1. Introduction
Citizen insecurity is a serious problem in all countries, especially in Latin America and the Caribbean, which have higher rates of criminal events, great insecurity, and a profound deterioration of trust in citizen surveillance institutions, such as the police and the army. An example of this situation is the prevalence of endemic levels of violence, where homicide rates have been growing steadily over time. The rate of homicides has remarkably increased from 25.9% in 2017 to 30% in 2020 in Central America and from 24.2% in 2017 to 29% in 2020 in South America [
1].
Criminal events increase due to unemployment, social and economic problems, among other reasons. Ecuador is one of the countries with a rising crime rate, even though the National Police carries out a continuous surveillance of sectors with high crime incidences to reduce this problem. The homicide rate in Ecuador was 5.78% in 2017 and 7.78% in 2020, which represents a relevant increase [
2].
With the motivation of improving citizen security, this study proposes an algorithm for forecasting locations with a high probability of crime. This prediction is then used for the generation of patrol routes in a given area. A database with spatial–temporal information of the crimes that occurred in Quito City, Ecuador, from January to December 2017 is used.
The patrol route planning is a complex problem as it involves location, hotspots, manpower, and scheduling of vehicles and human resources. To deal with it, the application of several computational methods to develop efficient algorithms is required. The combination of various artificial intelligence (AI) and machine learning (ML) techniques has proven effective in decision-making applications in diverse settings [
3,
4]. That is the strategy proposed in this research, that has provided succesful results in this specific application.
The hybrid system here designed combines some intelligent data processing techniques for decision making. First, geographic data from the most conflictive areas regarding crimes are grouped using the k-means clustering algorithm. Statistical methods are then used to identify critical points in each region defined by a cluster, and linear regression functions are used for the prediction of future crime points. Subsequently, an analysis of the probability of the occurrence of crimes is carried out according to geographical location and temporal information available. With this information, fuzzy logic is applied so to consider several criteria in the drawing of the patrol route. The algorithm has been tested on various real-world scenarios, with useful and satisfactory results. This strategy provides relevant information for the management of police resources, which allows better use of these means and the reduction of urban crimes.
The novelty of the proposal consists of showing how some well-known intelligent techniques are configured and combined to develop an efficient tool for patrol route generation. It has been proved in several fields that hybrid systems are necessary to address the complexity of real problems. In this work, the sequence of activities is key to design the route generation algorithm, together with the consideration of spacial-temporal information. The main contributions of this article can be then summarized as follows: (1) Geographic segmentation of crimes to obtain points with high crime rates (hotspots) in an automatic way. (2) Forecasting of future spatial crime locations based on historic information. (3) Design of optimal patrol routes based on crime probability considering spatio-temporal data. Fuzzy logic uses distance and travel time between surveillance way-points to minimize resources cost and response time emergencies.
The structure of the paper is as follows. In
Section 2 some relevant related works on crime data analysis are discussed. The materials and methods used are described in
Section 3.
Section 4 and
Section 5 detail the flow and operation of the algorithm, as well as the application of ML and statistical techniques. In
Section 6, simulation results and analysis of the data obtained are presented. The paper ends with the conclusions and future lines of research.
2. Related Works
The analysis and prediction of crimes have raised great interest because of their usefulness in improving citizen security. This topic has been approached from different points of view. Regression and AI techniques have been frequently applied although papers suing space–time information are not so common. To mention some examples, in the research developed by [
5], the crimes forecasting is done by applying a deep neural network architecture, identifying evolutionary patterns of crimes and the relationship between space–time information. Crime points (geospatial) are then transformed into crime heat maps for the same sector of a city and time. Subsequently, convolutional hierarchical structures are applied to train a crime prediction model with heat maps. Esquivel [
6] applied convolutional neural networks and a short- and a long-term memory network for crime prediction in the city of Baltimore, USA. It uses spatial and temporal correlations of historical crime data for future predictions. An inspirational paper was the one by Farjami [
7], who proposed a genetic-fuzzy algorithm for spatial-temporal crime prediction. First, available information is processed, which consists of the geographical location (latitude, longitude) and the time of crimes. Then, a forecasting model is built to determine the time and place where future crimes will occur. Finally, the model is evaluated with simulated data from the city of Tehran, Iran. Hu [
8] applied Bayesian spatial–temporal modeling for urban crime and analyzed its trend in the city of Wuhan, China. It uses socio-economic and population variables such as people agglomeration places, unemployment, tourist and residential places, and so on. Vural [
9] used the Naïve Bayes theory to identify an offender with the highest probability of executing a criminal act based on the deliquent’s history. The information conveyed is the date, geographical location, type, and some crime data. The proposed model works with a georeferenced information system that visualizes various characteristics of crimes and identifies patterns on a defined territory. Win [
10] proposed a fuzzy grouping algorithm of criminal activities to detect patterns of criminal behavior. This algorithm predicts hotspots by using geospatial information in various cities in Iraq, Pakistan, Afghanistan, and India.
Regression is also commonly applied in this area. An interesting related paper is the one by Catlett [
11], who applied auto regressive models on spatial–temporal information to automatically identify high-risk crime regions in highly populated urban areas. A spatial grouping of the dataset is carried out to detect these regions of high crime density. Finally, an integrated moving average auto-regressive prediction model is generated to forecast the reliably forecast crime trends in each region. Kadar [
12] used space–time, socio-economic, meteorological, and temporal information from a real environment in the city of Aargau, Switzerland. For the predictive model, logistic regression with regularization, bagging (random forests), and boosting (AdaBoost) were applied. Cowen [
13] analyzed the relationship between rates of theft and assault crimes. They combined ordinary least square regression models and statistical analysis of geospatial data patterns in different time periods in Miami-Dade, Florida, between 2007 and 2015. Piza [
14] carried out a spatio-temporal analysis of residential thefts, automobiles, and other motor vehicles in Indianapolis City. Multimodal linear regression models were applied to predict crimes and their relationship with future events (search for the initial event in a chain of criminal events).
The Cokriging algorithm, a generalized form of multivariate linear regression model, has also been used in some recent works, such as that by [
15]. This article analyzes historical crime data in urban areas of Cincinnati City, Ohio. The information is structured in time series, with time information being the main variable and urban areas as a secondary variable. The results show an increase in the correlation between urban areas and reported crimes. This space–time Cokriging prediction model was also used by [
16], with historical crime movement data in Zigong, China. The temporary models are generated weekly, biweekly, and quarterly, with geospatial information of the offender, obtaining improved results in short periods. In [
17] authors combine a logistic regression and a neural network to predict three crime categories in a certain spatial region in the city of Amsterdam, Netherlands. Monthly predictions are made in two periods of the day: day and night. The results show that the monthly predictions give better results than the biweekly ones.
Regarding some of the techniques applied in our article, Hu [
18] used the kernel density algorithm with space–time data for the prediction of hotspots of residential robberies in Baton City, Louisiana, USA. A cross-validation threshold and statistical tests were used to identify false positives and negatives. Fuentes-Santos [
19] also applied kernel density for the analysis of spatial–temporal patterns of shots in Rio de Janeiro City, Brazil. They applied first- and second-order non-parametric inference tools to the reported events and compared them with crime prediction hotspot models, identifying chronic critical points. Ristea [
20] detailed the distribution and spatial correlation between the historical records of reported crimes and their geographical location, socio-economic and environmental variables, and messages published on social networks from Chicago City, Illinois, USA. The most suitable variables for the study are selected, and the kernel density method is applied for crime prediction with a linear regression.
Other ML algorithms have been used to obtain predictive models. Umair [
21] analyzed social networks for crime prediction. Specifically, language recognition has been used to predict hotspots. Random forest and k-nearest neighbor were applied in this paper with good results.
Hajela [
22] analyzed criminal events recorded in New York to generate a spatial– temporal predictive model. The prediction aimed to identify hotspots in delimited geographic sectors by applying k-means clustering. Another contribution in the prediction of hotspots is the research of Lee [
23], wherein the proposed model uses criminal information from the cities of Portland and Cincinnati. The algorithm applies population heterogeneity to identify hotspot locations. Subsequently, a dependency model is applied in historical periods divided by months to efficiently determine points of high crime rates. In [
24], it is proposed the use of statistical metrics and a geospatial grid of crime data for crime prediction in Portland City, USA.
On the other hand, route generation and path planning are strategies developed and applied in very different fields. Although it is possible to find many scientific papers that deals with this topic, mainly on any type of autonomous vehicles and mobile robots, it is not so common to find them regarding people routes. Concerning the first ones, in [
25], a survey of the existing approaches for trajectory planning for Autonomous Vehicles (AVs) can be found. In [
26], an offline route planning method and online navigation of AVs with reinforcement learning are analyzed. This proposal obtained encouraging results by building different routes based on some initial criteria. A survey on vehicle routing problems with time windows using meta-heuristic algorithms can be found in [
27]. According to the authors, the most common methods applied to autonomous vehicles are Artificial Bee Colony algorithm (ABC), Ant Colony Optimization (ACO), Particle Swarm Optimization (PSO), among others. The paper by [
28] presents a survey on some bio-inspired algorithms applied to robot route planning. The most widely used techniques are described, such as ant colony, evolutionary strategies and genetic algorithms, swarm algorithms, etc. Interestingly, the paper concludes that most of those bio-inspired algorithms do not give optimal results in real-time route planning problems, as it takes them a long time to generate an optimal route. Similarly, route generation algorithms are applied for machining processes and transport in [
29]. The proposal by [
30] details a method of planning tourist urban routes applying multi-objective genetic algorithms. This work improves the accuracy by combining internal and external tourist hot spots to optimize the route. The data used for this study have been obtained from a geographic information system (GIS) to generate a road network for the city of Chengdu, China.
