
Improving the Deeplabv3+ Model with Attention Mechanisms Applied to Eye Detection and Segmentation


Abstract
:1. Introduction
- (1)
- The proposed dataset (EIMDSD) allows more accurate eye detection and eye image segmentation. The dataset is used to establish different scenarios of detection and segmentation.
- (2)
- As deep learning models are used to evaluate the results of eye detection and eye region segmentation on the proposed dataset, the evaluation result helps select appropriate models for eye detection and eye image segmentation.
- (3)
- The improved DeepLabv3+ network architecture (IDLN) with the convolutional block attention module (CBAM) and the MobileNetV2 can replace the ResNet-101 network. The IDLN also achieves reliable segmentation performance.
2. Related Works
- Asymmetric Non-local Neural Networks (ANN) [26] for semantic segmentation have Asymmetric Pyramid Non-local Block (APNB) and Asymmetric Fusion Non-local Block (AFNB). The cross-entropy is the loss function of ANN.
- Bilateral Segmentation Network (BiSeNet V2) [27] involves a detailed branch to capture low-level details and generate high-resolution feature representation and a semantic branch to obtain high-level semantic context. A Guided Aggregation Layer is to enhance mutual connections and fuses feature representations. Softmax loss is the loss function of BiSeNet V2.
- Dual Attention Network (DANet) [28] adaptively integrates local features with global dependencies. Two types of attention modules on top of traditional dilated FCN are used to model the semantic interdependencies in spatial and channel dimensions, respectively. Multiple losses are added to the loss function.
