
A Systematic Literature Review of Student’ Performance Prediction Using Machine Learning Techniques


Abstract
:1. Introduction
- Predict the performance of students at risk in academic institutions
- Determine and predict students’ dropout from on-going courses
- Evaluate students’ performance based on dynamic and static data
- Determine the remedial plans for the observed cases in the first three objectives
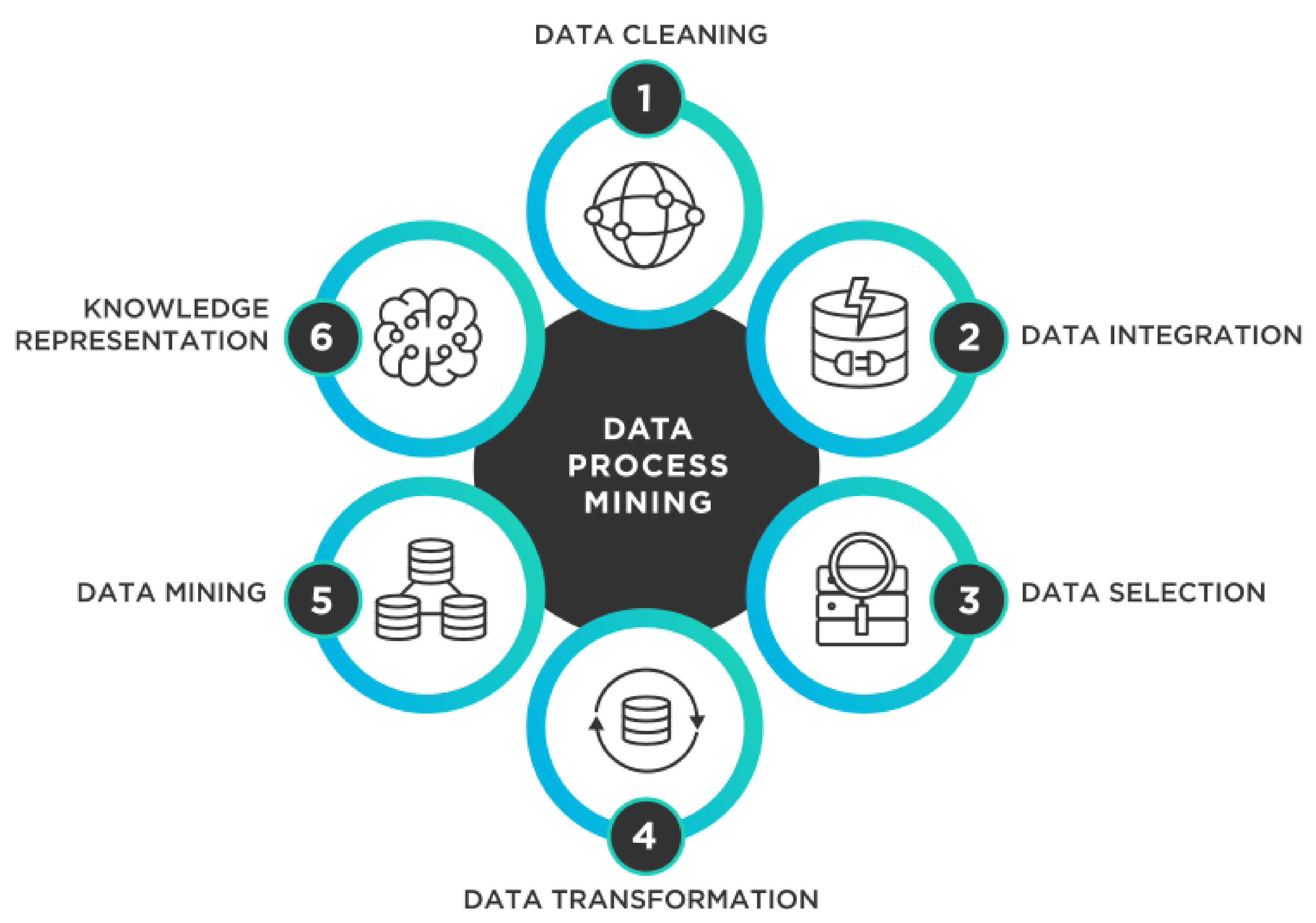
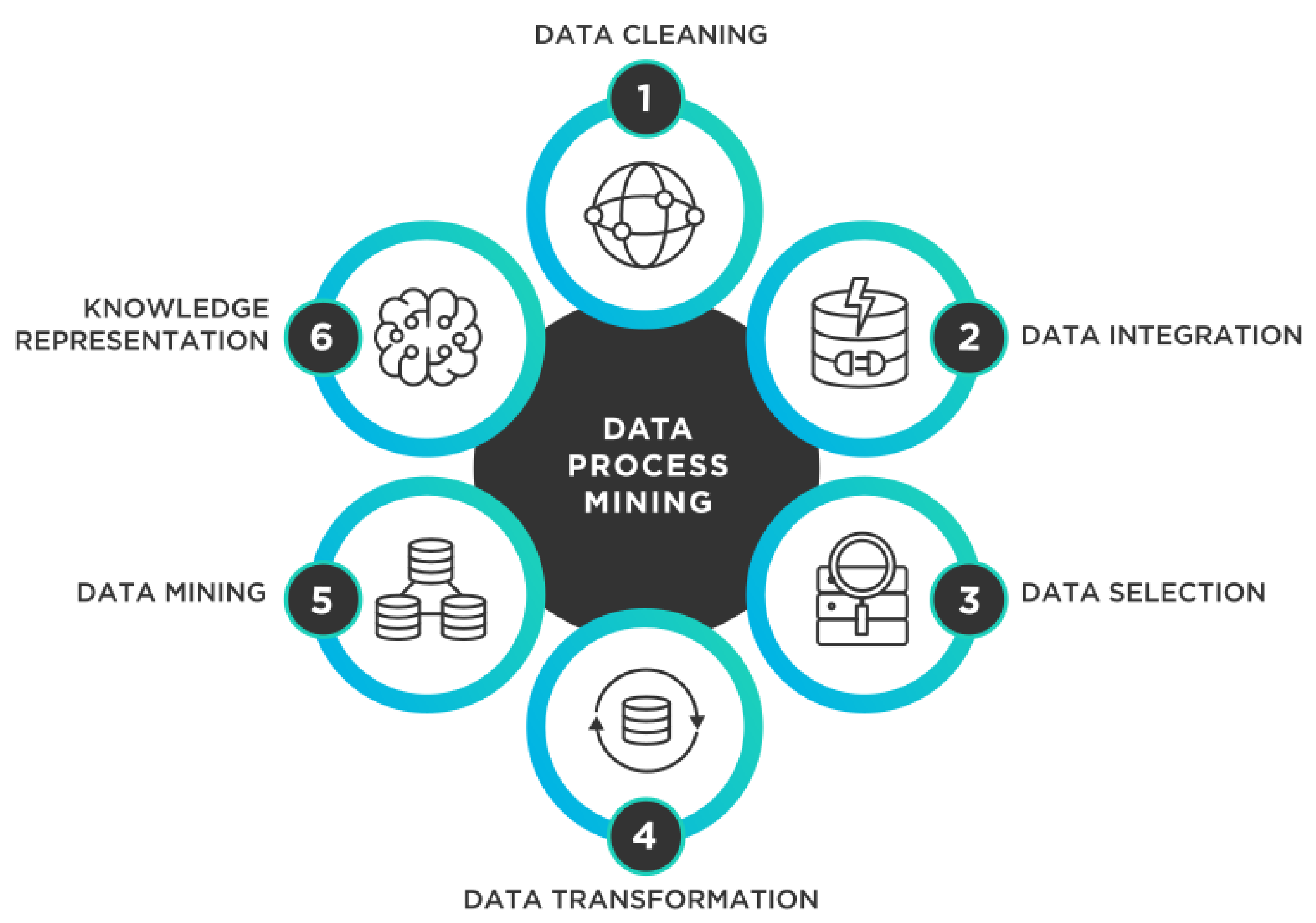
2. Research Method
2.1. Research Questions
- What type of problems exist in the literature for Student Performance Prediction?
