

Unsupervised Image Translation Using Multi-Scale Residual GAN


Abstract
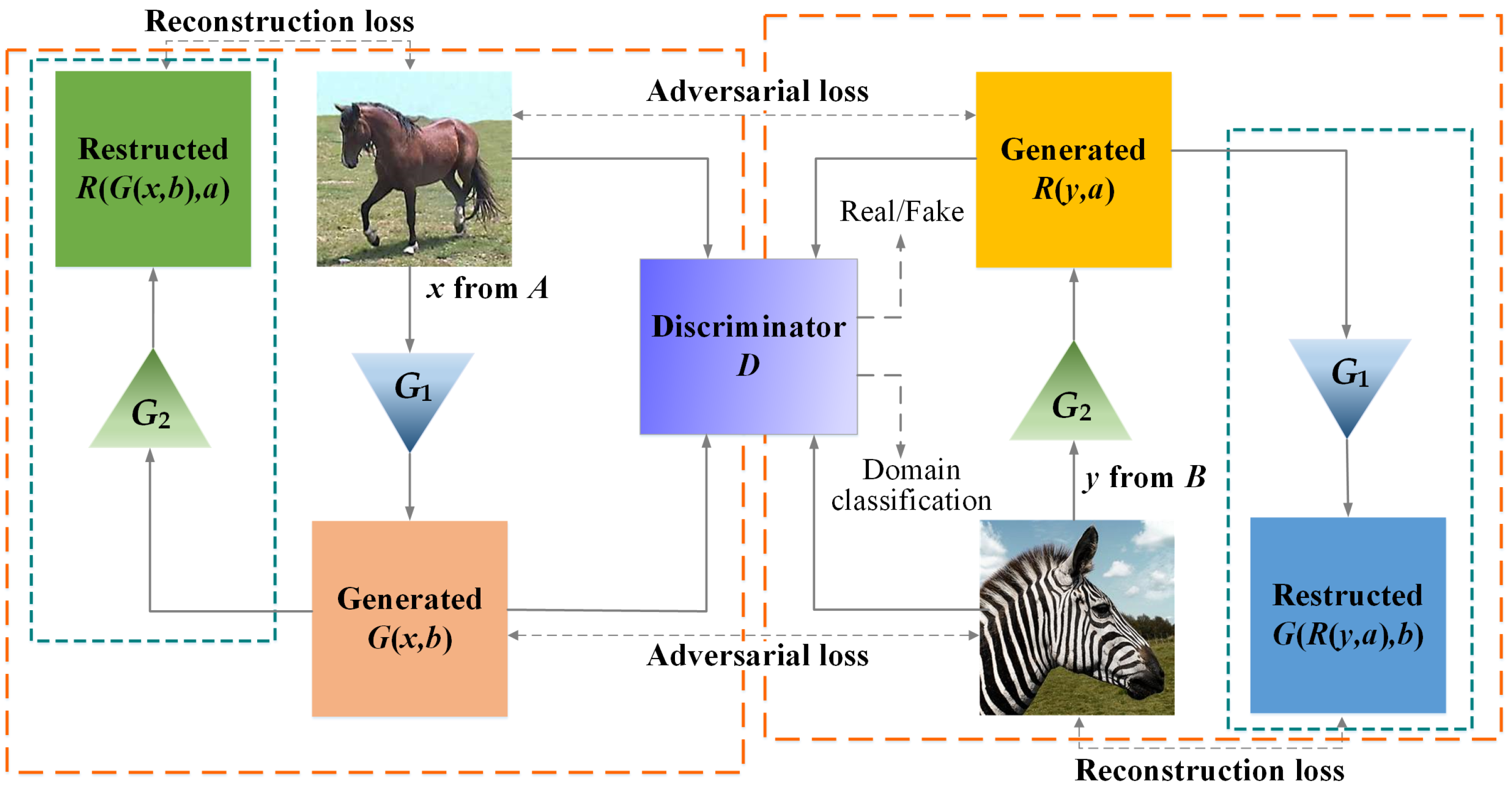
:1. Introduction
2. Related Work
2.1. Generative Adversarial Networks (GANs)
2.2. Image-to-Image Translation
3. Proposed Model
3.1. Generator
- First, a convolution processing is executed on each channel for adjusting the number of channel dimensions;
- Second, residual units are carried out to output the feature maps with the corresponding sizes;
- Third, through layer-by-layer up-samplings, the smaller feature maps are spliced with the larger ones;
- Fourth, after a series of up-sampling operations, the feature map with the same size as the original image is obtained;
- Last, the obtained feature map is spliced with the original image, and through the last convolutional layer, the final stylized image is obtained.
