1. Introduction
In today’s world, software is becoming more and more important in economy, healthcare, society, and other aspects of life [
1,
2,
3]. In order to ensure the quality, reliability and stability of software, many methods have been proposed [
4,
5]. Software project risk management has become the focus of attention. A risk is an uncertain event or condition that may or may not occur. If it happens, the positive or negative impact effect on one or more objectives. Project teams endeavor to identify and evaluate known and emergent risks throughout the software life cycle. However, risk factors are so complex and uncertain that the effective identification and evaluation of them is still an open issue.
Most research has focused on risk analysis and risk management [
6,
7,
8]. Different theories and techniques have been used to deal with risks. For example, a scheme to incorporate Bayesian belief networks in software project risk management presented by Fanv et al. [
9]. Hu et al. [
10] proposed a model using BNs with causality constraints for risk analysis of software development projects. Odzaly et al. [
11] described the underlying risk management model in an Agile risk tool. An assessment model based on the combination of backpropagation neural network (BPNN) and rough set theory (RST) was put forward by Li et al. [
12]. A computational model for the reduction of the probability of project failure through the prediction of risks was proposed by Filippetto et al. [
13].
Among these methods, expert opinion and judgment are usually used to perform a risk assessment. One method of making statistical inferences and decisions based on expert opinion and judgment is expert knowledge elicitation. The related literature is extensive [
14,
15,
16]. Since most experts prefer to express their opinions in a qualitative way, the expert elicitation procedure is full of subjectivity and uncertainty. It is important to provide a reliable framework for dealing with expert judgments [
17]. Fuzzy set theory [
18] is a common and accepted way of dealing with expert opinion and judgment. However, it has several flaws in expressing the hesitancy among several risk values. In some cases, due to a lack of experience or information, experts may not use a single risk level to describe their assessment, but rather hesitate between several risk values. For example, hesitation is between possible and very possible. The traditional fuzzy evaluation matrix cannot express the hesitation in the assessment. Furthermore, forming a fuzzy evaluation matrix takes a lot of time [
19]. The fuzzy matrix needs to adjust assignment several times. The fuzzy matrix becomes more complex as the number of risk factors increases. Furthermore, it is not very efficient when dealing with complex fuzzy arithmetic operations. Therefore, it is necessary to propose a method that can efficiently represent multiple subsets without using matrices.
To solve these problems, a data-driven risk assessment model, based on Dempster–Shafer evidence theory (DST) [
20,
21], Deng entropy [
22] and risk matrix [
23], is proposed. Due to effectively deal with uncertain information, DST is widely used in decision-making [
24,
25,
26], risk analysis [
27], information fusion [
28,
29], uncertainty measurements [
30], fault diagnosis [
31,
32,
33], time-series [
34], IoT applications [
35] and many other fields [
36,
37]. Since most experts prefer to express their opinions with linguistic information, such as good, better, best, bad, worse, worst, DST can effectively deal with uncertain information about linguistic expressions involved in risk evaluation [
38,
39]. At the same time, it can also deal with the situation of multiple subsets due to the hesitation of experts. In some methods, the weights of experts or attributes are artificially assigned or not taken into account, which may lead to subjective results. Hence, expert assessments need to be adjusted reasonably. In the DST framework, Deng entropy is one of the most useful methods to measure uncertainty, and it has been applied in multi-sensor information fusion [
40,
41], decision-making [
42,
43], risk and reliability assessment [
44] and other applications. The higher the Deng entropy, the more uncertainty there is. Therefore, in our proposed model, Deng entropy is used to measure the uncertain degree of assessments, and then obtain objective criteria weights given by experts. In addition, probability and severity are two critical descriptors of risk. As a convenient and efficient risk assessment tool, the risk matrix method has been widely used in the engineering field. It can be used to make a comprehensive assessment of probability and severity [
45,
46,
47].
The main contributions of this paper are as follows:
- (1)
Combining qualitative and quantitative factors at different scales. Various scales are used in the assessment, which are in line with real-world scenarios and help the experts to effectively express their opinion.
- (2)
A method based on DST and Deng entropy is used for software risk assessment, which can adjust the expert assessment value and deal with the conflicting value in the assessment. This method makes the assessment more objective.
- (3)
Development of a data-driven software risk evaluation model, which is an integration of DST, Deng entropy and risk matrix. The data can be converted into BPAs as soon as the experts give their evaluation values. After that, the BPAs are weighted and fused. Finally, risk rankings are obtained and provide information for risk decisions. It is effective not only in measuring uncertainty measures, but also in expert evaluation conflict handling and expert evaluation opinion integration.
This paper is structured as follows: In
Section 2, basic definitions and operations of DST and Deng entropy are reviewed. In
Section 3, the method of risk assessment framework is illustrated and the knowledge of software risk identification and risk assessment is introduced. An evidential model based on DST—the Deng entropy risk matrix—is proposed. In
Section 4, a case application is shown. The results and discussion are presented in
Section 5, and conclusions are drawn in
Section 6.
