1. Introduction
Classification is one of the processes commonly completed by researchers in machine learning (ML). In general, the purpose of classification is to assign an object to one of the categories that has been predefined. Currently, there are various algorithms for classification, such as Decision Tree, Artificial Neural Network, Random Forest, Fuzzy Logic, and many more, including Rough Set Theory (RST). To obtain the best result, selecting the proper algorithm is crucial by considering not only the accuracy but also the cost of training, cost of testing, and cost of the implementation. Another important factor is whether the classification model needs to be built as a white or black box model. If a white box model is expected, a method such as Decision Tree, Fuzzy Logic, or RST can be applied because this method can produce transparent decision rules.
In a dataset that will be processed for classification, attributes that have continuous values are often found. Hence, the data of the attributes cannot be directly processed by a classifier that requires discrete data, such as RST. To be able to process the dataset, a discretization process should be carried out first.
Currently, there are many state-of-the-art methods for discretization, as reported in Refs. [
1,
2]. Based on this report, there are two main groups of discretization methods, i.e., supervised and unsupervised. This work also conducted a survey, finding that the popular methods for unsupervised discretization use an equal-width and equal-frequency base. The disadvantage of this unsupervised method is that we cannot be sure whether the discrete results are optimal since there is no feedback to measure the optimality of discrete results at the time of the process. To generate optimal discretized values, a supervised method should be applied. One of the popular methods for supervised discretization is entropy-based [
1]. However, the next question is whether the entropy-based method will be suitable or not for RST-based classifiers.
This paper aims to improve the classification performance using the RST method on various datasets with continuous values obtained from UCI. The contribution of this study is to propose data pre-processing methods related to discretization before carrying out the classification process. The proposed method starts with applying k-means to discretize continuous value attributes, then optimizes them by using a genetic algorithm (GA) that involves one of the RST instruments, called the dependency coefficient, to maintain the quality of the dataset as the original after the implementation of the discrete process.
By involving one of the RST elements in the discretization process, it is expected that the discretization results will be suitable for the RST-based classifier. Thus, the novelty of the proposed method compared to other discretization processes is that the method is based on approximation quality with the expectation that it will give better results to be used by the RST-based classifier because the approximation is controlled by one of the RST elements from the beginning.
This paper is organized as follows:
Section 2 explains the theoretical basis of the RST, which begins with the concept of approximation in the framework of rough sets, and then continues with an explanation of the basic notions and characteristics of the RST.
Section 3 presents the need for discretization and its various techniques, especially those related to the proposed method.
Section 4 describes the basic concepts of the proposed method and the algorithm in pseudo-code form.
Section 5 presents the experimental framework, the datasets used, and other popular discretization methods.
Section 6 describes the analysis of the experimental results, and this paper is concluded in
Section 7.
2. Basic Notions
Before the detailed description of the method proposed in this article is discussed, a basic picture of RST that was first proposed by Zdzislaw Pawlak in 1982 will be given. This RST method is intended to classify and analyze imprecise, uncertain, or incomplete information and knowledge [
3,
4]. The underlying concept of the RST is the size approximation of the lower and upper sets. The approximation of the size of the lower subset is determined by the group of objects that are becoming members of the desired subset. Meanwhile, the size of the upper subset approximation is determined by the possible group of objects to become a member of the desired subset. Any subset defined or bordered by an upper–lower approximation is called a Rough Set [
3]. Since it was proposed, RST has been used as a valuable tool for solving various problems, such as for imprecise or uncertain knowledge representation, knowledge analysis, quality measurement of the information available on the data pattern, data dependency and uncertainty analysis, and information reduction [
5].
This RST approach also contributes to the artificial intelligence (AI) foundation, especially in machine learning, knowledge discovery, decision analysis, expert systems, inductive reasoning, and pattern recognition [
3].
The rough sets approach has many advantages. Some of the most prominent advantages of applying RST are 6:
Efficient in finding hidden patterns in the dataset;
Able to identify difficult data relationships;
Able to reduce the amount of data to a minimum (data reduction);
Able to evaluate the level of significance of the data;
Able to produce a set of rules for transparent classification.
The following sub-sections will explain the basic and important philosophies associated with RST to be discussed based on Refs. [
3,
6,
7,
8,
9].
2.1. Equivalent Relations
Let be a non-empty set, whereas and are elements of . If is a symbol of a relation so that is a relation function between and , then is said to be an equivalent relation when it meets three properties as follows:
Reflexive: for all in ;
Symmetric: if , then ;
Transitive: if and , then .
If in , then is the equivalence class of with respect to .
