1. Introduction
With the development of communication technology, satellite internet has become an important part of the next generation of global communication systems [
1,
2], which provides internet service of low latency and high bandwidth (broadband) [
3]. The United States, the European Union, Russia and China have developed their own satellite internet constellation (SIC) programs, such as Starlink and Telesat, which are being established [
4,
5].
The orbit of a satellite can be divided into High-Earth Orbit (HEO), Medium-Earth Orbit (MEO) and Low-Earth Orbit (LEO) in terms of altitude. Because of the benefits of low latency and the development of inter-satellite link (ISL) technology, the LEO satellite network has attracted much attention [
6,
7]. However, the topology of the network is much more complicated than that of HEO or MEO satellite networks due to the fact that the satellites in LEO move very fast [
8]. Therefore, with a view to the characteristics of high-speed movement, the selection of an appropriate communication routing becomes the key of LEO satellite network data transmission.
At present, satellite routing algorithms can be divided into the Centralized Routing Algorithm (CRA) and Distributed Routing Algorithm (DRA) [
9,
10]. In CRA, the control center plans routing and sends results to the others in the network based on the collected status information of each satellite [
11]. Furthermore, the topology within each time period is assumed static by dividing the time into several intervals, and then the shortest-route algorithms, such as Dijkstra’s algorithm, are used for route planning in each time interval [
12]. DRA is a connectionless routing algorithm that does not consider global nodes, reducing the requirement of memory space effectively. Nevertheless, the DRA requires high online processing capacity at each node and may not yield optimal solutions [
13].
In addition, according to different goals, such as network connectivity, terminal utilization, average end-to-end distance, etc., different optimization methods will produce different network topologies [
14,
15]. In [
16,
17,
18], for a satellite network using inter-satellite laser link (ISLL), a random link allocation scheme was proposed, which randomly generates a connected network topology and has the goal of maximizing the number of links, showing that the logical connections to be formed depend on the line-of-sight visibility of satellites.
In terms of ISLL, due to the platform vibration, internal system noise and pointing error, there is a possibility of failure in satellite links [
19]. In [
20,
21]; with the assumption of constant probability of failure and transmitted power, the modified Rayleigh method was used to calculate the pointing error and the optimal root-mean-square width of the Gaussian beam. In [
