1. Introduction
In practical applications, especially in medical fields and engineering sciences, lifetime studies are a useful tool to investigate the survival unit distribution. When analyzing data from these studies, an important component is the assumed lifetime distribution. Some common lifetime distributions include the exponential, generalized exponential, Rayleigh, Pareto, and Weibull, to name a few. Besides these common life distributions, the Gompertz distribution (Gompertz [
1]) is also frequently used to analyze lifetime data. Further, it is used to describe growth in plants, animals, bacteria, and cancer cells, see Willemse and Koppelaar [
2]. In recent studies, the Gompertz model has been successfully used to characterize growth curves in many fields, including biology, crop science, medicine, engineering, computer science, economics, marketing, human mortality, human demographics, and actuarial mortality, to name a few. Due to the recent global spread of COVID-19 cases, this distribution has been used to predict and estimate the number of COVID-19 cases in different countries. For instance, Rodriguez et al. [
3] predicted a different number of COVID-19 cases in Mexico using the Gompertz model. According to Jia et al. [
4], the Gompertz model has been applied successfully to forecast the amount of COVID-19 infections in China. The Gompertz distribution is thus worthwhile to investigate in this paper due to its numerous uses and applications.
The mathematical symbols for the probability density function (PDF) and cumulative distribution function (CDF) related to the Gompertz distribution are given, respectively, by
and
The reliability or survival function and the failure rate function become, respectively
where,
is the scale parameter and
is the shape parameter. The failure rate (hazard) function
increases or decreases monotonically, and the log(
) is linear with
t. It is known Gompertz distribution is a flexible model that can be skewed to the left or the right by varying the values of
and
. Where the parameter
satisfies the criteria listed below:
If , then where , hence is monotonically decreasing.
If , the PDF (1) will monotonically increase when and decrease when
If , then the hazard monotonically decreases over time t.
If , the hazard then monotonically increases with time
When , the Gompertz distribution tends to become exponential.
The inference of the unknown lifetime parameters of the Gompertz distribution based on censoring data has been widely discussed in the last two decades. Including, for example, Jaheen [
5] investigated this distribution based on progressive Type-II censoring using a Bayesian methodology. Also, based on progressive Type-II censored samples, Wu et al. [
6] developed point and interval estimators for the parameters of the Gompertz distribution. Wu et al. [
7] explored the estimation of Gompertz distribution with a Type-II progressive censoring scheme, where the units are randomly removed. Ismail [
8] used step stress partially accelerated life tests with two stress levels and Type-I censoring and the Gompertz distribution as a life model to apply the Bayesian technique to the estimation problem. The point and interval estimations of a two-parameter Gompertz distribution under partially accelerated life tests with Type-II censoring were also covered by Ismail [
9]. Soliman et al. [
10] have dealt with parameter estimation using progressive first-failure censored data. Soliman and Al Sobhi [
11] analyzed first-failure progressive data to deal with the estimation of Gompertz distribution. The Bayes estimation and expected termination time for the competing risks model for the Gompertz distribution under progressively hybrid censoring with binomial removals have been taken into consideration by Wu and Shi [
12]. The statistical inference for the Gompertz distribution with Type-II progressive hybrid data and generalized progressively hybrid censored data have been covered in El-Din et al. [
13].
Due to resource shortages, time restraints, employee changes, and accidents, data cannot be fully completed in practice when studying lifetime experiments. Experimenters use filtering or censoring techniques to shorten testing times and associated expenses. The two most common forms of censored systems in literature are Type-I and Type-II. With Type-I censoring, the test is over at a pre-fixed time, whereas with Type-II censoring, only the first
m failed units in a random sample of size
n (
) are observed. Or equivalent, the experiment stops when it collects a specified amount of data. Although this method is easy to implement, it has the potential to waste a lot of test time. Furthermore, until the test is over, no unit can be taken out of it. In order to increase the effectiveness of the experiment, progressive Type-II censoring was suggested. With this censoring method, test units can be eliminated at different points throughout the experiment. We refer to Balakrishnan and Cramer [
14] for additional information. The following illustrates how the progressive Type-II censoring model works.
Denote
,
as the respective lifetimes of the
n units that are placed on a life test. the progressive Type-II censoring scheme
(
) and the number of units observed
m (
) are determined before the experiment.
and
. The remaining
units are arbitrarily removed from the experiment once the
ith failure is noticed. As long as this rule is followed, the experiment will continue until
m failures are observed and here the experiment ends. As a result, the observed statistics for the progressive Type-II right censoring order are (
,
,….,
). This model simulates the real-world scenario where some units are lost or removed throughout the experiment, which makes it more logical than Type-II censoring. Even while progressive censorship can considerably increase the effectiveness of the experiment, the trial’s runtime is frequently still too long. In many cases, it is important to know how long before a particular event occurs, especially in clinical research. Ng et al. [
15] suggested adaptive Type-II progressive censoring to improve the effectiveness of statistical inference and reduce overall test duration. This plan operates as follows: Consider putting
n identical units through a life test. The observed number of failures
is predetermined, and the test time is permitted to extend beyond the time
T that is specified beforehand. The progressive censoring method
ℜ is specified, although some of the
values may change accordingly during the life test. As explained above, after the
ith failure is noticed during the life test,
units are at random removed from the test. We write
,
, to represent the
m fully observed lifetimes. If the
mth failure time occurs before time
T (i.e.
), the test ends at time
using the same progressive censoring scheme (
), where
. If
Jth failure time happens before time
T, i.e.,
, where
and
, then we adapt the number of units progressively withdrawn from test upon failures by setting
, and at the time
all remaining units
are eliminated, where
. So, in this situation, the effectively applied progressive censored scheme is (
). In this study, we employ
instead of
;
. One of the following two scenarios might represent the observed data under-considered censoring scheme:
Case 1, if , where
Case 2, if .
It should be noted that Type-II and Type-II progressive censoring schemes are both extensions of the the adaptive Type-II censored scheme. While adaptive Type-II censored scheme reduces to Type-II censoring scheme if , , no units will be removed, and if , , () survival units will be eliminated at random during the trial, adaptive Type-II censored scheme is exactly Type-II progressive censored scheme.
