Abstract
We present a portrait-generation framework that can control composite attributes. Our target attribute covers the three global attributes of age, sex, and race. We built control vectors for the garget attributes and attached them to the latent vector that produced portrait images. Our generator was devised using the StyleGAN generator, and our discriminator has a dual structure for qualities and attributes. Our framework successfully generated 24 faces with the same identity while varying the three attributes. We evaluated our results from three aspects. The identity of the generated faces was estimated using Frechet inception distance, and the attributes of the generated faces were validated using a facial-attribute recognition model. We also performed a user study for further evaluation.
MSC:
68T45
1. Introduction
Since Goodfellow et al. presented the generative adversarial network (GAN) [1], various image-generation techniques have emerged in deep learning. Recently, some techniques [2,3,4,5] have generated very realistic images that could be recognized as real images.
One of the major directions of image-generation research is conditional image generation where users specify additional information to control the content or style of the generated images. Some of them employ information embedded in text [6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21], and others employ visual information such as segmentation maps or sketches [22,23,24,25]. Several works employed both types of information [26,27].
Among various image-generation frameworks, we focused on a conditional portrait-generation framework that produces head-cut portrait images. Many portrait-generation or -manipulation schemes employ text to specify their conditions [17,20,26,27]. The information embedded in the control text covers a very wide range of information, including age, sex, race, appearance such as hair color and facial hair, and attachments such as sunglasses. However, various combinations of information raise difficulties in controlling the generation or manipulation of the results. Furthermore, complex combinations of the conditions, “such as young Asian female”, raise other difficulties for a conditional portrait-generation scheme.
As a first step of developing a conditional portrait-generation framework, we examined the attributes of a portrait and extracted those that could be shared with portraits of identical groups. We denote those attributes as group attributes, since most portraits that belong to a group share similar attributes and are distinguished from the portraits of different groups. For example, portraits with young-age attributes have a distinct appearance from those with old-age attributes. We suggest three group attributes: sex, race and age. These three attributes are key conditional vectors for our conditional portrait-generation framework.
We designed our conditional portrait-generation framework using StyleGAN [3], which generates very visually pleasing portraits of state-of-the-art (SOTA) quality. We devised it to produce latent vectors that embed conditional vectors for group attributes. These condition-embedded latent vectors were fed into our portrait-generation model to produce various portraits that satisfied our conditions. We attached another discriminator to our framework since our result images had to satisfy two requirements: quality and attribute. The generated portrait images should show visually pleasing qualities with attributes that specify the embedded conditions. Therefore, our framework possesses double discriminators for both requirements.
Our framework produced 24 different portraits from the same latent vector. Figure 1 illustrates a series of resulting images of our framework. Therefore, we evaluate our generated portrait images from two aspects. In the first evaluation, we show that the portraits from the same latent vector showed similar appearances by proving that the portraits from the same latent vector showed the lowest Frechet inception distance (FID) values. In the second evaluation, we applied several existing models that recognized sex, race, and age in our generated images to show that the conditions were embedded in the images.
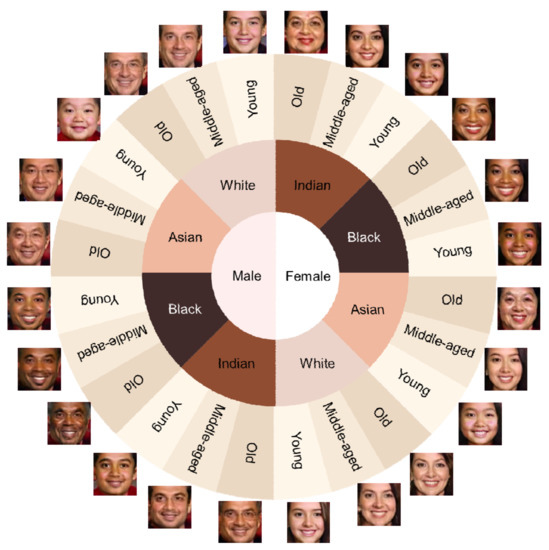
Figure 1.
Teaser image of our framework, which produces 24 different portrait images by varying three group attributes: sex, race, and age. Sex had two values: male and female; race had four: White, Asian, Black, and Indian; age had three: young, middle-aged, and old.
2. Related Work
2.1. Image Generation
2.1.1. Unconditional Image Generation
The progress of image-generation research can now generate realistic high-resolution images. Karras et al. [2] proposed progressively growing GAN (PGGAN), which gradually improves the resolution of generated images. PGGAN adds layers with higher-resolution details to its generator and discriminator as training progresses. This strategy improves the resolution of the generated images.