2. Preliminaries
Dealing with uncertainty is still an open issue [
48]. Various methods have been proposed, such as intuitionistic fuzzy values [
49,
50,
51] and others [
52]. These methods were applied in medical analysis, clustering, network congestion alleviating, search engine optimization techniques, etc. [
53,
54,
55]. As an effective method for handling uncertainty, Dempster–Shafer evidence theory is well studied [
56]. Some basic concepts and operations are presented in this section.
2.1. Dempster–Shafer Evidence Theory
Dempster–Shafer evidence theory (DST) was proposed by Dempster [
20] and then expanded by Shafer [
21]. The basic concepts are described below.
Definition 1. Let Θ be a finite set with n exclusive and exhaustive elements, Θ = {}. The Θ is called the framework of identification (FOD). The power set of Θ consists of elements, which is denoted as, Definition 2. m is a mass function or a basic probability assignment (BPA), which satisfies , with the following constraints: If > 0, then A is called a focal element. represents the belief value supporting evidence A. For more information about mass function, please refer to [57,58]. Definition 3. For a proposition , the belief function is defined as, The plausibility function Pl: is defined as, [Bel(A), Pl(A)] is the belief interval of the proposition A.
Definition 4. Given the two BPAs indicated by and , their combination is mathematically defined as [21],where , Conflict coefficient is k, which indicates the conflict degree between two BPAs. When means is consistent with , and when means totally contradicts , that is, the two pieces of evidence strongly support different hypotheses, and these hypotheses are incompatible [59]. Example 1. Suppose Θ = {A, B}, two BPAs as follows, As shown in Example 1, it can be see that the value of
support the object A and
support the object B, while
and
. They also have multiple objects, while
and
. According to the Equations (
5) and (
6),
2.2. Deng Entropy
Entropy is widely used in many fields, such as politics, economics, sociology, informatics, etc. There are many studies on entropy [
60,
61].
Definition 5. Deng entropy is proposed in [22], which is a measure of uncertainty. Furthermore, it has been further improved in dealing with information volume [40,62]. It can be described as,where m is a BPA defined on the FOD, and A is a focal element of m, is the cardinality of A. Through a simple transformation, it can also be described as Deng entropy is an improvement of Shannon entropy. The belief for each focal element in the Deng entropy is divided into
. If there is no uncertainty, i.e.,
, the Deng entropy can degenerate to the Shannon entropy. Some properties and extension of Deng entropy are discussed in [
63]. More research can be found in [
64,
65,
66].
Example 2. Suppose there is an expert evaluation, the frame of discernment is {A, B}. m(A) = 0.7, which represents the expert’s belief in A. The remaining belief is 0.3, representing the expert’s hesitation. The remaining belief is assigned to {A, B}, m(AB) = 0.3. The Deng entropy of the expert evaluation is calculated by Equation (7). Example 3. Suppose there is an expert evaluation, the frame of discernment is {A, B, C}. m(A) = 0.7, m(ABC) = 0.3. The Deng entropy of the expert evaluation is calculated by Equation (7). From the above two examples, it can be seen that the value of the Deng entropy is related to the hesitation value of the experts in the evaluation. By using Deng entropy, the degree of uncertainty in evaluation information can be determined so that objective weights can be calculated. Therefore, it is a good method to apply Deng entropy in risk assessment.
3. Methodology
Some methods are introduced in this section. Software risk identification is shown in
Section 3.1. Software risk assessment is explained in
Section 3.2. An evidential software risk evaluation model DST—Deng entropy risk matrix (DDERM)—is illustrated in
Section 3.3.
3.1. Software Risk Identification
Risk identification is the first step in risk management. With the development of technology and the improvement of project management methods, a number of methods have been proposed to identify risks, such as the Delphi method, expert judgment, graphical techniques, brainstorming and other methods. Several risks are discussed in the different studies, as shown in
Table 1.
