Abstract
The Sharpe ratio is a measure based on the theory of mean variance, it is the measure of the performance of a portfolio when the risk can be measured through the standard deviation. This paper suggests a Sharpe-ratio portfolio solution using a second order cone programming (SOCP). We use the penalty-regularized method to represent the nonlinear portfolio problem. We present a computationally tractable way to determining the Sharpe-ratio portfolio. A Markov chain structure is employed to represent the underlying asset price process. In order to determine the optimal portfolio in Markov chains, a new hybrid optimization programming method for SOCP is proposed. The suggested method’s efficiency and efficacy are demonstrated using a numerical example.
MSC:
91G10; 60J20; 60J22
1. Introduction
1.1. Brief Review
Markowitz [1] proposed the mean-variance portfolio (MVP) which is a fundamental contribution in the field of finance; currently, models based on it continue to be developed. In its most basic version, it assumes n risky assets. Their returns over the period are modeled as a random vector such that represents the mean and is the covariance, where denotes the expectation operator. The mathematical formulation’s decision variable is , which indicates the percentage of the available budget invested in asset i. If , it means that short selling is not allowed.
The return of a portfolio is a scalar (random variable) given by , then the mean return of is , and the risk, measured by the variance, is given by . We suppose that an admissible portfolio is restricted to being contained within a closed convex set .
The selection of a portfolio is a risk–return trade-off. The minimum variance MVP issue is used to define the optimal trade-off as
where r is the minimum required expected rate of return,
and e is a vector of size n whose components are ones. In this problem, we determine the portfolio that minimizes the risk while still meeting the asset allocation and portfolio budget constraints.
The objective of the Markowitz framework is to achieve a balance between the average return of the portfolio and its risk, which is measured by the variance, that is, we look for the highest return with the lowest risk that may exist among all the possibilities.
Another type of mean-variance analysis called the risk-adjusted expected return is expressed as
The dual objectives of this formulation are to maximize the portfolio expected return while minimizing variance, where is a risk-aversion coefficient determined by the investors, and is the capital budget constraint.
Let us denote the function of the Pareto frontier
where the trajectory of the optimal solution defines a concave curve increasing over (standard deviation) for which
The best risk–return trade-off of the assets is found in the strictly concave section of the curve, which is known as the efficient frontier. A portfolio is efficient if for any other portfolio having the same expected return, its variance satisfies . The performance of a portfolio with a uncertainty model is characterized by the set of return–risk pairing computed using the variables across the set
If there is no asset allocation restriction (except for the portfolio budget constraint), the two-fund theorem states that the efficient frontier is a hyperbola and that every efficient portfolio can be two-fold in terms of the mean and the variance as a combination of these two efficient funds (portfolios) [2]. To obtain the efficient frontier of a portfolio, the average return is needed, which is given by () and the standard deviation given by (). The efficient frontier can be computed using the Sharpe-ratio maximization [3,4]
where is the return of a risk-free asset (a risk-free asset is typically regarded to have no risk or variance). The Sharpe-ratio maximization problem is named from the aim of Equation (1), which measures the excess of return () normalized by the standard deviation ().
The efficient frontier is defined as the locations on the frontier of the portfolio with expected returns greater than the expected return of the portfolio with the smallest variance. The portfolio with the least variance among all portfolios is the most efficient. All portfolios in the efficient frontier are optimal according to the risk profile of the investor, which is the choice of parameters.
1.2. Related Work
The Markowitz [1] single-period mean-variance portfolio is defined as a model that maximizes the terminal wealth while minimizing risk using variance as a criterion. The idea is to enable an investor to seek the maximum potential return by determining a risk tolerance threshold. Trends, which are seen as inclinations of securities to move in a specific manner over time, control the markets. Mathematical models, which detect patterns when the price meets support and resistance levels throughout time, are used by investors to forecast securities movements [5].
We structure the Markowitz mean-variance portfolio as a system whose variables are represented by a discrete-time Markov chain to solve these challenges. We look at a specific type of discrete-time Markov mean-variance portfolio model and find the portfolio strategy that minimizes total risk, given a fixed anticipated return.
