Abstract
In this article, we propose a robust quantitative prescribed performance control (PPC) strategy for unknown strict-feedback systems, capable of quantitatively designing convergence time and minimizing overshoot. Firstly, a new quantitative prescribed performance mechanism is proposed to impose boundary constraint on tracking errors. Then, back-stepping is used to exploit virtual controllers and actual controllers based on the Nussbaum function, without requiring any prior knowledge of system unknown dynamics. Compared with the existing methodologies, the main contribution of this paper is that it can guarantee predetermined convergence time and zero overshoot for tracking errors and meanwhile there is no need for any fuzzy/neural approximation. Finally, compared simulation results are given to validate the effectiveness and advantage.
Keywords:
quantitative prescribed performance; transient performance; convergence time; overshoot; back-stepping MSC:
93D15
1. Introduction
Recently, prescribed performance control (PPC) has caused increasing interest and there have been many successful uses of PPC in a series of dynamic systems [1,2,3,4,5]. Compared with the other existing control strategies, the clear superiority of PPC is that it can impose boundary constraints on the convergence process of control errors, being expected to seek satisfactory transient performance and steady-state performance. The common technique of current PPC theories is to develop various types of performance functions which are further used to constrain control errors. Owing to the different considered focuses, lots of new performance functions [6,7,8] have been developed. It is noted that Bechlioulis’ constraint envelope [1] needs to be constructed according to the sign of initial tracking error and thus the control law needs to be designed repeatedly according to the positive or negative conditions, which may further lead to the control switching problem in different situations and also seriously reduces its engineering practicability. For this reason, a new performance function is designed in [6]. By setting a sufficiently large initial value for the performance function, the PPC [6] can get rid of the dependence on the initial value of the tracking error and the operability of the PPC algorithm is enhanced to a certain extent. The convergence time of the traditional PPC constraint envelope [1,6] is difficult to calculate by comprehensively using all the design parameters of the performance function. In order to overcome this defect, finite/fixed time performance functions [7] are devised based on the relevant ideas of the finite time sliding mode control to ensure that the tracking error converges to the steady state within the arbitrarily set time. In addition, in [8], an improved PPC approach with the ability to readjust boundaries is exploited to guarantee the tracking errors with desired prescribed performance.
Despite the excellent developments mentioned above, it is worth pointing out all of the existing PPC methodologies are qualitative ones, while the mechanism of quantitative constraint is still unclear. Based on PPC, the starting point is to exploit performance functions to constrain control errors. Then, the error transformation approach is adopted such that the “constrained” system is equivalently transformed into an unconstrained one which is convenient for controller design [1]. The newly defined transformed error, instead of the initial tracking error, is used to exploit feedback controllers. The boundedness of the transformed error is equivalent to the guarantees of the spurred prescribed performance. The original intention of PPC is to achieve good transient performance, which is determined by the formulations of performance functions. Performance functions contain several design parameters whose values directly affect the transient performance such as overshoot and convergence time of control errors. Unfortunately, the current PPC methods only qualitatively select appropriate design parameters for performance functions for the sake of obtaining satisfactory performance indices. However, what design parameters are appropriate? Moreover, how are appropriate design parameters for the quantitative designing of performance indices selected? None of this is clear. Actually, no schemes exist to quantitatively design overshoot and convergence time for tracking errors.
It is well known that the strict-feedback system is one of the most representational dynamic systems. The control system design for such systems has attracted extensive attention and achieved gratifying results [9,10,11,12]. Many practical systems such as robots, manipulators, servo mechanisms, aircraft, spacecraft and vessels can be represented as strict-feedback formulations. It is impossible to develop a model which can completely describe the actual system accurately. As a result, system uncertainties are inevitable. Considering a more rigorous condition, it is usually supposed that the system model is completely unknown. On this basis, fuzzy/neural approximation is a commonly used strategy [13,14,15,16,17,18]. The existing studies [9,10,12,14,15,19,20] consider a class of partially unknown strict-feedback systems; that is, the system functions are unknown while the control gains are assumed to be known constants. Thanks to the universal approximation property, fuzzy systems and neural networks are applied to estimate the unknown system functions and the convergences of estimation errors are ensured by regulation laws exploited for the elements of fuzzy/neural weight vectors [9,10,12,14,15,19,20]. Further, more general cases are investigated [17,18] and the authors suppose that both the system functions and control gains are unknown. Despite all this, a strict precondition that the bounds of unknown control gains must be known in advance is still necessary for control design. The fuzzy/neural approximation approach is used to estimate the hybrid function consisting of system functions and control gains, avoiding repeated approximations of both of them. Such a strict precondition [17,18] is removed in another study [21], but the sign of unknown control gain is still a priori information. In the last several years, lots of PPC-based control studies of strict-feedback systems have been reported [1,2,3,22,23]. Unfortunately, all of them cannot quantitatively set prescribed performance (i.e., overshoot and convergence time) for control errors. Moreover, the uncertainty rejection ability is accomplished via fuzzy/neural approximation at the expense of reducing real-time performance because of high computational online learning schemes. In addition, very strict preconditions for control gains seriously damage the operability and application prospect. For this reason, this paper proposes a novel quantitative PPC strategy for a type of unknown strict-feedback systems, capable of minimizing overshoot and quantitatively setting the convergence time, while no strict precondition or neural/fuzzy approximation is required. The special contributions are summarized as follows.
(1) Unlike the existing qualitative PPC [1,2,3,22,23], we develop a new type of performance function which guarantees quantitative prescribed performance (i.e., minimize the overshoot and quantitatively set the convergence time), being able to achieve given time convergence of control errors without overshoot.
(2) In the current studies [9,10,12,14,15,17,18,19,20,21], there needs to be the prior knowledge of the signs and the bounds of control gains. However, the proposed method is addressed based on a weaker precondition that both the control gains and the system functions are completely unknown continuous functions.
(3) Different from traditional fuzzy/neural-approximation-based adaptive control strategies [9,10,11,12,13,14,15,16], which suffer from high computational burden caused by multifarious online learning parameters required for fuzzy/neural weight vectors, this study exploits an approximation-free approach, utilizing the Nussbaum-type function, for unknown strict-feedback systems, while the computational burden is reduced effectively.
2. Problem Statement and Preliminaries
2.1. System Model
We utilize the following strict-feedback dynamic system
where is the state, is the control input and is the output. The system function and the control gain are unknown continuous functions.
Control objective: system states converge to their reference commands in a given time and the convergence time can be arbitrarily adjustable and the convergence overshoot is minimal.
Assumption 1
([13]). It is assumed that there exist constants such that
Assumption 2.
It is supposed that and are unknown continuous functions and the value of is nonzero.
Remark 1.
The existing studies [9,10,12,14,15,17,18,19,20] assume that is a known constant or is a bounded unknown function; that is, , where and are the lower bound and the upper bound. Due to uncertainties and disturbances, we cannot always obtain a known control gain . Moreover, it is also extremely difficult to obtain and for control design. In this article, is the basic controllability requirement for (1) and such a precondition is much looser in comparison with [9,10,12,14,15,17,18,19,20].
2.2. Quantitative Prescribed Performance
To accomplish the spurred control objective, we propose a new prescribed performance approach, being different from all of the existing ones, namely quantitative prescribed performance, which is capable of quantitatively designing the convergence time and minimizing the overshoot.
The addressed prescribed performance boundary is
where the tracking error is constrained by the newly developed performance functions and
where with , , , and .
The constraint performance by boundary (3) is clearly shown in Figure 1. Figure 1 reveals that if the tracking error is limited to the constraint boundary (3), then its transient performance and steady state performance can be quantitatively set as needed. Moreover, can converge its steady-state value in a given time and there is no convergence overshoot. If we choose , then and are linearly convergent in the transient process (See Figure 1b). Otherwise, the convergences of and are nonlinear.
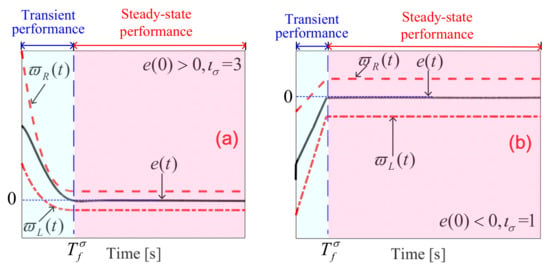
Figure 1.
Prescribed performance boundary (3); (a) ; (b) .
We make the following transformation to facilitate control design
with the error transformed function which satisfies and , where the transformed error is derived from (5) as
Theorem 1.
Proof.
