Abstract
Analysing autoregressive counts over time remains a relevant and evolving matter of interest, where oftentimes the assumption of normality is made for the error terms. In the case when data are discrete, the Poisson model may be assumed for the structure of the error terms. In order to address the equidispersion restriction of the Poisson distribution, various alternative considerations have been investigated in such an integer environment. This paper, inspired by the integer autoregressive process of order 1, incorporates negative binomial shape mixtures via a compound Poisson Lindley model for the error terms. The systematic construction of this model is offered and motivated, and is analysed comparatively against common alternate candidates with a number of simulation and data analyses. This work provides insight into noncentral-type behaviour in both the continuous Lindley model and in the discrete case for meaningful application and consideration in integer autoregressive environments.
MSC:
62M10; 62E15; 60E05
1. Introduction
The analysis and modelling of data in a meaningful way remains a relevant and evolving focus within fundamental statistical research among practitioners of statistics and data science alike. Many fields, including medicine, security surveillance, information technology, and finance, among others, remain bound to parametric theoretical innovation for impactful data analysis and understanding; therefore, the sustained development of statistical models with insightful flexibility is essential for understanding data being generated around users in all aspects of life.
1.1. The Lindley Distribution as Departure Point
The Lindley distribution [1] has a rich and varied background in terms of generalisations and implementation within lifetime modeling, Bayes inference, and fiducial inference within different theoretical and applied contexts; it is constructed as a finite continuous two-component mixture of an exponential and a gamma distribution (indicated by “Exp” and “Gam”, respectively) with common scale and shape 2 parameters, with density function
for with mixing proportion and 0 otherwise. The Lindley distribution is substantially more flexible in its mathematical characteristics in comparison to the exponential distribution [2] via this mixture. Plentiful attention has been paid to this model for its parameter and flexibility enrichment and improved model fits based on a variety of methods [3,4,5]. Recently, [6] introduced and studied a noncentral-type Lindley model where the gamma component in (1) is substituted with a noncentral gamma distribution with scale, shape, and noncentral parameters with the density function (see [7])
for , where denotes the gamma function. Essentially, (2) is defined as an infinite shape mixture of the usual gamma distribution with the Poisson mass, with parameter . The resulting noncentral-type Lindley density function is provided by
for , where denotes the hypergeometric function of scalar argument with one lower parameter. For the purposes of this paper, the distribution with density function (3) is referred to as the noncentral Lindley of type I, and is denoted . Note that when , (1) is naturally recovered. This noncentral parameter has an interpretative meaning for noncentrality (considering that the usual gamma distribution only has shape and scale parameters), and in the ncLI case has been observed to act as an insightful parameter addition to a model otherwise characterised only by a scale parameter .
The Lindley distribution has been employed in a compounding approach to create discrete counterparts via the Poisson distribution for implementation, both as a standalone counting model [8,9,10] and within integer-valued autoregressive (INAR) environments. This paper has a particular focus on the systematic development of a counting model that is based in fundamental statistical theory while being practically motivated within an INAR focus.
1.2. Lindley Counting Models: INAR and Other Cases
When modelling count data, the Poisson distribution is widely used in various statistical environments and models such as regression and time series analysis thanks to its tractability and ease of implementation. A major restriction of the Poisson distribution is the assumption of equidispersion, that is, when the mean and variance Var of a random variable X are equal, leading to the dispersion index . In reality, this assumption of the Poisson distribution is generally violated. In order to address this restriction, various researchers have proposed alternative discrete distributions to capture and more accurately describe overdispersion, many of which are described as compound or mixed Poisson distributions; this is the case when the Poisson parameter, say, , acts as a random variable in itself, with the particular distribution for known as the mixing distribution. A classical mixed Poisson distribution is the negative binomial (NB) distribution, in which the mixing distribution is defined as the gamma distribution. Due to the NB distribution being restrictive in modelling larger levels of skewness and kurtosis, more flexible distributions have been researched and proposed. Using the compounding method, [11,12] proposed the Poisson distribution with its parameter being described by the Lindley distribution, known as the Poisson–Lindley (PL) distribution. Extended and more flexible considerations include the generalised Poisson–Lindley distribution, a new three-parameter Poisson–Lindley distribution, and the two-parameter discrete Poisson-generalised Lindley distribution, as proposed by [13,14,15], respectively.
Within the integer time series environment, [16] suggested the PL distribution for the errors defined for the INAR process based on the binomial thinning operator (initially proposed by [17,18]). Altun [19] introduced Poisson-weighted exponential errors (via compounding) for the INAR(1) process, which were fitted to real data. Altun [20] compounded the Poisson distribution using the Bilal distribution [21], for which the Poisson–Bilal distribution is considered as the error structure for the INAR(1) process. Altun et al. [22] introduced the Poisson mixture with quasi-xgamma errors for the modelling of earthquake counts. The Poisson-transmuted exponential distribution (proposed by [23,24]) and the zero-modified PL distribution (proposed by [25,26]) have both been considered for the error structure in the INAR(1) process for modelling overdispersed and zero-inflated counts, of which the latter can be used for the modelling of zero-deflated data as well. Most recently, [27] suggested the Poisson binomial-exponential 2 distribution (proposed and constructed by [28]) for the error structure of an INAR(1) process, whereas [29] proposed a one-parameter discrete distribution by compounding the Poisson distribution through the use of the xgamma distribution.
In [6], the authors introduced and studied the discrete counterpart of (3) as mixing distribution within a compound Poisson framework and subsequently applied it within an integer-valued autoregressive environment. Suppose a variable X follows a Poisson distribution with parameter , and let with density function (3). Then, via the compounding method, the mass function for X is provided by
for representing counts and denoting the confluent hypergeometric function of scalar argument with one upper and one lower parameter. This model, denoted as , inherits a range of flexible options for the practitioner when modeling overdispersed count data as compared to the Poisson model where .
1.3. Contributions and Foci of This Paper
For further insight into attaining ranges of increased kurtosis and the DI, this paper investigates in a comparative manner the incorporation of infinite negative binomial mass on the shape of the gamma distribution that forms a component within the noncentral Lindley environment; here, we refer to this as the noncentral Lindley of type II. In fact, [30] discusses the meaningful comparison between the Poisson and the negative binomial distributions, and as such the theoretical development and practical implementation of this negative binomial consideration (compared to the more frequently considered Poisson mass) remains convincing within the statistical literature. Subsequently, this adaptation is illustrated in the integer case and comparatively investigated with the existing model of the Poisson shape mixture of the gamma. This theoretical investigation and contribution is applied in an autoregressive count framework of order 1 (i.e., integer autoregressive process of order 1, or INAR(1)). Therefore the contributions of this paper can be summarised as follows:
- A (continuous) noncentral Lindley type II (i.e., ncLII) distribution is systematically constructed, and statistical characteristics are derived;
- A (discrete) counting model based on this noncentral Lindley type II distribution is derived via compounding with the Poisson distribution (i.e., PncLII), together with essential statistical characteristics;
- Key insights are attained through investigation of the skewness, kurtosis, and the DI compared to the work of [6]; and finally,
- This discrete counting model is implemented and illustrated as an error structure (i.e., ) within an INAR(1) environment and juxtaposed against the PncLI for the error structures in a simulation study and real data applications.
The rest of this paper is outlined as follows. In Section 2, the methodological approach to the construction of the ncLII and PncLII distributions are described, together with statistical characteristics and a discussion of key insights related to skewness, kurtosis, and the DI. Section 3 illustrates the execution and performance of the developed results within the INAR(1) environment, and Section 4 contains final thoughts. All computations were carried out using [31] in a Win 64 environment with a 1.30 GHz/Intel(R) Core(TM) i7-1035G7 CPU Processor and 8.0 GB RAM.
2. Construction
Consider a gamma distribution with infinite negative binomial mass on the shape parameter (see [32]), such that
where , and , which can be viewed as a noncentral type due to correspondence with (3). Note that when , geometric mass is used on the shape parameter of the gamma distribution. Using (5) instead of the usual gamma distribution in (1), the density function of the resulting ncLII distribution is given by
where denotes the confluent hypergeometric function of scalar argument with a single upper and lower parameter, and we denote . Note that (6) reduces to the usual Lindley (1) when . The flexibility of this ncLII distribution is evident from Figure 1 and Figure 2, which illustrate the behaviour of various parameter choices on the density function (6). The moment generating function (MGF) and moments of with density function (6) are introduced in the following theorem.
Theorem 1.
Suppose that the random variable Y is distributed as ncLII with density function (6). Then, the MGF and moments of Y are given by:
respectively, where , and represents the Gauss hypergeometric function of scalar argument with two upper and one lower parameter(s); see [33].
