
POI Recommendation Method of Neural Matrix Factorization Integrating Auxiliary Attribute Information

Abstract
:1. Introduction
- Employing the k-means and TF-IDF algorithms to construct the auxiliary attribute information of users (including user preference category and user high activity location) and the auxiliary attribute information of POIs (including category of POI, popularity POI, and region of POI) from user check-in data.
- For the optimum use of auxiliary attribute information, a convolutional neural network is used to learn the expression of auxiliary attribute information, and an attention mechanism is introduced to distinguish the importance of auxiliary attribute information. The complete latent feature vectors of users and POIs are expressed as the integration of the auxiliary attribute information feature vectors of users and POIs with the latent feature vectors of users and POIs.
- Based on the NCF framework, a novel neural matrix factorization method (NueMF-CAA) for POI recommendation is proposed. The method incorporates the auxiliary attribute information of users and POIs and uses GMF and MLP to deeply explore the interactions between users and POIs.
- Based on the Foursquare dataset and Weibo dataset, the feasibility and effectiveness of NueMF-CAA for POI recommendation are verified.
2. Method
2.1. Problem Definition
2.2. Overall Framework
2.3. Constructing Auxiliary Attribute Information
2.3.1. Constructing Auxiliary Attribute Information of POIs
- Randomly select POIs from the set of POIs as the initial cluster center;
- Calculate the Euclidean distance from the remaining POIs to the cluster center, and put the closest POIs into the corresponding class to form a new class. The calculation of is shown in Formula (2):
- Take the mean of all the latitudes and longitudes of POIs in the current cluster as the new center point and update the POIs closest to the cluster center;
- Until the objective function converges or the cluster center remains unchanged, it will transfer to 2;
- Output POI clustering results.
2.3.2. Constructing Auxiliary Attribute Information of Users
2.4. Learning Linear Interactions between Users and POIs
2.5. Learning Nonlinear Interactions between Users and POIs
2.6. Neural Matrix Factorization Integrating Auxiliary Attribute Information
3. Experimental Results and Analysis
3.1. Dataset
3.2. Comparison Method
- MF [32]: the method is a traditional recommendation model in recommender systems. It maps users and POIs into a latent low-dimensional space and computes the similarity between the two for recommendation results.
- NeuMF [11]: the model is implemented based on the NCF framework. Two models are proposed under the NCF framework, namely generalized matrix factorization and multilayer perceptron. NeuMF is a fusion model of these two models.
- CoupledCF [20]: this work builds on non-IID learning to propose a neural user–item coupling learning for collaborative filtering. CoupledCF jointly learns explicit and implicit couplings between users and items.
- GMF-CAA: the nonlinear kernels are not considered to model the interactions between users and POIs.
- MLP-CAA: the linear kernels are not considered to model the interactions between users and POIs.
- NeuMF-A: user and POI auxiliary attribute information is not processed using the convolutional attention mechanism.