The boundedness of means that there exists a positive constant such that . Then, (6) can be rewritten as
From (7), we further have
It is found that
The right side of (9) satisfies
The left side of (9) also satisfies
From (11), we finally obtain
It is concluded that the boundedness of is equivalent to (3). This completes the proof. □
3. Main Results
3.1. Controller Design
This subsection presents the design process of a quantitative prescribed performance controller for an unknown strict-feedback system (1) without using fuzzy/neural approximation based on back-stepping.
The tracking errors are defined as
are constrained by performance functions and
with
where , , , , and are design parameters and .
To facilitate control design, the “constrained” inequality (15) should be transformed into the following unconstrained one
with .
From (16), the transformed errors are derived as
Remark 2.
Notice that it is difficult to design control protocols directly using the inequality (15). We utilize an equivalent transformation approach to transform inequality (15) into Equation (16), which facilitates the control design and guarantees the spurred prescribed performance by stabilizing the transformed errors .
The time derivative dynamics of is
with
Based on the back-stepping design procedure, virtual controllers , the actual controller and the regulation law are designed as
where and are design parameters and is the Nussbaum function [2,24,25,26,27] with the argument .
Remark 3.
In the existing studies [9,10,12,14,15,17,18,19,20,21], the control gain should be strictly positive (or negative). However, in this article, such prior knowledge on the signs of is not required, which is owing to the adoption of the Nussbaum function in Equation (20b). In the stability proof, the property of the Nussbaum function (i.e., Lemma 1 in [2]) guarantees that the closed-loop control system is stable even when the control gain is unknown.
The following filters are introduced to handle the problem of “explosion of terms”.
where are design parameters and are the estimations of .
3.2. Stability Analysis
Theorem 2.
Proof.
The filter errors are defined as
□
It is derived from (23) that
The existing study [20] shows that there exist non-negative continuous functions abbreviated as , such that
This means that
The Lyapunov function candidate is chosen as
Employing (27), the time derivative of is
We abbreviate as . Because , , and are bounded, there exists a positive constant such that . Furthermore, due to
(29) becomes
The boundedness of means that continuous functions and are also bounded; that is, and , where and are positive constants. We further have and . Hence, (32) becomes
+ + and are bounded and their upper bounds are denoted by and . Then, (33) becomes
By Young’s inequality, we know . Thereby, (35) becomes
with
Multiplying by on both sides of (36) yields
Then, (38) becomes
Based on Lemma 1 in [2], we know that is bounded, which implies that all the signals involved in are bounded; that is, transformed errors are bounded. Hence the spurred prescribed performance (15) is also guaranteed according to Theorem 1. This is the end of the proof.
Remark 4.