Risk factors always change with the environment. Meanwhile, different software projects have different risks. Based on the literature review discussed in
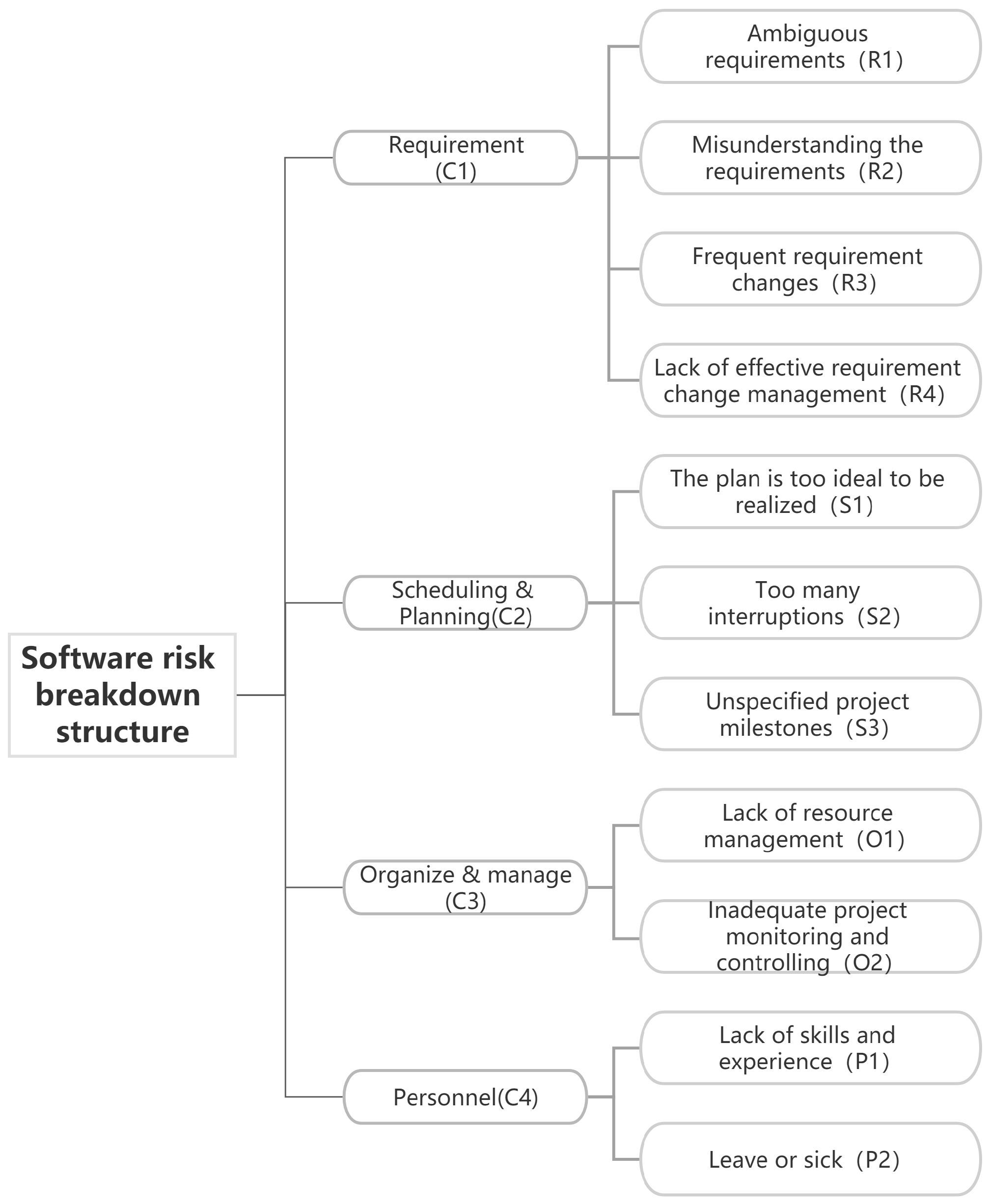
Table 1, as well as on the previous experience of experts and analysis of the actual project situation, the DMs consider four types of risk factors in this project: requirement risks (C1), scheduling and planning risks (C2), organize and manage risks (C3) and personnel risks (C4). Details in
Table 2. The software risk breakdown structure is shown in
Figure 1. In the requirement risks (C1), there are four most common risks including ambiguous requirements (R1), misunderstanding the requirements risks (R2), frequent requirement changes (R3) and lack of effective requirement change management (R4). Scheduling and planning risks (C2) contains three risks: the plan is too ideal to be realized (S1), too many interruptions (S2), and unspecified project milestones (S3). Lack of resource management (O1) and inadequate project monitoring and controlling (O2) are in the organize and manage risks (C3). Lack of skills and experience (P1) and leave or sick (P2) are the most common personnel risks (C4).
Notably, some of these risk factors may not be independent. For example, lack of skills and experience (P1) may make it easier to misunderstand requirements (R2). However, the more risk factors there are, the more difficult it is to quantitatively measure the relationship between risk factors. Therefore, in the proposed model, the assessed values of the experts are considered to have taken into account the interrelationship between the risk factors.
3.2. Software Risk Assessment
Software risk assessment is to quantify the probability of risk and severity of loss, and then to obtain the overall level of system risk. The definition of risk can be shown as follows [
74],
Probability and severity are two aspects of risk. The levels and linguistic terms for these two aspects are listed in
Table 3 and
Table 4. There are five levels of probability, from low to high: very unlikely, unlikely, even, possible and very possible. Severity also contains five levels: very little, little, medium, serious and catastrophic. There are four levels of risk, as shown in
Table 5.
