

Testing Multivariate Normality Based on F-Representative Points

Abstract
:1. Introduction
2. The MVN Test Based on the -Representative Points
2.1. A Brief Review on Affine Invariance
2.2. The Jackknife Distance
- (1)
- the adjusted Jackknife distance has an exact F-distribution:
- (2)
- are asymptotically independent.
2.3. The Chi-Squared Test Based on the F-Representative Points
3. A Monte Carlo Study
3.1. A Comparison between Empirical Type I Error Rates
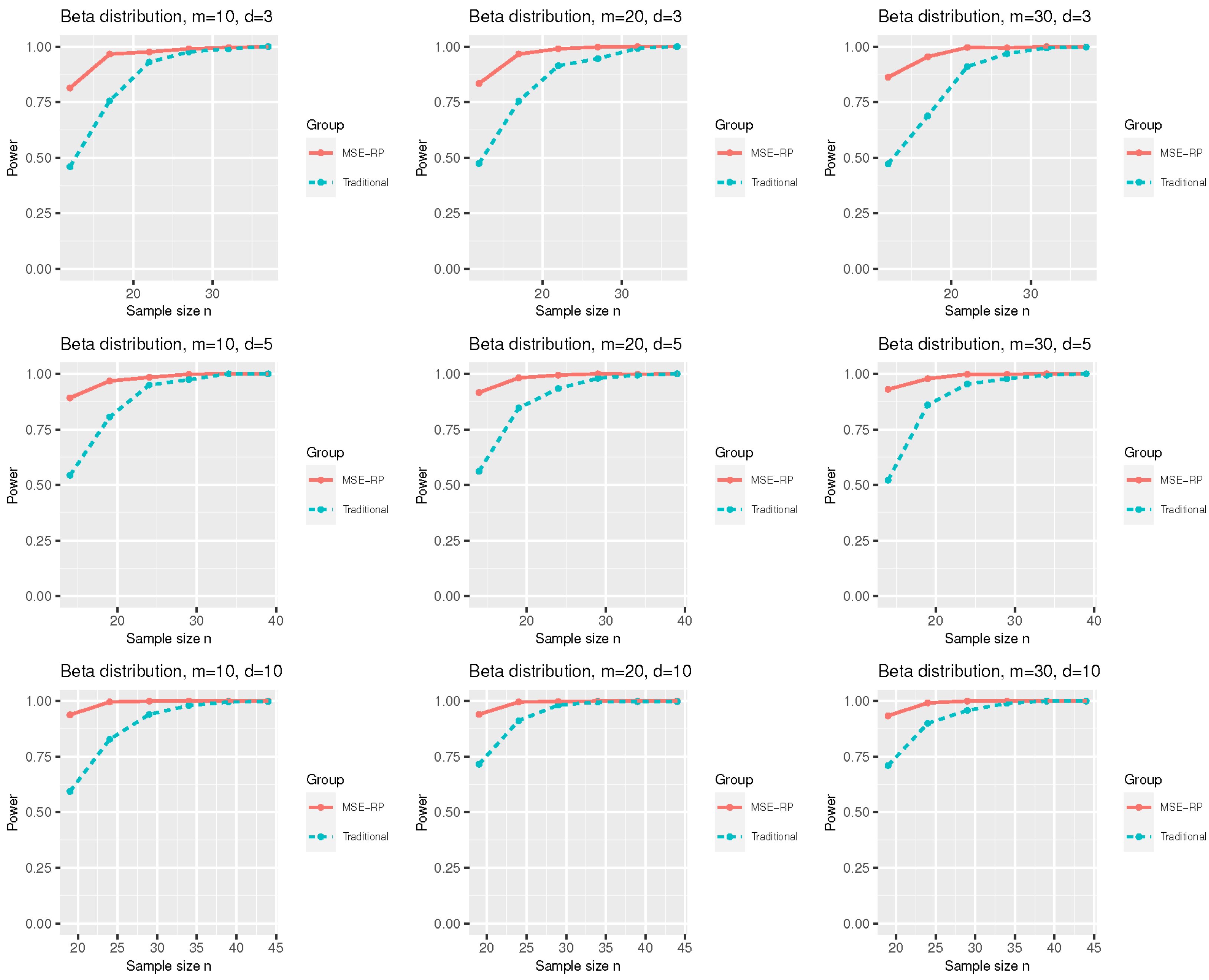
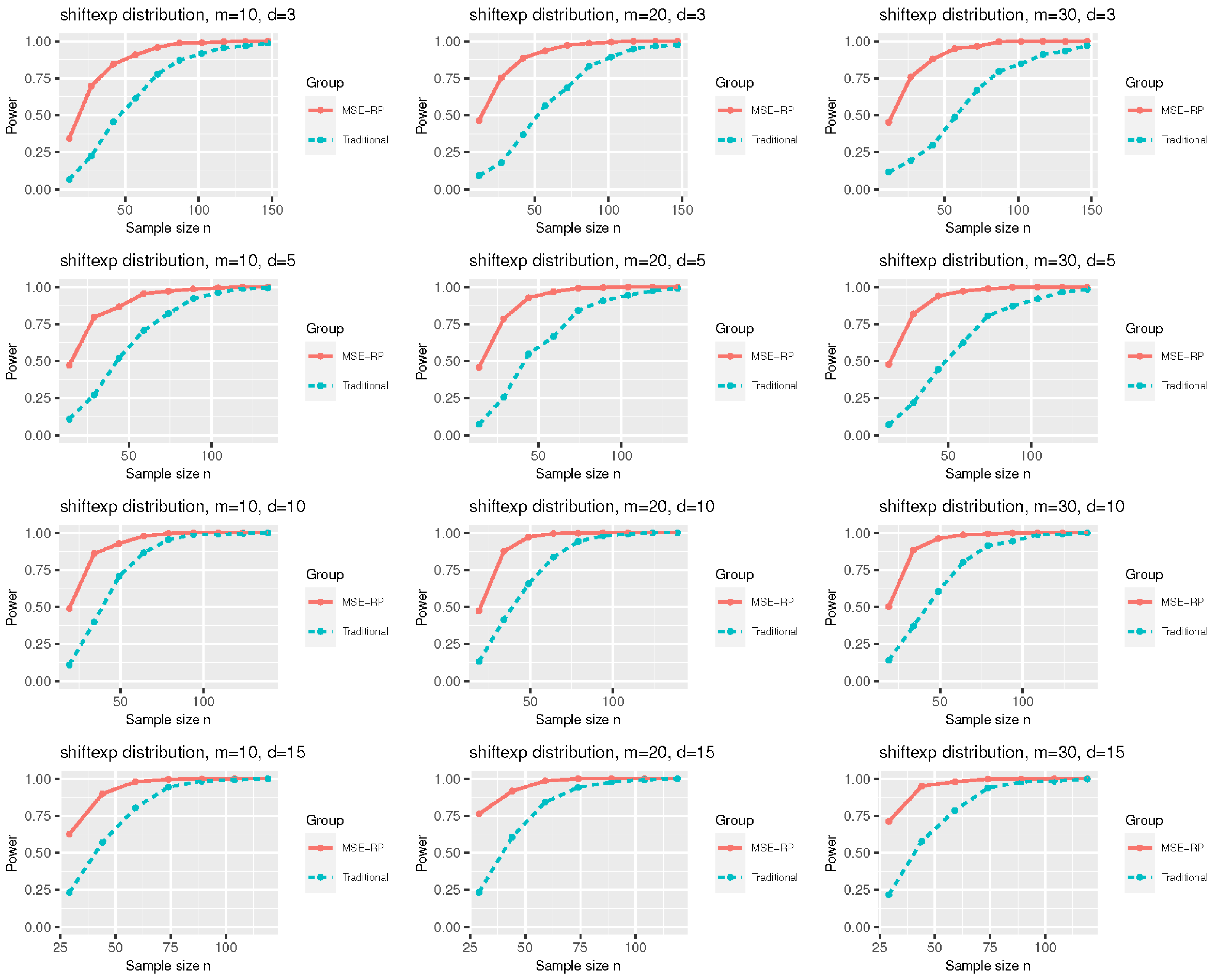
3.2. A Power Comparison
- (1)
- The multivariate t-distribution has a density function of the formwhere “” stands for the Euclidean norm of a vector, and let the degree of freedom ;
- (2)
- The -generalized normal distribution with has a density function of the form by (Goodman and Kotz [55]):where is a parameter. Let in the simulation and denote it by g-normal;
- (3)
- The shifted i.i.d. with i.i.d. marginals, each marginal has the same distribution as that of the random variable , where , the univariate chi-squared distribution with 1 degree of freedom and ;
- (4)
- The distribution consists of i.i.d. normal marginals and i.i.d. marginals, where stands for the integer part of ;
- (5)
- The shifted i.i.d. with i.i.d. marginals, each marginal has the same distribution as that of the random variable , where , the univariate exponential distribution.