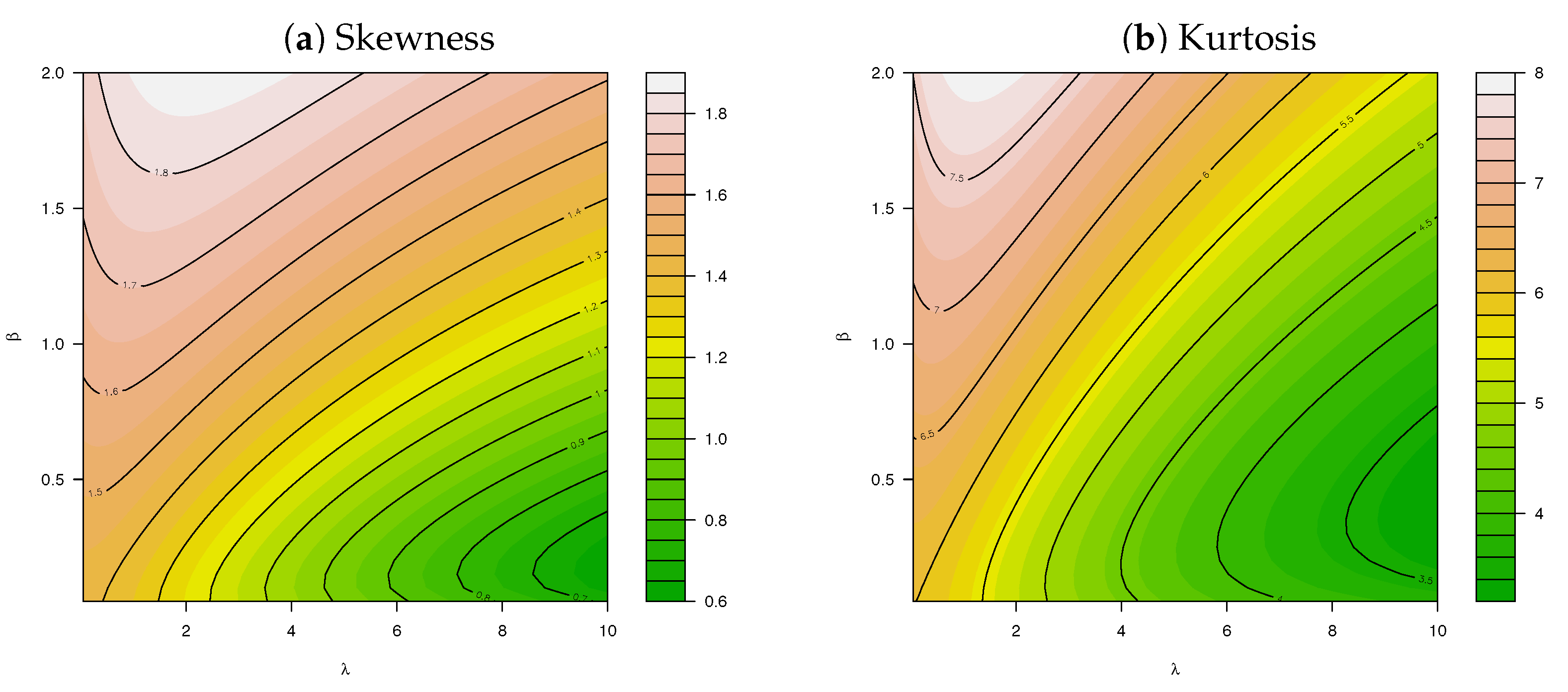
Due to closed form expressions in Theorem 1, (8) can be used to obtain various characteristics of interest for the ncLII distribution such as the mean, variance, skewness, and kurtosis. The expressions for calculating these characteristics are provided in Appendix A, for which the skewness and kurtosis levels are illustrated in Figure 3 and Figure 4, respectively, for different values of . The additional flexibility of the ncLII distribution, especially with regard to its increased levels of skewness and kurtosis, is evident from Figure 3 and Figure 4, respectively, particularly when comparing these characteristics to those of the ncLI distribution described and illustrated in Appendix B, Figure A1.
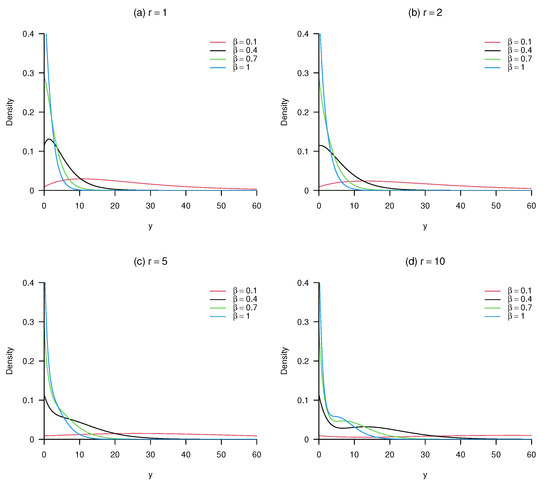
Figure 1.
Shapes of the density function (6) for different values of (, r) and .
Figure 1.
Shapes of the density function (6) for different values of (, r) and .
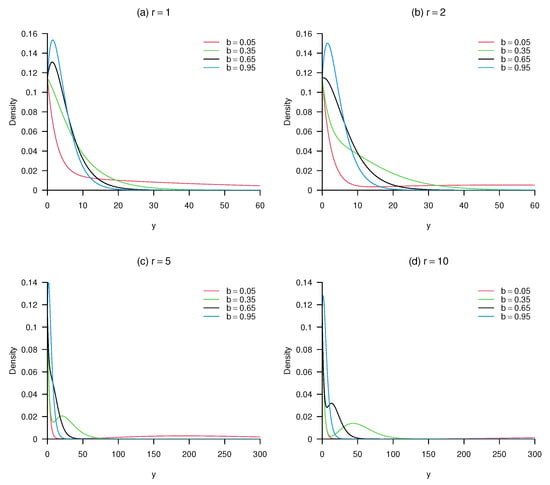
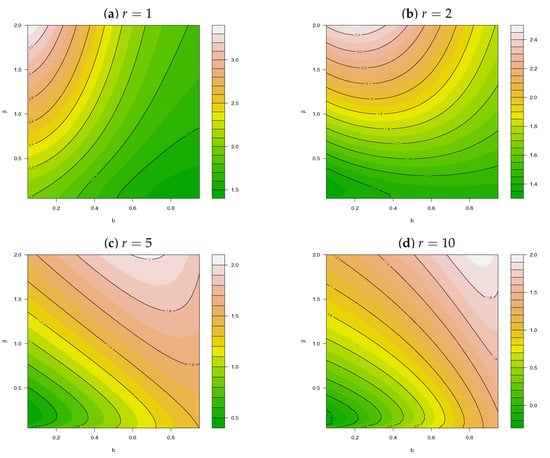
Figure 3.
Skewness for for different values of and .
Figure 3.
Skewness for for different values of and .
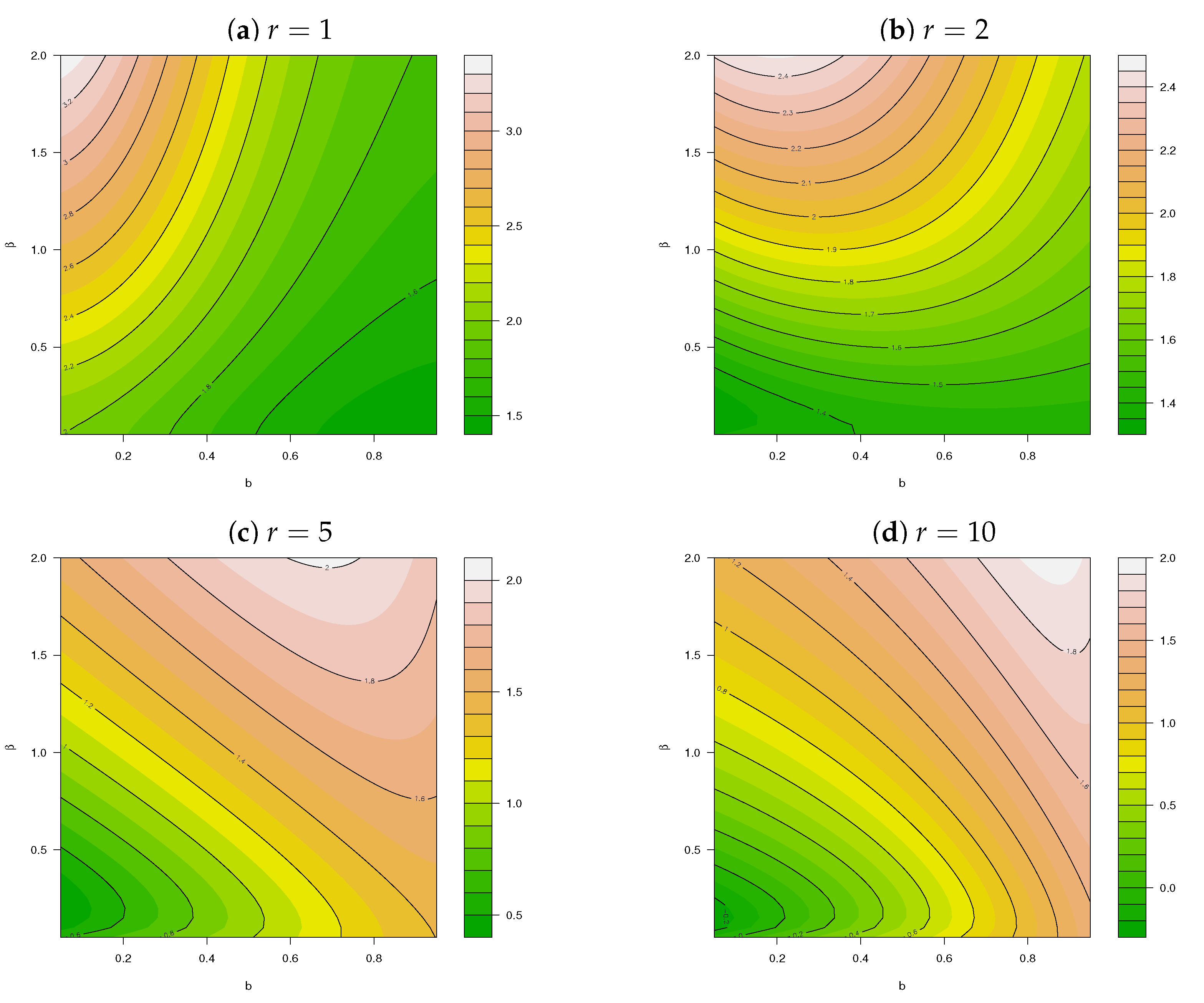
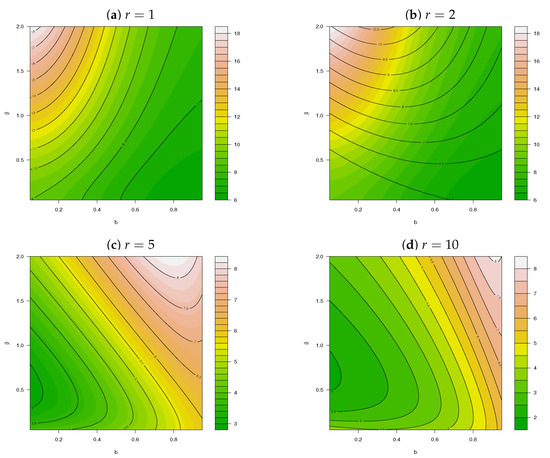
Figure 4.