22], based on the space optical communication link equation, the signal-to-noise ratio equations were given for the inter-satellite coherent optical receiving system with different aberrations.
In this paper, for an LEO satellite network, we establish the model with stochastic link failure, based on the task revenue, switching times and routing costs. To tackle this challenging problem, an improved Genetic Algorithm (GA) is proposed which changes the means of initial solution generation. The main contributions of this work are stated as follows:
- (1)
Different from previous studies [
23,
24], we consider the case of ISLL failure by treating communication tasks as stochastic events and calculate the probability of failure in the network.
- (2)
To optimize the topology of the network, the improved Genetic Algorithm based on A* (GA-AS) is proposed, including a new initial population generation strategy that produces initial solutions to provide an optimization direction, resulting in effectively reducing the computation cost.
The remainder of this paper is organized as follows. The LEO satellite network model, including optimization constraints and objective functions, is established with stochastic link failure in
Section 2. In
Section 3, the GA-AS is proposed and the improved A* strategy is explained in detail. Simulation results under different task scales and population size are presented in
Section 4. Finally, conclusions are provided in
Section 5.
2. Mathematical Model
2.1. LEO Satellite Network Formation
According to the area and function, the system can be divided into three parts: space, ground and user segment. In this paper, we assume that the space segment contains only satellites. The ground segment includes functional entities such as gateway stations and network management centers, and the user segment consists of various types of terminal equipment and application facilities.
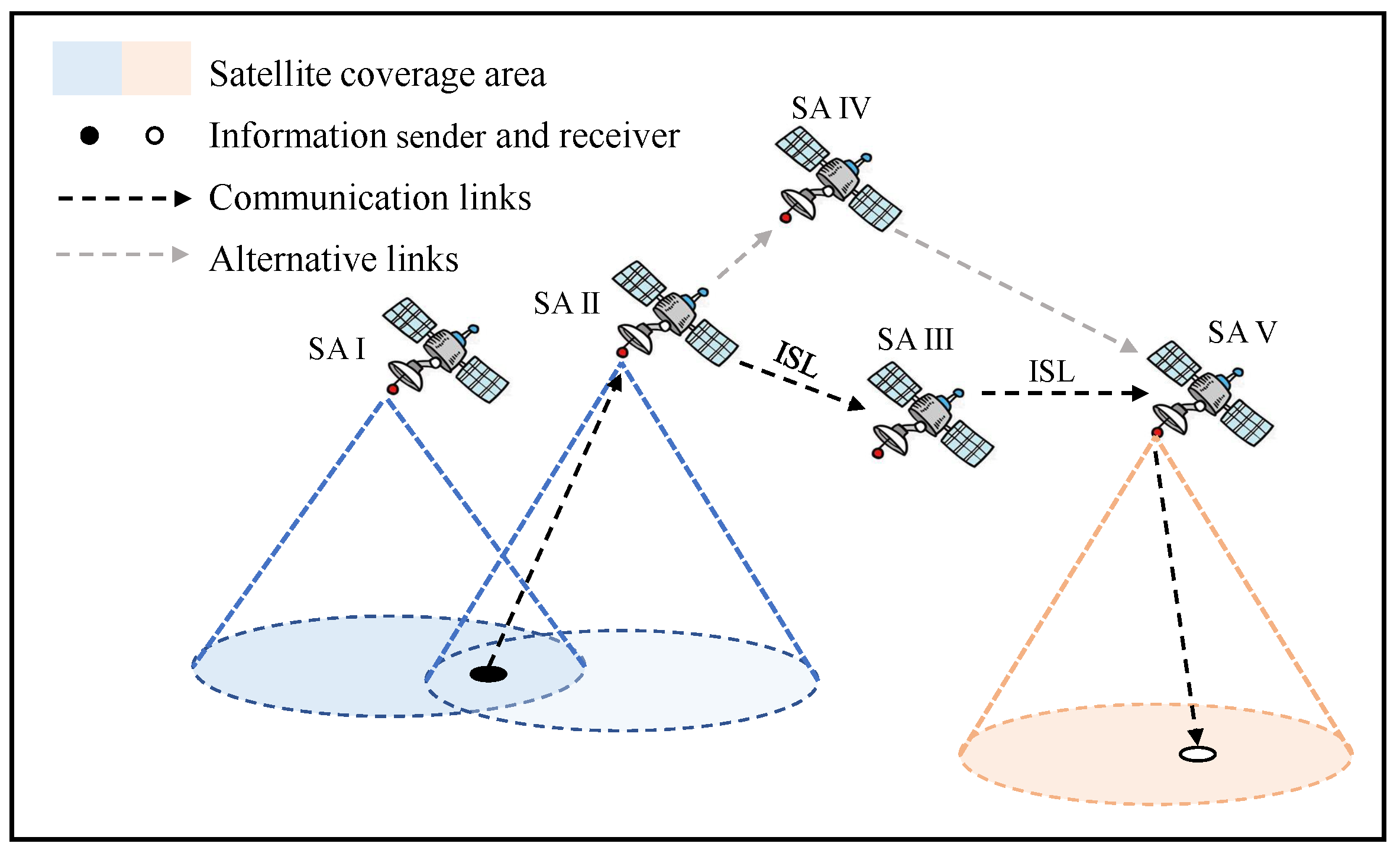
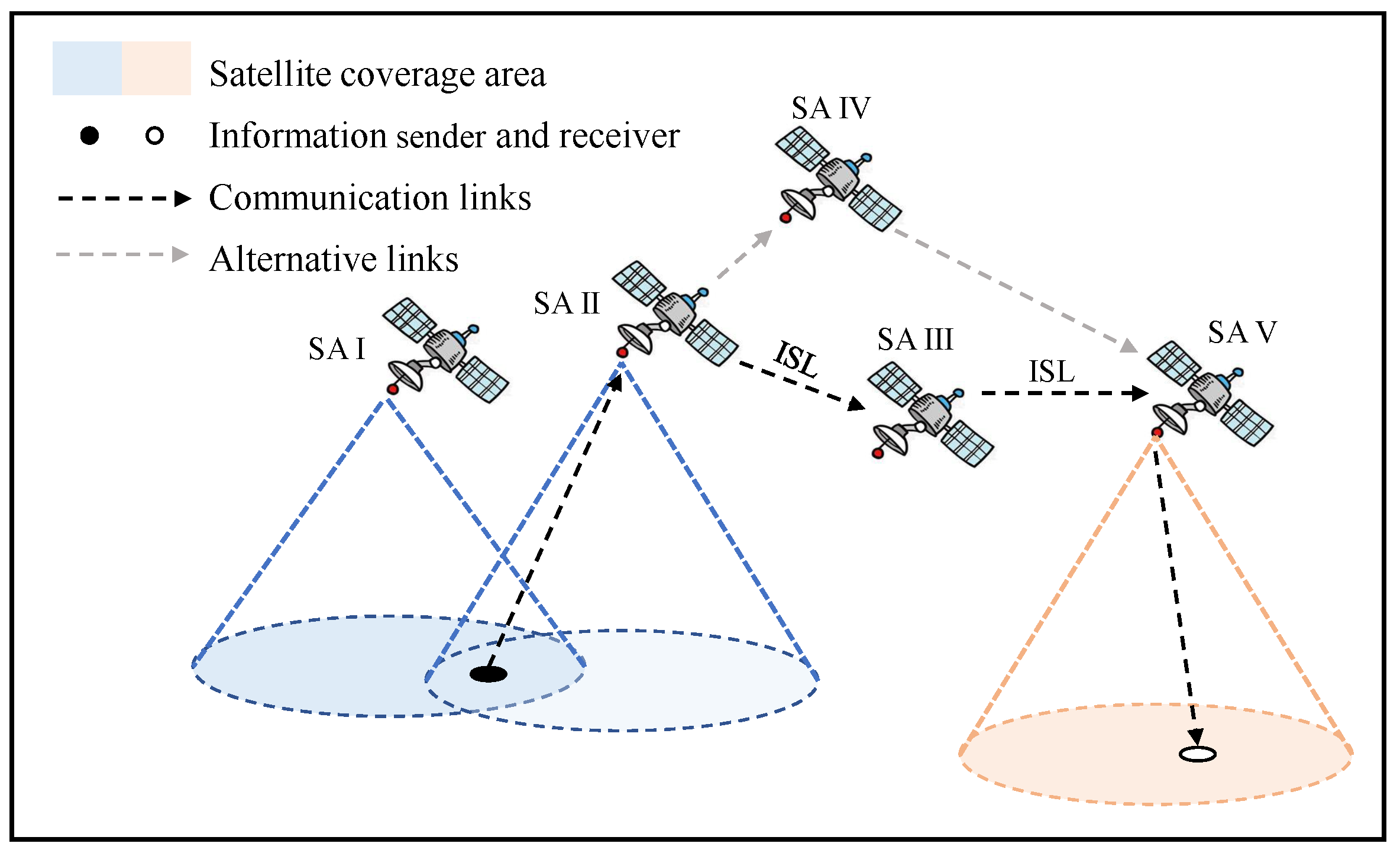
The simplified model of the LEO satellite network is shown in
Figure 1, which includes five satellites. Usually, the user segment selects the upper satellite (SA I) and communicates with it through microwave, and then transmits data to the satellite (SA V) above the ground station via the relay satellite through ISLL, and finally the SA V communicates with the ground segment via microwave. Since the system adopts ISLL, the quality and range of transmission are greatly improved compared to microwave. On the one hand, link failure may occur during the communication due to the transmission errors and system noise. On the other hand, the complexity of the topology will increase significantly with the number of satellites due to the adoption of ISL.
