




Intelligent Prediction of Maximum Ground Settlement Induced by EPB Shield Tunneling Using Automated Machine Learning Techniques


Abstract
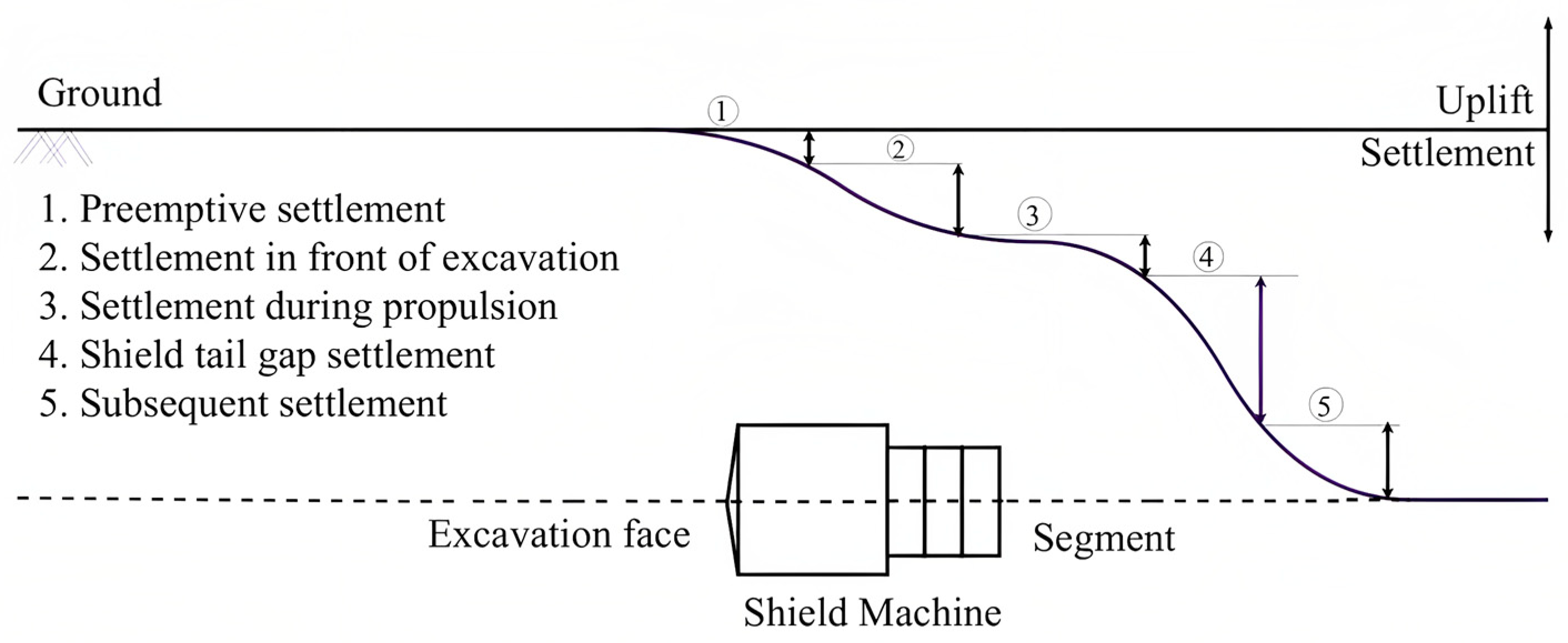
:1. Introduction

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Related Literature | Method | Output Parameters | Data Points |
|---|---|---|---|
| Shi (1998) [24] | BP | Sc, Si, Sf | 356 |
| Suwansawat (2006) [31] | BP | G | 49 |
| Santos (2008) [26] | BP | G | 81 |
| Darabi (2012) [32] | BP | G | 53 |
| Pourtaghi (2012) [33] | Wavelet, BP | G | 49 |
| Ahangari (2015) [28] | ANFIS, GEP | G | 53 |
| Zhou (2016) [34] | RF | G | 66 |
| Bouayad (2017) [27] | ANFIS | G | 95 |
| Zhang (2017) [30] | LSSVM | G | 55 |
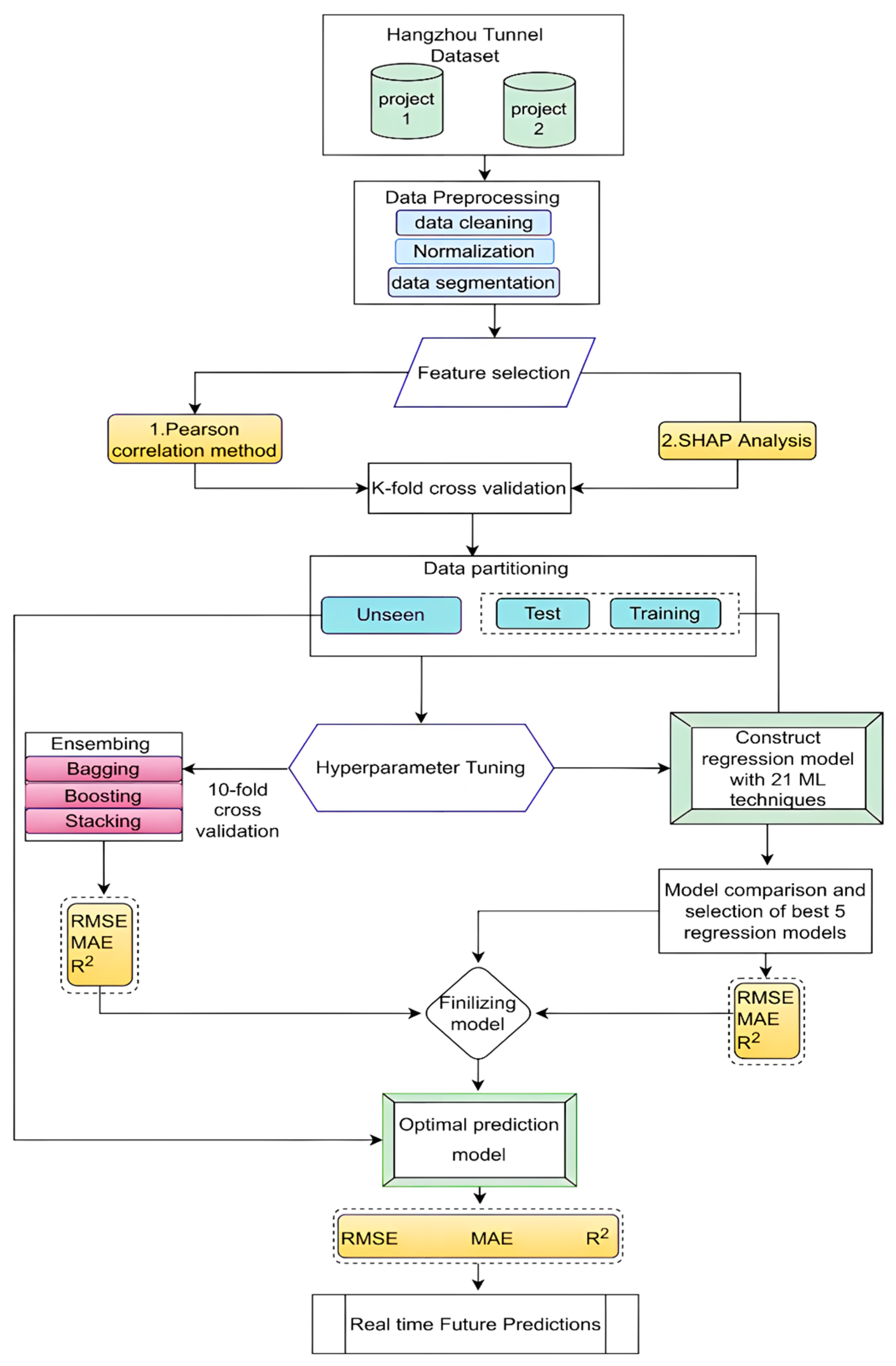
2. Establishment of Surface Deformation Database for Shield Tunneling
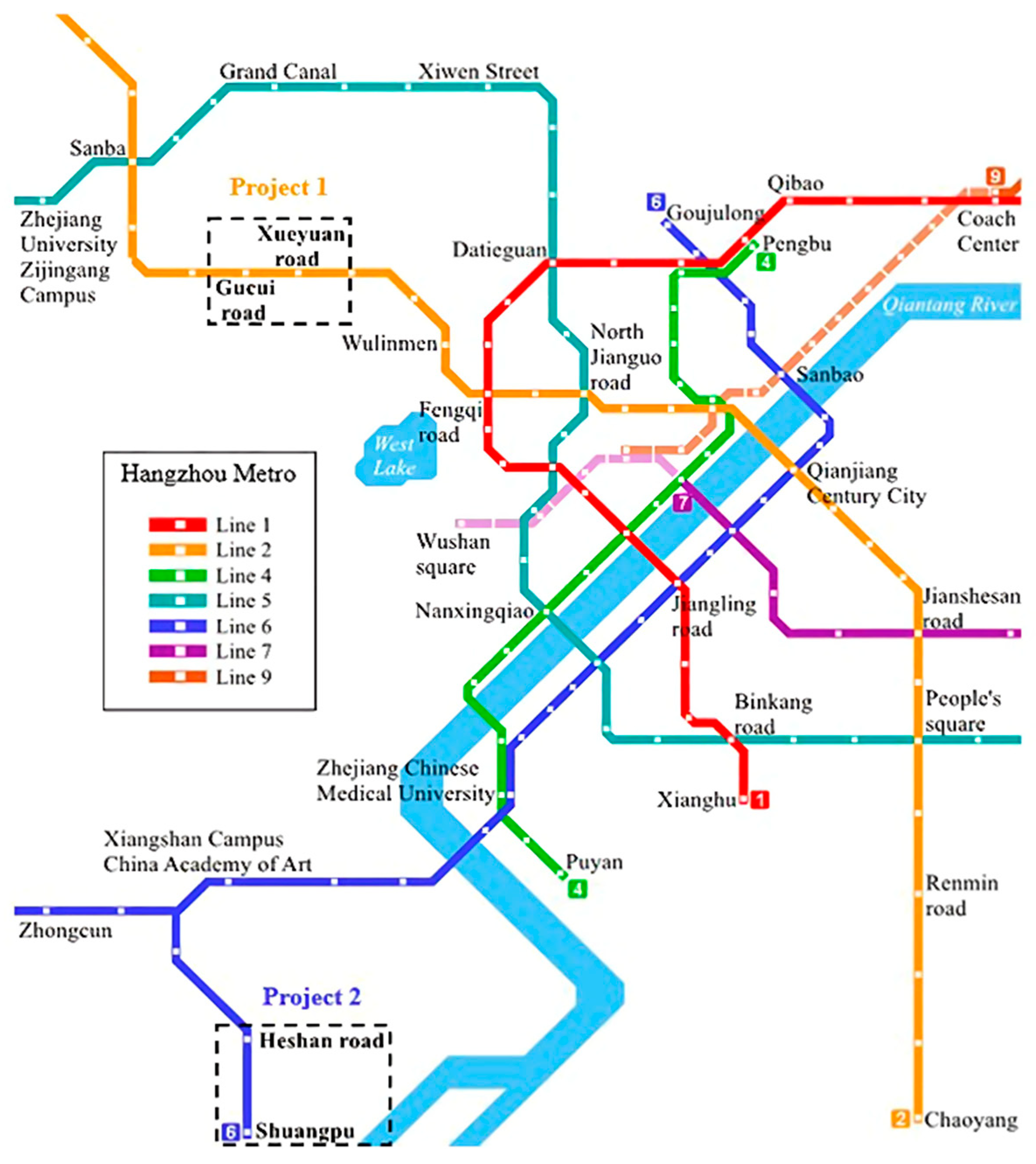
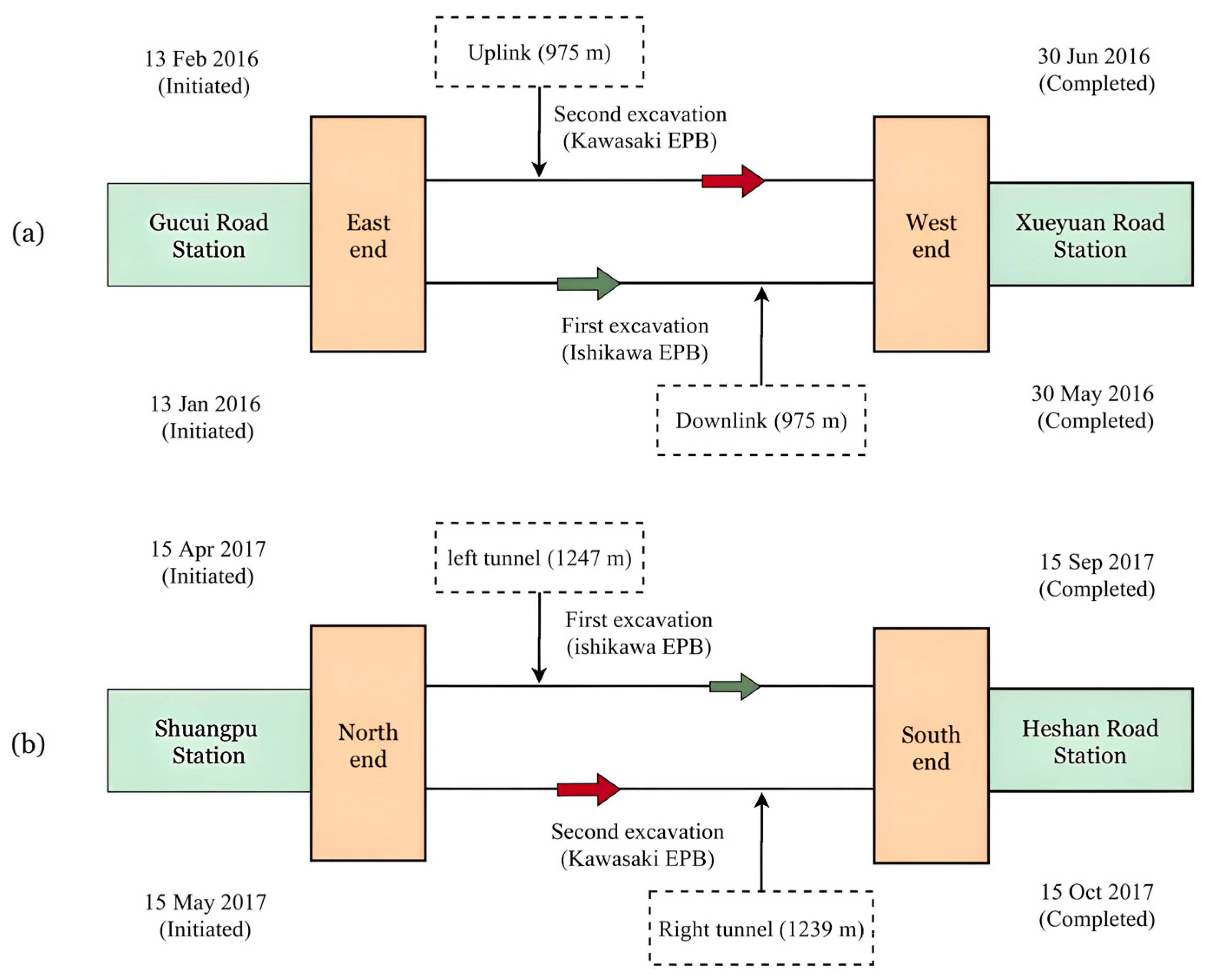
2.1. Project Overview
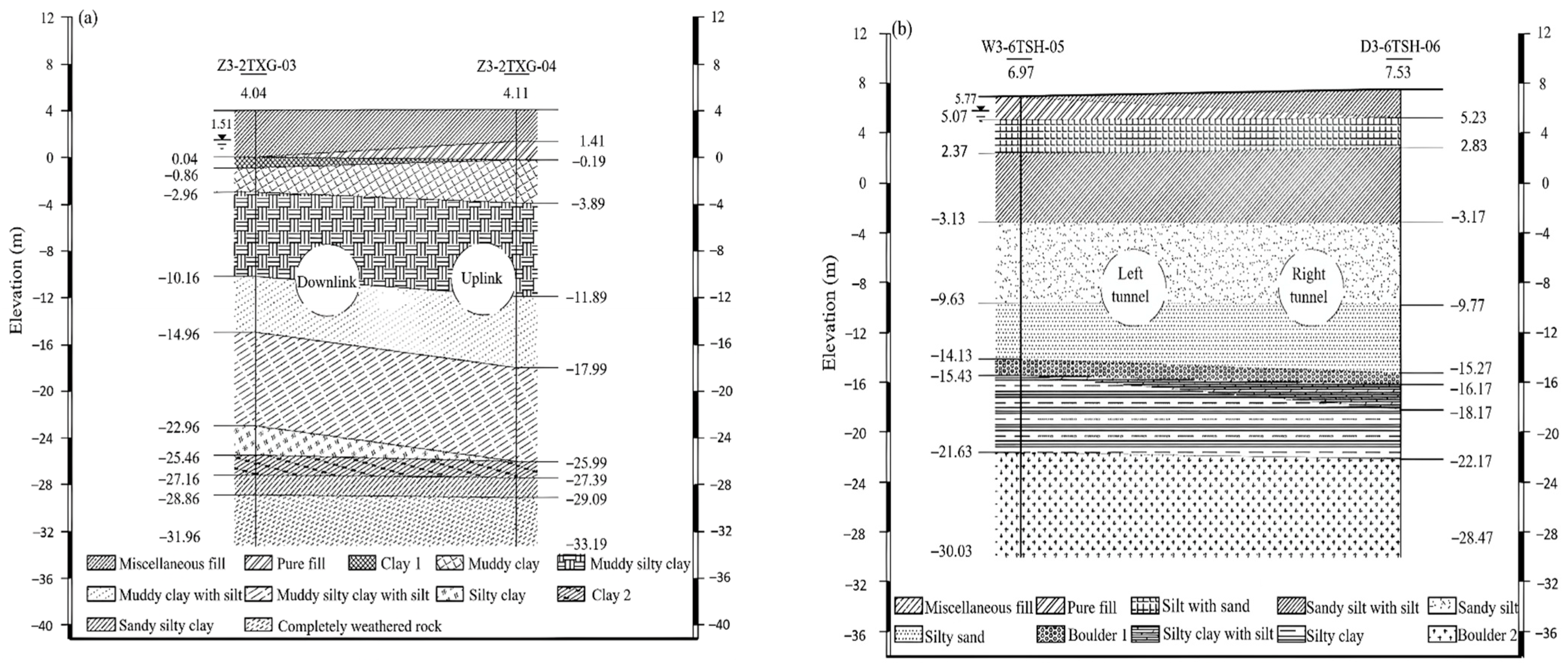
2.2. Engineering Geology
2.3. Preliminary Selection of Input Parameters
2.4. Data Pre-Processing
2.4.1. Data Normalization
2.4.2. Cross-Validation Method
3. Feature Selection
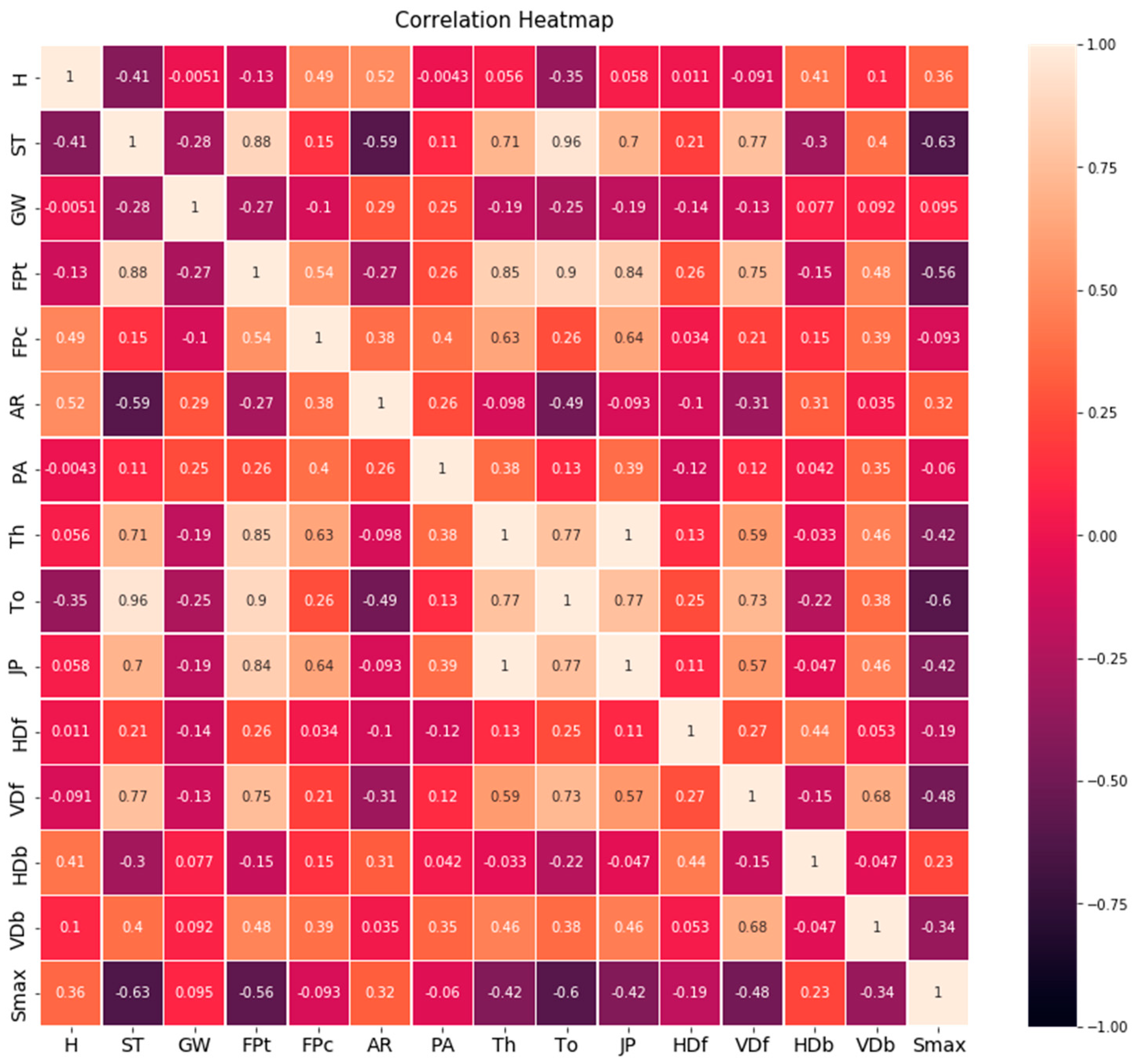
3.1. Analysis 1: Pearson Correlation Method
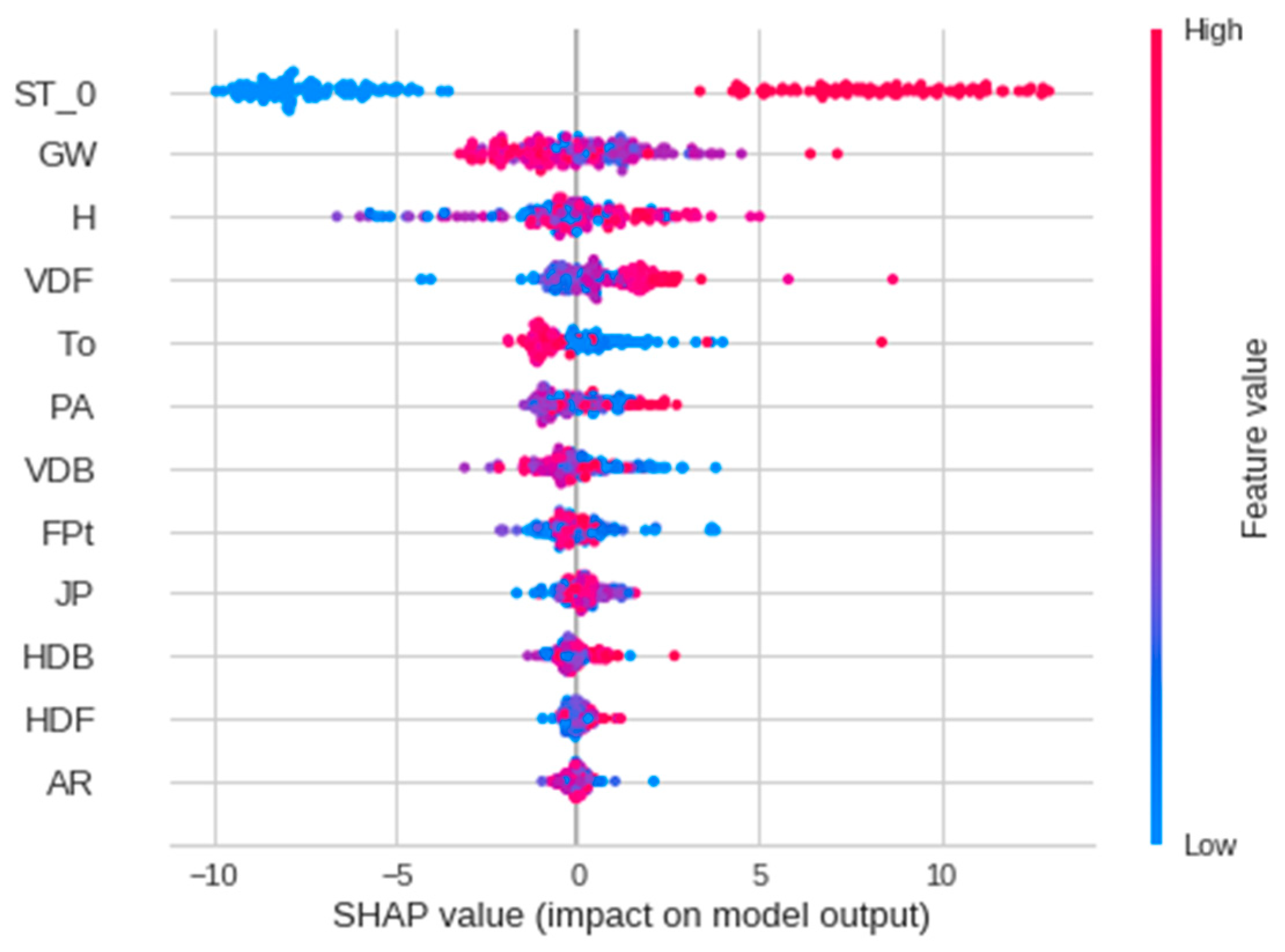
