1. Introduction
Alternatives to fossil fuel resources are becoming increasingly important. Besides an efficient generation of energy, it is also important to store it, ideally with minimal losses over long periods of time. The recent
geothermal energy storage (GES) technology shown in
Figure 1 represents a potentially very attractive approach to energy storage. The GES is realised in natural underground sites, for instance using large soil tanks. Such tanks are partially surrounded by insulating walls and, depending on their depth, soils with different heat conduction and capacity properties. It is a very cost effective technology that may be used in both new construction and refurbishment.
In contrast to classic underground energy storage where tanks are employed that are fully closed and do not interact with their environment, the technical realisation of GES is characterised by a downwardly open heat tank. This is one of the aspects that makes the technology highly cost effective since it is not required to excavate the ground to a large degree. It is sufficient to excavate a relatively small area that represents the tank, staying thereby close to the surface. In the resulting pit, the heating pipes are installed, and one has to insulate the walls of the pit for instance by use of Styrofoam. The pit is typically only filled with the original soil. The second aspect that makes the GES technology cost effective compared to traditional closed thermal storage systems is given by considering the dimensions needed to provide sufficient capacity to store energy in practice. The advantage of the open tank is that the heat energy is effectively stored by the earth in and below the tank, making its capacity extremely high in real application, providing in practice a multiple of the capacity that is making up the actual tank.
We are especially interested in the potential of GES to store excess energy generated during the summer, e.g., by use of solar cells, for heating in winter. This becomes a very important issue when considering the entire heating system in dependence on weather conditions, day, night and annual rhythms over one year or even several years in time. Even though there are already working GES, particularly for single-family homes and smaller office buildings, well-founded evidence or simulations are required to assess the profitableness of a GES. This is of great importance with regard to the optimal dimensioning of the heat tank, which is the most expensive design factor. Moreover, this will also be very important in order to adopt this technique for large office complexes.
To study the reliability of such systems, it is important to know how they behave over long time spans for several months or years. The problem may be formulated in terms of a parabolic partial differential equation (PDE) model given by the heat equation related to space and time. In order to describe the heat transfer in the GES set-up adequately enough to tackle this task, the mathematical model including contact and boundary conditions must first be described. Subsequently, the simulation of heat evolution is run as long as the user requires. Let us stress in this context that the simulation may not be performed offline, since the planning of a GES may typically require communication between engineers, architects and the customer, often directly at construction sites. Thus, the simulation may ideally be performed at most in a few minutes during the discussion.
The simulation of heat transfer is of fundamental importance in diverse scientific fields; however, even nowadays it is still a challenging task to devise a method that combines reasonable accuracy and computational efficiency. Especially, when working with multi-dimensional problems, the computational performance of a solver is a key requirement. The long-term integration that needs to be performed in order to simulate seasonal energy storage represents an additional challenge. Standard methods are not designed to combine high efficiency and temporal accuracy, so a practical analysis of time integration methods for the heat equation in the context of GES is absolutely essential.
There exist countless methods to solve the heat equation PDE numerically. As examples, let us mention finite difference, finite volume or finite element methods, which discretise the spatial dimensions into
ordinary differential equations (ODEs) according to the method of lines procedure. Afterwards, the temporal integration can either be performed explicitly or implicitly. Explicit schemes are based on simple sparse matrix-vector multiplications in which the allowed time step size has a rather small upper bound, rendering the explicit strategy unsuitable for long-term evaluations. On the other hand, the use of implicit schemes leads to the task to solve a linear system of equations in each time step, whereby the number of variables related to the multi-dimensional GES may extend up to several million. The implicit schemes do not suffer from restrictions on the time step size
in theory, but a fast solver for large sparse linear systems of equations is needed. To this end, sparse direct [
1] or sparse iterative solvers [
2] are commonly used. The direct solvers are characterised by computing very accurate solutions, but may be linked to high algorithmic complexity. In contrast, iterative methods have low complexity; however, they contain parameters that make their application not a straight forward task in a challenging setting. As another numerical aspect that has to be kept in mind when using implicit methods for applications involving source terms, one has to update the contributions of the sources using relatively small time intervals for obtaining an accurate simulation.
The classic solvers such as explicit schemes, sparse direct or sparse iterative solvers, are relatively simple to implement or based on existing sophisticated software packages; however, as indicated, their efficiency is related to severe time step size restrictions in the case of explicit methods, or high effort for solving large linear systems of equations when regarding implicit methods. For making any of these approaches efficient enough to tackle our application, two widely used techniques in their respective scientific fields called fast explicit diffusion (FED) and model order reduction (MOR), can be helpful to significantly reduce the computational effort compared to conventional methods.
The FED approach [
3] originating from image processing, combines the advantage of an explicit evaluation with the possibility to achieve high integration times in just a few steps of evaluation. The underlying key idea is the use of suitable cycles with varying time step sizes, relying on a unique mixture of small and very large step sizes. On this basis, FED is substantially more efficient than the classic explicit scheme and it is based simultaneously on cheap matrix-vector multiplications. In order to avoid some drawbacks of the FED method, the advanced
fast semi-iterative (FSI) method [
4] can be used and is applied here; however, the design of the cycles requires special consideration.