- What solutions are proposed to address these problems?
- What is the overall research productivity in this field?
2.2. Data Sources
2.3. Used Search Terms
- EDM OR Performance OR eLearning OR Machine Learning OR Data Mining
- Educational Data Mining OR Student Performance Prediction OR Evaluations of Students OR Performance Analysis of Students OR Learning Curve Prediction
- Students’ Intervention OR Dropout Prediction OR Student’s risks OR Students monitoring OR Requirements of students OR Performance management of students OR student classification.
- Predict* AND student AND machine learning
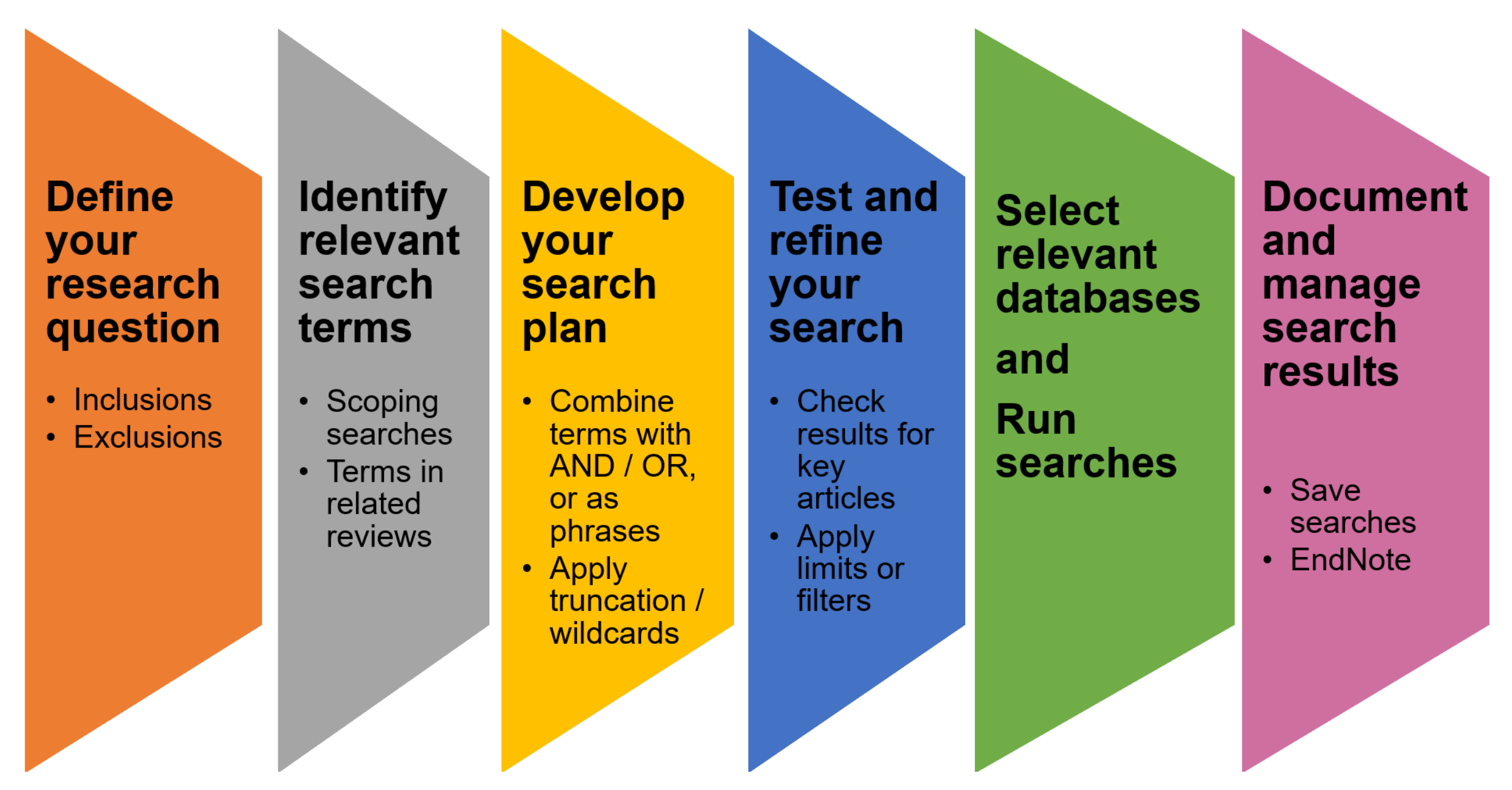
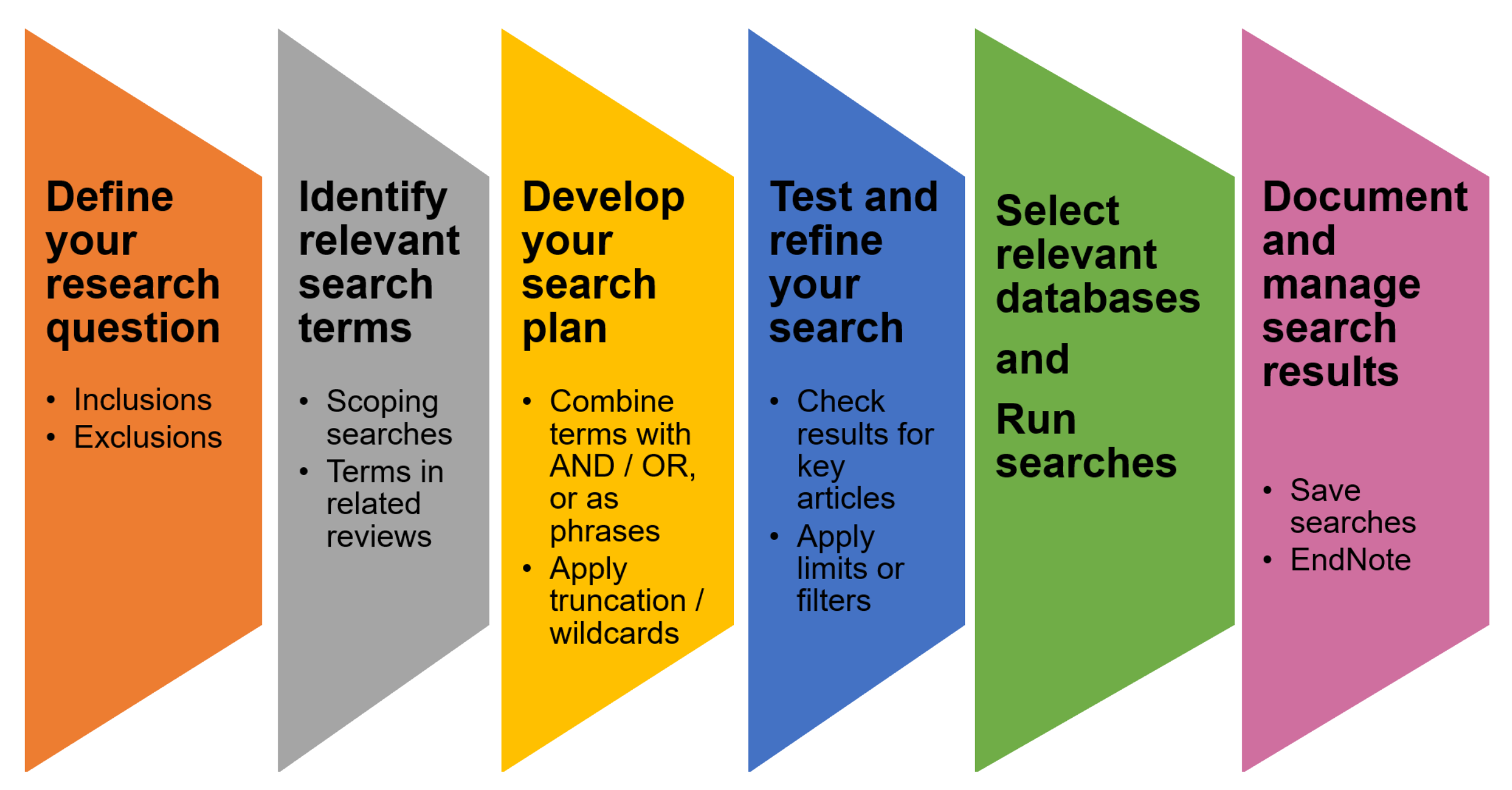
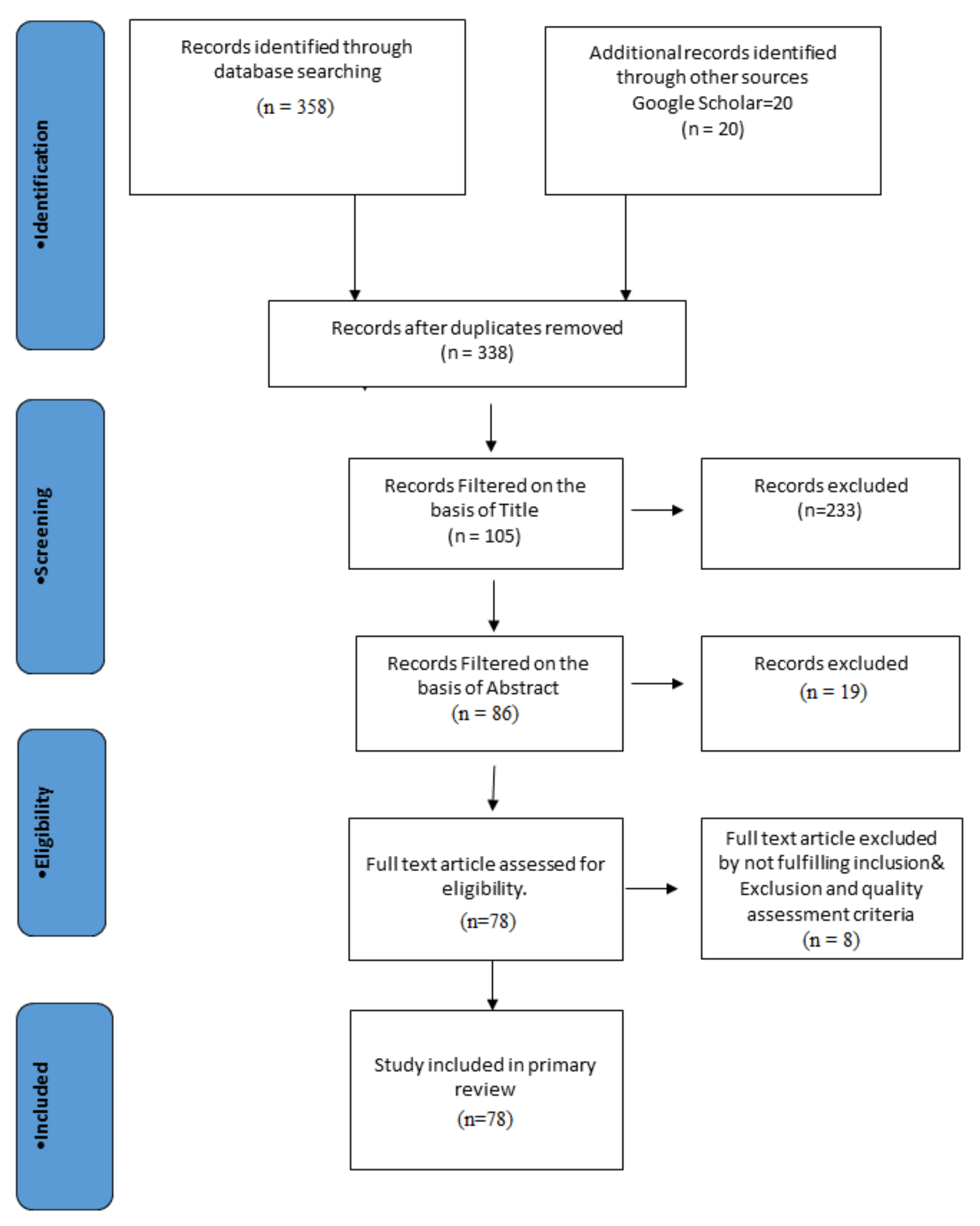
2.4. The Paper Selection Procedure for Review
2.5. Inclusion and Exclusion Criteria
2.5.1. Inclusion
- Studies related to Student’s Performance Prediction;
- Research Papers that were accepted and published in a blind peer-reviewed Journals or conferences;
- Papers that were from 2009 to 2021 era;
- Paper that were in the English language.
2.5.2. Exclusion
- Studies other than Student’s Performance Prediction using ML.
- Papers which had not conducted experiments or had validation of proposed methods.
- Short papers, Editorials, Business Posters, Patents, already conducted Reviews, Technical Reports, Wikipedia Articles, Survey Studies, and extended papers of already reviewed papers.
2.6. Selection Execution
2.7. Quality Assessment Criteria
- QC1: are review objectives clearly defined?
- QC2: are proposed methods well defined?
- QC3: is proposed accuracy measured and validated?
- QC4: are limitations of the review explicitly stated?
3. Results and Discussion
3.1. Predicting the Performance of Students at Risk Using ML
