Application-Specific SoC Design Using Core Mapping to 3D Mesh NoCs with Nonlinear Area Optimization and Simulated Annealing

 ,
,
Abstract
1. Introduction
2. Related Work
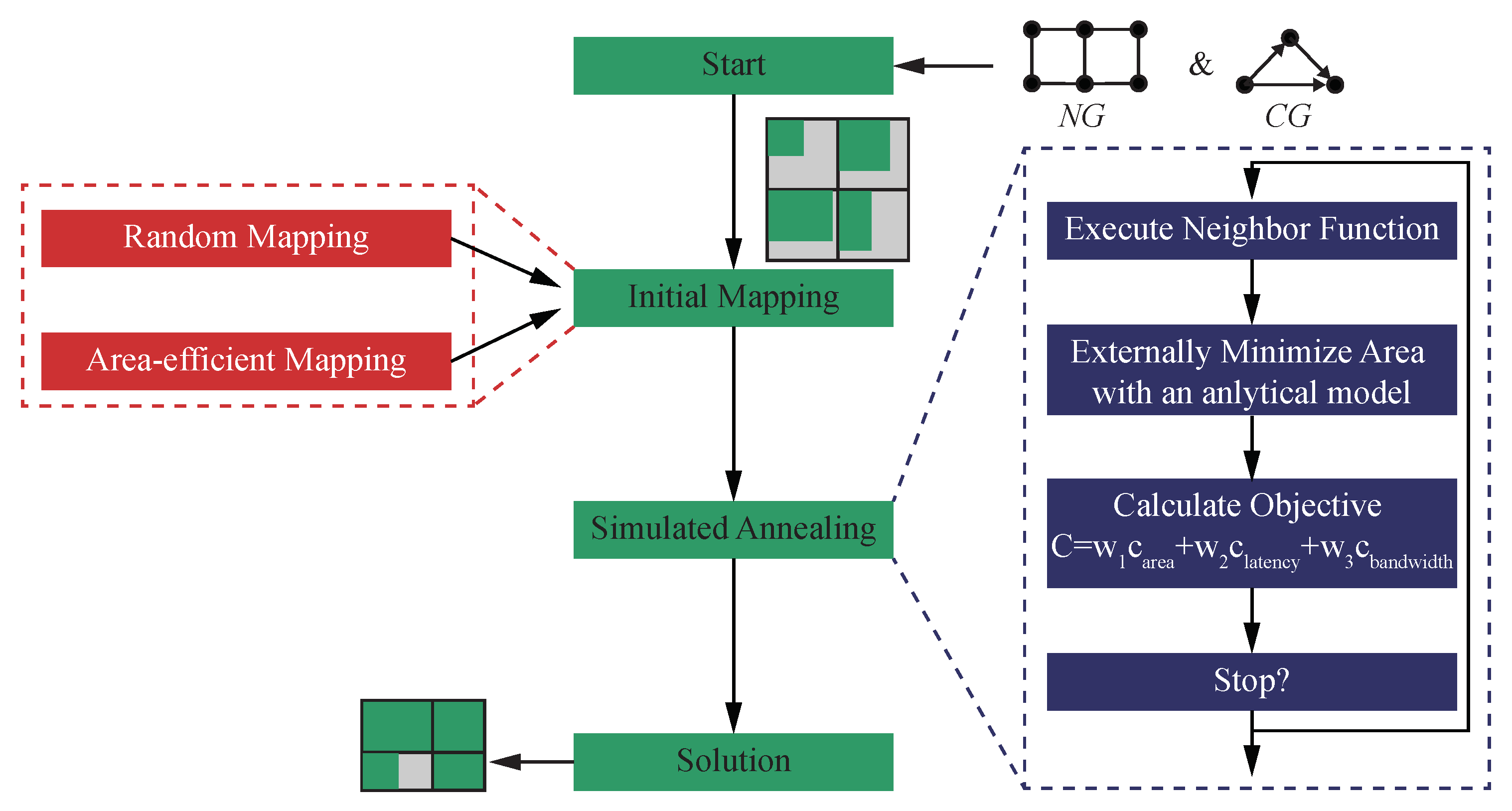
3. Area-Aware Core Mapping with Simulated Annealing
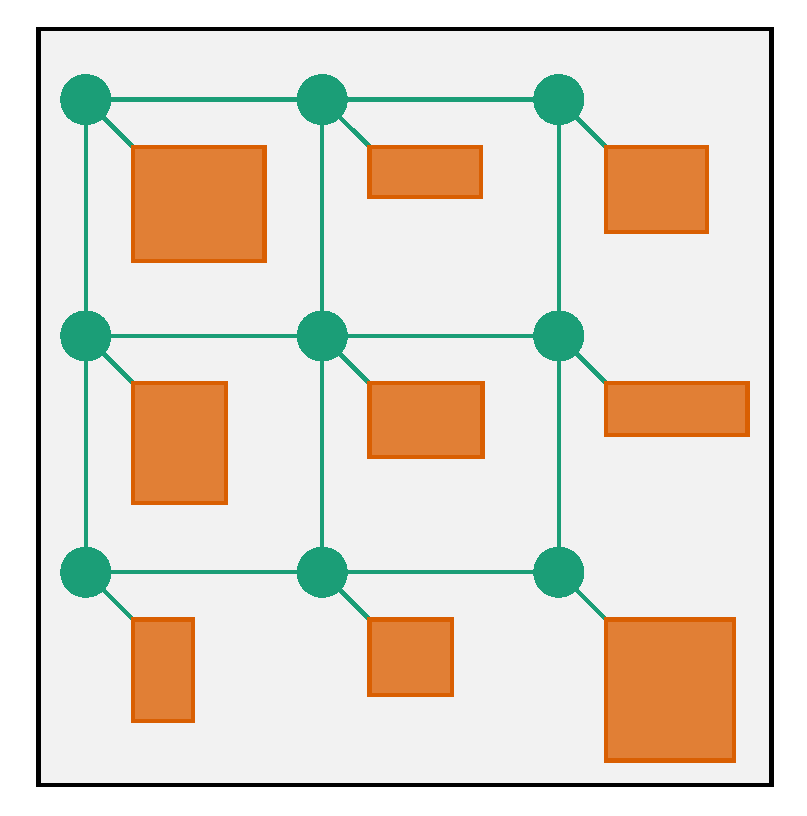
3.1. Problem Definition
3.2. Simulated Annealing
- Randomly generated:The function is generated such that each core is assigned to one random tile .
- Area-efficient:The floorplan will be packed area-efficiently, i.e., with minimal whitespace, if all tiles within a row and a column have a similar area. Such a good candidate can be found using a greedy strategy: The cores are sorted descending by area. The tiles are filled from the upper left corner. The cores are assigned to the next free tile in the current row or column, while row and column assignment