The MOR methods represent another possible approach for reducing the computational complexity of PDE simulations. Such techniques can be applied to approximate the underlying ODE system (i.e., discretised in space but not in time at this stage) by a significantly reduced system, which is by its reduced dimension naturally much faster to solve. The idea of the MOR approach is that the reduced semi-discrete model preserves the main characteristics of the original ODE system. In the last decades, many different MOR methods have been developed, see, e.g., [
5,
6] for an overview; however, many of them are technically based on solving eigenvalue problems, Lyapunov equations or performing
singular value decomposition (SVD), so that many approaches are limited by construction to the reduction in small- to medium-scale dynamical systems. For solving large-scale problems, the powerful
Krylov subspace model order reduction (KSMOR) methods are most frequently used due to their superior numerical efficiency in this regime. This technique is directly related to matching the moments of the ODE system’s transfer function. Common applications of KSMOR techniques are in the field of circuit simulation, power systems, micro-electro-mechanical systems and computational electromagnetics, e.g., also linked to parabolic PDEs [
7,
8,
9,
10]. Although the basic aspects of the KSMOR technique are well understood, it is not easy to devise it in a way that yields an efficient scheme for resolving heat evolution if internal boundary conditions with large input vectors are involved, as in our case.
Let us also mention that there exist other popular strategies to speed up diffusion processes. For instance, the alternating direction implicit method and its variations [
11,
12] or also operator splitting methods, such as additive operator splitting [
13,
14] or multiplicative operator splitting [
13,
15]. The main idea of these techniques is to split the multi-dimensional problem into several one-dimensional problems which can then be efficiently solved using tridiagonal matrix algorithms; however, this approach induces a splitting error that increases with the magnitude of the time step size
. Moreover, external and internal boundary conditions have to be treated very carefully, which makes these methods difficult to apply in our setting.
1.1. Our Contributions
The long-term simulation of the heat equation related to the GES application requires advanced numerical methods specifically designed for the intended purpose. The main goal of this work is to discuss which methods are suitable for long-term simulations as appearing in real-world applications as considered here, and how they need to be used for the fundamental problem of heat evolution with internal and external boundary conditions as well as source terms. In this context, let us note that the methods we rely on are variations of schemes that already exist in the previous literature, and we show how to adapt them in order to obtain efficient schemes for the GES application. In some more detail, we provide the contributions below.
Considering our GES application, we precisely elaborate the complete continuous model and the corresponding discretisation, which is an important component for the numerical realisation. Especially, the matching conditions at the occurring interfaces lead to a large-dimensional input vector; therefore, they require special care when adapting the KSMOR technique. Since the long-term simulation of a three-dimensional GES is linked to extreme computational costs, it is a highly relevant point of interest if the model itself could be reduced for computational purposes. As one of our contributions, we demonstrate that the application of a two-dimensional and linear heat equation proves to be absolutely sufficient for the considered long-term simulation in our application. The latter is validated on real-world data by using temperature probes of a real, three-dimensional test field. The linear and dimensionally reduced model can then be used practically in place of the real (3D nonlinear) model, for either simulation purposes or parameter optimisation.
Let us turn to the numerical contributions of this work. We provide a comprehensive overview of the numerical solvers from various scientific areas that could be employed to tackle the intended task. In doing this, we thoroughly discuss the methods and the arising challenges in connection with long-term simulation of a GES. In order to improve the performance of the FED method, which has shown some promising first results [
16] (comparing the implicit Euler method and the FED scheme for a simple synthesis experiment), the recent FSI scheme is employed. We show how to use the FSI method to parabolic problems including sources/sinks, relying on the discussion in [
17]. Apart from that, we modify the original KSMOR technique for systems with a large number of inputs in a similar way as proposed in [
9]. In this context, let us note that we provide here to our best knowledge the first very detailed exposition of this kind of approach. We validate our numerical findings at the hand of two experiments using synthetic and real-world data, and show that one can obtain fast and accurate long-term simulations of typical GES facilities.
In total, we give a detailed overview of relevant, modern numerical solvers that can be helpful for tackling long-term heat evolution in many engineering fields. For a complete insight into the methods regarding theoretical and numerical aspects, we refer the interested reader to [
18].
1.2. Paper Organisation
This work is organised as follows. The
Section 2 contains the continuous model description including modelling the external and internal boundary conditions, and we also inform about generating the initial heat distribution. Afterwards, we recall the numerical realisation by spatial and temporal discretisation in
Section 3. In
Section 4 an extensive overview of the numerical solvers is given, we discuss the methods FED, FSI, direct solvers, iterative solvers, KSMOR and KSMOR
. The experimental evaluation presented in
Section 5 focuses on simulation quality and efficiency of the numerical solvers, by comparing two experiments. The paper is finished by a summary with our conclusion.
3. Discretisation of the Continuous-Scale Model
In this section, we provide the basic discretisation of the underlying continuous GES model, characterised via linear heat Equation (
2), different interior (
3)–(
5) and exterior (
6)–(
7), (
9) boundary conditions and initial heat distribution (
10). In doing so, we describe the discretisation aspects in space and time in detail in the following subsections.
The underlying computational domain (cf.
Figure 2) is given by a cuboid type form, so that we apply standard finite difference schemes for the discretisation of the continuous model, which will be sufficient for the application in this work.
3.1. Discretisation in Space
For reasons of simplicity, we consider in the following the two-dimensional rectangular domain with an equidistant mesh size in x- and y-direction, where denotes an approximation of the unknown function u at grid point and time t. For convenience only, we use the abbreviation .
The approximation of the spatial partial derivatives
and
in (
2) using standard central differences leads to
where
is the discretised heat source/sink.
As mentioned before, the interaction between different types of soils is modelled by Equations (
3) and (
4). In particular, we assume that no grid point is located exactly at the interface
. Exemplary, we define the interface as
, which is centrally located between the grid points
and
. Discretising (
3) at the interface
between two layers, denoted here as “
k” and “
l”, using the forward and backward difference results in
Due to (
4), we have
for the fictitious value
at the interface, which can then be calculated via
The latter scheme is visualised on the left in
Figure 3. Let us mention that the discretisation can also be achieved without using a fictitious value if one assumes that a grid point lies on the interface, see [
24].
