


STSM: Spatio-Temporal Shift Module for Efficient Action Recognition



Abstract
:1. Introduction
- We propose a plug-and-play Spatio-Temporal Shift Module (STSM), which is a module with zero computational complexity and parameters but powerful spatio-temporal modeling capabilities. A new perspective is proposed for efficient video model design by performing shift operations in different dimensions. Moreover, we revisit our spatio-temporal shift operation, which is essentially a convolution with a sparse convolution kernel, from the perspective of matrix algebra.
- Video action has strong spatio-temporal correlations, but action recognition models based on 2D CNNs backbone networks cannot effectively learn spatio-temporal features. To learn more spatio-temporal features at zero cost, we integrated the proposed STSM module in some typical 2D action recognition models in a plug-and-play fashion, such as TSN [2], TANet [16], and TDN [17] etc. Furthermore, our STSM combined with 2D action recognition models achieves higher performance than 3D action recognition models.
- Extensive experiments were conducted to verify the effectiveness of our method. Compared with existing methods, the proposed module achieves state-of-the-art or competitive results on the Kinetics-400 and Something-Something V2 datasets. Moreover, our STSM does not increase the computational complexity and parameters.
2. Related Work
2.1. 2D CNNs
2.2. 3D CNNs and (2+1)D CNNs Variants
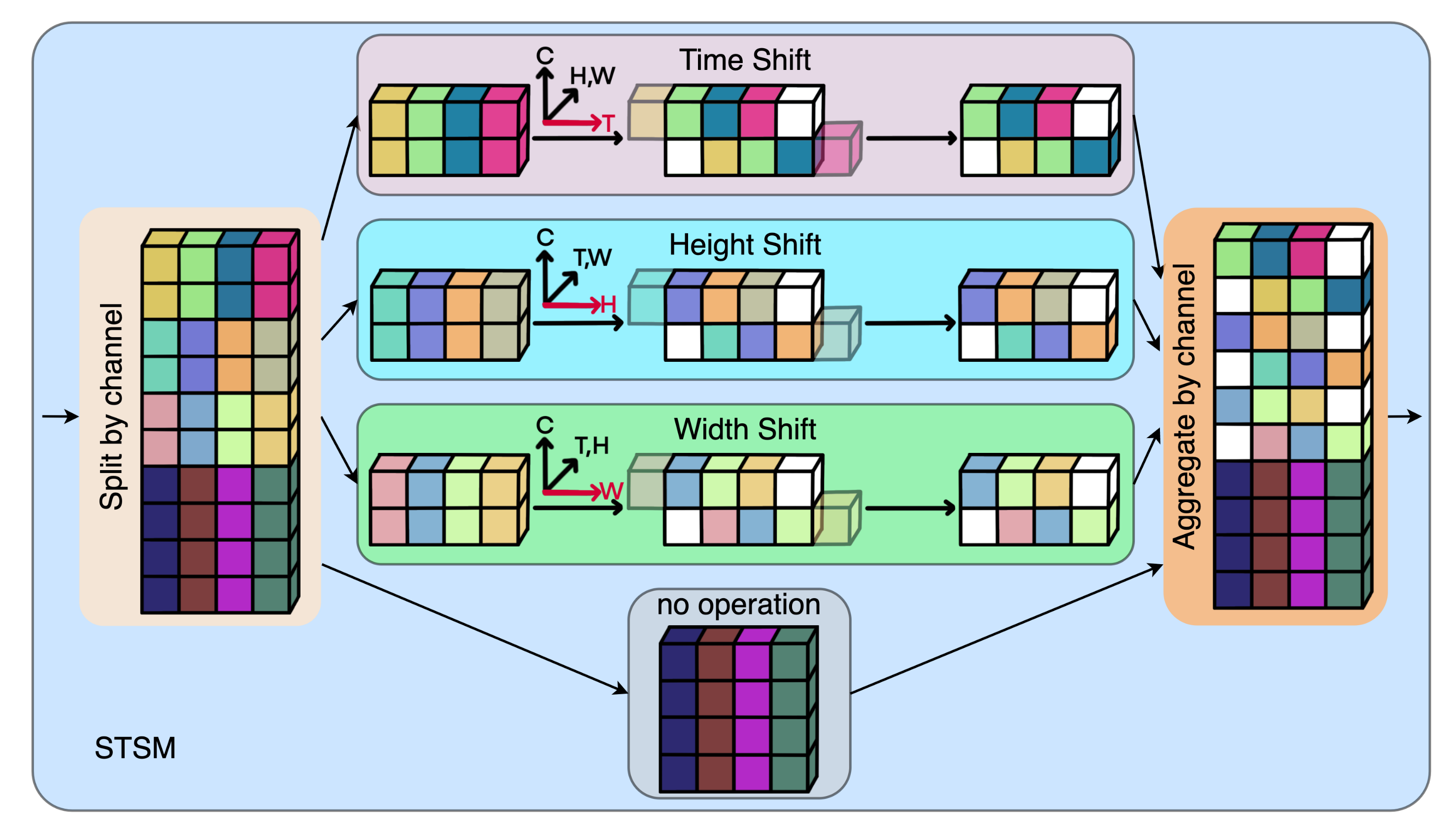
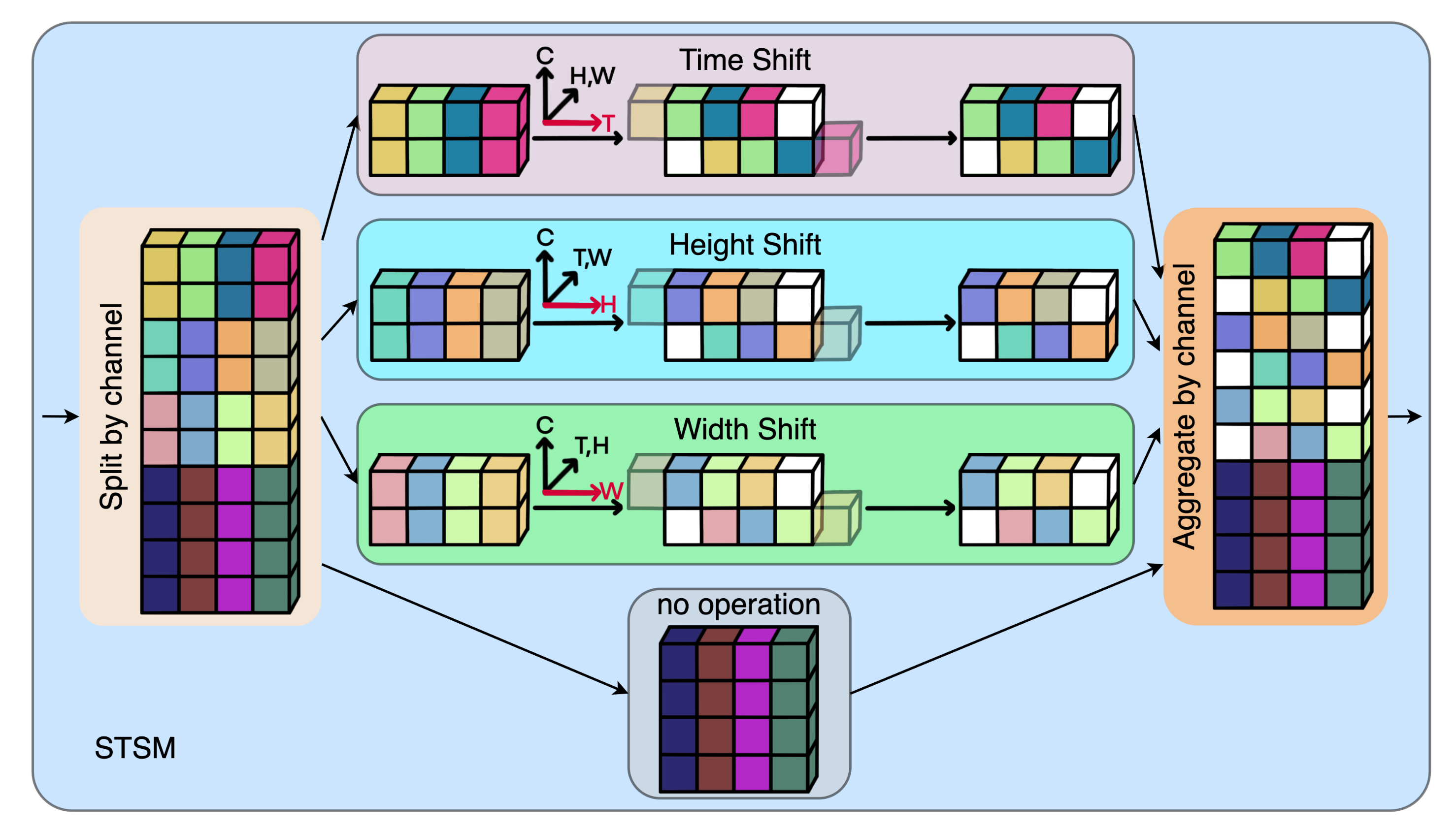
3. Spatio-Temporal Shift Module (STSM)
3.1. Efficient Action Recognition based on STSM
3.2. Spatio-Temporal Shift Operation
- The feature tensor is divided into four parts by channel, where T, C, H, W represent the time, channel, height and width dimensions, respectively. Assume that is the ratio of the number of channels in the shift operation to the total number of channels, then , .
- For feature tensor after segmentation, it is divided into two parts and according to the channel. Then and are shifted forward and backward by one position in the time dimension to obtain the shifted tensors . Next, we concatenate and into along the channel dimension.
- For the second tensor and third feature tensor after segmentation, the same shift operation as the first feature tensor is performed in the height dimension and the width dimension, respectively. Then we get the 1D shifted tensors .
- The remaining feature tensor remains unchanged.
- Finally, we concatenate the above four feature tensors , , , and along the channel dimension to obtain a 1D spatio-temporal shifted tensor .
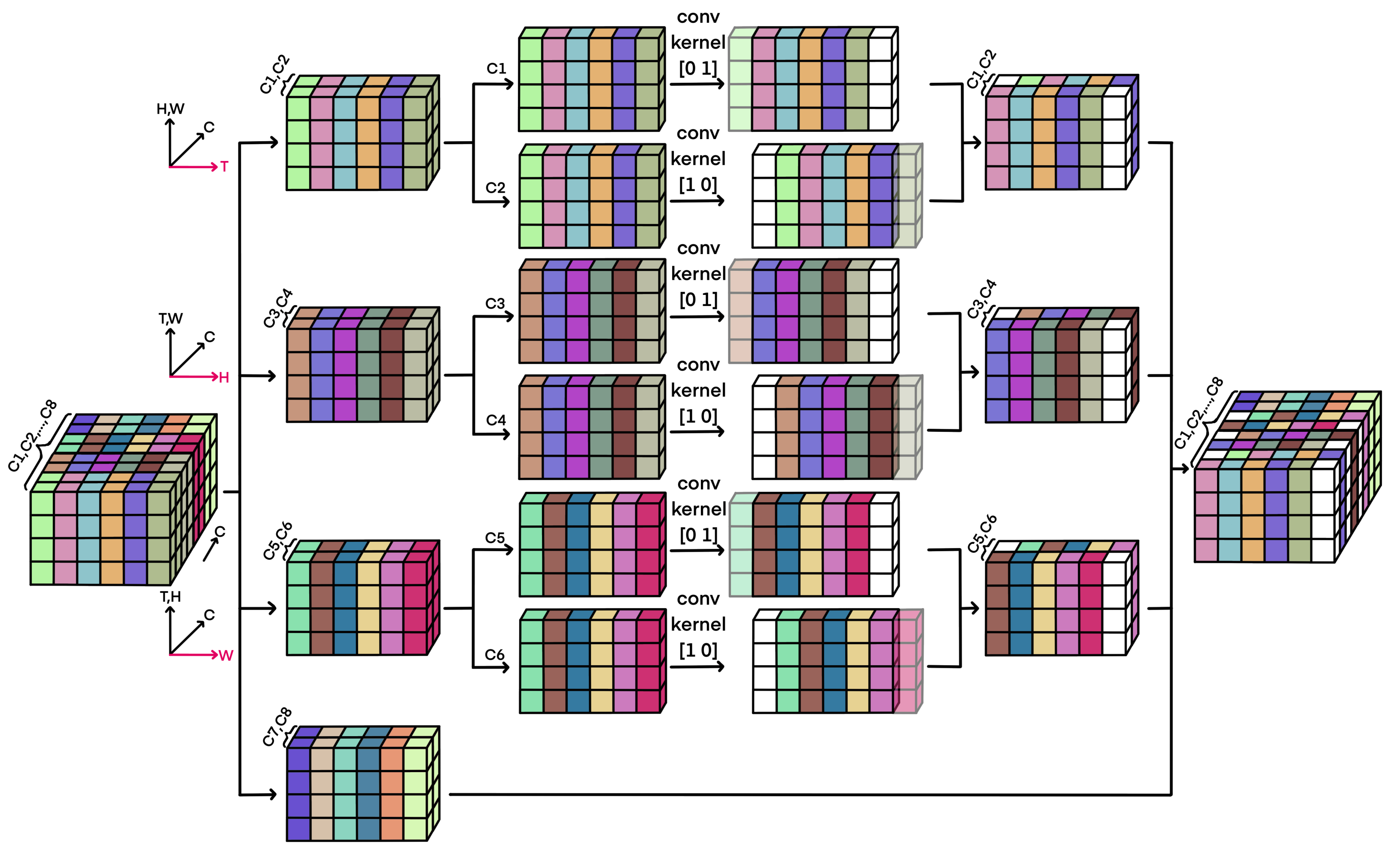
- Delete the rightmost column of the input matrix and add a column of zero vectors to the leftmost column.