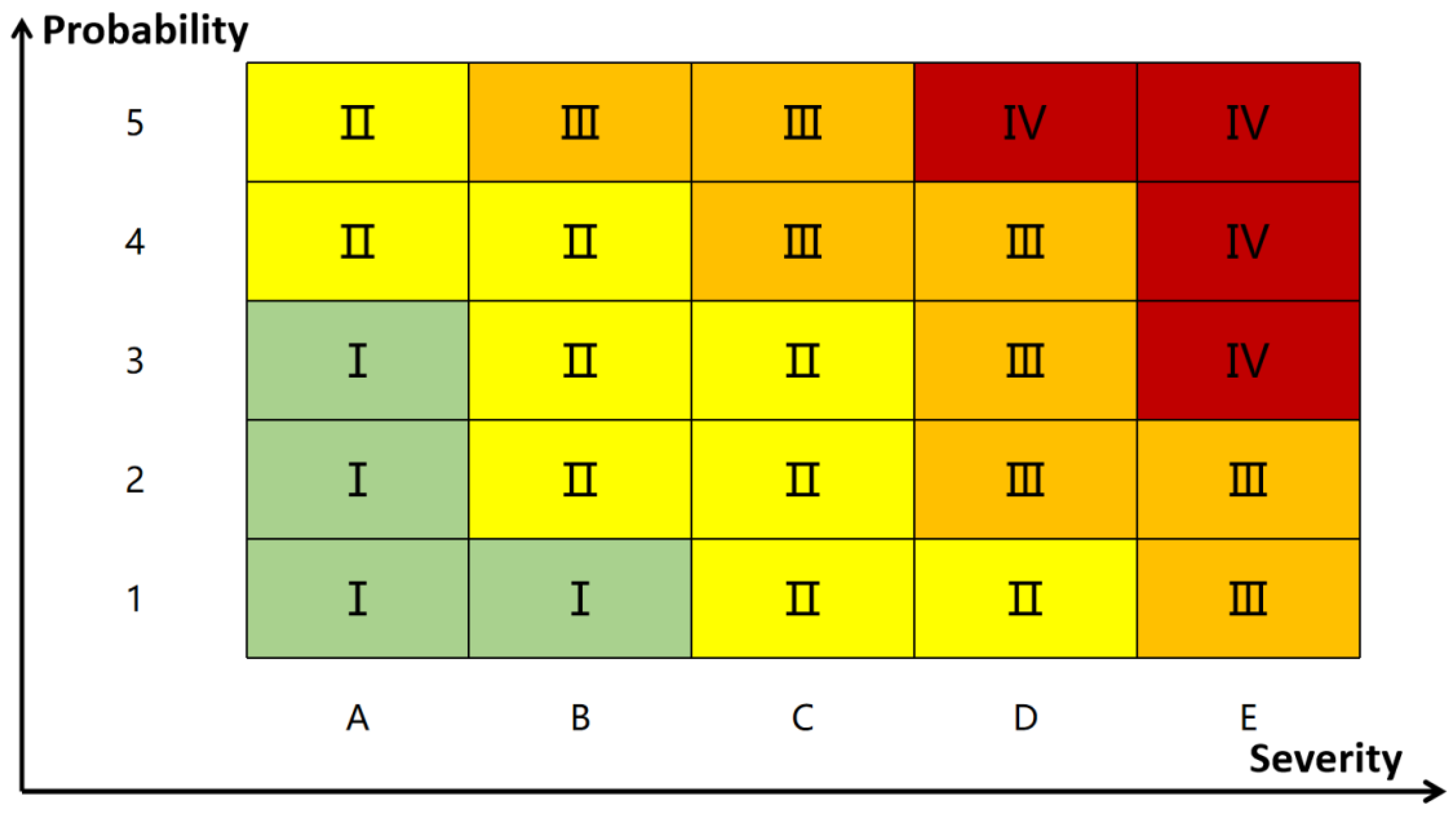
As a good risk management tool, risk matrix is widely used. According to Equation (
9) and the values in
Table 3,
Table 4 and
Table 5, a risk matrix is given in
Table 6 and its levels are shown in
Figure 2. If the severity of a risk is serious, but the probability of occurrence is very unlikely, the risk is still very low. Furthermore, if the probability is very possible, but the impact is little, the risk is medium. For example, the probability of risk R1 is level 4, and its severity is D. By querying the risk matrix, its risk level is III. Therefore, both factors must be taken into account to determine the risk level.
