
Cross Domain Data Generation for Smart Building Fault Detection and Diagnosis

Abstract
:1. Introduction
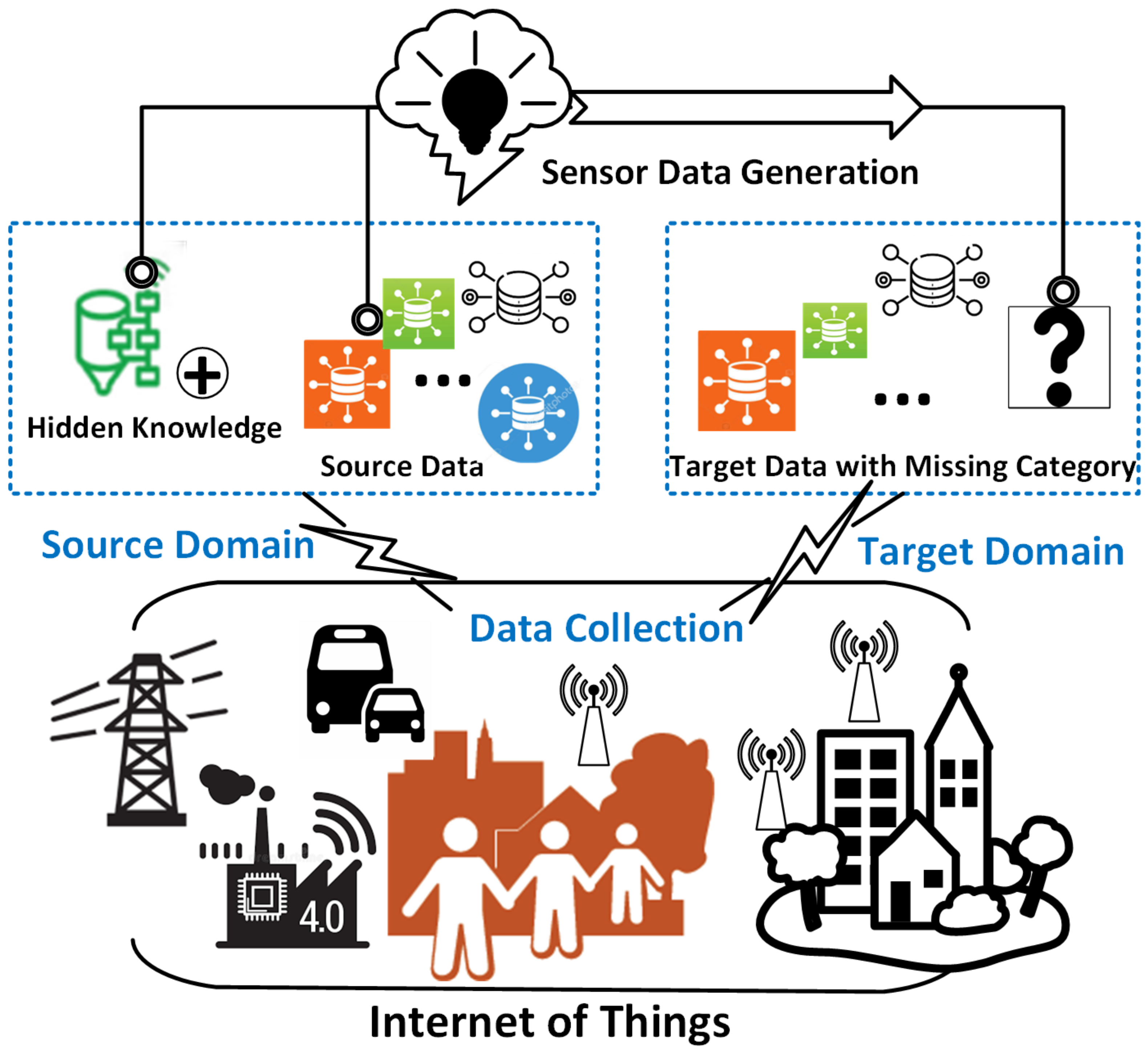
- Lack of real-life labeled fault data: Most well-labeled fault datasets are collected from experiments conducted in laboratory test beds or synthetic systems. Labeled fault data in real-life smart building systems are rare—the raw sensor measurements are typically unlabelled [14].
