1. Introduction
Aiming at the automation of processes, we intend to automate the very process of control systems development in order to make it fast and generic. This sounds especially relevant in the context of ever-increasing robotization and the emergence of a variety of robots as control objects. To reach this goal of all-round automation, it is necessary to generalize the needed tasks, that is, to formulate them in general mathematical statements, and then develop universal methods for solving them. However, the problem here is that despite the extensive theoretical background of control theory, today, there is a wide range of applied problems that do not have exact analytical solutions. At the same time, there is an objective need for solving them.
In fact, in robotics, most modern control systems for robots are programmed by hand, and engineers do not even set the general problems because there are no general ways to solve them. The developer, based on his experience, sets the structure of the control system, determines the control channels, types of regulators, and then adjusts the parameters of the given system so that they meet certain requirements [
1]. However, every problem can and should be considered an optimal one, defining not only the parameters, but also the structure of the control system optimally and, again, automatically.
If a robot has to perform rather simple actions, for example, moving from one point to another and going around some obstacles, then the program of its control system contains supposedly several hundreds of lines. In more complex control tasks, the programs that must control robots can include several tens or hundreds of thousands of lines. These programs will grow as the tasks or the robots structure become more complex. One can assume that a control system for a robot that repeats the actions of a fly must contain some millions of lines. It follows from that stated above that the manual creation of the robot control system is an unpromising direction. It is necessary to automate this process.
Any problem for robots, as well as any other control objects, can be formulated as a mathematical optimization problem, such as a problem of providing stability, an optimal control problem for finding optimal path in current real conditions, a problem of stabilization of movement along of the optimal path, a problem of avoiding collisions with static and dynamic obstacles, the problem of interaction with other control objects, the problem of precise achievement of some given terminal conditions and so on. The most general problem in robotics is feedback control synthesis. It assumes that a control system that makes the object reach its goal is designed as a function of the object state optimally according to given criteria. Even if the optimal control problem is solved and the optimal path is found, we must further ensure the movement of the object along the obtained trajectory to compensate for possible ever-existing uncertainties.
The general synthesis problem was formulated back in the early 1960s by Bellman [
2,
3], where the continuous-time nonlinear optimal control problem was solved through the Hamilton–Jacobi–Bellman equation, which is a nonlinear partial differential equation. Even in simple cases, the HJB equation may not have global analytic solutions. Various numerical methods based on dynamic programming have been proposed in the literature [
4,
5,
6,
7], including the modern adaptive dynamic programming technique [
8,
9,
10] and reinforcement learning [
11,
12,
13]. However, the main drawback of dynamic programming methods today is still the computational complexity required to describe the value function, which grows exponentially with the dimension of its domain.
A different way to construct a feedback optimal control is firstly to solve an optimal control problem by direct methods of nonlinear programming or by the indirect approach of the Pontryagin maximum principle and then to synthesize a feedback stabilization system in order to supply movement along the received optimal trajectory. For example, in [
14], points are placed on the trajectory, and the object is stabilized at these points. This is the most popular practical approach to feedback optimal control system design.
However, concerning the optimality criterion, this approach is not correct since it turns out that the optimal path is considered for one control object, and the introduced stabilization system changes the object so that the calculated path may not be optimal for the modified object model. In addition, when approaching a given point on the path, the system slows down, so it is necessary to carry out additional estimates in each specific task, according to the optimal moments of points switching.
In this work, we propose an inverse approach to feedback optimal control system synthesis. The general idea is the following. We firstly stabilize an object according to some point in the state space by solving the stabilization system synthesis problem. Note that this problem is computationally easier than the general synthesis problem. The stabilization task can be solved by a plain variety of methods depending on the complexity of the object model, particularly analytical methods of backstepping [
15,
16] or the analytical design of aggregated controllers [
17], or synthesis based on the application of the Lyapunov function [
18,
19], as well as any classical methods for liner systems, such as modal control [
20], differently tuned PID controllers [
21], and fuzzy [
22] and neural network [
23] controllers. In the overwhelming majority of cases, the control synthesis problem is solved analytically or technically by taking into account the specific properties of the mathematical model. Today, modern numerical machine learning methods can be applied to find a solution for generic dynamic objects [
24].
This new paradigm of machine learning control [
25,
26] allows to find some good near optimal solutions in a limited amount of time. However, due to the novelty of these methods, it becomes necessary to substantiate the results obtained by machine learning. In this paper, we introduce definitions of some machine properties of the system. We introduce the definition of machine learning control from our point of view, give machine proof of the existence of a specific property in some mathematical model, refine the definition of the feasibility property of the mathematical model of the control object and present the extended statement of the optimal control problem.
The addition of the stabilization system into the object model gives it a new property: at each moment of time, the object has a point of equilibrium. Thus, in the synthesized optimal control approach, the uncertainty in the right parts is compensated by the stability of the system relative to a point in the state space. Near the equilibrium point, all solutions converge. Now, we can solve the problem of optimal control through the optimal position of the equilibrium point. The found synthesized optimal control can be realized in the real object directly without additional feedback stabilization loops.
The paper is structured in the following order. After the introduction, the theoretical base of machine learning control is presented in
Section 2, introducing the main definitions and machine criteria for justification of the results received by machine numerical methods. Next, in
Section 3, we formulate the mathematical statement of the problem of feedback machine learning control, extending the optimal control problem statement with additional requirements. Then in
Section 4, the paper proposes a synthesized approach to the solution of the stated feedback optimal control problem. Algorithms for its solution are considered in
Section 5 and
Section 6, and computational examples of solving control problems for mobile robots are presented in
Section 7. In the experimental part, the computational examples of synthesized control application for solving feedback control problems in the class of feasible controls for mobile robots are presented.
2. Theoretical Base of Machine Learning Control
Summarizing various definitions of machine learning [
27,
28,
29], we can conclude that machine learning is an inexact numerical solution of some mathematical optimization problem, that is, the solution obtained by machine learning differs from the exact one by some known value but satisfies the researcher, and it can be improved with continuing learning. In all cases, different optimization algorithms are used for machine learning, but for these algorithms, it is enough to find a near optimal solution.
Let us introduce some definitions.
Definition 1. The machine learning problem is a search of an unknown function.
where
is a vector of function values,
,
is a vector of arguments,
,
is a vector of constant parameters,
,
This function during training approximates some data set, which is called the training sample:
where
is a training sample.
With unsupervised learning, this function is used for the minimization of some functional
where
is the goal achievement time.
Definition 2. Machine learning is finding a solution of the optimization problem in the given Δ neighborhood of the optimal solution.
The peculiarity of machine learning is that learning does not require the exact achievement of minimum criterion (
3) or (
4):
where
is a given positive value determining a functional value achievable during learning. For criterion (
3), a minimum value is equal to zero. For criterion (
4), the minimal value can be unknown. Then, the limit minimum value can be used instead:
where
.
If, as a result of learning, the found function (
1) must acquire some properties, then the proof of the presence of these properties is confirmed by simulation.
where
is the Heaviside function
is a condition that determines whether a function property exists
where
K is a number of consecutive experiments performed with a positive result (
9), set to prove the presence of a property.
Definition 3. Machine learning control is a search of control function.
Machine learning searches for a function that, for some sets of arguments, returns the required values. Note that there can be many such functions, and all they can have various structures and parameter values.
According to the introduced Definitions 1–3, an optimization problem of the control function search must be formulated for machine learning control. A solution of this problem is not optimal, as the found function gives a value of the quality criterion close to optimal one. On the one hand, this might reduce the importance of the solution found, but on the other hand, it allows for solving very complex problems.
Let us be given a mathematical model of a control object. This model can be derived from physical laws or identified by some machine learning technique [
30,
31]. Generally, this model is described by a system of ordinary differential equations with a free control vector in the right-hand side:
where
is a state vector,
is a control vector,
The problem of control, including machine learning control, is to find a control function instead of the control vector
to make the differential equation system
acquire some new properties. For example, these can be such properties as stability, the optimality of solutions, and others.
In machine learning, the control function of these new properties of the control object has to be checked by a computer as well.
When the control function is derived analytically, then the system is guaranteed to have the desired property. In the case of machine learning control, events occur when the system does not have the desired property. Let us call them bad events. For example, the robot reaches the terminal position from almost all initial conditions, but does not reach it from some other initial condition. Although such events are rare with good training, they can occur, and the probability of its occurrence is not known. We also need to introduce some estimate when we can consider that the probability of the bad event is small, and we can consider learning to be successful, i.e., assume that the system has obtained the desired property.
The appearance of bad events is due to the presence of various uncertainties and disturbances in the system. According to Lyapunov [
32], the existing uncertainties can be considered uncertainties in the initial conditions.
Let us formulate a machine criterion of obtaining some property by a differential equation system. To define the property of the whole system (
13), it is enough to set a quantity
K of partial solutions that obtain this property.
Definition 4. If D experiments are carried out and in every i experiment, partial solutions of the differential equation perform the required property from any randomly selected initial conditions from the initial domain, and the existence of this property for the differential equation in this domain is proven by machine.
In other words, as the number of experiments increases, the probability of such a bad event, when the system does not have the desired property, tends to zero. From a mathematical point of view, this means that all private solutions for the domain of initial conditions have this property, except solutions for a subset of a zero measure.