2.2. Graph Theory
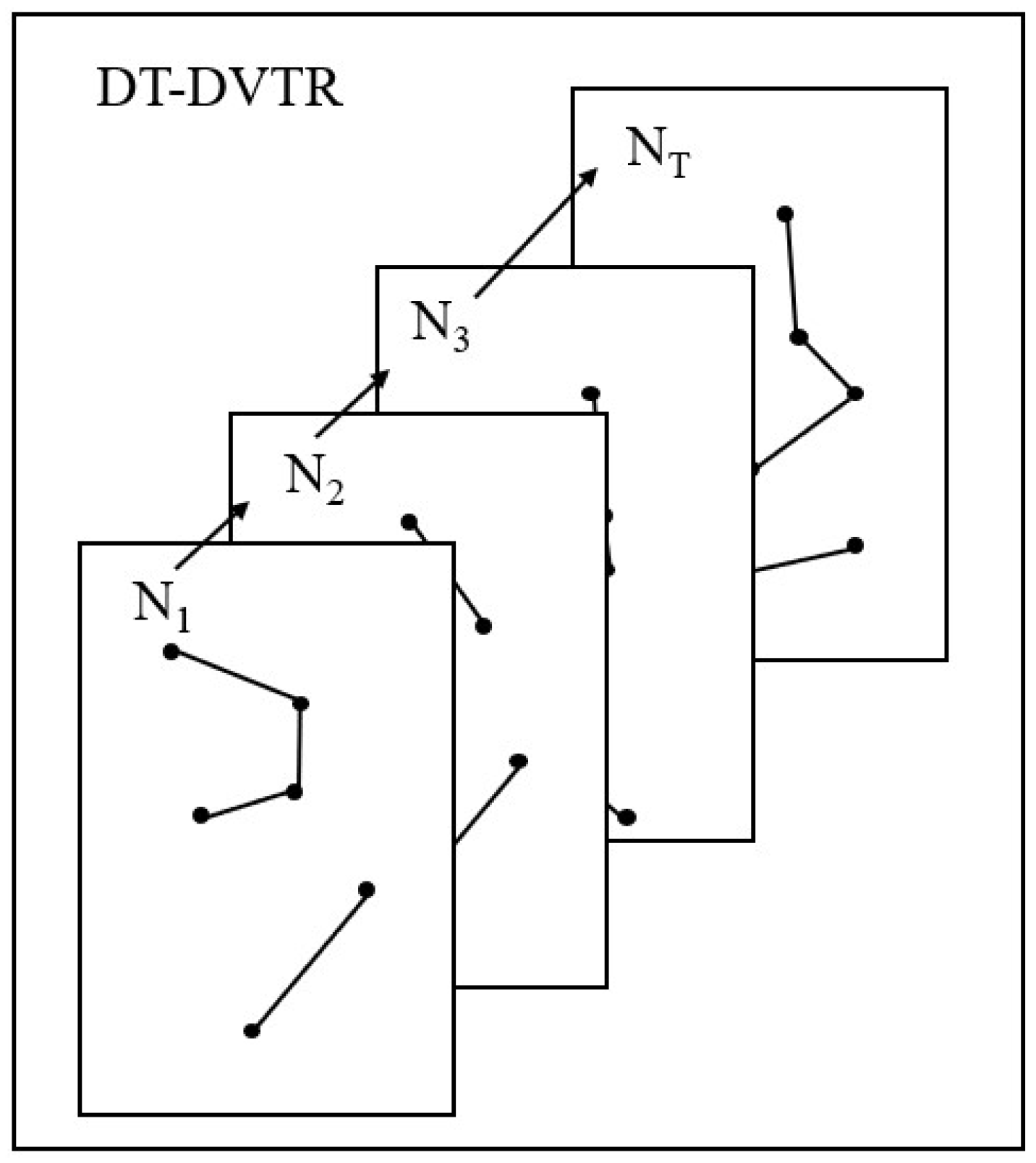
Satellites’ operation is cyclical, so the Discrete-Time Dynamic Virtual Topology Routing (DT-DVTR) method can be used to divide the time. In each time interval, as illustrated in
Figure 2, the satellite network topology can be approximately regarded as static.