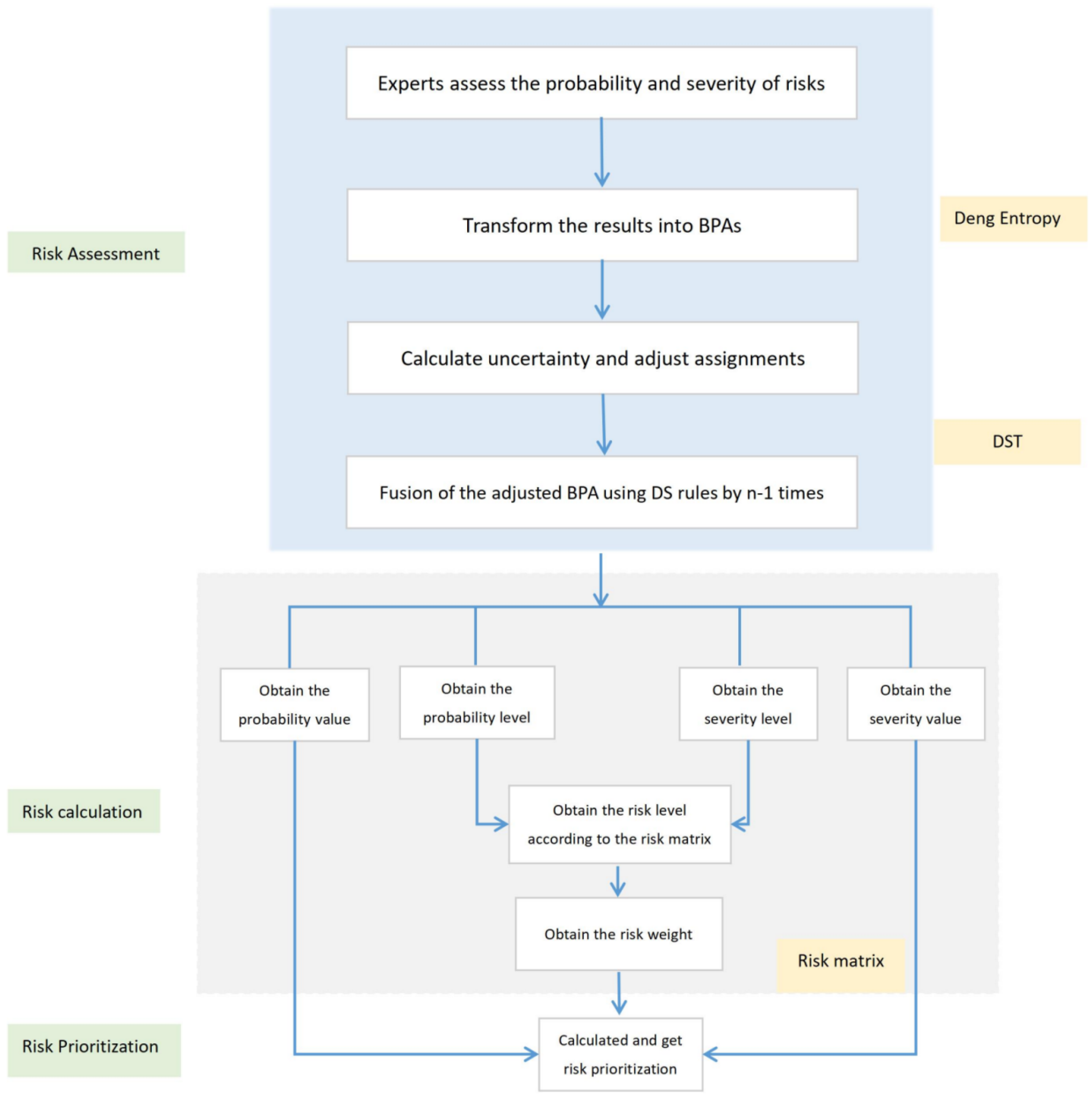
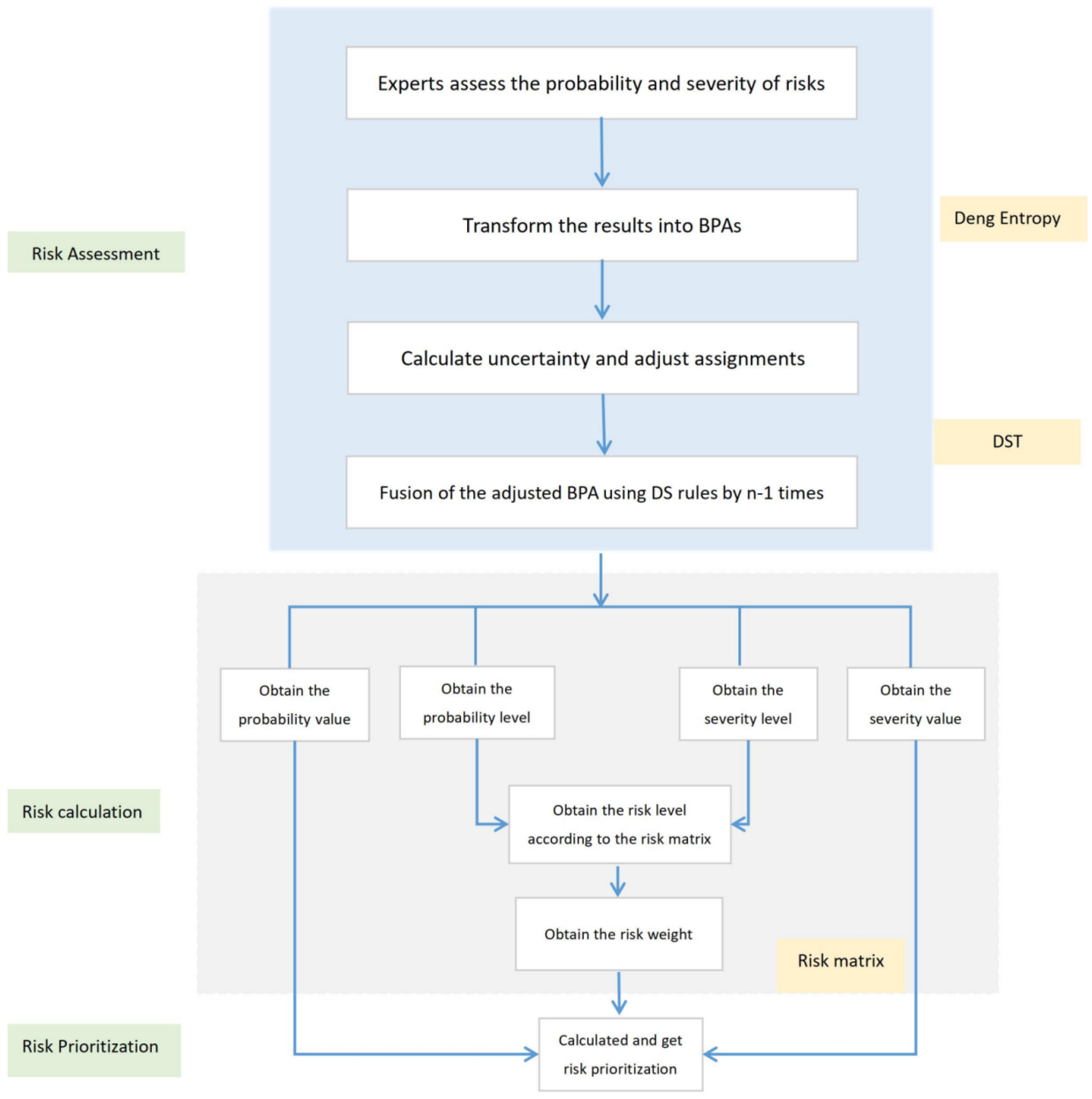
3.3. DST—Deng Entropy Risk Matrix Model
Good risk management is an important condition to ensure system reliability. For more research on reliability, please refer to [
75,
76]. A risk assessment model DST—Deng entropy risk matrix (DDERM) is proposed to deal with risk data. This model is composed of the following steps, as illustrated in
Figure 3.