Comparisons of Performance Prediction Approaches
3.2. Students Dropout Prediction Using ML
Comparisons of Dropout Prediction Approaches
3.3. Evaluation of Students’ Performance Based on Static Data and Dynamic Data
Application of Static and Dynamic Data Approaches
3.4. Remedial Action Plan
- Courtesy call at the start of the academic year
- The public message of welcome to the course via a virtual classroom
- The video conference welcoming session
- Email to potential dropout
- A telephone call to potential dropout
- A telephone call to potential dropout (from one or more courses)
Remedial Action Approaches
4. Discussion and Critical Review
- Most studies used minimal data to train the machine learning methods. However, it is a fact that ML algorithms need massive data in order to perform accurately.
- The review also revealed that a few studies have focused on class balancing or data balancing. Class balancing is mainly considered important in obtaining high classification performance [50].
- The temporal nature of features used for at-risk and dropout students’ predictions has not been studied to its potential. The values of these features change with time due to their dynamic nature. Incorporating temporal features for classification has the ability to enhance the predictor performance [40,48,67]. Khan et al. [67] examine the temporal features for text classification.
- It was also observed that the prediction of students at-risk and dropout studies for on-campus students utilized the dataset with a very minimal number of instances. Machine learning algorithms trained on small datasets might not achieve satisfactory results. Moreover, the data pre-processing technique can contribute significantly to more accurate results.