But papers on patrol routes are very few as they deal with a complex process, as claimed by [
31]. Despite its importance, the literature has not thoroughly studied patrol routing although patrolling is essential to handle insufficient police resources and reduce crime time response. Some recent papers have focused on well-known standard routing but they do not consider the crime data distribution in the spatio-temporal frame [
32]. They only address car route patrolling following a defined pattern. Nevertheless, the exciting review paper by [
31] analyzes different methods to define an efficient police patrol route. This survey describes many studies about the dynamic vehicle routing problem of the police to alleviate the detected knowledge gap on articles referring to policing.
In this survey, some hybrid methods to generate patrol routes, such as Genetic Algorithm (GA) and linear programming, are detailed. These hybrid models are more efficient in the local search and in the police patrol route problem.
In [
33], a research on route optimization for community patrol is presented. This study develops a simulation multi-agent model with genetic algorithms, directed graph model, and GIS map. The GIS allows visualizing the environment of the patrol inspection geographic area but it does not allow representing the route information. Another related paper is [
32], which develops a mathematical model to improve the planning of route patrolling and speeds up the time response to possible accidents of police vehicles. This model also minimizes the cost of vehicle resources. A hybrid solution approach that integrates genetic algorithms and continuous approximation (CA) is applied. In this case, the hotspots and patrol routes are represented in a graph with information about maximum response time. In a previous conference paper, [
34] used the same crime database as in this paper to propose a clustering algorithm to identify the hotpots of high crime rate concentration and that way, to predict the future crime points.
Finally, the model proposed by [
35] describes a visual based classification of crime activities in a street-level environment with the goal of identifying high and low crime areas. The model uses semantic categories such as roads, buildings, and others elements extracted from images of a GIS system. They use deep learning to image segmentation. The study was applied to two cities in the USA with high accuracy results, between 95% and 98%.
As it is possible to see, the patrol routing is a complex problem that usually requires merging different techniques to cover all the steps of this important task.
Table 1 presents a summary of works (last five years) on crime prediction and patrolling routes generation. It shows the criminal event datasets, models and methodologies used. The nomenclature of the columns is as follows: C (city), S (spatial information), T (temporal information), LR (linear regression), Cl (clustering), NN (neural networks), FL (fuzzy logic), RF (random forest), St (statistical methods), KDE (kernel density estimation), RL (Reinforcement Learning), GA (genetic algorithms). The common objective of these works is to identify geospatial crime concentration points and thus, to develop strategies to improve security. We want to highlight that only few papers use spatial–temporal information. They commonly apply several AI and ML techniques for the analysis, grouping, and prediction of criminal events. In the summary shown in
Table 1, the mark “🗸” means the methodolgy applied; otherwise the symbol “-” is used to indicate that this specific technique was not used.
The main differences with the research here mentioned and our work can be summarized as follows. First, the objective of this article is to design optimal surveillance routes, not only the spatio-temporal prediction of crimes. Another significant contribution is that it determines the temporal order of the patrol way points, based on the temporal probability of the crimes, distance, and time with a real API. Finally, several AI and ML techniques are combined, specifically regression, kernel density, clustering, and fuzzy logic, to cover all the steps of the route generation process.
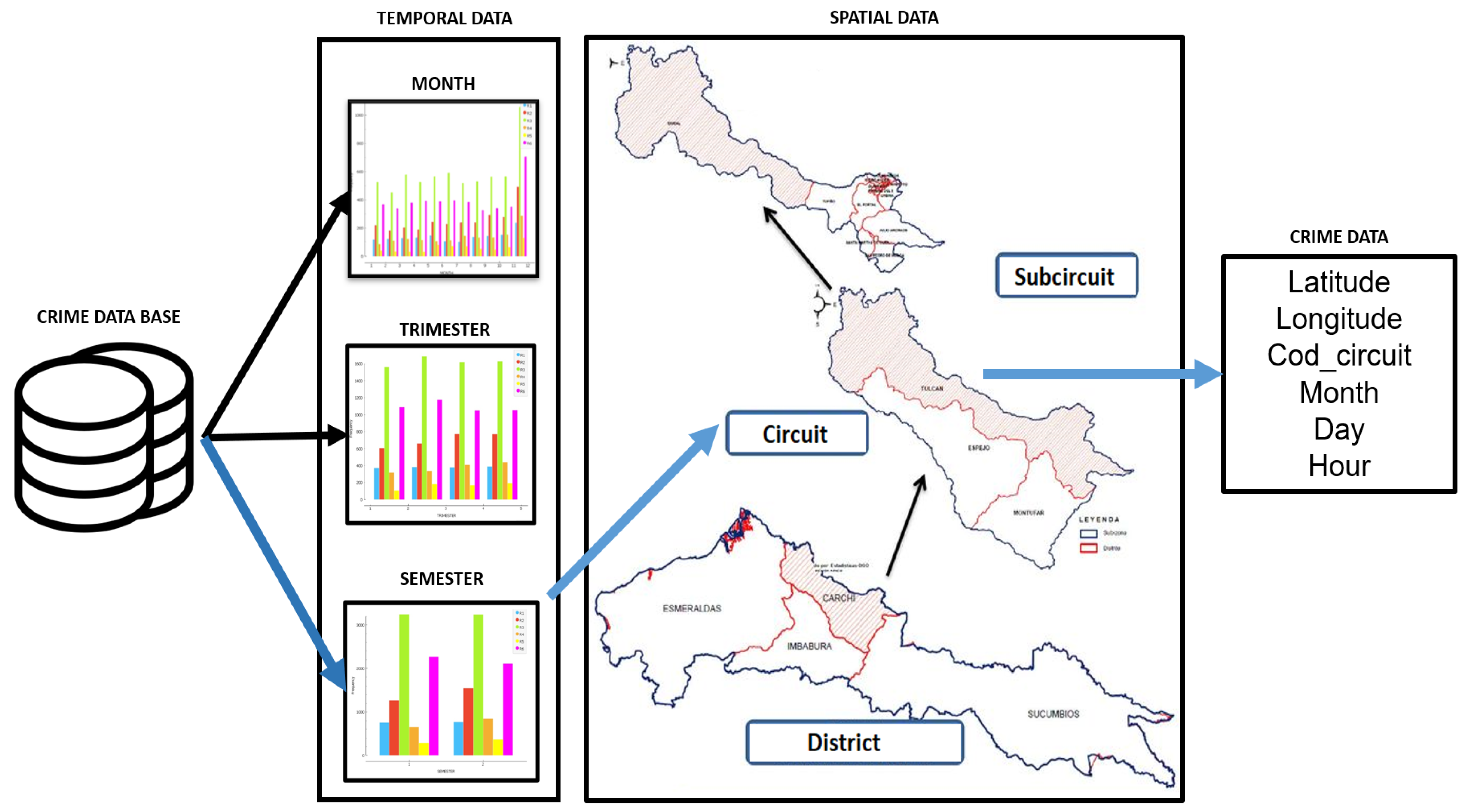
5. Crime Prediction Smart Patrol Algorithm (CPSPA)
The crime prediction smart patrol algorithm (CPSPA) uses the characteristics selected in the previous section. It works with circuits, , where n is the number of the circuit. Each circuit has a set of crimes, , where m is the number of registered crimes. Each offense is defined as , where ,, are the temporal information, and , are the spatial information.
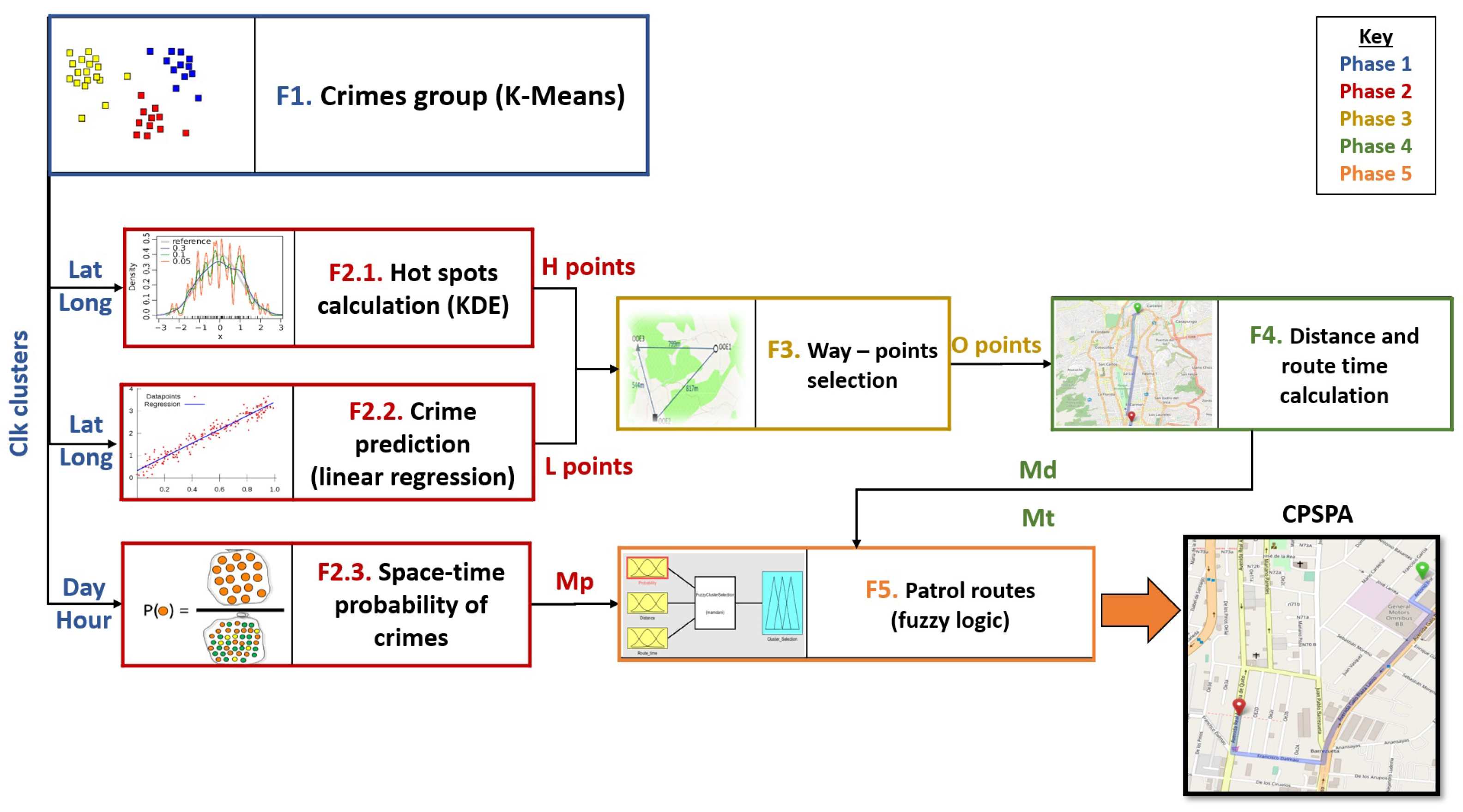
The CPSPA algorithm is structured in five phases (
Figure 5). Along them, different ML techniques and statistical analysis are applied depending on the objective, to finally determine the prediction of possible crimes and propose the optimal route that a police officer should take during a surveillance turn.
