2.1. Determination of Predicted Parameters
To begin the study, it is necessary to identify the possible factors influencing the adoption of measures. As for Moscow, the decrees of the mayor of Moscow do not indicate specific indicators used to make decisions on restrictions on the movement of the population [
28,
29]. However, the features of COVID-19 are already well known, which is characterized by high contagiousness, a long incubation period, and a rather high probability of serious complications requiring inpatient treatment. All of these factors combine to quickly overwhelm the healthcare system. Therefore, it is natural to take the number of infections per day and the number of hospitalized patients with COVID-19 per day as the baseline indicators of the study. The first parameter reflects the spread of new coronavirus infection, and the second parameter (the number of hospitalized) reflects the load on the bed fund and the healthcare system as a whole. The achievement of a certain critical level by these parameters becomes a significant reason for deciding to impose restrictions.
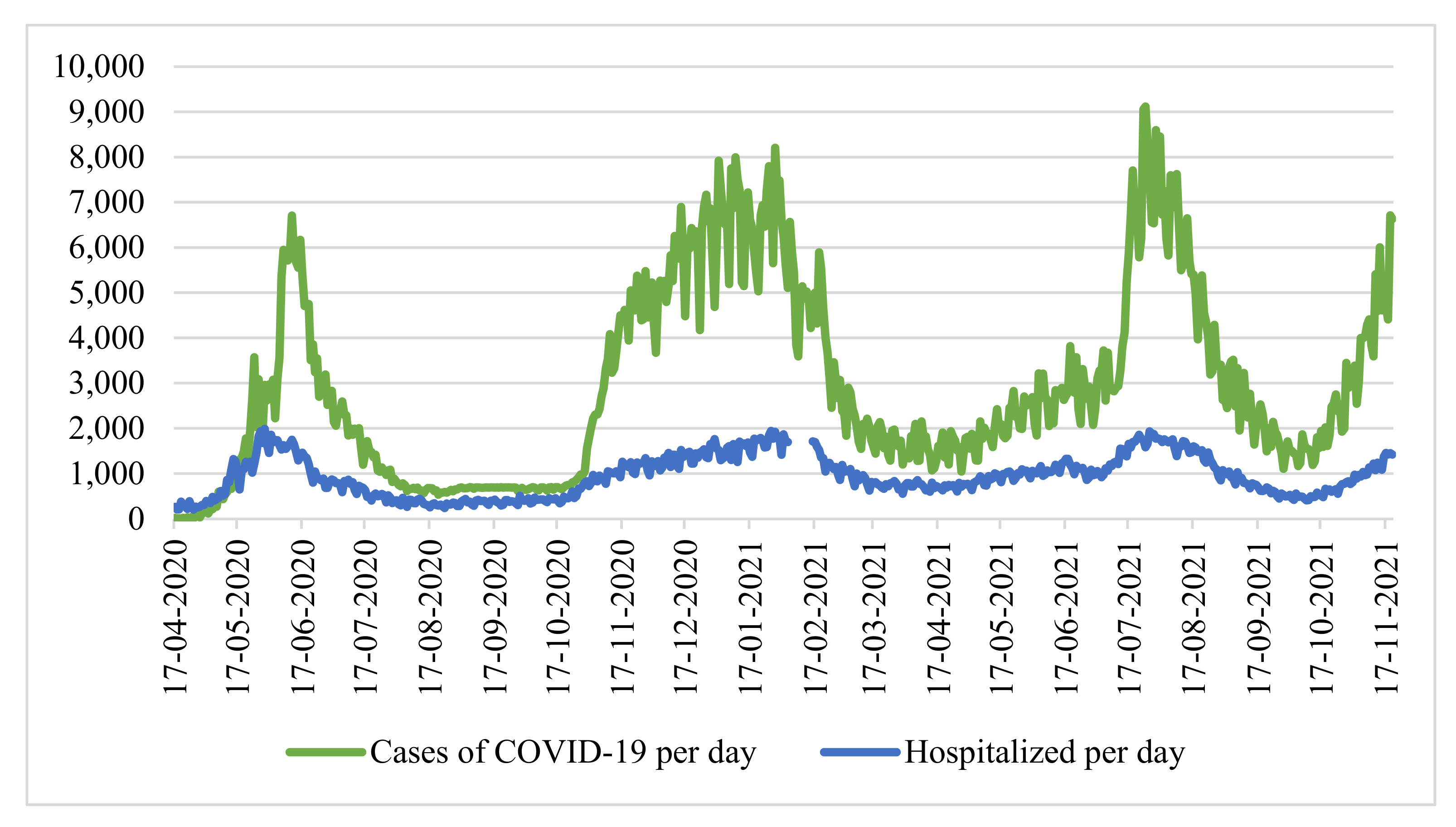
We conducted a study using the example of Moscow. We considered the time series of cases of coronavirus infection and the number of hospitalized patients in the city of Moscow from 12 March 2020 to 15 October 2021 (
Figure 1) [
30]. At the same time, there are no data for the period from 31 December 2020 to 10 January 2021, since the Moscow operational headquarters did not publish statistics on the number of hospitalized individuals with a new coronavirus infection during this period.