Now we can redefine some properties of differential equations into appropriate machine properties.
Let the computer check the new properties in terminal time interval, .
Let, in the state space of differential equation system (
13), a manifold of the dimension
be defined by
Definition 5. In some domain , the following properties are performed: for given quantity K of initial conditions , for the partial solution of differential Equation (13) . Then, where , and Then, differential equation system (13) is machine stable on a bound time interval relative to the manifold (15). If a dimension of the manifold equals to 0, then a machine stable equilibrium point is obtained. Coordinates of this point in the state space are determined from solving the algebraic equation system,
The definition of machine stability uses a manifold (
15) that can be expressed from the partial solution. Let
be a partial solution of differential Equation (
13):
Let us solve one component (
19) relative to
t. Let it be the last component:
After inserting Equation (
20) in solution (
19), a one-dimensional manifold is received:
Machine stability relative to the manifold (
21) is the machine stability of solution (
19) of differential Equation (
13).
Now consider the equilibrium points of some generic differential equation:
where
,
.
Analytically, the equilibrium points are defined as solutions of the system of algebraic equations:
Machine-determined equilibrium points
are the points that satisfy the following condition:
and
,
,
,
where
is a given small positive number.
Definition 6. An equilibrium point of differential Equation (22) is stable if there is a domain , such that it contains a sphere where is located completely in this domain , and , a partial solution of differential Equation (22), will reach the point for limited time where .
The sphere is introduced here in order to guarantee that the equilibrium point is inside the region and exclude it from falling on the boundary.
The introduced machine interpretations of the known properties of objects eliminate the need to analytically prove the existence of these properties for an object since this is often very laborious or completely impossible. This allows further solving complex technical problems by machine methods and checking the achievement of the required properties by machine.
3. Machine Learning Feedback Control
Recall our goal. We want to automate the design of an automatic control system. For this purpose, it is necessary to formulate for the computer the control problem and make the computer solve it automatically and design a control system for a control object without human.
To do this, let us formulate the problem in a general mathematical setting of optimal control.
The mathematical model of the control object is given in the form of differential equation system (
10).
The initial condition is given:
Given the terminal position as a goal,
The quality criterion is given in the form of an integral functional:
It is necessary to find a control function in the form
where
, which makes object (
10) achieve given goal (
29) with the optimal value of quality criterion (
30). A found control function (
31) has to satisfy the boundaries:
We are looking for control as a function of the state of the object, which corresponds to the principle of feedback control. It is generally accepted that this type of control is implemented in real systems since it allows leveling the inaccuracies of the model.
Definition 7. For a mathematical model to correspond to a dynamic real object, it is necessary and sufficient that the mathematical estimation error of the real object state does not increase over time.
That is, the introduction of the feedback control to the differential equation system gives the system some property that allows the object to achieve the goal with the optimal quality value, that is, to be feasible. The question is, what is this property?
It is clear that not all control systems are feasible. For example, optimal but open-loop control systems do not have the feasibility property. Conversely, Lyapunov-stable systems are feasible. However, there are examples when the solution is not Lyapunov stable but at the same time it is feasible [
32]. For example, when moving through points, the movement itself to a point is Lyapunov stable, but movement along a trajectory consisting of points is not Lyapunov stable, but this control is now most often implemented. Thus, it becomes necessary to formulate a property that makes it possible to determine the feasibility of the system.
In fact, by introducing a feedback system, we change the differential equations of the system so that a certain area appears around some particular solution of the system (the optimal trajectory) such that other trajectories that fall into this area will not leave it.
This trajectory is a partial solution of differential equation
for the found optimal control.
Definition 8. The partial solution of differential Equation (22) has a compressibility property if, for any other partial solution , the following conditions are performed. where , , then such, that for any Hypothesis 1. To realize the found optimal control function (31) in the real control object, the optimal trajectory must compressibility properties (34) and (35). Obviously, if a control function provides performing properties (
34) and (
35), then this control function according to Definition 8 can be realized in the real object directly. According to Definition 8, an unstable differential equation cannot be realized. Highly unstable systems exist, but they cannot be described by unstable differential equations because these differential equations cannot estimate the state of unstable objects in time. Any small error in the initial conditions for the unstable differential equation of a mathematical model will be increasing over time. To estimate the state of an unstable object, it is necessary to use a stable differential equation.
Thus, to solve the stated feedback optimal control problem, it is necessary to construct such a control function (
31) that makes the object (
10) achieve given goal (
29) with the optimal value of quality criterion (
30) and obtain required properties (
34) and (
35).
4. Synthesized Optimal Control Approach for the Solution of the Stated Problem
In this section, we propose our synthesized optimal control approach [
33] that completely satisfies requirements (
34) and (
35) in the construction of optimal control (
31).
The idea of the approach consists in providing the object with the existence of some equilibrium point in the state space and then constructing such a control function that controls the position of the equilibrium point in order to make the object reach the goal with the optimal value of the quality criterion.
Initially, the control synthesis problem is solved to provide the existence of the equilibrium point. As a result, the control function in the following form is found:
where
in each fixed moment of time is some point in the state space that affects the position of the equilibrium point of the differential equation:
The control function (
38) must satisfy restrictions for any position of the point
For any value
, the differential equation system (
37) has an equilibrium point
:
A matrix of Jacobi
computed in the equilibrium point
has all eigenvalues in the left part of the complex plane.
where
, , .
In many cases, the equilibrium point coincides with the point , but in some cases, it is impossible. For example, if the differential equation system includes an equation , then the component of the equilibrium point will have only value 0 for any values of components .
Note that when this control synthesis problem is solved by some machine learning method, conditions (
41) and (
42) cannot be checked for each mathematical expression
of the control function because these are very time-consuming procedures. In machine learning control, to prove the stability in an equilibrium point, Definition 6 is used.
To synthesize control function (
36), it is necessary to determine domain
and then to determine equilibrium point
. If the equilibrium point is equal to point
, then the control function is searched in the form of (
36), where
.
Computationally, to provide a stable property of equilibrium point
, the synthesis problem (
10)–(
12) is solved with the terminal point
, the initial domain
, and the quality criterion
where
is the weight coefficient,
where
is the time of achievement of the terminal position (
29) from the initial condition
of the set of initial conditions
,
,
where
and
are given positive values,
is a partial solution of the system
for initial conditions
,
,
In the second stage, the following optimal control problem is solved. The mathematical model of the control object is given in the form of (
37), and the initial conditions are given as (
28). It is necessary to find control as a function of time:
in order to minimize the functional
The obtained control
allows performing conditions (
34) and (
35); therefore, it can be realized in the real object.
Further in the paper, we discuss the machine learning methods appropriate to solve the described problems and show the examples of applying the proposed approach to the solution of two different robotic tasks.
5. Symbolic Regression for Machine Learning
According to the introduced Definitions 1, 2 and 3, the task of searching for the needed control function (
36) in the first step is to be considered a machine learning task.
A search of an unknown function consists in searching for the structure and parameters of this function. Usually structures of the functions are set by a researcher on the base of data analysis, experience, or intuition. Today different universal structures become popular such as various mathematical series and artificial neural networks. If a structure of the needed function is set, then machine learning searches for the optimal values of parameters according to some criterion [
34].
An ML technique such as symbolic regression allows to look for the optimal structure of the needed function and parameters as well [
35].
Symbolic regression methods have made huge strides over the past decade and recently, the importance of interpretable machine learning has been recognized by the wider scientific community. However, to a greater extent, symbolic regression methods are used for so-called supervised machine learning, when there are some data that need to be approximated [
36,
37,
38,
39].
The considered problem of machine learning for control does not have a training set, and the search for a control function must be based on minimizing the quality criterion. This approach, in conventional terminology, refers to unsupervised learning. In this direction, there are much fewer examples due to the complexity of the search. In [
40,
41,
42], the control functions are searched as linear combinations of basic functions, and mainly smooth functions are used as basic functions. We perform the control function search [
43,
44] in the form of function nesting, which allows to obtain more complex mathematical expressions, and also use a wider set of basic functions, including discontinuous functions.
All symbolic regression methods code the searched mathematical expression in the form of special code and search for the optimal solutionon the space of codes by a special genetic algorithm. For this purpose, a special crossover operation is developed. The application of a special crossover operation for two codes of parents allows to receive two new codes of child chromosomes. Different crossover operations are used for different code forms.
A complex crossover operation in symbolic regression methods, in our opinion, makes it difficult to find a solution. Creating new possible solutions as a result of a complex crossover operation is similar to generating new possible solutions. Therefore, the search process does not use the properties of evolution and is more like a random search. In order for the search algorithms of symbolic regression methods to have metaheuristic evolutionary properties, it is necessary that new possible solutions obtained by transforming existing possible solutions have the property of inheritance.
Definition 9. The evolutionary algorithm has an inheritance property, if among the new possible solutions obtained, as a result of the evolutionary transformations of existing possible solutions, named parents, at least a given part of the new possible solutions have functional values, which differ from the functional values of the parents by not more than a given value.
A universal approach to provide the inheritance property to any symbolic regression algorithm is using the principle of small variations of the basic solution [
45]. The application of this principle makes it possible to find solutions that are close to optimal in a reasonable time.