- Most of the research studies tackled the problem as a classification task. Whereas very few studies focused on clustering algorithms that detected the classes of students’ in the dataset. Furthermore, the problems mentioned above are treated as binary classification while several other classes would be introduced to help the management develop more effective intervention plans.
- Less attention has been paid to feature engineering tasks, where the types of features can influence the predictor’s performance. Three features were primarily used in the studies, i.e., students’ demographics, academic, and e-learning interaction session logs.
- It was also observed that most of the studies used traditional machine learning algorithms such as SVM, DT, NB, KNN, etc., and only a few have investigated the potential of deep learning algorithms.
- Last but not least, the current literature does not consider the dynamic nature of student performance. The students’ performance is an evolving process and improves or drops steadily. The performance of predictors on real-time dynamic data is yet to be explored.
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| RF | Random Forest |
| LG | Logestic Regression |
| NN | Neural Network |
| SVM | Support Vector Machine |
| MLP | Multi layer Perceptron |
| DT | Decision Tree |
| NB | Naive Bayes |
| KNN | K-nearest neighbors |
| SMOTE | Synthetic Minority Over-sampling Technique |
References
- Romero, C.; Ventura, S.; Pechenizkiy, M.; Baker, R.S. Handbook of Educational Data Mining; CRC Press: Boca Raton, FL, USA, 2010. [Google Scholar]
- Hernández-Blanco, A.; Herrera-Flores, B.; Tomás, D.; Navarro-Colorado, B. A systematic review of deep learning approaches to educational data mining. Complexity 2019, 2019, 1306039. [Google Scholar] [CrossRef]
- Bengio, Y.; Lecun, Y.; Hinton, G. Deep Learning for AI. Commun. ACM 2021, 64, 58–65. [Google Scholar] [CrossRef]
- Lykourentzou, I.; Giannoukos, I.; Mpardis, G.; Nikolopoulos, V.; Loumos, V. Early and dynamic student achievement prediction in e-learning courses using neural networks. J. Am. Soc. Inf. Sci. Technol. 2009, 60, 372–380. [Google Scholar] [CrossRef]
- Kuzilek, J.; Hlosta, M.; Herrmannova, D.; Zdrahal, Z.; Wolff, A. OU Analyse: Analysing at-risk students at The Open University. Learn. Anal. Rev. 2015, 2015, 1–16. [Google Scholar]
- He, J.; Bailey, J.; Rubinstein, B.I.; Zhang, R. Identifying at-risk students in massive open online courses. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Kloft, M.; Stiehler, F.; Zheng, Z.; Pinkwart, N. Predicting MOOC dropout over weeks using machine learning methods. In Proceedings of the EMNLP 2014 Workshop on Analysis of Large Scale Social Interaction in MOOCs; Department of Computer Science, Humboldt University of Berlin: Berlin, Germany, 2014; pp. 60–65. [Google Scholar]
- Alapont, J.; Bella-Sanjuán, A.; Ferri, C.; Hernández-Orallo, J.; Llopis-Llopis, J.; Ramírez-Quintana, M. Specialised tools for automating data mining for hospital management. In Proceedings of the First East European Conference on Health Care Modelling and Computation, Craiova, Romania, 31 August–2 September 2005; pp. 7–19. [Google Scholar]
- Hellas, A.; Ihantola, P.; Petersen, A.; Ajanovski, V.V.; Gutica, M.; Hynninen, T.; Knutas, A.; Leinonen, J.; Messom, C.; Liao, S.N. Predicting academic performance: A systematic literature review. In Proceedings of the Companion of the 23rd Annual ACM Conference on Innovation and Technology in Computer Science Education, Larnaca, Cyprus, 2–4 July 2018; pp. 175–199. [Google Scholar]
- Alyahyan, E.; Düştegör, D. Predicting academic success in higher education: Literature review and best practices. Int. J. Educ. Technol. High. Educ. 2020, 17, 1–21. [Google Scholar] [CrossRef] [Green Version]
- Namoun, A.; Alshanqiti, A. Predicting student performance using data mining and learning analytics techniques: A systematic literature review. Appl. Sci. 2021, 11, 237. [Google Scholar] [CrossRef]
- Okoli, C. A guide to conducting a standalone systematic literature review. Commun. Assoc. Inf. Syst. 2015, 37, 43. [Google Scholar] [CrossRef] [Green Version]
- Kitchenham, B. Procedures for Performing Systematic Reviews; Keele University: Keele, UK, 2004; Volume 33, pp. 1–26. [Google Scholar]
- Piper, R.J. How to write a systematic literature review: A guide for medical students. Natl. AMR Foster. Med. Res. 2013, 1, 1–8. [Google Scholar]
- Bhandari, M.; Guyatt, G.H.; Montori, V.; Devereaux, P.; Swiontkowski, M.F. User’s guide to the orthopaedic literature: How to use a systematic literature review. JBJS 2002, 84, 1672–1682. [Google Scholar] [CrossRef] [Green Version]
- Loumos, V. Dropout prediction in e-learning courses through the combination of machine learning techniques. Comput. Educ. 2009, 53, 950–965. [Google Scholar]
- Kotsiantis, S. Educational data mining: A case study for predicting dropout-prone students. Int. J. Knowl. Eng. Soft Data Paradig. 2009, 1, 101–111. [Google Scholar] [CrossRef]
- Kovacic, Z. Early Prediction of Student Success: Mining Students’ Enrolment Data. In Proceedings of the Informing Science and Information Technology Education Joint Conference, Cassino, Italy, 19–24 June 2010. [Google Scholar]
- Kotsiantis, S.; Patriarcheas, K.; Xenos, M. A combinational incremental ensemble of classifiers as a technique for predicting students. Perform. Distance Educ. Knowl.-Based Syst. 2010, 23, 529–535. [Google Scholar] [CrossRef]
- Quadri, M.; Kalyankar, N. Drop out feature of student data for academic performance using decision tree techniques. Glob. J. Comput. Sci. Technol. 2010, 10. ISSN 0975-4172. Available online: https://computerresearch.org/index.php/computer/article/view/891 (accessed on 15 August 2021).
- Marquez-Vera, C.; Romero, C.; Ventura, S. Predicting school failure using data mining. In Proceedings of the 4th International Conference on Educational Data Mining, Eindhoven, The Netherlands, 6–8 July 2011. [Google Scholar]
- Galbraith, C.; Merrill, G.; Kline, D. Are student evaluations of teaching effectiveness valid for measuring student learning outcomes in business-related classes? A neural network and Bayesian analyses. Res. High Educ. 2011, 53, 353–374. [Google Scholar] [CrossRef]
- Kotsiantis, S.B. Use of machine learning techniques for educational proposes: A decision support system for forecasting students’ grades. Artif. Intell. Rev. 2012, 37, 331–344. [Google Scholar] [CrossRef]
- Osmanbegovic, E.; Suljic, M. Data mining approach for predicting student performance. Econ. Rev. J. Econ. Bus. 2012, 10, 3–12. [Google Scholar]
- Baradwaj, B.K.; Pal, S. Mining educational data to analyze students’ performance. arXiv 2012, arXiv:1201.3417. [Google Scholar]
- Pal, S. Mining educational data to reduce dropout rates of engineering students. Int. J. Inf. Eng. Electron. Bus. 2012, 4, 1–7. [Google Scholar] [CrossRef]
- Thaker, K.; Huang, Y.; Brusilovsky, P.; Daqing, H. Dynamic knowledge modeling with heterogeneous activities for adaptive textbooks. In Proceedings of the 11th International Conference on Educational Data Mining, Buffalo, NY, USA, 15–18 July 2018. [Google Scholar]
- Watson, C.; Li, F.W.; Godwin, J.L. Predicting performance in an introductory programming course by logging and analyzing student programming behavior. In Proceedings of the IEEE 13th International Conference on Advanced Learning Technologies, Beijing, China, 15–18 July 2013; pp. 319–323. [Google Scholar]
- Márquez-Vera, C.; Cano, A.; Romero, C.; Ventura, S. Predicting student failure at school using genetic programming and different data mining approaches with high dimensional and imbalanced data. Appl. Intell. 2013, 38, 315–330. [Google Scholar] [CrossRef]
- Plagge, M. Using artificial neural networks to predict the first-year traditional students’ second-year retention rates. In Proceedings of the 51st ACM Southeast Conference, Savannah, GA, USA, 4–6 April 2013. [Google Scholar]
- Elhassan, A.; Jenhani, I.; Brahim, G. Remedial actions recommendation via multi-label classification: A course learning improvement method. Int. J. Mach. Learn. Comput. 2018, 8, 583–588. [Google Scholar]
- Hu, Y.H.; Lo, C.L.; Shih, S.P. Developing early warning systems to predict students. Online Learn. Perform. Comput. Hum. Behav. 2014, 36, 469–478. [Google Scholar] [CrossRef]
- Villagra-Arnedo, C.J.; Gallego-Duran, F.; Compan, P.; Largo, F.; Molina-Carmona, R. Predicting Academic Performance from Behavioral and Learning Data. 2016. Available online: http://hdl.handle.net/10045/57216 (accessed on 2 January 2021).