3.2. Discriminator
3.3. Loss Functions
3.3.1. Adversarial Loss
3.3.2. Reconstructed Loss
4. Experiments
4.1. Datasets and Setup
4.2. Model Settings
4.3. Training Method and Strategy
4.3.1. Group Normalization
4.3.2. Weight Initialization and Activation Functions
4.3.3. Optimization and Learning Rate
4.4. Results and Analysis
4.4.1. Comparative Results and Analysis
4.4.2. Time Performance Analysis
4.4.3. Analysis on Different Inputs and Training Strategies
4.4.4. User Studies
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Luan, F.J.; Paris, S.; Shechtman, E.; Bala, K. Deep photo style transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6997–7005. [Google Scholar]
- Dumoulin, V.; Shlens, J.; Kudlur, M. A Learned Representation For Artistic Style. In Proceedings of the 5th International Conference on Learning Representations (ICLR)—Conference Track Proceedings, Toulon, France, 24–26 April 2017. [Google Scholar]
- Johnson, J.; Alahi, A.; Li, F.F. Perceptual Losses for Real-Time Style Transfer and Super-Resolution. In Proceedings of the European Conference of Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.H.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar]
- Zhu, J.Y.; Zhang, R.; Pathak, D.; Darrell, T.; Efros, A.A.; Wang, O.; Shechtman, E. Toward multimodal image-to-image translation. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 466–477. [Google Scholar]
- Laffont, P.Y.; Ren, Z.; Tao, X.; Qian, C.; Hays, J. Transient attributes for high-level understanding and editing of outdoor scenes. ACM Trans. Graph. 2014, 33, 149–159. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Wang, X.; Gupta, A. Generative image modeling using style and structure adversarial networks. In Proceedings of the European Conference of Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 318–335. [Google Scholar]
- Tang, H.; Xu, D.; Wang, W.; Sebe, N. Dual Generator Generative Adversarial Networks for Multi-Domain Image-to-Image Translation. In Proceedings of the 14th Asian Conference on Computer Vision (ACCV), Perth, Australia, 2–6 December 2018; pp. 3–21. [Google Scholar]
- Turn Memories into Art Using Artificial Intelligence. Available online: http://prisma-ai.com (accessed on 13 April 2021).
- Ostagram. Available online: https://www.ostagram.me (accessed on 13 April 2021).
- Deep Forger: Paint Photos in the Style of Famous Artists. Available online: http://deepforger.com (accessed on 13 April 2021).
- Versa. Available online: https://www.versa-ai.com (accessed on 13 April 2021).
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Wang, T.C.; Liu, M.Y.; Zhu, J.Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8798–8807. [Google Scholar]
- Liu, Y.F.; Qin, Z.C.; Wang, H.; Luo, Z. Auto-painter: Cartoon Image Generation from Sketch by Using Conditional Wasserstein Generative Adversarial Networks. Neurocomputing 2018, 311, 78–87. [Google Scholar] [CrossRef]
- Yi, Z.; Zhang, H.; Tan, P.; Gong, M.L. DualGAN: Unsupervised Dual Learning for Image-to-Image Translation. In Proceedings of the International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2868–2876. [Google Scholar]
- Kim, T.; Cha, M.; Kim, H.; Lee, J.K.; Kim, J. Learning to Discover Cross-Domain Relations with Generative Adversarial Networks. In Proceedings of the 34th International Conference on Machine Learning (ICML), Sydney, Australia, 6–11 August 2017; Volume 4, pp. 2941–2949. [Google Scholar]
- Zhu, J.-Y.; Krahenbuhl, P.; Shechtman, E.; Efros, A.A. Generative visual manipulation on the natural image manifold. In Proceedings of the European Conference of Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; LNCS 9909; pp. 597–613. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein GAN. arXiv 2017, arXiv:1701.07875. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A. Improved Training of Wasserstein GANs. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 5768–5778. [Google Scholar]
- Cao, F.D.; Zhao, H.C.; Liu, P.F.; Li, P.X. Input limited Wasserstein GAN. In Proceedings of the SPIE, Second Target Recognition and Artificial Intelligence Summit Forum, Shenyang, China, 28–30 August 2019; Volume 11427. [Google Scholar]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image superresolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zhang, J.; Shu, Y.; Xu, S.; Cao, G.; Zhong, F.; Liu, M.; Qin, X. Sparsely grouped multi-task generative adversarial networks for facial attribute manipulation. In Proceedings of the ACM Multimedia Conference on Multimedia Conference (MM), Seoul, Korea, 22–26 October 2018; pp. 392–401. [Google Scholar]
- Mathesul, S.; Bhutkar, G.; Rambhad, A. AttnGAN: Realistic Text-to-Image Synthesis with Attentional Generative Adversarial Networks. In Proceedings of the IFIP Conference on Human-Computer Interaction, Bari, Italy, 30 August–3 September 2021. [Google Scholar]
