1. Introduction
Suppose that there are
k (
) populations, and the distribution function of the
i-th population is
, where
,
are parameter vectors (
), and
A is the parameter space. In other words, the
k populations share the same type of distribution but may have different structures as
(
) varies. Consider the hypothesis
This test for homogeneity arises, for example, in the comparison of a number of different treatments, processes, varieties, or locations, when one wishes to test whether these differences have any effect on an outcome X, where X can be a scalar or a vector.
If
F is the normal distribution function, the standard analysis of variance (ANOVA) for testing the above hypothesis has been widely used by a number of investigators. For example, Dou [
1] employed this method in a parametric study of a developed statistical model. However, the standard ANOVA is not suitable for other distributions.
Due to the complexity of the real world, the form of
F may not be known in many applications. In this nonparametric setting, the Kruskal–Wallis test (KWT) provides tests of the null hypothesis that independent samples from two or more groups come from identical populations. Refer to Lehmann [
2] for the theory and applications of KWT.
Here, we provide a brief definition for KWT and its limiting distributions. First, the data of all samples in a single series are arranged in an ascending order, and a rank is assigned to each data in the ascending order too. In the case of a repeated value, or a tie, assign ranks to them by averaging their rank position.For example, if the sample number is even, the rank of the median is the average rank of the two numbers before and after it. The KWT statistics for the
k independent samples, each of size
, is
where
, and
is the sum of the ranks (from all samples pooled). For the
i-th sample, we have
where
is the rank (from all samples pooled) of the
j-th observation in the
i-th sample. The null hypothesis of this test is that all
k distribution functions are equal. It is shown, under the null hypothesis and some regularity conditions, that
As mentioned above, when the form of the F may not be known in many applications. KWT can be used to perform consistency tests for multiple populations. As KWT constructs statistics based on sample rank, its test efficacy is good when the sample size is large. However, when the sample size is small, the statistics constructed based on sample rank carry much less sample information. In other words, KWT is obviously going to be a lot worse. So we introduce the empirical likelihood method; here, we provide a brief definition for it.
The empirical likelihood method as a nonparametric technique for statistical inference in the nonparametric setting was introduced by Owen [
3,
4] and has many advantages over other nonparametric test methods such as the normal-approximation-based method and the bootstrap method, as put forward by Hall and La Scala [
5] and Hall [
6]. The Wilks’ theorem, Bartlett correction and the ability of using auxiliary information are three striking properties of the empirical likelihood methods. Chen and Qin [
7] proved that the empirical likelihood method can be seamlessly applied to finite population estimation problems, and more accurate statistical inference can be obtained through the effective use of auxiliary information. Zhang [
8] developed a new class of
M function estimators and quantile estimators with some auxiliary information, using the empirical likelihood technique. A natural question is whether and how an empirical likelihood method can efficiently use the auxiliary information to decide whether several samples should be regarded as those that come from the same population. In this paper, an empirical likelihood ratio test (ELRT) statistics is constructed for testing the homogeneity of several nonparametric populations in the presence of some auxiliary information. Since the auxiliary information is not employed in the KWT method, KWT may be less powerful than ELRT in the field of population distribution consistency. A comprehensive comparison between ELRT and KWT was conducted and is presented in
Section 3.
We note that there exist a few other approaches which allow to incorporate auxiliary information in statistics testing. For example, the method based on the auxiliary information in a form of vectors of unbiased estimates in Tarima and Pavlov [
9] (T&P (2006)) may be used in the context of this article. The asymptotic properties of the above work are analyzed by Albertus [
10]. Tarima and Pavlov used additional information to construct parameter estimation statistics, and completed parameter estimation by adding data sources. Therefore, we will compare ELRT and T&P (2006) separately in the numerical simulation part.
The form of
F is unknown in the present study. However, it is assumed that some auxiliary information about the distribution function
is available in the sense that there exist
known functions
such that
where
and
is an
r-dimensional vector.