2.2. Information System and Relationship Indiscernibility
Let
be an Information System
, where
is a set of non-empty objects called universe,
is a set of attributes,
is the union among the attribute domains in
, and
is the description of the total function. For classification, the set of attributes,
is divided into condition attributes denoted by
and a decision attribute denoted by
. When the attributes of the information table have been divided into condition and decision attributes, then the table is called a decision table. The element of
can be called object, case, instance, or observation [
10]. The attributes can be called features, variables, or characteristic conditions. If an attribute
is given, then:
for
.
is called the set of values of
.
If , , then an indiscernibility relation can be defined as: for all , or in the statement that the two objects are said to be indiscernible when the two objects are indistinguishable since they do not have sufficient differences in the set of attributes called . The equivalence class of indiscernibility relation is denoted by .
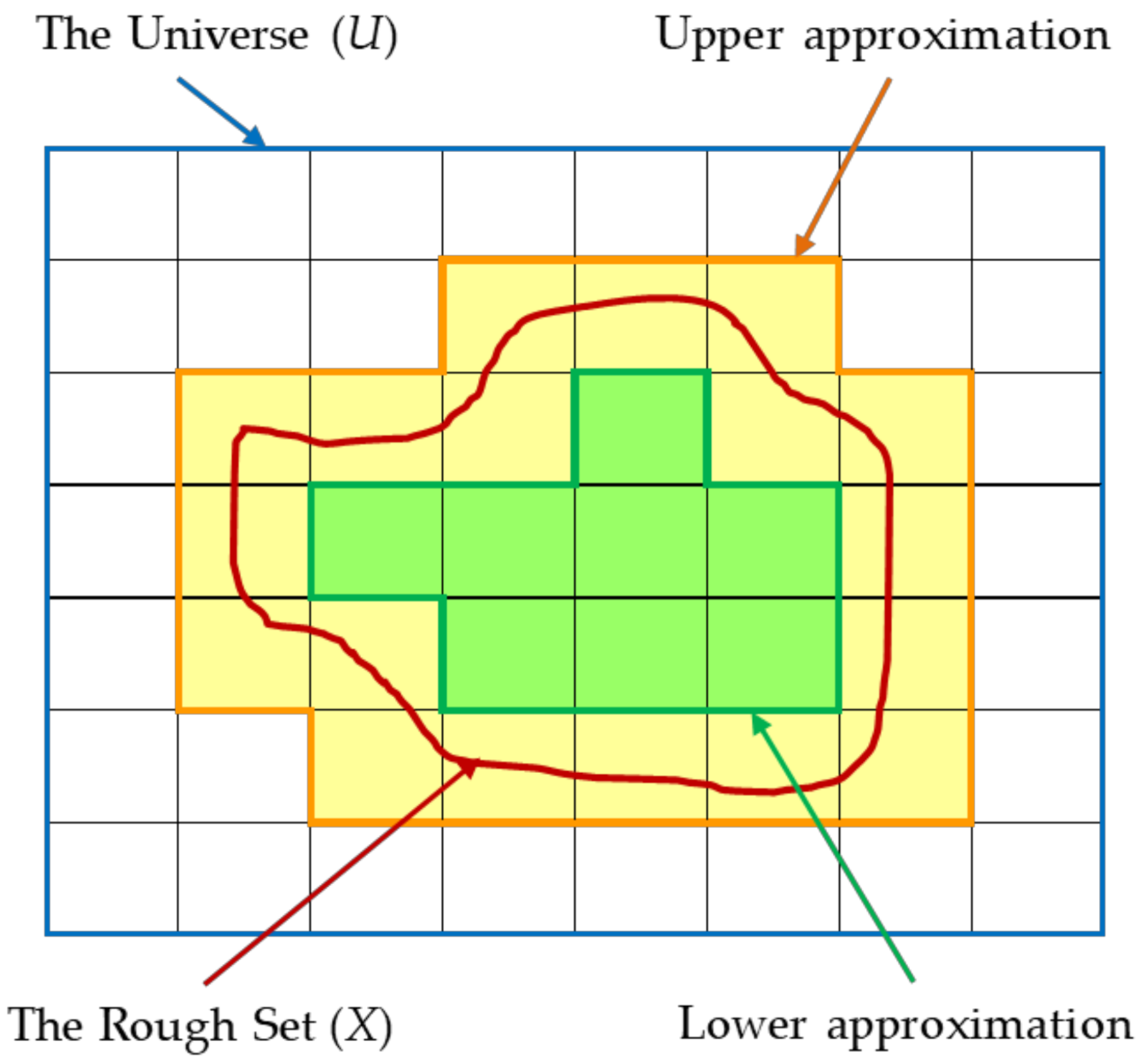
2.3. Lower Approximation Subset
Let
, where
is a set of condition attributes, and
; then, the
B-lower approximation subset of
is the set of all elements of
that can be classified exactly as an element of
, and it is shown in Equation (1):
2.4. Upper Approximation Subset
A
B-upper approximation subset of
is the set of all elements of
that may be classified as elements of
, and this is shown in Equation (2):
2.5. Boundary Region Subset
This subset contains a group of elements as defined in Equation (3). This set contains objects that, whether they belong to the
classification, cannot be determined exactly.