3.3. Experimental Settings
3.4. Analysis of Experimental Results
3.4.1. Cluster Analysis
3.4.2. Predictive Factors Analysis
3.4.3. Algorithm Comparison and Analysis
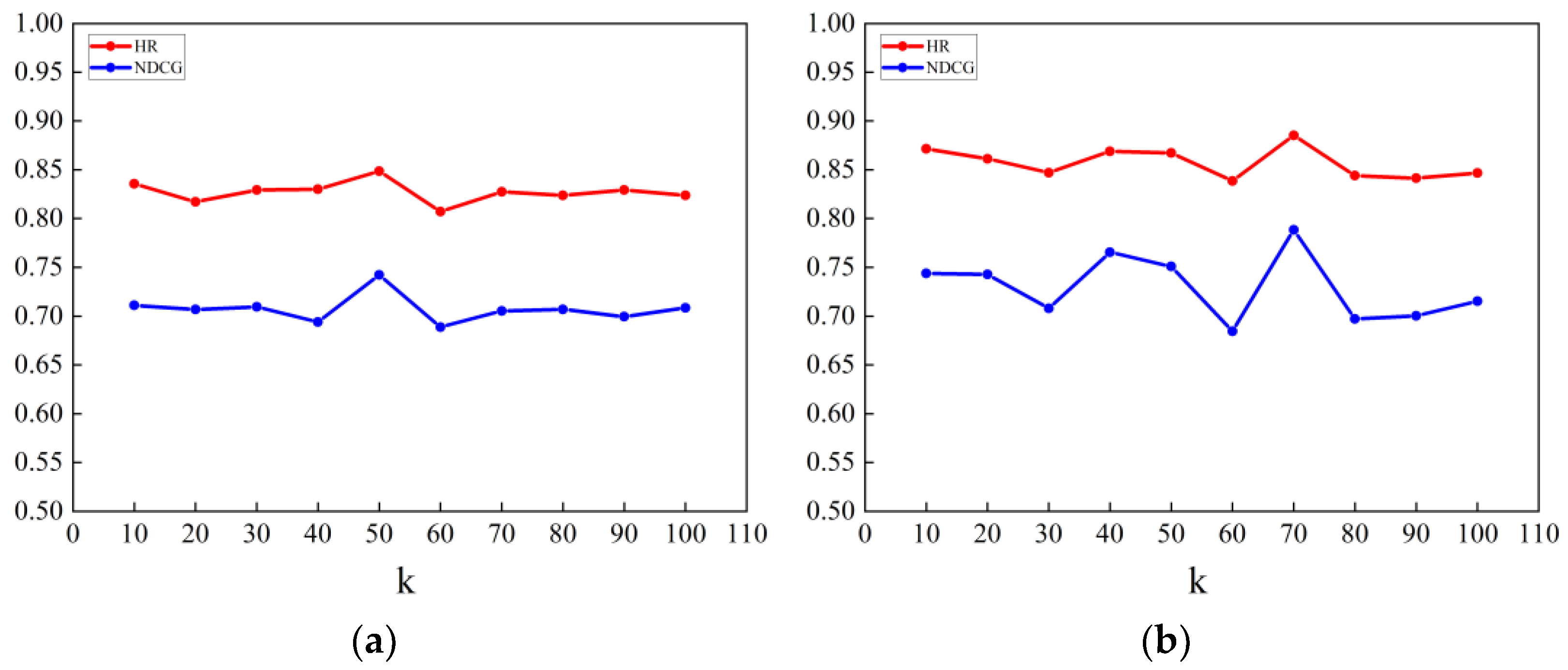
3.4.4. The Influence of Various Factors in the NeuMF-CAA Method on the Experimental Results
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lu, J.; Wu, D.; Mao, M.; Wang, W.; Zhang, G. Recommender system application developments: A survey. Decis. Support Syst. 2015, 74, 12–32. [Google Scholar] [CrossRef]
- Zhang, G.; Wang, J.; Jiang, N.; Sheng, Y. A point of interest recommendation method based on hawkes process. Acta Geod. Cartogr. Sin. 2018, 47, 9. [Google Scholar]
- Xu, C.; Liu, D.; Mei, X. Exploring an efficient POI recommendation model based on user characteristics and spatial-temporal factors. Mathematics 2021, 9, 2673. [Google Scholar] [CrossRef]
- Liu, Y. An experimental evaluation of point-of-interest recommendation in location-based social networks. Proc. Vldb Endow. 2017, 10, 1010–1021. [Google Scholar] [CrossRef]
- Zhang, J.-D.; Chow, C.-Y. iGSLR: Personalized geo-social location recommendation: A kernel density estimation approach. In Proceedings of the 21st ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Orlando, FL, USA, 5–8 November 2013. [Google Scholar]
- Yue, S.; Larson, M.; Hanjalic, A. Collaborative filtering beyond the User-Item matrix: A survey of the state of the art and future challenges. ACM Comput. Surv. 2014, 47, 1–45. [Google Scholar]
- Chen, C.; Yang, H.; King, I.; Lyu, M. Fused matrix factorization with geographical and social influence in location-based social networks. In Proceedings of the National Conference on Artificial Intelligence, Toronto, ON, Canada, 22–26 July 2012. [Google Scholar]
- He, Y.; Wang, Z.; Zhou, X.; Liu, Y. Point of interest recommendation algorithm integrating social geographical information based on weighted matrix factorization. J. Jilin Univ. 2022, 1–10. [Google Scholar] [CrossRef]
- Lian, D.; Zhao, C.; Xie, X.; Sun, G.; Chen, E.; Rui, Y. GeoMF: Joint geographical modeling and matrix factorization for point-of-interest recommendation. In Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining, New York, NY, USA, 24–27 August 2014; pp. 831–840. [Google Scholar]
- Li, T. Research on Recommendation Model Based on Deep Learning. Master’s Thesis, Southwest University, Chongqing, China, 2019. [Google Scholar]
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T.-S. Neural collaborative filtering. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017. [Google Scholar]
- Meng, X.; Qi, X.; Zhang, G.; Zhang, X.; Wang, L. A POI recommendation approach based on user-POI coupling relationships. CAAI Trans. Intell. Syst. 2021, 16, 228–236. [Google Scholar]
- Feng, H.; Huang, K.; Li, J.; Gao, R.; Liu, D.; Song, C. Hybrid point of interest recommendation algorithm based on deep learning. J. Electron. Inf. Technol. 2019, 4, 880–887. [Google Scholar]