In contrast, modelling the relation between soil and insulation, condition (
4) must be replaced by (
5). Discretisation of (
5) at
using the forward and backward differences gives
which can be rewritten as
Moreover, the Equation (
13) can be transformed into
Equations (
16) and (
17) form a system of linear equations for the two unknowns
and
by means of
The latter system has a unique solution for
and can be solved with Cramer’s rule. The used scheme at the interface including a jump condition is shown on the right in
Figure 3. We mention that another possible discretisation is presented in [
24].
Lastly, the exterior boundary conditions must be discretised. In case of the upper domain boundaries at the topmost layer of ground, interfaces
and fictitious values
for
are again incorporated. Using the standard first-order spatial discretisation
linked to the discretised condition (
6) as
leads to
Let us note that, when using first-order discretisations, the accuracy at the boundary is formally by one order worse than the error of the boundary-free discrete equation; however, it is a matter of definition of boundary location to understand the same finite difference expression as a central discretisation of the derivative between the considered points, which is again of second order—this means we do not have to expect any error deterioration. What is important here is the symmetry preservation of the underlying Laplacian matrix L, which, for later application of the numerical solvers, is of great importance.
The remaining conditions concerning the lateral and lower domain boundaries are fixed via
where
is the depth of the
j-th grid layer. Let us mention that the three-dimensional case can be handled analogously.
3.2. Arising System of Ordinary Differential Equations
Let us now summarise the components of the proposed two-dimensional discretisation (
12), (
14), (
18) and (
21)–(
23) which end up in a semi-discrete ODE system. In particular, a function defined on all grid points may be represented by now as an
N-dimensional vector
where
N is the total number of all grid points with linear grid point numbering from top left to bottom right.
The proposed spatial discretisation of the GES by applying finite differences on a regular grid with constant grid size
h results into an ODE system, one ODE for each grid point, with the notation
as follows:
with temperature vector
, temperature vectors
(continuity condition) and
(discontinuity condition) for fictitious points at the two different types of interfaces, ambient temperature
, groundwater temperature
, undisturbed ground temperature vector
and source/sink vector
. The conditions at the lateral boundaries on
considered here are identical, therefore it is sufficient that the input vector
is of size
m. At this point it should be mentioned that the values for
and
depend on the user-defined size setting of the insulating walls and geometry setting of the considered source/sink, respectively.
The matrices
,
,
and
collect the terms of the basic discretisation and are not shown in detail. The remaining matrices, which correspond to the ambient temperature, the groundwater temperature and the undisturbed ground temperature, have the following simple structure:
with
, the identity matrix
. the null matrix
, and where
depend on material parameters. The mark ”—“ within (
27) indicates that the discretisation points of the underlying rectangular computational domain are considered row by row. Finally, the discrete initial condition is given by (
10) with
.
3.3. Time Integration
The application of the proposed spatial discretisations leads to the ODE system (
25), which can be represented as
with input matrix and input vector
Thereby, we specify the input matrix
with
and make use of stacked vectors for defining
. Let us comment that the time-dependent large-scale input
controls the model by boundary conditions and heat sources/sinks. Further we note, although the matching conditions at the interfaces corresponding to
and
are not user-defined controls, one has to handle these as indirect inputs. In addition, the Laplacian matrix
L is symmetric and negative definite which is large, sparse and structured. The definiteness follows directly from its strictly diagonal dominance and negative diagonal entries according to Gershgorin’s circle theorem [
25].
The most frequently used class for solving a system of ODEs are time stepping methods, in which the time variable in (
28) is discretised by
. Discrete time stepping methods of ODEs can be achieved using standard numerical integration so-called
time integration methods; for an excellent overview, we refer to [
26,
27]. Let us briefly recall the standard methods that we apply in this work. Common time integration schemes are the
explicit Euler (EE) method, the
implicit Euler (IE) method and the trapezoidal rule known as
Crank–Nicolson (CN) method. Usually, the implicit CN method is preferably used compared to IE due to its second-order convergence in time and at the same time marginally higher computational costs. Consequently, besides the EE method, we consider here only the CN method for the numerical solution of the underlying model problem. Let us note that the IE method has been investigated in our previous conference paper [
16].
To apply time discretisation methods, time intervals are defined in order to subdivide the complete integration time into a partition. The resulting numerical methods then generate approximations at the different time levels . We mention that uniform partitions of time intervals are used in this work.
3.3.1. Explicit Euler
The use of the fundamental lemma of calculus for the left-hand side and the left-hand rectangle method for the approximation of the integral on the right-hand side of (
28) over the time interval
gives
with the uniform time step size
. Finally, using the notation
, the well-known fully discrete EE method
with
, the identity matrix
and the given data
is obtained. Due to the fact that the values
and
at time
are known, the new values
at time
can easily be computed by simple sparse matrix-vector multiplication. Schemes in this form are known as
explicit methods and are well-suited for parallel computing such as
graphics processing units (GPUs); however, it is well-known that explicit methods such as EE are only conditionally stable, see, e.g., [
28] and the stability requirement leads to a severe limitation in the size of the time step
. In general, the typical time step size restriction has a rather small upper bound in the case of stiff ODE systems, more precisely the stability requirement, which depends quadratically on the spatial grid size, yields a time step size limitation
. As a consequence, explicit schemes are usually considered to be extremely inefficient numerical methods from a computational point of view.
