1. Introduction
In this paper, we consider a box-constrained global optimization problem of the form:
where
suppose to be the Lipschitz-continuous objective function,
is the input vector, and the feasible region
is an
n-dimensional hyper-rectangle
. The objective function can be non-linear, non-differentiable, non-convex, multi-modal, and potentially a “black-box.” In a black-box case, analytical information is unavailable and can be obtained only by evaluating the function at feasible points. Therefore, traditional derivative-information based local optimization methods cannot be used in this situation.
Among derivative-free global optimization algorithms addressing the black-box problem, two main classes [
1] are stochastic meta-heuristic algorithms [
2,
3,
4] and deterministic ones [
5,
6]. The
DIRECT algorithm developed by Jones [
7] is a popular and widely used deterministic solution technique for various real-world optimization problems [
8,
9,
10,
11,
12]. The proposed algorithm is an extension of the classical Lipschitz optimization [
13,
14,
15], which no longer requires the knowledge of the Lipschitz constant. The
DIRECT algorithm [
7] seeks global optima by dividing the most promising hyper-rectangles and evaluating the objective function at their centers.
Since the original algorithm introduction, many researchers have suggested various modifications or extensions of the
DIRECT algorithm in various directions. Recent extensive numerical studies [
1,
16,
17] show that
DIRECT-type algorithms are often among the most efficient derivative-free global optimization solution techniques. Various hybridized approaches [
10,
18,
19] that are enriched with local search procedures are among the most effective [
16,
17,
20]. However, on average, among traditional (non-hybridized)
DIRECT-type algorithms, two-step (global and local) Pareto selection scheme-based approaches,
DIRECT-GL [
17],
1-DTC-GL [
21], often showed the best performance [
17]. Moreover, for complex multi-modal and non-convex problems, they often outperformed hybrid ones.
Nevertheless, in a recent survey [
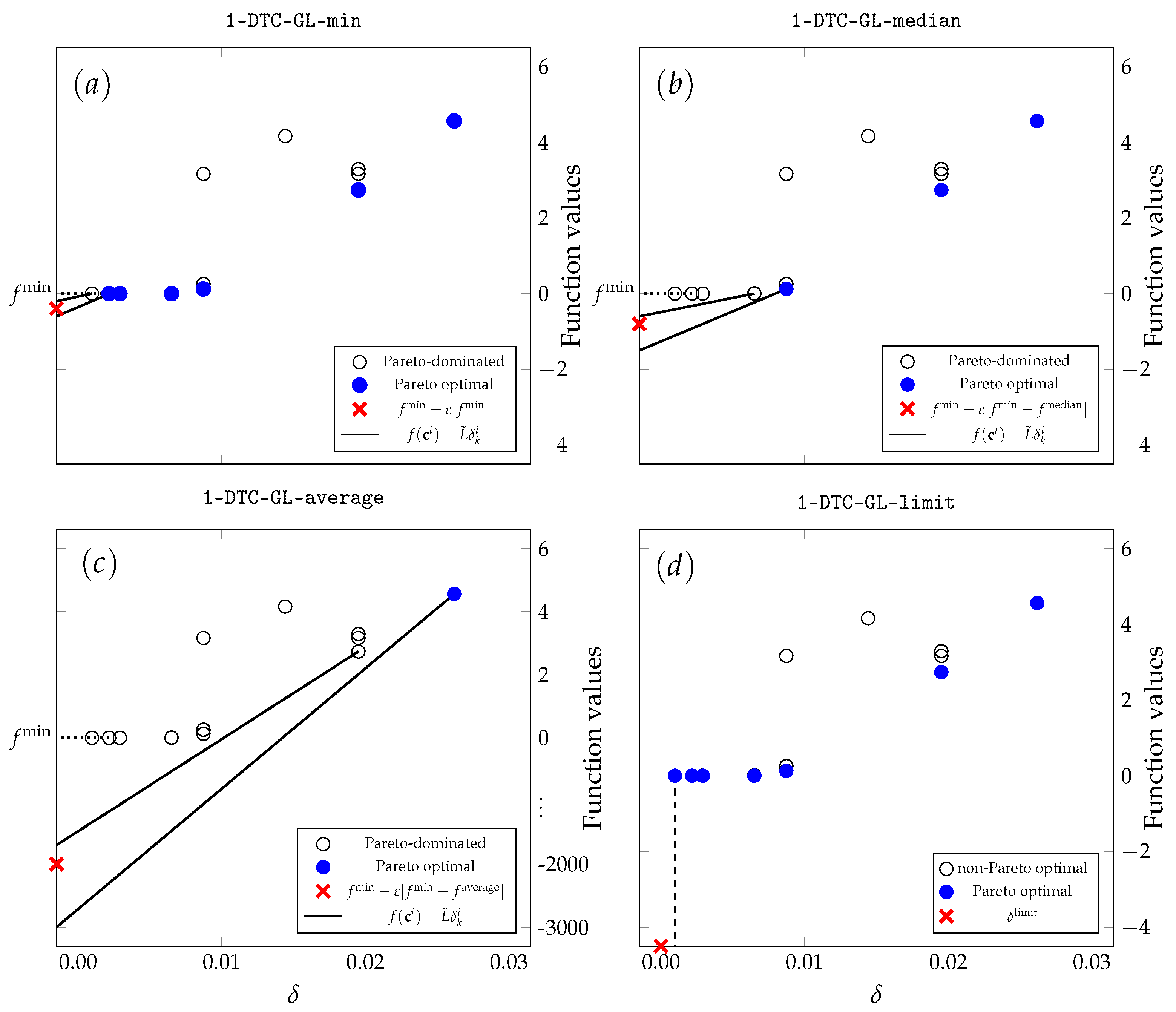
22], two possible shortcomings of such two-step Pareto selection were specified. First, these scheme-based algorithms have no protection against “over-exploring” a local minimum, e.g., no limitation of how small the size of selected potentially optimal hyper-rectangles (POHs) can be. Secondly, a balancing strategy between global and local candidate selection is missing. The two-step-based Pareto selection scheme performs global and local search-oriented selection at each iteration. If the current best solution has remained unchanged for several iterations, it can be deduced that the local selection step is potentially unnecessary.