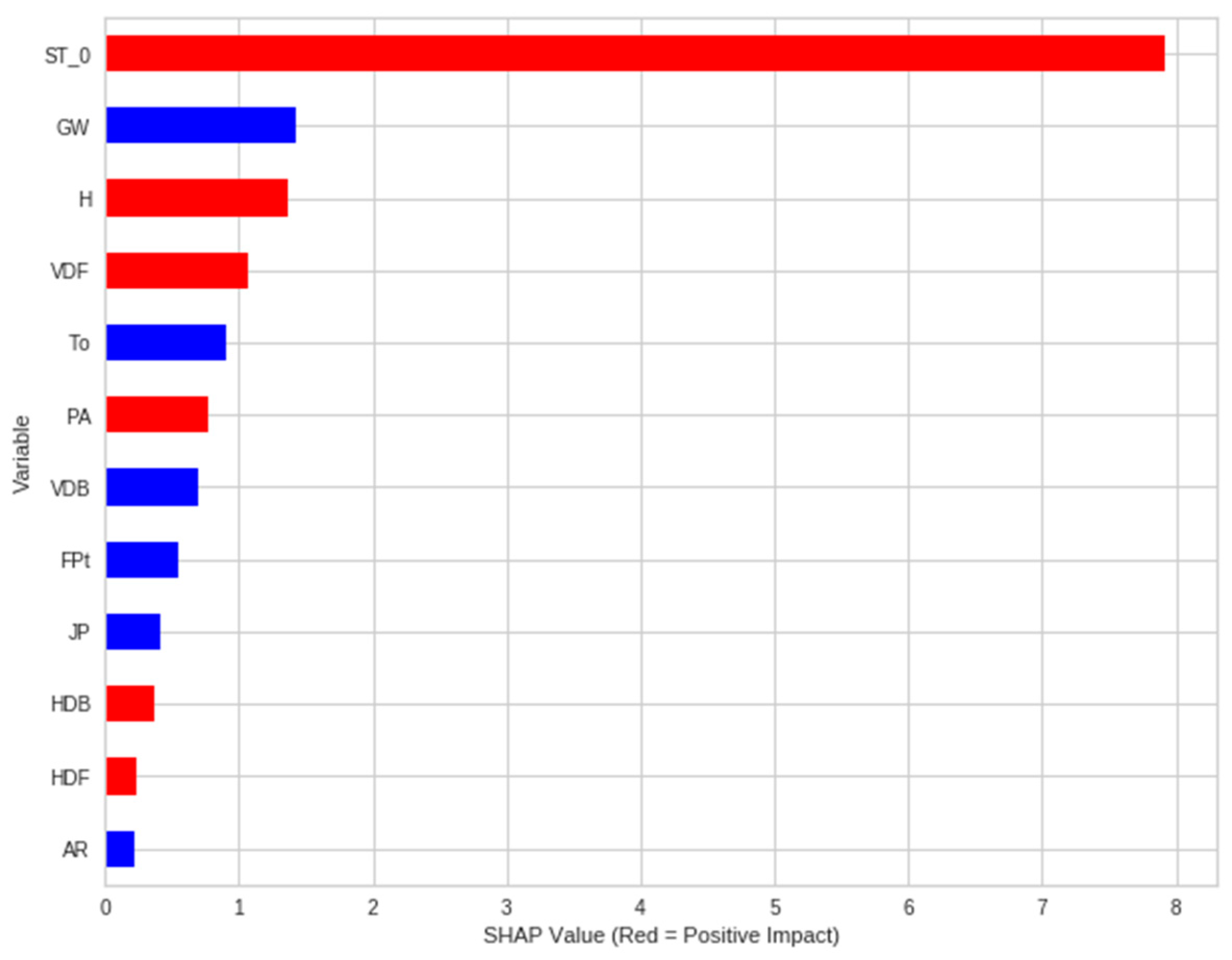
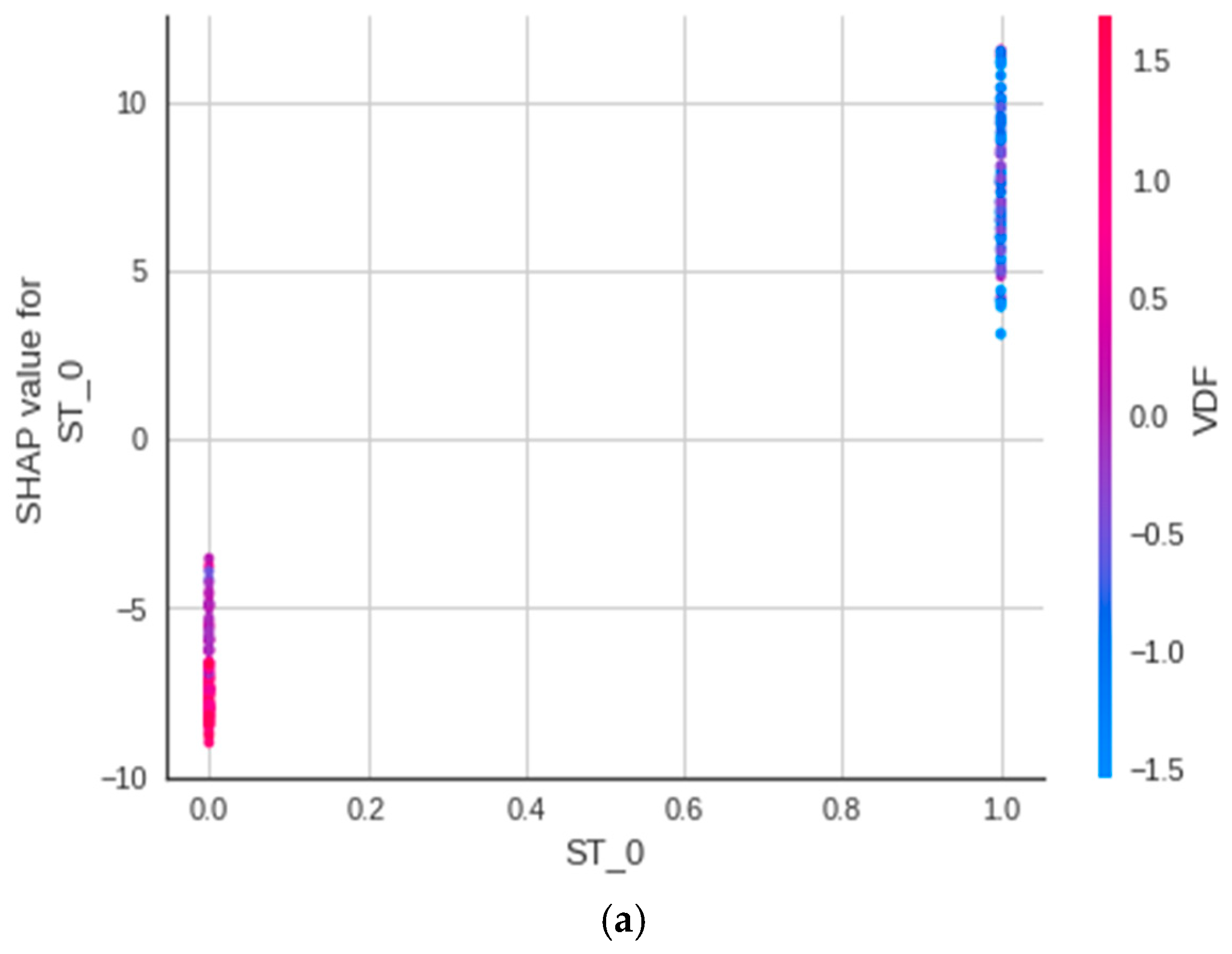
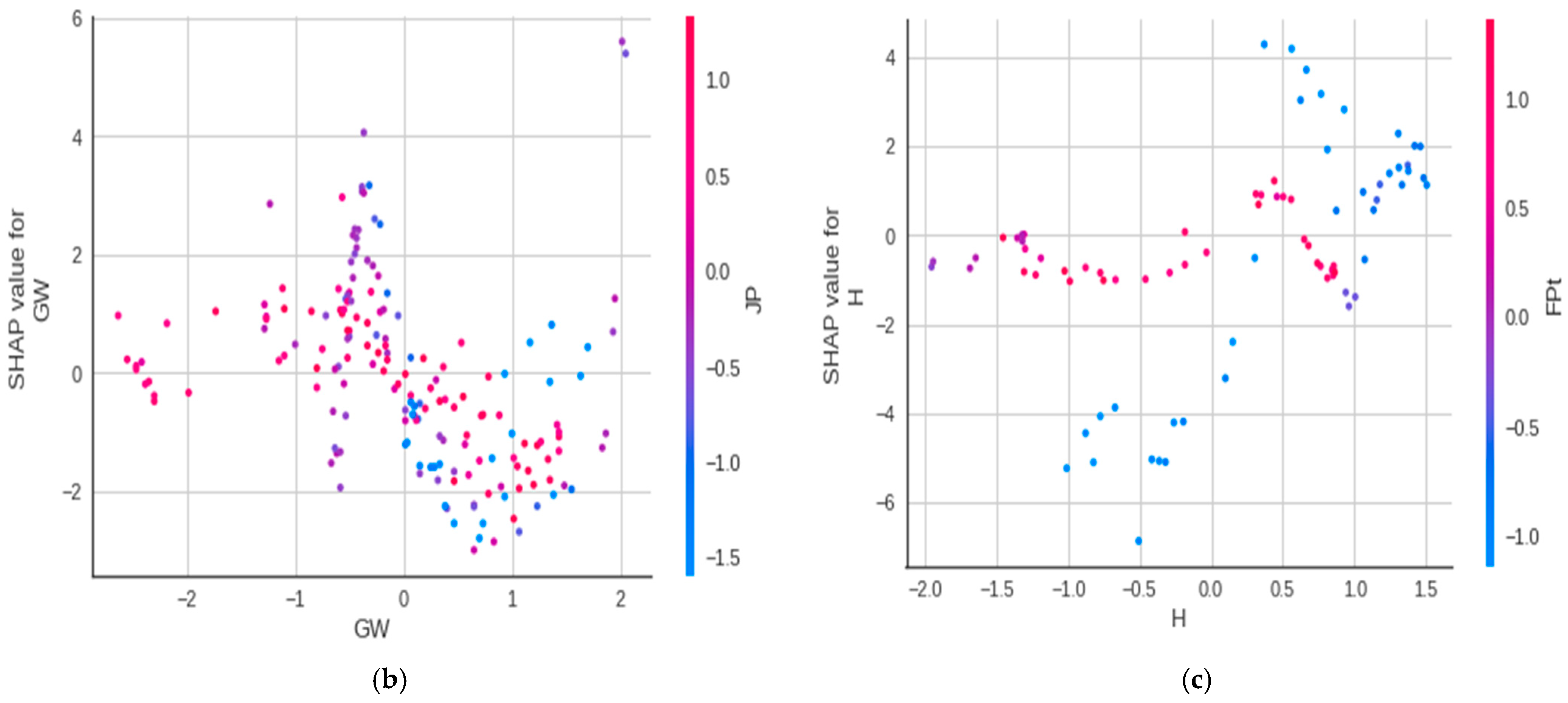
3.2. Analysis 2: Shapley Additive Explanations (SHAP)
4. Research Methodology
4.1. Machine Learning Techniques
5. Results and Discussion
5.1. Experimental Design
5.2. Performance Analysis
5.2.1. Performance of Regression Models
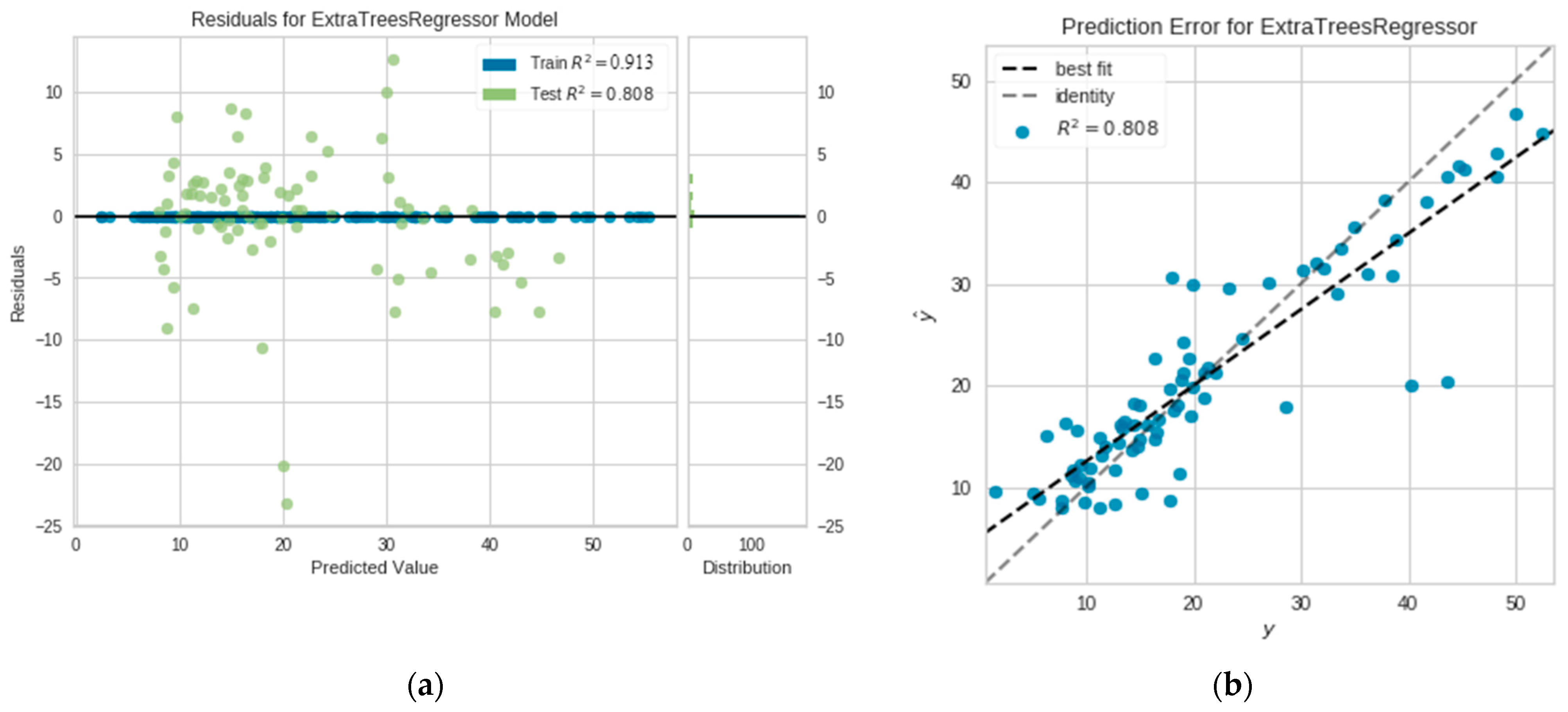
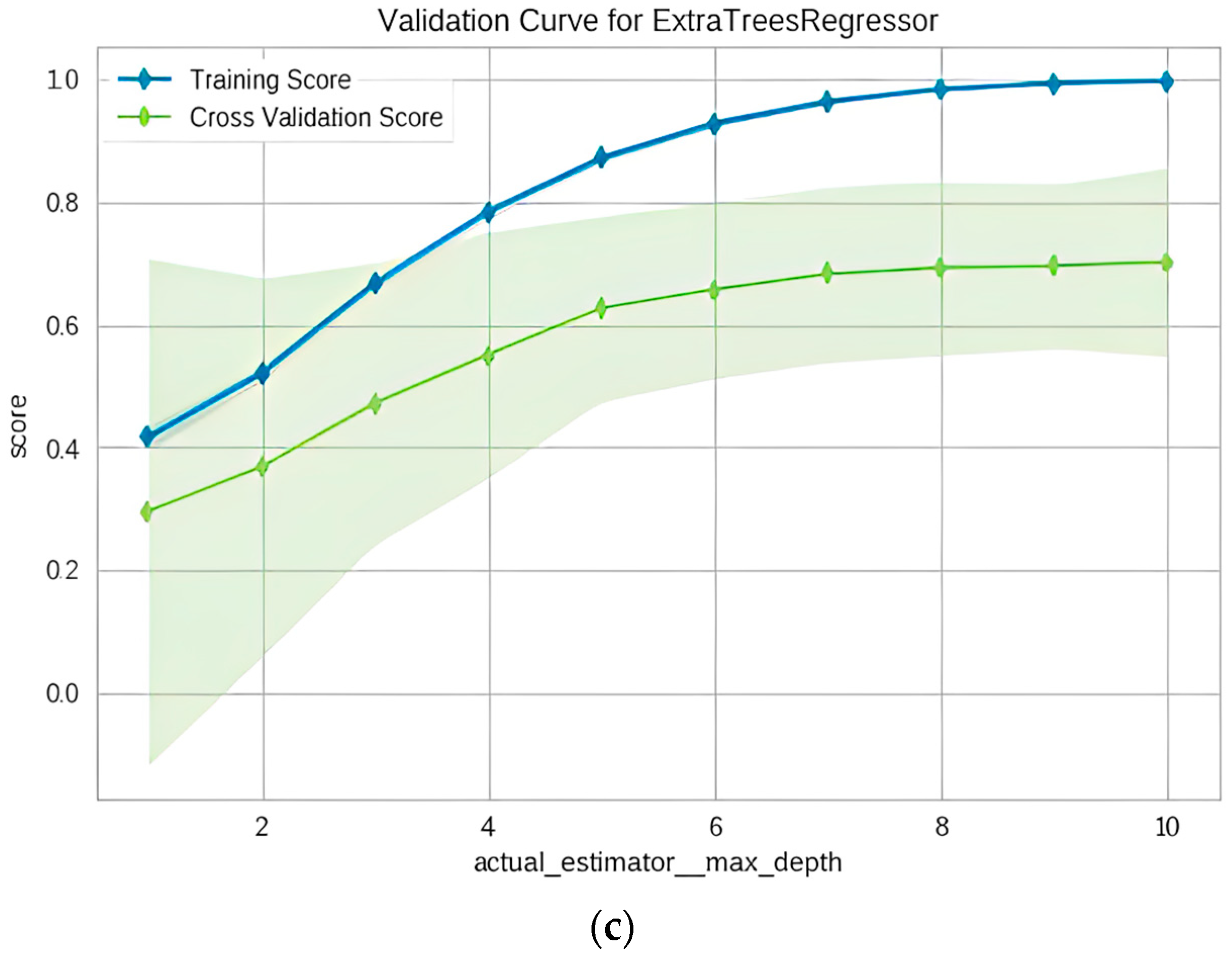
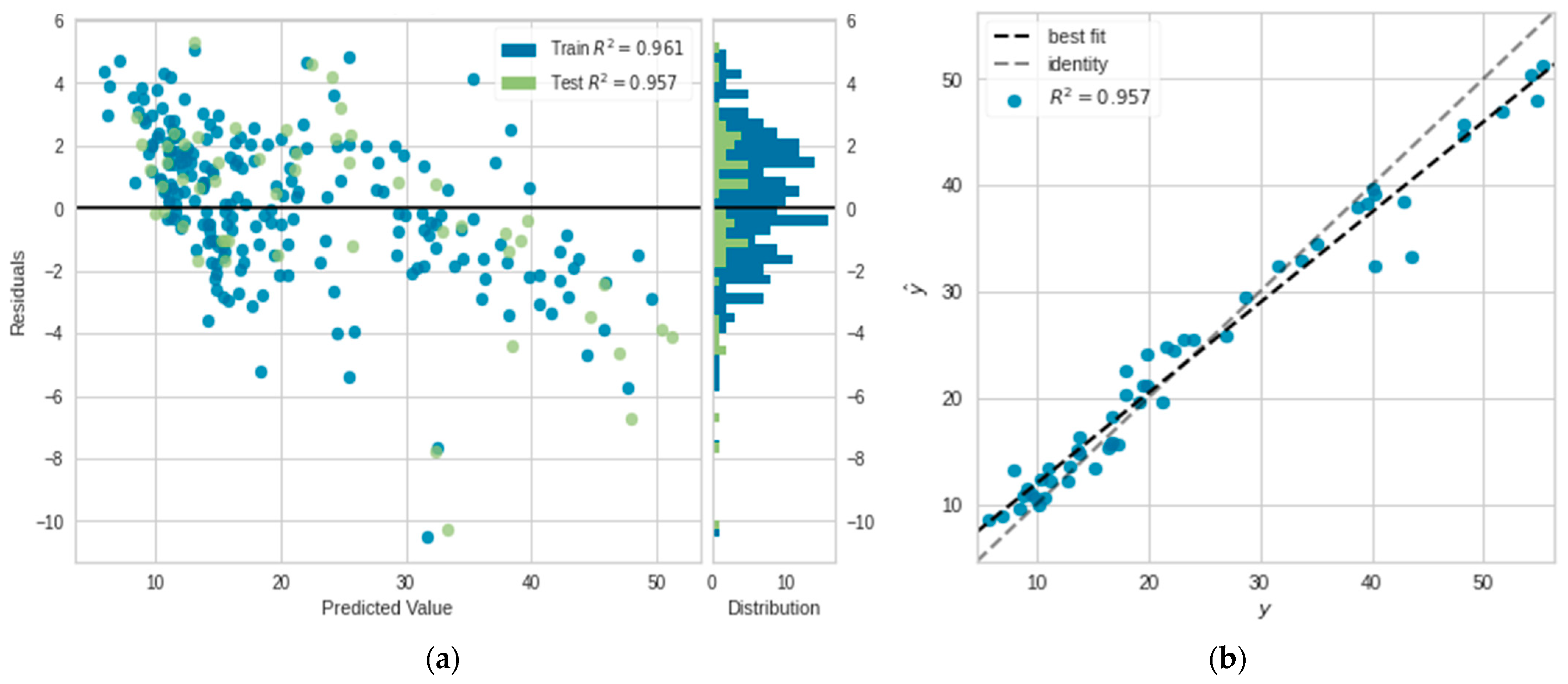
5.2.2. Performance of the Extra Tree Regressor
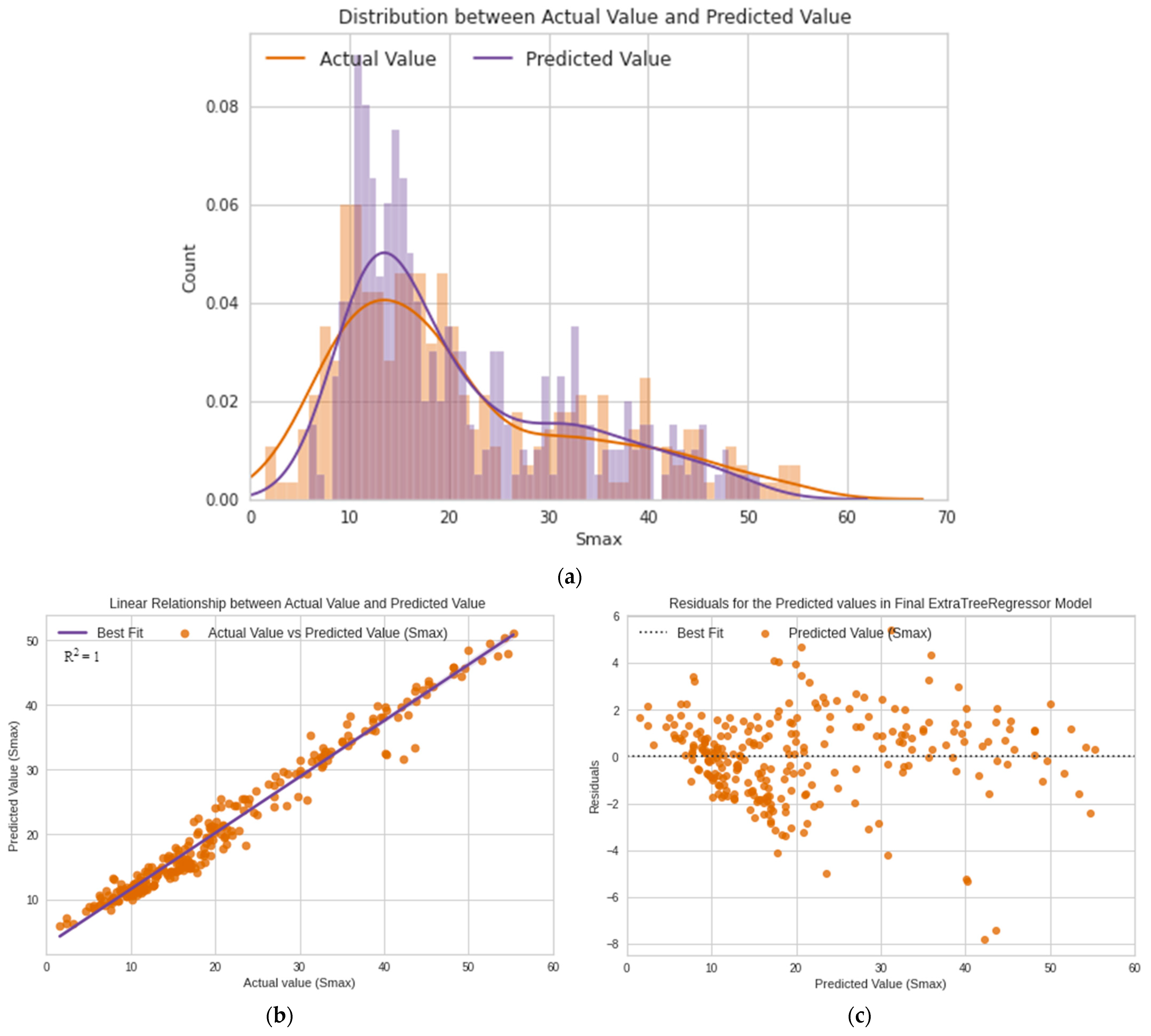
5.2.3. Prediction of Unseen Data
5.3. Analysis of Model on Entire Dataset
6. Conclusions
- Feature selection is essential to address when predicting Smax due to shield tunneling. It is recommended to compare at least two feature selection methods, especially when there needs to be more information about the relationship between input and output parameters. Herein, H, ST, GW, FPt, PA, To, JP, VDF, and VDb significantly impact the maximum surface settlement caused by tunneling based on the features selected from the Pearson correlation method. However, deciding which feature to select may be challenging when there is a weak correlation with the desired output.
