1. Introduction
In the era of big data, a large number of scientific literature contains valuable potential information. Accurately identifying the hot spots in the development of disciplines, precisely predicting the development trend of science and technology, and rationally allocating scientific research resources, which have become the focus of common attention of experts and decision-makers in various fields. In particular, as the basis of scientific and technological information analysis, the identification and evolution of the topic of scientific literature is attracting more and more attention.
Traditional literature topic analysis and research mostly use bibliometric methods, such as citation analysis [
1] and co-word analysis [
2]. Citation analysis is to analyze the relationship between scientific literature and relevant features (such as keywords) by counting the frequency of citations. Co-word analysis is to count the number of occurrences of a group of keywords in the literature, which reflects the correlation between keywords, and the structural changes of disciplines represented by the keywords are analyzed. However, the semantic expressiveness and importance of keywords in different pieces of literature are often ignored. With the development of big data technology, semantic analysis, and artificial intelligence methods have emerged. The knowledge graph is a visualization method combining citation analysis with co-word analysis [
3], which displays the core structure, development, and evolution process of disciplines by constructing a semantic network. Research on literature topics based on text mining [
4] is becoming more and more common, which solves the problems to some extent such as the lack of integrity and objectivity caused by the analysis of external characteristics of documents and the lack of in-depth analysis level. Li [
5] found out high-frequency keywords through co-occurrence analysis, then calculated the co-occurrence matrix by Ochiia coefficient, found literature topics through cluster analysis, defined the time series of topic popularity, and realized topic classification, and evolution trend analysis. Zhang et al. [
6] proposed a new K-Means clustering method combined with a word embedding model, which can effectively extract topics from literature data. The method has the advantages of fast, simple, high efficiency, and scalability, but the defects of K-Means will have a great impact on topic analysis. By reviewing the literature on value justice in the energy sector, Wildt et al. [
7] explained the difference between the proposed methods and the conventional method based on keywords. The new method provides a more comprehensive overview of the relevance of energy justice, but the physical meaning of singular value decomposition is difficult to understand, and the clustering effect of word meaning is difficult to control. Current topic models have been able to extract high-quality topic words, which can improve the current situation that co-word analysis can not effectively express the semantic relationship between words, and effectively reveal the true reflection information of the topic. However, the above mentioned approaches still have some defects. Many high-frequency but meaningless words will affect the effectiveness of the topic analysis, and the determination of the number of topics also has great controversy and subjectivity. Besides, linguistic features such as synonyms, polysemy, and homonymy need to be considered [
8].
To accurately mine topics, many scholars have proposed specific topic models. Latent Dirichlet Allocation (LDA) is the most commonly used topic model, and improved models based on LDA have been proposed continuously [
9]. Jung et al. argued that there are differences between topics and keywords, topics are fuzzy concepts conceived by the author. Therefore, an author-based topic model was proposed [
10]. However, LDA models do not consider the correlation between words, the performance of LDA models is limited. Deep learning has significant advantages in text mining [
11], and various topic models based on neural networks have been derived. Natural Language Processing (NLP) is an important application of deep learning in text analysis, which considers the language syntax and language semantics. Thus, NLP effectively improves the accuracy of tasks such as text classification or text mining [
12]. Based on adversarial training, Wang et al. proposed a novel topic model, which is called the “Adversarial-neural Topic Model”. With the rapid development of NLP, the text model is improved, and the topic mining is more accurate [
13]. Compared with the traditional LDA model, the performance of the novel model has significant advantages. Through NLP techniques, the tasks of text mining can be effectively completed. Recently, Kim et al. proposed a model called “architext”, which is designed for tight integration in interactive hierarchical topic modeling systems, and has good performance in large data sets [
14]. Besides, a topic model based on a distributed system can greatly improve the training efficiency [
15]. At present, topic models are constantly developing, and both accuracy and efficiency are optimized.