Equation (
2) defines a group of estimating equations. Those equations are widely applicable and particularly powerful when the data model is not specified by a full parametric likelihood function, as elaborated by Hansen [
11] and Godambe and Heyde [
12] among many others. Qin and Lawless [
13] showed that an empirical likelihood approach produces a semiparametric efficient parameter estimate. In this study,
is required. Excellent explanations related to this requirement are given by Qin and Lawless [
13] and Zhang [
8]. More related results of statistical inference using the estimating equations can be found in Wang and Chen [
14] and Zhou et al. [
15], among others.
This assumption (
2) is natural in practice; as in most commonly used distribution families, the distribution is usually determined by some of its moments, such as the mean, variance, skewness, kurtosis and so on. For example, if
X is the amount of a type of grains and one suspects that there could be some differences in the amount of the grains, among several populations, caused by the amount of fertilizer, we may set
and
. On the other hand, if one suspects that the use of the fertilizer may not only cause the change of amount of grains but also the change of the variance of
X, then we may set
and
, where
. These could be initially assessed by comparing the histograms of the data sets of populations which are under consideration. In addition to the above (partial) information, we may know some extra information. For example, we may know some moments of
X or may know that the distribution of
X is symmetric about some points.
Based on (
2), we will construct an empirical likelihood ratio test (ELRT) to test
. It is shown that the limiting distribution of the ELRT under
is
, and thus the testing method for
is ready to use, where
is the chi-squared random variable with
degrees of freedom.
The rest of the paper is organized as follows. The main results of this study are presented in
Section 2. Results of a simulation study on the finite sample performance of the ELRT are reported in
Section 3. We conclude and give some remarks on our future work in
Section 4. Finally, the proof of the main results is presented in
Section 5.
2. Main Results
For
, suppose that data
are independently distributed as
(unknown) and that all
are independent. Let
and
is the parameter space of
and an open set of
. Let
Here, is the probability mass, which represents the probability that the random variable values , both of which are non-negative, and the sum is 1. Similarly, represents the probability that the random variable values when .
Applying the method proposed by Qin and Lawless [
13], the ELRT for testing
can be defined as
The ELRT rejects for large values of .
For every
, assume that 0 is in the convex hull of
. Then, according to the Lagrange multiplier method, one can obtain
where
is the solution of the equation
Similarly, for
,
where
is the solution of the equation
The log-empirical likelihood function for data
is therefore defined by
Suppose that there is a
that maximizes
, then the
is called the maximum empirical likelihood estimator (MELE) of
. Suppose that, in addition,
is differentiable in
, then
will be a solution of the empirical likelihood equation
where
is the
-element of the
matrix
.
Similarly, for
, the log-empirical likelihood function for
is defined by
The MELE of
under the
i-th sample is denoted as
, which is a solution of the empirical likelihood equations
We assume that all
and
are consistent estimators of
as
. Then the
can be rewritten as
Let
X be a population with a distribution
,
be the true value of
, and
be the
-norm of a matrix
M. To obtain the asymptotic distribution of
, we need some regularity conditions as follows Qin and Lawless [
13] (pp. 305–306):
(A) is positive definite, is continuous in a neighborhood of , and are bounded by a function in this neighborhood, and the rank of is p, where .
(B) is continuous in in a neighborhood of and is bounded by a function in this neighborhood, where .
The main results of this study are presented as follows.
Theorem 1. Suppose assumptions (A) and (B) are satisfied, then, under , as , we havewhere is the chi-squared random variable with degrees of freedom. Remark 1. If we use in Equation (11) in stead of Equation (6) as the original definition, where and are the roots of related likelihood equations, then Theorem 1 still holds true. This can be seen from the proof of Theorem 1. In other words, and do not need to be the MELEs to have the results of Theorem 1. To sum up, we constructed an ELRT statistic for testing the homogeneity of several nonparametric populations in the presence of some auxiliary information when the population distribution is unknown, and proved the asymptotic distribution of ELRT as a chi-square distribution under some regularity conditions when the null hypothesis is true. Next we will begin the numerical simulation. In this section, we will calculate the rejection rates of ELRT and compared with those of the Kruskal–Wallis test under several alternatives and compare the powers of them.
3. Simulation Results
Several commonly used distribution families were used in our simulations. The collective distribution and related parameter information are shown in
Table 1.