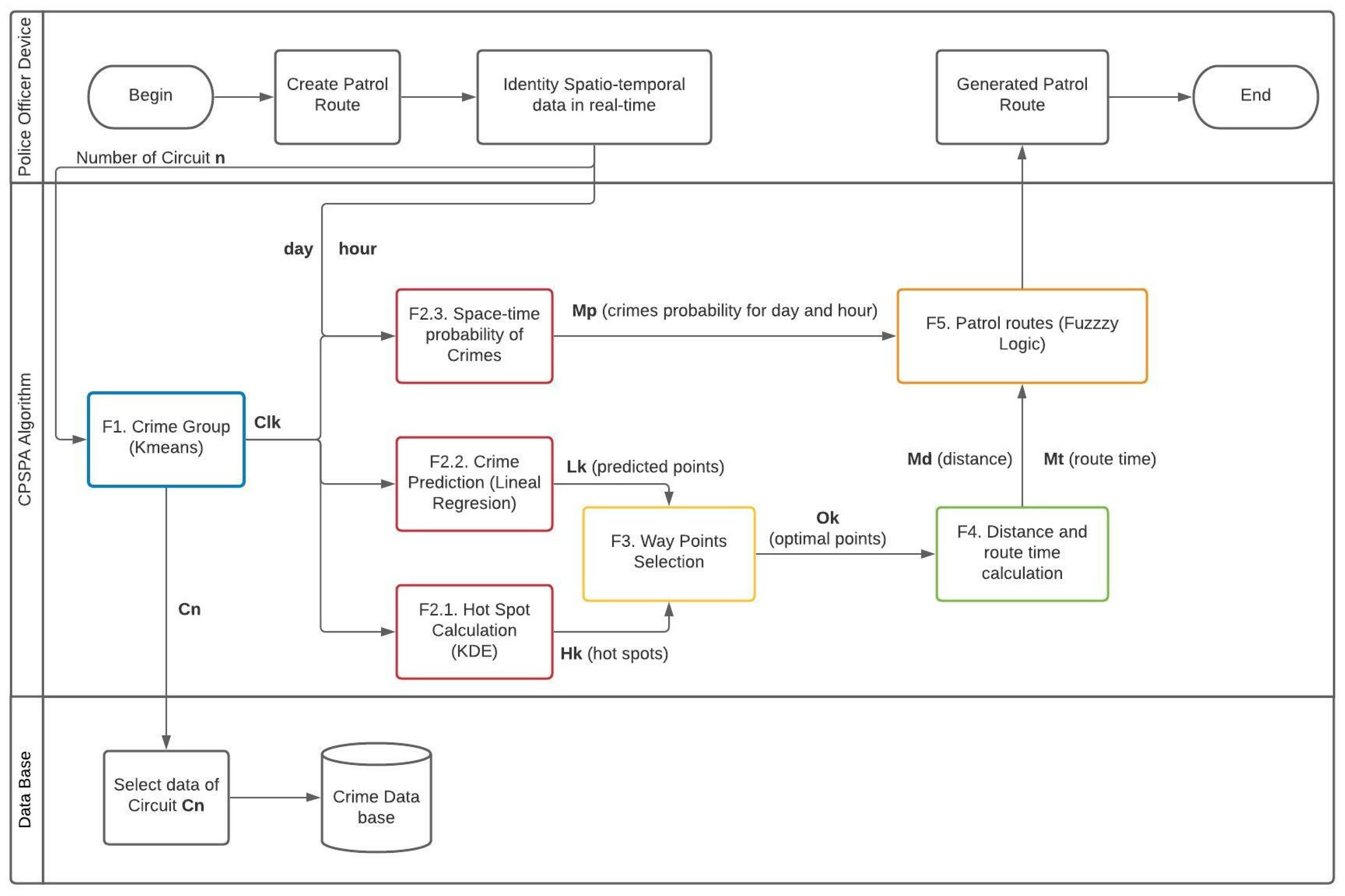
To clarify the algorithm, although the different steps are going to be described in detaile in the next sections,
Figure 6 shows the activity UML diagrams. It shows the interaction among the Police Officer Device, the CPSPA algorithm and the database. The sequence of actions carried out to patrol the most conflictive points for each surveillance shift is shown. This diagram has as inputs the circuit that is being patrolled,
, and day and time of the patrol. The output is the police patrol route obtained, that consists of a starting point, some way-points along the route, and the final point. This diagram includes all the phases of the CPSPA algorithm.
In addition,
Figure 7 presents the sequence diagram of the operation of the CPSPA algorithm. It is possible to see how some of the activities can be carried out in parallel.
The selected initial conditions of the experiments, after data analysis (
Section 3), are the circuits
,
y
, all of them belonging to
district, due to the high number of reported crime records. The Matlab 2021a software and the Nvidia Geforce GTX 1050 GPU with frame buffer: 4 GB GDDR5, 7 Gbps memory speed have been used for the simulation. The phases of the algorithm are described below.
5.1. Phase 1. Crime Grouping from Criminal Database
In this phase (see
Figure 5), the crimes of a
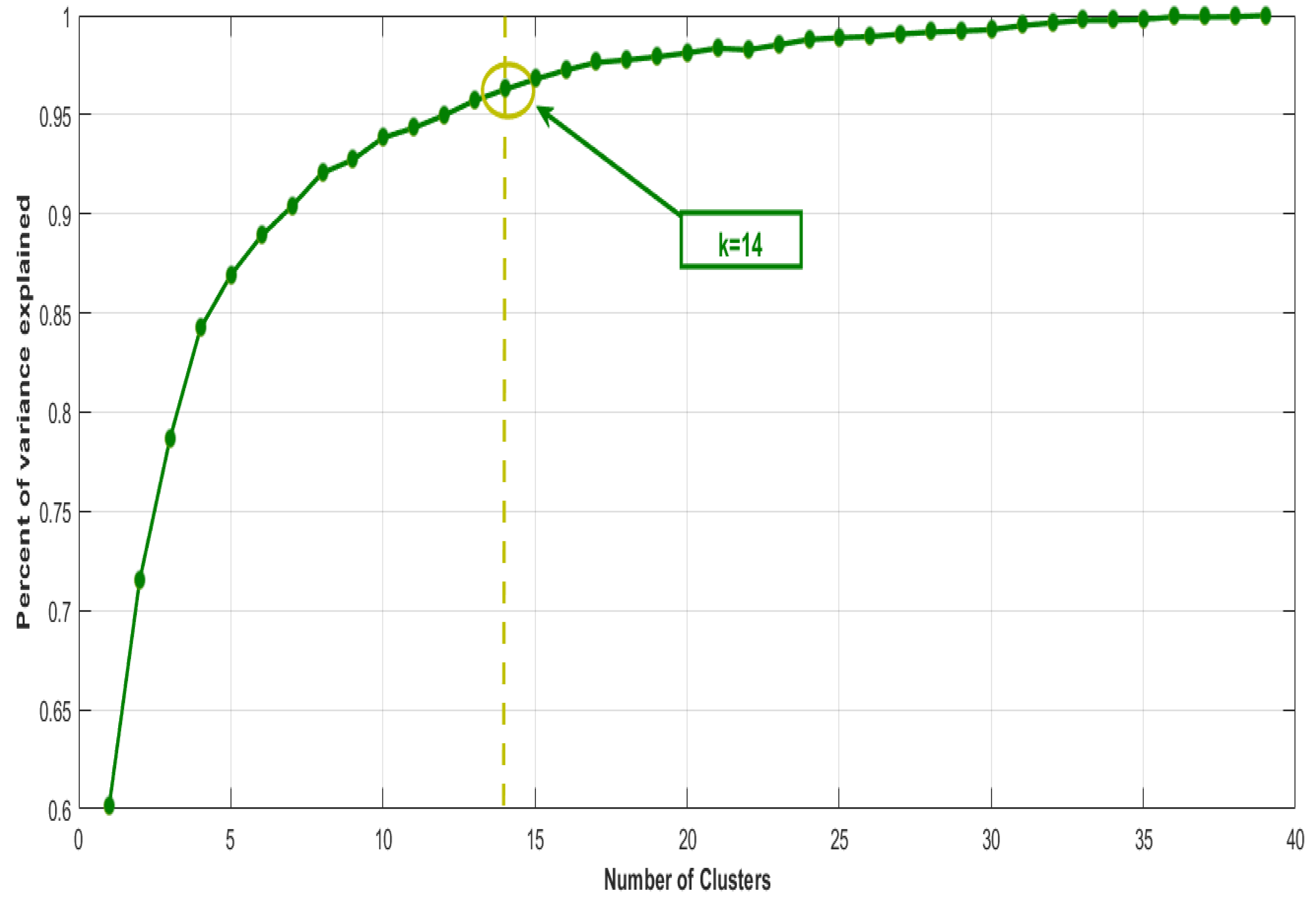
circuit are grouped using the k-means algorithm. As it is an unsupervised clustering, the optimal number of clusters
k is obtained with the Elbow method. The objective is to determine the most conflicting areas,
(clusters), in circuit
, to analyze crimes in more detail. A number of crimes