Karras et al. [3] presented StyleGAN, which introduced the concept of latent space to the architecture of PGGAN by mapping latent code z to intermediate latent space W. The W space of StyleGAN has disentangled properties that could be used to control the attributes of the generated images. However, we found frequent artifacts in the images generated by StyleGAN.
Later, Karras et al. [4] proposed StyleGAN2 to resolve this problem. They more efficiently modified the structure of StyleGAN, and improved the image quality by using the path length regularizer. Recently, Karras et al. [5] proposed StyleGAN3, which removes the aliasing problem of StyleGAN2. This series of studies successfully presented an image-generation framework of realistic quality and high resolution. However, this framework suffers from controlling generated images to accommodate users’ desires.
2.1.2. Conditional Image Generation
Researchers have presented various schemes that generate images according to specific conditions. Most of them exploit text to specify their conditions. Schemes that embed conditions specified in the text into their generation models generate images of, for example, birds, flowers, and landscapes. Zhang et al. [8] presented StackGAN, which consisted of two phase networks. In the first phase network, primitives such as the shape and color of the target object are generated. In the second, the results of the previous phase are refined to express the details of the images. Zhang et al. [11] improved StackGAN into StackGAN++, whose training process is more stable than that of StackGAN. Xu et al. [10] proposed AttnGAN, which generates the details of images by focusing on relevant words in the text. An image–text matching loss is calculated when training a generator using a deep attentional multimodal similarity model. Tao et al. [18] presented DFGAN, which generates high-quality images with only one generator and discriminator.
2.1.3. Conditional Portrait Generation
Many studies presented conditional portrait-generation schemes that employ conditions embedded in visual clues such as sketches or semantic segmentation maps. Xia et al. [23] presented a generation model composed of two-staged GANs to produce a portrait image from a sketch. The calibration network, the first-stage GAN, refines poorly drawn sketch images. The synthesis network, the second-stage GAN, produces portrait images from sketches refined by the calibration network. Xia et al. [26] presented TediGAN, which produces portrait images using text as a guide. From text that describes portraits to generate, TediGAN produces a realistic portrait image corresponding to the input text. TediGAN learns the association between text and image by projecting both to the latent space of StyleGAN. Attributes of the generated portraits can be adjusted using a control mechanism based on style mixing. Yang et al. [27] proposed S2FGAN, which generates portrait images from well-drawn sketches. They introduced a new loss function for their purpose.
2.2. Image Manipulation
2.2.1. Conditional Image Manipulation
Instead of generating new image from conditions and latent vectors, some researchers presented image-manipulation schemes that modified the contents of an image according to the specified conditions [7,9,15,16]. Most of the target images of these schemes were of flowers, birds, and landscapes. They commonly employ natural language descriptions for their conditions. They aim to modify regions in the input image that match the text description according to the conditions, but to preserve the regions that are irrelevant to the text. Nam et al. [9] classified the attributes of the input text using a text-adaptive discriminator, and used them as signals for feedback to the generator. Lie et al. [15] learned the association between text and image using the text–image affine combination module, and corrected the contents of the image that did not correspond to text. Lastly, they completed the missing contents using the detail correction module. Li et al. [16] also presented a lightweight model that achieved excellent manipulation performance.
2.2.2. Conditional Portrait Manipulation
Some image-manipulation studies aim at processing portrait images. Liu et al. [17] presented an image-to-image translation model using unsupervised learning that changes the characteristics of the input portrait image through a command-like sentence that simply describes the characteristics of the input portraits. They separate content features and attribute representations for an improved control. There have been discussions about using the latent space of StyleGAN for image manipulation [3]. Patashnik et al. [20] presented StyleCLIP, which manipulates portrait images by applying their CLIP model as a loss network. This approach optimizes text-guided latent vectors. The text-guided mapper processes input portrait images in the literal space of StyleGAN to create latent code w, which becomes the input vector of a pretrained StyleGAN that produces manipulated portrait images.
2.3. Latent Space Manipulation
Several image-manipulation and -generation studies presented StyleGAN-based technologies that controlled the latent space in the process of manipulation and generation.
Abdal et al. [28] proposed an effective algorithm for embedding images into the latent space of StyleGAN in order to execute operations such as semantic image manipulation, image morphing, style transfer, and expression transfer. It is difficult to use various semantics that appear in the latent space of GAN for real-image editing. They resolved the problems of existing inversion methods by focusing more on the latent space than on the reconstructed image.
Shen et al. [29] analyzed the latent space of pretrained GANs including PGGAN or StyleGAN and found that the latent code of a well-trained generative model actually learnt disentangled presentation after linear transformations. They presented a scheme that manipulates images such as the presence or absence of sex, age, expression, and eye classes, etc.