Kurtosis for for different values of and .
Figure 4.
Kurtosis for for different values of and .
For the discretised counterpart, suppose a variable X follows a Poisson distribution with parameter , while is distributed as ncLII with density function as in (6). Then, using the compounding method, the mass function for X is given by
for representing counts, where denotes the Gauss hypergeometric function of scalar argument with two upper and one lower parameter(s) and . As in the continuous case, (9) reduces to the usual PL of [11,12] when . The probability generating function (PGF) and factorial moments of X with mass function (9) are given in the following theorem.
Theorem 2.
Suppose that the random variable X is distributed as PncLII with mass function (9). Then, the PGF and factorial moments of X are given by:
where , with and denoting the Gauss hypergeometric function of scalar argument with two upper and one lower parameter(s).
Remark 1.
By replacing s with in (10), the MGF of the distribution in (9) is obtained. It is valuable to emphasise the value of these closed form expressions, especially when one is interested in assessing degrees of skewness and kurtosis of a random variable X. This may be done via direct computation of these equations, but access to cumulants to be utilised in such computations is also feasible by considering (10) such that where this computation typically could include Stirling numbers of the second kind [32].
Figure 5 illustrates specific shapes of the mass function (9), with the means indicated in red, displaying similar behaviour to that of its continuous counterpart (6) in Figure 1 and Figure 2. The following effects from changes in r and b can be observed from Figure 5:
Using the results from Theorem 2, the mean and variance for the PncLII distribution are provided by
and
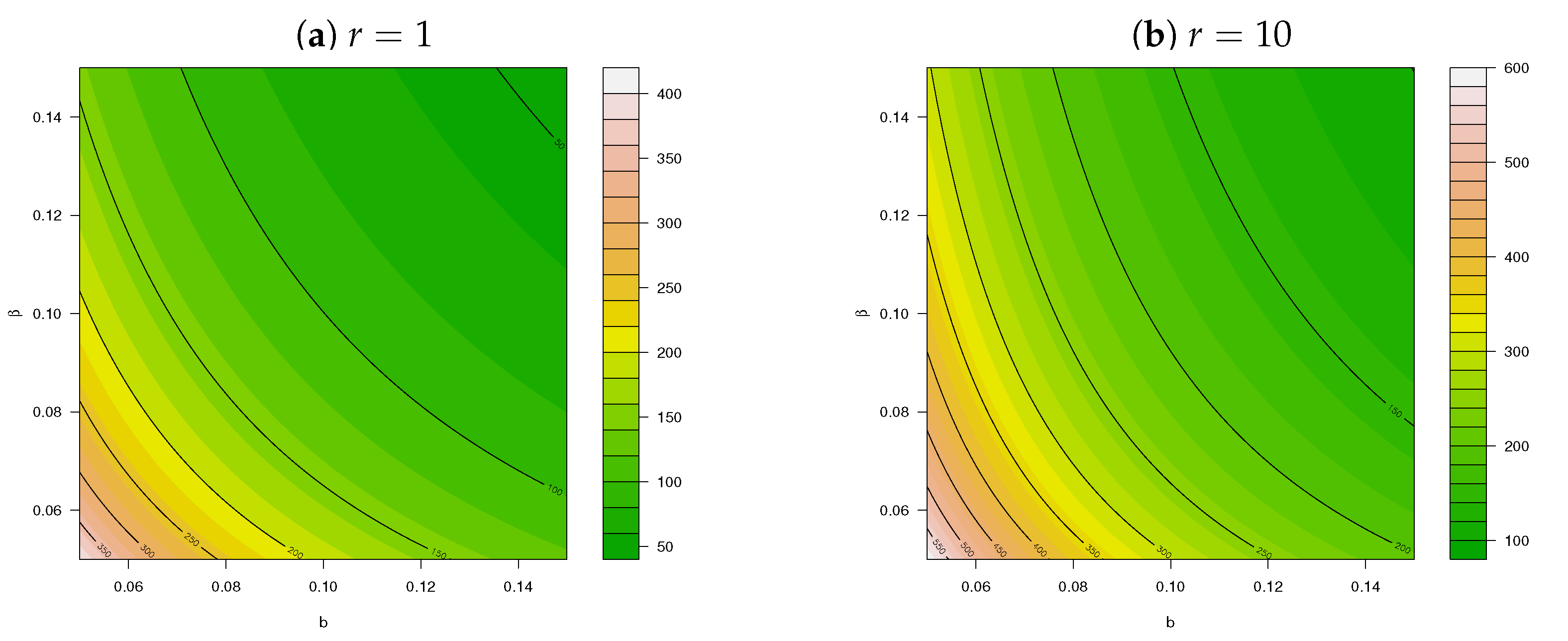
From (12) and (13), it is clear that for the PncLII distribution, implying overdispersion (that is ) and making the PncLII distribution ideal for modelling overdispersed count data sets. The behaviour of this DI is illustrated for different values of (for and ) in Figure 6, emphasizing the additional flexibility and increased levels in the DI of the PncLII distribution in comparison to the PncLI distribution illustrated in Appendix C, Figure A2.
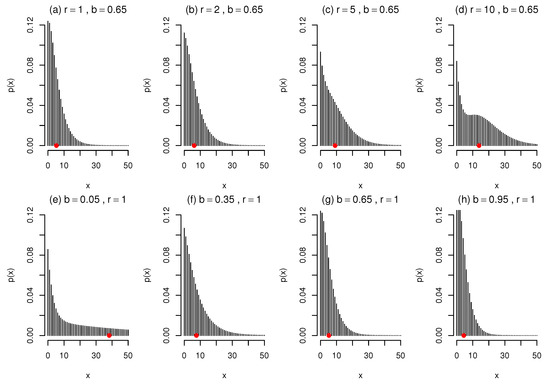
Figure 5.
Shapes of the mass function (9) for different values of (b, r) and , with means indicated in red.
Figure 5.
Shapes of the mass function (9) for different values of (b, r) and , with means indicated in red.
