

A Dual-Stream Dental Panoramic X-Ray Image Segmentation Method Based on Transformer Heterogeneous Feature Complementation



Abstract
1. Introduction
- 1.
- To address the challenge of effectively coordinating global contextual information and local detailed features in tooth segmentation tasks, we constructed a dual-stream network architecture comprising a parallel Transformer-based semantic parsing branch and a CNN-based detail capturing path. The Transformer branch captures global contextual information and long-range dependencies among pixels, while the CNN branch provides rich local details for precise dental segmentation. This global-local complementary mechanism effectively achieves collaborative optimization of global context modeling and local feature extraction, fully leveraging the strengths of both approaches to enhance the overall performance of tooth segmentation.
- 2.
- To address the challenges posed by the complex spatial distribution and diverse morphological details in dental anatomical structures, this paper proposes a Pooling-Cooperative Convolutional Module (PCM). The module employs three pooling operations with weighted feature weighting to represent dental centroids, thereby enhancing the spatial feature representation capability of CNN branches and improving their detail extraction performance. A latent edge extraction module is designed to enhance the synergistic representation of periodontal boundary features and internal textural features, thereby improving the accuracy of boundary segmentation.
- 3.
- To address the modality heterogeneity between CNN and Transformer, a Semantic Transformation Module (STM) is designed, which performs semantic space mapping on CNN-extracted localized detail features to reconfigure them into high-dimensional semantic information compatible with Transformer architectures. An Interactive Fusion Module (IFM) is designed to achieve multi-scale feature fusion from Transformer and CNN, ensuring that the fused features simultaneously retain global contextual dependencies and local fine-grained information, thereby enhancing the model’s recognition accuracy for low-resolution semantic features and its representational capacity for complex spatial information.
