
Adapting the H.264 Standard to the Internet of Vehicles


Abstract
:1. Introduction
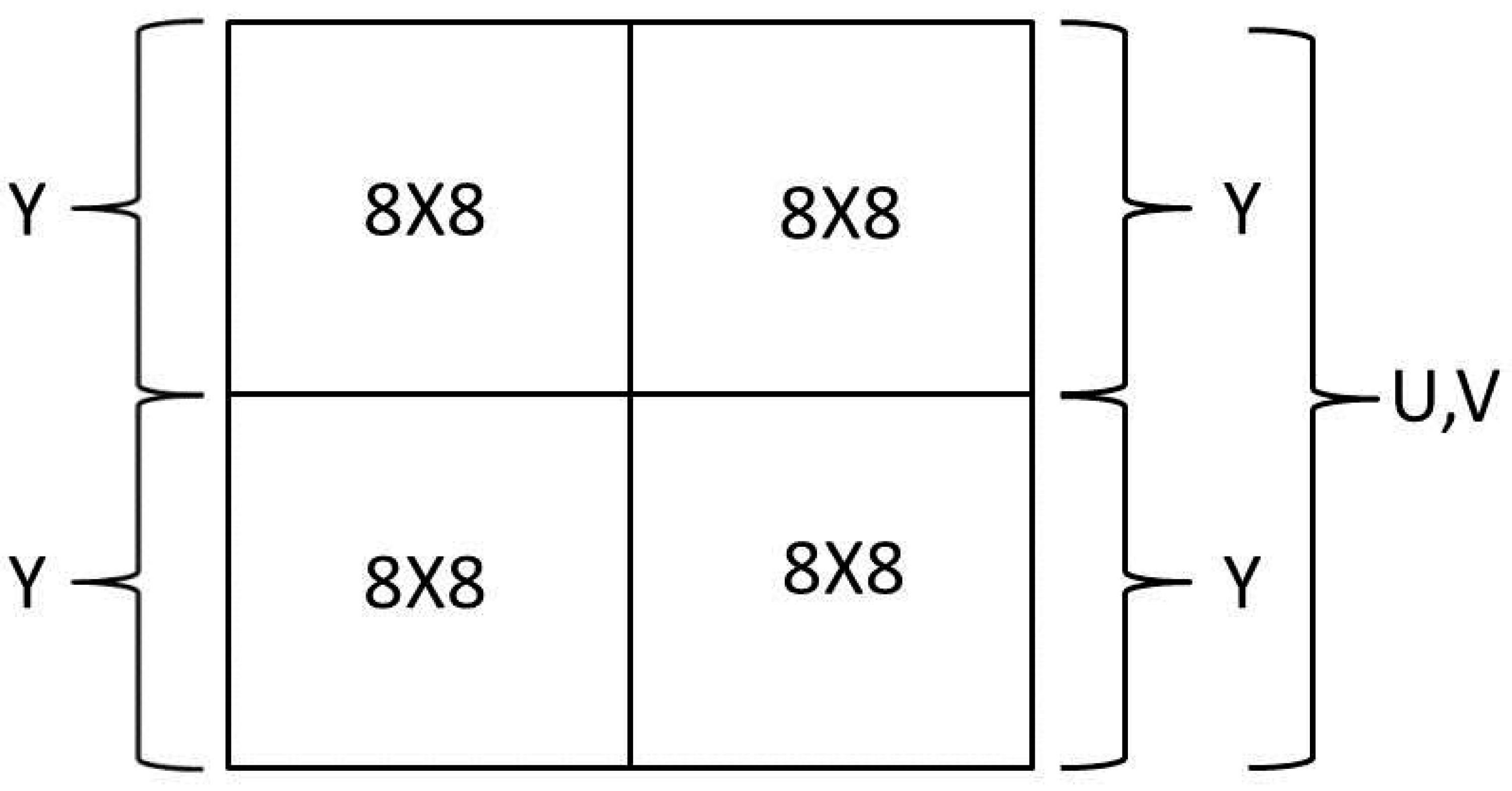
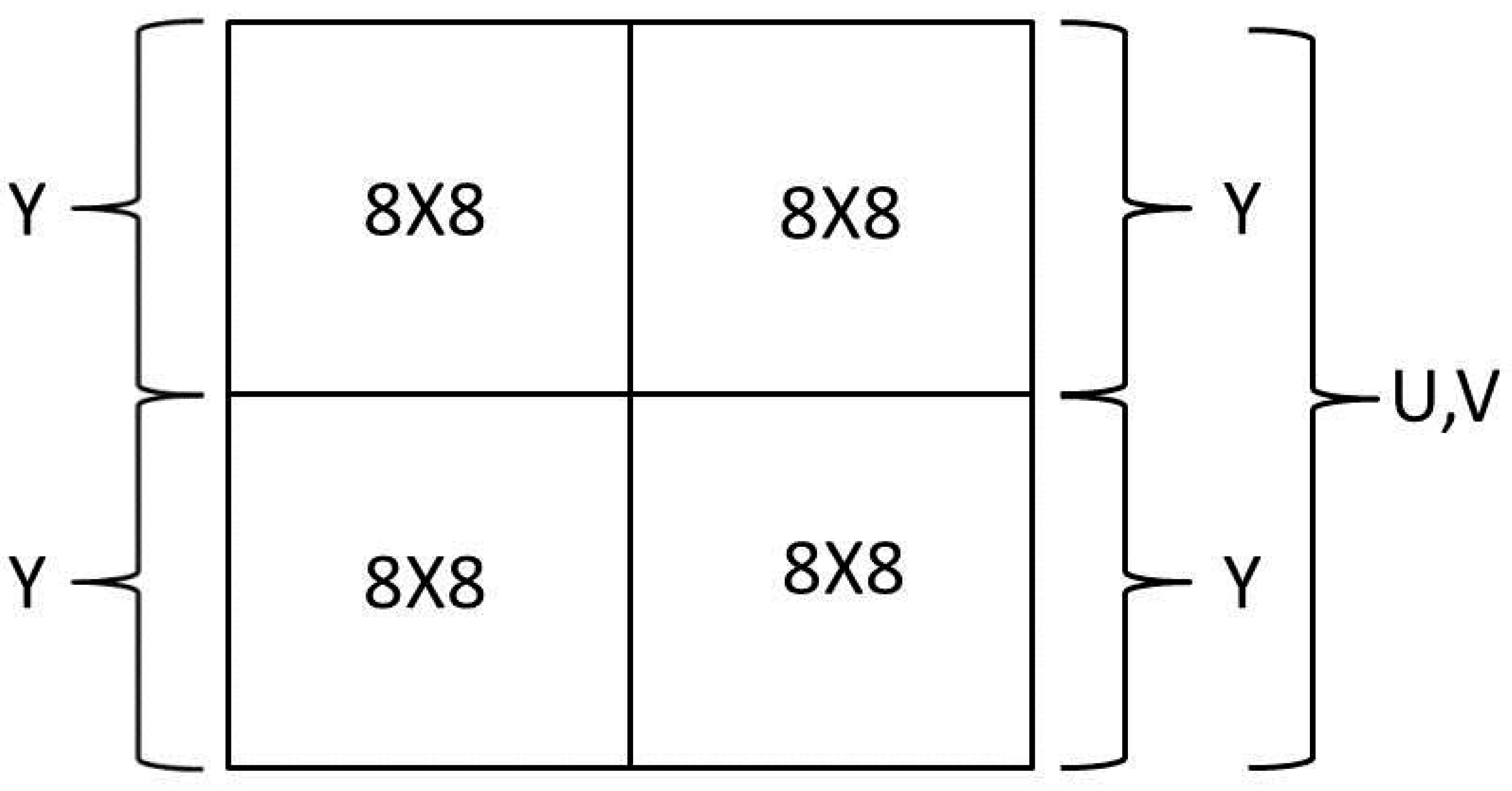
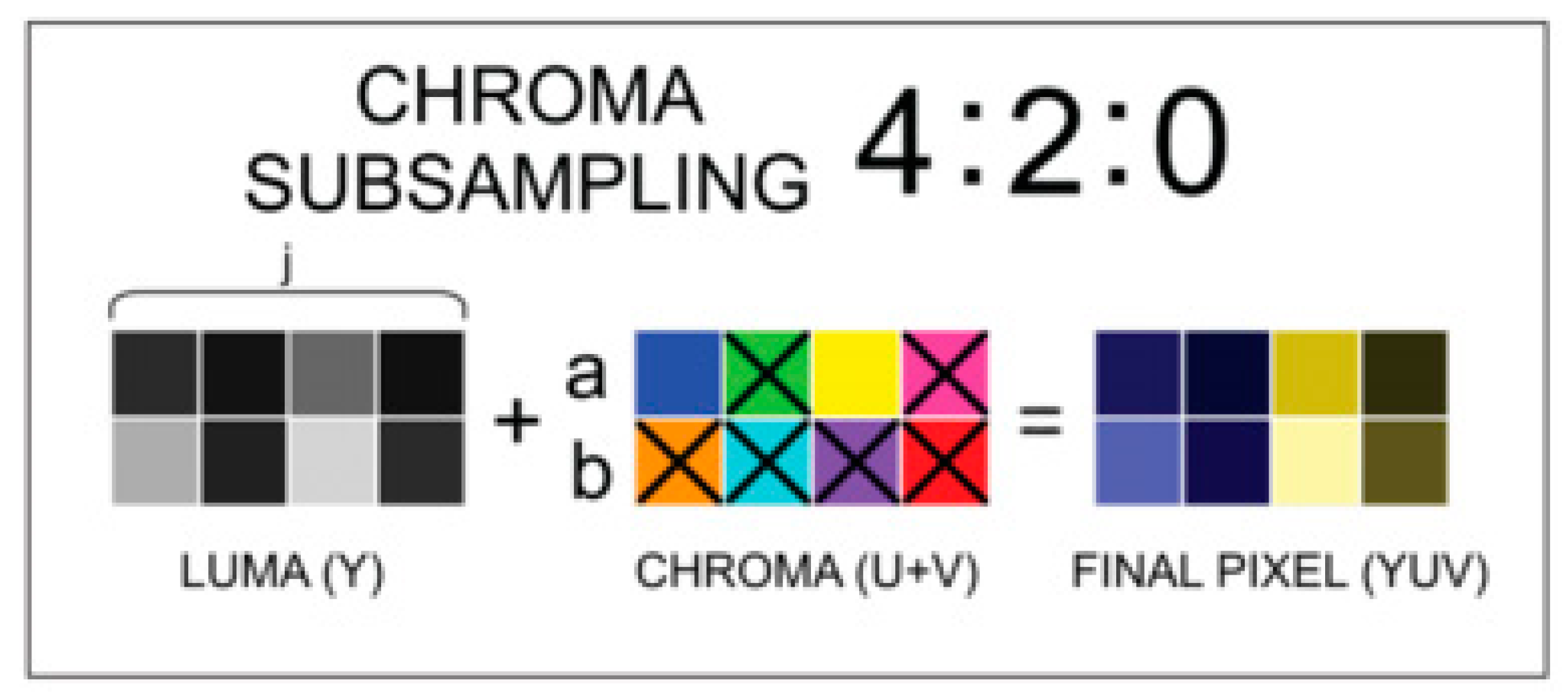
2. Background
- I-frames (intracoded frames)—standalone frames containing all the data required to show the frame. Actually, this frame is very similar to a JPEG still image [17].
- P-frames (predictive frames)—predicted from another decoded frame.
- B-frames (bidirectional predicted frames)—predicted from both a previously decoded frame and a yet-to-come decoded frame.
- Transform each block to a frequency space employing the forward discrete cosine transform (FDCT) [18].
- Employ quantization; i.e., each value is divided by a predefined quantization coefficient and next rounded to an integer value [19].
- Compress the file employing a version of canonical Huffman codes [20].
3. Motivation
4. Reduced Image Quality
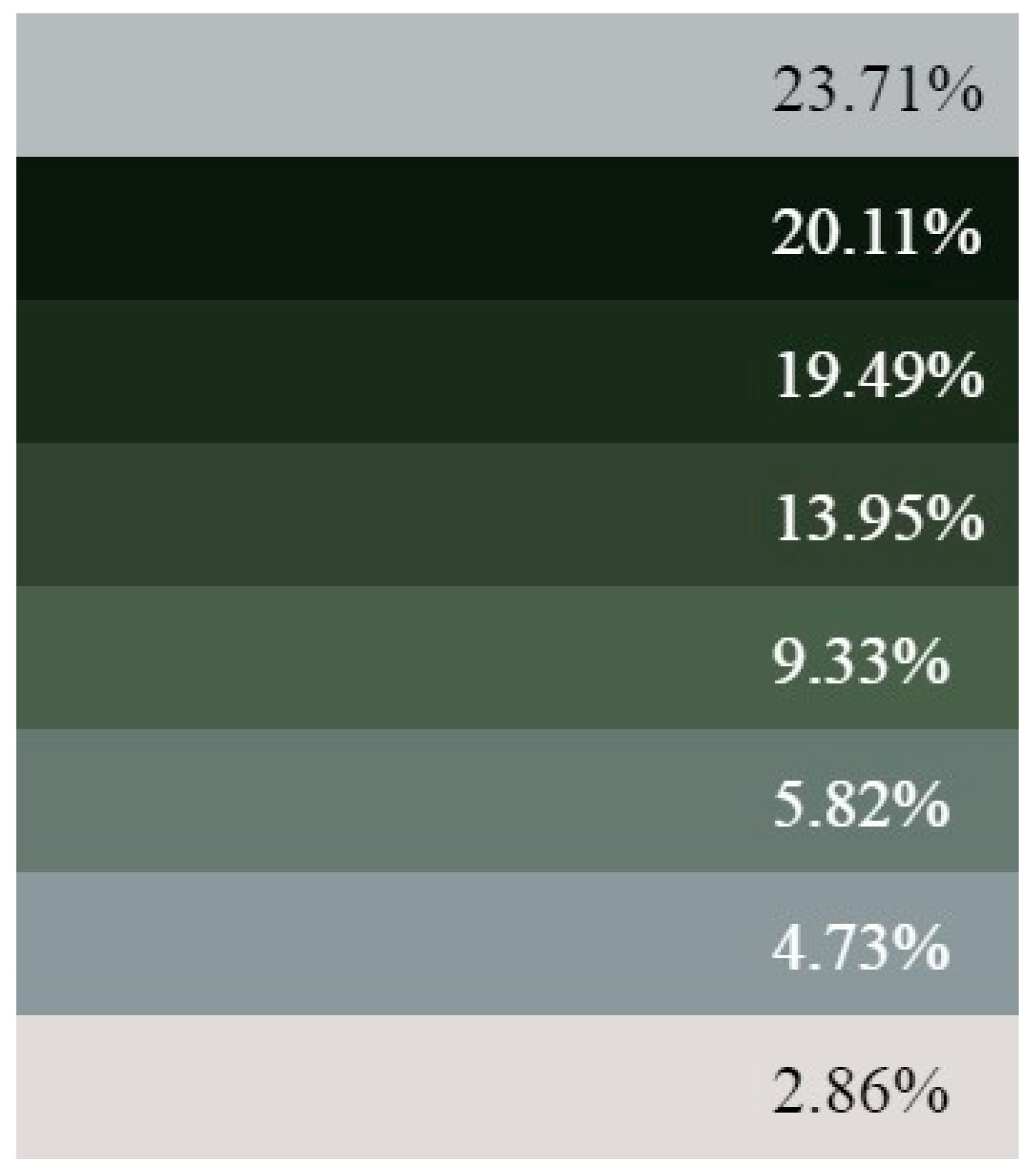
| Algorithm 1 Selecting the 8 most frequent colors |
| Sort the colors by their count values. Take the top 8 colors. Calculate the variance of each pair of colors using Equation (1): Begin Find from the pair (x1,x2) the color with the smaller occurrences and remove it from the top 8 colors Add from the sorted list the next top color. Calculate the variances of the new color with the old colors End |