Time series can be used for both clustering [
16] and transforming into complex networks [
17]. Traditional analysis approaches such as clustering and classification can be used to study the relationship between topics, but lack of consideration of the impact of time factors on the study of topic evolution features. Meanwhile, although the research results can reflect the relationship between topics, the applicability of the conclusions to other topics needs further study. Topic analysis can be marked according to users’ interests. Knowledge labels are subjective, and the relationship between topics is reflected in a parallel structure. There is a lack of explicit representation and analysis of subordination, and there is no strict knowledge architecture. The topic network structure has a certain level and subordinate relationship, which can be used to reflect the hierarchical relationship within the knowledge network according to certain knowledge processing steps and the constraints of the corresponding knowledge management norms. Time series data mining techniques and approaches can study the relationship of a certain object from the perspective of time change. Through the time series data transformation of topic features, relevant techniques and approaches can be used to study the topic evolution relationship. Zhu et al. used LDA model to extract topics, and constructed “word-topic” coupling network [
18]. Wu et al. proposed a new approach based on the LDA model, and predicted the trends of specific topics [
19]. While time series clustering is a popular research approach [
20]. Combined with complex networks, time series clustering can improve the clustering effect [
21]. Using time series data, combining clustering with complex network algorithms to mine popular topics, is an innovative approach. Therefore, considering the different importance of different keywords in each literature, the keyword information is transformed into a topic co-occurrence time series that reflects the change of the topic, and the topic analysis is carried out from the perspective of complex network clustering. Therefore, by considering the different importance of different keywords in each literature, the keywords are transformed into a topic co-occurrence time series that reflects the topic change, and the topic analysis is achieved from the perspective of complex network clustering. To construct the similarity matrix and topic network of the topic co-occurrence time series data, the initial core topics in related fields are obtained by keyword importance and Affinity Propagation (AP) clustering algorithm [
