
Mispronunciation Detection and Diagnosis with Articulatory-Level Feedback Generation for Non-Native Arabic Speech


Abstract
:1. Introduction
- We show the robustness of applying deep-learning-based object detectors for MDD (we name this system MDD-Object) and providing articulatory feedback by treating the phonemes and their AFs as objects with multiple labels within spectral images.
- We evaluate the proposed systems using the developed corpora, Arabic-CAPT and Arabic-CAPT-S, and we compare the performance with a state-of-the-art end-to-end MDD technique (we name this system MDD-E2E).
- We propose applying fusion between the proposed MDD-Object and end-to-end MDD technique (we name this system MDD-Object -E2E) systems.
2. Related Work
2.1. MDD for the Arabic Language Using Traditional Methods
2.2. MDD for Arabic Language Using Deep Learning Methods
2.3. Overview of Recent Works on MDD for Non-Arabic Languages
2.4. Limitations of Research on MDD for Non-Native Arabic Speech
3. The Developed Corpora: Arabic-CAPT and Arabic-CAPT-S
3.1. Non-Native Arabic Speech Corpus (Arabic-CAPT)
- The database was developed for Arabic speaker recognition as a main target, but it was also designed to be useful for other applications, mainly speech recognition and speech processing of non-native Arabic speech.
- The corpus was recorded over three different sessions in three different environments and using four different channels.
- The corpus consisted of recording male and female speakers, where the male speakers included Saudi, Arab, and non-Arab speakers.
3.2. Synthesized Non-Native Arabic Speech Corpus (Arabic-CAPT-S)
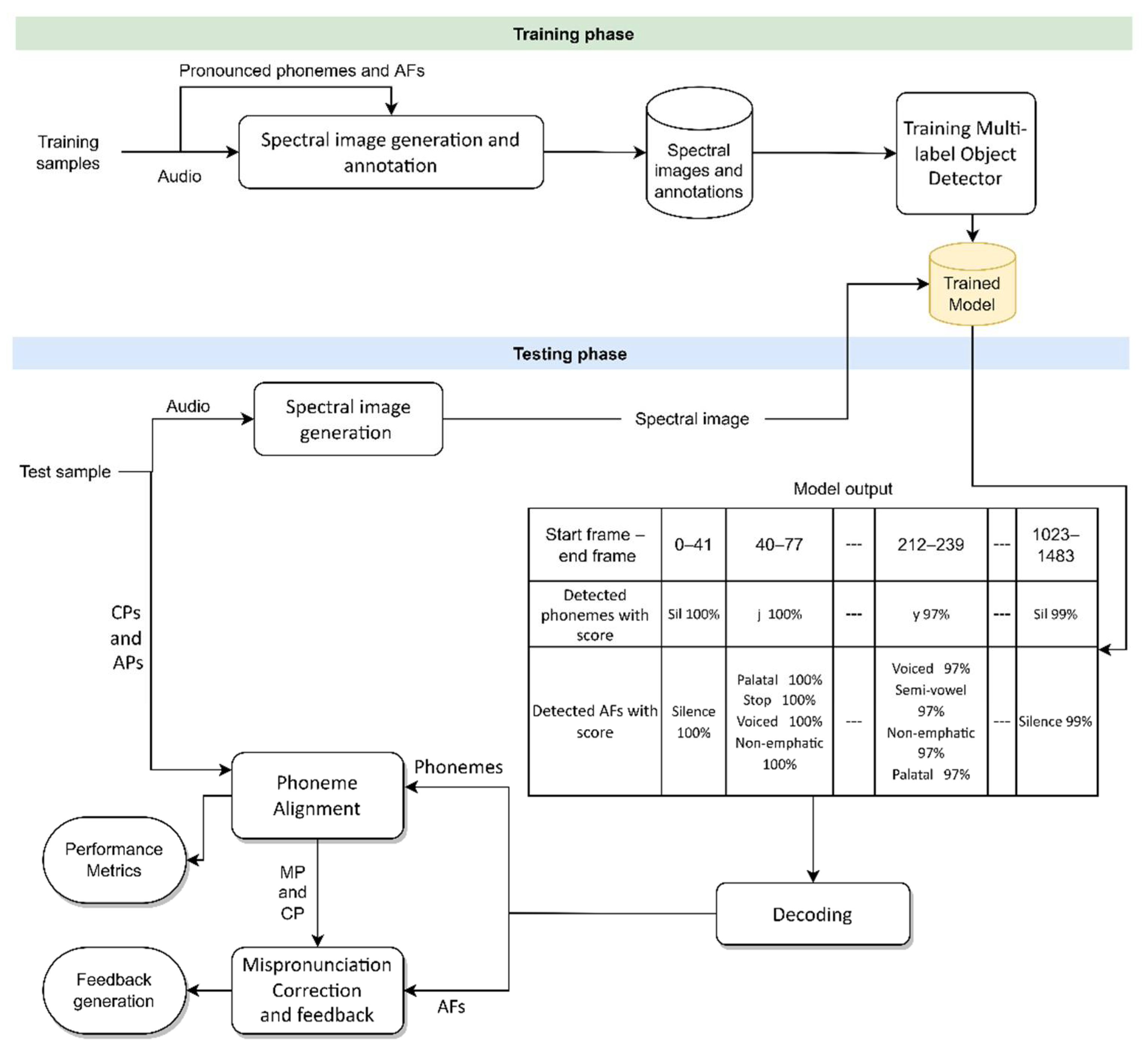
4. The Proposed Object Detection-Based MDD (MDD-Object)
4.1. Spectral Image Generation and Annotation
4.2. Multi-Label Object Detector: Selection, Optimization, and Training
4.2.1. Selection of Object Detector and Hyper-Parameter Optimization
4.2.2. Model Training
4.3. Decoder
4.4. Phoneme Alignment and Performance Metrics Evaluation
4.5. Mispronunciation Correction and Feedback
5. Application of End-to-End MDD to Non-Native Arabic Speech (MDD-E2E)
6. Application of Decision Level Fusion between MDD-Object and MDD-E2E (MDD-Object-E2E)
7. Experimental Results
7.1. Results of the Non-Native Phoneme Recognition Task
7.2. Results of MDD Task
7.3. Result of AF Detection Task
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Daniel, J. Education and the COVID-19 pandemic. Prospects 2020, 49, 91–96. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ghazi-Saidi, L.; Criffield, A.; Kracl, C.L.; McKelvey, M.; Obasi, S.N.; Vu, P. Moving from Face-to-Face to Remote Instruction in a Higher Education Institution during a Pandemic: Multiple Case Studies. Int. J. Technol. Educ. Sci. 2020, 4, 370–383. [Google Scholar] [CrossRef]
- Neri, A.; Cucchiarini, C.; Strik, H.; Boves, L. The pedagogy-technology interface in computer assisted pronunciation training. Comput. Assist. Lang. Learn. 2002, 15, 441–467. [Google Scholar] [CrossRef]