Zhu et al. [30] presented an indomain GAN inversion scheme that guaranteed that the latent code inverted by their scheme was semantically measurable for manipulation. They trained a domain-guided encoder to project an image into a latent space, and proposed a domain-regularized optimization scheme to better fine-tune the latent code generated by this encoder and more properly reconstruct an image.
3. Model
Our model is composed of four modules: a mapping function f, a generator G, a discriminator , and an auxiliary discriminator . The structure of our model is presented in Figure 2.
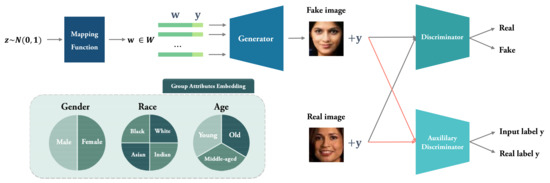
Figure 2.
Our model is executed as follows. Mapping function f, the first module of our model, produces latent vectors from random noises via eight fully connected layers. We built an input vector by concatenating the latent vector with a conditional vector that designates the group attributes. Generator G, the second module of our model, produces a synthesized image from the input vector. Discriminator , our third module, discriminates whether the synthesized image is real or fake. Auxiliary discriminator , our fourth module, discriminates the group attributes of a synthesized image by classifying the image.
3.1. Mapping Function
Most image-generation models exploit random vector z as the input of their generator. However, many studies [3,4,5] claimed that latent vector W, which is produced through a mapping function from a random vector z, is more effective in producing images of better quality. StyleGAN [3] has proven that latent vector W is disentangled, and the course of variation is properly separated using perceptual path length. We also employed the latent vector to compose the input vector for our model.
The shape of W in our model was (1, 512, 12). The last dimension of W depends on the resolution of result image. The conditional vector is concatenated to the latent vector to build our input vector. Each w in W, which is the input to each layer of the generator, is independently concatenated by the conditional vector. We had three conditional vectors to reflect three group attributes: sex, age and race. The conditional vector for sex had two values: male and female; the vector for age had three: young, middle-aged, old; the vector for race had four: Asian, White, Black, Indian. The conditional vector was expressed as one-hot vector for the concatenation to W.
3.2. Generator
We built our generator G by employing the generator of StyleGAN [3] to produce our results. Each layer of G processed the input vector, which was a concatenation of a latent vector and a conditional vector, through standard deviation, convolution, and normalization. This process was repeated to produce images of high resolution.
The discriminator examines whether a resulting image is real or fake. The loss functions that we employed in this model were and are expressed as follows:
where G denotes the generator, , the discriminator, and the auxiliary discriminator. We trained our model by simultaneously maximizing and minimizing . Our model is conditional probabilistic generative since it produces images using conditional probability.
3.3. Auxiliary Discriminator
We examined whether our resulting image obeyed the specified conditions. Odena et al. [31], who produced one the most well-known conditional generative adversarial networks, employed an auxiliary discriminator for this purpose. Some studies [31,32,33,34,35,36] employed an auxiliary discriminator for similar purposes. We employed the VGG-Face model [37], which classifies images into 24 labels, as our auxiliary discriminator.
4. Implementation and Results
4.1. Implementation
We employed the StyleGAN2 model [4] as the backbone network of our framework. We implemented this model on a server with double Geforce RTX-3090Ti CPUs. The dataset that we employed had more than 10,000 images. We accelerated the training process by setting the image size to be . The training process was executed 70,000 times, which took about 2 weeks. We set the learning rate to be 0.0002.
4.2. Training Dataset
We employed the UTKFace dataset for training, which had more than 20,000 aligned and cropped facial images. This dataset was selected since it had annotations regarding the age, sex, and race of the facial images. This annotation corresponds to the global attributes we aim to express in conditional portrait generation.
4.3. Results
Our model produced solution images in Figure 3. We present three sets of 24 portrait images generated by combining the three group attributes of their values in Figure 4, Figure 5 and Figure 6.

Figure 3.
The results of our model: varying values of three group attributes.

Figure 4.
First set of results of our model: faces from an identical latent vector with 24 different group attributes.

Figure 5.
Second set of results of our model: faces from an identical latent vector with 24 different group attributes.
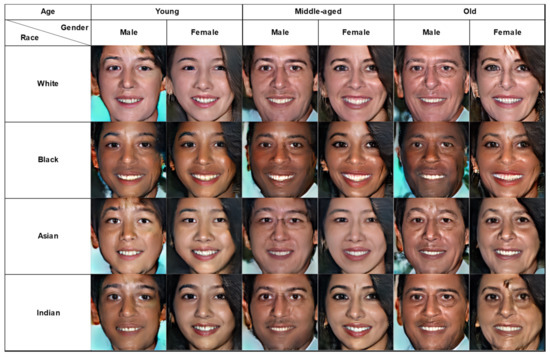
Figure 6.