- Fast segmentation convolutional neural network (Fast-SCNN) [29] is an encoder-decoder framework for offline semantic image segmentation. The cross-entropy is the loss function of Fast-SCNN.
- Fully Convolutional Networks (FCNs) [30] with downsampling and upsampling inside the network efficiently make a pixel-wise dense prediction for predicting a label for each pixel in an image. The per-pixel multinomial logistic loss is the loss function of FCN.
- Interlaced Sparse Self-Attention (ISANet) for Semantic Segmentation [31] has two successive attention modules each of which is estimated with a sparse affinity matrix. The first and the second attention module is used to estimate the affinities within a subset of positions that have long and short spatial interval distances, respectively. The auxiliary loss is the loss function of ISANet.
- Object-Contextual Representations (OCRNet) [32] for semantic segmentation characterizes a pixel by exploiting the representation of the corresponding object class. The object regions are learned under the supervision of ground-truth segmentation. The object region representation is computed by aggregating the representations of the pixels lying in the object region. The cross-entropy is the loss function of OCRNet.
- Pyramid scene parsing network (PSPNet) [33] uses a CNN to obtain the feature map with the dilated network strategy to extract the feature map capability of global context information by different-region-based context aggregation through the pyramid pooling module. The softmax loss and auxiliary loss are the loss functions of PSPNet.