In this study, only three populations were compared. In the simulations, it was supposed that we only know the means of the populations. On the one hand, under the combination of sample size, we took the true value of the distribution under the null hypothesis to generate three distribution populations, and calculated the value of
. The simulation was repeated 5000 times to obtain 5000 corresponding
values. Then, the quantiles of
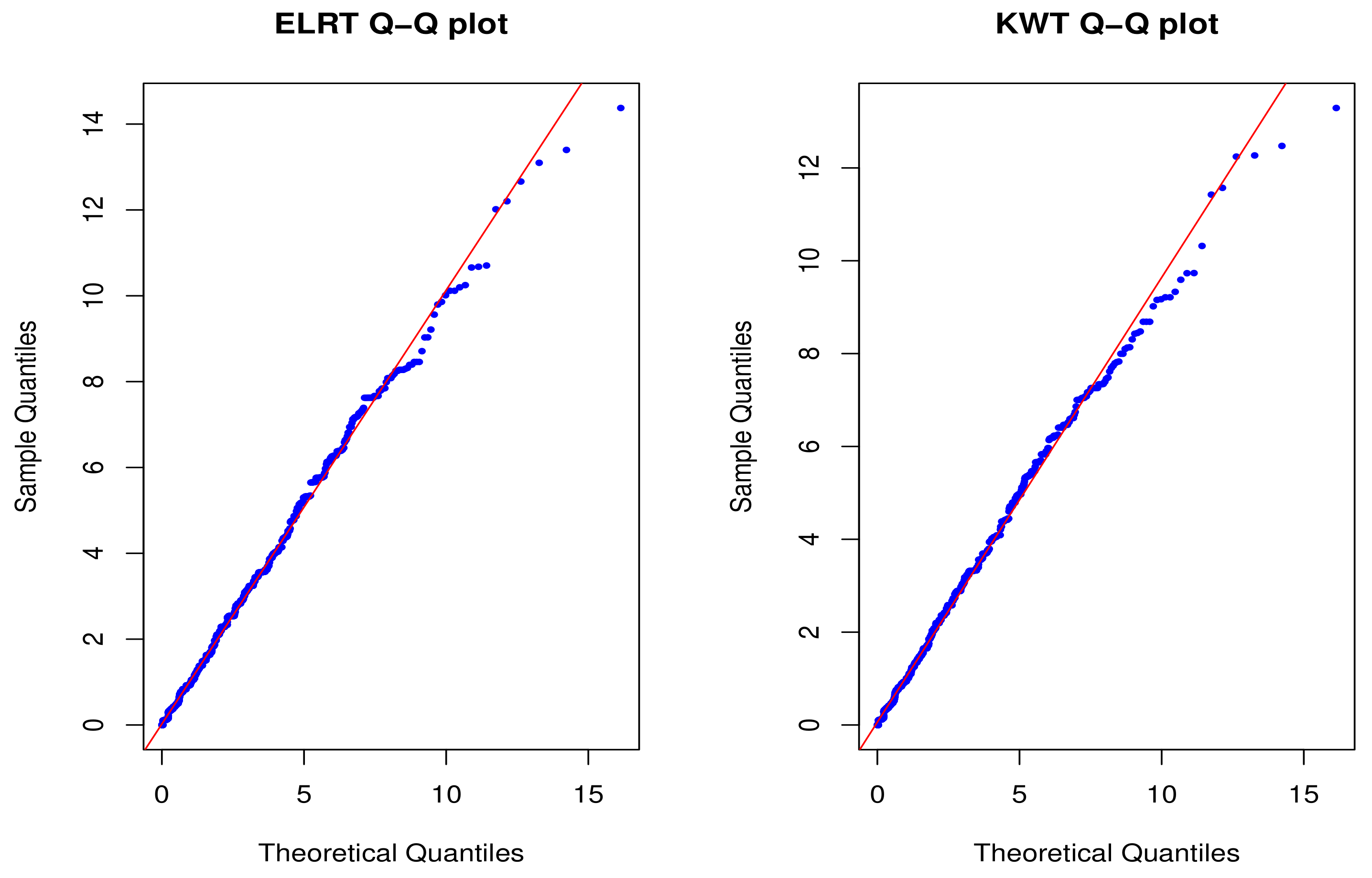
samples obtained were compared with the quantiles of the Chi-square distribution in Theorem 1. Finally, the Q-Q diagram of ELRT was made as well as the Q-Q diagram of KWT under the same conditions (
Figure 1,
Figure 2,
Figure 3,
Figure 4,
Figure 5 and
Figure 6). Here the abscissa is the theoretical quantile value, and the ordinate is the quantile value of the distribution population. It can be seen from
Figure 1,
Figure 2,
Figure 3,
Figure 4,
Figure 5 and
Figure 6 that when the null hypothesis is true, the Q-Q diagrams of ERLT and KWT can prove that the asymptotic distribution of the test statistics given in this chapter obeys the Chi-square distribution when the null hypothesis is true.