- Limited transferability of labeled fault data: The existing well-labeled fault datasets should not be directly applied to similar smart building systems as the environmental factors and equipment settings can be different from the laboratory test-beds or synthetic smart building systems and are constantly changing (e.g., due to seasonal changes) [15].
- A ACDG framework was proposed to generate unknown target faults based on known faults for the learning task in a target setting.
- Unlike existing TL-based FDD work, the proposed ACDG framework captured both the inter-domain knowledge and the intra-domain class relations.
- With experiments on the ASHRAE RP-1312 dataset, the proposed ACDG framework was proven to generate building faults in one season based on their counterparts in other seasons.
- While this paper has focused on building fault generation, the proposed ACDG framework is general and should also apply to other sensor data generation applications.
2. Related Works
2.1. Generative Adversarial Networks
2.2. Transfer Learning
- Instance-based Transfer: It is intuitively assumed that certain parts of the data in the source domain can be reused for learning in the target domain by re-weighting [32,33]. These approaches can be viewed as an improvement of the semi-supervised learning method by using unlabelled data to transfer data (either through re-weighting or projection) from the source domain to the target domain. In contrast, little hidden knowledge about the data and system structure is revealed and conveyed.
- Feather Representation Transfer: In this case, transfer learning is enhanced from the previous case where unlabelled data is applied directly by digging “robust” features in the source domain and then transferring them to help with the target task [34,35]. By projecting the features learned in the source domain to the target domain with a new representation, the performance of the target can be somewhat improved. However, the knowledge conveyed by feature transfer is limited due to information loss during projection.
- Parameter Transfer: Assuming that the source tasks and the target tasks share some parameters or prior distributions of the hyper-parameters of the models [36,37], this kind of transfer learning tries to discover the shared parameters or priors from the source domain and then share them, e.g., through Bayesian priors, across different domains. Although effective, this kind of transfer strongly requires the two domains to share similar distributions. Otherwise, the shared parameters would not be much helpful.
- Knowledge Transfer: The aforementioned transfer learning methods all attempt to unify the data distributions in source and target domains by projection or alignment. In these cases, intrinsic patterns in the source data may not be fully uncovered as the relational knowledge between two domains is not comprehensively considered. Researchers proposed to learn the data relationship between two domains with models capable of learning representations, e.g., deep neural networks [38]. The learned embedding of hidden data patterns between different domains is a key factor in this kind of transfer learning and thus results in a well-known sub-filed called domain adaptation [39,40].
3. Adversarial Cross Domain Data Generation Framework
3.1. Problem Statement
3.2. Architecture
3.3. Methodology
3.4. ACDG Losses
4. Mechanical System and Dataset
4.1. AHU and Typical Faults
4.2. Data
5. Experiments and Results
5.1. Experiment Set-Up
5.2. Distributional Quality of ACDG Generated Data
5.3. Classification Performance with Data Generation
5.4. Fault Detection and Diagnosis with ACDG