4. Illustrative Examples
5. Concluding Remarks
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| i.i.d. | Independent identically distributed |
| Mahalanobis distances | M-distance |
| MVN | Multivariate normality |
| MSE | Mean square error |
| RPs | Representative points |
| UVN | Univariate normality tests |
Appendix A. An Algorithm for MSE-RPs of the F-Distribution
Appendix B. R Code for Computing F-Representative Points


Appendix C. Additional Power Comparisons



References
- Mardia, K.V. Measures of multivariate skewnees and kurtosis with applications. Biometrika 1970, 57, 519–530. [Google Scholar] [CrossRef]
- Mardia, K.V. Applications of some measures of multivariate skewness and kurtosis for testing normality and robustness studies. Sankhy A 1974, 36, 115–128. [Google Scholar]
- Mardia, K.V. Tests of univariate and multivariate normality. Handb. Stat. 1980, 1, 297–320. [Google Scholar]
- Koziol, J.A. A class of invariant procedures for assessing multivariate normality. Biometrika 1982, 69, 423–427. [Google Scholar] [CrossRef]
- Koziol, J.A. Assessing multivariate normality: A compendium. Commun. Stat. Theory Methods 1986, 15, 2763–2783. [Google Scholar] [CrossRef]
- Mudholkar, G.S.; McDermott, M.; Srivastava, D.K. A test of p-variate normality. Biometrika 1992, 79, 850–854. [Google Scholar] [CrossRef]
- Liang, J.; Bentler, P.M. A t-distribution plot to detect non-multinormality. Comput. Stat. Data Anal. 1995, 30, 31–44. [Google Scholar] [CrossRef]
- Liang, J.; Li, R.; Fang, H.; Fang, K.T. Testing multinormality based on low-dimensional projection. J. Stat. Plan. Inference 2000, 86, 129–141. [Google Scholar] [CrossRef]
- Henze, N. Invariant tests for multivariate normality: A critical review. Stat. Papers 2002, 43, 467–507. [Google Scholar] [CrossRef]
- Mecklin, C.J.; Mundfrom, D.J. An appraisal and bibliography of tests for multivariate normality. Int. Stat. Rev. 2004, 72, 123–138. [Google Scholar] [CrossRef]
- Thulin, M. Tests for multivariate normality based on canonical correlations. Stat. Meth. Appl. 2014, 23, 189–208. [Google Scholar] [CrossRef] [Green Version]
- Szekely, G.J.; Rizzo, M.L. Energy statistics: A class of statistics based on distances. J. Stat. Plan. Inference 2013, 143, 1249–1272. [Google Scholar] [CrossRef]
- Tenreiro, C. A new test for multivariate normality by combining extreme and nonextreme BHEP tests. Commun. Stat. Simul. Comput. 2017, 46, 1746–1759. [Google Scholar] [CrossRef]
- Kim, I.; Park, S. Likelihood ratio test for multivariate normality. Commun. Stat. Theory Meth. 2018, 47, 1923–1934. [Google Scholar] [CrossRef]
- Enomoto, R.; Hanusz, Z.; Hara, A.; Seo, T. Multivariate normality test using normalizing transformation for Mardia’s multivariate kurtosis. Commun. Stat. Simul. Comput. 2020, 49, 684–698. [Google Scholar] [CrossRef]
- Andrews, D.F.; Gnanadesikan, R.; Warner, J.L. Methods for assessing multivariate normality. Proc. Int. Symp. Multivar. Anal. 1973, 3, 95–116. [Google Scholar]