- Delete the bottom row of the matrix obtained in the previous step, and add a row of zero vectors to the top row.
4. Experimental Setting
4.1. Datasets and Evaluation Metrics
4.2. Implementation Details
4.2.1. Training
4.2.2. Inference
5. Experimental Results
5.1. Ablation Analysis
5.1.1. Paramter Choice
5.1.2. Different Shift Operations
5.2. Different Backbone
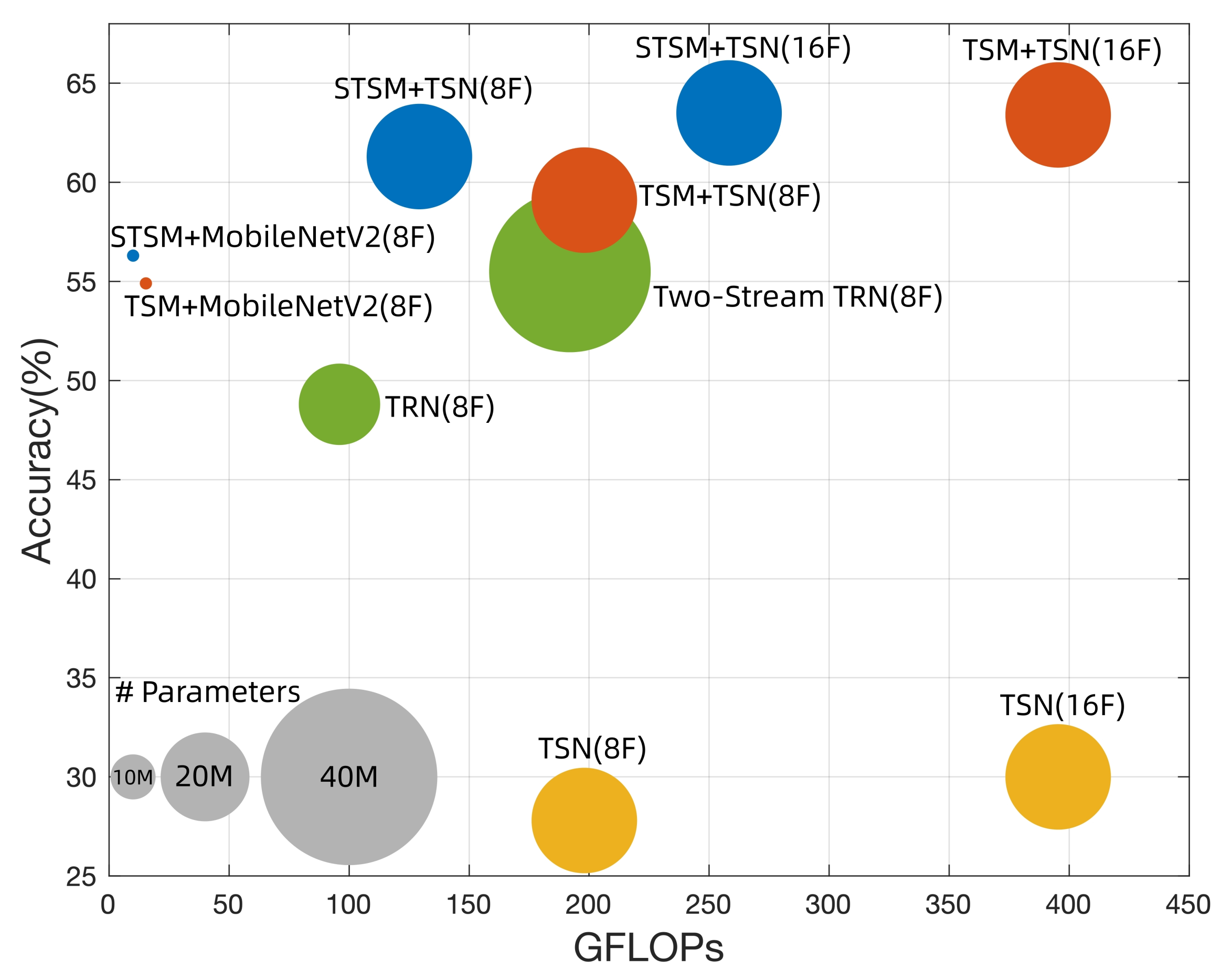
5.3. Comparison with State-of-the-Arts
5.3.1. Kinetics-400
5.3.2. Something-Something V2
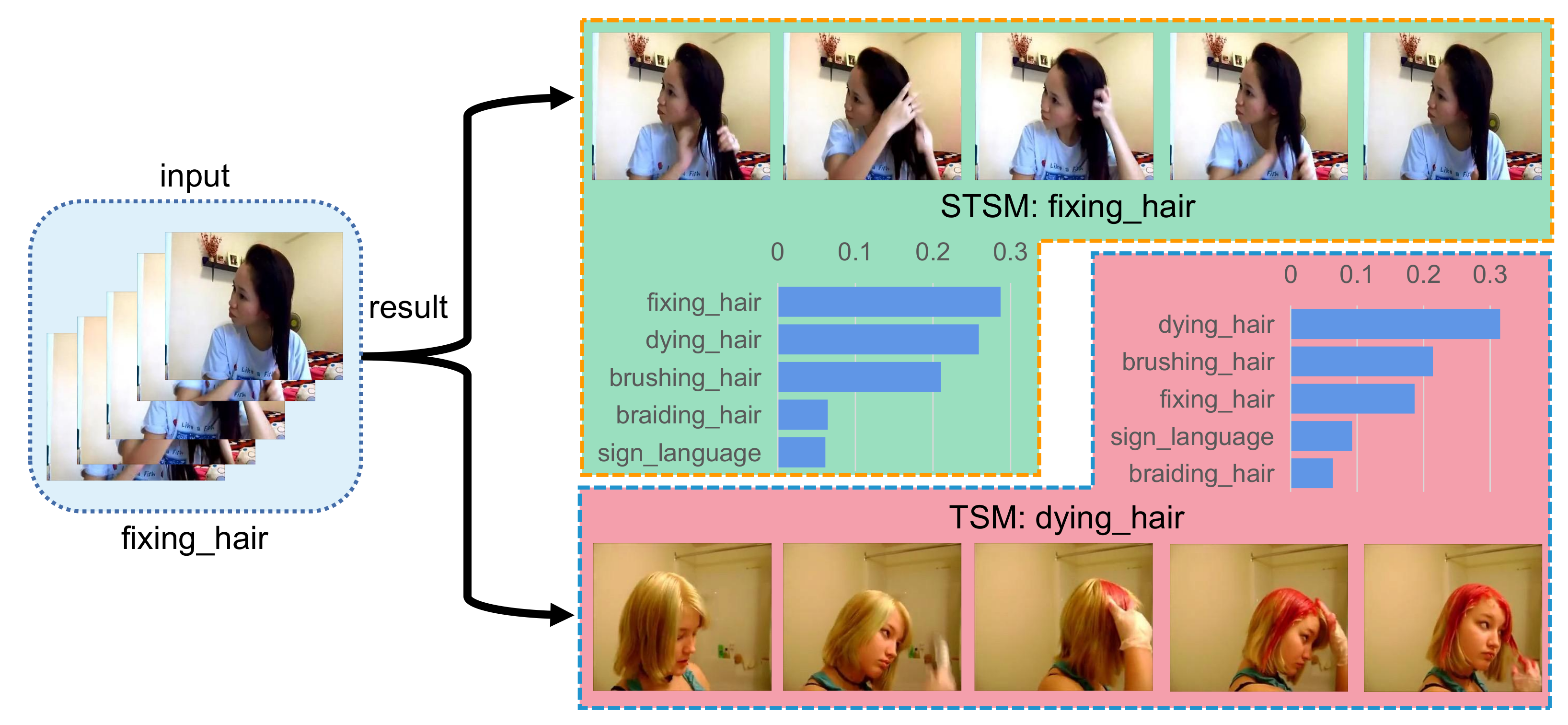
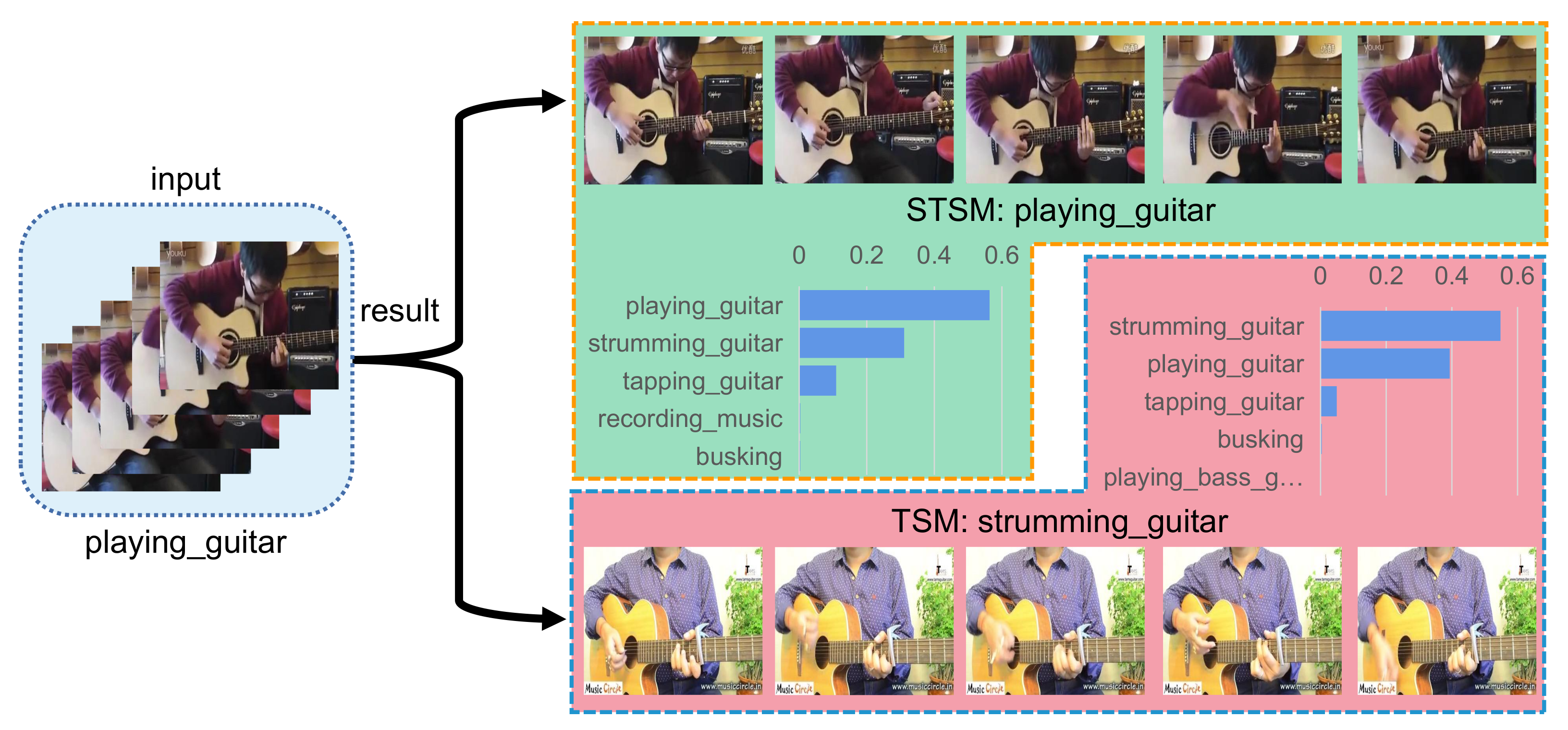
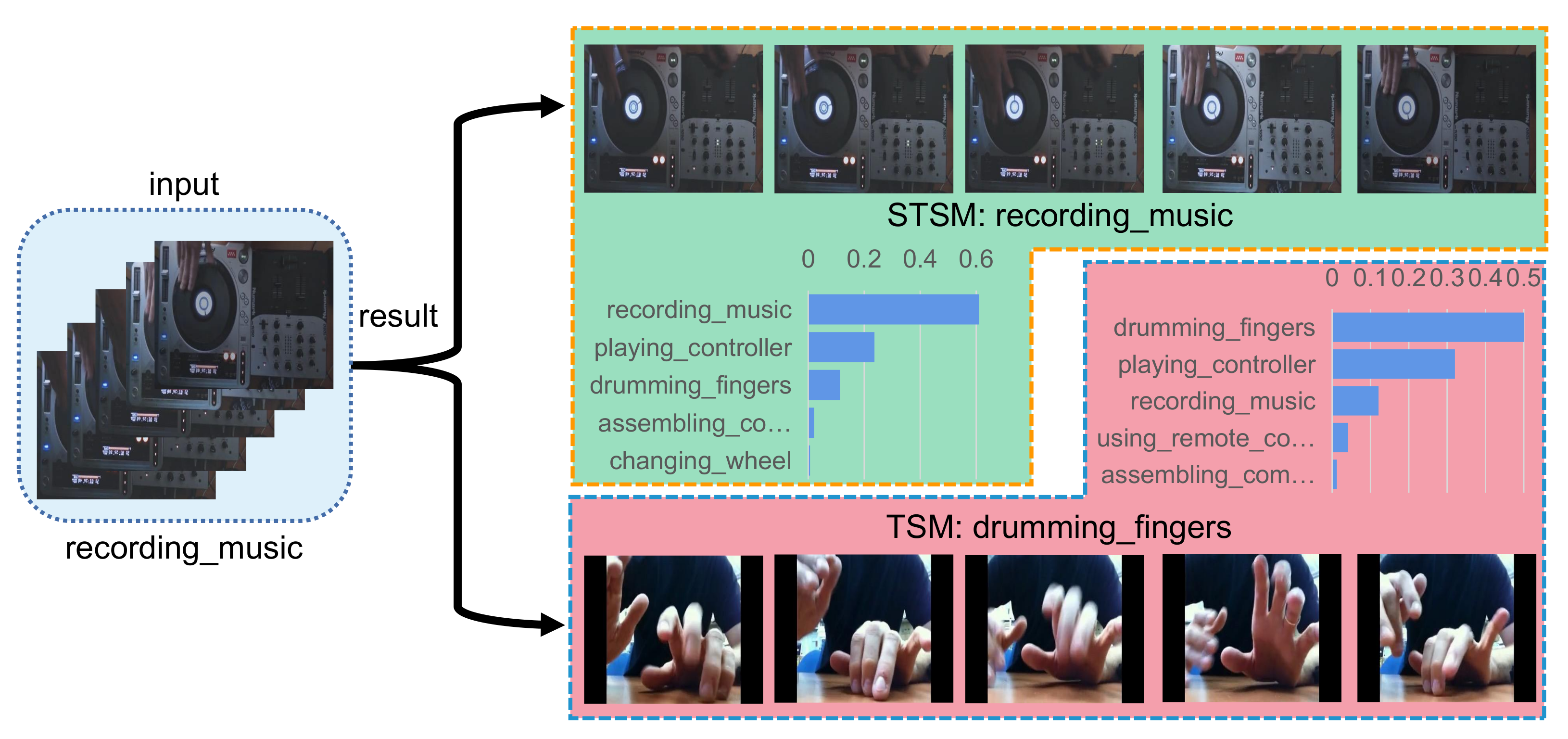
5.4. Qualitative Results on Some Typical Samples
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Simonyan, K.; Zisserman, A. Two-Stream Convolutional Networks for Action Recognition in Videos. In Proceedings of the NIPS, Montreal, QC, Canada, 8–13 December 2014; pp. 568–576. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Gool, L.V. Temporal segment networks: Towards good practices for deep action recognition. In Proceedings of the ECCV, Amsterdam, The Netherlands, 8–16 December 2016. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. In Proceedings of the CVPR, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Lin, J.; Gan, C.; Han, S. TSM: Temporal Shift Module for Efficient Video Understanding. In Proceedings of the ICCV, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Li, Y.; Ji, B.; Shi, X.; Zhang, J.; Kang, B.; Wang, L. TEA: Temporal Excitation and Aggregation for Action Recognition. In Proceedings of the CVPR, virtually, 14–19 June 2020. [Google Scholar]
- Yang, C.; Xu, Y.; Shi, J.; Dai, B.; Zhou, B. Temporal Pyramid Network for Action Recognition. In Proceedings of the CVPR, virtually, 14–19 June 2020. [Google Scholar]
- Liu, X.; Pintea, S.L.; Nejadasl, F.K.; Booij, O.; van Gemert, J.C. No Frame Left Behind: Full Video Action Recognition. In Proceedings of the CVPR, virtually, 19–25 June 2021; pp. 14892–14901. [Google Scholar]