There have been a lot of discussions recently about the adaptive Type-II censored scheme. As an illustration, Sobhi and Soliman [
16] worked with the exponentiated Weibull distribution, they investigated the estimate of its parameters, reliability, and hazard functions. They employed the approach of Bayesian estimation as well as the MLE under the adaptive Type-II censored scheme. ML and Bayes estimates for the unknown parameters of the inverse Weibull distribution under the adaptive Type-II censored scheme were described by Nassar and Abo-Kasem [
17]. According to the adaptive Type-II censored scheme, Sewailem and Baklizi [
18] investigated the ML and Bayes estimates for the log-logistic distribution parameters. The estimations of entropy for inverse Weibull distributions using the adaptive Type-II censored scheme were developed by Xu and Gui [
19]. The parameters of an exponentiated inverted Rayleigh model were calculated by Panahi and Moradi [
20]. They studied the MLE and Bayesian analysis under an adaptive Type-II censored hybrid censored scheme. Chen and Gui [
21] concentrated on a statistical analysis of the Chen and Gui Chen model with adaptive progressive Type-II censoring. Kumarswamy-exponential distribution was taken into consideration in the adaptive progressive Type-II censoring technique by Mohan and Chacko [
22]. Under the adaptive progressive Type-II censoring scheme, Hora et al. [
23] considered the classical and Bayesian inferences for unknown parameters of the inverse Lomax distribution. Recently, using the adaptive Type-II progressive censored sample from the Gompertz distribution, Amein et al. [
24] examined several estimation strategies.
The adaptive Type-II progressive censored is used in this paper instead of Type-I, Type-II, and Type-II progressive censored schemes because it favors experiments where units must be disassembled at different stages of failure before the appropriate intended sample size is reached and also has a predetermined time during which the experiment can occur.
In some medical or engineering studies, individuals may fail due to different failure causes. In literature, it refers to the competing risks model. According to the competing risks model, observable data include the individual failure time and a cause-of-failure indicator. These failure factors might or might not be independent. In most cases, when analyzing data on competing risks, the failure factors are considered to be independent of each other. For example, a patient can die from breast cancer or stroke, but he cannot die from both. In the same field, when studying thyroid cancer, three causal factors play a possible role in thyroid cancer. The first is radiation exposure, the second is an elevated level of thyroid-stimulating hormone, and the third suggested factor is prolonged exposure to iodine deficiency. Based on the assessment of these factors, patients are divided into low or high-risk groups.
Another example is applied in the industrial and mechanical fields, an assembly device may fail to break the welding/bond plate front due to fatigue, or low electrical/optical signal (voltage, current, or light intensity) to an unacceptable level due to aging deterioration. In this example, the electronic product fails due to two independent elements of failure: welding interface fracture (catastrophic failure or difficult failure) and brightness of electrical/optical signal reductions (degradation failure or fine failure). Crowder [
25] is a reliable source for a comprehensive investigation of several competing risk models.
Many academics have recently studied statistical inference for the parameters of various lifetime parametric models utilizing various censoring techniques with competing risk data. Kundu et al. [
26], for instance, took into account the analysis of competing risks data when the data are progressively Type-II censored from exponential distributions. Based on progressive Type-II censoring of competing risks, Pareek et al. [
27] determined the MLEs of the parameters of Weibull distributions and their asymptotic variance-covariance. When the lifetime distributions are Weibull distributions, Kundu and Pradhan [
28] studied the Bayesian inference of the unknown parameters of the progressively censored competing risks data. The estimators of the parameters for Lomax distributions were determined by Cramer and Schmiedt [
29] using a progressive Type-II censoring competitive risks model. For the distribution parameters, they calculated the expected Fisher information matrices and MLEs. Generalized exponential distribution with adaptive Type-II progressive hybrid censored competing risks data was studied by Ashour and Nassar [
30]. A competing risks model with a generalized Type I hybrid censoring method was presented by Mao et al. [
31]. They estimated both exact and approximate confidence intervals using the exact distributions, asymptotic distributions, and parametric bootstrap approaches, respectively. Wu and Shi [
12] developed the Bayes estimation for the two-parameter Gompertz distribution competitive risks model under Type-I gradually hybrid censoring scheme with binomial removals. The point estimate and point prediction for a class of an exponential distribution with Type-I progressively interval-censored competing risks data were studied by Ahmadi et al. [
32]. Dey et al. [
33] took into account the Bayesian analysis of modified Weibull distribution under progressively censored competing risk models. Inference techniques for the Weibull distribution under adaptive Type-I progressive hybrid censored competing risks data are described by Ashour and Nassar [
34]. Additionally, a competing risk model using exponential distributions and the adaptive Type-II progressively censoring scheme is also taken into account by Hemmati and Khorram [
35]. They developed MLEs of unknown parameters and constructed the confidence intervals as well as the two different bootstraps of different unknown parameters. The Bayes estimates and associated two-sides probability intervals were also likewise driven by them. Azizi et al. [
36] considered statistical inference for a competing risks model using Weibull data with progressive interval censoring. Based on progressive Type-II censored competing risks data with binomial removals, Chacko and Mohan [
37] developed the Bayesian analysis of the Weibull distribution. Baghestani and Baharanchi [
38] investigate an improper Weibull distribution for competing for risk analysis using a Bayesian technique. The statistical inference of the Burr-XII distribution under progressive Type-II censored competing risks data with binomial removals has been studied by Qin and Gui [
39]. Progressive Type-II censored competing risks data from the linear exponential distribution have been examined by Davies and Volterman [
40]. In the adaptive Progressive Type-II censored model with independent competing risks, Ren and Gui [
41] proposed several of statistical inference techniques to estimate the parameters and reliability of the Weibull distribution. Recent research by Lodhi et al. [
42] examined a competing risks model utilizing the Gompertz distribution under progressive Type-II censoring where failure cause probability distributions are identically distributed with a similar scale and variable shape parameters.
The major goal of this research is to analyze the adaptive progressively Type-II censored with competing risks sample from the Gompertz distribution because there aren’t many relevant works that deal with adaptive progressively Type-II censored competing risks data. The model parameters and reliability function are estimated using the maximum likelihood method. In this method, with the help of the graphical method, developed by Balakrishnan and Kateri [
43], the issue of the starting value of the MLEs is resolved here. The existence and uniqueness of the MLEs of the model parameters are established. The Newton-Rapshon (NR) method and the stochastic expectation-maximization (SEM) algorithm are the two algorithms that are being taken into consideration to numerically determine the MLEs for the parameters. We cover interval estimation using the two approximation information matrix methods and the bootstrap method. With the assumption that the model parameters follow independent gamma priors for the two different shape parameters and inverted gamma for the scale parameter, the Bayes estimators and associated credible intervals are then obtained using the Metropolis-Hasting (MH) algorithm based on squared error (SE) and linear-exponential (LINEX) loss functions. Last but not least, through Monte Carlo simulation, the performances of estimates are assessed using average bias and mean squared error (MSE) for point estimation and average length and probability coverage for interval estimation.
The remaining portions of this article are structured as follows: We describe the model in
Section 2 of the paper. The MLEs of the unknown parameters based on the NR and SEM techniques are discussed in
Section 3 of this article. We also present the estimated confidence intervals using the corresponding MLEs’ normalcy requirement. In
Section 4, The bootstrap confidence intervals for the unknown parameters as well as the reliability function are obtained. The Markov chain Monte Carlo (MCMC) approach is used in
Section 5 to approximate the Bayesian estimates and to generate MCMC intervals for the unknowns.
