5.1. Anomaly Detection
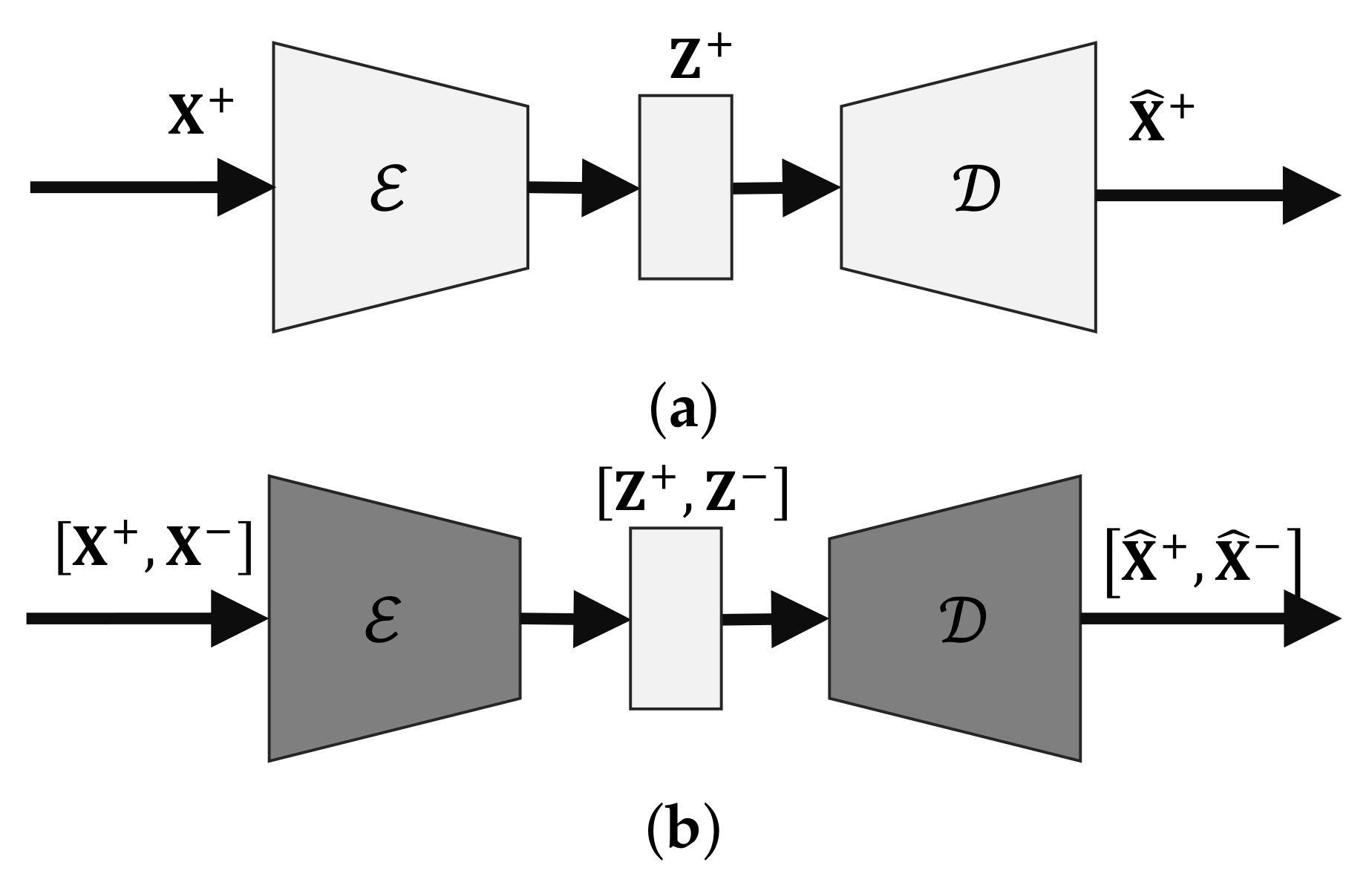
In this section, we test LIS-AE for anomaly detection on image data in unsupervised settings. Given a standard classification dataset, we group a set of classes together into a new dataset and consider it the “normal” dataset. The rest of the classes that are not in the normal nor in the negative datasets are considered anomalies. During training, our model is presented only with the normal dataset and the additional negative dataset. We evaluate the performance on test data comprising both the “normal” and “anomalous” groups.
For MNIST and Fashion-MNIST, the encoder network consists of two convolutional layers with LeakyReLU non-linearities followed by a fully connected bottleneck layer with a tanh activation function. The decoder network consists of a fully connected layer followed by a LeakyReLU and two deconvolution layers with LeakyReLU activation functions and a final convolution layer with sigmoid situated at the final output. For SVHN and CIFAR-10 we use latent layers with larger sizes and higher capacity networks with the same depth. It is worth noting that the choice of latent layer size has the most effect on performance for all models (compared to other hyper-parameters). We report the best performing latent dimension for all models.