Third set of results of our model: faces from an identical latent vector with 24 different group attributes.
5. Evaluation
We performed three evaluations for our conditional portrait-generation framework. We first examined whether the faces in the 24 portraits had been generated from an identical latent vector to prove that the differences of the generated faces were from the different attributes and not from the latent vector. Second, we examined whether the faces in the generated portraits followed their embedded conditional vector. We employed an existing face classification model and compared its classification performance with that of of our generated faces. In the third evaluation, we performed a human study to compare the performance of recognizing attributes of generated and real faces.
5.1. Identity Preservation for a Latent Vector
Identity preservation is measured by comparing the similarity of two generated faces using Frechet inception distance (FID). In many facial generation and manipulation studies [3,4,5,30,38,39,40,41], FID is employed to evaluate results. A pair of faces preserve identity better than another pair of faces do if the FID value of the pair is smaller than that of the other pair.
We examined whether the identity of faces generated from a same latent vector was better preserved than the identity of faces from different latent vectors was, of which the steps are illustrated in Figure 7. We explain the process for the pair of (, ).
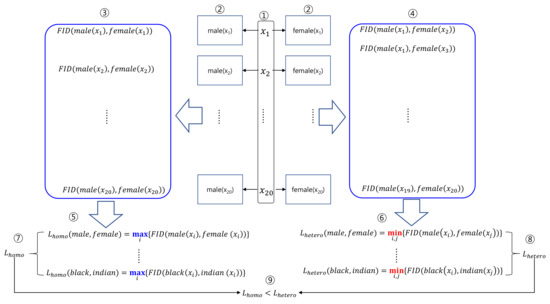
Figure 7.
Process of measuring the preservation of identity.
- Step 1. We generated 20 latent vectors: .
- Step 2. From these latent vectors, we generated 2 pairs of 20 facial images: and .
- Step 3. For the male and female images generated from the same latent vector, we estimated 20 FID values as .
- Step 4. For the male and female images generated from the different latent vector, we estimated 380 FID values as .
- Step 5. From s, we estimated as follows:
- Step 6. From s, we estimated as follows:
- Step 7. We estimated s for the rest pairs of conditions and concatenate to build .
- Step 8. We estimated s for the rest pairs of conditions, and concatenate to build .
- Step 9. We compared and to examine whether the identity of faces generated from the same latent vector was better preserved than the identity of faces from different latent vectors.
In this strategy of evaluation, was estimated as the of s between the faces from same latent vectors, and was estimated as the of s from faces from different latent vectors. The preservation of identity is more convincing if is estimated using the maximum, and is estimated using the minimum. and were 10-fold vectors whose components were estimated from , , , , , , , , , and . The and values are shown in Table 1. For the 10 pairs of the comparison, was smaller than . Therefore, faces generated from the same latent vector preserved the identity better than faces from different latent vectors did.

Table 1.
Comparison of differences of faces that belonged to different groups in sex.
5.2. Attribute Recognition
We employed VGG-Face [37], one of the most widely-used attribute recognition models, to examine whether this model could recognize the attributes of our results, and to compare its accuracy with that from real faces. For the recognition of attributes, we retrained the VGG-Face model with various datasets, including CelebA [42], FairFace [43], and UTKFace [44].
After retraining, we applied the generated and real images to VGG-Face, and examined the accuracy. Table 2 presents the average accuracy on sex and compares it with real faces, Table 3 presents age, and Table 4 presents race. VGG-Face model recognized the attributes of real faces better than those of generated faces. The sex attribute showed the greatest differences with a range of 0.17–0.21, while the race attribute showed the smallest difference with a range of 0.03–0.11. The differences for the age attribute were in the range of 0.06–0.14. These differences show that the attributes of our generated images were recognized relatively properly by an existing face attribute recognition model.
Table 2.
Accuracy of a facial recognition model on sex recognition for generated and real images.
Table 3.
Accuracy of a facial recognition model on age recognition for generated and real images.
Table 4.
Accuracy of a facial recognition model on racial recognition for generated and real images.
5.3. User Study
The last evaluation was a user study. We aimed to prove that human participants could recognize the attributes on the generated images, and measure the pattern of recognition with that of the attributes on the real images.
5.3.1. Purpose of the User Study
The purpose of this study was threefold.
- Measuring the recognition of attributes for the generated images.
- Comparing the recognition of the attributes for real and generated images.
- Analyzing the recognition patterns of real and generated images.