are alternating. If a row/column is full, tiles will be assigned to the adjacent one. Figuratively speaking, the tiles are filled from the upper left corner to the bottom right corner.
4. Area Optimization for a Given Mapping Using Linear and Nonlinear Models
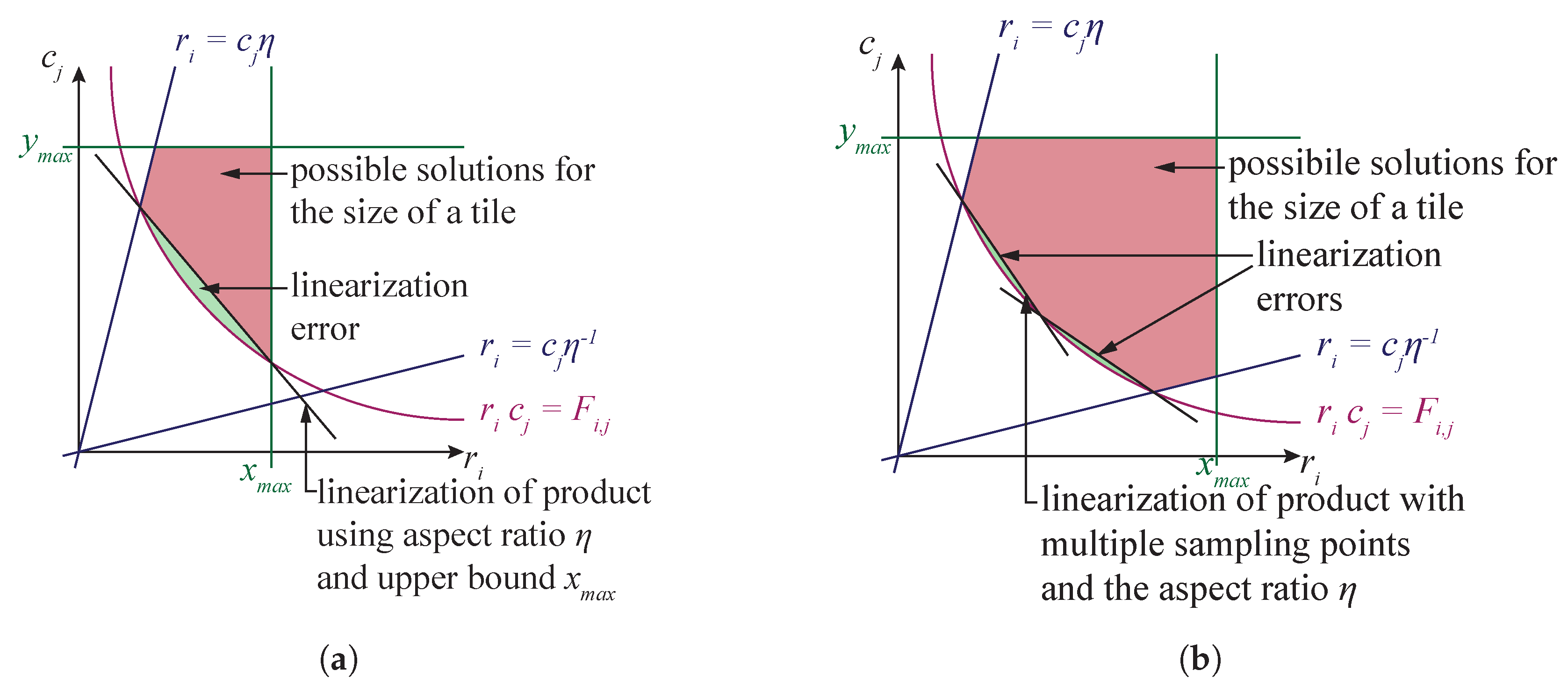
4.1. Linear Model
4.2. Nonlinear Model
5. Results
5.1. Simulated Annealing (SA) vs. Particle Swarm Optimization (PSO)
5.2. Linear vs. Non-Linear Model
- A 3D SoC with two layers and five tiles, of which three tiles are in layer 1 and two tiles are in layer 2.
- A 3D SoC with four layers and 10 tiles per layer connected by a 2 × 5 mesh NoC.
- A 3D SoC with four layers and 20 tiles per layer connected by a 4 × 5 mesh NoC.
- Performance. In benchmark 1, the summed chip area is 68.7 mm2 from the LP and 59.8 mm2 from the SDP. In benchmark 2, the summed chip area is 832 mm2 from the LP and 695 mm2 from the SDP. In benchmark 3, the summed chip area is 1272 mm2 from the LP and 1188 mm2 from the SDP. Since in the lowest layer there is no TSV area required (there are no keep-out-zones using via-middle-process-flow), this layer is smaller.
- Runtime. The difference in runtime between LP and SDP is between 6× and 31%. The LP loses its runtime advantage for larger inputs.
- Model Properties. We also report inequality and variable count. The linear model requires inequalities and variables. The nonlinear model requires inequalities and variables. Thus, the SDP has considerably more variables and inequalities. However, both models are very small in comparison to common use cases for LP and SDP solvers with millions of variables and equations. Therefore, the models do not largely differentiate in terms of memory usage.