Denote the number of cases of COVID-19 infection per day by the function
f(
t), and the number of hospitalized by the function
φ(
t), where t is a step in time (day). To check whether it is necessary to simultaneously use both indicators, we calculated the Pearson correlation coefficient:
where:
—number of cases per day
,
—number of hospitalized per day
,
and
—the arithmetic mean of the sample. To eliminate the difference in sample size associated with the lack of data on hospitalizations from 31 December 2020 to 10 December 2020, the corresponding values for the number of infections were removed.
The correlation coefficient for the entire sample size is 0.866735, which characterizes the level of linear relationship as high. However, considering the periods of “waves”, we note that the number of hospitalized people grows in proportion to the number of infected individuals. Therefore, in the period from 1 October 2020 to 31 December 2020 (main stage “second” wave of coronavirus), the coefficient was only 0.627 (weak—moderate on the scale of E.P. Golubkov), and during the period of active growth of the third wave (from 9 June 2021 to 22 July 2021), the coefficient was 0.636 (moderate).
This discrepancy is explained by the following: in periods between waves of morbidity, the healthcare system can hospitalize a larger number of patients (including those with mild and moderate disease), and during a period of active growth, the healthcare system is forced to refuse hospitalization for patients with mild and moderately mild disease due to insufficient bed capacity, hospitalizing only moderately and seriously ill patients. Due to this fact, during periods of “waves”, the correlation between the number of hospitalized and sick people is noticeably weak, as a result of which it is necessary to consider both factors as influencing the decision to introduce measures aimed at improving the sanitary and epidemiological situation.
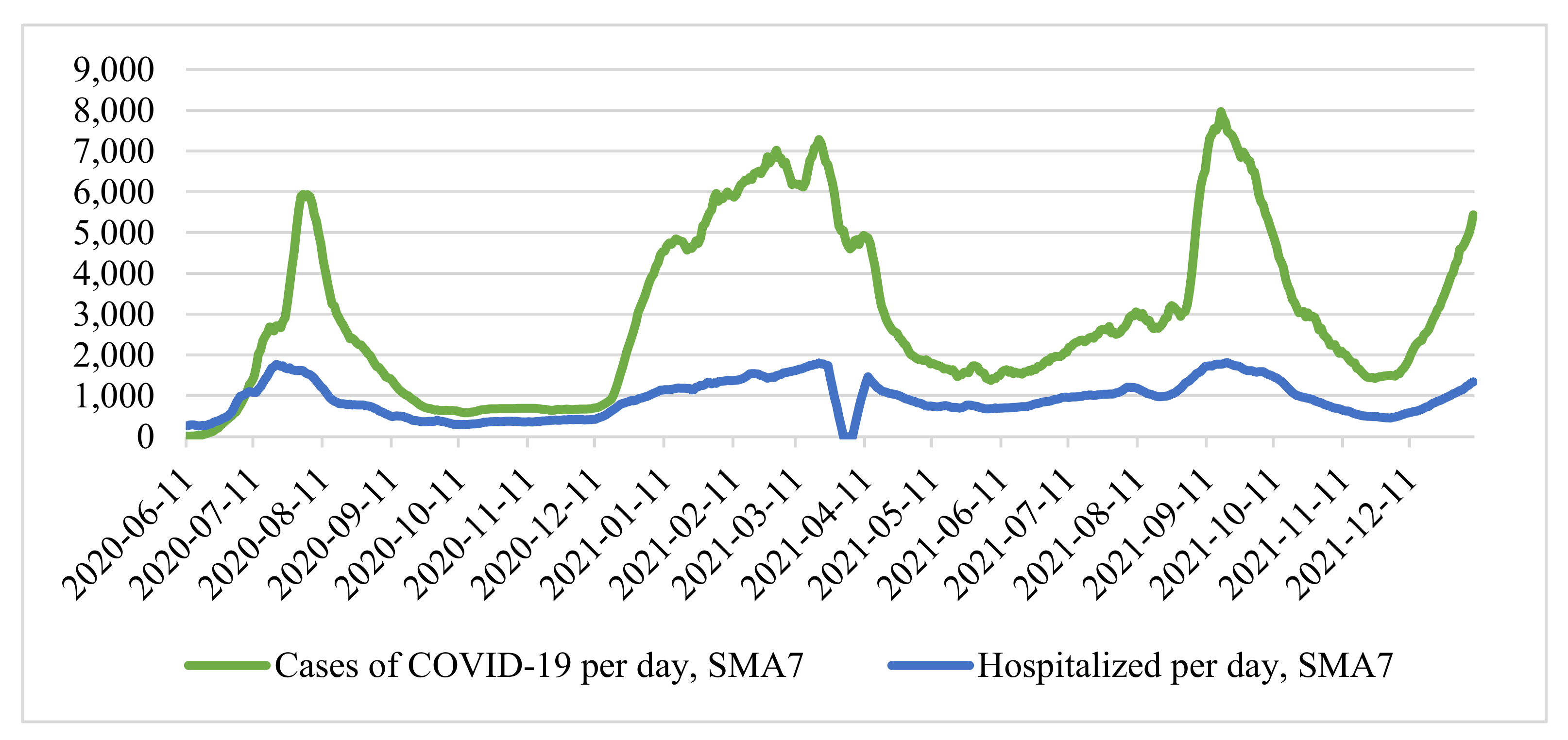
Since the time series above (
Figure 1) is characterized by strong daily changes, we applied a seven-day moving average, simple moving average (
SMA7):
where:
is the number of cases of hospitalizations at the point
. As a result, we obtained a smoothed time series (
Figure 2).