Supposing a satellite network is divided into static topologies, which is composed of n satellites in period T, the cth topology can be represented by a static directed graph . Nonempty finite set and represent the node and edge set, respectively. Matrix represents the adjacency matrix if ; otherwise, . The adjacent set of node is defined as . The in-degree matrix of is denoted by , where is the number of edges with as the end node, which is called the in-degree of . Correspondingly, is defined as the out-degree matrix, where represents the number of edges with as the starting node, which is called the out-degree of . The cost matrix is denoted by , where represents the cost of .
2.3. LEO Satellite Network Model
2.3.1. Communication Routing Model
Suppose is the set of communication tasks in , and each task contains a start node and a end node , which denoted as . We make the following assumptions:
Assumption 1: For , there are feasible paths ( means that there is at least one feasible path in ). All feasible paths form the set .
Assumption 2: An arbitrary feasible path consists of non-repeating edges. is used to represent , and vice versa.
The routing selection of is equivalent to selecting a path with the least cost from the . Let be the optimal path in , and all optimal paths form the optimal path set . The optimal connection matrix of is represented by with the property that if , ; otherwise, .
2.3.2. Link Switch Model
The satellite undergoes a series of works such as alignment before establishing the ISLL. It costs more and takes more time to establish new communications than to maintain the previous connection. We suppose that in any two adjacent
and
,
and
are the optimal path sets, respectively,
and
are the corresponding optimal connection matrix, respectively.
is the switch matrix of
, and
is defined as:
In particular, we define .
2.4. Stochastic Link Failure Model
2.4.1. Inter-Satellite Laser Link Signal (ISLL) Model
It is assumed that the ISLL system adopts Intensity Modulation Direct Detection and Gaussian beam with the direction from satellite
i to
j. According to [
22], the received luminous power
of satellite
j can be expressed as:
where
is the emitted luminous power;
is the emitted antenna gain;
is the received antenna gain;
and
are the transmitting and receiving antenna efficiency, respectively;
is the pointing error loss factor, where
is the pointing error deviation angle;
is the laser wavelength ;
is the transmission distance.
The detector of satellite
j converts the received luminous power
into current signal
, which is expressed as:
where
R is the responsivity. Combining Equations (
2) and (
3), we obtain:
2.4.2. Pointing Error
The beam radial pointing error angle of satellite
i is denoted by
, where
and
represent the pointing error angle of azimuth and pitch, respectively. Thus,
obeys the Beckman distribution [
25] and approximates it to the modified Rayleigh distribution with parameter
[
20]. The approximate expressions of the probability density function (PDF) and cumulative distribution function (CDF) of
are obtained as:
where
2.4.3. Stochastic Link Failure
Generally, when the channel capacity
C is insufficient to meet the requirement of transmission rate
, we refer to this situation as communication failure. The stochastic failure matrix is denoted by
, where
represents the probability of communication failure from satellite
i to
j, expressed as
where
S denotes the signal-to-noise ratio (SNR). Since
increases monotonically with
S, the failure probability can be shown as
In the formula, a is the preset threshold, and is the inverse function of .
At the receiving system, the signal has additive white Gaussian noise with mean of 0 and variance of
after the photoelectric detector. Therefore, the instantaneous signal-to-noise ratio
S of the electrical signal received can be represented as:
Combining Equations (
4), (
6) and (
10), the CDF of
S can be indicated as
where
For a given threshold
a, the failure probability is calculated by
2.5. Operational Constraints
Based on the above discussion, we establish a multi-constraint satisfaction model of the LEO satellite network. Some assumptions are made as follows:
The on-board power consumption of satellites is only affected by the number of ISL;
Attenuation of microwave is ignored due to other reasons such as outside interference;
Once satellite communication starts, it cannot be interrupted;
During the entire period , the quantity of satellites remains the same.
According to the characteristics and operational regulations of the satellite formation, some constraints can be listed as follows:
- (1)
Communication constraints between satellite and gateway station.
If the
ith satellite is visible to the
pth gateway station, the angle
between the vector of the satellite’s centroid pointing to the gateway station and connecting the satellite to the center of the Earth cannot exceed the satellite’s maximum offset capability
, expressed as:
- (2)
Communication constraints between satellite and user terminals.
If the
ith satellite is visible to the
qth user, the angle
between the vector of the satellite’s centroid pointing to the terminal and connecting the satellite to the center of the Earth cannot exceed the satellite’s maximum offset capability
. It is expressed as:
- (3)
Satellite’s microwave communication capability constraints.
When the satellite communicates with ground gateways and terminals, data uploads and downloads occur. The data upload speed
and download speed
of satellite
i cannot exceed the maximum values
and
, expressed as:
- (4)
Satellite laser communication capability constraints.
The number of inter-satellite links established by satellites at the same time is limited; that is, the out-degree
and in-degree
of the satellite
i cannot exceed their maximum values
and
. This is expressed as:
- (5)
ISLL communication range restriction.
The communication distance
between satellite
i and
j cannot exceed the maximum
, expressed as:
2.6. Objective Function
The function
represents the revenue of tasks, expressed as:
where
represents the priority of task
, and
represents the probability of
being executed. The calculation formula of
is as follows:
Function
represents the number of all new links in the graph
, expressed as:
where
is an element in
.
Function
represents the total cost of the graph
, expressed as:
Taking into account the different magnitudes and importance of
,
and
, the non-dimensional parameter
and weight
are introduced into the objective function
f. The optimization objective is defined as:
where
represents the weight coefficient, set according to the actual situation.