22], and the topic co-occurrence time series are constructed according to the time sequence and the frequency of topic co-occurrence. The topic co-occurrence time series are divided into subsequences through sliding windows, and the cosine similarity measure is used to search the most similar subsequence segments [
23]. By community detection (Louvain) [
24], the topic network is clustered to realize the topic extraction and analysis of literature. The literature data related to “network information security” from 2005 to 2019 collected by China National Knowledge Infrastructure (CNKI) [
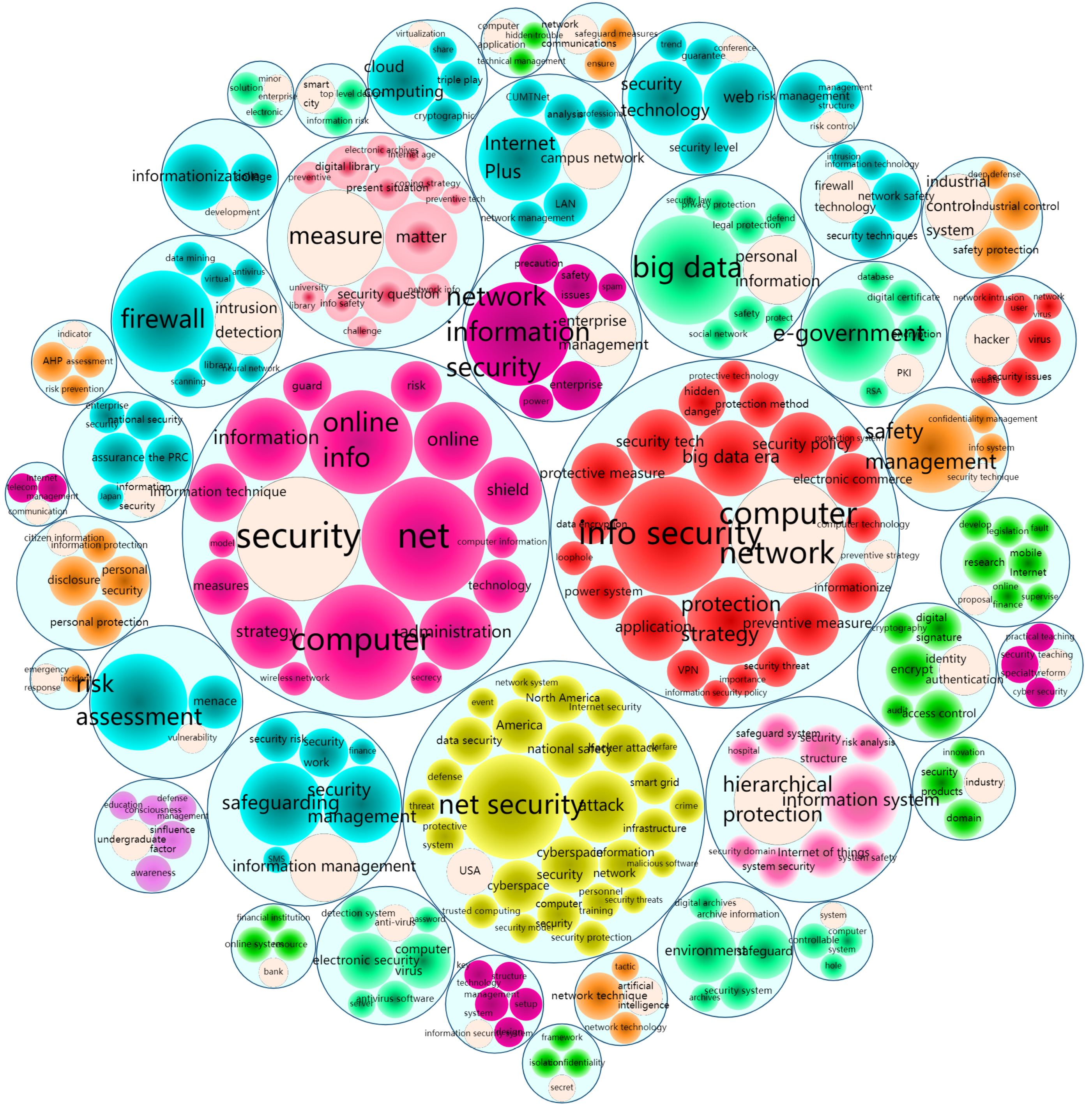
25] is taken as the data source. This paper constructs and analyzes the topic network in network information security, identify the core hot topics within a specific period of time and the deep-seated relationships within and between topics, then provide decision support for related scientific research institutions and personnel on subject research.
This paper has made some contributions from research methods: (1) The topic co-occurrence sequence similarity matrix is constructed by sliding windows, which avoids the impact of traditional hard partitioning on topic results and reveals the deep relationships between topics in a fine-grained way. (2) Cosine similarity is used to measure topic co-occurrence subsequence similarity, and the correlation between topics is measured from the shape and trend of the sequence data to avoid the impact of zero co-occurrence frequency on the measurement results. (3) The relationship between topic time series is transformed into a topic network. The more similar subsequences in the two time series, the more similar the relationship between the two topics is. The relationship between time series data is preserved, and the influence of abnormal data in the series on the similarity measurement of the whole series is reduced. Meanwhile, combined with Matrix Profile (MP) [
26], the time complexity of similarity measurements of topic co-occurrence time series is reduced.
The structure is as follows:
Section 2 introduces the research framework, methods, and algorithms.
Section 3 mainly visualizes the research results and provides suggestions. Finally,
Section 4 summarizes the full text, and puts forward our shortcomings and prospects.
2. Methodology
This section introduces the acquisition of core topics, the similarity measurement of topic co-occurrence sequences, and the construction of community networks, including AP clustering, sequence division with matrix profile, and Louvain algorithm.