- Revell-Rogerson, P.M. Computer-Assisted Pronunciation Training (CAPT): Current Issues and Future Directions. RELC J. 2021, 52, 189–205. [Google Scholar] [CrossRef]
- Cheng, V.C.-W.; Lau, V.K.-T.; Lam, R.W.-K.; Zhan, T.-J.; Chan, P.-K. Improving English Phoneme Pronunciation with Automatic Speech Recognition Using Voice Chatbot. In Proceedings of the International Conference on Technology in Education, Online, 17 December 2020; pp. 88–99. [Google Scholar]
- Yan, B.C.; Wu, M.C.; Hung, H.T.; Chen, B. An end-to-end mispronunciation detection system for L2 English speech leveraging novel anti-phone modeling. In Proceedings of the Annual Conference of the International Speech Communication Association, Shanghai, China, 25–29 October 2020; pp. 3032–3036. [Google Scholar] [CrossRef]
- Duan, R.; Kawahara, T.; Dantsuji, M.; Nanjo, H. Efficient learning of articulatory models based on multi-label training and label correction for pronunciation learning. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 6239–6243. [Google Scholar]
- Engwall, O.; Bälter, O. Pronunciation feedback from real and virtual language teachers. Comput. Assist. Lang. Learn. 2007, 20, 235–262. [Google Scholar] [CrossRef]
- Balas, V.E.; Roy, S.S.; Sharma, D.; Samui, P. Handbook of Deep Learning Applications; Springer: Berlin/Heidelberg, Germany, 2019; Volume 136. [Google Scholar]
- Pal, S.K.; Pramanik, A.; Maiti, J.; Mitra, P. Deep learning in multi-object detection and tracking: State of the art. Appl. Intell. 2021, 51, 6400–6429. [Google Scholar] [CrossRef]
- Jiao, L.; Zhang, F.; Liu, F.; Yang, S.; Li, L.; Feng, Z.; Qu, R. A Survey of Deep Learning-Based Object Detection. IEEE Access 2019, 7, 128837–128868. [Google Scholar] [CrossRef]
- Elhoseny, M. Multi-object Detection and Tracking (MODT) Machine Learning Model for Real-Time Video Surveillance Systems. Circuits Syst. Signal Process. 2020, 39, 611–630. [Google Scholar] [CrossRef]
- Segal, Y.; Fuchs, T.S.; Keshet, J. Speechyolo: Detection and localization of speech objects. In Proceedings of the Annual Conference of the International Speech Communication Association, Graz, Austria, 15–19 September 2019; pp. 4210–4214. [Google Scholar]
- Algabri, M.; Mathkour, H.; Bencherif, M.A.; Alsulaiman, M.; Mekhtiche, M.A. Towards Deep Object Detection Techniques for Phoneme Recognition. IEEE Access 2020, 8, 54663–54680. [Google Scholar] [CrossRef]
- Algabri, M.; Mathkour, H.; Alsulaiman, M.M.; Bencherif, M.A. Deep learning-based detection of articulatory features in arabic and english speech. Sensors 2021, 21, 1205. [Google Scholar] [CrossRef]
- Duan, R.; Kawahara, T.; Dantsuji, M.; Nanjo, H. Cross-Lingual Transfer Learning of Non-Native Acoustic Modeling for Pronunciation Error Detection and Diagnosis. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 28, 391–401. [Google Scholar] [CrossRef] [Green Version]