2. Related Work
3. Research Design
3.1. Overall Architecture
3.2. Pooling-Cooperative Convolutional Module
3.3. Semantic Transformation Module
3.4. Interactive Fusion Module
4. Experimental Analysis
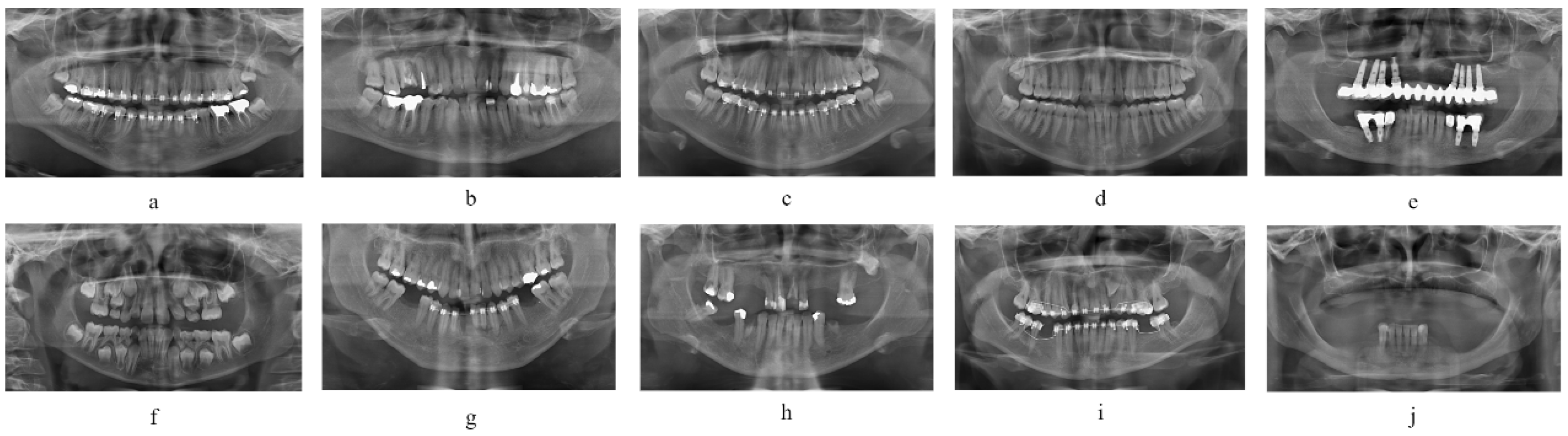
4.1. Dataset
4.2. Experimental Setup
4.3. Comparative Experiments
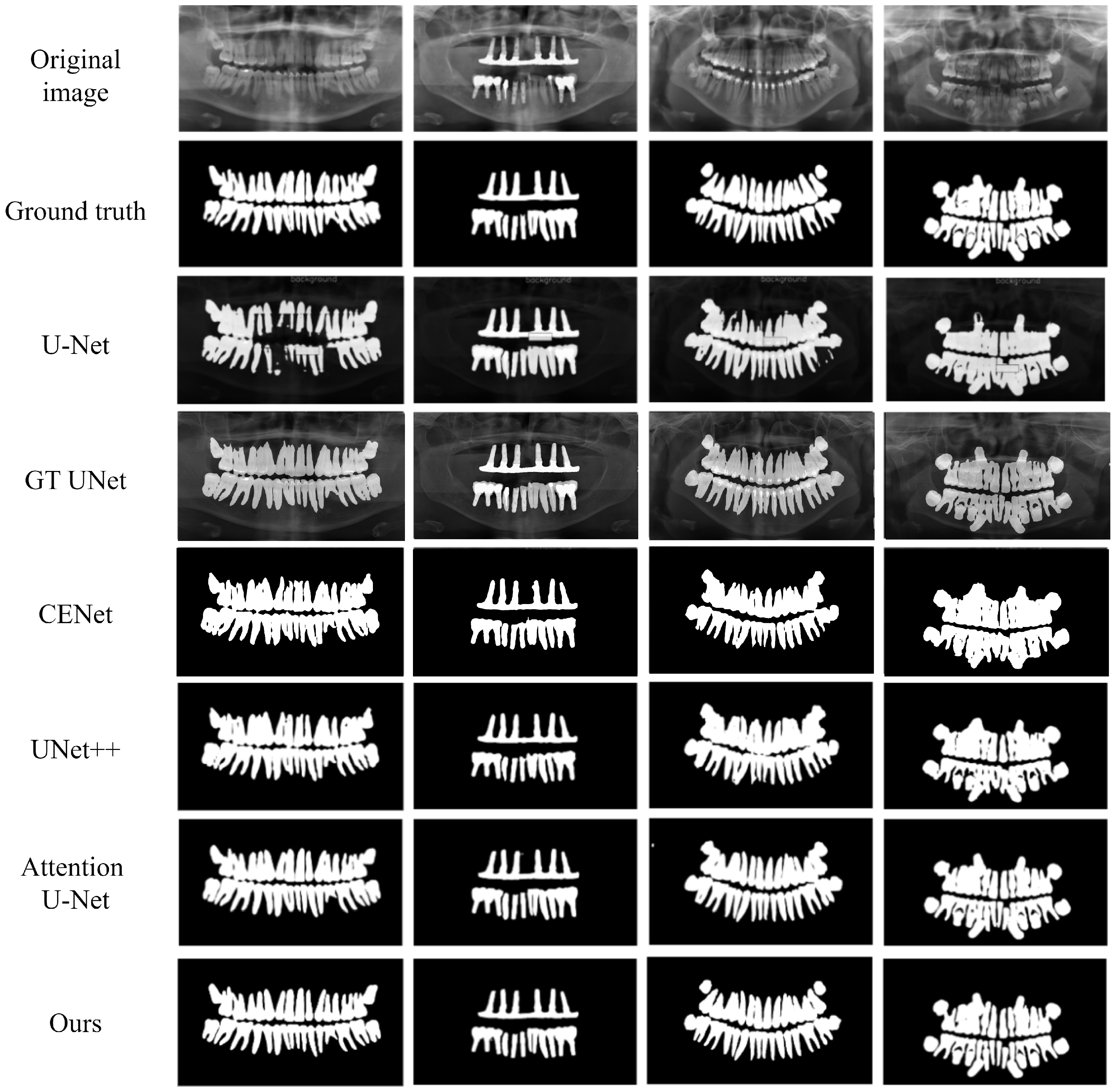
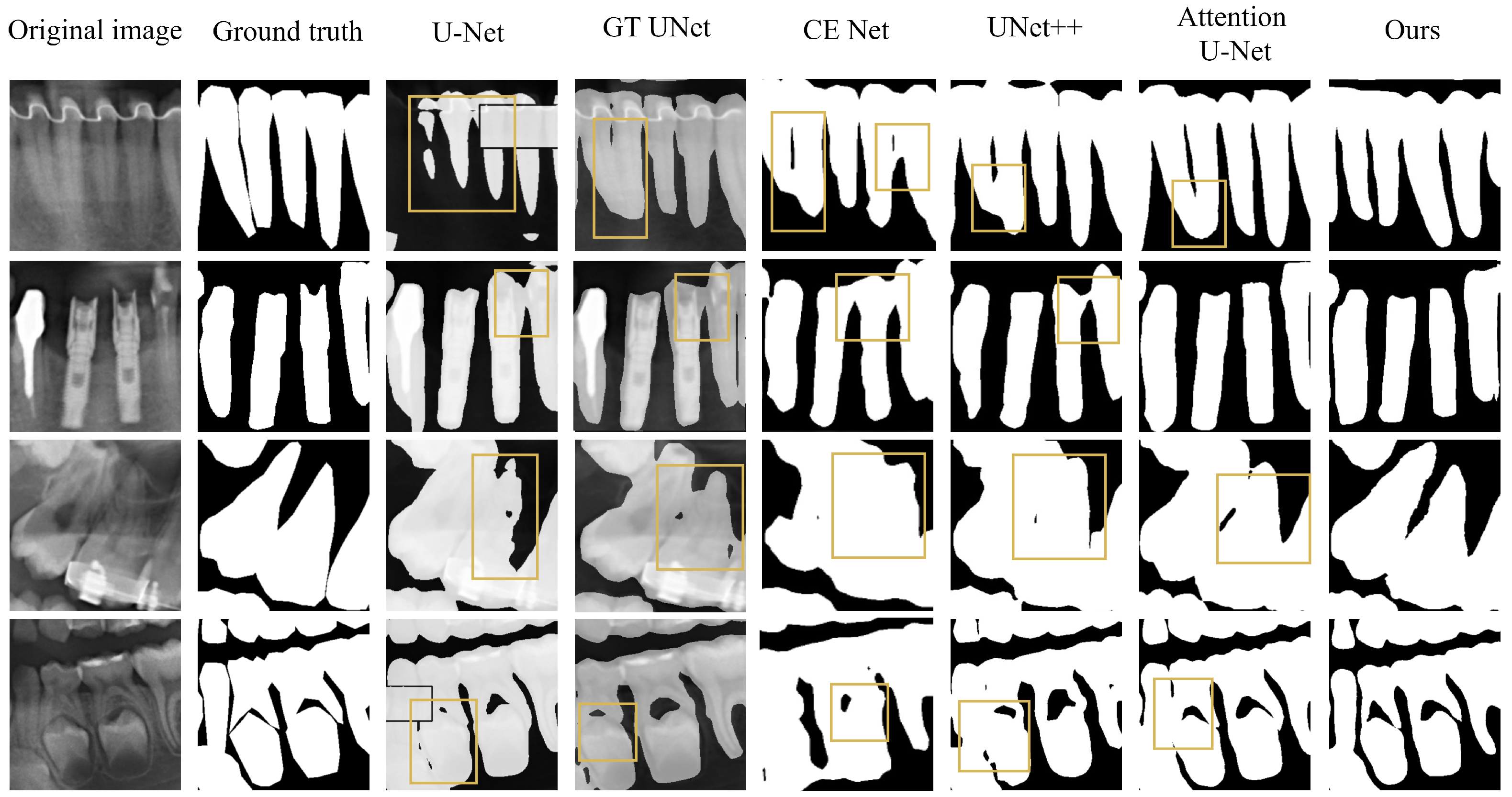
4.3.1. Comparative Experimental Analysis of U-Net-like Networks
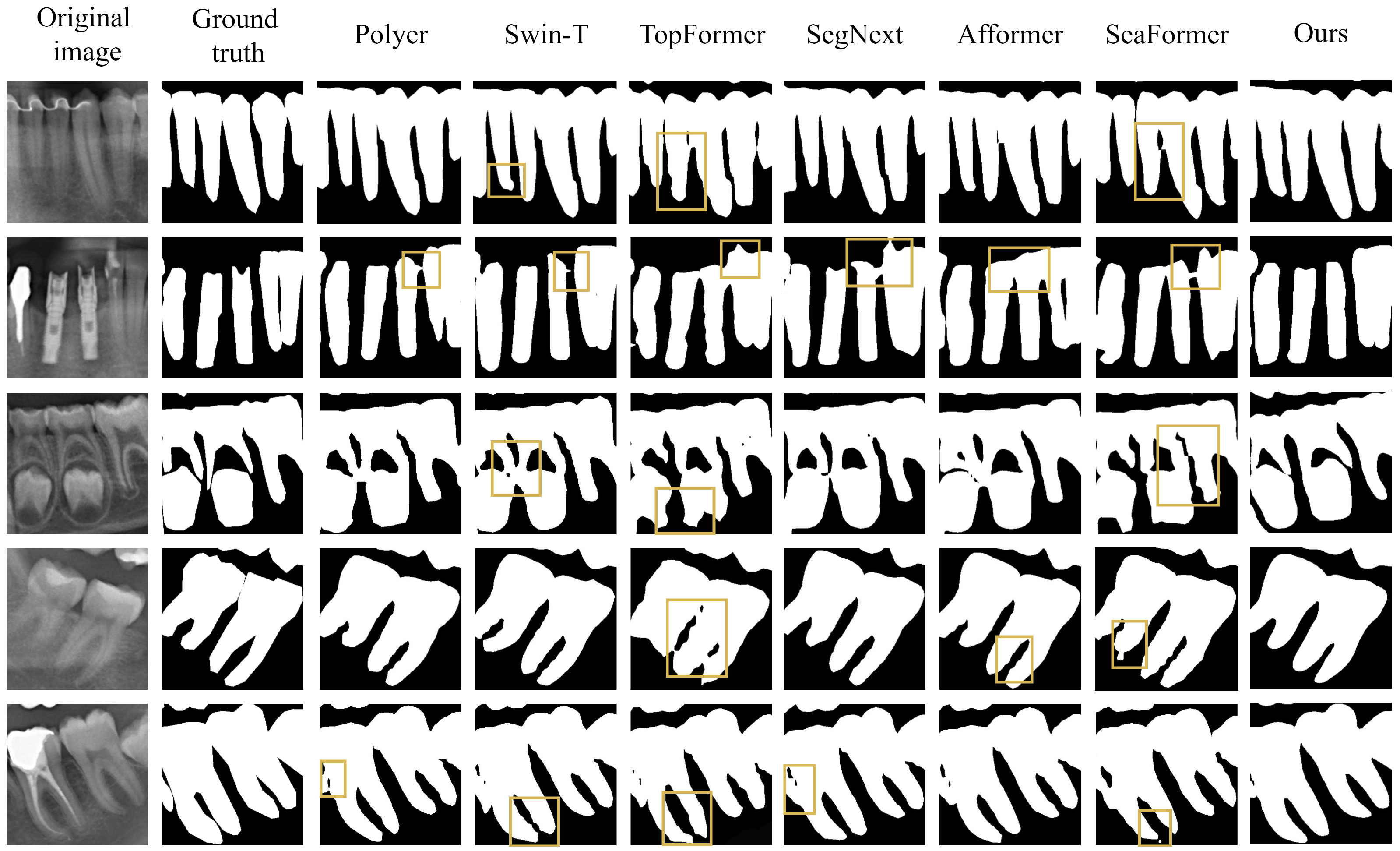
4.3.2. Comparative Experimental Analysis of Transformer-like Networks
4.4. Ablation Study Analysis
4.4.1. Ablation Study on the Pooling-Cooperative Convolutional Module
4.4.2. Ablation Study on the Semantic Transformation Module
4.4.3. Ablation Study on the Interactive Fusion Module
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lin, P.; Huang, P.; Huang, P.; Hsu, H.; Chen, C. Teeth segmentation of dental periapical radiographs based on local singularity analysis. Comput. Methods Programs Biomed. 2014, 113, 433–445. [Google Scholar] [CrossRef] [PubMed]
- Park, K.J.; Kwak, K.C. A trends analysis of dental image processing. In Proceedings of the 2019 17th International Conference on ICT and Knowledge Engineering (ICT&KE), Bangkok, Thailand, 20–22 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–5. [Google Scholar]
- Arora, S.; Tripathy, S.K.; Gupta, R.; Srivastava, R. Exploiting multimodal CNN architecture for automated teeth segmentation on dental panoramic X-ray images. Proc. Inst. Mech. Eng. Part H J. Eng. Med. 2023, 237, 395–405. [Google Scholar] [CrossRef] [PubMed]
- Hou, S.; Zhou, T.; Liu, Y.; Dang, P.; Lu, H.; Shi, H. Teeth U-Net: A segmentation model of dental panoramic X-ray images for context semantics and contrast enhancement. Comput. Biol. Med. 2023, 152, 106296. [Google Scholar] [CrossRef] [PubMed]