- Wolff, A. Modelling student online behavior in a virtual learning environment. arXiv 2018, arXiv:1811.06369. [Google Scholar]
- Ye, C.; Biswas, G. Early prediction of student dropout and performance in MOOCs using higher granularity temporal information. J. Learn. Anal. 2014, 1, 169–172. [Google Scholar] [CrossRef]
- Yukselturk, E.; Ozekes, S.; Turel, Y. Predicting dropout student: An application of data mining methods in an online education program. Eur. J. Open Distance e-Learn. 2014, 17, 118–133. [Google Scholar] [CrossRef] [Green Version]
- Tan, M.; Shao, P. Prediction of student dropout in e-learning program through the use of machine learning method. Int. J. Emerg. Technol. Learn. (iJET) 2015, 10, 11–17. [Google Scholar] [CrossRef]
- Lakkaraju, H.; Aguiar, E.; Shan, C.; Miller, D.; Bhanpuri, N.; Ghani, R.; Addison, K. A machine learning framework to identify students at risk of adverse academic outcomes. In Proceedings of the 21st ACM SIGKDD, International Conference on Knowledge Discovery and Data, Sydney, NSW, Australia, 10–13 August 2015. [Google Scholar]
- Ahmad, F.; Ismail, N.; Aziz, A. The prediction of students academic performance using classification data mining techniques. Appl. Math. Sci. 2015, 9, 6415–6426. [Google Scholar] [CrossRef]
- Fei, M.; Yeung, D.Y. Temporal models for predicting student dropout in massive open online courses. In Proceedings of the IEEE International Conference on Data Mining Workshop (ICDMW), Atlantic City, NJ, USA, 14–17 November 2015. [Google Scholar]
- Sara, N.B.; Halland, R.; Igel, C.; Alstrup, S. High-school dropout prediction using machine learning: A danish large-scale study. In Proceedings of the Eu-European Symposium on Artificial Neural Networks, Computational Intelligence, Bruges, Belgium, 22–24 April 2015. [Google Scholar]
- Kostopoulos, G.; Kotsiantis, S.; Pintelas, P. Estimating student dropout in distance higher education using semi-supervised techniques. In Proceedings of the 19th Panhellenic Conference on Informatics, Athens, Greece, 1–3 October 2015; pp. 38–43. [Google Scholar]
- Xing, W.; Chen, X.; Stein, J.; Marcinkowski, M. Temporal predication of dropouts in MOOCs: Reaching the low hanging fruit through stacking generalization. Comput. Hum. Behav. 2016, 58, 119–129. [Google Scholar] [CrossRef]
- Vihavainen, A.; Vikberg, T.; Luukkainen, M.; Pärtel, M. Scaffolding students’ learning using test my code. In Proceedings of the 18th ACM Conference on Innovation and Technology in Computer Science Education, Canterbury, UK, 1–3 July 2013; pp. 117–122. [Google Scholar]
- Ahmed, A.; Elaraby, I. Data mining: A prediction for student’s performance using classification method. World J. Comput. Appl. Technol. 2014, 2, 43–47. [Google Scholar] [CrossRef]
- Al-Barrak, M.; Al-Razgan, M. Predicting Students’ final GPA using decision trees: A case study. Int. J. Inf. Educ. Technol. 2016, 6, 528. [Google Scholar] [CrossRef] [Green Version]
- Marbouti, F.; Diefes-Dux, H.; Madhavan, K. Models for early prediction of at-risk students in a course using standards-based grading. Comput. Educ. 2016, 103, 1–15. [Google Scholar] [CrossRef] [Green Version]
- Wang, W.; Yu, H.; Miao, C. Deep model for dropout prediction in MOOCs. In Proceedings of the 2nd International Conference on Crowd Science and Engineering, Beijing, China, 6–9 July 2017; pp. 26–32. [Google Scholar]
- Aulck, L.; Velagapudi, N.; Blumenstock, J.; West, J. Predicting student dropout in higher education. arXiv 2016, arXiv:1606.06364. [Google Scholar]
- Marquez-Vera, C.; Cano, A.; Romero, C.; Noaman, A.; Fardoun, H.; Ventura, S. Early dropout prediction using data mining: A case study with high school students. Expert Syst. 2016, 33, 107–124. [Google Scholar] [CrossRef]
- Burgos, C.; Campanario, M.; de la Pena, D.; Lara, J.; Lizcano, D.; Martınez, M. Data mining for modeling students performance: A tutoring action plan to prevent academic dropout. Comput. Electr. Eng. 2017, 66, 541–556. [Google Scholar] [CrossRef]
- Ahadi, A.; Lister, R.; Haapala, H.; Vihavainen, A. Exploring machine learning methods to automatically identify students need of assistance. In Proceedings of the Eleventh Annual International Conference on International Computing Education Research, Omaha, NE, USA, 9–13 July 2015; pp. 121–130. [Google Scholar]
- Iqbal, Z.; Qadir, J.; Mian, A.; Kamiran, F. Machine learning-based student grade prediction: A case study. arXiv 2017, arXiv:1708.08744. [Google Scholar]
- Zhang, W.; Huang, X.; Wang, S.; Shu, J.; Liu, H.; Chen, H. Student performance prediction via online learning behavior analytics. In Proceedings of the International Symposium on Educational Technology (ISET), Hong Kong, China, 27–29 June 2017. [Google Scholar]
- Almarabeh, H. Analysis of students’ performance by using different data mining classifiers. Int. J. Mod. Educ. Comput. Sci. 2017, 9, 9. [Google Scholar] [CrossRef] [Green Version]
- Xu, J.; Moon, K.; Schaar, M.D. A machine learning approach for tracking and predicting student performance in degree programs. IEEE J. Sel. Top. Signal Process. 2017, 11, 742–753. [Google Scholar] [CrossRef]
- Al-Shehri, H.; Al-Qarni, A.; Al-Saati, L.; Batoaq, A.; Badukhen, H.; Alrashed, S.; Alhiyafi, J.; Olatunji, S. Student performance prediction using support vector machine and k-nearest neighbor. In Proceedings of the 2017 IEEE 30th Canadian Conference on Electrical and Computer Engineering (CCECE), Windsor, ON, Canada, 30 April–3 May 2017. [Google Scholar]
- Alowibdi, J. Predicting student performance using advanced learning analytics. In Proceedings of the 26th International Conference on World Wide Web Companion, International World Wide Web Conferences Steering Committee, Perth, Australia, 3–7 April 2017; pp. 415–421. [Google Scholar]
