
A Machine Learning Pipeline for Forecasting Time Series in the Banking Sector


Abstract
:1. Introduction
2. Related Work
3. Problem Statement
- (1)
- The predictive period. A significant drawback of some models is that the prediction period is limited to a few points, which is unacceptable in the absolute majority of applied problems (Andrawis et al. 2011).
- (2)
- Data preprocessing and preparation. Autoregressive models are based on the assumption that the original time series is stationary, which contradicts reality in actual data. As a result, researchers have to spend much time making the time series stationary for such models. This problem is especially acute when the number of time series exceeds hundreds and thousands. Respectively, it becomes difficult to look for a way to make each time series stationary (Draper and Smith 1998; Yohannes and Webb 1999).
- (3)
- Computational complexity. Almost all the models listed above need to select a certain number of parameters, and the more complex the model, the more parameters in it need to be tuned (Draper and Smith 1998; Yohannes and Webb 1999; Morariu et al. 2009). Consequently, this imposes limitations on the performance of the forecasting system itself.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Criteria | Regression | Autoregressive | Exp. Smoothing | Decision Trees | Neural Network |
|---|---|---|---|---|---|
| Flexibility and adaptability | + | − | − | + | − |
| Ease of choice of architecture, the need to select parameters | + | + | − | − | − |
| Ability to simulate nonlinear processes | − | − | + | + | + |
| Model learning rate | + | − | − | + | − |
| Consideration of categorical features: | − | − | − | + | + |
| Training set requirements | N | ND | N | − | N |
- N—denotes that data should be normalized.
- S—denotes that it is required to bring the series to a stationary form.
- “+”—models are flexible and adapt when the distribution of the target value changes1;
- “−”—models are inflexible and do not adapt with a sharp change in features because they are tied to the parameters of seasonality. With a sharp change in the distribution of the target value, retraining is required.
- “+”—non-linear connections are taken into account.
- “−”—linear relationships only.
- “+”—fast (comparable to SVM in computational complexity).
- “−”—the method is computationally intensive (comparable to ANN in complexity).
- “+”—taken into account. No conversion required.
4. Methods
4.1. Formation of a Feature Space
- One-hot encoding of calendar features (day of the week, month, weekend, holiday, reduced working day, etc.).
- Lagged variables (time series values for previous days).
- Rolling statistics grouped by calendar features (average, variance, minimum, maximum, etc.).
- Events of massive payments (advance payment, salary, etc.).
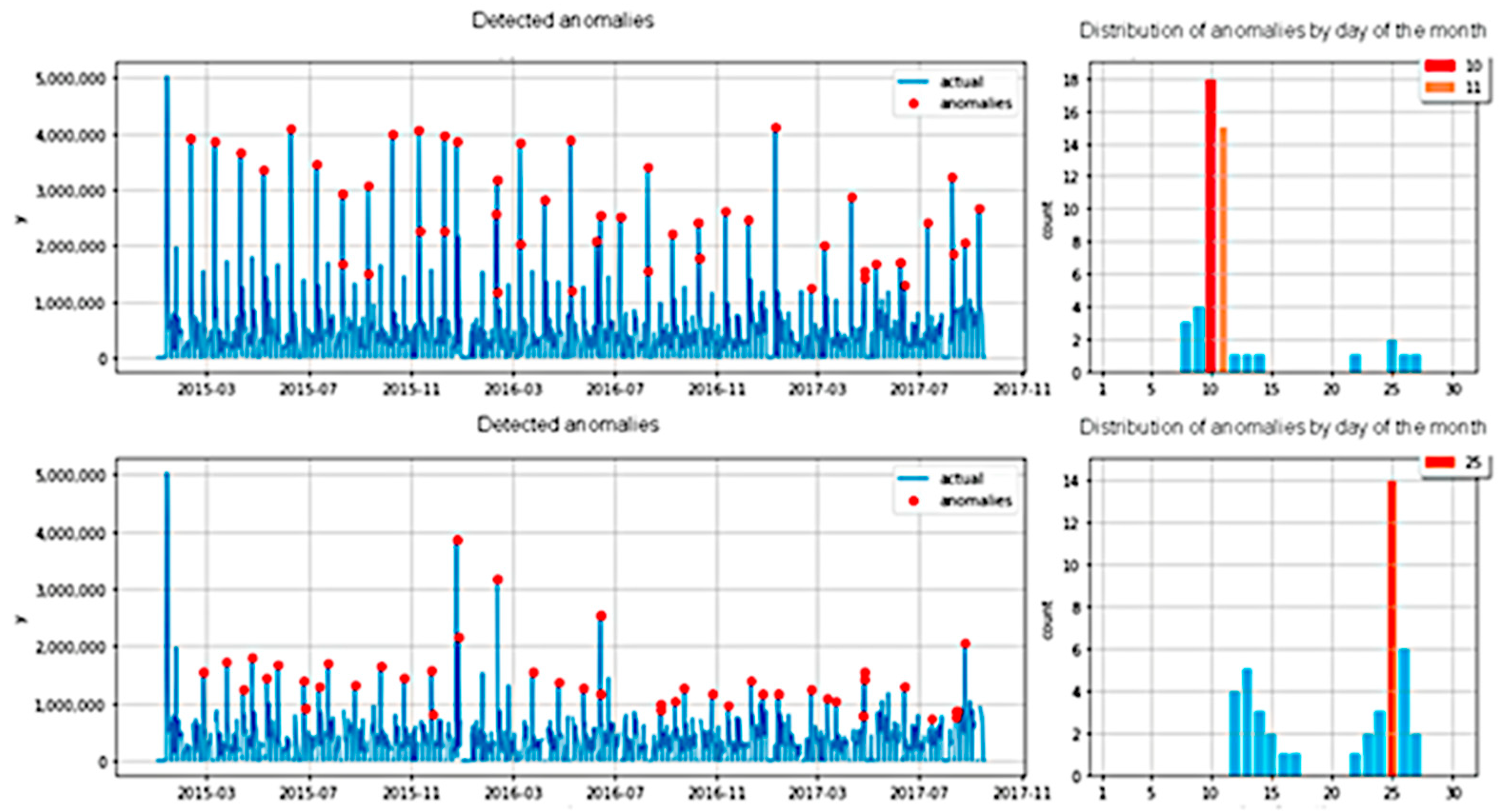
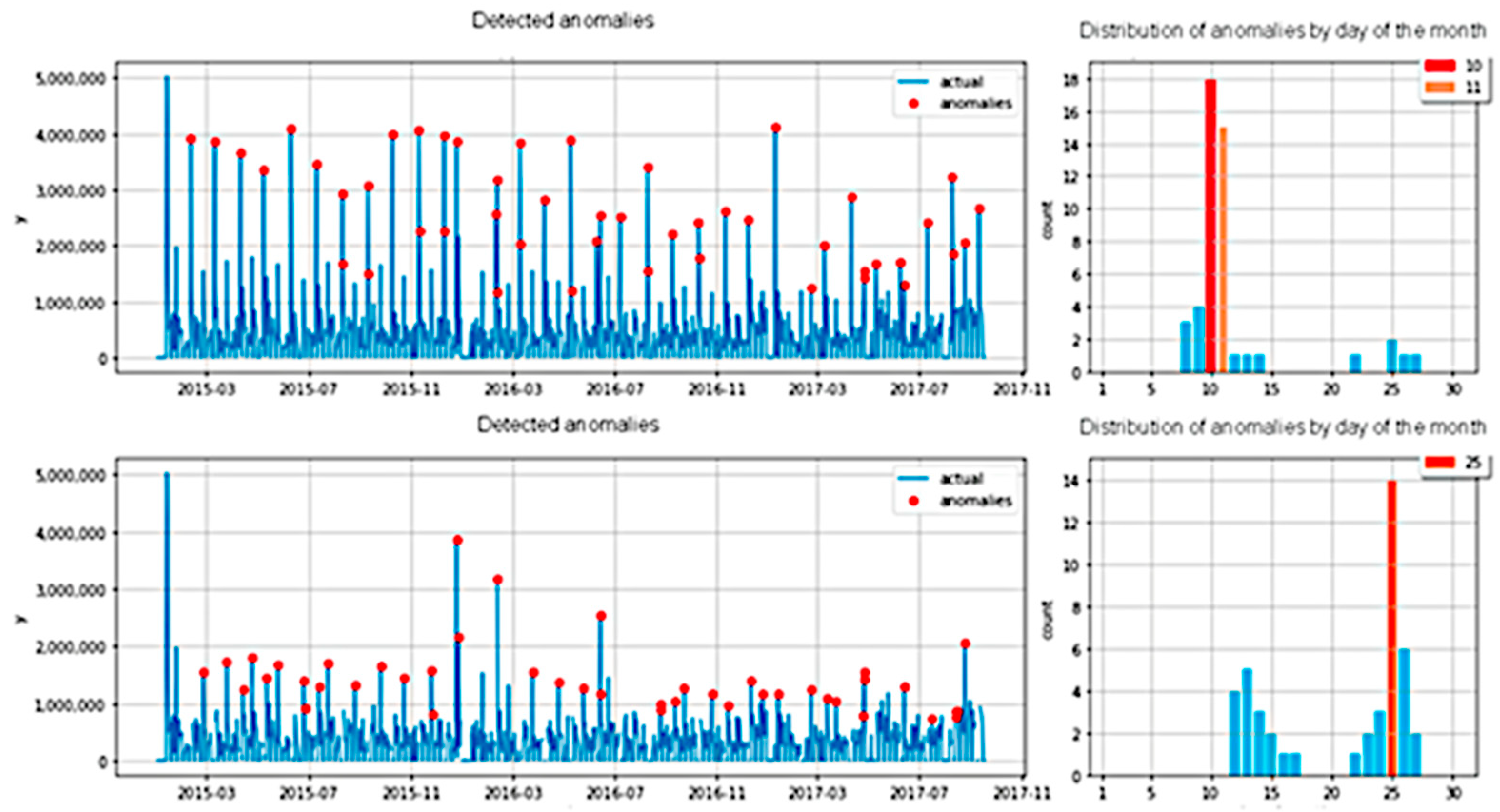
4.2. Anomaly Detection
- Periodic anomalies.