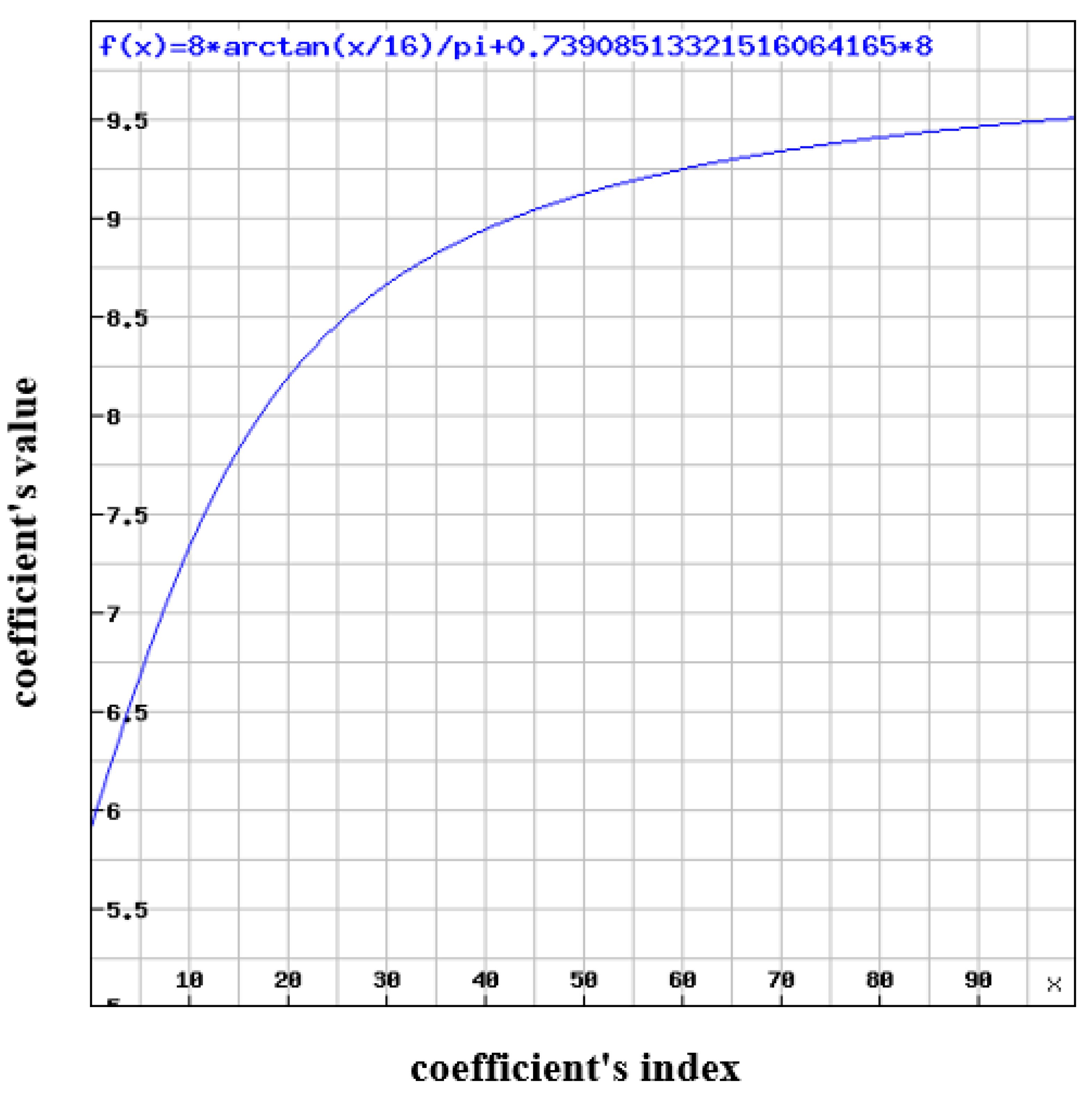
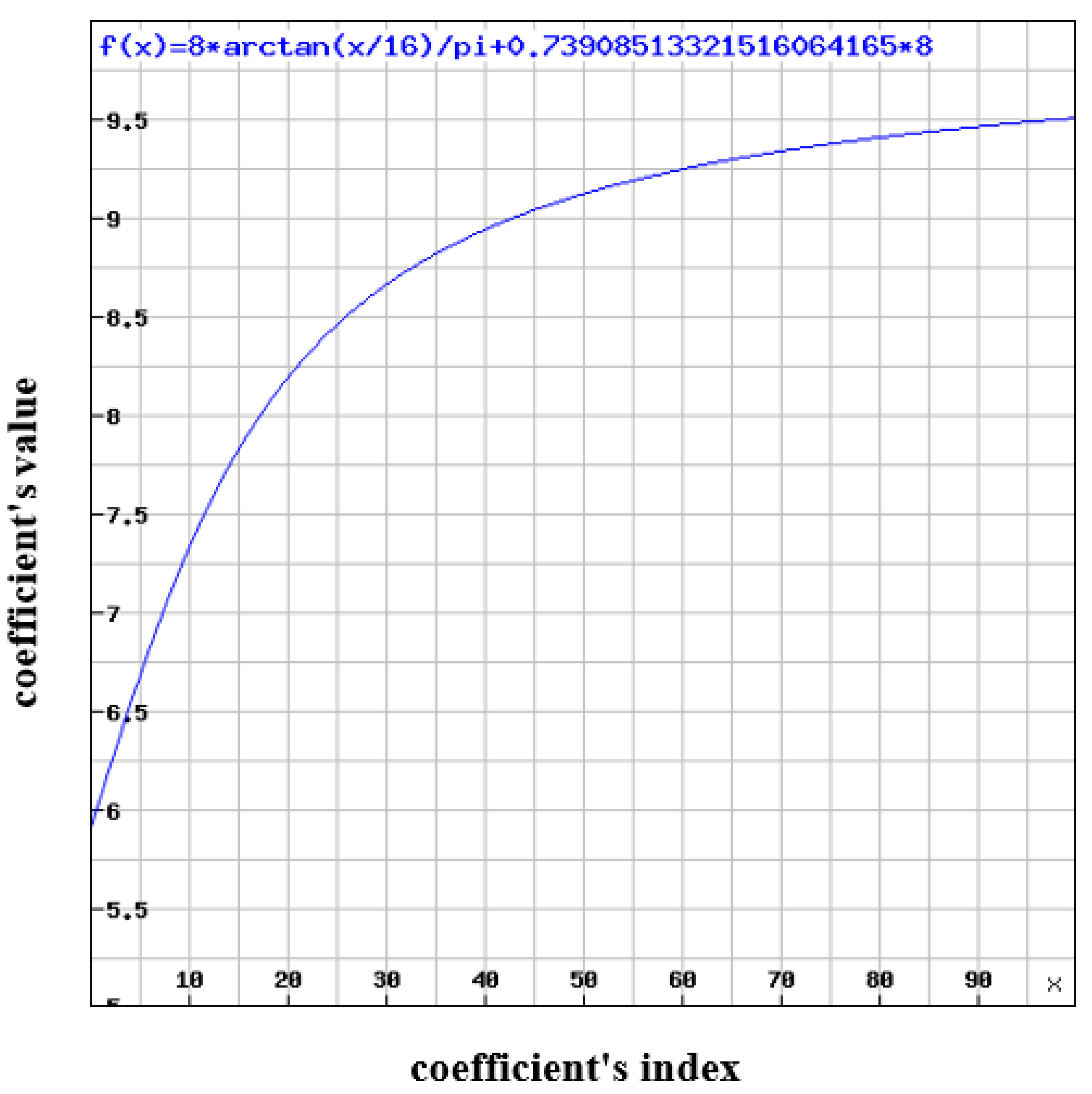
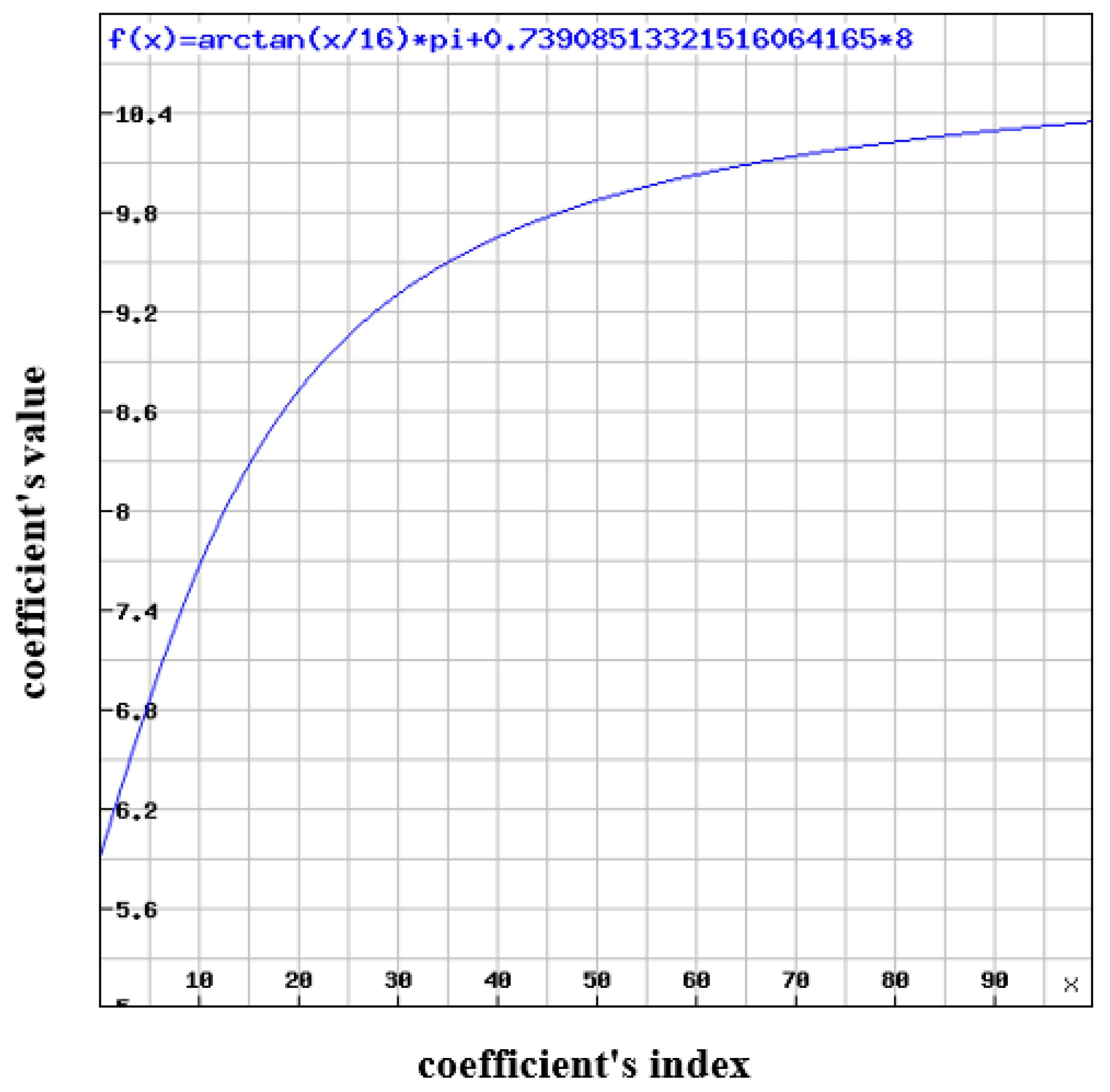
5. H.264 Quantization Tables
6. Results
7. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Punchihewa, A.; Bailey, D. A Review of Emerging Video Codecs: Challenges and Opportunities. In Proceedings of the 2020 35th IEEE International Conference on Image and Vision Computing New Zealand (IVCNZ), Wellington, New Zealand, 25–27 November 2020; pp. 1–6. [Google Scholar]
- Lu, Y.; Li, S. A review on developing status of stereo video technology. In Proceedings of the 2012 IEEE International Conference on Computer Science and Information Processing (CSIP), Xi’an, China, 24–26 August 2012; pp. 715–718. [Google Scholar]
- Bahri, N.; Werda, I.; Grandpierre, T.; Ayed MA, B.; Masmoudi, N.; Akil, M. Optimizations for real-time implementation of H.264/AVC video encoder on DSP processor. Int. Rev. Comput. Softw. (IRECOS) 2013, 8, 2025–2035. [Google Scholar]
- Kang, K.D. A Review of Efficient Real-Time Decision Making in the Internet of Things. Technologies 2022, 10, 12. [Google Scholar] [CrossRef]