In [
24], this principle was applied to Cartesian genetic programming, and it improved the search process of the optimal solution. In the present paper, in the experimental part, the network operator method [
46] is used, which was developed exactly for the solution of the control synthesis problem and was the first method where the principle of small variations was applied.
6. Hybrid Algorithm for Optimal Control Problem
The second step of the proposed approach (
49) is essentially a pure optimization problem. Today, most generic optimization algorithms are based on population search [
47], and so we also use them as a main technique, but according to the task, any other optimization algorithm can also be appropriate.
For the most complex optimal control problems with complex phase constraints, we propose to use a hybrid algorithm that combines GA [
48], GWO [
49] and PSO [
50]. As we experimentally noticed, such a combination of the evolutionary algorithms allows to avoid the local minimum in complex tasks. A pseudocode of the algorithm can be found in
Appendix A.
7. Computational Experiment
To demonstrate the proposed synthesized approach for the machine learning feedback control problem solution, let us consider two different optimal control tasks with mobile robots in complex environments with phase constraints.
7.1. Two Mobile Robots with Bottlenecks Phase Constraints
The first task we considered was to make two robots switch places with each other while accurately passing through the given areas, as if through bottlenecks.
The mathematical model of the control object has the following form:
where
,
, and
are coordinates of the state vector of the first mobile robot,
,
, and
are coordinates of the state vector of the second mobile robot,
and
are components of the control vector for the first robot, and
and
are components of the control vector for the second robot.
The values of control are limited:
The initial and terminal conditions are given:
The quality functional is given:
where
is a Heaviside step function
, , , , , , , , , , , , , , , , .
In the first stage, according to the proposed approach, the control synthesis problem is solved in order to provide the existence of the equilibrium point.
The stabilization system was received by the network operator method. As far as the received expressions of the control function, both the encoded and decoded forms are too long, so we place them into the
Appendix B.
In the second stage, it is necessary to solve the optimal control problem and to find the control function in the form of piece-wise constant control function
where
,
is a time interval,
, and
K is the number of time intervals
To solve the optimal control problem and find
,
, the described hybrid algorithm was used. The following optimal solution was found:
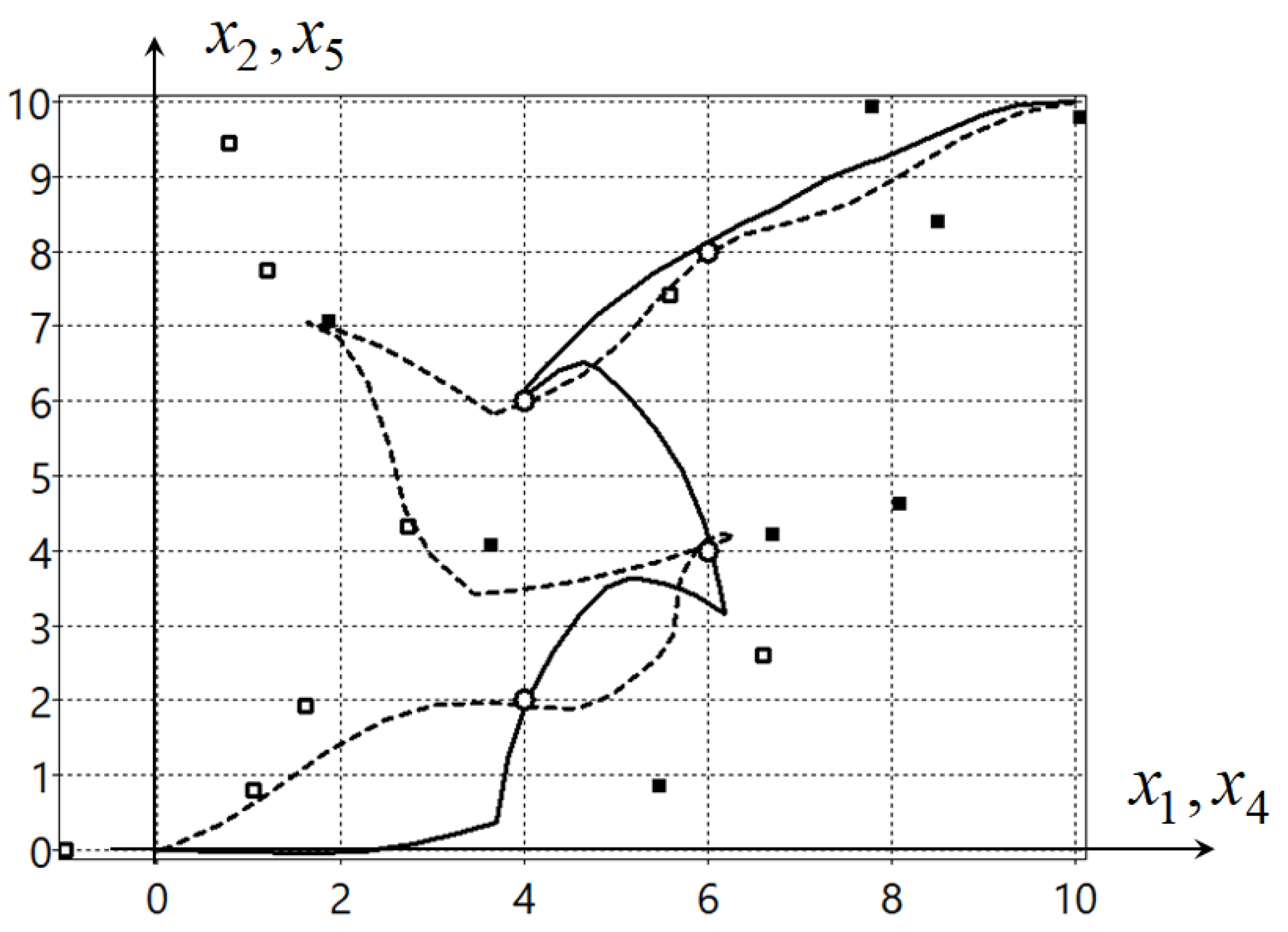
Optimal trajectories on horizontal plane for robots are presented in
Figure 1.
In the
Figure 1 the solid black line is a trajectory of the first robot, the dash line is a trajectory of the second robot, the small circles are the bottlenecks, the small black squares are the optimal control points (
63) for the first robot, and the small white squares are the optimal control points (
63) for the second robot. The optimal value of the functional (
56) is
.
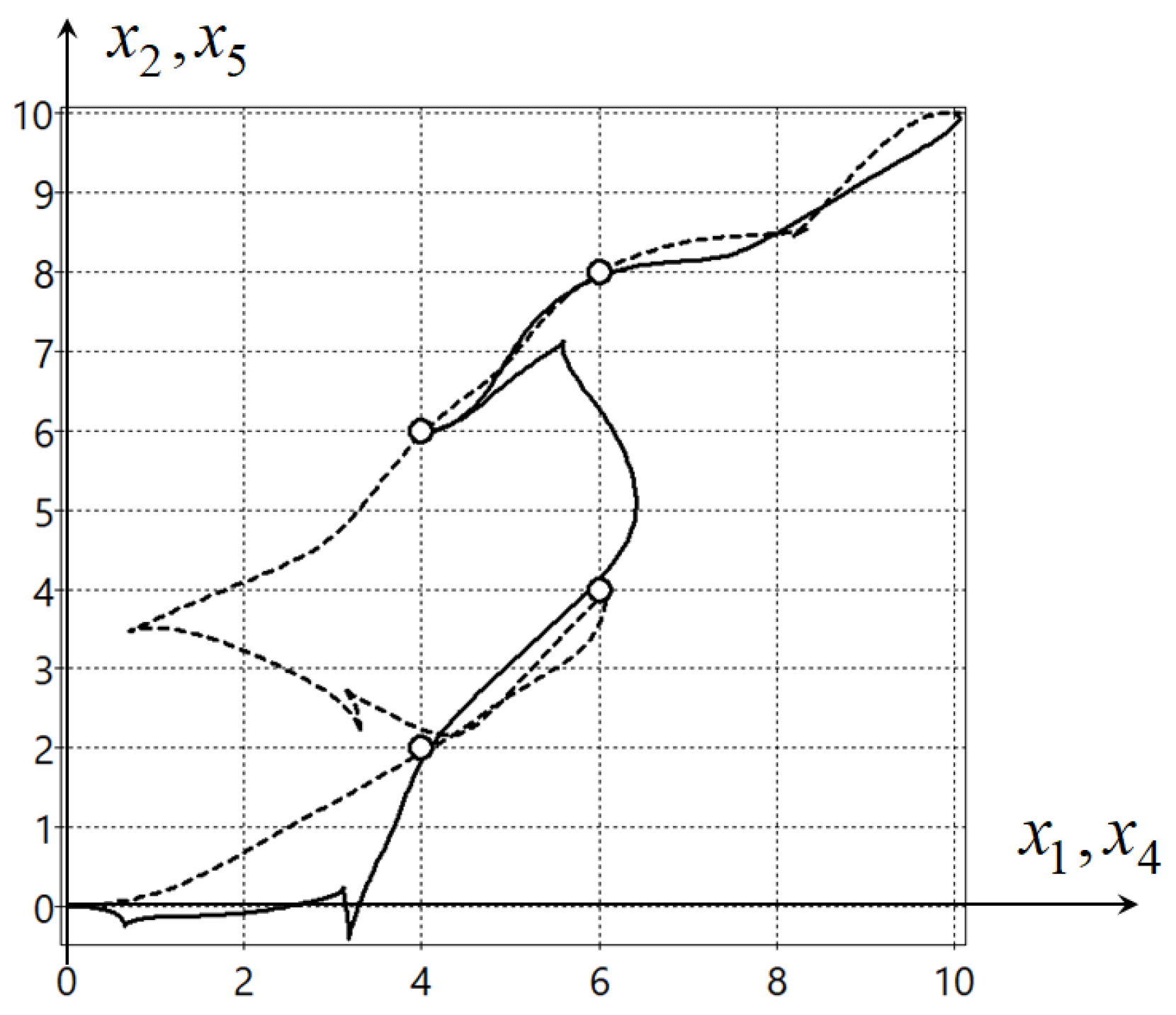
For comparison, the optimal control problem (
52)–(
60) was solved by the direct approach of optimal control. For this purpose, the time axis was divided on
intervals. The control function is found in the form of the piece-wise linear function
where
where
,
,
is a time interval,
,
In total, it is necessary to find 96 parameters, . The problem was very difficult for many evolutionary algorithms. The most successful in solving this problem was the described hybrid evolutionary algorithm.