- Nagrecha, S.; Dillon, J.; Chawla, N. Mooc dropout prediction: Lessons learned from making pipelines interpretable. In Proceedings of the 26th International Conference, World Wide Web Companion, International World Wide Web Conferences Steering Committee, Perth, Australia, 3–7 April 2017; pp. 351–359. [Google Scholar]
- Liang, J.; Li, C.; Zheng, L. Machine learning application in MOOCs: Dropout prediction. In Proceedings of the 11th International Conference on Computer Science & Education (ICCSE), Nagoya, Japan, 23–25 August 2016; pp. 52–57. [Google Scholar]
- Al-Obeidat, F.; Tubaishat, A.; Dillon, A.; Shah, B. Analyzing students performance using multi-criteria classification. Clust. Comput. 2018, 21, 623–632. [Google Scholar] [CrossRef]
- Kaviyarasi, R.; Balasubramanian, T. Exploring the high potential factors that affect students. Acad. Perform. Int. J. Educ. Manag. Eng. 2018, 8, 15. [Google Scholar]
- Zaffar, M.; Iskander, S.; Hashmani, M. A study of feature selection algorithms for predicting students academic performance. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 541–549. [Google Scholar] [CrossRef]
- Chui, K.; Fung, D.; Lytras, M.; Lam, T. Predicting at-risk university students in a virtual learning environment via a machine learning algorithm. Comput. Hum. Behav. 2020, 107, 105584. [Google Scholar] [CrossRef]
- Masci, C.; Johnes, G.; Agasisti, T. Student and school performance across countries: A machine learning approach. Eur. J. Oper. Res. 2018, 269, 1072–1085. [Google Scholar] [CrossRef] [Green Version]
- Xing, W.; Du, D. Dropout prediction in MOOCs: Using deep learning for personalized intervention. J. Educ. Comput. Res. 2019, 57, 547–570. [Google Scholar] [CrossRef]
- Khan, S.; Islam, M.; Aleem, M.; Iqbal, M. Temporal specificity-based text classification for information retrieval. Turk. J. Electr. Eng. Comput. Sci. 2018, 26, 2915–2926. [Google Scholar] [CrossRef] [Green Version]
- Livieris, I.; Drakopoulou, K.; Tampakas, V.; Mikropoulos, T.; Pintelas, P. Predicting secondary school students. Perform. Util. Semi-Supervised Learn. Approach J. Educ. Comput. Res. 2019, 57, 448–470. [Google Scholar]
- Nieto, Y.; García-Díaz, V.; Montenegro, C.; Crespo, R.G. Supporting academic decision making at higher educational institutions using machine learning-based algorithms. Soft Comput. 2019, 23, 4145–4153. [Google Scholar] [CrossRef]
- Desmarais, M.; Naceur, R.; Beheshti, B. Linear models of student skills for static data. In UMAP Workshops; Citeseer: University Park, PA, USA, 2012. [Google Scholar]
- Oyedeji, A.O.; Salami, A.M.; Folorunsho, O.; Abolade, O.R. Analysis and Prediction of Student Academic Performance Using Machine Learning. J. Inf. Technol. Comput. Eng. 2020, 4, 10–15. [Google Scholar] [CrossRef] [Green Version]
- Alhusban, S.; Shatnawi, M.; Yasin, M.B.; Hmeidi, I. Measuring and Enhancing the Performance of Undergraduate Student Using Machine Learning Tools. In Proceedings of the 2020 11th International Conference on Information and Communication Systems (ICICS), Copenhagen, Denmark, 24–26 August 2020; pp. 261–265. [Google Scholar]
- Gafarov, F.; Rudneva, Y.B.; Sharifov, U.Y.; Trofimova, A.; Bormotov, P. Analysis of Students’ Academic Performance by Using Machine Learning Tools. In Proceedings of the International Scientific Conference “Digitalization of Education: History, Trends and Prospects” (DETP 2020), Yekaterinburg, Russia, 23–24 April 2020; Atlantis Press: Paris, France, 2020; pp. 574–579. [Google Scholar]
- Walia, N.; Kumar, M.; Nayar, N.; Mehta, G. Student’s Academic Performance Prediction in Academic using Data Mining Techniques. In Proceedings of the International Conference on Innovative Computing & Communications (ICICC); Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Wakelam, E.; Jefferies, A.; Davey, N.; Sun, Y. The potential for student performance prediction in small cohorts with minimal available attributes. Br. J. Educ. Technol. 2020, 51, 347–370. [Google Scholar] [CrossRef] [Green Version]
- Hussain, K.; Talpur, N.; Aftab, M.U.; NoLastName, Z. A Novel Metaheuristic Approach to Optimization of Neuro-Fuzzy System for Students’ Performance Prediction. J. Soft Comput. Data Min. 2020, 1, 1–9. [Google Scholar] [CrossRef]
- Ghorbani, R.; Ghousi, R. Comparing Different Resampling Methods in Predicting Students’ Performance Using Machine Learning Techniques. IEEE Access 2020, 8, 67899–67911. [Google Scholar] [CrossRef]
- Aggarwal, D.; Mittal, S.; Bali, V. Significance of Non-Academic Parameters for Predicting Student Performance Using Ensemble Learning Techniques. Int. J. Syst. Dyn. Appl. 2021, 10, 38–49. [Google Scholar]
- Zeineddine, H.; Braendle, U.; Farah, A. Enhancing prediction of student success: Automated machine learning approach. Comput. Electr. Eng. 2021, 89, 106903. [Google Scholar] [CrossRef]
- OuahiMariame, S.K. Feature Engineering, Mining for Predicting Student Success based on Interaction with the Virtual Learning Environment using Artificial Neural Network. Ann. Rom. Soc. Cell Biol. 2021, 25, 12734–12746. [Google Scholar]
- Hussain, M.; Zhu, W.; Zhang, W.; Abidi, S.; Ali, S. Using machine learning to predict student difficulties from learning session data. Artif. Intell. Rev. 2019, 52, 381–407. [Google Scholar] [CrossRef]
- Thai-Nghe, N.; Drumond, L.; Krohn-Grimberghe, A.; Schmidt-Thieme, L. Recommender system for predicting student performance. Proc. Comput. Sci. 2010, 1, 2811–2819. [Google Scholar] [CrossRef] [Green Version]
- Buenaño-Fernández, D.; Gil, D.; Luján-Mora, S. Application of machine learning in predicting performance for computer engineering students: A case study. Sustainability 2019, 11, 2833. [Google Scholar] [CrossRef] [Green Version]
- Reddy, P.; Reddy, R. Student Performance Analyser Using Supervised Learning Algorithms. 2021. Available online: https://easychair.org/publications/preprint/QhZK (accessed on 4 August 2021).