- Wang, Z.; She, Q.; Smolic, A. ACTION-Net: Multipath Excitation for Action Recognition. In Proceedings of the CVPR, virtually, 19–25 June 2021. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning Spatiotemporal Features With 3D Convolutional Networks. In Proceedings of the ICCV, Santiago, Chile, 13–16 December 2015. [Google Scholar]
- Qiu, Z.; Yao, T.; Mei, T. Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks. In Proceedings of the ICCV, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Xie, S.; Sun, C.; Huang, J.; Tu, Z.; Murphy, K. Rethinking spatiotemporal feature learning: Speed-accuracy trade-offs in video classification. In Proceedings of the ECCV, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Tran, D.; Wang, H.; Torresani, L.; Ray, J.; LeCun, Y.; Paluri, M. A Closer Look at Spatiotemporal Convolutions for Action Recognition. In Proceedings of the CVPR, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Kay, W.; Carreira, J.; Simonyan, K.; Zhang, B.; Hillier, C.; Vijayanarasimhan, S.; Viola, F.; Green, T.; Back, T.; Natsev, P.; et al. The Kinetics Human Action Video Dataset. arXiv 2017, arXiv:1705.06950. [Google Scholar]
- Goyal, R.; Ebrahimi Kahou, S.; Michalski, V.; Materzynska, J.; Westphal, S.; Kim, H.; Haenel, V.; Fruend, I.; Yianilos, P.; Mueller-Freitag, M.; et al. The “Something Something” Video Database for Learning and Evaluating Visual Common Sense. In Proceedings of the ICCV, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Zhou, B.; Andonian, A.; Oliva, A.; Torralba, A. Temporal Relational Reasoning in Videos. In Proceedings of the ECCV, Munich, Germany, 8–14 September 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2018; Volume 11205, pp. 831–846. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, L.; Wu, W.; Qian, C.; Lu, T. TAM: Temporal Adaptive Module for Video Recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), virtually, 11–17 October 2021; pp. 13708–13718. [Google Scholar]
- Wang, L.; Tong, Z.; Ji, B.; Wu, G. TDN: Temporal Difference Networks for Efficient Action Recognition. In Proceedings of the CVPR, virtually, 19–25 June 2021. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the NIPS, Lake Tahow, NV, USA, 3–6 December 2012; pp. 1106–1114. [Google Scholar]