We note that some proposals and studies have already been carried out in the context of the
DIRECT algorithm. In [
17], we have experimentally investigated a few strategies [
7,
23,
24,
25,
26] devoted to preventing the original
DIRECT algorithm from selecting tiny hyper-rectangles around current local minima. Moreover, the same study also investigated different strategies for balancing global and local phases [
10,
18,
27,
28]. However, we cannot generalize from these results which strategy is the most efficient, as individual algorithms were compared, which may have varied not only in the selection step but also in other steps such as partitioning and sampling. It is therefore unclear which of the proposed improvements has the most potential to prevent excessive local refinement.
Contributions and Structure
The main contributions of this work are summarized below:
It reviews the proposed techniques for excessive local refinement reduction for DIRECT-type algorithms.
It experimentally validates them on one of the fastest two-step Pareto selection based 1-DTC-GL algorithm.
It accurately assesses the impact of each of them and, based on these results, makes recommendations for DIRECT-type algorithms in general.
All six of the newly developed DIRECT-type algorithmic variations are freely available to anyone, ensuring complete reproducibility and re-usability of all results.
The rest of the paper is organized as follows.
Section 2.1 reviews the original
DIRECT algorithm.
Section 2.2 describes a two-step Pareto selection-based
DIRECT-GL algorithm. The review of existing local refinement reduction techniques for
DIRECT-type algorithms is given in
Section 2.3. New
1-DTC-GL algorithmic variations are given in
Section 2.4. The numerical investigation using 287
DIRECTGOLib v1.2 test problems is presented and discussed in
Section 3. Finally,
Section 4 concludes the paper and highlights possible future directions.
3. Results and Discussions
In this section, we compare the performance of six techniques for reducing the local refinement applied to the
1-DTC-GL algorithm, which showed promising results in our recent computational studies [
17,
21]. Six newly constructed algorithmic modifications are empirically evaluated and compared with the original
1-DTC-GL algorithm. The algorithmic variations are examined using the most up-to-date version of the
DIRECTGOLib v1.2 [
35] library. A summary and properties of all box-constrained optimization problems from
DIRECTGOLib v1.2 [
35] are given in
Appendix A,
Table A1 and
Table A2.