- U-Net [34] is an architecture for semantic segmentation. It consists of a contracting path and an expansive path. The contracting path follows the typical architecture of a convolutional network. Every step in the expansive path consists of an upsampling of the feature map. The energy function is computed by a pixel-wise softmax over the final feature map combined with the cross entropy loss function.
- DeepLab [35] eliminates several downsamplings in ResNet to maintain high resolution and utilizes convolutions with large dilations to enlarge receptive fields. The sum of cross-entropy terms is the loss function of DeepLab.
3. Methodology
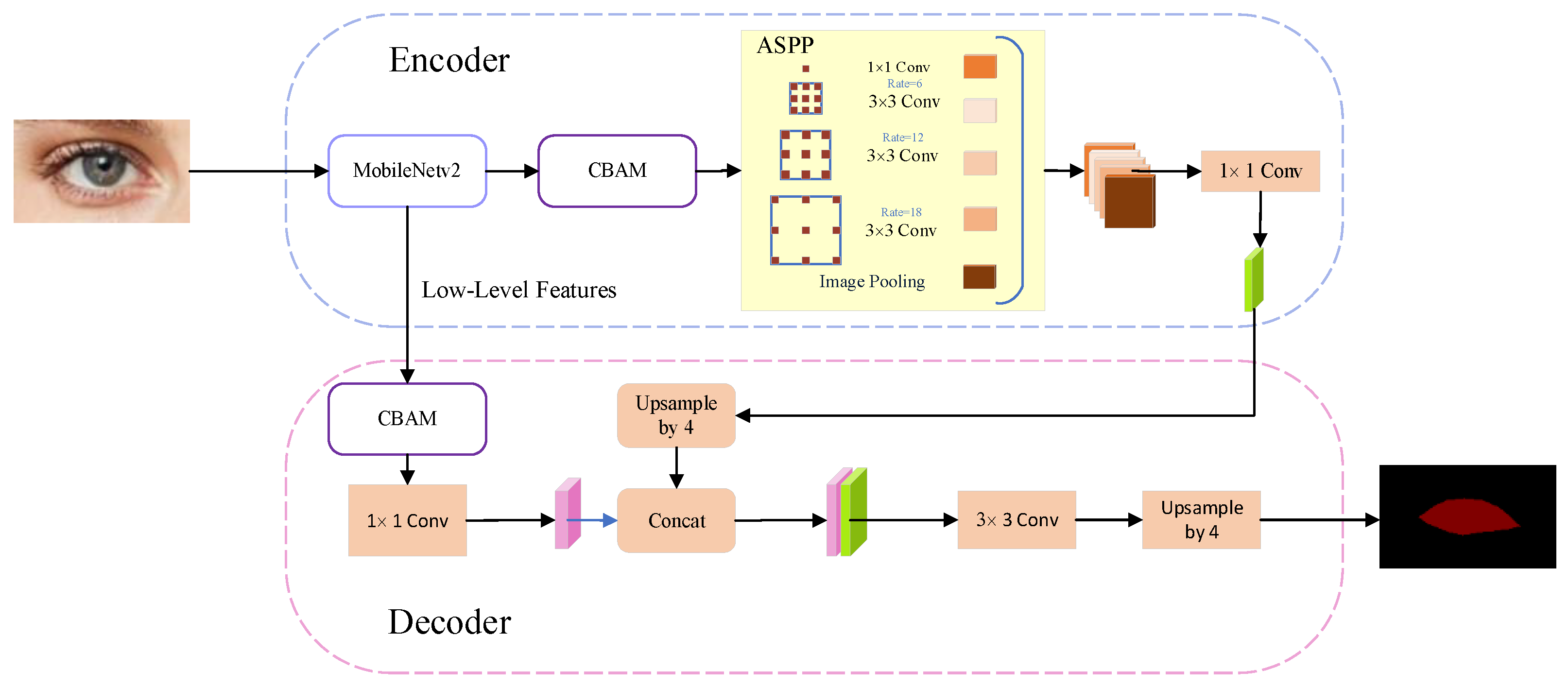
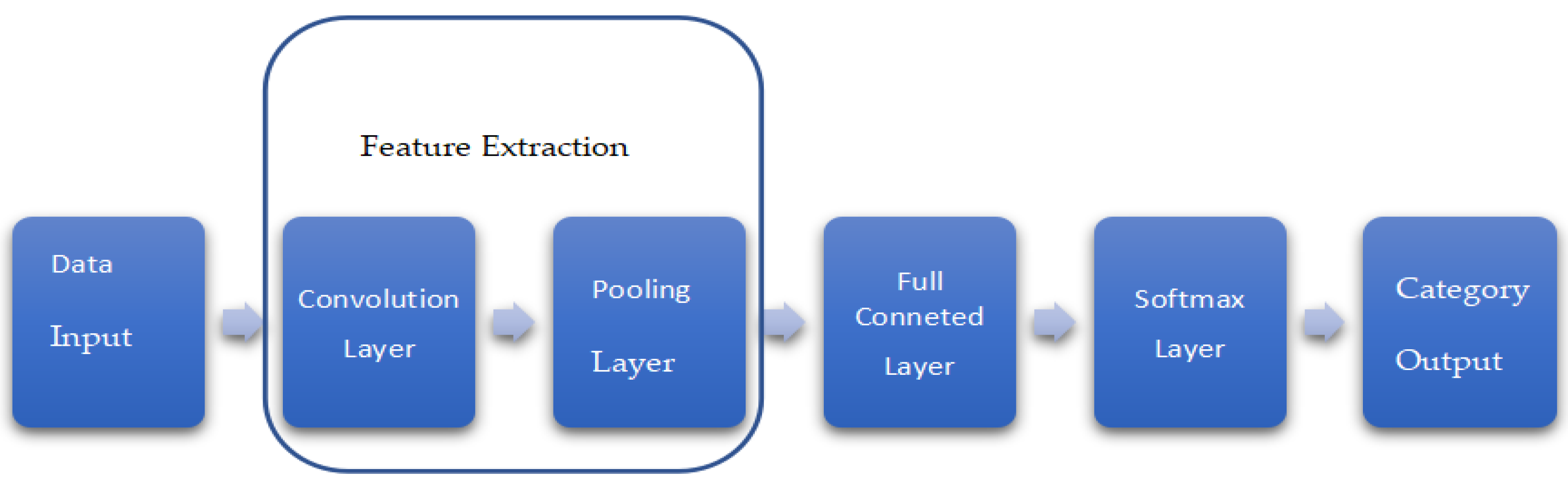
3.1. Improvement of DeepLabv3+ Network Architecture
3.2. Evaluation of the Dataset and the Model
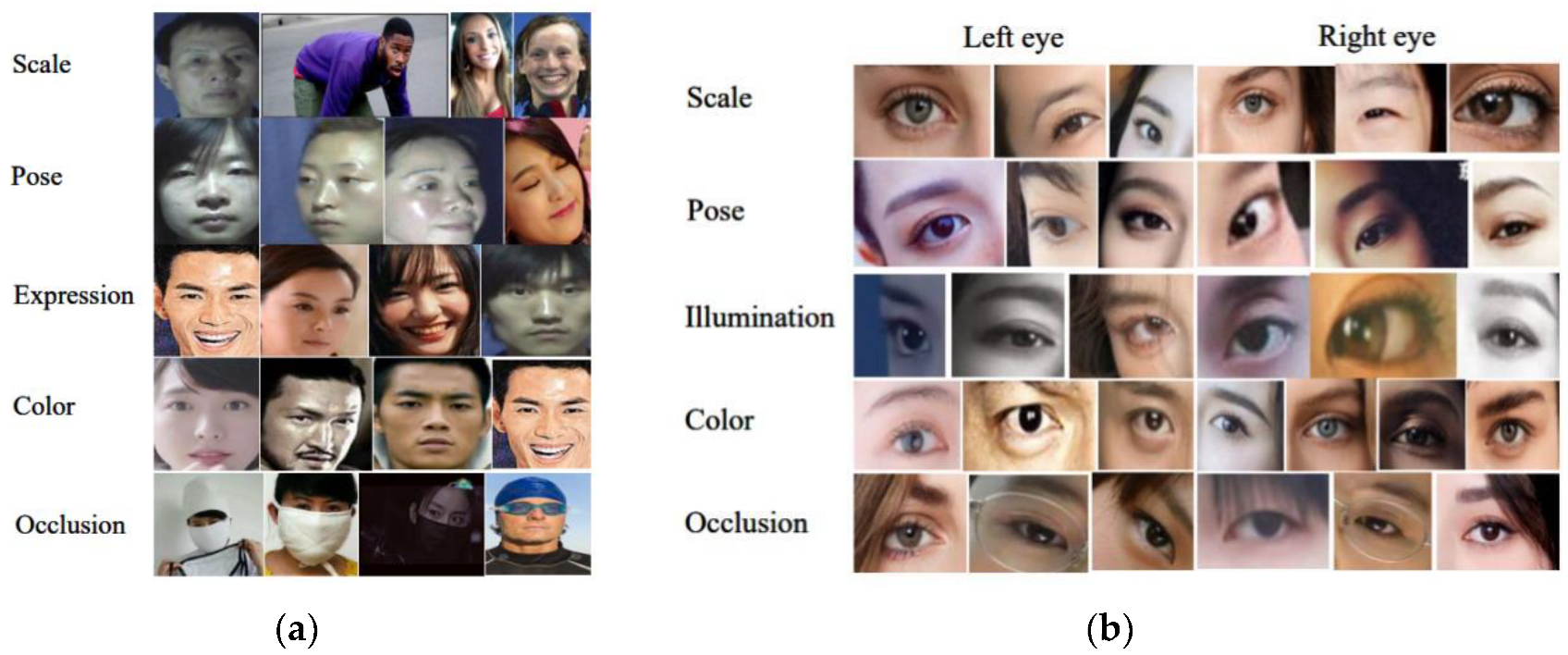
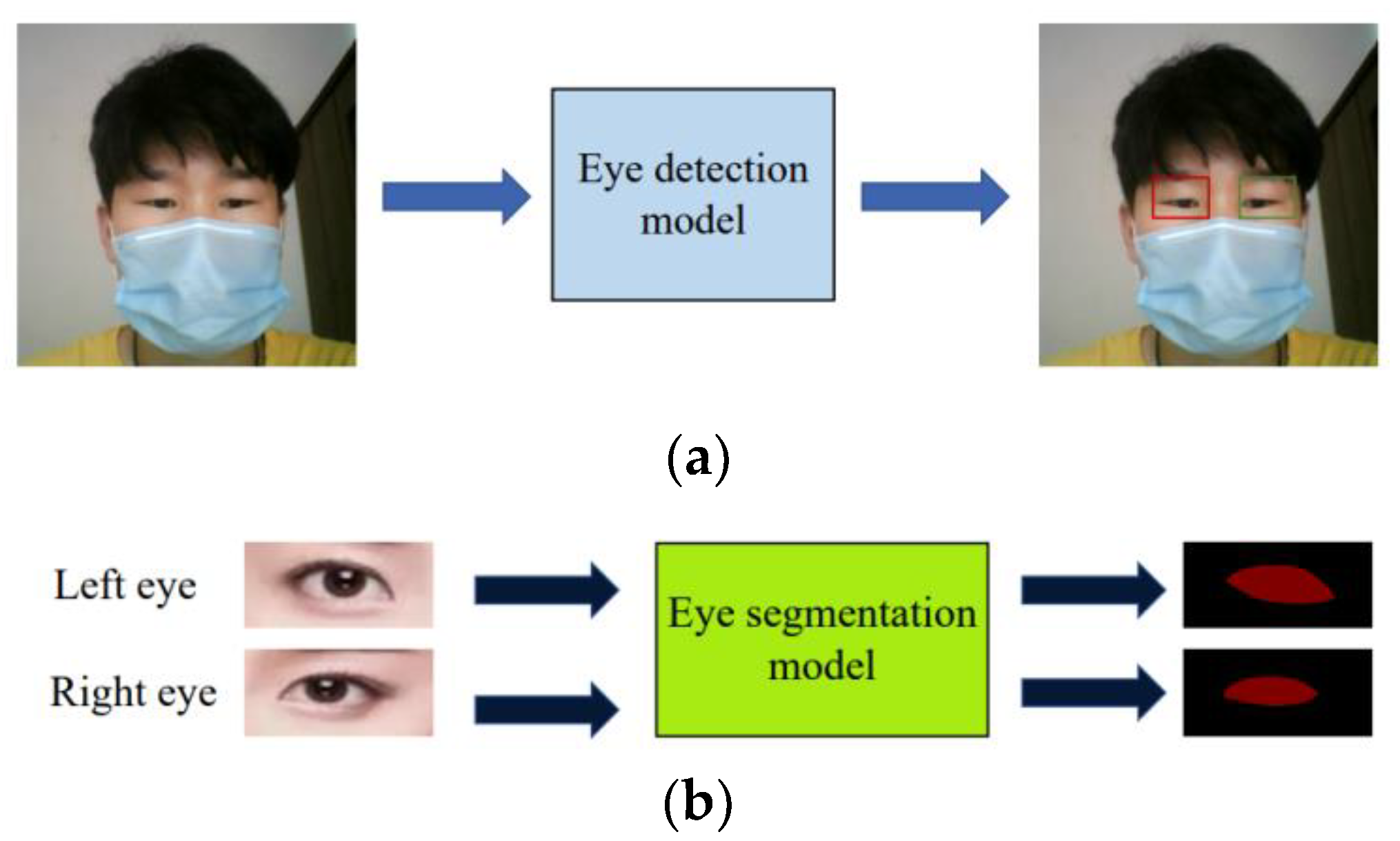
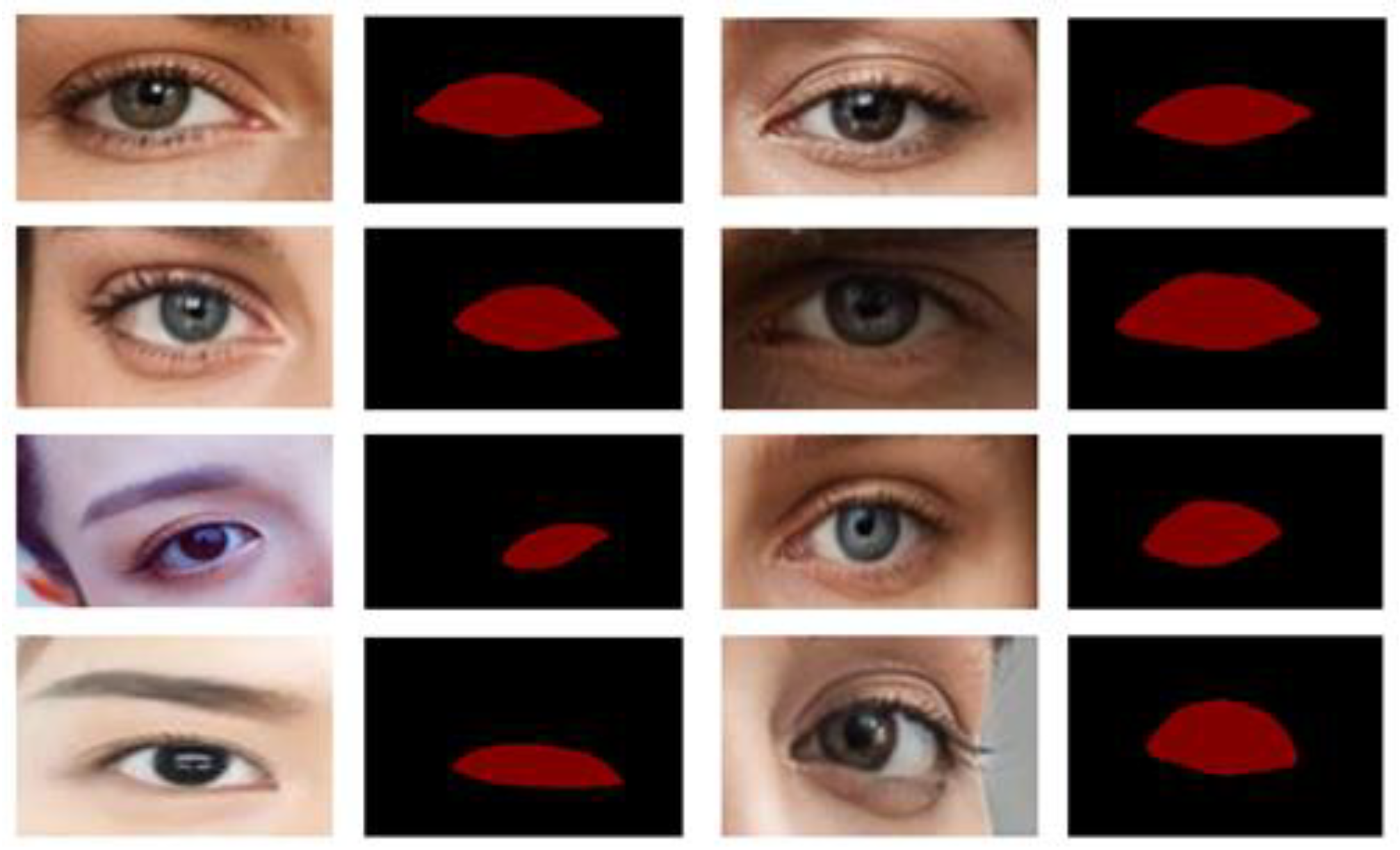
3.3. Dataset and Data Collection
- (1)
- The characteristics of the left and right eyes were defined, and the images of the eyes were obtained from the images of WIDER, WEAFD, and other collected images. Approximately, 3000 images were collected.
- (2)
- The images were manually checked and cleaned up. Images with incorrect characteristics were removed to ensure correct segmentation. From the images that only showed one eye due to head orientation, we collected the images of one eye. The obtained dataset was thought to be appropriate for application.