- Gnanadesikan, R. Methods for Statistical Data Analysis of Multivariate Observations; Wiley: New York, NY, USA, 1977. [Google Scholar]
- Looney, S.W. How to use tests for univariate normality to assess multivariate normality. Am. Stat. 1995, 39, 75–79. [Google Scholar]
- Royston, J.P. Some techniques for assessing multivariate normality based on the Shapiro-Wilk W. Appl. Stat. 1983, 32, 121–133. [Google Scholar] [CrossRef]
- Royston, J.P. Approximating the Shapiro-Wilk W-Test for non-normality. Stat. Comput. 1992, 2, 117–119. [Google Scholar] [CrossRef]
- Royston, J.P. Remark AS R94: A remark on Algorithm AS 181: The W test for normality. Appl. Stat. 1995, 44, 547–551. [Google Scholar] [CrossRef]
- Horswell, R.L.; Looney, S.W. A comparison of tests for multivariate normality that are based on measures of multivariate skewness and kurtosis. Stat. Comput. Simul. 1992, 42, 21–38. [Google Scholar] [CrossRef]
- Romeu, J.L.; Ozturk, A. A comparative study of goodness-of-fit tests for multivariate normality. J. Multivar. Anal. 1993, 46, 309–334. [Google Scholar] [CrossRef] [Green Version]
- Young, D.M.; Seaman, S.L.; Seaman, J.W. A comparison of six test statistics for detecting multivariate nonnormality which utilize the multivariate squared-radii statistic. Texas J. Sci. 1995, 47, 21–38. [Google Scholar]
- Beirlant, J.; Mason, D.M.; Vynckier, C. Goodness-of-fit analysis for multivariate normality based on generalized quantiles. Comput. Stat. Data Anal. 1999, 30, 119–142. [Google Scholar] [CrossRef]
- Mecklin, C.J. A Comparison of the Power of Classical and Newer Tests of Multivariate Normality. Ph.D. Thesis, University of Northern Colorado, Greeley, CO, USA, 2000. [Google Scholar]
- Mecklin, C.J.; Mundfrom, D.J. A Monte Carlo comparison of the Type I and Type II error rates of tests of multivariate normality. J. Stat. Comput. Simul. 2005, 75, 93–107. [Google Scholar] [CrossRef]
- Ward, P.J. Goodness-of-Fit Tests for Multivariate Normality. Ph.D. Thesis, University of Alabama, Tuscaloosa, AL, USA, 1988. [Google Scholar]
- Ahn, S.K. F-Probability plot and its applications to multivariate normality. Commun. Stat. Theory Methods 1992, 21, 997–1023. [Google Scholar] [CrossRef]
- Fang, K.T.; He, S.D. The Problem of Selecting a Given Number of Representative Points in a Normal Population and a Generalized Mill’s Ratio; Technical Report; U.S. Army Research Office Contract DAAG 29-82-K-0156; Department of Stanford University: Stanford, CA, USA, 1982. [Google Scholar]
- Flury, B. Estimation of principal points. Appl. Stat. 1993, 42, 139–151. [Google Scholar] [CrossRef]
- Cox, D.R. Note on grouping. J. Am. Stat. Assoc. 1957, 52, 543–547. [Google Scholar] [CrossRef]
- Max, J. Quantizing for minimum distortion. IEEE Trans. Inf. Theory 1960, 6, 7–12. [Google Scholar] [CrossRef]