Table A1 provides the characteristics of 67 test problems with fixed dimensions, while
Table A2 presents 55 test problems with varying dimensionality. In both tables, the main features are reported: problem number (#), problem name, source, dimension (
n), default optimization domain (
D), perturbed optimization domain (
), problem type, and known minimum (
). The default domains are taken from the literature and listed in the third column of
Table A1 and
Table A2. For some problems, the original domain is perturbed (
) so that the solutions are not located at their midpoints or other locations favorable for any tested algorithm. Some of these test problems have several variants, e.g.
AckleyN,
BiggsEXP,
Bohachevsky,
Hartman,
ModSchaffer, and
Shekel. All test problems listed in
Table A2 can be tested for varying dimensionality. For the 55 test problems that can be used specifying any dimension size (
n), we considered four different values,
and 20, leading to the 287 test problems (see the summary in
Table 1).
Implementation and testing are performed using an Intel R Core
[email protected] GHz Processor, 16 GB of RAM, and
MATLAB R2022a software running on the Windows 10 Education operating system. The results returned by the algorithms were compared with the solution for each problem. An algorithm was assumed to have solved the test problem if it returned a solution whose objective function value did not exceed
error. For all analytical test cases where the global optimal value
is known prior, a stopping criterion based on the percentage error
was applied:
where
is the known global optimum. The algorithms were stopped if the percentage error became smaller than the set value
or if the number of function evaluations exceeded the prescribed
.
Three criteria were recorded for each algorithm: the average number of function evaluations
, the average number of iterations
, and the average execution time
measured in seconds.
Table 2 summarizes experimental results on 287 test problems from
DIRECTGOLib v1.2. Here, the first column gives the algorithm’s name, while the second column indicates the criteria. Average values are given in columns three to eleven, solving different subsets of test problems, such as low dimensional
, higher-dimensionality
, convex, non-convex, uni-modal, multi-modal, problems with global minimum value equal to zero, or only those with a non-zero global minimum. The twelfth column shows the median values, while the last column shows the success rate as the proportion of solved problems.
As can be seen from the
success rate values,
1-DTC-GL-gb ranks first among the seven algorithmic variations tested. However, the difference between the first two places is minimal. The
1-DTC-GL-gb algorithm solved only one more problem (225) than the original
1-DTC-GL algorithm (224). It indicates that the original
1-DTC-GL, which does not require additional parameters as
1-DTC-GL-gb, can successfully handle the excessive local refinement. The third best is
1-DTC-GL-limit , and the fourth is
1-DTC-GL-min, based on the original
DIRECT strategy for excessive local refinement prevention.
1-DTC-GL-rev is only in fifth place but works well on uni-modal test problems. Meanwhile, the worst algorithms are
1-DTC-GL-average and
1-DTC-GL-median. The [
25] technique applied in the
1-DTC-GL-average algorithm worsened the overall average number of objective function evaluations by
compared to
1-DTC-GL. Further, it was observed that the
1-DTC-GL-average algorithm had suffered the most on test problems with
, but the opposite when
.
These findings suggest that the restriction on selecting small hyper-rectangles may prevent the algorithm from converging to a solution, even with the relatively low accuracy used in this study. It is especially apparent when the solution is equal to zero. All tested local refinement reduction techniques hurt 1-DTC-GL performance.
Not surprisingly, the lowest overall average number of objective function evaluations is obtained again with the 1-DTC-GL-gb algorithm and is approximately lower than with the second best, 1-DTC-GL. As can be seen, ranking the algorithms in terms of success rate and overall average results is analogous, since the success rate depends directly on the number of functions.
Furthermore, although the lowest value median is obtained again with the 1-DTC-GL-gb algorithm, the second best is the 1-DTC-GL-rev. The median values mean that 1-DTC-GL-gb can solve at least half of these test problems with the best performance. Interestingly, 1-DTC-GL-rev was only in fifth place regarding the overall success rate but is second in median value. Like 1-DTC-GL-gb, it restricts local selection, and it seems this technique has the most potential to combat excessive local refinement. According to the median value, the original 1-DTC-GL is only in fifth place, and a value of around 30% is higher than 1-DTC-GL-gb. Moreover, the 1-DTC-GL-gb algorithm proved to be the most effective for non-convex, multi-modal, , , and subsets of test problems.