- Chandrashekar, G.; AlQarni, S.; Bumann, E.E.; Lee, Y. Collaborative deep learning model for tooth segmentation and identification using panoramic radiographs. Comput. Biol. Med. 2022, 148, 105829. [Google Scholar] [CrossRef] [PubMed]
- Li, P.; Gao, C.; Lian, C.; Meng, D. Spatial Prior-Guided Bi-Directional Cross-Attention Transformers for Tooth Instance Segmentation. IEEE Trans. Med. Imaging 2024, 43, 3936–3948. [Google Scholar] [CrossRef] [PubMed]
- Ma, T.; Yang, Y.; Zhai, J.; Yang, J.; Zhang, J. A tooth segmentation method based on multiple geometric feature learning. Healthcare 2022, 10, 2089. [Google Scholar] [CrossRef] [PubMed]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Radhiyah, A.; Harsono, T.; Sigit, R. Comparison study of Gaussian and histogram equalization filter on dental radiograph segmentation for labelling dental radiograph. In Proceedings of the 2016 International Conference on Knowledge Creation and Intelligent Computing (KCIC), Manado, Indonesia, 15–17 November 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 253–258. [Google Scholar]
- Tikhe, S.V.; Naik, A.M.; Bhide, S.D.; Saravanan, T.; Kaliyamurthie, K. Algorithm to identify enamel caries and interproximal caries using dental digital radiographs. In Proceedings of the 2016 IEEE 6th International Conference on Advanced Computing (IACC), Bhimavaram, India, 27–28 February 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 225–228. [Google Scholar]
- Alsmadi, M.K. A hybrid Fuzzy C-Means and Neutrosophic for jaw lesions segmentation. Ain Shams Eng. J. 2018, 9, 697–706. [Google Scholar] [CrossRef]
- Trivedi, D.N.; Modi, C.K. Dental contour extraction using ISEF Algorithm for human identification. In Proceedings of the 2011 3rd International Conference on Electronics Computer Technology, Kanyakumari, India, 8–10 April 2011; IEEE: Piscataway, NJ, USA, 2011; Volume 6, pp. 6–10. [Google Scholar]