At the same time, the simulated rejection rates of ELRT and KWT under several alternatives were compared using 5000 Monte Carlo trials with various sample sizes. It should be noted here that the rejection rate is calculated as follows:
where the reslt. KWT is calculated from the samples by KWT statistics, and quantl. KWT is calculated from the samples under the alternatives by Chi-square distribution, and m is the number of samples. The significant level was always set as 0.05 in the simulations. Results of these comparisons were reported in
Table 2. In addition, we simulated the rejection rates of KWT and ELRT under the original hypothesis, and the results are shown in
Table 3. From these results, it can be seen that the simulated powers are quite good for both tests, even for moderate sample sizes with better performance, as sample sizes increase and ELRT performs better than KWT.
On the other hand, we consider that T&P (2006) also performs parameter estimation research based on additional information, so we will separately compare the ELRT proposed by T&P (2006) in this paper. The results are shown in
Table 4. We can see some interesting results from the comparison results. For example, T&P (2006) is more dependent on the normal sample, that is to say, when the comparison sample is biased to the normal sample, the test efficacy of T&P (2006) is very effective; when deviating from the normal condition, T&P (2006) showed poor test efficacy compared with ELRT. In other words, the advantage of ELRT over T&P (2006) is that researchers do not need to select approximately normal statistics for inter-group comparisons. At the same time, from the perspective of the sample size, ELRT is more suitable for the multi-population consistency test with a small sample size.
4. Conclusions
In this study, we discussed the consistency test of the population when the population distribution is unknown, and constructed an ELRT statistic for testing the homogeneity of several nonparametric populations in the presence of some auxiliary information.Meanwhile, we proved the distribution of ELRT both theoretically and numerically and calculated the rejection rates of ELRT and compared with those of the Kruskal–Wallis test under several alternatives. In addition, the efficacy of ELRT and T&P (2006) were compared separately.
The results show that, firstly, the asymptotic distribution of ELRT as a chi-square distribution under some regularity conditions when the null hypothesis is true. Secondly, the rejection rates of ELRT are bigger than those of KWT, as the sample sizes increase when the sample is small. In other words, the proposed ELRT could be more powerful than the Kruskal–Wallis test, as extra information can be more efficiently employed by ELRT. Thirdly, the advantage of ELRT over T&P (2006) is that researchers do not need to select approximately normal statistics for inter-group comparisons. At the same time, compared with T&P (2006), ELRT is more suitable for multi-population consistency test with small sample size.
This discussion will be applied to the field of biological information. For example, when two samples are from the data of an experimental group and a control group, the statistics we constructed will be able to test whether the experimental processing is effective. If the overall distributions of the two data are equal, it means that the experimental processing is ineffective, otherwise it means that the experimental processing is effective. Although some good main conclusions and simulation results were obtained in this paper, there are still many problems to be further discussed in the future. On one hand, the study presented in this paper is based on simple random samples, so more complex cases (such as mixed cases or dependent samples) should be considered. On the other hand, the simulations of one-parameter distributions were completed in this paper, while the simulations of multi-parameter distributions still need to be completed. Therefore, in the future, we will continue to complete the simulation of population consistency for multi-parameter distributions by ELRT and construct a new ELRT statistics above multi-population consistency under complex samples.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}