
Deep Object Occlusion Relationship Detection Based on Associative Embedding Clustering


Abstract
1. Introduction
- Reframes occlusion relationship detection by introducing a triplet representation to characterize spatial occlusion relationships between objects.
- Proposes DOORD-AECNet, a novel dual-branch network architecture for detecting occlusion relationships, with separate branches for occlusion detection and target detection.
- Introduces an innovative associative embedding clustering approach to effectively match occlusion, foreground targets, and background targets as triplets.
- Develops a novel “pull” and “push” loss mechanism to cluster related elements and separate unrelated ones using embedding vectors.
- Creates a new large-scale occlusion location dataset based on KITTI images [30], providing valuable resources for occlusion research.
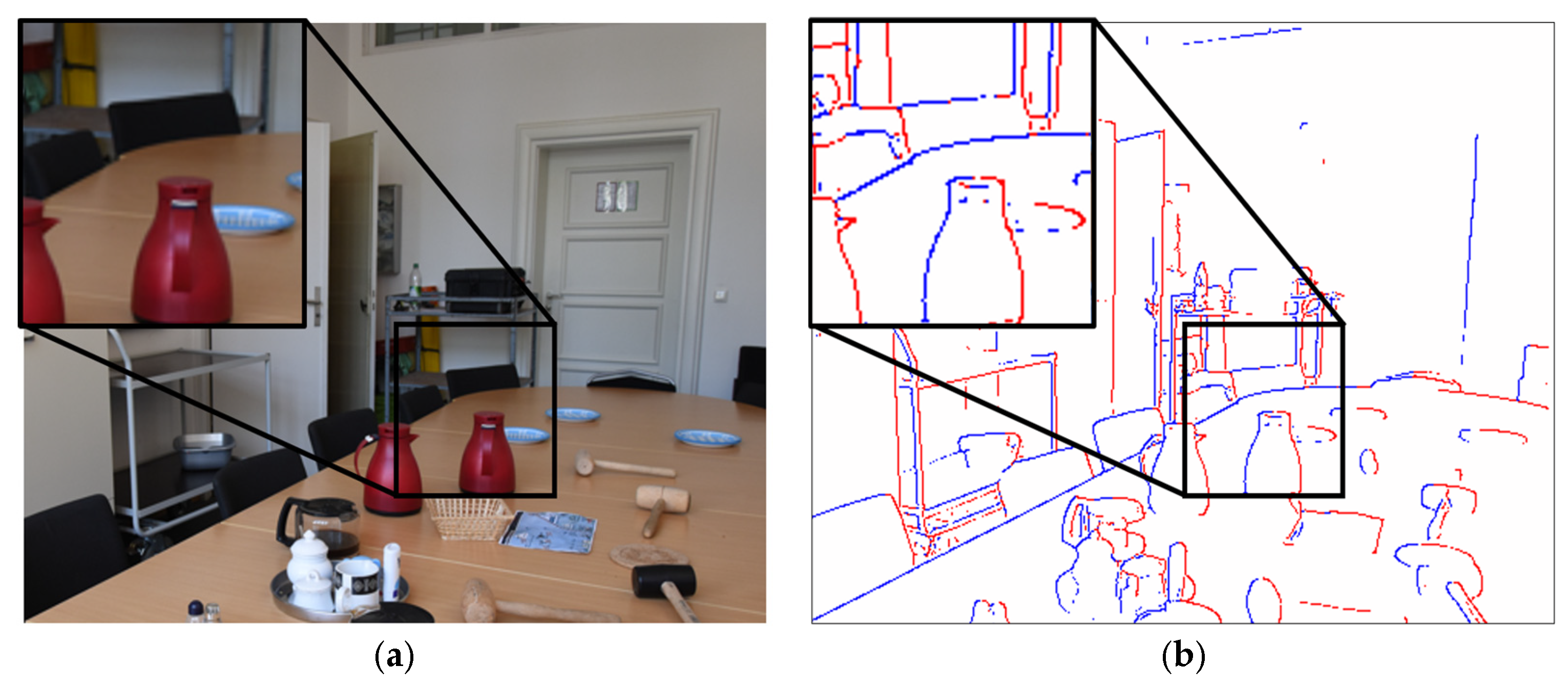
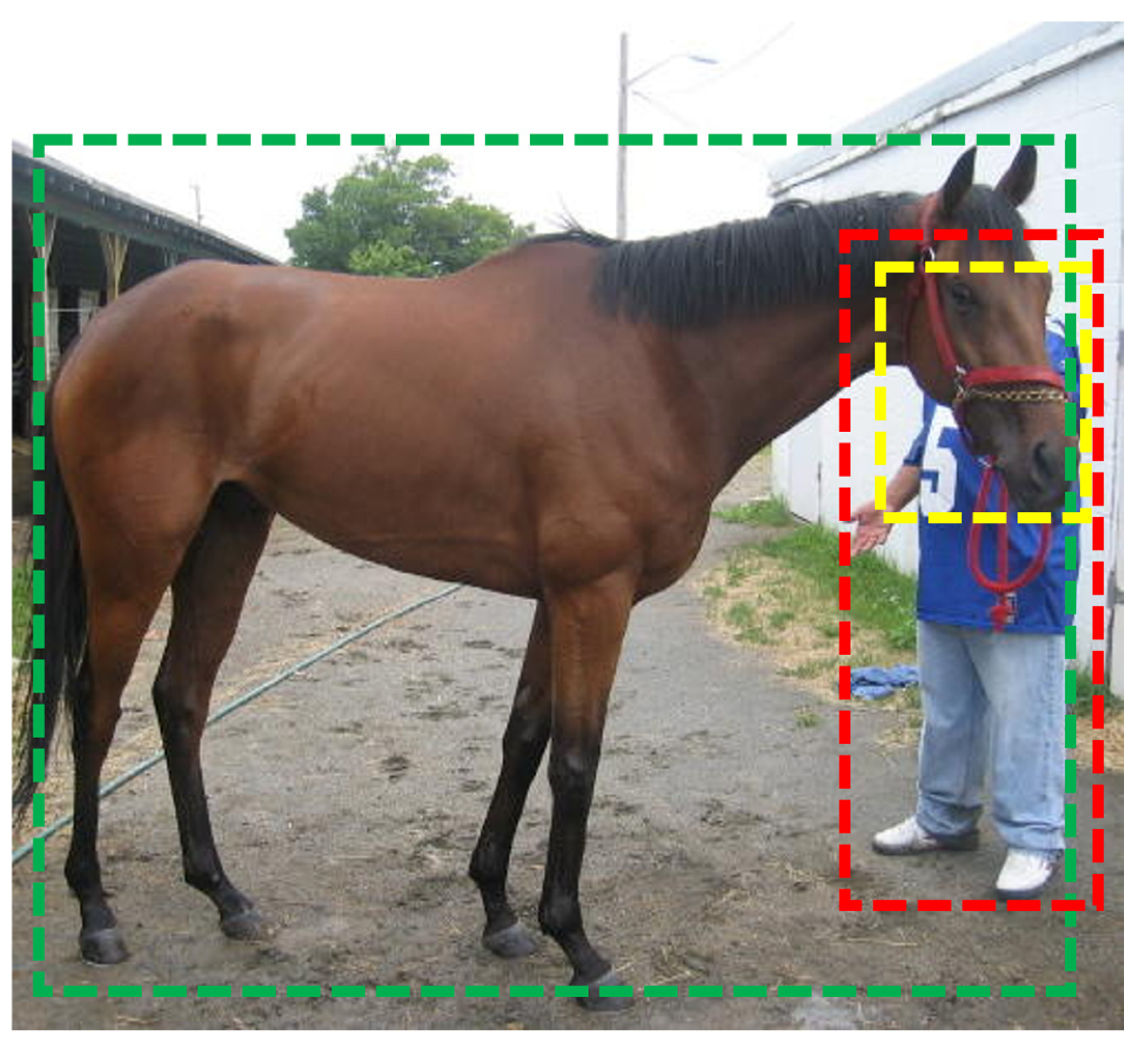
2. Occlusion Relationship Between Objects in an Image
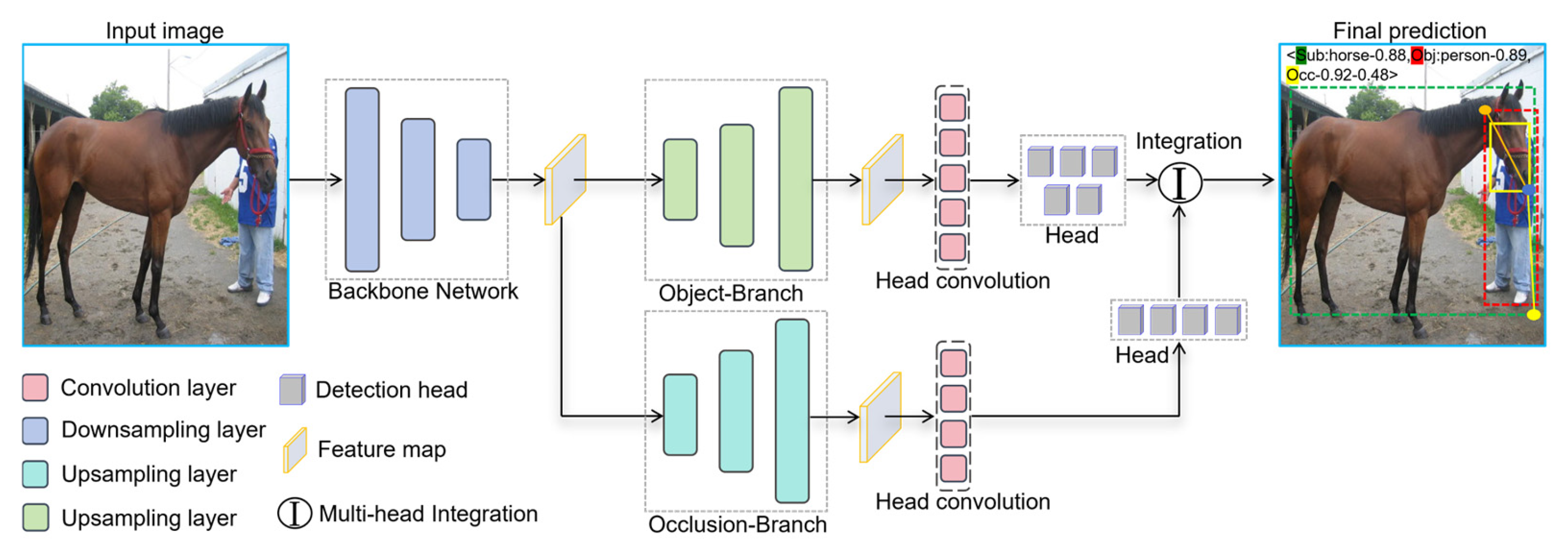
3. Deep Object Occlusion Relationship Detection Framework Design
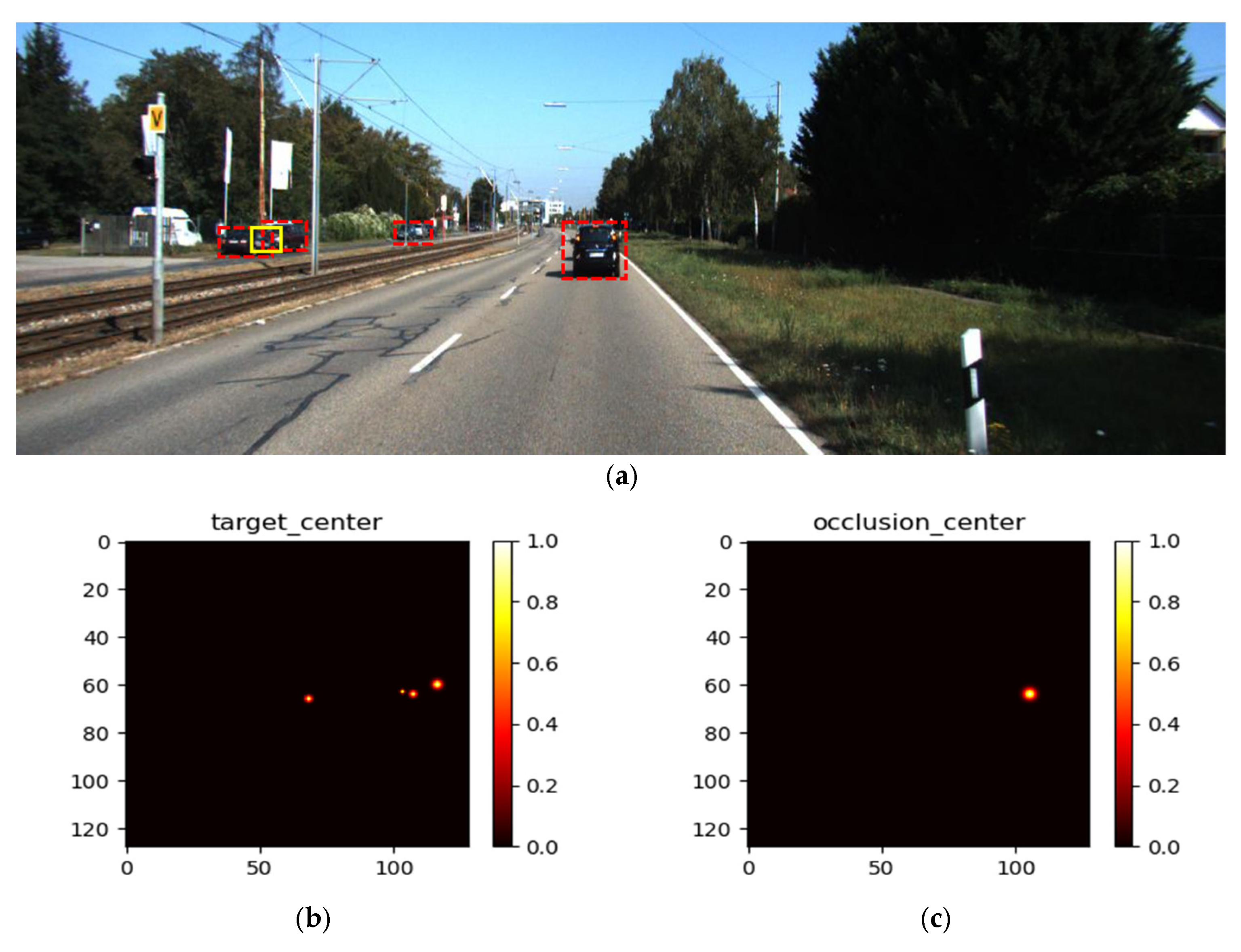
3.1. Detecting Occlusion Relationship Elements
3.2. Grouping Occlusion Relationship Elements with Associative Embedding Clustering
3.3. Multi-Head Integration
| Algorithm 1 DOORD-AEC inference algorithm |
| Input: Image I |
| Output: Triplet set of occlusion relationship |
| 1: Image I pass through DOORD-AECNet |
| 2: Position all elements (occlusion, subject and object) |
| 3: Get set So, Sp and Sb from detected elements |
| 4: for i = 1, 2, …, w do |
| 5: Get eocci from So |
| 6: for j = 1, 2, …, m do |
| 7: Get Sij= (eocci − eforj)2 and Oij = (eocci − ebacj)2 |
| 8: end for |
| 9: Get the set of distance Ds = {Si0, Si1, …, Sim} with subject, get the set of distance Do = {Oi0, Oi1, …,Oim} |
| 10: Get subject and object through the index Index(Min(Ds)) and Index(Min(Do)) |
| 11: Get a triplet of occlusion relationship |