5.3. SA for Area-Aware Core Mapping with Linear vs. Nonlinear Models
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Murali, S.; Coenen, M.; Radulescu, A.; Goossens, K.; De Micheli, G. A Methodology for Mapping Multiple Use-Cases onto Networks on Chips. In Proceedings of the Conference on Design, Automation and Test in Europe, Munich, Germany, 6–10 March 2006. [Google Scholar] [CrossRef]
- Srinivasan, K.; Chatha, K.S.; Konjevod, G. Linear-programming-based techniques for synthesis of network-on-chip architectures. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2006, 14, 407–420. [Google Scholar] [CrossRef]
- Joseph, J.M.; Ermel, D.; Drewes, T.; Bamberg, L.; García-Oritz, A.; Pionteck, T. Area Optimization with Non-Linear Models in Core Mapping for System-on-Chips. In Proceedings of the 8th International Conference on Modern Circuits and Systems Technologies (MOCAST), Thessaloniki, Greece, 13–15 May 2019. [Google Scholar] [CrossRef]
- Lin, L.-Y.; Wang, C.-Y.; Huang, P.-J.; Chou, C.-C.; Jou, J.-Y. Communication-driven task binding for multiprocessor with latency insensitive network-on-chip. In Proceedings of the Asia and South Pacific Design Automation Conference (ASP-DAC), Shanghai, China, 21–21 January 2005. [Google Scholar] [CrossRef]
- Satish, N.; Ravindran, K.; Keutzer, K. A Decomposition-based Constraint Optimization Approach for Statically Scheduling Task Graphs with Communication Delays to Multiprocessors. In Proceedings of the Conference on Design, Automation and Test in Europe, Nice, France, 16–20 April 2007. [Google Scholar]
- Zarándy, Á. Focal-Plane Sensor-Processor Chips; Springer: Berlin, Germany, 2011. [Google Scholar]
- Rhee, C.-E.; Jeong, H.-Y.; Ha, S. Many-to-many core-switch mapping in 2-D mesh NoC architectures. In Proceedings of the IEEE International Conference on Computer Design (ICCD): VLSI in Computers and Processors, San Jose, CA, USA, 11–13 October 2004. [Google Scholar] [CrossRef]
- Murali, S.; Benini, L.; De Micheli, G.; De Micheli, G.; De Micheli, G. Mapping and Physical Planning of Networks-on-chip Architectures with Quality-of-service Guarantees. In Proceedings of the 2005 Asia and South Pacific Design Automation Conference, Shanghai, China, 18–21 January 2005. [Google Scholar] [CrossRef]
- Ostler, C.; Chatha, K.S. An ILP Formulation for System-level Application Mapping on Network Processor Architectures. In Proceedings of the Conference on Design, Automation and Test in Europe, Nice, France, 16–20 April 2007. [Google Scholar]
- Ozturk, O.; Kandemir, M.; Son, S.W. An ilp based approach to reducing energy consumption in nocbased CMPS. In Proceedings of the 2007 international symposium on Low power electronics and design (ISLPED), Portland, OR, USA, 27–29 August 2007. [Google Scholar] [CrossRef]
- Hu, J.; Marculescu, R. Energy-aware mapping for tile-based NoC architectures under performance constraints. In Proceedings of the 2003 Asia and South Pacific Design Automation Conference, Kitakyushu, Japan, 21–24 January 2003. [Google Scholar]
- Lei, T.; Kumar, S. A two-step genetic algorithm for mapping task graphs to a network on chip architecture. In Proceedings of the Euromicro Symposium on Digital System Design, Belek-Antalya, Turkey, 1–6 September 2003. [Google Scholar] [CrossRef]
- Manna, K.; Swami, S.; Chattopadhyay, S.; Sengupta, I. Integrated Through-Silicon Via Placement and Application Mapping for 3D Mesh-Based NoC Design. ACM Trans. Embedded Comput. Syst. 2016, 16. [Google Scholar] [CrossRef]
- Cong, J.; Wei, J.; Zhang, Y. A thermal-driven floorplanning algorithm for 3D ICs. In Proceedings of the IEEE/ACM International Conference on Computer Aided Design (ICCAD), San Jose, CA, USA, 7–11 November 2004. [Google Scholar] [CrossRef]