- Guo, H.; Tang, R.; Ye, Y.; Li, Z.; He, X. DeepFM: A factorization-machine based neural network for CTR prediction. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, Melbourne, VIC, Australia, 19–25 August 2017. [Google Scholar]
- Deng, Z.; Huang, L.; Wang, C.; Lai, J.; Yu, P. DeepCF: A unified framework of representation learning and matching function learning in recommender system. In Proceedings of the 33rd AAAI, Honolulu, HI, USA, 27 January–1 February 2019; pp. 61–68. [Google Scholar]
- Ning, J.; Xuequn, W.U.; Liu, Z. Multi-user location recommendation considering road accessibility and Time-Cost. Geomatics Inf. Sci. Wuhan Univ. 2019, 44, 633–639. [Google Scholar]
- Zhu, J.; Ming, Q. POI recommendation by incorporating trust-distrust relationship in LBSN. J. Commun. 2018, 39, 157–165. [Google Scholar]
- Baral, R.; Li, T. Exploiting the roles of aspects in personalized POI recommender systems. Data Min. Knowl. Discov. 2018, 32, 320–343. [Google Scholar] [CrossRef]
- Wang, Y.; Li, H.; Wang, T.; Zhu, J. The mining and analysis of emergency information in sudden events based on social media. Geomat. Inf. Sci. Wuhan Univ. 2016. [Google Scholar] [CrossRef]
- Zhang, Q.; Cao, L.; Zhu, C.; Li, Z.; Sun, J. CoupledCF: Learning explicit and implicit User-item couplings in recommendation for deep collaborative filtering. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence {IJCAI-18}, Stockholm, Sweden, 13–19 July 2018. [Google Scholar]
- Wei, H.; Li, K.; Hao, X.; Tian, Z. Integrating spatial relationship into a matrix factorization model for POI recommendation. Geomat. Inf. Sci. Wuhan Univ. 2021, 46, 681–690. [Google Scholar]
- Chen, J.; Shen, J.; Chen, P. Point of interest recommendation integrating review and image semantic information. Comput. Eng. Appl. 2020, 56, 160–167. [Google Scholar]
- Wang, X. POI recommendation model based on graph embedding and GRU. Comput. Syst. Appl. 2021, 30, 40–47. [Google Scholar]
- Aliannejadi, M.; Rafailidis, D.; Crestani, F. A collaborative ranking model with multiple location-based similarities for venue suggestion. In Proceedings of the 2018 ACM SIGIR International Conference on Theory of Information Retrieval, Tianjin, China, 14–17 September 2018; pp. 19–26. [Google Scholar]
- Geng, B.; Jiao, L.; Gong, M.; Li, L.; Wu, Y. A two-step personalized location recommendation based on multi-objective immune algorithm. Inf. Sci. 2018, 475, 161–181. [Google Scholar] [CrossRef]
- Gao, Z. Research on Interest Point Recommendation Method Based on Category Information. Ph.D. Thesis, Beijing University of Technology, Beijing, China, 2015. [Google Scholar]
- Chen, X.; Chen, C.; Liu, K. Scenic travel route planning based on multi-sourced and heterogeneous crowd-sourced data. J. Zhejiang Univ. 2016, 50, 1183–1188. [Google Scholar]
