1. Introduction
The major goal of this paper is to find the local and global minima of a convex and non-convex function. The local and global minimization problems are defined as follows.
Definition 1. A local minimum of the function f, is an input element with for all neighboring . If , it is formulated by Definition 2. The point is called the global minimizer of the function f; such that . When , then the problem can be formulated by In both problems (formulae) is the range in which we find the global minimizer of . is continuously differentiable.
Global optimization (GO) attempts to find the approximate solution of the objective function are shown in Problem (
2).
However, this task can be difficult since the knowledge about f is usually only local. On the other hand, the fastest algorithms (LO) prefer to find a local point since these algorithms are not capable of finding the global solution at each run.
The bottom line is that the core difference between the GO methods and the LO algorithms is as follows: the GO methods focus on solving Problem (
2) over the given set, while the task of the LO methods is to solve (
1). Consequently, solving Problem (
1) is relatively simple by using deterministic (classical) local optimization methods. On the contrary, finding the global optimum of Problem (
2) is an NP-hard problem.
Challenging problems arise in different application fields, for example, technical sciences, industrial engineering, economics, networks, chemical engineering, etc. See [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11].
Recently, many optimization algorithms have been proposed to deal with these problems. The thoughts of those suggested methods rely on the standard of meta-heuristic strategies (random search).
There are different classifications for meta-heuristic methods [
12].
Mohamed et al. [
7] presented a brief description of these classifications.
In random algorithms, the minimization technique relies partly on probability.
In contrast, in the deterministic algorithms, a guessing scale is not utilized. Hence, deterministic techniques need an exhaustive examination over the research domain of function
f to find the approximate solution to Problem (
2) at each run. Otherwise, they fail in this task.
Therefore, finding the approximate solution to Problem (
2) by using random techniques can be proved by the asymptotic convergence probability. See [
13,
14,
15].
There are many deterministic methods that have been proposed for dealing with the local optimization problems. See, for example, Refs. [
16,
17,
18,
19,
20].
The most popular deterministic method is the CG method [
18]. CG methods are exceedingly utilized to find the local minimizer of Problem (
1) [
21].
However, the CG algorithms have a numerical weakness, so their subsequent actions might be low if a little step is created away from the local point. Hence, for solving this issue, a line-search technique is combined with the CG technique to create a globally convergent algorithm [
22,
23].
Therefore, many conjugant gradient line-search methods are suggested; see, for example, refs. [
18,
24,
25,
26,
27,
28].
The CG method is an efficient and inexpensive technique to deal with Problem (
1).
The CG method is an iterative algorithm. Therefore, the candidate solutions are generated by the following recursive formula.
where the step size
, and the directions
are created by the following formula:
where
denotes the gradient vector of the function
f at the point
.
Several versions of the CG methods are suggested. The core difference between those CG algorithms relies on choosing the parameter
[
18,
27,
28,
29]. The main features of the CG method are as follows: it has low memory requirements, it is strongly local, and it has global convergence properties [
30].
Many authors presented several studies to analyze the CG method; see, for example, Refs. [
31,
32].
In 1964, the authors of [
33] applied the CG methods to nonlinear problems, and they proposed the following parameter.
The authors of [
34,
35] established the global convergence of the scheme defined in (
5); they used an exact line search and an inexact line search respectively.
However, the author of [
36] showed that there are some cases that have some strays; these jamming occurrences happen when the search directions
are almost orthogonal to the gradient vector
[
18].
The authors of [
37,
38] presented a modification of the parameter
for treating the noise event denoted in [
36]. Hence, they proposed the following parameter.
where
. When a noise occurs
,
, and
, i.e., when jamming happens, the search direction
is no longer perpendicular to the gradient vector
, but it is aligned with the vector
. This built-in restart advantage of the
parameter usually has better quick convergence when compared to the parameter
[
18].
The authors of [
39] proposed an approach closely related to
, and it is defined as follows.
in the case that step-size
is found by an exact line search algorithm. Hence, by (
4) and the orthogonality situation
, the following can be obtained:
Therefore,
when the step size
is calculated by an exact line search method. Other fundamentals formulas of the parameter
which contain one term are listed as follows.
Formula (
9) was proposed by [
40].
Formula (
10) was proposed by Dai and Yuan [
41]. It is noteworthy that when the
f is quadratic and step size
is selected to reduce
f along
, the options of the parameter
mentioned above are alike for the generic nonlinear function.
Different alternatives have fully different convergence possessions [
18].
Many version of the parameter
have been proposed in two- and three terms; see, for example, Refs. [
32,
42,
43,
44,
45,
46,
47,
48,
49,
50].
For example, in the following two approaches, we present some modifications to obtain a new CG method. See
Section 2.
Formula (
11) was proposed by [
30].
where
is a constant. Formula (
12) was proposed by [
49]. The denominator
in the
is modified to
in the
. This procedure may help the
stay in a trusted area automatically beneath each iteration [
49]. Furthermore, in a situation
,
decreases to
with
calculated to satisfy the inexact line search. Moreover,
decreases to
under the exact line search.
Consequently, by using a line search method, the CG method can satisfy the following descent condition:
where
is a constant.
The sufficient descent condition (
13) has a core task in the convergence analysis of the algorithms. See [
17,
30,
31,
32,
35,
41,
49,
51,
52].
However, the CG method has a numerical obstacle; its sub-sequential phases might be low if a little step is created away from the intended point [
49].
Recently, the authors of [
48,
49] proved that the CG algorithm includes powerful convergence features if it satisfies the trust-region feature that is determined by
where
is a constant. It is shown, therefore, that the trust-region property can enable the search direction
to be bounded in the trust radius [
49]. Numerous researchers proposed many CG algorithms that give perfect results and powerful convergence properties. See [
30,
48,
49,
51].
The selection of the right step size can help the CG algorithms to achieve global convergence.
The exact line search is defined as follows:
It is clear that in big-scale problems, the exact line search cannot be used.
Therefore, there are many techniques to achieve this task. Formula (
15), for example, the weak Wolfe–Powell algorithm (WWP), is a popular technique, and it is exceedingly utilized. The WWP technique is designed to find the step size
to satisfy the following inequalities:
and
where
and
are constants.
Inequality (
16) is named the Armijo condition, and the WWP line search decreases to strong Wolfe–Powell (SWP) by substituting Inequality (
17) with the following inequality:
Generally, under the WWP line search, it is assumed that the gradient
is Lipschitz continuous in the convergence analysis. Therefore, the following inequality is satisfied:
with
L is a constant
.
In fact, the CG technique with the line search methods has proven notability in solving the local optimization problem [
18,
27,
28]. However, in trying to solve Problem (
2), the CG method fails to achieve this task per run because it is trapped to a local point. To prevent sticking in a local point, random parameters are used [
53].
We can summarize the essence of the above discussions as follows.
Recently, there have been many and many proposed approaches presented to improve the performance of deterministic methods, such as CG methods, gradient descent methods, Newton methods, etc. Those new approaches are designed to deal with the local optimization problems. See, for example, Refs. [
16,
17,
18,
19,
20].
On the other hand, a plentiful number of stochastic approaches are suggested to deal with the global optimization problems. See, for example, Refs. [
1,
2,
4,
5,
7,
54].
Therefore, to gain the features of both deterministic and stochastic methods, many studies presented several ideas and suggestions to combine deterministic and stochastic techniques to obtain a new technique that is efficient and effective in solving Problem (
2). Numerical outcomes demonstrated that the interbreed between classical and stochastic techniques has been hugely successful. See [
55,
56,
57,
58,
59].
This work focuses on solving the local and global minimization problems. So, the first part of this study trades with Problem (
1) by suggesting a new modified CG method, while the second part of this paper presents a new random approach that includes three formulae by which the candidate solutions are generated randomly.
Therefore, the new proposed stochastic approach is combined with the new modified CG method that is proposed in the first part of this paper to obtain a new hybrid stochastic conjugate gradient algorithm that solves Problem (
2). The new hybrid stochastic conjugate gradient algorithm has four formulae by which the candidate solutions are created. One of the four formulae is a purely deterministic formula, the second one is a mixture of deterministic and stochastic parameters, and the other two formulas contain parameters generated randomly. The bottom line is that we can claim that the main merit that makes the new hybrid algorithm capable of finding the approximate solution to the global minimum of a non-convex function comes from the hybridization of random and non-random parameters.
Consequently, the contribution of this paper is divided into two parts.
Part I presents the following contributions.
A new modified CG technique is proposed and added with a line search for obtaining a globally convergent algorithm that solves Problem (
1). It is abbreviated by SHZ.
The convergence analysis of the SHZ algorithm is designed.
The gradient vector is estimated by using a numerical approximation approach (DFF); step-size h (interval) is randomly.
The convergence analysis of the DFF method is designed.
The four FR, SH, HZ and MZH methods are designed like the SHZ algorithm to solve Problem (
1).
Numerical experiments of the five SHZ FR, SH, HZ and MZH algorithms are analyzed by using the performance profiles.
Part II presents the following contributions.
- ⋄
Stochastic parameters are designed (SP).
- ⋄
The five SHZ, FR, SH, HZ and MZH algorithms are hybridized with the SP technique to obtain five hybrid algorithms; HSSHZ, HSFR, HSSH, HSHZ and HSMZH. These five algorithms solve Problem (
2).
- ⋄
Numerical experiments of the five HSSHZ, HSFR, HSSH, HSHZ and HSMZH algorithms are analyzed by using the performance profiles.