| 12: Get triplet set of all the occlusion relationship |
| 13: end for |
3.4. Architecture of DOORD-AECNet
4. Experiments and Analysis
4.1. Dataset and Experimental Setup
4.2. Model Training
4.3. Metric and Results
4.4. Network Architecture Design Experiments
4.5. Comparison with State-of-the-Art Methods
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hasan, M.A.; Haque, F.; Sabuj, S.R.; Sarker, H.; Goni, M.O.F.; Rahman, F.; Rashid, M.M. An End-to-End Lightweight Multi-Scale CNN for the Classification of Lung and Colon Cancer with XAI Integration. Technologies 2024, 12, 56. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2012, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Visin, F.; Kastner, K.; Cho, K.; Matteucci, M.; Courville, A.; Bengio, Y. ReNet: A Recurrent Neural Network Based Alternative to Convolutional Networks. Comput. Sci. 2015, 25, 2983–2996. [Google Scholar]
- Tan, M.; Le, Q. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. Int. Conf. Mach. Learn. 2019, 97, 6105–6114. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Farhadi, A.; Redmon, J. YOLOv3: An Incremental Improvement. Comput. Vis. Pattern Recognit. 2018, 1804, 1–6. [Google Scholar]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. Int. J. Comput. Vis. 2020, 128, 642–656. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Girshick, J.H.; Tal, E.B.; Zou, D.C. Microsoft COCO: Common objects in context. In Computer vision–ECCV 2014: 13th European conference, zurich, Switzerland, September 6–12, 2014, Proceedings, Part v 13; Springer International Publishing: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Dutta, M.; Sujan, M.R.I.; Mojumdar, M.U.; Chakraborty, N.R.; Marouf, A.A.; Rokne, J.G.; Alhajj, R. Rice Leaf Disease Classification—A Comparative Approach Using Convolutional Neural Network (CNN), Cascading Autoencoder with Attention Residual U-Net (CAAR-U-Net), and MobileNet-V2 Architectures. Technologies 2024, 12, 214. [Google Scholar] [CrossRef]