However, the improvement in the performance of 1-DTC-GL-gb also had some negative consequences. In general, the 1-DTC-GL-gb algorithm required more iterations than the best algorithm for this criterion, 1-DTC-GL. Since the 1-DTC-GL algorithm has no limitation on selecting extremely small and locally located hyper-rectangles, it results in more calculations of the objective functions being performed per iteration. Moreover, the average execution time is best with the original 1-DTC-GL algorithm. The local refinement reduction techniques increased the total number of iterations as well as the average running time of the algorithms. From this, we can summarize that in the case of cheap test functions, the original 1-DTC-GL is the best of all the algorithms tested, meaning that the local refinement reduction schemes are redundant. However, when the objective functions are expensive, the local refinement reduction techniques improve the performance, and 1-DTC-GL-gb is the best technique among all tested.
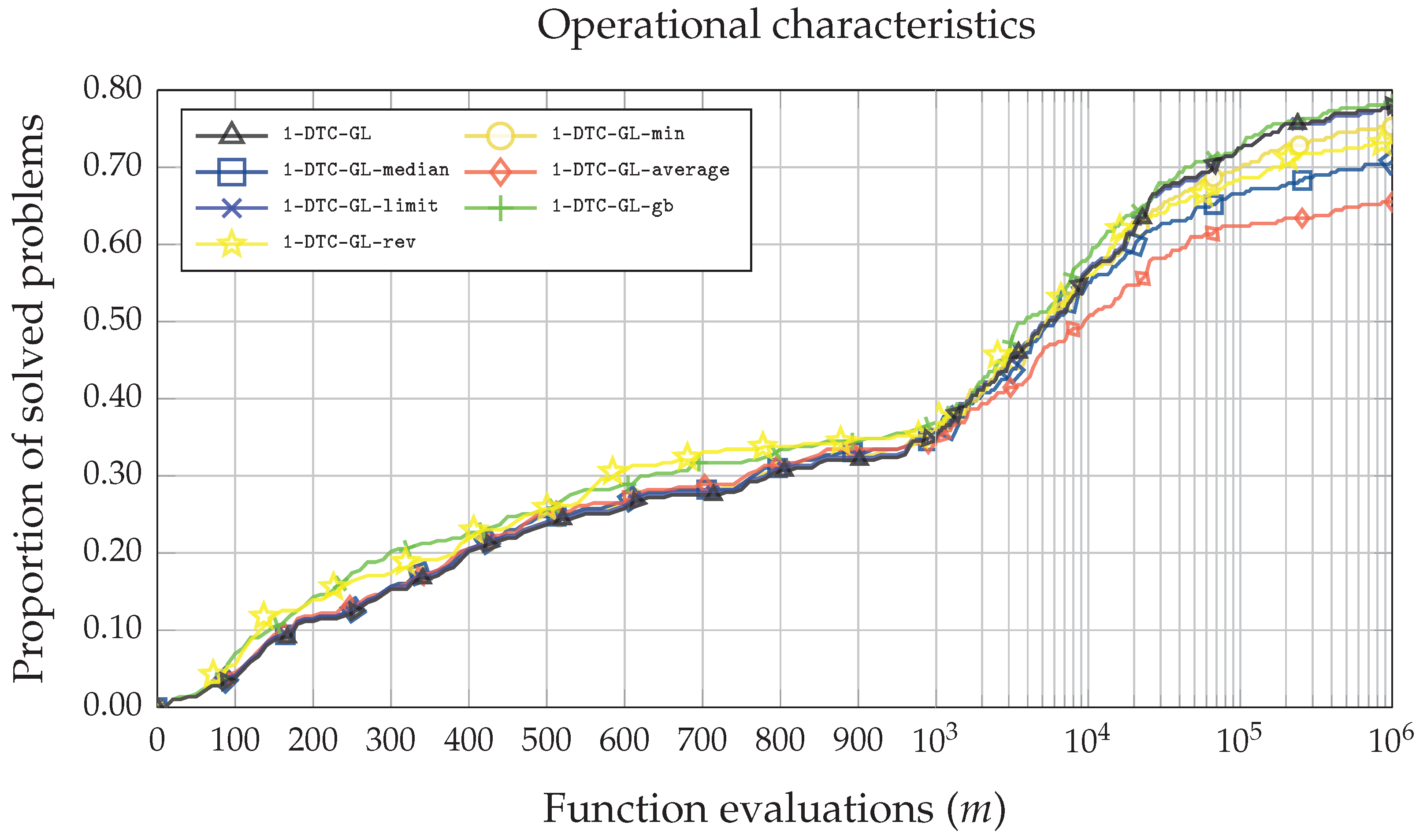
Furthermore,
Figure 4 produces line plots of the operational characteristics [
36,
37], showing the relationship between the number of problems solved and the number of function evaluations. Four out of six techniques (
1-DTC-GL-median,
1-DTC-GL-average,
1-DTC-GL-min,
1-DTC-GL-rev) implemented to restrict the selection of small hyper-rectangles had almost no impact on the original