3.4. Performance Indexes for Benchmark Evaluation
3.4.1. Performance Indexes of Detection
3.4.2. Performance Indexes of Image Segmentation
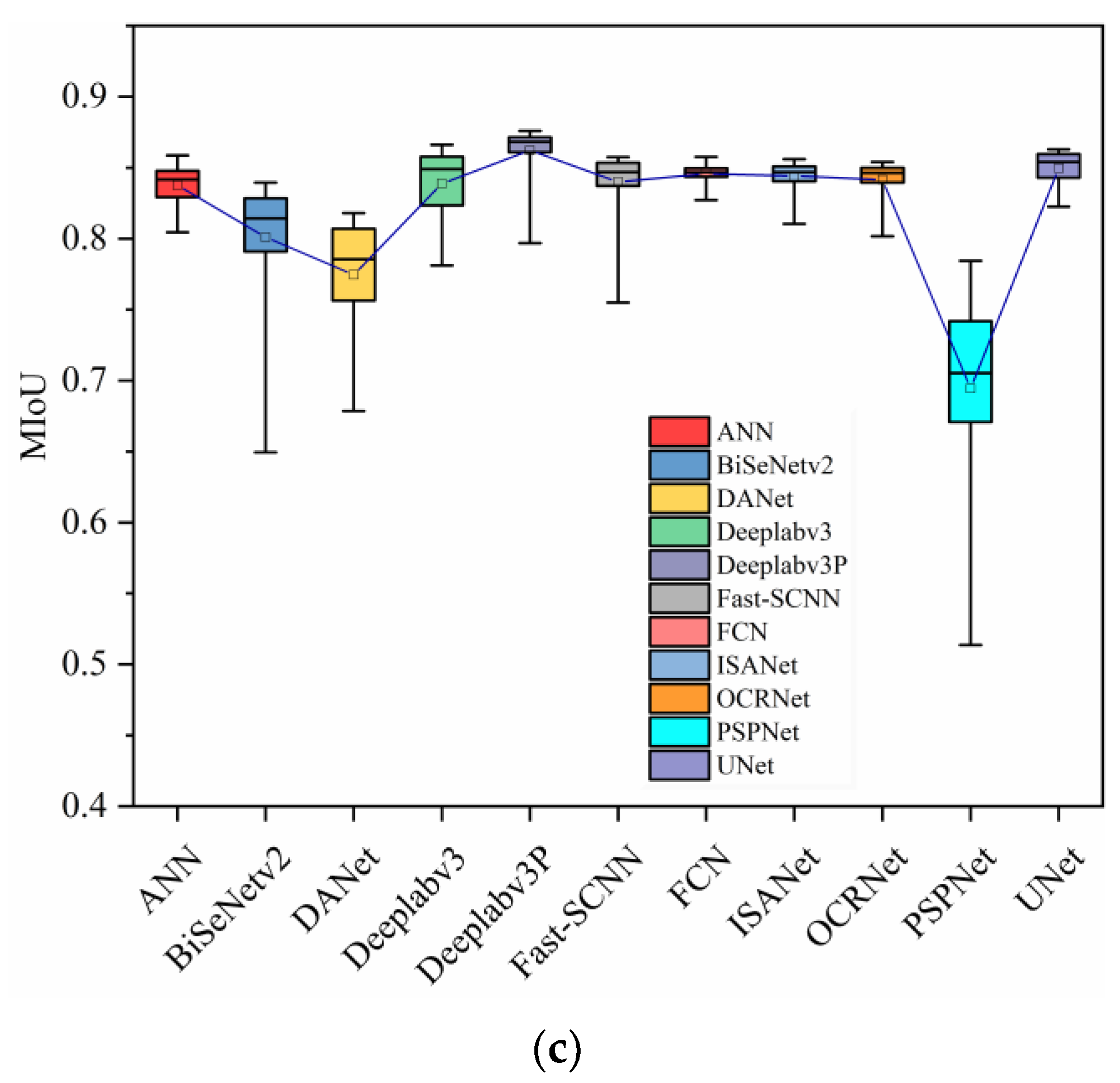
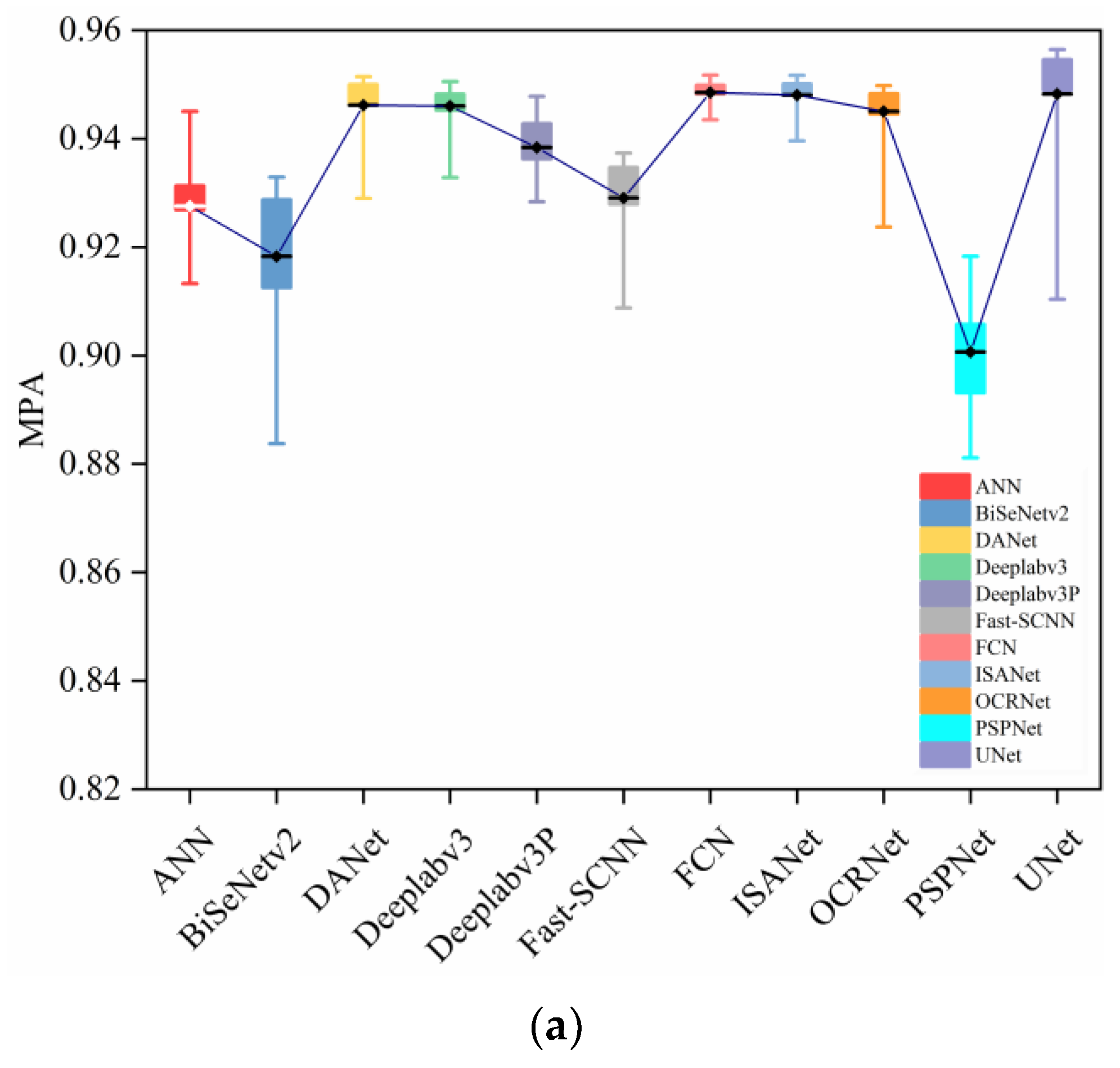
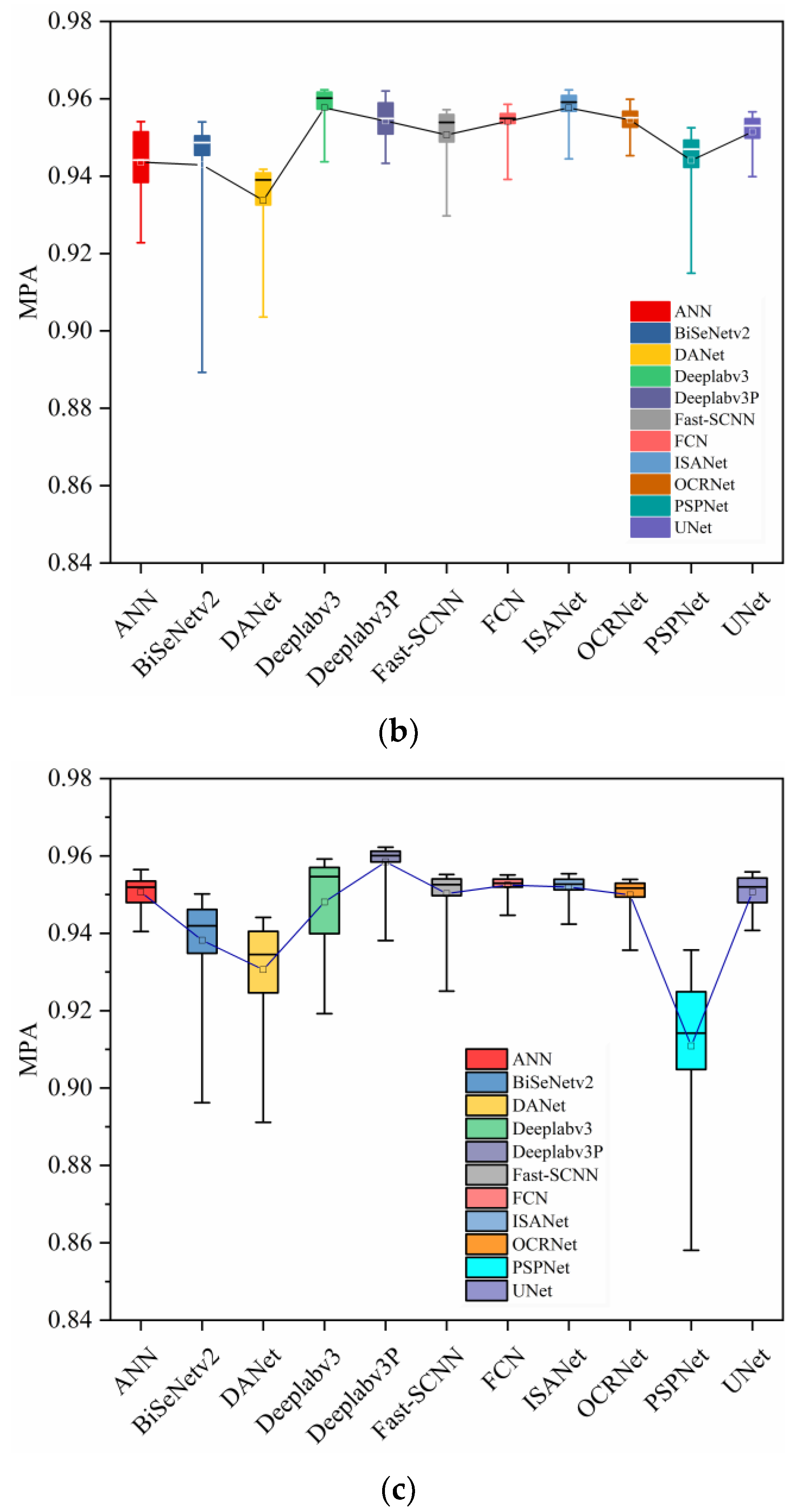
4. Results and Discussion
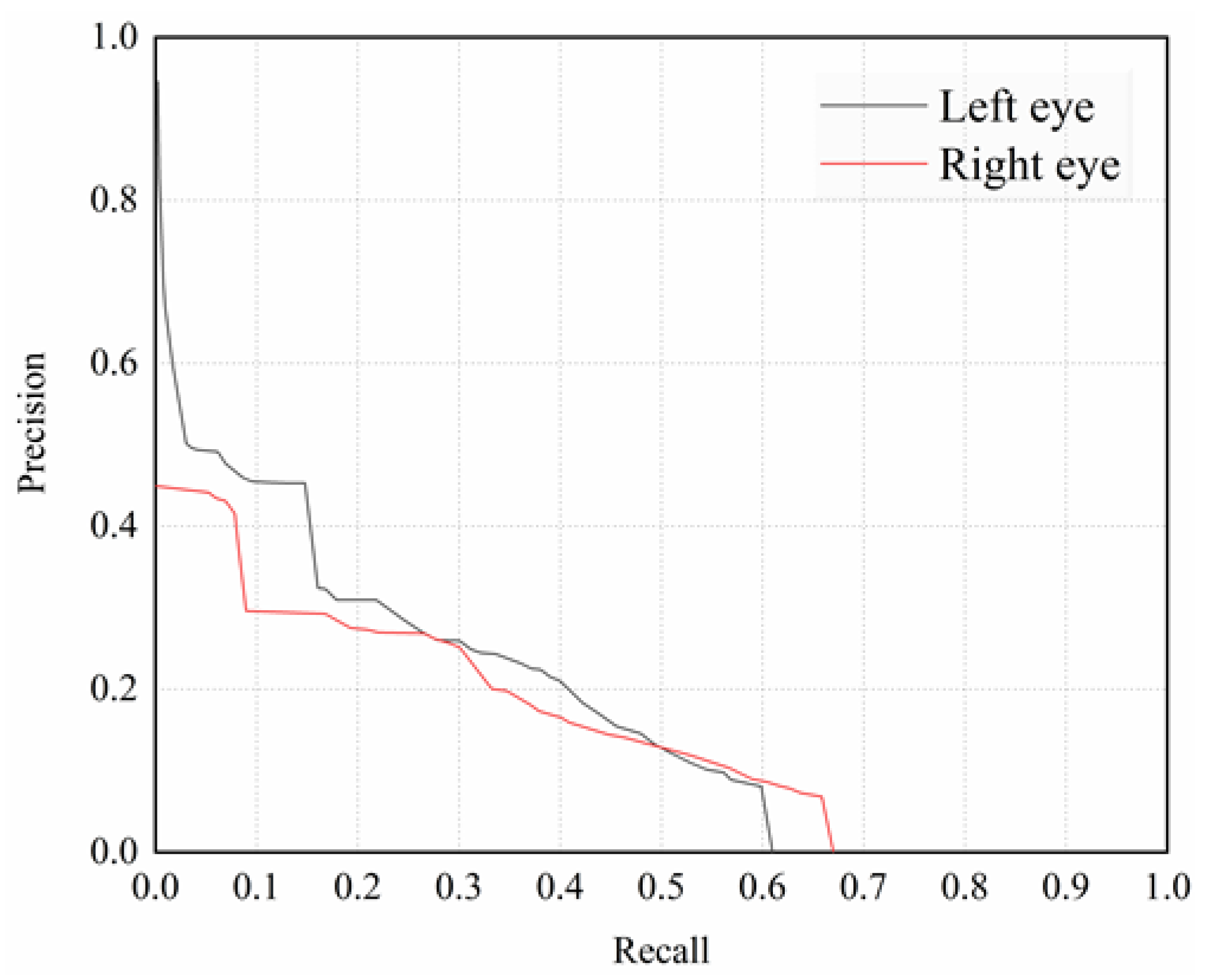
4.1. Model Evaluation in Eye Detection
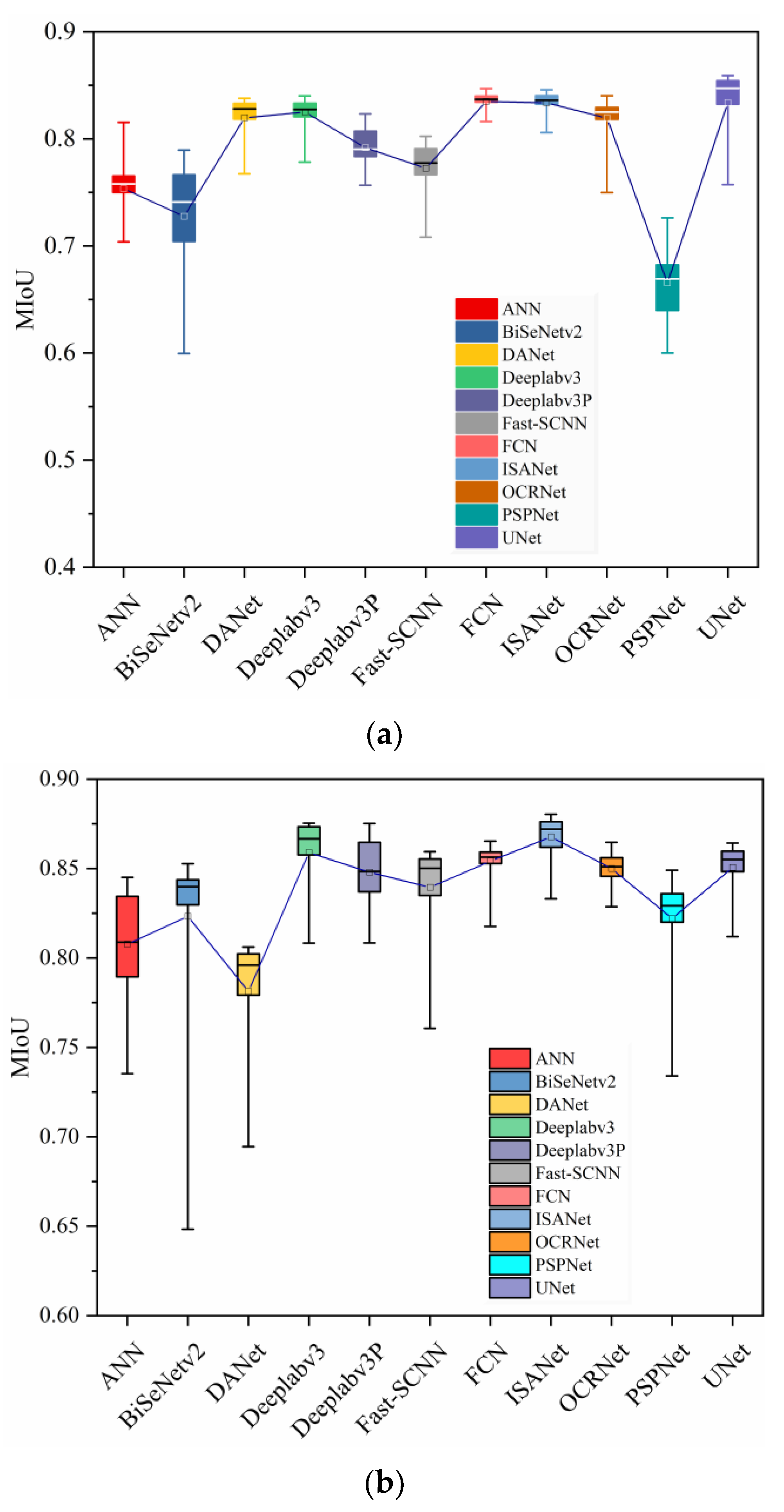
4.2. Model Evaluation in Eye Segmentation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Fuhl, W. Image-Based Extraction of Eye Features for Robust Eye Tracking. Ph.D. Thesis, University of Tübingen, Tübingen, Germany, 2019. [Google Scholar]
- Chuk, T.; Chan, A.B.; Shimojo, S.; Hsiao, J.H. Eye movement analysis with switching hidden Markov models. Behav. Res. Methods 2020, 52, 1026–1043. [Google Scholar] [CrossRef] [PubMed]
- Wang, K.; Zhao, R.; Ji, Q. A hierarchical generative model for eye image synthesis and eye gaze estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 440–448. [Google Scholar]
- Harezlak, K.; Kasprowski, P. Application of eye tracking in medicine: A survey, research issues and challenges. Comput. Med. Imaging Graph. 2018, 65, 176–190. [Google Scholar] [CrossRef] [PubMed]
- Lv, Z.; Chen, D.; Lou, R.; Song, H. Industrial security solution for virtual reality. Proc. IEEE Internet Things J. 2021, 8, 6273–6281. [Google Scholar] [CrossRef]
- Abbasi, M.; Khosravi, M.R. A robust and accurate particle filter-based pupil detection method for big data sets of eye video. J. Grid Comput. 2020, 18, 305–325. [Google Scholar] [CrossRef]
- Gou, C.; Wu, Y.; Wang, K.; Wang, K.; Wang, F.; Ji, Q. A joint cascaded framework for simultaneous eye detection and eye state estimation. Pattern Recognit. 2017, 67, 23–31. [Google Scholar] [CrossRef] [Green Version]
- Jung, Y.; Kim, D.; Son, B.; Kim, J. An eye detection method robust to eyeglasses for mobile iris recognition. Expert Syst. Appl. 2017, 67, 178–188. [Google Scholar] [CrossRef]