Section 6 presents a Monte Carlo simulation analysis that contrasts the results of the various approaches. This part also introduces actual data sets to demonstrate the efficacy of the methods used in this paper. Several conclusions are provided as a conclusion in
Section 7.
6. Analyzing Application Data
The significance of the theoretical findings that were discussed in the preceding parts will be clarified in this section using a few examples from the medical fields and industry. This section’s investigation of two real-world data sets supports the proposed point and interval estimates of unknown parameters and the reliability function.
6.1. Application to Reticulum Cell Sarcoma
In the first application, we take into account the data provided by Hoel [
56]. For review, this data is also illustrated by [
26,
27,
29]. According to these data, male mice and rats received 300 roentgens of radiation when they were 5 to 6 weeks old. In searching for the causes that led to the death of each mouse, the following reasons were reached: (1) Thymic lymphoma, (2) Reticulum cell sarcoma, or (3) Other causes. Here, we classify the reticulum cell sarcoma as cause 1, and the other two causes of death are combined to form cause 2. This data contained
observations. Of which 38 are due to the first cause of death and 39 are due to the second cause of death.
Cause 1: 317, 318, 399, 495, 525, 536, 549, 552, 554, 557, 558, 571, 586, 594, 596, 605, 612, 621, 628, 631, 636, 643, 647, 648, 649, 661, 663, 666, 670, 695, 697, 700, 705, 712, 713, 738, 748, 753.
Cause 2: 40, 42, 51, 62, 163, 179, 206, 222, 228, 252, 259, 282, 324, 333, 341, 366, 385, 407, 420, 431, 441, 461, 462, 482, 517, 517, 524, 564, 567, 586, 619, 620, 621, 622, 647, 651, 686, 761, 763.
Assuming independent Gompertz distributions for the latent cause of failures, using the hypotheses H
(Data follows the Gompertz distribution) and H
(Data does not follow the Gompertz distribution), a Chi-square (
) goodness-of-fit test as well as Kolmogorov-Smirnov (K-S) test are applied to test the goodness of fit of the proposed model to the two causes of failure. The values of the
and K-S test statistics are given in
Table 1.
Based on these results, for the two causes of failure, one can say that at
level of significance; the
observed value is less than the
tabulated value and the
p-value is also quite large in this case. Thus, we can not reject H
and the data set is fitted well with our model. In the same way, the computed K-S test statistics are higher than the critical value for the K-S test statistic. Additionally, as we can see, the p-values for the K-S test statistics for the Gompertz distribution are higher than the significance level (0.05), indicating that the Gompertz model generally well fits the previous real data. For further clarification, we provided
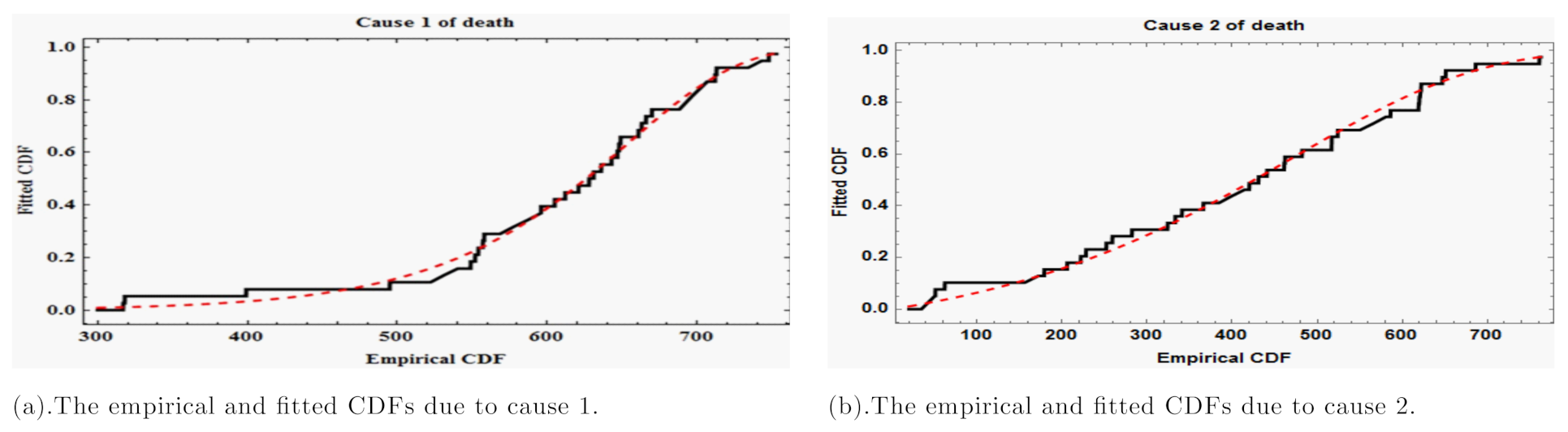
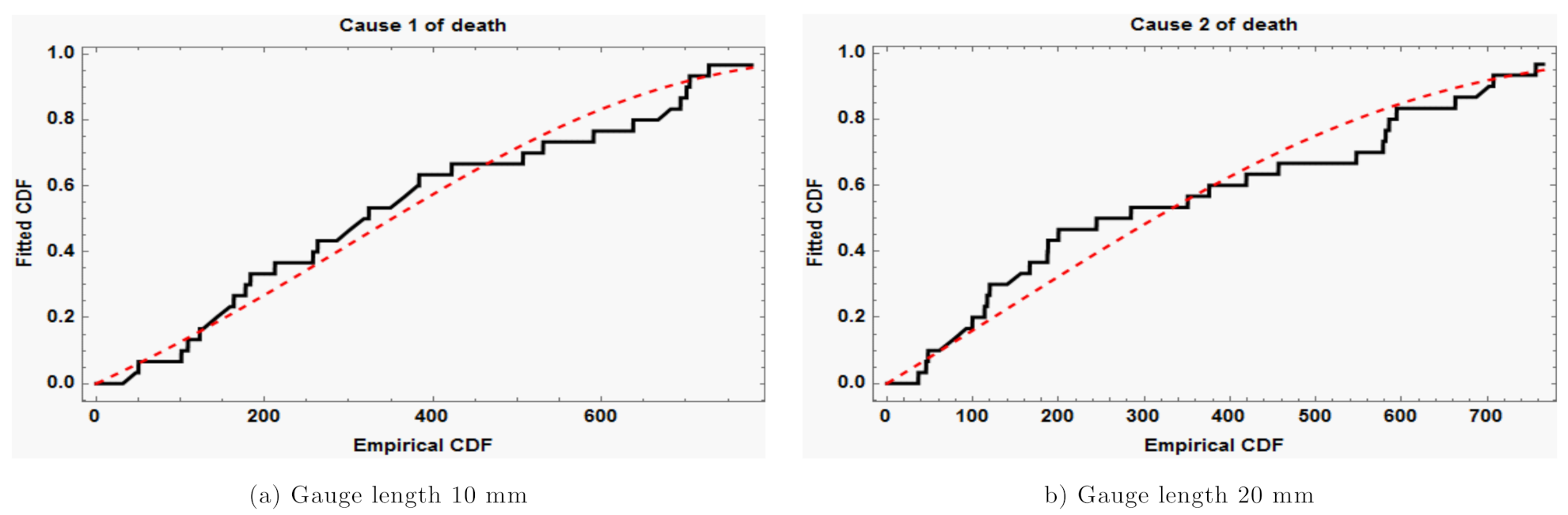
Figure 1, which contains both fitted and empirical CDFs of Gompertz distribution based on the two causes (
Figure 1a,b), computed at the estimated parameters. The figures show that the fitted distribution and empirical distribution are very similar. As a result, the Gompertz model provides an excellent fit to the provided data set in each scenario that results in death.