Consequently, the remainder of the study is arranged as follows.
Part I contains the following sections:
Section 2 presents a new modified CG- SHZ technique with its convergence analysis.
In
Section 3, the approximate value of the gradient vector is calculated by using the numerical differentiation.
Section 4 presents the numerical investigations of the local minimization problem. Part II contains the following sections:
Section 5 presents a random approach for unconstrained global optimization.
Section 6 presents the hybridization of the conjugate gradient method with stochastic parameters. The numerical experiments of Problem (
2) are presented in
Section 7. Some concluding remarks are given in
Section 8.
Part I: Local Minimization Problem
In this part, a new modified CG technique is presented, the convergence analysis of this technique is designed, the numerical differentiation approach is utilized to calculate the approximate values of the first derivative, the five algorithms are designed to solve Problem (
1), and their numerical experiments are analyzed by using the performance profiles.
2. Suggested CG Method
Recently, the authors of [
49] suggested a new MHZ-CG method, relying on the study which was proposed by the authors of [
30]. The MHZ method contains the sufficient descent and the trust-region features independent of a line search technique. The parameter of the MHZ is defined by (
12).
Therefore, the story in this section begins with the authors of [
30] who proposed a new CG-HZ method, where the parameter of the HZ method is defined by (
11). The parameter
can ensure that
satisfies the following inequality:
where (
20) is proved by [
30]. If the step size
is calculated by the true line search, then
decreases to the
that was proposed by [
39] because
is true [
49].
Hence, for obtaining the global convergence for a general function, Hager and Zhang [
30] dynamically adjusted the down limitation of
by
,
, where
is a constant.
Many researchers have suggested several modifications and refinements to improve the performance of the CG-HZ algorithm. The latest version of the CG-HZ method was offered by [
49]. Yuan et al. [
49] presented some modifications to the HZ-CG method, and the result was obtaining the new CG-MHZ algorithm.
The CG-MHZ algorithm contains a sufficient condition and the trust-region feature.
The research direction of the MHZ-CG technique is designed as follows:
where the
is defined by (
12).
In this paper, the MHZ method is extended and modified to obtain a new proposed method called the SHZ method such that the SHZ method has a sufficient condition and the trust-region feature. This method is defined as follows:
where the
, the
and
are defined as follows. The parameter
is changed randomly at each iteration and its values are taken from the range
and
. The values of
and
are calculated by
where
Itr is the number of iterations, and after the
Itr number of iterations,
and
are computed. Then, we set
, while
is defined by
Hence, when , inevitably reduces to one of the following methods as follows.
If
and
, the
reduces to the
. Otherwise,
reduces to
or to
under the exact line search [
49]. This procedure gives the advantages of the MHZ, HZ and HS methods to the proposed SHZ method. In other words, the SHZ algorithm gains the characteristics of the three MHZ, HZ and HS algorithms. This is why the SHZ algorithm is superior to the four other MHZ, HZ, HS and FR methods.
Note: The authors of [
49] imposed that the
is a constant, while the parameter
is modified dynamically at each iteration.
Convergence Analysis of Algorithm 1
In this section, we present the features of Algorithm 1. We also present the convergence analysis of this algorithm, and we show that the search direction
that is defined by Formula (
23) satisfies the sufficient descent condition and the trust-region merit, which are defined by Formulae (
13) and (
14), respectively.
| Algorithm 1 A conjugate gradient method (CG-SHZ). |
- Input:
, , , , a starting point and . - Output:
the local minimizer of f, , the value of f at - 1:
Set and . - 2:
while. do - 3:
compute to satisfy ( 16) and ( 17). - 4:
Calculate a new point . - 5:
compute , - 6:
Set . - 7:
calculate the search direction by ( 23). - 8:
end while - 9:
return the local minimizer and its function value
|
Two sensible hypotheses are assumed as follows.
Hypothesis 1. We suppose that Problems (1) and (2) contain an objective function with the following characteristics: continuity and differentiability properties. Hypothesis 2. In some neighborhood ℵ of the level setthe gradient vector is Lipschitz continuous. This means that there is a fixed real number such thatfor all . Lemma 1. Suppose that the sequence is obtained by Algorithm 1. If , thenandwhere , , ρ is taken randomly from at each iteration of Algorithm 1, , and is the trust-region radius. Proof. If
,
, then
and
, which indicates (
27) and (
28) by picking
and
.
Merging (
23) with (
24), the result is obtaining the following:
The following inequality
is applied to the first term of the numerator of Inequality (
29), where
,
, and it is clear that
is right.
Therefore, the following inequality obtains
such that
where
. Since
and
, (
27) is true.
By using (
30), it is obvious that
Consequently, (
28) is met, where
. The proof is complete. □
Corollary 1. According to Formula (28) of Lemma 1, the following formula is met. Proof. Since
, where
, then
, therefore,
, hence
. Now, the final expression is summed as
. The result is obtaining the following inequality:
. Therefore, (
31) is met. □
Under the assumptions, we give a helpful lemma that was basically proved by Zoutendijk [
60] and Wolfe [
61], Wolfe [
62].
Lemma 2. Assume that the is the initial point by which Assumption 1 is satisfied. Regarding any algorithm of Formula (23), is a descent direction, and satisfies the standard Wolfe conditions (16) and (17). Hence, the following inequality is met: Proof. It tracks Formula (
17), such that
On the other hand, the Lipschitz condition (
19) implies
The above two inequalities give
which with (
16) implies that
where
. By summing (
36) and with the observation that
f is limited below, we see that (
32) holds, which concludes the proof. □
Theorem 1. Suppose that Hypotheses 1 and 2 hold, and by utilizing the outcome of Corollary 1, the sequence that is generated by Algorithm 1 satisfies the following: Proof. By contradiction, suppose that (
37) is not true; then, for some
, the following inequality is true:
Hence, with inequality (
38) and (
27), we obtain
Then, we have
and by summing the final expression, we obtain
Therefore, the above leads to a contradiction with (
32). So, (
37) is met. □
Note 1: The search direction
that is defined by Formula (
23) satisfies the sufficient descent condition which is defined by Formula (
13).
Note 2: Lemma 1 guarantees that Algorithm 1 has a sufficient descent property and the trust-region feature automatically.
Note 3: Theorem 1 confirms that the series that is obtained by Algorithm 1 approaches to 0 as long as .
In the next section, the numerical differentiation approach is discussed by which the first derivative is estimated and the step size is computed.
3. Numerical Differentiation
We now turn our attention to the numerical approximation to compute the approximate value of the gradient vector. In precept, it can be possible to find an analytic form for the first derivative for any continuous and differentiable function. However, in some cases, the analytic form is very complicated. The numerical approximation of the derivative may be sufficient for some purposes.
In this paper, the values of the , and the direction are computed by using the numerical differentiation method. Moreover, we have another step size and research directions that are generated randomly.
Several suggested methods have given fair outcomes for computing the gradient vector values numerically. See [
63,
64,
65,
66,
67].
The common approaches by which the first derivative is computed are the finite difference approximation methods. Therefore, the first derivative
can be estimated by the following numerical differentiation formula:
where
h is limited and little, but it is not necessarily infinitesimally small.
Reasonably, if the value of the
h is small, the approximated value of the first derivative may improve. The forward difference and the central difference are the familiar and common methods used in many studies; see for example, [
68,
69,
70,
71,
72].
The Taylor series can be used to derive these formulas. Thus, 3, 4 and 5 points can be utilized to derive these formulas, but it will be more costly than utilizing 2 points. The central difference method is known to include aspects of both accuracy and precision [
73] but it needs
function evaluations against the forward-difference approximation approach, which needs
n function evaluations for each iteration. So, in this study, the forward-difference approximation approach is used, because it is a cheap method and it has sensible precision [
66,
68].
The advantage of the finite difference approximation approaches relies on choosing the fit values of the h.
Error approximation of the first derivative is discussed in the next section.
Therefore, the discussion of the error analysis guides us to define an appropriate finite-difference interval for the forward-difference approximation that balances the truncation error that grows from the error in the Taylor formula, and the magnitude error that is obtained from noise during computing the function values [
66].
3.1. Error Analysis
Formula (
41) contains the forward-difference approximation form that is used to estimate the first derivative of the function
f. Its errors are proportional to some power of the values of
h. Therefore, it appears that the errors go on to reduce if
h is reduced. However, it is a part of the problem since it is assumed only the truncation error yielded by truncating the high-order terms in the Taylor series expansion and does not take into account the round-off error induced by quantization. The round-off error is beside the truncation error; all of them are discussed in this section as follows.
Regarding this goal, suppose that the function values , , are quantized to , , with the sizes of the round-off errors and all being smaller than some positive number , that is ; with .
Hence, the total error of the forward difference approximation defined by (
41) is derived by
Hence,
with
. Therefore, the upper bound of the error is illustrated by the right-hand side of Formula (
43). The maximum limited of error contains two expressions; the first comes from the rounding error and in inverse proportion to step-size
h, whilst the second comes from the truncation error and in direct proportion to
h. These two parts can be formulated as a function
with respect to
h as follows
. Now, if we find the minimizer
of the function
, then the value
is the upper bound of the total error. Hence
, then
Therefore, it can be concluded that as we create small values of h, the round-off error might grow, whilst the truncation error reduces. It is called the “step-size dilemma”.
Consequently, there have to be some optimal values of the
for the forward difference approximation formula, as derived analytically in (
44). However, Formula (
44) is only of theoretical value and cannot be used practically to determine
because we do not have any information about the second derivative and, therefore, we cannot estimate the values of
.