In the result, the following solution was obtained:
The functional value is
. The optimal trajectories on the horizontal plane are presented in
Figure 2.
To analyze the received results, these optimal control functions were tested for the mathematical model with perturbations:
where
is a function that returns a random number from diapason
at every call, and
is a constant value.
For the system (
68), disturbances were also introduced into the initial conditions
where
is a constant value. The results of the tests are presented in
Table 1. For every disturbance, 10 tests were performed. In
Table 1,
is an average functional value for synthesized control,
is a standard deviation for values
,
is an average functional value for direct control, and
is a standard deviation for values
.
As the test results show, synthesized control is much less susceptible to perturbations of the mathematical model and the initial conditions than direct control. Direct optimal control is the most sensitive to disturbances of initial conditions. Even the smallest disturbances of the initial conditions make direct control unacceptable. The results show that the synthesized control obtains the compression property, and it is feasible in real systems.
7.2. Synthesized Control for Omni-Mecanum-Wheeled Robot
A mecanum robot has special wheels that allow it to move under a direct angle to its direction of axis without any turns [
51]. In
Figure 3, an example of a mecanum robot is shown.
Consider the optimal control problem, where two identical mecanum robots have to swap their places in some area with obstacles and without collisions for a minimal amount of time.
The mathematical model of the control object is the following:
where
,
, and
are the state vector coordinates of the first mecanum robot,
,
, and
are the state vector coordinates of the second mecanum robot,
,
,
, and
are components of the control vector of the first mecanum robot,
,
,
, and
are components of the control vector of the first mecanum robot, and
and
are geometric parameters of the robots,
,
.
The control is restricted:
where
and
are given lower and upper limits for values of control, respectively,
.
The initial state is given:
The terminal state is given:
where
is the time of achievement of the terminal state. It is determined by Equation (
57) with
,
.
The quality criterion includes phase constraints and the accuracy of the terminal state achievement.
where
and
are the penalty coefficient, where
and
,
is a weight coefficient,
,
,
is a Heaviside step function (
59), and
is determined by Equation (
58):
, , , , , , , , , , , , .
According to the synthesized method, initially, the feedback control synthesis problem is solved, such that the closed-loop control system is stable relative to some equilibrium point in the state space. For this purpose, again, the network operator method is used.
Since the robots are the same, we make the synthesis of the stabilization system for one robot, for example, the first robot.
In the result, the network operator method found the following control function:
where
,
,
,
,
,
,
For the second robot in the control function (
77), it is necessary to replace
,
with
,
, and