- Abdou, S.M.; Hamid, S.E.; Rashwan, M.; Samir, A.; Abdel-Hamid, O.; Shahin, M.; Nazih, W. Computer aided pronunciation learning system using speech recognition techniques. In Proceedings of the Ninth International Conference on Spoken Language Processing, Pittsburgh, PA, USA, 17–21 September 2006. [Google Scholar]
- Tabbaa, H.M.A.; Soudan, B. Computer-Aided Training for Quranic Recitation. Procedia Soc. Behav. Sci. 2015, 192, 778–787. [Google Scholar] [CrossRef] [Green Version]
- Hindi, A.A.; Alsulaiman, M.; Muhammad, G.; Al-Kahtani, S. Automatic pronunciation error detection of nonnative Arabic Speech. In Proceedings of the 2014 IEEE/ACS 11th International Conference on Computer Systems and Applications (AICCSA), Doha, Qatar, 10–13 November 2014; pp. 190–197. [Google Scholar]
- Alsulaiman, M.; Ali, Z.; Muhammed, G.; Bencherif, M.; Mahmood, A. KSU speech database: Text selection, recording and verification. In Proceedings of the 2013 European Modelling Symposium, Manchester, UK, 20–22 November 2013; pp. 237–242. [Google Scholar]
- Alsulaiman, M.; Muhammad, G.; Bencherif, M.A.; Mahmood, A.; Ali, Z. KSU rich Arabic speech database. Information 2013, 16, 4231–4253. [Google Scholar]
- Maqsood, M.; Habib, H.A.; Anwar, S.M.; Ghazanfar, M.A.; Nawaz, T. A Comparative Study of Classifier Based Mispronunciation Detection System for Confusing Arabic Phoneme Pairs. Nucleus 2017, 54, 114–120. [Google Scholar]
- Maqsood, M.; Habib, H.A.; Nawaz, T. An efficientmis pronunciation detection system using discriminative acoustic phonetic features for arabic consonants. Int. Arab J. Inf. Technol. 2019, 16, 242–250. [Google Scholar]
- Nazir, F.; Majeed, M.N.; Ghazanfar, M.A.; Maqsood, M. Mispronunciation detection using deep convolutional neural network features and transfer learning-based model for Arabic phonemes. IEEE Access 2019, 7, 52589–52608. [Google Scholar] [CrossRef]
- Akhtar, S.; Hussain, F.; Raja, F.R.; Ehatisham-ul-haq, M.; Baloch, N.K.; Ishmanov, F.; Zikria, Y.B. Improving mispronunciation detection of Arabic words for non-native learners using deep convolutional neural network features. Electronics 2020, 9, 963. [Google Scholar] [CrossRef]
- Ziafat, N.; Ahmad, H.F.; Fatima, I.; Zia, M.; Alhumam, A.; Rajpoot, K. Correct Pronunciation Detection of the Arabic Alphabet Using Deep Learning. Appl. Sci. 2021, 11, 2508. [Google Scholar] [CrossRef]
- Boyer, F.; Rouas, J.-L. End-to-End Speech Recognition: A review for the French Language. arXiv 2019, arXiv:1910.08502. [Google Scholar]
- Watanabe, S.; Boyer, F.; Chang, X.; Guo, P.; Hayashi, T.; Higuchi, Y.; Hori, T.; Huang, W.-C.; Inaguma, H.; Kamo, N. The 2020 ESPnet update: New features, broadened applications, performance improvements, and future plans. In Proceedings of the 2021 IEEE Data Science and Learning Workshop (DSLW), Toronto, ON, Canada, 5–6 June 2021. [Google Scholar] [CrossRef]