We determined the “critical” values of the parameters based on the dates of the introduction of measures aimed at stabilizing the epidemiological situation: 13 November 2020 to 13 June 2021. It is known that the duration of the disease from the moment of onset of symptoms in the case of moderate to severe averages 28 days [
31]. Taking this into account, we determined the cumulative number of patients in the period up to the moment
= 13.11.2020 at
, in the period before
= 13.06.2021 at
:
Similarly, we determines the cumulative number of hospitalized individuals in the period up to the moments
—for
and
—for
:
At the time of making decisions on the introduction of new restrictive measures, the indicators of the cumulative number of hospitalized
and
are approximately similar. However, the difference between
and
is significant. From the smoothed time series of the number of cases (
Figure 2), it can be seen that the growth of incidence rates in the first case is more uniform than in the second, which was more “explosive”.
For a more detailed analysis, we used the
Rt Coronavirus Spread Index, also known as the effective reproductive number. This indicator reflected the rate of growth of new cases of new coronavirus infection, calculated using the “4 by 4” method:
where
is the current day. In other words, the number of people infected in the last 4 days (including the current one) is divided by the number of people infected in the previous 4 days.
This indicator, used by Rospotrebnadzor as a metric for deciding whether to soften or strengthen restrictive measures, shows how many people manage to infect one infected person before they are isolated. If Rt < 1, Rospotrebnadzor recommends starting to mitigate restrictive measures. The calculation according to the “4 by 4” formula makes it possible to smooth out daily fluctuations in the number of detected cases of COVID-19 infection, occurring due to the different number of tests taken and processed to detect a new coronavirus infection.
The spread of coronavirus was also considered in conjunction with the baseline reproduction rate
R0 (baseline reproductive number).
R0 is the average number of people who are infected by one carrier in a naive population, that is, a population whose citizens do not have immunity to this disease at all and do not take any measures to protect themselves from it. We can say that at the beginning of the epidemic,
Rt coincided with
R0. The baseline reproduction rate cannot be measured directly, and its value depends on the chosen model of the infection mechanism and, at the same time, remains constant. Several studies also indicate that the basic reproductive number
R0 does not take into account the presence of “super-spreaders” and individual differences in infectivity and is often highly distorted [
32,
33,
34]. Therefore, for research purposes, the
R0 level is not of interest.
We considered the dynamics of the index in the first and second moments during the three days before and after the introduction of measures to reduce the incidence (
Table 1).
With the introduction of restrictive measures in November 2020, the average value of the index was 1.02. When the restrictive measures were introduced in June 2021, the average value of the index was 1.54. Moreover, in June 2021, there was a significant increase in the number of cases of the disease, which had an additional impact on the decision to introduce restrictive measures.
2.2. Forecasting Based on the Exponential Model
For further analysis and prognosis, it is required to approximate the values of the number of cases of the disease and the number of hospitalizations. Note that during the period of increasing incidence, the growth is exponential. Thus, the function of the number of cases of the disease can be represented as:
where
,
—some ratios. Whence, after taking the logarithm, we obtain:
Suppose
, then the function can be represented as:
In this case, the problem is reduced to estimating the parameters of the paired linear regression model using the least-squares method:
Then the estimates of the coefficients can be found by the formula:
Approximating the data on the smoothed time series from 1 September 2021 to 16 October 2021, we obtain:
We compared the data of the time series of smoothed values of infection cases and the resulting function (
Figure 3).
In this case, the coefficient of determination was 0.9918, which characterizes the model on the segment as satisfactory. Note that forecasting based on the exponential model allows us to very accurately simulate the initial growth period occurring in real-time.