In
Table 1, we compare LIS-AE with several autoencoder-based anomaly detection models as baselines, all of which share the exact same architecture. It is worth noting that the most direct comparison is between LIS-AE and AE since not only do they have the same architecture, they have the exact same encoder and decoder weights and their performance is merely measured before and after the latent-shaping phase. We use a different variant of RepNN with a sigmoid activation function
placed before the
staircase function approximation described in
Section 2. This is mainly used because
“squashing” the input between 0 and 1 before passing it to the staircase function gives a more robust and easy-to-train network. We only report the best results for Sig-RepNN with 4 activation levels. For anomaly GAN (AnoGAN) [
31], we follow the implementation described in [
32]. We train a W-GAN [
33] with gradient penalty and report performance for two anomaly scores, namely, encoder-generator reconstruction loss and additional feature-matching distance score in the discriminator feature space (AnoGAN-FM).
For AnoGAN, Linear-AE, AE, VAE, RepNN, MemAE, and LIS-A, we use reconstruction error
such that if
the input is considered an anomaly. Varying the threshold
, we are able to compute the area under the curve (AUC) as a measure of performance. Similarly, for OC-SVDD (equivalently OC-SVM with rbf kernel) and OC-DSVDD, we vary the inverse length scale
and use a predicted class label. For kernel density estimation (KDE) [