- Zhang, H.; Kyaw, Z.; Chang, S.-F.; Chua, T.-S. Visual Translation Embedding Network for Visual Relation Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3107–3115. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as Points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Ntousis, O.; Makris, E.; Tsanakas, P.; Pavlatos, C. A Dual-Stage Processing Architecture for Unmanned Aerial Vehicle Object Detection and Tracking Using Lightweight Onboard and Ground Server Computations. Technologies 2025, 13, 35. [Google Scholar] [CrossRef]
- Wang, P.; Yuille, A. DOC: Deep Occlusion Estimation from a Single Image. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part I 14; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 545–561. [Google Scholar]
- Wang, G.; Wang, X.; Li, F.W.B.; Liang, X. DOOBNet: Deep Object Occlusion Boundary Detection from an Image. In Computer Vision–ACCV 2018: 14th Asian Conference on Computer Vision, Perth, Australia, December 2–6, 2018, Revised Selected Papers, Part VI 14; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 686–702. [Google Scholar]
- Lu, R.; Xue, F.; Zhou, M.; Ming, A.; Zhou, Y. Occlusion-Shared and Feature-Separated Network for Occlusion Relationship Reasoning. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 10342–10351. [Google Scholar]
- Feng, P.; She, Q.; Zhu, L.; Li, J.; Zhang, L.; Feng, Z.; Wang, C.; Li, C.; Kang, X.; Ming, A. MT-ORL: Multi-Task Occlusion Relationship Learning. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 9344–9353. [Google Scholar]
- Li, J.; Chen, T.; Ji, K.; Li, Q. OADB-Net: An Occlusion-Aware Dual-Branch Network for Pedestrian Detection. IEEE Trans. Intell. Transp. Syst. 2025, 26, 1617–1630. [Google Scholar]
- Li, Z.; Zheng, B.; Chao, D.; Zhu, W.; Li, H.; Duan, J.; Zhang, X.; Zhang, Z.; Fu, W.; Zhang, Y. Underwater-YOLO: Underwater Object Detection Network with Dilated Deformable Convolutions and Dual-Branch Occlusion Attention Mechanism. J. Mar. Sci. Eng. 2024, 12, 2291. [Google Scholar] [CrossRef]