- Acharya, A.; Sinha, D. Early prediction of students performance using machine learning techniques. Int. J. Comput. Appl. 2014, 107, 37–43. [Google Scholar] [CrossRef]
- Muzamal, J.H.; Tariq, Z.; Khan, U.G. Crowd Counting with respect to Age and Gender by using Faster R-CNN based Detection. In Proceedings of the 2019 International Conference on Applied and Engineering Mathematics (ICAEM), Taxila, Pakistan, 27–29 August 2019; Volume 10, pp. 157–161. [Google Scholar]
- Jenhani, I.; Brahim, G.; Elhassan, A. Course learning outcome performance improvement: A remedial action classification-based approach. In Proceedings of the 2016 15th IEEE International Conference on Machine Learning and Applications (ICMLA), Anaheim, CA, USA, 18–20 December 2016; pp. 408–413. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Identifiers | Databases | Access Date | URL | Results |
|---|---|---|---|---|
| Sr.1 | ResearchGate | 4 February 2021 | https://www.researchgate.net/ | 83 |
| Sr.2 | IEEE Xplore Digital Library | 4 February 2021 | https://ieeexplore.ieee.org/ | 78 |
| Sr.3 | Springer Link | 6 February 2021 | https://link.springer.com/ | 20 |
| Sr.4 | Association for Computing Machinery | 4 February 2021 | https://dl.acm.org/ | 39 |
| Sr.5 | Scopus | 4 February 2021 | https://www.scopus.com/ | 33 |
| Sr.6 | Directory of Open Access Journals | 4 February 2021 | https://doaj.org// | 54 |
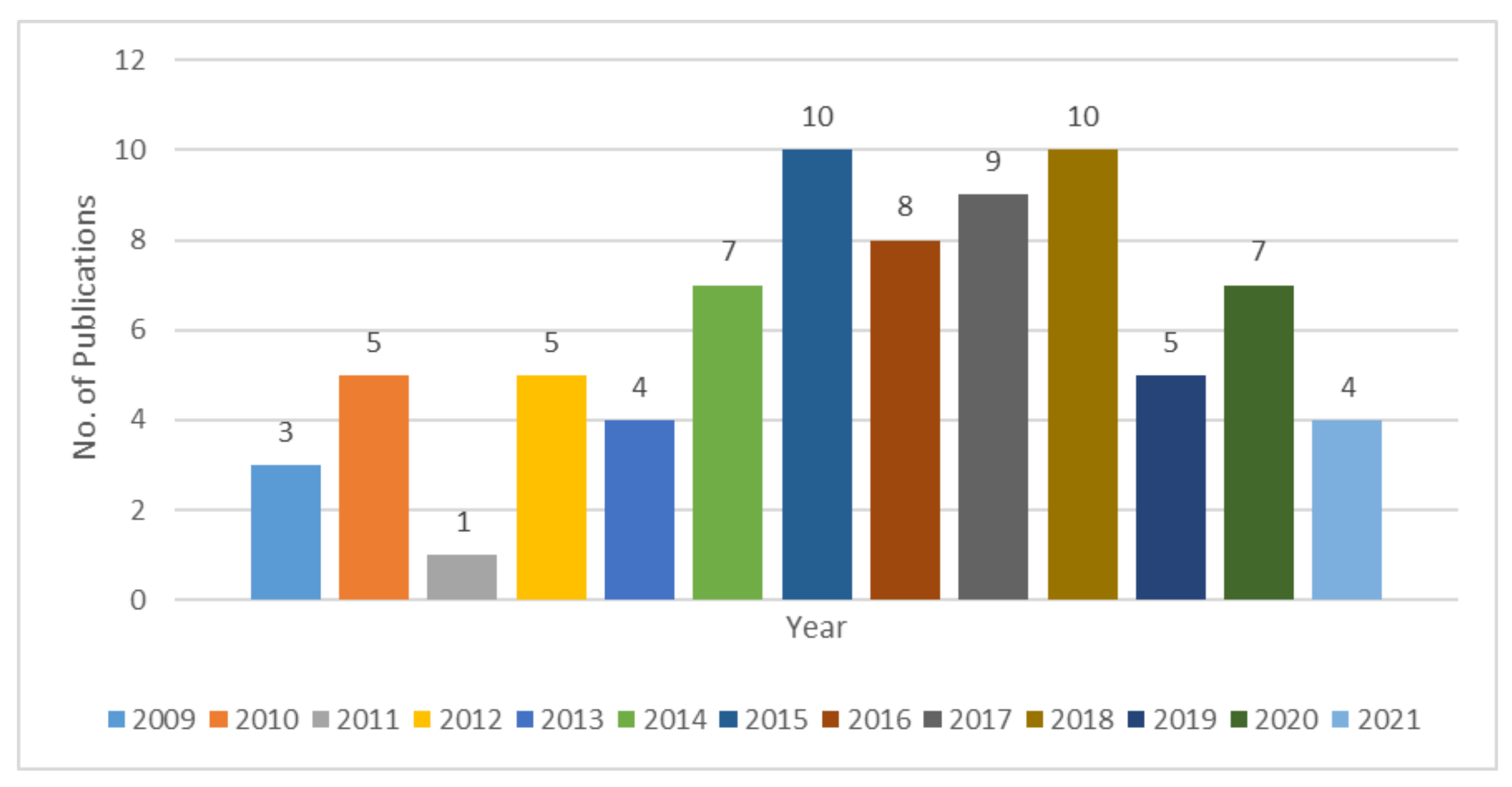
| Year | References | Count |
|---|---|---|
| 2009 | [4,16,17] | 3 |
| 2010 | [1,18,19,20,21] | 5 |
| 2011 | [22] | 1 |
| 2012 | [23,24,25,26,27] | 5 |
| 2013 | [28,29,30,31] | 4 |
| 2014 | [7,32,33,34,35,36,37] | 7 |
| 2015 | [5,6,38,39,40,41,42,43,44,45] | 10 |
| 2016 | [31,46,47,48,49,50,51,52] | 8 |
| 2017 | [51,53,54,55,56,57,58,59,60] | 9 |
| 2018 | [33,45,51,61,62,63,64,65,66,67] | 10 |
| 2019 | [2,57,68,69,70] | 5 |
| 2020 | [71,72,73,74,75,76,77] | 7 |
| 2021 | [78,79,80] | 4 |
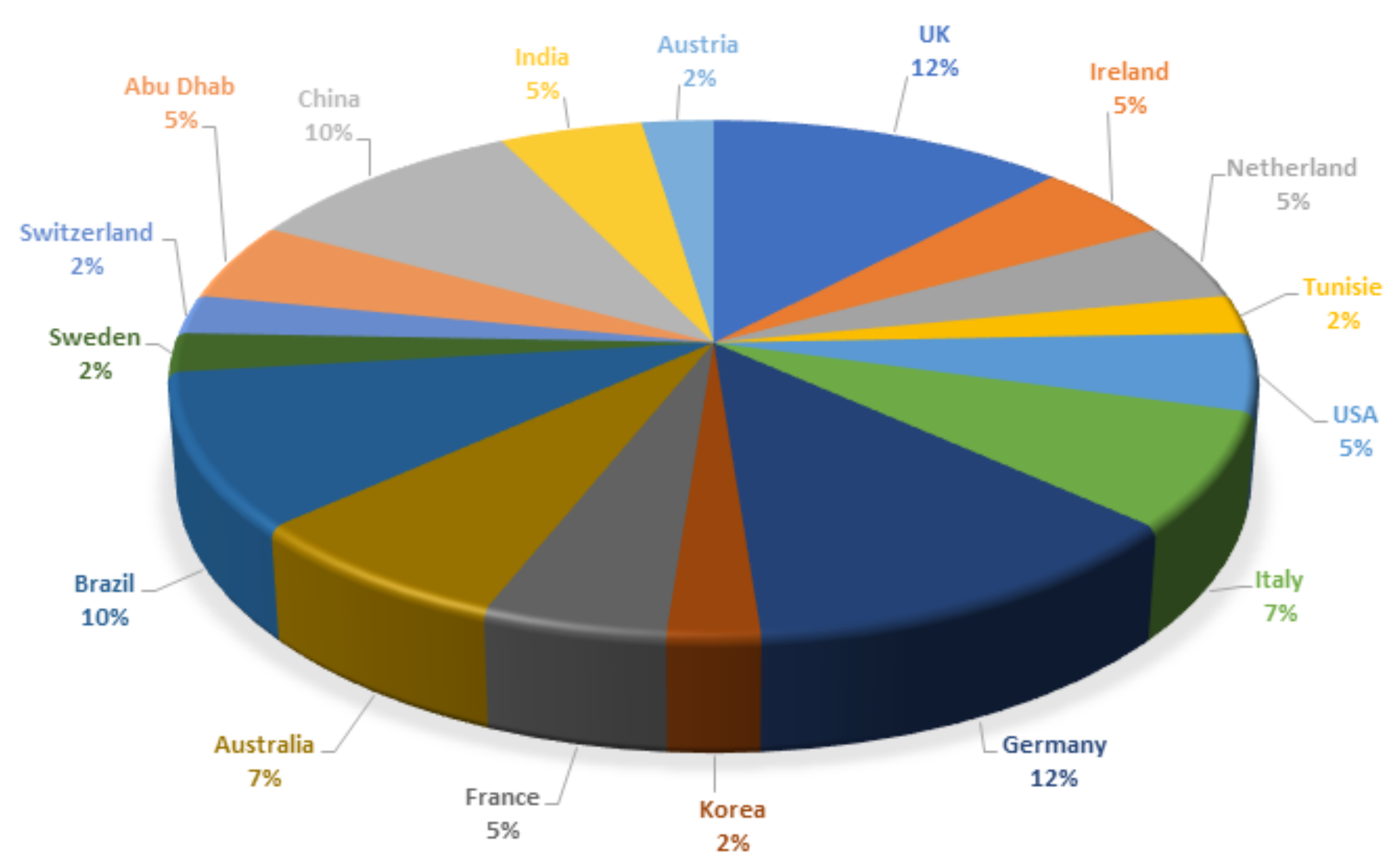
| No. | Country | Sample Size |
|---|---|---|
| 1 | Canada | 20,058 |
| 2 | Australia | 14,530 |
| 3 | UK | 14,157 |
| 4 | Italy | 11,586 |
| 5 | Spain | 6736 |
| 6 | Japan | 6647 |
| 7 | Germany | 6504 |
| 8 | France | 6108 |
| 9 | US | 5712 |
| Approach | Methodology | Attributes | Algorithms | Count | References |
|---|---|---|---|---|---|
| Performance prediction | Early prediction- ML Incremental ensemble Recommender system Automatic measurement Dynamic approach Semi-supervised ML | Socio-demographic Teaching effectiveness Student’s platform interaction Students’ activity log 1st-year students Secondary schools | Rule- base NB, 1-NN, and WINDOW MT, NN, LR, LWLR, SVM, NB, DT, MLP WATWIN LR-SEQ, LR-SIM, DT, Rule-based & NB YATSI, SVM, ANN | 2 2 5 2 3 6 | [18,58] [19,22] [23,24,82] [25,28] [28,29] [6,34,39] [68,69,78,79,80] |
| Identification of students at-risk | ML framework Reducing feature set size Student previous grades Predictive models-grading Factors affecting-at-risk | At-risk of failing to graduate Early prediction of at-risk students Final GPA results Identification of students at risk Fast Learner, Average & Slow Learner | SVM, RF, LR, Adaboost, CART, and DT CART, C4.5, MLP, NB, KNN & SMO CF MF, RBM, GBDT, KNN, SVM, RF, DT, LDA, Adaboost LR, SVM, DT, MLP, NB, and KNN Extra Tree (ET), RTV-SVM | 3 1 3 2 3 | [32,38,45] [85] [46,53,54] [47,57] [62,63,64] |