34], we vary the threshold
over the log-likelihood scores. For isolation forest (IF) [
35], we vary the threshold
over the anomaly score calculated by the isolation forest algorithm.
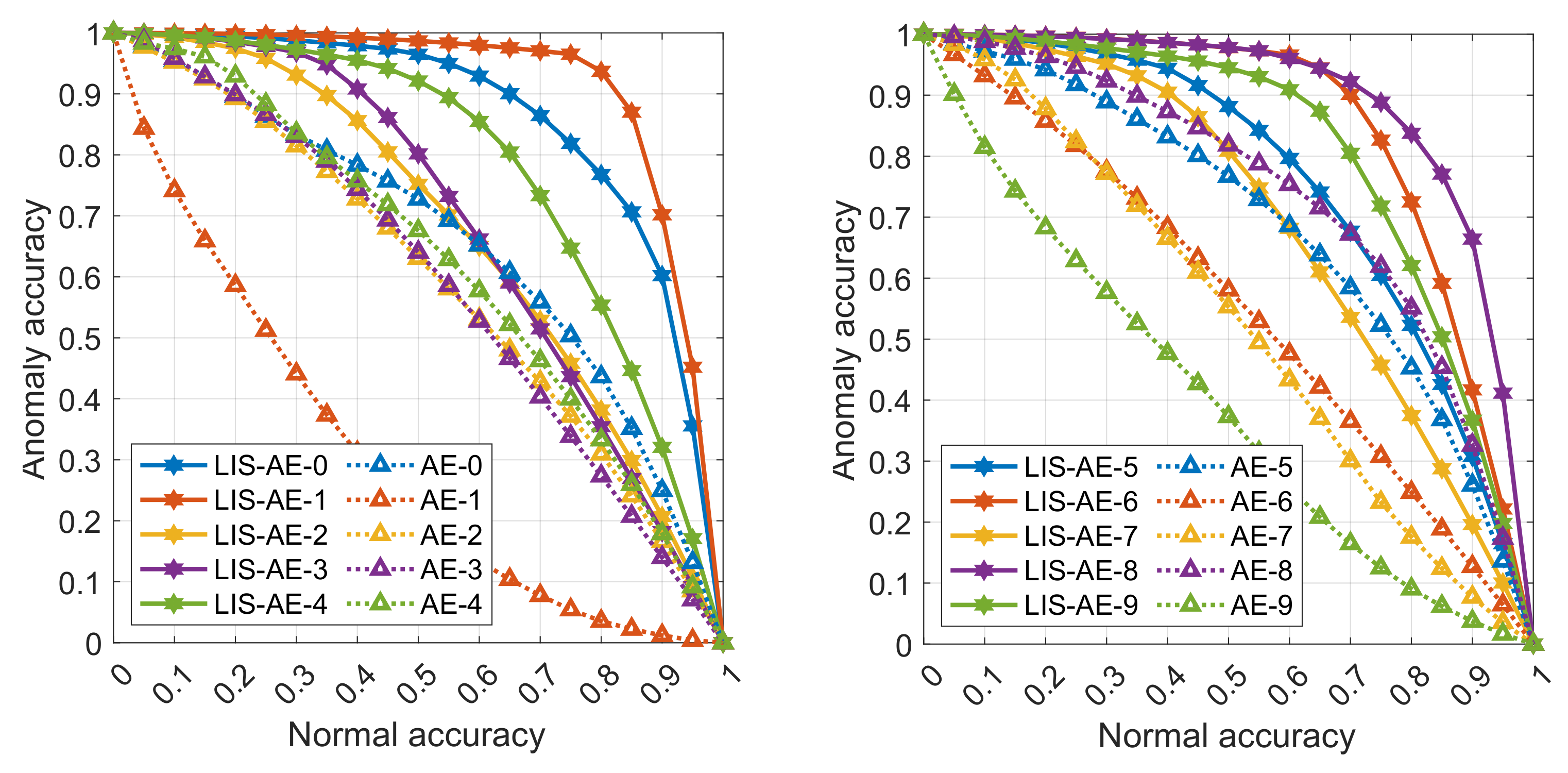
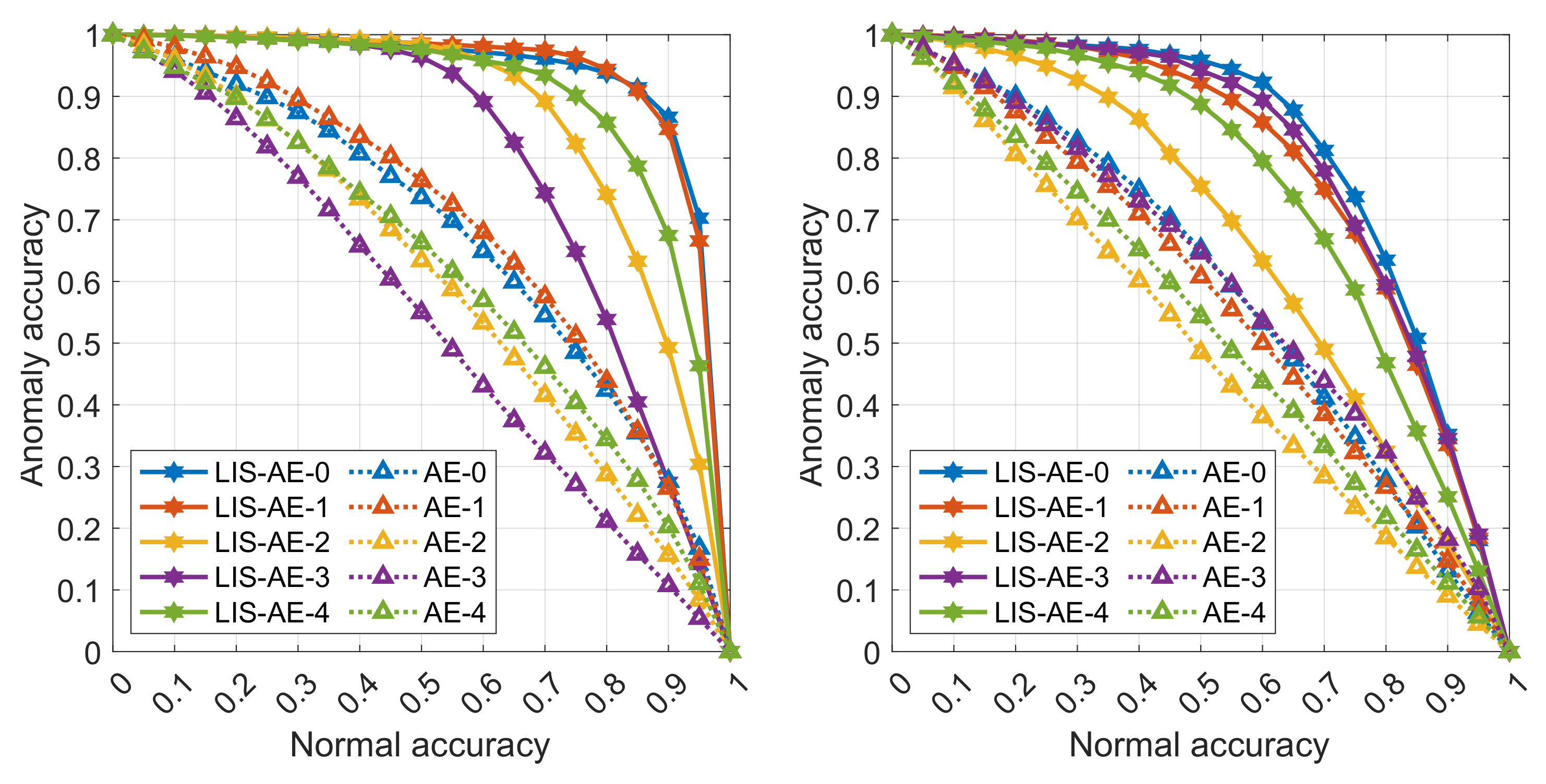
The datasets tested in
Table 1 are MNIST and Fashion-MNIST. To train LIS-AE on MNIST we use Omniglot [
36] as our negative dataset since it shares similar compositional characteristics with MNIST. Since Omniglot is a relatively small dataset, we diversify the negative examples with various augmentation techniques, namely, Gaussian blurring, random cropping, and horizontal and vertical flipping. We test two settings for MNIST, a 1-class setting where the normal dataset is one particular class and the rest of the dataset classes are considered anomalies. The process is repeated for all classes and the average AUC for 10 classes is reported. Another setting is 2-class MNIST where the normal dataset consists of two classes and the remaining classes are considered anomalies. For example, the first task contains digits 0 and 1 and the remaining digits are considered anomalies, the second task contains digit 2 and 3, and so forth. This setting is more challenging since there is more than one class present in the normal dataset. For Fashion-MNIST, the choice of the negative example is different. We use the
next class as the negative dataset and we do not include it with anomalies (i.e., the remaining classes) during test time.