In
Figure 3, it can be seen that
is lagging from the real number of cases per day, but it is the lag of the function
« from the actual current indicators that will increase the forecast accuracy over a short time interval since the values of
will be higher than the increase in morbidity in the long run. Since, at the moment, the average value of the
index in the period over the past 7 days is 1.1, it is logical to assume that the critical value of the number of cases of the disease, further denoted as
is more likely to impact the value of
(143,496 people) than the value of
, since in June, there was a rapid increase in cases, which is currently not observed. Similarly, we assumed that the critical value of the number of hospitalized individuals, hereinafter denoted as
, was more likely to impact the value of
(34,848 people).
We apply the same approximation method for the values of the function of the number of hospitalized patients
, as a result of which:
We compared the data of the time series of smoothed values of the number of hospitalized people and the resulting function (
Figure 4).
In this case, the coefficient of determination was 0.9869, which also characterized the model on the segment as quite good.
For forecasting, we defined the confidence interval estimates of the coefficients
for the period from 1 September 2021 to 17 October 2021 from the exponential model of the approximation functions
and
, corresponding to the reliability of 95% according to the formulas:
where
is a two-sided critical point of the student distribution with 45 degrees of freedom, corresponding to a probability of 0.05,
is an unbiased estimate of the standard deviation of the regression equation.
We denoted the values of the point estimates of the coefficients
and
for the base forecast, the positive forecast, the lower limit of the confidence interval, the negative, and the upper limit confidence interval (
Table 2).
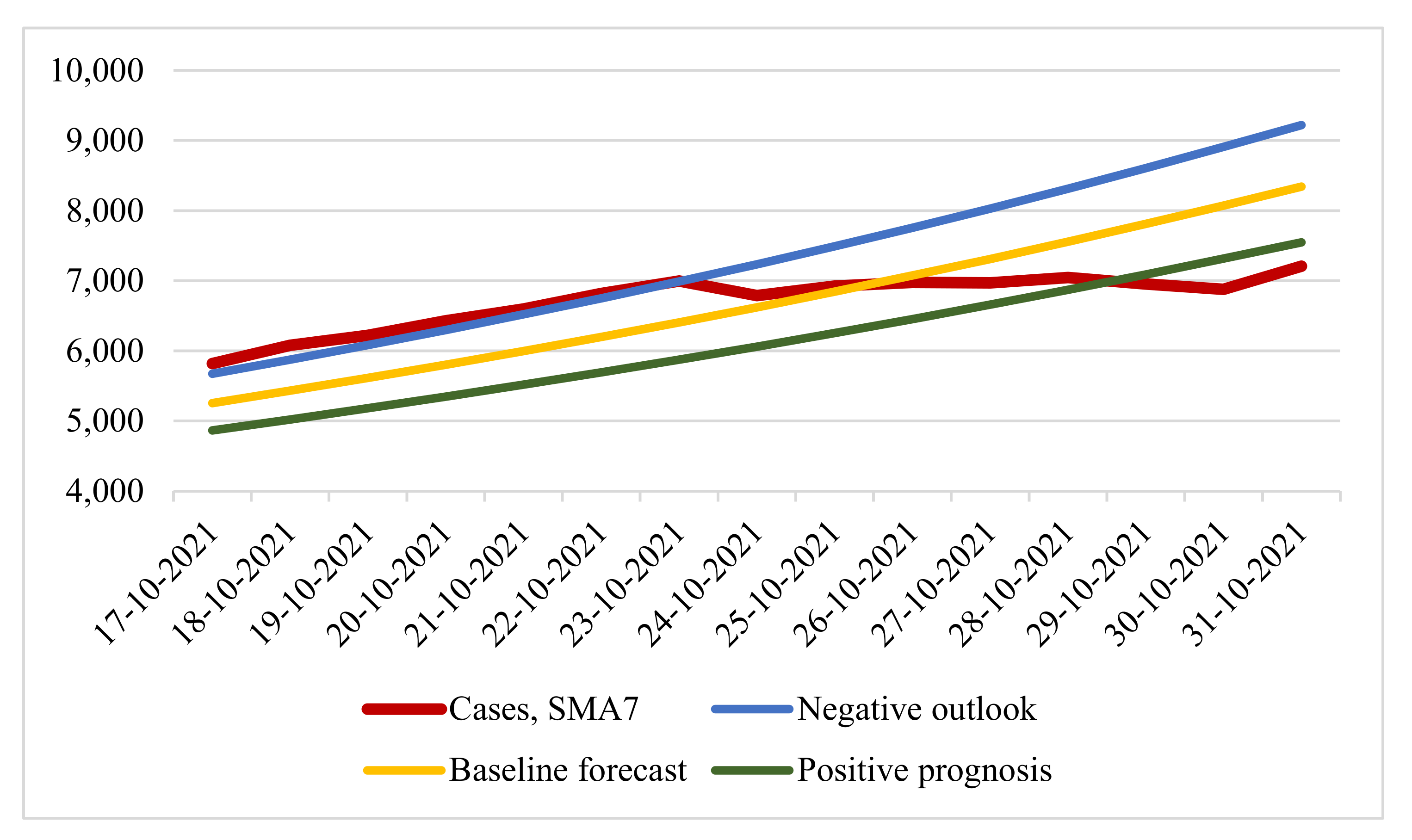
Based on the factors listed above, we considered the forecast of a seven-day moving average of cases of COVID-19 infection from 17 October 2021 to 10 November 2021 based on the values of the function
(
Figure 5).