- Rahmani, H.A.; Aliannejadi, M.; Ahmadian, S.; Baratchi, M.; Afsharchi, M.; Crestani, F. LGLMF: Local geographical based logistic matrix factorization model for POI recommendation. In Proceedings of the Asia Information Retrieval Symposium, Hong Kong, China, 7–9 November 2019. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Liu, J.; Zhang, Z.; Yang, C.; Xu, S.; Chen, C.; Qiu, A.; Zhang, F. Personalized city region of interests recommendation method based on city block and check-in data. Acta Geod. Cartogr. Sin. 2022, 51, 1797–1806. [Google Scholar]
- AutoNavi Map API. Available online: https://lbs.amap.com/ (accessed on 1 May 2022).
- Koren, Y.; Bell, R.; Volinsky, C.J.C. Matrix factorization techniques for recommender systems. Comput. J. 2009, 42, 30–37. [Google Scholar] [CrossRef]
- Bayer, I.; He, X.; Kanagal, B.; Rendle, S. A generic coordinate descent framework for learning from implicit feedback. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 1341–1350. [Google Scholar]
- He, X.; Zhang, H.; Kan, M.-Y.; Chua, T.-S. Fast matrix factorization for online recommendation with implicit feedback. In Proceedings of the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval, Pisa, Italy, 17–21 July 2016; pp. 549–558. [Google Scholar]
- Elkahky, A.M.; Song, Y.; He, X. A multi-view deep learning approach for cross domain user modeling in recommendation systems. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 278–288. [Google Scholar]
- Keras. Available online: https://baike.baidu.com/item/Keras/22792516?fr=aladdin (accessed on 1 May 2022).
- Elbow Method. Available online: https://en.wikipedia.org/wiki/Elbow_method_(clustering) (accessed on 1 May 2022).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Statistical Accounts | Foursquare | |
|---|---|---|
| Number of users | 1083 | 11,436 |
| Number of POIs | 10,250 | 17,565 |
| Number of check-ins | 172,838 | 731,044 |
| Category of POI | 251 | 130 |
| Average number of POI check-ins by users | 159 | 64 |
| Sparsity/% | 98.44 | 99.64 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Xu, S.; Jiang, T.; Wang, Y.; Ma, Y.; Liu, Y. POI Recommendation Method of Neural Matrix Factorization Integrating Auxiliary Attribute Information. Mathematics 2022, 10, 3411. https://doi.org/10.3390/math10193411
Li X, Xu S, Jiang T, Wang Y, Ma Y, Liu Y. POI Recommendation Method of Neural Matrix Factorization Integrating Auxiliary Attribute Information. Mathematics. 2022; 10(19):3411. https://doi.org/10.3390/math10193411
Chicago/Turabian StyleLi, Xiaoyan, Shenghua Xu, Tao Jiang, Yong Wang, Yu Ma, and Yiming Liu. 2022. "POI Recommendation Method of Neural Matrix Factorization Integrating Auxiliary Attribute Information" Mathematics 10, no. 19: 3411. https://doi.org/10.3390/math10193411
APA StyleLi, X., Xu, S., Jiang, T., Wang, Y., Ma, Y., & Liu, Y. (2022). POI Recommendation Method of Neural Matrix Factorization Integrating Auxiliary Attribute Information. Mathematics, 10(19), 3411. https://doi.org/10.3390/math10193411