- Joseph, J.M.; Ermel, D.; Bamberg, L.; García-Ortiz, A.; Pionteck, T. System-level optimization of Network-on-Chips for heterogeneous 3D System-on-Chips. arXiv 2019, arXiv:cs.AR/1909.13807. [Google Scholar]
- Lu, Z.; Xia, L.; Jantsch, A. Cluster-based Simulated Annealing for Mapping Cores onto 2D Mesh Networks on Chip. In Proceedings of the 11th IEEE Workshop on Design and Diagnostics of Electronic Circuits and Systems, Bratislava, Slovakia, 16–18 April 2008. [Google Scholar] [CrossRef]
- Zhong, L.; Sheng, J.; Jing, M.; Yu, Z.; Zeng, X.; Zhou, D. An optimized mapping algorithm based on Simulated Annealing for regular NoC architecture. In Proceedings of the 9th IEEE International Conference on ASIC, Xiamen, China, 25–28 October 2011. [Google Scholar] [CrossRef]
- Kashi, S.; Patooghy, A.; Rahmatiy, D.; Fazeli, M.; Kinsy, M.A. Application Specific Networks-on-Chip Synthesis: An Energy Efficient Approach. In Proceedings of the 2018 IEEE Computer Society Annual Symposium on VLSI (ISVLSI), Hong Kong, China, 8–11 July 2018. [Google Scholar] [CrossRef]
- Li, B.; Wang, X.; Singh, A.K.; Mak, T. On runtime communication- and thermal-aware application mapping in 3D NoC. In Proceedings of the 11th IEEE/ACM International Symposium on Networks-on-Chip (NOCS), Seoul, Korea, 19–20 October 2017. [Google Scholar]
- Murali, S.; Micheli, G.D. Bandwidth-constrained mapping of cores onto NoC architectures. In Proceedings of the Design, Automation and Test in Europe Conference and Exhibition, Paris, France, 16–20 February 2004. [Google Scholar] [CrossRef]
- Korte, B.; Vygen, J. Combinatorial Optimization: Theory and Algorithms, 5th ed.; Springer: Berlin, Germany, 2012. [Google Scholar]
- Lacksonen, T.A. Static and Dynamic Layout Problems with Varying Areas. J. Oper. Res. Soc. 1994, 45, 59–69. [Google Scholar] [CrossRef]
- Sahu, P.K.; Chattopadhyay, S. A survey on application mapping strategies for Network-on-Chip design. J. Syst. Archit. 2013, 59, 60–76. [Google Scholar] [CrossRef]
- Joseph, J. System-Level Optimization of NoCs for Hetergeneous 3D SoCs. 2019. Available online: https://github.com/jmjos/A-3D-NoC-DSE (accessed on 8 October 2019).
- IBM. ILOG CPLEX Optimization Studio CPLEX User’s Manual 12.8; Armonk: New York, NY, USA, 2017. [Google Scholar]
- Mosek ApS. Mosek User Manual; Mosek ApS: Kopenhagen, Denmark, 2018. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Vertical Connection Count | Hop Distance × Bandwidth [Hd Mb] | Difference | |||
|---|---|---|---|---|---|
| PSO | Proposed | ||||
| mean | std | mean | std | ||
| 1 | 12,229 | 0 | 12,229 | 0 | 0% |
| 2 | 10,591 | 581 | 9005 | 0 | 15% |
| 3 | 8894 | 102 | 8659 | 0 | 3% |
| 4 | 9013 | 364 | 8595 | 0 | 5% |
| 5 | 8725 | 155 | 8595 | 0 | 1% |
| 6 | 8723 | 148 | 8595 | 0 | 1% |
| 7 | 8595 | 0 | 8595 | 0 | 0% |
| 8 | 8595 | 0 | 8595 | 0 | 0% |
| Average Improvement | 3.125% | ||||
| Vertical Connection Count | Hop Distance × Bandwidth [Hd Mb] | Difference | |||
|---|---|---|---|---|---|
| PSO | Proposed | ||||
| mean | std | mean | std | ||
| 1 | 43,330 | 0 | 43,330 | 0 | 0% |
| 2 | 38,274 | 163 | 37,954 | 395 | 1% |
| 3 | 34,636 | 0 | 33,854 | 0 | 2% |
| 4 | 34,217 | 674 | 32,382 | 0 | 5% |
| 5 | 33,249 | 555 | 31,014 | 0 | 7% |
| 6 | 32,351 | 699 | 30,168 | 0 | 7% |
| 7 | 31,920 | 575 | 29,916 | 0 | 6% |
| 8 | 30,767 | 679 | 29,744 | 0 | 3% |
| 9 | 30,767 | 679 | 29,744 | 0 | 3% |
| 10 | 30,318 | 453 | 29,712 | 0 | 2% |
| 11 | 30,235 | 409 | 29,712 | 0 | 2% |
| 12 | 29,764 | 69 | 29,712 | 0 | 0% |
| 13 | 29,996 | 340 | 29,712 | 0 | 1% |