In this period, we considered the cumulative number of infections over the last 28 days and defined it as the “critical” value = 150,000 people:
With the baseline forecast, the first date of reaching the critical value: 29 October 2021.
In case of a negative forecast, the first date of reaching the critical value: 28 October 2021.
With a positive forecast, the first date of reaching the critical value: 31 October 2021.
Similarly, we considered the forecast of a seven-day moving average number of hospitalizations based on the values of the function
for the same period (
Figure 6).
In this period, we considered the cumulative number of hospitalizations for the last 28 days and defined it as the “critical” value = 36,000 people:
With the baseline forecast, the first date of reaching the critical value: 29 October 2021.
In case of a negative forecast, the first date of reaching the critical value: 27 October 2021.
With a positive forecast, the first date of reaching the critical value: 30 October 2021.
Thus, based on the forecasts made, it is most likely that measures aimed at stabilizing the epidemiological situation will be taken in the period from 27 October to 31 October.
At the time of 30 October 2021, the constructed forecast was confirmed. By the decree of the mayor of Moscow, restrictions were introduced on 28 October (negative scenario according to the forecast). We then considered the seven-day rolling COVID-19 case and forecast options for the period from 17 October 2021 to 31 October 2021 (
Figure 7).
We evaluated the forecast accuracy for 15 days (from 17 October 2021 to 31 October 2021) of three scenarios with real data on the number of smoothed cases of COVID-19 infection using two metrics: root mean square error (RMSE) and mean absolute percentage error (MAPE) (
Table 3).
The table values concerning a baseline forecast with MAPE 8.596% and RMSE 655.951 showed more accurate forecast results. It can be seen that, until 23 October, the situation developed according to a negative forecast, and the introduction of restrictive measures was announced on 21 October. At the same time, it was reported that the situation was developing according to a negative forecast. However, from 24 October, the real number of cases of infection deviated from the predicted values. Here, the disadvantages of using exponential regression models for the long term are fully manifested: the number of infection cases has a “wavy” appearance, which the exponential model cannot display, as a result of which it becomes necessary to use other forecasting methods.
2.3. Determination of the Dataset and Neural Network Architectures
For further research, we turned to machine learning methods. In this case, the task of forecasting time series belongs to the supervised learning class. To form the sample, the data on the number of cases of COVID-19 infection were used from 20 countries: Austria, Belgium, Great Britain, Hungary, Germany, Israel, Iran, Spain, Italy, Canada, the Netherlands, Poland, Russia, Romania, Serbia, USA, France, Czech Republic, Switzerland, Japan, and data from the city of Moscow in the period from 18 March 2020 to 3 December 2021 [
28,
35,
36]. These countries were selected according to two criteria: a population of more than 8 million people and a developed healthcare system. Together, these criteria made it possible to obtain sufficiently accurate and objective data on the number of cases of coronavirus infection.
To reduce the influence of daily fluctuations, a seven-day simple moving average (SMA7) was applied to the entire sample size. For the adequate operation of the neural network to all the values of these systems from the dataset separately, we applied the normalization function
:
where
is SMA7 infections per day,
and
are the the maximum and a minimum number of cases of COVID-19 infection in the system, respectively. To normalize the data, the MinMaxScaler class from the scikit-learn library was used. Thus, all values were in the range from 0 to 1 in the corresponding scale.