Compared with the existing PPC approaches [1,2,3,4,5,6,7,8], the special novelty of the addressed method is that it can guarantee tracking errors converge their steady-state values in a given time and the convergence time can be arbitrarily quantitatively designed. Furthermore, the overshoot of tracking error convergence is also minimal.
Remark 5.

To reject system unknown dynamics, fuzzy/neural approximations [13,14,15,16,17,18] are common methods. Despite the global approximation ability of fuzzy systems and neural networks, the real-time performance may not be satisfied due to high computational load caused by lots of online learning/adaptive parameters. For one unknown function/term, one fuzzy/neural system is required. To obtain desired fuzzy/neural approximate performance, the elements of fuzzy/neural systems’ weight vectors should be updated online. As a result, those elements (usually, the number of elements is quite large) become adaptive parameters and adaptive laws should be devised and updated online for all the adaptive parameters. In addition, the direct adaptive control methodology [25,28] is also a common strategy to handle system uncertainties. Direct adaptive control methodologies directly estimate every unknown/uncertain parameter. Thus, for every unknown/uncertain parameter, we should design an adaptive law for it. It is worthy pointing out that adaptive parameters play the same role for both fuzzy/neural controls and direct adaptive control. This is because for every adaptive parameter (for both fuzzy/NN controls and direct adaptive control methodologies), one adaptive