- Feng, Y.; Fu, G.; Chen, Q.; Chen, K. SED-MDD: Towards Sentence Dependent End-To-End Mispronunciation Detection and Diagnosis. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 3492–3496. [Google Scholar]
- Leung, W.-K.; Liu, X.; Meng, H. CNN-RNN-CTC based end-to-end mispronunciation detection and diagnosis. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 8132–8136. [Google Scholar]
- Zhang, Z.; Wang, Y.; Yang, J. Text-conditioned Transformer for automatic pronunciation error detection. Speech Commun. 2021, 130, 55–63. [Google Scholar] [CrossRef]
- Lo, T.H.; Weng, S.Y.; Chang, H.J.; Chen, B. An effective end-to-end modeling approach for mispronunciation detection. In Proceedings of the Annual Conference of the International Speech Communication Association, Shanghai, China, 25–29 October 2020; pp. 3027–3031. [Google Scholar] [CrossRef]
- Zhang, L.; Zhao, Z.; Ma, C.; Shan, L.; Sun, H.; Jiang, L.; Deng, S.; Gao, C. End-to-End Automatic Pronunciation Error Detection Based on Improved Hybrid CTC/Attention Architecture. Sensors 2020, 20, 1809. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhao, G.; Sonsaat, S.; Silpachai, A.; Lucic, I.; Chukharev-Hudilainen, E.; Levis, J.; Gutierrez-Osuna, R. L2-Arctic: A non-native English speech corpus. In Proceedings of the Annuale Conference International Speech Communication Association Interspeech, Hyderabad, India, 2–6 September 2018; pp. 2783–2787. [Google Scholar] [CrossRef] [Green Version]
- Li, K.; Qian, X.; Meng, H. Mispronunciation detection and diagnosis in l2 english speech using multidistribution deep neural networks. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 25, 193–207. [Google Scholar] [CrossRef] [Green Version]
- Chen, N.F.; Tong, R.; Wee, D.; Lee, P.; Ma, B.; Li, H. iCALL corpus: Mandarin Chinese spoken by non-native speakers of European descent. In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Benarousse, L.; Grieco, J.; Geoffrois, E.; Series, R.; Steeneken, H.; Stumpf, H.; Swail, C.; Thiel, D. The NATO native and non-native (N4) speech corpus. In Proceedings of the Workshop on Multilingual Speech and Language Processing, Aalborg, Denmark, 17 April 2001. [Google Scholar]
- Pettarin, A. Aeneas is a Python/C Library and a Set of Tools to Automagically Synchronize Audio and Text (Aka Forced Alignment). GitHub In Repository; GitHub. 2017. Available online: https://github.com/readbeyond/aeneas (accessed on 10 June 2022).
- McAuliffe, M.; Socolof, M.; Mihuc, S.; Wagner, M.; Sonderegger, M. Montreal Forced Aligner: Trainable Text-Speech Alignment Using Kaldi. Interspeech 2017, 2017, 498–502. [Google Scholar]
- Halabi, N. Modern Standard Arabic Phonetics for Speech Synthesis. Ph.D. Thesis, University of Southampton, Southampton, UK, 2016. [Google Scholar]
- Halabi, N. Arabic Phonetiser, GitHub In Repository; GitHub. 2016. Available online: https://github.com/nawarhalabi/Arabic-Phonetiser (accessed on 10 June 2022).