- Marsot, M.; Mei, J.; Shan, X.; Ye, L.; Feng, P.; Yan, X.; Li, C.; Zhao, Y. An adaptive pig face recognition approach using convolutional neural networks. Comput. Electron. Agric. 2020, 173, 105386. [Google Scholar] [CrossRef]
- Shi, S.; Tang, W.Z.; Wang, Y.Y. A review on fatigue driving detection. In Proceedings of the 4th Annual International Conference on Information Technology and Applications, Changsha, China, 29–31 October 2021; EDP Sciences: Les Ulis, France, 2017; Volume 12, p. 01019. [Google Scholar]
- Kothari, R.; Yang, Z.; Kanan, C.; Bailey, R.; Pelz, J.B.; Diaz, G.J. Gaze-in-wild: A dataset for studying eye and head coordination in everyday activities. Sci. Rep. 2020, 10, 2539. [Google Scholar] [CrossRef] [PubMed]
- Wu, Z.; Rajendran, S.; van As, T.; Zimmermann, J.; Badrinarayanan, V.; Rabinovich, A. MagicEyes: A large scale eye gaze estimation dataset for mixed reality. arXiv 2020, arXiv:2003.08806. [Google Scholar]
- Kim, J.; Stengel, M.; Majercik, A.; de Mello, S.; Dunn, D.; Laine, S.; McGuire, M.; Luebke, D. Nvgaze: An anatomically-informed dataset for low-latency, near-eye gaze estimation. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, UK, 4–9 May 2019; pp. 1–12. [Google Scholar]
- Fuhl, W.; Santini, T.; Geisler, D.; Kübler, T.C.; Rosenstiel, W.; Kasneci, E. Eyes Wide Open? Eyelid Location and Eye Aperture Estimation for Pervasive Eye Tracking in Real-World Scenarios. In Proceedings of the ACM International Joint Conference on Pervasive and Ubiquitous Computing: Adjunct, Heidelberg, Germany, 12–16 September 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 1656–1665. [Google Scholar]
- Garbin, S.J.; Komogortsev, O.; Cavin, R.; Hughes, G.; Shen, Y.; Schuetz, I.; Talathi, S.S. Dataset for eye tracking on a virtual reality platform. In Proceedings of the ACM Symposium on Eye Tracking Research and Applications, Stuttgart, Germany, 2–5 June 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 1–10. [Google Scholar]
- McMurrough, C.D.; Metsis, V.a.; Rich, J.; Makedon, F. An eye tracking dataset for point of gaze detection. In Proceedings of the Symposium on Eye Tracking Research and Applications, Santa Barbara, CA, USA, 28–30 March 2012; Association for Computing Machinery: New York, NY, USA, 2012; pp. 305–308. [Google Scholar]