- SHAP-based feature selection algorithms comprehend the output of a complex ML model and facilitate model validation by allowing the user to investigate how various features contribute to the model’s prediction. The SHAP analysis performed in this study revealed that the most critical parameters affecting tunneling-induced ground settlements were soil type (ST), torque (To), cover depth (H), groundwater level (GW), and tunneling deviation. These prudent factors identified by the model enable engineers and shield operators to reasonably manage shield operations.
- It is feasible and most reliable to calculate the maximum ground settlement (Smax) during the construction of earth pressure balanced (EPB) shield tunneling by the proposed AutoML models. According to the statistical and graphical results, the extra-tree regressor’s predictive ability is the best among all 21 AutoML models. Furthermore, the prediction results on unseen data indicate that the model’s predicted performance is acceptable and within the project’s tolerances. As a result, the prediction results generated from the AutoML-based extra tree regressor model are the most reliable, indicating that the model can be employed in real projects when completely-new deep excavation data are imported.
Limitations
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, P. A novel feature selection method based on global sensitivity analysis with application in machine learning-based prediction model. Appl. Soft Comput. 2019, 85, 105859. [Google Scholar] [CrossRef]
- Chen, R.P.; Lin, X.T.; Kang, X.; Zhong, Z.Q.; Liu, Y.; Zhang, P.; Wu, H.N. Deformation and stress characteristics of existing twin tunnels induced by close-distance EPBS under-crossing. Tunn. Undergr. Space Technol. 2018, 82, 468–488. [Google Scholar] [CrossRef]
- Chen, D.F.; Feng, X.T.; Xu, D.P.; Jiang, Q.; Yang, C.X.; Yao, P.P. Use of an improved ANN model to predict collapse depth of thin and extremely thin layered rock strata during tunnelling. Tunn. Undergr. Space Technol. 2016, 51, 372–386. [Google Scholar] [CrossRef]
- Zhang, Z.; Huang, M. Geotechnical influence on existing subway tunnels induced by multiline tunneling in Shanghai soft soil. Comput. Geotech. 2014, 56, 121–132. [Google Scholar] [CrossRef]
- Jiang, M.; Yin, Z.Y. Influence of soil conditioning on ground deformation during longitudinal tunneling. C. R. Mec. 2014, 342, 189–197. [Google Scholar] [CrossRef]
- Zhang, W.G.; Li, H.R.; Wu, C.Z.; Li, Y.Q.; Liu, Z.Q.; Liu, H.L. Soft computing approach for prediction of surface settlement induced by earth pressure balance shield tunneling. Undergr. Space 2021, 6, 353–363. [Google Scholar] [CrossRef]