- Anomalies that do not have a periodicity.
- —the upper limit of the cumulative sum.
- —the lower limit of the cumulative amount.
- —values of the time series in the test window.
- —the average of the time series in the learning window.
- —standard deviation of the time series in the learning window.
- —is the number of standard deviations to summarize the changes.
- —the number of standard deviations for the threshold value.
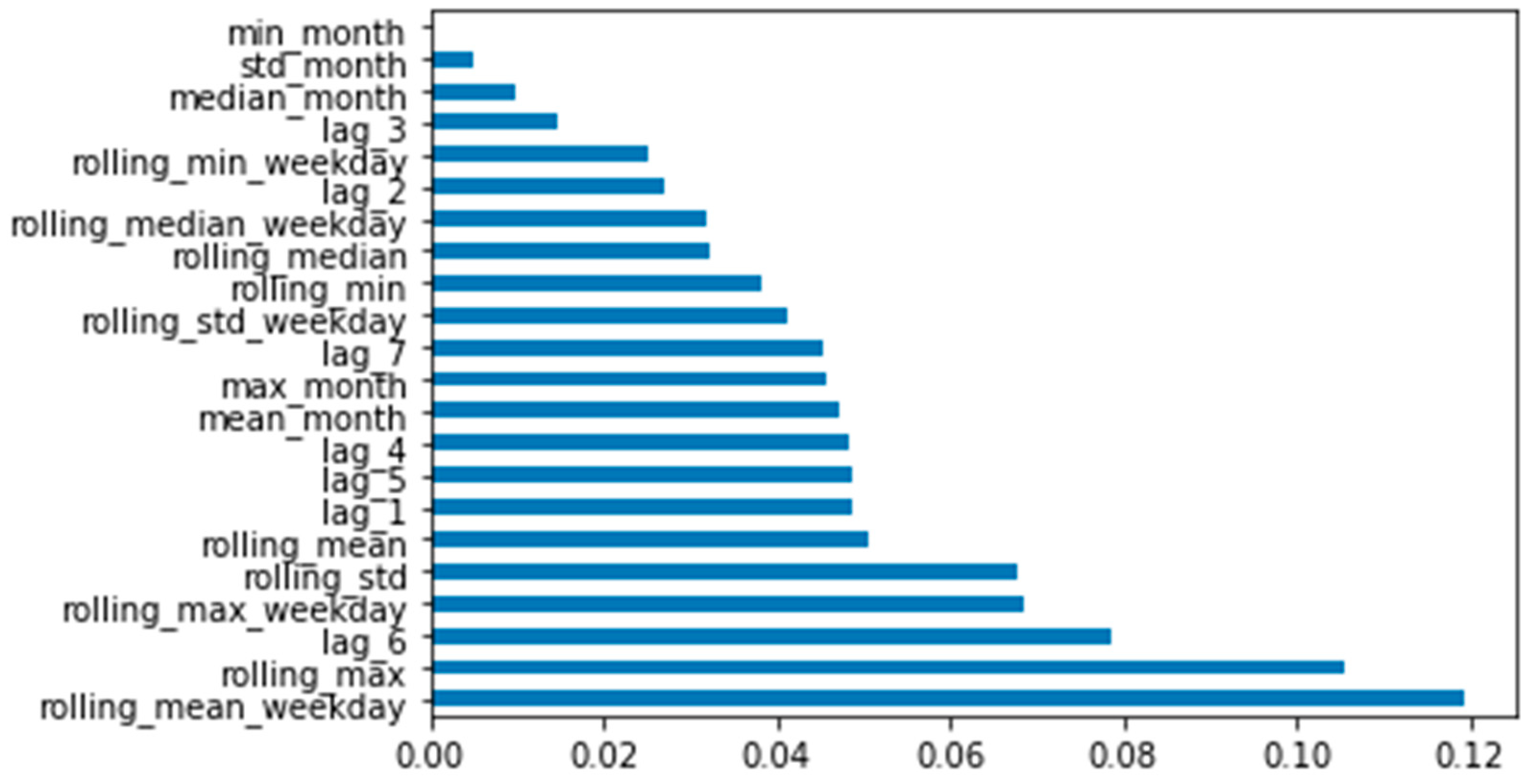
4.3. Feature Selection
4.4. Building Models
4.5. Selection of Hyperparameters
- x—set of model hyperparameters.