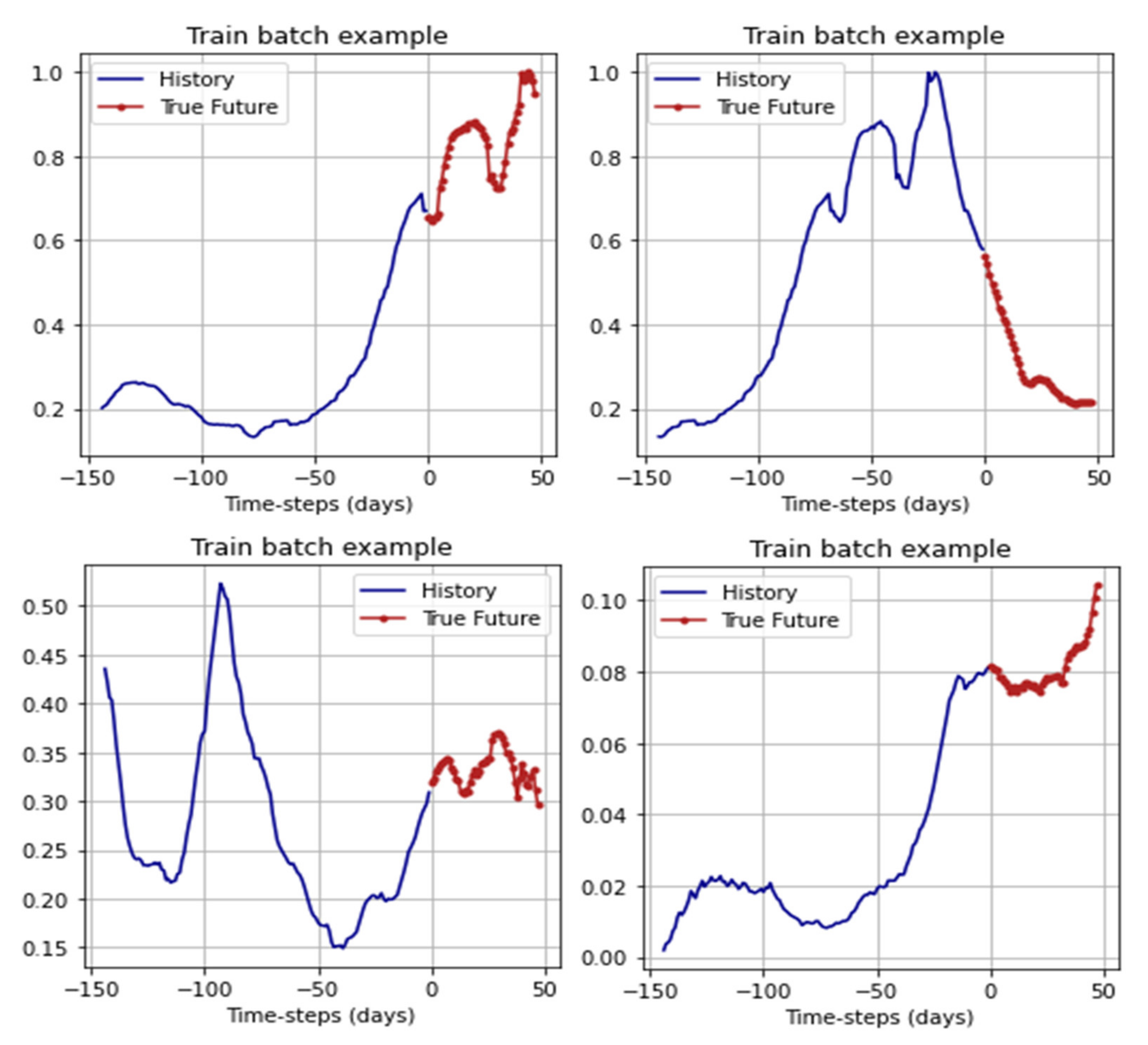
Figure 8 show examples of data from several systems.
The dataset length was 626 values, of which 67% (419 values from each system) were intended for the training sample, and the remaining 33% (207 values from each system) were intended for the validation sample. The entire amount of data was 13,146 values.
For training, the networks received batches: 144 days before the forecast period as data based on which the forecast was made, and 48 days for the forecast. From the original dataset, 5775 batches were generated for training and 315 batches for validation. For efficiency, the batchhes were shuffled using the shuffle method from the TensorFlow framework. Examples of the batches are shown in
Figure 9.