- Salamon, J.; Bello, J.P. Deep convolutional neural networks and data augmentation for environmental sound classification. IEEE Signal Process. Lett. 2017, 24, 279–283. [Google Scholar] [CrossRef]
- Raileanu, R.; Goldstein, M.; Yarats, D.; Kostrikov, I.; Fergus, R. Automatic Data Augmentation for Generalization in Deep Reinforcement Learning. arXiv 2020, arXiv:2006.12862. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Rosenberg, A.; Zhang, Y.; Ramabhadran, B.; Jia, Y.; Moreno, P.; Wu, Y.; Wu, Z. Speech recognition with augmented synthesized speech. In Proceedings of the 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Singapore, 14–18 December 2019; pp. 996–1002. [Google Scholar]
- Li, J.; Gadde, R.; Ginsburg, B.; Lavrukhin, V. Training Neural Speech Recognition Systems with Synthetic Speech Augmentation. arXiv 2018, arXiv:1811.00707. [Google Scholar]
- Korzekwa, D.; Barra-Chicote, R.; Zaporowski, S.; Beringer, G.; Lorenzo-Trueba, J.; Serafinowicz, A.; Droppo, J.; Drugman, T.; Kostek, B. Detection of lexical stress errors in non-native (L2) english with data augmentation and attention. In Proceedings of the Annual Conference of the International Speech Communication Association, Brno, Czech Republic, 15–19 September 2021; Volume 2, pp. 1446–1450. [Google Scholar] [CrossRef]
- Ren, Y.; Hu, C.; Tan, X.; Qin, T.; Zhao, S.; Zhao, Z.; Liu, T.Y. FastSpeech 2: Fast and High-Quality End-to-End Text to Speech. In Proceedings of the International Conference on Learning Representations, Online, 26 April–1 May 2020. [Google Scholar]
- Lin, Y.; Wang, L.; Dang, J.; Li, S.; Ding, C. End-to-End articulatory modeling for dysarthric articulatory attribute detection. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 7349–7353. [Google Scholar]
- Qamhan, M.A.; Alotaibi, Y.A.; Seddiq, Y.M.; Meftah, A.H.; Selouani, S.A. Sequence-to-Sequence Acoustic-to-Phonetic Conversion using Spectrograms and Deep Learning. IEEE Access 2021, 9, 80209–80220. [Google Scholar] [CrossRef]
- Seddiq, Y.; Alotaibi, Y.A.; Selouani, S.-A.; Meftah, A.H. Distinctive Phonetic Features Modeling and Extraction Using Deep Neural Networks. IEEE Access 2019, 7, 81382–81396. [Google Scholar] [CrossRef]
- Abdultwab, K.S. Sound substitution in consonants by learners of Arabic as a second language:Applied study on students of Arabic Linguistics Institute. In Proceedings of the Third International Conference for the Arabic Linguistics Institute in King Saud University, Riyadh, Saudi Arabia, 6–7 March 2019; pp. 157–202. (In Arabic). [Google Scholar]
- Alghamdi, M. Arabic Phonetics and Phonology; Al-Toubah Bookshop: Al Riyadh, Saudi Arabia, 2015. (In Arabic) [Google Scholar]
- Zenkel, T.; Sanabria, R.; Metze, F.; Niehues, J.; Sperber, M.; Stüker, S.; Waibel, A. Comparison of decoding strategies for CTC acoustic models. In Proceedings of the Annual Conference of the International Speech Communication Association, Stockholm, Sweden, 20–24 August 2017; pp. 513–517. [Google Scholar] [CrossRef] [Green Version]
- Young, S.; Evermann, G.; Gales, M.J.F.; Hain, T. The HTK Book; Cambridge University Engineering Department: Cambridge, UK, 2002; Volume 3, p. 12. [Google Scholar]