,
, with
, respectively.
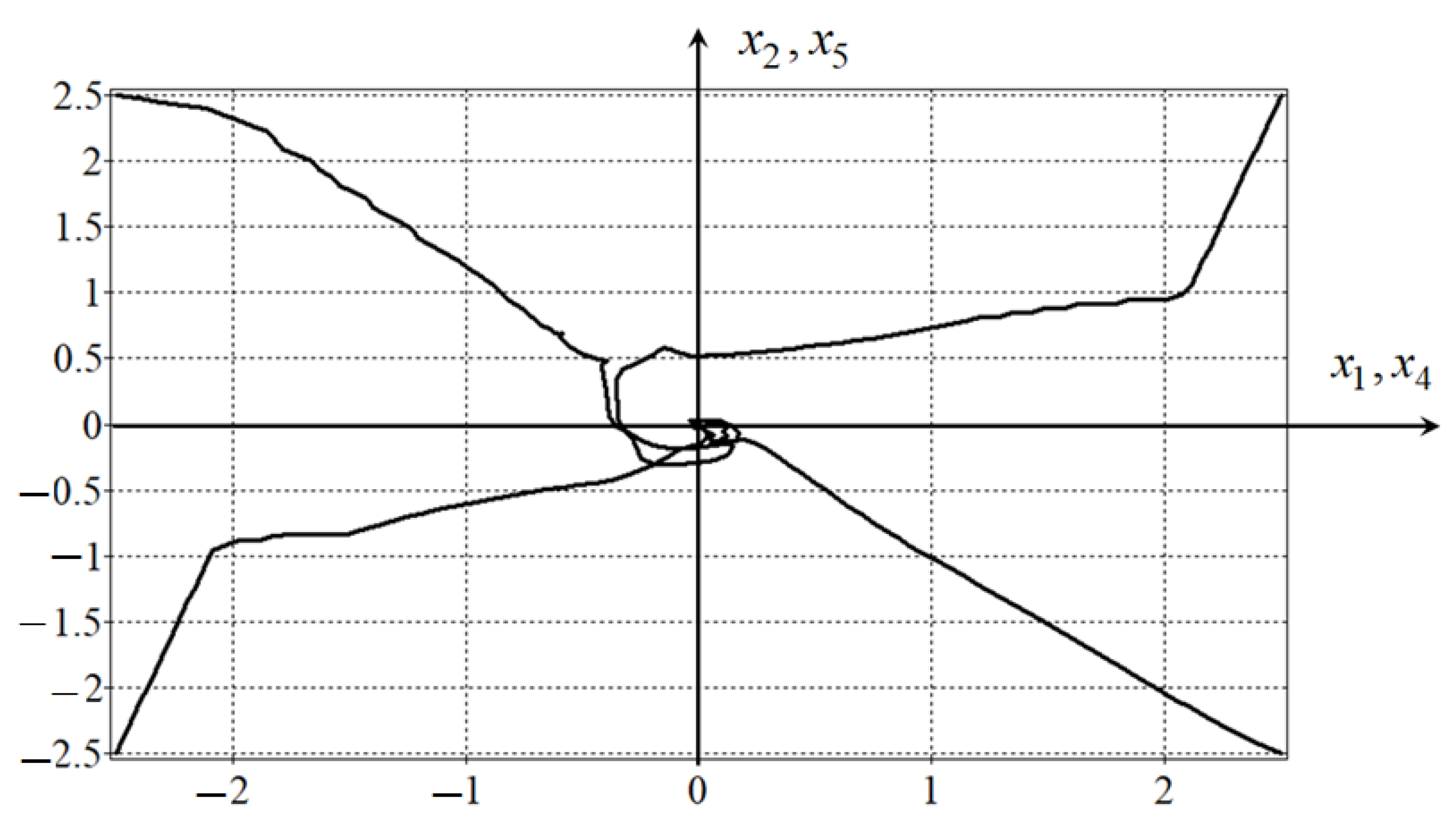
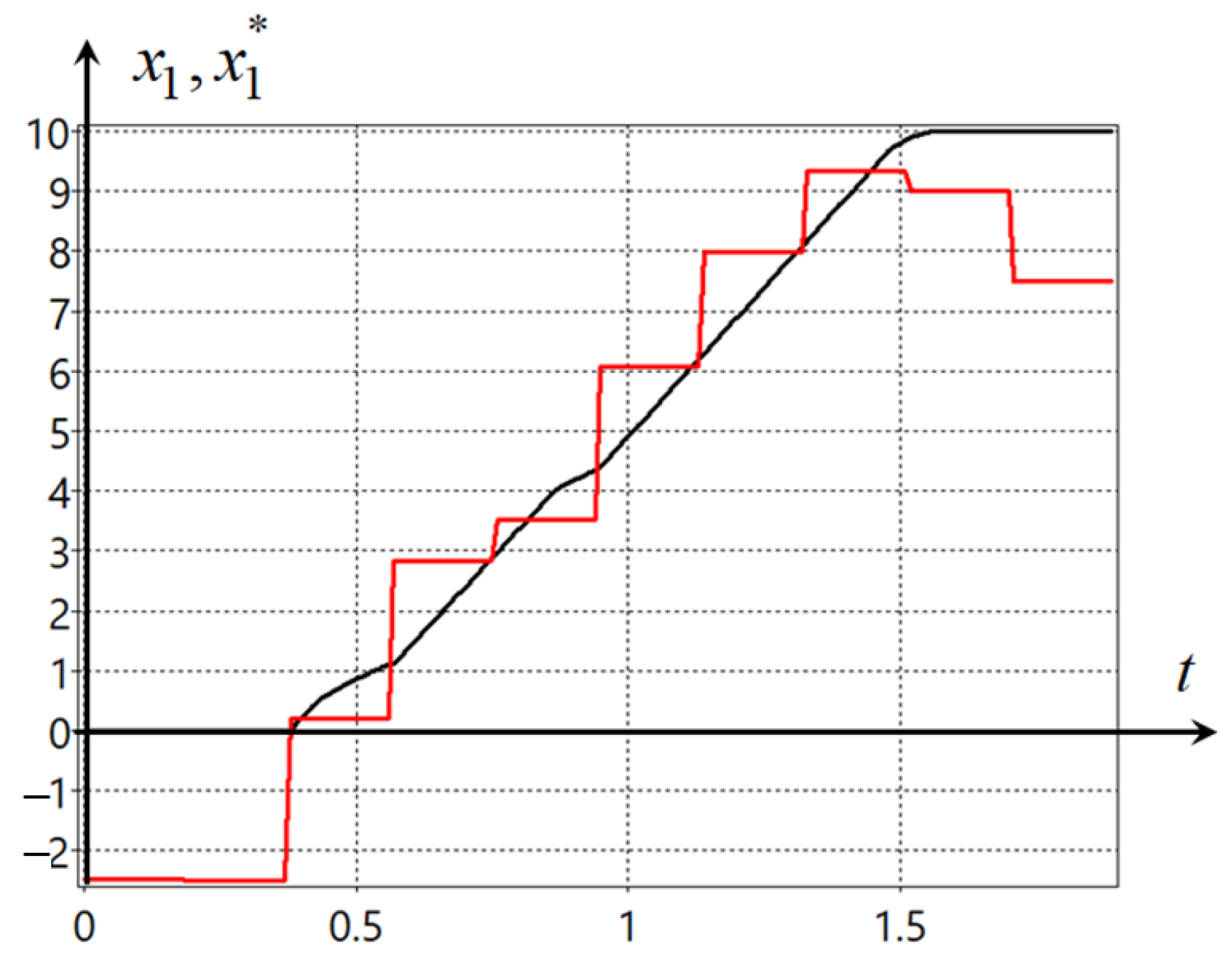
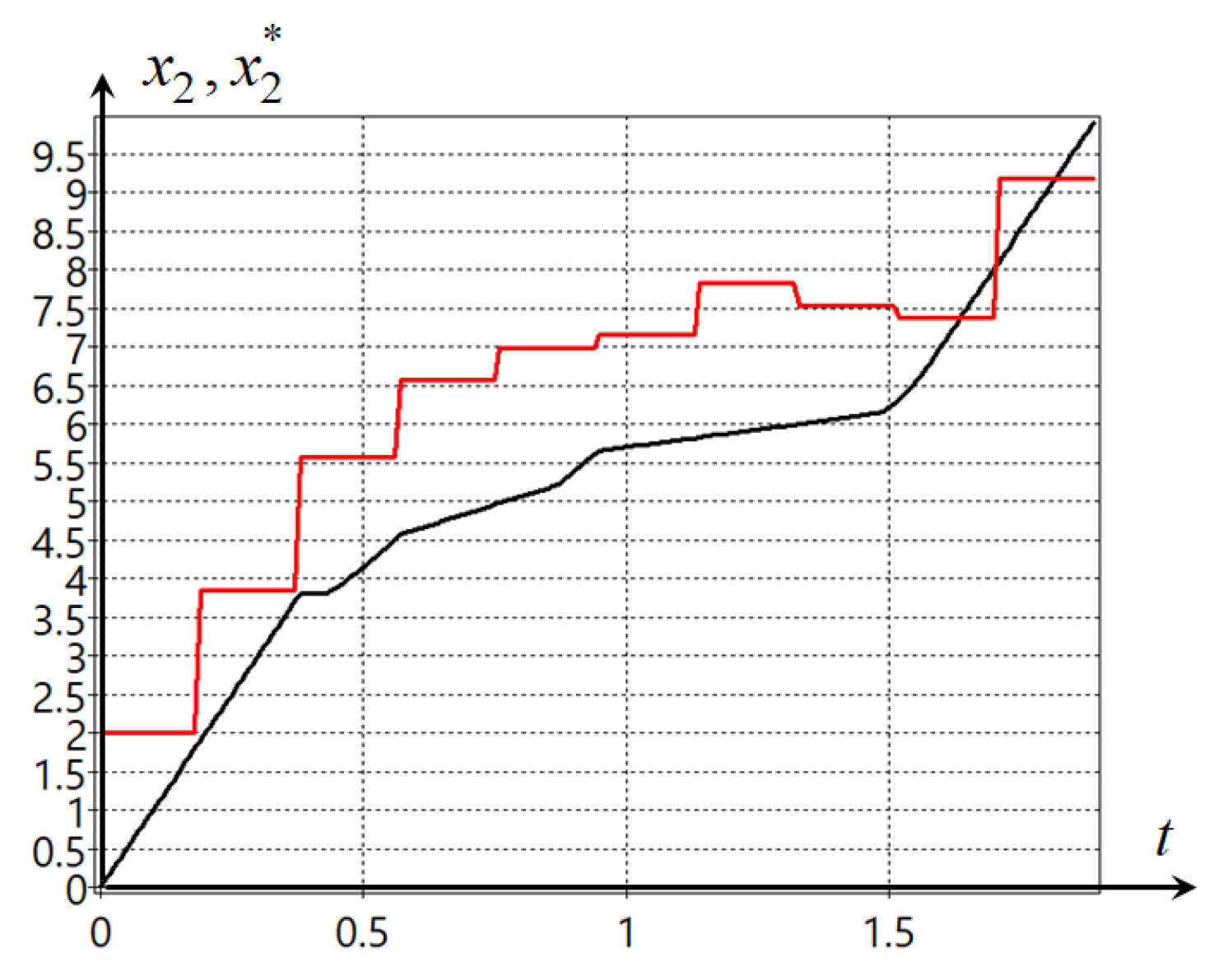
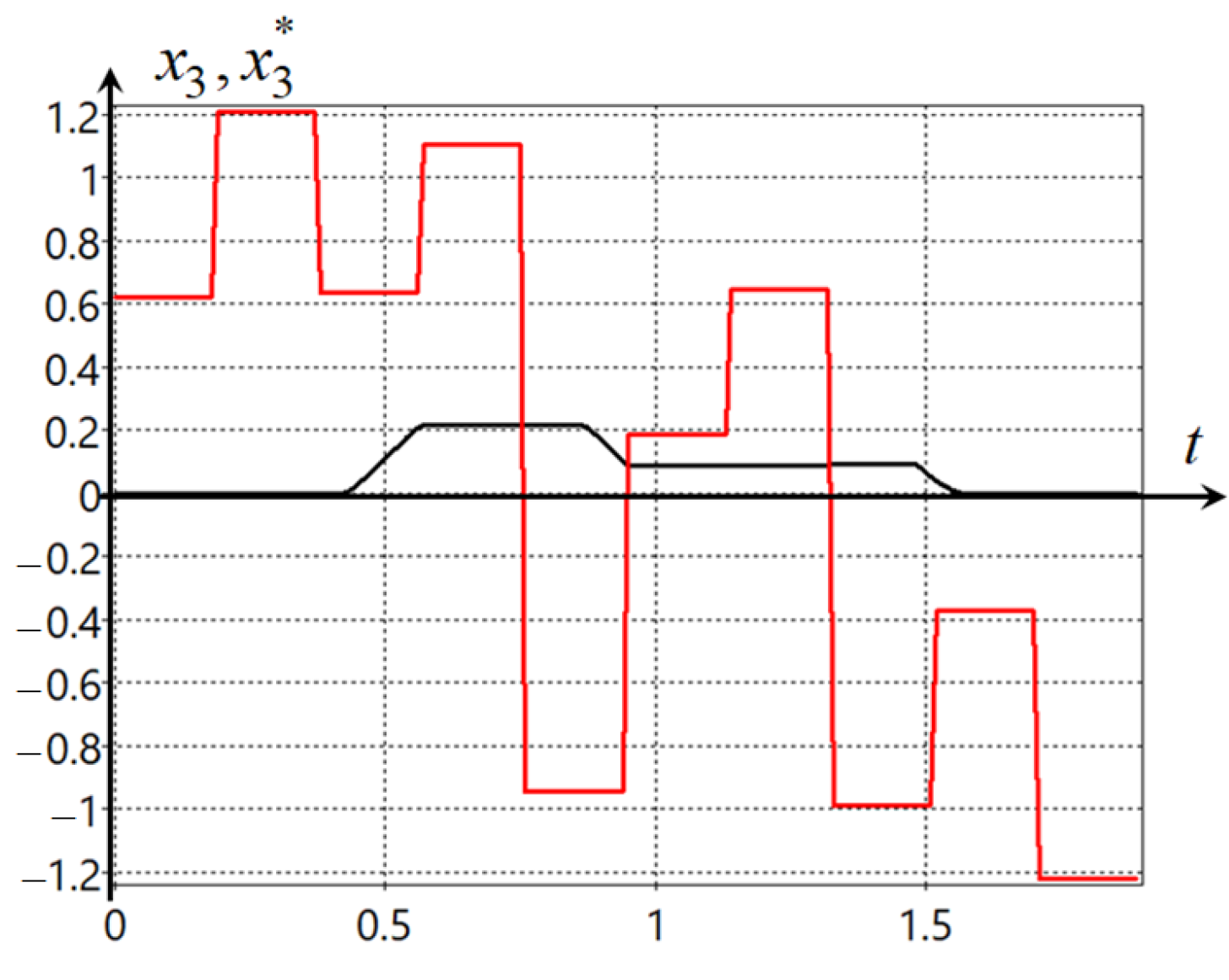
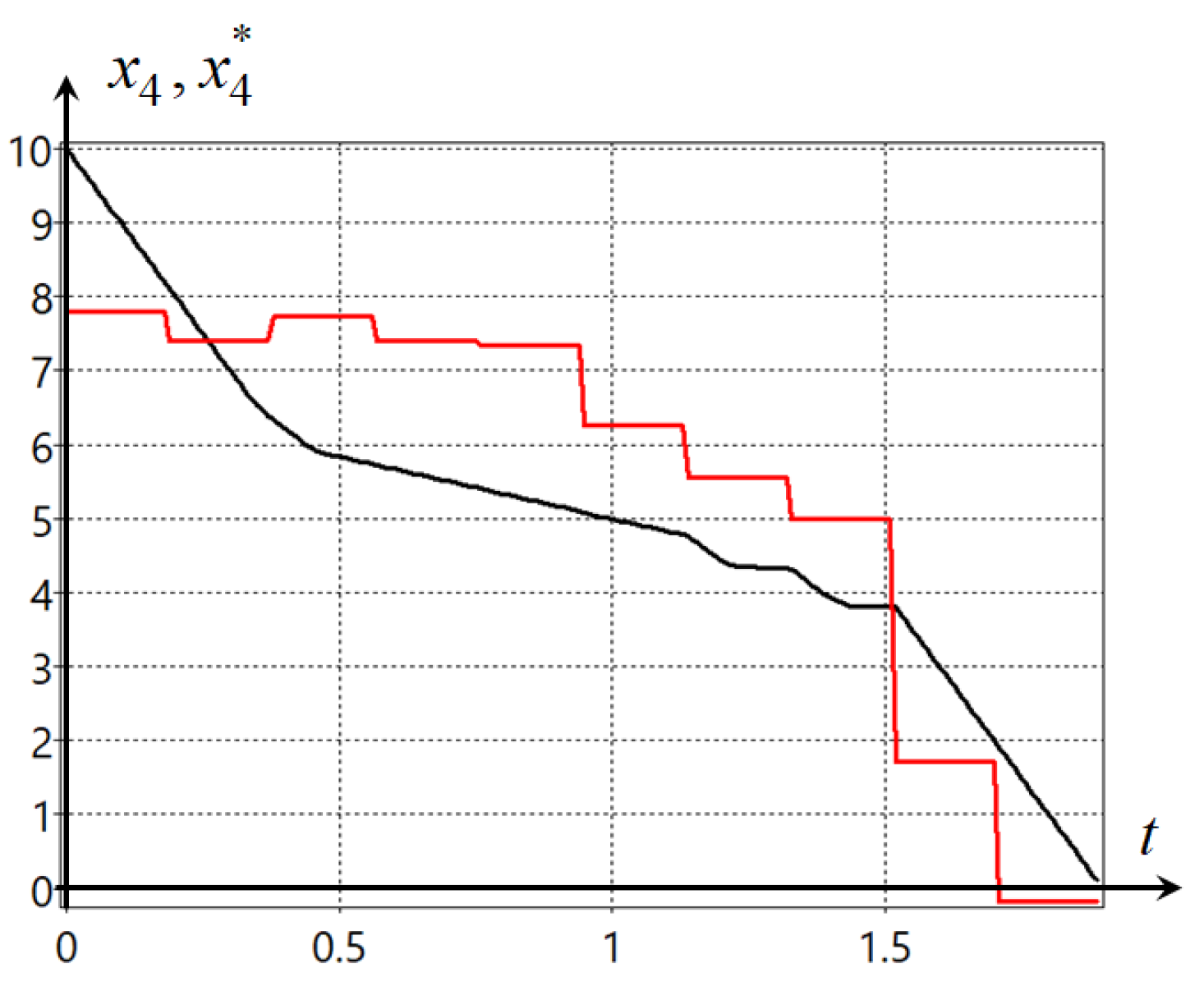
Plots of the trajectories of the robot movement from four initial states are presented in
Figure 4.
On the second stage, the optimal control problem (
70)–(
74) is solved for the closed loop control system with the control function (
77). A control on the second stage is vector
, determining the position of the stable equilibrium point in the state space. For solving the optimal control problem, the time axis is divided on the intervals, and in each interval, a control function is approximated by a piece-wise constant function. The value of the interval is equal to
.
where
,
,
D is the number of intervals,
In total, it was necessary to find an optimal vector with
parameters:
For solving the problem, the hybrid evolutionary algorithm was applied. The values of the parameters were restricted:
where
.
The following solution was obtained:
The optimal value of the functional (
74) is
.
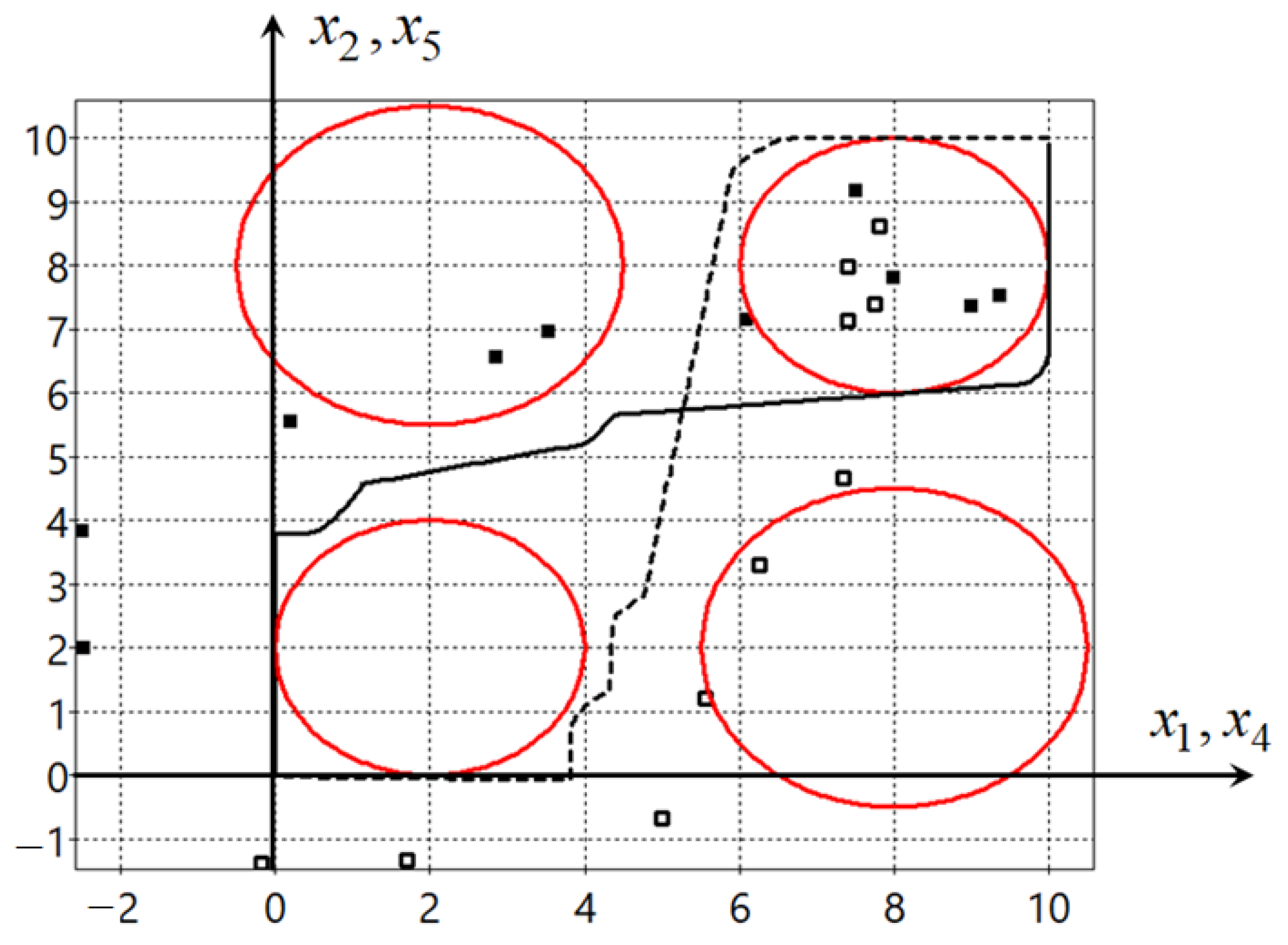
Optimal trajectories on the horizontal plane of two robots are presented in
Figure 5. The solid line is the trajectory of the first robot, the dash line is the trajectory of the second robot, the red circles are the phase constraints, the black small squares are projections of control
on the horizontal plane for the first robot, and the white small squares are projections of control
on the horizontal plane for the second robot.