r has been reported in the area that represents each cluster, that is,
. As an example: within district
the circuit
is analyzed, which has 1539 crimes,
, reported in 2017. The k-means algorithm is applied with the Elbow method, and the optimal number of clusters is determined,
(
Figure 8). In
Figure 9, the
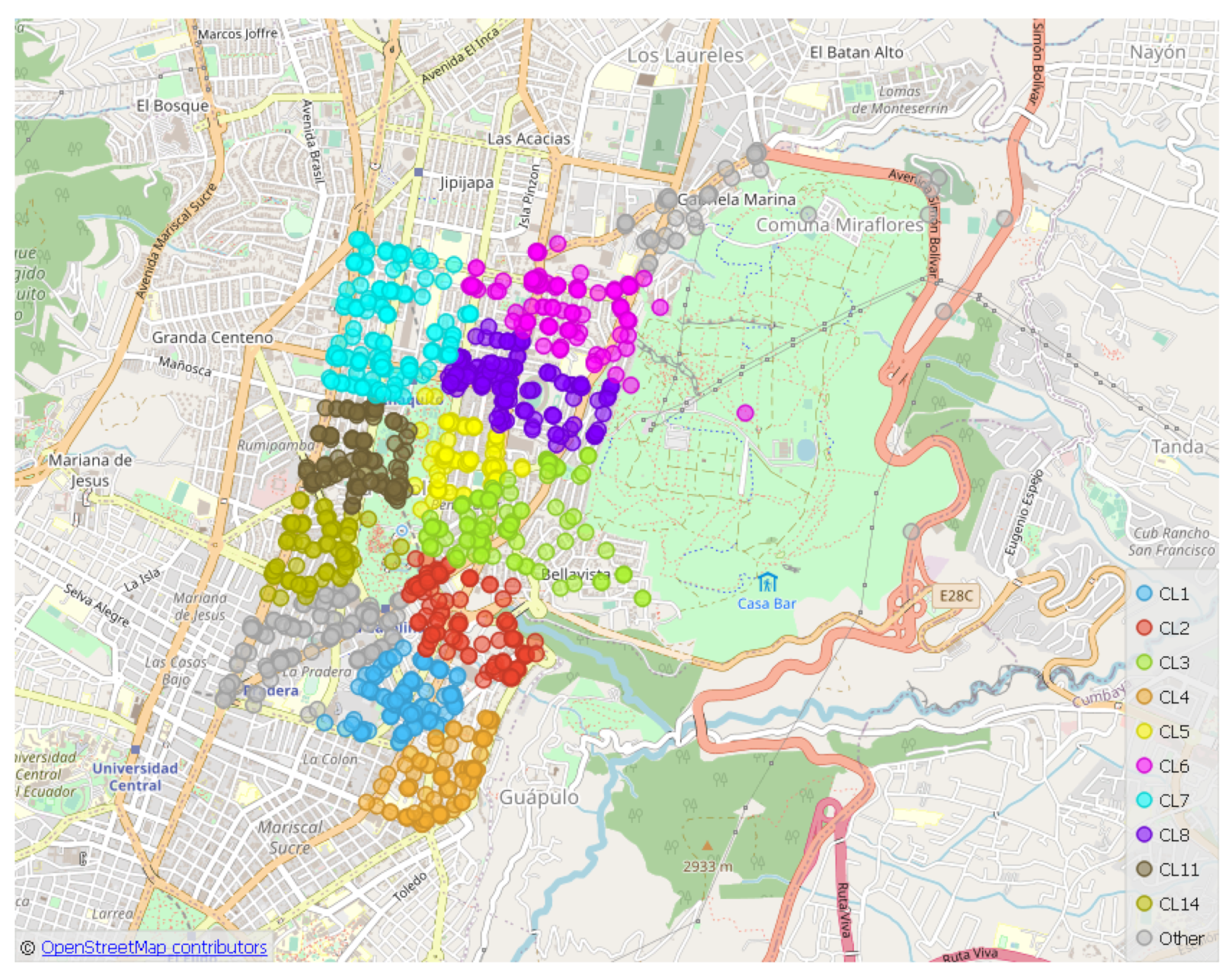
k groups are represented for the
circuit in OpenStreetMap.
The k-means method has been applied because it is a well-know algorithtm that suits the objective of this phase, which is to determine crime concentration zones, including several geographic areas, as sub-circuits, although any other grouping algorithm may be used. Besides, the outcomes of its application gave similar results to those of the expert. Finally, k-means is simple, easy and quick to use and implement in an online real system.
5.2. Phase 2. Calculation of Hotspots, Prediction, and Probability of Crimes
At this stage, the spatial information, latitude, and longitude, is used to calculate hotspots (Phase 2.1,
Section 5.2.1) and perform crime prediction in each cluster, (Phase 2.2,
Section 5.2.2). With the temporal information, the spatial-temporal distribution of crimes is calculated (Phase 2.3,
Section 5.2.3) (see
Figure 5).
5.2.1. Phase 2.1. Calculation of Hotspots by Applying KDE
Hotspots are crime concentration points, defined as
. That is, a hotspot is calculated for each cluster determined in Phase 1,
Section 5.1. KDE Equation (
3) is applied to the spatial data of each crime,
, to obtain the hotspot vector
H.
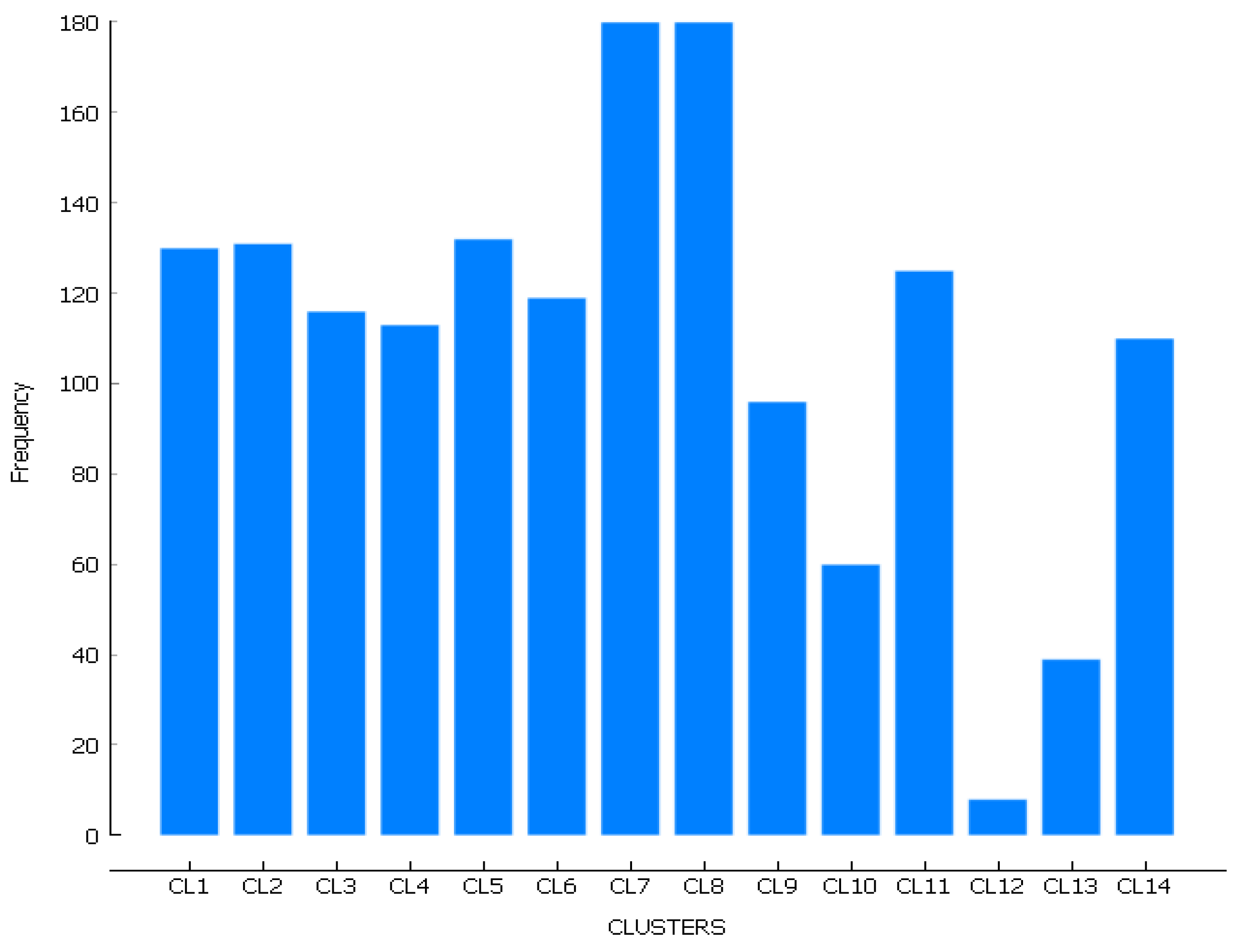
In the example, each of the 14 clusters in
circuit has several records (offenses), with a maximum of
in clusters
and
, and a minimum of
in
(
Figure 10).
