In order to verify the effectiveness of the troubleshooting mode selection method based on SIF-SVM that has been proposed in this paper, we used the fault record text data accumulated by a new fixed-wing UAV. The data were recorded in Chinese with a total of 662 samples. Some data are shown in
Table 2. The recorded faults involved four systems: the ground system (1), the power system (2), the flight control system (3), and the aircraft platform (4). According to the UAV troubleshooting mode selection modeling based on SIF-SVM, the experiment mainly included fault phenomenon text data preprocessing, text feature extraction based on Word2Vec and model construction based on SIF-SVM.
5.3. UAV Troubleshooting Mode Selection Based on SIF-SVM
According to the modeling process proposed above, in order to select the correct troubleshooting mode to respond to fault signaling by the UAV, we had to first establish the fault location model. Using the information fusion method, the fault location and fault phenomenon text features were then fused, and the troubleshooting mode selection model was established. The independent variable data set based on information fusion is shown in
Table 5.
According to the complexity of actual UAV troubleshooting modes and expert experience, the independent variables were divided into three categories and labeled, as shown in
Table 6. As a result, the troubleshooting selection mode could be simplified, and preliminary troubleshooting procedures could be provided to field maintenance personnel.
In order to verify the effectiveness of the troubleshooting mode selection method based on the SIF-SVM, both in theory and in practice, we constructed three models for comparison, as shown in
Table 7. By comparing the effects of Model 1 and Model 2, we theoretically verified the effectiveness of the SIF-SVM; using Model 3, we verified the effectiveness of the SIF-SVM under real-world conditions.
We used the
e1071 package (version 1.7) in
R (version 1.0.3) to build the SVM model on a computer with the AMD Ryzen 7 1700 Eight-Core Processor, 3 GHz CPU, and 32 GB RAM. We randomly selected two-thirds of the data to train the model and used the remaining data as the test set to verify the predictive ability of the model. We selected accuracy, precision, recall, and
-score as the evaluation indicators of the model effect. Because this paper aimed to solve a multi-classification problem, we use the calculation method of the multi-classification problem to calculate these indexes [
29]. In order to compare the Word2Vec text feature extraction of UAV fault records, we also used the popular TF-IDF, LDA, and Doc2Vec models for text feature extraction and established the model. Moreover, we also compare the effects of different text vector dimensions on the model.
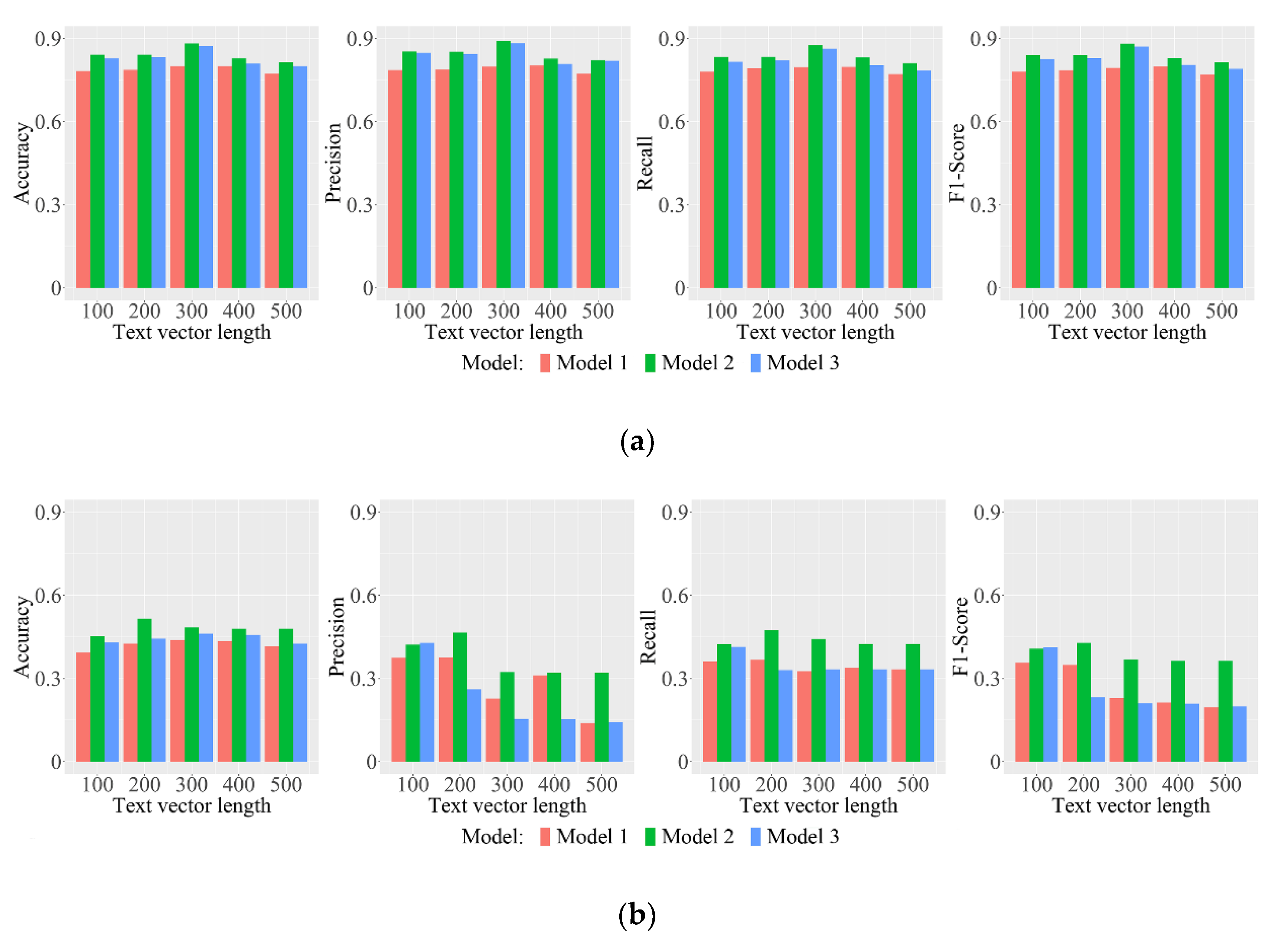
As can be seen from