5.3.2. Preparation of User Study
- (1)
- Preparation of Test Images
We prepared 240 portrait images comprising 120 generated images and 120 real images. The 120 generated images were from 5 latent vectors. Therefore, the generated images were grouped into 24 categories of identical attributes, each of which had 5 different portrait images. The attributes varied from (female, young, Asian) to (male, old, Indian). The real images were collected to follow the distribution of the generated images.
- (2)
- Preparation of Participants
We hired 20 participants for our user study, of which 13 were in their twenties, and 7 in their thirties; 11 were male and 9 were female; 7 were undergraduates, and 13 were graduate.
5.3.3. Execution of the User Study
We shuffled the generated and real images before presenting them to a participant, who was asked to guess and mark the attribute of an image. For each portrait, we asked three questions:
- Q1. Sex: mark the sex of the person in the portrait: female or male.
- Q2. Age: mark the age of the person in the portrait: young, middle-aged, or old.
- Q3. Race: mark the race of the person in the portrait: Asian, White, Black, or Indian.
When the participant correctly marked an attribute, the score for the attribute increased. For example, if they marked female for (female, young, Asian) images, then the sex score increased. For a wrong marking, the score did not increase. Our participants took 21–29 min for marking 240 portrait images. On average, it took 24.3 min. We had 24 combinations of attributes, and each combination could achieve 100 points, since each had 5 images and 20 participants marking the answer.
5.3.4. Results of the User Study
In Table 5, we present the scores of the three questions on the portraits. For a portrait with a combination of three attributes, for example, (male, young, Asian), we had 100 answers for a real image, and 100 for a generated image. In Figure 8, we also illustrate three scores aggregated for each attribute. According to Table 5, human participants recorded 97.21–99.58 for real images, and 91.04–96.63 for generated images.
Table 5.
Results of the user study: Scores of three attributes for each combination of attributes are presented. We compared these scores for real and generated images. Red bold figures denote those outside the average—standard deviation. The red figures denote they were in (average, average—standard deviation). Dark gray cells denote that the scores in the real and generated images were both red bold figures, and light gray cells denote that that the scores in real and generated images were red or red bold figures.
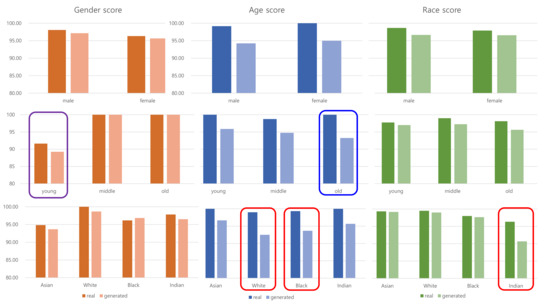
Figure 8.
Comparison of the user study. Three rows represent sex, age, and race, and three columns represent sex, age, and race scores, respectively. The generated images recorded four relatively lower scores than those of real images, which are marked as blue and red rectangles. Another notable indication was the sex score for young, which is marked as a violet rectangle. This score was the worst in both real and generated images.
5.3.5. Analysis of the User Study
From this user study, we could draw the following points.
- Comparison of real and generated images. Human participants showed higher scores on real images than those on generated images for all thee attributes. The difference of the scores vary from 0.79 to 4.96. Sex showed the least difference, and age showed the largest difference.
- Least scored attribute. Table 5 shows that the sex score for young faces was the least for both real and generated images, where the score was notably the least for six of the eight combinations of attributes (see the red figures with gray cells in Table 5 and the violet rectangle in Figure 8). We present the real and generated images for young faces in the upper row of Figure 9, where the sex of the faces in the images is hard to distinguish.
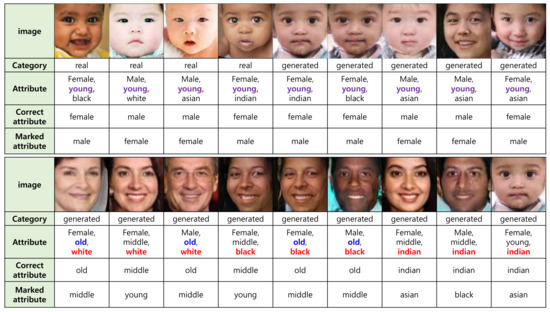 Figure 9. Incorrectly marked faces. Images in the upper row are real or generated portraits of young attributes. Their sex was marked incorrectly. Images in the lower row are all generated portraits of various races. Their ages and races were marked incorrectly.