- Modi, C.K.; Desai, N.P. A simple and novel algorithm for automatic selection of ROI for dental radiograph segmentation. In Proceedings of the 2011 24th Canadian Conference on Electrical and Computer Engineering (CCECE), Niagara Falls, ON, Canada, 8–11 May 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 000504–000507. [Google Scholar]
- Haghanifar, A.; Majdabadi, M.M.; Haghanifar, S.; Choi, Y.; Ko, S.B. PaXNet: Tooth segmentation and dental caries detection in panoramic X-ray using ensemble transfer learning and capsule classifier. Multimed. Tools Appl. 2023, 82, 27659–27679. [Google Scholar] [CrossRef]
- Tekin, B.Y.; Ozcan, C.; Pekince, A.; Yasa, Y. An enhanced tooth segmentation and numbering according to FDI notation in bitewing radiographs. Comput. Biol. Med. 2022, 146, 105547. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015 Proceedings of the 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Koch, T.L.; Perslev, M.; Igel, C.; Brandt, S.S. Accurate segmentation of dental panoramic radiographs with U-Nets. In Proceedings of the 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), Venice, Italy, 8–11 April 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 15–19. [Google Scholar]
- Zhao, Y.; Li, P.; Gao, C.; Liu, Y.; Chen, Q.; Yang, F.; Meng, D. TSASNet: Tooth segmentation on dental panoramic X-ray images by Two-Stage Attention Segmentation Network. Knowl.-Based Syst. 2020, 206, 106338. [Google Scholar] [CrossRef]
- Ma, T.; Zhou, X.; Yang, J.; Meng, B.; Qian, J.; Zhang, J.; Ge, G. Dental lesion segmentation using an improved icnet network with attention. Micromachines 2022, 13, 1920. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. Transunet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Li, Y.; Wang, S.; Wang, J.; Zeng, G.; Liu, W.; Zhang, Q.; Jin, Q.; Wang, Y. Gt u-net: A u-net like group transformer network for tooth root segmentation. In Proceedings of the Machine Learning in Medical Imaging: 12th International Workshop, MLMI 2021, Held in Conjunction with MICCAI 2021, Strasbourg, France, 27 September 2021; Proceedings 12. Springer: Cham, Switzerland, 2021; pp. 386–395. [Google Scholar]