- Wiseman, Y. Autonomous vehicles. In Research Anthology on Cross-Disciplinary Designs and Applications of Automation; IGI Global: Hershey, PA, USA, 2022; pp. 878–889. [Google Scholar]
- Liu, X.; Li, Y.; Dai, C.; Li, P.; Yang, L.T. An efficient H. 264/AVC to HEVC transcoder for real-time video communication in Internet of Vehicles. IEEE Internet Things J. 2018, 5, 3186–3197. [Google Scholar] [CrossRef]
- Budati, A.K.; Islam, S.; Hasan, M.K.; Safie, N.; Bahar, N.; Ghazal, T.M. Optimized Visual Internet of Things for Video Streaming Enhancement in 5G Sensor Network Devices. Sensors 2023, 23, 5072. [Google Scholar] [CrossRef] [PubMed]
- Zhou, J.; Zhou, D.; Zhang, H.; Hong, Y.; Liu, P.; Goto, S. A 136 cycles/MB, luma-chroma parallelized H. 264/AVC deblocking filter for QFHD applications. In Proceedings of the 2009 IEEE International Conference on Multimedia and Expo, New York, NY, USA, 28 June–July 2009; pp. 1134–1137. [Google Scholar]
- Sharrab, Y.O.; Sarhan, N.J. Detailed comparative analysis of vp8 and h. 264. In Proceedings of the 2012 IEEE International Symposium on Multimedia, Irvine, CA, USA, 10–12 December 2012; pp. 133–140. [Google Scholar]
- Ho, Y.H.; Lin, C.H.; Chen, P.Y.; Chen, M.J.; Chang, C.P.; Peng, W.H.; Hang, H.M. Learned video compression for yuv 4:2:0 content using flow-based conditional inter-frame coding. In Proceedings of the 2022 IEEE International Symposium on Circuits and Systems (ISCAS), Austin TX, USA, 28 May–1 June 2022; pp. 829–833. [Google Scholar]