- Liang, R.Z.; Xia, T.D.; Lin, C.G.; Yu, F. Analysis of surface deformation and horizontal displacement of deep soil caused by shield driving. J. Rock Mech. Eng. 2015, 34, 583–593. [Google Scholar]
- Mair, R.J. Subsurface settlement profiles above tunnels in clays. Geotechnique 1993, 43, 315–320. [Google Scholar] [CrossRef]
- Standing, J.R. Greenfield ground response to EPBM tunnelling in London Clay. Geotechnique 2013, 63, 989–1007. [Google Scholar]
- Zhu, C.H.; Li, N. Estimation and regularity analysis of maximal surface settlement induced by subway construction. Chin. J. Rock Mech. Eng. 2017, 1, 3543–3560. [Google Scholar]
- Karakus, M.; Fowell, R.J. 2-D and 3-D finite element analyses for the settlement due to soft ground tunnelling. Tunn. Undergr. Space Technol. 2006, 21, 392. [Google Scholar] [CrossRef]
- Peck, R.B. Deep excavations and tunneling in soft ground. In Proceedings of the 7th ICSMFE, Mexico City, Mexico, 25–29 August 1969; pp. 225–290. [Google Scholar]
- Attewell, P.B.; Yeates, J.; Selby, A.R. Soil Movements Induced by Tunnelling and Their Effects on Pipelines and Structures. United States; 1986. Available online: https://www.osti.gov/biblio/7052176 (accessed on 1 August 2022).