2.1. Research Framework
To address the lack of deep-seated relationships within and between topics in traditional research, based on the importance of keywords and the core topics obtained by AP clustering, the co-existence sequences between the two topics are calculated. Each co-existence sequence is divided into sequence segments according to sliding windows by matrix profile. The similarity between all subsequences is calculated by cosine similarity measure to search for the most similar subsequences corresponding to each subsequence. The number of subsequences that are most similar between each topic sequence is counted, which is the similarity values between the two topics, and a similarity matrix is obtained. According to the similarity matrix, the network is constructed. The topic is the vertex of the network, and the two topics with the most similar subsequence segments are connected. Through community detection, the topic network is divided. The closely related topics are divided into a community, indicating that the topics in the same community are strongly correlated, and the topics in different communities are weakly correlated or uncorrelated, resulting in the “high cohesion and weak coupling” effect of topic division. The specific research framework is as shown in
Figure 1.
2.2. Core Topic
The existing literature topic recognition research mainly uses the co-word analysis to construct the keyword similarity matrix, and then uses the multi-dimensional scale analysis or hierarchical clustering to cluster, and extracts and analyzes the topic according to the specified multi-dimensional scale or clustering number. Traditional topic analysis lacks consideration for the topic performance of keywords in different literature, and the number of clusters needs to be set artificially. Therefore, the topic results may not necessarily reflect the connotation of the core topics. To compensate for such shortcomings, the order of keywords in different documents is considered, and the importance of keywords in literature data is calculated. The weighted similarity matrix of keywords is adaptively clustered by AP clustering, and then the core topics of the corresponding keyword clusters are represented by the center of each cluster. Meanwhile, the topic of evolution law changing with time is proposed. Finally, the initial core topics of related fields are obtained.
For the set with
N literature, the keyword similarity measurement based on importance is used, the formula is as follows:
where
and
respectively represents the weight of the keyword
i and
j corresponding to the keyword
and the keyword
in literature
P,
represents the two keywords
i and
j jointly appear in the keyword set
of literature
P.
If literature
P has
keywords, the keyword set in order
is listed. In literature
P, the importance of the
k-th keyword to the description of the document topic is as follows:
The similarity of the target keywords
is calculated, and the similarity matrix
of the target keywords are obtained. To realize clustering analysis of keywords, AP clustering is used for the similarity matrix. The clustering results aggregate keywords with high similarity into clusters, and each cluster forms a topic with keywords corresponding to the center of the cluster as the most descriptive object, and
K topics
T can be obtained. The formula is as follows:
where
T =
.
2.3. Co-Occurrence Time Series
Co-occurrence time series can detect the temporal relationship patterns of the “event” [
27]. Considering that the topics are paid different attention in different time periods and have obvious temporal characteristics, according to the occurrence time of the topics, the calculation of co-occurrence frequency between each pair of topics over time can reflect the evolutionary correlation between topics. The information features of a topic
h can be described by its co-occurrence features with other topics, and the co-occurrence features between topics are characterized by the co-occurrence between keywords contained in the topic. If the frequency of co-occurrence between topic
and another topic
in a certain period
t is
, then the information feature of the topic
is expressed as
, which is the co-occurrence frequency vector of topic
and other topics, where
L is the number of topics and
. Besides, a topic reflects the common information and common knowledge of multiple keywords, that is, keywords with common knowledge can be expressed by a core keyword through clustering. Therefore, the co-occurrence frequency of topic
and topic
in period
t can be reflected by the co-occurrence frequency between the keywords covered by the two topics. The formula is as follows:
where
and
are the
n-th and
m-th keywords in topic
and topic
respectively,
k and
s are the number of keywords covered in the two topics respectively.
In topic analysis, some topics have a high degree of attention, while others have a low degree of attention, which means there are significant differences in popularity between topics. Therefore, it is necessary to eliminate the influence of the difference in topic information features caused by different disciplines or research directions. A description of the topic information features is defined as the ratio of the topic’s co-occurrence relationship
to the topic popularity
. The topic popularity can be reflected by the frequency of keywords in a given period covered by the topic, and the topic popularity is defined as
. Therefore, the information features of topic
described by topic
in period
t can be expressed as:
The information features of topic
depicted by topic
in period
t are reflected by the co-occurrence relationship between topic
and
in period
t, and the information features reflect the correlation between the two topics. If period
t is extended to several periods
, then the information features of topic
represented by topic
can be expressed as the co-occurrence sequence between two topics, which is called “topic co-occurrence sequence”. The formula is as follows:
where
represents the length of time.