- f(x) —our current guess.
- —the current optimal set of hyperparameters.
- —conditional probability that the model is optimal provided that these hyperparameters are applied X.
5. Results and Discussion
- —the predicted value of the time series at the time i.
- yi—the actual value of the time series at the time i.
- t—the number of elements in the sample.
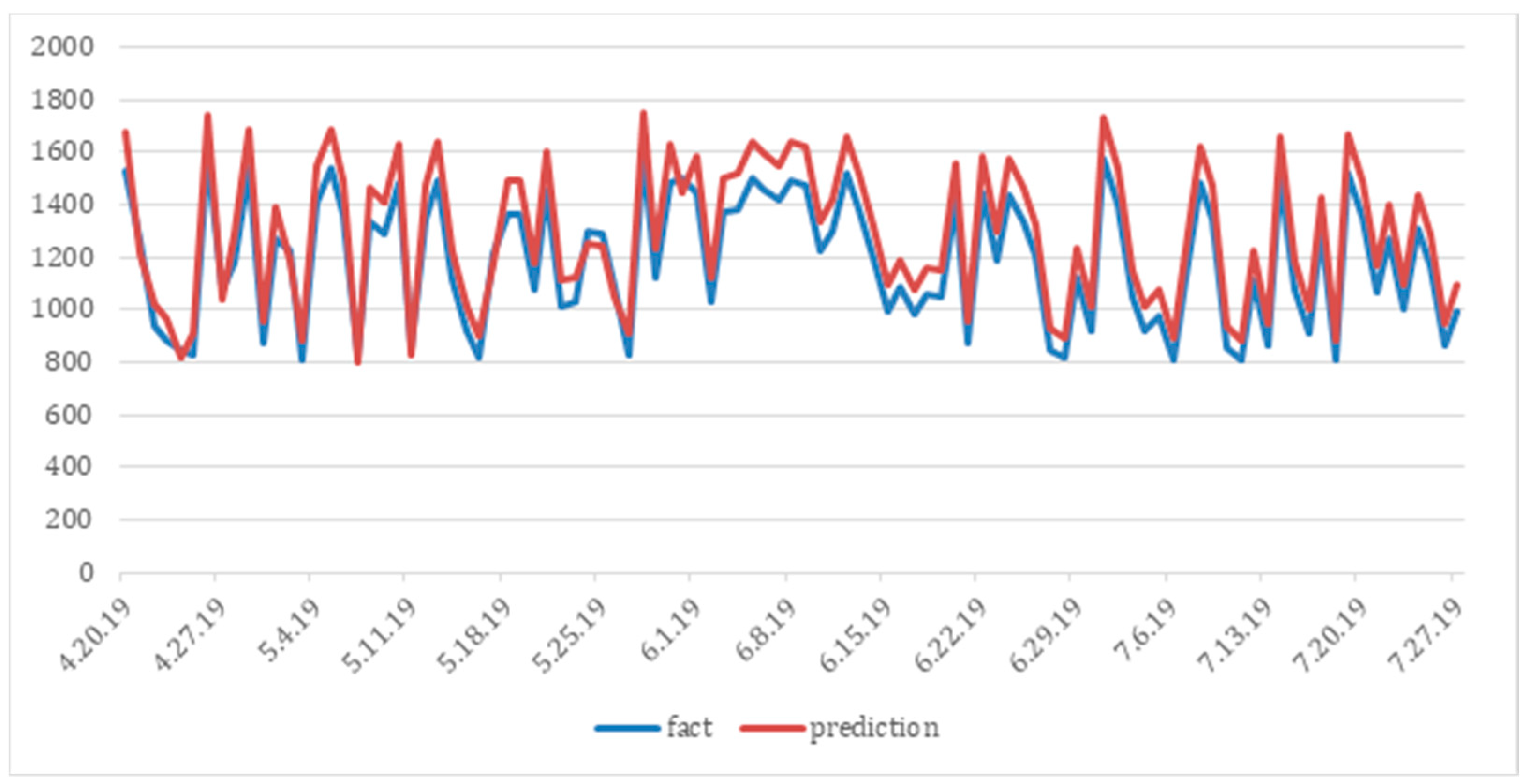
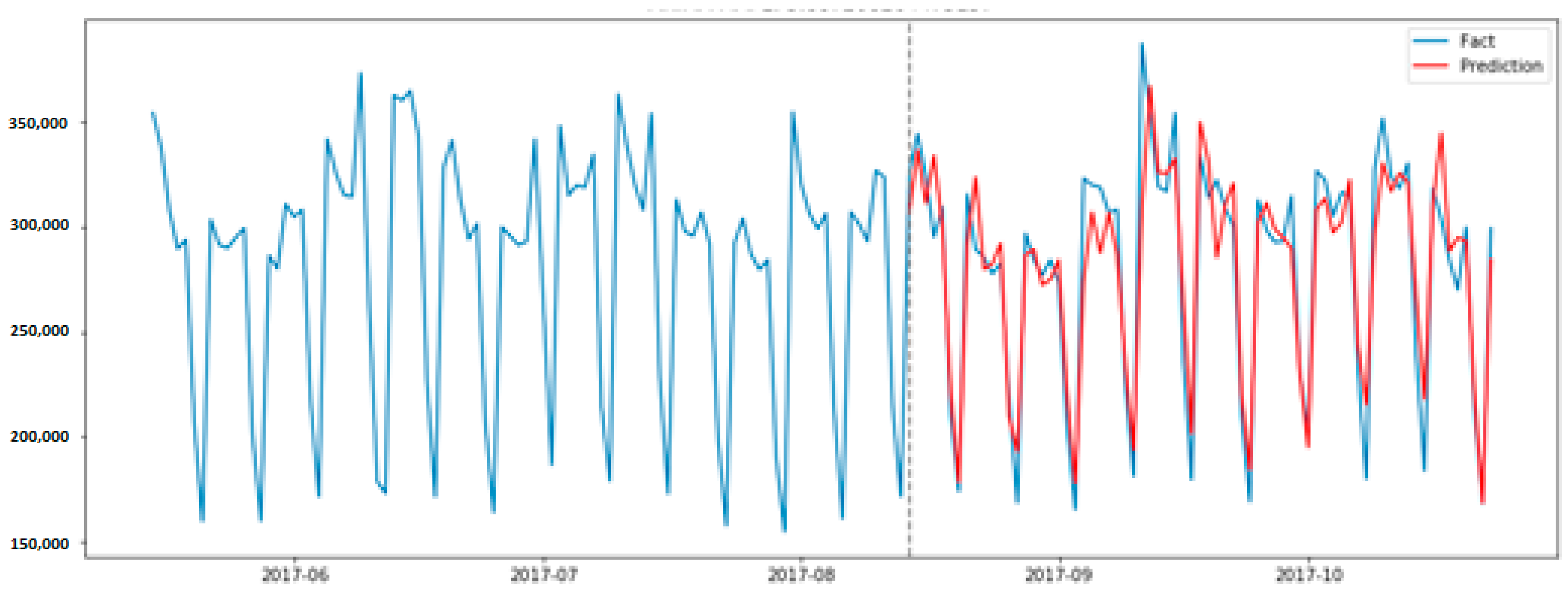
5.1. Case 1. Forecasting Demand in ATMs
5.2. Case 2. Forecasting the Load on Cash Centers
5.3. Case 3. Forecasting the Load on the Call Centers
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
| 1 | This refers to the ability of models based on specific ones to maintain their predictive ability with a sharp change in the distribution of the value of features in the composition of time series. Flexible models do not explicitly set the parameters of seasonality and trend, and as a result, they are able to make more robust predictions. |
| 2 | https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.OneHotEncoder.html (accessed on 27 September 2021). |
| 3 | https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.LabelEncoder.html# (accessed on 27 September 2021). |
References
- Adeodato, Paulo, Adrian Arnaud, Germano Vasconcelos, Rodrigo Cunha, and Domingos Monteiro. 2014. NN5 Forecasting Competition-ADEODATO Paulo-CIn UFPE-BRAZIL. Available online: http://www.neural-forecasting-competition.com/NN5/ (accessed on 15 December 2021).
- Aguilar-Rivera, Rubén, Manuel Valenzuela-Rendón, and J. J. Rodríguez-Ortiz. 2015. Genetic algorithms and Darwinian approaches in financial applications: A survey. Expert Systems with Applications 42: 7684–97. [Google Scholar] [CrossRef]
- Aliev, Rafik Aziz, Bijan Fazlollahi, and Rashad Rafik Aliev. 2004. Soft Computing in Electronic Business. In Soft Computing and Its Applications in Business and Economics. Berlin/Heidelberg: Springer, pp. 431–46. [Google Scholar] [CrossRef]