Therefore, there are many approaches which have been presented to deal with the step-size dilemma.
Recently, Shi et al. [
66] proposed a bisection search for finding a finite-difference interval for a finite-difference method. Their approach was presented to balance the truncation error that grows from the error in the Taylor formula and the measurement error obtained from noise in the function evaluation. According to their numerical experience, the finite-difference interval
are bounded between the following ranges
,
and
by using the forward and central differences to estimate the values of the first derivative of the
f.
Additionally, the authors of [
68] gave a study of the theoretical and practical comparison of the approximate values of the gradient vector in derivative-free optimization. These authors analyzed some approaches for approximating gradients of noisy functions utilizing only function values; those techniques include a finite difference.
The values of the finite difference interval are as follows .
According to the earlier investigations, the core of the difference between all approaches is to determine the step size h. Hence, the value of the step size is ranged between this range .
In this paper, the h is designed in a way that makes its values generated randomly. Additionally, the values of the h are connected to the function values per iteration to cover this domain, thus the feature here is that the value of h is modified per iteration randomly.
Therefore, a fresh approach to define the is presented in the following section.
3.2. Selecting a Step-Size h
The forward difference approach is a cheap method compared to the different techniques.
The forward difference approach has shown promising results for minimizing noisy black-box functions [
66].
Depending on the hypotheses which are listed in
Section 2, let
be any starting point, thus function
f satisfies the following
, for
. The numerical outcomes that are given in the past papers denote that the values of step-size
h belong to the following range
.
Therefore, the next Algorithm 2 is created to generate the values of the
randomly from the intervals
.
| Algorithm 2 Algorithm for calculating the values of . |
Step 1: At each iteration k, we generate a set random values between , and , and this set of random values is denoted by . Step 2: The minimum and maximum of the set are extracted, respectively, as follows , and set . Step 3: The function value f is calculated at each k; . |
Now we determine two cases according to the function values of the as follows.
Case 1: If
, the value of the
h is determined by
Case 2: If , the value of the h is determined by a random way from the range .
Example: In this example, we show how the above algorithm is run.
Let us suppose that the point has four different values as starting points with four different values of f, for example, and suppose we generate the set as random values between , and such that , ; hence, , since , then we set and . If , , and then , and , we set , then .
Finally, if , then .
The above example shows how Case 1 is implemented by using Formula (
45).
Regarding Case 2 when , the value of the is taken randomly from the range .
3.3. Estimating Gradient Vector
The forward finite difference (DFF) is utilized to compute the approximate value of the gradient vector of function
f at
by
where
is the finite difference interval defined in
Section 3.2, and
is the
column of the identity matrix.
Therefore, , is the approximate value of the gradient vector of function f at point .
Therefore, the step size is defined in the following.
The function is estimated by utilizing Taylor’s expansion up to the linear term around the point , for each iteration k. Then we have
We define the quadratic model of
at
as
Set
where
is the step size along the −
. The optimal value of the
is picked by solving the following subproblem:
. This gives
Therefore,
where
.
3.4. Convergence Analysis of DFF
The condition which is usually utilized in the convergence analysis of first-order methods with inexact gradient (DFF) vectors is defined by
for some
. This condition is introduced by [
74,
75] and it is called a norm condition. This condition denotes that the
is a descent direction for the function
f [
68].
However, condition (
49) cannot be applied, unless we know
; therefore, this condition might be hard or impossible to verify.
There are many authors who have attempted to deal with this issue; see, for example, Refs. [
68,
76,
77,
78,
79]. Byrd et al. [
76] suggested a practical approach to estimate
, and they utilized it to guarantee some approximation of (
49). Cartis and Scheinberg [
77] and Paquette and Scheinberg [
79] replaced condition (
49) by
where
, and convergence rate analysis were derived for a line search method that has access to deterministic function values in [
77] and stochastic function values (with additional assumptions) in [
79]. Berahas et al. [
68] established conditions under which (
49) holds. For the forward finite differences method (DFF), they set
.
Therefore, we present the following
Theorem 2. Under Assumptions 1 and 2 of Section 2, let denote the forward finite difference approximation to the gradient . Then, for all , the following inequality is true:where the value of theis estimated by (47). We know thatandare the norm infinity and the 2-norm, respectively, and they are defined byand then According to (
46) which defines the gradient approximation by forward differences, the vector of
is described by
, wherer
, then
and therefore, the next inequality is true
By using (
48), (
51), (
54) and (
55), we obtain
.
Therefore, the theorem holds.
4. Numerical Experiments of Part I
All experiments were run on a PC with Intel(R) Core(TM) i5-3230M
[email protected] 2.60 GHz with RAM 4.00 GB of memory on a Windows 10 operating system. The five methods were coded by utilizing MATLAB version 8.5.0.197613 (R2015a) and the machine epsilon was about
.
The model optimization test problems are categorized into two types. The first type is the test problems that contain a convex function, while the second type include a non-convex function. Both kinds of test problems are listed in
Table 1,
Table 2,
Table 3,
Table 4,
Table 5,
Table 6,
Table 7 and
Table 8 such that the second type of the test problem is referred to by *. Columns 1–4 of
Table 1 give the data of the test problems as follows: the abbreviation of the function
f is given on Column 1, the number of variables
n is listed on Column 2, the exact function value
at the global point
is presented on Column 3, and the exact value of the norm of the gradient
vector is given by Column 4, where the mark “−” denotes that the value of the norm of the gradient
for the convex function satisfies the stopping criterion
. Columns 5–8 are as Columns 1–4.
The numerical results for the local minimizers of all test problems are listed in
Table 2,
Table 3,
Table 4,
Table 5,
Table 6,
Table 7 and
Table 8. Columns 1–2 and 8–9 contain the abbreviation of the function
f and the number of the variables
n, respectively. Columns 3–7 contain the abbreviation of each algorithm of the five algorithm SHZ, MHZ, HZ, HS and FR, which present the number of worst iterations, number of worst function evaluations, number of best iterations, number of best function evaluations, average of time (CPU), average of the number of iterations and average of the number of function evaluations, respectively. Columns 10–14 are similar to Columns 3–7.
Note 1: It is worth noting that the full name for each test function is mentioned in
Appendix A according to the reference in which the test problem is.
Note 2: F denotes that the algorithm has failed to find the local minimizer of the function
f according to the stopping criteria of Algorithm 1 which are listed in
Section 4.1 below.
The stopping criteria of Algorithm 1 are as follows.
4.1. Stopping Criteria of Algorithm 1
Since this section focuses in finding a local minimizer of all test problems, the stopping criteria of Algorithm 1 can be defined as follows.
According to the discussions of the convergence analysis which are mentioned in the previous sections, the stopping criterion of Algorithm 1 is, if
is satisfied, Algorithm 1 stops, where
. However, the exact value of the gradient vector is unknown since the value of the gradient vector is estimated by Formula (
46); therefore, this condition is replaced by
or
, i.e., if one of them is met, Algorithm 1 stops, where
, FEs denotes the maximum function evaluations and
n is the number variables of the
f.
In the following section, the performance profile is presented as an easy tool to compare the performance of our proposed method versus other methods in finding local minimizers of convex or non-convex functions regarding the worst and best numbers of iterations and function evaluations, the average of CPU time and the average of iterations and function evaluations, respectively.
4.2. Performance Profiles
The performance profile is the best tool for testing the performance of the proposed algorithms [
80,
81,
82,
83,
84].
In this paper, the five algorithms’ performance evaluation standards are as follows: the worst and best numbers of iterations and function emulations, and the average of the CPU time, iterations and function emulations. They are abbreviated as itr.w, itr.be, FEs.w, FEs.be, time.a, itr.a and EFs.a, respectively. In the remainder of the paper, the set Fit will be used to denote the seven criteria; .
Therefore, the numerical outcomes are presented in the form of performance profiles, as depicted in [
82]. The most important characteristic of the performance profiles is that they can be shown in one figure by plotting for the different solvers a cumulative distribution function
.
The performance ratio is defined by first setting , where , P is a set of test problems, S is the set of solvers, and is the value obtained by solver s on test problem p.
Then, define , where is the number of test problems.
The value of is the probability that the solver will win over the remaining ones, i.e., it will yield a value lower than the values of the remaining ones.
In the following, the performance profiles are utilized to evaluate the performance of the five methods: SHZ, MHZ, HZ, SH and FR.
Therefore, in this paper, the term indicates one element of the set Fit, is the number of test problems. We have 46 unconstrained test problems, 14 of which include non-convex functions. The group of solvers finds the local minimizers of the 46 test problems; therefore, the values of the are taken from the results of the 46 test problems as follows.
Each solver
s of the set
S is run 51 times for each of the 46 problems; at each run, every element of the set Fit has owned its value. So, they are analyzed in the following.
where
is an element of the Fit for the test problem
p by using the solver
s.
Note: Formula (
56) means that if the final result, obtained by a solver
, satisfies Inequality (
57), then the first branch of (
56) is computed. Otherwise, we set
.
where
.
Therefore, the performance profile of solver s is defined as follows:
Therefore, the performance profile for solver s is then given by the following function:
As we mentioned above, and .
By definition of
,
denotes the fraction of test problems for which solver
s performs the best. In general,
can be explained as the probability for solver
that the performance ratio
is within a factor
of the best possible ratio. Additionally, the essential characteristic of performance profiles is that they present data on the proportional performance of numerous solvers [
82,
83].