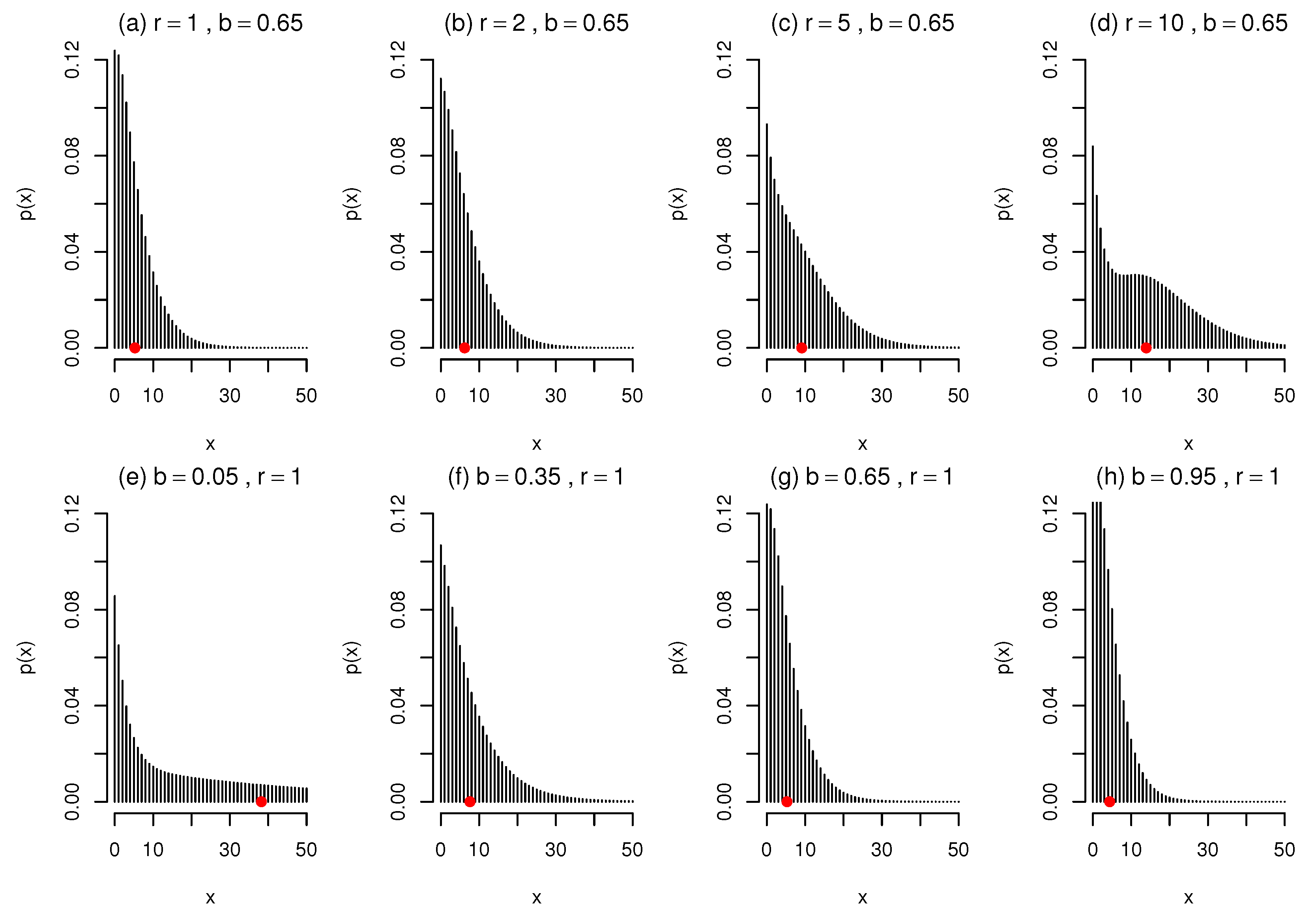
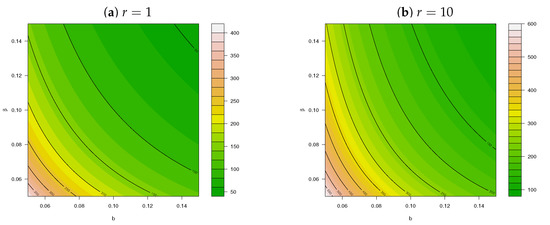
Figure 6.
Dispersion index for for different values of and .
Figure 6.
Dispersion index for for different values of and .
3. Implementation
Suppose that represents the (non-negative) autoregressive count at time t. The INAR(1) process is defined by
for , where and “∘” denotes the binomial thinning operator defined such that , where is a Bernoulli random variable with (see [34] for details). Furthermore, represents the error structure of discrete nature, with mean and finite variance such that represents counts measured over time.
The INAR(1) process in (14) can be described as a homogeneous Markov chain, and thus the one-step transition probability of the process is given by
where , for ; in the case of this study, is provided by (9). Given and (calculated using (12) and (13), respectively), the mean and variance for the INAR(1) process itself are provided by and , respectively (see [34,35]). In order to account for overdispersion, which is often encountered in count data, the contributions of [6,16] are valuable for proposing theoretical departures from the restrictive equidispersion property of the commonly used Poisson distribution.
Assuming for fixed values of r in (14), conditional maximum likelihood is used to fit the INAR(1) process with the conditional log-likelihood function, defined as
where is the vector of maximum likelihood estimates of the parameters and denotes the mass function in (9).
3.1. Simulation
This section evaluates the finite-sample performance of the maximum likelihood estimator for the INAR(1) process with . The following steps were implemented for this purpose:
- Define the theoretical parameters , , , and , and set the simulation replication number equal to 500.
- Generate errors for sample sizes such that with .
- (a)
- Generate variates.
- (b)
- Generate the errors such that .
- Generate the time series with binomial variates such that
- Because the stationary marginal distribution of is not explicitly available, a burn-in period should be generated, of which the corresponding marginal distributions then converge to the desired stationary marginal distribution [34]; in this case, we initialise .
- In order to estimate under various sample sizes, the conditional log-likelihood function (16) is maximised using the optim() function in .
- The bias and mean squared error (MSE) are calculated for each of the estimators for the different sample sizes of T, where
The results for the simulation described above are graphically summarised in Figure 7. With the biases and MSEs approaching the desired value of zero, it can be concluded that the maximum likelihood estimators perform well for small to moderate sample sizes, especially for and p, indicating the consistency of .
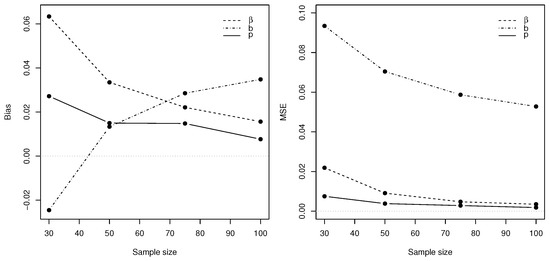
Figure 7.
Bias and MSE of , and for a simulated INAR-PncLII(1) process.
Figure 7.
Bias and MSE of , and for a simulated INAR-PncLII(1) process.
3.2. Real-Data Applications
For this section, consider the following data sets:
- Daily number of downloads of certain software for the period from June 2006 to February 2007 (sample size ) [36].
- Yearly number of terrorism incidents in Australia for years 1970 to 2015 (sample size ). The data are available in the Ecdat package of software.
- Monthly number of strikes leading to at least 1000 workers being idle (published by the U.S. Bureau of Labor Statistics, http://www.bls.gov/wsp/, accessed on 1 December 2021). The time period from January 1994 to December 2002 (sample size ) is considered.
Here, the INAR(1) process in (14) is fitted to the above-mentioned data while assuming for fixed values of r. In particular, the obtained results in this paper are contextualised versus the PncLI candidate from [6], together with the usual Poisson, NB, and PL contenders. The negative log-likelihood () and Akaike information criterion (AIC) values are compared in order to identify the model that fits the data best, with the latter defined as
where M denotes the number of parameters in the model [37]. Models with the smallest and AIC values are identified as those with the best fit. In order to evaluate the accuracy of the fitted models, the Pearson residuals
are analysed for using the results in Remark 1 of [6]. For an accurate model, the residuals should be uncorrelated with a mean and variance close to values of 0 and 1, respectively [34].