- Andrawis, Robert R., Amir F. Atiya, and Hisham El-Shishiny. 2011. Forecast combinations of computational intelligence and linear models for the NN5 time series forecasting competition. International Journal of Forecasting 27: 672–88. [Google Scholar] [CrossRef]
- Arabani, Soodabeh Poorzaker, and Hosein Ebrahimpour Komleh. 2019. The Improvement of Forecasting ATMs Cash Demand of Iran Banking Network Using Convolutional Neural Network. Arabian Journal for Science and Engineering 44: 3733–43. [Google Scholar] [CrossRef]
- Asad, Muhammad, Muhammad Shahzaib, Yusra Abbasi, and Muhammad Rafi. 2020. A Long-Short-Term-Memory Based Model for Predicting ATM Replenishment Amount. Paper present at the 2020 21st International Arab Conference on Information Technology (ACIT), Giza, Egypt, November 28–30. [Google Scholar] [CrossRef]
- Atsalakis, George S., and Kimon P. Valavanis. 2009. Surveying stock market forecasting techniques—Part II: Soft computing methods. Expert Systems with Applications 36: 5932–41. [Google Scholar] [CrossRef]
- Aue, Alexander, Lajos Horváth, Mario Kühn, and Josef Steinebach. 2012. On the reaction time of moving sum detectors. Journal of Statistical Planning and Inference 142: 2271–88. [Google Scholar] [CrossRef]
- Bahrammirzaee, Arash. 2010. Comparative survey of artificial intelligence applications in finance: Artificial neural networks, expert system and hybrid intelligent systems. Neural Computing & Applications 19: 1165–95. [Google Scholar] [CrossRef]
- Baptista, Ricardo, and Matthias Poloczek. 2018. Bayesian Optimization of Combinatorial Structures. International Conference on Machine Learning, Proceedings of Machine Learning Research. pp. 462–71. Available online: http://proceedings.mlr.press/v80/baptista18a.html (accessed on 15 December 2021).