2.6. Rough Set
A set obtained by the lower and upper approximations is called a rough set. When a rough set is found, then it must be
.
Figure 1 illustrates each set that meets Equations (1)–(3).
2.7. Crisp Set
If , then the set is called a crisp set.
2.8. Positive Region Subset
This is a set that has an object of the universal set
U that can be classified or partitioned into certain classes of
U/
D using the set of attributes
C, as shown in Equation (4).
where
U/
D is the partitioning of
U based on the attribute values of
D and
is the notation of lower approximation of the set
with respect to
. The positive region of the subset
belonging to the partition
is also called the lower approximation of the set
. The positive region of a decision attribute with respect to a subset
approximately represents the quality of
. The union of the positive and the boundary regions yields the upper approximation [
7].
2.9. Dependency Coefficient
Let
be a decision table. The dependency coefficient between attribute condition
and attribute decision
can be formulated as in Equation (5) as follows:
The value of the dependency coefficient is in the range from 0 to 1. This coefficient represents a portion of the objects that can be correctly classified against the total. If , then is completely related to , if , then is said to have partial relation on , and if , then has no dependency to . A decision table depends on the feature set condition when all values on the decision feature can be uniquely determined by the condition attribute values.
2.10. Reduction of Attributes
As explained in
Section 2.2., it is possible that two or more objects are indiscernible because they do not have enough different attribute values. In this case, it is necessary to make savings so that only one element of the equivalence class is required to represent the whole class. To be able to make savings, some additional notions are needed.
Let be an information system, , and let . It can be said that a is dispensable in if ; otherwise, is indispensable in . A set is called independent if all of its attributes are indispensable.
Any subset of is called a reduct of if is independent and .
Therefore, reduct is the minimal set of attributes without changing the classification results when using all attributes. In other words, the attributes not in reduct are considered redundant and have no effect on classification.
2.11. Discernibility Matrix and Function
Reducts have several properties, one of which is the validity of the relation, as shown in Equation (6). Let
be a subset of
. The
core of
is the set off all indispensable attributes of
[
10].
where
is the set of all
reducts of
.
In order to easily calculate
reduct and
core, discernibility matrix can be used [
10], which is defined as follows.
Let
be an information system with
objects. The discernibility matrix of
is a symmetric
matrix with entries in
, as given in Equation (7).
A discernibility function
for an information system
is a Boolean function of
Boolean variables
(corresponding to the attribute
), defined as follows:
where
.
3. Discretization
Discretization is one of the data preprocessing activity types performed in the preparation stage as well as data normalization, data cleaning, data integration, and so on. Often, data preprocessing needs to be performed to improve the efficiency in subsequent processes [
11]. It is also needed to meet the requirements of the method or algorithm to be executed. The rough-set-theory-based method is one of the methods that requires data in the discrete form. Therefore, if the dataset to be processed is in continuous mode, then the discretization process is required.
There are several well-known discretization techniques that can be categorized based on how the discretization process is carried out. When it is carried out by referring to the labels that have been provided in the dataset, then it is called supervised discretization, while, if the label is not available, then it is categorized as unsupervised discretization [
11].
Discretization by binning is one of the discretization techniques based on a specified number of bins. If the dataset has a label, then the number of bins for discretization can be determined for as many as the number of classes on the label, while, for a dataset with no label, an unsupervised technique, such as clustering, should be applied.
3.1. k-Means
Cluster analysis or clustering is one of the most popular methods for discretization. This technique can be used to discretize a numeric attribute,
, by dividing the values of
into several clusters [
11]. This experiment applies the
k-means method to discretize the numeric attributes of the dataset.
k-means is a centroid-based method. Assume
is one of the numeric attributes of a dataset
. Partitioning can be performed on the
attribute into
clusters,
, where
and
for
). In
k-means, the centroid,
, of a cluster
is the center point that is defined as the mean of the points assigned to the cluster. The difference between a point,
, and its centroid,
, is measured using a distance function,
. The most popular formula to measure the distance is by using the Euclidean distance formula, as shown by Equation (9).
Because k-means is one of the unsupervised techniques, then the value of is not known and it is usually defined through trial and error iteratively to find the optimum value. To automate this trial-and-error process, an optimization technique should be applied. There are many optimization techniques available, but this experiment employs genetic algorithm (GA) technique to find the optimum value for .