- Hatamizadeh, A.; Tang, Y.; Nath, V.; Yang, D.; Myronenko, A.; Landman, B.; Roth, H.R.; Xu, D. Unetr: Transformers for 3d medical image segmentation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 574–584. [Google Scholar]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-unet: Unet-like pure transformer for medical image segmentation. In Proceedings of the European Conference on Computer Vision 2022, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 205–218. [Google Scholar]
- Cheng, B.; Misra, I.; Schwing, A.G.; Kirillov, A.; Girdhar, R. Masked-attention mask transformer for universal image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2022, New Orleans, LA, USA, 18–24 June 2022; pp. 1290–1299. [Google Scholar]
- Ma, T.; Dang, Z.; Yang, Y.; Yang, J.; Li, J. Dental panoramic X-ray image segmentation for multi-feature coordinate position learning. Digit. Health 2024, 10, 20552076241277154. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Gou, Y.; Li, B.; Peng, D.; Lv, J.; Peng, X. Comprehensive and delicate: An efficient transformer for image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2023, Vancouver, BC, Canada, 17–24 June 2023; pp. 14122–14132. [Google Scholar]
- Li, J.; Wen, Y.; He, L. Scconv: Spatial and channel reconstruction convolution for feature redundancy. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2023, Vancouver, BC, Canada, 17–24 June 2023; pp. 6153–6162. [Google Scholar]
- Zhang, Y.; Ye, F.; Chen, L.; Xu, F.; Chen, X.; Wu, H.; Cao, M.; Li, Y.; Wang, Y.; Huang, X. Children’s dental panoramic radiographs dataset for caries segmentation and dental disease detection. Sci. Data 2023, 10, 380. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: 4th International Workshop, DLMIA 2018, and 8th International Workshop, ML-CDS 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, 20 September 2018; Proceedings 4; Springer: Cham, Switzerland, 2018; pp. 3–11. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Gu, Z.; Cheng, J.; Fu, H.; Zhou, K.; Hao, H.; Zhao, Y.; Zhang, T.; Gao, S.; Liu, J. Ce-net: Context encoder network for 2d medical image segmentation. IEEE Trans. Med. Imaging 2019, 38, 2281–2292. [Google Scholar] [CrossRef] [PubMed]
- Shao, H.; Zhang, Y.; Hou, Q. Polyper: Boundary sensitive polyp segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence 2024, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 4731–4739. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision 2021, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Zhang, W.; Huang, Z.; Luo, G.; Chen, T.; Wang, X.; Liu, W.; Yu, G.; Shen, C. Topformer: Token pyramid transformer for mobile semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2022, New Orleans, LA, USA, 18–24 June 2022; pp. 12083–12093. [Google Scholar]
- Guo, M.H.; Lu, C.Z.; Hou, Q.; Liu, Z.; Cheng, M.M.; Hu, S.M. Segnext: Rethinking convolutional attention design for semantic segmentation. Adv. Neural Inf. Process. Syst. 2022, 35, 1140–1156. [Google Scholar]
- Dong, B.; Wang, P.; Wang, F. Head-free lightweight semantic segmentation with linear transformer. In Proceedings of the AAAI Conference on Artificial Intelligence 2023, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 516–524. [Google Scholar]
- Wan, Q.; Huang, Z.; Lu, J.; Yu, G.; Zhang, L. Seaformer: Squeeze-enhanced axial transformer for mobile semantic segmentation. In Proceedings of the Eleventh International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Xu, Z.; Wu, D.; Yu, C.; Chu, X.; Sang, N.; Gao, C. Sctnet: Single-branch cnn with transformer semantic information for real-time segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence 2024, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 6378–6386. [Google Scholar]