Figure 6, the troubleshooting mode selection model (Model 2 and Model 3) constructed based on the SIF-SVM was better at determining the fault troubleshooting mode through the fault phenomenon description. The comparison of the two models showed that the location of the fault was necessary information for the UAV troubleshooting mode selection. After adding the location information of the fault, the model’s selection was improved, and troubleshooting mode selection based on the reported fault was more accurate. In the comparison of Model 1 with Model 3, we found that in a real-world UAV maintenance scenario, using the fault phenomenon to locate the fault, and then using the positioning results for information fusion, after which the troubleshooting mode was selected, was a more effective method than determining the troubleshooting mode only through the fault phenomenon. Because Model 3 used the fault location information judged by the fault location model, there was a risk of error as compared to the real fault location information used by Model 2. Therefore, it had been expected that the performance of Model 3 would be slightly lower than that of Model 2.
The text features extracted by Word2Vec were effective for modeling, as can be seen from
Figure 6a. In different text vector dimensions, accuracy, precision, and recall of Model 3 achieved more than 80%. When the text vector dimension was 300, the modeling effect was the best: the accuracy was 0.8733, the precision was 0.8831, and the recall was 0.8633. As shown in
Figure 6b, the text features extracted by Doc2Vec were poor for modeling. The essence of LDA was subject extraction of the text, so the text vector length was set to 50, 100, 150, 200, and 250. As can be seen from
Figure 6c, when the text vector length was 200, the effect of Model 3 was the best, and the accuracy, precision, and recall were 0.7738, 0.8198, and 0.7480, respectively. TF-IDF extracted text features through the importance of words in the corpus, so the length of the text vector was generally the number of words contained in the corpus. The model based on the text features of TF-IDF was effective. The accuracy, precision, and recall of Model 3 were 0.8100, 0.8971, and 0.7798, respectively.
The best modeling based on each text feature extraction method is shown in
Table 8. The modeling based on Word2Vec text feature extraction was the best. The modeling of the text feature extraction based on TF-IDF was also good, and its accuracy rate reached 0.8971, but the length of text vector was much larger, as compared to that of Word2Vec. In practice, this would lead to a serious computational burden. Therefore, using Word2Vec text feature extraction, when the length of text vector is 300, is the best, most efficient option.
In the actual UAV maintenance scenario (i.e., the scenario used in Model 3), the proposed troubleshooting mode selection process was a two-stage model. Within this framework, we acquired the fault location, and then selected the troubleshooting mode. As shown in
Table 9, in the fault location stage, the model accuracy, precision, and recall reached 0.9005, 0.8994, and 0.8984, respectively. It showed that the fault location model could accurately locate the fault location of the UAV. In the troubleshooting mode selection stage, the model could also accurately determine the fault handling mode. The confusion matrix of the model results of the two stages is shown in
Figure 7.



 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}