3.2.1. Number of Downloads of Certain Software
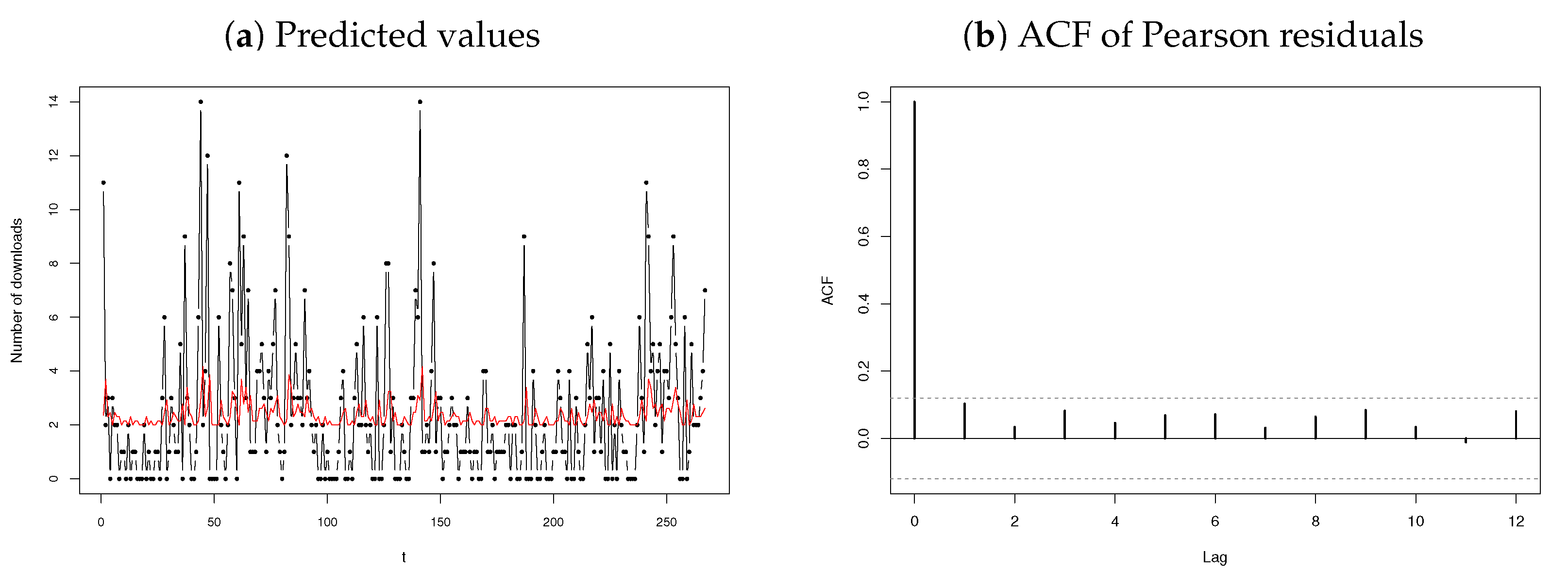
The first dataset under consideration is the daily number of downloads of certain software for the period from June 2006 to February 2007 (see [36]). The series consists of observations with a sample mean and variance of 2.4007 and 7.5061, respectively. The time plot, marginal distribution, autocorrelation function (ACF), and partial autocorrelation function (PACF) are presented in Figure 8, of which Figure 8c,d indicates that an AR(1)-type process is an appropriate choice for fitting the download data, as suggested by the significant sample partial autocorrelation at only lag 1. Because the data are of a particularly discrete nature, an INAR(1) process (14) is suggested with an error structure characterised by a discrete distribution allowing for overdispersion due to a sample .
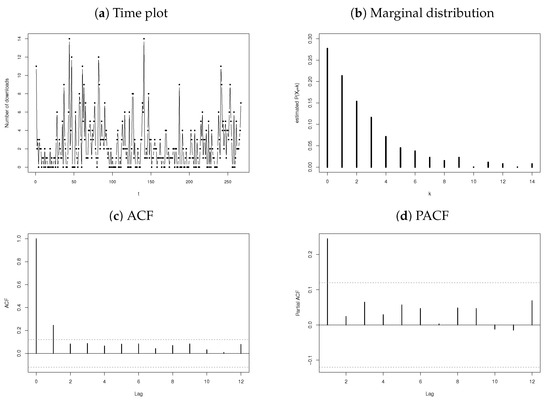
Figure 8.
Time plot, observed marginal distribution, ACF, and PACF for the download data.
Figure 8.
Time plot, observed marginal distribution, ACF, and PACF for the download data.
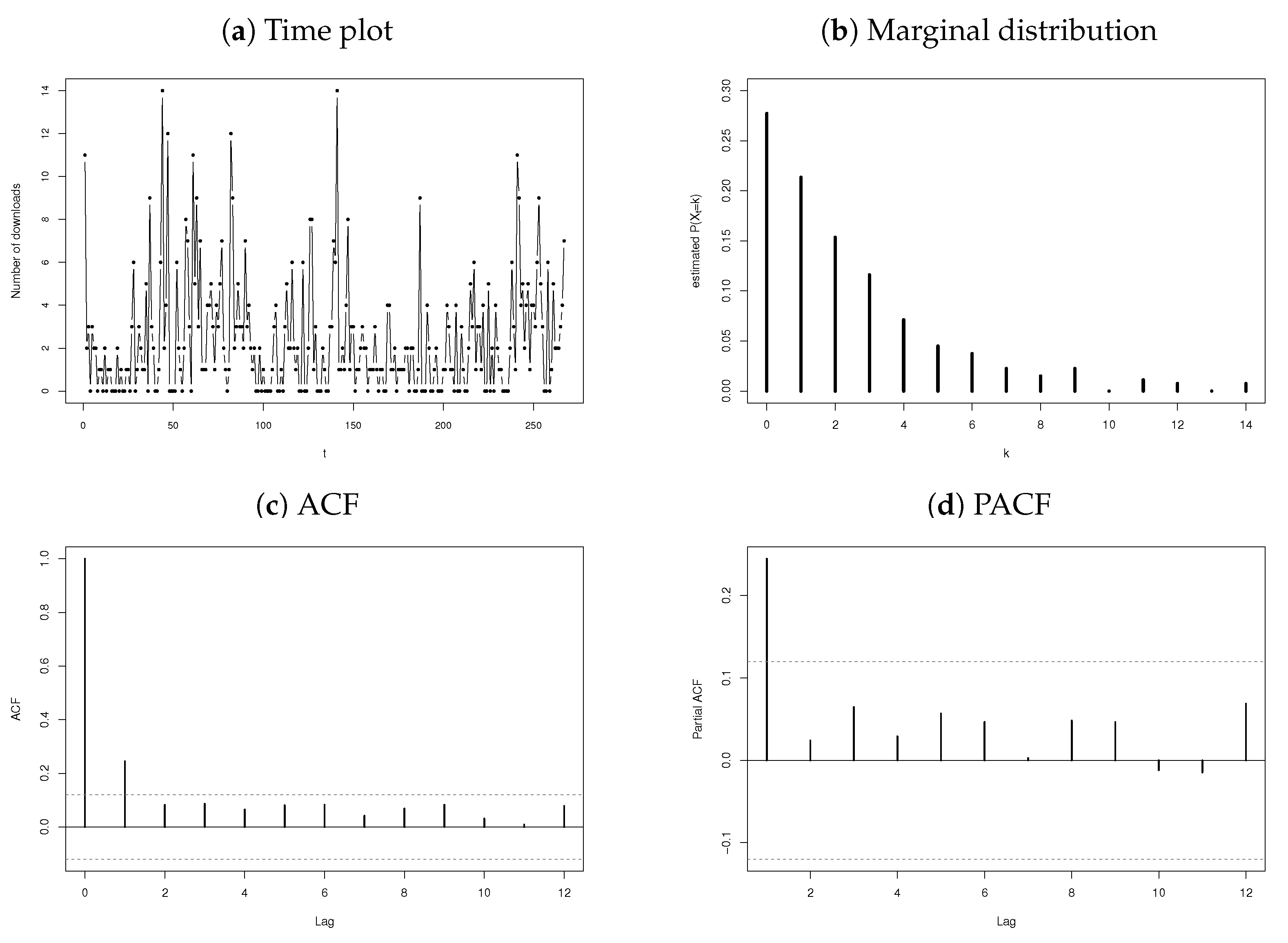
Table 1 summarises the conditional maximum likelihood estimation results for the INAR(1) process assuming various distributions for the error structure. Best fits are indicated in bold, with the smallest and AIC values, it is found that the proposed INAR-PncLII(1) for and fits the downloads data best relative to its considered competitors. In addition to the AIC values, the proposed model for yields a better estimated variance than for , suggesting a slightly better fit, even though the proposed model for estimates the best in terms of the variance.

Table 1.
Estimated parameters (with standard errors in italics and parentheses), goodness of fit statistics, fitted mean, and fitted variance of considered models for the downloads data.
In order the evaluate the accuracy of the proposed model for , the Pearson residuals are calculated and analysed using (17). The residuals yield a mean and variance of and , respectively, with no significant autocorrelation shown in Figure 9b, indicating a good fit. Based on the obtained results and the discussion above, the fitted model is provided by
where . The predicted values for the number of downloads, illustrated in Figure 9a, can be calculated as
and for as
where represents the estimated mean of the error structure, calculated using (12). It can be noted that the autoregressive estimate is small (though significant) due to a large number of zeros observed in the data; refer to Figure 8. This small value of results in the predicted values centralising around , as evident from Figure 9a.
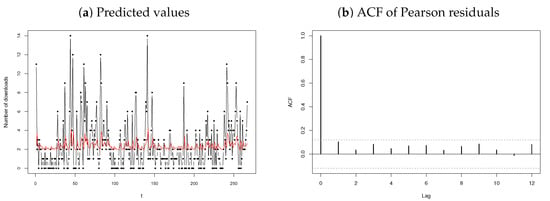
Figure 9.
Predicted values (in red) and Pearson residuals’ ACF for the download data.
Figure 9.
Predicted values (in red) and Pearson residuals’ ACF for the download data.
3.2.2. Number of Terrorism Incidents
As a second illustration, we consider the yearly number of terrorism incidents in Australia for the years 1970 to 2015. The series consists of observations, with a sample mean and variance of 1.9556 and 5.6798, respectively. The time plot, marginal distribution, ACF, and PACF are presented in Figure 10, of which Figure 10c,d indicates that an AR(1)-type process is an appropriate choice for fitting the terrorism data. Because these data are again of discrete-nature, an INAR(1) process (14) is suggested with an error structure characterised by a discrete distribution allowing for overdispersion due to a sample .
