
Performance Evaluation of Query Plan Recommendation with Apache Hadoop and Apache Spark


Abstract
:1. Introduction
- (i)
- Presenting a parallel query plan recommendation method using the MapReduce model.
- (ii)
- Implementing the parallel query plan recommendation technique using Apache Hadoop and Apache Spark distributed frameworks.
- (iii)
- Evaluating the performance of the implemented algorithm with multiple-query datasets.
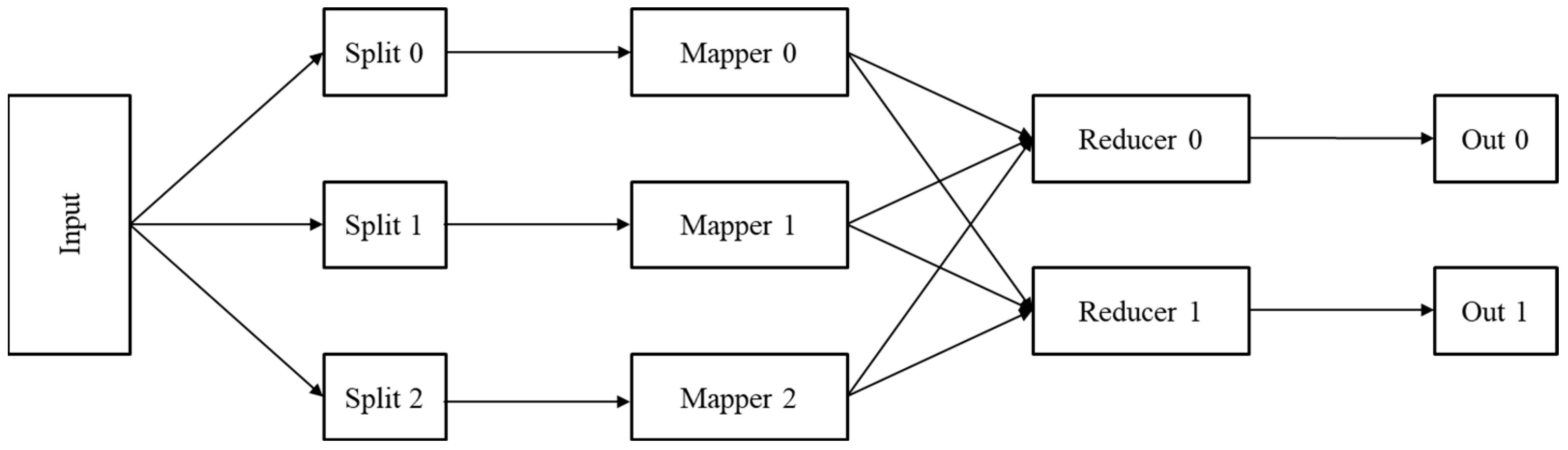
2. Overview and Background
2.1. Apache Hadoop
2.2. MapReduce
2.3. Apache Spark
3. Methodology
3.1. Query Preprocessing
3.2. Query Tokenizing
3.3. Feature Weighting based on TF using MapReduce
| Algorithm 1: The number of each term in every query |
| Input: query Output: The total number of occurrences of each token (term) in every query (queryID); ((term, queryID), sum) 1: class Mapper: A key/value pair is generated for each query. 2: function map (query) 3: for all term query.split() do//The query is divided into smaller units (term) 4: emit ((term, queryID), 1) //The number 1 is assigend as the value to each term. 5: end for 6: end function 7: end class |
| 1: class Reducer: The total number of occurrences of each term in a query is counted. 2: function reduce ((term, queryID), counts [ c1, c2, …]) 3: sum = 0 4: for all count counts do 5: sum += count 6: end for 7: emit ((term, queryID), sum)//Key: term and queryID, Value:The number of repetitions of a term in a query. 8: end function 9: end class |
| Algorithm 2: The total terms of each query |
| Input: The number of each token in each query ((term, queryID), sum) Output: The total number of terms (sum) in a query ((queryID, N), (term, sum)) 1: class Mapper: All terms in each query are grouped. 2: function map ((term, queryID), sum) 3: for all element (term, queryID) do 4: emit (queryID, (term, sum)) //Key: queryID, Value: The term and the number of repetitions of each term in a query. 5: end for 6: end function 7: end class |
| 1: class Reducer: The total number of terms in a query is computed. 2: function reduce (queryID, (term, sum)) 3: N = 0 //N is the total number of terms in a query. 4: for all tuple (term, sum) do 5: N = N + sum 6: end for 7: emit ((queryID, N), (term, sum)) 8: end function 9: end class |
| Algorithm 3: The weights of each feature |
| Input: The total number of terms in a query ((queryID, N), (term, sum)) Output: The weights of each feature ((queryID), (term, tf)) 1: class Mapper: 2: function map (queryID, N), (term, sum)) 3: for all element (term, sum) do 4: emit ((term, (queryID, sum, N)) 5: end for 6: end function 7: end class |
| 1: class Reducer: The term frequency is calculated. 2: function reduce ((term, (queryID, sum, N)) 3: for all element in (queryID, sum, N) do 5: tf = sum/N; 6: end for 7: emit ((queryID), (term, tf)); 8: end function 9: end class |
3.4. Similarity Measurement using MapReduce
| Algorithm 4: The Cosine similarity of the produced query vectors |
| Input: query vectors Output: The Cosine similarity between the produced query vectors 1: class Mapper: The key/value pair is formed. 2: function map (queries) 3: for i = 0 to n //Where n is the total number of queries. 4: for j = i + 1 to n 5: emit ((q [i].id, q[j].id), (q[i].tf, q[j].tf))//The term frequency values are assigned as the value. 6: end for 7: end for 8: end function 9: end class |
| 1: class Reducer: The Cosine similarity is calculated for each pair of queries. 2: function reduce ((q1, q2), (q1.tf, q2.tf)) 3: 4: emit ((q1, q2), cosine) 5: end function 6: end class |