- Mindlin, R.D. Force at a point in the interior of a semi-infinite solid. Physics 1936, 7, 195–202. [Google Scholar] [CrossRef]
- Hagiwara, T.; Grant, R.J.; Calvello, M.; Taylor, R.N. The effect of overlying strata on the distribution of ground movements induced by tunnelling in clay. Soils Found. 1999, 39, 63–73. [Google Scholar] [CrossRef] [PubMed]
- Cheng, C.Y.; Dasari, G.R.; Chow, Y.K.; Leung, C.F. Finite element analysis of tunnel–soil–pile interaction using displacement controlled model. Tunn. Undergr. Space Technol. 2007, 22, 450–466. [Google Scholar] [CrossRef]
- Kasper, T.; Meschke, G. A 3D finite element simulation model for TBM tunnelling in soft ground. Int. J. Numer. Anal. Methods Geomech. 2004, 28, 1441–1460. [Google Scholar] [CrossRef]
- Ng, C.W.; Fong, K.Y.; Liu, H.L. The effects of existing horseshoe-shaped tunnel sizes on circular crossing tunnel interactions: Three-dimensional numerical analyses. Tunn. Undergr. Space Technol. 2018, 77, 68–79. [Google Scholar] [CrossRef]
- Jin, Y.F.; Zhu, B.Q.; Yin, Z.Y.; Zhang, D.M. Three-dimensional numerical analysis of the interaction of two crossing tunnels in soft clay. Undergr. Space 2019, 4, 310–327. [Google Scholar] [CrossRef]
- Qi, C.; Tang, X. Slope stability prediction using integrated metaheuristic and machine learning approaches: A comparative study. Comput. Ind. Eng. 2018, 118, 112–122. [Google Scholar] [CrossRef]
- Zhang, L.; Shi, B.; Zhu, H.; Yu, X.B.; Han, H.; Fan, X. (PSO-SVM-based deep displacement prediction of Majiagou landslide considering the deformation hysteresis effect. Landslides 2021, 18, 179–193. [Google Scholar] [CrossRef]
- Zhang, L.; Shi, B.; Zhu, H.; Yu, X.; Wei, G. A machine learning method for inclinometer lateral deflection calculation based on distributed strain sensing technology. Bull. Eng. Geol. Environ. 2020, 79, 3383–3401. [Google Scholar] [CrossRef]
- Zhang, W.; Li, Y.; Wu, C.; Li, H.; Goh AT, C.; Liu, H. Prediction of lining response for twin tunnels constructed in anisotropic clay using machine learning techniques. Undergr. Space 2020, 7, 122–133. [Google Scholar] [CrossRef]
- Shi, J.; Ortigao JA, R.; Bai, J. Modular neural networks for predicting settlements during tunneling. J. Geotech. Geoenviron. Eng. 1998, 124, 389–395. [Google Scholar] [CrossRef]
- Suwansawat, S.; Einstein, H.H. Describing settlement troughs over twin tunnels using a superposition technique. J. Geotech. Geoenviron. Eng. 2007, 133, 445–468. [Google Scholar] [CrossRef]
- Santos, O.J., Jr.; Celestino, T.B. Artificial neural networks analysis of Sao Paulo subway tunnel settlement data. Tunn. Undergr. Space Technol. 2008, 23, 481–491. [Google Scholar] [CrossRef]
- Bouayad, D.; Emeriault, F. Modeling the relationship between ground surface settlements induced by shield tunneling and the operational and geological parameters based on the hybrid PCA/ANFIS method. Tunn. Undergr. Space Technol. 2017, 68, 142–152. [Google Scholar] [CrossRef]
- Ahangari, K.; Moeinossadat, S.R.; Behnia, D. Estimation of tunnelling-induced settlement by modern intelligent methods. Soils Found. 2015, 55, 737–748. [Google Scholar] [CrossRef]
- Goh, A.T.; Zhang, W.; Zhang, Y.; Xiao, Y.; Xiang, Y. Determination of earth pressure balance tunnel-related maximum surface settlement: A multivariate adaptive regression splines approach. Bull. Eng. Geol. Environ. 2018, 77, 489–500. [Google Scholar] [CrossRef]
- Zhang, L.; Wu, X.; Ji, W.; AbouRizk, S.M. Intelligent approach to estimation of tunnel-induced ground settlement using wavelet packet and support vector machines. J. Comput. Civ. Eng. 2017, 31, 04016053. [Google Scholar] [CrossRef]
- Suwansawat, S.; Einstein, H.H. Artificial neural networks for predicting the maximum surface settlement caused by EPB shield tunneling. Tunn. Undergr. Space Technol. 2006, 21, 133–150. [Google Scholar] [CrossRef]
- Darabi, A.; Ahangari, K.; Noorzad, A.; Arab, A. Subsidence estimation utilizing various approaches—A case study: Tehran No. 3 subway line. Tunn. Undergr. Space Technol. 2012, 31, 117–127. [Google Scholar] [CrossRef]
- Pourtaghi, A.; Lotfollahi-Yaghin, M.A. Wavenet ability assessment in comparison to ANN for predicting the maximum surface settlement caused by tunneling. Tunn. Undergr. Space Technol. 2012, 28, 257–271. [Google Scholar] [CrossRef]
- Zhou, J.; Shi, X.; Du, K.; Qiu, X.; Li, X.; Mitri, H.S. Feasibility of Random-Forest approach for prediction of ground settlements induced by the construction of a shield-driven tunnel. Int. J. Geomech. 2016, 17, 04016129. [Google Scholar] [CrossRef]
- Shao, C.; Lan, D. Optimal control of an earth pressure balance shield with tunnel face stability. Autom. Constr. 2014, 46, 22–29. [Google Scholar] [CrossRef]
- Armaghani, D.J.; Mohamad, E.T.; Narayanasamy, M.S.; Narita, N.; Yagiz, S. Development of hybrid intelligent models for predicting TBM penetration rate in hard rock condition. Tunn. Undergr. Space Technol. 2017, 63, 29–32. [Google Scholar] [CrossRef]
- Zhang, P.; Chen, R.P.; Wu, H.N. Real-time analysis and regulation of EPB shield steering using Random Forest. Autom. Constr. 2019, 106, 102860. [Google Scholar] [CrossRef]
- Linardatos, P.; Papastefanopoulos, V.; Kotsiantis, S. Explainable AI: A review of machine learning interpretability methods. Entropy 2021, 23, 18. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A Unified Approach to Interpreting Model Predictions. Advances in Neural Information Processing Systems. 2017, Volume 30. Available online: https://papers.nips.cc/paper/2017 (accessed on 1 August 2022).
- Ali, M. (April 2022). PyCaret: An Open Source, Low-Code Machine Learning Library in Python. (PyCaret Version 2.3.5). Available online: https://www.pycaret.Org (accessed on 1 August 2022).
- Kannangara, K.P.M.; Zhou, W.H.; Ding, Z.; Hong, Z.H. Investigation of feature contribution to shield tunneling-induced settlement using Shapley additive explanations method. J. Rock Mech. Geotech. Eng. 2022, 14, pp. 1052–1063.
- GB/T50123-1999; Standard for Soil Test Method. China Planning Press: Beijing, China, 1999. (In Chinese)
- Kim, C.Y.; Bae, G.J.; Hong, S.W.; Park, C.H.; Moon, H.K.; Shin, H.S. Neural network based prediction of ground surface settlements due to tunnelling. Comput. Geotech. 2001, 28, 517–547. [Google Scholar] [CrossRef]
- Ding, L.; Wang, F.; Luo, H.; Yu, M.; Wu, X. Feedforward analysis for shield-ground system. J. Comput. Civ. Eng. 2013, 27, 231–242. [Google Scholar] [CrossRef]
- Chen, R.; Meng, F.; Li, Z.; Ye, Y.; Ye, J. Investigation of response of metro tunnels due to adjacent large excavation and protective measures in soft soils. Tunn. Undergr. Space Technol. 2016, 58, 224–235. [Google Scholar] [CrossRef]
- Feng, X.T.; Zhang, C.; Qiu, S.; Zhou, H.; Jiang, Q.; Li, S. Dynamic design method for deep hard rock tunnels and its application. J. Rock Mech. Geotech. Eng. 2016, 8, 443–461. [Google Scholar] [CrossRef]
- Morovatdar, A.; Palassi, M.; Ashtiani, R.S. Effect of pipe characteristics in umbrella arch method on controlling tunneling-induced settlements in soft grounds. J. Rock Mech. Geotech. Eng. 2020, 12, 984–1000. [Google Scholar] [CrossRef]
- Meng, F.Y.; Chen, R.P.; Kang, X. Effects of tunneling-induced soil disturbance on the post-construction settlement in structured soft soils. Tunn. Undergr. Space Technol. 2018, 80, 53–63. [Google Scholar] [CrossRef]
- Dammyr, Ø.; Nilsen, B.; Gollegger, J. Feasibility of tunnel boring through weakness zones in deep Norwegian subsea tunnels. Tunn. Undergr. Space Technol. 2017, 69, 133–146. [Google Scholar] [CrossRef]
- Qin, S.; Xu, T.; Zhou, W.H. Predicting pore-water pressure in front of a TBM using a deep learning approach. Int. J. Geomech. 2021, 21, 04021140. [Google Scholar] [CrossRef]
- Kannangara, K.K.P.M.; Ding, Z.; Zhou, W.H. Surface settlements induced by twin tunneling in silty sand. Undergr. Space 2022, 7, 58–75. [Google Scholar] [CrossRef]
- Zhou, C.; Xu, H.; Ding, L.; Wei, L.; Zhou, Y. Dynamic prediction for attitude and position in shield tunneling: A deep learning method. Autom. ConStruct. 2019, 105, 102840. [Google Scholar] [CrossRef]
- Nawi, N.M.; Atomi, W.H.; Rehman, M.Z. The effect of data pre-processing on optimized training of artificial neural networks. Procedia Technol. 2013, 11, 32–39. [Google Scholar] [CrossRef]
- Braga-Neto, U.; Hashimoto, R.; Dougherty, E.R.; Nguyen, D.V.; Carroll, R.J. Is cross-validation better than resubstitution for ranking genes. Bioinformatics 2004, 20, 253–258. [Google Scholar] [CrossRef]
- Zhang, P.W. Hybrid meta-heuristic and machine learning algorithms for tunneling-induced settlement prediction: A comparative study. Tunn. Undergr. Space Technol. 2020, 99, 103383. [Google Scholar] [CrossRef]
- Zhang, P.Y. Intelligent modelling of clay compressibility using hybrid meta-heuristic and machine learning algorithms. Geosci. Front. 2021, 12, 441–452. [Google Scholar] [CrossRef]
- Tan, C.P. Surface subsidence prediction based on grey relational support vector machine. J. Cent. South Univ. (Nat. Sci. Ed.) 2012, 43, 632–637. [Google Scholar]
- Cheng, Z.L.; Zhou, W.H.; Ding, Z.; Guo, Y.X. Estimation of spatiotemporal response of rooted soil using a machine learning approach. J. Zhejiang Univ. Sci. A 2020, 21, 462–477. [Google Scholar] [CrossRef]
- Pearson, K. Notes on Regression and Inheritance in the Case of Two Parents. Proc. R. Soc. Lond. 1895, 58, 240–242. [Google Scholar] [CrossRef]
- Štrumbelj, E.; Kononenko, I. Explaining prediction models and individual predictions with feature contributions. Knowl. Inf. Syst. 2014, 41, 647–665. [Google Scholar] [CrossRef]
- Parsa, A.B.; Movahedi, A.; Taghipour, H.; Derrible, S.; Mohammadian, A.K. Toward safer highways, application of XGBoost and SHAP for real-time accident detection and feature analysis. Accid. Anal. Prev. 2020, 136, 105405. [Google Scholar] [CrossRef]
- Siew, H.L.; Nordin, M.J. Regression techniques for the prediction of stock price trend. In Proceedings of the International Conference on Statistics in Science, Langkawi, Malaysia, 10–12 September 2012. [Google Scholar]
- Jiang, P.; Chen, J. Displacement prediction of landslide based on generalized regression neural networks with K-fold cross-validation. Neurocomputing 2016, 198, 40–47. [Google Scholar] [CrossRef]
- Handa, R. Prediction of Foreign Exchange Rate Using Regression Techniques. 2017. Available online: https://www.semanticscholar.org/paper/PREDICTION-OF-FOREIGN-EXCHANGE-RATE-USING-Sharma/f3feac47eafb58a1c200082c895cd591b09e020a (accessed on 1 August 2022).