3. Optimization Method
The complexity of the network topology increases dramatically with the number of satellites. On the one hand, it is hard to solve the multi-constraint problem by various shortest-route algorithms; on the other hand, the initial solution of intelligent optimization algorithms is generally generated by a stochastic approach, so there is a large uncertainty in the optimization direction. Based on the above considerations, we propose the improved GA algorithm based on A* (GA-AS), which introduces the roulette wheel selection into the A* algorithm to generate a series of solutions, and then the solutions are used as the initial population of the Genetic Algorithm (GA).
3.1. Improved Genetic Algorithm Based on A* (GA-AS)
GA is a self-organizing and self-adaptive artificial intelligence technology that simulates the evolutionary process and mechanism of natural organisms to solve problems. The basic framework of GA-AS is similar to GA’s but the initial solution generator has been significantly modified. Here, we give the framework of GA-AS, and the flow of it is shown in Algorithm 1.
Initialization: The initial population needs to be generated before the iterative calculation is performed. Assuming that the population size is N, we adopt the improved A* strategy and run the algorithm N times to generate the initial population in this work.
Coding: The coding is the process of establishing the mapping relationship between phenotype and genotype. We use natural number coding to transform the problem into an optimal combination problem.
Selection: In this process, the principle of competition in nature is simulated by calculating the fitness value, which is the criterion for assessing individuals’ performance, and then the outstanding individual is selected.
Heredity: This part includes crossover and mutation. Inspired by biology, the offspring is produced by gene crossover and mutation of parents. Usually, the offspring shares almost features of the parents, and it is possible for the offspring to have properties that the parent does not have due to the mutation operator.
In GA-AS, when the genotypes change, the population needs to be filtered to screen out the individuals who violate the constraints. In this work, for addressing the situation, we use the penalty strategy by reducing the objective function value
f to obtain fitness value
, as shown in Equation (
26), and therefore
may be negative.
where
n is the number of constraint violations, and
M is a constant.
| Algorithm 1 Improved Genetic Algorithm Based on A* (GA-AS) |
![Aerospace 09 00322 i001]() |
3.2. Improved A* (A-Star) Strategy
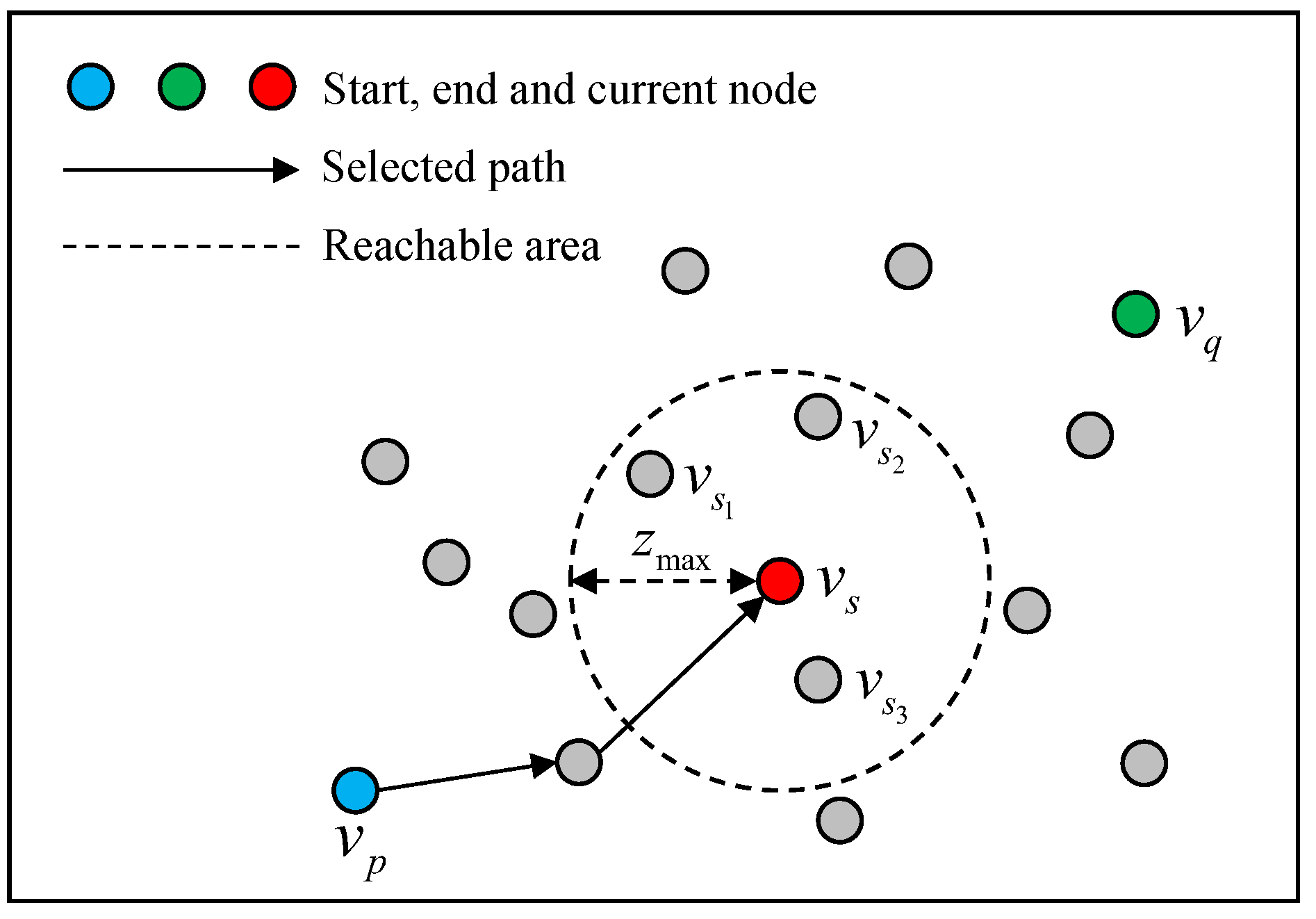
We introduce the roulette wheel selection into the A* algorithm to obtain the improved A* strategy. For different paths, the strategy making the high-cost paths has non-zero probability of selection, as shown in
Figure 3. In
,
represents the partial of
, and
denotes the end node that
passes through. The
is called the reachable node set of
when it satisfies the following conditions:
, satisfy and .