- Luo, J.; Liu, Y.; Wang, H.; Ding, M.; Lan, X. Grasp Manipulation Relationship Detection based on Graph Sample and Aggregation. In Proceedings of the 2024 IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, 13–17 May 2024; pp. 4098–4104. [Google Scholar]
- Zhang, Y.; Liang, Y.; Wang, J.; Zhu, H.; Wang, Z. Enhanced Multi-Object Tracking via Embedded Graph Matching and Differentiable Sinkhorn Assignment: Addressing Challenges in Occlusion and Varying Object Appearances. Vis. Comput. 2025, 1–9. [Google Scholar] [CrossRef]
- Liu, C.; Li, H.; Wang, Z.; Xu, R. Reconciling Global and Local Optimal Label Assignments for Heavily Occluded Pedestrian Detection. Multimed. Syst. 2024, 30, 100. [Google Scholar] [CrossRef]
- Zhai, Y.; Chen, N.; Guo, C.; Wang, Q.; Wang, Y. Graph Convolution Detection Method of Transmission Line Fitting Based on Orientation Reasoning. Signal Image Video Process. 2024, 18, 3603–3614. [Google Scholar]
- Sun, H.; Li, Y.; Yang, G.; Su, Z.; Luo, K. View Adaptive Multi-Object Tracking Method Based on Depth Relationship Cues. Complex Intell. Syst. 2025, 11, 145. [Google Scholar]
- Qiu, X.; Xao, Y.; Wang, C.; Marlet, R. Pixel-Pair Occlusion Relationship Map (P2ORM): Formulation, Inference and Application. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part IV 16; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 690–708. [Google Scholar]
- Liu, Z.; Wu, Z.; Tóth, R. SMOKE: Single-Stage Monocular 3D Object Detection via Keypoint Estimation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 4289–4298. [Google Scholar]
- He, A.; Wang, X. Research on Object Detection Algorithm Based on Anchor-free. In Proceedings of the 2023 International Conference on Advances in Electrical Engineering and Computer Applications (AEECA), Dalian, China, 18–19 August 2023; pp. 712–717. [Google Scholar]