The numerical outcomes of the five methods are analyzed by using the performance profiles as follows.
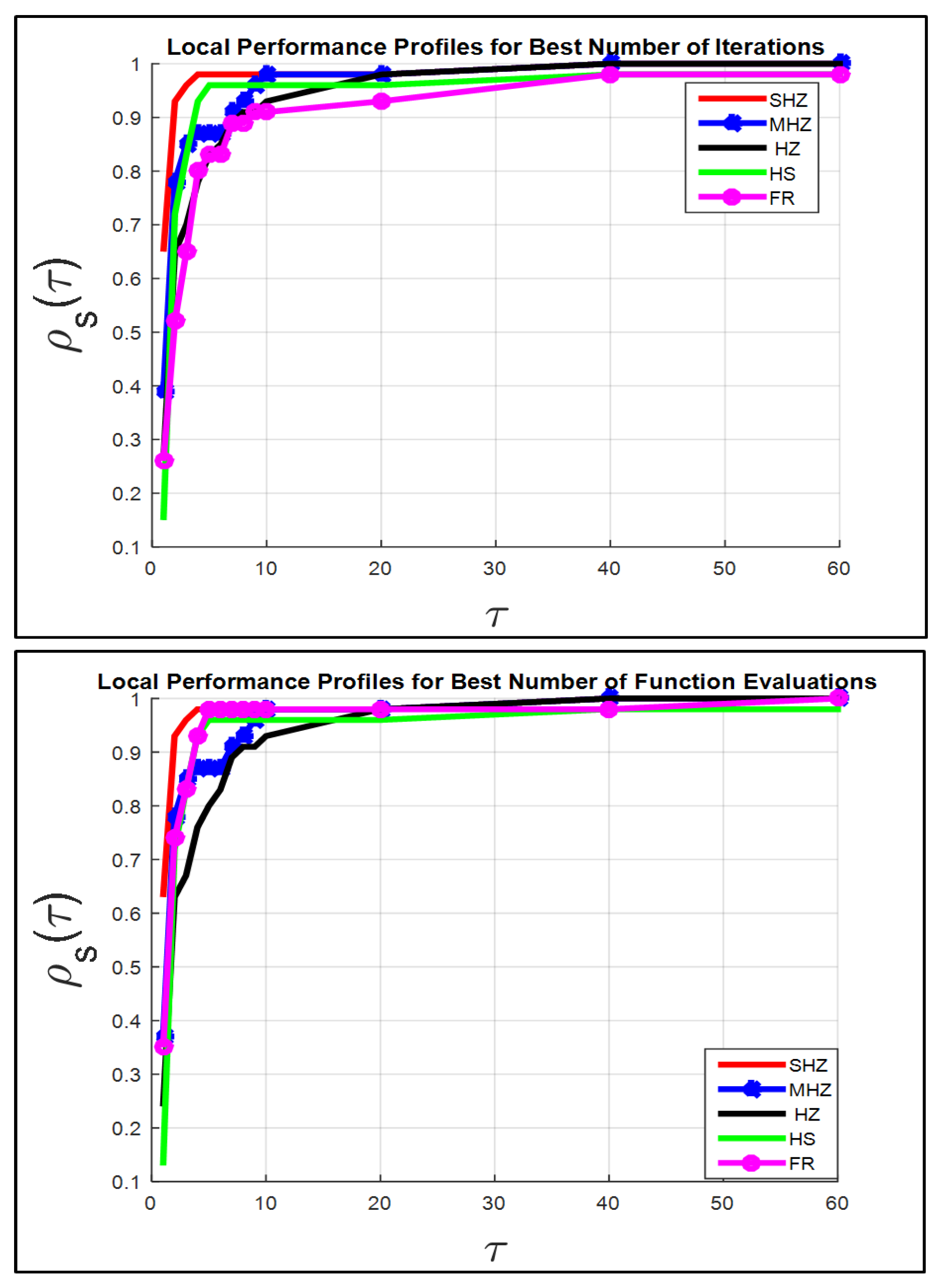
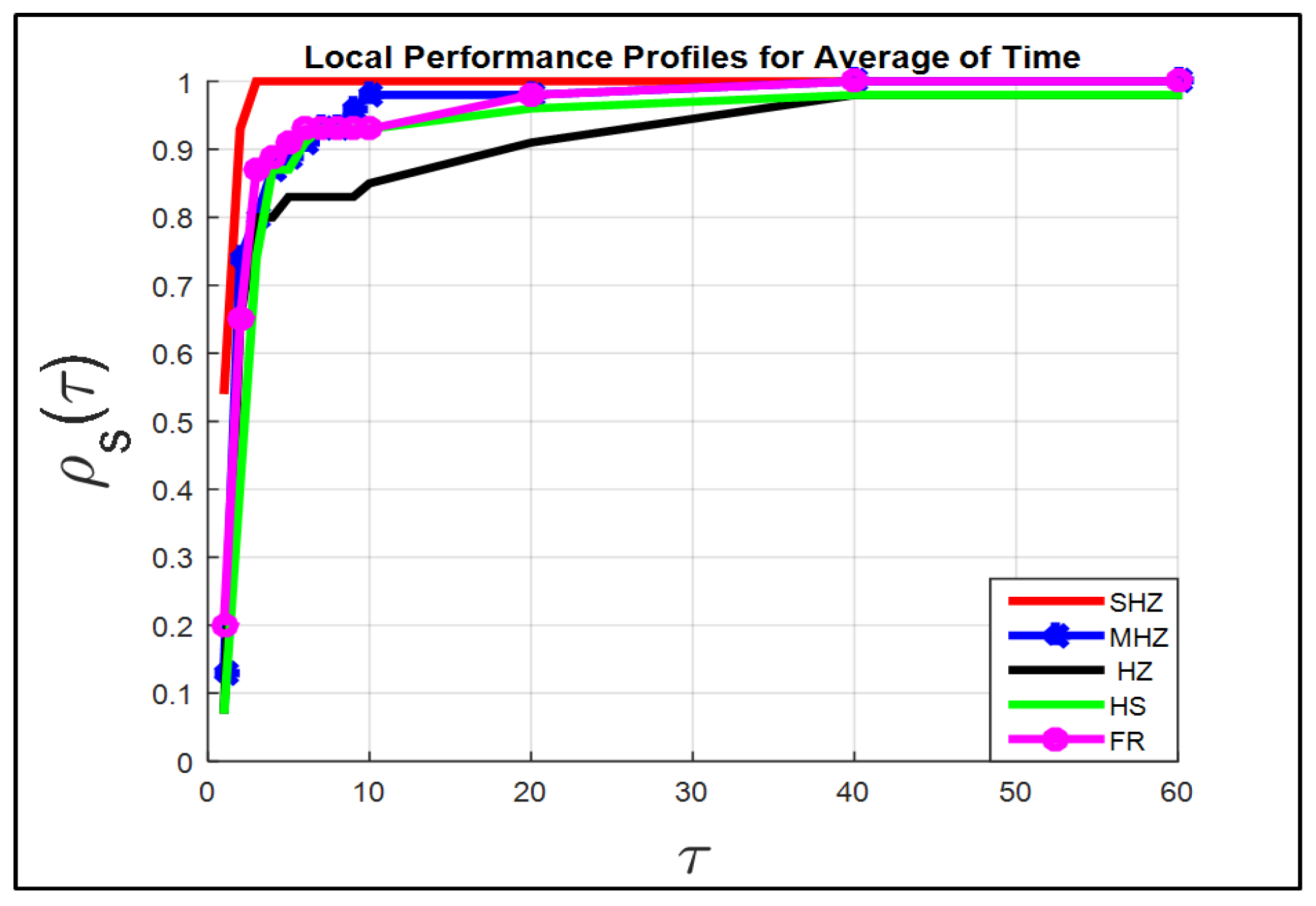
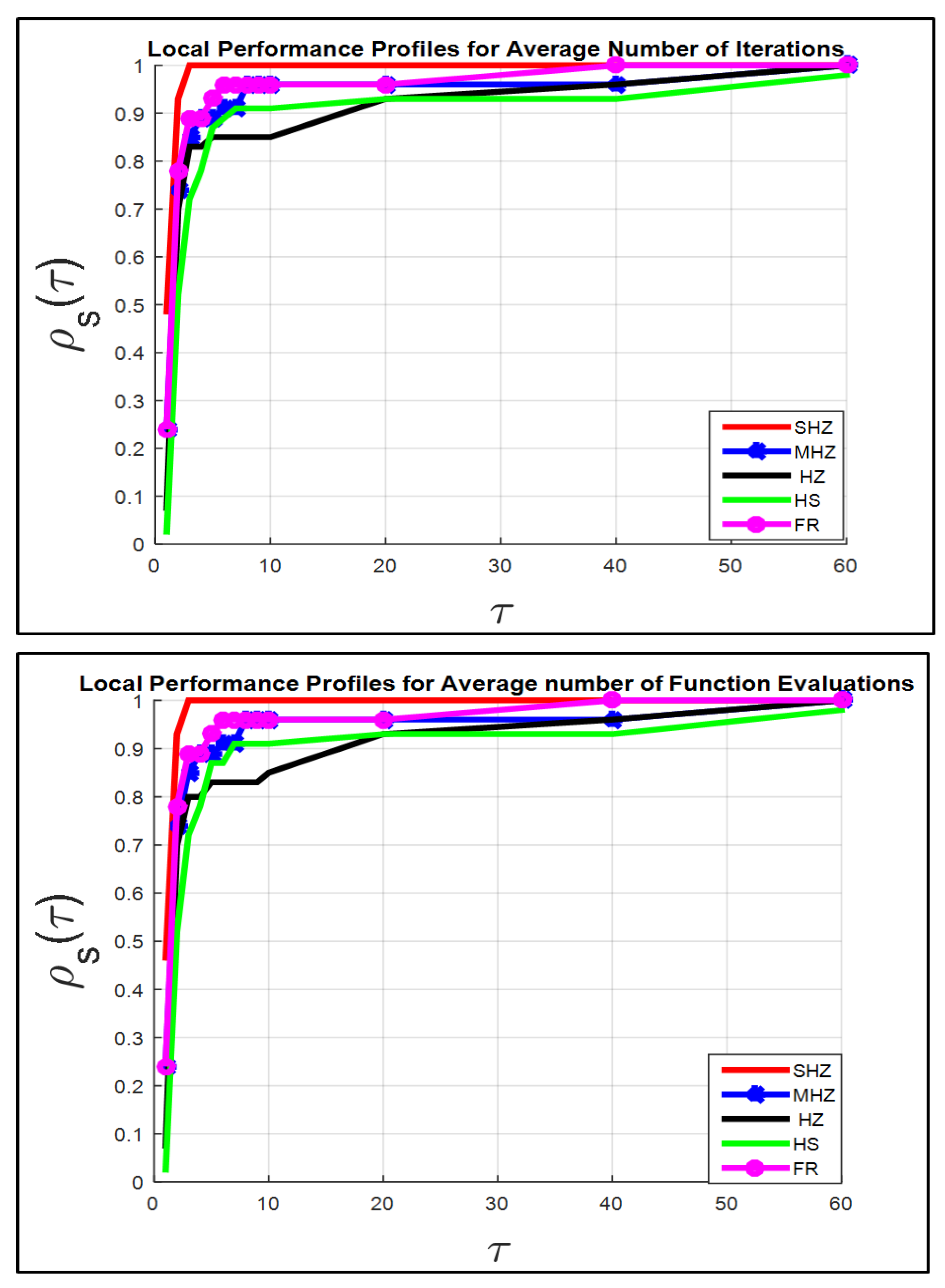
Figure 1,
Figure 2,
Figure 3 and
Figure 4 show the performance profiles of the set solvers
S, for each element of the set Fit, respectively.