Figure 5 shows very clearly, as in the previous example with bottlenecks, that the equilibrium points are located not on the trajectory of the robot, as is done with conventional stabilization, but outside the trajectory. By placing points on the trajectory, we can lose quality because when approaching the equilibrium point, the robot must slow down. Such an optimal arrangement of points ensures the optimal value of the functional.
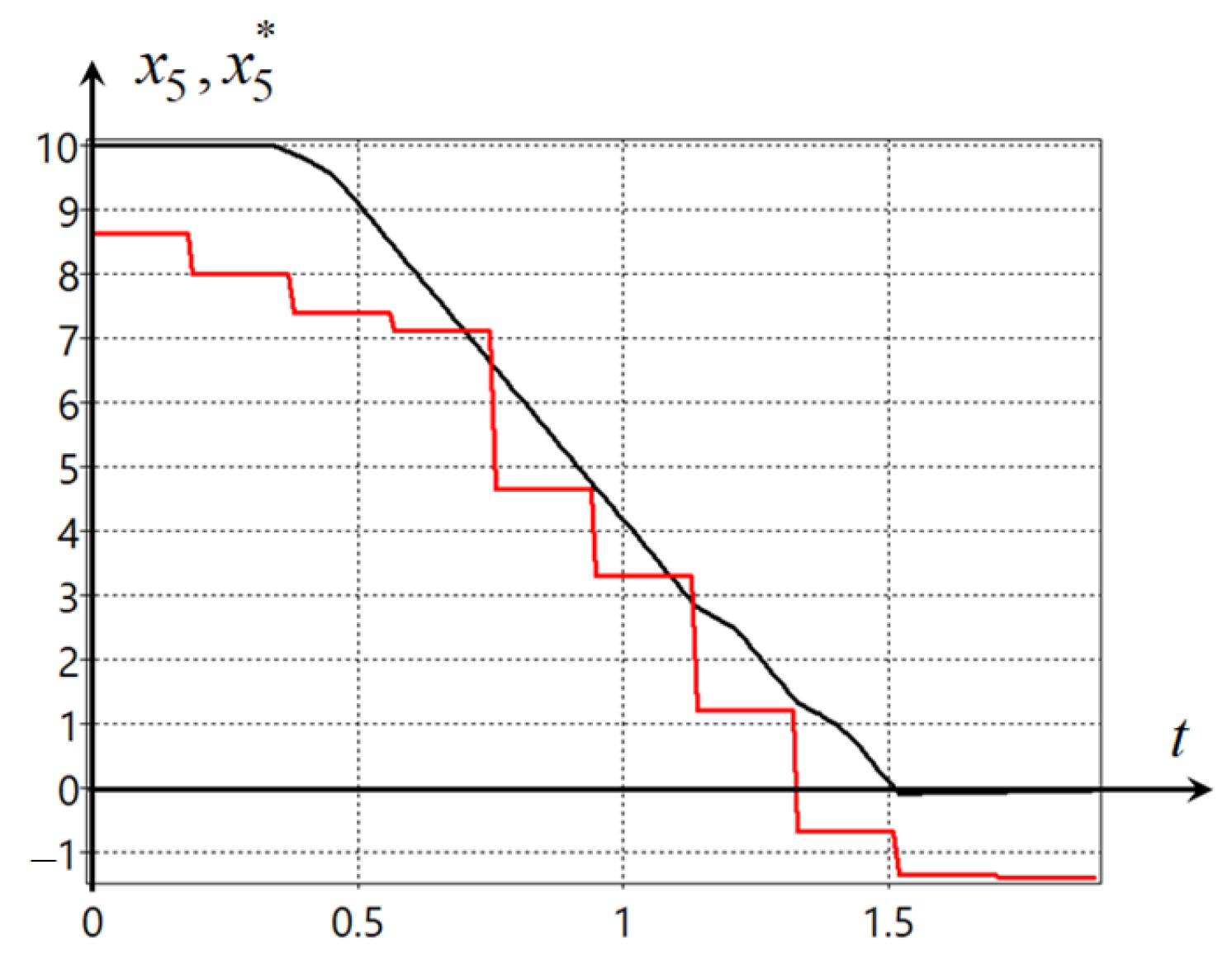
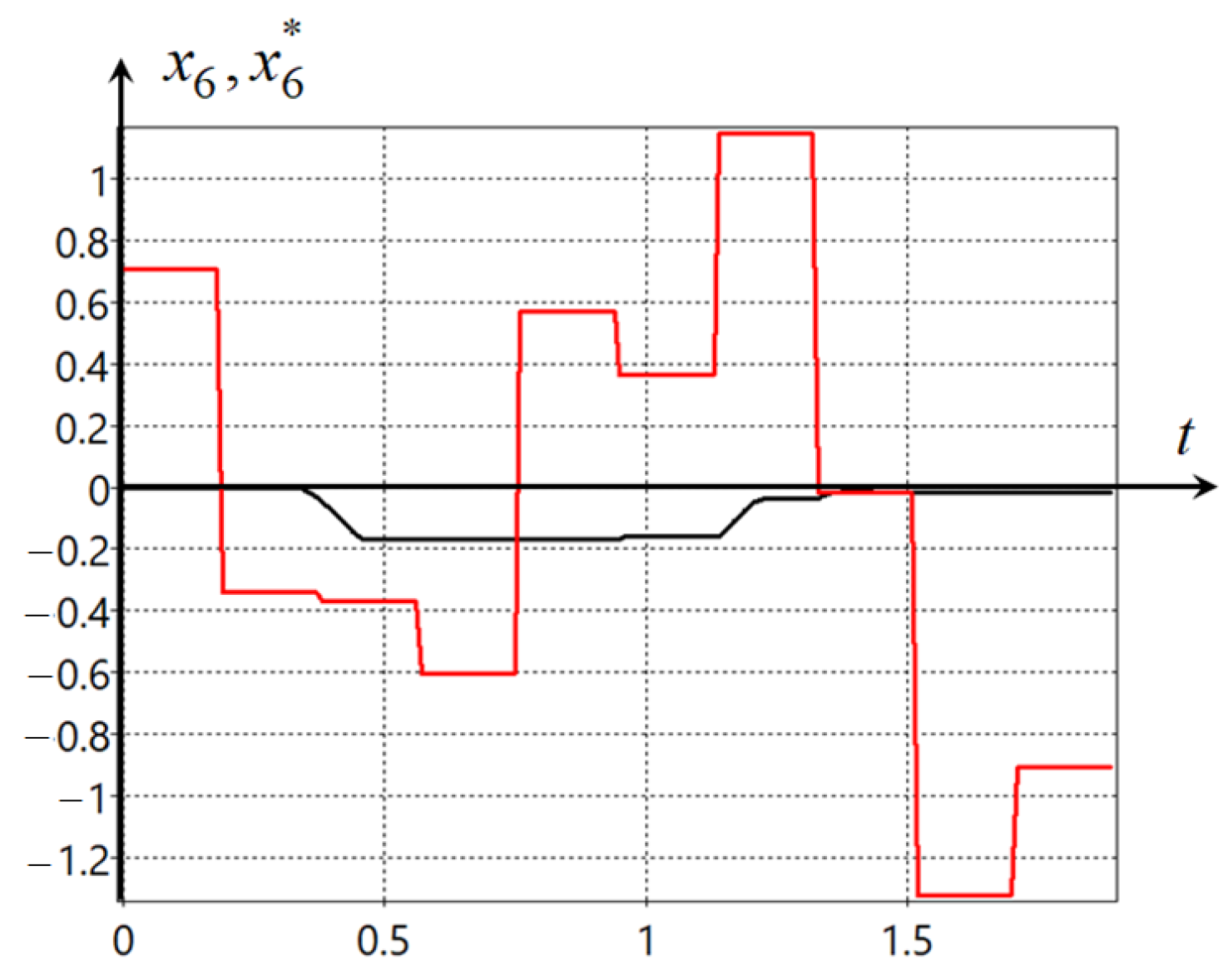
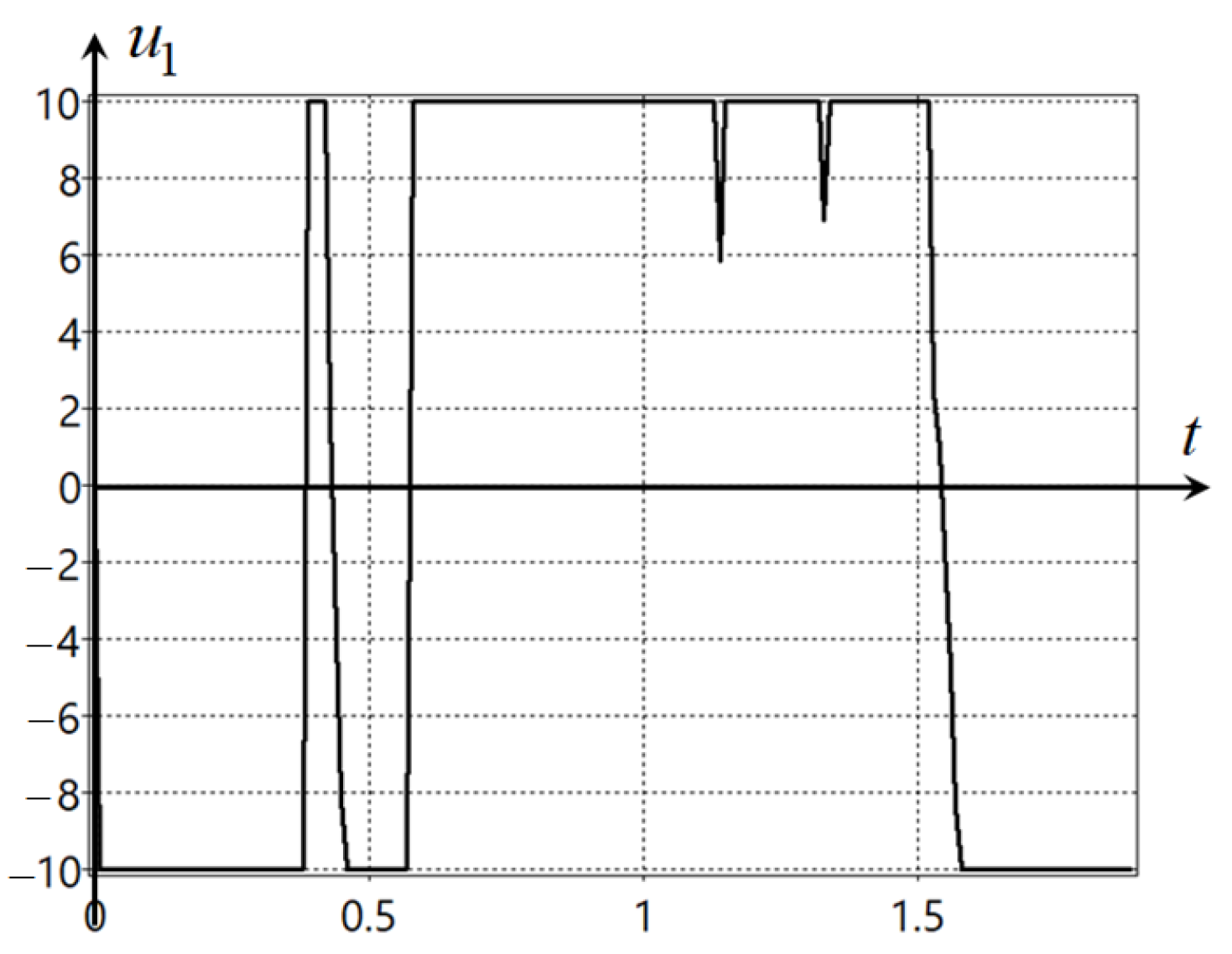
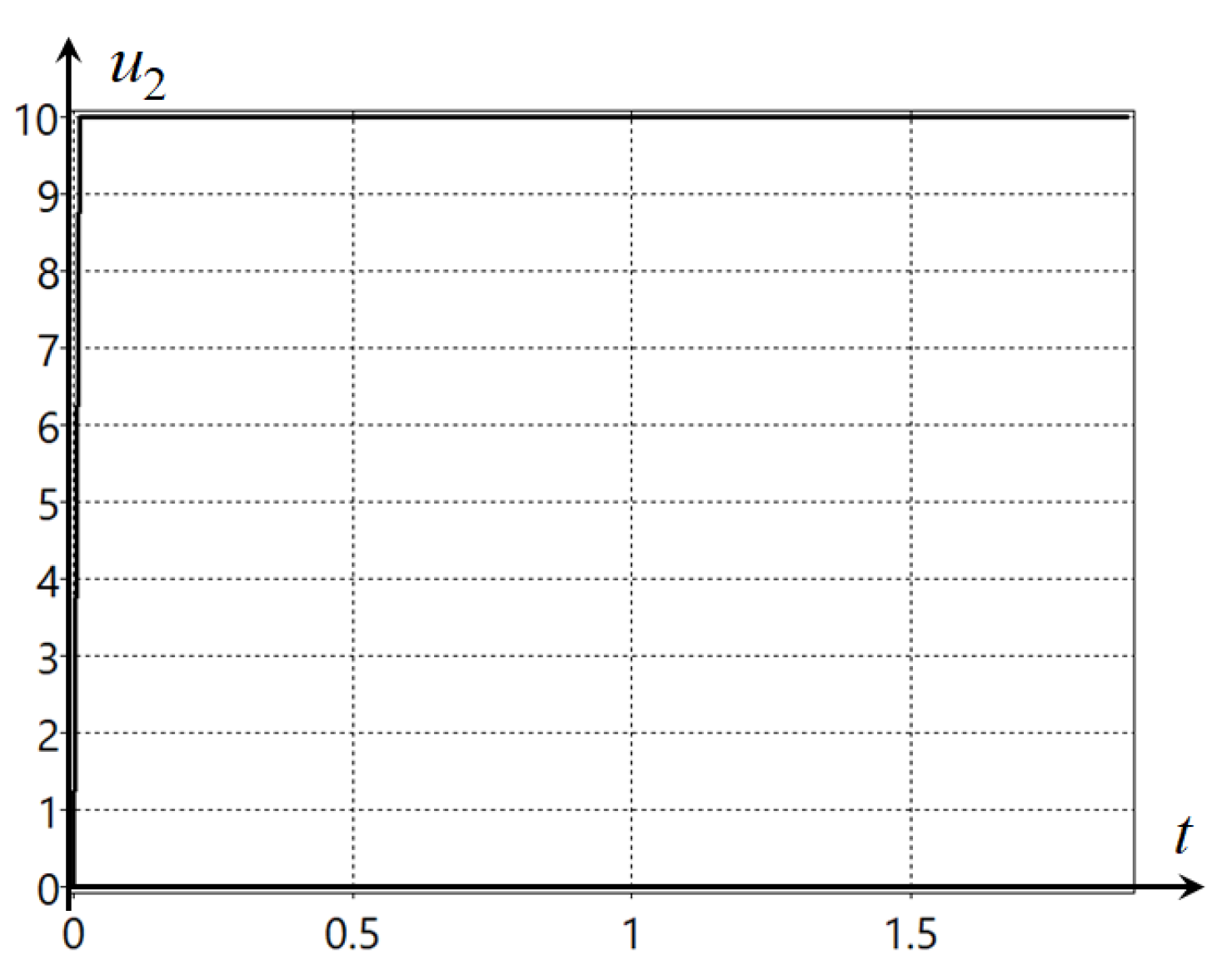
In this example, we would like to note the following. It occurs that two components of the control vector are enough to control the mecanum robot. The other two components have limit values and do not change during the control process. This can be seen in the additional control plots presented in
Appendix C. However, indeed, we noted that in the mathematical model of the mecanum robot (
70), the control was redundant,
. So, the computer itself found a solution for how to proceed in this case, and in the solution found, the two components of control, in fact, do not participate in the search for the optimal solution. This is one of the more successful demonstrations of intelligent machine automation of the process of creating control systems.
8. Discussion
In this work, we are laying the theoretical foundations of machine learning control. The main feature is that the machine proof of various properties is implemented experimentally basing on examples. In particular, this is what happens in neural networks, when experiments are carried out on a test sample to check whether the system achieves certain properties. We formulate several machine properties in the control system design. In the future, the proposed formal descriptions can be developed, new properties of systems can be considered, and quantitative probabilistic estimates can be given based on positive test results.