- Qian, X.; Soong, F.K.; Meng, H. Discriminative acoustic model for improving mispronunciation detection and diagnosis in computer-aided pronunciation training (CAPT). In Proceedings of the Eleventh Annual Conference of the International Speech Communication Association, Chiba, Japan, 26–30 September 2010. [Google Scholar]
- Wang, Y.-B.; Lee, L. Supervised detection and unsupervised discovery of pronunciation error patterns for computer-assisted language learning. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 23, 564–579. [Google Scholar] [CrossRef]
- Amodei, D.; Ananthanarayanan, S.; Anubhai, R.; Bai, J.; Battenberg, E.; Case, C.; Casper, J.; Catanzaro, B.; Cheng, Q.; Chen, G.; et al. Deep speech 2: End-to-end speech recognition in english and mandarin. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19 June 2016; pp. 173–182. [Google Scholar]
- Li, J.; Wu, Y.; Gaur, Y.; Wang, C.; Zhao, R.; Liu, S. On the comparison of popular end-to-end models for large scale speech recognition. arXiv 2020, arXiv:2005.14327. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, Y.; Yang, J. Mispronunciation Detection and Correction via Discrete Acoustic Units. arXiv 2021, arXiv:2108.05517. [Google Scholar]
- Jiang, S.W.F.; Yan, B.C.; Lo, T.H.; Chao, F.A.; Chen, B. Towards Robust Mispronunciation Detection and Diagnosis for L2 English Learners with Accent-Modulating Methods. In Proceedings of the 2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Cartagena, Colombia, 13–17 December 2021; pp. 1065–1070. [Google Scholar] [CrossRef]
- Wu, M.; Li, K.; Leung, W.K.; Meng, H. Transformer based end-to-end mispronunciation detection and diagnosis. In Proceedings of the Annual Conference International Speech Communication Association Interspeech, Brno, Czech Republic, 30 August–3 September 2021; Volume 2, pp. 1471–1475. [Google Scholar] [CrossRef]
- Fu, K.; Lin, J.; Ke, D.; Xie, Y.; Zhang, J.; Lin, B. A Full Text-Dependent End to End Mispronunciation Detection and Diagnosis with Easy Data Augmentation Techniques. arXiv 2021, arXiv:2104.08428. [Google Scholar]
- Ganaie, M.A.; Hu, M.; Malik, A.K.; Tanveer, M.; Suganthan, P.N. Ensemble deep learning: A review. arXiv 2021, arXiv:2104.02395. [Google Scholar] [CrossRef]
- Eskenazi, M. An overview of spoken language technology for education. Speech Commun. 2009, 51, 832–844. [Google Scholar] [CrossRef]
- King, S.; Taylor, P. Detection of phonological features in continuous speech using neural networks. Comput. Speech Lang. 2000, 14, 333–353. [Google Scholar] [CrossRef] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Canonical Text | Phonetic Transcription |
|---|---|
| [صِفْرْ وَاحِدْ إِثنانْ ثَلاثهْ أَرْبعهْ خَمْسَهْ سِتَّهْ سَبعهْ ثَمَانِيَهْ تِسْعَهْ] | [Sifr wa2Hid HZithna2n thala2thh HZarbEh xamsah sitah sabEh thama2niyah tisEah] |
| [فَحْصْ فَحْمْ فَسْحْ فَصْمْ مَزْحْ مَغْصْ نِصْفْ نَهْشْ نَفْعْ نَفْسْ] | [faHS faHam fasH faSm mazH magS niSf nahsh nafE nafs] |
| [بِالوَالِدَينِ إِحْسَانًا] | [bilwa2lidayni HZiHsa2nan] |
| [اِستَقِمْ كَمَا أُمِرْتَ] | [HZistaqim kama HZumirta] |
| [هَلْ هَارَ] | [hal ha2ra] |
| [ضَمِنْتُ شَغَفَكُمْ] | [Damintu shagafakum] |
| [أَبْصَرَ ثُعبَاناً وَلَم يَظلِمْهُ] | [HZabSara thuEba2nan walam yaZlimhu] |
| Arabic phoneme | ء | ب | ت | ث | ج | ح | خ | د | ذ | ر | ز | س | ش | ص | ض | ط | ظ |
| IPA symbol | Ɂ | b | t | θ | ʒ | ħ | x | d | ð | r | z | s | ʃ | sˁ | dˁ | tˁ | ðˤ |
| English symbol | HZ | b | t | th | j | H | x | d | TH | r | z | s | sh | S | D | T | Z |