The performance profile depicted on the left of
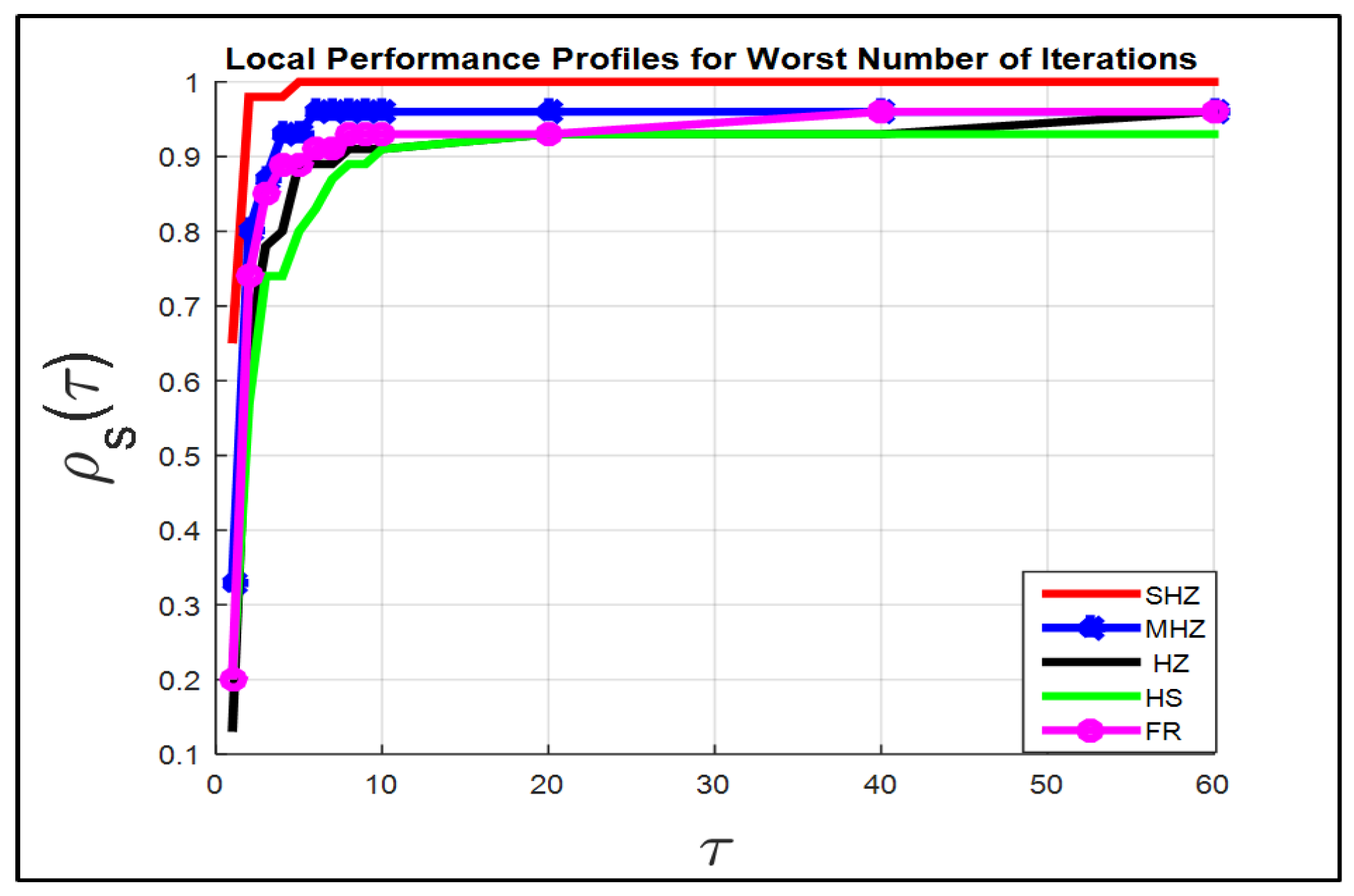
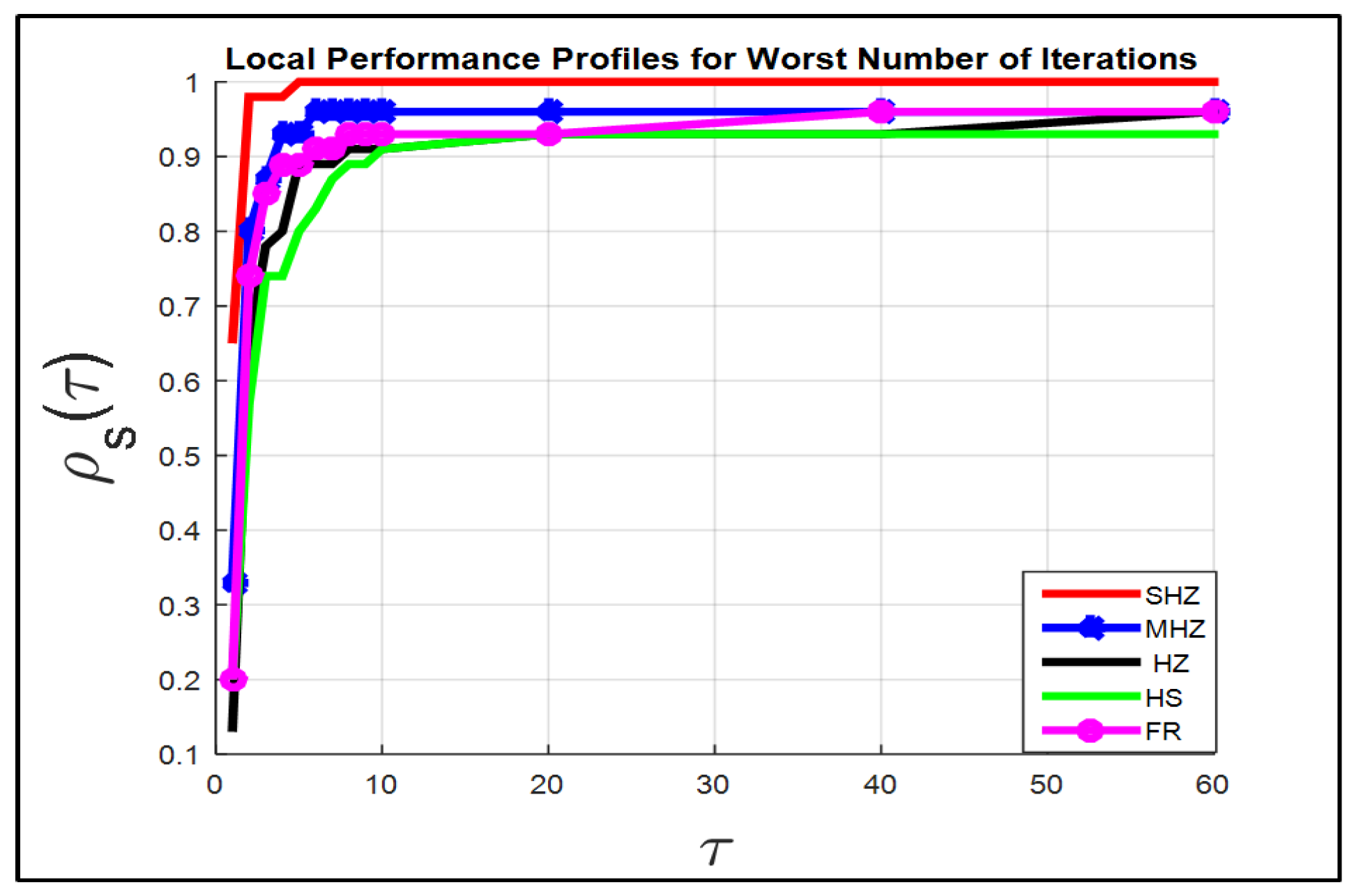
Figure 1 (in the term itr.w) compares the five techniques for a set of the 46 test problems.