- Catal, Cagatay, Ayse Fenerci, Burcak Ozdemir, and Onur Gulmez. 2015. Improvement of Demand Forecasting Models with Special Days. Procedia Computer Science 59: 262–67. [Google Scholar] [CrossRef] [Green Version]
- Cavalcante, Rodolfo C., Rodrigo C. Brasileiro, Victor LF Souza, Jarley P. Nobrega, and Adriano LI Oliveira. 2016. Computational Intelligence and Financial Markets: A Survey and Future Directions. Expert Systems with Applications 55: 194–211. [Google Scholar] [CrossRef]
- Cerqueira, Vitor, Luis Torgo, and Igor Mozetič. 2020. Evaluating time series forecasting models: An empirical study on performance estimation methods. Machine Learning 109: 1997–2028. [Google Scholar] [CrossRef]
- Chatterjee, Amitava, O. Felix Ayadi, and Bryan E. Boone. 2000. Artificial Neural Network and the Financial Markets: A Survey. Managerial Finance 26: 32–45. [Google Scholar] [CrossRef]
- Chen, Shu-Heng. 2002. Genetic Algorithms and Genetic Programming in Computational Finance: An Overview of the Book. In Genetic Algorithms and Genetic Programming in Computational Finance. Boston: Springer, pp. 1–26. [Google Scholar] [CrossRef]
- Claesen, Marc, and Bart De Moor. 2015. Hyperparameter Search in Machine Learning. arXiv arXiv:1502.02127. [Google Scholar]
- Das, Abhimanyu, and David Kempe. 2011. Submodular meets Spectral: Greedy Algorithms for Subset Selection, Sparse Approximation and Dictionary Selection. arXiv arXiv:1102.3975. [Google Scholar]
- Draper, Norman R., and Harry Smith. 1998. Applied Regression Analysis. Wiley Series in Probability and Statistics; New York: Wiley. [Google Scholar] [CrossRef]
- Dymowa, Ludmila. 2011. Soft Computing in Economics and Finance. Intelligent Systems Reference Library. Berlin/Heidelberg: Springer. [Google Scholar] [CrossRef]
- Ekinci, Yeliz, Jye-Chyi Lu, and Ekrem Duman. 2015. Optimization of ATM cash replenishment with group-demand forecasts. Expert Systems with Applications 42: 3480–90. [Google Scholar] [CrossRef]
- Ekinci, Yeliz, Nicoleta Serban, and Ekrem Duman. 2019. Optimal ATM replenishment policies under demand uncertainty. Operational Research 21: 999–1029. [Google Scholar] [CrossRef]
- Elmsili, B., and B. Outtaj. 2018. Artificial neural networks applications in economics and management research: An exploratory literature review. Paper present at the 4th International Conference on Optimization and Applications (ICOA), ENSET of Mohammedia, BP 159, BD Hassan II, Mohammedia, Morocco, April 26–27. [Google Scholar] [CrossRef]
- Fremdt, Stefan. 2015. Page’s sequential procedure for change-point detection in time series regression. Statistics 49: 128–55. [Google Scholar] [CrossRef] [Green Version]
- Hasheminejad, Seyed Mohammad Hossein, and Zahra Reisjafari. 2017. ATM management prediction using Artificial Intelligence techniques: A survey. Intelligent Decision Technologies 11: 375–98. [Google Scholar] [CrossRef]
- Hewamalage, Hansika, Christoph Bergmeir, and Kasun Bandara. 2021. Recurrent Neural Networks for Time Series Forecasting: Current status and future directions. International Journal of Forecasting 37: 388–427. [Google Scholar] [CrossRef]
- Hu, Yong, Kang Liu, Xiangzhou Zhang, Lijun Su, E. W. T. Ngai, and Mei Liu. 2015. Application of evolutionary computation for rule discovery in stock algorithmic trading: A literature review. Applied Soft Computing 36: 534–51. [Google Scholar] [CrossRef]
- Jadwal, Pankaj Kumar, Sonal Jain, Umesh Gupta, and Prashant Khanna. 2018. K-Means Clustering with Neural Networks for ATM Cash Repository Prediction. Paper present at the Information and Communication Technology for Intelligent Systems (ICTIS 2017), Ahmedabad, India, March 25–26; vol. 1, pp. 588–96. [Google Scholar] [CrossRef]
- Kamini, Venkatesh, Vadlamani Ravi, and D. Nagesh Kumar. 2014. Chaotic time series analysis with neural networks to forecast cash demand in ATMs. Paper present at the 2014 IEEE International Conference on Computational Intelligence and Computing Research, Coimbatore, India, December 18–20. [Google Scholar] [CrossRef]