In this experiment, is optimum if the value is as minimal as possible without losing the quality of the information of the dataset. This experiment uses function, as shown in Equation (5).
3.2. Genetic Algorithm
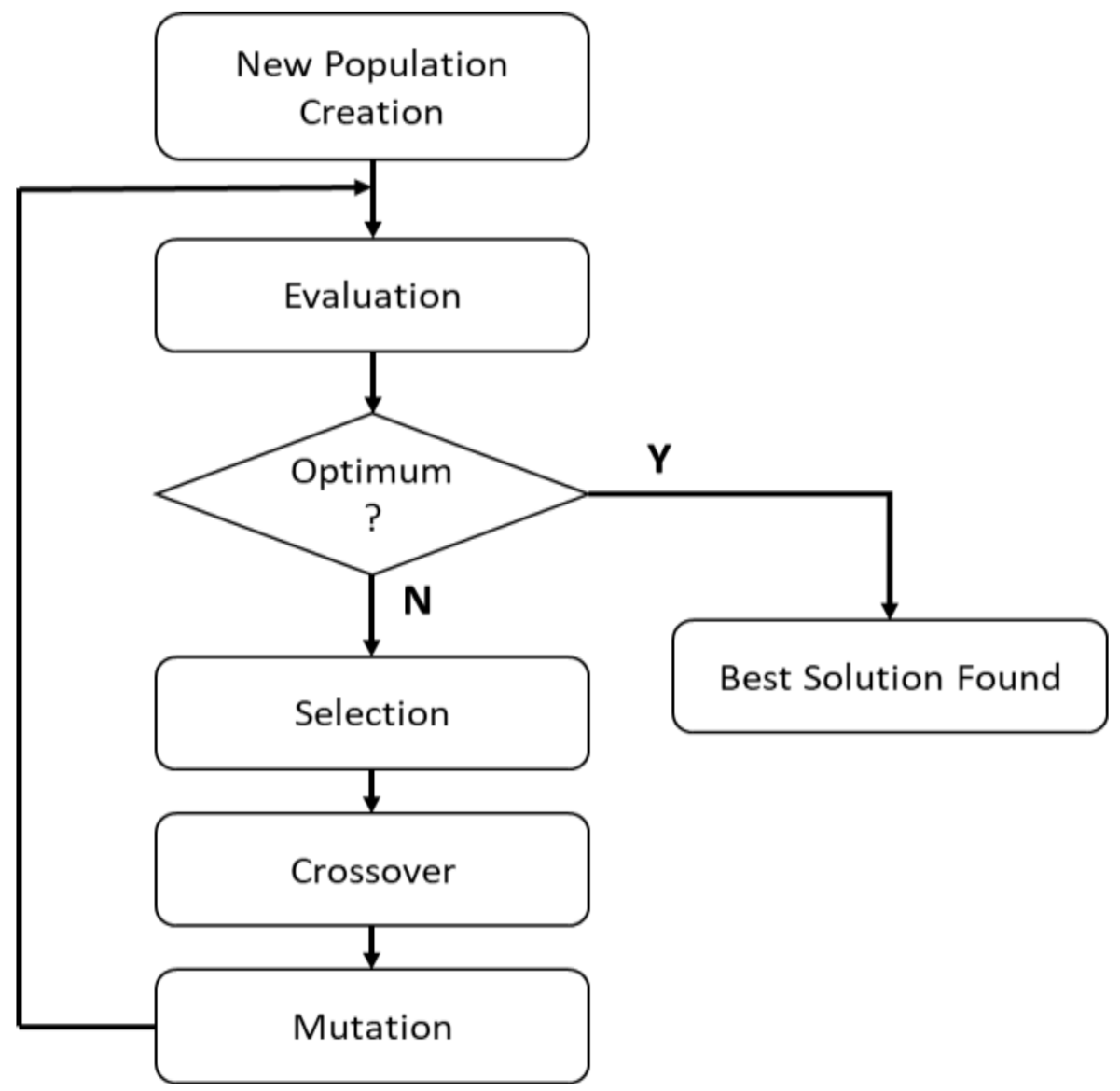
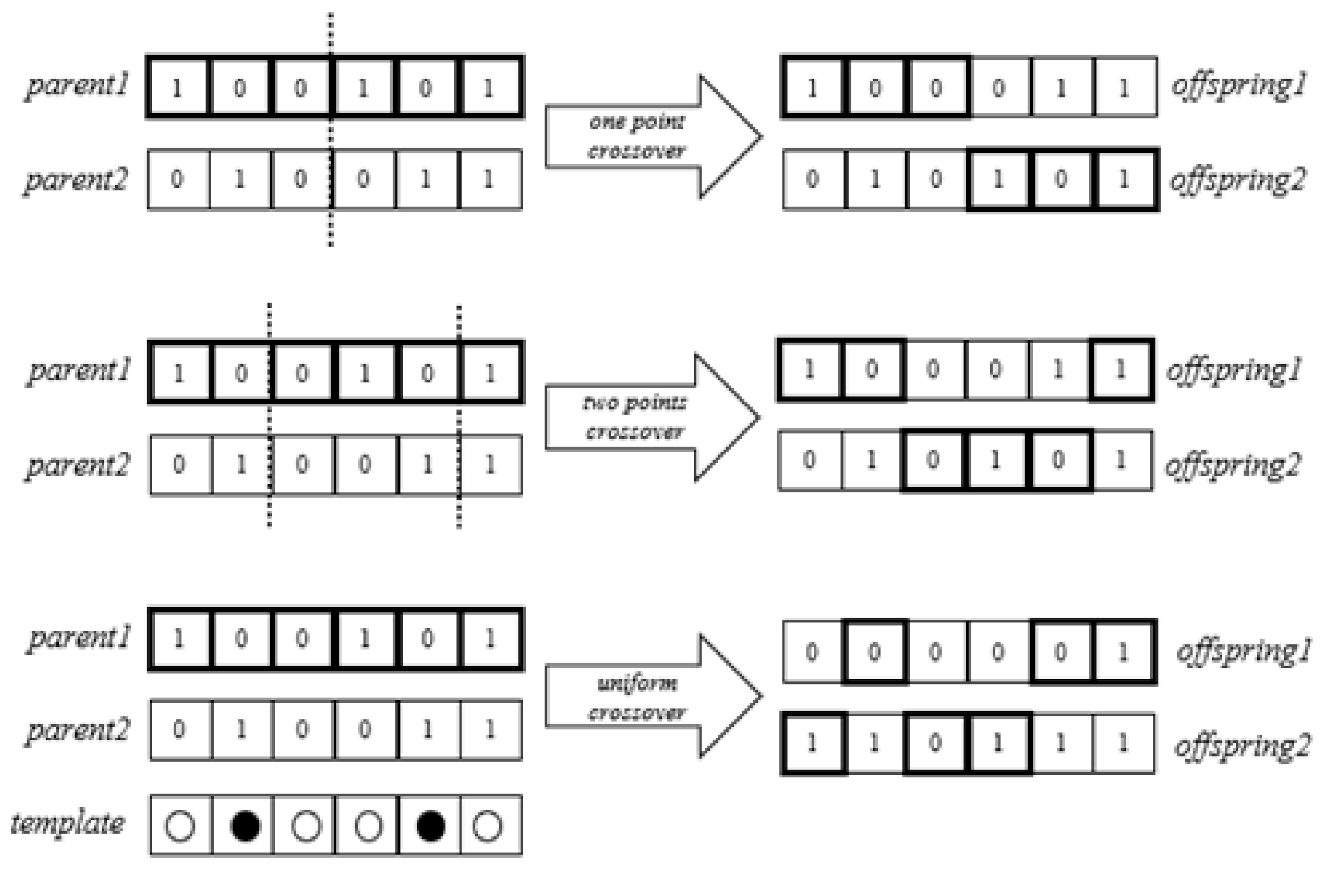
Genetic algorithm (GA) is an algorithm inspired by biological phenomena, namely the process of genetic evolution from the creation of a population that consists of some individuals who later experience genetic evolution. There are three genetic processes that occur, i.e., selection, crossover, and mutation, to obtain new individuals who are expected to be stronger or fitter during the next cycle selection process [
12].
Figure 2 shows GA’s operational processes.
Figure 3 illustrates the crossover process.
4. Proposed Method
The concept of the proposed method for the discretization in this experiment is the integration of RST, k-means, and GA. An RST is used to measure the dependency coefficient, which can be used to define the approximation quality. Therefore, the transformed dataset after the discretization process will not decrease the quality of the information from the original dataset. To measure the approximation quality, the formula of RST dependency coefficient, , as shown in Equation (5), is applied.
Further, k-means is applied to cluster continuum data attributes. The result is the number of bins or clusters of the attributes. The bins are then transformed into discrete values. The GA function is used to minimize the number of bins or clusters of every attribute, which, at the same time, must meet the constraint in which the value of is equal to or any value that is targeted. Minimizing the number of bins is expected to generate the most optimum number of RST rules, which make the classification process become more efficient. The following algorithm of the proposed method is developed to find the most optimal discretization scenario of an Information System.
As shown on the pseudo-code, the algorithm of the proposed method begins with reading the training dataset to construct a table called , where is a set of objects, is a set of the attributes, is a set of values of the attributes, and is a function of the relationship between the object and the attributes. This table is then transformed into a decision table, called , where is the condition attribute set and is the decision attribute set that satisfies .