Figure 10.
Time plot, observed marginal distribution, ACF, and PACF for the terrorism data.
Figure 10.
Time plot, observed marginal distribution, ACF, and PACF for the terrorism data.
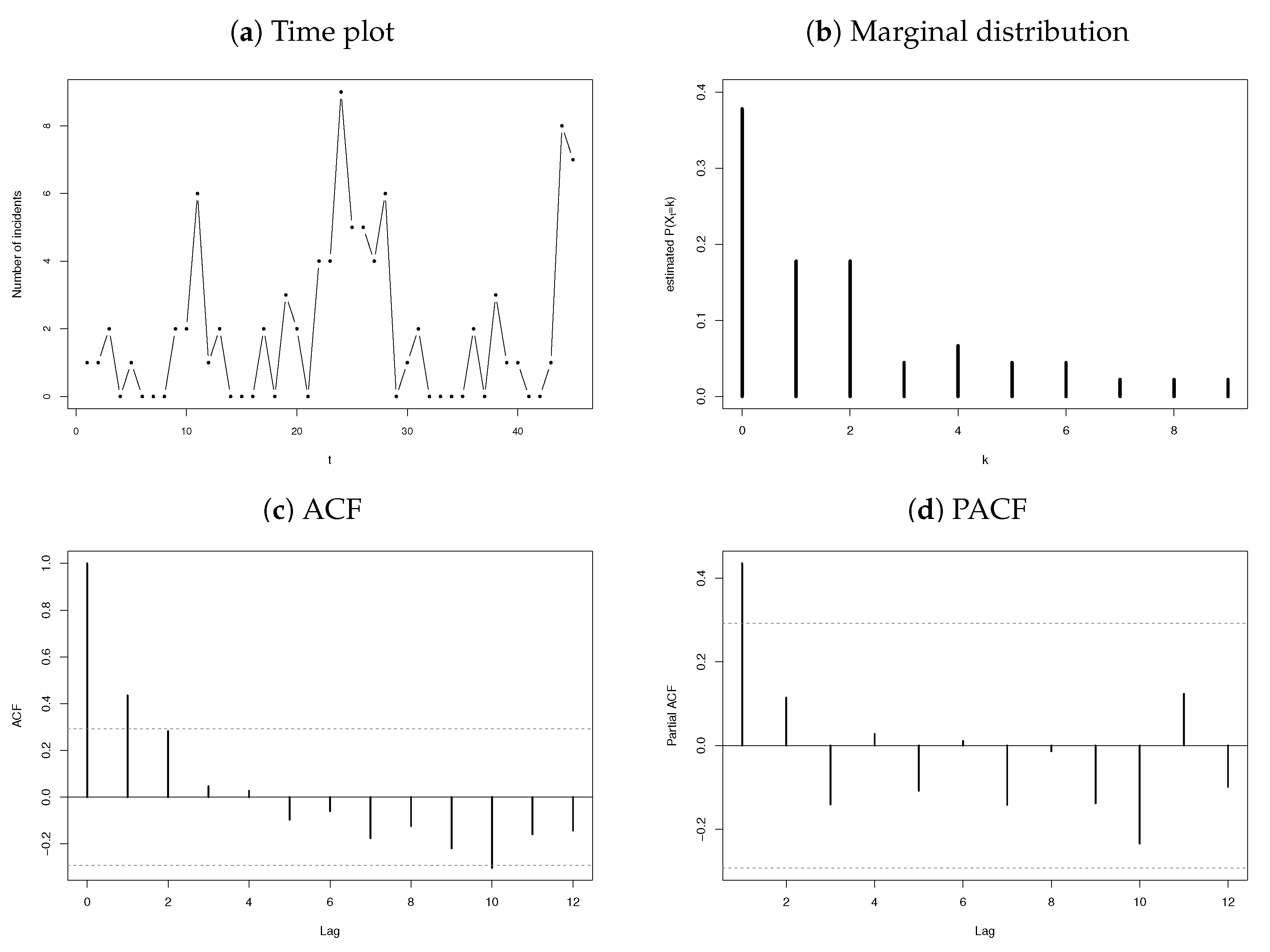
Table 2 summarises the conditional maximum likelihood estimation results for the INAR(1) process assuming various distributions for the error structure. For this application, the INAR(1) process with PL errors yields the smallest AIC value, although the proposed INAR-PncLII(1) for competes well with the smallest negative log-likelihood (), estimating a mean and variance close to the sample statistics.
Table 2.
Estimated parameters (with standard errors in parentheses), goodness of fit statistics, fitted mean, and fitted variance of considered models for the terrorism data.
In order the evaluate the accuracy of the proposed model for , the Pearson residuals are calculated, from which a mean and variance of and , respectively. No significant autocorrelation is shown in Figure 11b, indicating an accurate model. The fitted model is provided by
where . The predicted values for the number of terrorism incidents are illustrated in Figure 11a. Similar to the previous application, is small (though significant) due to a large number of zeros, leading to predicted values centralising around .
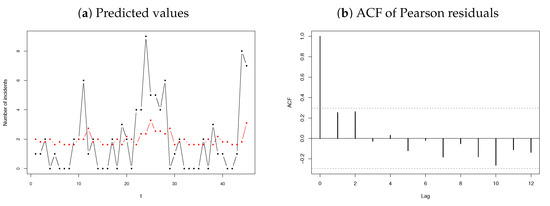
Figure 11.
Predicted values (in red) and ACF of the Pearson residuals for the terrorism data.
Figure 11.
Predicted values (in red) and ACF of the Pearson residuals for the terrorism data.
3.2.3. Number of Strikes
Finally, the monthly number of strikes leading to at least 1000 workers being idle for the time period from January 1994 to December 2002 (published by the U.S. Bureau of Labor Statistics, http://www.bls.gov/wsp/, accessed on 1 December 2021) is considered. This series consists of observations, with a sample mean and variance of 4.9444 and 7.9221, respectively. The time plot, marginal distribution, ACF, and PACF are presented in Figure 12. Similar to the previous applications, Figure 12c,d indicates that an AR(1)-type process is an appropriate choice for fitting the strike data, and as the data consist of integer values, an INAR(1) process (14) is suggested, with an error structure characterised by a discrete distribution allowing for overdispersion due to a sample .
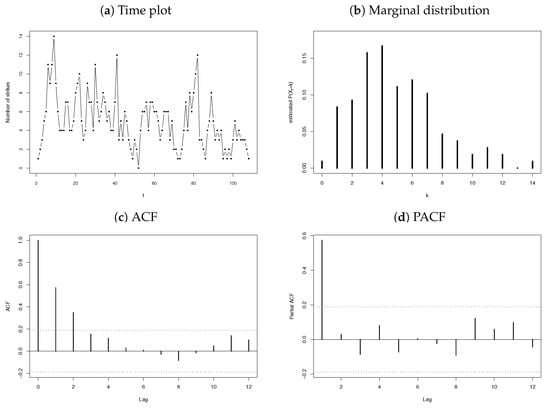
Figure 12.
Time plot, observed marginal distribution, ACF, and PACF for the strike data.
Figure 12.
Time plot, observed marginal distribution, ACF, and PACF for the strike data.
Table 3 summarises the conditional maximum likelihood estimation results for the INAR(1) process assuming various distributions for the error structure. For this application, the INAR(1) with an error structure described by the NB distribution is the best fit, with the smallest and AIC values and the estimated mean and variance closest to the sample statistics. Regarding the fitting of the proposed INAR-PncLII(1), it should be noted that b is estimated close to 1 regardless of the value of r, suggesting a PL distribution for the error structure, as (6) holds the usual PL as a special case of .
Table 3.
Estimated parameters (with standard errors in parentheses), goodness of fit statistics, fitted mean, and fitted variance of considered models for the strike data.
In order to evaluate the accuracy of the proposed INAR-PncLII(1) model for , the Pearson residuals are calculated and analysed. These residuals yield a mean and variance of and , respectively, with no significant autocorrelation shown in Figure 13b. These results indicate a good fit of the data, even though the fit seems slightly better for the previous datasets. Based on the obtained results and the discussion above, the fitted INAR-PncLII(1) model is provided by
where , suggesting . The corresponding predicted values based on the INAR-PncLII(1) model are illustrated in Figure 13a.
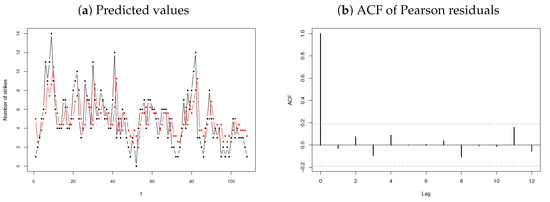
Figure 13.
Predicted values (in red) and ACF of the Pearson residuals for the strike data.
Figure 13.
Predicted values (in red) and ACF of the Pearson residuals for the strike data.