Step 1. Each expert makes judgments on each risk in the risk list, including both probability and severity;
Step 2. Transform the assessment results into BPAs;
Step 3. Calculate uncertainty and adjust assignments;
Step 3.1. Calculate the uncertainty.
where
ℜ represents different risk factors, such as R1, R2, S1, O1, O2, P1, and so on. For each
ℜ, there are
n experts’ assigned values.
is the assignment of the i-th expert.
is the frame of discernment of probability, and
= {1, 2, 3, 4, 5}.
is the frame of discernment of severity, and
= {A, B, C, D, E}.
Step 3.2. Calculate
w using Equations (
12) and (
13).
Step 3.3. Modify each BPA.
Step 4. Fusion of the adjusted BPAs using DS rules. If there are n experts,
n − 1 times of fusion are performed.
where
k is conflicting factors.
Step 5. According to the result of fusion, the values of probability and severity can be obtained. Meanwhile, the level of probability and severity can also be obtained.
Step 6. According to the risk matrix in
Figure 2, risk levels are obtained by using the probability level and the severity level.
Step 7. Get the weight of risk based on risk level, as shown in
Table 7.
Step 8. Calculate and get risk prioritization.
4. A Case Application
This case is an application of software risk management. Software risk management is closely related to software quality. In recent years, the problem of poor quality software has occurred frequently, seriously affecting the production and lives of people. Therefore, it is necessary to establish an effective risk assessment model for better risk management.
As we know, effectively representing, aggregating and ranking risk factors should be the key issues in risk management. In the application, after risk identification, eleven risk factors are listed in
Table 2. Three experts were invited to assess the risk. In order to represent the assessed values effectively, the assessed values are converted to BPAs. Meanwhile, Deng entropy and DST are used to aggregate risks. Finally, the risk matrix is used to calculate the risk ranking.
Step 1. For the eleven key factors in
Table 2, three experts were invited to express their opinions on probability and severity according to the levels defined in
Table 3 and
Table 4. Here, we assume that the experts have the same knowledge weights. Evaluation are given in
Table 8. For instance, the risk R1, 4 (80%) means that expert 1 is 80% sure that the probability of risk is “Possible.” Furthermore, D (60%) means that the severity of “Serious” is 60%, which is the estimate given by expert 1.
Step 2. Transform the assessment results into BPAs.
For risk P1, the BPAs of the probability are as follows,
The BPAs of the severity are as shown below,
Since , if the BPAs of a risk given by an expert is not equal to 1, assign the remaining value to .
Step 3. Calculate uncertainty and adjust assignments.
Step 3.1. Calculate the uncertainty. Still using P1 as an example, base on Equation (
10) the uncertainty degree of probability is calculated as follows:
Base on Equation (
11) the uncertainty degree of severity is
.
Step 3.2. The
w can be described by Equation (
12).
In the same way, use Equation (
13) to calculate other
w of P1,
.
Step 3.3. Modify each BPA based on Equations (
14) and (
15).
In the same way, .
Step 4. Fusion of the adjusted BPAs using DS rules by n-1 times based on Equations (
16) and (
17). Because there are three sets of BPAs, it needs to fused two times.
Step 5. According to the result of fusion, the values of probability and severity can be obtained. Meanwhile, the probability and severity levels can also be obtained. The fuse results are presented in
Table 9.
Step 6. According to the risk matrix, the probability level and the severity level can be used to obtain the risk level, as shown in
Table 10.
Step 7. Get the weight of risk based on risk level, as shown in
Table 7.