- Zhou, X.; Zhuo, J.; Krähenbühl, P. Bottom-Up Object Detection by Grouping Extreme and Center Points. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 850–859. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Keypoint Triplets for Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6568–6577. [Google Scholar]
- Cao, Z.; Hidalgo, G.; Simon, T.; Wei, S.-E.; Sheikh, Y. OpenPose: Realtime Multi-Person 2D Pose Estimation Using Part Affinity Fields. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 172–186. [Google Scholar]
- Newell, A.; Deng, J. Pixels to Graphs by Associative Embedding. arXiv 2017, arXiv:1706.07365. [Google Scholar] [CrossRef]
- Frome, A.; Singer, Y.; Sha, F.; Malik, J. Learning Globally-Consistent Local Distance Functions for Shape-Based Image Retrieval and Classification. In Proceedings of the 2007 IEEE 11th International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar]
- Newell, A.; Huang, Z.; Deng, J. Associative Embedding: End-to-End Learning for Joint Detection and Grouping. arXiv 2017, arXiv:1611.05424. [Google Scholar] [CrossRef]
- Hua, G.; Li, L.; Liu, S. Multipath Affinage Stacked-Hourglass Networks for Human Pose Estimation. Front. Comput. Sci. 2020, 14, 144701. [Google Scholar] [CrossRef]
- Park, S.; Kim, T.; Lee, K.; Kwak, N. Music Source Separation Using Stacked Hourglass Networks. arXiv 2018, arXiv:1805.08559. [Google Scholar] [CrossRef]
- Hu, T.; Xao, X.; Min, G.; Najjari, N. An Adaptive Stacked Hourglass Network with Kalman Filter for Estimating 2D Human Pose in Video. Expert Syst. 2021, 38, e12552. [Google Scholar] [CrossRef]
- Antonesi, G.; Rancea, A.; Cioara, T.; Anghel, I. Graph Learning and Deep Neural Network Ensemble for Supporting Cognitive Decline Assessment. Technologies 2024, 12, 3. [Google Scholar] [CrossRef]
- Gonzalez-Rodriguez, J.R.; Cordova-Esparza, D.M.; Terven, J.A. Towards a Bidirectional Mexican Sign Language-Spanish Translation System: A Deep Learning Approach. Technologies 2024, 12, 7. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Lu, C.; Krishna, R.; Bernstein, M.; Fei-Fei, L. Visual Relationship Detection with Language Priors. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part I 14; Springer International Publishin: Berlin/Heidelberg, Germany, 2016; pp. 852–869. [Google Scholar]