The SHZ method has the best performance for the 46 test problems; this means that our suggested approach is capable of finding a local minimizer to the 46 test problems as fast as, or faster than, the other four approaches.
For instance, if , the SHZ technique is capable of finding the local minimizer for of problems versus the , , and of a set of test problems solved by the MHZ, HS, FR and HZ methods, respectively.
In general, the term itr.w, displays that all test problems are solved by SHZ against of test problems solved by the MHZ, HZ and FR methods respectively, while of test problems are solved by the HS method. At , all test problems are solved by the MHZ, HZ and FR methods respectively, while of test problems are solved by the HS.
The right graph of
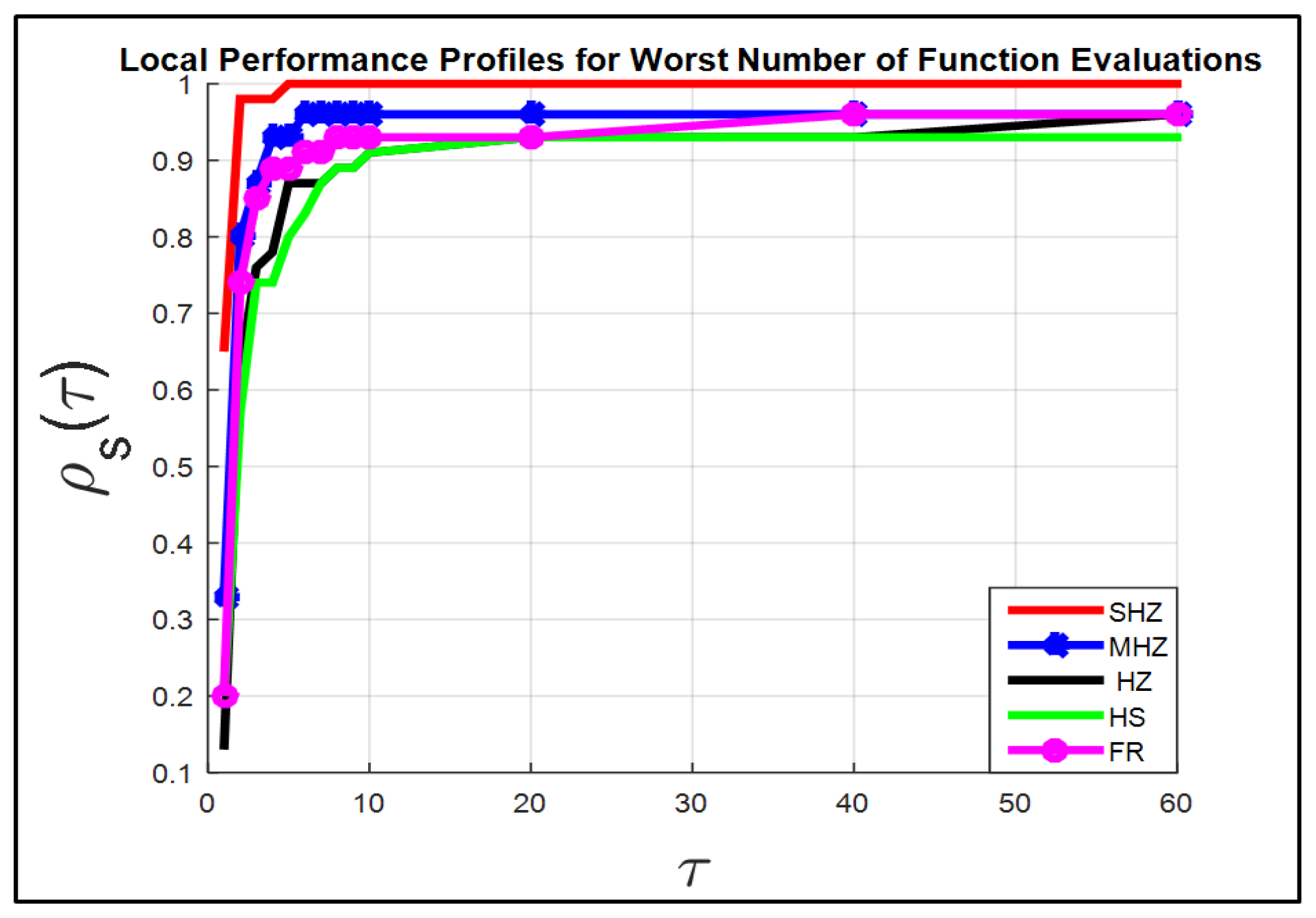
Figure 1 shows that the method SHZ is capable of finding the local minimum of all test problems regarding term FEs.w.
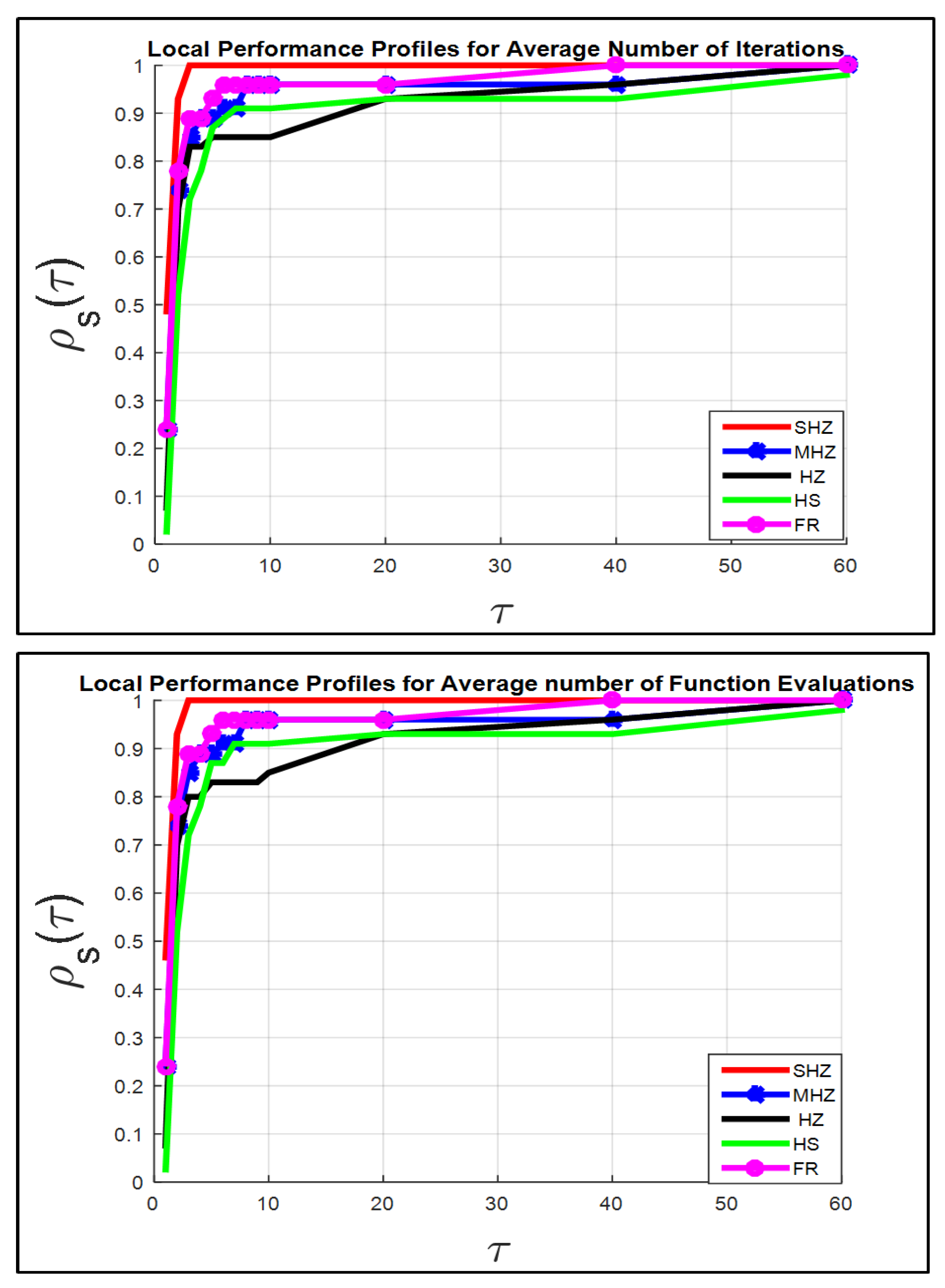
The rest of
Figure 2,
Figure 3 and
Figure 4 show that the SHZ algorithm is superior to the four algorithms regarding the rest of the terms of the set Fit.