The Sharpe ratio is a measure of portfolio performance as long as the risk can be adequately measured through the standard deviation, and it is usually effective for normally distributed returns. However, there are works, such as Zakamouline and Koekebakker et al. [6] in which they generalized the evaluation of portfolio performance using the Sharpe ratio. Lu and Li et al. [7] with their study identified a theoretical reasonable value of the Sharpe ratio; to this end, they proposed a formula to estimate an expected value for the Sharpe ratio, bounding it in the option pricing model. Kourtis et al. [8] provided how to assess the value of efficient portfolios. Portfolio optimization for Markov chains with restrictions has a significant body of work. See these articles for a survey of the impact of transaction costs on portfolio optimization [9,10]. Portfolio optimization for Markov chains with restrictions has a significant body of work. Sanchez et al. [11] proposed a novel mean-variance customer portfolio optimization approach for a class of ergodic-finite controllable Markov chains, according to citation percent. Sanchez et al. [12] built on the work of [11] by presenting a recurrent reinforcement-learning strategy for controlled Markov chains that adapts policies based on preprocessing and an actor–critic architecture. Clempner and Poznyak [13] investigated the applicability of the penalty regularized expected utilities approach for solving the mean-variance Markowitz customer portfolio optimization issue. In controlled partially observable Markov decision processes, Asiain et al. [14] presented a reinforcement-learning method for calculating the customer portfolio with transaction costs. Garcia-Galicia et al. [15] looked at a continuous-time portfolio strategy for continuous-time discrete-state Markov decision processes with transaction costs requiring temporal penalization. Using the extraproximal technique confined to a finite discrete temporal, ergodic, and controlled Markov chains, Dominguez and Clempner [16] solved the multi-period mean-variance customer-constrained Markowitz’s portfolio optimization issue. Garcia-Galicia et al. [17] looked at policy optimization in the context of continuous-time reinforcement learning for financial portfolio management, where the underlying asset portfolio process is assumed to have a continuous-time discrete-state Markov chain structure with simplex and ergodicity constraints. The portfolio problem’s purpose is to redistribute a fund across various financial assets. Meghwani and Thakur [18] developed a tri-objective portfolio optimization model with risk, return, and transaction cost as the objectives, as well as a method for successfully handling equality constraints. Vazquez and Clempner [19] developed a portfolio technique based on a Lagrangian regularization method. The literature differs depending on whether you use continuous or discrete time, a finite or infinite horizon, and so on [20,21,22,23,24,25,26].
Tikhonov’s regularization has gained a lot of interest in application sectors [27,28]. It is one of the most prominent ways to solve discrete ill-posed minimization problems. The use of Tikhonov’s regularization to create successful algorithms is still a developing topic. To solve the Markowitz MV portfolio model, for example, several strategies based on Tikhonov’s regularization have been devised [11,12,13,19,29,30].
1.3. Main Results
This paper proposes a solution to the Sharpe-ratio portfolio optimization issue, which is based on a market model and allows for the formulation of risk reduction, security returns, and performance assessment. We assume that securities trading occurs in discrete time steps. We assume that the financial market is arbitrage free, meaning that no arbitrage portfolio exists. The premise of an arbitrage-free market is proposed with the goal of obtaining a pricing system that is compatible with the market’s principal asset price.
The main results are summarized as follows:
- Consider the problem of Sharpe-ratio portfolio selection.
- Formulate a regularization approach based on the penalty technique.
- Compute the optimal Sharpe-ratio portfolio using the new algorithm approach.
- Propose a financial mathematical method that is combined with increased computing capacity to produce a powerful solution to the problem.
1.4. Organization of the Paper
2. Sharpe-Ratio Solver
If we denote
, where is the Euclidian norm and satisfies that we have that the Sharpe-ratio portfolio minimization [3,4] can be expressed as
Let us introduce the variable such that
such that with Now, consider the following second-order cone programming (SOCP) for the Sharpe-ratio portfolio
Under an affine mapping, the collection of points meeting a second-order cone constraint is the inverse image of the unit second-order cone given by
The standard or unit second-order cone of dimension is defined as
Remark 1.
The constraints, which are analogous to requiring the affine function to lie in the second-order cone in lead to the SOCP.
It is possible that finding a minimum solution is not unique. We employ the penalization method and introduce a Tokhonov’s regularizator with regularization parameters to solve the ill-posed issue, which consists of
Clearly, the optimization problem
has a unique solution since the optimized function (3) is strongly convex if . Considering , the following property holds:
and we have
The concept behind the portfolio’s function is as follows: if the penalty parameter approaches zero in a specific way, we may suppose that and , which are the optimization problem’s portfolio solution
tend toward the set of all the portfolio solutions to the original portfolio optimization problem (2), i.e., the distance
is defined as
Solver method for the Sharpe-ratio portfolio
where for variable c
3. Markov Approach for the Sharpe-Ratio Portfolio
3.1. Markov Model
Let us consider a discrete-time problem in which n takes integer values, i.e., . Assume is a control variable whose value is determined at time n. The partial sequence of controls (or decisions) taken throughout the first n phases is denoted by . The control variable is chosen based on the knowledge that (which determines everything else). However, a more cost-effective portrayal of the past is frequently adequate. For instance, we may not require knowledge about the full path traveled up to time n, but merely the location to which it has led us. The concept behind a state variable is that its value at time n called , can be calculated using known values and follows a plant equation (or law of motion) . The optimal is a function only of , i.e., .
Consider a stochastic evolution where the x and u histories at time n are denoted by and . As previously stated, the state structure is defined by the fact that the process development is specified by a state variable x, which has the value at time .
A discrete-time Markov chain is a tuple , where X is the state space, U is the action space and is the transition probability distribution (i.e., the stochastic version of the plant equation). A Markov decision process is the tuple defined by , where is the immediate utility function by choice of controls .