By using the censoring scheme ··· and an ideal total test time , we generate an adaptive progressively Type II censored sample of size from the complete data. The generated data is obtained as:
(40, 2), (42,2), (51, 2), (62,2), (179, 2), (206, 2), (222, 2), (228, 2), (252, 2), (259, 2), (282, 2), (317, 1), (318, 1), (324, 2), (341, 2), (366, 2), (385, 2), (399, 1), (461, 2), (517, 2), (549, 1), (557, 1), (586, 1), (636, 1), (649, 1).
From the above generated data, we observed failure due to cause 1, failures due to cause 2 and only 21 observed failures () were observed before time . Thus, we have . Here, this sample will be utilized to perform numerical calculations on the results obtained through theoretical in earlier sections.
The iteration method and SEM algorithm, which are both covered in
Section 3 and
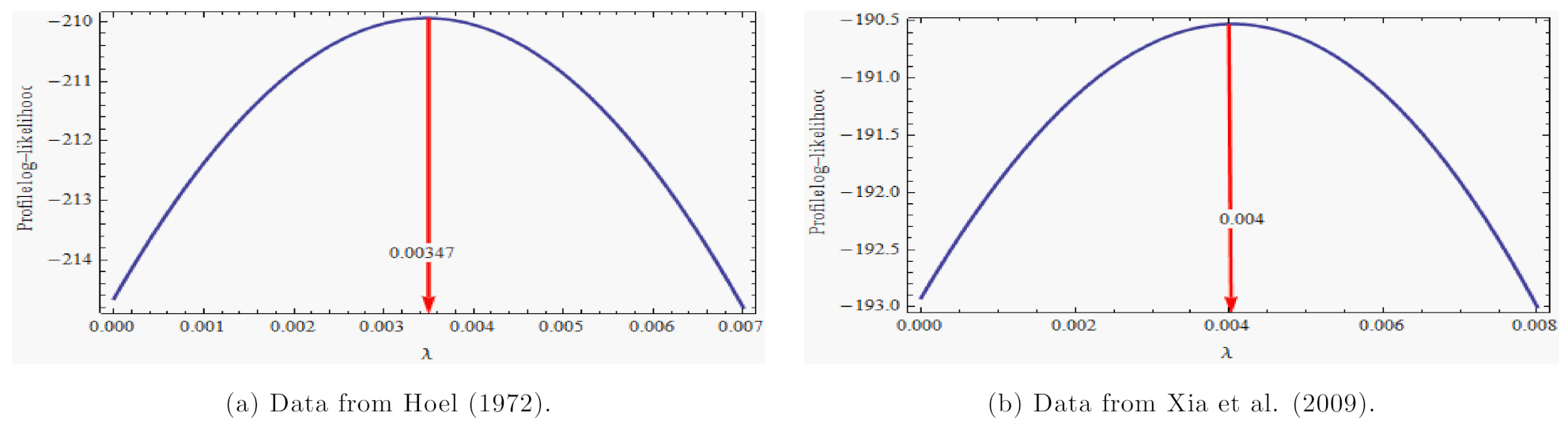
Section 4, are used to calculate the MLE of unknown parameters. Based on Hoel’data, we plot the profile log-likelihood function (13) before calculating the MLEs, see
Figure 2a. From this figure, it can be seen that the profile log-likelihood function is unimodal with the mode falling between 0.003 and 0.004. It indicates that the MLE of
is unique.
Additionally, a graphical technique developed by [
43] is used to calculate the MLE of the shape parameter
.
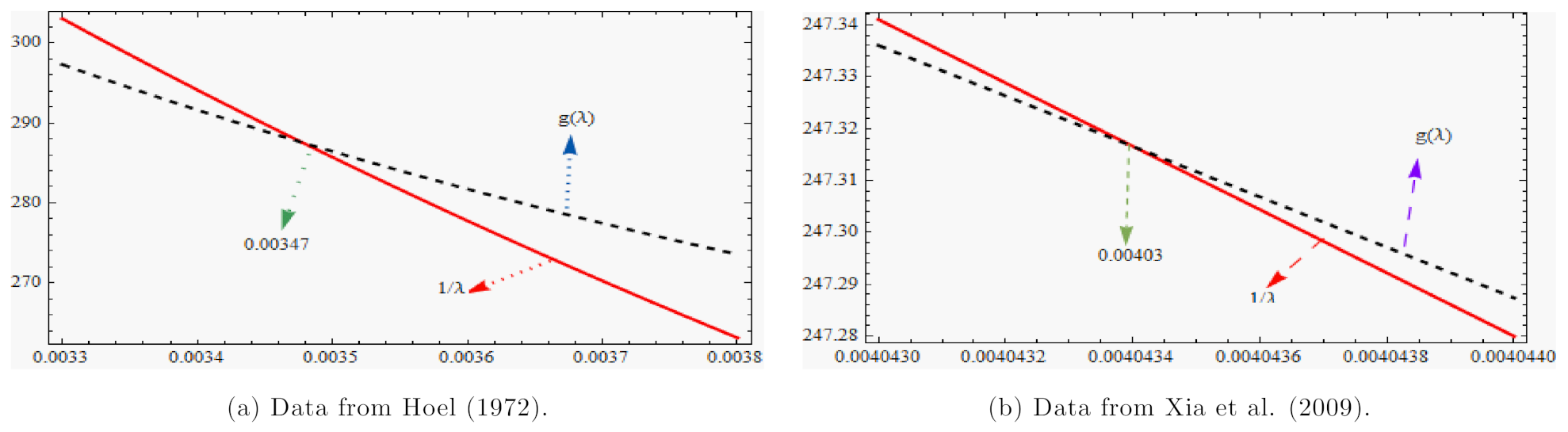
Figure 3a shows the curves of (
) and
based on Hoel [
56] data. According to
Figure 3a, the intersection of the two functions
and
is roughly at 0.00347. Therefore, to begin the iteration to determine the MLE of
, we suggest choosing
as the initial value, and stopping the process when
. The MLEs of
,
, and
are computed based on NR method using the estimated initial value of
, and the results are presented in
Table 2 along with the estimated standard errors. The reliability function
is computed at time
.