- Gunjal, B.L.; Mali, S.N. Comparative performance analysis of DWT-SVD based color image watermarking technique in YUV, RGB and YIQ color spaces. Int. J. Comput. Theory Eng. 2011, 3, 714. [Google Scholar] [CrossRef] [Green Version]
- Sinha, A.K.; Mishra, D. Deep Video Compression using Compressed P-Frame Resampling. In Proceedings of the 2021 National Conference on Communications (NCC), Virtual Conference, 7–30 July 2021; pp. 1–6. [Google Scholar]
- KVMGalore. 2023. Available online: http://kb.kvmgalore.com/lookup/ (accessed on 9 May 2023).
- Hsia, S.C.; Chou, Y.C. VLSI implementation of high-throughput parallel H. 264/AVC baseline intra-predictor. IET Circuits Devices Syst. 2014, 8, 10–18. [Google Scholar] [CrossRef]
- Dumic, E.; Mustra, M.; Grgic, S.; Gvozden, G. Image quality of 4:2:2 and 4:2:0 chroma subsampling formats. In Proceedings of the 2009 IEEE international symposium ELMAR, Zadar, Croatia, 28–30 September 2009; pp. 19–24. [Google Scholar]
- Shahid, Z.; Chaumont, M.; Puech, W. Fast protection of H. 264/AVC by selective encryption of CAVLC and CABAC for I and P frames. IEEE Trans. Circuits Syst. Video Technol. 2011, 21, 565–576. [Google Scholar]