law is needed. As to a continuous control system, the adaptive law is essentially a differential equation. In the numerical simulation, we usually use the fourth order Runge–Kutta method to calculate the differential equation (adaptive law). As a result, one differential equation (adaptive law) becomes five algebraic equations. It is for this reason that both the existing fuzzy/neural controls [13,14,15,16,17,18] and direct adaptive control methodologies [25,28] will cause lots of computation costs (see Table 1), which will further harm the real-time performance of the control system. Fortunately, the proposed approximation-avoidance-based approach has no adaptive parameter. Thus the proposed method only has algebraic equation operation, which avoids a large amount of calculation of differential equations (adaptive laws). This reveals that the computational load is much lower in comparison with the controllers addressed in [13,17,18,28].
Table 1.
The comparison of approximation parameters.
4. Simulation Results
In this section, compared simulation results are presented to verify the superiority. The following strict-feedback system is considered.
with and .
The reference command is chosen as . Based on the results in Section 3, we design the following controllers, regulation law and filter.
The proposed method is compared with a direct neural control (DNC) strategy [29]. Design parameters are designed as: , , and = 0.1. The prescribed performance functions are designed as
with
We consider the following two cases.
Case 1: The initial tracking errors and are positive. The design parameters of performance functions are chosen as , , , , , , , , , , and .
Case 2: The initial tracking errors and are negative. The design parameters of performance functions are chosen as , , , , , , , , , , and .
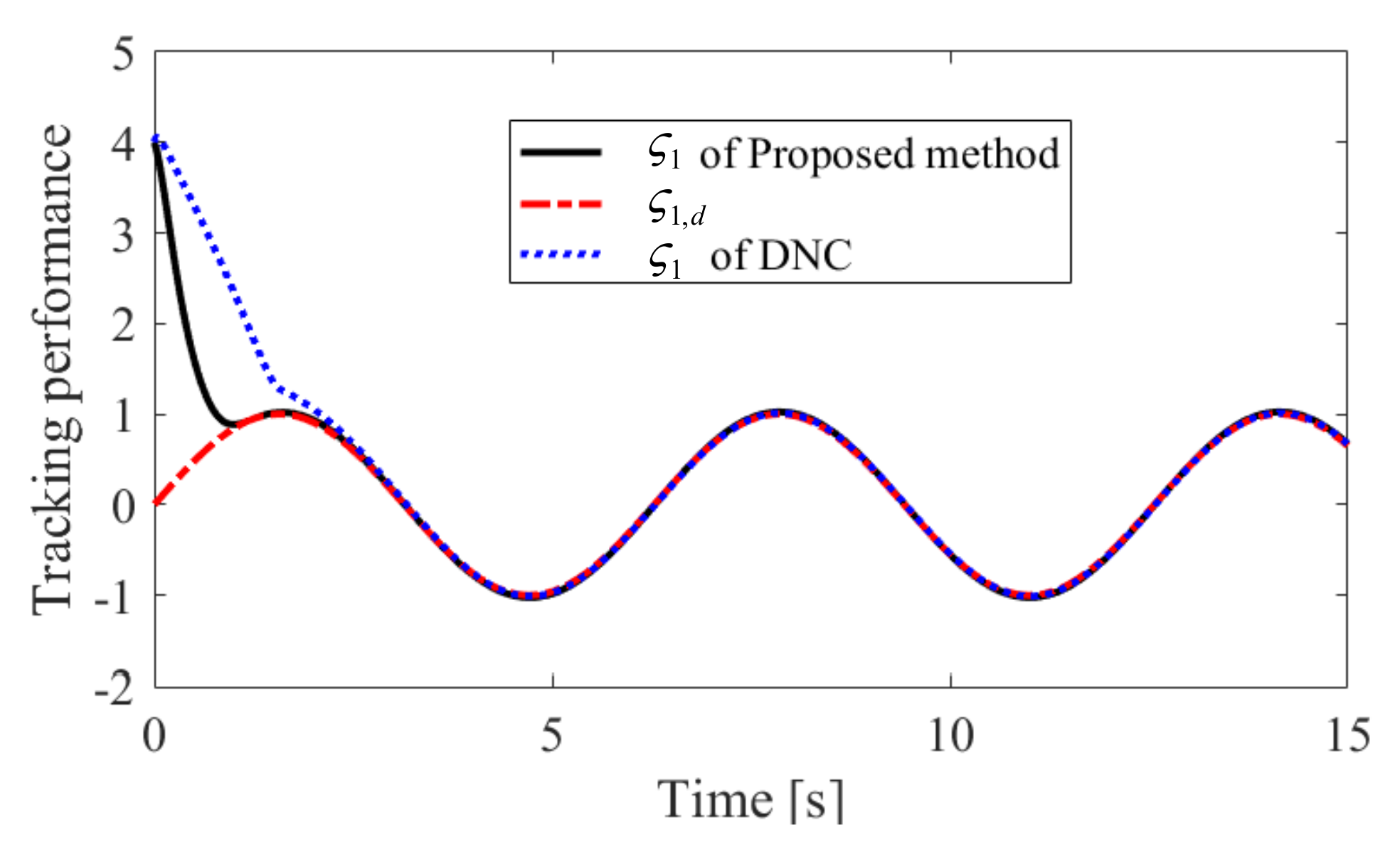
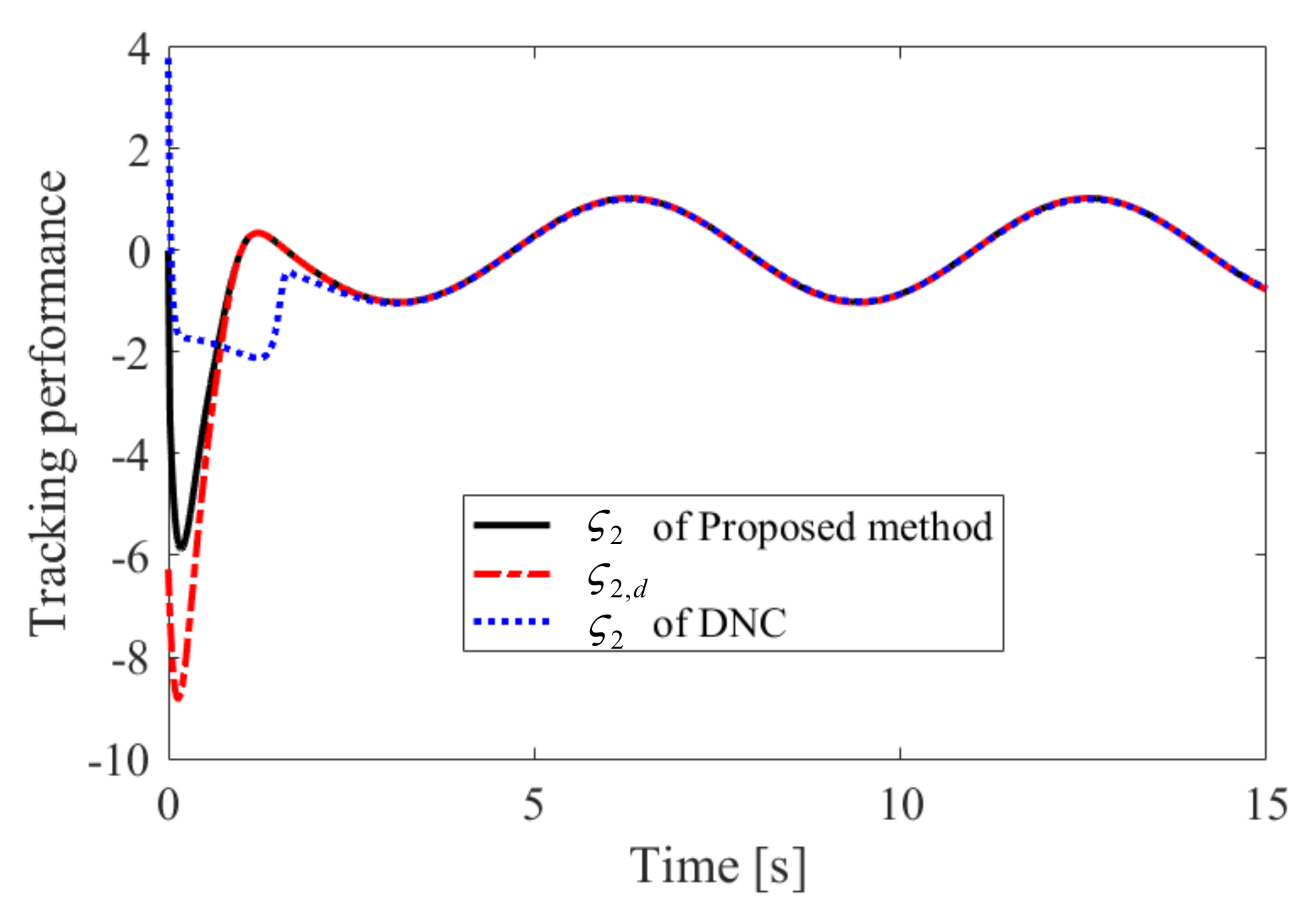
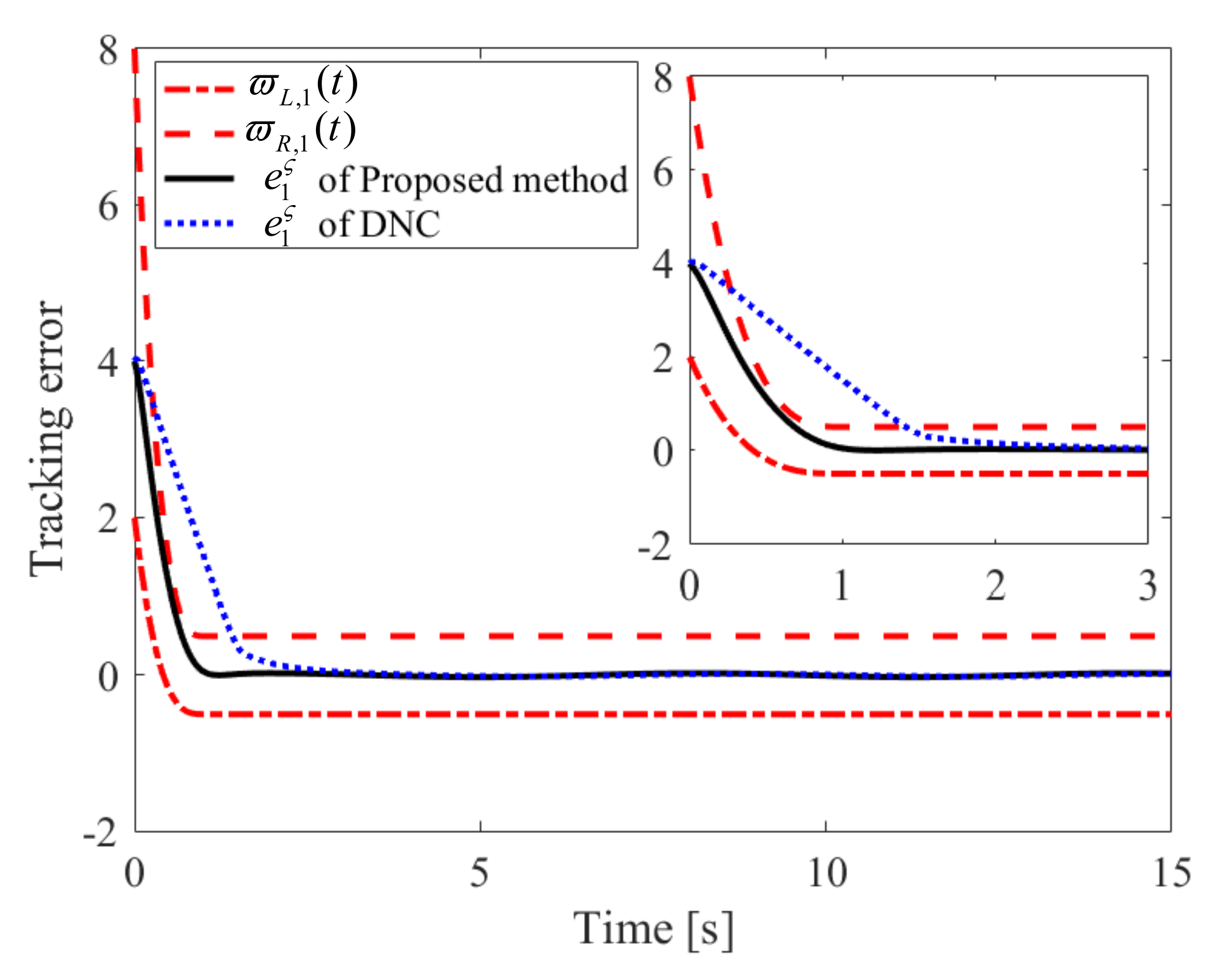
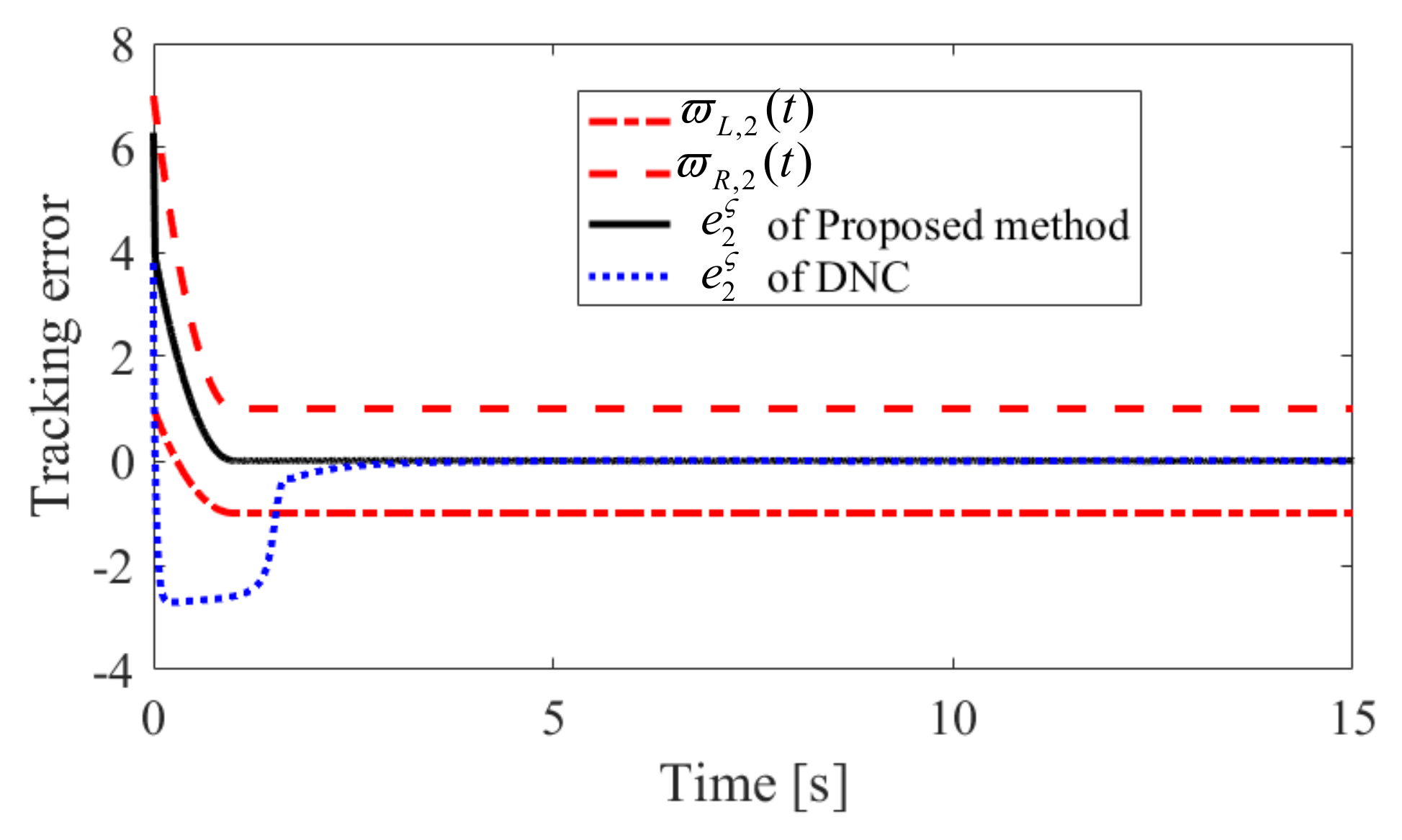
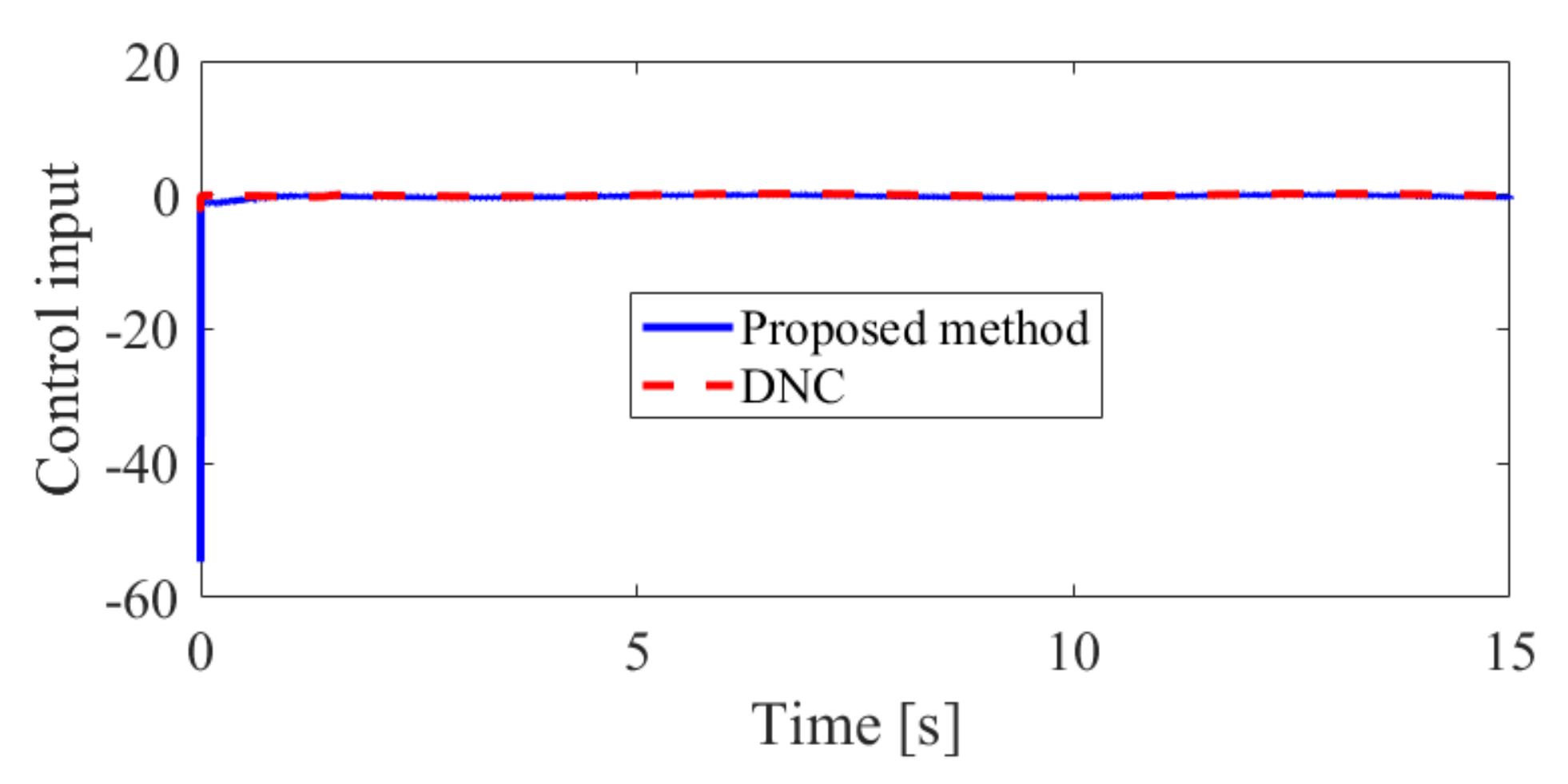
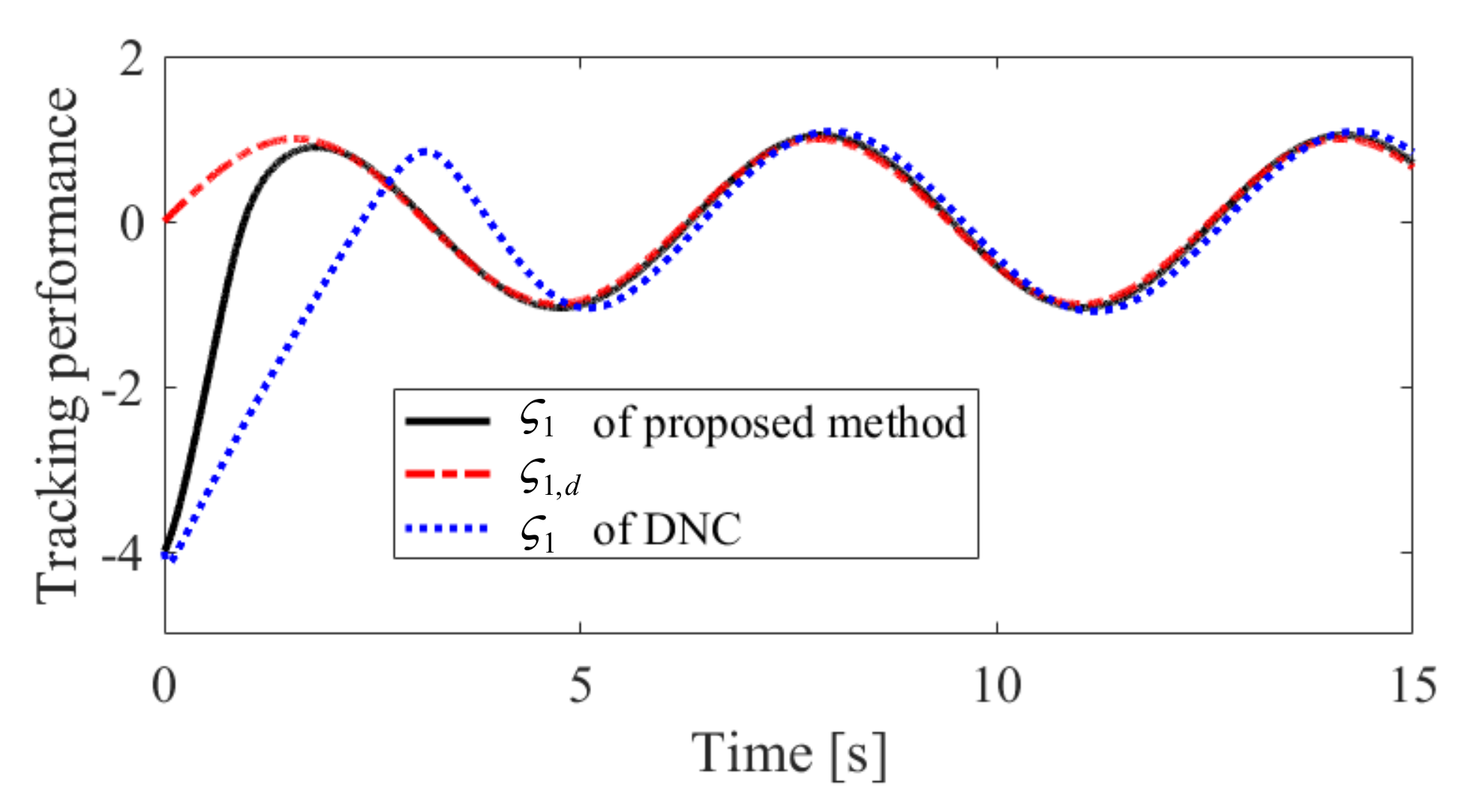
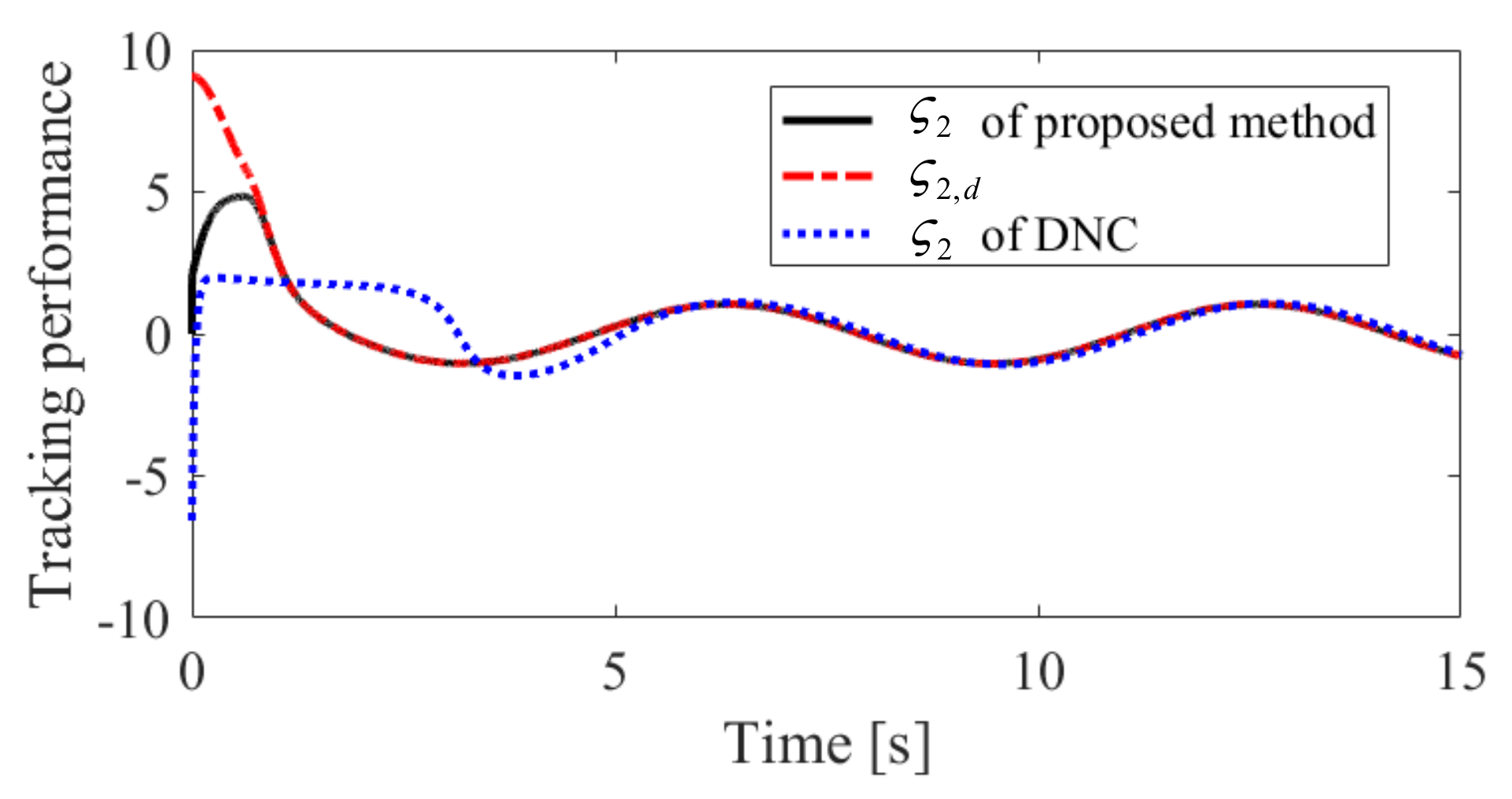
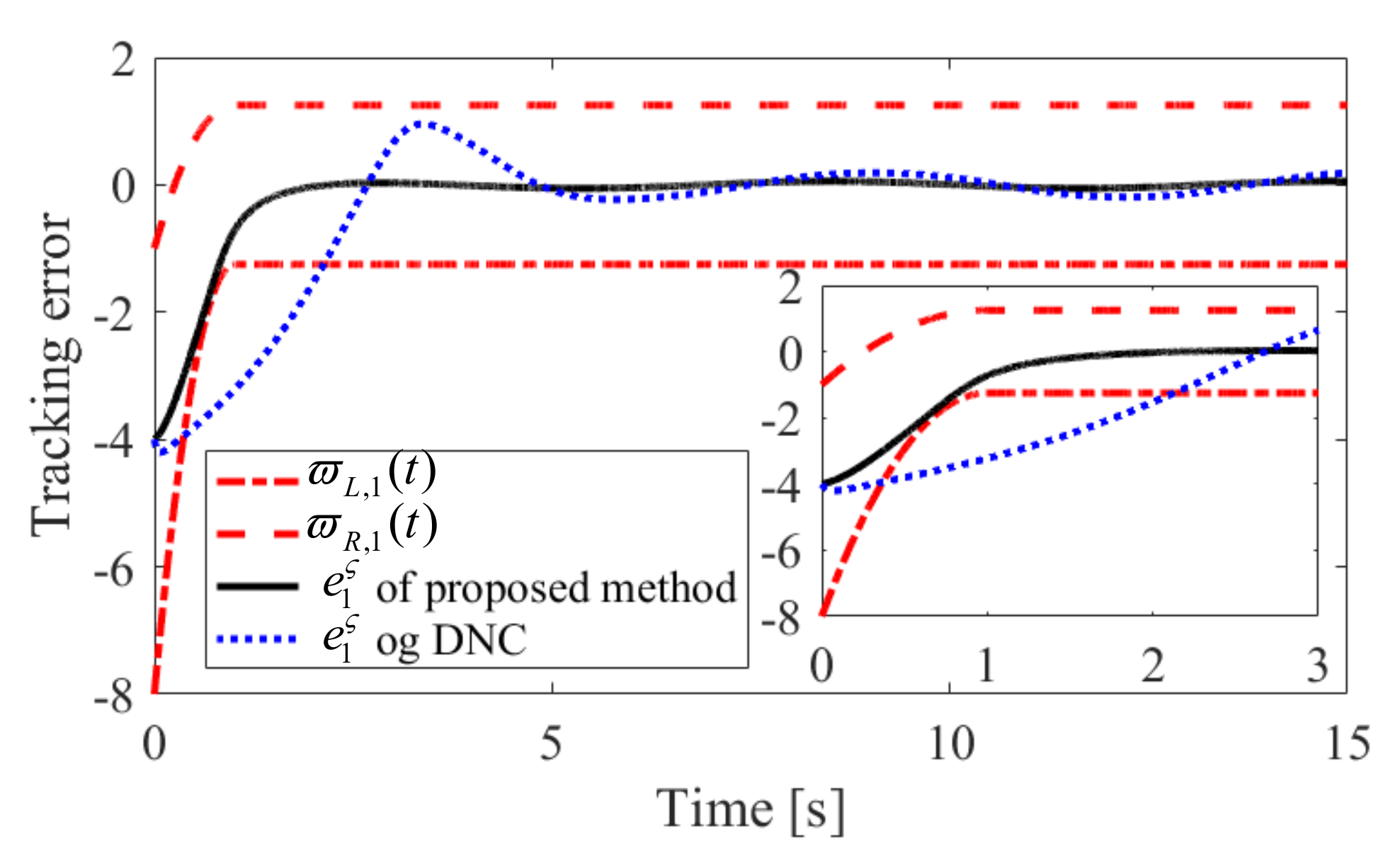
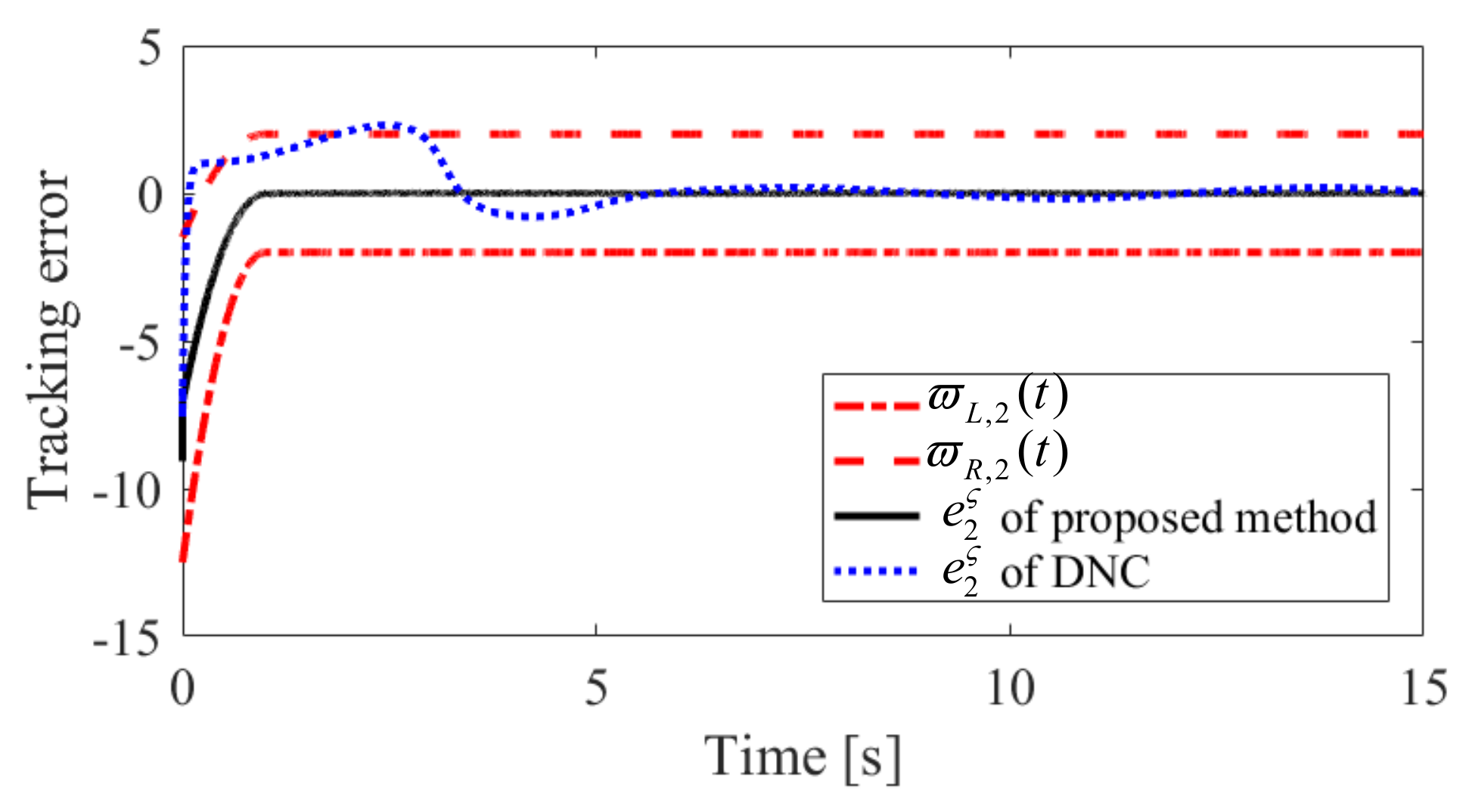
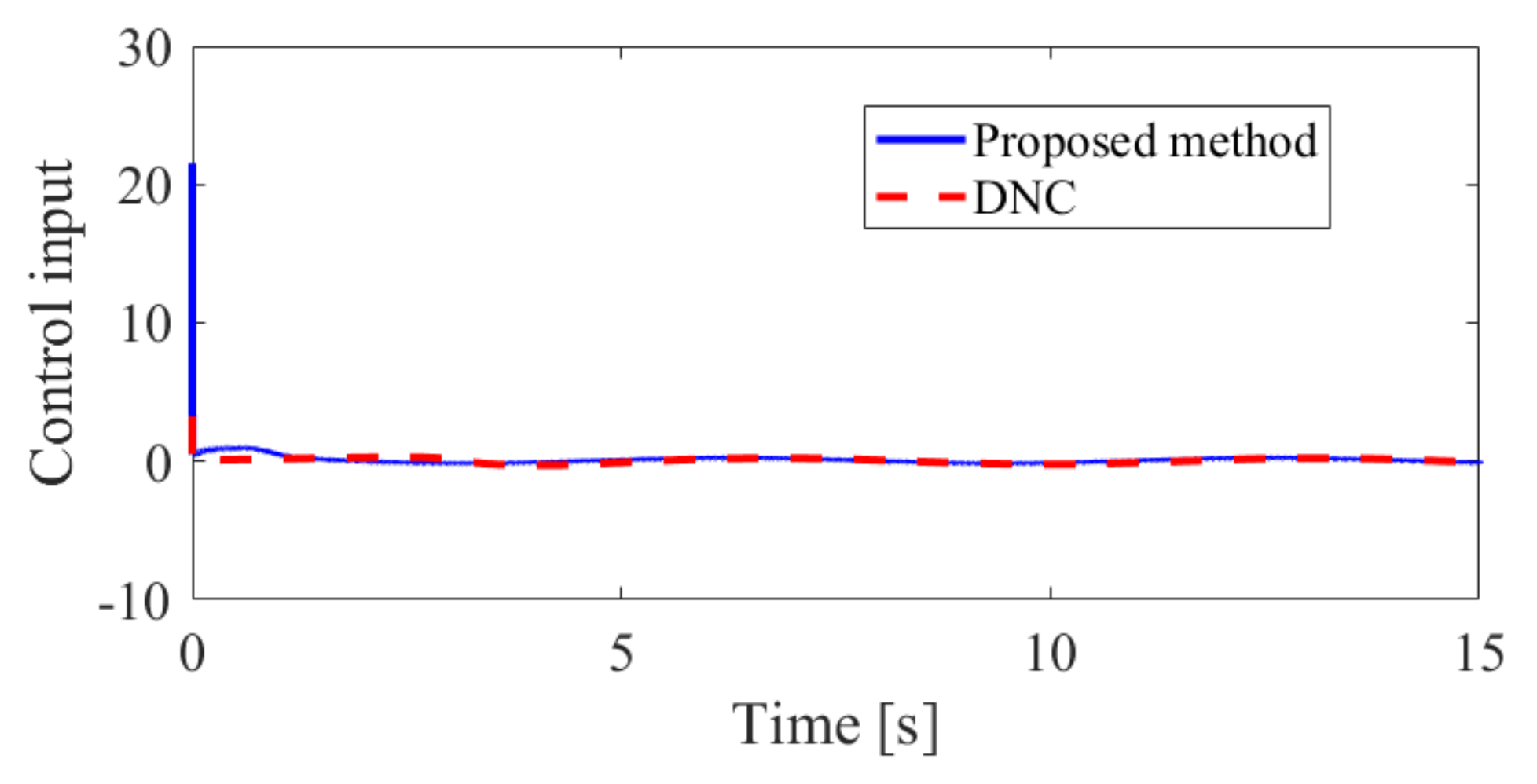
The obtained simulation results, depicted in Figure 2, Figure 3, Figure 4, Figure 5, Figure 6, Figure 7, Figure 8, Figure 9, Figure 10 and Figure 11, indicate that the proposed method can provide stable tracking of reference commands (see Figure 2, Figure 3, Figure 7 and Figure 8), capable of guaranteeing the desired prescribed performance, for both cases. Figure 4, Figure 5, Figure 9 and Figure 10 clearly show that the proposed method can guarantee tracking errors with satisfied prescribed performance; that is, tracking errors can converge to their steady-state values in a given time without overshoot. Moreover, in comparison with DNC, the proposed method can guarantee tracking errors with better transient performance (i.e., shorter convergence time and smaller overshoot. See Figure 4 and Figure 5) and smaller steady-state values of tracking errors (see Figure 9 and Figure 10). Finally, the control input is presented in Figure 6 and Figure 11.