Next, we use the SEM method created in
Section 3.2 to compute the MLEs of
,
,
and
. For the SEM algorithm, the associated MLEs’ initial values of
,
and
are established using the NR approach and
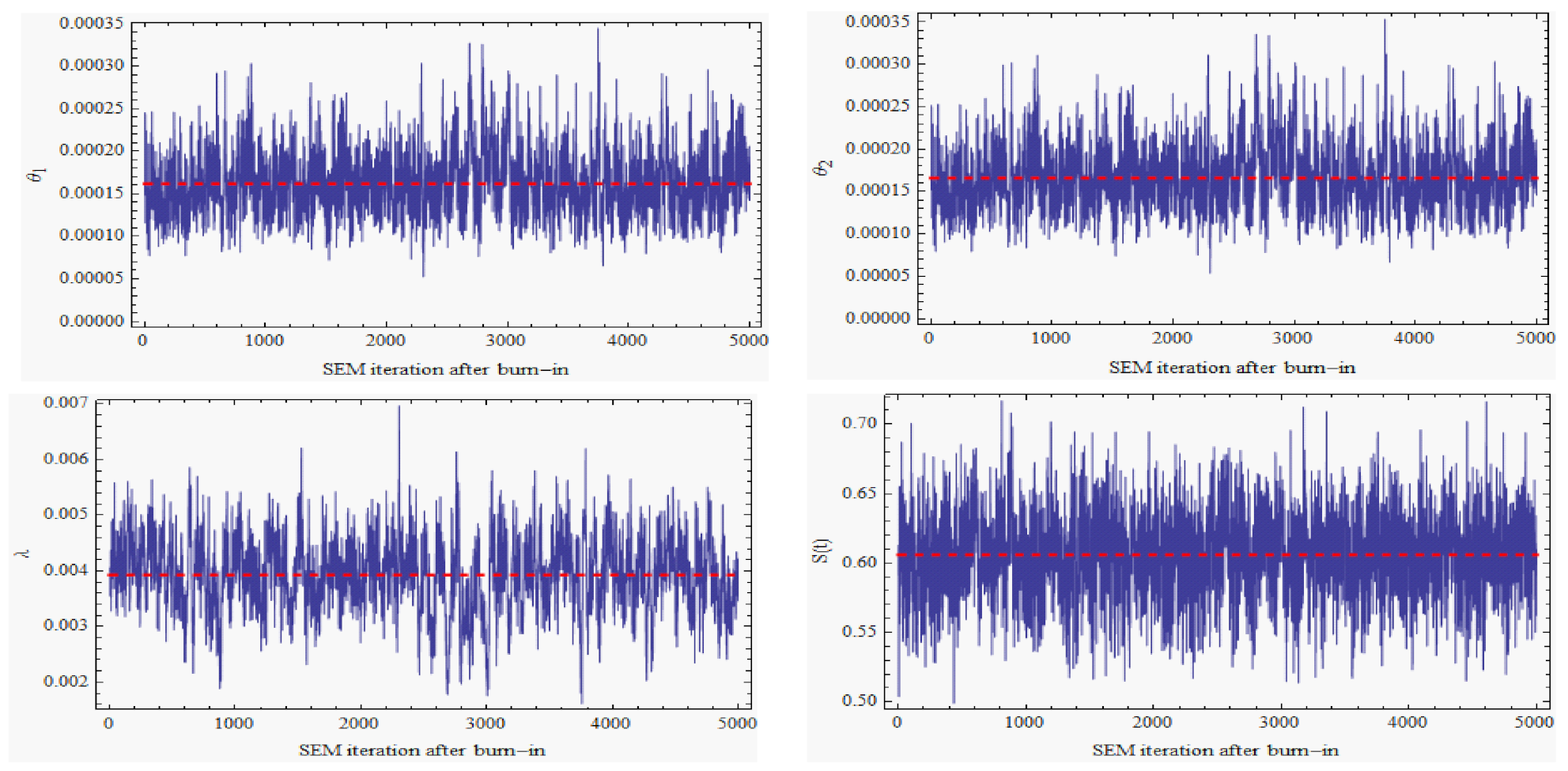
is assumed to be the number of SEM cycles. The first 100 cycles are employed as a burn-in period, and the following 5000 cycles are averaged to estimate the unknown parameters
,
,
, and
. The trace plots of these parameters against the SEM cycles are displayed in
Figure 4. In this figure, the red horizontal lines represent the SEM cycles, and the parameter values bounce around them without exhibiting an upward or downward trend. This signifies that a stationary distribution for the Markov Chain {
} has been reached. To approach the MLE, the average of the sequence {
} would be sufficient. The computed and reported standard errors (SEs) for the MLEs derived using the SEM technique are shown also in
Table 2. Using both the NR and the SEM techniques, the asymptotic 95% confidence intervals of
,
,
, and
are computed, and the results are presented in
Table 3. Furthermore, the results of the computation of the 95% confidence intervals using the Boot-p and Boot-t with
bootstrap replications were also reported in
Table 3.