1-DTC-GL algorithm solving the simplest test problems. All these four algorithms have almost identical performance curves to
1-DTC-GL. They were able to solve approximately
(95 out of 287) test problems when the maximum allowed number of function evaluations was 1000. However, as the maximum allowed number of function evaluations increases, the performance efficiency of the four approaches starts to deteriorate compared to the original
1-DTC-GL algorithm. The algorithms with the worst performance are
1-DTC-GL-average and
1-DTC-GL-median. The best performance was achieved with the
1-DTC-GL-gb and
1-DTC-GL-rev algorithms. Moreover, while for simpler problems,
1-DTC-GL-rev performed well, for more complex problems, the efficiency deteriorates. The
1-DTC-GL-gb is the only algorithm with the same or better performance than the original
1-DTC-GL algorithm.
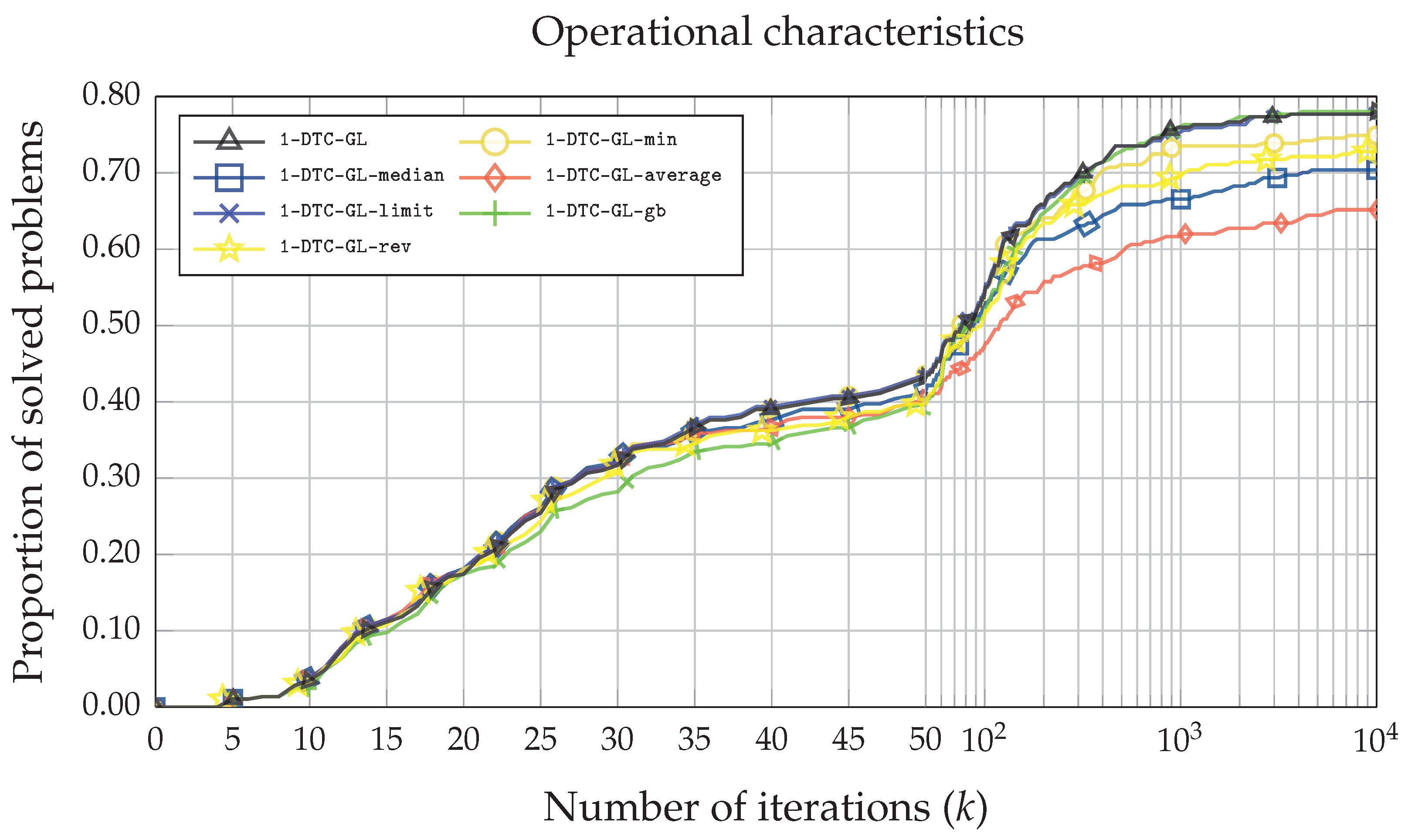
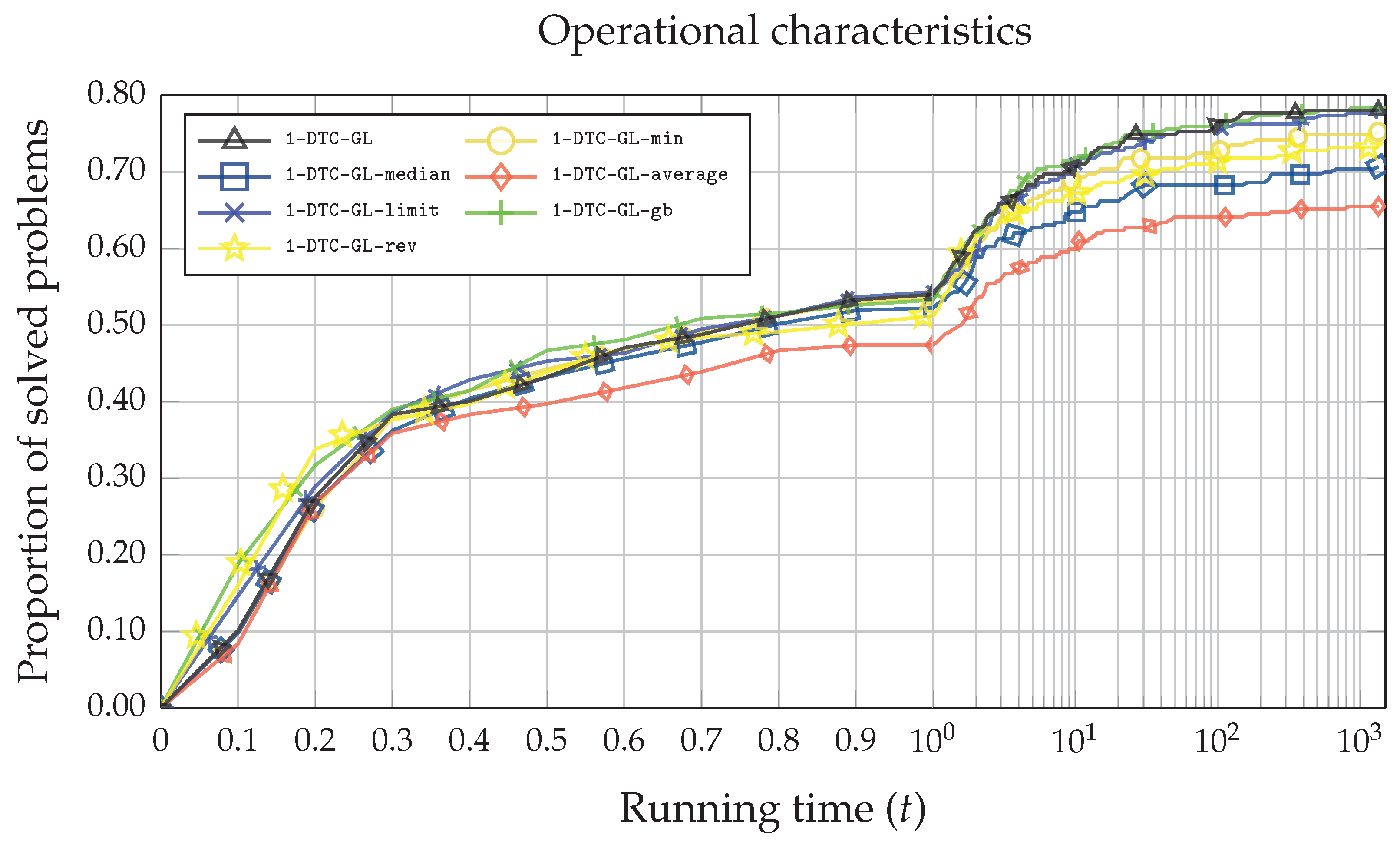
Finally, in
Figure 5 and
Figure 6, the operational characteristics based on the number of iterations of the function and the execution time are illustrated. Although the average number of iterations (
) using the
1-DTC-GL algorithm is the lowest (see
Table 2),
Figure 5 reveals that at least two other algorithms (
1-DTC-GL-limit and
1-DTC-GL-gb) perform similarly. A similar situation can be seen in
Figure 6, where the