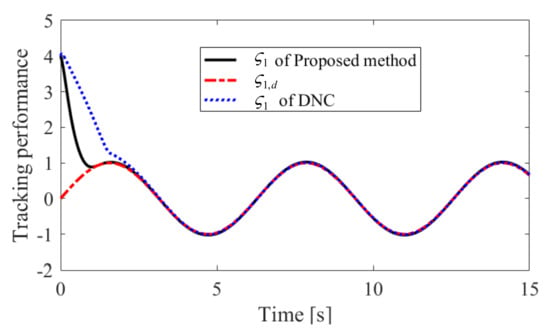
Figure 2.
Tracking performance of in Case 1.
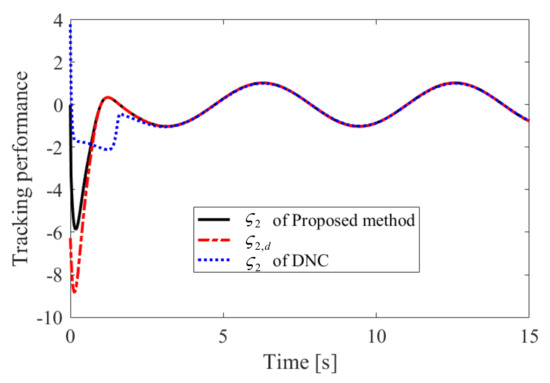
Figure 3.
Tracking performance of in Case 1.
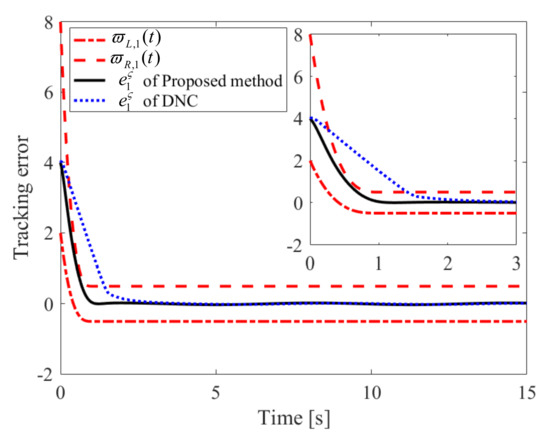
Figure 4.
Convergence performance of in Case 1.
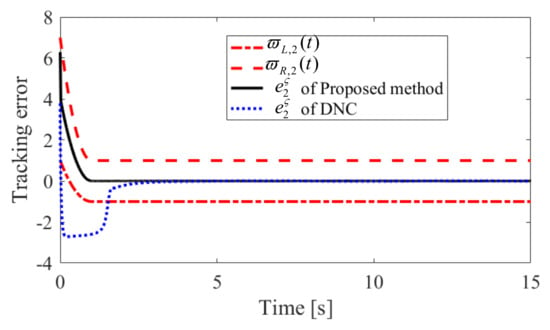
Figure 5.
Convergence performance of in Case 1.
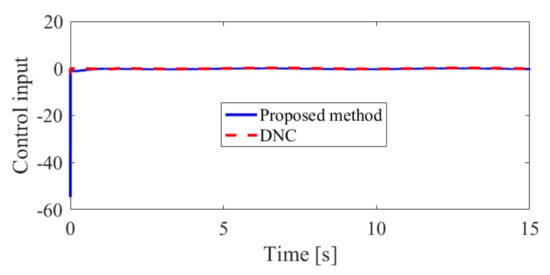
Figure 6.
The control input in Case 1.
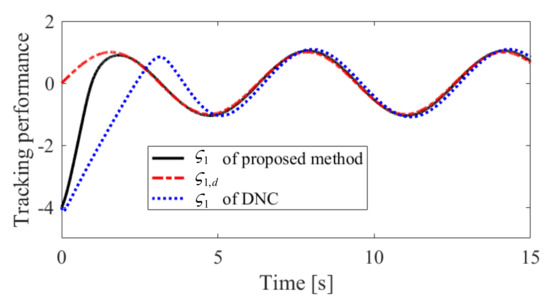
Figure 7.
Tracking performance of in Case 2.
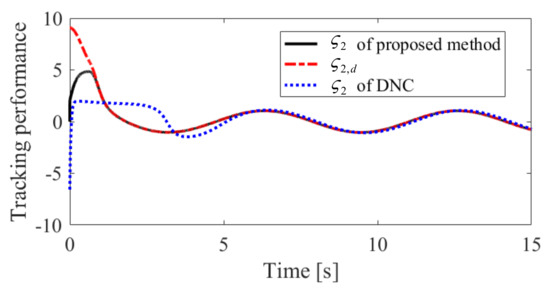
Figure 8.
Tracking performance of in Case 2.
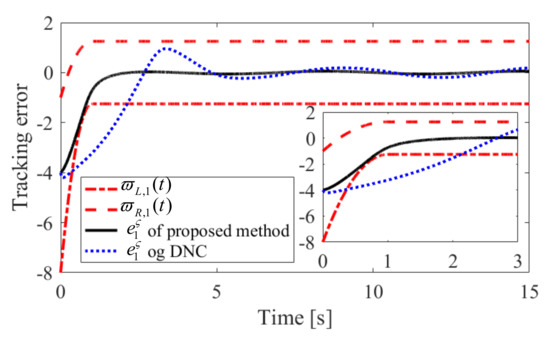
Figure 9.
Convergence performance of in Case 2.
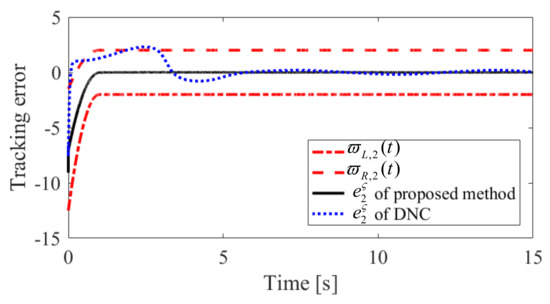
Figure 10.
Convergence performance of in Case 2.
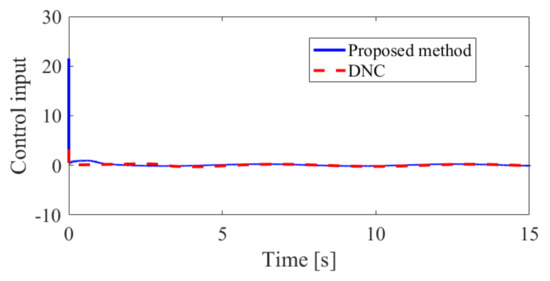
Figure 11.
The control input in Case 2.
5. Conclusions
A new PPC strategy able to quantitatively design transient performance indices such as convergence time and overshoot is investigated for a type of strict-feedback system with unknown dynamics. A new kind of performance function is designed to quantitatively constrain tracking errors with prescribed performance guarantees. Then, error transformed functions are introduced to facilitate control developments, from which transformed errors are derived for back-stepping controller design. Furthermore, from the benefit of the Nussbaum function, the addressed controller can reject unknown system dynamics without any fuzzy/neural approximation. The stability of the closed-loop system is proved and the superiority of the proposed method is verified via simulation results. Our next research direction is to introduce the reinforcement-learning and simplified neural approximation approaches [30,31,32] to further enhance the tracking performance of the proposed strategy.
Author Contributions
Investigation, Y.F.; Writing, X.B. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by Young Talent Support Project for Science and Technology (Grant No. 18-JCJQ-QT-007).
Data Availability Statement
The experimental data used to support the findings of this study are available from the corresponding author upon request.
Conflicts of Interest
The authors declare that they have no conflict of interest.