- Wu, R.; Xu, K.; Liu, C.; Zhuang, N.; Mu, Y. Localize, Assemble, and Predicate: Contextual Object Proposal Embedding for Visual Relation Detection. AAAI Conf. Artif. Intell. 2020, 34, 12297–12304. [Google Scholar]
- Li, Y.; Ouyang, W.; Wang, X. ViP-CNN: A Visual Phrase Reasoning Convolutional Neural Network for Visual Relationship Detection. arXiv 2017, arXiv:1702.07191. [Google Scholar]
- Sharifzadeh, S.; Baharlou, S.M.; Berrendorf, M.; Koner, R.; Tresp, V. Improving Visual Relation Detection using Depth Maps. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 3597–3604. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Milo, R.; Shen-Orr, S.; Itzkovitz, S.; Kashtan, N.; Chklovskii, D.; Alon, U. Network Motifs: Simple Building Blocks of Complex Networks. Science 2002, 298, 824–827. [Google Scholar] [CrossRef]
- Ronneberger, O.; Philipp, F.; Thomas, B. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5–9, 2015, Proceedings, Part III 18; Springer International Publishing: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Layer Name | Size (in/out) | Channels (in → out) | Layer Type | Activation | Note |
|---|---|---|---|---|---|---|
| Input | input | 512 × 512 512 × 512 | 3 → 3 | - | - | Input image |
| Backbone | Conv1 | 512 × 512 256 × 256 | 3 → 64 | [7 × 7, 64], stride = 2, padding = 3 | ReLU + BN | |
| Maxpool | 256 × 256 128 × 128 | 64 → 64 | Maxpool 3 × 3, stride = 2, padding = 1 | - | - | |
| Stage 1 | 128 × 128 128 × 128 | 64 → 256 | [1 × 1, 64] [3 × 3, 64] [1 × 1, 256] × 3 stride = 1, padding = 1 | ReLU + BN | Skip connection | |
| Stage 2 | 128 × 128 64 × 64 | 256 → 512 | [1 × 1, 128] [3 × 3, 128] [1 × 1, 512] × 4 stride = 2, padding = 1 | ReLU + BN | Skip connection | |
| Stage 3 | 64 × 64 32 × 32 | 512 → 1024 | [1 × 1, 256] [3 × 3, 256] [1 × 1, 1024] × 23 stride = 2, padding = 1 | ReLU + BN | Skip connection | |