2.4. Similarity Measurement
By measuring the similarity between the co-occurrence sequences of each topic, the strength of the relationship between the two topics can be obtained. Traditional time series’ similarity mostly adopts two measurements: Euclidean distance and Dynamic Time Warping (DTW) [
28]. These two measurements measure the similarity between sequences from the numerical value, and have high requirements for numerical similarity. Combined with practical applications, many similar topic co-occurrence sequences cannot be completely consistent in all positions, and there will be some numerical differences. Such differences will be amplified when using Euclidean distance or DTW, resulting in the measurement error of the relationship between the following topics. Therefore, the similarity between topics is measured by the similarity of subsequence fragments. Each topic co-occurrence sequence is divided through the sliding window to get all co-occurrence subsequence segments. To search the topic corresponding to the most similar subsequence fragment, cosine similarity comparisons are made one by one with all other topic co-occurrence sequences, and the similarity between the two topics is increased by 1. In essence, the more similar subsequence fragments the two topic time series have, the more likely the two topic time series are to be similar. For all topic co-occurrence time series, the subsequence segments of all sequences are matched in the same time window, the most similar two subsequence segments are searched under the time window, and the correlation matrix between all topic co-occurrence sequences is calculated by the time window movements.
Assuming that there are two topic time series, they are
and
, the length of sliding time window is
l. The two subsequence sets of time series
X and
Y obtained by moving the window are
and
. The distance between
and each element in
is calculated, and a vector with length
is obtained. According to matrix profile, the minimum distance between all subsequences in
and
is
. The formula is as follows:
where
is a variant measure of Euclidean distance or cosine similarity of sequence segments
and
. Topic co-occurrence time series data usually have a value of 0, cosine similarity variants are more likely to be chosen as the vector distance measurement of sequence segments, and the formula is as follows:
For a data set
H composed of
n topic co-occurrence time series, the length of the time moving window is
l, and the subsequence fragment set of all topic co-occurrence sequences in the
k-th time window is recorded as
,
represents the subsequence segment of the
i-th topic time series under the
k-th time window, and the length of the sequence segment is
l. Assuming that
, and
represents a sequence fragment set that excludes sequence fragments
from the subsequence fragment set
, that is,
. To get that the subsequence most similar to topic
i appears in topic
under the
k-th time window,
and
are substituted into Equation (
4) to calculate
, the formula of
is:
where
. By moving the time window
times with a length of
l, the similarity matrix between topics is expressed as
, and the similarity
between topic
i and topic
j is as follows:
where
is a symbolic function. The Equation (
7) counts the number of times the subsequence fragments of topic
i are most similar to those of topic
j in different time windows. The optimal matching of similarity between subsequence segments in the same time window is not symmetrical, and the similarity or correlation between topic co-occurrence time series is described by the similarity or correlation between the parts of subsequence segments. Therefore, the correlation between the final topics is not symmetrical, that is,
. In topic analysis, the relationship between topics usually changes in different periods, and the asymmetric similarity measurements reflect the relationship between topics in different periods.
2.5. Topic Complex Network and Community Detection
Based on the similarity matrix , the topic complex network is constructed as , is the network node set, is the topic i in the dataset, and n is the size of the dataset. is the directed edge set of a network, where . is the edge weight set, and represents the correlation between topic i and topic j, topics and are sequences represented by points and respectively.
Louvain is a community detection algorithm based on modularity, which can detect the hierarchical community structure. The optimization goal is to maximize the modularity of the community network, and the optimization efficiency and optimization effect are relatively good. Modularity [
29] can evaluate the effect of community network division, whose physical significance is that the number of sides of a community is only different from that in random cases, and the value range is
. Modularity is defined as follows:
where
is the weight of the edges between nodes
i and
j. If the complex network is not a weighted graph, the weight of all edges is the same and is 1,
is the sum (degree) of the weights of the edges connected to node
i.
is the community of node
i,
is the sum of the weights of all edges.