References
- Bechlioulis, C.P.; Rovithakis, G.A. A low-complexity global approximation-free control scheme with prescribed performance for unknown pure feedback systems. Automatica 2014, 50, 1217–1226. [Google Scholar] [CrossRef]
- Bu, X.; Xiao, Y.; Lei, H. An Adaptive Critic Design-Based Fuzzy Neural Controller for Hypersonic Vehicles: Predefined Behavioral Nonaffine Control. IEEE/ASME Trans. Mechatron. 2019, 24, 1871–1881. [Google Scholar] [CrossRef]
- Bu, X.; Jiang, B.; Lei, H. Non-fragile Quantitative Prescribed Performance Control of Waverider Vehicles with Actuator Saturation. IEEE Trans. Aerosp. Electron. Syst. 2022, 58, 3538–3548. [Google Scholar] [CrossRef]
- Bu, X. Air-Breathing Hypersonic Vehicles Funnel Control Using Neural Approximation of Non-affine Dynamics. IEEE/ASME Trans. Mechatron. 2018, 23, 2099–2108. [Google Scholar] [CrossRef]
- Bu, X.; Qi, Q.; Jiang, B. A Simplified Finite-Time Fuzzy Neural Controller with Prescribed Performance Applied to Waverider Aircraft. IEEE Trans. Fuzzy Syst. 2021, 30, 2529–2537. [Google Scholar] [CrossRef]
- Bu, X.; Wu, X.; Zhu, F.; Huang, J.; Ma, Z.; Zhang, R. Novel prescribed performance neural control of a flexible air-breathing hypersonic vehicle with unknown initial errors. ISA Trans. 2015, 59, 149–159. [Google Scholar] [CrossRef]
- Liang, H.; Zhang, Y.; Huang, T.; Ma, H. Prescribed Performance Cooperative Control for Multiagent Systems with Input Quantization. IEEE Trans. Cybern. 2020, 50, 1810–1819. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Hu, J.; Li, J.; Liu, B. Improved prescribed performance control for nonaffine pure-feedback systems with input saturation. Int. J. Robust Nonlinear Control. 2019, 29, 1769–1788. [Google Scholar] [CrossRef]
- Li, Y.; Tong, S.; Li, T. Adaptive Fuzzy Output Feedback Dynamic Surface Control of Interconnected Nonlinear Pure-Feedback Systems. IEEE Trans. Cybern. 2015, 45, 138–149. [Google Scholar] [CrossRef]
- Li, Y.; Tong, S.; Li, T. Composite Adaptive Fuzzy Output Feedback Control Design for Uncertain Nonlinear Strict-Feedback Systems with Input Saturation. IEEE Trans. Cybern. 2015, 45, 2299–2308. [Google Scholar] [CrossRef] [PubMed]
- Wang, F.; Liu, Z.; Zhang, Y.; Chen, C.L.P. Adaptive Fuzzy Control for a Class of Stochastic Pure-Feedback Nonlinear Systems with Unknown Hysteresis. IEEE Trans. Fuzzy Syst. 2016, 24, 140–152. [Google Scholar] [CrossRef]
- Sun, K.; Li, Y.; Tong, S. Fuzzy Adaptive Output Feedback Optimal Control Design for Strict-Feedback Nonlinear Systems. IEEE Trans. Syst. Man Cybern. Syst. 2017, 47, 33–44. [Google Scholar] [CrossRef]
- Gao, T.; Liu, Y.; Liu, L.; Li, D. Adaptive Neural Network-Based Control for a Class of Nonlinear Pure-Feedback Systems with Time-Varying Full State Constraints. IEEE/CAA J. Autom. Sin. 2018, 5, 923–933. [Google Scholar] [CrossRef]
- Choi, Y.H.; Yoo, S.J. Filter-Driven-Approximation-Based Control for a Class of Pure-Feedback Systems with Unknown Nonlinearities by State and Output Feedback. IEEE Trans. Syst. Man Cybern. Syst. 2018, 48, 161–176. [Google Scholar] [CrossRef]
- Zerari, N.; Chemachema, M.; Essounbouli, N. Neural Network Based Adaptive Tracking Control for a Class of Pure Feedback Nonlinear Systems with Input Saturation. IEEE/CAA J. Autom. Sin. 2019, 6, 278–290. [Google Scholar] [CrossRef]
- Wu, J.; Wu, Z.; Li, J.; Wang, G.; Zhao, H.; Chen, W. Practical Adaptive Fuzzy Control of Nonlinear Pure-Feedback Systems with Quantized Nonlinearity Input. IEEE Trans. Syst. Man Cybern. Syst. 2019, 49, 638–648. [Google Scholar] [CrossRef]
- Tan, L.N. Distributed H∞ Optimal Tracking Control for Strict-Feedback Nonlinear Large-Scale Systems with Disturbances and Saturating Actuators. IEEE Trans. Syst. Man Cybern. Syst. 2020, 50, 4719–4731. [Google Scholar] [CrossRef]
- Chen, Q.; Shi, H.; Sun, M. Echo State Network-Based Backstepping Adaptive Iterative Learning Control for Strict-Feedback Systems: An Error-Tracking Approach. IEEE Trans. Cybern. 2020, 50, 3009–3022. [Google Scholar] [CrossRef]
- Qiu, J.; Su, K.; Wang, T.; Gao, H. Observer-Based Fuzzy Adaptive Event-Triggered Control for Pure-Feedback Nonlinear Systems with Prescribed Performance. IEEE Trans. Fuzzy Syst. 2019, 27, 2152–2162. [Google Scholar] [CrossRef]
- Bu, X.; Qi, Q. Fuzzy optimal tracking control of hypersonic flight vehicles via single-network adaptive critic design. IEEE Trans. Fuzzy Syst. 2022, 30, 270–278. [Google Scholar] [CrossRef]
- Zhang, J.; Yang, G. Fuzzy Adaptive Output Feedback Control of Uncertain Nonlinear Systems with Prescribed Performance. IEEE Trans. Cybern. 2018, 48, 1342–1354. [Google Scholar] [CrossRef]
- Yang, Z.; Zong, X.; Wang, G. Adaptive prescribed performance tracking control for uncertain strict-feedback Multiple Inputs and Multiple Outputs nonlinear systems based on generalized fuzzy hyperbolic model. Int. J. Adapt. Control. Signal Process. 2020, 34, 1847–1864. [Google Scholar] [CrossRef]
- Gao, S.; Dong, H.; Zheng, W. Robust resilient control for parametric strict feedback systems with prescribed output and virtual tracking errors. Int. J. Robust Nonlinear Control. 2019, 29, 6212–6226. [Google Scholar] [CrossRef]
- Bu, X.; Wei, D.; Wu, X.; Huang, J. Guaranteeing preselected tracking quality for air-breathing hypersonic non-affine models with an unknown control direction via concise neural control. J. Frankl. Inst. 2016, 353, 3207–3232. [Google Scholar] [CrossRef]
- Bu, X. Guaranteeing prescribed output tracking performance for air-breathing hypersonic vehicles via non-affine back-stepping control design. Nonlinear Dyn. 2018, 91, 525–538. [Google Scholar] [CrossRef]
- Liu, Z.; Dong, X.; Xue, J.; Li, H.; Chen, Y. Adaptive neural control for a class of pure-feedback nonlinear systems via dynamic surface technique. IEEE Trans. Neural Netw. Learn. Syst. 2016, 27, 1969–1975. [Google Scholar] [CrossRef]
- Liu, Z.; Huang, J.; Wen, C.; Su, X. Distributed control of nonlinear systems with unknown time-varying control coefficients: A novel Nussbaum Function approach. IEEE Trans. Autom. Control. 2022. [Google Scholar] [CrossRef]
- Xu, B.; Huang, X.; Wang, D.; Sun, F. Dynamic surface control of constrained hypersonic flight models with parameter estimation and actuator compensation. Asian J. Control. 2014, 16, 162–174. [Google Scholar] [CrossRef]
- Bu, X.; Wu, X.; Ma, Z.; Zhang, R. Nonsingular direct neural control of air-breathing hypersonic vehicle via back-stepping. Neurocomputing 2015, 153, 164–173. [Google Scholar] [CrossRef]
- Park, J.; Kim, S.; Park, T. Output-Feedback Adaptive Neural Controller for Uncertain Pure-Feedback Nonlinear Systems Using a High-Order Sliding Mode Observer. IEEE Trans. Neural Networks Learn. Syst. 2019, 30, 1596–1601. [Google Scholar] [CrossRef]
- Bu, X.; He, G.; Wang, K. Tracking control of air-breathing hypersonic vehicles with non-affine dynamics via improved neural back-stepping design. ISA Trans. 2018, 75, 88–100. [Google Scholar] [CrossRef]
- Vu, V.; Pham, T.; Dao, P. Disturbance observer-based adaptive reinforcement learning for perturbed uncertain surface vessels. ISA Trans. 2022. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).