3.3. Discussion
In these data analyses, the proposed PncLII model performs favourably compared to other commonly considered candidates, such as the INAR-P(1), INAR-NB(1), INAR-PL(1), and INAR-PcnLI(1). Certain models, such as INAR-PL(1) and INAR-PncLI(1), have the ability to account for departures from the inherent theoretical restrictions imposed by the usual Poisson candidate (INAR-P(1)), and the flexibility that b and the choice of r offers the practitioner in a real modelling scenario is evident. This is further supported by the close estimation of the variance by INAR-PncLII(1) in the case of the download data, for example. Equally valuable, the options and ranges of skewness and kurtosis that PncLII inherits from the ncLII model are of value within the INAR environment illustrated in Figure 3 and Figure 4. In the future, it might be worthwhile to consider alternative weight constructions for , as well as to further consider the ncLII (6) developed in this paper as a candidate for error structures in the usual autoregressive cases, for example, juxtaposed against results similar to those of [38].
4. Conclusions
In recent years, positive-support distributions have enjoyed the attention of many researchers seeking to effect generalisations. In the case of this paper, the Lindley distribution is adapted in a meaningful and implementable way via infinite negative binomial shape mixtures within the gamma component, resulting in the ncLII distribution. This approach, inspired by the work of [6], generalises the fundamental Lindley model (1) in a meaningful way by extending the skewness and kurtosis of this model to allow broad flexibility to the practitioner, together with computable and closed-form expressions of the density function and statistical characteristics.
INAR processes are convenient for implementation when the error structure follows a pure Poisson model; however, this may be practically restrictive due to the inherent equidispersion property. For this reason, this paper introduces and studies a subsequent PncLII model that acts as contender for the PncLI model of [6]. This model’s competitive performance in the implementation within the INAR(1) environment and has closed-form mathematical characteristics make it an attractive and meaningful contender in both discrete data environment and INAR realms.
Author Contributions
Conceptualization, A.v.d.M. and J.T.F.; methodology, A.v.d.M. and J.T.F.; software, A.v.d.M.; formal analysis, A.v.d.M. and J.T.F.; writing—original draft preparation, J.T.F.; writing—review and editing, A.v.d.M.; supervision, J.T.F.; funding acquisition, J.T.F. All authors have read and agreed to the published version of the manuscript.
Funding
This work was based upon research supported in part by the National Research Foundation (NRF) of South Africa, grant RA201125576565, nr 145681; the RDP296/2022 grant from the University of Pretoria, South Africa; support from the Department of Library Services based at the University of Pretoria; the University Capacity Development Grant 656-2022; and the Centre of Excellence in Mathematical and Statistical Sciences grant nr #2022-047-STA, based at the University of the Witwatersrand, Johannesburg, South Africa. The opinions expressed and conclusions arrived at are those of the authors and are not necessarily to be attributed to the NRF.
Institutional Review Board Statement
This research was carried out under ethical clearance NAS116/2022 from the University of Pretoria.
Informed Consent Statement
This manuscript does not contain any studies with human participants, animals, or informed consent.
Data Availability Statement
Data in this study are available at https://drive.google.com/drive/folders/1pxymEy37SqJ8nqdBjj4MJ_-DxhiJ8TXC?usp=sharing, accessed on 4 November 2022.
Acknowledgments
The authors further thank two anonymous reviewers along with the associate editor for constructive feedback which led to an improved version of this manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| Exp | Exponential |
| Gam | Gamma |
| Bin | Binomial |
| ncLI | noncentral Lindley of type I |
| ncLII | noncentral Lindley of type II |
| PncLI | Poisson noncentral Lindley of type I |
| PncLII | Poisson noncentral Lindley of type II |
| DI | Dispersion index |
| NB | Negative binomial |
| INAR | Integer autoregressive |
| MGF | Moment-generating function |
| MSE | Mean squared error |
| PGF | Probability-generating function |
| ACF | Autocorrelation function |
| PACF | Partial autocorrelation function |
| AIC | Akaike’s information criterion |
Appendix A. Moments of the Noncentral Lindley of Type II
Suppose that the random variable with density function (6). Then, using (8), the first four moments of Y are provided as follows:
where represents the Gauss hypergeometric function of scalar argument with two upper and one lower parameter(s); see [33]. Using these four moments, the levels of skewness and kurtosis for Y can be calculated as follows:
where and define the mean and variance of Y, respectively.
Appendix B. Moments of the Noncentral Lindley of Type I
Suppose that the random variable with density function (3). Then, the moments of Y are provided by
where and represents the confluent hypergeometric function of scalar argument with one upper and one lower parameter (see [6,33]). Using (A1), the levels of skewness and kurtosis for Y can be calculated as described in Appendix A. These characteristics are illustrated in Figure A1a and Figure A1b, respectively, for different values of and .
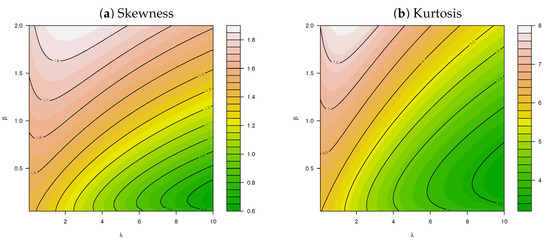
Figure A1.
Skewness and kurtosis for Y∼ ncLI() for different values of and .
Figure A1.
Skewness and kurtosis for Y∼ ncLI() for different values of and .
Appendix C. Moments of the Poisson Noncentral Lindley of Type I
Suppose that the random variable with mass function (4). Then, the factorial moment of X is provided by
where and represents the confluent hypergeometric function of scalar argument with one upper and one lower parameter (see [6,33]). Using (A2), the first two moments of X are provided by
and
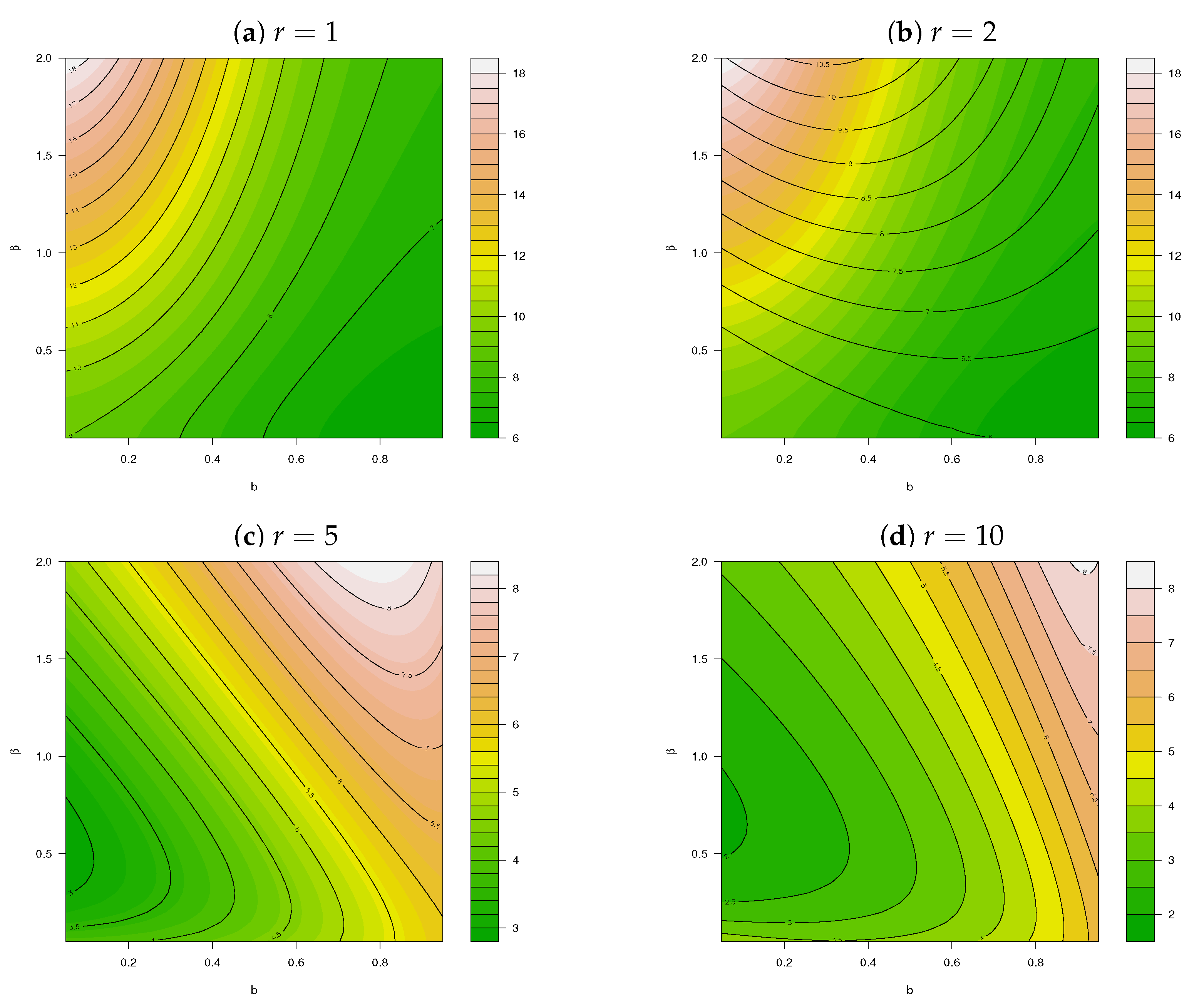
where and define the mean and variance of X, respectively. Thus, the DI for X can be calculated as , as illustrated in Figure A2 for different values of and .