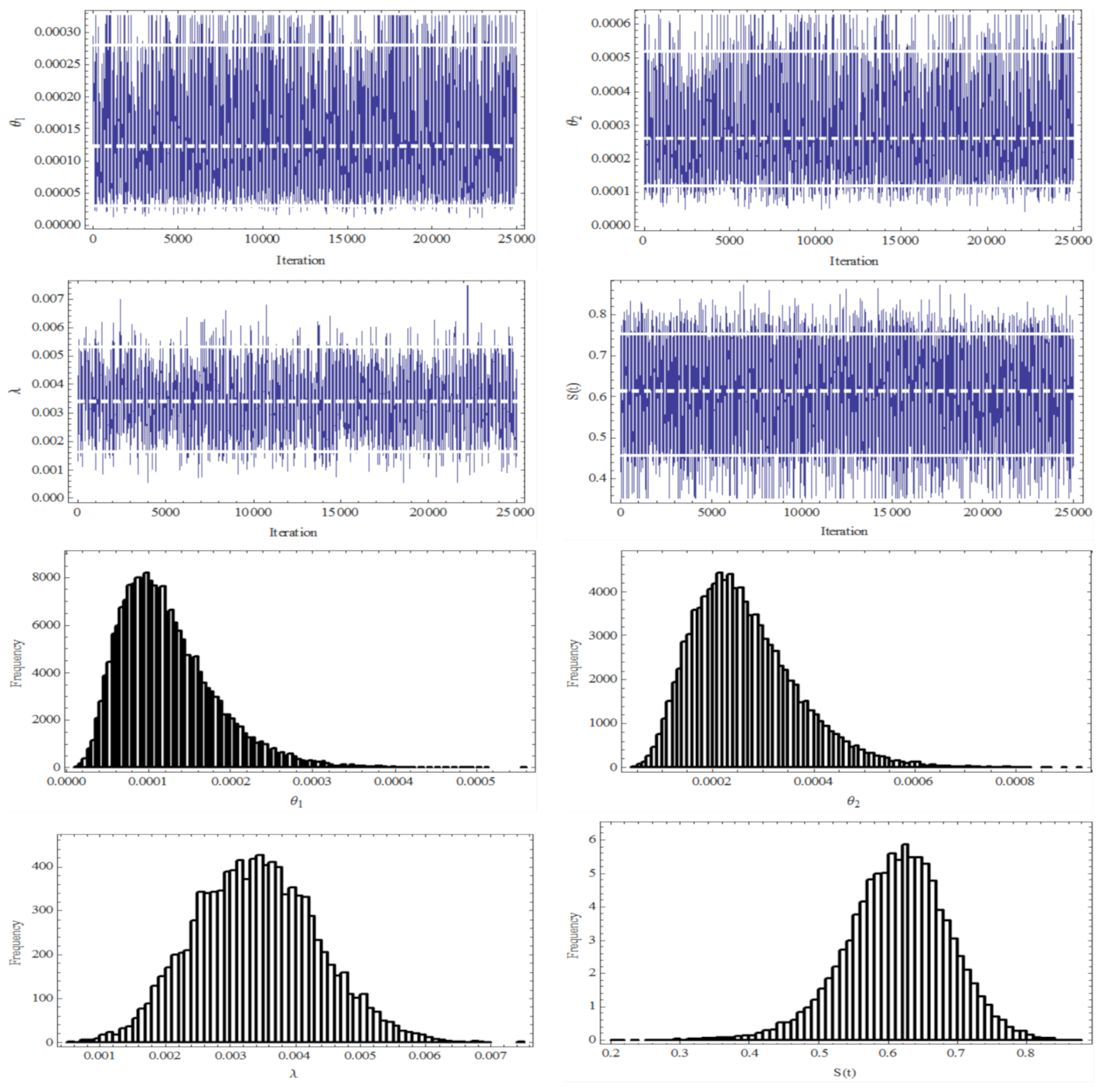
The Bayes estimates of , , , and versus the SE and LINEX loss functions will now be calculated using the MCMC samples. Since we don’t know anything about the unknown parameters beforehand, we consider their noninformative gamma priors to be . Nobody is not aware of the fact that for the LINEX loss function, implies that overestimation results in more penalty than underestimation and the converse is true for . Additionally, the LINEX loss function becomes symmetric for c near zero and behaves similar to the SE loss function.
When the LINEX loss function is taken into consideration, Bayes estimates are generated for two alternative values of
c, where
. As was mentioned earlier in
Section 5, the posterior analysis was conducted using a hybrid technique that included the Gibbs chain and Metropolis-Hastings. In order to run the MCMC sampler algorithm, the initial values for the three parameters
,
and
were assumed to be their MLEs. With
samples and the first
iterations serving as the burn-in period, we generate the Markov chain samples. The trace plots of the
MCMC outputs for the posterior distribution of
,
,
, and
are shown in
Figure 5 (first row) to verify the MCMC method’s convergence. Also,
Figure 5 displays histogram plots (second row) of the samples that we generated using the M-H algorithm for
,
,
, and
. It is clear that the MCMC method converges extremely effectively. In
Table 2 and
Table 3, point Bayes estimates for
,
,
, and
are produced together with the corresponding 95% credible ranges. The estimated standard errors of the Bayes estimates are also calculated and are shown in
Table 2.
6.2. Application to Breaking Strengths of Jute Fibres
Jute fibers contain a wide range of applications and become one of the most important fibers in the manufacture of bio-compounds. For instance, jute fibers are mainly used in the textile industry, where they are used to make clothes, ropes, bed covers, bags, shoelaces, etc. To a large extent, jute fibers also made their way into the automotive sector, where it is used to make cup holders, various parts of the instrument cluster, and door panels. According to a real-world data set published by Xia et al. [
57], two different gauge lengths are what lead to the breaking strengths failure data of jute fiber. We denote
if the breaking strengths of jute fiber of gauge length 10 mm and
if the the breaking strengths of jute fiber of gauge length 20 mm. The breaking strengths of jute fibres at 10 mm, and 20 mm gauge lengths are provided in
Table 4. These two independent data sets representing two groups of breaking strengths samples as competing risks data, say cause 1 and cause 2, respectively.
Before processing, it was determined whether or not these data sets could be analyzed using the Gompertz distributions. Let random variables
and
be breaking strengths of jute fiber of gauge length 10 mm and 20 mm, respectively. Based on the MLEs via NR method, we first obtain the K-S with the corresponding
p-values between the fitted distribution and the empirical CDF for two random variables
and
.
Table 5 summarizes the results. The results do not allow us to reject the null hypothesis but force us to accept that the data comes from the Gompertz distribution. This is done for both cause 1 and cause 2.
Figure 6 displays the fitted and empirical distribution functions. The two distributions for the two random variables
and
are a reasonably close match.
The previous data set was utilized in this illustration to simulate an adaptive progressive Type-II censored sample with , ideal total test time , and a progressive censoring scheme
For clarity, is given as a short form of . Thus, the observed adaptive progressive Type-II censored sample of size m from the original complete sample of size is
(36.75, 2), (43.93, 1), (45.58, 2), (48.01, 2), (50.16, 1), (71.46, 2), (83.55, 2), (99.72, 2), (108.94, 1), (113.85, 2), (116.99, 2), (119.86, 2), (151.48, 1), (163.4, 1), (177.25, 1), (183.16, 1), (187.13, 2), (200.16, 2), (212.13, 1), (284.64, 2), (323.83, 1), (350.7, 2), (353.24, 1), (375.81, 2), (383.43, 1).