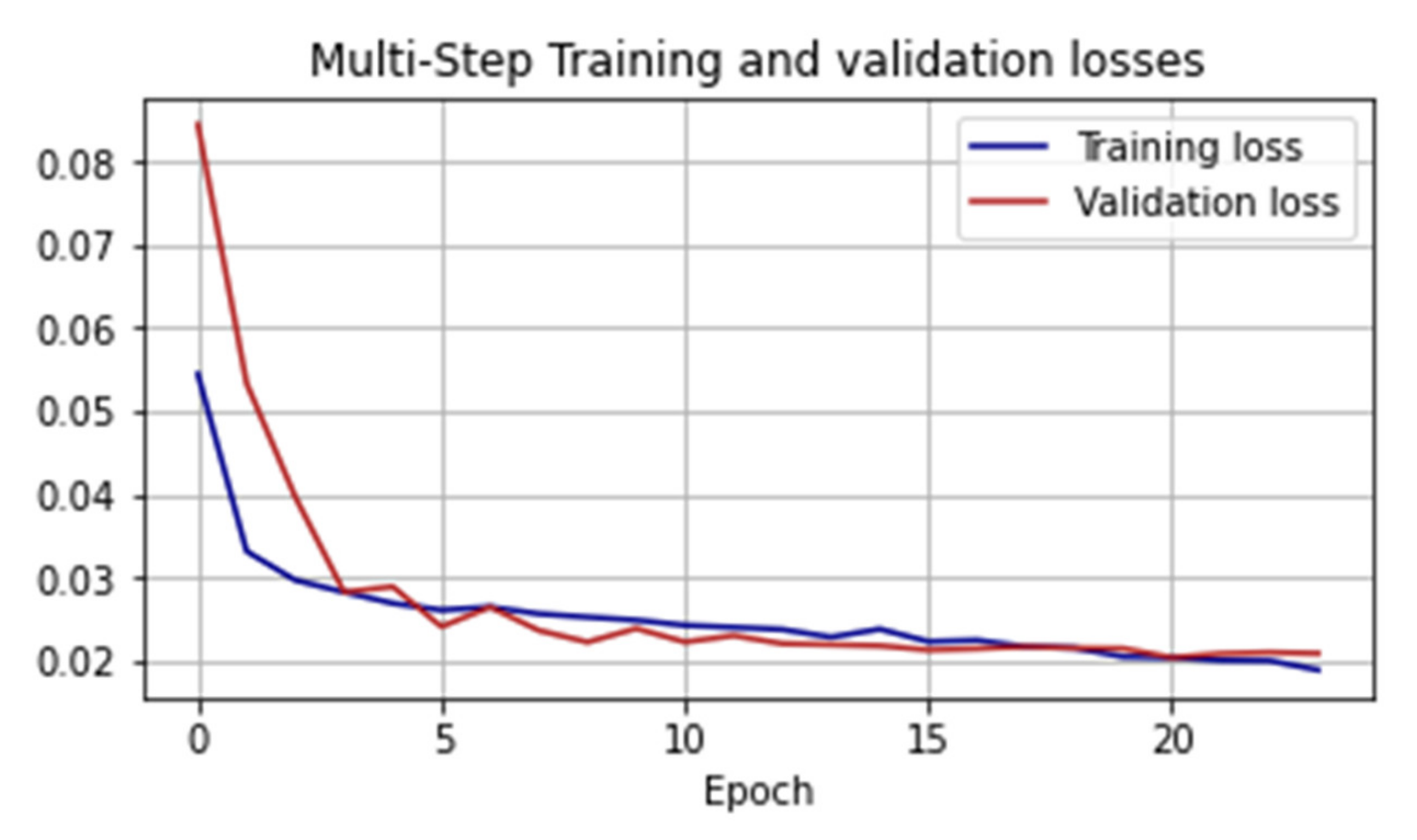
To predict the time series of the number of cases of COVID-19 infection, we used two types of neural networks: long short-time memory (LSTM) and a convolutional neural network. We considered in more detail the architecture of the LSTM recurrent neural network, which is one of the most suitable ML-models for forecasting time series. The main advantage of this architecture is its good adaptability to learning and forecasting in a situation where key events (in our case, the “waves” of the coronavirus) are separated by indefinite time intervals, and their time boundaries are different. The architecture of the LSTM RNN network can be represented as:
where,
is the input vector,
is the loss layer,
is the input gate layer,
are the state vectors,
is the output gate layer,
is the target (output) vector,
are the vectors of parameters (weights) [
37].
In this case, the neural network was trained to predict 48 days based on data from the previous 144 days. Thus, the input vector
is:
where,
is the number of cases of COVID-19, SMA7. Since the number of neurons in the output layer is determined by the number of forecast days, this value is 48 pieces. LSTM RNNs work with sequences and require data of the following form as input: [observations, time interval, number of signs]. In our case, the time interval was equal to one (the step is equal to one day). Therefore, we took a closer look at the two hidden layers.
The first hidden layer consisted of 144 LSTM blocks with the activation function in the form of a hyperbolic tangent. The second hidden layer consisted of 48 LSTM blocks and used the rectified linear unit (ReLU) as the activation function. Between the two hidden layers was dropout with a factor of 0.3 to combat overfitting. The total number of parameters for training in this network model was 123,504. In more detail, the proposed architecture with the names of layers from the TensorFlow framework can be seen in
Table 4.