- Phillips, P.J.; Bowyer, K.W.; Flynn, P.J. Comments on the CASIA version 1.0 Iris Data Set. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1869–1870. [Google Scholar] [CrossRef] [Green Version]
- Proença, H.; Filipe, S.; Santos, R.; Oliveira, J.; Alexandre, L.A. The UBIRIS.v2: A Database of visible wavelength iris images captured on-the-move and at-a-distance. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1529–1535. [Google Scholar] [CrossRef]
- Proença, H.; Alexandre, L.A. UBIRIS: A noisy iris image database. In Proceedings of the International Conference on Image Analysis and Processing, Cagliari, Italy, 6–8 September 2015; Springer: Berlin/Heidelberg, Germany, 2005; pp. 970–977. [Google Scholar]
- Fuhl, W.; Santini, T.; Kübler, T.C.; Kasneci, E. ElSe: Ellipse Selection for Robust Pupil Detection in Real-World Environments. In Proceedings of the Ninth Biennial ACM Symposium on Eye Tracking Research & Applications, Charleston, SC, USA, 14–17 March 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 123–130. [Google Scholar]
- Tonsen, M.; Zhang, X.; Sugano, Y.; Bulling, A. Labelled pupils in the wild: A dataset for studying pupil detection in unconstrained environments. In Proceedings of the Ninth Biennial ACM Symposium on Eye Tracking Research & Applications, Charleston, SC, USA, 14–17 March 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 139–142. [Google Scholar]
- Das, A.; Pal, U.; Blumenstein, M.; Wang, C.; He, Y.; Zhu, Y.; Sun, Z. Sclera Segmentation Benchmarking Competition in Cross-resolution Environment. In Proceedings of the 2019 International Conference on Biometrics (ICB), Crete, Greece, 4–7 June 2019; pp. 1–7. [Google Scholar]
- Santini, T.; Fuhl, W.; Kübler, T.; Kasneci, E. Bayesian identification of fixations, saccades, and smooth pursuits. In Proceedings of the Ninth Biennial ACM Symposium on Eye Tracking Research & Applications, Charleston, SC, USA, 14–17 March 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 163–170. [Google Scholar]