, satisfy or .
The calculation formulas for the selection probability
and cumulative probability
of any node
are as follows:
Among them,
represents the estimated cost of
,
represents the actual cost of
, and
represents the estimated cost between
and
. The calculation formula is:
In particular, define
. When
satisfies the following formula, choose
as the next path node:
where the random variable
.
Before implementation of the improved A* strategy, an Open List and a Closed List ought to be established, which are used to record the nodes that need to be and have been investigated, respectively. The flow of the improved A* strategy is shown in Algorithm 2.
| Algorithm 2 The improve A* strategy. |
![Aerospace 09 00322 i002]() |
4. Simulation Experiment and Analysis
4.1. Stochastic Link Failure Experiment
This section analyzes the effects of transmission distance and transmitting power on the failure probability in ISLL systems. For each case, transmit gain , receive gain , transmit efficiency , receive efficiency , laser wavelength , responsivity R, noise variance and threshold a are set to , , , , , , , . Azimuth pointing error and pitch pointing error are set to , , respectively, where and .
Table 1 lists the relationships between transmit power, transmission distance and failure probability under the above-mentioned condition. As can be seen from
Table 1, in the condition of the same transmit power, the probability of failure is proportional to transmission distance, and it is very small and can be ignored, while the transmission distance is less than 1000 km. In addition, the transmission power is inversely proportional to the probability failure under the condition of the same transmission distance.
4.2. Optimization Results
