
A Parallel Convolution and Decision Fusion-Based Flower Classification Method


Abstract
:1. Introduction
- This paper designs a simple but effective parallel convolution block (PCB). E-VGG16 is obtained by integrating modules such as PCB and GAP into the VGG16 model, which effectively improves the performance of the model.
- Multiple variants are obtained by embedding PCB in different positions of E-VGG16, and information entropy is introduced to fuse the decisions of multiple variants, thereby further improving the classification accuracy.
- Extensive experiments on Oxford Flower102 and Oxford Flower17 datasets show that the classification accuracy of the proposed method can reach 97.69% and 98.38%, respectively, which significantly outperforms the state-of-the-art algorithms.
2. Related Works
2.1. Flower Classification
2.1.1. Traditional Methods
2.1.2. Deep Learning-Based Methods
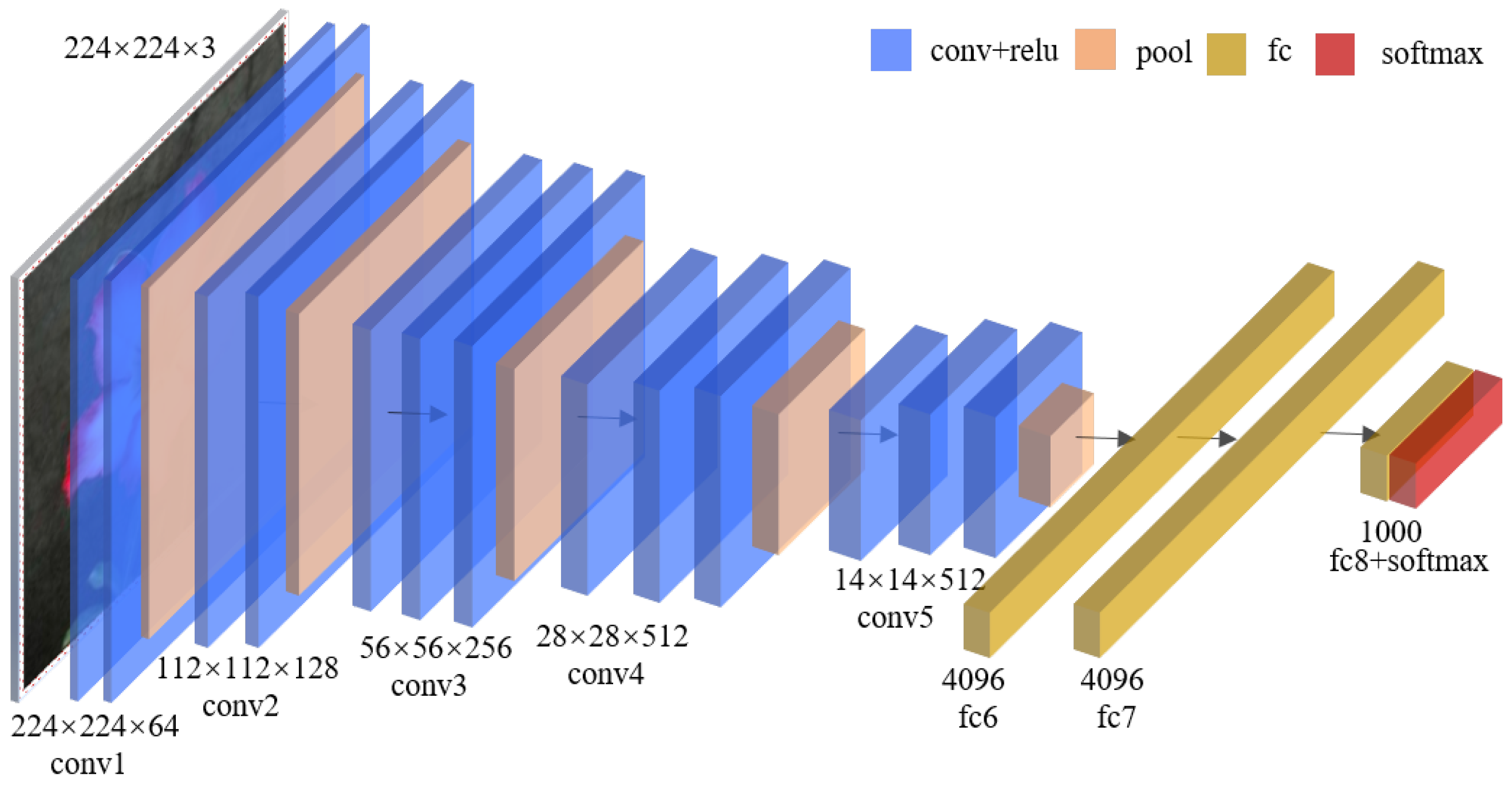
2.2. VGG16
3. The Proposed Method
3.1. E-VGG16
3.1.1. PCB
3.1.2. 1 × 1 Convolutional Layer
3.1.3. BN Layer
3.1.4. GAP Layer
3.2. Decision Fusion
4. Experiments
4.1. Environments
4.2. Experiments on Oxford Flower102
4.2.1. Effects of BN Layer
4.2.2. The Effects of PCB
- (1)
- The effect of the number of parallel convolutional layers k
- (2)
- The effects of 1 × 1 convolutional layer and max-pooling layer in PCB
- (3)
- Effects of embedding positions of PCB
4.2.3. The Effects of Decision Fusion
4.2.4. Comparison with the State-of-the-Art Methods
4.3. Experiments on Oxford Flower17
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- UK, Royal Botanic Gardens. State of the World’s Plants Report-2016; Royal Botanic Gardens: Richmond, UK, 2016. [Google Scholar]
- Yann, L.C.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar]
- Donahue, J.; Jia, Y.Q.; Vinyals, O.; Hoffman, J. Decaf: A deep convolutional activation feature for generic visual recognition. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 142–149. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.Q.; Sermanet, P. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Huang, G.; Liu, Z.; Van, D.; Weinberger, K. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Pang, C.; Wang, W.H.; Lan, R.S.; Shi, Z. Bilinear pyramid network for flower species categorization. Multimed. Tools Appl. 2021, 80, 215–225. [Google Scholar] [CrossRef]
- Simon, M.; Rodner, E. Neural activation constellations: Unsupervised part model discovery with convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Xie, L.x.; Wang, J.D.; Lin, W.Y.; Zhang, B. Towards reversal-invariant image representation. Int. J. Comput. Vis. 2017, 123, 226–250. [Google Scholar] [CrossRef]