- Park, J.H.; Lee, S.H.; Lim, K.S.; Kim, J.H.; Kim, S. A flexible transform processor architecture for multi-CODECs (JPEG, MPEG-2, 4 and H. 264). In Proceedings of the 2006 IEEE International Symposium on Circuits and Systems (ISCAS), Kos, Greece, 21–24 May 2006. [Google Scholar]
- Okade, M.; Mukherjee, J. Discrete Cosine Transform: A Revolutionary Transform That Transformed Human Lives [CAS 101]. IEEE Circuits Syst. Mag. 2022, 22, 58–61. [Google Scholar]
- Malvar, H.S.; Hallapuro, A.; Karczewicz, M.; Kerofsky, L. Low-complexity transform and quantization in H. 264/AVC. IEEE Trans. Circuits Syst. Video Technol. 2003, 13, 598–603. [Google Scholar]
- Klein, S.T.; Wiseman, Y. Parallel Huffman decoding with applications to JPEG files. Comput. J. 2003, 46, 487–497. [Google Scholar] [CrossRef] [Green Version]
- Vetro, A.; Wiegand, T.; Sullivan, G.J. Overview of the stereo and multiview video coding extensions of the H. 264/MPEG-4 AVC standard. Proc. IEEE 2011, 99, 626–642. [Google Scholar] [CrossRef] [Green Version]
- Abou-Zeid, H.; Pervez, F.; Adinoyi, A.; Aljlayl, M.; Yanikomeroglu, H. Cellular V2X transmission for connected and autonomous vehicles standardization, applications, and enabling technologies. IEEE Consum. Electron. Mag. 2019, 8, 91–98. [Google Scholar]