- Girshick, R.B.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the CVPR, virtually, 19–25 June 2021; pp. 580–587. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.C.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the NIPS, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the ICLR, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the CVPR, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the ICML, Lille, France, 6–11 July 2015; Bach, F.R., Blei, D.M., Eds.; JMLR Workshop and Conference Proceedings; MLResearch Press: Singapore, 2015; Volume 37, pp. 448–456. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the CVPR, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Zhang, B.; Wang, L.; Wang, Z.; Qiao, Y.; Wang, H. Real-Time Action Recognition with Enhanced Motion Vector CNNs. In Proceedings of the CVPR, Las Vegas, NV, USA, 27–30 June 2016; pp. 2718–2726. [Google Scholar] [CrossRef]
- Luo, C.; Yuille, A.L. Grouped Spatial-Temporal Aggregation for Efficient Action Recognition. In Proceedings of the ICCV, Seoul, Korea, 27 October–2 November 2019; pp. 5511–5520. [Google Scholar] [CrossRef]
- Sudhakaran, S.; Escalera, S.; Lanz, O. Gate-Shift Networks for Video Action Recognition. In Proceedings of the CVPR, virtually, 14–19 June 2020; pp. 1099–1108. [Google Scholar] [CrossRef]
- Liu, Z.; Luo, D.; Wang, Y.; Wang, L.; Tai, Y.; Wang, C.; Li, J.; Huang, F.; Lu, T. TEINet: Towards an Efficient Architecture for Video Recognition. In Proceedings of the AAAI, New York, NY, USA, 7–12 February 2020; pp. 11669–11676. [Google Scholar]
- Wang, M.; Xing, J.; Su, J.; Chen, J.; Yong, L. Learning SpatioTemporal and Motion Features in a Unified 2D Network for Action Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2022. [Google Scholar] [CrossRef] [PubMed]
- He, D.; Zhou, Z.; Gan, C.; Li, F.; Liu, X.; Li, Y.; Wang, L.; Wen, S. StNet: Local and Global Spatial-Temporal Modeling for Action Recognition. In Proceedings of the AAAI, Honolulu, HI, USA, 27 January–1 February 2019; pp. 8401–8408. [Google Scholar] [CrossRef]
- Zolfaghari, M.; Singh, K.; Brox, T. ECO: Efficient Convolutional Network for Online Video Understanding. In Proceedings of the ECCV, Munich, Germany, 8–14 September 2018; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2018; Volume 11206, pp. 713–730. [Google Scholar] [CrossRef]
