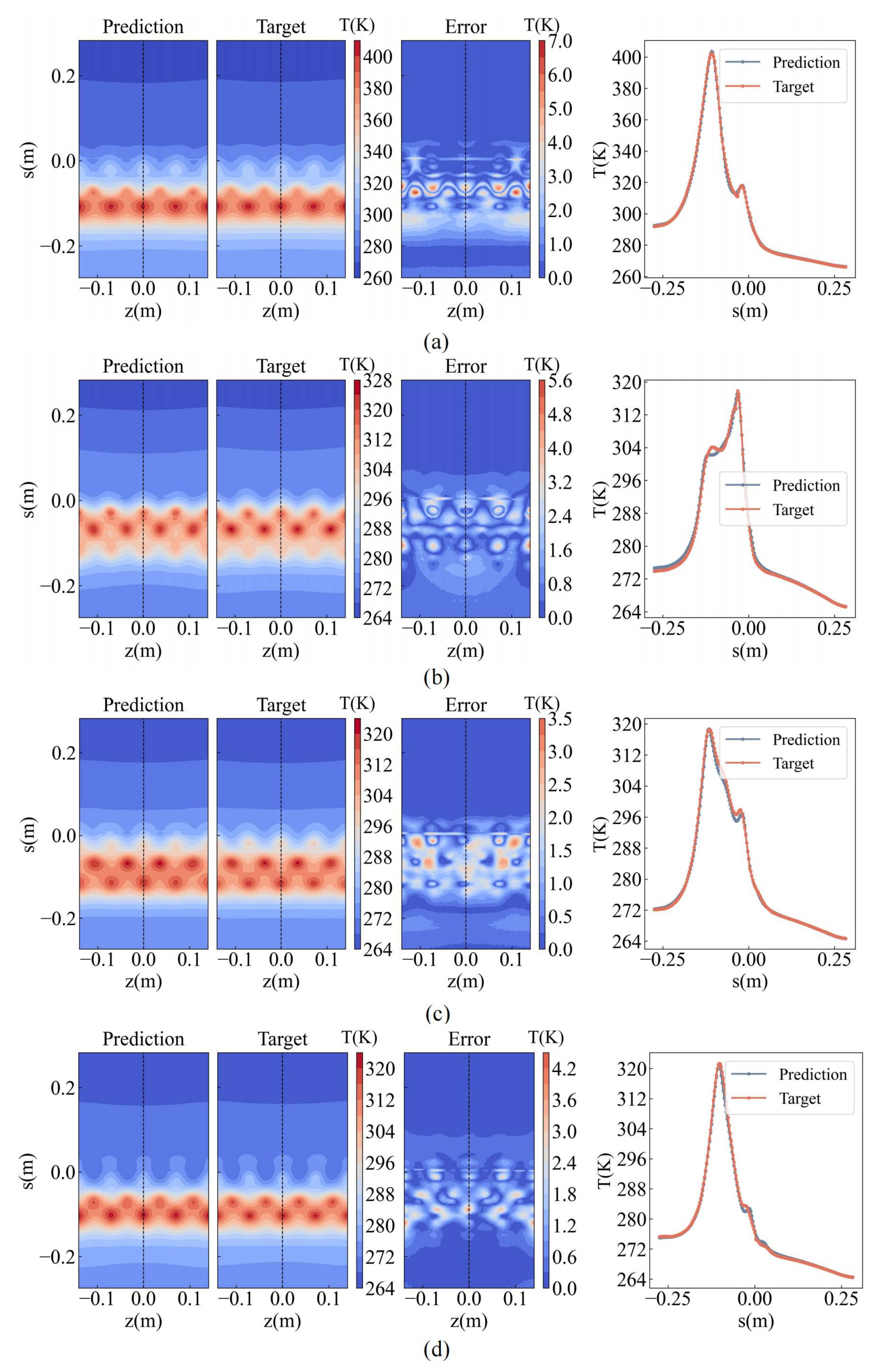
4.3.2. Prediction Results and Analysis
4.4. Temperature Distribution Prediction Based on High-Dimensional Model
4.4.1. Comparative Test Results Analysis of High-Dimensional Model
4.4.2. Prediction Results and Analysis
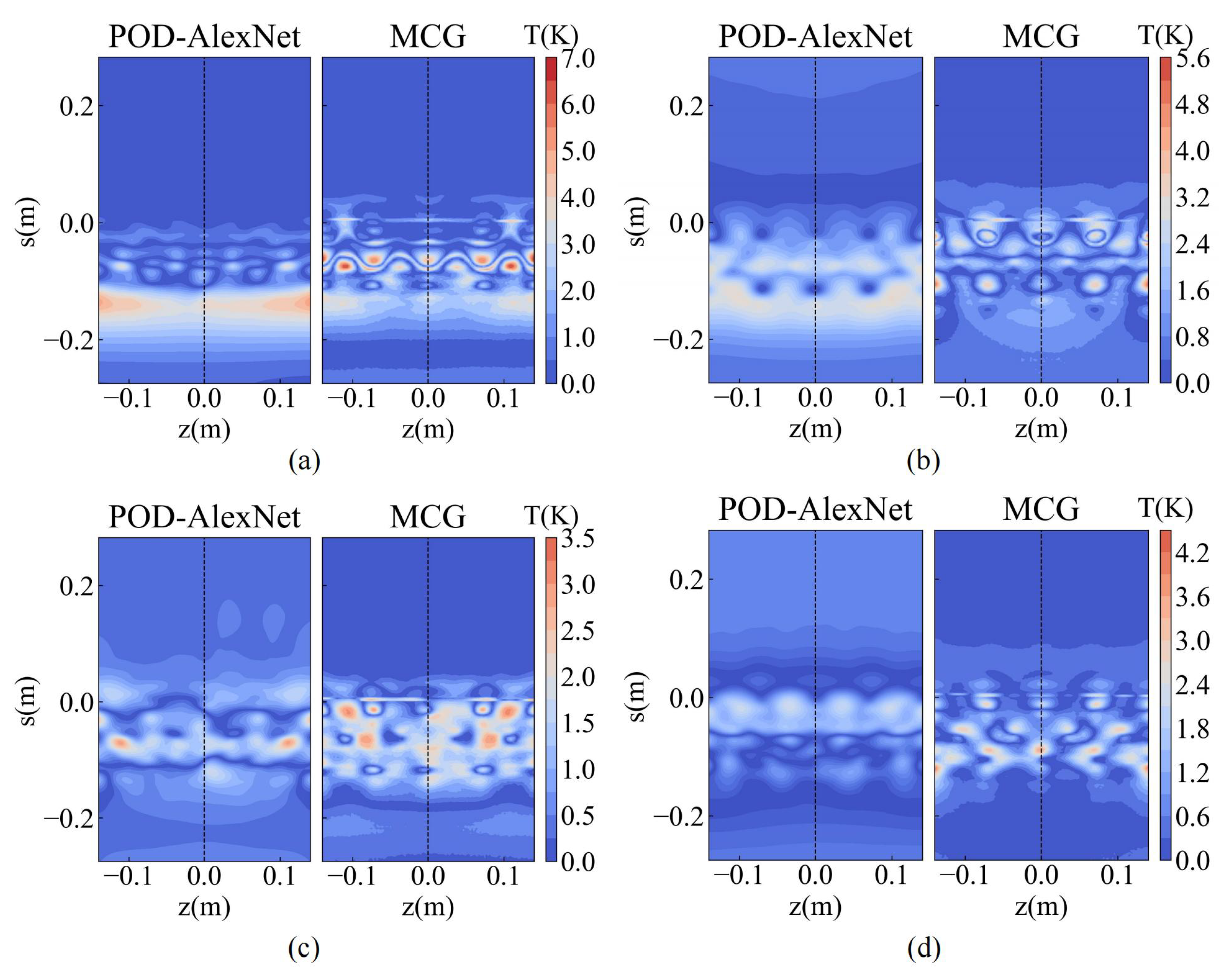
4.5. Comparative Analysis of POD-Alexnet and MCG
5. Conclusions
- (1)
- The POD-AlexNet model enables rapid predictions of the POD fitting coefficients and obtains anti-icing temperature distributions by reconstructing the POD basis modes based on these fitting coefficients. By selecting the appropriate neural network model, AlexNet, the RMSE of test samples is less than 2, the MRE is less than 0.5%, the MAE is less than 1.5, and the MPA is higher than 95%. In addition, the time cost for predicting each sample is about 1 ms, achieving fast and efficient prediction.