This section compares the experimental results of GA and GA-AS. The experiment randomly generates several tasks and environments, including satellites, user terminals and ground stations. The parameter settings are as follows, where mutation probability
, genetic probability
, crossover probability
, weight
, transmission power
. Other parameter settings are consistent with
Section 4.1.
Table 2 lists the optimization results of GA-AS with different task sizes under the condition of population size
. The final value refers to the final result obtained by the GA-AS. It can be seen from
Table 2 that when the number of tasks
is set to 41, the average fitness value of the initial population is roughly
of the final value. As the task size grows, the distribution range and mean value decrease. When
, the fitness value of the initial population is distributed in 61%∼88% of the final value, and the mean value is around
of it, indicating that the new initial-solution generation strategy can produce a good initial population.
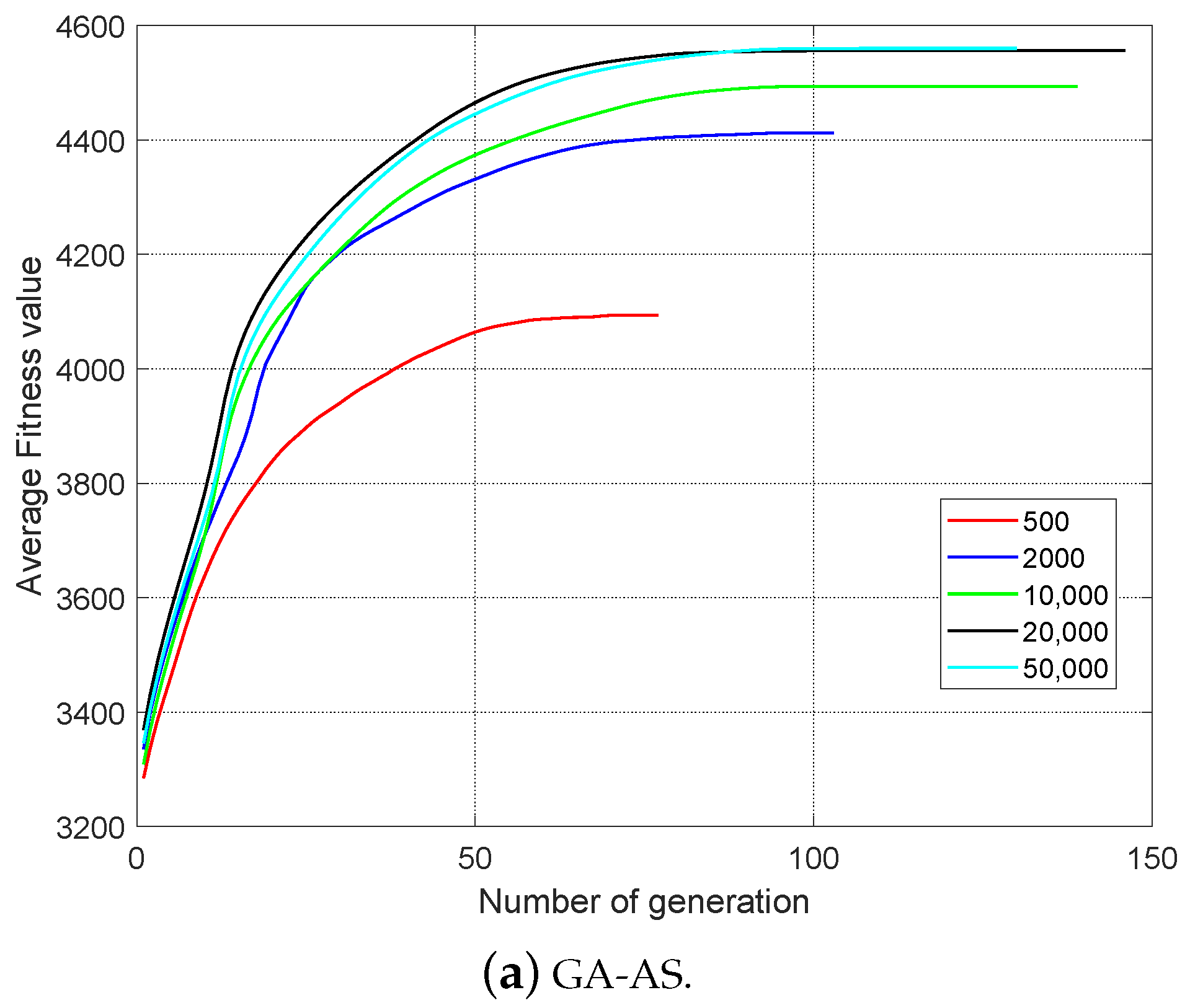
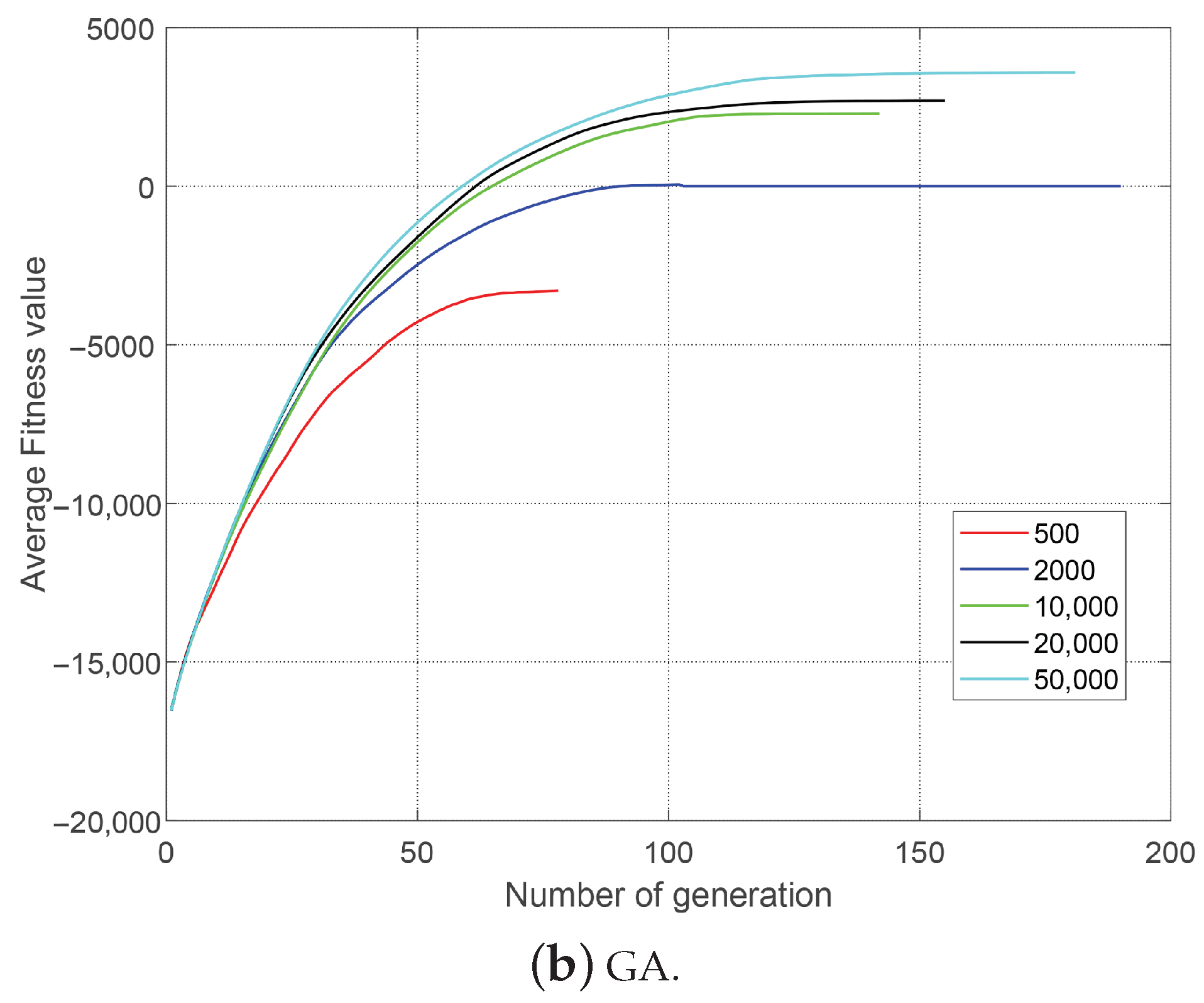
Figure 4 and
Table 3 list the optimization results of GA-AS and GA with different population sizes when
and
. Since penalties were used in the experiment, the fitness values may be negative. It can be seen from
Figure 4 and
Table 3 that the optimization capability of GA-AS is significantly better than GA when
and improves as the population size increases. When the
reaches 2000, it has little effect on the optimization of GA-AS to increase the
due to the quite good performance. However, GA has almost no optimization ability when
is less than 2000 and it reached 50,000, which can be considered undesirable. Moreover, the performance of GA-AS is always better than GA under the same population size.