After the dataset is loaded, the process continues with the setting of the GA process, starting from the number of chromosomes, which is associated with the number of attributes, and followed by the number of genes for each chromosome, which is associated with the number of centroids or bins of the respective attribute. After the setting of the GA parameters is completed, it continues by executing the GA processes based on
Figure 2 and
Figure 3. The objective function of the GA is to minimize the number of bins for each attribute with a certain value of
as the constraint.
The end of the GA iteration contains the process to convert the chromosome values into the attribute bin values. When the maximum iteration is achieved, then the bin values of each attribute are considered optimum and then are used to discretize the condition of attribute values.
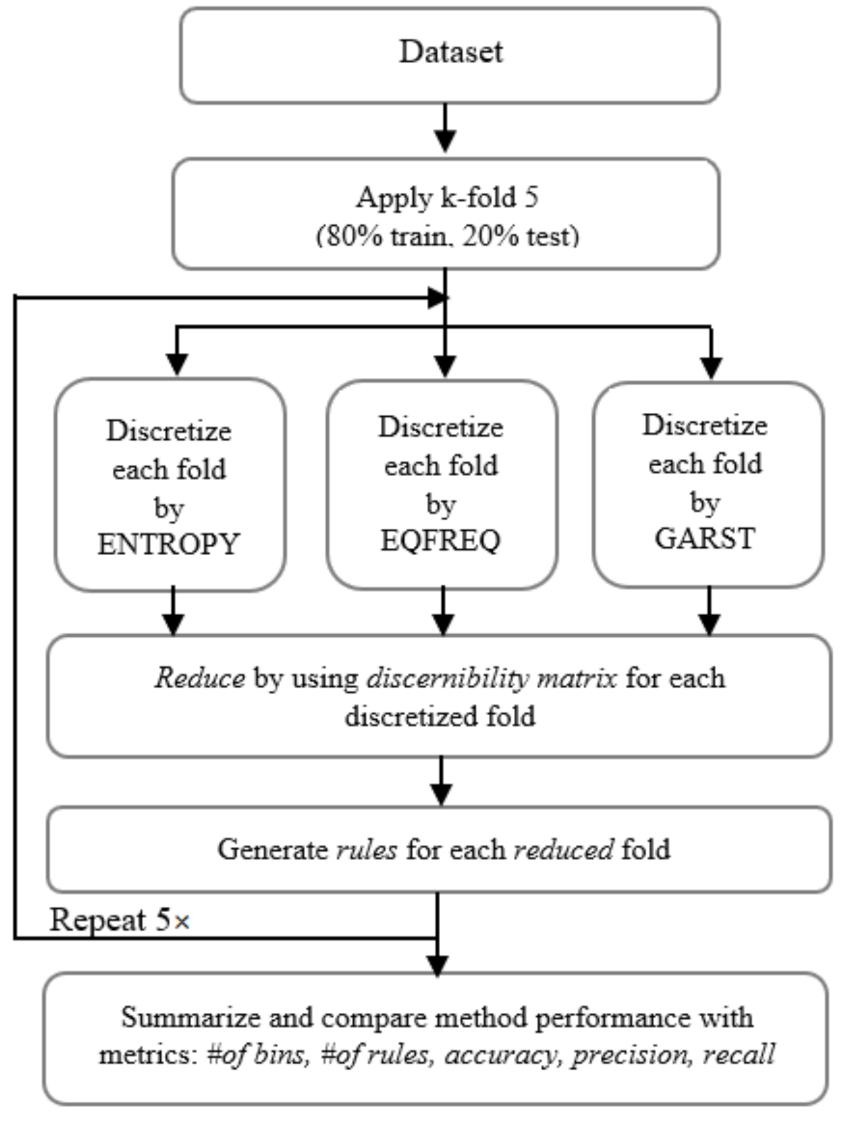
5. Experimental Setup
In this section, the test results of the proposed algorithm are compared with two popular discretization algorithms, namely equal-frequency, which is processed using unsupervised learning, and entropy-based, which uses supervised learning.
Four datasets downloaded from the UCI data repository with details of the properties owned by each dataset shown in
Table 1 are selected. Those datasets are:
- 1.
iris;
- 2.
ecoli;
- 3.
wine;
- 4.
banknote.
The proposed algorithm was tested on four datasets and compared with two discretization methods, namely
equal-frequency and
entropy-based.
Figure 4 shows the flow of the research.
In the initial step, a k-fold mechanism with is applied to each dataset so that a ratio of 80:20 is obtained, where 80% of the data are used for the training and 20% for testing. The k-fold approach is applied to ensure that every record in the dataset becomes either a training or test dataset. With the application of k-fold, it is expected that the results of testing the algorithm can be more reliable. Each fold of each dataset is then discretized using three tested methods, namely: equal-frequency (EQFREQ), entropy-based (ENTROPY), and the proposed method, which is based on genetic algorithm and rough set theory (GARST).