- Toğaçar, M.; Ergen, B.; Cömert, Z. Classification of flower species by using features extracted from the intersection of feature selection methods in convolutional neural network models. Measurement 2020, 158, 107703. [Google Scholar] [CrossRef]
- Cıbuk, M.; Budak, U.; Guo, Y.H.; Ince, M. Efficient deep features selections and classification for flower species recognition. Measurement 2019, 137, 7–13. [Google Scholar] [CrossRef]
- Bae, K.I.; Park, J. Flower classification with modified multimodal convolutional neural networks. Expert Syst. Appl. 2020, 159, 113455. [Google Scholar] [CrossRef]
- Liu, Y.Y.; Tang, F.; Zhou, D.W.; Meng, Y.P. Flower classification via convolutional neural network. In Proceedings of the 2016 IEEE International Conference on Functional-Structural Plant Growth Modeling, Simulation, Visualization and Applications (FSPMA), Qingdao, China, 7–11 November 2016. [Google Scholar]
- Huang, C.; Li, H.L.; Xie, Y.R.; Wu, Q.B.; Luo, B. PBC: Polygon-based classifier for fine-grained categorization. IEEE Trans. Multimed. 2016, 19, 673–684. [Google Scholar] [CrossRef]
- Wei, X.S.; Luo, J.H.; Wu, J.X.; Zhou, Z.H. Selective convolutional descriptor aggregation for fine-grained image retrieval. IEEE Trans. Image Process. 2017, 26, 2868–2881. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, C.; Huang, L.; Wei, Z.Q.; Zhang, W.F. Subtler mixed attention network on fine-grained image classification. Appl. Intell. 2021, 51, 7903–7916. [Google Scholar] [CrossRef]
- Zheng, L.; Zhao, Y.; Wang, S.; Wang, J.; Tian, Q. Good practice in CNN feature transfer. arXiv 2016, arXiv:1604.00133. [Google Scholar]
- Ahmed, K.T.; Irtaza, A.; Iqbal, M.A. Fusion of local and global features for effective image extraction. Appl. Intell. 2017, 47, 526–543. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005. [Google Scholar]
- Jégou, H.; Douze, M.; Schmid, C.; Pérez, P. Aggregating local descriptors into a compact image representation. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Peng, X.J.; Zou, C.Q.; Qiao, Y.; Peng, Q. Action recognition with stacked fisher vectors. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Sánchez, J.; Perronnin, F.; Mensink, T.; Verbeek, J. Image classification with the fisher vector: Theory and practice. Int. J. Comput. Vis. 2013, 105, 222–245. [Google Scholar] [CrossRef]
- Mabrouk, A.B.; Najjar, A.; Zagrouba, E. Image flower recognition based on a new method for color feature extraction. In Proceedings of the 2014 International Conference on Computer Vision Theory and Applications (VISAPP), Lisbon, Portugal, 5–8 January 2014. [Google Scholar]