Step 8. Calculate and get risk prioritization. Based on Equation (
18), calculated the overall value of risk, which is in the last column of
Table 10. Then use the largest data as the final value for each risk level as shown in
Table 11 and
Figure 4. Finally, prioritize the risks.
5. Results and Discussion
In this section, the results are analyzed. Furthermore, to demonstrate the advantages of the proposed method, a discussion is presented in the following.
5.1. Results
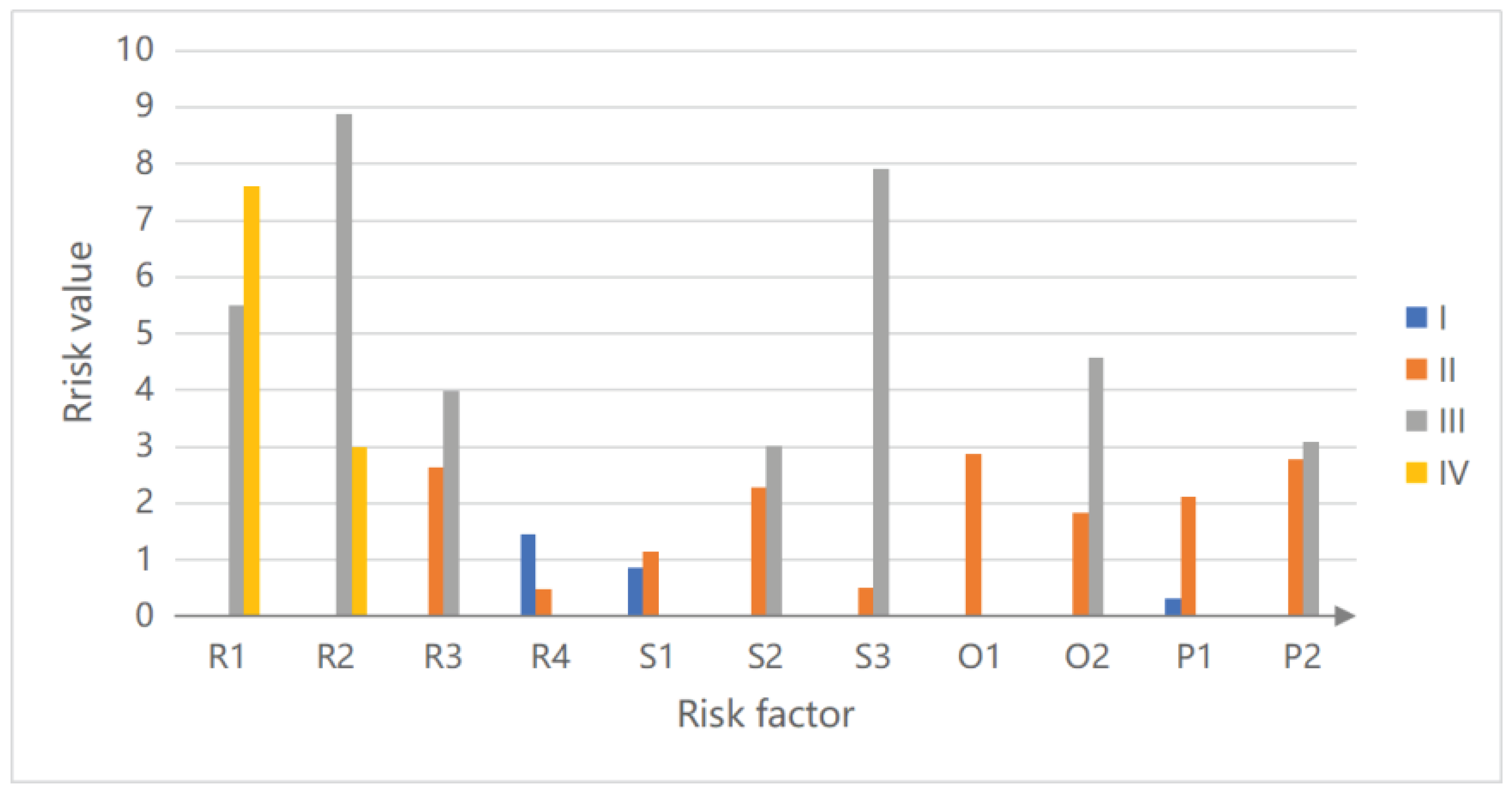
According to
Table 11 and
Figure 4, the results of the proposed risk assessment model DDERM can be seen from two perspectives.
For each risk factor, there may be different risk levels. For example, R1 contains two levels—one is III and the other is IV, while O1 has only one risk level II. The project manager and DM can consider whether to focus on high-level or low-level risk factors, according to the specific situation of the project, the nature of risks, different software life cycle periods, and risk preferences.
For each risk level, the risk factors can be sorted. In level I, R4 > S1 > P1. In level II, O1 > P2 > R3 > S4 > P1 > O2 > S1 > S3 > R4. R2 > S3 > R1 > O2 > R3 > P2 > S2 in level III. Furthermore, R1 > R2 in level IV. This means that, for the highest risk level ’High’, R1 must be focused first, and then R2. R2 is the most important in level ’Significant’. For the risk level ’Medium’, O1 is the most concerned. In ’Low’, R4 needs the most attention. The project manager and DMs can make decisions based on different risk levels.