- Katarya, Rahul, and Anmol Mahajan. 2017. A survey of neural network techniques in market trend analysis. Paper present at the 2017 International Conference on Intelligent Sustainable Systems (ICISS), Tirupur, India, December 7–8. [Google Scholar] [CrossRef]
- Khanarsa, Paisit, and Krung Sinapiromsaran. 2017. Multiple ARIMA subsequences aggregate time series model to forecast cash in ATM. Paper present at the 2017 9th International Conference on Knowledge and Smart Technology (KST), Wolfenbüttel, Germany, February 1–4. [Google Scholar] [CrossRef]
- Kovalerchuk, Boris, and Evgenii Vityaev. 2006. Data Mining in Finance: Advances in Relational and Hybrid Methods. Berlin/Heidelberg: Springer Science & Business Media, Available online: https://play.google.com/store/books/details?id=quDlBwAAQBAJ (accessed on 15 December 2021).
- Li, Yuhong, and Weihua Ma. 2010. Applications of Artificial Neural Networks in Financial Economics: A Survey. Paper present at the 2010 International Symposium on Computational Intelligence and Design, Hangzhou, China, October 29–31. [Google Scholar] [CrossRef]
- Lundberg, Scott M., and Su-In Lee. 2017. A Unified Approach to Interpreting Model Predictions. arXiv arXiv:1705.07874. [Google Scholar]
- Morariu, Nicolae, Eugenia Iancu, and Sorin Vlad. 2009. A Neural Network Model for Time-Series Forecasting. Journal for Economic Forecasting 4: 213–23. Available online: https://ipe.ro/rjef/rjef4_09/rjef4_09_13.pdf (accessed on 15 December 2021).
- Nair, Binoy B., and V. P. Mohandas. 2014. Artificial intelligence applications in financial forecasting—A survey and some empirical results. Intelligent Decision Technologies 9: 99–140. [Google Scholar] [CrossRef]
- Ozer, Fazilet, Ismail Hakki Toroslu, Pinar Karagoz, and Ferhat Yucel. 2019. Dynamic Programming Solution to ATM Cash Replenishment Optimization Problem. In International Conference on Intelligent Computing & Optimization. Cham: Springer, pp. 428–37. [Google Scholar] [CrossRef]
- Ponsich, Antonin, Antonio Lopez Jaimes, and Carlos A. Coello Coello. 2013. A Survey on Multiobjective Evolutionary Algorithms for the Solution of the Portfolio Optimization Problem and Other Finance and Economics Applications. IEEE Transactions on Evolutionary Computation 17: 321–44. [Google Scholar] [CrossRef]
- Pradeepkumar, Dadabada, and Vadlamani Ravi. 2018. Soft computing hybrids for FOREX rate prediction: A comprehensive review. Computers & Operations Research 99: 262–84. [Google Scholar] [CrossRef]
- Rafi, Muhammad, Mohammad Taha Wahab, Muhammad Bilal Khan, and Hani Raza. 2020. ATM Cash Prediction Using Time Series Approach. Paper present at the 2020 3rd International Conference on Computing, Mathematics and Engineering Technologies (iCoMET), Sindh, Pakistan, January 29–30. [Google Scholar] [CrossRef]
- Rajwani, Akber, Tahir Syed, Behraj Khan, and Sadaf Behlim. Regression Analysis for ATM Cash Flow Prediction. Paper present at the International Conference on Frontiers of Information Technology (FIT), Islamabad, Pakistan, December 18–20. [CrossRef]
- Rong, Jingfeng, and Di Wang. 2021. Research on Prediction of the Cash Usage in Banks Based on LSTM of Improved Gray Wolf Optimizer. Journal of Physics: Conference Series 1769: 012031. [Google Scholar] [CrossRef]
- Serengil, Sefik Ilkin, and Alper Ozpinar. 2019. ATM Cash Flow Prediction and Replenishment Optimization with ANN. Uluslararası Muhendislik Arastirma ve Gelistirme Dergisi 11: 402–8. [Google Scholar] [CrossRef]
- Sezer, Omer Berat, Mehmet Ugur Gudelek, and Ahmet Murat Ozbayoglu. 2020. Financial time series forecasting with deep learning: A systematic literature review: 2005–2019. Applied Soft Computing 90: 106181. [Google Scholar] [CrossRef] [Green Version]
- Shcherbitsky, V. V., A. A. Panachev, M. A. Medvedeva, and E. I. Kazakova. 2019. On the prediction of dispenser status in ATM using gradient boosting method. AIP Conference Proceedings 2186: 050015. [Google Scholar] [CrossRef]