- Bay, H.; Tuytelaars, T.; Gool, L.V. Surf: Speeded up robust features. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006. [Google Scholar]
- Kishotha, S.; Mayurathan, B. Machine learning approach to improve flower classification using multiple feature set. In Proceedings of the 2019 14th Conference on Industrial and Information Systems (ICIIS), Kandy, Sri Lanka, 18–20 December 2019. [Google Scholar]
- Soleimanipour, A.; Chegini, G.R. A vision-based hybrid approach for identification of Anthurium flower cultivars. Comput. Electron. Agric. 2020, 174, 105460. [Google Scholar] [CrossRef]
- Abdelghafour, F.; Rosu, R.; Keresztes, B.; Germain, C.; Da, C.J. A Bayesian framework for joint structure and colour based pixel-wise classification of grapevine proximal images. Comput. Electron. Agric. 2019, 158, 345–357. [Google Scholar] [CrossRef]
- Hiary, H.; Saadeh, H.; Saadeh, M.; Yaqub, M. Flower classification using deep convolutional neural networks. IET Comput. Vis. 2018, 12, 855–862. [Google Scholar] [CrossRef]
- Tang, J.H.; Li, Z.C.; Lai, H.J.; Zhang, L.Y.; Yan, S.C. Personalized age progression with bi-level aging dictionary learning. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 905–917. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. Comput. Sci. 2015, 37, 2048–2057. [Google Scholar]
- Antol, S.; Agrawal, A.; Lu, J. Vqa: Visual question answering. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Shu, X.B.; Qi, G.J.; Tang, J.H.; Wang, J.D. Weakly-shared deep transfer networks for heterogeneous-domain knowledge propagation. In Proceedings of the 23rd ACM International Conference on Multimedia, Brisbane, Australia, 26–30 October 2015. [Google Scholar]
- Qin, M.; Xi, Y.H.; Jiang, F. A new improved convolutional neural network flower image recognition model. In Proceedings of the 2019 IEEE Symposium Series on Computational Intelligence (SSCI), Xiamen, China, 6–9 December 2019. [Google Scholar]
- Jia, L.Y.; Tang, J.L.; Li, M.J.; You, J.G.; Ding, J.M.; Chen, Y.N. TWE-WSD: An effective topical word embedding based word sense disambiguation. CAAI Trans. Intell. Technol. 2021, 6, 72–79. [Google Scholar] [CrossRef]
- Lin, M.; Chen, Q.; Yan, S.C. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015. [Google Scholar]
- Howard, A.G.; Zhu, M.L.; Chen, B. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Kohlhepp, B. Deep learning for computer vision with Python. Comput. Rev. 2020, 61, 9–10. [Google Scholar]
- Chen, W.C.; Liu, W.B.; Li, K.Y.; Wang, P.; Zhu, H.X.; Zhang, Y.Y.; Hang, C. Rail crack recognition based on adaptive weighting multi-classifier fusion decision. Measurement 2018, 123, 102–114. [Google Scholar] [CrossRef]