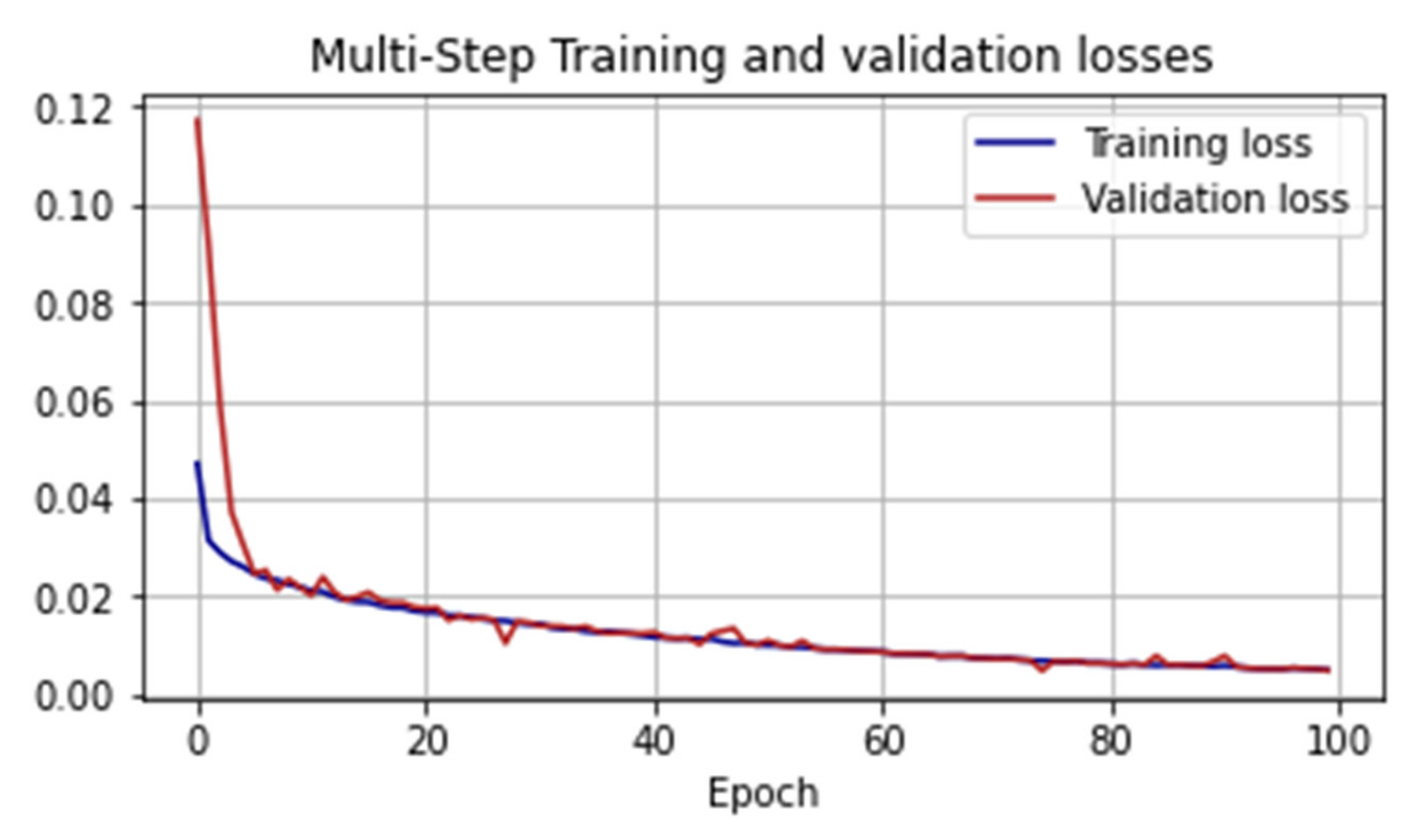
We also took a closer look at the architecture of the second neural network for predicting cases of COVID-19 infection—the convolutional neural network. The principle of operation of this network is to alternate convolutional layers and subsampling layers (pooling layers).
In this model, the first convolution layer formed 64 output filters in convolution; the size of the one-dimensional convolution window was two. Then there was a downsampling layer with a window size equal to the convolution window size, that is, 2, and a flattened layer. This was followed by two fully connected layers of 50 neurons and 48 output neurons. The total number of trained parameters was 229890. In more detail, the network architecture with the names of the layers from the TensorFlow framework is given in
Table 5.
The classical indicator was used as the loss functions for training both networks of mean squared error (
:
where,
is the true meaning,
is the estimated value.
We considered in more detail the choice of the optimization algorithm. There are many different methods, but the most preferable is the method of adaptive estimation of the moment, Adam, due to the combination of the accumulation of the motion of the gradient of the loss function and the relatively weak update of weights for typical features.
We considered its work in more detail. First, the algorithm updates the exponential moving averages of the gradient
, which is the estimate of the 1st moment (mean):
where
is a hyperparameter that controls the exponential decay rates of the sliding, while
.
is the objective function gradient (vector of partial derivatives
. On the recommendation of the authors for machine learning problems
[
38]. To estimate the frequency of the gradient change, the average non-centered variance is used)
:
where,
—similar
the hyperparameter that controls the exponential decay rates of the sliding, and is taken as 0.999 as the most appropriate value for machine learning problems [
39,
40]. However, these slides are initialized as vectors close to zero (and the values will accumulate for a long time). To correct this problem, the first and second moments
and
are calculated, corrected for displacement:
As a result, the weights are updated according to the rule:
where,
—learning rate,
smoothing parameter.



 ,
, 















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}