3.3.2. Crank–Nicolson
Moreover, aside the limitation on the stability requirement on
, the EE method is additionally characterised just by first-order approximation to the exact solution. A common alternative is the implicit CN method, which is second-order in time and moreover numerically stable. Applying the trapezoidal rule for the integral approximation of the right-hand side of (
28) gives
which leads to the popular fully discrete CN scheme
Computing the values
at time
requires the solution of a system of linear equations as well as a sparse matrix-vector multiplication in each time step. Consequently, this scheme is more numerically intensive than the EE method; however, the considerable advantage of an implicit method is the numerical stability independently of the time step size
, cf. [
28]. At this point, it should be noted that the CN method is sensitive to problems with discontinuous initial conditions and can lead to undesirable oscillations in the numerical solution, but this is not the case with the GES application.
3.4. Summary on Discretisation
To solve the GES model problem numerically, the continuous PDE model must be discretised. Using the method of lines, i.e., discretising the spatial derivatives first, a semi-discretised system of ODEs (
28) with only one independent variable is obtained. Afterwards an approximate solution for the initial value ODE problem must be computed; therefore, a temporal grid is introduced. Time integration methods are typically used to design a numerical scheme. Here, we recalled the first-order EE scheme (
31) and the second-order CN method (
33). These baseline schemes are mainly used in our work for comparison purposes.
5. Comparison of Solvers for Long-Term GES Simulation
The numerical long-term simulation of the GES model considered in this work, is mainly focused on the explicit FSI method, the implicit sparse direct/iterative solver and the KSMOR technique, introduced in the section before. In the following, we evaluate the proposed numerical solvers by two different experiments and assess their performance in terms of approximation quality and central processing unit (CPU) time. As methods of choice we consider:
EE method. An estimation of the upper bound is necessary.
FSI scheme. By knowing , the number M of cycles is the only tuning parameter.
Sparse direct solver applied to the implicit CN method (called direct CN). The internal MATLAB-function decomposition including a Cholesky factorisation is used. The tuning parameter is the time step size .
Sparse iterative solver using PCG applied to the implicit CN method (called iterative CN). User-defined parameters are time step size and the tolerance ; the latter quantity is required to terminate the algorithm. The preconditioners IC or MIC are employed for PCG. Another tuning parameter is required, which corresponds to a numerical fill-in strategy IC() or MIC().
KSMOR method. This technique can be tuned by the number of projection subspaces and snapshot data used. The selected expansion point is fixed to . The sparse direct solver is applied to compute the Krylov subspace generated by the block Arnoldi method. The reduced model is then solved via direct CN scheme for a chosen .
To evaluate the accuracy of the methods, the solution of the EE scheme is used as reference. Based on a simplified GES application without a source term, we first examine the optimal selection of some important parameters within the methods used. Second, we validate the method performances on real data including sources. In addition, a uniform grid with
is considered in all experiments and the evaluation is measured by the
-error defined as
between the reference solution
and the numerical solution
.
Let us mention that to evaluate the accuracy of the methods, we also consider a simple artificial setup in
Appendix B, where the solution can be stated in closed form. Furthermore, we note that all experiments were performed in MATLAB R2018b with an Intel Xeon(R) CPU E5-2609 v3 CPU. All CPU times presented incorporate the modelling (linear system, preconditioning and reduction) and the numerical resolution; therefore, the performances are easily comparable.
5.1. Geothermal Energy Storage Simulation without Source
First, we consider the simulation of a GES under real-world conditions without sources/sinks. The heat tank is assumed to be placed underground, closed on its sides and upwards, compare
Figure 2. The lower part is open to accommodate for the heat delivery. The thermophysical properties of the materials used are assumed to be constant and are given in
Table 3. In this setup, we specify that the upper and the lower ground have the same material properties, and further parameters are fixed to
and
. As mentioned in
Section 2.3, the external conditions are given via time-dependent Robin (
6), time- and space-dependent Dirichlet (
7) and non-homogeneous Dirichlet boundary conditions (
9) with
.
For the evaluation, a two-dimensional rectangular domain is considered given by in meters, whereby the heat tank with size m has an installation depth of m. The thickness of the insulation is determined to 12 cm. Moreover, a mid-size model problem is considered by setting cm ( grid points) and the stopping time is assumed to be s (around 30 days). As initialisation, the temperature is simply fixed to 30 degrees for the heat tank, 20 degrees for the insulation and 10 degrees otherwise.
Let us first discuss the spatial dimensioning of the underlying model. The original geothermal field is given in 3D, but it is clear that its fundamental simulation is computationally more expensive than a two-dimensional model. In fact, however, a full three-dimensional simulation is not necessary, which can be explained as follows: the considered model problem is isotropic, homogeneous, linear and characterised by an almost symmetrical structure (concerning the spatial environment) with slow heat propagation (low diffusivity). This allows the physical behaviour of the three-dimensional continuous model to be approximated by considering a cross-section of a 3D geothermal field in 2D, especially when dealing with long-term evolutions. The proposed heuristic approach can be theoretically supported by a closer look at the fundamental solution (heat kernel) of the linear heat equation. More precisely, the fundamental solution is radial in the spatial variable, but depends on a dimensional-dependent scaling factor, see, e.g., [
63]. Aside from the purely physical justification, we confirm the reduction in the spatial model dimensions by comparing the results in 2D and 3D using the EE method. Further in the paper, we show that the approach is justified by taking real data into account.