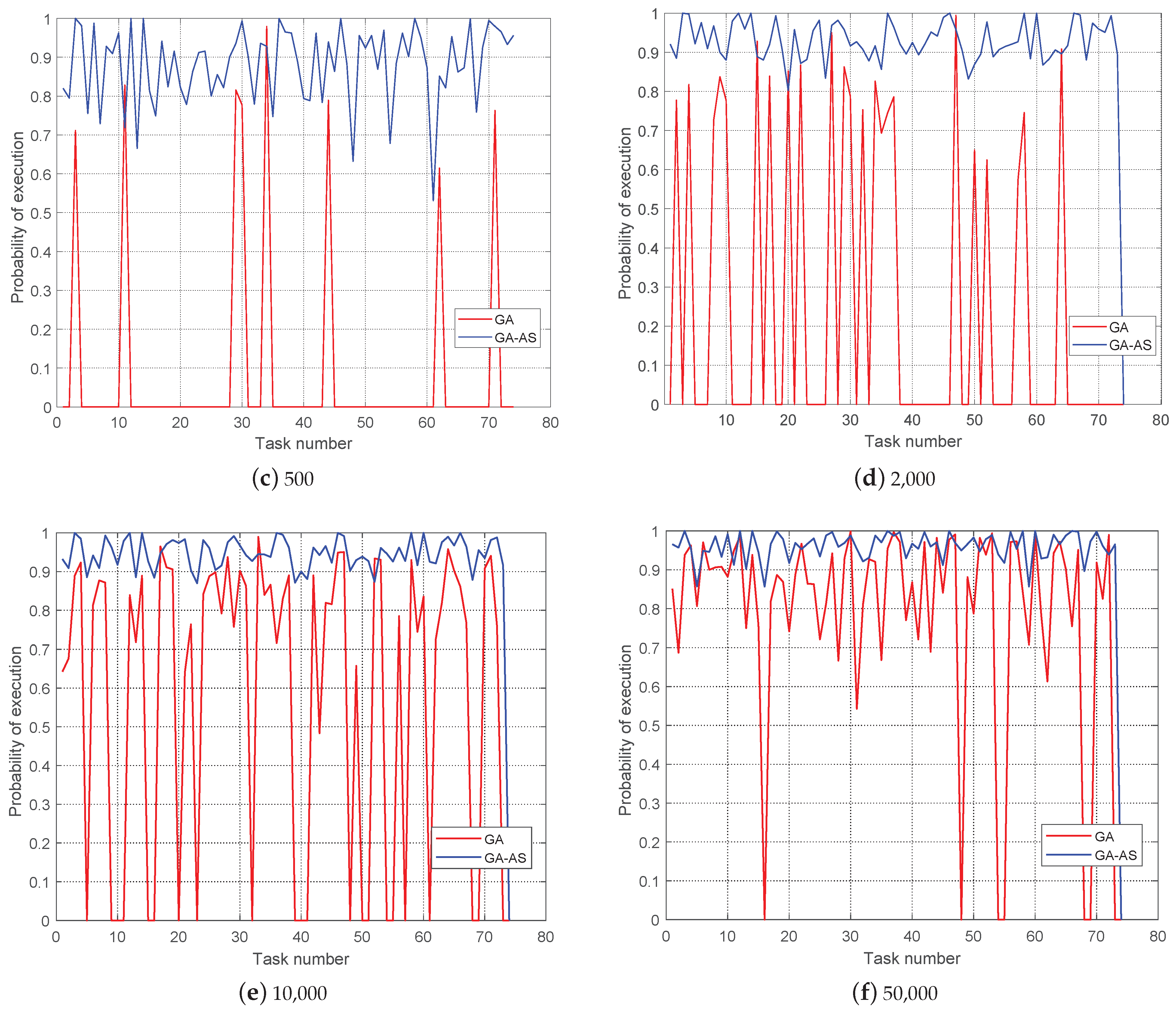
Figure 5 shows the probability of task execution for GA and GA-AS for different population sizes with
, and the value is correlated with the stochastic link failure. For GA-AS, at the population size of 500, most task execution probabilities are greater than
and increase with
. In contrast, at a population size of 500 in GA, most of the tasks could not be executed and the optimization performance was improved with increasing population size, but there was still a considerable gap between the GA and GA-AS results.
4.3. Analysis of Complexity
As can be seen from Algorithm 1, the GA requires several iterations of computation under the condition that the population size is , so the time complexity of it is approximated as and the space complexity is approximated as . Compared with GA, GA-AS differs mainly in its initial population generation method, which is shown in Algorithm 2, so its time and space complexity can be approximated as and , respectively. Since the complexity of the improved A* strategy is smaller than that of the GA, the time and space complexity of GA-AS remains the same as the GA.
The running times of GA and GA-AS with the same computer configuration are shown in
Table 3. As can be seen from
Table 3, the running time of GA-AS is almost always larger than that of GA for the same population size, and this extra time can be considered as the running time of the improved A* strategy.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}