- Wang, L.; Li, W.; Li, W.; Van Gool, L. Appearance-and-Relation Networks for Video Classification. In Proceedings of the CVPR, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. SlowFast Networks for Video Recognition. In Proceedings of the ICCV, Seoul, Korea, 27 October–2 November 2019; pp. 6201–6210. [Google Scholar] [CrossRef] [Green Version]
- Fu, J.; Gao, J.; Xu, C. Learning Semantic-Aware Spatial-Temporal Attention for Interpretable Action Recognition. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 5213–5224. [Google Scholar] [CrossRef]
- Fayyaz, M.; Bahrami, E.; Diba, A.; Noroozi, M.; Adeli, E.; Van Gool, L.; Gall, J. 3D CNNs With Adaptive Temporal Feature Resolutions. In Proceedings of the CVPR, virtually, 19–25 June 2021; pp. 4731–4740. [Google Scholar]
- Wang, H.; Xia, T.; Li, H.; Gu, X.; Lv, W.; Wang, Y. A Channel-Wise Spatial-Temporal Aggregation Network for Action Recognition. Mathematics 2021, 9, 3226. [Google Scholar] [CrossRef]
- Luo, H.; Lin, G.; Yao, Y.; Tang, Z.; Wu, Q.; Hua, X. Dense Semantics-Assisted Networks for Video Action Recognition. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 3073–3084. [Google Scholar] [CrossRef]
- Shen, Z.; Wu, X.J.; Xu, T. FEXNet: Foreground Extraction Network for Human Action Recognition. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 3141–3151. [Google Scholar] [CrossRef]
- Kumawat, S.; Verma, M.; Nakashima, Y.; Raman, S. Depthwise Spatio-Temporal STFT Convolutional Neural Networks for Human Action Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 4839–4851. [Google Scholar] [CrossRef] [PubMed]
- Wu, B.; Wan, A.; Yue, X.; Jin, P.; Zhao, S.; Golmant, N.; Gholaminejad, A.; Gonzalez, J.; Keutzer, K. Shift: A Zero FLOP, Zero Parameter Alternative to Spatial Convolutions. In Proceedings of the CVPR, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Contributors, M. OpenMMLab’s Next Generation Video Understanding Toolbox and Benchmark. 2020. Available online: https://github.com/open-mmlab/mmaction2 (accessed on 30 July 2022).