Therefore, the SHZ technique includes the characteristics of efficiency, reliability and effectiveness in solving Problem (
1) compared to the other four methods.
Note: The power of the SHZ technique comes from the fact that the SHZ method gains the features of the four methods MHZ, HZ and HS, as we mentioned in
Section 2.
Part II: Global Minimization Problem
It is worth mentioning that the final results of Part I for the second set of test problems contain some global minimizers at some runs for some non-convex functions. This means that the pure CG technique could not find the global minimizer of the second type of test problems for each run because it is a local method.
Therefore, to make this method capable of solving Problem (
2) per run, the random technique is proposed and it is added to the CG approach to gain a new PS-CG hybrid technique that solves Problem (
2). In many studies, the numerical outcomes indicated that the interbreed between a classical method and a random technique is very successful in overcoming the weakness of these methods. See [
55,
56,
57,
58,
59].
Consequently, this part of the paper seeks to solve Problem (
2).
Therefore, each method of the five CG methods mentioned in Part I is hybridized with the stochastic technique to obtain five algorithms to try to solve Problem (
2).
In the next section, a stochastic technique is presented.
5. Random Technique
In this section, a new random parameter “SP” is presented. This stochastic technique contains three different formulas by which three different points are generated. This set of formulas is combined with the CG method to obtain a new algorithm that solves Problem (
2).
Random Parameters (SP Technique)
Step 1: The first point is computed as follows, generate
is as a random vector, set
,
, where the interval
is divided into Itr of fractions and at every iteration
k, the parameter
takes one value of the Itr and then computes
as a research direction with the step lengths, where
,
n is the of number variables, Itr is the number of iterations, and
denotes the signs of the
and is defined by
Thus, a point is calculated as follows:
where
is the best point obtained yet, and then we compute
.
Step 2: The second point is defined by
where
,
is defined by (
47),
is a random number, and the
is defined by (
23). Then, we compute
.
Step 3: This point is defined by
where
,
,
is the function value at the point
that has been accepted, and
is a stochastic variable picked from the feasible range of the objective function. This means that for
,
a and
b are the lower and upper bounds of the feasible range, respectively, and the random vector
with its signs
is defined by the first step.
Therefore, we calculate .
For finding the global minimizer of a non-convex function, the above stochastic technique is used since Algorithm 1 is not capable of finding the global solution at each run. In other words, in some runs, Algorithm 1 fails to find the global solution to this function due to it sticking to a local point.
In the following example, we show how the SP algorithm is run.
Example: This example shows how the three steps of the SP algorithm are implemented.
We use the first test problem of the list of the test problems that are listed in
Appendix A.
, to facilitate an explanation of the mechanism of using the Sp algorithm (Formulas (
61)–(
63)), we use the following easy information about the function
,
is the number of the variables,
, or
, where
represents the best solution has been accepted so far or the starting point; hence, the function values at the two points are
and
.
Supposing is the number of iterations, the interval is divided into five fractions with step size , and thus the set of this fractions is , let k be 3 which means the algorithm is at the third iteration. Then, , . Let be , then
Therefore, the new solution is computed by Formula (
61) as follows.
or .
The function values at both points are as follows.
or .
Therefore,
; this means the solution that is generated by Formula (
61) reduces the function value.
In the following, we explain how the candidate solution is generated by Formula (
62).
Let
. By using Formula (
45), we obtain
as the step size
h (a random interval) to the difference approximations method, and then we have
,
.
Therefore, the values of the function at the three points , and are listed in the following.
, and .
We compute the approximate value of the gradient vector by Formula (
46) as follows:
, where
is defined by (
47).
We consider because we do not have information about the value of the in this illustration example.