- (2)
- The MCG model enables the rapid and direct predictions of anti-icing surface temperature distributions. It achieves an RMSE of 1.75 on the test set, an MRE of 3.23‰, an MAE of 1.02, and an MPA of 96.97%. Additionally, the average single-sample prediction time is about 5.5 ms, which is a significant improvement compared to the traditional numerical simulation method, which takes hours or even days.
- (3)
- The error distribution of POD-AlexNet is relatively uniform; in contrast, the MCG exhibits localized high-error points. However, the overall error distribution of the MCG is significantly lower than that of the POD-AlexNet. In general, the POD-AlexNet and MCG models can provide faster predictions of anti-icing surface temperature distributions than traditional numerical simulation methods with acceptable error, which supports the design of aircraft hot-air anti-icing systems based on optimization methods such as genetic algorithms.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Nomenclature
| D | the diameter of jet holes |
| H | flight altitude, km |
| L | jet hole spacing, mm |
| l | the total number of grids |
| m | the total number of samples |
| hot-air mass flow rate for a single jet hole, | |
| the number of grids with accurate predictions for the i-th sample | |
| total bleed air pressure, MPa | |
| total bleed air temperature, K | |
| temperature at far-field, K | |
| the target value of i-th sample at j-th grid | |
| the predicted value of i-th sample at j-th grid | |
| the average prediction time for a single sample, ms | |
| x-coordinate of the piccolo tube center, mm | |
| y-coordinate of the piccolo tube center, mm | |
| the outflow direction angle of jet holes in the middle row, ° | |
| relative angle between the positive y-axis direction jet hole and the middle row, ° | |
| relative angle between the negative y-axis direction jet hole and the middle row, ° | |
| the value of in the baseline design | |
| Abbreviations | |
| AoA | angle of attack, ° |
| LWC | liquid water content, |
| Ma | Mach number |
| MAE | mean absolute error, K |
| MPA | mean prediction accuracy |
| MRE | mean relative error |
| MVD | median volumetric diameter, mm |
| RMSE | root mean square error |
References
- Yang, Q.; Guo, X.; Zheng, H.; Dong, W. Single- and multi-objective optimization of an aircraft hot-air anti-icing system based on Reduced Order Method. Appl. Therm. Eng. 2023, 219, 119543. [Google Scholar] [CrossRef]
- Filburn, T. Anti-ice and Deice Systems for Wings, Nacelles, and Instruments. In Commercial Aviation in the Jet Era and the Systems That Make It Possible; Springer International Publishing: Cham, Switzerland, 2020; pp. 99–109. [Google Scholar] [CrossRef]
- Hannat, R.; Weiss, J.; Garnier, F.; Morency, F. Application of the Dual Kriging Method for the Design of Hot-Air-Based Aircraft Wing Anti-Icing System. Eng. Appl. Comput. Fluid Mech. 2014, 8, 530–548. [Google Scholar] [CrossRef]
- Hoffmann Domingos, R.; da Cunha Brandão Reis, B.; Martins da Silva, D.; Malatesta, V. Numerical Simulation of Hot-Air Piccolo Tubes for Icing Protection Systems. In Handbook of Numerical Simulation of In-Flight Icing; Habashi, W.G., Ed.; Springer International Publishing: Cham, Switzerland, 2020; pp. 1–30. [Google Scholar] [CrossRef]
- Dong, W.; Zhu, J.; Zheng, M.; Chen, Y. Thermal Analysis and Testing of Nonrotating Cone with Hot-Air Anti-Icing System. J. Propuls. Power 2015, 31, 1–8. [Google Scholar] [CrossRef]
- Dong, W.; Zheng, M.; Zhu, J.; Lei, G.; Zhao, Q. Experimental Investigation on Anti-Icing Performance of an Engine Inlet Strut. J. Propuls. Power 2017, 33, 379–386. [Google Scholar] [CrossRef]