- Fang, K.T. Application of the theory of the conditional distribution for the standardization of clothes. Acta Math. Appl. Sin. 1976, 2, 62–74. (In Chinese) [Google Scholar]
- Flury, B. Principal points. Biometrika 1990, 77, 33–41. [Google Scholar] [CrossRef]
- Tarpey, T. Self-consistency algorithms. J. Comput. Graph. Stat. 1999, 8, 889–905. [Google Scholar]
- Fang, K.; Zhou, M.; Wang, W. Applications of the representative points in statistical simulations. Sci. China Math. 2014, 57, 2609–2620. (In Chinese) [Google Scholar] [CrossRef]
- Fang, K.; He, P.; Yang, J. Set of representative points of statistical distributions and their applications. Sci. Sin. Math. 2020, 50, 1–20. (In Chinese) [Google Scholar]
- Feller, W. An Introduction to Probability Theory and Its Applications; Wiley: New York, NY, USA, 1970; Volume 2. [Google Scholar]
- Van der Vaart, A.W. Asymptotic Statistics; Cambridge University Press: New York, NY, USA, 1988. [Google Scholar]
- Al-Labadi, L.; Fazeli Asl, F.; Saberi, Z. A Necessary Bayesian Nonparametric Test for Assessing Multivariate Normality. Math. Methods Stat. 2021, 30, 64–81. [Google Scholar] [CrossRef]
- Sturges, H. The choice of a class-interval. J. Am. Stat. Assoc. 1926, 21, 65–66. [Google Scholar] [CrossRef]
- Mann, H.; Wald, A. On the Choice of the Number of Class Intervals in the Application of the Chi Square Test. Ann. Math. Stat. 1942, 13, 306–317. [Google Scholar] [CrossRef]
- Williams, C.A. On the choice of the number and width of classes for the Chi-square test of goodness of fit. J. Am. Stat. Assoc. 1950, 45, 77–86. [Google Scholar]
- Dahiya, R.C.; Gurland, J. How Many Classes in the Pearson Chi-Square Test? J. Am. Stat. Assoc. 1973, 68, 707–712. [Google Scholar]
- Mineo, A. A new grouping method for the right evaluation of the Chi-square test of goodness-of-fit. Scand. J. Stat. 1979, 6, 145–153. [Google Scholar]
- Harrison, R.H. Choosing the Optimum Number of Classes in the Chi-Square Test for Arbitrary Power Levels. Indian J. Stat. 1985, 47, 319–324. [Google Scholar] [CrossRef]
- Kallenberg, W. On moderate and large deviations in multinomial distributions. Ann. Stat. 1985, 13, 1554–1580. [Google Scholar] [CrossRef]
- Kallenberg, W.; Oosterhoff, J.; Schriever, B. The number of classes in Chi-squared goodness-of-fit tests. J. Am. Stat. Assoc. 1985, 80, 959–968. [Google Scholar] [CrossRef]
- Oosterhoff, J. The choice of cells in Chi-square tests. Stat. Neerl. 1985, 39, 115–128. [Google Scholar] [CrossRef]
- Quine, M.; Robinson, J. Efficiencies of Chi-square and likelihood ratio goodness-of-fit tests. Ann. Stat. 1985, 13, 727–742. [Google Scholar] [CrossRef]
- D’Agostini, R.B.; Stephens, M.A. Goodness-of-Fit Techniques, Statistics: Textbooks and Monographs; Marcel Dekker: New York, NY, USA, 1986. [Google Scholar]
- Koehler, K.; Gann, F. Chi-squared goodness-of-fit tests: Cell selection and power. Commun. Stat. Simul. Comput. 1990, 19, 1265–1278. [Google Scholar] [CrossRef]