The transition function and the common prior distribution perfectly describe the behavior represented by a Markov chain, where , where denotes the set of all probability distributions over X. The Markov chains are self-contained. The absolute values of the utility function are bounded by some constant. We assume that each Markov chain is irreducible, recurrent and aperiodic (ergodic), and that P is its unique invariant distribution. Then, we have . As well, there exists a state which is recurrent for every distribution P.
To formulate the optimization issue related with MDP, let be a stationary policy, where is the U-simplex, which maps state–space X to a probability distribution on action–space U and determines randomized actions based on the current state . As a result, we obtain that under policy , the action is chosen based on the probability distribution . Let be the admissible set of Markov policies, i.e.,
In this model, the current value of the state is observable, i.e., when selecting , is known. We assume that , where is the observed history at time n.
Given the Markovian structure of the state processes, the utility at state vector with policy and probability distribution can be written as
such that .
A policy is called a optimal if for each maximizes the conditional mathematical expectation of the utility function considering the history process in period n, and set of possible states period is fixed such that cannot be changed hereafter, i.e., it achieves the optimal policy by solving the conditional optimization problem given by
where is the average utility function. Under the previous assumptions the admissible set is nonempty, therefore there exists an optimum policy in the class of stationary Markovian policies.
The variance is given by
Finally, the portfolio is defined by
The distribution vector is defined as
In the ergodic case, which we are dealing with, these probabilities exponentially quickly converge to the stationary distributions, that is, . From now on, we consider stationary distributions (we are considering the one-period portfolio).
3.2. Portfolio Model’s Compliance with MARKOV
Consider a variable v defined as
such
where is Kronecker’s variable. The following relationship holds true is the ergodic case
It is straightforward to determine that belongs to the simplex