According to Gershgorin’s circle theorem the time step size restriction for the two-dimensional model problem is given by
s. Consequently, 6250 iterations have to be performed to reach the final stopping time
, whereby the corresponding CPU time of EE amount to 11.1 s. In contrast, the upper stability bound of the underlying three-dimensional problem is determined with
so that 9380 iterations for the simulation are necessary. In this case, the discrete domain is defined by
N =
grid points, which enlarges the size of the system matrix considerably and thus increases the computational effort. Consequently, the entire simulation requires around 20,000 s which is considered unsatisfactory. As expected,
Figure 4 confirms the use of a two-dimensional model as a substitute. First, it shows almost equal radial thermal behaviour when comparing the 2D and 3D models, in which the latter is evaluated via a cross-section along the middle of the 3D-GES. Second, a comparison of two artificial temporal temperature profiles S1 and S2 demonstrate the expected similarities of the 2D and 3D simulation results. Of course, there are slight deviations in heat evolution between the 2D and 3D models, but the benefit of computational performance is more valuable than computing an extremely accurate 3D long-term simulation. Overall, we consider the dimensionality reduction in the model as a pragmatic proceeding to obtain fast and accurate enough long-term simulations of typical GES. In the further course, we compare the proposed methods using the 2D-GES model on both synthetic and real data.
Let us emphasise that for the following evaluations of the solvers no analytical solution is available and a reference solution is required. In general, the EE method provides the most precise solution (cf.
Appendix B) that can be used as reference solution for a fair comparison. To this end, we assess the
-error at a fixed moment in time and the corresponding CPU time between the solutions of EE and the tested solver for the experiment without source term. In doing so, we do not consider a full error computation along the temporal axis because the methods yield completely different sampling rates, which potentially leading to unfair comparisons.
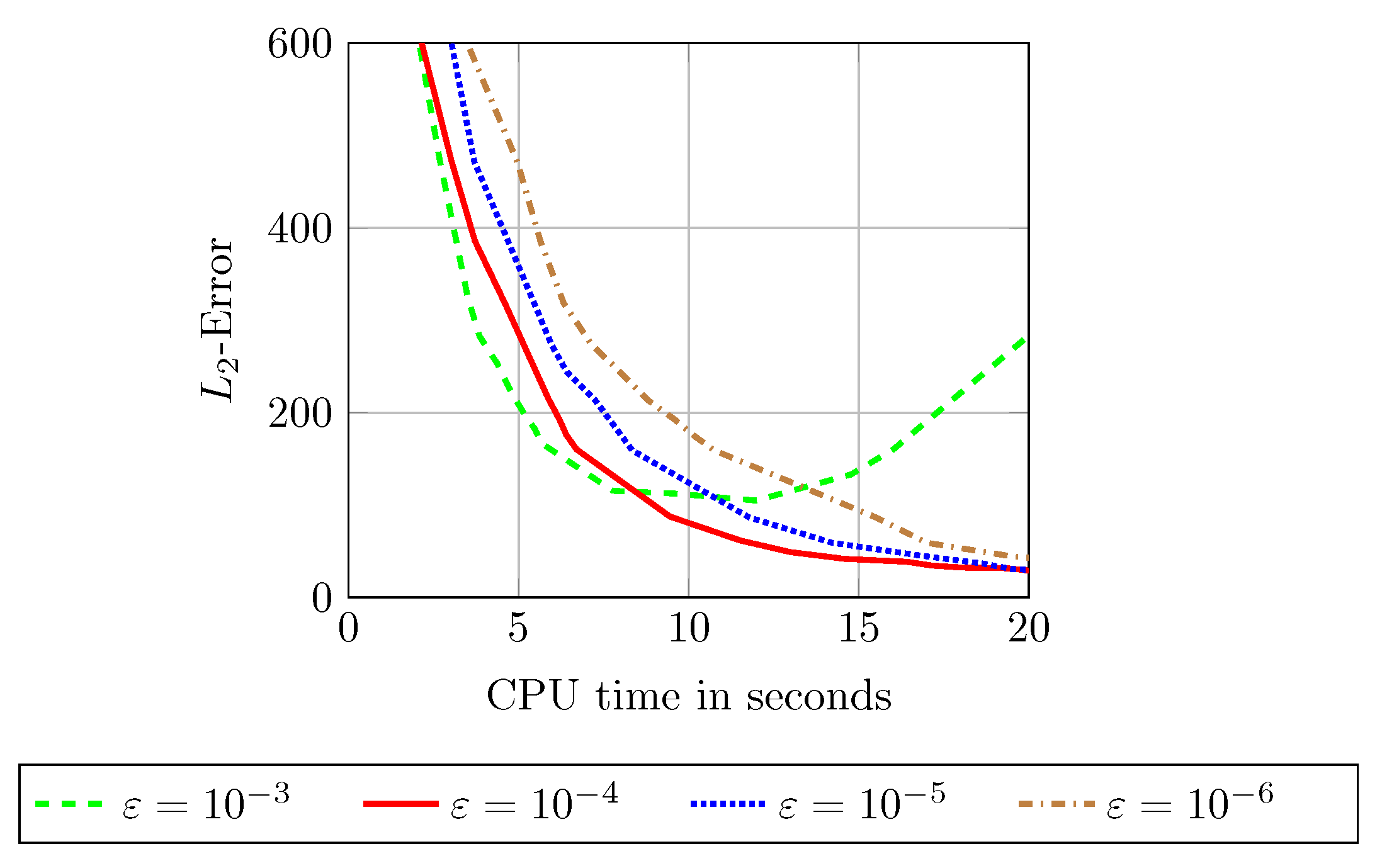
We now study the iterative solver and its parameters involved. For this purpose, the influence of the stopping criterion on the accuracy and the CPU time is analysed in
Figure 5. The value
provides the best trade-off and is assumed to be fixed for all following tests. Due to the size of the system matrix a preconditioning is suitable. By consideration of the specified preconditioners,
Figure 6 shows that MIC(
) outperforms both CG and IC(
). Based on this investigation, we use MIC(
) for all further experiments.