- Wang, J.; Gou, C.; Wu, Q.; Feng, H.; Han, J.; Ding, E.; Wang, J. Rtformer: Efficient design for real-time semantic segmentation with transformer. Adv. Neural Inf. Process. Syst. 2022, 35, 7423–7436. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Tooth Type | Count |
|---|---|---|
| a | Restored normal dentition images with orthodontic appliances | 73 |
| b | Restored normal dentition images (excluding orthodontic appliances) | 220 |
| c | Normal dentition images with orthodontic appliances (excluding dental restorations) | 45 |
| d | Normal dentition images without dental restorations or orthodontic appliances | 140 |
| e | Dental images with dental implants | 120 |
| f | Dental images with supernumerary teeth (>32 teeth) | 170 |
| g | Edentulous images with dental restorations and orthodontic appliances | 115 |
| h | Edentulous images with dental restorations (excluding orthodontic appliances) | 457 |
| i | Edentulous images with orthodontic appliances (excluding dental restorations) | 45 |
| j | Edentulous images without dental restorations or orthodontic appliances | 115 |
| Method | IoU (%) | Precision (%) | Accuracy (%) | Dice (%) | Params (M) | FPS |
|---|---|---|---|---|---|---|
| U-Net | 85.73 | 93.45 | 90.89 | 92.10 | 7.7 | 152.4 |
| GT UNet | 85.70 | 91.66 | 95.74 | 92.56 | 32.1 | 81.2 |
| CE Net | 88.47 | 94.57 | 95.26 | 93.63 | 29.7 | 123.5 |
| U-Net++ | 90.48 | 94.41 | 97.09 | 93.48 | 9.12 | 105.8 |
| Att U-Net | 90.79 | 93.05 | 97.22 | 93.91 | 8.75 | 120.0 |
| Ours | 91.49 | 94.59 | 97.42 | 94.54 | 17.4 | 136.6 |
| Method | IoU (%) | Precision (%) | Accuracy (%) | Dice (%) | Params (M) | FPS |
|---|---|---|---|---|---|---|
| Polyer | 87.10 | 90.66 | 95.94 | 92.96 | 28.0 | 138.9 |
| Swin-T | 90.47 | 93.57 | 95.26 | 93.63 | 28.3 | 128.4 |
| TopFormer | 88.19 | 93.14 | 94.06 | 93.59 | 5.7 | 106.7 |
| SegNext | 87.77 | 92.89 | 93.80 | 93.34 | 27.7 | 78.3 |
| Afformer | 88.03 | 93.51 | 93.47 | 93.49 | 3.0 | 148.4 |
| SeaFormer | 85.70 | 91.92 | 92.27 | 92.09 | 1.8 | 103.6 |