| Stage 4 | 32 × 32 16 × 16 | 1024 → 2048 | [1 × 1, 512] [3 × 3, 512] [1 × 1, 2048] × 3 stride = 2, padding = 1 | ReLU + BN | Skip connection | |
| Object Branch | Upconv1_1 | 16 × 16 32 × 32 | 2048 → 256 | [3 × 3, 256], stride = 1, padding = 1 [4 × 4, 256]^T, stride = 2, padding = 1 | ReLU + BN | Fed by “stage 4” |
| Upconv1_2 | 32 × 32 64 × 64 | 256 → 128 | [3 × 3, 128], stride = 1, padding = 1 [4 × 4, 128]^T, stride = 2, padding = 1 | ReLU + BN | Fed by “Upconv1_1” | |
| Upconv1_3 | 64 × 64 128 × 128 | 128 → 64 | [3 × 3, 128], stride = 1, padding = 1 [4 × 4, 64]^T, stride = 2, padding = 1 | ReLU + BN | Fed by “Upconv1_2” | |
| Occlusion Branch | Upconv2_1 | 16 × 16 32 × 32 | 2048 → 256 | [3 × 3, 256], stride = 1, padding = 1 [4 × 4, 256]^T, stride = 2, padding = 1 | ReLU + BN | Fed by “stage 4” |
| Upconv2_2 | 32 × 32 64 × 64 | 256 → 128 | [3 × 3, 128], stride = 1, padding = 1 [4 × 4, 128]^T, stride = 2, padding = 1 | ReLU + BN | Fed by “Upconv2_1” | |
| Upconv2_3 | 64 × 64 128 × 128 | 128 → 64 | [3 × 3, 128], stride = 1, padding = 1 [4 × 4, 64]^T, stride = 2, padding = 1 | ReLU + BN | Fed by “Upconv2_2” | |
| Head Convolution | Target_cen | 128 × 128 128 × 128 | 64 → 7 | [3 × 3, 64] stride = 1, padding = 1 [3 × 3, 7] stride = 1 | ReLU + BN | Fed by “Upconv1_3” |
| Target_wh | 128 × 128 128 × 128 | 64 → 2 | [3 × 3, 64] stride = 1, padding = 1 [3 × 3, 2] stride = 1 | ReLU | Fed by “Upconv1_3” | |
| Target_off | 128 × 128 128 × 128 | 64 → 2 | [3 × 3, 64] stride = 1, padding = 1 [3 × 3, 2] stride = 1 | ReLU | Fed by “Upconv1_3” | |
| Sub_emb | 128 × 128 128 × 128 | 64 → 1 | [3 × 3, 64] stride = 1, padding = 1 [3 × 3, 1] stride = 1 | ReLU | Fed by “Upconv1_3” | |
| Obj_emb | 128 × 128 128 × 128 | 64 → 1 | [3 × 3, 64] stride = 1, padding = 1 [3 × 3, 1] stride = 1 | ReLU | Fed by “Upconv1_3” | |
| Occlusion_cen | 128 × 128 128 × 128 | 64 → 1 | [3 × 3, 64] stride = 1, padding = 1 [3 × 3, 1] stride = 1 | ReLU + Sigmoid | Fed by “Upconv2_3” | |