Discretization with the EQFREQ and ENTROPY methods was concluded on the Rosetta software ver. 1.4.41. Meanwhile, the proposed method was developed by using Python 3.8 based on Algorithm 1.
| Algorithm 1.Pseudo-code of proposed method. |
| Input: A dataset in the form of Table |
| Output: Optimum numbers of bins for each condition attribute in the form of discretized table = (U, C, D, Vc disc, f) |
| Create decision table , ; |
| Introduce integer variable or any integer value; |
| Introduce scalar and vector variables Size, max Generation, constraintGA, |
| Chromosome, Individu, Fitness, Parents, Offsprings, New Pop for the GA processes; |
| genBitintegerbineary(maxK); numChromcardinality(C); |
| popSize 30 or any integer value; |
| maxGeneration 50 or any integer value; |
| forindv 1 to popSize do |
| for chr 1 to numChrom do |
| Chromosome[chr] binary; |
| end |
| Individu[indv] [Chromosome[numChrom]]; |
| end |
| constraintGA 0.8 or any real value between 0.0 and 1.0; |
| Introduce vector variables Bins, DiscrV, |
| for |
| for indv 1 to popSize do |
| for chr 1 to numChrom do |
| Bins[chr] = KMeans(C[chr], binary |
| End |
|
| Discr_V[c] ← discretize(V[c], Bins[c]); |
| [indvc] calc(Discr) by referring to Eq. 2.5; |
| [indvc] constraintGA then |
| |
| vaule; |
| End |
| End |
| Parents to create parents; the |
| Individu have smaller Fitness value will have chance to be selected as a parent; |
| Offspringscrossover(Parents) to create Offsprings; |
| NewPopmutate(Offsprings); |
| Run transform(NewPop) to create new list of Individu in the form of |
| [Individu[1],…, Individu[popSize]]; |
| end |
| return DiscT = |
After the
5-fold datasets have been discretized, each fold is reduced and then rules generation is performed using the Rosetta software. The
reduct process is carried out using the RST method based on a discernibility matrix, and rule generation using the application of Boolean algebra to the built discernibility matrix, as described in
Section 2. This process is repeated five times for each dataset due to the application of
5-fold.
The final step of this experiment is to compare the performance of the three methods. The measuring instruments used in the experiment and their explanations are listed in
Table 2.
To ensure that there is a difference in performance between the three tested methods, the statistical Friedman test method was applied to this experiment. The Friedman test is a statistical measuring tool used to determine whether there is a statistically significant difference in the average value of three or more groups [
13]. If the
p-value of the Friedman test is less than 0.05, then there is a significant difference. The post hoc test was used as a continuation of the Friedman test to determine which group had a significant difference compared to the other groups.
6. Results and Discussion
After the entire process is completed, the last step is to review the performance of each discretization method.
Table 3 shows the performance comparison of the discretization methods of the
equal-frequency (EQFREQ),
entropy-based (ENTROPY), and genetic algorithm and rough set theory (GARST) proposed in this paper.
Compared to the performance of the EQFREQ and ENTROPY discretization methods, it is confirmed that the proposed method (GARST) has a better performance, showing the smallest number of the generated bins and rules across three datasets, namely iris, wine, and banknote. The ENTROPY method indicates a better performance for the ecoli dataset, demonstrated by the smallest number of bins; however, the GARST method is still superior because it succeeded in generating the smallest number of rules in all the datasets, including ecoli.
Table 4 shows the test results that are presented in statistical measures, namely average and standard deviation. From this table, it can be seen that the GARST method has the highest average
accuracy,
precision, and
recall, and has competitive values for standard deviation.