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ciftler, B.S.; Dikmese, S.; Güvenç, İ.; Akkaya, K.; Kadri, A. Occupancy counting with burst and intermittent signals in smart buildings. IEEE Internet Things J. 2017, 5, 724–735. [Google Scholar] [CrossRef]
- Schumann, A.; Hayes, J.; Pompey, P.; Verscheure, O. Adaptable fault identification for smart buildings. In Proceedings of the In Workshops at the Twenty-Fifth AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 7–8 August 2011. [Google Scholar]
- Li, D.; Hu, G.; Spanos, C.J. A data-driven strategy for detection and diagnosis of building chiller faults using linear discriminant analysis. Energy Build. 2016, 128, 519–529. [Google Scholar] [CrossRef]
- Li, D.; Zhou, Y.; Hu, G.; Spanos, C.J. Identifying Unseen Faults for Smart Buildings by Incorporating Expert Knowledge With Data. IEEE Trans. Autom. Sci. Eng. 2018, 16, 1412–1425. [Google Scholar] [CrossRef] [Green Version]
- Wang, B.; Liu, D.; Peng, Y.; Peng, X. Multivariate regression-based fault detection and recovery of UAV flight data. IEEE Trans. Instrum. Meas. 2019, 69, 3527–3537. [Google Scholar] [CrossRef]
- Joshuva, A.; Sugumaran, V. A comparative study of Bayes classifiers for blade fault diagnosis in wind turbines through vibration signals. Struct. Durab. Health Monit. 2017, 11, 69. [Google Scholar]
- Jin, B.; Li, D.; Srinivasan, S.; Ng, S.K.; Poolla, K.; Sangiovanni-Vincentelli, A. Detecting and diagnosing incipient building faults using uncertainty information from deep neural networks. In Proceedings of the In 2019 IEEE International Conference on Prognostics and Health Management (ICPHM), San Francisco, CA, USA, 17–20 June 2019; pp. 1–8. [Google Scholar]
- Cheng, F.; Cai, W.; Zhang, X.; Liao, H.; Cui, C. Fault detection and diagnosis for Air Handling Unit based on multiscale convolutional neural networks. Energy Build. 2021, 236, 110795. [Google Scholar] [CrossRef]
- Guo, Y.; Chen, H. Fault diagnosis of VRF air-conditioning system based on improved Gaussian mixture model with PCA approach. Int. J. Refrig. 2020, 118, 1–11. [Google Scholar] [CrossRef]
- Liu, S.; Xu, L.; Li, Q.; Zhao, X.; Li, D. Fault diagnosis of water quality monitoring devices based on multiclass support vector machines and rule-based decision trees. IEEE Access 2018, 6, 22184–22195. [Google Scholar] [CrossRef]
- Zhou, Y.; Baek, J.Y.; Li, D.; Spanos, C.J. Optimal Training and Efficient Model Selection for Parameterized Large Margin Learning. In Advances in Knowledge Discovery and Data Mining; Springer: Cham, Switzerland, 2016; pp. 52–64. [Google Scholar]
- Li, D.; Zhou, Y.; Hu, G.; Spanos, C.J. Fault Detection and Diagnosis for Building Cooling System With A Tree-structured Learning Method. Energy Build. 2016, 127, 540–551. [Google Scholar] [CrossRef]
- Li, D.; Zhou, Y.; Hu, G.; Spanos, C.J. Fusing system configuration information for building cooling plant Fault Detection and severity level identification. In Proceedings of the 2016 IEEE International Conference on Automation Science and Engineering (CASE), Fort Worth, TX, USA, 21–25 August 2016; pp. 1319–1325. [Google Scholar]
- Čolaković, A.; Hadžialić, M. Internet of Things (IoT): A review of enabling technologies, challenges, and open research issues. Comput. Networks 2018, 144, 17–39. [Google Scholar] [CrossRef]
- Daissaoui, A.; Boulmakoul, A.; Karim, L.; Lbath, A. IoT and big data analytics for smart buildings: A survey. Procedia Comput. Sci. 2020, 170, 161–168. [Google Scholar] [CrossRef]
- Schein, J.; Bushby, S.T.; Castro, N.S.; House, J.M. Results From Field Testing of Air Handling Unit and Variable Air Volume Box Fault Detection Tools; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2003. [Google Scholar]