We note that LIS-AE achieves superior performance to all compared approaches, however, we also notice that these settings are comparatively easy and all tested models performed adequately including classical non-deep approaches.
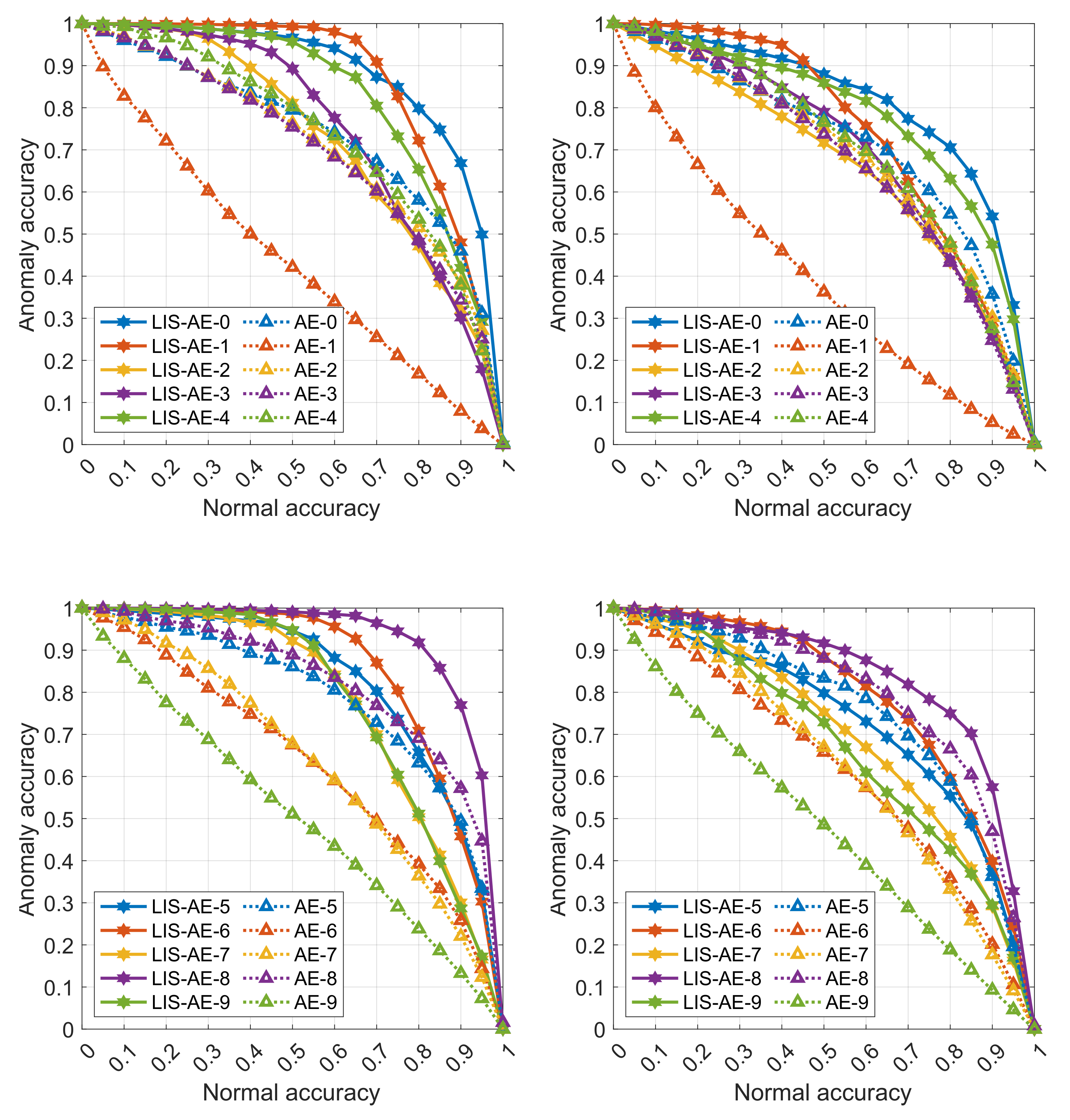
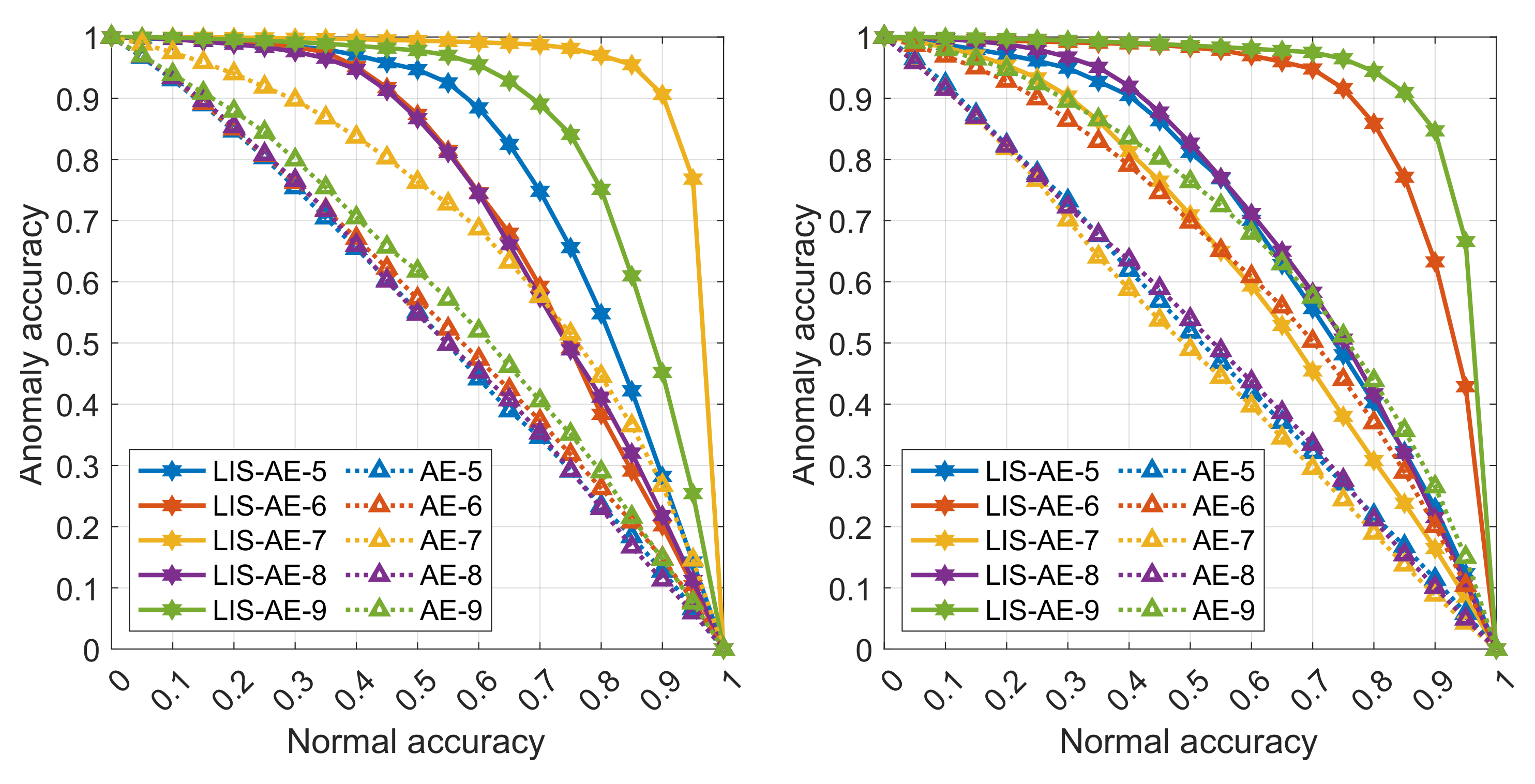
In
Table 2, we show performance on SVHN and CIFAR-10 which are more complex dataests compared to MNIST and Fashion-MNIST. To train LIS-AE, we split each dataset into two datasets, and each split is used as