x-axis indicates the time in seconds while the
y-axis represents the proportion of the problems solved. The most straightforward problems are solved slightly faster using
1-DTC-GL-rev and
1-DTC-GL-gb algorithms. However, as the execution time increases (
), the performance efficiency of
1-DTC-GL and
1-DTC-GL-gb becomes almost identical, although the average time of the
1-DTC-GL algorithm is better (see
in
Table 2).
4. Conclusions and Potential Future Directions
This study reviewed existing excessive local refinement reduction techniques in the DIRECT context. The six identified techniques were applied to one of the fastest two-step Pareto selection-based algorithms (1-DTC-GL). As other algorithmic parameters were unchanged, this allowed us to assess the impact of each of them objectively.
The seven 1-DTC-GL algorithms were compared using three criteria: the average number of function evaluations, the average number of iterations and the average execution time. In terms of the number of objective functions, the 1-DTC-GL-gb algorithm performed the best, but only one less objective function solved 1-DTC-GL. The other five strategies tested hurt the speed of the original algorithm 1-DTC-GL. This finding made it clear that the restriction on selecting small hyper-rectangles may prevent the algorithms from converging to a solution, even with the relatively low accuracy used in this study. This is particularly evident when the solution to the problem equals zero. No strategy used in 1-DTC-GL has resulted in any noticeable improvements in this case, but instead has worsened it. Interestingly, in terms of iterations and execution time, the original algorithm 1-DTC-GL performed the best. That is because the local refinement reduction techniques increase the total number of iterations, as well as the average running time of the algorithms.
To sum up, the original
1-DTC-GL is the best of all tested algorithms for the cheap test functions, meaning that the local refinement reduction scheme is redundant. However, when objective functions are expensive, local refinement reduction techniques improve performance, and
1-DTC-GL-gb is the best algorithm among all tested. However, its effectiveness is also limited. Therefore, one of the potential future directions is the development of better-suited local refinement reduction techniques for two-step Pareto selection-based
DIRECT-type algorithms. Another potential direction is the integration of all
DIRECT-type algorithms into the new web-based tool for algebraic modeling and mathematical optimization [
38,
39]. Finally, since
1-DTC-GL is a
DIRECT-type algorithm, the results of this paper can also be generalized to any
DIRECT-type algorithm. We leave this as another promising future direction.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}