- Han, J.; Pei, J.; Kamber, M. Data Mining: Concepts and Techniques; Elsevier: Amsterdam, The Netherlands, 2011. [Google Scholar]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Yoav Freund, R.E. A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef]
- Wang, G.; Hao, J.; Ma, J.; Jiang, H. A comparative assessment of ensemble learning for credit scoring. Expert Syst. Appl. 2011, 38, 223–230. [Google Scholar] [CrossRef]














| Project | Soil Type | ϒ (kN/m3) | φ° | c (kPa) | Gs | e |
|---|---|---|---|---|---|---|
| 1 | Miscellaneous fill | (18) | ||||
| Pure fill | (18.5) | |||||
| Clay 1 | 18.2 | 10 | 12 | 2.74 | 1.095 | |
| Muddy clay | 17.6 | 13 | 10 | 2.73 | 1.247 | |
| Muddy silty clay | 17.6 | 14 | 10 | 2.72 | 1.218 | |
| Muddy clay with silt | 17.5 | 14 | 11 | 2.72 | 1.22 | |
| Muddy silty clay with silt | 18.1 | 18 | 12 | 2.71 | 1.067 | |
| Silty clay | 17.6 | 14 | 12 | 2.73 | 1.204 | |
| Clay 2 | 17.4 | 12 | 15 | 2.74 | 1.243 | |
| Sandy silty clay | 20.2 | 22 | 14 | 2.69 | 0.608 | |
| Completely weathered rock | ||||||
| 2 | Miscellaneous fill | (18) | ||||
| Pure fill | (17.5) | |||||
| Silt with sand | 19.4 | 26 | 8 | 2.69 | 0.768 | |
| Sandy silt with silt | 19.5 | 28 | 5.5 | 2.69 | 0.742 | |
| Sandy silt | 19.7 | 29 | 4.5 | 2.68 | 0.706 | |
| Silty sand | 19.7 | 31.5 | 4 | 2.68 | 0.687 | |
| Boulder 1 | 36 | 5 | ||||
| Silty clay with silt | 17.1 | 13 | 14 | 2.71 | 1.283 | |
| Silty clay | 20.1 | 21 | 28 | 2.71 | 0.66 | |
| Boulder 2 | 40 | 6 |
| Category | Parameters | Symbol | Unit |
|---|---|---|---|
| Tunnel geometry | Cover depth | H | m |
| Geological conditions | Soil type a | ST | - |
| Groundwater level | GW | m | |
| Shield operational parameters | Face pressure (top) | FPt | kPa |
| Face pressure (center) b | FPc | kPa | |
| Advance rate | AR | mm/min | |
| Pitching angle | PA | ° | |
| Thrust | Th | kN | |
| Torque | To | kN m | |
| Jack pressure | JP | kPa | |
| Horizontal deviation (front) | HDf | mm | |
| Vertical deviation (front) | VDf | mm | |
| Horizontal deviation (back) | HDb | mm | |
| Vertical deviation (back) | VDb | mm | |
| Target variable | Maximum surface settlement | Smax | mm |
| No. | Ring | H (m) | ST | GW (m) | FPt (kPa) | FPc (kPa) | AR(mm/min) | PA (°) | Th (kN) | To (kN/m) | JP (kPa) | HD (mm) | VDF (mm) | HD (mm) | VDB (mm) | Smax (mm) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 5 | 9.03 | 1 | 1.46 | 40 | 95 | 0 | −0.1 | 9345 | 1937 | 8700 | −34 | 53 | 27 | −53 | 4.65 |
| 2 | 9 | 9.05 | 1 | 1.57 | 0 | 70 | 7 | −0.22 | 27,124 | 1305 | 24,600 | −63 | −67 | 5 | −55 | 5.52 |
| 3 | 14 | 9.07 | 1 | 1.68 | 80 | 140 | 31 | 0 | 19,986 | 2310 | 17,700 | −80 | −43 | −23 | −62 | 40.11 |
| 4 | 18 | 9.09 | 1 | 1.79 | 110 | 180 | 59 | −0.1 | 16,804 | 1965 | 4700 | −78 | −43 | −46 | −48 | 8.8 |
| 5 | 22 | 9.1 | 1 | 1.9 | 110 | 180 | 45 | −0.2 | 20,275 | 1937 | 18,500 | −49 | −31 | −62 | −44 | 8.76 |
| 6 | 26 | 9.13 | 1 | 2.01 | 120 | 190 | 32 | −0.2 | 17,478 | 2529 | 16,075 | −37 | −17 | −54 | 42 | 18.67 |
| 7 | 30 | 9.25 | 1 | 2.12 | 110 | 180 | 34 | −0.6 | 18,907 | 2289 | null | −31 | −45 | −37 | −15 | 16.16 |
| 8 | 34 | 9.36 | 1 | 2.22 | 110 | 195 | 30 | −0.77 | 17,459 | 2567 | 16,200 | −32 | −46 | −29 | −21 | 6.45 |
| 9 | 39 | null | 1 | 2.33 | 120 | 190 | 42 | −0.7 | 19,564 | 2036 | 18,050 | −15 | −65 | −20 | −51 | 2.41 |
| 10 | 43 | 9.6 | 1 | 2.44 | 110 | 170 | 29 | −0.7 | null | 2874 | 18,250 | −8 | −53 | −13 | −57 | 3.18 |
| 11 | 51 | 9.83 | 1 | 2.66 | 130 | 205 | 36 | −1 | 19,344 | 2853 | 17,800 | −1 | −55 | 5 | −46 | 1.58 |
| 12 | 55 | 9.94 | 1 | 2.49 | 130 | 205 | 48 | −1 | 19,726 | 2153 | 18,000 | 1 | −58 | 17 | −55 | 7.61 |
| 13 | 59 | 10.04 | 1 | 2.33 | 130 | 205 | 41 | −1 | 17,758 | 2250 | 16,300 | 14 | −47 | 16 | −49 | 10.12 |
| 14 | 64 | 10.14 | 1 | 2.16 | 130 | 200 | 38 | −1 | 18,297 | 2778 | 16,900 | −18 | −45 | −8 | −44 | 11.77 |
| 15 | 68 | 10.24 | 1 | 2 | 130 | 205 | 38 | −1.1 | 18,597 | 2657 | 16,975 | 4 | −35 | 7 | −31 | 12.97 |
| 16 | 72 | 10.34 | 1 | 1.84 | 120 | 190 | 35 | −1.2 | 18,693 | 2278 | 17,225 | −18 | −39 | 16 | −13 | 15.45 |
| 17 | 76 | 10.43 | 1 | 1.67 | 130 | 205 | 46 | −1.2 | 17,618 | 2095 | 15,750 | −42 | −44 | −5 | −14 | 21.3 |
| 18 | 80 | 10.53 | 1 | 1.51 | 130 | 200 | 45 | null | 17,885 | 1953 | 15,775 | −31 | −47 | −29 | −19 | 16.11 |
| 19 | 84 | null | 1 | 1.34 | 130 | 200 | 43 | −1.1 | 18,490 | 2567 | 16,900 | −15 | −47 | −30 | −33 | 11.6 |
| 20 | 89 | 10.73 | 1 | 1.21 | 140 | 205 | 44 | −1.1 | 18,923 | 2049 | 17,400 | −18 | −39 | −16 | −32 | 14.35 |
| 21 | 50 | 10.91 | 0 | 112.0 | 60 | 160 | 51 | −1.33 | 10,655 | 481 | 9500 | 13 | −55 | 10 | −4 | 12.1 |
| 22 | 55 | 11.05 | 0 | 240.0 | 50 | 170 | 50 | −1.42 | 11,270 | 506 | 10,100 | 29 | −48 | 42 | 2 | 16.7 |
| 23 | 85 | 11.89 | 0 | 12.2 | 50 | 190 | 62 | −1.49 | 10,307 | 518 | 9100 | 4 | −87 | 17 | −31 | 26.9 |
| 24 | 90 | 12.03 | 0 | 11.9 | 60 | 215 | 63 | −1.17 | 10,703 | 522 | 9525 | 21 | −69 | 35 | −60 | 28.5 |
| 25 | 100 | 12.31 | 0 | 32.4 | 40 | 170 | 57 | −1.31 | 12,307 | 569 | 10,875 | −22 | −66 | 47 | −40 | 40.2 |
| Parameter Count | Count | Mean Count | Std. Count | Min. Count | 25% Count | 50% Count | 75% Count | Max. Count |
|---|---|---|---|---|---|---|---|---|
| H | 264 | 14.5 | 2.7 | 9.03 | 11.98 | 15.07 | 16.71 | 18.70 |
| ST | 264 | 0.52 | 0.5 | 0 | 0 | 1 | 1 | 1 |
| GW | 264 | 1.96 | 0.6 | 0.36 | 1.63 | 1.93 | 2.40 | 3.18 |
| FPt | 264 | 122.6 | 62.12 | 0 | 70 | 110 | 182.5 | 230 |
| FPc | 264 | 232.3 | 37 | 70 | 205 | 240 | 260 | 310 |
| AR | 264 | 58.40 | 11.76 | 0 | 53 | 60 | 66 | 80 |
| PA | 264 | −0.09 | 0.78 | −1.49 | −0.77 | −0.20 | 0.38 | 1.37 |
| Th | 264 | 19,592.6 | 4404.27 | 0 | 17,194.0 | 19,331.0 | 23,280.0 | 27433.0 |
| To | 264 | 1537.85 | 956.04 | 0 | 569.75 | 19,210.0 | 2481.5 | 3180 |
| JP | 264 | 17,862.2 | 3992.54 | 25 | 15,750.0 | 17,850.0 | 21,131.25 | 24950.0 |
| HDf | 264 | −8.74 | 23.70 | −80 | −22.25 | −12 | 2.25 | 69 |
| VDf | 264 | −47.14 | 39.57 | −125 | −76 | −48 | −14 | 36 |
| HDb | 264 | 22.97 | 25.57 | −62 | 8 | 23 | 39.25 | 107 |
| VDb | 264 | −25.07 | 35.80 | −126 | −51 | −26 | −4 | 54 |
| Smax | 264 | 20.87 | 12.48 | 1.58 | 11.225 | 16.95 | 28082 | 55.30 |
| No. | Ring | H (m) | ST | GW (m) | FPt (kPa) | FPc (kPa) | AR(mm/min) | PA (°) | Th (kN) | To (kN/m) | JP (kPa) | HD (mm) | VDF (mm) | HD (mm) | VDB (mm) | Smax (mm) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 5 | 9.03 | 1 | 1.46 | 40 | 95 | 0 | −0.1 | 9345 | 1937 | 8700 | −34 | 53 | 27 | −53 | 4.65 |
| 2 | 9 | 9.05 | 1 | 1.57 | 0 | 70 | 7 | −0.2 | 27,124 | 1305 | 24,600 | −63 | −67 | 5 | −55 | 5.52 |
| 3 | 14 | 9.07 | 1 | 1.68 | 80 | 140 | 31 | 0 | 19,986 | 2310 | 17,700 | −80 | −43 | −23 | −62 | 40.11 |
| 4 | 18 | 9.09 | 1 | 1.79 | 110 | 180 | 59 | −0.1 | 16,804 | 1965 | 4700 | −78 | −43 | −46 | −48 | 8.8 |
| 5 | 22 | 9.1 | 1 | 1.9 | 110 | 180 | 45 | −0.2 | 20,275 | 1937 | 18,500 | −49 | −31 | −62 | −44 | 8.76 |
| 6 | 26 | 9.13 | 1 | 2.01 | 120 | 190 | 32 | −0.2 | 17,478 | 2529 | 16,075 | −37 | −17 | −54 | −42 | 18.67 |
| 7 | 30 | 9.25 | 1 | 2.12 | 110 | 180 | 34 | −0.6 | 18,907 | 2289 | 17,950 | −31 | −45 | −37 | −15 | 16.16 |
| 8 | 34 | 9.36 | 1 | 2.22 | 110 | 195 | 30 | −0.77 | 17,459 | 2567 | 16,200 | −32 | −46 | −29 | −21 | 6.45 |
| 9 | 39 | 9.48 | 1 | 2.33 | 120 | 190 | 42 | −0.7 | 19,564 | 2036 | 18,050 | −15 | −65 | −20 | −51 | 2.41 |
| 10 | 43 | 9.6 | 1 | 2.44 | 110 | 170 | 29 | −0.7 | 19,778 | 2874 | 18,250 | −8 | −53 | −13 | −57 | 3.18 |
| 11 | 51 | 9.83 | 1 | 2.66 | 130 | 205 | 36 | −1 | 19,344 | 2853 | 17,800 | −1 | −55 | 5 | −46 | 1.58 |
| 12 | 55 | 9.94 | 1 | 2.49 | 130 | 205 | 48 | −1 | 19,726 | 2153 | 18,000 | 1 | −58 | 17 | −55 | 7.61 |
| 13 | 59 | 10.04 | 1 | 2.33 | 130 | 205 | 41 | −1 | 17,758 | 2250 | 16,300 | 14 | −47 | 16 | −49 | 10.12 |