negative examples for the other one. Note that we only test on the remaining classes which are not in the normal nor the negative datasets. For example, the first dataset from CIFAR-10 has five classes, namely, airplane, automobile, bird, cat, and deer while the second one has dog, frog, horse, ship, and truck.
Training on airplane as the first normal task, LIS-AE maximizes the loss for samples drawn from the negative dataset (dog, frog, ship, and so forth). We then test its performance on airplane as the normal class and only on automobile, bird, cat, and deer as anomalies. Note that we do not test on dog, frog, and other classes in the negative dataset. This process is repeated for all 10 classes and the average AUC is reported. As mentioned in
Section 4.2, we introduce LinSep-LIS-AE as an improvement over base standard LIS-AE. The difference between the two models is only in the first phase where a binary cross-entropy loss is added to ensure that positive and negative examples are linearly separable during the second phase. The last two entries of the table are supervised upper bounds for each variant where the negative dataset is the same as outliers. In
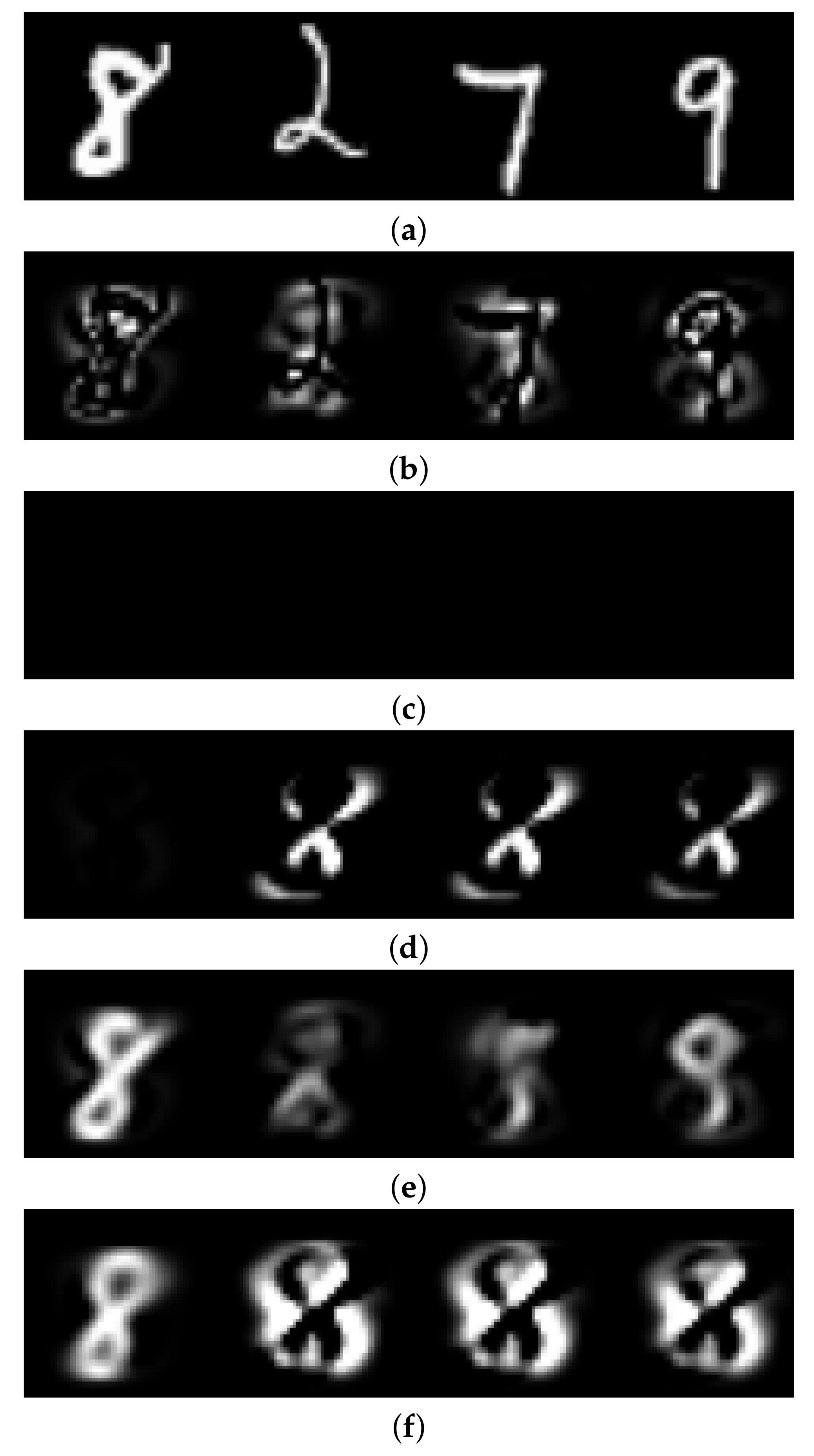
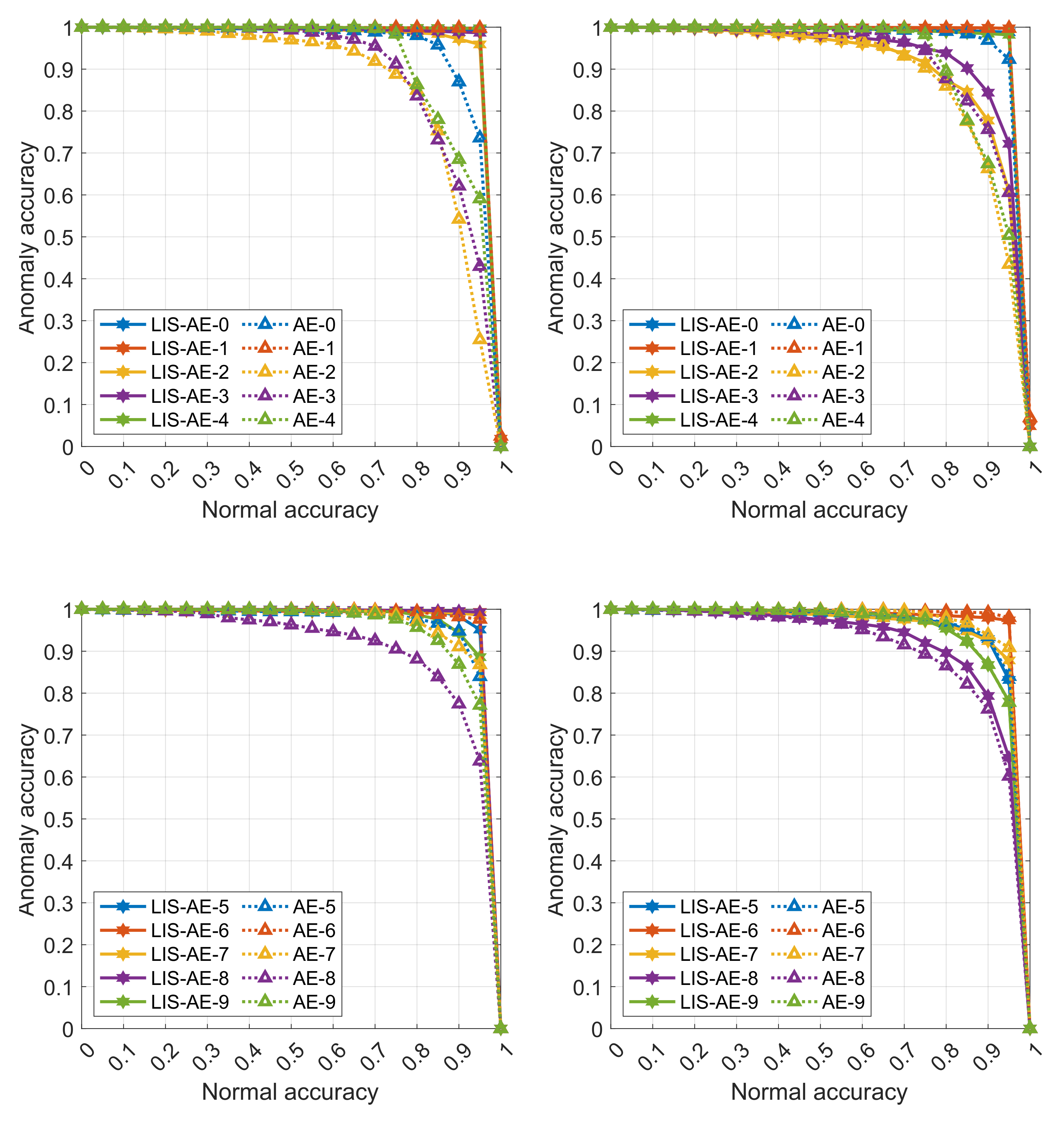
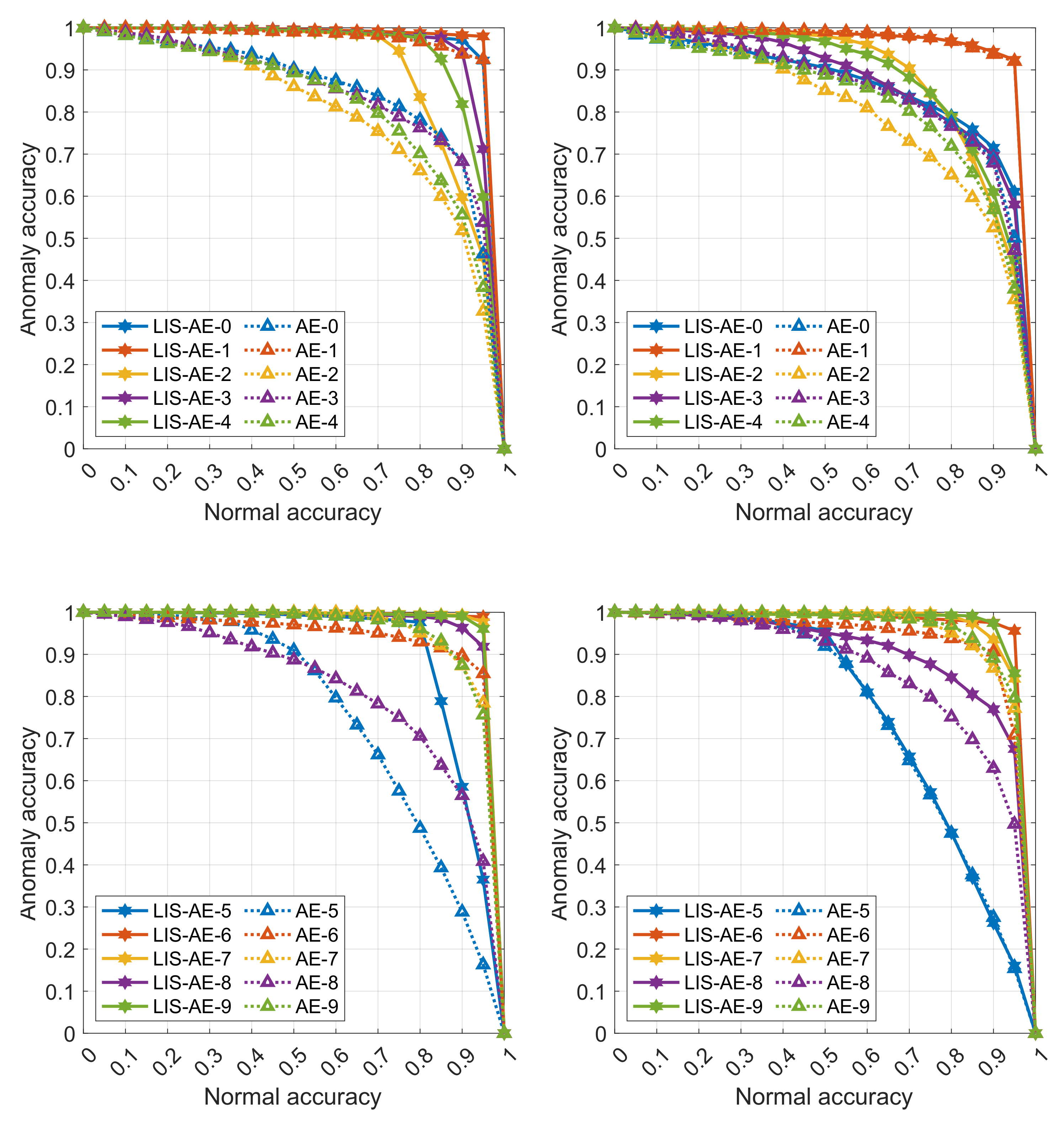
Figure 3, we see that standard AE is prone to generalize well for other classes which is not a desired property for anomaly detection. In contrast, LIS-AE only reconstructs
normal data faithfully which translates to the large performance gap we see in
Figure 4.