- Ravi, A.; Rao, K.R. Performance analysis comparison of the Dirac video codec with H 264/MPEG-4 Part 10 AVC. Int. J. Wavelets Multiresolut. Inf. Process. 2011, 9, 635–654. [Google Scholar] [CrossRef] [Green Version]
- Jiang, X.; Yu, F.R.; Song, T.; Leung, V.C. Resource allocation of video streaming over vehicular networks: A survey, some research issues and challenges. IEEE Trans. Intell. Transp. Syst. 2021, 23, 5955–5975. [Google Scholar] [CrossRef]
- Amor, M.B.; Kammoun, F.; Masmodi, N. A pretreatment using saliency map Harris to improve MSU blocking metric performance for encoding H. 264/AVC: Saliency map for video quality assessment. In Proceedings of the 2016 IEEE International Image Processing, Applications and Systems (IPAS), Hammamet, Tunisia, 5–7 November 2016; pp. 1–4. [Google Scholar]
- Briggs, K. A precise calculation of the Feigenbaum constants. Math. Comput. 1991, 57, 435–439. [Google Scholar]
- Soyak, E.; Tsaftaris, S.A.; Katsaggelos, A.K. Quantization optimized H. 264 encoding for traffic video tracking applications. In Proceedings of the 2010 IEEE International Conference on Image Processing, Hong Kong, 26–29 September 2010; pp. 1241–1244. [Google Scholar]
- Wiseman, Y. JPEG Quantization Tables for GPS Maps. Autom. Control. Comput. Sci. 2021, 55, 568–576. [Google Scholar] [CrossRef]