- Nilsback, M.; Zisserman, A. Automated flower classification over a large number of classes. In Proceedings of the 2008 Sixth Indian Conference on Computer Vision, Graphics & Image Processing, Washington, DC, USA, 16–19 December 2008. [Google Scholar]
- Nilsback, M.E.; Zisserman, A. A visual vocabulary for flower classification. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006. [Google Scholar]
- Azizpour, H.; Razavian, A.S.; Sullivan, J.; Maki, A.; Carlsson, S. From generic to specific deep representations for visual recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Yoo, D.; Park, S.; Lee, J. Multi-scale pyramid pooling for deep convolutional representation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Xu, Y.; Zhang, Q.; Wang, L. Metric forests based on Gaussian mixture model for visual image classification. Soft Comput. 2018, 22, 499–509. [Google Scholar] [CrossRef]
- Xia, X.L.; Xu, C.; Nan, B. Inception-v3 for flower classification. In Proceedings of the 2017 2nd International Conference on Image, Vision and Computing (ICIVC), Chengdu, China, 2–4 June 2017. [Google Scholar]
- Chakraborti, T.; McCane, B.; Mills, S.; Pal, U. Collaborative representation based fine-grained species recognition. In Proceedings of the 2016 International Conference on Image and Vision Computing New Zealand (IVCNZ), Palmerston North, New Zealand, 21–22 November 2016. [Google Scholar]
- Zhu, J.; Yu, J.; Wang, C.; Li, F.Z. Object recognition via contextual color attention. J. Vis. Commun. Image Represent. 2015, 27, 44–56. [Google Scholar] [CrossRef]
- Xie, G.S.; Zhang, X.Y.; Shu, X.B.; Yan, S.C.; Liu, C.L. Task-driven feature pooling for image classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Zhang, C.J.; Huang, Q.M.; Tian, Q. Contextual exemplar classifier-based image representation for classification. IEEE Trans. Circuits Syst. Video Technol. 2016, 27, 1691–1699. [Google Scholar] [CrossRef]
- Zhang, C.J.; Li, R.Y.; Huang, Q.M.; Tian, Q. Hierarchical deep semantic representation for visual categorization. Neurocomputing 2017, 257, 88–96. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Schemes | ||||
|---|---|---|---|---|
| 0 | 93.97 | 94.50 | 93.51 | 93.53 |
| 1 | 95.55 | 95.67 | 95.22 | 95.21 |
| 2 | 95.66 | 95.85 | 94.80 | 95.33 |
| 3 | 95.42 | 95.25 | 95.26 | 95.05 |
| 4 | 94.33 | 94.28 | 93.90 | 93.73 |
| 5 | 94.91 | 95.23 | 95.18 | 94.87 |
| 6 | 94.60 | 94.89 | 94.39 | 94.32 |
| 7 | 95.18 | 95.41 | 94.83 | 94.85 |
| k | ||||
|---|---|---|---|---|
| 0 | 88.75 | 88.87 | 87.72 | 87.52 |
| 1 | 96.04 | 96.04 | 95.78 | 95.62 |
| 2 | 96.28 | 96.37 | 95.97 | 95.97 |
| 3 | 96.62 | 96.62 | 96.43 | 96.28 |