We also notice that despite CIFAR-10 being more complex than SVHN, most reconstruction-based models perform better on CIFAR-10 than on SVHN. This is due to the fact that the difference between SVHN classes in terms of reconstruction is not as large since they share similar compositional features and appear in samples from other classes while, for CIFAR-10, classes vary significantly (e.g., digit-2 and digit-3 on a wall vs. truck and bird).
5.2. Ablation
In this section, we investigate the effect of the nature of negative dataset and linear separability of positive and negative examples. In
Table 3 we train LIS-AE on different negative and positive datasets. Similar to
Table 2, we split each positive dataset into two datasets and follow the same settings as before with the exception of “
None” and “
Supervised” cases. The “
None” case indicates that no negative examples have been used whereas the
Supervised case indicates that both outliers and negative datasets share the same classes. Note that this case is different from the case where the positive and negative datasets come from the same dataset. Unless stated otherwise, we only test on classes (outliers) that are not in the positive nor in the negative datasets. For example, when MNIST is used as a source for both positive and negative datasets, the positive data starts with class 0 and the negative dataset consists of classes 5 to 9 where the outliers are classes 1 to 4. This process is repeated for all 10 classes present in each dataset and the average AUC is reported. Overall, using a negative dataset resulted in a significant increase in performance in every case except for two important cases, namely, when Fashion-MNIST and CIFAR-10 were used as negative datasets for MNIST and SVHN, respectively. This could be explained by the fact that the model was not capable of reconstructing Fashion-MNIST and CIFAR-10 classes in the first place. Moreover, shaping the latent layer in such a way that maximizes the loss for Fashion-MNIST and CIFAR-10 classes does not guarantee any advantage for anomaly detection of similar digit classes present in MNIST and SVHN. This, coupled with the fact that this process in practice forces the model to ignore some samples from the normal dataset to balance the two losses, results in the performance degradation we observe in these two cases.
Table 4 is an excerpt of the complete table in
Appendix A.1 where we examine the effect of each class present in the negative dataset on anomaly detection performance for other test classes from the CIFAR-10 dataset. We split CIFAR-10 into two separate datasets, the first split is used for selecting classes as negative datasets and the other split is used as outliers. For each class in CIFAR-10 we train eight models in different settings, the first setting is
None where we train a standard autoencoder with no negative examples as the base model. The remaining seven settings differ in the second phase, and we select one class as our negative dataset and test the model performance on each individual class from the outlier dataset. The
combined setting is similar to the setting described in
Section 5.1 where we combine all negative classes in one 5-class negative dataset. Note that these classes are not the same as the classes in the outlier test dataset except for the final setting, which is an upper-bound supervised setting where the negative dataset comprises classes that are in the outlier dataset except for the positive class. This process is then repeated for all 10 classes in CIFAR-10. Overall, we observe a significant performance increase over the base model with the general trend of negative classes significantly increasing anomaly detection performance for similar outliers. For example, the
dog class drastically improves performance on the cat class but not so much for the
plane class. However, we also notice two important exceptions, namely, when the
horse class is used as the negative dataset for the
car class, we notice a significant performance increase for the relatively similar
deer class as expected, however, when the
horse class is used as the negative dataset for the same
deer class, we notice that the performance does not improve as in the first case and even degrades for the car class.
Other notable examples of this observation can be found in the appendices where, for instance, the
dog class improves performance on cat outliers, but causes noticeable degradation when used as the negative dataset for the same cat class. The gained performance, in the first case, is due to the fact that these classes share similar compositional features and backgrounds. However, in the second case, the same property makes it difficult to balance the minimization and maximization loss during the latent-shaping phase. For example, car and truck images are very similar in this scenario so that minimizing and maximizing the loss at the same time becomes contradictory. As posited in
Section 4.2, we mitigate this issue by adding a binary cross-entropy loss while training in the first phase to ensure that the input of the latent layer is linearly separable for positive and negative examples. Notice that, unlike other approaches [
23,
24], this does not require a labeled positive or negative dataset and relies only on the fact that we have two distinct datasets. This linear separability makes the second phase of training relatively easier and less contradictory. In
Table 5, we see that LinSep-LIS-AE mitigates this issue for the aforementioned cases and gives the AUC increase we observe in
Table 2.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