The utility function in terms of v-variables is determined by
To obtain the variables of interest after the portfolio model is solved, we have a stationary distribution and the policy (portfolio) may be recovered using the following formulae
Associating these variables with the notions above define the vector
such that the regularized portfolio return is defined as
and satisfies
then,
As a result,
where is the return risk-free asset in terms of Markov chains.
3.3. Solver for Markov Chains
Let us consider
Considering the SOCP for the Sharpe-ratio approach, we have
We have
The optimization problem becomes
Solver method for the Sharpe ratio in Markov chains
4. Numerical Example
Under the one-period horizon, we assume that investors expect the same probability distribution of returns and target the portfolio with the lowest risk. We believe that there is no inflation or interest rate shift, and that the markets are in a state of equilibrium. To get closer to the actual world, we assume that trading has transaction costs and that investors can trade limitless quantities on an arbitrage-free market.
The proposed method implies that
Developing further, we have
Hence,
Finally,
For the proposed problem, we have that the set X has eight states and the set U three controls. The initial parameters and are set to be and . For the method, the initial point portfolio is set to be in the middle of the simplex, as well as the initial distribution. The value of is set to be . As well, and .
The resulting portfolio is given by
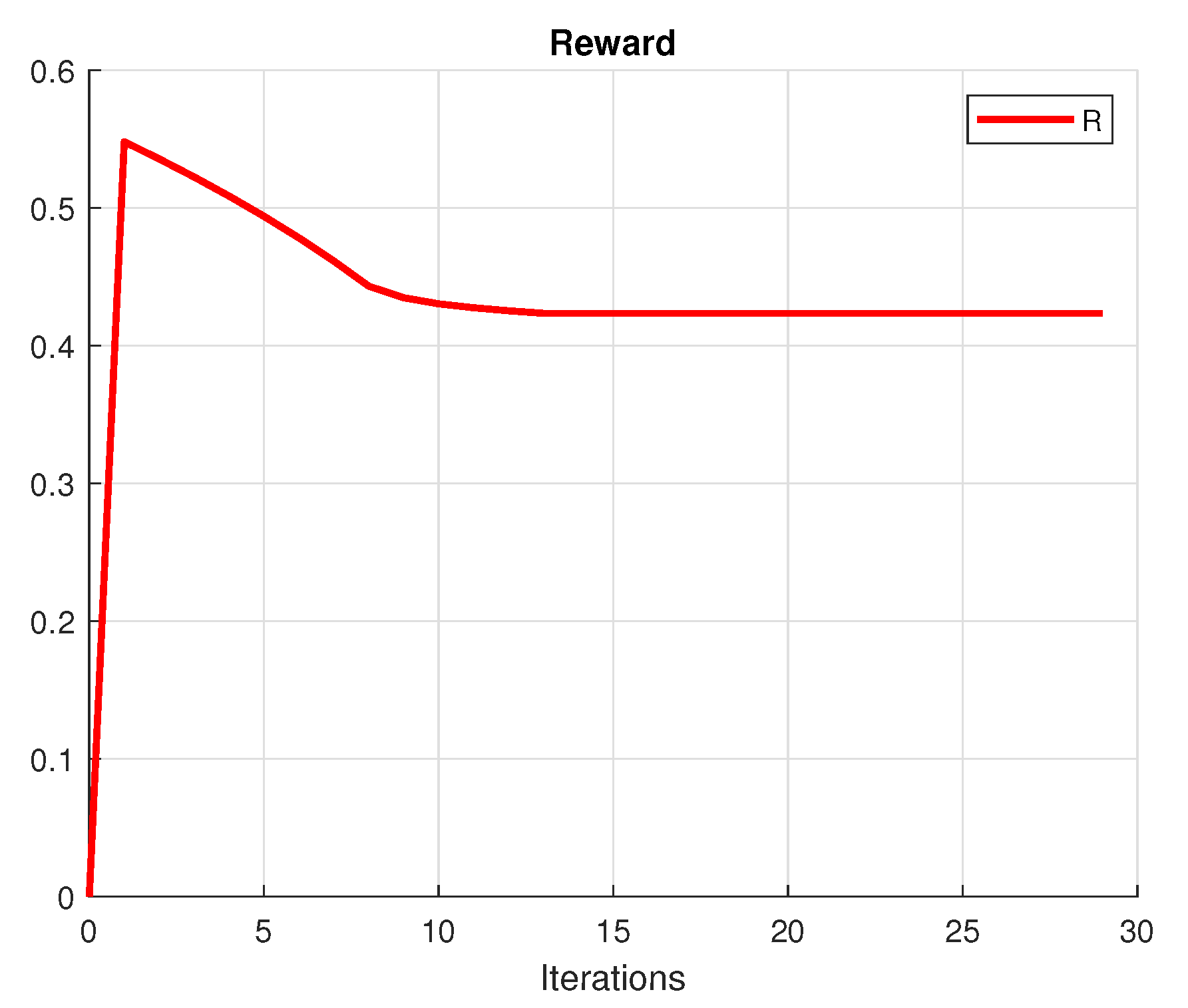
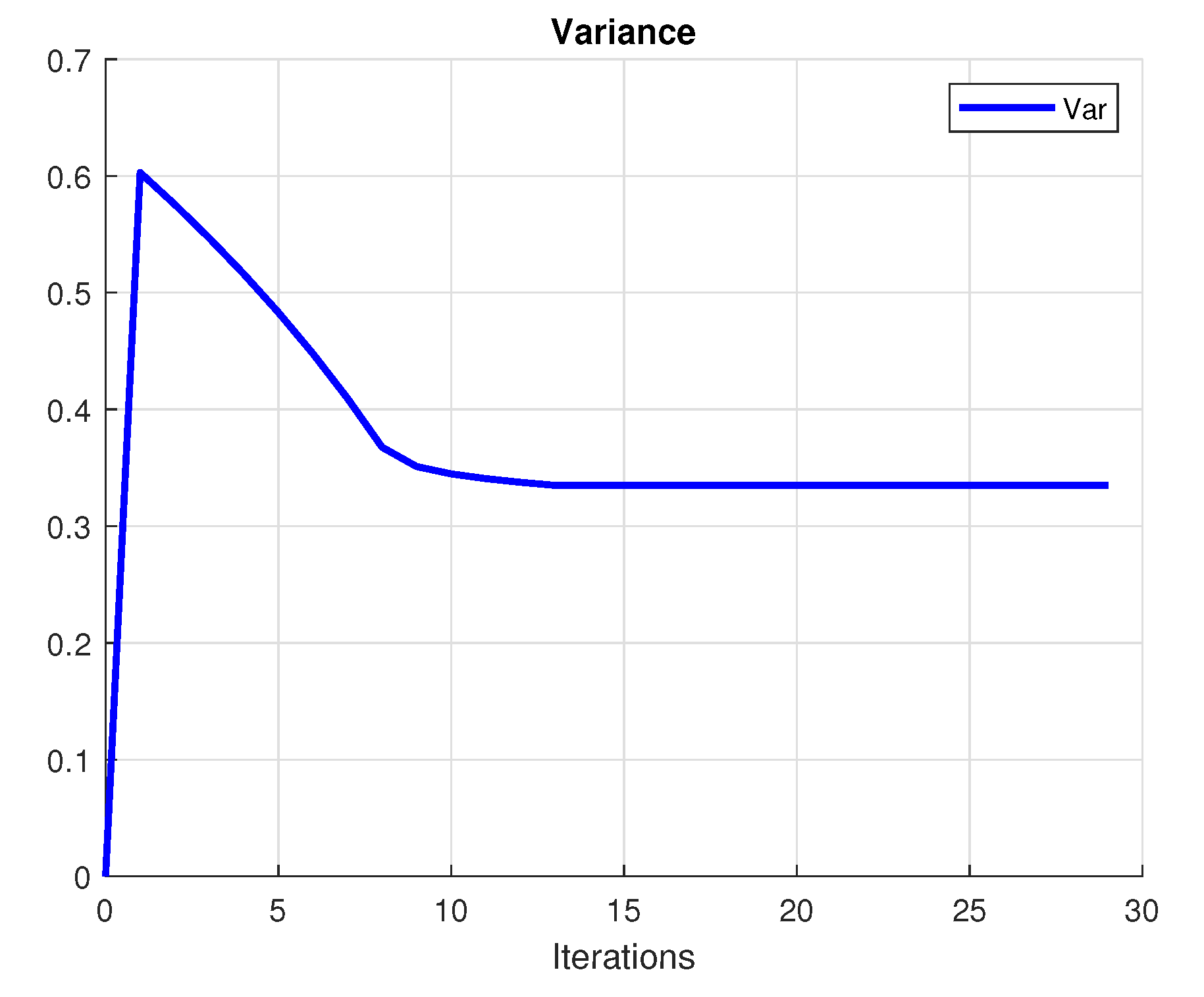
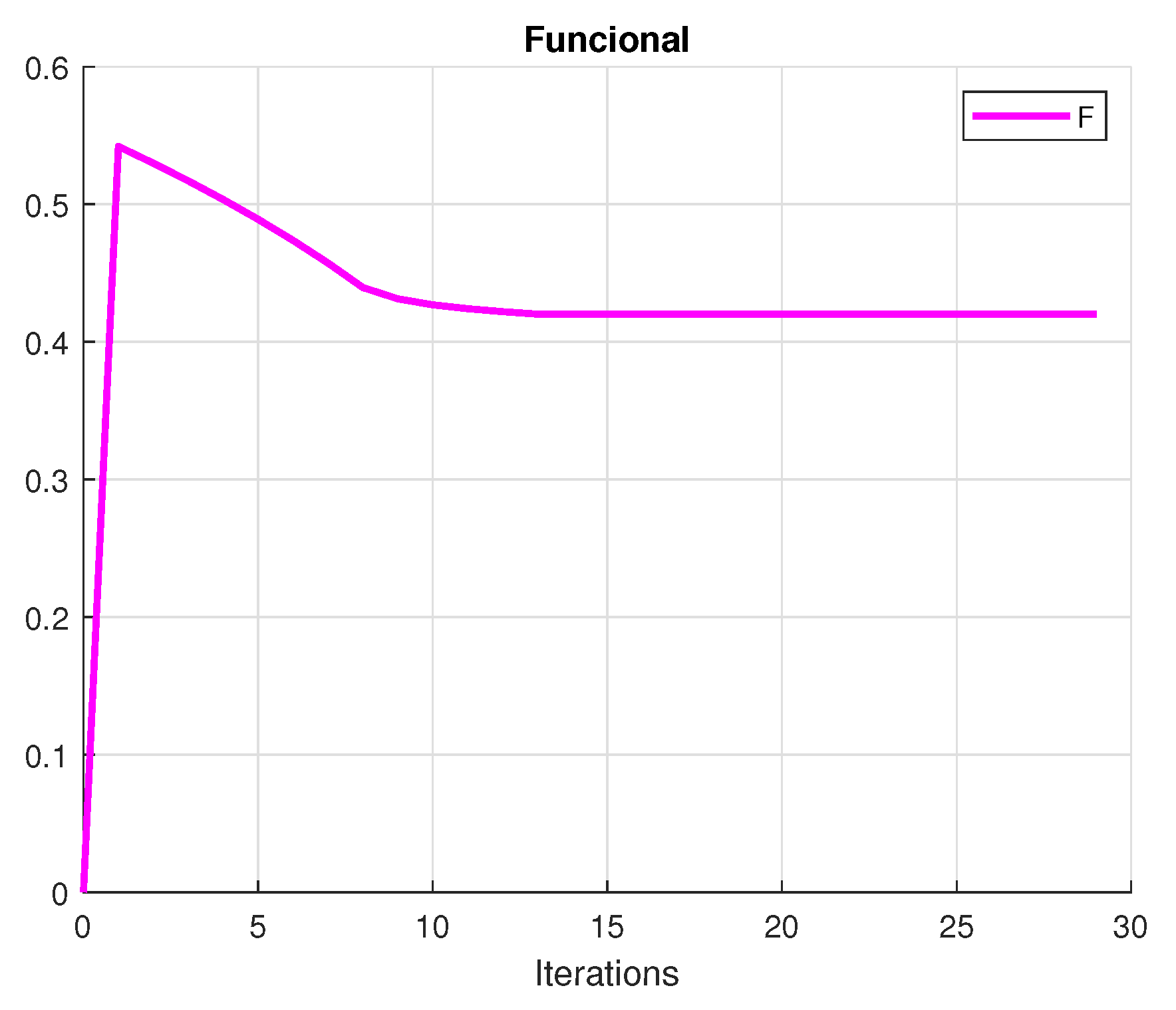
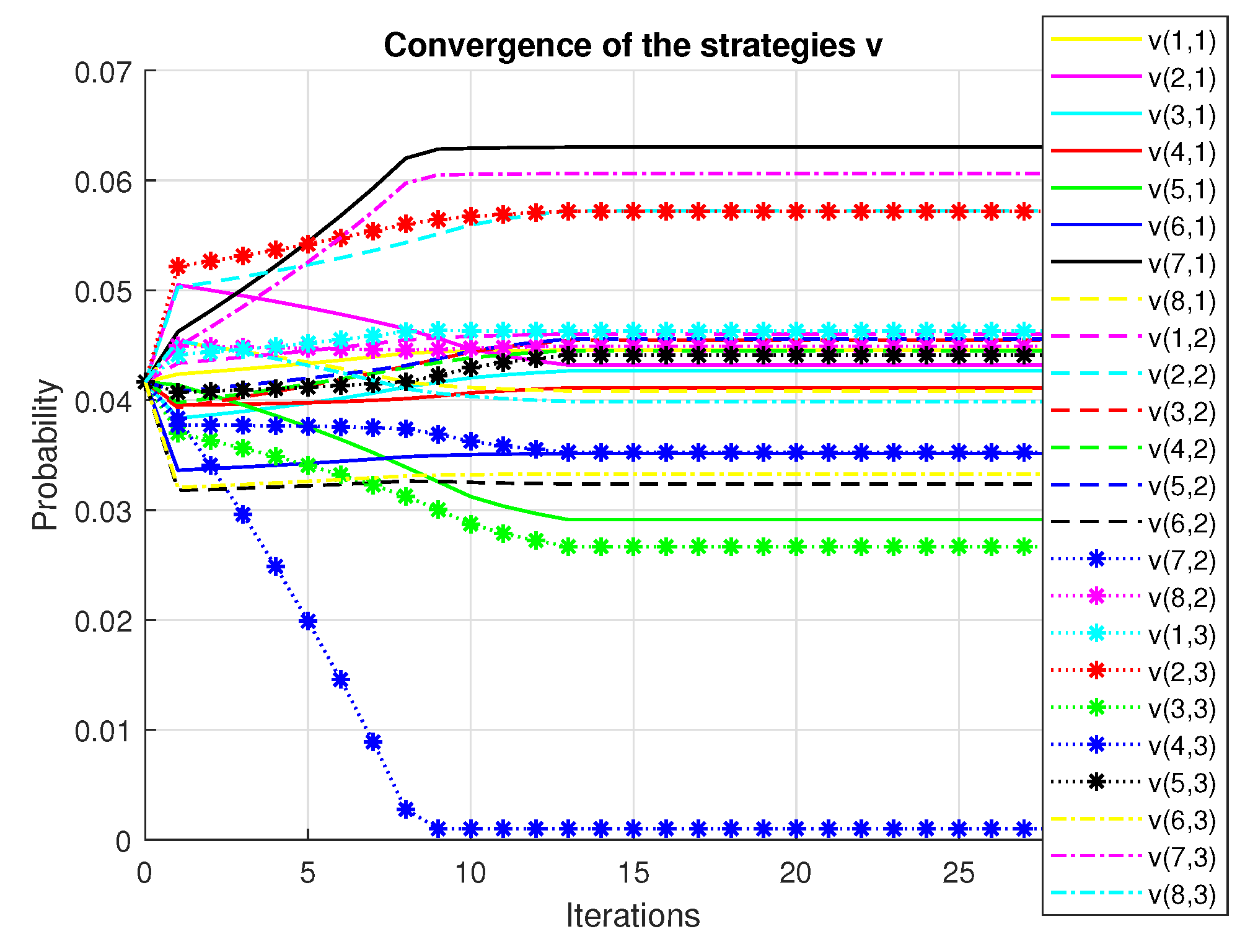
The investor’s primary purpose is to make a profit. A rational investor tries to choose the portfolio with the lowest risk that achieves this goal. To achieve this purpose, we create a mean-variance diagram with all of the conceivable hazardous asset portfolios, where the points indicate the returns and the risk (variance) of the portfolios. Figure 1 presents the convergence of the utility, Figure 2 shows the variance and Figure 3 plots the convergence of the functional. Figure 4 shows the convergence of the portfolio strategies.
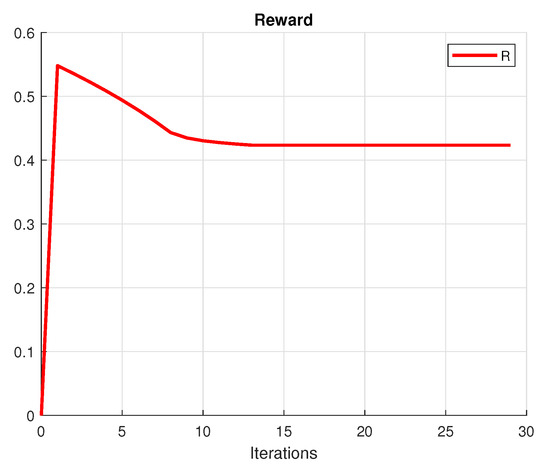
Figure 1.
Utility value of the portfolio.
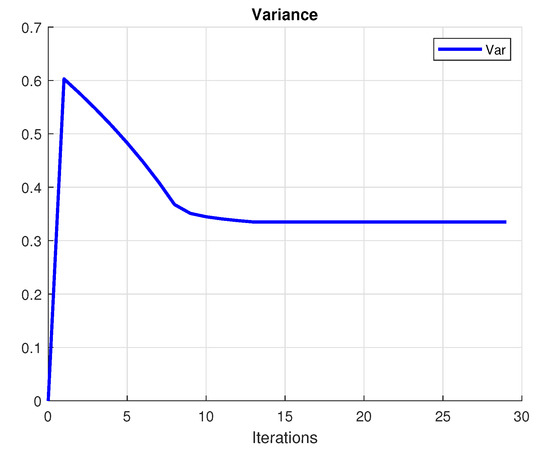
Figure 2.