Here,
and
, and
. Thus, we have
. To find an initial guess of
, we display the profile log-likelihood function of in
Figure 2 to determine an initial guess of, and it is obvious that the profile log-likelihood is a unimodal function with a mode close to
. Furthermore, the position at which the two functions
and
overlap in
Figure 3b is quite close to
. Then, according to
Figure 2 and
Figure 3, the initial value of
can be thought of as
. The MLEs of
,
,
, and
are obtained via both NR method and SEM algorithm with
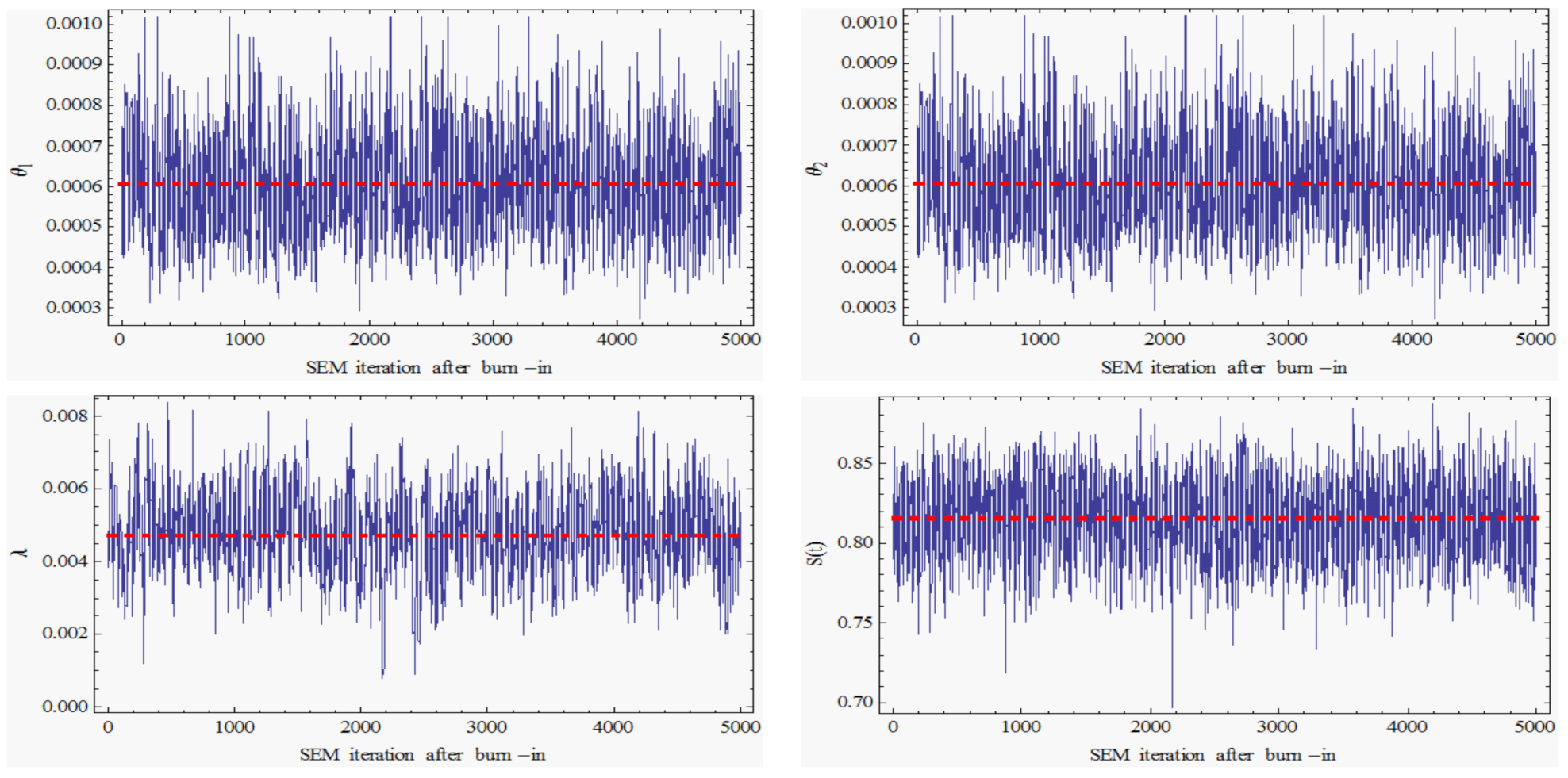
. For the SEM algorithm, we used 5100 iterations and the first 100 iterations were used as burn-in. The trace graphs of these parameters versus the SEM cycles are shown in
Figure 7. The average of the iterations after the burn-in should be used to estimate the parameters because
Figure 7 indicates that SEM iterations have converged to a density function.
Table 6 reports the MLEs with the NR and SEM algorithm of size 5000. Using noninformative gamma priors,
Table 6 also includes the Bayes estimates of
,
,
, and
with respect to the squared error (SE) loss function and the LINEX with
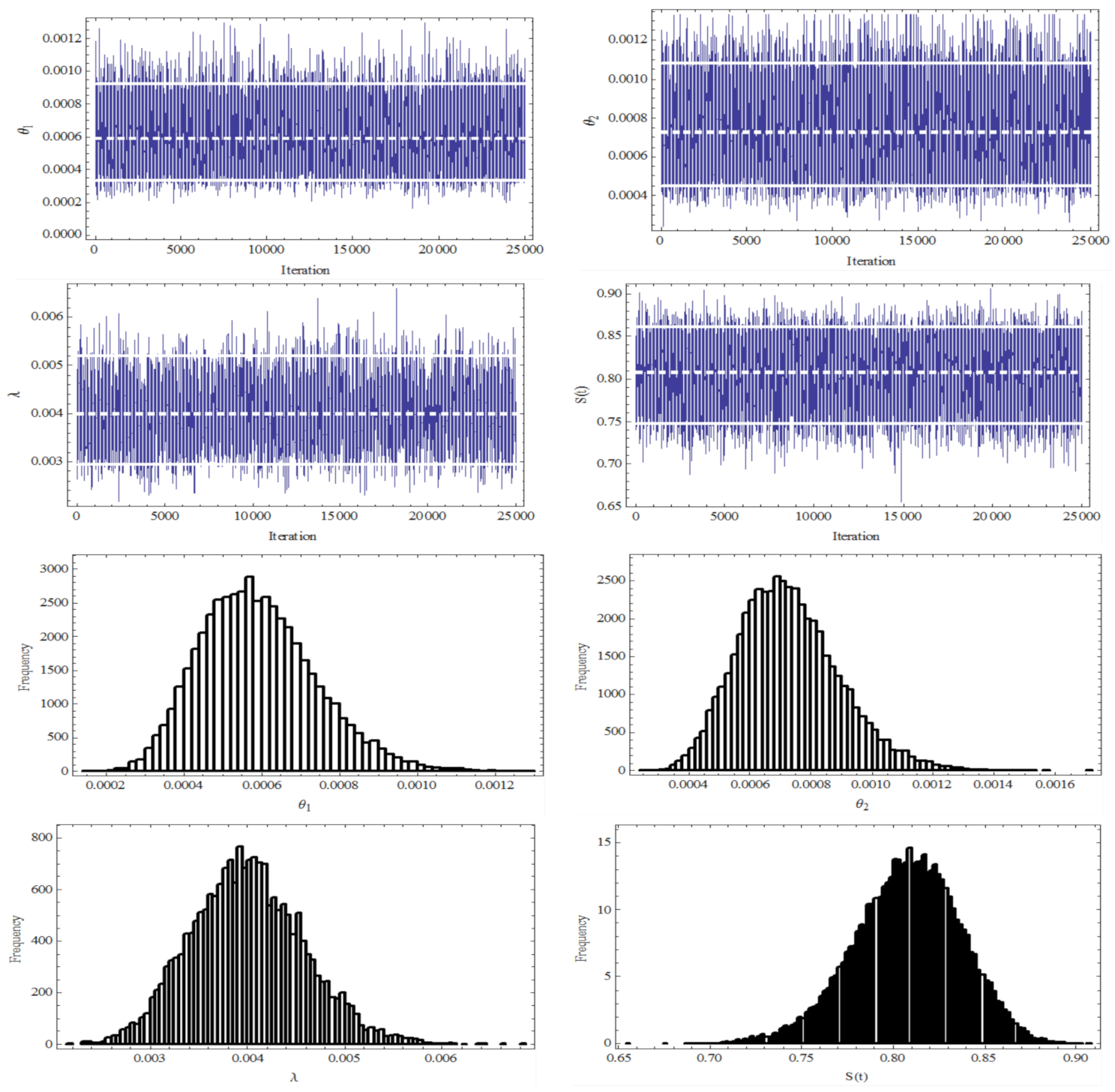
. The trace plots and the histograms of the MCMC outputs of
,
,
, and
based are represented in
Figure 8. It is evident that from
Figure 8, the MCMC procedure converges very well. Finally, the 95% asymptotic confidence intervals, bootstrap confidence intervals (Boot-p and Boot-t), and Bayes credible intervals for all parameters
,
,
, and
are tabulated in
Table 7.