To demonstrate the beneficial applicability of the CN method in general, we compare its results with those of IE in
Appendix C.1.
Due to external, lateral time- and space-dependent Dirichlet boundary conditions and internal matching conditions, the model has to deal with many inputs. In particular, the input variable results in , with and , while does not have to be taken into account due to the identical material properties of both soils (upper and lower ground).
To overcome the efficiency limitation of KSMOR (see
Appendix C.2) we apply the KSMOR
approach, proposed in
Section 4.3.2. In doing this, we initially set
and vary the size of the snapshot data as visualised on the left in
Figure 7. Obviously, increasing
s leads to better approximations; however, a saturation occurs for high values
s, for which
provides the best performance trade-off. In a second test, we increase the number of subspaces
q for
used, see on the right in
Figure 7. As expected, increasing the moment matching property improves also the accuracy. Unfortunately, large values
q are associated with high computational costs. Overall, KSMOR
is much more efficient compared to the original KSMOR method (cf.
Appendix C.2).
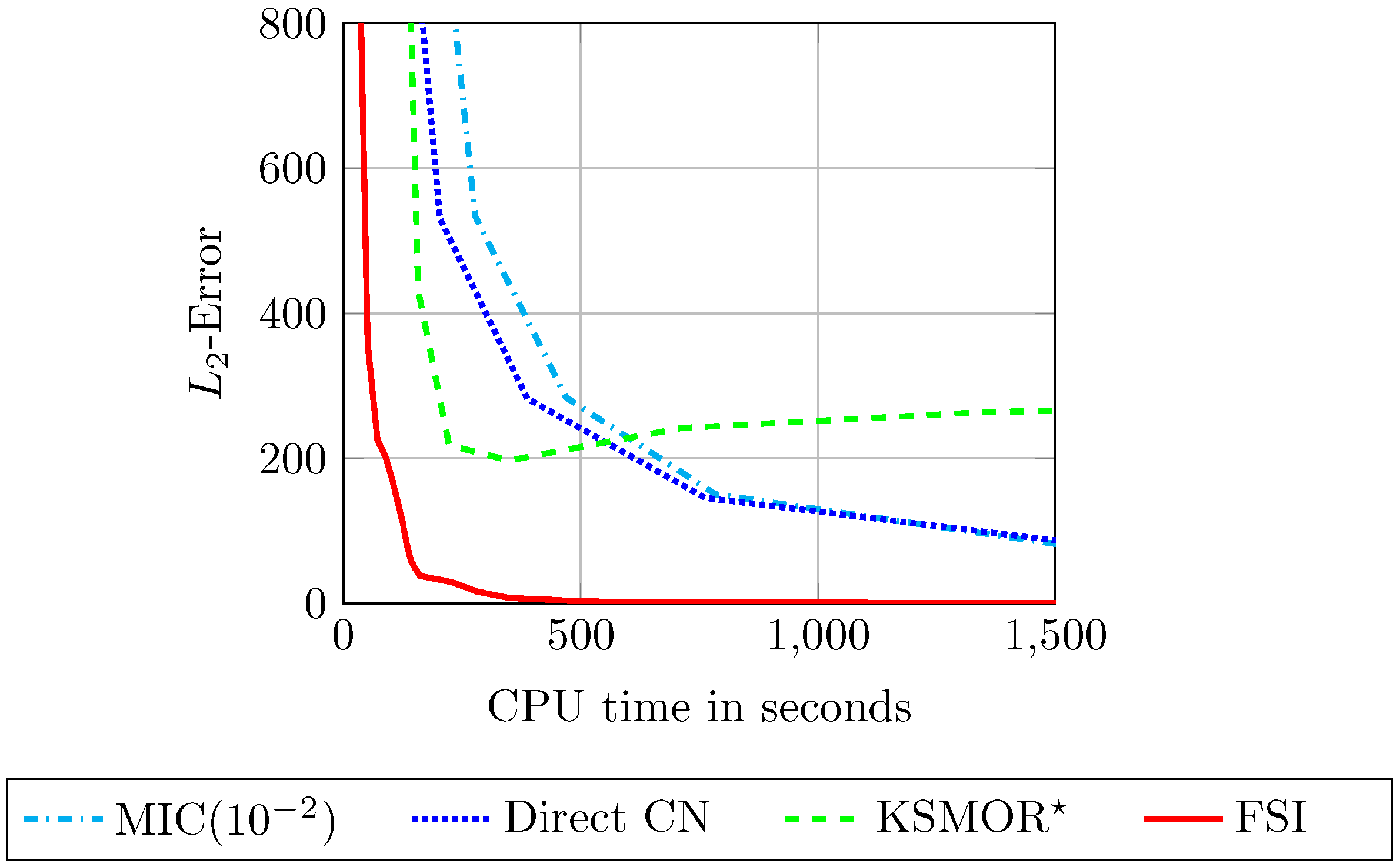
5.1.1. Comparison of the Solvers
Finally, a full comparison of the methods tested—direct CN, iterative CN using MIC(
), FSI and KSMOR
—is shown in
Figure 8.
Solving the CN method with the sparse direct solver is more efficient than with the iterative solver. Only for more accurate solutions, which correspond to small time step sizes , both implicit solvers perform comparably well due to a faster convergence of the iterative solver.
The KSMOR
technique, in which the parameters
and
are fixed, achieves the worst performance in comparison to the other methods. In contrast to the investigated test example in
Section 4.3.2, the selected number of snapshots has to be relatively large. In combination with the number of Krylov subspaces directly related to expensive offline precomputations and the additional enlargement of the reduced solution (
A15), the KSMOR
approach cannot maintain the efficiency of the other solvers.