- Fuhl, W.; Geisler, D.; Rosenstiel, W.; Kasneci, E. The Applicability of Cycle GANs for Pupil and Eyelid Segmentation, Data Generation, and Image Refinement. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Fuhl, W.; Rosenstiel, W.; Kasneci, E. 500,000 Images closer to eyelid and pupil segmentation. In Proceeding of the Computer Analysis of Images and Patterns. CAIP 2019 (Lecture Notes in Computer Science); Salerno, Italy, 3–5 September 2019, Vento, M., Percannella, G., Eds.; Springer: Cham, Switzerland, 2019; pp. 336–347. [Google Scholar]
- Zhu, Z.; Xu, M.; Bai, S.; Huang, T.; Bai, X. Asymmetric non-local neural networks for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 593–602. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Yu, C.; Gao, C.; Wang, J.; Yu, G.; Shen, C.; Sang, N. Bisenet v2: Bilateral network with guided aggregation for real-time semantic segmentation. Int. J. Comput. Vis. 2021, 129, 3051–3068. [Google Scholar] [CrossRef]
- Poudel, R.P.K.; Liwicki, S.; Cipolla, R. Fast-scnn: Fast semantic segmentation network. arXiv 2019, arXiv:1902.04502. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Huang, L.; Yuan, Y.; Guo, J.; Zhang, C.; Chen, X.; Wang, J. Interlaced sparse self-attention for semantic segmentation. arXiv 2019, arXiv:1907.12273. [Google Scholar]
- Yuan, Y.; Chen, X.; Wang, J. Object-contextual representations for semantic segmentation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 173–190. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Chen, L.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. arXiv 2016, arXiv:1606.00915. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, L.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Liu, C.; Chen, L.C.; Schroff, F.; Adam, H.; Hua, W.; Yuille, A.L.; Li, F.F. Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. arXiv 2018, arXiv:1802.02611. Available online: http://arxiv.org/abs/1802.02611 (accessed on 7 February 2018).