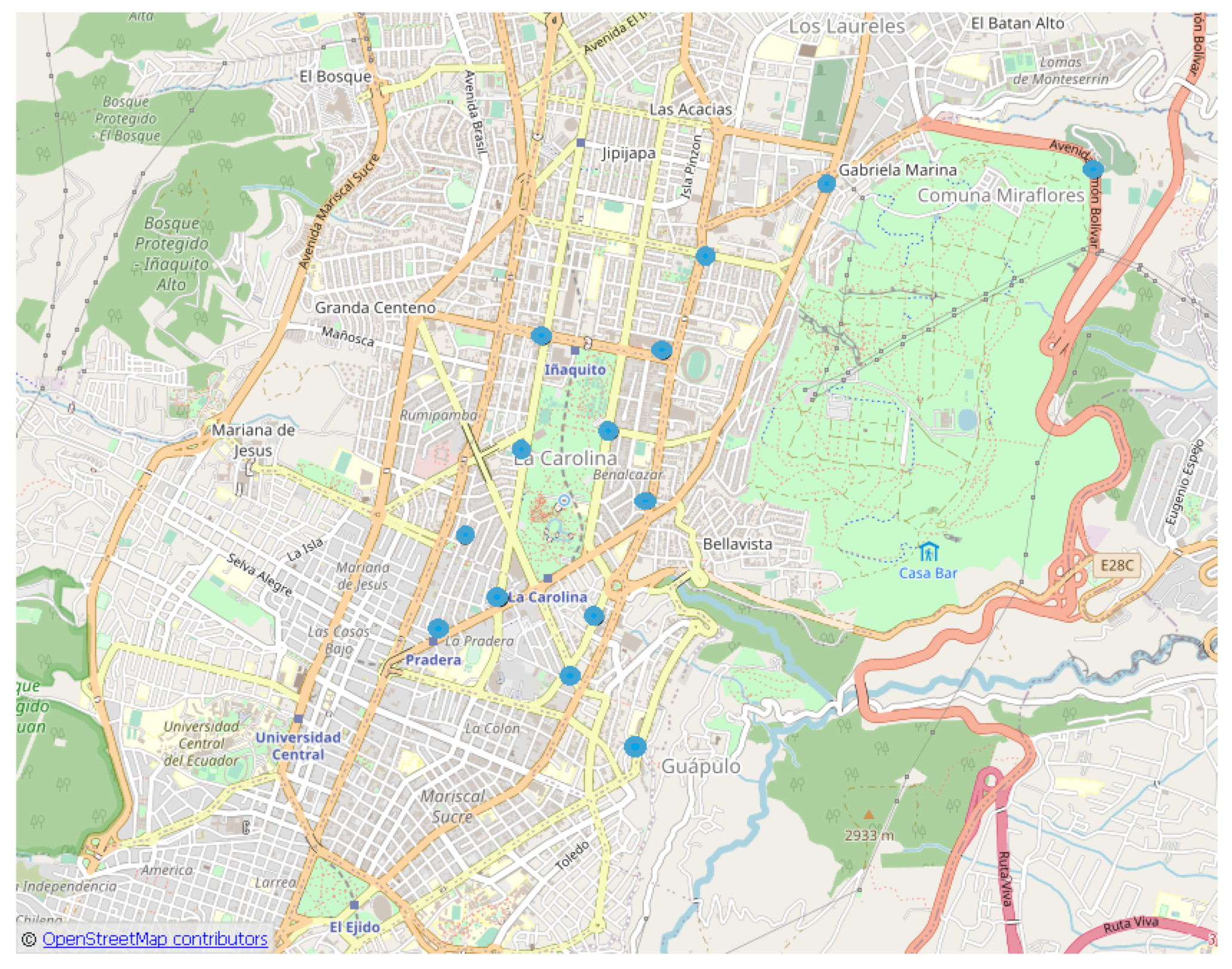
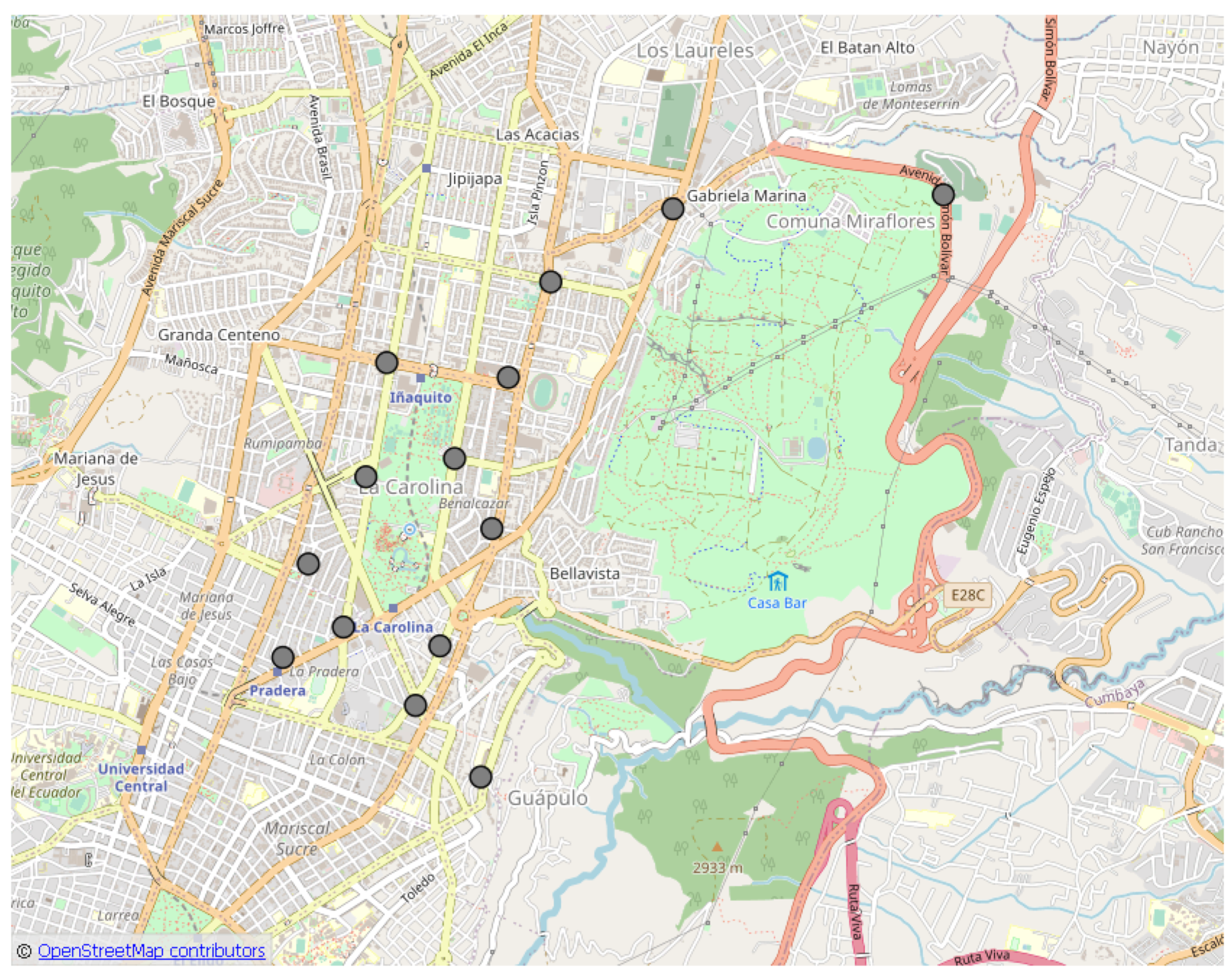
H points with the highest concentration (hotspots) of crimes that result from applying KDE are represented by the blue circles in
Figure 11, one for each cluster, for the
circuit.
The light blue circles in
Figure 11 represent the position of the point with the highest crime concentration within each cluster.
5.2.2. Phase 2.2. Crime Point Prediction via Linear Regression
In Phase 2.2 (see
Figure 5), linear regression is used to obtaine models that can be used for crime prediction. To do so, Equation (
4) is applied to the crime records of each cluster
. Thus, the
L points where the concentration of crimes may be higher,
,
, are obtained.
The crimes were ordered chronologically, . Then, with the spatial information, two linear functions are generated for each cluster, that is, and . That is, predicts the future crime concentration point of the k cluster. Those two linear functions have been obtained for each of the 14 clusters of the circuit.
For instance, for cluster the equations obtained when applying the linear regression are: for latitute and for longitude. The obtained was and the resulted regresion point was . The R-squared values were between and for the 14 clusters.
5.2.3. Phase 2.3. Space-Time Probability of Crimes
In this last step of Phase 2 (see
Figure 5), a crime probability matrix
is calculated for each
cluster for the days and hours of a patrol turn. The
matrix has dimensions (row, column), where
,
,
number of days,
number of patrol hours, and
number of clusters. The four columns of
matrix represent the day, time, cluster, and probability of crimes; hence,
.
The matrix is obtained by applying Algorithm 1. The variables and symbols used are as follows. The datasets are divided into three surveillance turns, as carried out by the Ecuadorian National Police for their patrols. Turn 1 covers the schedule from 00:00 to 7:59, turn 2 runs from 8:00 a.m. to 3:59 p.m., and turn 3 runs from 4:00 p.m. to 11:59 p.m.
The total amount of crime on a circuit is
. Each offense is assigned to a day (
), hour (
), and cluster
. The crimes on a given day and time are
. The number of crimes per day, hour, and cluster is
. Equation (
5) is applied to calculate the probability that a crime will take place that day, time, and in the spatial location of a given cluster.