The results in
Figure 8 clearly demonstrate the superior efficiency of FSI, which outperforms all other methods. This is mainly explained by two facts: first, FSI is an accelerated explicit method and is built on cheap matrix-vector multiplications. Second, the input
can be updated within one FSI-cycle. Further, it is this update process, including the external and internal boundary conditions, that is of great importance for an accurate approximation. In this context, we also show a performance comparison of the two fast explicit solvers FED and FSI in
Appendix C.3.
We would like to point out once again that the generated results are based on a mid-size model problem. In
Appendix C.4, we additionally present that the same solver performances are preserved for a large-scale problem for which we repeat this experiment on a finer grid.
5.1.2. Observations on KSMOR
From an engineering point of view a more detailed investigation of the approximation behaviour regarding the underlying model shows that small values
s and
q are deemed appropriate. A visualisation of the results between the absolute differences of EE and KSMOR
for
and a different number of
s and
q is shown in
Figure 9. As expected, increasing the number of snapshots
s or subspaces
q leads to better results in terms of the maximum error and the
-error. An individual change of
s and
q leads to a kind of saturation behaviour, so that both parameters require relatively large values for a very accurate approximation.
Moreover, a reasonable number of snapshots
s is significantly important because less data lead to strong artefacts at the interfaces where the matching conditions between different materials have to be fulfilled. This observation is a consequence of the proposed input matrix reduction, which clarifies the interdependence between snapshot data and the errors at the interfaces. Due to the fact that small values of
s and
q only influence the area around the interfaces (cf.
Figure 9), which is generally negligible for a reasonable reproduction of the long-term GES simulation, the use of KSMOR
appears to be significantly appropriate.
Based on the presented findings, we investigate the performances of FSI, direct CN and KSMOR with and on real data.
5.2. Geothermal Energy Storage Simulation on Real Data
Lastly, we present a comparison concerning a full error computation along the temporal axis using the two-dimensional GES simulation including sources. The evaluation is based on real data, in particular matching of temperature probes of a test field and its thermal behaviour given in 3D, cf.
Figure 10. In this way, the experiment will also demonstrate that the proposed linear two-dimensional model is sufficient to reproduce the heat exchange correctly.
For this experiment, the thermophysical properties of the materials used are assumed to be constant and are given in
Table 4. The other parameters are fixed to
and
. The two-dimensional rectangular domain is defined via
in meters, whereby the size of the heat tank amounts to
m. The installation depth and the insulation thickness are determined as 70 and 12 cm, respectively. In addition, the thermal energy
with the specific heat capacity
c, the mass
m of the fluid and temperature change of the inlet and return temperatures
is given over a period of
s (around 243 days). The parameters are fixed to
and
and the source term is simply distributed over three pipe levels inside the heat tank. Moreover, the mesh size is fixed to
(
grid points), which leads to the upper stability bound
. The initial heat distribution is generated by the Laplace interpolation (see
Appendix D.1).
In order to validate the correct heat exchange behaviour, we initially apply the EE method to the two-dimensional GES model. The visualisation of the real temperature probe B1 (measuring point 3rd from the top, see
Figure 10) compared to EE is shown exemplary on the top left in
Figure 11. The result clearly demonstrates the appropriate use of a two-dimensional simulation of a 3D-GES model. Note that one may use any working probe to come to the same conclusion.
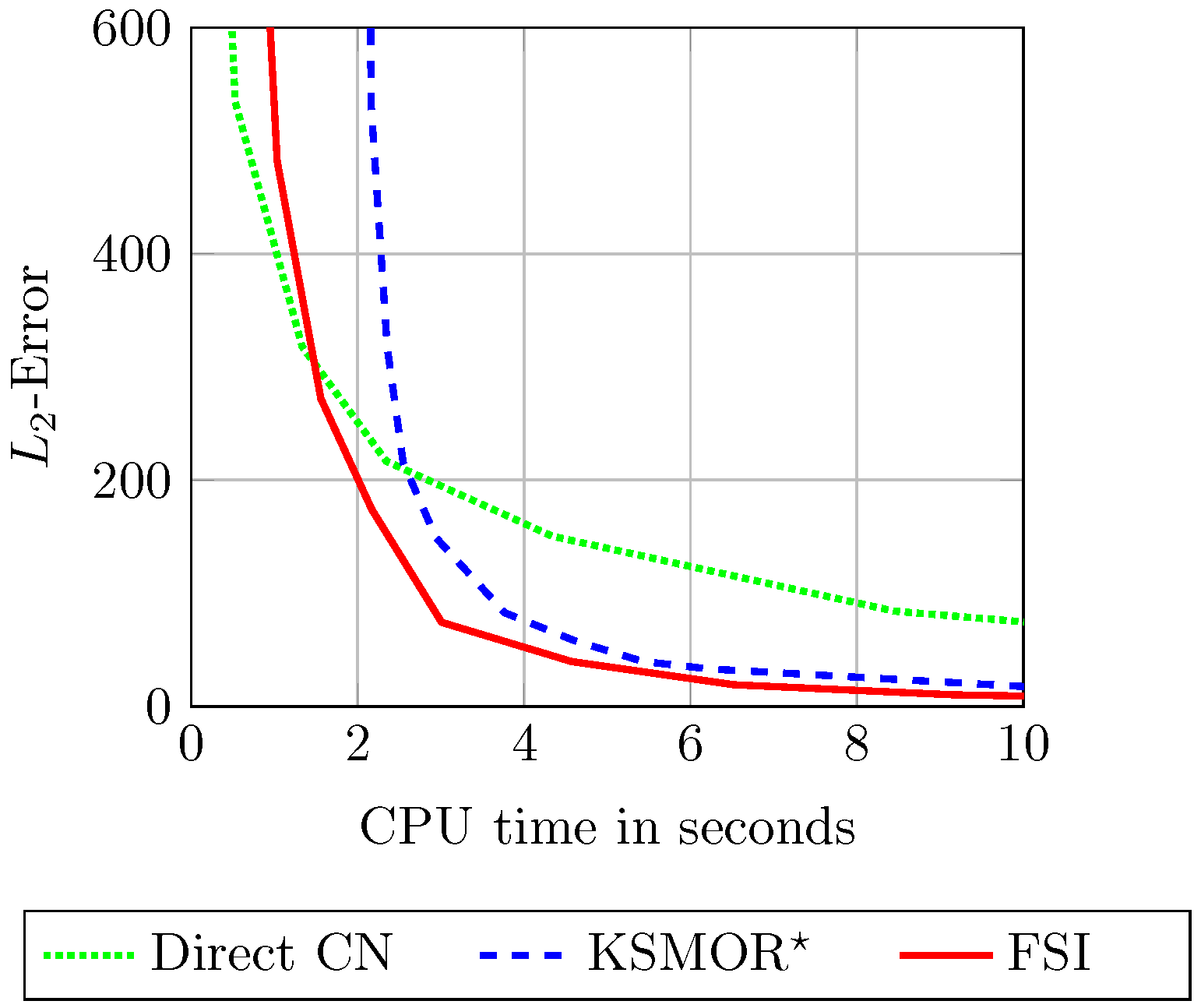
Building on the validation, the performances of FSI, direct CN and KSMOR
with
and
are identified using the temperature probe B1 by two variants. First, a visual assessment of the approximations compared to real data is illustrated in
Figure 11. In the experiment documented in
Figure 11 we give quickly computed approximations (CPU time of 10 s) in comparison with EE (CPU time of 69 s). Second, the relation between the
-error (along the temporal axis) and the corresponding CPU time is evaluated in