| 14 | 64 | 10.14 | 1 | 2.16 | 130 | 200 | 38 | −1 | 18,297 | 2778 | 16,900 | −18 | −45 | −8 | −44 | 11.77 |
| 15 | 68 | 10.24 | 1 | 2 | 130 | 205 | 38 | −1.1 | 18,597 | 2657 | 16,975 | 4 | −35 | 7 | −31 | 12.97 |
| 16 | 72 | 10.34 | 1 | 1.84 | 120 | 190 | 35 | −1.2 | 18,693 | 2278 | 17,225 | −18 | −39 | 16 | −13 | 15.45 |
| 17 | 76 | 10.43 | 1 | 1.67 | 130 | 205 | 46 | −1.2 | 17,618 | 2095 | 15,750 | −42 | −44 | −5 | −14 | 21.3 |
| 18 | 80 | 10.53 | 1 | 1.51 | 130 | 200 | 45 | −1.2 | 17,885 | 1953 | 15,775 | −31 | −47 | −29 | −19 | 16.11 |
| 19 | 84 | 10.63 | 1 | 1.34 | 130 | 200 | 43 | −1.1 | 18,490 | 2567 | 16,900 | −15 | −47 | −30 | −33 | 11.6 |
| 20 | 89 | 10.73 | 1 | 1.21 | 140 | 205 | 44 | −1.1 | 18,923 | 2049 | 17,400 | −18 | −39 | −16 | −32 | 14.35 |
| 21 | 50 | 10.91 | 0 | 112.0 | 60 | 160 | 51 | −1.33 | 10,655 | 481 | 9500 | 13 | −55 | 10 | −4 | 12.1 |
| 22 | 55 | 11.05 | 0 | 240.0 | 50 | 170 | 50 | −1.42 | 11,270 | 506 | 10,100 | 29 | −48 | 42 | 2 | 16.7 |
| 23 | 85 | 11.89 | 0 | 12.2 | 50 | 190 | 62 | −1.49 | 10,307 | 518 | 9100 | 4 | −87 | 17 | −31 | 26.9 |
| 24 | 90 | 12.03 | 0 | 11.9 | 60 | 215 | 63 | −1.17 | 10,703 | 522 | 9525 | 21 | −69 | 35 | −60 | 28.5 |
| 25 | 100 | 12.31 | 0 | 32.4 | 40 | 170 | 57 | −1.31 | 12,307 | 569 | 10,875 | −22 | −66 | 47 | −40 | 40.2 |
| No. | Estimator | Description |
|---|---|---|
| 1 | Extra tree Regressor | A regressor with multiple decision trees, which is highly randomized, is only used in the ensemble methods. |
| 2 | Random Forest Regressor | The algorithm establishes multiple decision trees by randomly sampling, and obtains the overall regression prediction results by averaging the results of all trees. |
| 3 | Gradient Boosting Regressor | An algorithm for combining multiple simple models into a composite model. |
| 4 | Light Gradient Boosting Machine | The algorithm adopts a distributed gradient lifting framework based on decision tree algorithm, which can solve the problems encountered by GBDT in massive data. |
| 5 | AdaBoost Regressor | This algorithm trains different weak regressors for the same training set and combines them to form a stronger final regressor. |
| 6 | Extreme gradient boosting | The algorithm is optimized on the framework of GBDT, which is efficient, flexible and portable. |
| 7 | K neighbors Regressor | A simple algorithm for predicting the target value on all available cases based on a similarity measure. |
| 8 | Decision Tree Regressor | A method of approximating the value of a discrete function. The induction algorithm is used to generate readable rules and decision trees, and the decision is used to analyze new data. |
| 9 | Support vector machine | A generalized linear classifier for binary classification of data according to supervised learning. |
| 10 | Bayesian Ridge | A probability model for estimating regression problems. |
| 11 | Ridge Regression | A biased estimation regression method dedicated to the analysis of collinearity data is essentially an improved least squares estimation method. |
| 12 | CatBoost Regressor | An algorithm based on symmetric decision tree, which can efficiently and reasonably handle categorical features. |
| 13 | Linear Regression | A linear approach that shows the relationship between a dependent variable and one or more independent variables. |
| 14 | Least Angle Regression | A statistical analysis method that uses regression analysis to determine the quantitative relationship between multiple variables. |
| 15 | Huber Regressor | A linear regression that replaces the loss function of MSE with huber loss. |
| 16 | Orthogonal Matching Pursuit | A nonlinear adaptive algorithm using a super complete dictionary for signal decomposition. |
| 17 | Elastic Net | A linear regression model applied to multiple correlated features. |
| 18 | Lasso Regression | A compressed estimate. It constructs a penalty function to obtain a more refined model, which is a biased estimate for processing data with complex collinearity. |
| 19 | Passive aggressive Regressor | Online learning algorithms for both classification and regression. |
| 20 | Random sample consensus | An iterative method that estimates the parameters of a mathematical model from a set of observed data containing outliers that do not affect the estimates. |
| 21 | Theil-Sen regressor | A robust model for fitting straight lines in nonparametric statistics. |
| No. | Model | MAE | R2 | RMSE | MAE | R2 | RMSE |
|---|---|---|---|---|---|---|---|
| Training | Training | Training | Test | Test | Test | ||
| 1 | Extra tree Regressor | 3.7 | 0.891 | 4.5 | 3.8 | 0.791 | 5.5 |
| 2 | Random Forest Regressor | 4.2 | 0.857 | 5.0 | 4.3 | 0.753 | 6.1 |
| 3 | Gradient Boosting Regressor | 4.3 | 0.846 | 5.1 | 3.8 | 0.788 | 5.6 |
| 4 | Light Gradient Boosting Machine | 4.5 | 0.826 | 5.5 | 3.97 | 0.762 | 6.0 |
| 5 | AdaBoost Regressor | 4.4 | 0.834 | 5.2 | 5 | 0.736 | 6.4 |
| 6 | Extreme gradient boosting | 4.3 | 0.845 | 5.2 | 5.1 | 0.742 | 6.41 |
| 7 | K neighbors Regressor | 4.28 | 0.831 | 5.5 | 4.76 | 0.732 | 6.48 |
| 8 | Decision Tree Regressor | 4.7 | 0.691 | 5.5 | 5.67 | 0.599 | 8.0 |
| 9 | Support vector machine | 4.7 | 0.655 | 5.6 | 5.82 | 0.582 | 8.0 |
| 10 | Bayesian Ridge | 7.54 | 0.603 | 8.46 | 7.1 | 0.47 | 9.02 |
| 11 | Ridge Regression | 7.59 | 0.602 | 8.48 | 6.80 | 0.51 | 8.74 |
| 12 | CatBoost Regressor | 7.62 | 0.592 | 8.52 | 6.72 | 0.55 | 8.77 |
| 13 | Linear Regression | 7.70 | 0.57 | 8.76 | 6.76 | 0.50 | 8.82 |
| 14 | Least Angle Regression | 7.70 | 0.57 | 8.76 | 6.76 | 0.51 | 8.82 |
| 15 | Huber Regressor | 7.57 | 0.57 | 8.73 | 6.61 | 0.51 | 8.73 |
| 16 | Orthogonal Matching Pursuit | 7.9 | 0.55 | 9.23 | 7.6 | 0.36 | 10.1 |
| 17 | Elastic Net | 8.1 | 0.52 | 9.31 | 7.62 | 0.40 | 9.6 |
| 18 | Lasso Regression | 7.70 | 0.57 | 8.76 | 7.77 | 0.40 | 9.63 |
| 19 | Passive aggressive Regressor | 8.1 | 0.42 | 10.44 | 8.56 | 0.19 | 11.20 |
| 20 | Random sample consensus | 7.43 | -0.33 | 8.43 | 10.10 | -0.10 | 12.49 |
| 21 | Theil-Sen regressor | 7.43 | -0.33 | 8.43 | 10.10 | -0.10 | 12.49 |
| No. | Model | MAE | R2 | RMSE | MAE | R2 | RMSE |
|---|---|---|---|---|---|---|---|
| Training | Training | Training | Test | Test | Test | ||
| 1 | Extra tree Regressor | 3.4 | 0.913 | 4.04 | 3.7 | 0.808 | 5.2 |
| 2 | Random Forest Regressor | 4.2 | 0.861 | 5.0 | 4.3 | 0.786 | 5.4 |
| 3 | Gradient Boosting Regressor | 4.3 | 0.854 | 5.1 | 3.8 | 0.792 | 5.5 |
| 4 | AdaBoost Regressor | 4.4 | 0.849 | 5.1 | 5.0 | 0.763 | 5.9 |
| 5 | Light Gradient Boosting Machine | 4.5 | 0.842 | 5.5 | 3.9 | 0.778 | 6.0 |
| MAE | MSE | RMSE | R2 | RMSLE | MAPE | |
|---|---|---|---|---|---|---|
| Extra tree regressor | 2.1023 | 15.5794 | 3.9471 | 0.961 | 0.1664 | 0.1053 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hussaine, S.M.; Mu, L. Intelligent Prediction of Maximum Ground Settlement Induced by EPB Shield Tunneling Using Automated Machine Learning Techniques. Mathematics 2022, 10, 4637. https://doi.org/10.3390/math10244637
Hussaine SM, Mu L. Intelligent Prediction of Maximum Ground Settlement Induced by EPB Shield Tunneling Using Automated Machine Learning Techniques. Mathematics. 2022; 10(24):4637. https://doi.org/10.3390/math10244637
Chicago/Turabian StyleHussaine, Syed Mujtaba, and Linlong Mu. 2022. "Intelligent Prediction of Maximum Ground Settlement Induced by EPB Shield Tunneling Using Automated Machine Learning Techniques" Mathematics 10, no. 24: 4637. https://doi.org/10.3390/math10244637
APA StyleHussaine, S. M., & Mu, L. (2022). Intelligent Prediction of Maximum Ground Settlement Induced by EPB Shield Tunneling Using Automated Machine Learning Techniques. Mathematics, 10(24), 4637. https://doi.org/10.3390/math10244637