Figure 9. Incorrectly marked faces. Images in the upper row are real or generated portraits of young attributes. Their sex was marked incorrectly. Images in the lower row are all generated portraits of various races. Their ages and races were marked incorrectly. - Most differently scored attributes. Figure 8 indicates that the four following scores showed notable differences: age score for old attributes, White attributes, Black attributes, and race score for Indian attributes. The average difference of the scores on each attribute for real and generated images was 2.52, while these four differences were greater than 5. Even though these four scores on the generated images scored above 90 points, the difference from the points on real images varied in the range of 5.67–6.75. The relatively low scores for the generated images came from the limitations of our model, as it could not produce confusing attributes on the generated images. Incorrectly marked images that had these four attributes are presented in the bottom row of Figure 9.
5.4. Ablation Study
We employed two discriminators for our model: the primary discriminator contributed to the quality of the generated image, while the auxiliary discriminator contributed to the conditions. We tested our model with only the primary discriminator and compared the results with those from two discriminators. We generated 20 images using only the primary discriminator. The generated images are compared in Figure 10. As illustrated in Figure 10, the model without the auxiliary discriminator showed limitations in controlling the conditions of the generated images. The recognition ratios of the results were estimated with VGG-Face [37], which was employed in Section 5.2. The recognition ratios are compared in Table 6.

Figure 10.
Ablation study: comparison of the results with or without auxiliary discriminator.
Table 6.
Comparison of recognition ratios for the ablation study.
6. Comparison
We compared our results with those from important existing works from the viewpoints of conditional generation and identity preservation.
6.1. Comparison of Conditional Generation
Since existing works are limited in applying conditions for portrait generation, we restricted six conditions: male, female, young, old, Asian, and Indian. We selected two existing works: TediGAN [26] and StyleCLIP [20]. We generated 20 portrait images for each condition, and estimated the recognition ratio of the portrait images. VGG-Face [37], the recognition model that we employed in Section 5.2, was also employed for estimating the recognition ratio. The generated images are presented in Figure 11 and the recognition ratios are in Table 7. For the six conditions that we compared, ours showed the best recognition ratios for five conditions. Therefore, our model produced portrait images that corresponded to the conditions better than existing models did.

Figure 11.
Comparison 1: conditional generation.
Table 7.
Comparison of our recognition ratios with those of existing studies. The red figures are maximum recognition ratio in each column.
6.2. Comparison of Identity Preservation
We could not find many studies that preserved the identity of a face while conditions such as sex, age, and face varied. Therefore, we compared our method with StyleCLIP [20], one of the SOTA style mixing studies. However, StyleCLIP is restricted to control only a single condition. We tested six conditional variations: male to female, female to male, White to Asian, Asian to White, middle-aged to old, and old to middle-aged. We tested each conditional variation for 20 images and illustrate one sample in Figure 12. For each pair of generated images of the same identity, we estimated the differences of the faces using FID and averaged them. The average FID values are presented in Table 8. For the six cases that we compared, ours had better recognition ratios for six cases. Therefore, our model better preserved the identity of faces through the conditions than existing work did.

Figure 12.
Comparison 2: identity preservation.
Table 8.
Comparison of the average FIDs of our method and StyleCLIP. The red figures are maximum FID in each column.
7. Conclusions and Future Works
We presented a GAN-based portrait-generation framework that could composite various attributes such as age, sex, and race. For this purpose, we designed a StyleGAN-based structure that could process latent vectors with conditional vectors that assigned the attributes. We devised a dual discriminator for simultaneously the quality and attributes of the generated faces. We produced faces wth 24 different attributes that comprised two sex attributes, three age attributes, and four race attributes. We validated our results with various schemes, namely, identity preservation, attribute recognition, and a user study.
We aim to extend our facial generation model to control identity attributes that could be guided by layouts such as segmentation maps or sketches. This approach could allow for us to control the very composite attributes of a face. Another direction is to extend the facial generation framework to a head generation framework with hair and poses.
Author Contributions
Conceptualization, H.Y.; Methodology, J.K.; Writing—original draft, K.M.; Writing—review & editing, H.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This study was supported by NRF of Korea. The fund No.’s are 2021R1G1A1009800 and 2021R1F1A106028611.