Figure 12. Additional data for comparison of the findings described are listed in
Appendix D.2. In both investigations, the FSI scheme is still considered as a superior method, which provides a fast computation combined with high accuracy. Nevertheless, the KSMOR
method is also very efficient. As in the previous tests, the direct CN method provides the worst performance.
Finally, FSI and KSMOR
are tested on the temperature probe B6 (5th from the top) and B9 (2nd from the top), see
Figure 13. Both schemes achieve the desired reproduction of heat distribution behaviour compared to the real data; however, the KSMOR
results may also exhibit oscillations, especially in a local area around the interfaces between different materials. This illustrates again that the numerical solutions obtained by KSMOR
are locally representative away from the interfaces if
q and
s are chosen in a competitive range in our application, whereas the FSI method correctly reproduces the global behaviour of the underlying GES model.
6. Summary and Conclusions
In this work, we have demonstrated that a model based on a linear heat equation equipped with external and internal boundary conditions is suitable to realistically represent the long-term behaviour of the GES. Moreover, we showed experimentally based on real-world data from a three-dimensional test field that even a two-dimensional GES simulation is sufficient to tackle the long term simulation task. As a result, the computational costs can be extremely reduced and a long-term simulation is practicable.
In view of the possible candidates for an efficient numerical simulation, a state-of-the-art method that appears to be attractive is the KSMOR scheme. In our model problem we have seen that this scheme is not easy to apply, since the underlying semi-discretised model is linked with a large input vector in consequence of the modelled boundary conditions. Independent of the numerical approach, it has also been noticed that the presence of sources and boundary conditions makes the long-term simulation issue in practice delicate to handle. With these fundamental difficulties, we have illuminated in detail that it is not straightforward to device an efficient and accurate enough numerical scheme.
In total, we have demonstrated the practical usability of the FSI scheme and the KSMOR variant introduced here as KSMOR, which turn out to be the two most powerful methods among the schemes in this paper for our GES application. The explicit FSI scheme borrowed from image processing, is highly efficient due to cost-effective matrix-vector multiplications and the natural frequent update process of the input vector within the approach. In addition to this, it is by the construction of the FSI method, which can also use modern parallel architectures such as GPUs, that we can further increase the efficiency. Let us also note here that to our best knowledge, our paper provides the first application of FSI outside of the field of image processing. Our proposed efficient KSMOR technique uses an input-matrix reduction via snapshots and generates a small-sized reduced order model, which can then be resolved easily using the direct solver. We illustrated and analysed the viability of KSMOR, which is in this form a new variant of existing schemes. At this point it, should be stressed that compared to previous works in the area of KSMOR schemes, we have made our method here explicit in all the details and important parameters, which is by the computational experience gained in the course of this work highly relevant for practical application.
Apart from the fact that FSI and KSMOR are predestined solvers for tackling the long-term simulation of a GES, we have specifically discussed the local and global behaviour of their solutions. Summarising our findings, we (absolutely) suggest the use of the FSI scheme when the global behaviour of solutions is of interest. Let us also mention that this may be of preference in the context of our application, since this takes into account general configurations, also away from interfaces, to measure temperatures by probes in realistic environments. Otherwise, for local areas but away from interfaces, both techniques perform equally effective.
Overall, we have precisely analysed the features of all applied solvers and simultaneously illustrated their properties using different experiments. For these reasons the comprehensive work given here provides, from our point of view, a reasonable overview of the state-of-the-art numerical solvers of various scientific areas and may help greatly in approaching similar problems in many engineering fields.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}