| Occlusion_wh | 128 × 128 128 × 128 | 64 → 2 | [3 × 3, 64] stride = 1, padding = 1 [3 × 3, 2] stride = 1 | ReLU | Fed by “Upconv2_3” | |
| Occlusion_off | 128 × 128 128 × 128 | 64 → 2 | [3 × 3, 64] stride = 1, padding = 1 [3 × 3, 2] stride = 1 | ReLU | Fed by “Upconv2_3” | |
| Occ_emb | 128 × 128 128 × 128 | 64 → 1 | [3 × 3, 64] stride = 1, padding = 1 [3 × 3, 1] stride = 1 | ReLU | Fed by “Upconv2_3” | |
| Integration | - | - | - | - | - | Multi-head integration |
| Task | Score_Threhold | Overlap T | F1 | Recall | Precision | AP |
|---|---|---|---|---|---|---|
| Occlusion relationship detection | 0.5 | 0.3 | 0.70 | 0.57 | 0.91 | 0.63 |
| 0.5 | 0.4 | 0.68 | 0.55 | 0.89 | 0.60 | |
| 0.5 | 0.5 | 0.65 | 0.53 | 0.85 | 0.56 | |
| 0.5 | 0.6 | 0.60 | 0.49 | 0.78 | 0.48 | |
| 0.5 | 0.7 | 0.49 | 0.40 | 0.64 | 0.35 |
| Method | Score_Threhold | Overlap T | mAP |
|---|---|---|---|
| YOLOV8 | 0.5 | 0.5 | 0.870 |
| CenterNet | 0.5 | 0.5 | 0.805 |
| DOORD-AECNet | 0.5 | 0.5 | 0.810 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gong, P.; Zheng, K.; Liu, T.; Jiang, Y.; Zhao, H. Deep Object Occlusion Relationship Detection Based on Associative Embedding Clustering. Technologies 2025, 13, 143. https://doi.org/10.3390/technologies13040143
Gong P, Zheng K, Liu T, Jiang Y, Zhao H. Deep Object Occlusion Relationship Detection Based on Associative Embedding Clustering. Technologies. 2025; 13(4):143. https://doi.org/10.3390/technologies13040143
Chicago/Turabian StyleGong, Peiyong, Kai Zheng, Ting Liu, Yi Jiang, and Huixuan Zhao. 2025. "Deep Object Occlusion Relationship Detection Based on Associative Embedding Clustering" Technologies 13, no. 4: 143. https://doi.org/10.3390/technologies13040143
APA StyleGong, P., Zheng, K., Liu, T., Jiang, Y., & Zhao, H. (2025). Deep Object Occlusion Relationship Detection Based on Associative Embedding Clustering. Technologies, 13(4), 143. https://doi.org/10.3390/technologies13040143