That is, the quotient between all the crimes in a cluster and the total number of crimes in the circuit. For example, the probability of a crime on a Monday () at 6:00 p.m. () in cluster 3 () would be: .
The Mp matrix has a dimension of 588 × 4. An example of a row is: .
5.3. Phase 3. Selection of Surveillance Points
In this Phase 3 (see
Figure 5), the information obtained in previous subsections will be integrated to determine the way points that the patrol route must follow. First, hotspots
are obtained in each cluster, which may or may not coincide with the prediction points of maximum crime
. The distance between them is calculated so that if they are very distant from each other, a midpoint will be obtained. If they are very close to each other, the hotspot
will be selected.
| Algorithm 1 Obtaining the Crime Probability Matrix in a Cluster. |
Inputs: %turn start time% %turn end time% Output: %Crime Probability Matrix% for to do for to do for , to k do for to do if ( AND then end if if ( AND AND ) then end if end for ; ; ; ; ; end for end for end for
|
The Euclidean distance between
and
, is applied.
The distance must meet the following conditions to determine the waypoints:
where
is a constant (threshold) that limits the maximum distance between the hot spot
and the predicted point
, defined as
(1 km). With this expression, a vector is obtained with the way-points
, which the patrol route should go through.
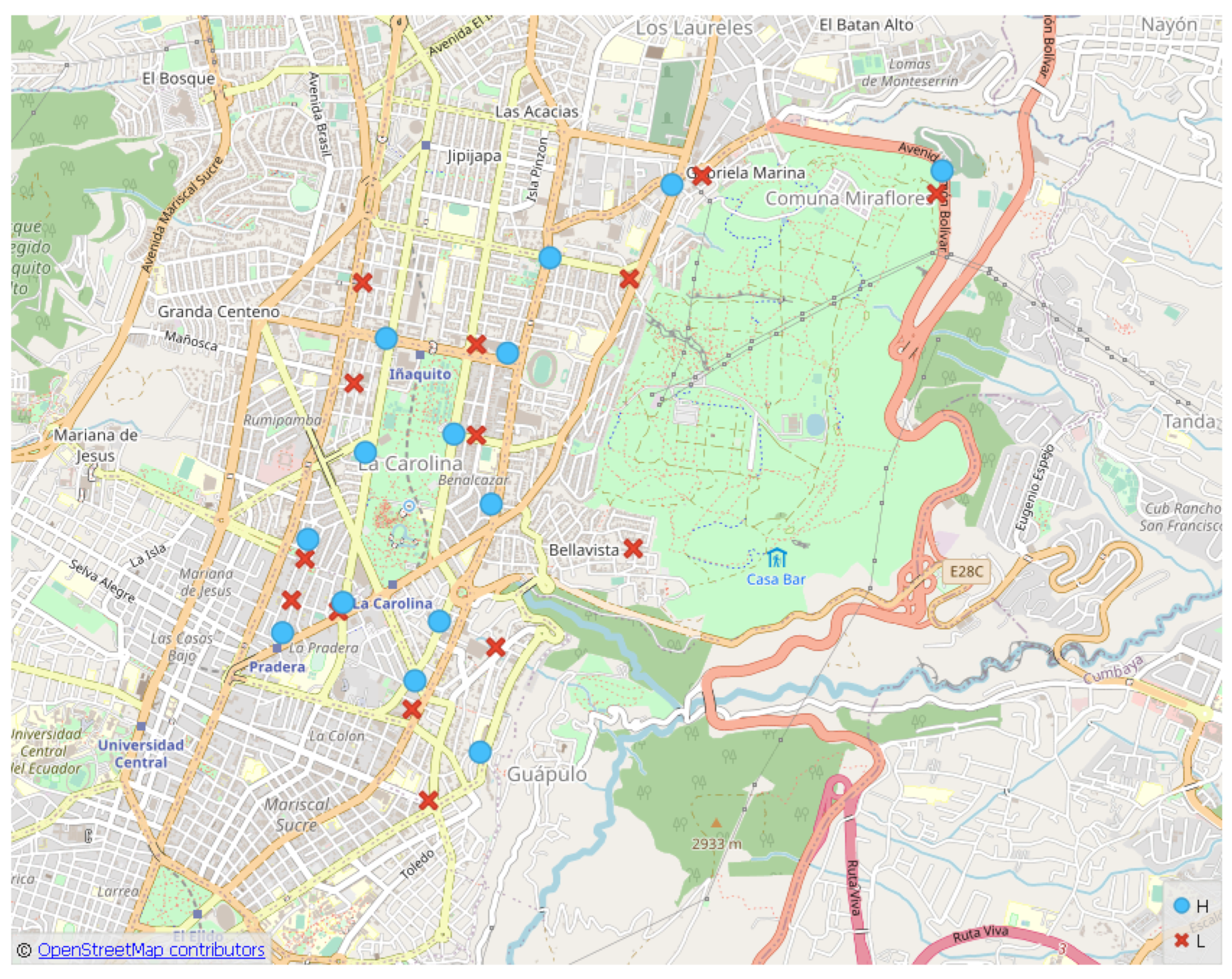
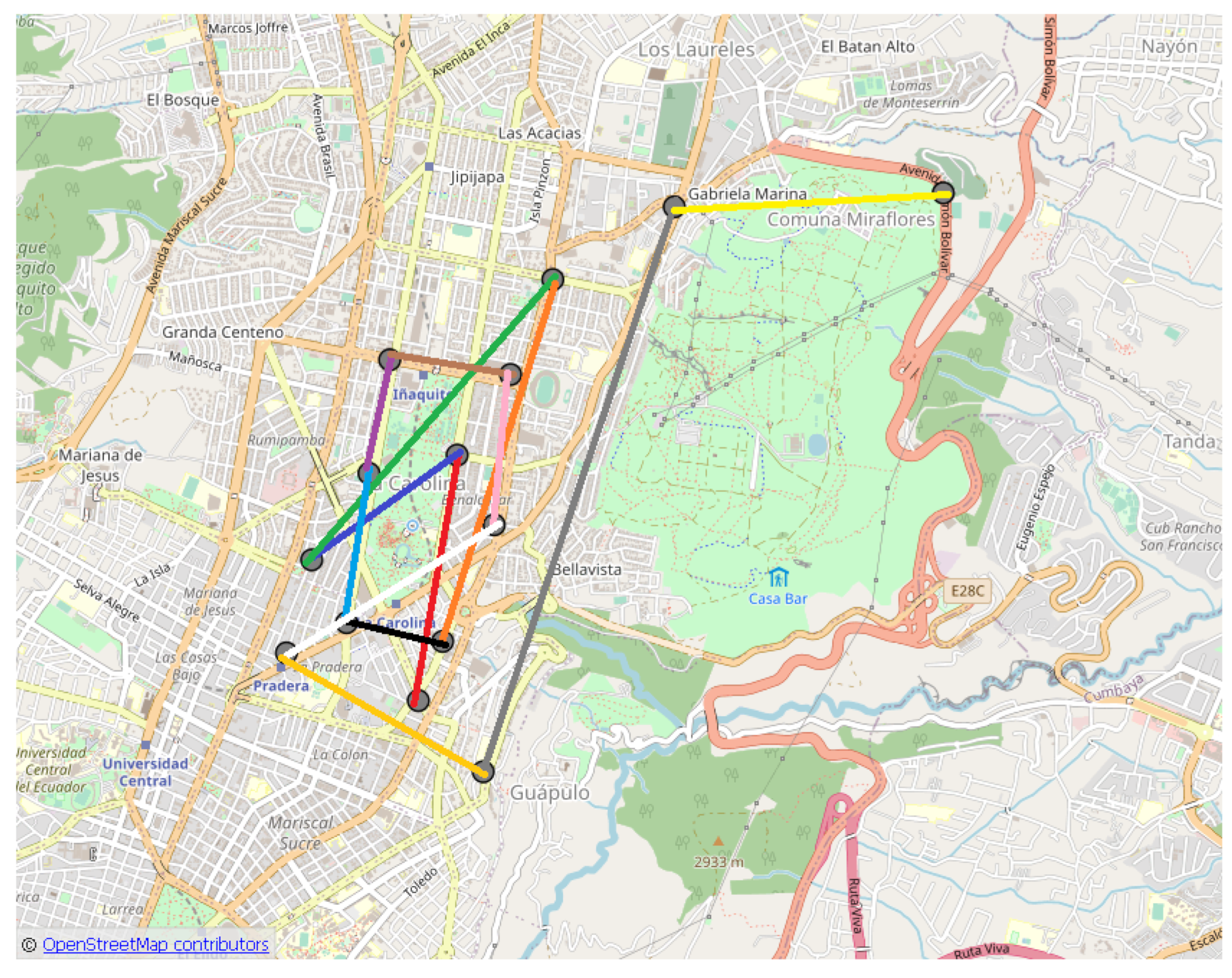
In
Figure 12, the points
(light blue circles) and
(x red markers) are shown. In
Figure 13, the points
(gray circles) resulting from the selection of points for the routes of the
circuit are presented. Each cluster has one point.
As an example of this phase, in cluster
, the hotspot is
(
,
), and the prediction shows
(
,
), where
. Hence,
is calculated as follows:
The resulting way-point has the coordinates .
%vspace-6pt
5.4. Phase 4. Distances and Route Time Calculation with OpenStreetMap API
The distance and driving time between the way points must be determined to find the best patrol route. In a city, a distance may be small but it may take a long time to travel due to the conditions of the road or due to traffic at certain times. To obtain realistic values, the distance and travel time between the way points are obtained with the API (Application Programming Interface) of the OpenStreetMap application. The result is represented in the square matrices (distance in km) and (time in minutes) from the initial point to the end point .
The distanceAPI (distance of travel) function is applied to obtain the elements,
, of the matrix
.
In our case, the matrix
, has the results of the distance API(
,
) functions, where, for example, the distance between
and
is
.