- Wen, J.; Li, S. Tools for Evaluating Fault Detection and Diagnostic Methods for Air-Handling Units; Drexel University. ASHRAE: Philadelphia, PA, USA, 2011. [Google Scholar]
- Rubin, D.B. The bayesian bootstrap. Ann. Stat. 1981, 9, 130–134. [Google Scholar] [CrossRef]
- Miller, R.G. The jackknife-a review. Biometrika 1974, 61, 1–15. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the In Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Bernardino, R.P.; Torr, P. An embarrassingly simple approach to zero-shot learning. In Proceedings of the In International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2152–2161. [Google Scholar]
- Li, W.; Huang, R.; Li, J.; Liao, Y.; Chen, Z.; He, G.; Yan, R.; Gryllias, K. A perspective survey on deep transfer learning for fault diagnosis in industrial scenarios: Theories, applications and challenges. Mech. Syst. Signal Process. 2022, 167, 108487. [Google Scholar] [CrossRef]
- Zou, H.; Zhou, Y.; Yang, J.; Liu, H.; Das, H.P.; Spanos, C.J. Consensus adversarial domain adaptation. In Proceedings of the AAAI Conference on Artificial Intelligence, Atlanta, GA, USA, 8–12 October 2019; Volume 3, pp. 5997–6004. [Google Scholar]
- Liu, X.; Yu, W.; Liang, F.; Griffith, D.; Golmie, N. Towards Deep Transfer Learning in Industrial Internet of Things. IEEE Internet Things J. 2021, 8, 12163–12175. [Google Scholar] [CrossRef]
- Feng, L.; Zhao, C. Fault Description Based Attribute Transfer for Zero-Sample Industrial Fault Diagnosis. IEEE Trans. Ind. Inform. 2020, 17, 1852–1862. [Google Scholar] [CrossRef]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Mehdi, M.; Simon OsinderoMirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2017, arXiv:1411.1784. [Google Scholar]
- Olof, M. C-RNN-GAN: Continuous recurrent neural networks with adversarial training. arXiv 2016, arXiv:1611.09904. [Google Scholar]
- Cristóbal, E.; Hyland, S.L.; Rätsch, G. Real-valued (medical) time series generation with recurrent conditional GANs. arXiv 2017, arXiv:1706.02633. [Google Scholar]
- Kim, T.; Cha, M.; Kim, H.; Lee, J.K.; Kim, J. Learning to discover cross-domain relations with generative adversarial networks. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, Sydney, Australia, 6–11 August 2017; pp. 1857–1865. [Google Scholar]
- Jialin, P.S.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar]
- Liu, Z.H.; Lu, B.L.; Wei, H.L.; Chen, L.; Li, X.H.; Wang, C.T. A stacked auto-encoder based partial adversarial domain adaptation model for intelligent fault diagnosis of rotating machines. IEEE Trans. Ind. Informatics 2020, 10, 6798–6809. [Google Scholar] [CrossRef]
- Li, W.; Chen, Z.; He, G. A novel weighted adversarial transfer network for partial domain fault diagnosis of machinery. IEEE Trans. Ind. Informatics 2020, 3, 1753–1762. [Google Scholar] [CrossRef]
- Yang, B.; Lee, C.G.; Lei, Y.; Li, N.; Lu, N. Deep partial transfer learning network: A method to selectively transfer diagnostic knowledge across related machine. Mech. Syst. Signal Process. 2021, 156, 107618. [Google Scholar] [CrossRef]
- Deng, Y.; Huang, D.; Du, S.; Li, G.; Zhao, C.; Lv, J. A double-layer attention based adversarial network for partial transfer learning in machinery fault diagnosis. Comput. Ind. 2021, 127, 103399. [Google Scholar] [CrossRef]
- Jiao, J.; Zhao, M.; Lin, J.; Ding, C. Classifier Inconsistency-Based Domain Adaptation Network for Partial Transfer Intelligent Diagnosis. IEEE Trans. Ind. Informatics 2019, 16, 5965–5974. [Google Scholar] [CrossRef]