| 14 | 29,805 | 208 | 29,712 | 0 | 0% |
| 15 | 29,712 | 0 | 29,712 | 0 | 0% |
| 16 | 29,712 | 0 | 29,712 | 0 | 0% |
| Average Improvement | 2.563% | ||||
| Layer | Area [mm2] | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 5 PEs | 40 PEs | 80 PEs | |||||||
| LP | SDP | Δ | LP | SDP | Δ | LP | SDP | Δ | |
| 1 | 43.0 | 36.8 | −14.4% | 211 | 178 | −15.6% | 364 | 301 | −17.4% |
| 2 | 25.7 | 23.0 | −10.5% | 222 | 180 | −18.9% | 379 | 313 | −17.4% |
| 3 | — | — | — | 214 | 183 | −14.5% | 378 | 313 | −17.2% |
| 4 | — | — | — | 185 | 154 | −16.8% | 316 | 261 | −17.4% |
| Average AreaReduction | −12.5% | −16.5% | −17.3% | ||||||
| Average runtime [s] | |||||||||
| 0.4 | 2.9 | +625% | 3.9 | 7.5 | +92.3% | 12.2 | 16.0 | +31.1% | |
| Inequality count | |||||||||
| 16 | 31 | +94% | 88 | 436 | +395% | 168 | 1644 | +879% | |
| Variable count | |||||||||
| 9 | 21 | +133% | 32 | 112 | +250% | 40 | 200 | +400% | |
| Area [mm2] | Hop Distance × Bandwidth | Bandwidth [Bits] | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| mean | std | Ratio | mean | std | Ratio | mean | std | Ratio | |||
| H256 dec | mp3 dec | Baseline [2] | 11,301 | — | — | 19,858 | — | — | 4060 | — | — |
| Baseline with SDP | 10,178 | — | −9.94% | 19,858 | — | 0.0% | 4060 | — | 0.0% | ||
| Initial solution | 7902 | — | −30.1% | 33,707 | — | +69.7% | 7994 | — | +96.9% | ||
| SA communication () | 11,699 | 1598 | +3.52% | 20,449 | 404 | +2.98% | 4265 | 201 | +5.05% | ||
| Normalized SA with SDP | 8244 | 505 | −27.1% | 21,280 | 624 | +7.16% | 4452 | 674 | +9.66% | ||
| H263 enc | mp3 dec | Baseline [2] | 12,535 | — | — | 255,324 | — | — | 84,884 | — | — |
| Baseline with SDP | 10,178 | — | −18.8% | 255,324 | — | 0.0% | 84,884 | — | 0.0% | ||
| Initial solution | 6993 | — | −44.2% | 525,537 | — | +106% | 85,244 | — | +0.42% | ||
| SA communication () | 15,762 | 1723 | −25.7% | 241,479 | 15,333 | −5.42% | 73,012 | 14,302 | −14.0% | ||
| Normalized SA with SDP | 10,474 | 2148 | −16.4% | 250,187 | 14,763 | −2.0% | 73,161 | 17,497 | −13.8% | ||
| mp3 enc | mp3 dec | Baseline [2] | 8568 | — | — | 17546 | — | — | 4085 | — | — |
| Baseline with SDP | 8091 | — | −5.57% | 17,546 | — | 0.0% | 4085 | — | 0.0% | ||
| Initial solution | 7281 | — | −15.0% | 39,171 | — | +123.3% | 6560 | — | +60.1% | ||
| SA communication () | 10,779 | 1460 | +25.8% | 17,341 | 342 | −1.17% | 5065 | 906 | +24.0% | ||
| Normalized SA with SDP | 8516 | 796 | −0.61% | 17,572 | 487 | +0.15% | 4974 | 902 | +21.8% | ||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Joseph, J.M.; Ermel, D.; Bamberg, L.; García-Oritz, A.; Pionteck, T. Application-Specific SoC Design Using Core Mapping to 3D Mesh NoCs with Nonlinear Area Optimization and Simulated Annealing. Technologies 2020, 8, 10. https://doi.org/10.3390/technologies8010010
Joseph JM, Ermel D, Bamberg L, García-Oritz A, Pionteck T. Application-Specific SoC Design Using Core Mapping to 3D Mesh NoCs with Nonlinear Area Optimization and Simulated Annealing. Technologies. 2020; 8(1):10. https://doi.org/10.3390/technologies8010010
Chicago/Turabian StyleJoseph, Jan Moritz, Dominik Ermel, Lennart Bamberg, Alberto García-Oritz, and Thilo Pionteck. 2020. "Application-Specific SoC Design Using Core Mapping to 3D Mesh NoCs with Nonlinear Area Optimization and Simulated Annealing" Technologies 8, no. 1: 10. https://doi.org/10.3390/technologies8010010
APA StyleJoseph, J. M., Ermel, D., Bamberg, L., García-Oritz, A., & Pionteck, T. (2020). Application-Specific SoC Design Using Core Mapping to 3D Mesh NoCs with Nonlinear Area Optimization and Simulated Annealing. Technologies, 8(1), 10. https://doi.org/10.3390/technologies8010010