- Roy Choudhury, A.; Vanguri, R.; Jambawalikar, S.R.; Kumar, P. Segmentation of Brain Tumors Using DeepLabv3; Springer International Publishing: Cham, Switzerland, 2019; pp. 154–167. [Google Scholar]
- Li, Q.-H.; Li, C.-P.; Zhang, J.; Chen, H.; Wang, S.-Q. Survey of compressed deep neural network. Comput. Sci. 2019, 46, 1–14. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- WIDER FACE: A Face Detection Benchmark. Available online: http://shuoyang1213.me/WIDERFACE/ (accessed on 31 March 2017).
- Srinivas, N.; Atwal, H.; Rose, D.C.; Mahalingam, G.; Ricanek, K.; Bolme, D.S. Age, Gender, and Fine-Grained Ethnicity Prediction Using Convolutional Neural Networks for the East Asian Face Dataset. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; pp. 953–960. [Google Scholar]
- Face Dataset Collection and Annotation. Available online: http://www.surfing.ai/face-data/ (accessed on 1 January 2021).
- Data Open and Sharing. Available online: https://developer.apollo.auto/docs/promise.html (accessed on 3 July 2020).
- Data for Competition. Available online: https://datafountain.cn/datasets (accessed on 1 January 2020).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | AP for the Left Eye | AP for the Right Eye | MAP |
|---|---|---|---|
| YOLOv3 | 55.98 | 63.67 | 59.825 |
| Faster R-CNN | 17.47 | 14.88 | 16.175 |
| Method | Images | MIoU | MPA | Kappa | Runtime (FPS) |
|---|---|---|---|---|---|
| ANN | 300 | 0.8229 | 0.9459 | 0.7973 | 16.39 |
| BiSeNetv2 | 300 | 0.7993 | 0.9376 | 0.7657 | 17.54 |
| DANet | 300 | 0.8441 | 0.9508 | 0.8247 | 10.53 |
| Deeplabv3 | 300 | 0.8469 | 0.9524 | 0.8283 | 19.23 |
| Deeplabv3P | 300 | 0.8250 | 0.9482 | 0.8002 | 28.88 |
| Fast-SCNN | 300 | 0.8119 | 0.9397 | 0.7832 | 13.16 |
| FCN | 300 | 0.8476 | 0.9522 | 0.8293 | 6.45 |
| ISANet | 300 | 0.8491 | 0.9530 | 0.8311 | 15.38 |
| OCRNet | 300 | 0.8406 | 0.9507 | 0.8203 | 6.13 |
| PSPNet | 300 | 0.7457 | 0.9236 | 0.6898 | 14.71 |
| UNet | 300 | 0.8593 | 0.9562 | 0.8437 | 26.73 |
| Method | Images | MIoU | MPA | Kappa | Runtime (FPS) |
|---|---|---|---|---|---|
| ANN | 300 | 0.8492 | 0.9537 | 0.8311 | 15.61 |
| BiSeNetv2 | 300 | 0.8528 | 0.9535 | 0.8358 | 16.13 |
| DANet | 300 | 0.8117 | 0.9438 | 0.7823 | 10.31 |
| Deeplabv3 | 300 | 0.8756 | 0.9616 | 0.8635 | 19.80 |
| Deeplabv3P | 300 | 0.8800 | 0.9629 | 0.8688 | 27.83 |
| Fast-SCNN | 300 | 0.8619 | 0.9577 | 0.8468 | 14.83 |
| FCN | 300 | 0.8658 | 0.9584 | 0.8517 | 7.46 |
| ISANet | 300 | 0.8813 | 0.9634 | 0.8704 | 14.08 |
| OCRNet | 300 | 0.8657 | 0.9598 | 0.8513 | 7.30 |
| PSPNet | 300 | 0.8498 | 0.9530 | 0.8320 | 19.23 |
| UNet | 300 | 0.8688 | 0.9575 | 0.8555 | 25.71 |
| Method | Images | MIoU | MPA | Kappa | Runtime (FPS) |
|---|---|---|---|---|---|
| ANN | 600 | 0.8630 | 0.9570 | 0.8483 | 15.15 |
| BiSeNetv2 | 600 | 0.8421 | 0.9502 | 0.8223 | 14.93 |
| DANet | 600 | 0.8182 | 0.9441 | 0.7911 | 19.61 |
| Deeplabv3 | 600 | 0.8662 | 0.9592 | 0.8521 | 18.52 |
| Deeplabv3P | 600 | 0.8763 | 0.9619 | 0.8643 | 28.50 |
| Fast-SCNN | 600 | 0.8586 | 0.9552 | 0.8430 | 16.95 |
| FCN | 600 | 0.8580 | 0.9551 | 0.8422 | 5.85 |
| ISANet | 600 | 0.8580 | 0.9554 | 0.8421 | 16.13 |
| OCRNet | 600 | 0.8619 | 0.9567 | 0.8469 | 6.25 |
| PSPNet | 600 | 0.8019 | 0.9389 | 0.7692 | 14.29 |
| UNet | 600 | 0.8658 | 0.9568 | 0.8519 | 27.78 |
| IDLN | 600 | 0.8825 | 0.9624 | 0.8655 | 34.10 |
| Models | Images | MIoU | MPA | Parameters (MB) |
|---|---|---|---|---|
| DeepLabv3+-Xception | 600 | 0.8684 | 0.9494 | 208.70 |
| DeepLabv3+-ResNet50 | 600 | 0.8763 | 0.9619 | 204.13 |
| DeepLabv3+-MobileNetv2 | 600 | 0.8589 | 0.9302 | 22.18 |
| IDLN | 600 | 0.8825 | 0.9624 | 22.37 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hsu, C.-Y.; Hu, R.; Xiang, Y.; Long, X.; Li, Z. Improving the Deeplabv3+ Model with Attention Mechanisms Applied to Eye Detection and Segmentation. Mathematics 2022, 10, 2597. https://doi.org/10.3390/math10152597
Hsu C-Y, Hu R, Xiang Y, Long X, Li Z. Improving the Deeplabv3+ Model with Attention Mechanisms Applied to Eye Detection and Segmentation. Mathematics. 2022; 10(15):2597. https://doi.org/10.3390/math10152597
Chicago/Turabian StyleHsu, Chih-Yu, Rong Hu, Yunjie Xiang, Xionghui Long, and Zuoyong Li. 2022. "Improving the Deeplabv3+ Model with Attention Mechanisms Applied to Eye Detection and Segmentation" Mathematics 10, no. 15: 2597. https://doi.org/10.3390/math10152597
APA StyleHsu, C.-Y., Hu, R., Xiang, Y., Long, X., & Li, Z. (2022). Improving the Deeplabv3+ Model with Attention Mechanisms Applied to Eye Detection and Segmentation. Mathematics, 10(15), 2597. https://doi.org/10.3390/math10152597