Now, we apply Formula (
62), as follows
, we take
as a random number from the range
, then
, the function value at the point
is
.
We note that the , i.e., the function value is reduced by the point .
In the following, we explain how the candidate solution is generated by Formula (
63).
, is as a random vector picked from the range , and then .
We compute the function value at the point ; .
We note that the . Therefore, the point minimizes the function value.
According to the above example that illustrates the mechanism of Formulas (
61)–(
63), we deduce the following results.
Remark 1. Formulas (3), (61) and (62) are the main formulas which are used in the new hybrid proposed algorithm that is described in Section 6. However, Formula (63) is used when that is defined by Formula (25); in this case, Algorithm 3 reaches a critical point, thus if this point is the approximate value of the global minimizer point of the f, then Algorithm 3 stops according to the condition in Line 4 or Line 1 of Algorithm 3. Otherwise, the candidate solution is generated by Formula (63); see Section 6. Consequently, in this example, at iteration , the result which is obtained by Formula (63) cannot be taken into account due to the . Remark 2. All Formulas (61)–(63) minimize the function value from any starting point. 7. Numerical Experiments of Part II
The numerical results for the second test problems (non-convex functions) are presented, and these results are obtained by Algorithm 3.
The performance profiles tool that is described in Part I is used here for assessing the achievement of Algorithm 3 that contains five alternatives of algorithms as we mentioned above in
Section 6.
The numerical results of the second type of the test problems are listed in
Table 9,
Table 10,
Table 11,
Table 12,
Table 13,
Table 14 and
Table 15. Columns 1–2 and 8–9 contain the abbreviation of the function
f and the number of the unknowns
n, respectively. Columns 3–7 contain the abbreviation of each algorithm of the five algorithm HSSHZ, HSMHZ, HSHZ, HSHS and HSFR, which present the number of worst iterations, number of worst function evaluations, number of best iterations, number of best function evaluations, average of time (CPU), average of number of iterations and average of number of function evaluations, respectively. Columns 10–14 are similar to Columns 3–7.
Note: F denotes that the algorithm has failed to find the local minimizer of the function
f according to the stopping criteria of Algorithm 3 which are listed in
Section 6.
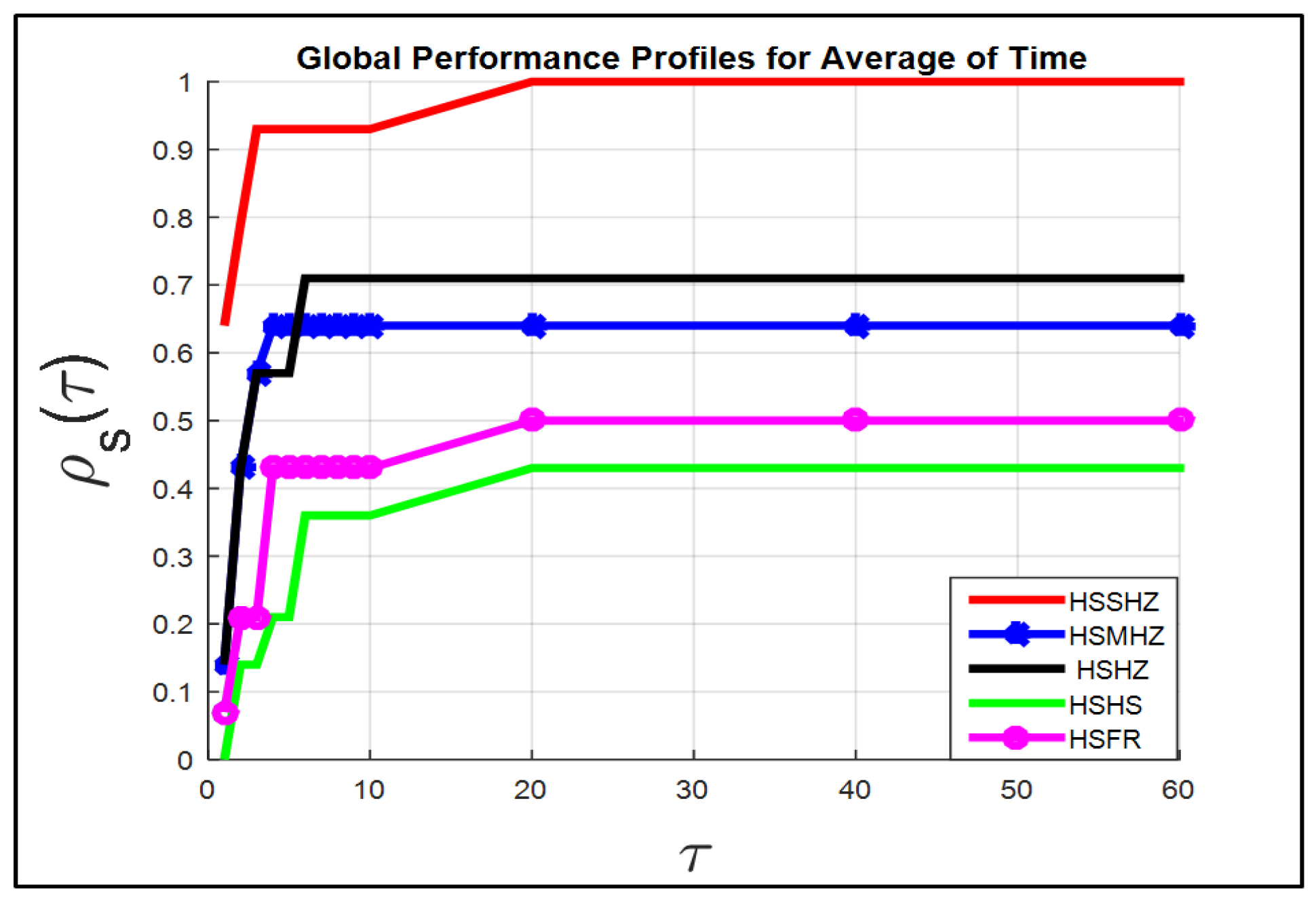
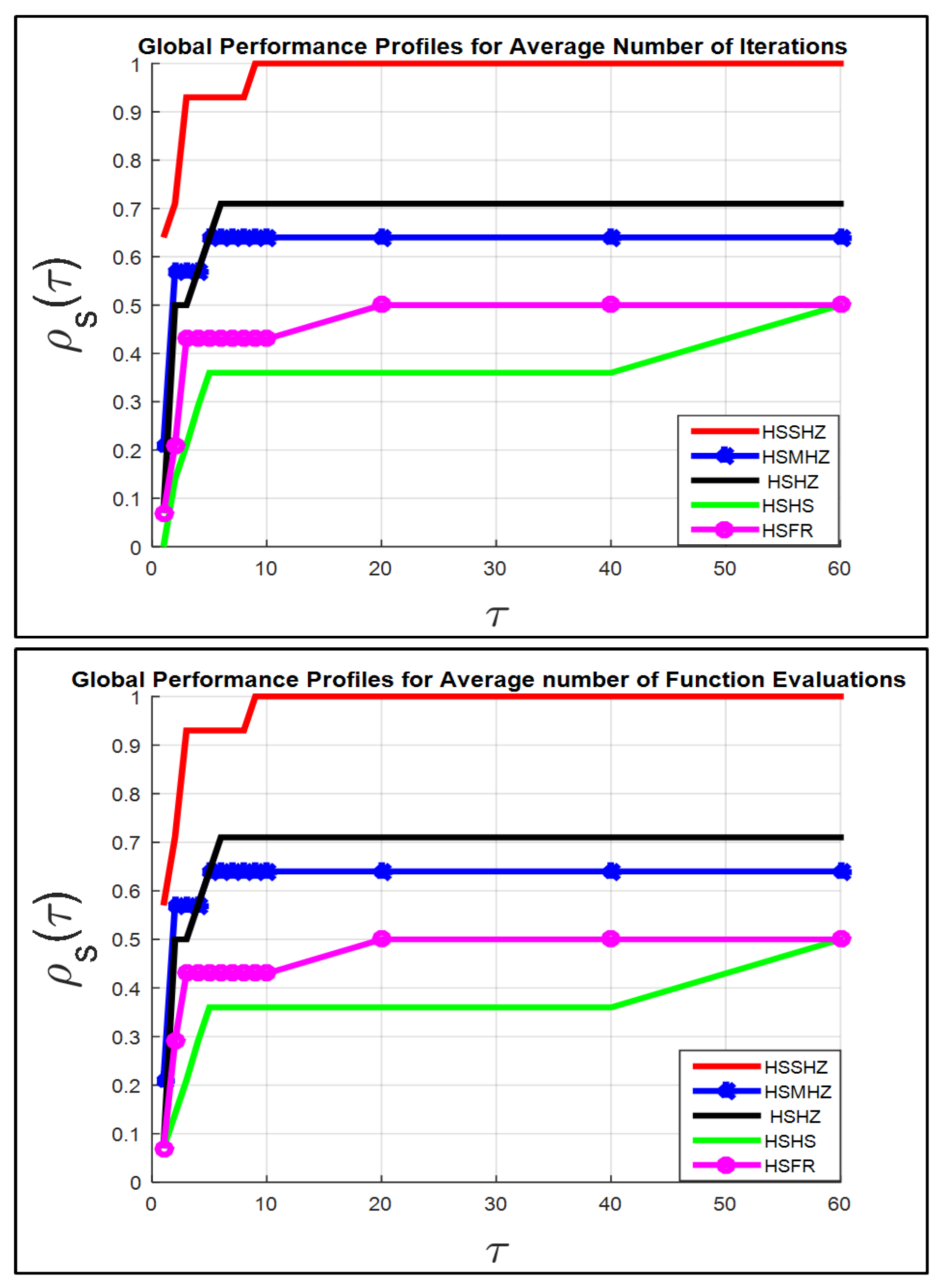
The performance profiles for the five algorithms are analyzed as follows.
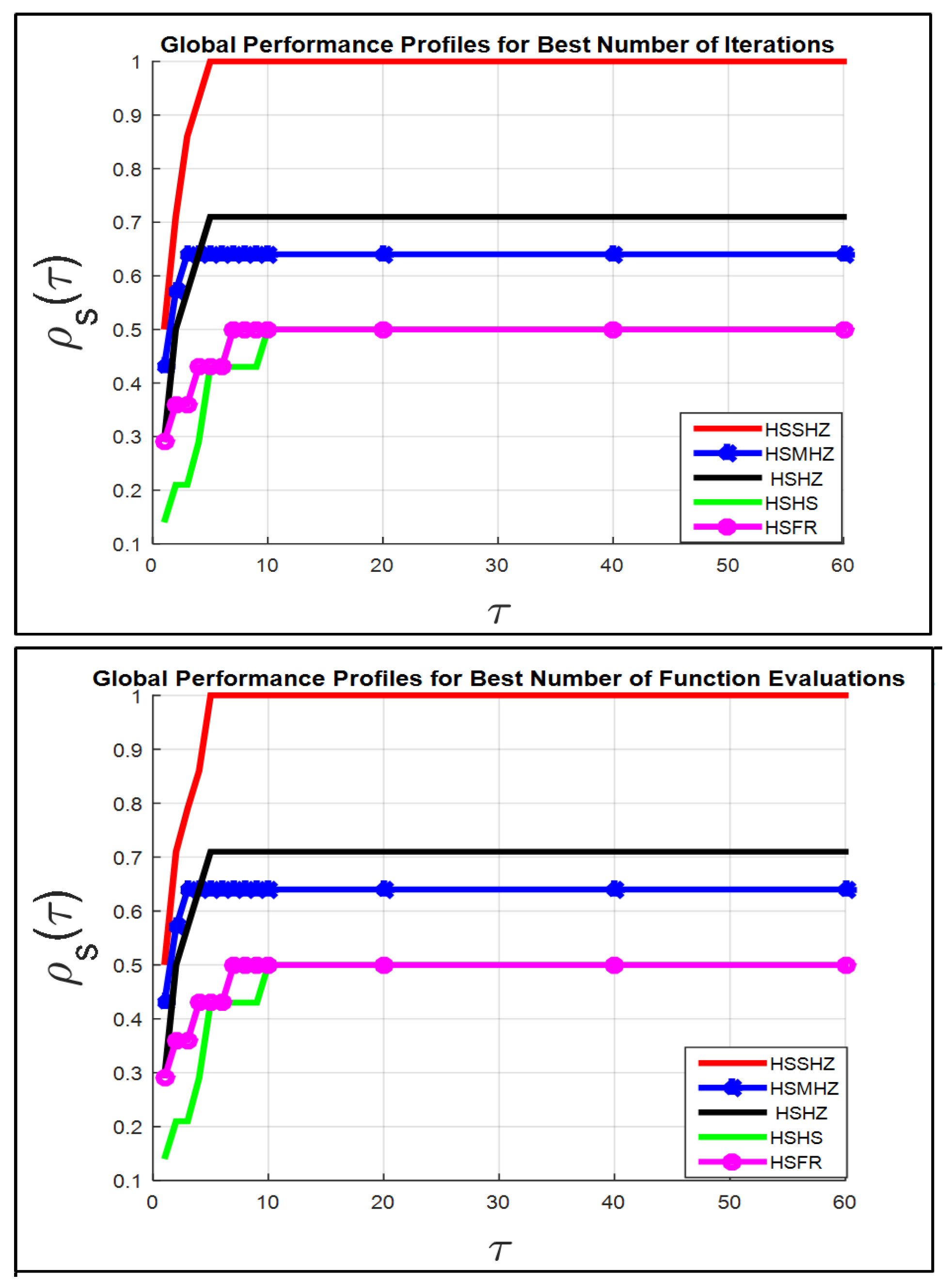
The performance profiles which are drawn on the left of
Figure 5 (in the term itr.w) compares 5 methods for the 14 test problems.
The HSSHZ technique has a good achievement (for the term itr.w) for all test problems, which indicates that the HSSHZ technique is capable of solving Problem (
2) as fast as or faster than the four techniques.
For instance, if , the HSSHZ algorithm solves of the 14 test problems against , , and , of the 14 test problems solved by the HSMHZ, HSHZ, HSFR and HSHS algorithms, respectively.
In general, for the term itr.w, exhibits that the second type of the test problems are solved by HSSHZ, while , , and of test problems are solved by the HSMHZ, HSHZ, HSHS and HSFR algorithms respectively.
Figure 5,
Figure 6,
Figure 7 and
Figure 8 demonstrate that the performance of the HSSHZ technique is better than the performance of the four techniques regarding the seven standards listed in the set Fit, respectively.
Therefore, the HSSHZ technique includes the characteristics of efficiency, reliability and effectiveness in finding the global minimizer of the non-convex function f compared to the other four methods.
It is worth observing that the power of the HSSHZ algorithm comes from the fact that the SHZ method gains the features of the four methods, MHZ, HZ, HS and FR, as mentioned in
Section 2.
Note 1: In Algorithm 3, a run is considered successful if Inequality (
64) is met.
where
is the exact global solution that is listed in Columns 3 and 7 of
Table 1, respectively, and the
is the final result obtained by Algorithm 3.
Note 2: Formula (
56) means if the final result
, obtained by Algorithm 3 satisfies Inequality (
64), then the first branch of (
56) is computed; otherwise, we set
.

 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}