| Ours | 91.49 | 94.91 | 97.42 | 94.54 | 17.4 | 136.6 |
| Max Pooling | Average Pooling | Median Pooling | IoU (%) | Dice (%) |
|---|---|---|---|---|
| 89.08 | 92.81 | |||
| ✓ | 90.59 | 93.37 | ||
| ✓ | 89.85 | 92.79 | ||
| ✓ | 89.41 | 92.06 | ||
| ✓ | ✓ | 89.66 | 93.16 | |
| ✓ | ✓ | 89.51 | 93.06 | |
| ✓ | ✓ | 90.31 | 93.46 | |
| ✓ | ✓ | ✓ | 90.74 | 94.04 |
| Module | IoU (%) | Precision (%) | Accuracy (%) | Dice (%) |
|---|---|---|---|---|
| SegFormer | 89.17 | 93.46 | 96.62 | 93.15 |
| GFABlock | 88.85 | 92.54 | 95.17 | 92.69 |
| MSCANBlock | 87.69 | 93.64 | 95.64 | 92.53 |
| CFBlock | 89.31 | 93.62 | 96.82 | 93.16 |
| STM (Ours) | 89.79 | 93.91 | 97.03 | 93.54 |
| Method | IoU (%) | Precision (%) | Accuracy (%) | Dice (%) |
|---|---|---|---|---|
| w/o IFM | 87.88 | 92.87 | 92.74 | 92.81 |
| w/CRU | 88.19 | 92.40 | 96.62 | 93.10 |
| w/SRU | 88.31 | 92.72 | 96.42 | 93.36 |
| IFM (Ours) | 90.45 | 93.71 | 96.62 | 93.52 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, T.; Li, J.; Dang, Z.; Li, Y.; Li, Y. A Dual-Stream Dental Panoramic X-Ray Image Segmentation Method Based on Transformer Heterogeneous Feature Complementation. Technologies 2025, 13, 293. https://doi.org/10.3390/technologies13070293
Ma T, Li J, Dang Z, Li Y, Li Y. A Dual-Stream Dental Panoramic X-Ray Image Segmentation Method Based on Transformer Heterogeneous Feature Complementation. Technologies. 2025; 13(7):293. https://doi.org/10.3390/technologies13070293
Chicago/Turabian StyleMa, Tian, Jiahui Li, Zhenrui Dang, Yawen Li, and Yuancheng Li. 2025. "A Dual-Stream Dental Panoramic X-Ray Image Segmentation Method Based on Transformer Heterogeneous Feature Complementation" Technologies 13, no. 7: 293. https://doi.org/10.3390/technologies13070293
APA StyleMa, T., Li, J., Dang, Z., Li, Y., & Li, Y. (2025). A Dual-Stream Dental Panoramic X-Ray Image Segmentation Method Based on Transformer Heterogeneous Feature Complementation. Technologies, 13(7), 293. https://doi.org/10.3390/technologies13070293