- Guo, Z.; Zheng, M.; Yang, Q.; Guo, X.; Dong, W. Effects of flow parameters on thermal performance of an inner-liner anti-icing system with jets impingement heat transfer. Chin. J. Aeronaut. 2021, 34, 119–132. [Google Scholar] [CrossRef]
- Liu, Y.; Yi, X. Investigations on Hot Air Anti-Icing Characteristics with Internal Jet-Induced Swirling Flow. Aerospace 2024, 11, 270. [Google Scholar] [CrossRef]
- Ni, Z.; Liu, S.; Zhang, J.; Wang, M.; Wang, Z. Influnce of environment parameters on anti-icing heat load for aircraft. J. Aerosp. Power 2021, 36, 8–14. [Google Scholar] [CrossRef]
- Mao, H.; Lin, X.; Li, Z.; Shen, X.; Zhao, W. Anti-Icing System Performance Prediction Using POD and PSO-BP Neural Networks. Aerospace 2024, 11, 430. [Google Scholar] [CrossRef]
- Jung, S.; Raj, L.P.; Rahimi, A.; Jeong, H.; Myong, R.S. Performance evaluation of electrothermal anti-icing systems for a rotorcraft engine air intake using a meta model. Aerosp. Sci. Technol. 2020, 106, 106174. [Google Scholar] [CrossRef]
- Abdelghany, E.S.; Farghaly, M.B.; Almalki, M.M.; Sarhan, H.H.; Essa, M.E.S.M. Machine Learning and IoT Trends for Intelligent Prediction of Aircraft Wing Anti-Icing System Temperature. Aerospace 2023, 10, 676. [Google Scholar] [CrossRef]
- Ran, L.; Xiong, J.; Zhao, Z.; Zuo, C.; Yi, X. Prediction of Surface Temperature Change Trend of Electric Heating Anti-icing and De-icing Based on Machine Learning. Equip. Environ. Eng. 2021, 18, 29–35. [Google Scholar]
- McKay, M.D.; Beckman, R.J.; Conover, W.J. Comparison of Three Methods for Selecting Values of Input Variables in the Analysis of Output from a Computer Code. Technometrics 1979, 21, 239–245. [Google Scholar] [CrossRef]
- Yang, Q.; Zheng, H.; Guo, X.; Dong, W. Experimental validation and tightly coupled numerical simulation of hot air anti-icing system based on an extended mass and heat transfer model. Int. J. Heat Mass Transf. 2023, 217, 124645. [Google Scholar] [CrossRef]
- Ruan, d.R.; Kevin, J.; Barbara, H. Aerodynamic design of an electronics pod to maximise its carriage envelope on a fast-jet aircraft. Aircr. Eng. Aerosp. Technol. 2024, 96, 10–18. [Google Scholar] [CrossRef]
- Gutierrez-Castillo, P.; Thomases, B. Proper Orthogonal Decomposition (POD) of the flow dynamics for a viscoelastic fluid in a four-roll mill geometry at the Stokes limit. J. Non-Newton. Fluid Mech. 2019, 264, 48–61. [Google Scholar] [CrossRef]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation Applied to Handwritten Zip Code Recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Boureau, Y.L.; Ponce, J.; LeCun, Y. A theoretical analysis of feature pooling in visual recognition. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 111–118. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Rumelhart, D.E.; Hintont, G.E.; Williams, R.J. Learning by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Cho, K.; van Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Zhu, Y.; Yang, J.; Zhong, S.; Zhu, W.; Li, Z.; Wei, T.; Li, Y.; Gu, T. Research on Temperature Forecast Correction by Dynamic Weight Integration Based on Multi-neural Networks. J. Trop. Meteorol. 2024, 40, 156. [Google Scholar] [CrossRef]
- Lippmann, R.P. An introduction to computing with neural nets. ACM SIGARCH Comput. Archit. News 1988, 16, 7–25. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. arXiv 2022, arXiv:1312.6114. [Google Scholar]
- Velarde, G.; Brañez, P.; Bueno, A.; Heredia, R.; Lopez-Ledezma, M. An Open Source and Reproducible Implementation of LSTM and GRU Networks for Time Series Forecasting. Eng. Proc. 2022, 18, 30. [Google Scholar] [CrossRef]