| Arabic phoneme | ع | غ | ف | ق | ك | ل | م | ن | ه | و | ي | فتحه | ضمة | كسره | الف مد | واو مد | ياء مد |
| IPA symbol | ʕ | ɣ | f | q | k | l | m | n | h | w | j | a | u | i | a: | u: | i: |
| English symbol | E | g | f | q | k | l | m | n | h | w | y | a | u | i | a2 | u2 | i2 |
| Arabic-CAPT | Arabic-CAPT-S | ||
|---|---|---|---|
| Type of data | Real | Synthetic | |
| Speakers | 62 | 62 | |
| Utterances | 1611 | 7254 | |
| Recording hours | 2.36 | 7.11 | |
| Correct phonemes | 54,171 | 255,502 | |
| Substitution Errors | # | 1080 | 17,422 |
| % | 2 | 6.4 | |
| Insertions Errors | # | 1139 | - |
| % | 2.1 | - | |
| Deletion Errors | # | 690 | - |
| % | 1.3 | - | |
| Total Errors | # | 2899 | 17,422 |
| % | 5.1 | 6.4 | |
| AF Category (# of Classes) | Class | Arabic Phonemes | IPA |
|---|---|---|---|
|
Place (10) | Bilabial | م، ب، و | m, b, w |
| Labio-dental | ف | f | |
| Inter-dental | ث، ذ، ظ | θ, ð, ðˤ | |
| Alveo-dental | ت، د، ر، ز، س، ص، ض، ط ،ل، ن | t, d, r, z, s, sˁ, dˁ, tˁ, l, n | |
| Palatal | ي | j | |
| Alveo-palatal | ج، ش | ʒ, ʃ | |
| Velar | ك | k | |
| Uvular | خ، غ، ق | x, ɣ, q | |
| Pharyngeal | ح، ع | ħ, ʕ | |
| Glottal | ء، هـ | Ɂ, h | |
|
Manner (6) | Stop | ء، ب، ت، د، ض، ط، ق، ك | Ɂ, b, t, d, dˁ, tˁ, q, k |
| Fricative | ث، ح، خ، ذ، ز، س، ش، ص، ظ، ع، غ، ف، هـ | θ, ħ, x, ð, z, s, ʃ, sˁ, ðˤ, ʕ, ɣ, f, h | |
| Affricate | ج | ʒ | |
| Nasal | م، ن | m, n | |
| Laterals | ل | l | |
| Trill | ر | r | |
|
Manner–Voice (2) | Voiced | ب، ج، د، ذ، ر، ز، ض، ظ، ع، غ، ل، م، ن، و، ي | b, ʒ, d, ð, r, z, dˁ, ðˤ, ʕ, ɣ, l, m, n, w, j |
| Unvoiced | ء، ت، ث، ح، خ، س، ش، ص، ط، ف، ق، ك، هـ | Ɂ, t, θ, ħ, x, s, ʃ, sˁ, tˁ, f, q, k, h | |
|
Manner–Emphatic (3) | Emphatic-stop | ض، ط | dˁ, tˁ |
| Emphatic-fricative | ص، ظ | sˁ, ðˤ | |
| Non-emphatic | ء، ب، ت، ث، ج، ح، خ، د، ذ، ر، ز، س، ش، ع، غ، ف، ق، ك، ل، م، ن، هـ، و، ي | Ɂ, b, t, θ, ʒ, ħ, x, d, ð, r, z, s, ʃ, ʕ, ɣ, f, q, k, l, m, n, h, w, j | |
|
Vowel (2) | Vowel | فتحة، ضمة، كسرة، الف مد، واو مد، ياء مد | a, u, I, a:, u:, i: |
| Semi-vowel | و، ي | w, j |
| AFs Categories | ||||||
|---|---|---|---|---|---|---|
| Place | Manner | Manner–Voice | Manner–Emphatic | Vowel | ||
| Phonemes | /f/ | Labio-dental | Fricative | Unvoiced | Non-emphatic | - |
| /a/ | - | - | - | - | Vowel | |
| /H/ | Pharyngeal | Fricative | Unvoiced | Non-emphatic | - | |
| /S/ | Alveo-dental | Fricative | Unvoiced | Emphatic-fricative | - | |
| Parameter | Default Values | Best Values Selected by GA |
|---|---|---|
| Learning rate | 0.001 | 0.000482 |
| Momentum | 0.9 | 0.898543 |
| Decay | 0.0005 | 0.000567 |
| Flip | 0 | False |
| blur | 0 | True |
| Gaussian_noise | 0 | True |
| mixup | 0 | False |
| mosaic | 0 | False |
| Saturation | 1.5 | 0.709779 |
| Exposure | 1.5 | 0.760187 |
| Hue | 0.1 | 0.039356 |
| Activation function | leaky | swish |
| Filter size | 3 | 7 |
| Maximum objects | 200 | 226 |
| Jitter | 0.3 | 0.100393 |
| Ignore threshold | 0.7 | 0.551836 |
| Anchors | (4,7), (7,15), (13,25), (25,42), (41,67), (75,49), (91,162), (158,205), (250,332) | (9,32), (14,32), (19,32), (24,32), (30,32), (40,32), (61,32), (127,32), (325,32) |
| Initial Training Phase | Fine Tuning Phase | ||||
|---|---|---|---|---|---|
| Training Set | Validation Set | Training Set | Validation Set | Testing Set | |