Data Availability Statement
Not available.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Bengio, Y. Generative Adversarial Networks. In Proceedings of the NeurIPS, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive Growing of GANs for Improved Quality, Stability, and Variation. In Proceedings of the ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A Style-Based Generator Architecture for Generative Adversarial Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4401–4410. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and Improving the Image Quality of StyleGAN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 8110–8119. [Google Scholar]
- Karras, T.; Aittala, M.; Laine, S.; Harkonen, E.; Hellsten, J.; Lehtinen, J.; Aila, T. Alias-Free Generative Adversarial Networks. In Proceedings of the NeurIPS, Virtual, 6–14 December 2021; pp. 852–863. [Google Scholar]
- Reed, S.; Akata, Z.; Yan, X.; Longeswaran, L.; Schiele, B.; Lee, H. Generative adversarial text to image synthesis. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 1060–1069. [Google Scholar]
- Dong, H.; Yu, S.; Wu, C.; Guo, Y. Semantic Image Synthesis via Adversarial Learning. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5706–5714. [Google Scholar]
- Zhang, H.; Xu, T.; Li, H.; Zhang, S.; Wang, X.; Huang, X.; Metaxas, D.N. StackGAN: Text to Photo-Realistic Image Synthesis With Stacked Generative Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5907–5915. [Google Scholar]
- Nam, S.; Kim, Y.; Kim, S.J. Text-Adaptive Generative Adversarial Networks: Manipulating Images with Natural Language. In Proceedings of the NeurIPS 2018, Montreal, PQ, Canada, 3–8 December 2018; pp. 42–51. [Google Scholar]
- Xu, T.; Zhang, P.; Huang, Q.; Zhang, H.; Gan, Z.; Huang, X.; He, X. AttnGAN: Fine-Grained Text to Image Generation With Attentional Generative Adversarial Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 1316–1324. [Google Scholar]
- Zhang, H.; Xu, T.; Li, H.; Zhang, S.; Wang, X.; Huang, X.; Metaxas, D.N. StackGAN++: Realistic Image Synthesis with Stacked Generative Adversarial Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 1947–1962. [Google Scholar] [CrossRef] [PubMed]
- Li, W.; Zhang, P.; Zhang, L.; Huang, Q.; He, X.; Lyu, S.; Gao, J. Object-Driven Text-To-Image Synthesis via Adversarial Training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 12174–12182. [Google Scholar]
- Zhu, M.; Pan, P.; Chen, W.; Yang, Y. DM-GAN: Dynamtic Memory Generative Adversarial Networks for Text-To-Image Synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5802–5810. [Google Scholar]
- Cheng, J.; Wu, F.; Tian, Y.; Wang, L.; Tao, D. RiFeGAN: Rich Feature Generation for Text-to-Image Synthesis From Prior Knowledge. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10911–10920. [Google Scholar]
- Li, B.; Qi, X.; Lukasiewicz, T.; Torr, P.H. ManiGAN: Text-Guided Image Manipulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 7880–7889. [Google Scholar]
- Li, B.; Qi, X.; Torr, P.; Lukasiewicz, T. Lightweight Generative Adversarial Networks for Text-Guided Image Manipulation. In Proceedings of the NeurIPS 2020, Virtual, 6–12 December 2020; pp. 22020–22031. [Google Scholar]
- Liu, Y.; Nadai, M.D.; Cai, D.; Li, H.; Alameda-Pineda, X.; Sebe, N.; Lepri, B. Describe What to Change: A Text-guided Unsupervised Image-to-image Translation Approach. In Proceedings of the ACM Multimedia, Seattle, WA, USA, 16 October 2020; pp. 1357–1365. [Google Scholar]
- Tao, M.; Tang, H.; Wu, F.; Jing, X.Y.; Bao, B.K.; Xu, C. DF-GAN: A Simple and Effective Baseline for Text-to-image Synthesis. arXiv 2020, arXiv:2008.05865. [Google Scholar]
- Koh, J.Y.; Baldridge, J.; Lee, H.; Yang, Y. Text-to-Image Generation Grounded by Fine-Grained User Attention. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision WACV, Virtual Conference, 5–9 January 2021; pp. 237–246. [Google Scholar]
- Patashnik, O.; Wu, Z.; Shechtman, E.; Cohen-Or, D.; Lischinski, D. StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery. In Proceedings of the IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, 10–17 October 2021; pp. 2085–2094. [Google Scholar]
- Ramesh, A.; Pavlov, M.; Goh, G.; Gray, S.; Voss, C.; Radford, A.; Chen, M.; Sutskever, I. Zero-Shot Text-to-Image Generation. In Proceedings of the PMLR, online, 22–23 November 2021; pp. 8821–8831. [Google Scholar]
- Ghosh, A.; Zhang, R.; Dokania, P.K.; Wang, O.; Efros, A.A.; Torr, P.H.S.; Shechtman, E. Interactive Sketch & Fill: Multiclass Sketch-to-Image Translation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV) 2019, Seoul, Korea, 27 October–2 November 2019; pp. 1171–1180. [Google Scholar]