- Yang, B.; Lei, Y.; Jia, F.; Li, N.; Du, Z. A polynomial kernel induced distance metric to improve deep transfer learning for fault diagnosis of machines. IEEE Trans. Ind. Electron. 2020, 67, 9747–9757. [Google Scholar] [CrossRef]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.W.; Kim, S.; Choo, J. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8789–8797. [Google Scholar]
- Xia, H.; Zhao, H.; Ding, Z. Adaptive adversarial network for source-free domain adaptation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 9010–9019. [Google Scholar]
- Liu, X.; Yoo, C.; Xing, F.; Oh, H.; El Fakhri, G.; Kang, J.W.; Woo, J. Deep unsupervised domain adaptation: A review of recent advances and perspectives. APSIPA Trans. Signal Inf. Process. 2018, 11, 2022. [Google Scholar] [CrossRef]
- Zhao, Y.; Wen, J.; Wang, S. Diagnostic Bayesian networks for diagnosing air handling units faults–Part II: Faults in coils and sensors. Appl. Therm. Eng. 2015, 90, 145–157. [Google Scholar] [CrossRef]
- Li, S.; Wen, J. Application of pattern matching method for detecting faults in air handling unit system. Autom. Constr. 2014, 43, 49–58. [Google Scholar] [CrossRef]
- Li, S.; Wen, J. A model-based fault detection and diagnostic methodology based on PCA method and wavelet transform. Energy Build. 2014, 68, 63–71. [Google Scholar] [CrossRef]
- Price, B.; Smith, T. Development and Validation of Optimal Strategies for Building Hvac Systems; Technical Report, ME-TEF-03-001; Department of Mechanical Engineering, The University of Iowa: Iowa City, IA, USA, 2003. [Google Scholar]
- Yu, Y.; Woradechjumroen, D.; Yu, D. A review of fault detection and diagnosis methodologies on air-handling units. Energy Build. 2014, 82, 550–562. [Google Scholar] [CrossRef]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fault Descriptions | Fault Name | Class Labels in Each Experiment | |||
|---|---|---|---|---|---|
| SD:Spring | TD:Winter | SD:Winter | TD:Spring | ||
| Normal Condition | NORMAL | Sp1 | Win1 | Win1 | Sp1 |
| EA Damper Stuck | EADS_FO | Sp2 | Win2 | Win2 | Sp2 |
| (Fully Open) | |||||
| Cooling Coil Valve Stuck | CCVS_FO | Sp3 | Win3 | Win3 | Sp3 |
| (Fully Open) | |||||
| EA Damper Stuck | EADS_FC * | Sp4 | SpWin4 * | Win4 | WinSp4 * |
| (Fully Closed) | |||||
| SD:Summer | TD:Spring | SD:Spring | TD:Summer | ||
| Normal Condition | NORMAL | Su1 | Sp1 | Sp1 | Su1 |
| Cooling Coil Valve Stuck | CCVS_FO | Su2 | Sp2 | Sp2 | Su2 |
| (Fully Open) | |||||
| Cooling Coil Valve Stuck | CCVS_FC | Su3 | Sp3 | Sp3 | Su3 |
| (Fully Close) | |||||
| OA Damper Stuck | OADS_FC * | Su4 | SuSp4 * | Sp4 | SpSu4 * |
| (Fully Close) | |||||
| SD:Summer | TD:Winter | SD:Winter | TD:Summer | ||
| Normal Condition | NORMAL | Su1 | Win1 | Win1 | Su1 |
| EA Damper Stuck | EADS_FC | Su2 | Win2 | Win2 | Su2 |
| (Fully Close) | |||||
| Cooling Coil Valve Stuck | CCVS_FO | Su3 | Win3 | Win3 | Su3 |
| (Fully Open) | |||||
| EA damper stuck | EADS_FO * | Su4 | SuWin4 * | Win4 | WinSu4 * |
| (Fully Open) | |||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, D.; Xu, Y.; Zhou, Y.; Gou, C.; Ng, S.-K. Cross Domain Data Generation for Smart Building Fault Detection and Diagnosis. Mathematics 2022, 10, 3970. https://doi.org/10.3390/math10213970
Li D, Xu Y, Zhou Y, Gou C, Ng S-K. Cross Domain Data Generation for Smart Building Fault Detection and Diagnosis. Mathematics. 2022; 10(21):3970. https://doi.org/10.3390/math10213970
Chicago/Turabian StyleLi, Dan, Yudong Xu, Yuxun Zhou, Chao Gou, and See-Kiong Ng. 2022. "Cross Domain Data Generation for Smart Building Fault Detection and Diagnosis" Mathematics 10, no. 21: 3970. https://doi.org/10.3390/math10213970
APA StyleLi, D., Xu, Y., Zhou, Y., Gou, C., & Ng, S.-K. (2022). Cross Domain Data Generation for Smart Building Fault Detection and Diagnosis. Mathematics, 10(21), 3970. https://doi.org/10.3390/math10213970