- Slack, Dylan, Sophie Hilgard, Emily Jia, Sameer Singh, and Himabindu Lakkaraju. 2020. Fooling LIME and SHAP. Paper present at the AAAI/ACM Conference on AI, Ethics, and Society, New York, NY, USA, May 19. [Google Scholar] [CrossRef]
- Tapia, Ma Guadalupe Castillo, and Carlos A. Coello Coello. 2007. Applications of multi-objective evolutionary algorithms in economics and finance: A survey. Paper present at the 2007 IEEE Congress on Evolutionary Computation, Singapore, September 25–28. [Google Scholar] [CrossRef]
- Tkáč, Michal, and Robert Verner. 2016. Artificial neural networks in business: Two decades of research. Applied Soft Computing 38: 788–804. [Google Scholar] [CrossRef]
- Vangala, Sarveswararao, and Ravi Vadlamani. 2020. ATM Cash Demand Forecasting in an Indian Bank with Chaos and Deep Learning. arXiv arXiv:2008.10365. [Google Scholar]
- Venkatesh, Kamini, Vadlamani Ravi, Anita Prinzie, and Dirk Van den Poel. 2014. Cash demand forecasting in ATMs by clustering and neural networks. European Journal of Operational Research 232: 383–92. [Google Scholar] [CrossRef]
- Yohannes, Yisehac, and Patrick Webb. 1999. Classification and Regression Trees, CART: A User Manual for Identifying Indicators of Vulnerability to Famine and Chronic Food Insecurity. Washington, DC: International Food Policy Research Institute, Available online: https://play.google.com/store/books/details?id=7iuq4ikyNdoC (accessed on 15 December 2021).







| Feature Name | Description |
|---|---|
| min_month | the minimum demand for a month |
| std_month | monthly demand standard deviation |
| median_month | monthly demand standard deviation |
| lag_3 | the amount of demand three days before the forecast point |
| rolling_min_weekday | the minimum demand value for two days of the same past (on two Tuesdays, on two Wednesdays) |
| lag_2 | the amount of demand two days before the forecast point |
| rolling_median_weekday | demand median for two days of the same past (on two Tuesdays, on two Wednesdays) |
| rolling_median | weekly medial demand value |
| rolling_median | weekly medial demand value |
| rolling_min | the minimum demand value for the week |
| rolling_std_weekday | weekly standard deviation from the demand point |
| lag_7 | the amount of demand seven days before the forecast point |
| max_month | the maximum demand for the past month |
| mean_month | the average demand for the past month |
| lag_4 | the amount of demand four days before the forecast point |
| lag_5 | the amount of demand five days before the forecast point |
| lag_1 | the amount of demand one day before the forecast point |
| rolling_mean | average monthly demand value |
| rolling _std | weekly demand standard deviation |
| rolling _max_weekday | the maximum demand value for two of the same past days of the week (on two Tuesdays, on two Wednesdays) |
| lag_6 | the amount of demand six days ago |
| rolling_max | maximum demand value for the week |
| rolling_mean_weekday | the average demand for two days of the same past (on two Tuesdays, on two Wednesdays) |
| Case No. | MAPE Score with Anomaly Detection | MAPE Score without Anomaly Detection |
|---|---|---|
| 1 | 18% | 29% |
| 2 | 11% | 24% |
| 3 | 8% | 18% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gorodetskaya, O.; Gobareva, Y.; Koroteev, M. A Machine Learning Pipeline for Forecasting Time Series in the Banking Sector. Economies 2021, 9, 205. https://doi.org/10.3390/economies9040205
Gorodetskaya O, Gobareva Y, Koroteev M. A Machine Learning Pipeline for Forecasting Time Series in the Banking Sector. Economies. 2021; 9(4):205. https://doi.org/10.3390/economies9040205
Chicago/Turabian StyleGorodetskaya, Olga, Yana Gobareva, and Mikhail Koroteev. 2021. "A Machine Learning Pipeline for Forecasting Time Series in the Banking Sector" Economies 9, no. 4: 205. https://doi.org/10.3390/economies9040205