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the CVPR, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Wang, X.; Girshick, R.B.; Gupta, A.; He, K. Non-local Neural Networks. arXiv 2017, arXiv:1711.07971. [Google Scholar]
- Feichtenhofer, C. X3D: Expanding Architectures for Efficient Video Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), virtually, 14–19 June 2020. [Google Scholar]
- Li, X.; Wang, Y.; Zhou, Z.; Qiao, Y. SmallBigNet: Integrating Core and Contextual Views for Video Classification. In Proceedings of the CVPR, virtually, 14–19 June 2020. [Google Scholar]
- Zhi, Y.; Tong, Z.; Wang, L.; Wu, G. MGSampler: An Explainable Sampling Strategy for Video Action Recognition. In Proceedings of the ICCV, virtually, 11–17 October 2021; pp. 1513–1522. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Setting | |||||||
|---|---|---|---|---|---|---|---|
| 0 | 1/8 | 1/4 | 3/8 | 1/2 | 3/4 | 1 | |
| Accuracy | 72.16 | 74.62 | 74.77 | 75.04 | 74.81 | 74.49 | 73.83 |
| Setting | Kinetics-400 | |||
|---|---|---|---|---|
| #F | GFLOPs | #Para | Top-1 | |
| TSN (R-50) from [4] | 8 | 24.3M | 70.6 | |
| T(TSM [4]) | 8 | 24.3M | 74.1 | |
| T(MMAction2) | 8 | 24.3M | 74.43 | |
| H | 8 | 24.3M | 72.25 | |
| W | 8 | 24.3M | 72.46 | |
| H+W | 8 | 24.3M | 72.53 | |
| HW | 8 | 24.3M | 72.36 | |
| Setting | Kinetics-400 | |||
|---|---|---|---|---|
| #F | GFLOPs | #Para | Top-1 | |
| TSN (R-50) from [4] | 8 | 24.3M | 70.6 | |
| T(TSM [4]) | 8 | 24.3M | 74.1 | |
| T(MMAction2) | 8 | 24.3M | 74.43 | |
| T+H+W | 8 | 24.3M | 75.04 | |
| T+HW | 8 | 24.3M | 74.68 | |
| T+H+W+HW | 8 | 24.3M | 74.5 | |
| TH+TW+HW | 8 | 24.3M | 74.95 | |
| T+H+W+TH+TW+HW | 8 | 24.3M | 74.84 | |
| Model | Kinetics-400 | |||
|---|---|---|---|---|
| Backbone | #F | GFLOPs | Top-1 | |
| TSN from [4] | 2D Mb_V2 | 8 | 66.5 | |
| TSM+TSN [4] | 2D Mb_V2 | 8 | 69.5 | |
| STSM+TSN | 2D Mb_V2 | 8 | 69.9 | |
| TSN from [4] | 2D R-50 | 8 | 70.6 | |
| TSM+TSN [4] | 2D R-50 | 8 | 74.1 | |
| STSM+TSN | 2D R-50 | 8 | 75.0 | |
| TSM+TSN [4] | 2D R-50 | 16 | 74.7 | |
| STSM+TSN | 2D R-50 | 16 | 75.8 | |
| Model | Something-Something V2 | |||
|---|---|---|---|---|
| Backbone | #F | GFLOPs | Top-1 | |
| TSM+TSN from [8] | 2D Mb_V2 | 8 | 54.9 | |
| STSM+TSN | 2D Mb_V2 | 8 | 56.3 | |
| TSN from [8] | 2D R-50 | 8 | 27.8 | |
| TSM+TSN [4] | 2D R-50 | 8 | 59.1 | |
| STSM+TSN | 2D R-50 | 8 | 61.3 | |
| TSN from [8] | 2D R-50 | 16 | 30 | |
| TSM+TSN [4] | 2D R-50 | 16 | 63.4 | |
| STSM+TSN | 2D R-50 | 16 | 63.5 | |
| Model | Backbone | Pretrain | #F | Image Size | GFLOPs | #Para | Top-1 (%) |
|---|---|---|---|---|---|---|---|
| SlowOnly [33] | 3D R-50 | ImageNet | 4 | 32.5M | 72.6 | ||
| TSN+TPN [6] | 3D R-50B | ImageNet | 8 | - | - | 73.5 | |
| Two-Stream I3D [3] | 3D BNInception | ImageNet | 64 + 64 | 216 × N/A | 25M | 74.2 | |
| T-STFT [39] | 3D BNInception | None | 64 | 6.27M | 75.0 | ||
| FEXNet [38] | 3D R-50 | ImageNet | 8 | 48.3 × 3 × 10 | - | 75.4 | |
| SlowFast [33] | 3D R-50 | ImageNet | 4 × 16 | 34.5M | 75.6 | ||
| SlowFast+ATFR [35] | 3D R-50 | ImageNet | 4 × 16 | 34.4M | 75.8 | ||
| X3D-M [45] | 3D R-50 | None | 16 | 3.8M | 76.0 | ||
| SmallBigNet [46] | 3D R-50 | ImageNet | 8 | - | 76.3 | ||
| DSA-CNNs [37] | 3D Rfn152 | IN+K400 | 12 | - | 76.5 | ||
| TANet [16] | (2+1)D R-50 | ImageNet | 8 | 25.6M | 76.3 | ||
| TSN+Mb_V2 from [4] | 2D Mb_V2 | ImageNet | 8 | 2.74M | 66.5 | ||
| TSM+Mb_V2 [4] | 2D Mb_V2 | ImageNet | 8 | 2.74M | 69.5 | ||