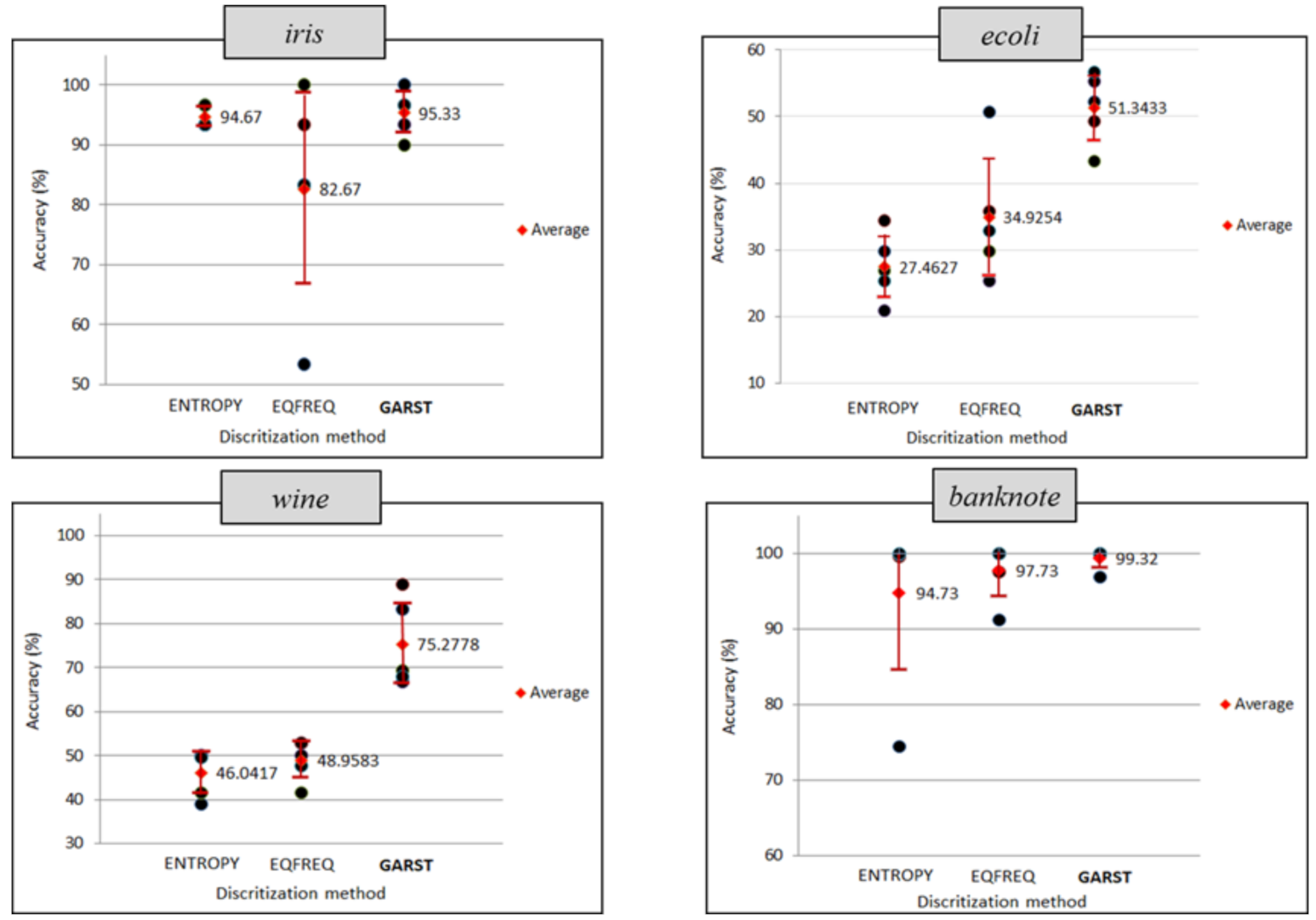
Figure 5 describes the distribution of the accuracy values for each test. From this figure, it can be seen that the GARST method produces consistent accuracy values, although it is not always superior. Thus, it can be concluded that the GARST method is generally proven to have a superior performance in terms of accuracy and reliability, as measured by precision and recall, compared to the other two methods.
According to non-parametric statistical testing, namely the Friedman test, as shown in
Table 5, the
p-value obtained is smaller than 0.05, so it can be concluded that there is a significant difference between the three methods. Meanwhile, from the post hoc test results, as shown in
Table 6, the
p-values of ENTROPY vs. GARST and EQFREQ vs. GARST are all less than 0.05, so it can be concluded that the GARST method is a method that has a significant difference compared to the other two methods.
7. Conclusions
A method to improve the accuracy and reliability of the RST-based classifier model has been proposed by involving the RST instruments at the beginning of the discretization process. This method uses a k-means-based discretization method optimized with a genetic algorithm (GA). As a result, the method was proven not to sacrifice the degree of information quality from the dataset and the performance was quite competitive compared to the popular state-of-the-art methods, namely equal-frequency and entropy-based. Moreover, the proposed discretization method based on k-means optimized by GA and using one of the rough set theory instruments has proven to be effective for use in the RST classifier.
The test of the discretization method proposed in this study uses four datasets that have different profiles in the 5-fold scenario, and the results were tested by using Friedman and post hoc tests; therefore, it can be concluded that the proposed method should be effective for discretization purposes to any dataset, especially for the RST-based classification cases. The disadvantage of this proposed method is an unstable speed during discrete processes, especially in the optimization of the number of bins. This is due to the application of a heuristic approach by GA.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}