| Predict the difficulties of the learning platform | Examination of ML methods | Difficulties encountered on the e-learning system | ANN, LR, SVM, NBC, and DT | 2 | [61,81] |
| Performance of classifiers | Cross comparison | Comparison between five ML-based classifiers | NB, BN, ID3, J48, and NN | 2 | [55,56] |
| Evaluation of MOOC in developed countries | Discriminants of the PISA 2005 test score | Characteristics of students and academic institutions | ML and statistical methods | 1 | [65] |
| Approach | Attributes | Algorithms | Count | References |
|---|---|---|---|---|
| Features for dropout prediction including temporal features | students’ personal characteristics and academic performance | DT, LR, SVM, ARTMAP, RF, CART, and NB | 10 | [17,20,37] [41,42,43] [48,59,60] [49] |
| Curriculum-based and student performance-based features | Students performance class imbalance issues | K-NN, SMOTE | 2 | [17,21] |
| Retention rate | Freshman students | DT, Artificial Neural Networks (ANN) | 2 | [26,30] |
| Dropout factors | Evaluation of useful temporal models (Hidden Markov Model (HMM) | RNN combined with LSTM | 3 | [35,36,40] |
| Early-stage prediction of possible student dropout | pre-college entry information, and transcript information | ICRM2 with SVM, NB, DT, ID3, DL, and KNN, CART, and Adabooting Tree | 4 | [26,51,66] [70] |
| Approach | Attributes | Algorithms | Count | References |
|---|---|---|---|---|
| Dynamic | Student performance data, student reading and quiz activity | K-NN, SMOTE, BM, SVM, NB, BN, DT, CR, ADTree, J48, and RF | 15 | [23,25,28,53,54,82] [21,47,57,62,63,64] [33,44,49,86] |
| Static | Enrolment and demographic data | Item Response Theory (IRT), ICRM2, SVM, NB, DT, ID3, DL, and KNN, CART and Adabooting Tree | 9 | [6,26,30,34,39,51,66] [27,70] |
| Both | Pre-college entry information, and transcript information | ICRM2 with SVM, DL, ID3, KNN, DT, LR, SVM, ARTMAP, RF, CART, and NB | 14 | [17,20,26,37,41,42,43] [45,48,49,59,60,66,70] |
| Approach | Attributes | Algorithms | Count | References |
|---|---|---|---|---|
| Early detection | Student performance | NB, BN, DT, CR, PART (Rule Learner), ADTree, J48, and RF | 12 | [17,20,28,37,41,42] [43,44,48,49,59,60] |
| Remedial action | course code, course learning outcome (CLO), NQFDomain, gender, section size, course level, semester, Haslab, assessment, U, M, A, E. | RARS, C4.5, NB and K-NN | 7 | [26,31,51,66,70] [45] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Albreiki, B.; Zaki, N.; Alashwal, H. A Systematic Literature Review of Student’ Performance Prediction Using Machine Learning Techniques. Educ. Sci. 2021, 11, 552. https://doi.org/10.3390/educsci11090552
Albreiki B, Zaki N, Alashwal H. A Systematic Literature Review of Student’ Performance Prediction Using Machine Learning Techniques. Education Sciences. 2021; 11(9):552. https://doi.org/10.3390/educsci11090552
Chicago/Turabian StyleAlbreiki, Balqis, Nazar Zaki, and Hany Alashwal. 2021. "A Systematic Literature Review of Student’ Performance Prediction Using Machine Learning Techniques" Education Sciences 11, no. 9: 552. https://doi.org/10.3390/educsci11090552
APA StyleAlbreiki, B., Zaki, N., & Alashwal, H. (2021). A Systematic Literature Review of Student’ Performance Prediction Using Machine Learning Techniques. Education Sciences, 11(9), 552. https://doi.org/10.3390/educsci11090552