In the same way, the OpenStreetMap timeAPI (travel time) function is used to calculate the route time,
, which are the elements of matrix
.
For instance, in the matrix
, timeAPI(
,
) between the points
and
is
.
5.5. Phase 5. Application of Fuzzy Logic to Determine Patrol Routes
Finally, once the way-points of route and the information on the probability of crimes and proximity, both in length (distance) and route time, have been determined, the route to be taken must be decided. A fuzzy decision-making system (FDSS) that uses probability matrices, , distances, , and route times, , has been designed.
Given that it is possible to obtain several solutions that can be equally valid, fuzzy logic is used because it allows the representation of variables including the uncertainty associated with route times, probability, and so on. The fuzzy decision-making system has three input variables, normalized to :
- 1.
Route distance - : distance from the initial point to the final point . This variable has been assigned three fuzzy sets with triangular membership functions: near (0 to ), middle ( to ), and far ( to ). They correspond to the information in matrix , with .
- 2.
Route time - : route time from the initial point to the final point . The same fuzzy sets have been assigned as for the previous variable. Travel times are found in matrix , with .
- 3.
Crime spot probability - : the probability of crimes at the destination point , on a given day and hour . Three fuzzy sets with triangular membership functions have been assigned to this variable: low (0 to ), medium ( to ), and high ( to ). These probabilities are identified in matrix .
The output variable is called point selection (), which determines if a way-point is selected as the next way point of the route. It outputs two fuzzy singletons: selected and unselected.
The fuzzy decision-making system rules are, for instance: If
is High and
is Middle and
is Near, then Point Selection is NOT SELECTED. The route implementation algorithm after applying the fuzzy decision system is shown in Algorithm 2.
| Algorithm 2 Patrol route Implementation. |
Inputs: % Way points % probability matrix % distance matrix % route times matrix Output: % order of points of the patrol route for to k do ; for do ; ; ; ; if == SELECTED then Carry out patrol of a ; ; end if end for end for
|
6. Results and Discussion
Numerous simulation experiments have been carried out with criminal records of the first (1729 reported crimes) and second (1498 reported crimes) semesters of 2017. The route algorithm is applied to circuits with a high incidence of crimes, specifically , y . These simulations will be compared with those carried out by a citizen security expert from the national police of Ecuador.
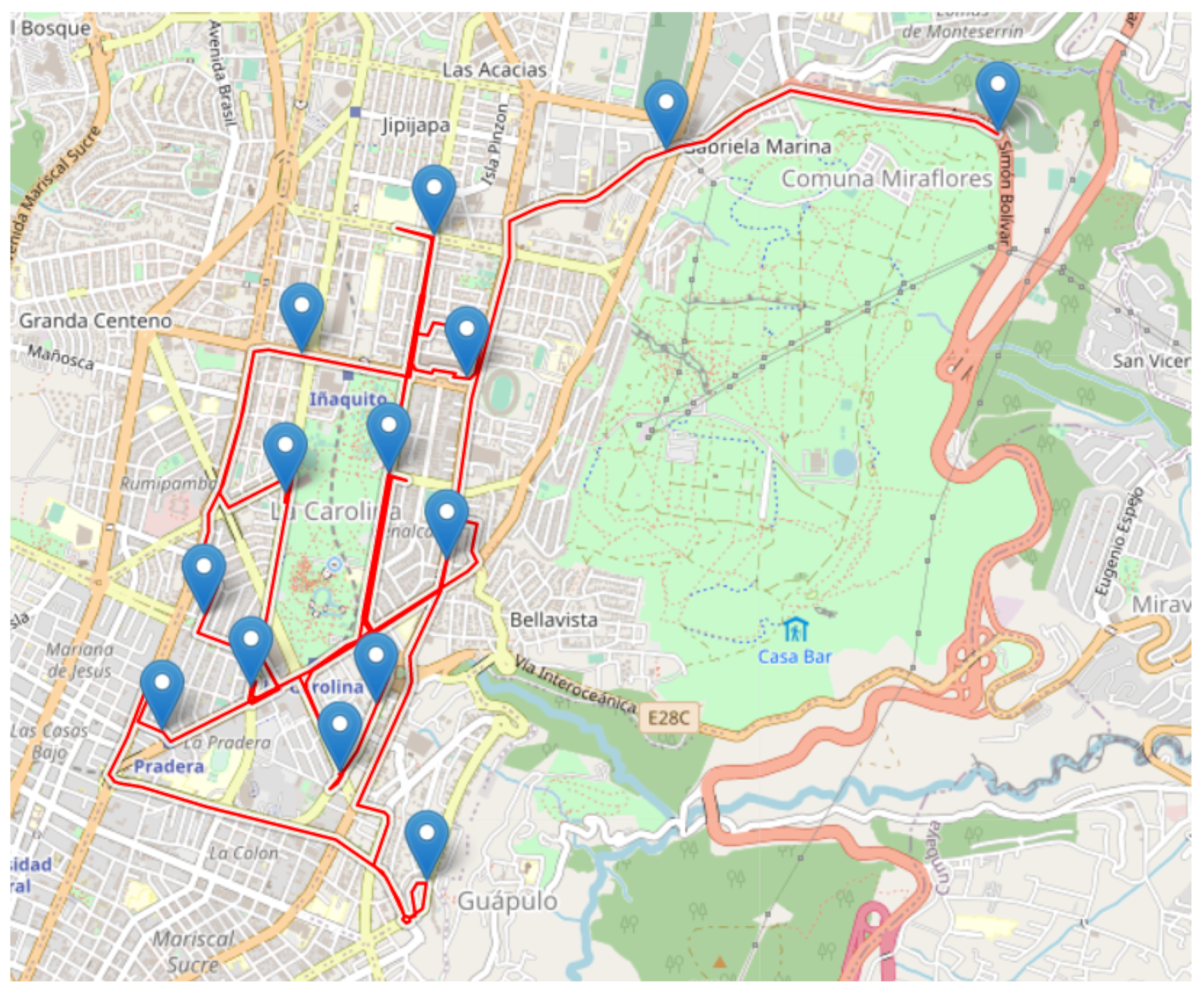
The results of the application of the decision made for the patrol route for a specific case are shown in
Figure 14 and
Figure 15 and
Table 2, where the probabilities (Equation (
5)), distances, route time, and time of the patrol between each of the points (blue points
Figure 15) are listed. In this specific example, the patrol day is
(Saturday), the start time is
, and the patrol starting point is
. The obtained patrol route is
km.
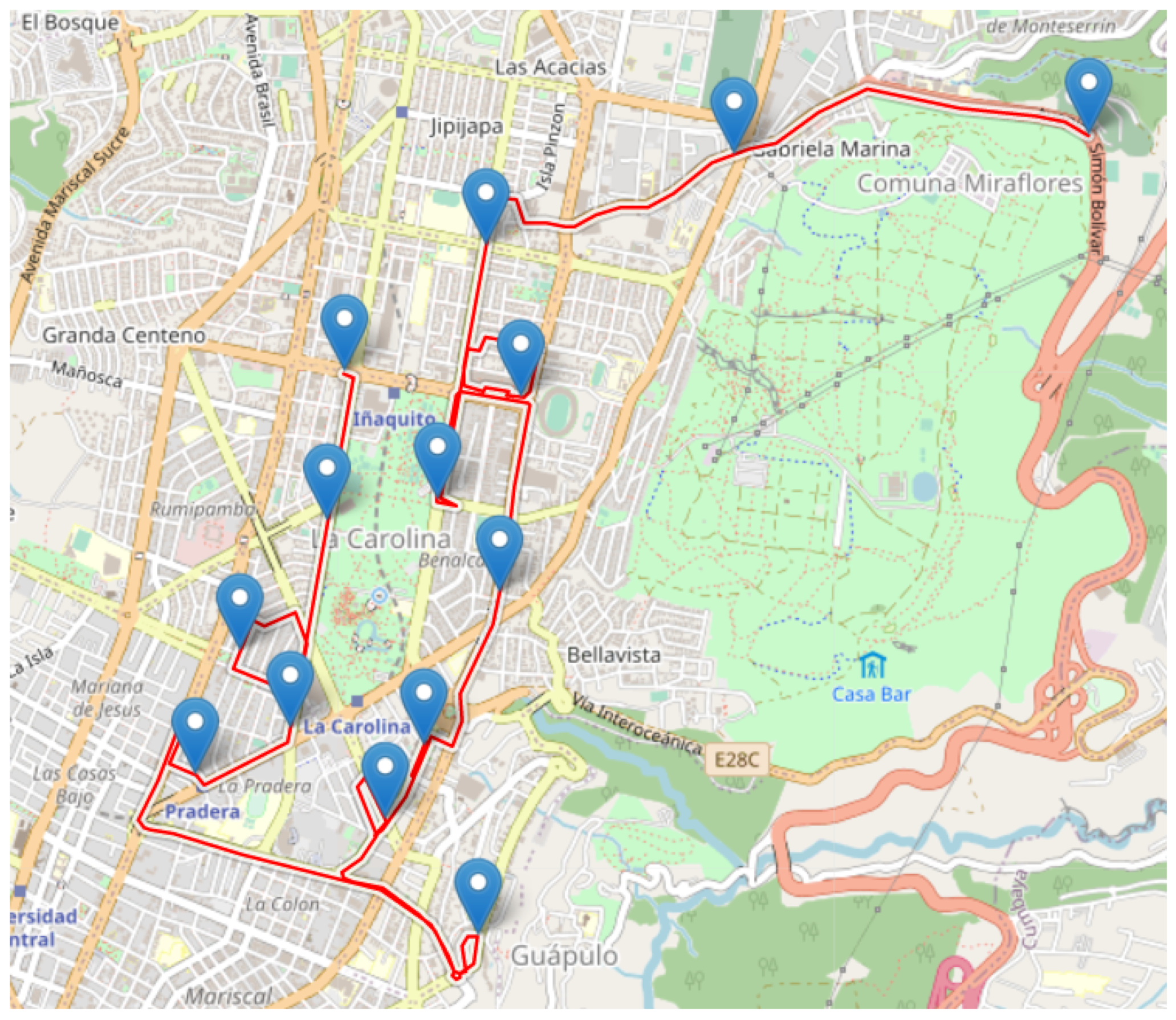
The results obtained by the security expert (
Table 3,
Figure 16 and
Figure 17) showed lower probability rate for each generated route. The expert has estimated the probability of the routes using date, hour and a specific geographical area. The distance obtained by the expert was 21.65 km, smaller in comparison to the one obtained by the proposed algorithm, 30.6 km. The total time patrolling route was 175 min, that is, slower than the CPSPA algorithm, with 111 min. In general, the results show that the CPSPA algorithm works with the most relevant variables and finds valid routes that may help find new routes with some advantages.