| TSN from [4] | 2D R-50 | ImageNet | 8 | 24.3M | 70.6 | ||
| TSM [4] | 2D R-50 | ImageNet | 8 | 24.3M | 74.1 | ||
| TSM [4] | 2D R-50 | ImageNet | 16 | 24.3M | 74.7 | ||
| TEA [5] | 2D R-50 | ImageNet | 8 | - | 75.0 | ||
| STM [29] | 2D R-50 | ImageNet | 8 | - | 75.5 | ||
| TSM+NL [4] | 2D R-50 | ImageNet | 8 | 31.7M | 75.7 | ||
| TDN [17] | 2D R-50 | ImageNet | 8 | - | 76.5 | ||
| STSM+Mb_V2 | 2D Mb_V2 | ImageNet | 8 | 2.74M | 69.9 | ||
| STSM+TSN | 2D R-50 | ImageNet | 8 | 24.3M | 75.0 | ||
| STSM+TSN | 2D R-50 | ImageNet | 16 | 24.3M | 75.8 | ||
| STSM+TSN+NL | 2D R-50 | ImageNet | 8 | 31.7M | 75.9 | ||
| STSM+TANet | (2+1)D R-50 | ImageNet | 8 | 25.6M | 76.4 | ||
| STSM+TDN | 2D R-50 | ImageNet | 8 | - | 76.7 |
| Model | Backbone | Pretrain | #F | Image Size | GFLOPs | #Para | Top-1 (%) |
|---|---|---|---|---|---|---|---|
| TSN+TPN [6] | 3D R-50 | ImageNet | 8 | - | - | 55.2 | |
| Two-Stream TRN [15] | 3D BNInception | ImageNet | 8 + 8 | 36.6M | 55.5 | ||
| ACTION-Net+Mb_V2 [8] | 3D Mb_V2 | ImageNet | 8 | 2.36M | 58.5 | ||
| SmallBigNet [46] | 3D R-50 | ImageNet | 8 | - | 61.6 | ||
| SlowFast from [35] | 3D R-50 | Kinetics-400 | 4 × 16 | 132.8 | 34.4M | 61.7 | |
| SlowFast+ATFR [35] | 3D R-50 | Kinetics-400 | 4 × 16 | 86.8 | 34.4M | 61.8 | |
| ACTION-Net [8] | 3D R-50 | ImageNet | 8 | 28.1M | 62.5 | ||
| T-STFT [39] | 3D BNInception | None | 64 | 6.27M | 63.1 | ||
| FEXNet [38] | 3D R-50 | ImageNet | 8 | 48.3 × 3 × 2 | - | 63.5 | |
| SmallBigNet [46] | 3D R-50 | ImageNet | 16 | - | 63.8 | ||
| CSTANet [36] | (2+1)D R-50 | ImageNet | 8 | 24.1M | 60.0 | ||
| TANet [16] | (2+1)D R-50 | ImageNet | 8 | 25.1M | 60.4 | ||
| CSTANet [36] | (2+1)D R-50 | ImageNet | 16 | 24.1M | 61.6 | ||
| TSN from [8] | 2D R-50 | Kinetics-400 | 8 | 23.8M | 27.8 | ||
| TSN from [8] | 2D R-50 | Kinetics-400 | 16 | 23.8M | 30.0 | ||
| TSM+Mb_V2 from [8] | 2D Mb_V2 | ImageNet | 8 | 2.45M | 54.9 | ||
| TSM [4] | 2D R-50 | ImageNet | 8 | 23.8M | 59.1 | ||
| MG-TSM [47] | 2D R-50 | ImageNet | 8 | - | - | 60.1 | |
| TSM+NL [4] | 2D R-50 | ImageNet | 8 | 31.7M | 61.0 | ||
| STM [29] | 2D R-50 | ImageNet | 8 | - | 62.8 | ||
| MG-TEA [47] | 2D R-50 | ImageNet | 8 | - | - | 62.5 | |
| TSM [4] | 2D R-50 | ImageNet | 16 | 23.8M | 63.4 | ||
| TDN [17] | 2D R-50 | ImageNet | 8 | - | 63.8 | ||
| STSM+Mb_V2 | 2D Mb_V2 | ImageNet | 8 | 2.45M | 56.3 | ||
| STSM+Mb_V2 | 2D Mb_V2 | ImageNet | 16 | 2.45M | 59.2 | ||
| STSM+TSN+NL | 2D R-50 | ImageNet | 8 | 31.7M | 61.2 | ||
| STSM+TSN | 2D R-50 | ImageNet | 8 | 23.8M | 61.3 | ||
| STSM + TANet | (2+1)D R-50 | ImageNet | 8 | 25.1M | 61.5 | ||
| STSM+TSN | 2D R-50 | ImageNet | 16 | 23.8M | 63.5 | ||
| STSM+TDN | 2D R-50 | ImageNet | 8 | - | 63.9 | ||
| STSM+TDN | 2D R-50 | ImageNet | 8 | - | 64.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Z.; An, G.; Zhang, R. STSM: Spatio-Temporal Shift Module for Efficient Action Recognition. Mathematics 2022, 10, 3290. https://doi.org/10.3390/math10183290
Yang Z, An G, Zhang R. STSM: Spatio-Temporal Shift Module for Efficient Action Recognition. Mathematics. 2022; 10(18):3290. https://doi.org/10.3390/math10183290
Chicago/Turabian StyleYang, Zhaoqilin, Gaoyun An, and Ruichen Zhang. 2022. "STSM: Spatio-Temporal Shift Module for Efficient Action Recognition" Mathematics 10, no. 18: 3290. https://doi.org/10.3390/math10183290
APA StyleYang, Z., An, G., & Zhang, R. (2022). STSM: Spatio-Temporal Shift Module for Efficient Action Recognition. Mathematics, 10(18), 3290. https://doi.org/10.3390/math10183290