3.5. Plan Recommendation
4. Experimental Set Up
5. Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Singh, V. Multi-objective Parametric Query Optimization for Distributed Database Systems. In Proceedings of Fifth International Conference on Soft Computing for Problem Solving; Springer: Singapore, 2016; pp. 219–233. [Google Scholar]
- Han, M.; Youn, J.; Lee, S.-G. Efficient query processing on distributed stream processing engine. In Proceedings of the 11th International Conference on Ubiquitous Information Management and Communication, Beppu, Japan, 5–7 January 2017; p. 29. [Google Scholar]
- Panahi, V.; Navimipour, N.J. Join query optimization in the distributed database system using an artificial bee colony algorithm and genetic operators. Concurr. Comput. Pract. Exp. 2019, 31, e5218. [Google Scholar] [CrossRef]
- Ghosh, A.; Parikh, J.; Sengar, V.S.; Haritsa, J.R. Plan selection based on query clustering. In Proceedings of the VLDB’02: Proceedings of the 28th International Conference on Very Large Databases, Hong Kong, China, 20–23 August 2002; pp. 179–190. [Google Scholar]
- Zahir, J.; El Qadi, A. A recommendation system for execution plans using machine learning. Math. Comput. Appl. 2016, 21, 23. [Google Scholar] [CrossRef]
- Zahir, J.; El Qadi, A.; Mouline, S. Access plan recommendation: A clustering based approach using queries similarity. In Proceedings of the 2014 Second World Conference on Complex Systems (WCCS), Agadir, Morocco, 10–12 November 2014; pp. 55–60. [Google Scholar]
- Azhir, E.; Navimipour, N.J.; Hosseinzadeh, M.; Sharifi, A.; Darwesh, A. An automatic clustering technique for query plan recommendation. Inf. Sci. 2021, 545, 620–632. [Google Scholar] [CrossRef]
- Azhir, E.; Navimipour, N.J.; Hosseinzadeh, M.; Sharifi, A.; Darwesh, A. An efficient automated incremental density-based algorithm for clustering and classification. Future Gener. Comput. Syst. 2021, 114, 665–678. [Google Scholar] [CrossRef]
- Dean, J.; Ghemawat, S. MapReduce: Simplified data processing on large clusters. Commun. ACM 2008, 51, 107–113. [Google Scholar] [CrossRef]
- Shabestari, F.; Rahmani, A.M.; Navimipour, N.J.; Jabbehdari, S. A taxonomy of software-based and hardware-based approaches for energy efficiency management in the Hadoop. J. Netw. Comput. Appl. 2019, 126, 162–177. [Google Scholar] [CrossRef]
- Zaharia, M.; Xin, R.S.; Wendell, P.; Das, T.; Armbrust, M.; Dave, A.; Meng, X.; Rosen, J.; Venkataraman, S.; Franklin, M.J. Apache spark: A unified engine for big data processing. Commun. ACM 2016, 59, 56–65. [Google Scholar] [CrossRef]
- Singh, S.; Rathi, V.K.; Chaudhary, B. Big data and cloud computing: Challenges and opportunities. Int. J. Innov. Eng. Technol. 2015, 5. [Google Scholar]
- Zaharia, M.; Chowdhury, M.; Franklin, M.J.; Shenker, S.; Stoica, I. Spark: Cluster computing with working sets. HotCloud 2010, 10, 95. [Google Scholar]
- Elsayed, A.; Mokhtar, H.M.; Ismail, O. Ontology based document clustering using mapreduce. arXiv 2015, arXiv:1505.02891. [Google Scholar] [CrossRef]
- Zewen, C.; Yao, Z. Parallel text clustering based on mapreduce. In Proceedings of the 2012 Second International Conference on Cloud and Green Computing, Xiangtan, China, 1–3 November 2012; pp. 226–229. [Google Scholar]
- Li, Y.; Luo, C.; Chung, S.M. A parallel text document clustering algorithm based on neighbors. Clust. Comput. 2015, 18, 933–948. [Google Scholar] [CrossRef]
- Makiyama, V.H.; Raddick, J.; Santos, R.D. Text Mining Applied to SQL Queries: A Case Study for the SDSS SkyServer; SIMBig: Cusco, Peru, 2015; pp. 66–72. [Google Scholar]