Based on the results, some explanations are needed. R4 > P1 means “lack of effective requirement change management” presents a higher risk than “lack of skills and experience”. This may be because requirements changes occur frequently, and in this case, there is a significant risk if requirements changes are not managed effectively. At the same time, the members of this project team are all experienced in development, in comparison, the risk of” lack of skills and experience”is less. In addition, R1 > R2, which means that ambiguous requirements are more risky than misunderstood requirements. The result seems unreasonable. However, in this case, the possibility for the requirements analysis to completely misunderstand the requirements may be less than the user’s ambiguity in expressing the requirements, so R1 > R2. The assessed values of the experts are considered to have taken into account the interrelationship between the risk factors.
5.2. Compared with Other Software Risk Assessment Method
In this section, we compare the constructed DDERM model with several existing methods, including Fuzzy set theory and hierarchical structure [
68,
77], Fuzzy DEMATEL, FMCDM, TODIM approaches [
69], DEMATEL, ANFIS MCDM and F-TODIM approaches [
70], entropy-based method [
67]. The comparison are shown in
Table 12. We can draw the following conclusions:
- (1)
In [
68,
77], the weights are given in advance. Thus, weights are static and subjective. In contrast, in the DDERM approach, the weights are measured by the degree of uncertainty in the assessment. The weights are objective and independent, and relate only to the assessment of risk factors. When different experts give different values for the same risk factor, the weights are definitely different. If the same expert evaluates different risks differently, the weights must be distinct. This means that the weight is dependent on how reliable the expert is for that risk. Besides, the evaluations of different experts have no effect on the weights of other experts.
- (2)
In [
69,
70], multiple modifications to the judgment matrix are frequently required because the judgment matrix created during the evaluation process is not completely consistent. The judgment matrix needs to be modified more than 4 times. In the DDERM approach, there is no need to establish and repeatedly adjust the matrix. Only expert evaluation and risk matrix are required. At the same time, DDERM has the advantage of DST in expressing uncertain information, which effectively assigns risk value to multi subsets.
- (3)
Using entropy-based method for software risk assessment in [
67]. However, it does not effectively solve the problem of conflicting information in the assessment. Similarly, it is well know that Dempster’s combination rule is very important for multi-source combination. However, when fusing the high conflicting evidences, counter-intuitive conditions often occur. For example, suppose there are two options A and B. There are ten experts in total. 1 expert is very sure that it is A (assuming BPA is 0.99). 9 experts choose B, but the BPA is not very high (assuming the BPA is 0.6 each). The choice is A after using the Dempster’s combination rule. However, obviously, we are more certain that the choice of 9 experts is correct. In DDERM method, based on the Deng entropy, the higher the entropy value gives higher weight, which can effectively solve the drawbacks of Dempster’s combination rule about conflicts. In the example above, using this approach effectively downplays the impact of individual expert errors on the overall assessment.
Table 12.
Comparison of different method of software risk assessment.
Table 12.
Comparison of different method of software risk assessment.
| Literature | Processing Method | Calculation of Weights | Complexity | Subjective/
Objectivity |
|---|
| [68,77] | Fuzzy set theory and hierarchical structure analysis | Given in advance | Convert the linguistic value to triangular fuzzy number and multiply the fuzzy numbers | Weights are static and relatively subjective |
| [69,70] | Fuzzy DEMATEL + FMCDM + TODIM/DEMATEL + ANFIS MCDM + IF-TODIM | Fuzzy DEMATEL + Fuzzy TODIM | Multiple adjustments fuzzy matrix | Using integrated fuzzy approaches, assessment results are relatively objective |
| [67] | Entropy | Entropy weight method | Simple calculation | Uncertainty is taken into account and relatively objective |
| Our method | DST+Deng entropy+Risk Matrix | Deng entropy | Using data-driven model that does not need to calculate and adjust parameters many times | Considers uncertainty and conflicts between experts, more objectivity |
6. Conclusions
The evaluation of software risks plays an important role in the field of software development. To efficiently assess the risk, in this paper, a data-driven software risk evaluation model is proposed. We first discussed the drawbacks of the existing methods. Then, 11 software risks were identified. The software risk breakdown structure and risk matrix were illustrated. Furthermore, an evidential software risk evaluation model based on DST, Deng entropy and risk matrix were proposed. Finally, we applied the proposed method to a case application and compared our results to existing methods. By comparison, the proposed method can express more uncertainties and help the domain experts to express their opinions effectively. Meanwhile, it can adjust the expert assessment value and deal with the conflicting values in the assessment. In short, our method not only overcomes the complexity of matrix method, but also improves the ability to handle uncertainty. However, some limitations are also highlighted. More software risk factors would increase the validity of the results, and multiple weights were not considered. The evaluation process needs to be repeated when the risk factors change, since risk assessment is a dynamic process that exists throughout the life cycle of software.
Our future research work will mainly focus on considering the weight of risk attributes, giving experts different knowledge weights and improving the model to increase its applicability.




{kind=link}
{kind=link}
{kind=link}
{kind=link}