An important result of the work is the expansion of the formulation of the optimal control problem and the introduction of additional requirements for the required control. Ensuring the introduced conditions additionally requires the introduction of feedback. The paper presents the approach of synthesized optimal control, which allows implementing optimal control systems, taking into account the introduced additional requirement. In this case, other approaches can be considered and proposed.
9. Conclusions
A general machine learning approach for the automatic design of feedback control systems for any dynamical nonlinear control objects is considered. The main perspective is the machine-automated development of control systems. According to this trend, the control system is obtained as a result of a machine solution of some formal mathematical control problem and it is to be implemented in the real object directly.
Since the control system is created by machine learning, the paper formulates a machine check of all the properties required from the control system. Mathematical statements of control problems and some theoretical justifications for solution of these problems by machine methods are presented. The paper introduces and discusses such notions as machine learning control, stability, optimality and feasibility of machine-made control systems. In this regard, substantiations are introduced for the machine learning feedback control approach based on symbolic regression and evolutionary algorithms.
Thus, the feedback control design is generalized and automated with a generic approach applicable to any nonlinear models, including machine-learning-identified models. It is shown that with this approach, the computer is able to propose interesting outstanding solutions, which sometimes an engineer cannot even suppose.
There is another feature in the proposed approach that can be developed in a good direction. It is possible to control an object by controlling the position of the equilibrium point both offline under predetermined operating conditions, and online, when the positions of the points can be optimally planned for some short term and then adjusted according to the situation. This is one more direction for further research and application of the presented approach.























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}