- Rechneronline. Draw Function Graphs. 2023. Available online: https://rechneronline.de/function-graphs/ (accessed on 9 May 2023).
- Yaqoob, I.; Khan, L.U.; Kazmi, S.A.; Imran, M.; Guizani, N.; Hong, C.S. Autonomous driving cars in smart cities: Recent advances, requirements, and challenges. IEEE Netw. 2019, 34, 174–181. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 3 | 2 | 2 | 3 | 5 | 8 | 10 | 12 |
| 2 | 2 | 3 | 4 | 5 | 12 | 12 | 11 |
| 3 | 3 | 3 | 5 | 8 | 11 | 14 | 11 |
| 3 | 3 | 4 | 6 | 10 | 17 | 16 | 12 |
| 4 | 4 | 7 | 11 | 14 | 22 | 21 | 15 |
| 5 | 7 | 11 | 13 | 16 | 21 | 23 | 18 |
| 10 | 13 | 16 | 17 | 21 | 24 | 24 | 20 |
| 14 | 18 | 19 | 20 | 22 | 20 | 21 | 20 |
| 3 | 4 | 5 | 9 | 20 | 20 | 20 | 20 |
| 4 | 4 | 5 | 13 | 20 | 20 | 20 | 20 |
| 5 | 5 | 11 | 20 | 20 | 20 | 20 | 20 |
| 9 | 13 | 20 | 20 | 20 | 20 | 20 | 20 |
| 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 |
| 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 |
| 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 |
| 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 |
| 6 | 6 | 6 | 6 | 8 | 8 | 9 | 9 |
| 6 | 6 | 6 | 6 | 8 | 8 | 9 | 9 |
| 6 | 6 | 6 | 6 | 8 | 8 | 9 | 9 |
| 6 | 6 | 6 | 8 | 8 | 9 | 9 | 9 |
| 8 | 8 | 8 | 8 | 9 | 9 | 9 | 9 |