- Xia, W.; Yang, Y.; Xue, J.H. Cali-Sketch: Stroke Calibration and Completion for High-Quality Face Image Generation from Poorly-Drawn Sketches. arXiv 2019, arXiv:1911.00426. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-To-Image Translation With Conditional Adversarial Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Wang, T.C.; Liu, M.Y.; Zhu, J.Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-Resolution Image Synthesis and Semantic Manipulation With Conditional GANs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8798–8807. [Google Scholar]
- Xia, W.; Yang, Y.; Xue, J.H.; Wu, B. TediGAN: Text-Guided Diverse Face Image Generation and Manipulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 2256–2265. [Google Scholar]
- Yang, Y.; Hossain, M.Z.; Gedeon, T.; Rahman, S. S2FGAN: Semantically Aware Interactive Sketch-To-Face Translation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV 2022), Waikoloa, HI, USA, 3–8 January 2022; pp. 1269–1278. [Google Scholar]
- Abdal, R.; Qin, Y.; Wonka, P. Image2StyleGAN: How to Embed Images Into the StyleGAN Latent Space? In Proceedings of the IEEE International Conference on Computer Vision (ICCV) 2019, Seoul, Korea, 27 October–2 November 2019; pp. 4432–4441. [Google Scholar]
- Shen, Y.; Gu, J.; Tang, X.; Zhou, B. Interpreting the Latent Space of GANs for Semantic Face Editing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 9243–9252. [Google Scholar]
- Zhu, J.; Shen, Y.; Zhao, D.; Zhou, B. In-Domain GAN Inversion for Real Image Editing. In Proceedings of the ECCV 2020, Glasgow, UK, 23 August 2020; pp. 592–608. [Google Scholar]
- Odena, A.; Olah, C.; Shlens, J. Conditional Image Synthesis with Auxiliary Classifier GANs. In Proceedings of the ICML 2017, Sydney, NSW, Australia, 6–11 August 2017; pp. 2642–2651. [Google Scholar]
- Kang, M.; Shim, W.; Cho, M.; Park, J. Rebooting ACGAN: Auxiliary Classifier GANs with Stable Training. In Proceedings of the NeurIPS, Virtual, 6–14 December 2021; pp. 23505–23518. [Google Scholar]
- Gong, M.; Xu, Y.; Li, C.; Zhang, K.; Batmanghelich, K. Twin Auxiliary Classifiers GAN. In Proceedings of the NeurIPS, Vancouver, BC, Canada, 8–14 December 2019; pp. 1328–1337. [Google Scholar]
- Kang, M.; Park, J. ContraGAN: Constrastive Learning for Conditional Image Generation. In Proceedings of the NeurIPS 2020, Virtual, 6–12 December 2020; pp. 21357–21369. [Google Scholar]
- Zhou, P.; Xie, L.; Ni, B.; Geng, C.; Tian, Q. Omni-GAN: On the Secretes of cGANs and Beyond. In Proceedings of the IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, 10–17 October 2021; pp. 14061–14071. [Google Scholar]
- Zhou, Z.; Cai, H.; Rong, S.; Song, Y.; Ren, K.; Zhang, W.; Yu, Y.; Wang, J. Activation Maximization Generative Adversarial Nets. arXiv 2017, arXiv:1703.02000. [Google Scholar]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A. Deep Face Recognition. In Proceedings of the BMVC 2015, Swansea, UK, 7–10 September 2015; pp. 41.1–41.12. [Google Scholar]
- Deng, Y.; Yang, J.; Chen, D.; Wen, F.; Tong, X. Disentangled and Controllable Face Image Generation via 3D Imitative-Contrastive Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 5154–5163. [Google Scholar]
- Kowalski, M.; Garbin, S.; Estellers, V.; Baltrusaitis, T.; Johnson, M.; Shotton, J. Config: Controllable neural face image generation. In Proceedings of the ECCV 2020, Glasgow, UK, 23 August 2020; pp. 299–315. [Google Scholar]
- Shoshan, A.; Bhonker, N.; Kviatkovsky, I.; Medioni, G. GAN-Control: Explicitly Controllable GANs. In Proceedings of the IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, 10–17 October 2021; pp. 14083–14093. [Google Scholar]
- Tov, O.; Alaluf, Y.; Nitzan, Y.; Patashnik, O.; Cohen-Or, D. Designing an Encoder for Stylegan Image Manipulation. ACM Trans. Graph. 2021, 40, 133. [Google Scholar] [CrossRef]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep Learning Face Attributes in the Wild. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3730–3738. [Google Scholar]
- Karkkainen, K.; Joo, J. FairFace: Face Attribute Dataset for Balanced Race, Gender, and Age for Bias Measurement and Mitigation. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision WACV, Virtual Conference, 5–9 January 2021; pp. 1548–1558. [Google Scholar]
- Zhang, Z.; Song, Y.; Qi, H. Age Progression/Regression by Conditional Adversarial Autoencoder. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 4352–4360. [Google Scholar]












Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).