In addition, as previously mentioned, the period of a semester (6 months) has been proved to have enough information of crimes to deal with, but still it may be not large enough for a more complete analysis of the data. Hence, to further test the algorithm, it has been applied to the second half of 2017 set of data.
Table 4 shows data and results working with this new data set: the number of crimes broken down into patrol turns in the first column; the
hotspots of the circuits that are then calculated, and the
predictions obtained of where crimes will take place for each circuit (Phase 2.2). If the distance between them is smaller than 1 km,
will be set as way point of the route
.
The results obtained regarding accuracy are quite similar to [
7,
35], proving that finding patterns and predicting future crimes with clustered crimes in space and time is possible. When the rest of the phases of the algorithm are applied, the way points of the patrol routes,
, are selected. The route distance, route time, and processing time of the proposed algorithm are then calculated (
Table 4). For each circuit, between 8 and 15 crime concentration points have been identified, depending on the schedule in which the surveillance is carried out. This value depends on the result obtained with k-means and the Elbow method.
A direct relationship was found between the number of crimes reported and the number of surveillance points. The number of crimes in turns 1 and 2 is smaller than in turn 3.
As shown in
Table 4, the time of the route in each circuit has an average of 140.77 min (2 h 34 min). As each turn is 8 h, the route takes 29.32% of the total shift time. Turns 2 and 3 require more time due to traffic. Furthermore, turn 3 has a higher number of crimes.
The distance of the route has an average of km, which is efficient for covering a geographical area of 36 km, with approximately 11,000 inhabitants. It depends on the number of way points of the route. The patrol distance increases for turn 2 and is even greater for turn 3.
For this reason, we initially analyzed the temporal data window to work with, as shown in
Section 4.1, with the primary objective of determining an optimal period and the necessary historical crime data so that the efficiency of the proposed algorithm is high while time processing is not so demanding. It is worth it to note that adding more data is not relevant to the goal of the algorithm, it could improve the precision a bit but increasing computional time.
Indeed, the average processing time of the algorithm has been calculated, it is 247.32 s. Phases 4 and 5 require more computational time due to the execution of the OpenStreetMap API and the making decision system. The API depends on the speed of the internet connection and the processor of the local computer. The decision-making system uses many resources to generate optimal routes, both for points with high probability and for proximity. As expected, the larger the amount of data, the longer the algorithm processing time.
Therefore, this proposed algorithm provides appropriate routes for all selected way-points in the order the fuzzy logic system determines. When compared with other routes designed by a security expert, results are similar in time and distance, though the proposed method tends to obtain quicker routes. The solutions have been projected on a map of the affected zones where the results have been verified, and the obtained routes are realistic. The analysis of results allows for testing the successful performance of this strategy.
7. Conclusions and Future Works
In this research, an algorithm for the detection of spatio-temporal sources of crime is proposed. The final goal is to design patrolling routes to optimize police resources, reduce crime time response and improve citizen security.
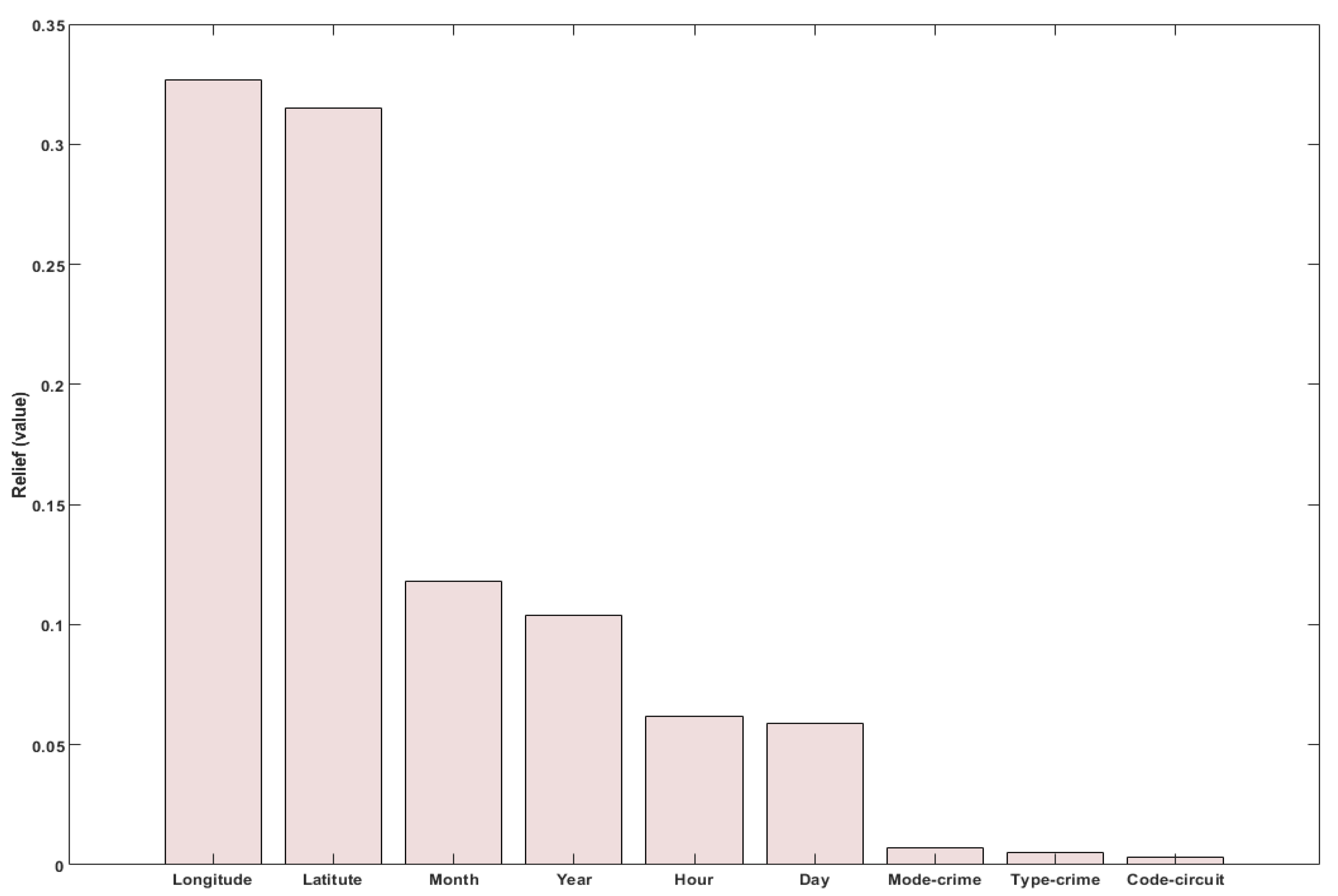
The algorithm consists of several phases and combines different artificial intelligent and ML techniques to deal with the available information. First, Relief and Information gain feature selection procedures are applied to obtain the relevant attributes. Hotspots with a high concentration of crime are identified by applying k-means clustering and KDE. A prediction of future crime points and the probability is obtained based on temporal information of the crimes. Spatial way points of routes are then calculated, and the real distance and travel time are computed with the OpenStreetMap API. Finally, a fuzzy inference system determines the order of the way-points in the route based on their probability, distance, and time.
The experimental evaluation was performed on a real crime dataset collected in Quito, Ecuador, in 2017. It allowed to conclude that this analysis makes it possible the use of information both in space and time of crimes committed in a region to determine policing more efficiently. Furthermore, the use of the OpenStreetMap API allows working with real measures and including traffic, giving more realistic solutions but at the cost of more computational time and resources.
The sequence of strategies applied along the procedure to determine the routes has been proved key to the succes of the algorithm. Besides, the hibridization of techniques has also been shown a must in order to address this type of complex problems. The complete development of the algorithm is presented, from the analysis and processing of the spatial and temporal information to the patrol routes generation. It allows to obtain automatically a patrolling route in a similar way to an expert.
To summarize, the main advantages of our proposal are that the route is automatically obtained, it is optimized in terms of time and distance, and the computational time is low. It is similar but more complete than the one proposed by the expert as it identifies the hot spots and future crime points, while the expert only works with hotspots in a specific area, so the available information is more limited. In addition, the routes obtained by the algorithm tend to be faster as they consider real time information of traffic.
For future research, we propose to study the generation of maps that incorporate temporal information of the surveillance zones to reduce the execution time of the algorithm and allows its use in real-time. It is also intended to continue analyzing the problem to improve patterns and prediction, incorporating information of the relationship between crimes and areas of population concentration, such as parks, shops, liquor stores, restaurants, and so on. From the algorithm point of view, other clustering techniques, such as Gaussian Mixture Models, Mean-Shift Clustering, and DBSCAN, may be tried to see how the tecnique chosed affects the results of the CPSPA algorithm.
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}