- Azhir, E.; Navimipour, N.J.; Hosseinzadeh, M.; Sharifi, A.; Darwesh, A. A technique for parallel query optimization using MapReduce framework and a semantic-based clustering method. PeerJ Comput. Sci. 2021, 7, e580. [Google Scholar] [CrossRef] [PubMed]
- Basha, S.A.K.; Basha, S.M.; Vincent, D.R.; Rajput, D.S. Challenges in storing and processing big data using Hadoop and Spark. In Deep Learning and Parallel Computing Environment for Bioengineering Systems; Elsevier: Amsterdam, The Netherlands, 2019; pp. 179–187. [Google Scholar]
- Ryza, S.; Laserson, U.; Owen, S.; Wills, J. Advanced Analytics with Spark: Patterns for Learning from Data at Scale; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2017. [Google Scholar]
- Kul, G.; Luong, D.T.A.; Xie, T.; Chandola, V.; Kennedy, O.; Upadhyaya, S. Similarity metrics for sql query clustering. IEEE Trans. Knowl. Data Eng. 2018, 30, 2408–2420. [Google Scholar] [CrossRef]
- Victor, G.-S.; Antonia, P.; Spyros, S. Csmr: A scalable algorithm for text clustering with cosine similarity and mapreduce. In Proceedings of the IFIP International Conference on Artificial Intelligence Applications and Innovations, Rhodes, Greece, 19–21 September 2014; Springer: Berlin/Heidelberg, Germany; pp. 211–220. [Google Scholar]
- Nguyen, L.; Amer, A.A. Advanced Cosine Measures for Collaborative Filtering. Adapt. Pers. 2019, 1, 21–41. [Google Scholar]
- Ester, M.; Kriegel, H.-P.; Sander, J.; Xu, X. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise; Kdd: Portland, OR, USA, 1996; Volume 96, pp. 226–231. [Google Scholar]
- Hahsler, M.; Piekenbrock, M.; Doran, D. dbscan: Fast density-based clustering with R. J. Stat. Softw. 2019, 91, 1–30. [Google Scholar] [CrossRef]
- Chandra, B.; Chawda, B.; Kar, B.; Reddy, K.M.; Shah, S.; Sudarshan, S. Data generation for testing and grading SQL queries. VLDB J. 2015, 24, 731–755. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Raw SQL Query | Tokenized SQL |
|---|---|
| SELECT name FROM instructor WHERE salary > 90,000 AND salary < 100,000 | SELECT name |
| FROM instructor | |
| WHERE salary |
| Tokenized SQL | Feature Vector |
|---|---|
| SELECT name FROM instructor WHERE salary | {‘SELECT name’ →1, ‘FROM instructor →1′, ‘WHERE salary’ →2}, |
| Features | Dataset | Number of Classes | Number of Individuals |
|---|---|---|---|
| S1 | 7 | 235 | |
| Selection | S2 | 14 | 593 |
| S3 | 18 | 1150 |
| Number of Worker Nodes | Number of Queries | Hadoop | Spark |
|---|---|---|---|
| 235 | 59 | 39 | |
| 1 | 593 | 152 | 58 |
| 1150 | 260 | 105 | |
| 235 | 57 | 25 | |
| 3 | 593 | 150 | 43 |
| 1150 | 255 | 92 | |
| 235 | 51 | 19 | |
| 5 | 593 | 130 | 33 |
| 1150 | 224 | 71 | |
| 235 | 45 | 15 | |
| 7 | 593 | 119 | 25 |
| 1150 | 197 | 50 | |
| 235 | 45 | 11 | |
| 9 | 593 | 119 | 22 |
| 1150 | 190 | 42 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Azhir, E.; Hosseinzadeh, M.; Khan, F.; Mosavi, A. Performance Evaluation of Query Plan Recommendation with Apache Hadoop and Apache Spark. Mathematics 2022, 10, 3517. https://doi.org/10.3390/math10193517
Azhir E, Hosseinzadeh M, Khan F, Mosavi A. Performance Evaluation of Query Plan Recommendation with Apache Hadoop and Apache Spark. Mathematics. 2022; 10(19):3517. https://doi.org/10.3390/math10193517
Chicago/Turabian StyleAzhir, Elham, Mehdi Hosseinzadeh, Faheem Khan, and Amir Mosavi. 2022. "Performance Evaluation of Query Plan Recommendation with Apache Hadoop and Apache Spark" Mathematics 10, no. 19: 3517. https://doi.org/10.3390/math10193517