It is clear that the MCMC technique is better than the ML method via NR or SEM algorithm in respect of estimated standard error. Further, it is observed from
Table 7 that the Boot-t intervals have shorter lengths than other intervals.
As can be seen in this previous examples, the outcomes of all estimates are similar. It should be noted that the MLEs produced by the SEM algorithm have the lowest standard errors. As a result, the performance of ML estimates acquired using the SEM algorithm is often superior to that of estimates obtained using the NR and MCMC methods with noninformative priors. We must provide numerical simulation to compare all methods accurately, clearly and objectively.
7. Simulation Study
In this section, we conduct a simulation analysis to evaluate the effectiveness of several estimation approaches for the unknwon parameters and reliability function covered in the preceding sections. We create adaptive Type-II progressive censored samples with competing risks from the Gompertz models by employing the algorithm described in
Section 2 for specific total sample sizes
, failure sample sizes
, and censoring schemes. The true values of
,
and
are assumed to be 0.05, 0.06, and 1.8, respectively. To create the appropriate samples, the progressive censoring schemes listed below are taken into account:
Scheme I: and ···,
Scheme II: ··· and ···
Scheme III: ··· and .
It should be noted that the first scheme is the left censoring scheme, where units are taken from the test at the time of the mth failure, the second scheme is the usual Type II progressive censoring scheme, and the third scheme is the Type II censoring scheme. Using the NR and SEM algorithm approaches, we compute MLEs of unknown parameters , , as well as reliability function based on generated data. We use the parameters’ true values as starting points for the SEM algorithm. Additionally, we perform the iterative procedure up to iterations with serving as the burn-in sample in order to apply the SEM algorithm. We utilize the NMaximize command of the Mathematica 11 package to solve the nonlinear equations and obtain the MLEs of the parameters. Under the SE and LINEX loss functions, the gamma prior distributions are used to obtain the Bayes estimates of unknown parameters. There are two distinct priors considered. First, we examine the non-informative priors for the three parameters , , and . In this case, we choose hyper-parameters such that . It is instructive to use a second prior in which the hyper-parameters are chosen so that the prior expectations equal the values of the corresponding true parameters, i.e., , , , and . This helps us to see how much does the informative prior effect contributes to the results obtained based on observed data. Additionally, when computing the Bayes estimates with regard to the LINEX loss function, we assume and , which, respectively, give more weight to underestimation and overestimation. These calculations are based on 10000 MCMC samples using Gibbs within the Metropolis method.
The accuracy of the point estimates (ML and Bayes) is compared against the bias and squared error values (MSE) in these settings. When evaluating the various interval estimations, we take into account the average interval lengths and the average interval coverage percentages (CPs). The scheme with the lowest mean squared error (MSE) of the estimator is considered to be the best one. In
Table 8,
Table 9,
Table 10,
Table 11, we show the bias and MSEs of the proposed estimates of the unknown parameters and reliability function. The results are presented by considering two different values of
(
,
). By using NR, the SEM algorithm, bootstrap (Boot-p and Boot-t), and MCMC intervals (with non-informative prior (NIP) and informative prior (IP)), the average length (AV) and coverage probability (CP) of 95% asymptotic confidence are provided in
Table 12,
Table 13,
Table 14 and
Table 15. The ALs and CPs are evaluated and summarized for various censoring combinations using 1000 sets of random samples and the Bootstrap confidence intervals are obtained in our simulations after
resampling.
The MSEs of MLEs decrease using NR and SEM approaches as well as Bayes estimates within the SEL and LINEX loss functions when T and n are fixed but m increases.
When T is fixed but n and m increases, the MSEs of all estimates generally decrease.
In most cases, when n and m are fixed but T increases, the MSEs increase.
In general, all the point estimates are completely effective because the corresponding average biases and MSEs are very small. Where, both the average bias and MSEs tend to zero when n and m increase.
We can see from the simulation results that the Bayes estimations perform better than the other estimates. When compared to all other estimates, the Bayes estimates based on the informative prior (IP) show fewer biases and MSEs. However, it is evident that the SEM method performs better than the NR method and Bayes estimates with uninformative priors (NIP).
The best MSEs for estimations of , ,and are those based on Bayes estimates under LINEX (). While is a better option for the under the LINEX loss function.
It is clear from the ALs and CPs for all confidence intervals (see
Table 12,
Table 13,
Table 14 and
Table 15) that the Bayes credible intervals based on IP offer lower widths and higher coverage probability than other approaches. So, for interval estimates, we advise adopting the Bayesian approach. Furthermore, we see that adopting the ML via the NR technique yields the longest ALs. It is evident from a comparison of the two approximation methods that the ALs confidence intervals obtained using the SEM algorithm method are smaller than those obtained using the NR method. In terms of having smaller ALs but greater CPs, we can observe that the Bayes estimates based on informative priors perform better than those based on noninformative priors for the two Bayesian intervals. Furthermore, when utilizing bootstrap Type intervals, the Boot-p strategy provides more precise confidence interval estimations than the Boot-t method. Additionally, when employing all approaches, the ALs get shorter as sample sizes
n and
m rise and the 95% CPs get closer to 0.95.
Although the Bayes estimators outperform all other estimators, the simulation results show that all point and interval estimators methods are efficient. The Bayes technique may be chosen if one has enough prior knowledge.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}