| 8 | 8 | 8 | 9 | 9 | 9 | 9 | 9 |
| 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 |
| 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 |
| 6 | 6 | 6 | 6 | 8 | 8 | 9 | 10 |
| 6 | 6 | 6 | 6 | 8 | 8 | 9 | 10 |
| 6 | 6 | 6 | 6 | 8 | 8 | 9 | 10 |
| 6 | 6 | 6 | 8 | 8 | 9 | 9 | 10 |
| 8 | 8 | 8 | 8 | 9 | 9 | 10 | 10 |
| 8 | 8 | 8 | 9 | 9 | 10 | 10 | 10 |
| 9 | 9 | 9 | 9 | 10 | 10 | 10 | 10 |
| 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 |
| Image | Reduction after the First Step | Reduction after the Second Step |
|---|---|---|
| Road | 31.936% | 46.510% |
| Parking lot | 35.154% | 42.533% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wiseman, Y. Adapting the H.264 Standard to the Internet of Vehicles. Technologies 2023, 11, 103. https://doi.org/10.3390/technologies11040103
Wiseman Y. Adapting the H.264 Standard to the Internet of Vehicles. Technologies. 2023; 11(4):103. https://doi.org/10.3390/technologies11040103
Chicago/Turabian StyleWiseman, Yair. 2023. "Adapting the H.264 Standard to the Internet of Vehicles" Technologies 11, no. 4: 103. https://doi.org/10.3390/technologies11040103
APA StyleWiseman, Y. (2023). Adapting the H.264 Standard to the Internet of Vehicles. Technologies, 11(4), 103. https://doi.org/10.3390/technologies11040103