Variance value of the portfolio.
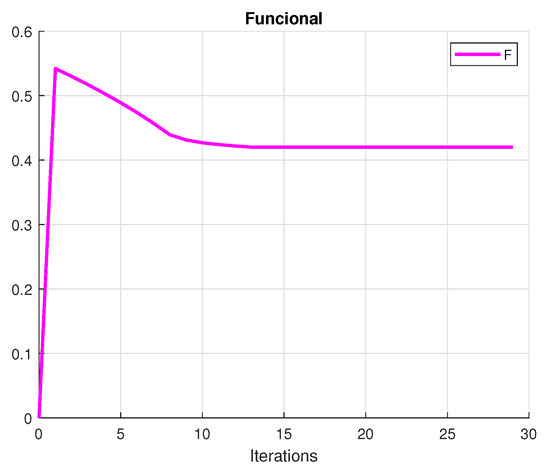
Figure 3.
Functional value of the portfolio.
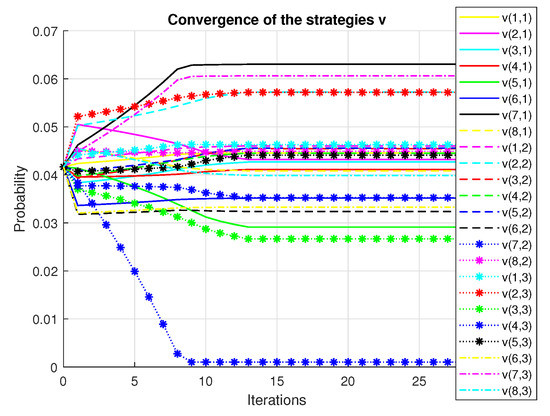
Figure 4.
Convergence of the strategies.
5. Conclusions
Financial market research has grown in importance, owing to the adoption of advanced mathematical tools for improved decision making. The need for more appropriate modeling techniques to handle the portfolio optimization problem has risen due to the enormous expansion in the diversity of financial assets. The Sharpe ratio is a popular performance indicator used to optimize the trade-off between rewards and risks. The Sharpe ratio can be applied to a variety of situations, including performance evaluation, risk management, and market efficiency testing.
This paper proposes a Sharpe-ratio portfolio solution. For ensuring strong convexity and the existence of a unique solution involving equality and inequality requirements, we employed a penalty function approach. The penalty regularized technique was employed to represent the nonlinear portfolio problem. For the proposed model, we suggest a computationally tractable way to determine the Sharpe-ratio portfolio. A Markov chain structure was used to model the underlying asset price process. In order to determine the optimal portfolio in Markov chains, a new hybrid optimization programming method was proposed. The suggested method’s efficiency and efficacy were demonstrated using a numerical example.
Author Contributions
Writing and original draft, L.L.O.-C. and J.B.C.; Writing, review and editing, A.A.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Secretaría de Investigación y Posgrado, Instituto Politécnico Nacional.
Institutional Review Board Statement
Ethical review and approval were waived for this study, since no human or animal resources were involved or mentioned in the study.
Informed Consent Statement
Not applicable.
Data Availability Statement
No real data sets have been used, only simulation examples are given.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
References
- Markowitz, H. Portfolio selection. J. Financ. 1952, 7, 77–98. [Google Scholar]
- Merton, R. An analytic derivation of the efficient portfoliofrontier. J. Financ. Quant. Anal. 1972, 4, 1851–1872. [Google Scholar] [CrossRef]
- Sharpe, W.F. Mutual Fund Performance. J. Bus. 1966, 39, 119–138. [Google Scholar] [CrossRef]
- Sharpe, W.F. The Sharpe Ratio. J. Portf. Manag. 1994, 21, 49–58. [Google Scholar] [CrossRef]
- Caruso, G.; Gattone, S.; Fortuna, F.; Di Battista, T. Cluster Analysis for mixed data: An application to credit risk evaluation. Soc.-Econ. Plan. Sci. 2021, 73, 100850. [Google Scholar] [CrossRef]
- Zakamouline, V.; Koekebakker, S. Portfolio performance evaluation with generalized sharpe ratios:beyond the mean and variance. J. Bank. Financ. 2009, 33, 1242–1254. [Google Scholar] [CrossRef]
- Lu, J.R.; Li, X.Y. Identifying the fair value of sharpe ratio by an option valuation approach. Q. Rev. Econ. Financ. 2021, 82, 63–70. [Google Scholar] [CrossRef]
- Kourtis, A. The Sharpe ratio of estimated efficient portfolios. Financ. Res. Lett. 2016, 17, 72–78. [Google Scholar] [CrossRef]
- Samuelson, P. Lifetime portfolio selection by dynamic stochastic programming. Rev. Econ. Stat. 1969, 51, 239–246. [Google Scholar] [CrossRef]
- Constantinides, G. Multiperiod consumption and investment behavior with convex transaction costs. Manag. Sci. 1979, 25, 1127–1137. [Google Scholar] [CrossRef]
- Sánchez, E.M.; Clempner, J.B.; Poznyak, A.S. Solving The Mean-Variance Customer Portfolio in Markov Chains Using Iterated Quadratic/Lagrange Programming: A Credit-Card Customer-Credit Limits Approach. Expert Syst. Appl. 2015, 42, 5315–5327. [Google Scholar] [CrossRef]