| MDD-object (baseline) | - | - | NN | NN | NN |
| MDD-object-G | - | - | |||
| MDD-object-G/N | N | N | |||
| MDD-object-G/S | S | S | |||
| MDD-object-G/NS | N+S | N+S | |||
| MDD-object-G-Large/NS | N+S | N+S | |||
| Arabic-CAPT | Arabic-CAPT-S | Native Speech | |||||
|---|---|---|---|---|---|---|---|
| Set | Train | Valid | Test | Train | Valid | Train | Valid |
| Speakers | 42 | 5 | 15 | 42 | 5 | 132 | 14 |
| Utterances | 1091 | 130 | 390 | 4914 | 585 | 3426 | 361 |
| Duration (Hours) | 1.65 | 0.16 | 0.54 | 4.79 | 0.6 | 4.11 | 0.43 |
| Training Set | Validation Set | Testing Set | |
|---|---|---|---|
| CNN-RNN-CTC | NN | NN | NN |
| CNN-RNN-CTC/N | N + NN | NN | NN |
| CNN-RNN-CTC/S | S + NN | NN | NN |
| CNN-RNN-CTC/NS | N + S + NN | NN | NN |
| System | Model | PER (%) |
|---|---|---|
| MDD-Object | MDD-Object (baseline) | 7.56 |
| MDD-Object-G | 4.93 | |
| MDD-Object-G/N | 4.75 | |
| MDD-Object-G/S | 4.71 | |
| MDD-Object-G/NS | 4.54 | |
| MDD-Object-G-Large/NS | 4.05 | |
| MDD-E2E | CNN-RNN-CTC (baseline) | 8.93 |
| CNN-RNN-CTC/N | 5.17 | |
| CNN-RNN-CTC/S | 6.17 | |
| CNN-RNN-CTC/NS | 4.59 | |
| MDD-Object-E2E | YOLO-CNN-RNN-CTC | 3.83 |
| System | Model | TA (%) | FAR (%) | FRR (%) | DA (%) | DER (%) | P (%) | R (%) | F1 (%) |
|---|---|---|---|---|---|---|---|---|---|
| MDD-Object | MDD-object (baseline) | 94.74 | 29.33 | 5.26 | 76.99 | 23.01 | 40.29 | 70.67 | 51.32 |
| MDD-object-G | 97.55 | 29.79 | 2.45 | 82.68 | 17.32 | 59.0 | 70.21 | 64.12 | |
| MDD-object-G/N | 97.99 | 32.83 | 2.01 | 81.22 | 18.78 | 62.70 | 67.17 | 64.86 | |
| MDD-object-G/S | 97.63 | 30.55 | 2.37 | 81.62 | 18.38 | 59.51 | 69.45 | 64.10 | |
| MDD-object-G/NS | 97.84 | 28.88 | 2.16 | 84.19 | 15.81 | 62.32 | 71.12 | 66.43 | |
| MDD-object-G-Large/NS | 97.96 | 24.16 | 2.04 | 84.97 | 15.03 | 65.06 | 75.84 | 70.04 | |
| MDD-E2E | CNN-RNN-CTC (baseline) | 94.14 | 20.67 | 5.86 | 75.10 | 24.9 | 40.47 | 79.33 | 53.59 |
| CNN-RNN-CTC/N | 97.62 | 24.32 | 2.38 | 82.53 | 17.47 | 61.48 | 75.68 | 67.85 | |
| CNN-RNN-CTC/S | 96.44 | 23.40 | 3.56 | 82.74 | 17.26 | 51.91 | 76.60 | 61.88 | |
| CNN-RNN-CTC/NS | 98.09 | 24.92 | 1.91 | 84.01 | 15.99 | 66.31 | 75.08 | 70.42 | |
| MDD-object-E2E | YOLO-CNN-RNN-CTC | 98.12 | 25.08 | 1.88 | 85.19 | 14.81 | 66.62 | 74.92 | 70.53 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Algabri, M.; Mathkour, H.; Alsulaiman, M.; Bencherif, M.A. Mispronunciation Detection and Diagnosis with Articulatory-Level Feedback Generation for Non-Native Arabic Speech. Mathematics 2022, 10, 2727. https://doi.org/10.3390/math10152727
Algabri M, Mathkour H, Alsulaiman M, Bencherif MA. Mispronunciation Detection and Diagnosis with Articulatory-Level Feedback Generation for Non-Native Arabic Speech. Mathematics. 2022; 10(15):2727. https://doi.org/10.3390/math10152727
Chicago/Turabian StyleAlgabri, Mohammed, Hassan Mathkour, Mansour Alsulaiman, and Mohamed A. Bencherif. 2022. "Mispronunciation Detection and Diagnosis with Articulatory-Level Feedback Generation for Non-Native Arabic Speech" Mathematics 10, no. 15: 2727. https://doi.org/10.3390/math10152727
APA StyleAlgabri, M., Mathkour, H., Alsulaiman, M., & Bencherif, M. A. (2022). Mispronunciation Detection and Diagnosis with Articulatory-Level Feedback Generation for Non-Native Arabic Speech. Mathematics, 10(15), 2727. https://doi.org/10.3390/math10152727