- Denton, E.L.; Chintala, S.; Szlam, A.; Fergus, R. Deep generative image models using a laplacian pyramid of adversarial networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 7–12 December 2015; pp. 1486–1494. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. In Proceedings of the International Conference on Learning Representations (ICLR)—Conference Track Proceedings, San Juan, PR, USA, 2–4 May 2016. [Google Scholar]
- Mao, X.D.; Li, Q.; Xie, H.R.; Lau, R.Y.K.; Wang, Z.; Smolley, S.P. Least squares generative adversarial networks. In Proceedings of the International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2813–2821. [Google Scholar]
- Zhang, H.; Xu, T.; Li, H. StackGAN: Text to Photo-Realistic Image Synthesis with Stacked Generative Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5908–5916. [Google Scholar]
- Jiang, W.; Liu, S.; Gao, C.; Cao, J.; He, R.; Feng, J.S.; Yan, S.C. PSGAN: Pose and Expression Robust Spatial-Aware GAN for Customizable Makeup Transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Hertzmann, A.; Jacobs, C.E.; Oliver, N.; Curless, B.; Salesin, D.H. Image analogies. In Proceedings of the ACM SIGGRAPH Conference on Computer Graphics, Los Angeles, CA, USA, 12–17 August 2001; pp. 327–340. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.-W.; Kim, S.; Choo, J. StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8789–8797. [Google Scholar]
- Sangkloy, P.; Lu, J.W.; Fang, C.; Yu, F.; Hays, J. Scribbler: Controlling deep image synthesis with sketch and color. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6836–6845. [Google Scholar]
- Karacan, L.; Akata, Z.; Erdem, A.; Erdem, E. Learning to generate images of outdoor scenes from attributes and semantic layouts. arXiv 2016, arXiv:1612.00215. [Google Scholar]
- Odena, A.; Olah, C.; Shlens, J. Conditional Image Synthesis With Auxiliary Classifier GANs. In Proceedings of the 32nd International Conference on International Conference on Machine Learning (ICML), Sydney, Australia, 6–11 August 2017; pp. 2642–2651. [Google Scholar]
- Yi, R.; Liu, Y.; Lai, Y.; Rosin, P.L. Unpaired Portrait Drawing Generation via Asymmetric Cycle Mapping. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 8214–8222. [Google Scholar]
- Liu, Y.; Nadai, M.D.; Cai, D.; Li, H.Y.; Alameda-Pineda, X.; Sebe, N.; Lepri, B. Describe What to Change: A Text-guided Unsupervised Image-to-Image Translation Approach. In Proceedings of the 28th ACM International Conference on Multimedia (MM), Seattle, WA, USA, 12–16 October 2020; pp. 1357–1365. [Google Scholar]
- Li, J.; Xiong, Z.; Liu, D.; Chen, X.J.; Zha, Z.J. Semantic Image Analogy with a Conditional Single-Image GAN. In Proceedings of the 28th ACM International Conference on Multimedia (MM), Seattle, WA, USA, 12–16 October 2020; pp. 637–645. [Google Scholar]
- Lee, C.-H.; Liu, Z.; Wu, L.; Luo, P. MaskGAN: Towards Diverse and Interactive Facial Image Manipulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 5548–5557. [Google Scholar]
- Li, C.; Wand, M. Precomputed real-time texture synthesis with markovian generative adversarial networks. In Proceedings of the European Conference of Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 702–716. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on International Conference on Machine Learning (ICML), Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Instance Normalization: The Missing Ingredient for Fast Stylization. arXiv 2016, arXiv:1607.08022. [Google Scholar]
- Wu, Y.; He, K. Group Normalization. Int. J. Comput. Vis. 2020, 128, 742–755. [Google Scholar] [CrossRef]
- Glorot, X.; Bengio, Y. Understanding the Difficulty of Training Deep Feedforward Neural Networks. J. Mach. Learn Res. 2010, 9, 249–256. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Iterations | MRGAN | GGAN | CycleGAN |
|---|---|---|---|
| 10 | 1.57 | 2.53 | 2.13 |
| 50 | 1.60 | 2.48 | 2.14 |
| 100 | 1.52 | 2.58 | 2.13 |
| 200 | 1.57 | 1.54 | 2.12 |
| Iterations | MRGAN | GGAN | CycleGAN |
|---|---|---|---|
| 10 | 0.238 | 0.355 | 0.290 |
| 50 | 0.242 | 0.353 | 0.290 |
| 100 | 0.239 | 0.354 | 0.291 |
| 200 | 0.239 | 0.354 | 0.293 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Li, W.; Wang, D.; Feng, S. Unsupervised Image Translation Using Multi-Scale Residual GAN. Mathematics 2022, 10, 4347. https://doi.org/10.3390/math10224347
Zhang Y, Li W, Wang D, Feng S. Unsupervised Image Translation Using Multi-Scale Residual GAN. Mathematics. 2022; 10(22):4347. https://doi.org/10.3390/math10224347
Chicago/Turabian StyleZhang, Yifei, Weipeng Li, Daling Wang, and Shi Feng. 2022. "Unsupervised Image Translation Using Multi-Scale Residual GAN" Mathematics 10, no. 22: 4347. https://doi.org/10.3390/math10224347
APA StyleZhang, Y., Li, W., Wang, D., & Feng, S. (2022). Unsupervised Image Translation Using Multi-Scale Residual GAN. Mathematics, 10(22), 4347. https://doi.org/10.3390/math10224347