| 4 | 96.66 | 96.85 | 96.37 | 96.33 |
| 5 | 96.51 | 96.73 | 96.25 | 96.21 |
| k | Layer | ||||
|---|---|---|---|---|---|
| 4 | - | 96.66 | 96.85 | 96.37 | 96.33 |
| 1 × 1 | 96.13 | 96.12 | 95.90 | 95.74 | |
| maxp | 96.74 | 96.84 | 96.65 | 96.53 | |
| all | 96.90 | 97.01 | 96.70 | 96.67 |
| Schemes | Combinations | ||||
|---|---|---|---|---|---|
| 1 | 96.49 | 95.74 | 96.01 | 95.94 | |
| 2 | 96.11 | 96.27 | 95.83 | 95.74 | |
| 3 | 96.90 | 97.01 | 96.70 | 96.67 | |
| 4 | + | 97.11 | 97.37 | 97.28 | 97.14 |
| 5 | + | 97.23 | 97.32 | 97.12 | 97.03 |
| 6 | + | 97.57 | 97.75 | 97.39 | 97.40 |
| 7 | + + | 97.69 | 97.74 | 97.82 | 97.65 |
| Method | Years | |
|---|---|---|
| VGG16 | 2014 | 91.05 |
| Azizpouret al. [45] | 2015 | 91.3 |
| Yoo et al. [46] | 2015 | 91.28 |
| Simon et al. [10] | 2015 | 95.3 |
| Xu et al. [47] | 2016 | 93.51 |
| Zheng et al. [19] | 2016 | 95.6 |
| Wei et al. [17] | 2016 | 92.1 |
| Liu et al. [15] | 2017 | 84.02 |
| Xia et al. [48] | 2017 | 94.0 |
| Xie et al. [11] | 2017 | 94.01 |
| Chakraborti et al. [49] | 2017 | 94.8 |
| Huang et al. [16] | 2017 | 96.1 |
| Hiary et al. [31] | 2018 | 97.1 |
| Cıbuk et al. [13] | 2019 | 95.70 |
| Bae et al. [14] | 2020 | 93.69 |
| Pang et al. [9] | 2020 | 94.2 |
| E-VGG16(ours) | 2022 | 96.90 |
| E-VGG16 + decision fusion (ours) | 2022 | 97.69 |
| Method | Years | |
|---|---|---|
| VGG16 | 2014 | 92.36 |
| Zhu et al. [50] | 2015 | 91.9 |
| Xie et al. [51] | 2015 | 94.8 |
| Zhang et al. [52] | 2016 | 93.7 |
| Zhang et al. [53] | 2017 | 87.1 |
| Xia et al. [48] | 2017 | 95.0 |
| Hiary et al. [31] | 2018 | 98.5 |
| Cıbuk et al. [13] | 2019 | 96.17 |
| Liu et al. [18] | 2021 | 97.35 |
| E-VGG16 (ours) | 2022 | 97.21 |
| E-VGG16 + decision fusion (ours) | 2022 | 98.38 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jia, L.; Zhai, H.; Yuan, X.; Jiang, Y.; Ding, J. A Parallel Convolution and Decision Fusion-Based Flower Classification Method. Mathematics 2022, 10, 2767. https://doi.org/10.3390/math10152767
Jia L, Zhai H, Yuan X, Jiang Y, Ding J. A Parallel Convolution and Decision Fusion-Based Flower Classification Method. Mathematics. 2022; 10(15):2767. https://doi.org/10.3390/math10152767
Chicago/Turabian StyleJia, Lianyin, Hongsong Zhai, Xiaohui Yuan, Ying Jiang, and Jiaman Ding. 2022. "A Parallel Convolution and Decision Fusion-Based Flower Classification Method" Mathematics 10, no. 15: 2767. https://doi.org/10.3390/math10152767
APA StyleJia, L., Zhai, H., Yuan, X., Jiang, Y., & Ding, J. (2022). A Parallel Convolution and Decision Fusion-Based Flower Classification Method. Mathematics, 10(15), 2767. https://doi.org/10.3390/math10152767