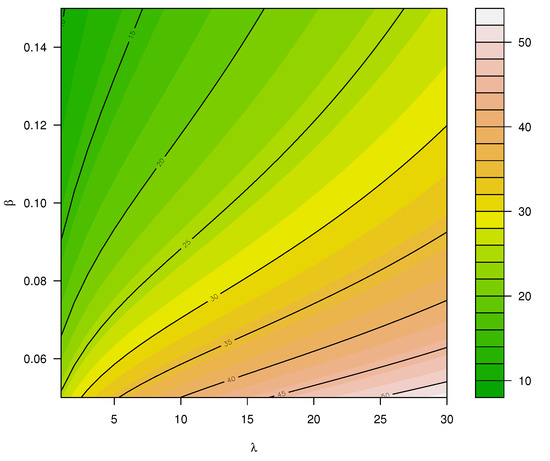
Figure A2.
Dispersion index for X∼ PncLI() for different values of (, ).
Figure A2.
Dispersion index for X∼ PncLI() for different values of (, ).
References
- Lindley, D.V. Fiducial distributions and Bayes’ theorem. J. R. Stat. Soc. Ser. B (Methodol.) 1958, 20, 102–107. [Google Scholar] [CrossRef]
- Ghitany, M.E.; Atieh, B.; Nadarajah, S. Lindley distribution and its application. Math. Comput. Simul. 2008, 78, 493–506. [Google Scholar] [CrossRef]
- Zakerzadeh, H.; Dolati, A. Generalized Lindley distribution. J. Math. Ext. 2009, 3, 13–25. [Google Scholar]
- Ghitany, M.; Al-Mutairi, D.K.; Balakrishnan, N.; Al-Enezi, L. Power Lindley distribution and associated inference. Comput. Stat. Data Anal. 2013, 64, 20–33. [Google Scholar] [CrossRef]
- Shanker, R.; Shukla, K.K.; Shanker, R.; Tekie, A. A three-parameter Lindley distribution. Am. J. Math. Stat. 2017, 7, 15–26. [Google Scholar]
- Ferreira, J.; van der Merwe, A. A Noncentral Lindley Construction Illustrated in an INAR (1) Environment. Stats 2022, 5, 70–88. [Google Scholar] [CrossRef]
- Knüsel, L.; Bablok, B. Computation of the noncentral gamma distribution. SIAM J. Sci. Comput. 1996, 17, 1224–1231. [Google Scholar] [CrossRef]
- Nadarajah, S.; Kotz, S. Compound mixed Poisson distributions I. Scand. Actuar. J. 2006, 2006, 141–162. [Google Scholar] [CrossRef]
- Nadarajah, S.; Kotz, S. Compound mixed Poisson distributions II. Scand. Actuar. J. 2006, 2006, 163–181. [Google Scholar] [CrossRef]
- Ferreira, J.; Bekker, A.; Arashi, M. Bivariate noncentral distributions: An approach via the compounding method. S. Afr. Stat. J. 2016, 50, 103–122. [Google Scholar] [CrossRef]
- Sankaran, M. The discrete Poisson-Lindley distribution. Biometrics 1970, 26, 145–149. [Google Scholar] [CrossRef]
- Ghitany, M.; Al-Mutairi, D. Estimation methods for the discrete Poisson–Lindley distribution. J. Stat. Comput. Simul. 2009, 79, 1–9. [Google Scholar] [CrossRef]
- Mahmoudi, E.; Zakerzadeh, H. Generalized poisson–Lindley distribution. Commun. Stat. Methods 2010, 39, 1785–1798. [Google Scholar] [CrossRef]
- Das, K.K.; Ahmad, J.; Bhattacharjee, S. A new three-parameter Poisson-Lindley distribution for modeling over dispersed count data. Int. J. Appl. Eng. Res. 2018, 13, 16468–16477. [Google Scholar]
- Altun, E. A new two-parameter discrete Poisson-generalized Lindley distribution with properties and applications to healthcare data sets. Comput. Stat. 2021, 36, 2841–2861. [Google Scholar] [CrossRef]
- Lívio, T.; Khan, N.M.; Bourguignon, M.; Bakouch, H.S. An INAR (1) model with Poisson–Lindley innovations. Econ. Bull. 2018, 38, 1505–1513. [Google Scholar]
- McKenzie, E. Some simple models for discrete variate time series. Water Resour. Bull. 1985, 21, 645–650. [Google Scholar] [CrossRef]
- Al-Osh, M.A.; Alzaid, A.A. First-order integer-valued autoregressive (INAR (1)) process. J. Time Ser. Anal. 1987, 8, 261–275. [Google Scholar] [CrossRef]
- Altun, E. A new generalization of geometric distribution with properties and applications. Commun. Stat.-Simul. Comput. 2020, 49, 793–807. [Google Scholar] [CrossRef]
- Altun, E. A new one-parameter discrete distribution with associated regression and integer-valued autoregressive models. Math. Slovaca 2020, 70, 979–994. [Google Scholar] [CrossRef]
- Abd-Elrahman, A.M. Utilizing ordered statistics in lifetime distributions production: A new lifetime distribution and applications. J. Probab. Stat. Sci. 2013, 11, 153–164. [Google Scholar]
- Altun, E.; Bhati, D.; Khan, N.M. A new approach to model the counts of earthquakes: INARPQX (1) process. SN Appl. Sci. 2021, 3, 1–17. [Google Scholar] [CrossRef] [PubMed]
- Bhati, D.; Kumawat, P.; Gómez-Déniz, E. A new count model generated from mixed Poisson transmuted exponential family with an application to health care data. Commun. Stat.-Theory Methods 2017, 46, 11060–11076. [Google Scholar] [CrossRef]
- Altun, E.; Khan, N.M. Modelling with the novel INAR (1)-PTE process. Methodol. Comput. Appl. Probab. 2022, 24, 1735–1751. [Google Scholar] [CrossRef]
- Xavier, D.; Santos-Neto, M.; Bourguignon, M.; Tomazella, V. Zero-Modified Poisson-Lindley distribution with applications in zero-inflated and zero-deflated count data. arXiv 2017, arXiv:1712.04088. [Google Scholar]
- Sharafi, M.; Sajjadnia, Z.; Zamani, A. A first-order integer-valued autoregressive process with zero-modified Poisson-Lindley distributed innovations. Commun. Stat.-Simul. Comput. 2020. [Google Scholar] [CrossRef]
- Zhang, J.; Zhu, F.; Khan, N.M. A new INAR model based on Poisson-BE2 innovations. Commun. Stat.-Theory Methods 2022. [Google Scholar] [CrossRef]
- Habibi, M.; Asgharzadeh, A. A new mixed Poisson distribution: Modeling and applications. J. Test. Eval. 2018, 46, 1728–1740. [Google Scholar] [CrossRef]
- Altun, E.; Cordeiro, G.M.; Ristić, M.M. An one-parameter compounding discrete distribution. J. Appl. Stat. 2022, 49, 1935–1956. [Google Scholar] [CrossRef]
- Simon, L.J. The negative binomial and Poisson distributions compared. Proc. Casualty Actuar. Soc. 1960, 47, 20–24. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2022. [Google Scholar]
- Bain, L.J.; Engelhardt, M. Introduction to Probability and Mathematical Statistics; Duxbury Press: Belmont, CA, USA, 1992; Volume 4. [Google Scholar]
- Gradshteyn, I.S.; Ryzhik, I.M. Table of Integrals, Series, and Products; Academic Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Weiß, C.H. An Introduction to Discrete-Valued Time Series; John Wiley & Sons: Hoboken, NJ, USA, 2018. [Google Scholar]
- Alzaid, A.; Al-Osh, M. First-order integer-valued autoregressive (INAR (1)) process: Distributional and regression properties. Stat. Neerl. 1988, 42, 53–61. [Google Scholar] [CrossRef]
- Weiß, C.H. Thinning operations for modeling time series of counts—a survey. AStA Adv. Stat. Anal. 2008, 92, 319–341. [Google Scholar] [CrossRef]
- Akaike, H. A new look at the statistical model identification. IEEE Trans. Autom. Control 1974, 19, 716–723. [Google Scholar] [CrossRef]
- Neethling, A.; Ferreira, J.; Bekker, A.; Naderi, M. Skew generalized normal innovations for the AR(p) process endorsing asymmetry. Symmetry 2020, 12, 1253. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).