- Bogdan, M. Data Driven Version of Pearson’s Chi-Square Test for Uniformity. J. Stat. Comput. Simul. 1995, 52, 217–237. [Google Scholar] [CrossRef]
- Goodman, T.R.; Kotz, S. Multivariate θ-generalized normal distributions. J. Multivar. Anal. 1973, 3, 204–219. [Google Scholar] [CrossRef] [Green Version]
- Henze, N.; Wagner, T. A New Approach to the BHEP tests for multivariate normality. J. Multivar. Anal. 1997, 62, 1–23. [Google Scholar] [CrossRef] [Green Version]
- Szekely, G.J.; Rizzo, M.L. The Energy of Data. Annu. Rev. Stat. Appl. 2017, 4, 447–479. [Google Scholar] [CrossRef] [Green Version]
- Elston, R.C.; Grizzle, J.E. Estimation of time-response curves and their confidence bands. Biometrics 1962, 18, 148–159. [Google Scholar] [CrossRef]
- Timm, N.H. Applied Multivariate Analysis; Springer: New York, NY, USA, 2002. [Google Scholar]
- Zhou, M.; Shao, Y. A powerful test for multivariate normality. J. Appl. Stat. 2015, 41, 351–363. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fisher, R.A. The use of multiple measurements in taxonomic problems. Ann. Eugen. 1936, 7, 179–188. [Google Scholar] [CrossRef]
- Srivastava, D.K.; Mudholkar, G.S. Goodness-of-fit tests for univariate and multivariate normal models. In Handbook of Statistics 22: Statistics in Industry; Elsevier: Amsterdam, The Netherlands, 2003. [Google Scholar]
- Shao, Y.; Zhou, M. A characterization of multivariate normality through univariate projections. J. Multivar. Anal. 2010, 101, 2637–2640. [Google Scholar] [CrossRef] [Green Version]
- Small, N. Marginal skewness and kurtosis in testing multivariate normality. Appl. Stat. 1980, 29, 85–87. [Google Scholar] [CrossRef]
- Rao, C.R. Tests of significance in multivariate analysis. Biometrika 1948, 33, 58–79. [Google Scholar] [CrossRef]
- Srivastava, M.S.; Hui, T.K. On assessing multivariate normality based on Shapiro-Wilk W statistic. Stat. Prob. Lett. 1987, 5, 15–18. [Google Scholar] [CrossRef]
- Shapiro, S.S.; Wilk, M.B. An analysis of variance test for normality (complete samples). Biometrika 1965, 52, 591–611. [Google Scholar] [CrossRef]
- Batsidis, A.; Martin, N.; Pardo, L.; Zografos, K. A Necessary Power Divergence Type Family Tests of Multivariate Normality. Commun. Stat. Simul. Comput. 2013, 42, 2253–2271. [Google Scholar] [CrossRef]
- Malkovich, J.F.; Afifi, A.A. On tests for multivariate normality. J. Am. Stat. Assoc. 1973, 68, 176–179. [Google Scholar] [CrossRef]
- McAssey, M.P. An empirical goodness-of-fit test for multivariate distributions. J. Appl. Stat. 2013, 40, 1120–1131. [Google Scholar] [CrossRef]
- Chakraborty, S.; Roychowdhury, M.K.; Sifuentes, J. High Precision Numerical Computation of Principal Points for Univariate Distributions. Sankhya B 2021, 83 (Suppl. 2), 558–584. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| n | m | Test | |||||
|---|---|---|---|---|---|---|---|
| 0.056 | 0.060 | 0.064 | 0.056 | 0.072 | |||
| 0.040 | 0.022 | 0.032 | 0.030 | 0.024 | |||