- Yu, T.; Li, X.; Cai, Y.; Sun, M.; Li, P. S2-MLP: Spatial-Shift MLP Architecture for Vision. In Proceedings of the 2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2022; pp. 3615–3624. [Google Scholar] [CrossRef]
- Zafar, N.; Haq, I.U.; Chughtai, J.u.R.; Shafiq, O. Applying Hybrid Lstm-Gru Model Based on Heterogeneous Data Sources for Traffic Speed Prediction in Urban Areas. Sensors 2022, 22, 3348. [Google Scholar] [CrossRef]
- Mateus, B.C.; Mendes, M.; Farinha, J.T.; Assis, R.; Cardoso, A.M. Comparing LSTM and GRU Models to Predict the Condition of a Pulp Paper Press. Energies 2021, 14, 6958. [Google Scholar] [CrossRef]
- Mienye, I.D.; Swart, T.G.; Obaido, G. Recurrent Neural Networks: A Comprehensive Review of Architectures, Variants, and Applications. Information 2024, 15, 517. [Google Scholar] [CrossRef]
- Zhang, Y.; Carvalho, D.; Valentino, M.; Pratt-Hartmann, I.; Freitas, A. Improving Semantic Control in Discrete Latent Spaces with Transformer Quantized Variational Autoencoders; Association for Computational Linguistics: St. Julian’s, Malta, 2024; pp. 1434–1450. [Google Scholar]
- Rocha, M.B.; Krohling, R.A. VAE-GNA: A variational autoencoder with Gaussian neurons in the latent space and attention mechanisms. Knowl. Inf. Syst. 2024, 66, 6415–6437. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Design Variables | L/D | /D | /D | / | / | / |
|---|---|---|---|---|---|---|
| Baseline | 14.6 | 0 | 0 | 1 | 0.86 | 0.73 |
| Range | [10, 20] | [−10, 7.5] | [−10, 7.5] | [0.54, 1.08] | [0.54, 1.08] | [0.54, 1.08] |
| H | AoA | Ma | MVD | LWC | ||||
|---|---|---|---|---|---|---|---|---|
| 6 km | 4° | 0.427 | 263.55 K | 20 μm | 0.43 g/ | 0.25 MPa | 555 K | 1.33 g/s |
| Networks | RMSE | MRE | MAE | MPA | |
|---|---|---|---|---|---|
| POD-MLP | 3.27 | 0.80% | 2.44 | 88.25% | 4.0 ms |
| POD-LSTEM | 11.19 | 2.46% | 7.74 | 57.28% | 0.7 ms |
| POD-GRU | 8.98 | 2.07% | 6.45 | 58.81% | 0.4 ms |
| POD-VAE | 4.16 | 0.93% | 2.87 | 83.57% | 0.4 ms |
| POD-UNet | 4.41 | 1.15% | 3.43 | 78.48% | 1.2 ms |
| POD-ResNet | 2.81 | 0.69% | 2.11 | 90.86% | 0.5 ms |
| POD-AlexNet | 1.99 | 0.47% | 1.45 | 95.83% | 1.0 ms |
| Networks | RMSE | MRE | MAE | MPA | |
|---|---|---|---|---|---|
| LeNet | 2.85 | 5.26‰ | 1.66 | 91.76% | 7.5 ms |
| AlexNet | 2.80 | 4.98‰ | 1.59 | 92.23% | 8.5 ms |
| UNet | 2.84 | 5.26‰ | 1.66 | 91.82% | 1.3 ms |
| VAE | 3.62 | 6.40‰ | 2.05 | 88.46% | 4.6 ms |
| LSTM-3L | 2.56 | 4.68‰ | 1.48 | 93.18% | 5.4 ms |
| GRU-3L | 2.47 | 4.56‰ | 1.45 | 93.64% | 5.5 ms |
| MCG | 1.75 | 3.23‰ | 1.02 | 96.97% | 5.5 ms |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chu, Z.; Geng, J.; Yang, Q.; Yi, X.; Dong, W. Prediction of Temperature Distribution on an Aircraft Hot-Air Anti-Icing Surface by ROM and Neural Networks. Aerospace 2024, 11, 930. https://doi.org/10.3390/aerospace11110930
Chu Z, Geng J, Yang Q, Yi X, Dong W. Prediction of Temperature Distribution on an Aircraft Hot-Air Anti-Icing Surface by ROM and Neural Networks. Aerospace. 2024; 11(11):930. https://doi.org/10.3390/aerospace11110930
Chicago/Turabian StyleChu, Ziying, Ji Geng, Qian Yang, Xian Yi, and Wei Dong. 2024. "Prediction of Temperature Distribution on an Aircraft Hot-Air Anti-Icing Surface by ROM and Neural Networks" Aerospace 11, no. 11: 930. https://doi.org/10.3390/aerospace11110930
APA StyleChu, Z., Geng, J., Yang, Q., Yi, X., & Dong, W. (2024). Prediction of Temperature Distribution on an Aircraft Hot-Air Anti-Icing Surface by ROM and Neural Networks. Aerospace, 11(11), 930. https://doi.org/10.3390/aerospace11110930