- Sánchez, E.M.; Clempner, J.B.; Poznyak, A.S. A priori-knowledge/actor-critic reinforcement learning architecture for computing the mean–variance customer portfolio: The case of bank marketing campaigns. Eng. Appl. Artif. Intell. 2015, 46 Pt A, 82–92. [Google Scholar] [CrossRef]
- Clempner, J.B.; Poznyak, A.S. Sparse mean–variance customer Markowitz portfolio optimization for Markov chains: A Tikhonov’s regularization penalty approach. Optim. Eng. 2018, 19, 383–417. [Google Scholar] [CrossRef]
- Asiain, E.; Clempner, J.B.; Poznyak, A.S. A Reinforcement Learning Approach for Solving the Mean Variance Customer Portfolio in Partially Observable Models. Int. J. Artif. Intell. Tools 2018, 27, 1850034. [Google Scholar] [CrossRef]
- Garcia-Galicia, M.; Carsteanu, A.A.; Clempner, J. Continuous-Time Mean Variance Portfolio with Transaction Costs: A Proximal Approach Involving Time Penalization. Int. J. Gen. Syst. 2019, 48, 91–111. [Google Scholar] [CrossRef]
- Domínguez, F.; Clempner, J.B. Multiperiod Mean-Variance Customer Constrained Portfolio Optimization For Finite Discrete-Time Markov Chains. Econ Comput Econ Cyb. 2019, 1, 39–56. [Google Scholar]
- Garcia-Galicia, M.; Carsteanu, A.A.; Clempner, J. Continuous-Time Learning Method For Customer Portfolio with Time Penalization. Expert Syst. Appl. 2019, 129, 27–36. [Google Scholar] [CrossRef]
- Meghwani, S.; Thakur, M. Multi-objective heuristic algorithms for practical portfolio optimization and rebalancing with transaction cost. Appl. Soft Comput. 2018, 67, 865–894. [Google Scholar] [CrossRef]
- Vazquez, E.; Clempner, J.B. Customer Portfolio Model Driven By Continuous-Time Markov Chains: An L2 Lagrangian Regularization Method. Econ. Comput. Econ. Cybern. Stud. Res. 2020, 2, 23–40. [Google Scholar]
- Akian, M.; Sulem, A.; Taksar, M. Dynamic optimization of long-term growth rate for a portfolio with transaction costs and logarithmic utility. Math. Financ. 2001, 11, 152–188. [Google Scholar] [CrossRef]
- Cvitanic, J.; Karatzas, I. Hedging and portfolio optimization under transaction costs: A martingale approach. Math. Financ. 1996, 6, 133–166. [Google Scholar] [CrossRef]
- Davis, M.; Norman, A. Portfolio selection with transaction costs. Math. Oper. Res. 1990, 15, 676–713. [Google Scholar] [CrossRef]
- Liu, H. Optimal consumption and investment with transaction costs and multiple risky assets. J. Financ. 2005, 59, 289–338. [Google Scholar] [CrossRef]
- Ziemba, W.; Vickson, R. Stochastic Optimization Models in Finance; World Scientific: Singapore, 2006. [Google Scholar]
- Nowak, P.; Romaniuk, M. Valuing catastrophe bonds involving correlation and CIR interest rate model. Comp. Appl. Math. 2018, 37, 365–394. [Google Scholar] [CrossRef]
- Mwanakatwe, P.; Song, L.; Hagenimana, E.; Wang, X. Management strategies for a defined contribution pension fund under the hybrid stochastic volatility model. Comp. Appl. Math. 2019, 38, 1–19. [Google Scholar] [CrossRef]
- Tikhonov, A.N.; Arsenin, V.Y. Solution of Ill-Posed Problems; Winston & Sons: Washington, DC, USA, 1977. [Google Scholar]
- Tikhonov, A.; Goncharsky, A.; Stepanov, V.; Yagola, A.G. Numerical Methods for the Solution of Ill-Posed Problems; Kluwer Academic Publishers: Alphen aan den Rijn, The Netherlands, 1995. [Google Scholar]
- Carrasco, M.; Noumon, N. Optimal Portfolio Selection Using Regularization; Citeseer: Gaithersburg, MD, USA, 2010. [Google Scholar]
- Fastrich, B.; Paterlini, S.; Winker, P. Constructing optimal sparse portfolios using regularization methods. Comput. Manag. Sci. 2015, 12, 417–434. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).