| 0.050 | 0.070 | 0.061 | 0.064 | 0.062 | |||
| 0.038 | 0.026 | 0.038 | 0.038 | 0.022 | |||
| 0.062 | 0.070 | 0.064 | 0.074 | 0.078 | |||
| 0.042 | 0.032 | 0.036 | 0.038 | 0.028 | |||
| 0.032 | 0.035 | 0.048 | 0.046 | 0.035 | |||
| 0.027 | 0.030 | 0.039 | 0.038 | 0.033 | |||
| 0.049 | 0.059 | 0.059 | 0.065 | 0.064 | |||
| 0.037 | 0.036 | 0.034 | 0.036 | 0.035 | |||
| 0.057 | 0.074 | 0.072 | 0.070 | 0.082 | |||
| 0.038 | 0.037 | 0.033 | 0.037 | 0.040 | |||
| 0.032 | 0.034 | 0.048 | 0.046 | 0.035 | |||
| 0.025 | 0.031 | 0.034 | 0.025 | 0.036 | |||
| 0.062 | 0.067 | 0.044 | 0.048 | 0.054 | |||
| 0.041 | 0.025 | 0.038 | 0.032 | 0.031 | |||
| 0.059 | 0.060 | 0.065 | 0.060 | 0.062 | |||
| 0.040 | 0.036 | 0.043 | 0.036 | 0.032 | |||
| 0.041 | 0.038 | 0.022 | 0.028 | 0.030 | |||
| 0.034 | 0.038 | 0.025 | 0.030 | 0.031 | |||
| 0.057 | 0.046 | 0.041 | 0.043 | 0.041 | |||
| 0.036 | 0.038 | 0.032 | 0.040 | 0.040 | |||
| 0.072 | 0.069 | 0.051 | 0.039 | 0.049 | |||
| 0.042 | 0.046 | 0.039 | 0.034 | 0.039 | |||
| 0.027 | 0.034 | 0.034 | 0.038 | 0.037 | |||
| 0.036 | 0.032 | 0.032 | 0.037 | 0.036 | |||
| 0.043 | 0.041 | 0.037 | 0.045 | 0.047 | |||
| 0.040 | 0.033 | 0.039 | 0.032 | 0.033 | |||
| 0.058 | 0.054 | 0.046 | 0.050 | 0.044 | |||
| 0.042 | 0.033 | 0.041 | 0.036 | 0.037 | |||
| 0.034 | 0.038 | 0.036 | 0.050 | 0.042 | |||
| 0.032 | 0.038 | 0.028 | 0.036 | 0.044 | |||
| 0.038 | 0.044 | 0.042 | 0.042 | 0.040 | |||
| 0.044 | 0.054 | 0.050 | 0.060 | 0.028 | |||
| 0.034 | 0.046 | 0.036 | 0.054 | 0.042 | |||
| 0.032 | 0.046 | 0.026 | 0.046 | 0.038 |
| Variables | -Test | |||
|---|---|---|---|---|
| 0.0016 | 0.0005 | |||
| 0.0669 | 0.1302 | 0.0839 | ||
| 0.0066 | 0.0199 | 0.0076 | ||
| 0.0179 | 0.0397 | 0.0979 | ||
| 0.0004 | <10 | <10 | ||
| 0.7110 | 0.3610 | 0.7566 |
| Variables | Skewness | Kurtosis | UVN Test 1 | Mardia’s MVN Test 2 |
|---|---|---|---|---|
| 0.3069 | −1.0682 | 0.3360 | Sk: 0.0093 | |
| 0.3111 | −0.8932 | 0.6020 | Ku: 0.1125 | |
| 0.0645 | −1.2076 | 0.5016 | ||
| 0.0648 | −1.4332 | 0.0905 | ||
| 0.3118 | −0.5736 | 0.0102 | Sk: | |
| 0.3158 | 0.1810 | 0.1012 | Ku: 0.8180 | |
| −0.2721 | −1.3955 | <0.0001 | ||
| −0.1019 | −1.3361 | <0.0001 | ||
| 0.8088 | −0.3535 | 0.0179 | Sk: | |
| 0.8322 | −0.2680 | 0.0135 | Ku: 0.0076 | |
| −0.1289 | −0.3767 | 0.0361 | ||
| 0.4417 | −0.7800 | 0.1185 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, S.; Liang, J.; Zhou, M.; Ye, H. Testing Multivariate Normality Based on F-Representative Points. Mathematics 2022, 10, 4300. https://doi.org/10.3390/math10224300
Wang S, Liang J, Zhou M, Ye H. Testing Multivariate Normality Based on F-Representative Points. Mathematics. 2022; 10(22):4300. https://doi.org/10.3390/math10224300
Chicago/Turabian StyleWang, Sirao, Jiajuan Liang, Min Zhou, and Huajun Ye. 2022. "Testing Multivariate Normality Based on F-Representative Points" Mathematics 10, no. 22: 4300. https://doi.org/10.3390/math10224300