The community detection algorithm based on modularity takes the maximization of modularity
Q as the optimization goal. The algorithm moves node
i to community
, and then calculates the change of modularity, measures if
i should be planned for community
by
, where
is as follows:
where
is the sum of the weights of the internal connecting edges of the community
,
is the sum of the edge weights connected to all nodes in the community
.
is the sum of weights of all edges connected by node
i,
is the sum of edge weights connected between node
i and nodes in community
, and
s is the sum of the weights of all edges in the network. Algorithm 1 calculates the change in modularity when
i is removed from the community.
| Algorithm 1 Louvain algorithm. |
Input: Network G Output: Divided community C - 1:
Initialize and set each node as a community - 2:
Calculate the modularity change of each node i according to Equation ( 12) - 3:
Select the node k with the largest - 4:
Divide node i into the community where k is located if the maximum is greater than 0 - 5:
Repeat the second step until the communities of all nodes no longer change. - 6:
Compress all nodes in the same community into a new node to get a new G - 7:
Repeat the first step until the modularity of the whole network remains unchanged, and then return C
|
In the first step of Algorithm 1, each node of the network is assigned a different community, the number of communities is the same as the number of nodes. In the second step, for each node i, to evaluate the modular gain change, the algorithm needs to remove i from the corresponding community, and then put i in the community of neighbor node j for calculation. In the third step and the fourth step, node i is placed in the community with the largest gain and positive value (in the case of a draw, a random rule is used). If the modularity changes to a negative value, i will remain in the original community. The more closely related topics are divided into a community, the topics of the same community are strongly related, and the topics of different communities are weakly related or irrelevant.
4. Conclusions
This paper proposes a topic network analysis approach for co-occurrence time series clustering, which takes the importance of keywords and the initial core topics obtained by AP clustering as the initial point. We construct the co-occurrence time series between topics in time order, and use the time window and the matrix profile to obtain the local correlation of the co-occurrence time series data, Then the similarity matrix reflecting the total correlation is obtained. Based on the similarity matrix, a topic complex network is constructed, and the community of the topic network is divided by the Louvain algorithm, which realizes the re-clustering of topics in related fields, and analyzes the deep relationship between and within topics. Through the analysis of the literature in the field of network information security, the results show that the new approach can reveal the popular topics in a specific field and the deep relationships in a fine-grained way from the perspective of the time change, which not only complements the application of time series data mining in topic analysis, but also provides decision support for institutions and personnel to grasp the subject research direction. The main innovations of this study are as follows: (1) The topic co-occurrence time series are constructed through the co-occurrence relationship between the keywords covered by the topic, and the relationship between topics is displayed from the fine-grained perspective of time and keywords. (2) The pattern matching of sub-segments of co-occurrence time series of different topics is achieved through the time moving window, and the total correlation between topics is reflected by local correlation. Combined with complex network analysis, the analysis and research of topic relations are more comprehensive and in-depth. (3) Topic clustering centers are independent of keyword popularity, and topics with broader concepts are more likely to become topic network centers.
In addition, there are some limitations. (1) The data is not pre-processed in detail. Some meaningless topics cannot provide substantive conclusions, and deleting meaningless topics in advance may obtain higher quality results. (2) Topic analysis approach provides a 5-year time window for the subsequence division of topic co-occurrence, which is referential but not objective enough. (3) When constructing the topic network, the similarity times of the co-occurrence topic time series segments are taken as the network edge weight, which may ignore the influence of the real distance of the optimal similar segments. The determination of the network edge weight by the true value of the similarity of the topic time series segments is a work that needs further research in the future. Moreover, to provide constructive suggestions for scholars in more fields and improve the applicability of conclusions, in the future work, the data scope can be expanded to multiple fields, and the data can be processed in more detail.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}